Milvus(21):过滤搜索、范围搜索、分组搜索
1 过滤搜索
ANN 搜索能找到与指定向量嵌入最相似的向量嵌入。但是,搜索结果不一定总是正确的。您可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件的实体。
1.1 概述
在 Milvus 中,过滤搜索根据应用过滤的阶段分为两种类型--标准过滤和迭代过滤。
1.1.1 标准过滤
如果 Collections 同时包含向量嵌入及其元数据,您可以在 ANN 搜索之前过滤元数据,以提高搜索结果的相关性。Milvus 收到携带过滤条件的搜索请求后,会将搜索范围限制在符合指定过滤条件的实体内。
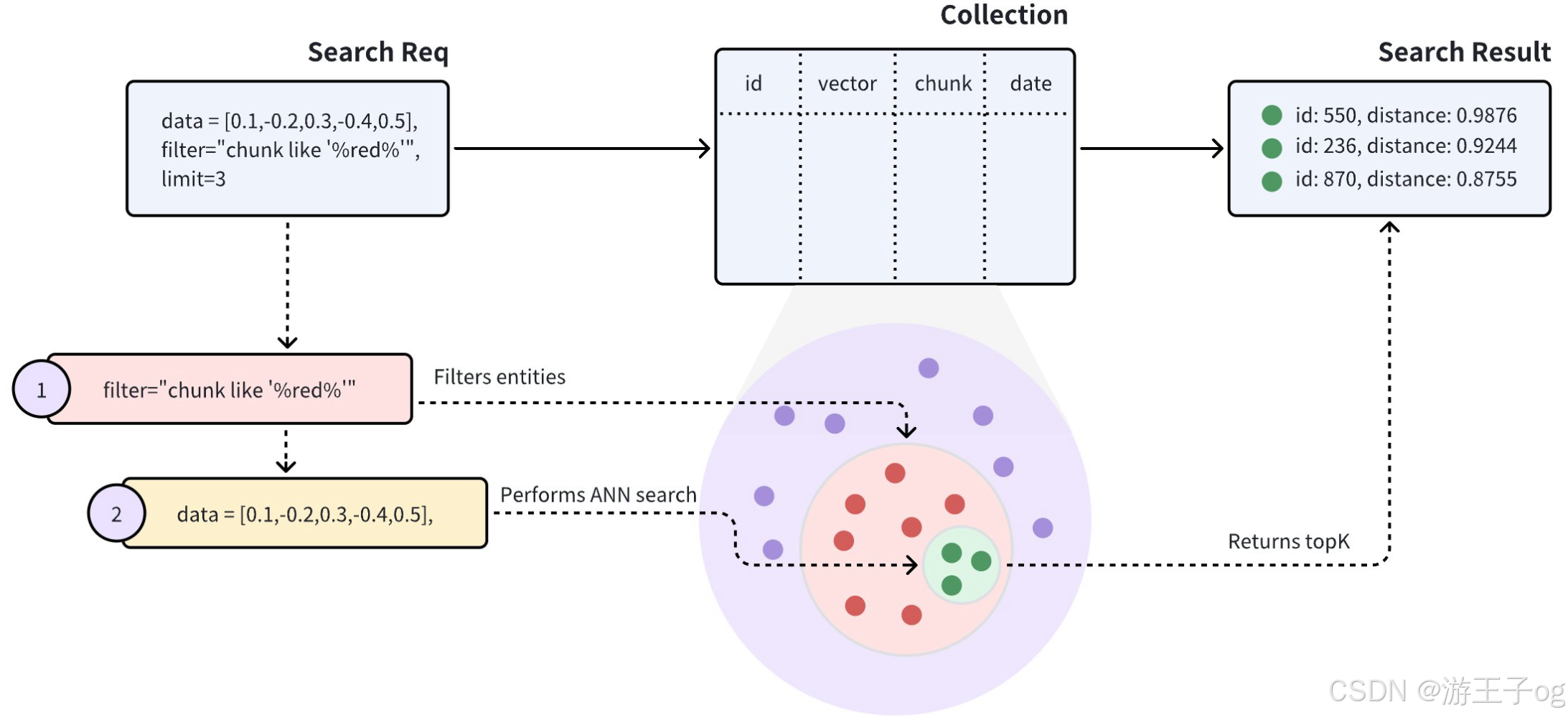
如上图所示,搜索请求携带chunk like "%red%" 作为过滤条件,表明 Milvus 应在chunk 字段中包含red 的所有实体内进行 ANN 搜索。具体来说,Milvus 会执行以下操作:
- 过滤符合搜索请求中过滤条件的实体。
- 在过滤后的实体中进行 ANN 搜索。
- 返回前 K 个实体。
1.1.2 迭代过滤
标准过滤过程能有效地将搜索范围缩小到很小的范围。但是,过于复杂的过滤表达式可能会导致非常高的搜索延迟。在这种情况下,迭代过滤可以作为一种替代方法,帮助减少标量过滤的工作量。
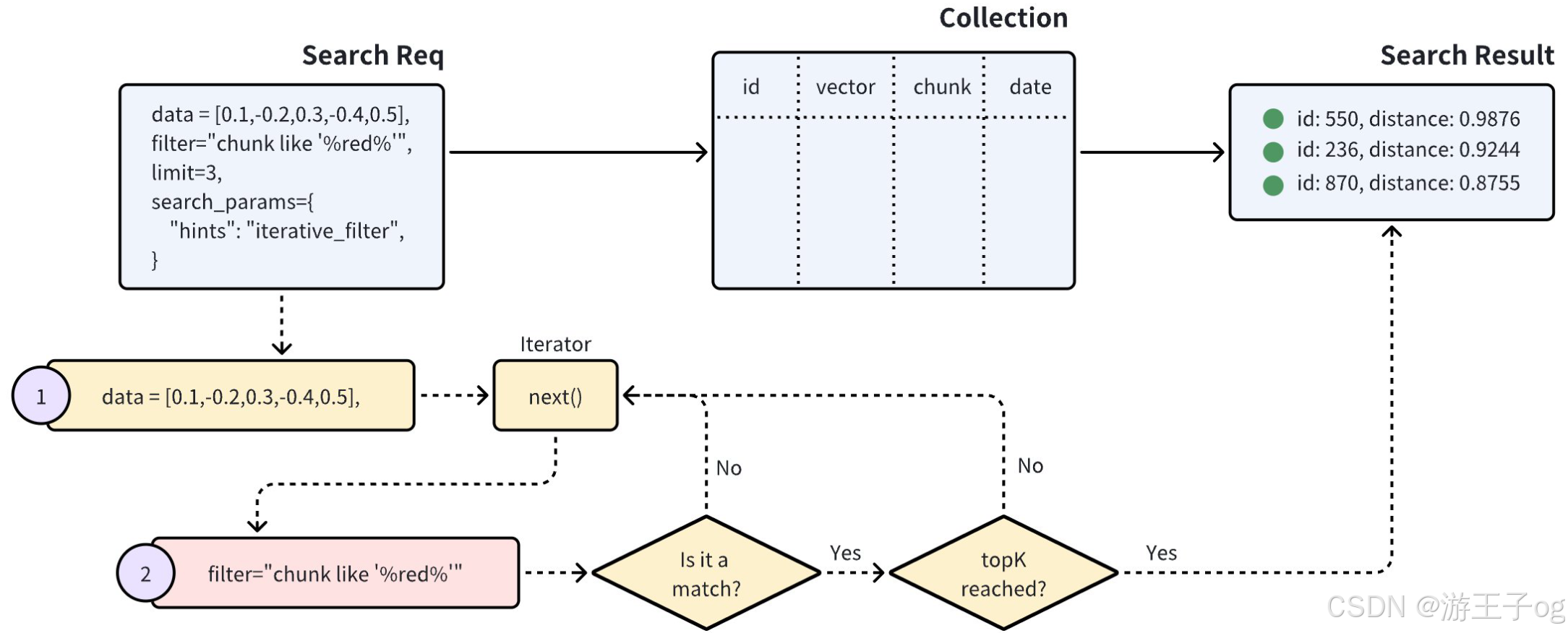
如上图所示,使用迭代过滤的搜索以迭代的方式执行向量搜索。迭代器返回的每个实体都要经过标量过滤,这个过程一直持续到达到指定的 topK 结果为止。这种方法大大减少了进行标量过滤的实体数量,特别有利于处理高度复杂的过滤表达式。不过,值得注意的是,迭代器一次处理一个实体。这种顺序方法可能会导致较长的处理时间或潜在的性能问题,尤其是在对大量实体进行标量过滤时。
1.2 示例
本节中的代码片段假定你已经在 Collections 中拥有以下实体。
[{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682", "likes": 165},{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025", "likes": 25},{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781", "likes": 764},{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298", "likes": 234},{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794", "likes": 122},{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222", "likes": 12},{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392", "likes": 58},{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510", "likes": 775},{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381", "likes": 876},{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976", "likes": 765}
]1.2.1 使用标准过滤进行搜索
下面的代码片段演示了使用标准过滤进行搜索,下面代码片段中的请求包含一个过滤条件和多个输出字段。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]res = client.search(collection_name="my_collection",data=[query_vector],limit=5,# highlight-startfilter='color like "red%" and likes > 50',output_fields=["color", "likes"]# highlight-end
)for hits in res:print("TopK results:")for hit in hits:print(hit) 搜索请求中的过滤条件为color like "red%" and likes > 50 。它使用 and 操作符包含两个条件:第一个条件要求在color 字段中查找值以red 开头的实体,其他条件要求在likes 字段中查找值大于50 的实体。符合这些要求的实体只有两个。当 top-K 设置为3 时,Milvus 将计算这两个实体与查询向量的距离,并将它们作为搜索结果返回。
[{"id": 4, "distance": 0.3345786594834839,"entity": {"vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794", "likes": 122}},{"id": 6, "distance": 0.6638239834383389,"entity": {"vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392", "likes": 58}},
]1.2.2 使用迭代过滤搜索
使用迭代过滤进行过滤搜索的方法如下:
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]res = client.search(collection_name="my_collection",data=[query_vector],limit=5,# highlight-startfilter='color like "red%" and likes > 50',output_fields=["color", "likes"],search_params={"hints": "iterative_filter"}# highlight-end
)for hits in res:print("TopK results:")for hit in hits:print(hit)2 范围搜索
范围搜索可将返回实体的距离或得分限制在特定范围内,从而提高搜索结果的相关性。
2.1 概述
执行范围搜索请求时,Milvus 以 ANN 搜索结果中与查询向量最相似的向量为圆心,以搜索请求中指定的半径为外圈半径,以range_filter为内圈半径,画出两个同心圆。所有相似度得分在这两个同心圆形成的环形区域内的向量都将被返回。这里,range_filter可以设置为0,表示将返回指定相似度得分(半径)范围内的所有实体。
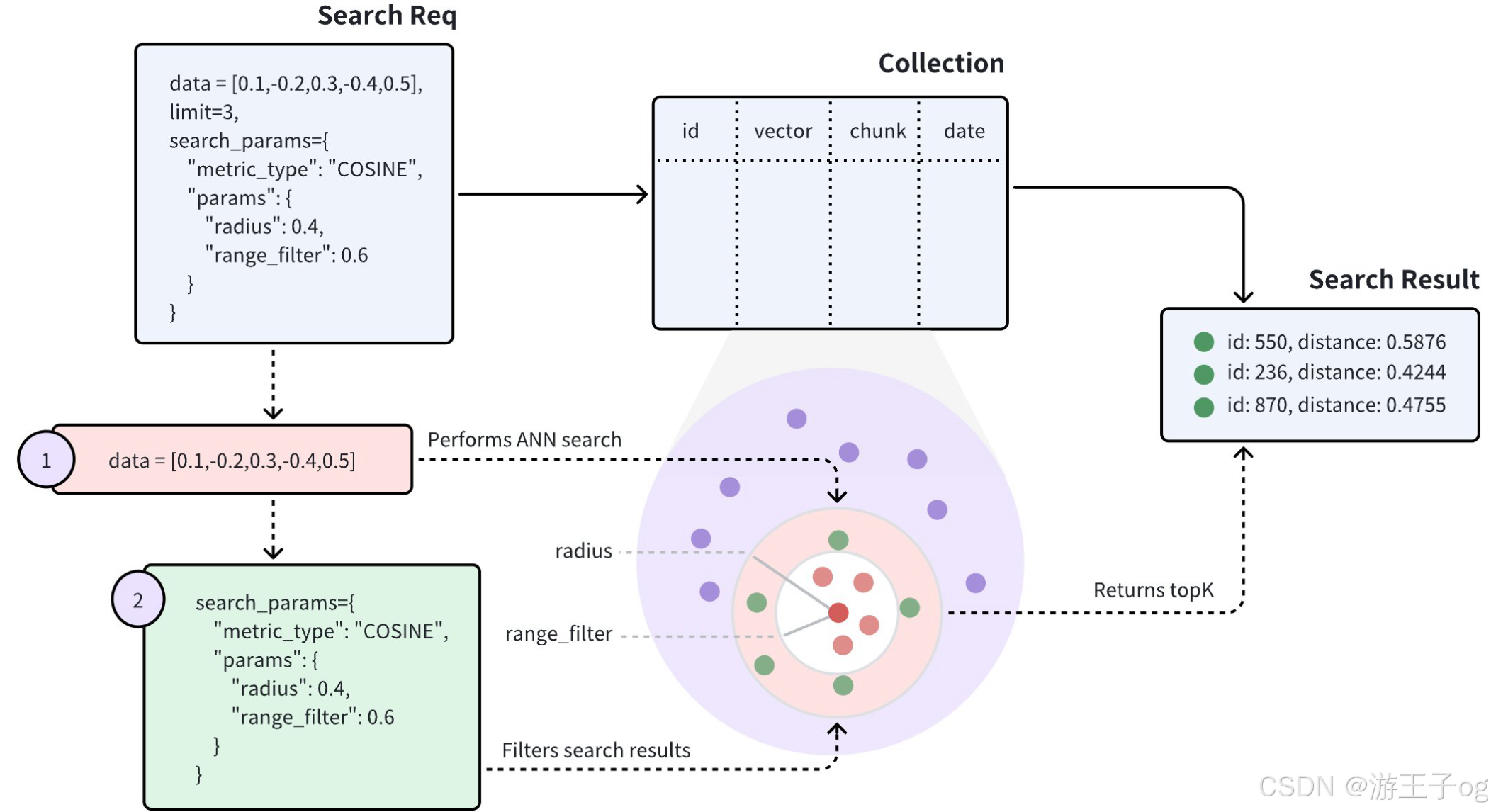
上图显示,范围搜索请求包含两个参数:半径和range_filter。收到范围搜索请求后,Milvus 会执行以下操作:
- 使用指定的度量类型(COSINE)查找与查询向量最相似的所有向量嵌入。
- 过滤与查询向量的距离或得分在半径和range_filter参数指定范围内的向量嵌入。
- 从筛选出的实体中返回前 K个实体。
设置radius和range_filter的方法因搜索的度量类型而异。下表列出了在不同度量类型下设置这两个参数的要求。
| 度量类型 | 名称 | 设置半径和范围筛选器的要求 |
|---|---|---|
|
| L2 距离越小,表示相似度越高。 | 要忽略最相似的向量 Embeddings,请确保 |
|
| IP 距离越大,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
|
| COSINE 距离越大,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
|
| Jaccard 距离越小,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
|
| 汉明距离越小,表示相似度越高。 | 要忽略最相似的向量嵌入,请确保 |
2.2 示例
以下代码片段中的搜索请求不带度量类型,表示使用默认度量类型COSINE。在这种情况下,请确保半径值小于range_filter值。在以下代码片段中,将radius 设为0.4 ,将range_filter 设为0.6 ,这样 Milvus 就会返回与查询向量的距离或分数在0.4至0.6 范围内的所有实体。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]res = client.search(collection_name="my_collection",data=[query_vector],limit=3,search_params={# highlight-start"params": {"radius": 0.4,"range_filter": 0.6}# highlight-end}
)for hits in res:print("TopK results:")for hit in hits:print(hit)3 分组搜索
分组搜索允许 Milvus 根据指定字段的值对搜索结果进行分组,以便在更高层次上汇总数据。例如,您可以使用基本的 ANN 搜索来查找与手头的图书相似的图书,但也可以使用分组搜索来查找可能涉及该图书所讨论主题的图书类别。
3.1 概述
当搜索结果中的实体在标量字段中共享相同值时,这表明它们在特定属性上相似,这可能会对搜索结果产生负面影响。假设一个 Collections 存储了多个文档(用docId 表示)。在将文档转换成向量时,为了尽可能多地保留语义信息,每份文档都会被分割成更小的、易于管理的段落(或块),并作为单独的实体存储。即使文档被分割成较小的段落,用户通常仍希望识别哪些文档与他们的需求最相关。
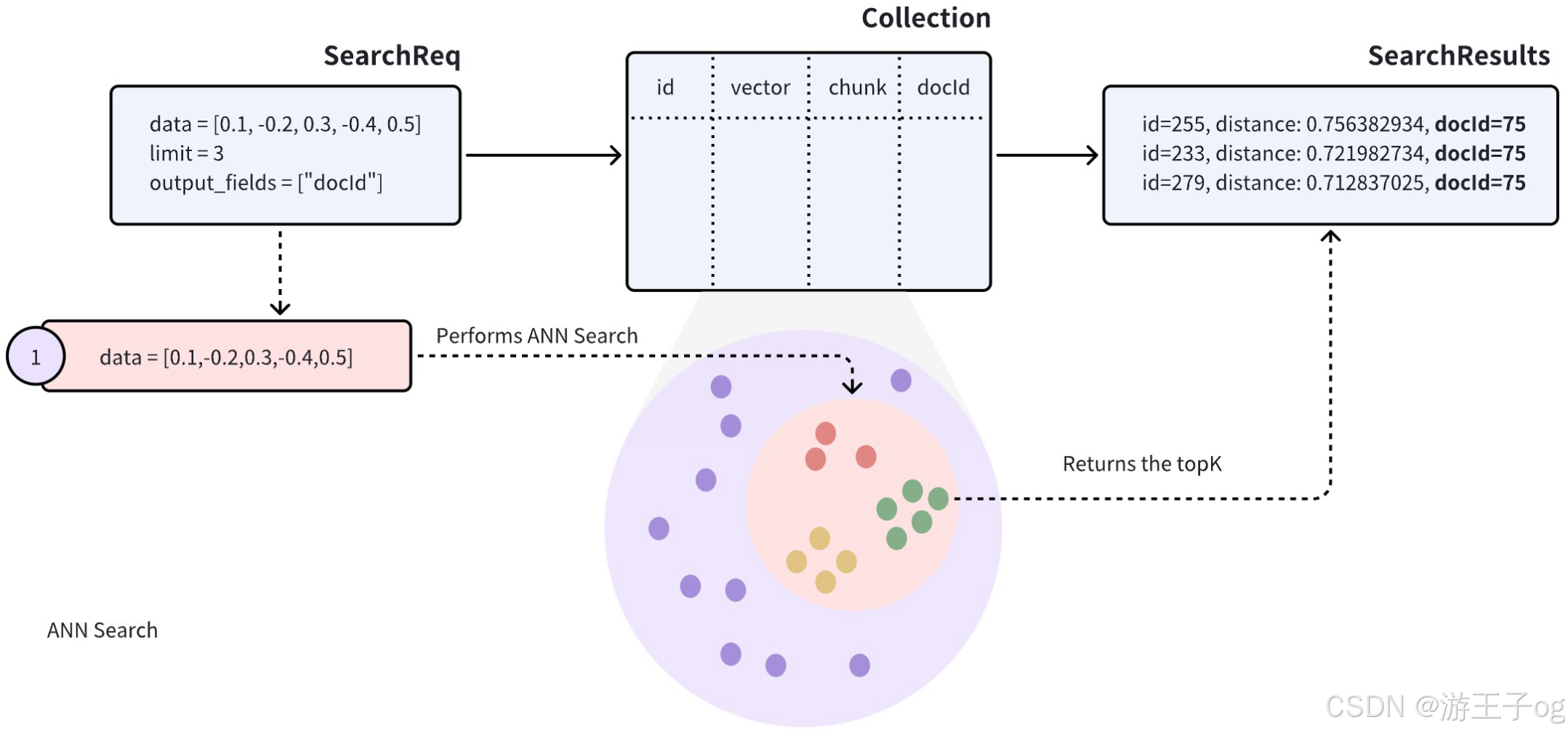
在对此类 Collections 执行近似近邻 (ANN) 搜索时,搜索结果可能包括同一文档中的多个段落,有可能导致其他文档被忽略,这可能与预期用例不符。
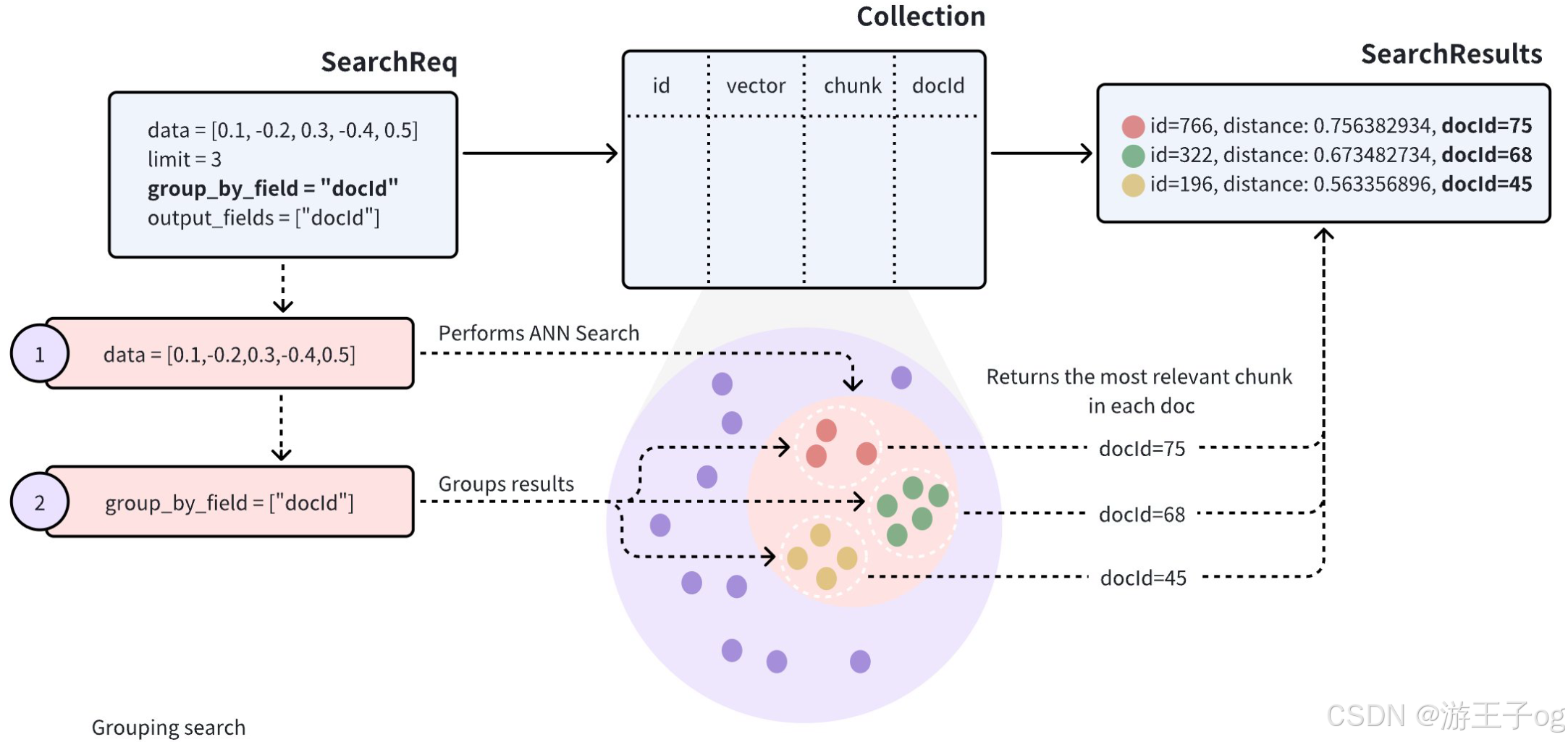
为了提高搜索结果的多样性,可以在搜索请求中添加group_by_field 参数来启用分组搜索。如图所示,您可以将group_by_field 设置为docId 。收到此请求后,Milvus 将
- 根据提供的查询向量执行 ANN 搜索,找到与查询最相似的所有实体。
- 按指定的
group_by_field对搜索结果进行分组,如docId。 - 根据
limit参数的定义,返回每个组的顶部结果,并从每个组中选出最相似的实体。
默认情况下,分组搜索每个组只返回一个实体。如果要增加每个组返回结果的数量,可以使用group_size 和strict_group_size 参数进行控制。
3.2 执行分组搜索
以下示例假定 Collections 包括id,vector,chunk 和docId 字段。
[{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "chunk": "pink_8682", "docId": 1},{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "chunk": "red_7025", "docId": 5},{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "chunk": "orange_6781", "docId": 2},{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "chunk": "pink_9298", "docId": 3},{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "chunk": "red_4794", "docId": 3},{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "chunk": "yellow_4222", "docId": 4},{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "chunk": "red_9392", "docId": 1},{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "chunk": "grey_8510", "docId": 2},{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "chunk": "white_9381", "docId": 5},{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "chunk": "purple_4976", "docId": 3},
] 在搜索请求中,将group_by_field 和output_fields 都设置为docId 。Milvus 将根据指定字段对结果进行分组,并从每个分组中返回最相似的实体,包括每个返回实体的docId 值。
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)query_vectors = [[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]# 组搜索结果
res = client.search(collection_name="my_collection",data=query_vectors,limit=3,group_by_field="docId",output_fields=["docId"]
)# 检索‘ docId ’列中的值
doc_ids = [result['entity']['docId'] for result in res[0]] 在上面的请求中,limit=3 表示系统将从三个组中返回搜索结果,每个组都包含与查询向量最相似的单个实体。
3.3 配置组大小
默认情况下,分组搜索每个组只返回一个实体。如果希望每组有多个结果,请调整group_size 和strict_group_size 参数。
# 组搜索结果
res = client.search(collection_name="my_collection", data=query_vectors, # 查询向量limit=5, # 返回的组数group_by_field="docId", # 分组字段group_size=2, # 从每个组返回2个实体strict_group_size=True, # 是否应严格执行group_size 设置的计数。output_fields=["docId"]
)在上面的示例中
group_size:指定每个组要返回的实体数量。例如,设置group_size=2意味着每个组(或每个docId)最好返回两个最相似的段落(或块)。如果未设置group_size,系统将默认为每组返回一个结果。strict_group_size:这个布尔参数控制着系统是否应严格执行group_size设置的计数。当strict_group_size=True时,系统将尝试在每个组中包含group_size所指定的实体的确切数量(例如两个段落),除非该组中没有足够的数据。默认情况下(strict_group_size=False),系统会优先满足limit参数指定的组数,而不是确保每个组都包含group_size实体。在数据分布不均衡的情况下,这种方法通常更有效。
3.4 注意事项
- 索引:此分组功能仅适用于使用这些索引类型编制索引的 Collections:flat、ivf_flat、ivf_sq8、hnsw、hnsw_pq、hnsw_prq、hnsw_sq、diskann、sparse_inverted_index。
- 组数:
limit参数控制返回搜索结果的组的数量,而不是每个组内实体的具体数量。设置适当的limit有助于控制搜索多样性和查询性能。如果数据分布密集或考虑性能问题,减少limit可以降低计算成本。 - 每组实体:
group_size参数控制每个组返回的实体数量。根据使用情况调整group_size可以增加搜索结果的丰富性。但是,如果数据分布不均,某些组返回的实体数量可能少于group_size的指定数量,尤其是在数据有限的情况下。 - 严格的组大小:当
strict_group_size=True时,系统将尝试为每个组返回指定数量的实体 (group_size),除非该组中没有足够的数据。此设置可确保每个组的实体数一致,但在数据分布不均或资源有限的情况下可能会导致性能下降。如果不需要严格的实体数,设置strict_group_size=False可以提高查询速度。
相关文章:
:过滤搜索、范围搜索、分组搜索)
Milvus(21):过滤搜索、范围搜索、分组搜索
1 过滤搜索 ANN 搜索能找到与指定向量嵌入最相似的向量嵌入。但是,搜索结果不一定总是正确的。您可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件…...

AD PCB布局时常用的操作命令
1. 框选 往右下方框选:选中矩形接触到的对象(选中整体才会被选中) 往左上方框选:选中矩形接触到的对象(选中局部,也是选中整体) 线选:快捷键S,弹出界面: …...
【论文+源码+SQL脚本】)
[免费]微信小程序医院预约挂号管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序医院预约挂号管理系统(uni-appSpringBoot后端Vue管理端),分享下哈。 项目视频演示 【免费】微信小程序医院预约挂号管理系统(uni-appSpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩…...

分析Docker容器Jvm 堆栈GC信息
# 打印jvm启动参数 docker exec -ti <容器名> jcmd 1 VM.flags-XX:CICompilerCount3 -XX:InitialHeapSize1073741824 -XX:MaxHeapSize2147483648 -XX:MaxMetaspaceSize157286400 -XX:MaxNewSize715653120 -XX:MinHeapDeltaBytes524288 -XX:NewSize357564416 -XX:OldSize7…...

Java——集合基础
一、集合与数组的特点对比 1.集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以发生改变 2.集合和数组的区别 共同点:都是存储数据的容器不同点:数组的容量是固定的,集合的容量是可变的 3.如果存储…...

spark MySQL数据库配置
Spark 连接 MySQL 数据库的配置 要让 Spark 与 MySQL 数据库实现连接,需要进行以下配置步骤。下面为你提供详细的操作指南和示例代码: 1. 添加 MySQL JDBC 驱动依赖 你得把 MySQL 的 JDBC 驱动添加到 Spark 的类路径中。可以通过以下两种方式来完成&a…...

http断点续传
🛑 默认的 http.server(Python 的 SimpleHTTPRequestHandler)在某些版本和实现中并不可靠地支持 HTTP Range 请求(即断点续传)。 尤其在 Python 3.7~3.10 之间的某些版本中,这种支持是不完整或不可预测的。…...

# YOLOv3:基于 PyTorch 的目标检测模型实现
YOLOv3:基于 PyTorch 的目标检测模型实现 引言 YOLOv3(You Only Look Once)是一种流行的单阶段目标检测算法,它能够直接在输入图像上预测边界框和类别概率。YOLOv3 的优势在于其高效性和准确性,使其在实时目标检测任…...

Mac修改hosts文件方法
Mac修改hosts文件方法 在 macOS 上修改 hosts 文件需要管理员权限 步骤 1:打开终端 通过 Spotlight 搜索(Command 空格)输入 Terminal,回车打开。或进入 应用程序 > 实用工具 > 终端。 步骤 2:备份 hosts 文件…...

构建你的第一个简单AI助手 - 入门实践
在当今AI迅速发展的时代,构建自己的AI助手不再是高不可攀的技术壁垒。即使对于刚接触AI开发的程序员,也可以利用现代大语言模型(LLM)API构建功能丰富的AI助手。本文将带您完成一个简单但实用的AI助手构建过程,帮助您在日常工作中提高效率。 …...

Qt在统信UOS及银河麒麟Kylin系统中进行软件开发的环境配置,打包发布和注意事项
前述 之前由于项目的产品需要,必须将原本Windows上的产品移植到信创环境,也就是现在的主流国产操作系统统信UOS及银河麒麟Kylin。 先大概讲下信创系统: 信创系统就像是中国自己打造的 “数字基建”,目的是让咱们国家的信息技术不…...

一个完整的项目示例:taro开发微信小程序
前一周完成了一个项目,体测成绩转换的工具,没做记录,。这次计划开发一个地图应用小程序,记录一下。方便给使用的人。 一、申请微信小程序,填写相应的信息,取得开发者ID。这个要给腾讯地图使用的。 二、申…...

二次封装 el-dialog 组件:打造更灵活的对话框解决方案
文章目录 引言为什么需要二次封装?封装思路代码实现1. 基础封装组件 (Dialog.vue)2. Vue中引入使用示例 封装后的优势进阶优化建议 总结 引言 在 Vue 项目中,Element UI 的 el-dialog 是一个非常实用的对话框组件。但在实际开发中,我们经常会…...

3.2 一点一世界
第一步:引入背景与动机 “一点一世界”这个概念来源于泰勒公式的思想,即通过一个点及其导数信息来近似描述整个函数的行为。这种方法在数学分析中非常有用,因为它允许我们将复杂的函数简化为多项式形式,从而更容易进行计算和理解…...

力扣第156场双周赛
1. 找到频率最高的元音和辅音 给你一个由小写英文字母(a 到 z)组成的字符串 s。你的任务是找出出现频率 最高 的元音(a、e、i、o、u 中的一个)和出现频率最高的辅音(除元音以外的所有字母),并返…...

学习日志05 java
1 java里面的类型转换怎么做?int转double为例 在 Java 里,把int转换为double有自动类型转换和强制类型转换两种方式。下面为你详细介绍: 自动类型转换(隐式转换) 由于double的取值范围比int大,Java 能够…...

4.7/Q1,GBD数据库最新文章解读
文章题目:Burden of non-COVID-19 lower respiratory infections in China (1990-2021): a global burden of disease study analysis DOI:10.1186/s12931-025-03197-7 中文标题:中国非 COVID-19 下呼吸道感染负担(1990-2021 年&a…...

do while
先进再查 import java.util.Scanner;public class Hello {public static void main(String[] args) {Scanner in new Scanner(System.in);int number in.nextInt();int count 0;do{number number / 10;count count 1;} while( number > 0 );System.out.println(count…...

MySQL 主从复制与读写分离
一、MySQL 主从复制 (0)概述 MySQL 主从复制是一种数据同步机制,允许数据从一个主数据库(Master)复制到一个或多个从数据库(Slave)。其主要用途包括: 数据冗余与灾备:通…...

CSS3 基础知识、原理及与CSS的区别
CSS3 基础知识、原理及与CSS的区别 CSS3 基础知识 CSS3 是 Cascading Style Sheets 的第3个版本,是CSS技术的升级版本,于1999年开始制订,2001年5月23日W3C完成了CSS3的工作草案。 CSS3 主要模块 选择器:更强大的元素选择方式盒…...

第十七章:Llama Factory 深度剖析:易用性背后的微调框架设计
章节引导:在模型定制的实践中,Llama Factory (github.com/hiyouga/LLaMA-Factory) 以其惊人的易用性和对多种开源大模型、多种参数高效微调方法(PEFT)的广泛支持,迅速成为开源社区的热门选择。你可能已经熟练掌握了如何…...

SpringSecurity当中的CSRF防范详解
CSRF防范 什么是CSER 以下是基于 CSRF 攻击过程的 顺序图 及详细解释,结合多个技术文档中的攻击流程: CSRF 攻击顺序图 #mermaid-svg-FqfMBQr8DsGRoY2C {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#m…...

CSRF防范歪招
不保存到Cookie里呗 如果每次请求都强制通过请求头携带Token,并且不将Token存储在Cookie中,这种设计可以有效防御CSRF攻击。以下是具体原因和关键实现要点: 1. 防御原理 CSRF攻击的本质是攻击者伪造用户的请求,利用浏览器自动携…...

MyBatis与MyBatis-Plus深度分析
MyBatis与MyBatis-Plus深度分析 一、MyBatis原理与基础 1. MyBatis核心原理 MyBatis是一个半自动ORM框架,主要原理包括: SQL与代码分离:通过XML或注解配置SQL语句动态SQL:提供if、choose、foreach等标签实现动态SQL结果集映射…...

STM32 变量加载到flash的过程中
在STM32中,BIN文件内需要加载到RAM的数据由链接脚本(Linker Script)和启动代码(Startup Code)共同决定,具体机制如下: 一、BIN文件内容结构 STM32的BIN文件包含三类数据: Co…...

TCP核心机制
1. TCP五大核心机制 1.1. 顺序问题(稳重不乱) 背景:网络传输中数据包可能因路径不同或网络波动导致乱序到达,需保证接收方能按正确顺序处理数据。 原理: 序列号(Sequence Number)࿱…...

6.3对象序列化
在 Java 中,ObjectInputStream 和 ObjectOutputStream 是用于实现对象序列化(Serialization)和反序列化(Deserialization)的核心类。通过这两个类,可以将对象转换为字节流进行存储或传输,并在需…...

Flutter小白入门指南
Flutter小白入门指南 🚀 轻松构建漂亮的跨平台应用 📑 目录 一、Flutter是什么? 为什么选择Flutter?Flutter工作原理 二、环境搭建与命令行 安装Flutter SDK常用Flutter命令创建第一个项目 三、Flutter基础语法 变量与类型函数条…...

Python -将MP4文件转为GIF图片
给大家提供一个工具代码,使用Python,将MP4格式的视频文件,转换为GIF图片 首先先安装必要的包: pip install imageio pip install imageio[ffmpeg] 工具代码: import imageio# 视频文件路径 video_path r""…...

51c嵌入式~电路~合集27
我自己的原文哦~ 一、7805应用电路 简介 如上图,7805 集成稳压电路。 7805是串联式三端稳压器,三个端口分别是电压输入端(IN),地线(GND),稳压输出(OUT)…...
)
数据结构—(链表,栈,队列,树)
本文章写的比较乱,属于是缝合怪,很多细节没处理,显得粗糙,日后完善,今天赶时间了。 1. 红黑树的修复篇章 2. 红黑树的代码理解(部分写道注释之中了) 3. 队列与栈的代码 4. 重要是理解物理逻辑&a…...
)
GitHub 趋势日报 (2025年05月12日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1harry0703/MoneyPrinterTurbo利用ai大模型,一键生成高清短视频使用…...

ebook2audiobook开源程序使用动态 AI 模型和语音克隆将电子书转换为带有章节和元数据的有声读物。支持 1,107+ 种语言
一、软件介绍 文末提供程序和源码下载 ebook2audiobook开源程序使用动态 AI 模型和语音克隆将电子书转换为带有章节和元数据的有声读物。支持 1,107 种语言。从电子书到带有章节和元数据的有声读物的 CPU/GPU 转换器,使用 XTTSv2、Bark、Vits、Fairseq、YourTTS …...
》阅读笔记:p39-p48)
《算法导论(第4版)》阅读笔记:p39-p48
《算法导论(第4版)》学习第 13 天,p39-p48 总结,总计 10 页。 一、技术总结 1. recurrence/recurrence equation 书里面 recurrence(递归式) 和 recurrence equation(递归方程) 指的是同一个东西。 二、英语总结(生词:2) 1. squint (1)…...

c语言第一个小游戏:贪吃蛇小游戏07
贪吃蛇吃饭喽 所谓贪吃蛇的食物,也就是创建一个和蛇身一样的结构体,只是这个结构体不是链表,也是将这个结构体设置hang和lie坐标,放进gamepic进行扫描,扫到了就也是做操作将 ## 打出来 #include <curses.h> #i…...
深度学习---神经网络原理与实现)
(七)深度学习---神经网络原理与实现
分类问题回归问题聚类问题各种复杂问题决策树√线性回归√K-means√神经网络√逻辑回归√岭回归密度聚类深度学习√集成学习√Lasso回归谱聚类条件随机场贝叶斯层次聚类隐马尔可夫模型支持向量机高斯混合聚类LDA主题模型 一.神经网络原理概述 二.神经网络的训练方法 三.基于Ker…...

VSCode中Node.js 使用教程
一、visual studio code下载与安装 二、修改vscode主题颜色 三、汉化 菜单view-->Command Palette...,输入Configure Display Language。 重启之后如下: 四、安装node.js Node.js 是一个基于Chrome V8引擎的JavaScript运行环境,使用了事件驱动、非阻…...

web 自动化之 KDT 关键字驱动详解
一、什么是关键字驱动? 1、什么是关键字驱动?(以关键字函数驱动测试) 关键字驱动又叫动作字驱动,把项目业务封装成关键字函数,再基于关键字函数实现自动化测试 2、关键字驱动测试原理 关键字驱动测试是一…...

web 自动化之 yaml 数据/日志/截图
文章目录 一、yaml 数据获取二、日志获取三、截图 一、yaml 数据获取 需要安装 PyYAML 库 import yaml import os from TestPOM.common import dir_config as Dirdef read_yaml(key,file_name"test_datas.yaml"):file_path os.path.join(Dir.testcases_dir, file_…...
)
基于javaweb的SpringBoot酒店管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

数学复习笔记 6
前言 复习一下行列式的一些基本的题。感觉网课有点没跟上了。今天花点时间跟上网课的进度。要紧跟进度,然后剩下的时间再去复习前面的内容。多复习,提升自己的解题能力。 行列式和矩阵 三年级,我现在是三年级下册。。。马上就要结束大学的…...

JS Map使用方法
JS Map使用方法 Map 是 ES6 引入的一种新的数据结构,它类似于对象(Object),但提供了更强大的键值对存储功能。 文章目录 JS Map使用方法基本特性基本用法创建 Map常用方法遍历方法 与 Object 的区别实际应用示例示例1:…...

大模型分布式光伏功率预测实现详解
一、引言 随着全球能源结构向可再生能源转型,光伏发电作为清洁能源的重要组成部分,其装机容量持续快速增长。然而,光伏发电具有显著的间歇性和波动性特点,给电力系统的稳定运行带来了巨大挑战。准确的光伏功率预测对于电网调度、电力市场交易和电站运营管理至关重要。近年…...

武汉大学无人机视角下的多目标指代理解新基准!RefDrone:无人机场景指代表达理解数据集
作者:Zhichao Sun, Yepeng Liu, Huachao Zhu, Yuliang Gu, Yuda Zou, Zelong Liu, Gui-Song Xia, Bo Du, Yongchao Xu 单位:武汉大学计算机学院 论文标题:RefDrone: A Challenging Benchmark for Drone Scene Referring Expression Compreh…...

【LLM模型】如何构建自己的MCP Server?
什么是 MCP? Model Context Protocol (MCP) 是一种协议,它允许大型语言模型(LLMs)访问自定义的工具和服务。Trae 中的智能体作为 MCP 客户端可以选择向 MCP Server 发起请求,以使用它们提供的工具。你可以自行添加 MC…...

SQL 索引优化指南:原理、知识点与实践案例
SQL 索引优化指南:原理、知识点与实践案例 索引的基本原理 索引是数据库中用于加速数据检索的数据结构,类似于书籍的目录。它通过创建额外的数据结构来存储部分数据,使得查询可以快速定位到所需数据而不必扫描整个表。 索引的工作原理 B-…...

java基础-方法的重写、super关键字
1.定义:子类可以根据需要改写从父类那继承来的方法,执行时,子类的方法会覆盖父类的方法 2.要求: (1)子类和父类的方法必须同名,同参数列表 (2)父类中private修饰的方法…...

技术并不能产生一个好的产品
技术是产生一个好的产品充分条件,不是必要条件。 当笔者到了40岁的年龄时间,发现再怎么努力提升技术,也没办法挽救烂的产品设计。 一个好的产品,首先要找准自己的定位,不能动不动就把自己拿一线品牌来比较。 好的产品…...

lubuntu 系统详解
Lubuntu 系统详解:轻量高效的 Ubuntu 衍生版 一、系统概述 定位与背景: Lubuntu 是 Ubuntu 的官方衍生版本(Flavor),专注于轻量性与高效性,旨在为低配置设备(如老旧电脑、上网本、低配笔记本 …...

《设备管理与维修》审核严吗?“修改后再投”是拒稿了吗?
有过论文投稿经验的朋友,可能在审核后收到过“修改后再投”的回复。有些期刊可能是真的建议投稿人在修改后再投稿,有些则可能是标准的拒稿模板。 《设备管理与维修》审核严吗?收到“修改后再投”的回复该怎么办?下面我就来分享下之…...