milvus+flask山寨《从零构建向量数据库》第7章case2
继续流水账完这本书,这个案例是打造文字形式的个人知识库雏形。
create_context_db:
# Milvus Setup Arguments
COLLECTION_NAME = 'text_content_search'
DIMENSION = 2048
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"# Inference Arguments
BATCH_SIZE = 128from pymilvus import MilvusClient,utility,connections
milvus_client = MilvusClient(uri="http://localhost:19530")# Connect to the instance
connections.connect(host=MILVUS_HOST,port=MILVUS_PORT)from markdown_processor import vectorize_segments,split_html_into_segmentstest_embedding = vectorize_segments(split_html_into_segments("<h1>RAG还是挺有意思的!</h1>"))
embedding_dim = len(test_embedding[0]) #原始的test_embedding的len结构是[[],[]]的形式
print(embedding_dim)
print(test_embedding[:10])# Remove any previous collection with the same name
if utility.has_collection(COLLECTION_NAME):utility.drop_collection(COLLECTION_NAME)milvus_client.create_collection(collection_name=COLLECTION_NAME,dimension=embedding_dim,metric_type="IP", # Inner product distanceconsistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
)#下面这个手法可以直接读取md文件,然后向量化存系统。
#from tqdm import tqdm
#data = []
#from glob import glob
#text_lines = []
#for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
# with open(file_path, "r") as file:
# file_text = file.read()
# text_lines += file_text.split("# ")
#
#for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
# data.append({"id": i, "vector": vectorize_segments(split_html_into_segments(line)), "text": line})
#
#milvus_client.insert(collection_name=COLLECTION_NAME, data=data)markdown_processor.py 这个文件如今大可不必了。
import markdown
from bs4 import BeautifulSoup #用于解析和操作HTML文档
from transformers import AutoTokenizer,AutoModel #用于自动加载预训练的模型以及分词器
import torch #用于深度学习计算def markdown_to_html(markdown_text):return markdown.markdown(markdown_text)def split_html_into_segments(html_text): #定义函数,将HTML文档分割成多个段落soup = BeautifulSoup(html_text,"html.parser") #解析HTML文档segments = [] #初始化一个列表用于存储分割后的段落#找HTML文档中的段落,标题,无序列表和有序列表标签for tag in soup.find_all(["h1","h2","h3","h4","h5","h6","p","ul","ol"]):segments.append(tag.get_text())return segments#定义函数,用于将文本段落转换为向量表示
def vectorize_segments(segments):# 使用预训练的分词器和模型,这里使用的是BAAI/bge-large-zh-v1.5 一个中文模型tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-large-zh-v1.5")model = AutoModel.from_pretrained("BAAI/bge-large-zh-v1.5")model.eval() #将模型定位评估模式,避免dropout等训练模式下的参数#使用分词器对文本段落进行编码,添加必要的填充和截断,并返回PyTorch张量格式encoded_input = tokenizer(segments,padding=True,truncation=True,return_tensors="pt")with torch.no_grad():model_output = model(**encoded_input) #将编码后的输入传递给模型,获取模型的输出sentence_embeddings = model_output[0][:,0] #从模型输出中提取句子向量化的结果#对句子的量化结果进行L2归一化,以便于后续的相似度比较或聚类分析sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings,p=2,dim=1)return sentence_embeddings
flask的app.py
from flask import Flask,request,jsonify
from flask import render_template
import requests
from markdown_processor import markdown_to_html, split_html_into_segments, vectorize_segments
from pymilvus import MilvusClientimport logging
import osMILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
COLLECTION_NAME = 'text_content_search'
TOP_K = 3app = Flask(__name__)
milvus_client = MilvusClient(uri="http://localhost:19530")@app.route("/")
def index():return render_template("index.html")@app.route('/upload', methods=['POST'])
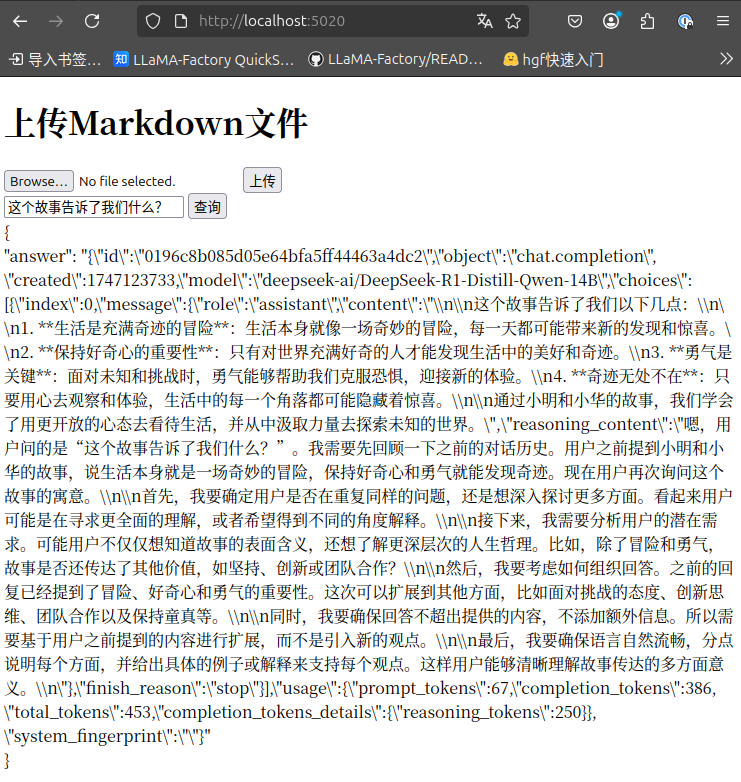
def upload():if 'file' not in request.files:return jsonify({'error': 'No file part in the request'}), 400file = request.files['file']if file.filename == '':return jsonify({'error': 'No file selected for uploading'}), 400markdown_text = file.read().decode('utf-8')html_text = markdown_to_html(markdown_text)segments = split_html_into_segments(html_text)vectors = vectorize_segments(segments)# 将向量上传到数据库data = []for i, (segment, vector) in enumerate(zip(segments, vectors)):data.append({"id": i + 1,"vector": vector.tolist(), "text": segment})milvus_client.insert(collection_name=COLLECTION_NAME, data=data)return jsonify({'message': '文件已处理并上传向量到数据库'})@app.route('/search', methods=['POST'])
def search():data = request.get_json()search_text = data.get('search')# 添加前缀到查询字符串instruction = "为这个句子生成表示以用于检索相关文章:"search_text_with_instruction = instruction + search_text# 向量化修改后的查询search_vector = vectorize_segments([search_text_with_instruction])[0].tolist()search_results = milvus_client.search(collection_name=COLLECTION_NAME,data=[search_vector], limit=3, # Return top 3 resultssearch_params={"metric_type": "IP", "params": {}}, # Inner product distanceoutput_fields=["text"], # Return the text field) # 构建与 LLM API 交互的消息列表messages = [{"role": "system", "content": "You are a helpful assistant. Answer questions based solely on the provided content without making assumptions or adding extra information."}] # 解析搜索结果for index,value in enumerate(search_results):#print(value)text = value[0]["entity"]["text"]print(text)messages.append({"role": "assistant", "content": text})messages.append({"role": "user", "content": search_text})# 向 deepseek 发送请求并获取答案 (用的silicon flow)url = "https://api.ap.siliconflow.com/v1/chat/completions"payload = {"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-14B","messages": messages,"stream": False,"max_tokens": 1000,"stop": None,"temperature": 0.7,"top_p": 0.7,"top_k": 10,"frequency_penalty": 0.5,"n": 1,"response_format": {"type": "text"},}headers = {"Authorization": "Bearer <#你自己的token>","Content-Type": "application/json"}response = requests.request("POST", url, json=payload, headers=headers)answer = response.textreturn jsonify({'answer': answer})if __name__ == '__main__':app.run(host='0.0.0.0', port=5020, debug=True)吐槽一下,silicon flow这种deepseek API免费问不到几个,就开始算钱咯。
小网站结构,以及其他杂代码,可以查看以及直接下载:https://www.ituring.com.cn/book/3305
相关文章:

milvus+flask山寨《从零构建向量数据库》第7章case2
继续流水账完这本书,这个案例是打造文字形式的个人知识库雏形。 create_context_db: # Milvus Setup Arguments COLLECTION_NAME text_content_search DIMENSION 2048 MILVUS_HOST "localhost" MILVUS_PORT "19530"# Inference Arguments…...

前端如何应对精确数字运算?用BigNumber.js解决JavaScript原生Number类型在处理大数或高精度计算时的局限性
目录 前端如何应对精确数字运算?用BigNumber.js解决JavaScript原生Number类型在处理大数或高精度计算时的局限性 一、BigNumber.js介绍 1、什么是 BigNumber.js? 2、作用领域 3、核心特性 二、安装配置与基础用法 1、引入 BigNumber.js 2、配置 …...

多目应用:三目相机在汽车智能驾驶领域的应用与技术创新
随着汽车智能驾驶技术不断完善,智能汽车也不断加速向全民普惠迈进,其中智驾“眼睛”三目视觉方案凭借低成本、高精度、强适配性成为众多汽车品牌关注的焦点。三目相机在汽车智能驾驶领域的创新应用,主要依托其多视角覆盖、高动态范围…...

webpack重构优化
好的,以下是一个关于如何通过重构 Webpack 构建策略来优化性能的示例。这个过程包括分析现有构建策略的问题、优化策略的制定以及具体的代码实现。 --- ### 项目背景 在参与公司的性能专项优化过程中,我发现现有的 Webpack 构建策略存在一些问题&#…...
英文题库(31-40))
MySQL 8.0 OCP(1Z0-908)英文题库(31-40)
目录 第31题题目分析正确答案 第32题题目分析正确答案 第33题题目分析正确答案: 第34题题目解析正确答案 第35题题目分析正确答案 第36题题目分析正确答案 第37题题目分析正确答案 第38题题目分析正确答案 第39题题目分析正确答案 第40题题目分析正确答案 第31题 Y…...

aardio - 虚表 —— vlistEx.listbar2 多层菜单演示
在 近我者赤 修改版的基础上,做了些许优化。 请升级到最新版本。 import win.ui; import godking.vlistEx.listbar2; import fonts.fontAwesome; /*DSG{{*/ mainForm win.form(text"多层折叠菜单";right1233;bottom713) mainForm.add({ custom{cls"…...

22.【.NET8 实战--孢子记账--从单体到微服务--转向微服务】--单体转微服务--增加公共代码
在拆分服务之前,我们需要先提取一些公共代码。本篇将重点新增日志记录、异常处理以及Redis的通用代码。这些组件将被整合到一个共享类库中,便于在微服务架构中高效复用。 Tip:在后续的教程中我们会穿插多篇提取公共代码的文章,帮助…...

EasyOps®5月热力焕新:三大核心模块重构效能边界
在应用系统管理中,我们将管理对象从「服务实例」优化为「部署实例」,这一改变旨在提升管理效率与数据展示清晰度。 此前,系统以 “IP Port” 组合定义服务实例。当同一 IP 下启用多个进程或端口时,会产生多个服务实例。比如一台…...

基于深度学习的工业OCR数字识别系统架构解析
一、项目场景 春晖数字识别视觉检测系统专注于工业自动化生产监控、设备运行数据记录等关键领域。系统通过高精度OCR算法,能够实时识别设备上显示的关键数据(如温度、压力、计数等),并定时存储至Excel文件中。这些数据对于生产过…...

R语言绘图 | 渐变火山图
客户要求绘制类似文章中的这种颜色渐变火山图,感觉挺好看的。网上找了一圈,发现有别人已经实现的类似代码,拿来修改后即可使用,这里做下记录,以便后期查找。 简单实现 library(tidyverse)library(ggrepel)library(ggf…...

Go语言——docker-compose部署etcd以及go使用其服务注册
一、docker-compsoe.yml文件如下 version: "3.5"services:etcd:hostname: etcdimage: bitnami/etcd:latestdeploy:replicas: 1restart_policy:condition: on-failureprivileged: truevolumes:# 持久化 etcd 数据到宿主机- "/app/apisix/etcd/data:/bitnami/etc…...

Tomcat的调优
目录 一. JVM 1.1 JVM的组成 1.2 运行时数据区域的组成 二. 垃圾回收 2.1 如何确认垃圾 1. 引用计数法 2. 根搜索算法 2.2 垃圾回收基本算法 1. 标记-清除算法(Mark-Sweep) 2. 标记-压缩算法(Mark-Compact) 3. 复制算法…...

Tomcat和Nginx的主要区别
1、功能定位 Nginx:核心是高并发HTTP服务器和反向代理服务器,擅长处理静态资源(如HTML、图片)和负载均衡。Tomcat:是Java应用服务器,主要用于运行动态内容(如JSP、Servlet)…...
)
Python训练营打卡——DAY24(2025.5.13)
目录 一、元组 1. 通俗解释 2. 元组的特点 3. 元组的创建 4. 元组的常见用法 二、可迭代对象 1. 定义 2. 示例 3. 通俗解释 三、OS 模块 1. 通俗解释 2. 目录树 四、作业 1. 准备工作 2. 实战代码示例 3. 重要概念解析 一、元组 是什么:一种…...

【TDengine源码阅读】DLL_EXPORT
2025年5月13日,周二清晨 #ifdef WINDOWS #define DLL_EXPORT __declspec(dllexport) #else #define DLL_EXPORT #endif为啥Linux和MacOS平台时宏为空,难道Linux和mac不用定义导出函数吗? 这段代码是一个跨平台的宏定义,用于处理不…...

电子科技浪潮下的华秋电子:慕尼黑上海电子展精彩回顾
为期3天的2025慕尼黑上海电子展(electronica China 2025)于17日在上海新国际博览中心落下帷幕。 展会那规模,真不是吹的!本届展会汇聚了1,794家国内外行业知名品牌企业的展商来 “摆摊”,展览面积大得像个超级大迷宫&…...

TDengine编译成功后的bin目录下的文件的作用
2025年5月13日,周二清晨 以下是TDengine工具集中各工具的功能说明: 核心工具 taosd • TDengine的核心服务进程,负责数据存储、查询和集群管理。 taos • 命令行客户端工具,用于连接TDengine服务器并执行SQL操作。 taosBenchma…...

spark sql基本操作
Spark SQL 是 Apache Spark 的一个模块,用于处理结构化数据。它允许用户使用标准的 SQL 语法来查询数据,并且可以无缝地与 Spark 的其他功能(如 DataFrame、Dataset 和 RDD)结合使用。以下是 Spark SQL 的基本使用方法和一些常见操…...

采购流程规范化如何实现?日事清流程自动化助力需求、采购、财务高效协作
采购审批流程全靠人推进,内耗严重,效率低下? 花重金上了OA,结果功能有局限、不灵活? 问题出在哪里?是我们的要求太多、太苛刻吗?NO! 流程名称: 采购审批管理 流程功能…...

影刀RPA开发-CSS选择器介绍
影刀RPA网页自动化开发,很多时候需要我们查看页面源码,查找相关的元素属性,这就需要我们有必要了解CSS选择器。本文做了些简单的介绍。希望对大家有帮助! 1. CSS选择器概述 1.1 定义与作用 CSS选择器是CSS(层叠样式…...
AT、科大讯飞靠什么坐上中国Ai牌桌?)
DeepSeek、B(不是百度)AT、科大讯飞靠什么坐上中国Ai牌桌?
在国产AI舞台上,DeepSeek、阿里、字节、腾讯、讯飞群雄逐鹿,好不热闹。 这场堪称“军备竞赛”的激烈角逐,绝非简单的市场竞争,而是一场关乎技术、创新与未来布局的深度博弈。在竞赛中,五大模型各显神通,以…...

MySQL全局优化
目录 1 硬件层面优化 1.1 CPU优化 1.2 内存优化 1.3 存储优化 1.4 网络优化 2 系统配置优化 2.1 操作系统配置 2.2 MySQL服务配置 3 库表结构优化 4 SQL及索引优化 mysql可以从四个层面考虑优化,分别是 硬件系统配置库表结构SQL及索引 从成本和优化效果来看…...

【github】主页显示star和fork
数据收集:定期(例如每天)获取你所有仓库的 Star 和 Fork 总数。数据存储:将收集到的数据(时间戳、总 Star 数、总 Fork 数)存储起来。图表生成:根据存储的数据生成变化曲线图(通常是…...

网站遭受扫描攻击,大量爬虫应对策略
网站的日志里突然有很多访问路径不存在的,有些ip地址也是国外的,而且访问是在深夜且次数非常频繁紧密。判定就是不怀好意的扫描网站寻找漏洞。也有些是爬虫,且是国外的爬虫,有的也是不知道的爬虫爬取网站。网站的真实流量不多&…...

【 Redis | 实战篇 秒杀实现 】
目录 前言: 1.全局ID生成器 2.秒杀优惠券 2.1.秒杀优惠券的基本实现 2.2.超卖问题 2.3.解决超卖问题的方案 2.4.基于乐观锁来解决超卖问题 3.秒杀一人一单 3.1.秒杀一人一单的基本实现 3.2.单机模式下的线程安全问题 3.3.集群模式下的线程安全问题 前言&…...
)
手搓传染病模型(SEIARW)
在传染病传播的研究中,水传播途径是一个重要的考量因素。SEAIRW 模型(易感者 S - 暴露者 E - 感染者 I - 无症状感染者 A - 康复者 R - 水中病原体 W)综合考虑了人与人接触传播以及水传播的双重机制,为分析此类传染病提供了全面的…...

【C++】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希
【C】深入理解 unordered 容器、布隆过滤器与分布式一致性哈希 在日常开发中,无论是数据结构优化、缓存设计,还是分布式架构搭建,unordered_map、布隆过滤器和一致性哈希都是绕不开的关键工具。它们高效、轻量,在性能与扩展性方面…...

第五天——贪心算法——射气球
1.题目 有一些球形气球贴在一个表示 XY 平面的平坦墙壁上。气球用一个二维整数数组 points 表示,其中 points[i] [xstart, xend] 表示第 i 个气球的水平直径范围从 xstart 到 xend。你并不知道这些气球的具体 y 坐标。 可以从 x 轴上的不同位置垂直向上࿰…...

麦肯锡110页PPT企业组织效能提升调研与诊断分析指南
“战略清晰、团队拼命、资源充足,但业绩就是卡在瓶颈期上不去……”这是许多中国企业面临的真实困境。表面看似健康的企业,往往隐藏着“组织亚健康”问题——跨部门扯皮、人才流失、决策迟缓、市场反应滞后……麦肯锡最新研究揭示:组织健康度…...
)
BFS算法篇——从晨曦到星辰,BFS算法在多源最短路径问题中的诗意航行(上)
文章目录 引言一、多源BFS的概述二、应用场景三、算法步骤四、代码实现五、代码解释六、总结 引言 在浩渺的图论宇宙中,图的每一条边、每一个节点都是故事的组成部分。每当我们站在一个复杂的迷宫前,开始感受它的深邃时,我们往往不再局限于从…...

理解 C# 中的各类指针
前言 变量可以理解成是一块内存位置的别名,访问变量也就是访问对应内存中的数据。 指针是一种特殊的变量,它存储了一个内存地址,这个内存地址代表了另一块内存的位置。 指针指向的可以是一个变量、一个数组元素、一个对象实例、一块非托管内存…...
)
MySQL 事务(二)
文章目录 事务隔离性理论理解隔离性隔离级别 事务隔离级别的设置和查看事务隔离级别读未提交读提交(不可重复读) 事务隔离性理论 理解隔离性 MySQL服务可能会同时被多个客户端进程(线程)访问,访问的方式以事务方式进行一个事务可能由多条SQL…...

【HarmonyOS】ArkTS开发应用的横竖屏切换
文章目录 1、简介2、静态 — 横竖屏切换2.1、效果2.2、实现原理2.3、module.json5 源码 3、动态 — 横竖屏切换3.1、应用随系统旋转切换横竖屏3.2、setPreferredOrientation 原理配置3.3、锁定旋转的情况下,手动设置横屏状态 1、简介 在完成全屏网页嵌套应用开发后…...

Linux中find命令用法核心要点提炼
大家好,欢迎来到程序视点!我是你们的老朋友.小二! 以下是针对Linux中find命令用法的核心要点提炼: 基础语法结构 find [路径] [选项] [操作]路径:查找目录(.表当前目录,/表根目录)…...

专栏项目框架介绍
项目整体实现框图 如下图所示,是该项目的整体框图,项目的功能概括为:PC端下发数据文件,FPGA板卡接收数据文件,缓存至DDR中,待数据文件发送完毕,循环读取DDR有效写区域数据,将DDR数据…...

WSL 安装 Debian 12 后,Linux 如何安装 vim ?
在 WSL 的 Debian 12 中安装 Vim 非常简单,只需使用 apt 包管理器即可。以下是详细步骤: 1. 更新软件包列表 首先打开终端,确保系统包列表是最新的: sudo apt update2. 安装 Vim 直接通过 apt 安装 Vim: sudo apt …...
)
【SpringBoot】从零开始全面解析Spring MVC (一)
本篇博客给大家带来的是SpringBoot的知识点, 本篇是SpringBoot入门, 介绍Spring MVC相关知识. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子…...

C++—特殊类设计设计模式
目录 C—特殊类设计&设计模式1.设计模式2.特殊类设计2.1设计一个无法被拷贝的类2.2设计一个只能在堆上创建对象的类2.3设计一个只能在栈上创建对象的类2.4设计一个类,无法被继承2.5设计一个类。这个类只能创建一个对象【单例模式】2.5.1懒汉模式实现2.5.2饿汉模…...

初入OpenCV
OpenCV简介 OpenCV是一个开源的跨平台计算机视觉库,它实现了图像处理和计算机视觉方面的很多通用算法。 应用场景: 目标识别:人脸、车辆、车牌、动物; 自动驾驶;医学影像分析; 视频内容理解分析ÿ…...
)
霍夫圆变换全面解析(OpenCV)
文章目录 一、霍夫圆变换基础1.1 霍夫圆变换概述1.2 圆的数学表达与参数化 二、霍夫圆变换算法实现2.1 标准霍夫圆变换算法流程2.2 参数空间的表示与优化 三、关键参数解析3.1 OpenCV中的HoughCircles参数3.2 参数调优策略 四、Python与OpenCV实现参考4.1 基本实现代码4.2 改进…...

互联网大厂Java求职面试:优惠券服务架构设计与AI增强实践-4
互联网大厂Java求职面试:优惠券服务架构设计与AI增强实践-4 场景设定 面试官:某互联网大厂技术总监,拥有超过10年大型互联网企业一线技术管理经验,擅长分布式架构、微服务治理、云原生等领域。 候选人:郑薪苦&#…...

项目中会出现的css样式
1.重复渐变边框 思路: 主要是用重复的背景渐变实现的 如图: <div class"card"><div class"container">全面收集中医癌毒临床医案,建立医案共享机制,构建癌毒病机知识图谱,便于医疗人…...

LeetCode[101]对称二叉树
思路: 对称二叉树是左右子树对称,而不是左右子树相等,所以假设一个树只有3个节点,那么判断这个数是否是对称二叉树,肯定是先判断左右两个树,然后再看根节点,这样递归顺序我们就确认了࿰…...
)
黑马k8s(四)
1.资源管理介绍 本章节主要介绍yaml语法和kubernetes的资源管理方式 2.YAML语言介绍 3.资源管理方式 命令式对象管理 dev下删除了pod,之后发现还有pod,把原来的pod删除了,重新启动了一个 命令式对象配置 声明式对象配置 命令式对象配置&…...

华为ensp实现跨vlan通信
要在网络拓扑中实现主机192.168.1.1、192.168.1.2和192.168.2.1之间的互相通信,需要正确配置交换机(S5700)和路由器(AR3260),以确保不同网段之间的通信(即VLAN间路由)。 网络拓扑分析…...

TCPIP详解 卷1协议 十 用户数据报协议和IP分片
10.1——用户数据报协议和 IP 分片 UDP是一种保留消息边界的简单的面向数据报的传输层协议。它不提供差错纠正、队列管理、重复消除、流量控制和拥塞控制。它提供差错检测,包含我们在传输层中碰到的第一个真实的端到端(end-to-end)校验和。这…...

Java笔记4
第一章 static关键字 2.1 概述 以前我们定义过如下类: public class Student {// 成员变量public String name;public char sex; // 男 女public int age;// 无参数构造方法public Student() {}// 有参数构造方法public Student(String a) {} }我们已经知道面向…...

Matlab 垂向七自由度轨道车辆开关型半主动控制
1、内容简介 Matlab 229-垂向七自由度轨道车辆开关型半主动控制 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

Matlab 短时交通流预测AR模型
1、内容简介 Matlab 230-短时交通流预测AR模型 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略城市道路短时交通流预测.pdf...

MYSQL之表的约束
表中真正约束字段的是数据类型, 但是只有数据类型约束就很单一, 也需要有一些额外的约束, 从而更好的保证数据的合法性, 从业务逻辑角度保证数据的正确性. 比如有一个字段是email, 要求是唯一的. 为什么要有表的约束? 表的约束: 表中一定要有各种约束, 通过约束, 让我们未来…...