《Python星球日记》 第63天:文本方向综合项目(新闻分类)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、项目需求分析
- 1. 项目背景与目标
- 2. 功能需求
- 3. 技术方案概述
- 二、数据清洗与文本预处理
- 1. 数据集介绍
- 2. 数据清洗步骤
- 3. 文本向量化
- 三、模型选择与训练
- 1. RNN模型
- 2. LSTM模型
- 3. Transformer模型
- 4. 模型比较与选择
- 四、结果可视化与评估
- 1. 类别分布与预测置信度
- 2. 错误分析
- 3. 词云可视化
- 五、模型部署与API构建
- 1. 构建RESTful API
- 2. 保存和加载组件
- 3. 部署建议
- 4. 使用示例
- 六、项目总结与扩展方向
- 1. 项目回顾
- 2. 可能的改进方向
- 3. 扩展应用场景
- 七、总结
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第62天:图像方向综合项目(猫狗分类)
大家好,欢迎来到Python星球的第63天!🪐
在经过前62天的学习旅程,我们已经掌握了从Python基础到机器学习、深度学习的各种知识。今天,我们将把所学的知识综合应用到一个实际的文本分类项目中,实现新闻类别的自动分类系统。这个项目将综合运用文本处理、深度学习和Web开发技术,帮助我们巩固所学知识并拓展实战经验。
一、项目需求分析
1. 项目背景与目标
随着互联网信息爆炸式增长,自动文本分类技术在信息过滤、内容推荐等领域发挥着越来越重要的作用。我们的项目目标是构建一个能够自动将新闻文章分类到预定义类别(如体育、政治、科技、娱乐等)的系统。
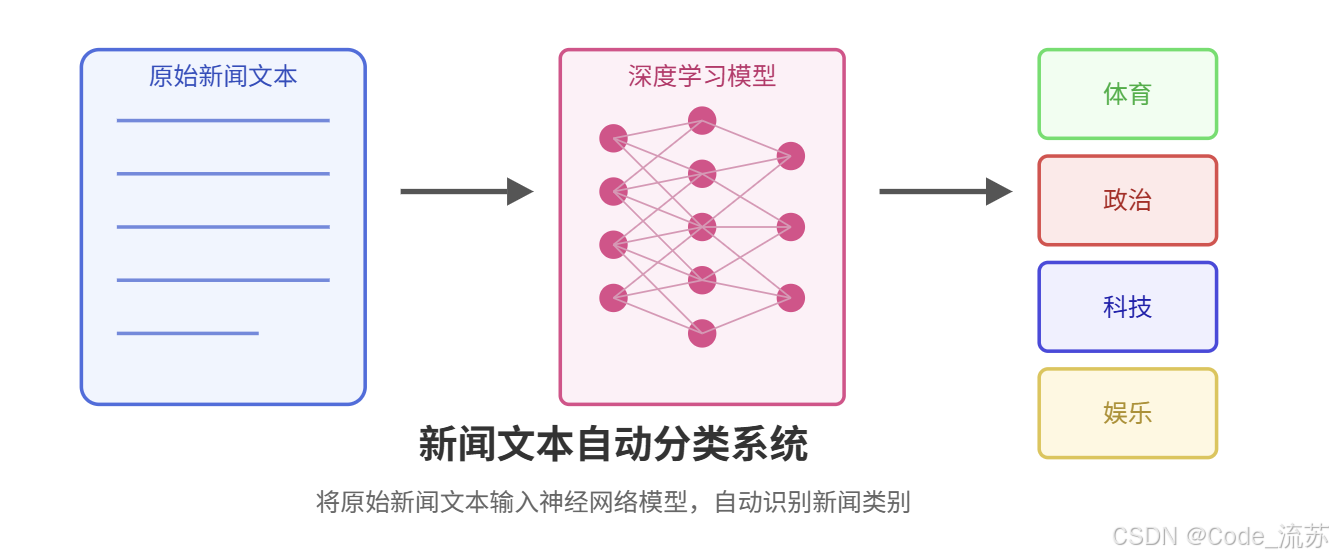
2. 功能需求
- 能够接收新闻文本内容作为输入
- 对输入文本进行预处理
- 使用训练好的深度学习模型预测新闻类别
- 返回预测结果及置信度
- 提供REST API接口供其他系统调用
3. 技术方案概述
二、数据清洗与文本预处理
1. 数据集介绍
对于新闻分类项目,我们将使用THUCNews数据集,这是一个中文新闻数据集,包含财经、体育、娱乐等多个类别的新闻文本。当然,你也可以选择其他类似的数据集,如BBC News或20 Newsgroups。
# 数据集加载示例
import pandas as pd
import os# 定义数据路径
data_path = "./thucnews/"
categories = ['体育', '财经', '科技', '娱乐', '时政', '教育', '社会']# 读取数据
data = []
labels = []for category_id, category in enumerate(categories):category_path = os.path.join(data_path, category)files = os.listdir(category_path)for file in files:with open(os.path.join(category_path, file), 'r', encoding='utf-8') as f:content = f.read()data.append(content)labels.append(category_id)# 创建DataFrame
news_df = pd.DataFrame({'content': data,'category_id': labels,'category': [categories[i] for i in labels]
})print(f"数据集大小: {len(news_df)}")
print(news_df.category.value_counts())
2. 数据清洗步骤
文本数据通常需要经过一系列清洗和预处理步骤,以提高模型的训练效果:

下面我们来实现文本预处理的具体代码:
import re
import jieba
import numpy as np
from sklearn.model_selection import train_test_split# 1. 去除HTML标签
def remove_html_tags(text):"""去除文本中的HTML标签"""clean = re.compile('<.*?>')return re.sub(clean, '', text)# 2. 去除特殊字符
def remove_special_chars(text):"""去除特殊字符,只保留中文、英文、数字和基本标点"""return re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9,。!?、;:""''()【】《》]', ' ', text)# 3. 中文分词
def chinese_word_cut(text):"""使用jieba进行中文分词"""return ' '.join(jieba.cut(text))# 4. 去除停用词
def remove_stopwords(text, stopwords_set):"""去除停用词"""words = text.split()filtered_words = [word for word in words if word not in stopwords_set]return ' '.join(filtered_words)# 加载停用词表
def load_stopwords(file_path='./stopwords.txt'):"""加载停用词表"""with open(file_path, 'r', encoding='utf-8') as f:stopwords = set([line.strip() for line in f.readlines()])return stopwords# 综合预处理函数
def preprocess_text(df, text_column='content', stopwords_path='./stopwords.txt'):"""对DataFrame中的文本列进行预处理"""# 加载停用词try:stopwords = load_stopwords(stopwords_path)except:print("停用词文件不存在,将不进行停用词过滤")stopwords = set()# 应用预处理函数df['clean_text'] = df[text_column].apply(remove_html_tags)df['clean_text'] = df['clean_text'].apply(remove_special_chars)df['clean_text'] = df['clean_text'].apply(chinese_word_cut)if stopwords:df['clean_text'] = df['clean_text'].apply(lambda x: remove_stopwords(x, stopwords))return df# 数据集划分
def split_dataset(df, test_size=0.2, val_size=0.1, random_state=42):"""将数据集划分为训练集、验证集和测试集"""# 先分离出测试集train_val, test = train_test_split(df, test_size=test_size, random_state=random_state, stratify=df['category_id'])# 从剩余数据中分离出验证集val_ratio = val_size / (1 - test_size)train, val = train_test_split(train_val, test_size=val_ratio, random_state=random_state, stratify=train_val['category_id'])print(f"训练集大小: {len(train)}")print(f"验证集大小: {len(val)}")print(f"测试集大小: {len(test)}")return train, val, test# 应用到我们的数据集
news_df_clean = preprocess_text(news_df)
train_df, val_df, test_df = split_dataset(news_df_clean)
3. 文本向量化
在深度学习模型中,我们需要将文本转换为数值向量形式。主要有以下几种方法:
- One-hot编码:最简单的表示形式,但维度高、稀疏
- 词袋模型(Bag of Words):统计词频,忽略词序
- TF-IDF:考虑词在文档和语料库中的重要性
- 词嵌入(Word Embedding):如Word2Vec、GloVe,能捕捉语义关系
- 预训练语言模型:如BERT的embedding层输出
对于我们的项目,将使用词嵌入和序列填充的方式:
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# 1. 创建分词器
max_words = 50000 # 词汇表大小
tokenizer = Tokenizer(num_words=max_words, oov_token='<UNK>')
tokenizer.fit_on_texts(train_df['clean_text'])# 词汇表大小
vocab_size = min(max_words, len(tokenizer.word_index) + 1)
print(f"词汇表大小: {vocab_size}")# 2. 转换文本为序列
train_sequences = tokenizer.texts_to_sequences(train_df['clean_text'])
val_sequences = tokenizer.texts_to_sequences(val_df['clean_text'])
test_sequences = tokenizer.texts_to_sequences(test_df['clean_text'])# 3. 序列填充
max_seq_length = 200 # 最大序列长度
train_padded = pad_sequences(train_sequences, maxlen=max_seq_length, padding='post', truncating='post')
val_padded = pad_sequences(val_sequences, maxlen=max_seq_length, padding='post', truncating='post')
test_padded = pad_sequences(test_sequences, maxlen=max_seq_length, padding='post', truncating='post')# 4. 准备标签
from tensorflow.keras.utils import to_categoricaltrain_labels = to_categorical(train_df['category_id'])
val_labels = to_categorical(val_df['category_id'])
test_labels = to_categorical(test_df['category_id'])print(f"特征形状: {train_padded.shape}")
print(f"标签形状: {train_labels.shape}")
三、模型选择与训练
对于文本分类任务,我们将尝试三种不同的深度学习模型架构:RNN、LSTM和Transformer,然后比较它们的性能。
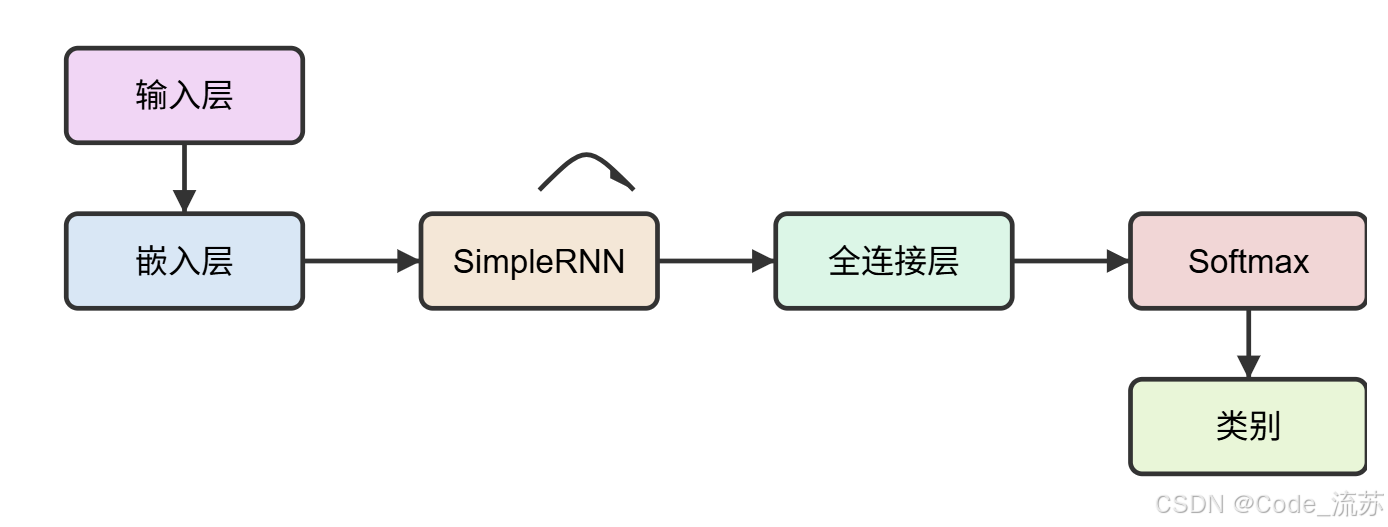
1. RNN模型
循环神经网络(RNN)是处理序列数据的基础模型,但存在长序列梯度消失问题。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, SimpleRNN, Dropout# RNN模型构建
def build_rnn_model(vocab_size, embedding_dim=100, max_length=200, num_classes=7):model = Sequential([# 嵌入层将词索引转换为密集向量Embedding(vocab_size, embedding_dim, input_length=max_length),# SimpleRNN层处理序列信息SimpleRNN(128, dropout=0.2, recurrent_dropout=0.2),# Dense层进行分类Dense(64, activation='relu'),Dropout(0.5),Dense(num_classes, activation='softmax')])# 编译模型model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])return model# 构建模型
embedding_dim = 100 # 词嵌入维度
rnn_model = build_rnn_model(vocab_size, embedding_dim, max_seq_length, len(categories))
rnn_model.summary()# 训练模型
rnn_history = rnn_model.fit(train_padded, train_labels,epochs=10,validation_data=(val_padded, val_labels),batch_size=64
)
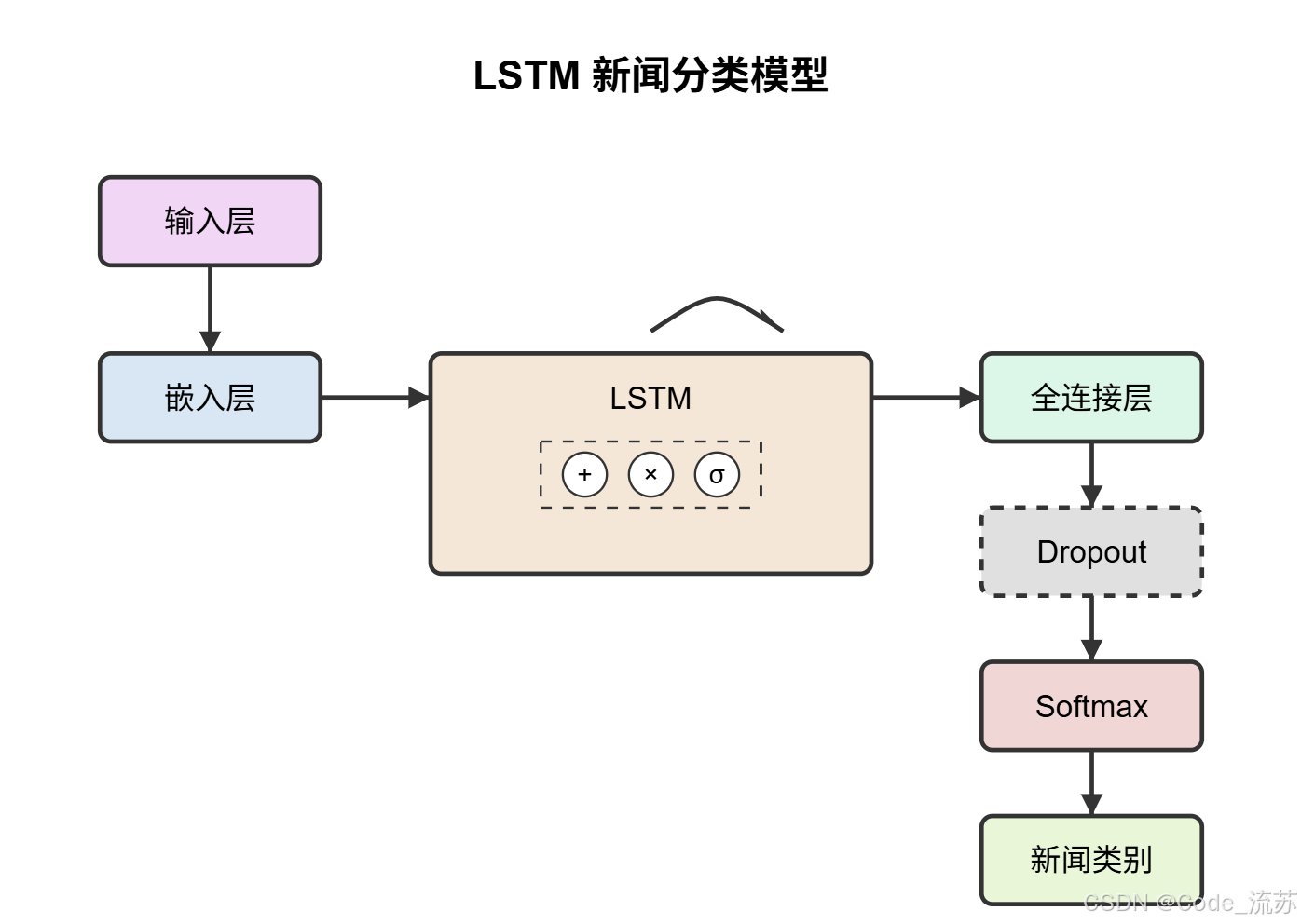
2. LSTM模型
长短期记忆网络(LSTM)是RNN的一种改进,能更好地处理长序列依赖问题。
from tensorflow.keras.layers import LSTM, Bidirectional# LSTM模型构建
def build_lstm_model(vocab_size, embedding_dim=100, max_length=200, num_classes=7):model = Sequential([# 嵌入层Embedding(vocab_size, embedding_dim, input_length=max_length),# 双向LSTM层可以捕捉前后文信息Bidirectional(LSTM(128, dropout=0.2, recurrent_dropout=0.2, return_sequences=True)),Bidirectional(LSTM(64, dropout=0.2, recurrent_dropout=0.2)),# Dense层进行分类Dense(64, activation='relu'),Dropout(0.5),Dense(num_classes, activation='softmax')])# 编译模型model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])return model# 构建模型
lstm_model = build_lstm_model(vocab_size, embedding_dim, max_seq_length, len(categories))
lstm_model.summary()# 训练模型
lstm_history = lstm_model.fit(train_padded, train_labels,epochs=10,validation_data=(val_padded, val_labels),batch_size=32 # LSTM更复杂,可以适当减小batch_size
)
3. Transformer模型
Transformer模型通过自注意力机制能够并行处理序列数据,是最新的NLP架构。
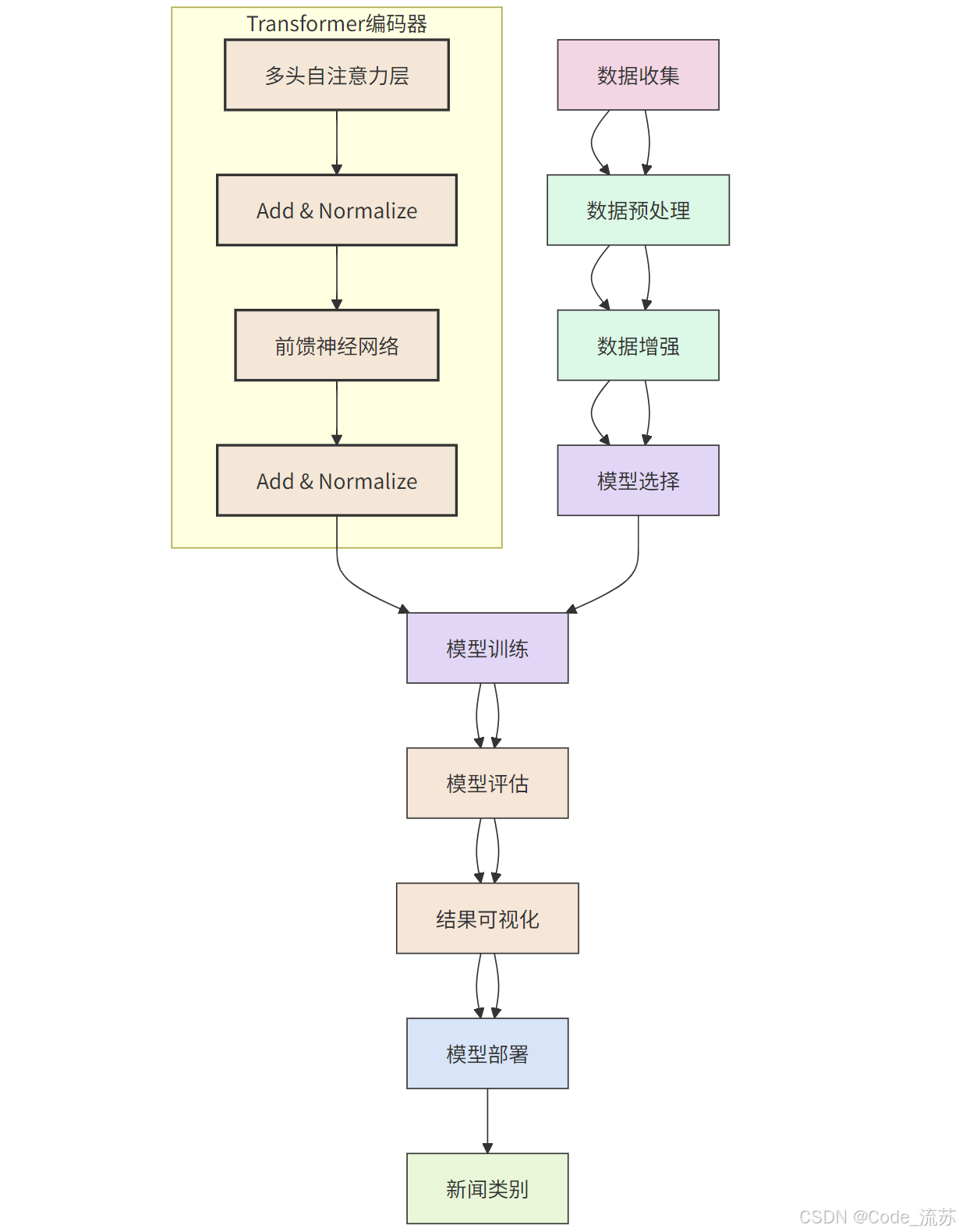
import tensorflow as tf
from tensorflow.keras.layers import Input, GlobalAveragePooling1D, LayerNormalization, MultiHeadAttention, Dense, Dropout, Embedding# Transformer模型构建
def build_transformer_model(vocab_size, embedding_dim=100, max_length=200, num_classes=7):# 输入层inputs = Input(shape=(max_length,))# 嵌入层embedding_layer = Embedding(vocab_size, embedding_dim)(inputs)# 位置编码(简化版,实际应用中可以使用三角函数实现)positions = tf.range(start=0, limit=max_length, delta=1)positions = Embedding(max_length, embedding_dim)(positions)x = embedding_layer + positions# Transformer编码器块num_heads = 8 # 注意力头数ff_dim = 256 # 前馈网络维度# 多头自注意力attention_output = MultiHeadAttention(num_heads=num_heads, key_dim=embedding_dim // num_heads)(x, x)attention_output = Dropout(0.1)(attention_output)x = LayerNormalization(epsilon=1e-6)(x + attention_output)# 前馈神经网络ffn_output = Dense(ff_dim, activation="relu")(x)ffn_output = Dense(embedding_dim)(ffn_output)ffn_output = Dropout(0.1)(ffn_output)x = LayerNormalization(epsilon=1e-6)(x + ffn_output)# 全局池化x = GlobalAveragePooling1D()(x)# 输出层x = Dense(64, activation="relu")(x)x = Dropout(0.5)(x)outputs = Dense(num_classes, activation="softmax")(x)# 构建模型model = tf.keras.Model(inputs=inputs, outputs=outputs)# 编译模型model.compile(optimizer="adam",loss="categorical_crossentropy",metrics=["accuracy"])return model# 构建模型
transformer_model = build_transformer_model(vocab_size, embedding_dim, max_seq_length, len(categories))
transformer_model.summary()# 训练模型
transformer_history = transformer_model.fit(train_padded, train_labels,epochs=10,validation_data=(val_padded, val_labels),batch_size=16 # Transformer更复杂,进一步减小batch_size
)
4. 模型比较与选择
我们需要对比三种模型在测试集上的表现,选择最佳模型:
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns# 绘制训练历史
def plot_history(histories, names):plt.figure(figsize=(12, 5))# 绘制准确率plt.subplot(1, 2, 1)for i, history in enumerate(histories):plt.plot(history.history['accuracy'], label=f'{names[i]} Train')plt.plot(history.history['val_accuracy'], label=f'{names[i]} Val')plt.title('模型准确率')plt.ylabel('准确率')plt.xlabel('轮次')plt.legend()# 绘制损失plt.subplot(1, 2, 2)for i, history in enumerate(histories):plt.plot(history.history['loss'], label=f'{names[i]} Train')plt.plot(history.history['val_loss'], label=f'{names[i]} Val')plt.title('模型损失')plt.ylabel('损失')plt.xlabel('轮次')plt.legend()plt.tight_layout()plt.show()# 评估模型
def evaluate_model(model, test_data, test_labels, name, tokenizer=None, categories=None):# 预测y_pred_probs = model.predict(test_data)y_pred = np.argmax(y_pred_probs, axis=1)y_true = np.argmax(test_labels, axis=1)# 打印分类报告print(f"===== {name} 模型评估 =====")print(classification_report(y_true, y_pred, target_names=categories))# 绘制混淆矩阵plt.figure(figsize=(10, 8))cm = confusion_matrix(y_true, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=categories, yticklabels=categories)plt.title(f'{name} 混淆矩阵')plt.ylabel('真实类别')plt.xlabel('预测类别')plt.tight_layout()plt.show()return y_pred_probs# 比较三个模型
histories = [rnn_history, lstm_history, transformer_history]
names = ['RNN', 'LSTM', 'Transformer']
plot_history(histories, names)# 评估各个模型
rnn_probs = evaluate_model(rnn_model, test_padded, test_labels, 'RNN', tokenizer, categories)
lstm_probs = evaluate_model(lstm_model, test_padded, test_labels, 'LSTM', tokenizer, categories)
transformer_probs = evaluate_model(transformer_model, test_padded, test_labels, 'Transformer', tokenizer, categories)# 假设LSTM模型表现最好,我们选择它作为最终模型
best_model = lstm_model
best_model.save('news_classifier_lstm.h5')
四、结果可视化与评估
1. 类别分布与预测置信度
可视化模型对各个类别的识别能力和置信度分布:
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns# 获取预测结果
y_pred_probs = best_model.predict(test_padded)
y_pred = np.argmax(y_pred_probs, axis=1)
y_true = np.argmax(test_labels, axis=1)# 1. 类别分布可视化
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.countplot(x=[categories[i] for i in y_true])
plt.title('真实类别分布')
plt.xticks(rotation=45)plt.subplot(1, 2, 2)
sns.countplot(x=[categories[i] for i in y_pred])
plt.title('预测类别分布')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()# 2. 预测置信度分布
plt.figure(figsize=(10, 6))
# 获取每个预测的最大置信度
confidences = np.max(y_pred_probs, axis=1)
# 按类别分组置信度
confidence_by_category = {}
for i, category_id in enumerate(y_pred):category = categories[category_id]if category not in confidence_by_category:confidence_by_category[category] = []confidence_by_category[category].append(confidences[i])# 使用箱形图显示每个类别的置信度分布
data = []
labels = []
for category, confs in confidence_by_category.items():data.extend(confs)labels.extend([category] * len(confs))sns.boxplot(x=labels, y=data)
plt.title('各类别预测置信度分布')
plt.ylabel('置信度')
plt.xlabel('类别')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
2. 错误分析
分析模型错误预测的案例,了解模型的局限性:
# 错误预测案例分析
def analyze_errors(model, test_data, test_texts, y_true, categories, n_examples=5):"""分析错误预测的案例"""y_pred_probs = model.predict(test_data)y_pred = np.argmax(y_pred_probs, axis=1)# 找出错误预测的索引error_indices = np.where(y_pred != y_true)[0]if len(error_indices) == 0:print("没有发现错误预测")return# 随机选择n个错误例子selected_indices = np.random.choice(error_indices, min(n_examples, len(error_indices)), replace=False)print("===== 错误预测案例分析 =====")for i, idx in enumerate(selected_indices):true_category = categories[y_true[idx]]pred_category = categories[y_pred[idx]]confidence = y_pred_probs[idx][y_pred[idx]] * 100print(f"案例 {i+1}:")print(f"文本: {test_texts[idx][:200]}...") # 只显示前200个字符print(f"真实类别: {true_category}")print(f"预测类别: {pred_category}")print(f"预测置信度: {confidence:.2f}%")print(f"可能原因: {'过度依赖特定关键词' if confidence > 90 else '内容主题混合或边界模糊'}")print('-' * 50)# 获取测试集文本
test_texts = test_df['clean_text'].tolist()
analyze_errors(best_model, test_padded, test_texts, y_true, categories)
3. 词云可视化
通过词云了解每个类别的特征词:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
from collections import Counter# 为每个类别生成词云
def generate_wordclouds(df, text_column, category_column, categories):"""为每个类别生成词云"""plt.figure(figsize=(15, 10))for i, category in enumerate(categories):# 获取该类别的所有文本category_texts = df[df[category_column] == category][text_column].tolist()if not category_texts:continue# 将所有文本合并combined_text = ' '.join(category_texts)# 分词并统计词频words = jieba.cut(combined_text)word_counts = Counter(words)# 过滤掉停用词和单个字符word_counts = {word: count for word, count in word_counts.items() if len(word) > 1 and word.strip()}# 生成词云wordcloud = WordCloud(font_path='simhei.ttf', # 指定中文字体width=400, height=300, background_color='white').generate_from_frequencies(word_counts)# 绘制词云plt.subplot(2, 4, i+1)plt.imshow(wordcloud, interpolation='bilinear')plt.title(category)plt.axis('off')plt.tight_layout()plt.show()# 生成每个类别的词云
generate_wordclouds(train_df, 'clean_text', 'category', categories)
五、模型部署与API构建
1. 构建RESTful API
使用Flask框架构建简单的REST API:
from flask import Flask, request, jsonify
import tensorflow as tf
import numpy as np
import pickle
import re
import jiebaapp = Flask(__name__)# 加载必要的组件
def load_model_components():"""加载模型和预处理组件"""# 加载模型model = tf.keras.models.load_model('news_classifier_lstm.h5')# 加载分词器with open('tokenizer.pickle', 'rb') as handle:tokenizer = pickle.load(handle)# 加载类别标签categories = ['体育', '财经', '科技', '娱乐', '时政', '教育', '社会']# 加载停用词try:with open('stopwords.txt', 'r', encoding='utf-8') as f:stopwords = set([line.strip() for line in f.readlines()])except:stopwords = set()return model, tokenizer, categories, stopwords# 预处理函数
def preprocess_text(text, stopwords):"""文本预处理"""# 去除HTML标签clean = re.compile('<.*?>')text = re.sub(clean, '', text)# 去除特殊字符text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9,。!?、;:""''()【】《》]', ' ', text)# 分词words = jieba.cut(text)# 去除停用词if stopwords:words = [word for word in words if word not in stopwords]return ' '.join(words)# 模型预测
def predict_category(text, model, tokenizer, categories, max_length=200):"""预测文本类别"""# 预处理文本processed_text = preprocess_text(text, stopwords)# 文本转序列sequence = tokenizer.texts_to_sequences([processed_text])# 序列填充padded = tf.keras.preprocessing.sequence.pad_sequences(sequence, maxlen=max_length, padding='post', truncating='post')# 预测prediction = model.predict(padded)[0]# 获取结果category_id = np.argmax(prediction)category = categories[category_id]confidence = float(prediction[category_id])# 获取各类别置信度category_confidences = {cat: float(prediction[i]) for i, cat in enumerate(categories)}return {'category': category,'confidence': confidence,'category_confidences': category_confidences}# 全局加载模型和预处理组件
print("加载模型和预处理组件...")
model, tokenizer, categories, stopwords = load_model_components()
print("模型加载完成!")# API路由
@app.route('/predict', methods=['POST'])
def predict():"""预测API路由"""# 获取请求数据data = request.json# 检查请求是否包含文本if 'text' not in data:return jsonify({'error': '请求中缺少文本字段'}), 400# 执行预测try:result = predict_category(data['text'], model, tokenizer, categories)return jsonify(result)except Exception as e:return jsonify({'error': str(e)}), 500# 健康检查路由
@app.route('/health', methods=['GET'])
def health():"""健康检查路由"""return jsonify({'status': 'ok'})if __name__ == '__main__':app.run(debug=True, host='0.0.0.0', port=5000)
2. 保存和加载组件
为了部署API,我们需要保存模型、分词器和其他必要组件:
# 保存分词器
import pickle
with open('tokenizer.pickle', 'wb') as handle:pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)# 保存模型
best_model.save('news_classifier_lstm.h5')# 保存停用词(如果使用)
with open('stopwords.txt', 'w', encoding='utf-8') as f:for word in stopwords:f.write(f"{word}\n")print("模型和预处理组件已保存!")
3. 部署建议
推荐使用Docker容器化部署我们的API服务,下面是一个简单的Dockerfile示例:
# Dockerfile
FROM python:3.8-slimWORKDIR /app# 复制必要文件
COPY requirements.txt .
COPY app.py .
COPY news_classifier_lstm.h5 .
COPY tokenizer.pickle .
COPY stopwords.txt .# 安装依赖
RUN pip install --no-cache-dir -r requirements.txt# 暴露端口
EXPOSE 5000# 启动应用
CMD ["python", "app.py"]
requirements.txt文件内容:
flask==2.0.1
tensorflow==2.6.0
numpy==1.19.5
jieba==0.42.1
4. 使用示例
下面是一个使用curl调用API的示例:
curl -X POST http://localhost:5000/predict \-H "Content-Type: application/json" \-d '{"text": "2025年第一季度,中国经济增长6.3%,这一数据超出市场预期。专家认为,消费需求回暖和出口增长是主要推动因素。"}'
返回结果示例:
{"category": "财经","confidence": 0.9782,"category_confidences": {"体育": 0.0002,"财经": 0.9782,"科技": 0.0132,"娱乐": 0.0003,"时政": 0.0065,"教育": 0.0008,"社会": 0.0008}
}
六、项目总结与扩展方向
1. 项目回顾
在这个项目中,我们完成了以下工作:
- 对新闻文本数据进行了清洗和预处理
- 构建并训练了三种深度学习模型:RNN、LSTM和Transformer
- 对模型进行了评估和错误分析
- 构建了RESTful API接口,实现了模型部署
2. 可能的改进方向
- 数据增强:使用同义词替换、回译等技术增加训练数据
- 预训练模型:使用BERT、RoBERTa等预训练模型进行微调
- 集成学习:结合多个模型的预测结果,提高分类准确率
- 多标签分类:支持一篇新闻属于多个类别的情况
- 实时学习:实现增量学习,不断从新数据中学习
3. 扩展应用场景
- 内容推荐系统:基于用户兴趣分类推荐相关新闻
- 情感分析:除了分类外,还可以分析新闻情感倾向
- 热点检测:结合时间信息,识别热点新闻话题
- 多语言支持:扩展支持多种语言的新闻分类
- 摘要生成:结合新闻分类与自动摘要功能
七、总结
通过这个文本分类项目,我们综合运用了之前学习的各种技术,从数据处理、模型构建到最终部署。深度学习在自然语言处理领域展现出了强大的能力,特别是RNN、LSTM和Transformer等序列模型,能够有效捕捉文本的语义信息。
在实际应用中,不同模型有各自的优缺点:RNN结构简单但难以处理长序列;LSTM能够解决长依赖问题但训练较慢;Transformer通过自注意力机制实现并行计算,但对计算资源要求更高。根据具体应用场景和资源条件,我们需要做出合适的选择。
最后,希望这个项目能帮助你将Python、深度学习和Web开发的知识融会贯通,为未来更复杂的NLP应用打下基础!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:
)
《Python星球日记》 第63天:文本方向综合项目(新闻分类)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、项目需求分析1. 项目背景与目标2. 功能需求3. 技术方案概述 二、数据清洗与…...
的实现方式)
面试题:请解释Java中的设计模式,并举例说明单例模式(Singleton Pattern)的实现方式
Java中的设计模式 设计模式是在软件开发过程中针对特定场景而使用的通用解决方案。设计模式可以帮助开发者编写出更加清晰、灵活和可维护的代码。设计模式分为三大类: 创建型模式:用于对象的创建过程,如单例模式、工厂模式、建造者模式等。…...

MySQL全量、增量备份与恢复
目录 一:MySQL数据库备份概述 1.数据备份的重要性 2.数据库备份类型 2.1从物理与逻辑的角度分类 物理备份 逻辑备份 2.2从数据库的备份策略角度分类 完全备份 差异备份 增量备份 3.常见的备份方法 3.1物理冷备份 3.2专用备份工具 MySQL dump或MySQL hot…...

rust 全栈应用框架dioxus server
接上一篇文章dioxus全栈应用框架的基本使用,支持web、desktop、mobile等平台。 可以先查看上一篇文章rust 全栈应用框架dioxus👈 既然是全栈框架,那肯定是得有后端服务的,之前创建的服务没有包含后端服务包,我们修改…...

Clinica集成化的开源平台-神经影像研究
Clinica集成化的开源平台-神经影像研究 🌟 Clinica集成化的开源平台-神经影像研究引言 🛠️ 一、环境搭建与数据准备1. 安装Clinica(附避坑指南)2. 数据标准化(BIDS格式处理) 🧠 二、sMRI预处理…...

LabVIEW中算法开发的系统化解决方案与优化
在 LabVIEW 开发环境中,算法实现是连接硬件数据采集与上层应用的核心环节。由于图形化编程范式与传统文本语言存在差异,LabVIEW 中的算法开发需要特别关注执行效率、代码可维护性以及与硬件资源的适配性。本文从算法架构设计、性能优化到工程实现&#x…...

【Pandas】pandas DataFrame cov
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...
)
【递归、搜索与回溯】专题一:递归(一)
📝前言说明: 本专栏主要记录本人递归,搜索与回溯算法的学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码…...

pythonocc 拉伸特征
micromamba install -c conda-forge pythonocc-core opencascade.js安装不起来,ai用pythonocc练个手 拉伸线框 线成面 from OCC.Core.gp import gp_Pnt, gp_Dir, gp_Vec from OCC.Core.BRepBuilderAPI import BRepBuilderAPI_MakeEdge, BRepBuilderAPI_MakeWire f…...

防爆手机与普通手机有什么区别
在石油化工、矿山能源、危化品运输等特殊行业中,一部手机的选择可能直接关系到生产安全与人员生命。防爆手机作为工业安全通信的核心工具,与日常使用的普通手机存在本质差异。本文将从技术原理、安全标准、功能设计及适用场景等维度,解析二者…...
)
动手学深度学习12.3.自动并行-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:无 本节教材地址:12.3. 自动并行 — 动手学深度学习 2.0.0 documentation 本节开源代…...

第二十二天打卡
数据预处理 import pandas as pd from sklearn.model_selection import train_test_splitdef data_preprocessing(file_path):"""泰坦尼克号生存预测数据预处理函数参数:file_path: 原始数据文件路径返回:preprocessed_data: 预处理后的数据集""&quo…...

SET NX互斥功能的实现原理
Redis 的 SET key value NX 命令通过其原子性和底层数据结构的特性实现互斥功能,具体实现如下: 1. 互斥功能的实现原理 SET NX 的核心是 原子性操作:当且仅当键(key)不存在时,才会设置键的值。Redis 的单线…...

前端 CSS 样式书写与选择器 基础知识
1.CSS介绍 CSS是Cascading Style Sheet的缩写,中文意思为"层叠样式表",它是网页的装饰者,用来修饰各标签 排版(大小、边距、背景、位置等)、改变字体的样式(字体大小、字体颜色、对齐方式等)。 2.CSS书写位置 2.1 样式表特征 层…...

一小时学会Docker使用!
文章目录 前言一、安装ssh连接工具二、安装docker三、Docker常见命令四、docker-compose使用 前言 Docker: Docker简单来说就是简化环境配置的,我们配置环境只需要简单的docker pull,docker run即可,而删除环境也很容易ÿ…...

android studio开发aar插件,并用uniapp开发APP使用这个aar
android studio开发aar插件,并用uniapp开发APP使用这个aar 使用android studio打包aar和Unity导入aar详解...

操作系统实战——QEMU模拟器搭建【rCore 操作系统】
操作系统大作业——QEMU模拟器搭建rCore操作系统 按照本篇步骤走,帮你少走很多弯路!博主在自己做的过程中踩了很多坑,过程还是很痛苦的,走了很多弯路,现在都已经在文章中把坑填平了,把弯路修直了。 创作不易…...

web:InfiniteScroll 无限滚动
InfiniteScroll 无限滚动 分页加载 <div class"data-box" v-infinite-scroll"loadMore"> <li v-fori in dataList></li> </div>form: {current: 1,size: 10,}loadMore(){console.log(this.dataList.length, this.total ,8888)if…...

【Redis 进阶】哨兵模式
思维导图: 一、哨兵模式概述 (一)传统主从复制模式的局限性 在传统的Redis主从复制架构中,若主节点发生故障,运维人员需手动执行故障转移操作,将一个从节点提升为新主节点,并逐一通知所有客户…...

告别卡顿,图片查看界的“速度与激情”
嘿,小伙伴们!今天电脑天空给大家介绍一款超好用的图片查看神器——ImageGlass!这可不是普通的图片查看软件哦,它简直就是图片界的“全能王”。首先,它能打开的图片格式多到让你眼花缭乱,什么PNG、JPEG、GIF…...
)
02_线性模型(回归分类模型)
用于分类的线性模型 线性模型也广泛应用于分类问题,可以利用下面的公式进行预测: $ \widehat y w[0]*x[0]w[1]*x[1]…w[p]*x[p]b > 0$ 公式看起来与线性回归的公式非常相似,但没有返回特征的加权求和,而是为预测设置了阈值…...

力扣2094题解
记录: 2025.5.12 题目: 思路: 暴力遍历。 解题步骤: 1.统计数字出现次数:使用数组cnt来记录输入数组中每个数字的出现次数。 2.生成三位偶数:通过循环从100开始,每次递增2,生成…...

人物角色设定机制
模块一:角色塑造进阶技巧 将角色设定(Character Headcanon)提升至更高层次 当您通过Character Headcanon Generator生成基础设定后,可运用以下专业技巧深化角色塑造: 情感核心图谱分析法 解构角色情感驱动机制及其情境表现: 主…...

Python动态渲染页面抓取之Selenium使用指南
目录 一、Selenium技术架构解析 二、环境搭建与基础配置 1. 组件安装 2. 驱动配置 3. 基础操作模板 三、动态内容抓取核心策略 1. 智能等待机制 2. 交互行为模拟 3. 反爬应对方案 四、实战案例:电商评论抓取 五、性能优化与异常处理 2. 异常捕获 六、进…...

智能手表 MCU 任务调度图
智能手表 MCU 任务调度图 处理器平台:ARM Cortex-M33 系统架构:事件驱动 多任务 RTOS RTOS:FreeRTOS(或同类实时内核) 一、任务调度概览 任务名称优先级周期性功能描述App_MainTask中否主循环调度器,系统…...

【C++】cout的格式输出
目录 一、cout的格式输出1、控制宽度和填充2、控制数值格式3、控制整数格式4、控制对齐方式 个人主页<—请点击 C专栏<—请点击 一、cout的格式输出 printf函数在输出数据的时候,可以指定格式来输出,比如:指定宽度、指定小数点后的位…...

私域流量新阵地:掌握Telegram私域运营全方法
在流量获取成本不断上升的今天,越来越多企业和品牌开始将目光转向“私域流量”——一条可以长期沉淀用户、反复转化的可持续增长之路。而在全球化趋势下,Telegram作为一款以高自由度、强隐私性著称的即时通讯平台,正在成为私域运营的新阵地。…...

Python Day23 学习
继续SHAP图绘制的学习 1. SHAP特征重要性条形图 特征重要性条形图(Feature Importance Bar Plot)是 SHAP 提供的一种全局解释工具,用于展示模型中各个特征对预测结果的重要性。以下是详细解释: 图的含义 - 横轴:表示…...

《ATPL地面培训教材13:飞行原理》——第12章:飞行力学基础
翻译:Leweslyh;工具:Cursor & Cluade 3.7;过程稿 第12章:飞行力学基础 目录 引言直线水平稳定飞行尾翼和升降舵直线稳定爬升爬升角重量、高度和温度的影响带动力下降紧急下降滑翔滑翔下降率转弯非对称推力飞行最…...
)
数据中台整体建设方案规划设计方案,数据中台建设汇报方案(PPT)
中台建设背景 在数字化转型浪潮下,企业需通过客户需求精准化、营销策略智能化、管理体系数字化三大核心方向构建竞争优势。本项目以渠道数据整合为基础,围绕客户精准化运营、营销智能化决策、管理数字化赋能三大目标,打造支撑一线业务场景的数…...
)
嵌入式软件--stm32 DAY 6 USART串口通讯(下)
1.寄存器轮询_收发字符串 通过寄存器轮询方式实现了收发单个字节之后,我们趁热打铁,争上游,进阶到字符串。字符串就是多个字符。很明显可以循环收发单个字节实现。 然后就是接收字符串。如果接受单个字符的函数放在while里,它也可…...

Flask如何读取配置信息
目录 一、使用 app.config 读取配置 二、设置配置的几种方式 1. 直接设置 2. 从 Python 文件加载 3. 从环境变量加载 4. 从字典加载 5. 从 .env 文件加载(推荐开发环境用) 三、读取配置值 四、最佳实践建议 在 Flask 中读取配置信息有几种常见方…...

AWS EC2源代码安装valkey命令行客户端
sudo yum -y install openssl-devel gcc wget https://github.com/valkey-io/valkey/archive/refs/tags/8.1.1.tar.gz tar xvzf 8.1.1.tar.gz cd valkey-8.1.1/ make distclean make valkey-cli BUILD_TLSyes参考 Connecting to nodes...

项目全栈实战-基于智能体、工作流、API模块化Docker集成的创业分析平台
目录 思维导图 前置知识 Docker是什么? Docker的核心概念: Docker在本项目中的作用 1. 环境隔离与一致性 2. 简化部署流程 3. 资源管理与扩展性 4. 服务整合与通信 5. 版本控制和回滚 6. 开发与生产环境一致性 总结 前端 1.小程序 2.web …...

如何快速入门大模型?
学习大模型的流程是什么 ? 提示词工程:只需掌握提问技巧即可使用大模型,通过优化提问方式获得更精准的模型输出套壳应用开发:在大模型生态上开发业务层产品(如AI主播、AI小助手等),只需调用API…...

《Flutter社交应用暗黑奥秘:模式适配与色彩的艺术》
暗黑模式已从一种新奇的功能演变为用户体验中不可或缺的一环。对于Flutter开发者而言,如何在社交应用中完美实现暗黑模式适配与色彩对比度优化,是一场充满挑战与惊喜的技术探索之旅。 暗黑模式,绝非仅仅是将界面颜色反转这么简单。从用户体验…...
:CUDA 加速方案)
【秣厉科技】LabVIEW工具包——OpenCV 教程(21):CUDA 加速方案
文章目录 前言一、方案总述二、改造步骤三、编程范例四、应用移植总结 前言 需要下载安装OpenCV工具包的朋友,请前往 此处 ;系统要求:Windows系统,LabVIEW>2018,兼容32位和64位。 一、方案总述 为了保持轻量化与普…...

flutter使用命令生成BinarySize分析图
flutter build ios --analyze-size 生成的文件,使用dev tools 可以分析具体的包大小...

高并发场景下的BI架构设计:衡石分布式查询引擎与缓存分级策略
在电商大促、金融交易时段或IoT实时监控场景中,企业BI系统常面临瞬时万级并发查询的冲击——运营团队需要实时追踪GMV波动,风控部门需秒级响应欺诈检测,产线监控需毫秒级反馈设备状态。传统单体架构的BI系统在此类场景下极易崩溃,…...

web 自动化之 selenium 下拉鼠标键盘文件上传
文章目录 一、下拉框操作二、键盘操作三、鼠标操作四、日期控件五、滚动条操作六、文件上传七、定位windows窗口及窗口的元素总结:页面及元素常用操作 一、下拉框操作 from selenium.webdriver.support.select import Select import time from selenium.webdriver.…...

Qt Creator 配置 Android 编译环境
Qt Creator 配置 Android 编译环境 环境配置流程下载JDK修改Qt Creator默认android配置文件修改sdk_definitions.json配置修改的内容 Qt Creator配置异常处理删除提示占用编译报错 环境 Qt Creator 版本 qtcreator-16.0.1Win10 嗯, Qt这个开发环境有点难折腾,搞了我三天… 配…...

主流编程语言中ORM工具全解析
在不同编程语言中,ORM(Object-Relational Mapping,对象关系映射)工具的设计目标都是简化数据库操作。 以下是主流语言中最常用的 ORM 工具,按语言分类介绍其特点、适用场景和典型案例。 一、Python 生态 Python 社区…...

详解RabbitMQ工作模式之发布确认模式
目录 发布确认模式 概述 消息丢失问题 发布确认的三种模式 实现步骤 应用场景 代码案例 引入依赖 常量类 单条确认 运行代码 批量确认 运行代码 异步确认 运行代码 对比批量确认和异步确认模式 发布确认模式 概述 发布确认模式用于确保消息已…...
)
Power BI 实操案例,将度量值转化为切片器(动态切换分析指标)
Power BI 实操案例,将度量值转化为切片器(动态切换分析指标) 想要在Power BI中让度量值也能像维度一样灵活筛选?没问题,这里就为你揭秘如何将度量值转化为切片器(动态切换分析指标)的实用方法&…...

利用散点图探索宇航员特征与太空任务之间的关系
利用散点图探索宇航员特征与太空任务之间的关系 import matplotlib.pyplot as plt import numpy as np import pandas as pdfrom flexitext import flexitext from matplotlib.patches import FancyArrowPatchplt.rcParams.update({"font.family": "Corbel&quo…...

人工智能的哲学与社会影响
人工智能(AI)的快速发展对人类社会的方方面面产生了深远的影响。在这部分中,我们将探讨AI对人与机器关系的影响、AI对就业和经济的潜在影响,以及人类与AI共存的可能性和道德议题。同时,我们还将针对大众对AI的一些常见…...

MySQL 中 UPDATE 结合 SELECT 和 UPDATE CASE WHEN 的示例
概述 以下是 MySQL 中 UPDATE 结合 SELECT 和 UPDATE CASE WHEN 的示例: 一、UPDATE 结合 SELECT(跨表更新) 场景:根据 orders 表中的订单总金额,更新 users 表中用户的 total_spent 字段。 -- 创建测试表 CREATE T…...

FPGA前瞻篇-计数器设计与实现实例
这是本篇文章的设计目标如下所示: 这个 Counter 模块是一个LED 闪烁计数器,设计目标是: 当输入时钟 clk 为 50 MHz 时,每 0.5 秒翻转一次 LED 灯状态。 随后我们开始补充理论知识。 计数是一种最简单基本的运算,计数器…...
)
运行Spark程序-在Idea中(二)
(四)使用Maven创建新项目 核心的操作步骤如下: 1.启动idea,选择新建项目。 2.将Scala添加到全局库中。 3.设置maven依赖项。修改pom.xml文件,添加如下: 4.下载依赖。添加完成之后,刷新Maven,它…...

Mosaic数据增强技术
Mosaic 数据增强技术是一种在计算机视觉领域广泛应用的数据增强方法。下面是Mosaic 数据增强技术原理的详细介绍 一、原理 Mosaic 数据增强是将多张图像(通常是 4 张)按照一定的规则拼接在一起,形成一张新的图像。在拼接过程中,会…...