第二十二天打卡
数据预处理
import pandas as pd
from sklearn.model_selection import train_test_splitdef data_preprocessing(file_path):"""泰坦尼克号生存预测数据预处理函数参数:file_path: 原始数据文件路径返回:preprocessed_data: 预处理后的数据集"""# 数据加载与初步查看data = pd.read_csv(file_path)# 缺失值处理age_mean = data['Age'].mean()data['Age'].fillna(age_mean, inplace=True)embarked_mode = data['Embarked'].mode()[0]data['Embarked'].fillna(embarked_mode, inplace=True)data.drop('Cabin', axis=1, inplace=True)# 分类变量编码data = pd.get_dummies(data, columns=['Sex', 'Embarked'], prefix=['Sex', 'Embarked'])# 异常值处理def remove_outliers_IQR(df, column):Q1 = df[column].quantile(0.25)Q3 = df[column].quantile(0.75)IQR = Q3 - Q1lower_bound = Q1 - 1.5 * IQRupper_bound = Q3 + 1.5 * IQRreturn df[(df[column] >= lower_bound) & (df[column] <= upper_bound)]data = remove_outliers_IQR(data, 'Fare')# 删除无用特征useless_columns = ['PassengerId', 'Name', 'Ticket']data.drop(useless_columns, axis=1, inplace=True)return datadef split_dataset(data, test_size=0.2, random_state=42):"""划分预处理后的数据为训练集和测试集参数:data: 预处理后的数据test_size: 测试集占比random_state: 随机种子返回:X_train, X_test, y_train, y_test: 划分后的训练集和测试集"""X = data.drop(['Survived'], axis=1) # 特征,axis=1表示按列删除y = data['Survived'] # 标签X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state) # 划分数据集# 训练集和测试集的形状print(f"训练集形状: {X_train.shape}, 测试集形状: {X_test.shape}") # 打印训练集和测试集的形状return X_train, X_test, y_train, y_test# ====================== 执行预处理和数据集划分 ======================
if __name__ == "__main__":input_file = "train.csv" # 确保文件在当前工作目录preprocessed_data = data_preprocessing(input_file)# 划分数据集X_train, X_test, y_train, y_test = split_dataset(preprocessed_data)# 保存预处理后的数据和划分后的数据集output_file = "train_preprocessed.csv"preprocessed_data.to_csv(output_file, index=False)print(f"\n预处理后数据已保存至:{output_file}")# 保存划分后的数据集(可选)pd.concat([X_train, y_train], axis=1).to_csv("train_split.csv", index=False)pd.concat([X_test, y_test], axis=1).to_csv("test_split.csv", index=False)print(f"训练集已保存至:train_split.csv")print(f"测试集已保存至:test_split.csv")模型
SVM
# SVM
svm_model = SVC(random_state=42)
svm_model.fit(X_train, y_train)
svm_pred = svm_model.predict(X_test)print("\nSVM 分类报告:")
print(classification_report(y_test, svm_pred)) # 打印分类报告
print("SVM 混淆矩阵:")
print(confusion_matrix(y_test, svm_pred)) # 打印混淆矩阵# 计算 SVM 评估指标,这些指标默认计算正类的性能
svm_accuracy = accuracy_score(y_test, svm_pred)
svm_precision = precision_score(y_test, svm_pred)
svm_recall = recall_score(y_test, svm_pred)
svm_f1 = f1_score(y_test, svm_pred)
print("SVM 模型评估指标:")
print(f"准确率: {svm_accuracy:.4f}")
print(f"精确率: {svm_precision:.4f}")
print(f"召回率: {svm_recall:.4f}")
print(f"F1 值: {svm_f1:.4f}")
KNN
# KNN
knn_model = KNeighborsClassifier()
knn_model.fit(X_train, y_train)
knn_pred = knn_model.predict(X_test)print("\nKNN 分类报告:")
print(classification_report(y_test, knn_pred))
print("KNN 混淆矩阵:")
print(confusion_matrix(y_test, knn_pred))knn_accuracy = accuracy_score(y_test, knn_pred)
knn_precision = precision_score(y_test, knn_pred)
knn_recall = recall_score(y_test, knn_pred)
knn_f1 = f1_score(y_test, knn_pred)
print("KNN 模型评估指标:")
print(f"准确率: {knn_accuracy:.4f}")
print(f"精确率: {knn_precision:.4f}")
print(f"召回率: {knn_recall:.4f}")
print(f"F1 值: {knn_f1:.4f}")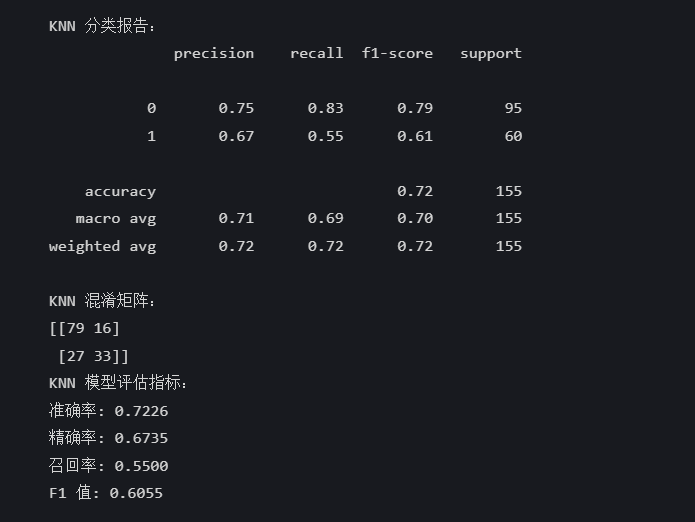
逻辑回归
# 逻辑回归
logreg_model = LogisticRegression(random_state=42)
logreg_model.fit(X_train, y_train)
logreg_pred = logreg_model.predict(X_test)print("\n逻辑回归 分类报告:")
print(classification_report(y_test, logreg_pred))
print("逻辑回归 混淆矩阵:")
print(confusion_matrix(y_test, logreg_pred))logreg_accuracy = accuracy_score(y_test, logreg_pred)
logreg_precision = precision_score(y_test, logreg_pred)
logreg_recall = recall_score(y_test, logreg_pred)
logreg_f1 = f1_score(y_test, logreg_pred)
print("逻辑回归 模型评估指标:")
print(f"准确率: {logreg_accuracy:.4f}")
print(f"精确率: {logreg_precision:.4f}")
print(f"召回率: {logreg_recall:.4f}")
print(f"F1 值: {logreg_f1:.4f}")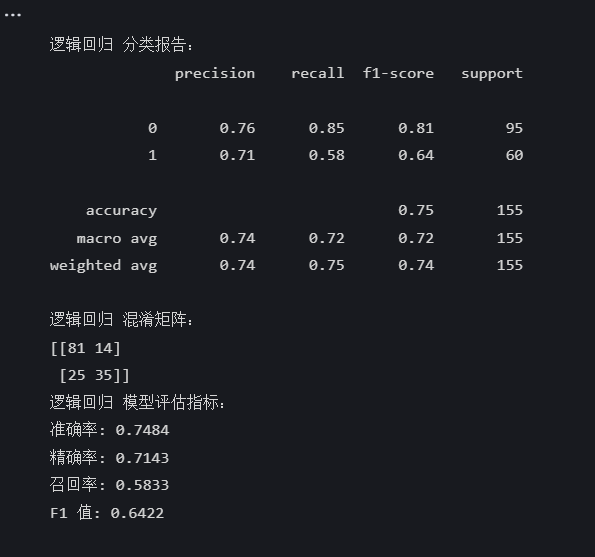
朴素贝叶斯
# 朴素贝叶斯
nb_model = GaussianNB()
nb_model.fit(X_train, y_train)
nb_pred = nb_model.predict(X_test)print("\n朴素贝叶斯 分类报告:")
print(classification_report(y_test, nb_pred))
print("朴素贝叶斯 混淆矩阵:")
print(confusion_matrix(y_test, nb_pred))nb_accuracy = accuracy_score(y_test, nb_pred)
nb_precision = precision_score(y_test, nb_pred)
nb_recall = recall_score(y_test, nb_pred)
nb_f1 = f1_score(y_test, nb_pred)
print("朴素贝叶斯 模型评估指标:")
print(f"准确率: {nb_accuracy:.4f}")
print(f"精确率: {nb_precision:.4f}")
print(f"召回率: {nb_recall:.4f}")
print(f"F1 值: {nb_f1:.4f}")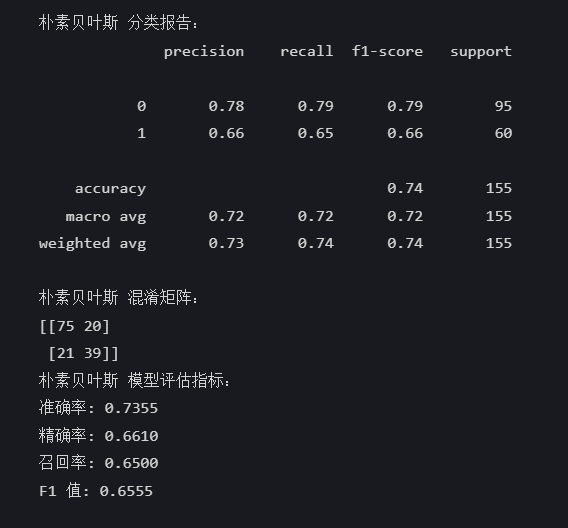
决策树
# 决策树
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)print("\n决策树 分类报告:")
print(classification_report(y_test, dt_pred))
print("决策树 混淆矩阵:")
print(confusion_matrix(y_test, dt_pred))dt_accuracy = accuracy_score(y_test, dt_pred)
dt_precision = precision_score(y_test, dt_pred)
dt_recall = recall_score(y_test, dt_pred)
dt_f1 = f1_score(y_test, dt_pred)
print("决策树 模型评估指标:")
print(f"准确率: {dt_accuracy:.4f}")
print(f"精确率: {dt_precision:.4f}")
print(f"召回率: {dt_recall:.4f}")
print(f"F1 值: {dt_f1:.4f}")随机森林
# 随机森林
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)print("\n随机森林 分类报告:")
print(classification_report(y_test, rf_pred))
print("随机森林 混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))rf_accuracy = accuracy_score(y_test, rf_pred)
rf_precision = precision_score(y_test, rf_pred)
rf_recall = recall_score(y_test, rf_pred)
rf_f1 = f1_score(y_test, rf_pred)
print("随机森林 模型评估指标:")
print(f"准确率: {rf_accuracy:.4f}")
print(f"精确率: {rf_precision:.4f}")
print(f"召回率: {rf_recall:.4f}") 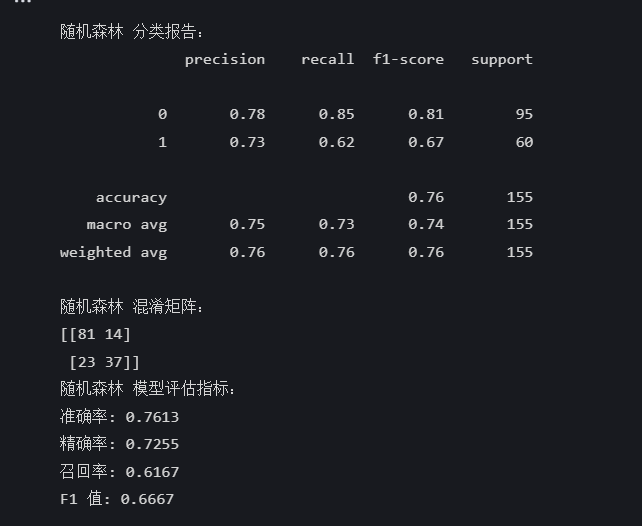
网格搜索优化
# --- 2. 网格搜索优化随机森林 ---
print("\n--- 2. 网格搜索优化随机森林 (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV
import time
# 定义要搜索的参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 创建网格搜索对象
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42), # 随机森林分类器param_grid=param_grid, # 参数网格cv=5, # 5折交叉验证n_jobs=-1, # 使用所有可用的CPU核心进行并行计算scoring='accuracy') # 使用准确率作为评分标准start_time = time.time()
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train) # 在训练集上训练,模型实例化和训练的方法都被封装在这个网格搜索对象里了
end_time = time.time()print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_) #best_params_属性返回最佳参数组合# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_ # 获取最佳模型
best_pred = best_model.predict(X_test) # 在测试集上进行预测print("\n网格搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))

贝叶斯优化
print("\n--- 2. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time# 定义要搜索的参数空间
search_space = {'n_estimators': Integer(50, 200),'max_depth': Integer(10, 30),'min_samples_split': Integer(2, 10),'min_samples_leaf': Integer(1, 4)
}# 创建贝叶斯优化搜索对象
bayes_search = BayesSearchCV(estimator=RandomForestClassifier(random_state=42),search_spaces=search_space,n_iter=32, # 迭代次数,可根据需要调整cv=5, # 5折交叉验证,这个参数是必须的,不能设置为1,否则就是在训练集上做预测了n_jobs=-1,scoring='accuracy'
)start_time = time.time()
# 在训练集上进行贝叶斯优化搜索
bayes_search.fit(X_train, y_train)
end_time = time.time()print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred)) 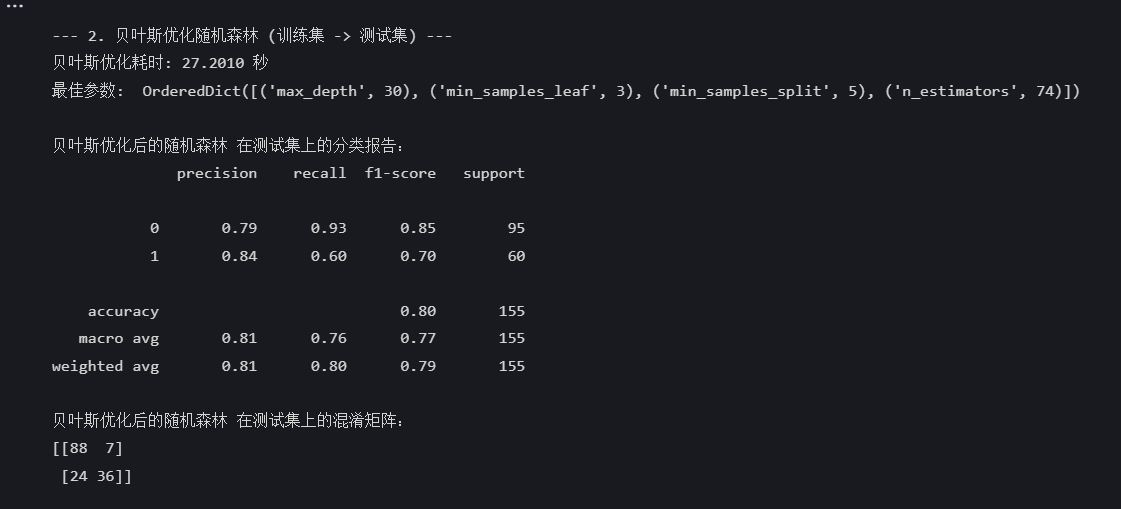
粒子群优化算法
import numpy as np # 导入NumPy库,用于处理数组和矩阵运算
import random # 导入random模块,用于生成随机数
import time # 导入time模块,用于计算优化耗时
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix # 导入评估指标
# --- 2. 粒子群优化算法优化随机森林 ---
print("\n--- 2. 粒子群优化算法优化随机森林 (训练集 -> 测试集) ---")# 定义适应度函数,本质就是构建了一个函数实现 参数--> 评估指标的映射
def fitness_function(params): n_estimators, max_depth, min_samples_split, min_samples_leaf = params # 序列解包,允许你将一个可迭代对象(如列表、元组、字符串等)中的元素依次赋值给多个变量。model = RandomForestClassifier(n_estimators=int(n_estimators),max_depth=int(max_depth),min_samples_split=int(min_samples_split),min_samples_leaf=int(min_samples_leaf),random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)return accuracy# 粒子群优化算法实现
def pso(num_particles, num_iterations, c1, c2, w, bounds): # 粒子群优化算法核心函数# num_particles:粒子的数量,即算法中用于搜索最优解的个体数量。# num_iterations:迭代次数,算法运行的最大循环次数。# c1:认知学习因子,用于控制粒子向自身历史最佳位置移动的程度。# c2:社会学习因子,用于控制粒子向全局最佳位置移动的程度。# w:惯性权重,控制粒子的惯性,影响粒子在搜索空间中的移动速度和方向。# bounds:超参数的取值范围,是一个包含多个元组的列表,每个元组表示一个超参数的最小值和最大值。num_params = len(bounds) particles = np.array([[random.uniform(bounds[i][0], bounds[i][1]) for i in range(num_params)] for _ inrange(num_particles)])velocities = np.array([[0] * num_params for _ in range(num_particles)])personal_best = particles.copy()personal_best_fitness = np.array([fitness_function(p) for p in particles])global_best_index = np.argmax(personal_best_fitness)global_best = personal_best[global_best_index]global_best_fitness = personal_best_fitness[global_best_index]for _ in range(num_iterations):r1 = np.array([[random.random() for _ in range(num_params)] for _ in range(num_particles)])r2 = np.array([[random.random() for _ in range(num_params)] for _ in range(num_particles)])velocities = w * velocities + c1 * r1 * (personal_best - particles) + c2 * r2 * (global_best - particles)particles = particles + velocitiesfor i in range(num_particles):for j in range(num_params):if particles[i][j] < bounds[j][0]:particles[i][j] = bounds[j][0]elif particles[i][j] > bounds[j][1]:particles[i][j] = bounds[j][1]fitness_values = np.array([fitness_function(p) for p in particles])improved_indices = fitness_values > personal_best_fitnesspersonal_best[improved_indices] = particles[improved_indices]personal_best_fitness[improved_indices] = fitness_values[improved_indices]current_best_index = np.argmax(personal_best_fitness)if personal_best_fitness[current_best_index] > global_best_fitness:global_best = personal_best[current_best_index]global_best_fitness = personal_best_fitness[current_best_index]return global_best, global_best_fitness# 超参数范围
bounds = [(50, 200), (10, 30), (2, 10), (1, 4)] # n_estimators, max_depth, min_samples_split, min_samples_leaf# 粒子群优化算法参数
num_particles = 20
num_iterations = 10
c1 = 1.5
c2 = 1.5
w = 0.5start_time = time.time()
best_params, best_fitness = pso(num_particles, num_iterations, c1, c2, w, bounds)
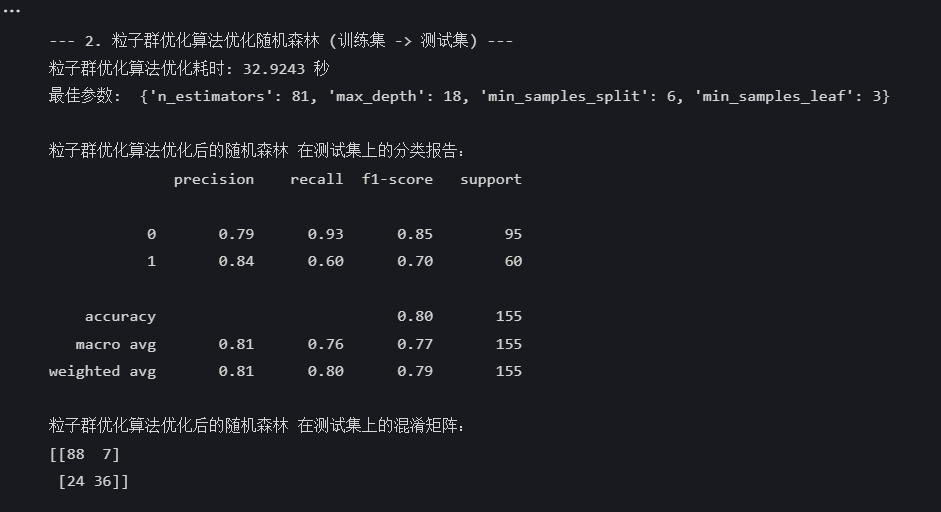
end_time = time.time()print(f"粒子群优化算法优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", {'n_estimators': int(best_params[0]),'max_depth': int(best_params[1]),'min_samples_split': int(best_params[2]),'min_samples_leaf': int(best_params[3])
})# 使用最佳参数的模型进行预测
best_model = RandomForestClassifier(n_estimators=int(best_params[0]),max_depth=int(best_params[1]),min_samples_split=int(best_params[2]),min_samples_leaf=int(best_params[3]),random_state=42)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n粒子群优化算法优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("粒子群优化算法优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
XGBOOST
# XGBoost
xgb_model = xgb.XGBClassifier(random_state=42)
xgb_model.fit(X_train, y_train)
xgb_pred = xgb_model.predict(X_test)print("\nXGBoost 分类报告:")
print(classification_report(y_test, xgb_pred))
print("XGBoost 混淆矩阵:")
print(confusion_matrix(y_test, xgb_pred))xgb_accuracy = accuracy_score(y_test, xgb_pred)
xgb_precision = precision_score(y_test, xgb_pred)
xgb_recall = recall_score(y_test, xgb_pred)
xgb_f1 = f1_score(y_test, xgb_pred)
print("XGBoost 模型评估指标:")
print(f"准确率: {xgb_accuracy:.4f}")
print(f"精确率: {xgb_precision:.4f}")
print(f"召回率: {xgb_recall:.4f}")
print(f"F1 值: {xgb_f1:.4f}") 
shape可解释性分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题# 加载数据并预处理
def data_preprocessing(file_path):data = pd.read_csv(file_path)# 缺失值处理data['Age'].fillna(data['Age'].mean(), inplace=True)data['Embarked'].fillna(data['Embarked'].mode()[0], inplace=True)data.drop('Cabin', axis=1, inplace=True)# 分类变量编码data = pd.get_dummies(data, columns=['Sex', 'Embarked'], prefix=['Sex', 'Embarked'])# 删除无用特征useless_columns = ['PassengerId', 'Name', 'Ticket']data.drop(useless_columns, axis=1, inplace=True)return data# 加载数据
data = data_preprocessing("train.csv")# 划分特征和目标变量
X = data.drop('Survived', axis=1)
y = data['Survived']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用粒子群优化后的最佳参数训练模型
best_params = [180, 28, 2, 1] # 示例参数,实际应使用PSO优化结果
model = RandomForestClassifier(n_estimators=int(best_params[0]),max_depth=int(best_params[1]),min_samples_split=int(best_params[2]),min_samples_leaf=int(best_params[3]),random_state=42
)
model.fit(X_train, y_train)# 预测并评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")# --------------------- SHAP可解释性分析 ---------------------
# 1. 初始化SHAP解释器
explainer = shap.TreeExplainer(model)# 2. 计算训练集样本的SHAP值
shap_values = explainer.shap_values(X_train)# --------------------- 全局解释 ---------------------
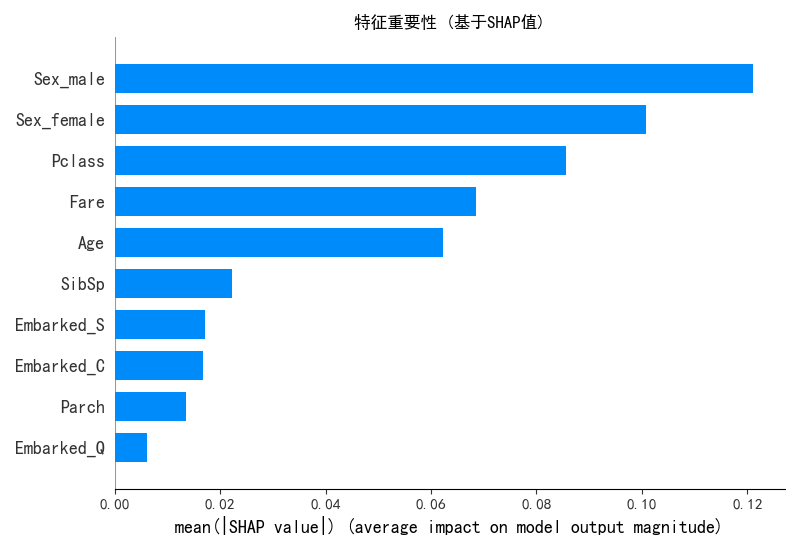
# 3. 特征重要性摘要图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values[1], X_train, plot_type="bar", show=False)
plt.title("特征重要性 (基于SHAP值)")
plt.tight_layout()
plt.savefig("shap_feature_importance.png")
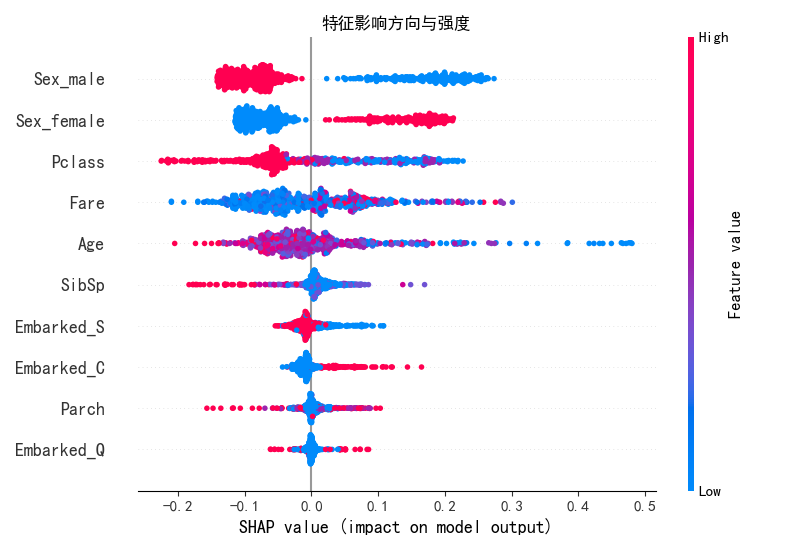
plt.close()# 4. 特征影响方向摘要图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values[1], X_train, show=False)
plt.title("特征影响方向与强度")
plt.tight_layout()
plt.savefig("shap_summary_plot.png")
plt.close()# 5. 依赖图 - 选择几个最重要的特征进行分析
for feature in X_train.columns:plt.figure(figsize=(10, 6))shap.dependence_plot(feature, shap_values[1], X_train, show=False)plt.tight_layout()plt.savefig(f"shap_dependence_{feature}.png")plt.close()# --------------------- 局部解释 ---------------------
# 6. 选择几个样本进行详细解释
sample_indices = [0, 1, 2, 3] # 选择前4个样本
for idx in sample_indices:plt.figure(figsize=(10, 6))shap.force_plot(explainer.expected_value[1], shap_values[1][idx], X_train.iloc[idx], matplotlib=True,show=False)plt.title(f"样本 {idx} 的SHAP解释 - 预测存活概率: {model.predict_proba(X_train.iloc[[idx]])[0][1]:.4f}")plt.tight_layout()plt.savefig(f"shap_force_plot_{idx}.png")plt.close()# 7. 决策图 - 展示特征如何影响最终决策
for idx in sample_indices:plt.figure(figsize=(12, 6))shap.decision_plot(explainer.expected_value[1], shap_values[1][idx], X_train.iloc[idx],feature_names=list(X_train.columns),show=False)plt.title(f"样本 {idx} 的决策路径")plt.tight_layout()plt.savefig(f"shap_decision_plot_{idx}.png")plt.close()# 8. 保存SHAP值用于后续分析
shap_data = pd.DataFrame(shap_values[1], columns=X_train.columns)
shap_data.to_csv("shap_values.csv", index=False)print("\nSHAP分析完成! 结果已保存为图片文件。")
聚类
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()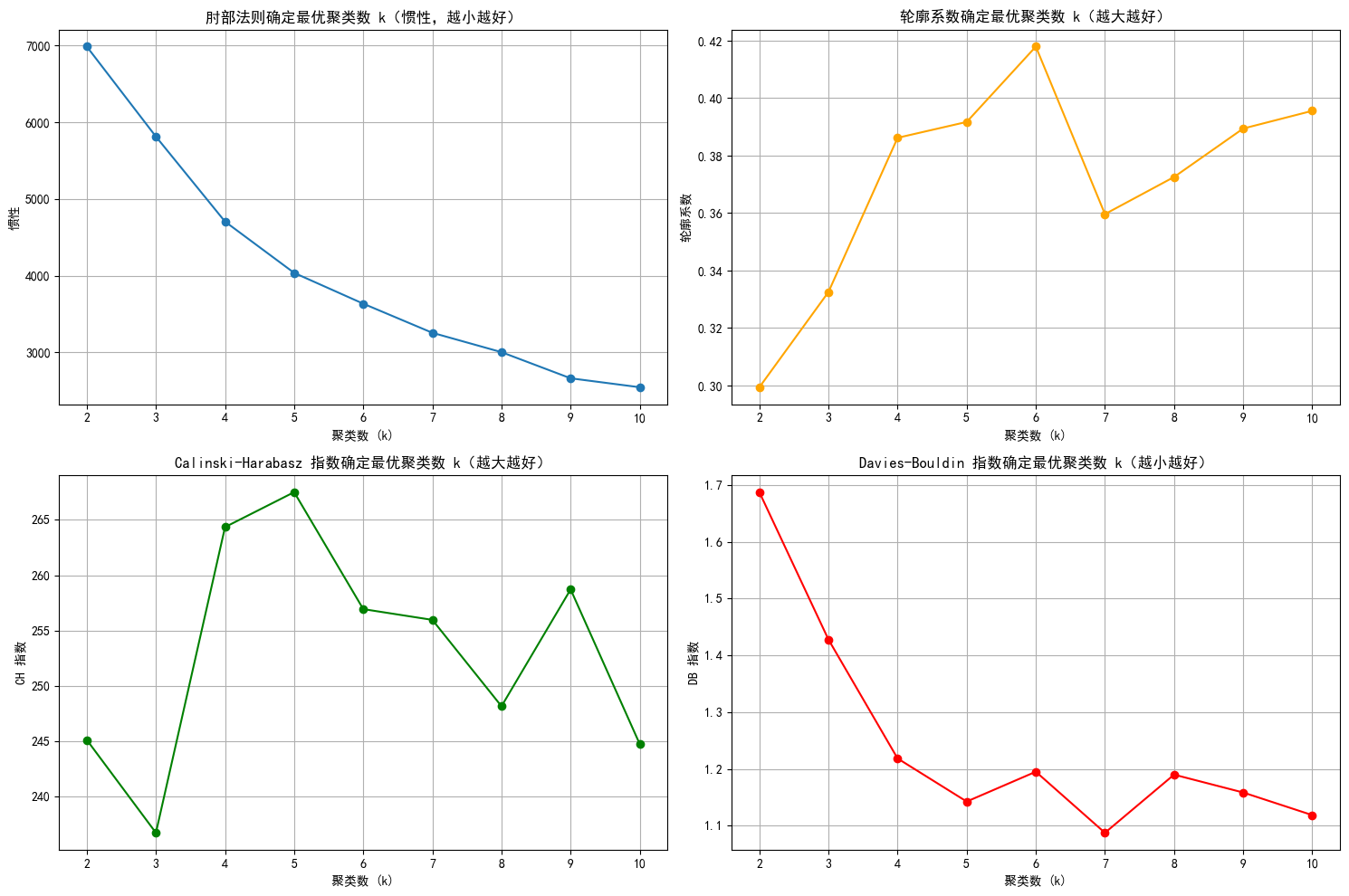
# 提示用户选择 k 值
selected_k = 5# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts()) 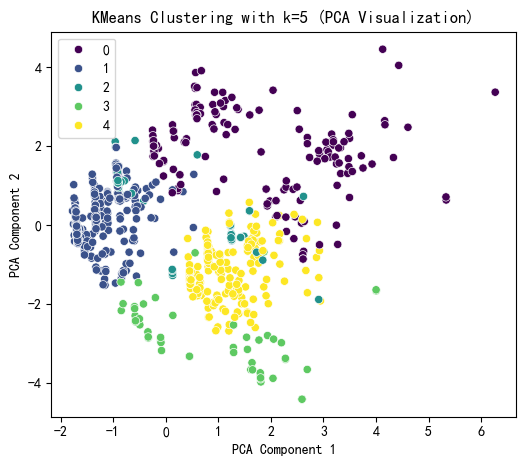
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()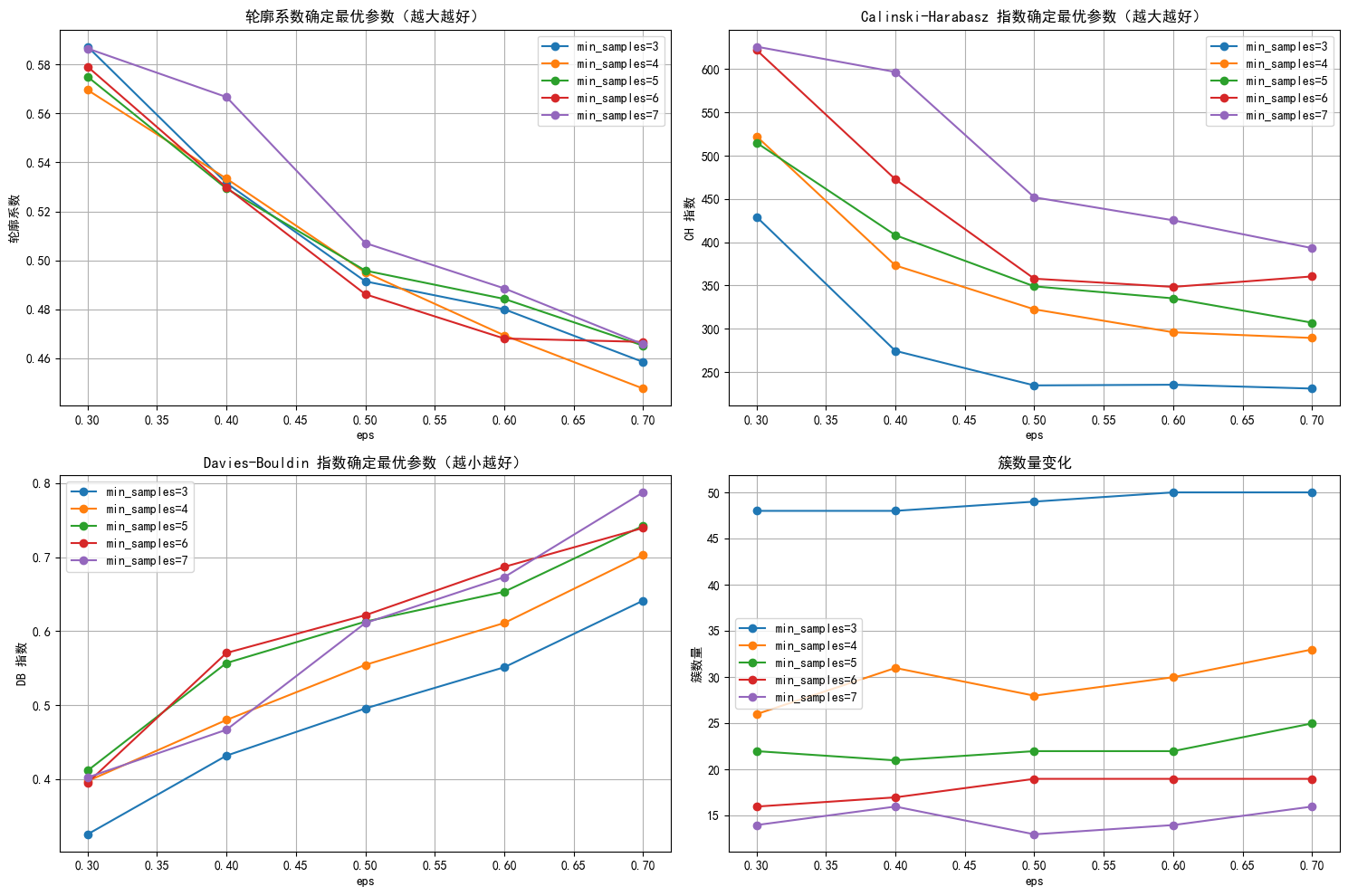
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.4 # 根据图表调整
selected_min_samples = 7 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts()) 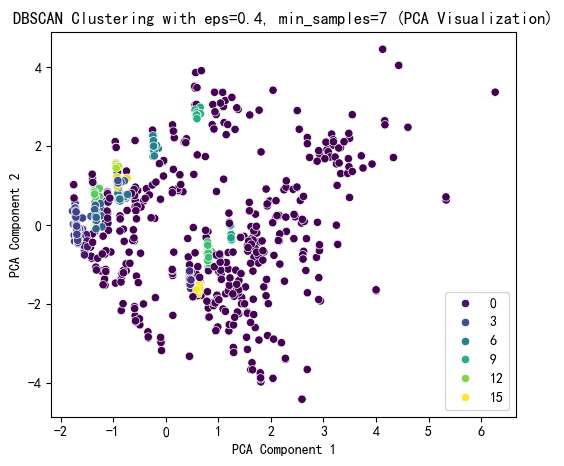
@浙大疏锦行
相关文章:

第二十二天打卡
数据预处理 import pandas as pd from sklearn.model_selection import train_test_splitdef data_preprocessing(file_path):"""泰坦尼克号生存预测数据预处理函数参数:file_path: 原始数据文件路径返回:preprocessed_data: 预处理后的数据集""&quo…...

SET NX互斥功能的实现原理
Redis 的 SET key value NX 命令通过其原子性和底层数据结构的特性实现互斥功能,具体实现如下: 1. 互斥功能的实现原理 SET NX 的核心是 原子性操作:当且仅当键(key)不存在时,才会设置键的值。Redis 的单线…...

前端 CSS 样式书写与选择器 基础知识
1.CSS介绍 CSS是Cascading Style Sheet的缩写,中文意思为"层叠样式表",它是网页的装饰者,用来修饰各标签 排版(大小、边距、背景、位置等)、改变字体的样式(字体大小、字体颜色、对齐方式等)。 2.CSS书写位置 2.1 样式表特征 层…...

一小时学会Docker使用!
文章目录 前言一、安装ssh连接工具二、安装docker三、Docker常见命令四、docker-compose使用 前言 Docker: Docker简单来说就是简化环境配置的,我们配置环境只需要简单的docker pull,docker run即可,而删除环境也很容易ÿ…...

android studio开发aar插件,并用uniapp开发APP使用这个aar
android studio开发aar插件,并用uniapp开发APP使用这个aar 使用android studio打包aar和Unity导入aar详解...

操作系统实战——QEMU模拟器搭建【rCore 操作系统】
操作系统大作业——QEMU模拟器搭建rCore操作系统 按照本篇步骤走,帮你少走很多弯路!博主在自己做的过程中踩了很多坑,过程还是很痛苦的,走了很多弯路,现在都已经在文章中把坑填平了,把弯路修直了。 创作不易…...

web:InfiniteScroll 无限滚动
InfiniteScroll 无限滚动 分页加载 <div class"data-box" v-infinite-scroll"loadMore"> <li v-fori in dataList></li> </div>form: {current: 1,size: 10,}loadMore(){console.log(this.dataList.length, this.total ,8888)if…...

【Redis 进阶】哨兵模式
思维导图: 一、哨兵模式概述 (一)传统主从复制模式的局限性 在传统的Redis主从复制架构中,若主节点发生故障,运维人员需手动执行故障转移操作,将一个从节点提升为新主节点,并逐一通知所有客户…...

告别卡顿,图片查看界的“速度与激情”
嘿,小伙伴们!今天电脑天空给大家介绍一款超好用的图片查看神器——ImageGlass!这可不是普通的图片查看软件哦,它简直就是图片界的“全能王”。首先,它能打开的图片格式多到让你眼花缭乱,什么PNG、JPEG、GIF…...
)
02_线性模型(回归分类模型)
用于分类的线性模型 线性模型也广泛应用于分类问题,可以利用下面的公式进行预测: $ \widehat y w[0]*x[0]w[1]*x[1]…w[p]*x[p]b > 0$ 公式看起来与线性回归的公式非常相似,但没有返回特征的加权求和,而是为预测设置了阈值…...

力扣2094题解
记录: 2025.5.12 题目: 思路: 暴力遍历。 解题步骤: 1.统计数字出现次数:使用数组cnt来记录输入数组中每个数字的出现次数。 2.生成三位偶数:通过循环从100开始,每次递增2,生成…...

人物角色设定机制
模块一:角色塑造进阶技巧 将角色设定(Character Headcanon)提升至更高层次 当您通过Character Headcanon Generator生成基础设定后,可运用以下专业技巧深化角色塑造: 情感核心图谱分析法 解构角色情感驱动机制及其情境表现: 主…...

Python动态渲染页面抓取之Selenium使用指南
目录 一、Selenium技术架构解析 二、环境搭建与基础配置 1. 组件安装 2. 驱动配置 3. 基础操作模板 三、动态内容抓取核心策略 1. 智能等待机制 2. 交互行为模拟 3. 反爬应对方案 四、实战案例:电商评论抓取 五、性能优化与异常处理 2. 异常捕获 六、进…...

智能手表 MCU 任务调度图
智能手表 MCU 任务调度图 处理器平台:ARM Cortex-M33 系统架构:事件驱动 多任务 RTOS RTOS:FreeRTOS(或同类实时内核) 一、任务调度概览 任务名称优先级周期性功能描述App_MainTask中否主循环调度器,系统…...

【C++】cout的格式输出
目录 一、cout的格式输出1、控制宽度和填充2、控制数值格式3、控制整数格式4、控制对齐方式 个人主页<—请点击 C专栏<—请点击 一、cout的格式输出 printf函数在输出数据的时候,可以指定格式来输出,比如:指定宽度、指定小数点后的位…...

私域流量新阵地:掌握Telegram私域运营全方法
在流量获取成本不断上升的今天,越来越多企业和品牌开始将目光转向“私域流量”——一条可以长期沉淀用户、反复转化的可持续增长之路。而在全球化趋势下,Telegram作为一款以高自由度、强隐私性著称的即时通讯平台,正在成为私域运营的新阵地。…...

Python Day23 学习
继续SHAP图绘制的学习 1. SHAP特征重要性条形图 特征重要性条形图(Feature Importance Bar Plot)是 SHAP 提供的一种全局解释工具,用于展示模型中各个特征对预测结果的重要性。以下是详细解释: 图的含义 - 横轴:表示…...

《ATPL地面培训教材13:飞行原理》——第12章:飞行力学基础
翻译:Leweslyh;工具:Cursor & Cluade 3.7;过程稿 第12章:飞行力学基础 目录 引言直线水平稳定飞行尾翼和升降舵直线稳定爬升爬升角重量、高度和温度的影响带动力下降紧急下降滑翔滑翔下降率转弯非对称推力飞行最…...
)
数据中台整体建设方案规划设计方案,数据中台建设汇报方案(PPT)
中台建设背景 在数字化转型浪潮下,企业需通过客户需求精准化、营销策略智能化、管理体系数字化三大核心方向构建竞争优势。本项目以渠道数据整合为基础,围绕客户精准化运营、营销智能化决策、管理数字化赋能三大目标,打造支撑一线业务场景的数…...
)
嵌入式软件--stm32 DAY 6 USART串口通讯(下)
1.寄存器轮询_收发字符串 通过寄存器轮询方式实现了收发单个字节之后,我们趁热打铁,争上游,进阶到字符串。字符串就是多个字符。很明显可以循环收发单个字节实现。 然后就是接收字符串。如果接受单个字符的函数放在while里,它也可…...

Flask如何读取配置信息
目录 一、使用 app.config 读取配置 二、设置配置的几种方式 1. 直接设置 2. 从 Python 文件加载 3. 从环境变量加载 4. 从字典加载 5. 从 .env 文件加载(推荐开发环境用) 三、读取配置值 四、最佳实践建议 在 Flask 中读取配置信息有几种常见方…...

AWS EC2源代码安装valkey命令行客户端
sudo yum -y install openssl-devel gcc wget https://github.com/valkey-io/valkey/archive/refs/tags/8.1.1.tar.gz tar xvzf 8.1.1.tar.gz cd valkey-8.1.1/ make distclean make valkey-cli BUILD_TLSyes参考 Connecting to nodes...

项目全栈实战-基于智能体、工作流、API模块化Docker集成的创业分析平台
目录 思维导图 前置知识 Docker是什么? Docker的核心概念: Docker在本项目中的作用 1. 环境隔离与一致性 2. 简化部署流程 3. 资源管理与扩展性 4. 服务整合与通信 5. 版本控制和回滚 6. 开发与生产环境一致性 总结 前端 1.小程序 2.web …...

如何快速入门大模型?
学习大模型的流程是什么 ? 提示词工程:只需掌握提问技巧即可使用大模型,通过优化提问方式获得更精准的模型输出套壳应用开发:在大模型生态上开发业务层产品(如AI主播、AI小助手等),只需调用API…...

《Flutter社交应用暗黑奥秘:模式适配与色彩的艺术》
暗黑模式已从一种新奇的功能演变为用户体验中不可或缺的一环。对于Flutter开发者而言,如何在社交应用中完美实现暗黑模式适配与色彩对比度优化,是一场充满挑战与惊喜的技术探索之旅。 暗黑模式,绝非仅仅是将界面颜色反转这么简单。从用户体验…...
:CUDA 加速方案)
【秣厉科技】LabVIEW工具包——OpenCV 教程(21):CUDA 加速方案
文章目录 前言一、方案总述二、改造步骤三、编程范例四、应用移植总结 前言 需要下载安装OpenCV工具包的朋友,请前往 此处 ;系统要求:Windows系统,LabVIEW>2018,兼容32位和64位。 一、方案总述 为了保持轻量化与普…...

flutter使用命令生成BinarySize分析图
flutter build ios --analyze-size 生成的文件,使用dev tools 可以分析具体的包大小...

高并发场景下的BI架构设计:衡石分布式查询引擎与缓存分级策略
在电商大促、金融交易时段或IoT实时监控场景中,企业BI系统常面临瞬时万级并发查询的冲击——运营团队需要实时追踪GMV波动,风控部门需秒级响应欺诈检测,产线监控需毫秒级反馈设备状态。传统单体架构的BI系统在此类场景下极易崩溃,…...

web 自动化之 selenium 下拉鼠标键盘文件上传
文章目录 一、下拉框操作二、键盘操作三、鼠标操作四、日期控件五、滚动条操作六、文件上传七、定位windows窗口及窗口的元素总结:页面及元素常用操作 一、下拉框操作 from selenium.webdriver.support.select import Select import time from selenium.webdriver.…...

Qt Creator 配置 Android 编译环境
Qt Creator 配置 Android 编译环境 环境配置流程下载JDK修改Qt Creator默认android配置文件修改sdk_definitions.json配置修改的内容 Qt Creator配置异常处理删除提示占用编译报错 环境 Qt Creator 版本 qtcreator-16.0.1Win10 嗯, Qt这个开发环境有点难折腾,搞了我三天… 配…...

主流编程语言中ORM工具全解析
在不同编程语言中,ORM(Object-Relational Mapping,对象关系映射)工具的设计目标都是简化数据库操作。 以下是主流语言中最常用的 ORM 工具,按语言分类介绍其特点、适用场景和典型案例。 一、Python 生态 Python 社区…...

详解RabbitMQ工作模式之发布确认模式
目录 发布确认模式 概述 消息丢失问题 发布确认的三种模式 实现步骤 应用场景 代码案例 引入依赖 常量类 单条确认 运行代码 批量确认 运行代码 异步确认 运行代码 对比批量确认和异步确认模式 发布确认模式 概述 发布确认模式用于确保消息已…...
)
Power BI 实操案例,将度量值转化为切片器(动态切换分析指标)
Power BI 实操案例,将度量值转化为切片器(动态切换分析指标) 想要在Power BI中让度量值也能像维度一样灵活筛选?没问题,这里就为你揭秘如何将度量值转化为切片器(动态切换分析指标)的实用方法&…...

利用散点图探索宇航员特征与太空任务之间的关系
利用散点图探索宇航员特征与太空任务之间的关系 import matplotlib.pyplot as plt import numpy as np import pandas as pdfrom flexitext import flexitext from matplotlib.patches import FancyArrowPatchplt.rcParams.update({"font.family": "Corbel&quo…...

人工智能的哲学与社会影响
人工智能(AI)的快速发展对人类社会的方方面面产生了深远的影响。在这部分中,我们将探讨AI对人与机器关系的影响、AI对就业和经济的潜在影响,以及人类与AI共存的可能性和道德议题。同时,我们还将针对大众对AI的一些常见…...

MySQL 中 UPDATE 结合 SELECT 和 UPDATE CASE WHEN 的示例
概述 以下是 MySQL 中 UPDATE 结合 SELECT 和 UPDATE CASE WHEN 的示例: 一、UPDATE 结合 SELECT(跨表更新) 场景:根据 orders 表中的订单总金额,更新 users 表中用户的 total_spent 字段。 -- 创建测试表 CREATE T…...

FPGA前瞻篇-计数器设计与实现实例
这是本篇文章的设计目标如下所示: 这个 Counter 模块是一个LED 闪烁计数器,设计目标是: 当输入时钟 clk 为 50 MHz 时,每 0.5 秒翻转一次 LED 灯状态。 随后我们开始补充理论知识。 计数是一种最简单基本的运算,计数器…...
)
运行Spark程序-在Idea中(二)
(四)使用Maven创建新项目 核心的操作步骤如下: 1.启动idea,选择新建项目。 2.将Scala添加到全局库中。 3.设置maven依赖项。修改pom.xml文件,添加如下: 4.下载依赖。添加完成之后,刷新Maven,它…...

Mosaic数据增强技术
Mosaic 数据增强技术是一种在计算机视觉领域广泛应用的数据增强方法。下面是Mosaic 数据增强技术原理的详细介绍 一、原理 Mosaic 数据增强是将多张图像(通常是 4 张)按照一定的规则拼接在一起,形成一张新的图像。在拼接过程中,会…...

Kafka、RabbitMQ 和 RocketMQ区别及上手难度
Kafka、RabbitMQ 和 RocketMQ 是三种流行的消息中间件,它们在设计理念、使用场景和上手难度上有显著差异。以下是它们的核心区别和上手难度分析: 1. 核心区别 特性KafkaRabbitMQRocketMQ设计目标高吞吐、分布式日志流处理通用的消息队列,强调…...

.NET 8 + Angular WebSocket 高并发性能优化
.NET 8 Angular WebSocket 高并发性能优化。 .NET 8 WebSocket 高并发性能优化 WebSocket 是一种全双工通信协议,允许客户端和服务端之间保持持久连接。在高并发场景下,优化 WebSocket 的性能至关重要。以下是针对 .NET 8 中 WebSocket 高并发性能优化…...

SimScape物理建模实例1--单质量-弹簧-阻尼系统
实例1模型下载: 【免费】simscape单质量弹簧阻尼模型资源-CSDN文库 如下图所示单质量弹簧阻尼系统,弹簧具有初始压缩量,假设为1m, 质量块除了受到自身重力作用以外,受到弹簧拉力,以及阻尼器阻尼力,根据牛顿…...

5.5.1 WPF中的动画2-基于路径的动画
何为动画?一般只会动。但所谓会动,还不仅包括位置移动,还包括角度旋转,颜色变化,透明度增减。动画本质上是一个时间段内某个属性值(位置、颜色等)的变化。因为属性有很多数据类型,它们变化也需要多种动画类比如: BooleanAnimationBase\ ByteAnimationBase\DoubleAnima…...

JVM对象分配与程序崩溃排查
一、new 对象在 JVM 中的过程 在 JVM 中通过 new 关键字创建对象时,会经历以下步骤: 内存分配 对象的内存分配在 堆(Heap) 中,优先在 新生代(Young Generation) 的 Eden 区 分配。分配方式取决…...

基于RT-Thread驱动EEPROM_AD24C02
基于RT-Thread驱动EEPROM_AD24C02 前言一、硬件设计二、软件设计三、测试1、eeprom_test()测试2、基础操作字节实验3、多字节读写 前言 存储容量2048位,内部组织256x8(2K),即256个字节的存储单元ÿ…...

VUE中通过DOM导出PDF
最终效果 前端导出PDF的核心在于样式的绘制上,这里其实直接使用CSS进行绘制和布局就行,只不过需要计算好每页DIV盒子的大小,防止一页放不下造成样式错乱。 项目依赖 项目是Vue3 TS npm i html2canvas1.4.1 npm i jspdf3.0.1工具类(htmlToPdf…...
)
sql语句面经手撕(定制整理版)
一张表 店铺id 商品id 销售数量 问:查询总销售数量最多的店铺 SELECT shop_id,SUM(quantity) AS total_quantity FROM sales GROUP BY shop_id ORDER BY total_quantity DESC LIMIT 1; 学生总分名最高的 SELECT student_id,SUM(score) AS total_score FROM score…...

pdf 不是扫描件,但却无法搜索关键词【问题尝试解决未果记录】
一、不是扫描件但不能搜索的原因 1. 情况一:文字被转成了“图形文字” 有些PDF文件虽然看起来像是文字,其实是图片或者矢量图格式,不能直接搜索。 2. 情况二:PDF被加密 有些PDF设置了“内容复制/提取”权限受限,即使…...

android14优化ntp时间同步
简介 网络时间协议NTP(Network Time Protocol)是TCP/IP协议族里面的一个应用层协议,用来使客户端和服务器之间进行时钟同步,提供高精准度的时间校正。 当机器的ntp时间同步出现问题时,可以从ntp配置方面进行优化&…...

【Ansible】之inventory主机清单
前言 本篇博客主要解释Ansible主机清单的相关配置知识 一、inventory 主机清单 Inventory支持对主机进行分组,每个组内可以定义多个主机,每个主机都可以定义在任何一个或多个主机组内。 如果是名称类似的主机,可以使用列表的方式表示各个主机…...