二、transformers基础组件之Tokenizer
在使用神经网络处理自然语言处理任务时,我们首先需要对数据进行预处理,将数据从字符串转换为神经网络可以接受的格式,一般会分为如下几步:
| - Step1 分词:使用分词器对文本数据进行分词(字、字词); - Step2 构建词典:根据数据集分词的结果,构建词典映射(这一步并不绝对,如果采用预训练词向量,词典映 射要根据词向量文件进行处理); - Step3 数据转换:根据构建好的词典,将分词处理后的数据做映射,将文本序列转换为数字序列; - Step4 数据填充与截断:在以batch输入到模型的方式中,需要对过短的数据进行填充,过长的数据进行截断, 保证数据长度符合模型能接受的范围,同时batch内的数据维度大小一致。 |
在transformers工具包中,只需要借助Tokenizer模块便可以快速的实现上述全部工作,它的功能就是将文本转换为神经网络可以处理的数据。Tokenizer工具包无需额外安装,会随着transformers一起安装。
1 Tokenizer 基本使用(对单条数据进行处理)
Tokenizer 基本使用:
(1) 加载保存(from_pretrained / save_pretrained)
(2) 句子分词(tokenize)
(3) 查看词典 (vocab)
(4) 索引转换(convert_tokens_to_ids / convert_ids_to_tokens)
(5) 填充截断(padding / truncation)
(6) 其他输入(attention_mask / token_type_ids)
不同的模型会对应不同的tokenizer。transformers中需要导入AutoTokenizer,AutoTokenizer会根据不同的模型导入对应的tokenizer
1.1. Tokenizer的加载与保存
from transformers import AutoTokenizer
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
tokenizer = AutoTokenizer.from_pretrained("../models/roberta-base-finetuned-dianping-chinese")
tokenizer打印结果如下:
BertTokenizerFast(name_or_path='/root/autodl-fs/models/roberta-base-finetuned-dianping-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right',
special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
将tokenizer 保存到本地后可以直接从本地加载
# tokenizer 保存到本地
tokenizer.save_pretrained("./roberta_tokenizer")
# 从本地加载tokenizer
tokenizer = AutoTokenizer.from_pretrained("./roberta_tokenizer/")
1.2. 句子分词
sen = "弱小的我也有大梦想!"
tokens = tokenizer.tokenize(sen)
#['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']
1.3. 查看字典
tokenizer.vocab
tokenizer.vocab_size #21128
{'##椪': 16551,'##瀅': 17157,'##蝕': 19128,'##魅': 20848,'##隱': 20460,'儆': 1024,'嫣': 2073,'簧': 5082,'镁': 7250,'maggie': 12423,'768': 12472,'1921': 10033,'焜': 4191,'渎': 3932,'鎂': 7110,'谥': 6471,'app': 8172,'噱': 1694,'goo': 9271,'345': 11434,'##rin': 13250,'ᆷ': 324,'redis': 12599,'/': 8027,'莅': 5797,
...'##轰': 19821,'387': 12716,'##齣': 21031,'##ント': 10002,...}
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
1.4. 索引转换
# 将词序列转换为id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
#[2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106]# 将id序列转换为token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
#['弱', '小', '的', '我', '也', '有', '大', '梦', '想', '!']# 将token序列转换为string
str_sen = tokenizer.convert_tokens_to_string(tokens)
#'弱 小 的 我 也 有 大 梦 想!'
上面的把各个步骤都分开了,简洁的方法:
# 将字符串转换为id序列,又称之为编码
ids = tokenizer.encode(sen, add_special_tokens=True)
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102]# 将id序列转换为字符串,又称之为解码
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
# '[CLS] 弱 小 的 我 也 有 大 梦 想! [SEP]'
下面的方法比上面多了两个special_tokens:[CLS]和[SEP],这是特定tokenizer给定的,句子开头和句子结尾
1.5. 填充与截断
以上是针对单条数据,如果是针对多条数据会涉及到填充和截断。把短的数据补齐,长的数据截断。
# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)
# [101, 2483, 2207, 4638, 102]
填充和阶段的长度包含了两个special_tokens:[CLS]和[SEP]
1.6. 其他输入部分
数据处理里面还有一个地方要特别注意:既然数据中存在着填充,就要告诉模型,哪些是填充,哪些是有效的数据。这个时候需要attention_mask。也就是说,对于上面的例子,ids为0的元素对应的attention_mask的元素应为0,不为0的元素位置attention_mask的元素应为0。
另外香BERT这样的模型需要token_type_ids标定是第几个句子。
1.6.1 手动生成方式(体现定义)
如果是手动设定attention_mask和token_type_ids如下:
attention_mask = [1 if idx != 0 else 0 for idx in ids]
token_type_ids = [0] * len(ids)
#ids: ([101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
#attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
#token_type_ids: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
1.6.2 快速调用方式
transformers肯定不会让手动生成,有自动的方法。就是encode_plus
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15)
使用encode_plus生成的是一个字典如下:
{
'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
}‘input_ids’:分此后转换的id
‘token_type_ids’:属于第几个句子
‘attention_mask’:1对应的’input_ids’元素是非填充元素,是真实有效的
调用encode_plus方法名字太长了,不好记,等效的方法就是可以直接用 tokenizer而不使用任何方法。
inputs = tokenizer(sen, padding="max_length", max_length=15)
得到和上面一样的结果:
{
'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
}
2 处理batch数据
上面是处理单条数据,现在看看怎么处理batch数据
sens = ["弱小的我也有大梦想","有梦想谁都了不起","追逐梦想的心,比梦想本身,更可贵"]
res = tokenizer(sens)
#{'input_ids': [[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 102], [101, 3300, 3457, 2682, 6443, 6963, 749, 679, 6629, 102], [101, 6841, 6852, 3457, 2682, 4638, 2552, 8024, 3683, 3457, 2682, 3315, 6716, 8024, 3291, 1377, 6586, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
sens是个列表有3个句子,得到的res是一个字典,包含:‘input_ids’;‘token_type_ids’;‘attention_mask’,每个都是一个列表,列表的每个元素对应每个句子’input_ids’;‘token_type_ids’;‘attention_mask’
以batch的方式去处理比一个一个的处理速度更快。
3 Fast/Slow Tokenizer
Tokenizer有快的版本和慢的版本
3.1 FastTokenizer
- 基于Rust实现,速度快
- offsets_mapping、 word_ids SlowTokenizer
sen = "弱小的我也有大Dreaming!"
fast_tokenizer = AutoTokenizer.from_pretrained(model_path)

FastTokenizer会有一些特殊的返回。比如return_offsets_mapping,用来指示每个token对应到原文的起始位置。
inputs = fast_tokenizer(sen, return_offsets_mapping=True)
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 10252, 8221, 106, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], # "弱小的我也有大Dreaming!"
# Dreaming被分为两个词(7, 12), (12, 15)
# 该字段中保存着每个token对应到原文中的起始与结束位置
'offset_mapping': [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 12), (12, 15), (15, 16), (0, 0)]
}
# word_ids方法,该方法会返回分词后token序列对应原始实际词的索引,特殊标记的值为None。
# Dreaming被分为两个词【7, 7】
inputs.word_ids()
# [None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
3.2 SlowTokenizer
- 基于Python实现,速度慢
slow_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
 两种方式的时间对比如下:
两种方式的时间对比如下:
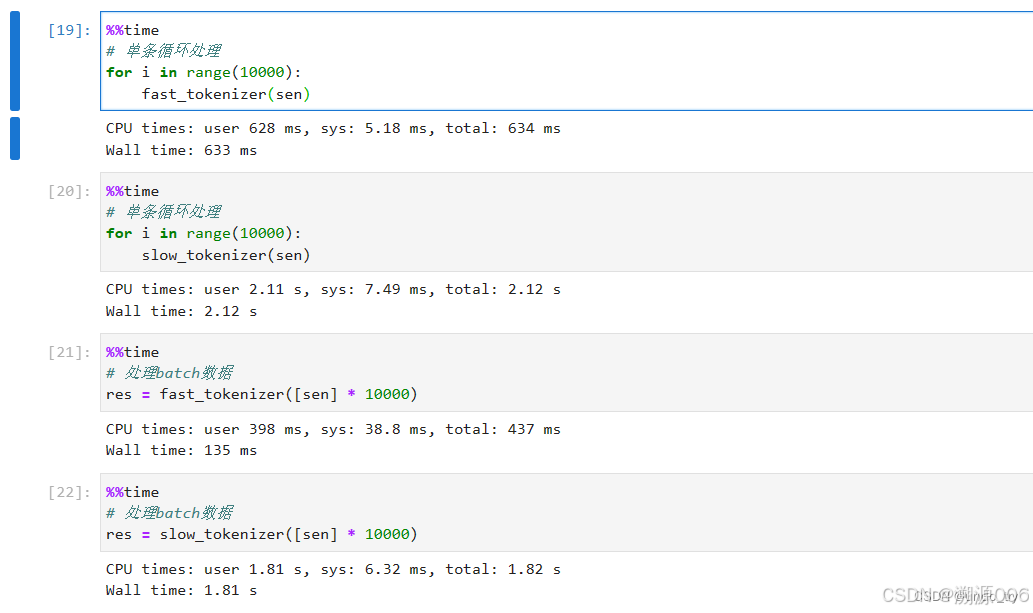
4 特殊Tokenizer的加载
一些非官方实现的模型,自己实现了tokenizer,如果想用他们自己实现的tokenizer,需要指定trust_remote_code=True。
from transformers import AutoTokenizer# 需要设置trust_remote_code=True
# 表示信任远程代码
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
tokenizer
即使保存到本地,然后从本地加载也要设置trust_remote_code=True
tokenizer.save_pretrained("chatglm_tokenizer")# 需要设置trust_remote_code=True
tokenizer = AutoTokenizer.from_pretrained("chatglm_tokenizer", trust_remote_code=True)
参考链接:【手把手带你实战HuggingFace Transformers-入门篇】基础组件之Tokenizer_哔哩哔哩_bilibili
Transformers基本组件(一)快速入门Pipeline、Tokenizer、Model_transformers.pipeline-CSDN博客
相关文章:
二、transformers基础组件之Tokenizer
在使用神经网络处理自然语言处理任务时,我们首先需要对数据进行预处理,将数据从字符串转换为神经网络可以接受的格式,一般会分为如下几步: - Step1 分词:使用分词器对文本数据进行分词(字、字词);- Step2 构建词典:根据数据集分词的结果,构建…...

git 报错:错误:RPC 失败。curl 28 Failed to connect to github.com port 443 after 75000
错误:RPC 失败。curl 28 Failed to connect to github.com port 443 after 75000 ms: Couldnt connect to server致命错误:在引用列表之后应该有一个 flush 包 方法一: 直接换一个域名:把 git clone https://github.com/zx59530…...
)
软考 系统架构设计师系列知识点之杂项集萃(56)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(55) 第91题 商业智能关注如何从业务数据中提取有用的信息,然后采用这些信息指导企业的业务开展。商业智能系统主要包括数据预处理、建立()、数据分…...

数据库的脱敏策略
数据库的脱敏策略:就是屏蔽敏感的数据 脱敏策略三要求: (1)表对象 (2)生效条件(脱敏列、脱敏函数) (3)二元组 常见的脱敏策略规则: 替换、重排、…...

Lora原理及实现浅析
Lora 什么是Lora Lora的原始论文为《LoRA: Low-Rank Adaptation of Large Language Models》,翻译为中文为“大语言模型的低秩自适应”。最初是为了解决大型语言模在进行任务特定微调时消耗大量资源的问题;随后也用在了Diffusion等领域,用于…...

力扣热题100之合并两个有序链表
题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 代码 方法一:新建一个链表 这里就先随便新建一个节点作为一个链表的头节点,然后每次遍历都将小的那个节点放入这个链表,遍历完一…...

Linux511SSH连接 禁止root登录 服务任务解决方案 scp Vmware三种模式回顾
创造一个临时文件 引用 scp -p 3712 atthistime.txt code11.1.1.100:/at ssh connect to host 11.1.1.100 port 22:No route to host lost connection 对方虚拟机是[rootlocalhost caozx26]# ll -d /at drwxr-xr-x. 2 root root 6 5月 11 11:10 /at sshd_config文件修改了port为…...

python实现用户登录
使用python实现用户登录,输入用户名和密码,进行验证,正确登录成功,错误登录失败,允许用户输入三次。 代码: 下面展示一些 内联代码片。 for i in range(3):username input(请输入用户名:)pas…...
2025最新(十五))
信息系统项目管理师-软考高级(软考高项)2025最新(十五)
个人笔记整理---仅供参考 第十五章项目风险管理 15.1管理基础 15.2项目风险管理过程 15.3规划风险管理 15.4识别风险 15.5实施定性风险分析 15.6实施定量风险分析 15.7规划风险应对 15.8实施风险应对 15.9监督风险...

力扣-二叉树-101 对称二叉树
思路 分解问题为,该节点的左孩子的左子树和右孩子的右子树是不是同一棵树 && 该节点的左孩子的右字数和右孩子的左子树是不是同一课树 && 该节点的左右孩子的值相不相同 代码 class Solution {public boolean isSymmetric(TreeNode root) {// 层…...

07.three官方示例+编辑器+AI快速学习webgl_buffergeometry_attributes_integer
本实例主要讲解内容 这个Three.js示例展示了WebGL 2环境下的整数属性渲染技术。通过创建大量随机分布的三角形,并为每个三角形分配不同的整数索引,实现了基于索引动态选择纹理的效果。 核心技术包括: WebGL 2环境下的整数属性支持顶点着色…...

Python Day 22 学习
学习讲义Day14安排的内容:SHAP图的绘制 SHAP模型的基本概念 参考学习的帖子:SHAP 可视化解释机器学习模型简介_shap图-CSDN博客 以下为学习该篇帖子的理解记录: Q. 什么是SHAP模型?它与机器学习模型的区别在哪儿? …...
6 - hid-ft260)
OrangePi Zero 3学习笔记(Android篇)6 - hid-ft260
目录 1. 将hid-ft260.c拷贝到Android目录内 2. 修改hid-ids.h 3. 修改hid-quirks.c 4. 修改Kconfig 5. 修改Makefile 6. 配置内核 7. 编译内核 8. 增加权限 9. 验证 在Android中添加驱动模块ko文件,以hid-ft260为例。 1. 将hid-ft260.c拷贝到Android目录内…...
连接oracle数据库失败)
部署Superset BI(五)连接oracle数据库失败
折腾完了hana和sqlserver数据库的连接,开始折腾oracle数据库连接 1.requirements-local.txt配置 尝试在requirements-local.txt中设置,结果容器弄瘫痪了,拉不起来了,只要又去掉修改 rootNocobase:/usr/superset/superset/docker# …...

快速搭建一个vue前端工程
一、环境准备 1、安装node.js 下载地址:Node.js 推荐版本如下: 2、检查node.js版本 node -v npm -v 二、安装Vue脚手架 Vue脚手架是Vue官方提供的标准化开发工具。vue官网:https://cn.vuejs.org/ 全局安装vue/cli (仅第一次…...

蓝桥杯14届 数三角
问题描述 小明在二维坐标系中放置了 n 个点,他想在其中选出一个包含三个点的子集,这三个点能组成三角形。然而这样的方案太多了,他决定只选择那些可以组成等腰三角形的方案。请帮他计算出一共有多少种选法可以组成等腰三角形? 输…...

在Python中计算函数耗时并超时自动退出
更多内容请见: python3案例和总结-专栏介绍和目录 文章目录 方法1:使用装饰器结合信号模块(仅Unix-like系统)方法2:使用多线程(跨平台解决方案)方法3:使用concurrent.futures(Python 3.2+)方法4:使用 multiprocessing + Process(跨平台)方法5:使用 time 手动计…...

jna总结1
java使用JNA调用dll的方法_(jnacalldllapi) native.loadlibrary(path-CSDN博客 JNA(Java Native Access):建立在JNI之上的Java开源框架,SUN主导开发,用来调用C、C代码,尤其是底层库文件(windows中叫dll文件,…...

[Java][Leetcode simple]26. 删除有序数组中的重复项
思路 第一个元素不动从第二个元素开始:只要跟上一个元素不一样就放入数组中 public int removeDuplicates(int[] nums) {int cnt1;for(int i 1; i < nums.length; i) {if(nums[i] ! nums[i-1]) {nums[cnt] nums[i];}}return cnt;}...

BUUCTF——Ezpop
BUUCTF——Ezpop 进入靶场 给了php代码 <?php //flag is in flag.php //WTF IS THIS? //Learn From https://ctf.ieki.xyz/library/php.html#%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E9%AD%94%E6%9C%AF%E6%96%B9%E6%B3%95 //And Crack It! class Modifier {protected $v…...

springboot3+vue3融合项目实战-大事件文章管理系统-更新用户密码
大致分为这三步 首先在usercontroller中增加updatePwd方法 PatchMapping ("/updatePwd")public Result updatePwd(RequestBody Map<String,String> params){//1.校验参数String oldPwd params.get("old_pwd");String newPwd params.get("n…...

用浏览器打开pdf,如何使用划词翻译?
1. 浏览器 | 扩展 | 获取 Microsoft Edge 扩展 2. 搜索 “沙拉查词” 点击“获取” 3. 扩展这里选择 管理扩展 勾选 “允许访问文件url” 注:这里一定要勾选,否则沙拉查词无法访问.pdf 文件!!!会出现下图错误 4. 右击…...

大模型项目:普通蓝牙音响接入DeepSeek,解锁语音交互新玩法
本文附带视频讲解 【代码宇宙019】技术方案:蓝牙音响接入DeepSeek,解锁语音交互新玩法_哔哩哔哩_bilibili 目录 效果演示 核心逻辑 技术实现 大模型对话(技术: LangChain4j 接入 DeepSeek) 语音识别(…...

split和join的区别
split和join是Python中用于处理字符串的两种方法,它们的主要区别在于功能和使用场景。 split()方法 split()方法用于将字符串按照指定的分隔符分割成多个子串,并返回这些子串组成的列表。如果不指定分隔符,则默认分割所有的空白字符&am…...
)
Qt坐标系 + 信号和槽 + connect函数(8)
文章目录 Qt坐标系信号和槽connect函数connect函数的介绍connect函数具体的使用方式一个简单的例子 两个问题咋知道的QPushButton有一个clicked信号官方文档找不到相关线索怎么办 简介:上篇文章:Qt 通过控件按钮实现hello world 命名规范(7&…...

Maven 公司内部私服中央仓库搭建 局域网仓库 资源共享 依赖包构建共享
介绍 公司内部私服搭建通常是为了更好地管理公司内部的依赖包和构建过程,避免直接使用外部 Maven 中央仓库。通过搭建私服,团队能够控制依赖的版本、提高构建速度并增强安全性。公司开发的一些公共工具库更换的提供给内部使用。 私服是一种特殊的远程仓…...

蓝桥杯14届国赛 合并数列
问题描述 小明发现有很多方案可以把一个很大的正整数拆成若干正整数的和。他采取了其中两种方案,分别将他们列为两个数组 {a1,a2,...,an} 和 {b1,b2,...,bm}。两个数组的和相同。 定义一次合并操作可以将某数组内相邻的两个数合并为一个新数,新数的值是…...

人工智能100问☞第20问:神经网络的基本原理是什么?
目录 一、通俗解释 二、专业解析 三、权威参考 神经网络通过模拟人脑神经元连接结构,借助多层神经元的前向传播(输入到输出逐层计算)与反向传播(误差逆向调整参数)机制,利用激活函数(如ReLU、Sigmoid)引入非线性特征,通过权重迭代优化实现从数据中自主学习,最终完…...

AMD FPGA书籍推荐-初学者、一线工程师适用
!](https://i-blog.csdnimg.cn/direct/b78c8f0d015240e28aaad985f0f6eca9.jpg...

CSS 盒子模型与元素定位
CSS 盒子模型与元素定位 一、元素类型与转换 1. 基本元素类型 块级元素 (block) 特点:独占一行,可设置宽高,默认宽度100%示例:<div>, <p>, <h1>-<h6>, <ul>, <li> 行内元素 (inline) 特…...

Java常用类-比较器
目录 一、为什么需要比较器?二、核心差异速记表三、Comparable:对象自带的 “默认规则”1. 核心作用2. 源码定义3. 实战:给Student类加默认规则4. 源码验证(以Integer为例) 四、Comparator:临时的 “外部规…...

【Linux系列】bash_profile 与 zshrc 的编辑与加载
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【大模型】解决最新的Dify1.3.1版本 无法基于Ollama成功添加模型
本地搭建参考链接,但是版本不是最新的1.3.1 DeepSeek Dify :零成本搭建企业级本地私有化知识库保姆级教程 windows环境下部署。 查看模型添加,提示成功,但实际模型接口返回值为空,即看不到已添加的模型。 解决方法…...

6.空气质量检测和语音播报
目录 传感器 传感器分类 数字量传感器 模拟量传感器 电压型模拟量传感器 电流型模拟量传感器 接收不同数字电平信号 KQM6600 简介 获取数据手册 关注手册的内容 KQM660硬件层 编辑 KQM协议层 语音识别和语音播报模块 SU03T作用 SU03T简介编辑 SU03T硬件层 …...

LeetCode 热题 100 543. 二叉树的直径
LeetCode 热题 100 | 543. 二叉树的直径 大家好,今天我们来解决一道经典的二叉树问题——二叉树的直径。这道题在 LeetCode 上被标记为简单难度,要求计算给定二叉树的直径。 问题描述 给你一棵二叉树的根节点,返回该树的直径。二叉树的直径…...
)
D. Explorer Space(dfs+剪枝)
Problem - 1517D - Codeforces 题目大意:给你一个n行m列的矩阵,以及每个点上下左右相邻点的边权,求出每个点任意走k步后再回到当前这个点的最小路程,如果不能回到起始点则输出-1 思路:既然走k步后要回到起始点&#…...

# KVstorageBaseRaft-cpp 项目 RPC 模块源码学习
KVstorageBaseRaft-cpp 项目 RPC 模块源码学习 。 一、项目简介 KVstorageBaseRaft-cpp 是一个基于 Raft 一致性算法实现的分布式 KV 存储系统,采用 C 开发。项目的核心目标是帮助开发者理解 Raft 原理和分布式 KV 存储的基本实现。RPC 模块是分布式系统通信的关…...
篇三:阅读与注释共用体类 QVariant 及其源代码,本类支持比较运算符 ==、!=。)
QT6 源(93)篇三:阅读与注释共用体类 QVariant 及其源代码,本类支持比较运算符 ==、!=。
(9) 本类支持比较运算符 、! : 可见, QString 类型里可存储多个 unicode 字符,即使只存储一个 unicode 字符也不等于 QChar。 (10)本源代码来自于头文件 qvariant . h : #ifndef Q…...
)
Qt开发经验 --- 避坑指南(13)
文章目录 [toc]1 安装Qt creator后无法使用debug调试2 安装VS后之间安装自带的Windows SDK3 Qt配置ssl4 ubuntu编译linuxdeployqt 更多精彩内容👉内容导航 👈👉Qt开发经验 👈 1 安装Qt creator后无法使用debug调试 安装最新版本Q…...

go 通过汇编学习atomic原子操作原理
文章目录 概要一、原理1.1、案例1.2、关键汇编 二、LOCK汇编指令2.1、 LOCK2.2、 原理2.2.1、 缓存行2.2.2、 缓存一致性之MESI协议2.2.3、lock原理 三、x86缓存发展四、x86 DMA发展参考 概要 在并发操作下,对一个简单的aa2的操作都会出错,这是因为这样…...

LOJ 6346 线段树:关于时间 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),另有一个存储三元组的列表 L L L. 有 m m m 个操作分两种: add ( l , r , k ) \operatorname{add}(l,r,k) add(l,r,k):将 ( l , r , …...
)
Python----神经网络(基于Alex Net的花卉分类项目)
一、基于Alex Net的花卉分类 1.1、项目背景 在当今快速发展的科技领域,计算机视觉已成为一个备受关注的研究方向。随着深度学习技术的不断进步,图像识别技术得到了显著提升,广泛应用于医疗、安防、自动驾驶等多个领域。其中,花卉…...

影刀RPA开发-魔法指令-玩转图片识别
聊聊天,就能生成指令! 1. 影刀RPA提取图片内容的方式 官方AI识别 集成的第三方识别指令 免费的识别指令 使用python自己编写识别代码,自己安装第三方库 import easyocr# 创建一个 EasyOCR 识别器,指定同时识别中文(简…...

从零开始开发纯血鸿蒙应用之XML解析
从零开始开发纯血鸿蒙应用 〇、前言一、鸿蒙SDK中的 XML API1、ohos.xml2、ohos.convertxml 三、XML 解析实践1、源数据结构2、定义映射关系3、定义接收对象4、获取文章信息 四、总结 〇、前言 在前后端的数据传输方面,论格式化形式,JSON格式自然是首选…...

运算放大器稳定性分析
我们常见的运放电路大多是在闭环状态。那么就必然遵循闭环控制系统的基本原理。闭环控制系统的核心是通过反馈来调节系统的输出,使其更接近期望值。 本文从闭环控制系统的角度,画出同相、反相差分电路的经典控制框图。有了控制框图就可以利用经典控制理论…...

python【扩展库】websockets
文章目录 介绍基础教程安装websockets接收与发送消息介绍 websockets基于python构建websocket服务、客户端的扩展库;官方文档;优点是正确性(严格测试,100%分支覆盖)、简单性(自管理连接)、健壮性、高性能(C扩展加速内存操作),双向通信;基于(python标准异步io框架)…...

leetcode 454. 4Sum II
题目描述 代码: class Solution { public:int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {unordered_map<int,int> table;int temp 0;for(auto n1:nums1){fo…...

MCP 传输层代码分析
MCP 传输层代码分析 MCP 整体架构说明 引用官方文档原文:Model Context Protocol (MCP) 构建在一个灵活且可扩展的架构上,使 LLM 应用和集成之间的无缝通信成为可能。具体架构细节可以参考文档(核心架构 - MCP 中文文档)。MCP 采…...
)
OBS studio 减少音频中的杂音(噪音)
1. 在混音器中关闭除 麦克风 之外的所有的音频输入设备 2.在滤镜中增加“噪声抑制”和“噪声门限”...

java的Stream流处理
Java Stream 流处理详解 Stream 是 Java 8 引入的一个强大的数据处理抽象,它允许你以声明式方式处理数据集合(类似于 SQL 语句),支持并行操作,提高了代码的可读性和处理效率。 一、Stream 的核心概念 1. 什么是 Str…...