大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
文章目录
- 一、简介
- 二、如何安装
- 2.1 安装
- 2.2 校验
- 三、开始使用
- 3.1 可视化界面
- 3.2 使用命令行
- 3.2.1 模型微调训练
- 3.2.2 模型合并
- 3.2.3 模型推理
- 3.2.4 模型评估
- 四、高级功能
- 4.1 分布训练
- 4.2 DeepSpeed
- 4.2.1 单机多卡
- 4.2.2 多机多卡
- 五、日志分析
一、简介
LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。
二、如何安装
2.1 安装
# 构建虚拟环境
conda create -n llamafactory python=3.10 -y && conda activate llamafactory
# 下载仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安装
pip install -e .
2.2 校验
llamafactory-cli version
三、开始使用
3.1 可视化界面
# 启动可视化界面
llamafactory-cli webui
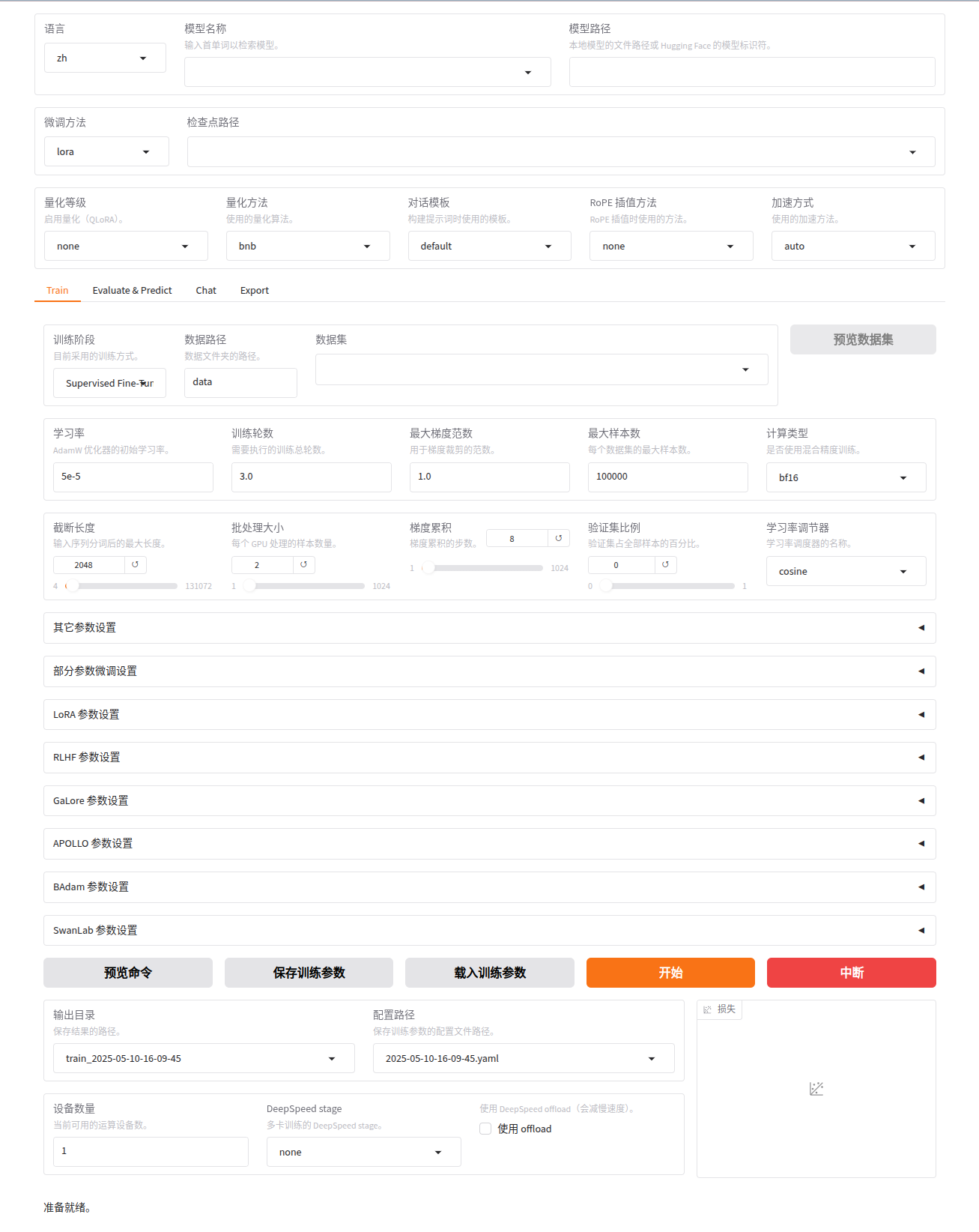
WebUI 主要分为四个界面:训练、评估与预测、对话、导出。
- 训练:
- 在开始训练模型之前,您需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
随后,点击 开始 按钮开始训练模型。
备注:
关于断点重连:适配器断点保存于output_dir目录下,请指定检查点路径以加载断点继续训练。
如果需要使用自定义数据集,需要在data/data_info.json中添加自定义数据集描述并确保数据集格式正确,否则可能会导致训练失败。
-
评估预测
- 模型训练完毕后,可以通过在评估与预测界面通过指定
模型及检查点路径在指定数据集上进行评估。
- 模型训练完毕后,可以通过在评估与预测界面通过指定
-
对话
- 通过在对话界面指定
模型、检查点路径及推理引擎后输入对话内容与模型进行对话观察效果。
- 通过在对话界面指定
-
导出
- 如果对模型效果满意并需要导出模型,您可以在导出界面通过指定
模型、检查点路径、分块大小、导出量化等级及校准数据集、导出设备、导出目录等参数后点击导出按钮导出模型。
- 如果对模型效果满意并需要导出模型,您可以在导出界面通过指定
3.2 使用命令行
3.2.1 模型微调训练
在 examples/train_lora 目录下有多个LoRA微调示例,以 llama3_lora_sft.yaml 为例,命令如下:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
备注:
LLaMA-Factory 默认使用所有可见的计算设备。根据需求可通过CUDA_VISIBLE_DEVICES或ASCEND_RT_VISIBLE_DEVICES指定计算设备。
参数说明:
| 名称 | 描述 |
|---|---|
| model_name_or_path | 模型名称或路径(指定本地路径,或从 huggingface 上下载) |
| stage | 训练阶段,可选: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO |
| do_train | true用于训练, false用于评估 |
| finetuning_type | 微调方式。可选: freeze, lora, full |
| lora_target | 采取LoRA方法的目标模块,默认值为 all。 |
| dataset | 使用的数据集,使用”,”分隔多个数据集 |
| template | 数据集模板,请保证数据集模板与模型相对应。 |
| output_dir | 输出路径 |
| logging_steps | 日志输出步数间隔 |
| save_steps | 模型断点保存间隔 |
| overwrite_output_dir | 是否允许覆盖输出目录 |
| per_device_train_batch_size | 每个设备上训练的批次大小 |
| gradient_accumulation_steps | 梯度积累步数 |
| max_grad_norm | 梯度裁剪阈值 |
| learning_rate | 学习率 |
| lr_scheduler_type | 学习率曲线,可选 linear, cosine, polynomial, constant 等。 |
| num_train_epochs | 训练周期数 |
| bf16 | 是否使用 bf16 格式 |
| warmup_ratio | 学习率预热比例 |
| warmup_steps | 学习率预热步数 |
| push_to_hub | 是否推送模型到 Huggingface |
目录说明:
examples/train_full:包含多个全参数微调示例。examples/train_lora:包含多个LoRA微调示例。examples/train_qlora:包含多个QLoRA微调示例。
3.2.2 模型合并
在 examples/merge_lora 目录下有多个模型合并示例,以 llama3_lora_sft.yaml 为例,命令如下:
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
adapter_name_or_path 需要与微调中的适配器输出路径 output_dir 相对应。
export_quantization_bit 为导出模型量化等级,可选 2, 3, 4, 8。
目录说明:
examples/merge_lora:包含多个LoRA合并示例。
3.2.3 模型推理
在 examples/inference 目录下有多个模型推理示例,以 llama3_lora_sft.yaml 为例,命令如下:
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
参数说明:
| 名称 | 描述 |
|---|---|
| model_name_or_path | 模型名称或路径(指定本地路径,或从HuggingFace Hub下载) |
| adapter_name_or_path | 适配器检查点路径(用于LoRA等微调方法的预训练适配器) |
| template | 对话模板(需与模型架构匹配,如LLaMA-2、ChatGLM等专用模板) |
| infer_backend | 推理引擎(可选:vllm、transformers、lightllm等) |
3.2.4 模型评估
-
通用能力评估
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml -
NLG 评估
llamafactory-cli train examples/extras/nlg_eval/llama3_lora_predict.yaml获得模型的
BLEU和ROUGE分数以评价模型生成质量。 -
评估相关参数
| 参数名称 | 类型 | 描述 | 默认值 | 可选值/备注 |
|---|---|---|---|---|
| task | str | 评估任务名称 | - | mmlu_test, ceval_validation, cmmlu_test |
| task_dir | str | 评估数据集存储目录 | “evaluation” | 相对或绝对路径 |
| batch_size | int | 每个GPU的评估批次大小 | 4 | 根据显存调整 |
| seed | int | 随机种子(保证可复现性) | 42 | - |
| lang | str | 评估语言 | “en” | en(英文), zh(中文) |
| n_shot | int | Few-shot学习使用的示例数量 | 5 | 0表示zero-shot |
| save_dir | str | 评估结果保存路径 | None | None时不保存 |
| download_mode | str | 数据集下载模式 | DownloadMode.REUSE_DATASET_IF_EXISTS | 存在则复用,否则下载 |
四、高级功能
4.1 分布训练
LLaMA-Factory 支持 单机多卡 和 多机多卡 分布式训练。同时也支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。
- DDP (DistributedDataParallel) 通过实现模型并行和数据并行实现训练加速。 使用
DDP的程序需要生成多个进程并且为每个进程创建一个DDP实例,他们之间通过torch.distributed库同步。 - DeepSpeed 是微软开发的分布式训练引擎,并提供
ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水线并行等优化技术。 - FSDP 通过全切片数据并行技术(Fully Sharded Data Parallel)来处理更多更大的模型。在
DDP中,每张 GPU 都各自保留了一份完整的模型参数和优化器参数。而FSDP切分了模型参数、梯度与优化器参数,使得每张GPU只保留这些参数的一部分。 除了并行技术之外,FSDP还支持将模型参数卸载至CPU,从而进一步降低显存需求。
| 引擎 | 数据切分 | 模型切分 | 优化器切分 | 参数卸载 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
4.2 DeepSpeed
由于 DeepSpeed 的显存优化技术,使得 DeepSpeed 在显存占用上具有明显优势,因此推荐使用 DeepSpeed 进行训练。
DeepSpeed 是由微软开发的一个开源深度学习优化库,旨在提高大模型训练的效率和速度。在使用 DeepSpeed 之前,您需要先估计训练任务的显存大小,再根据任务需求与资源情况选择合适的 ZeRO 阶段。
- ZeRO-1: 仅划分优化器参数,每个GPU各有一份完整的模型参数与梯度。
- ZeRO-2: 划分优化器参数与梯度,每个GPU各有一份完整的模型参数。
- ZeRO-3: 划分优化器参数、梯度与模型参数。
简单来说:从ZeRO-1到ZeRO-3,阶段数越高,显存需求越小,但是训练速度也依次变慢。此外,设置offload_param=cpu参数会大幅减小显存需求,但会极大地使训练速度减慢。因此,如果您有足够的显存, 应当使用ZeRO-1,并且确保offload_param=none。
4.2.1 单机多卡
启动 DeepSpeed 引擎,命令如下:
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
该配置文件中配置了 deepspeed 参数,具体如下:
deepspeed: examples/deepspeed/ds_z3_config.json
4.2.2 多机多卡
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
备注
关于hostfile:
hostfile的每一行指定一个节点,每行的格式为 slots=<num_slots> , 其中 是节点的主机名, <num_slots> 是该节点上的GPU数量。下面是一个例子:worker-1 slots=4 worker-2 slots=4请在 https://www.deepspeed.ai/getting-started/ 了解更多。
如果没有指定
hostfile变量,DeepSpeed会搜索/job/hostfile文件。如果仍未找到,那么DeepSpeed会使用本机上所有可用的GPU。
五、日志分析
在训练过程中,LLaMA-Factory 会输出详细的日志信息,包括训练进度、训练参数、训练时间等。这些日志信息可以帮助我们更好地了解训练过程,并针对问题进行优化和调整。以下解释训练时的一些参数:
[INFO|trainer.py:2409] 2025-04-01 15:49:20,010 >> ***** Running training *****
[INFO|trainer.py:2410] 2025-04-01 15:49:20,010 >> Num examples = 205
[INFO|trainer.py:2411] 2025-04-01 15:49:20,010 >> Num Epochs = 1,000
[INFO|trainer.py:2412] 2025-04-01 15:49:20,010 >> Instantaneous batch size per device = 8
[INFO|trainer.py:2415] 2025-04-01 15:49:20,010 >> Total train batch size (w. parallel, distributed & accumulation) = 64
[INFO|trainer.py:2416] 2025-04-01 15:49:20,010 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2417] 2025-04-01 15:49:20,010 >> Total optimization steps = 3,000
[INFO|trainer.py:2418] 2025-04-01 15:49:20,013 >> Number of trainable parameters = 73,859,072
参数解释:
-
单设备批大小(Instantaneous batch size per device)
- 指单个 GPU(或设备)在每次前向传播时处理的样本数量。
- 例如,如果
instantaneous_batch_size_per_device=8,则每个 GPU 一次处理 8 条数据。
-
设备数(Number of devices)
- 指并行训练的 GPU 数量(数据并行)。
- 例如,使用 4 个 GPU 时,
device_num=4。
-
梯度累积步数(Gradient accumulation steps)
- 由于显存限制,可能无法直接增大单设备批大小,因此通过多次前向传播累积梯度,再一次性更新参数。通过梯度累积,用较小的单设备批大小模拟大总批大小的训练效果。
- 例如,若
gradient_accumulation_steps=2,则每 2 次前向传播后才执行一次参数更新。
-
总批大小(Total train batch size)
- 是参数更新时实际使用的全局批量大小。总批大小越大,梯度估计越稳定,但需调整学习率(通常按比例增大)
在 LLaMA Factory 中,总批大小(Total train batch size)、单设备批大小(Instantaneous batch size per device)、设备数(Number of devices) 和 梯度累积步数(Gradient accumulation steps) 的关系可以用以下公式表示:
[
\text{总批大小} = \text{单设备批大小} \times \text{设备数} \times \text{梯度累积步数}
]
例如:
- 单设备批大小 = 8
- 设备数 = 4
- 梯度累积步数 = 2
- 则总批大小 = ( 8 \times 4 \times 2 = 64 )。
参考资料:
- Github
- README_zh.md
- 数据集文档
- 说明文档
相关文章:

大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
文章目录 一、简介二、如何安装2.1 安装2.2 校验 三、开始使用3.1 可视化界面3.2 使用命令行3.2.1 模型微调训练3.2.2 模型合并3.2.3 模型推理3.2.4 模型评估 四、高级功能4.1 分布训练4.2 DeepSpeed4.2.1 单机多卡4.2.2 多机多卡 五、日志分析 一、简介 LLaMA-Factory 是一个…...

游戏引擎学习第268天:合并调试链表与分组
回顾并为今天的内容设定基调 我们正在直播中开发完整的游戏,目前调试系统的开发已接近尾声。这个调试系统的构建过程经历了较长的时间,中间还暂停过一段时间去做硬件渲染路径的开发,并在已有的软件渲染路径基础上进行了扩展。后来我们又回到…...

【Linux系统编程】进程属性--标识符
1.PID 1.1什么是PID? 区分进程的唯一性 1.2如何查看进程? ps ajx | head -1 ; ps ajx | grep myproc 或者ps ajx | head -1 && ps ajx | grep myproc | grep -v grep(过滤掉grep本身这个进程) 1.3进程有哪两种&#…...

React文档-State数据扁平化
1、选择 State 结构 思考一下: 如果渲染列表, 并更新列表数据在下面展示~ state 过去常常是这样复制的: items [{ id: 0, title: pretzels}, ...]selectedItem {id: 0, title: pretzels} 改了之后是这样的:items [{ id: 0, …...

kotlin flow防抖
一 防抖设计 ✅ 1. 点击事件的防抖:用于防止频繁触发逻辑 🎯 适用场景: 用户连续快速点击按钮,可能会导致多次发送网络请求、CAN 指令或反复切换状态等副作用。所以我们通常在点击函数中处理防抖,例如: …...
)
基础语法(二)
Mysql基础语法(二) Mysql基础语法(二)主要介绍Mysql中稍微进阶一点的内容,会稍微有一些难度(博主个人认为)。学习完基础语法(一)和基础语法(二)之…...

FreeTex v0.2.0:功能升级/支持Mac
概述 FreeTex在发布之后,迎来很多反馈,本次根据主流的反馈建议,又进行一轮小升级,正式发布v0.2.0版本,主要升级点如下: 新增识别结果预览显示 Latex识别结果支持格式化输出 软件体积更小,并移…...

MacOS 用brew 安装、配置、启动Redis
MacOS 用brew 安装、配置、启动Redis 一、安装 brew install redis 二、启动 brew services start redis 三、用命令行检测 set name tom get name...

大型旋转机械信号分解算法模块
大型旋转机械信号分解算法模块,作为信号处理算法工具箱的主要功能模块,可应用于各类关键机械部件(轴承、齿轮、转子、联轴器等)的信号分析、故障探测、趋势劣化评估等,采用全Python语言,以B/S模式ÿ…...

Java 中的数据类型误导点!!!
在 Java 中,数据类型分为两大类:基本类型(Primitive Types) 和 引用类型(Reference Types)。它们的存储方式和行为完全不同。 1. 基本类型 Java 有 8 种基本数据类型,它们直接存储值ÿ…...

Linux--JsonCpp
1.JsonCpp 简介 JsonCpp 是一个用于 C 的 JSON 解析和生成库,支持 JSON 数据的读写、解析和序列化。它提供了简单的 API 来操作 JSON 对象、数组、字符串、数字等类型,是 C 开发中处理 JSON 数据的常用工具。 核心功能与类 JsonCpp 主要包含以下核心类…...
)
cv_connection (像halcon一样对区域进行打散)
主题: 分享一个自己用opencv写的小方法, 可以像halcon的connection算子一样, 对cv2.threshold得到的region进行打散, 并返回一个打散后的不相连的region的列表。 代码如下 def cv_connection(region):# he的拓扑信息为 后一…...

ConcurrentHashMap和锁
文章目录 JDK1.7的分段锁JDK1.8的volatileCAS synchronized可重入锁公平锁和非公平锁悲观锁和乐观锁 JDK1.7的分段锁 数据结构:数组(大数组 Segment 和小数组 HashEntry)链表 #mermaid-svg-dfSgz5E7tBmTbx14 {font-family:"trebuchet …...
)
黑马k8s(二)
集群环境搭建 1.环境规划 2.环境搭建-主机安装 主节点: 软件选择选择 基础设施服务器,这样安装系统完毕之后,会有很多软件我们可以直接使用了 系统点开,点一下完成 ip地址的设置:要跟虚拟网络编辑器,Net…...

LeetCode热题100--240.搜索二维矩阵--中等
1. 题目 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。 每列的元素从上到下升序排列。 示例 1: 输入:matrix [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[1…...

python校园新闻发布管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...
 如何配置? Spring Boot 是如何自动配置常见视图解析器的?)
Spring MVC 视图解析器 (ViewResolver) 如何配置? Spring Boot 是如何自动配置常见视图解析器的?
我们来详细分析一下视图解析器 (ViewResolver) 的配置以及 Spring Boot 是如何自动配置它们的。 视图解析器 (ViewResolver) 是什么? 在 Spring MVC 中,当控制器 (Controller) 方法处理完请求并返回一个逻辑视图名 (String) 时,DispatcherS…...

LeetCode 2918.数组的最小相等和:if-else
【LetMeFly】2918.数组的最小相等和:if-else 力扣题目链接:https://leetcode.cn/problems/minimum-equal-sum-of-two-arrays-after-replacing-zeros/ 给你两个由正整数和 0 组成的数组 nums1 和 nums2 。 你必须将两个数组中的 所有 0 替换为 严格 正…...

C++修炼:stack和queue
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...
题解)
欧拉计划 Project Euler 69(欧拉总计函数与最大值)题解
欧拉计划 Project Euler 69 题解 题干欧拉总计函数与最大值 思路code 题干 欧拉总计函数与最大值 小于 n n n且与 n n n互质的正整数的数量记为欧拉总计函数 φ ( n ) \varphi(n) φ(n),例如, 1 、 2 、 4 、 5 、 7 1、2、4、5、7 1、2、4、5、7和 8 …...

TCP Socket编程
最基本的Socket编程 想客户端和服务器能在网络中通信,就得使用 Socket 编程,它可以进行跨主机间通信。在创建Socket时可以选择传输层使用TCP还是UDP。相对于TCP来说,UDP更为简单,下面以TCP为例。 TCP服务端要先建立起来…...

[CLS] 向量是 BERT 类模型中一个特别重要的输出向量,它代表整个句子或文本的全局语义信息
[CLS] 向量是 BERT 类模型中一个特别重要的输出向量,它代表整个句子或文本的全局语义信息。 ✅ 什么是 [CLS] 在 BERT 模型中,每条输入前会加一个特殊的 token:[CLS](classification 的缩写)。这个 token 没有具体语义…...

47.电压跌落与瞬时中断干扰的防护改善措施
电压跌落与瞬时中断干扰的防护改善措施 1. 电压跌落与瞬时中断的影响机理2. 解决措施 1. 电压跌落与瞬时中断的影响机理 跌落发生的常见场景如下: (1)电源插头接触不良,瞬态中断即刻恢复; (2)电…...

LeetCode热题100 两数之和
目录 两数之和题目解析方法一暴力求解代码 方法二哈希代码 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸🥸🥸 C语言 🐿️🐿️🐿…...
三者区别▲)
【无标题】I/O复用(epoll)三者区别▲
一、SOCKET-IO复用技术 定义:SOCKET - IO复用技术是一种高效处理多个套接字(socket)的手段,能让单个线程同时监听多个文件描述符(如套接字)上的I/O事件(像可读、可写、异常)&#x…...

【数据结构】子串、前缀
子串 (Substring) 字符串中连续的一段字符序列,例如 "abc" 是 "abcd" 的子串。 特点:必须连续,顺序不可改变。 子序列 (Subsequence) 字符串中不连续但保持顺序的字符序列,例如 "acd" 是 "…...

[docker基础四]容器虚拟化基础之 LXC
目录 一 认识LXC 二 LXC容器操作实战 1)实战目的 2)基础知识 lxc-checkconfig lxc-create lxc-start lxc-ls lxc-info lxc-attach lxc-stop lxc-destory 3)安装LXC(我的是Ubuntu) 4)操作实战 1. 检查 lxc 是否运行…...

leetcode 2918. 数组的最小相等和 中等
给你两个由正整数和 0 组成的数组 nums1 和 nums2 。 你必须将两个数组中的 所有 0 替换为 严格 正整数,并且满足两个数组中所有元素的和 相等 。 返回 最小 相等和 ,如果无法使两数组相等,则返回 -1 。 示例 1: 输入…...

RT-Thread 深入系列 Part 5:物联网与网络应用实战
摘要 本文聚焦 RT-Thread 在物联网场景下的网络应用实战,从网络协议栈集成到 MQTT/CoAP/HTTP 客户端实现,再到 mbedTLS 安全通信与 OTA 升级,最后以阿里云、腾讯云和 OneNet 平台对接为案例,完整呈现端到端的物联网解决方案落地过程。 目录 网络协议栈:LWIP 与网络设备 MQ…...

onGAU:简化的生成式 AI UI界面,一个非常简单的 AI 图像生成器 UI 界面,使用 Dear PyGui 和 Diffusers 构建。
一、软件介绍 文末提供程序和源码下载 onGAU:简化的生成式 AI UI界面开源程序,一个非常简单的 AI 图像生成器 UI 界面,使用 Dear PyGui 和 Diffusers 构建。 二、Installation 安装 文末下载后解压缩 Run install.py with python to setup…...

Linux系统入门第十二章 --Shell编程之正则表达式
一、正则表达式 之前学习了 Shell 脚本的基础用法,已经可以利用条件判断、循环等语句编辑 Shell脚本。接下来我们将开始介绍一个很重要的概念-正则表达式(RegularExpression,RE) 1.正则表达式的定义 正则表达式又称正规表达式、常规表达式。在代码中常…...
)
Ubuntu22.04怎么退出Emergency Mode(紧急模式)
1.使用nano /etc/fstab命令进入fstab文件下; 2.将挂载项首行加#注释掉,修改完之后使用ctrlX退出; 3.重启即可退出紧急模式!...

IC ATE集成电路测试学习——开尔文连接
首先,我们先了解一下ATE在测试时的PMU测量原理。 驱动线路和感知线路 为了提升 PMU 驱动电压的精确度,常使用 4 条线路的结构:两条驱动线路传输电流,另两条感知线路监测我们感兴趣的点(通常是DUT)的电压。…...

Ubuntu 与 Windows 双系统环境下 NTFS 分区挂载教程
Ubuntu 与 Windows 双系统环境下 NTFS 分区挂载教程 摘要 本技术指南针对Ubuntu与Windows双系统用户,系统阐述NTFS分区挂载的技术原理与操作流程。通过规范的技术说明和专业的故障排除方案,帮助用户在异构操作系统环境下实现文件系统的无缝访问&#x…...

C++学习-入门到精通-【6】指针
C学习-入门到精通-【6】指针 指针 C学习-入门到精通-【6】指针一、指针的初始化二、指针运算符地址运算符&间接引用运算符* 三、使用指针的按引用传递方式四、内置数组标准库函数的begin和end内置数组的局限性 五、使用const修饰指针 一、指针的初始化 指针在声明或赋值时…...

数据集-目标检测系列- 冥想 检测数据集 close_eye>> DataBall
数据集-目标检测系列- 冥想 检测数据集 close * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitHub - XIAN-HHappy/ultralytics-yolo-…...

CoAP 协议介绍及应用场景
CoAP 协议,即受限应用协议(Constrained Application Protocol),是专为资源受限的设备和网络设计的一种应用层协议 ,旨在让小型、低功耗的设备能够接入物联网(IoT),并以最小的资源与更…...

【并发编程】基于 Redis 手写分布式锁
目录 一、基于 Redis 演示超卖现象 1.1 Redis 超卖现象 1.2 超卖现象解决方案 二、Redis 的乐观锁机制 2.1 原生客户端演示 2.2 业务代码实现 三、单机部署 Redis 实现分布式锁 3.1 分布式锁的演变和升级 3.2 setnx 实现分布式锁 3.2.1 递归调用实现分布式锁 3.2.2 循…...

adb命令查询不到设备?
一、背景 -----以鸿蒙系统为例,其他系统类似--- 1、确保adb在电脑上成功安装 2 、连接手机 adb devices 列表中无显示设备 二、解决 1. 手机打开开发者模式 手机型号不同,所以选项不一样 2. 一般流程是:设置--搜索--“开发”--会出现开…...

JavaScript 数组去重:11 种方法对比与实战指南
文章目录 前言一、使用 Set 数据结构二、使用 filter indexOf三、使用 reduce 累加器四、双重 for 循环五、利用对象属性唯一性六、先排序后去重七、使用 Map 数据结构八、使用 includes 方法九、优化处理 NaN 的 filter 方法十、利用 findIndex十一.利用Set和展开运算符处理多…...

SlideLoss与FocalLoss在YOLOv8分类损失中的应用及性能分析
文章目录 一、引言二、YOLOv8 损失函数概述三、SlideLoss 详解(一)SlideLoss 的原理(二)SlideLoss 的代码实现 四、FocalLoss 分类损失函数详解(一)FocalLoss 的原理(二)FocalLoss 的…...

AI 驱动数据库交互技术路线详解:角色、提示词工程与输入输出分析
引言 在人工智能与数据库深度融合的趋势下,理解AI在数据库交互流程中的具体角色、提示词工程的运用以及各步骤的输入输出情况,对于把握这一先进技术路线至关重要。本文将对其展开详细剖析。 一、AI 在数据库交互流程中的角色 (一࿰…...

Jmeter中的BeanShell如何使用?
在JMeter中,BeanShell 是一种基于Java语法的脚本工具,可以通过编写脚本实现动态逻辑处理、变量操作、条件判断等功能。以下是BeanShell的详细使用方法和常见场景示例: 1. BeanShell组件类型 JMeter提供多种BeanShell组件,根据场…...

JDBC工具类的三个版本
一、JDBC连接数据库的7个步骤 1、加载驱动 2、获取连接 3、编写sql 4、获取执行sql的stmt对象 有两种 stmt(存在sql注入问题 字符串拼接) pstmt(预编译可以防止sql注入) 5、执行sql 拿到结果集 6、遍历结果集 7、关闭资源…...

安达发|制药车间生产计划准备性的关键影响因素及优化策略研究
在高度规范的制药行业,生产计划的准备性直接影响企业的运营效率和合规水平。根据FDA统计,2024年因生产计划不当导致的药品短缺案例增加了23%,暴露出制药企业在生产计划管理方面的系统性挑战。本文将从设备、物料、人员、环境、法规五个维度&a…...

独立按键控制LED
目录 1.独立按键介绍 2.原理图 3.C51数据运输 解释:<< >> 编辑 解释:& | 解释:^ ~ 编辑 4.C51基本语句 5.按键的跳动 6.独立按键控制LED亮灭代码 第一步: 第二步: 第三步࿱…...

【Vue】vuex的getters mapState mapGetters mapMutations mapActions的使用
目录 一、getters 二、 mapState 三、 mapGetters 四、 mapMutations 五、 mapActions 学到这儿来个小总结:四个map方法的使用 总结不易~ 本章节对我有很大的收获, 希望对你也是!!! 本节素材已上传至Gitee&…...

小程序初始化加载时间优化 步骤思考与总结
回想起来,正确的小程序初始加载时间优化步骤应该为: 一、梳理小程序初始化的步骤,以用户点击小程序为开始(尽可能靠近),以页面渲染出来的时刻为结束—也就是用户感知到的时间。 二、页面渲染时࿰…...

前端弹性布局:用Flexbox构建现代网页的魔法指南
引言:布局的进化史 在网页设计的黑暗时代(2010年前),开发者们用float、position和inline-block这些原始工具进行布局,就像用石器时代的工具建造摩天大楼。直到2012年W3C正式推出Flexbox规范,前端世界终于迎…...

Python基于Django的高校教室管理系统【附源码、文档说明】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...