23、DeepSeekMath论文笔记(GRPO)
DeepSeekMath论文笔记
- 0、研究背景与目标
- 1、GRPO结构
- GRPO结构
- PPO知识点
- **1. PPO的网络模型结构**
- **2. GAE(广义优势估计)原理**
- **1. 优势函数的定义**
- 2.GAE(广义优势估计)
- 2、关键技术与方法
- 3、核心实验结果
- 4、结论与未来方向
- 关键问题与答案
- 1. **DeepSeekMath在数据处理上的核心创新点是什么?**
- 2. **GRPO算法相比传统PPO有何优势?**
- 3. **代码预训练对数学推理能力的影响如何?**
0、研究背景与目标
- 挑战与现状:
- 数学推理因结构化和复杂性对语言模型构成挑战,主流闭源模型(如GPT-4、Gemini-Ultra)未开源,而开源模型在MATH等基准测试中性能显著落后。
- 目标:通过数据优化和算法创新,提升开源模型数学推理能力,逼近闭源模型水平。


1、GRPO结构
GRPO结构
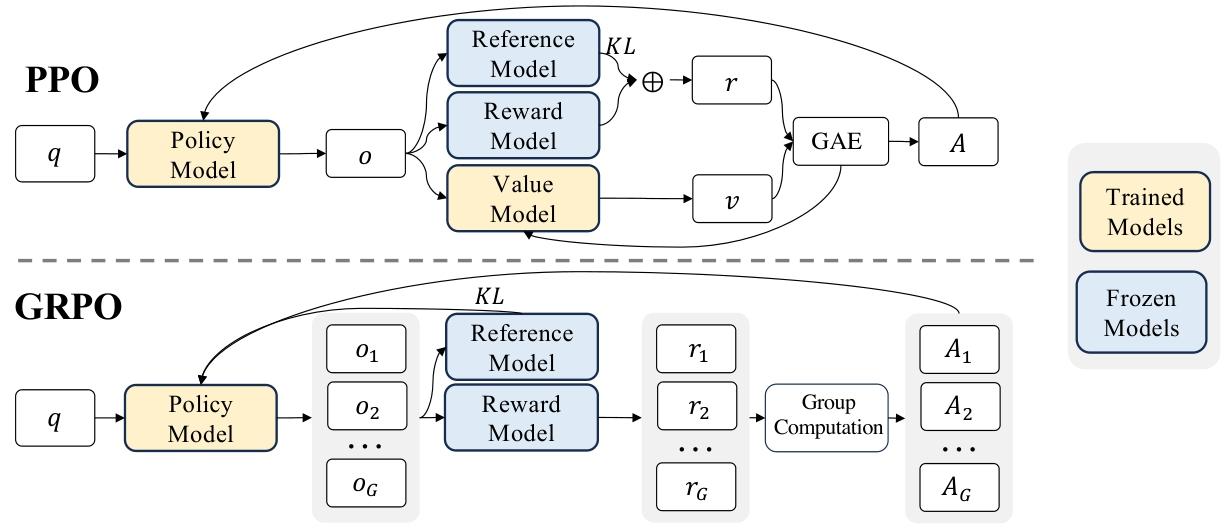
图 4 |PPO 和我们的 GRPO 示范。GRPO 放弃了价值模型,而是根据组分数估计基线,从而显著减少了训练资源。
近端策略优化(PPO)(舒尔曼等人,2017年)是一种演员 - 评论家强化学习算法,在大语言模型(LLMs)的强化学习微调阶段得到了广泛应用(欧阳等人,2022年)。具体来说,它通过最大化以下替代目标来优化大语言模型:
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] ( 1 ) \mathcal{J}_{PPO}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{old }}(O | q)\right] \frac{1}{|o|} \sum_{t = 1}^{|o|} \min \left[\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{\theta_{old }}\left(o_{t} | q, o_{<t}\right)} A_{t}, \text{clip}\left(\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{\theta_{old }}\left(o_{t} | q, o_{<t}\right)}, 1 - \varepsilon, 1 + \varepsilon\right) A_{t}\right] (1) JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At](1)
其中, π θ \pi_{\theta} πθ和 π θ o l d \pi_{\theta_{old}} πθold分别是当前策略模型和旧策略模型, q q q和 o o o分别是从问题数据集和旧策略 π θ o l d \pi_{\theta_{old}} πθold中采样得到的问题和输出。 ε \varepsilon ε是PPO中引入的与裁剪相关的超参数,用于稳定训练。 A t A_{t} At是优势值,通过应用广义优势估计(GAE)(舒尔曼等人,2015年)计算得出,该估计基于奖励值 { r ≥ t } \{r_{\geq t}\} {r≥t}和学习到的价值函数 V ψ V_{\psi} Vψ 。因此,在PPO中,价值函数需要与策略模型一起训练。为了减轻奖励模型的过度优化问题,标准做法是在每个令牌的奖励中添加来自参考模型的每个令牌的KL散度惩罚项(欧阳等人,2022年),即:
r t = r φ ( q , o ≤ t ) − β log π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) r_{t}=r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log\frac{\pi_{\theta}\left(o_{t} | q, o_{<t}\right)}{\pi_{ref}\left(o_{t} | q, o_{<t}\right)} rt=rφ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t)
其中, r φ r_{\varphi} rφ是奖励模型, π r e f \pi_{ref} πref是参考模型,通常是初始的监督微调(SFT)模型, β \beta β是KL散度惩罚项的系数。
由于PPO中使用的价值函数通常与策略模型规模相当,这会带来巨大的内存和计算负担。此外,在强化学习训练过程中,价值函数在优势值计算中被用作基线以减少方差。而在大语言模型的环境中,奖励模型通常只给最后一个令牌分配奖励分数,这可能会使精确到每个令牌的价值函数的训练变得复杂。
为了解决这个问题,如图4所示,我们提出了组相对策略优化(GRPO)。它无需像PPO那样进行额外的价值函数近似,而是使用针对同一问题产生的多个采样输出的平均奖励作为基线。更具体地说,对于每个问题 q q q,GRPO从旧策略 π θ o l d \pi_{\theta_{old}} πθold中采样一组输出 { o 1 , o 2 , ⋯ , o G } \{o_{1}, o_{2}, \cdots, o_{G}\} {o1,o2,⋯,oG},然后通过最大化以下目标来优化策略模型:
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } (3) \begin{aligned} \mathcal{J}_{GRPO}(\theta) & =\mathbb{E}\left[q \sim P(Q),\left\{o_{i}\right\}_{i = 1}^{G} \sim \pi_{\theta_{old}}(O | q)\right] \\ & \frac{1}{G} \sum_{i = 1}^{G} \frac{1}{|o_{i}|} \sum_{t = 1}^{|o_{i}|}\left\{\min \left[\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta_{old}}\left(o_{i, t} | q, o_{i,<t}\right)}\hat{A}_{i, t}, \text{clip}\left(\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta_{old}}\left(o_{i, t} | q, o_{i,<t}\right)}, 1 - \varepsilon, 1 + \varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{KL}\left[\pi_{\theta}|| \pi_{ref}\right]\right\} \end{aligned} \tag{3} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]}(3)
其中, ε \varepsilon ε和 β \beta β是超参数, A ^ i , t \hat{A}_{i, t} A^i,t是仅基于每组内输出的相对奖励计算得到的优势值,将在以下小节中详细介绍。GRPO利用组相对的方式计算优势值,这与奖励模型的比较性质非常契合,因为奖励模型通常是在同一问题的输出之间的比较数据集上进行训练的。还需注意的是,GRPO不是在奖励中添加KL散度惩罚项,而是通过直接将训练后的策略与参考策略之间的KL散度添加到损失中来进行正则化,避免了 A ^ i , t \hat{A}_{i, t} A^i,t计算的复杂化。并且,与公式(2)中使用的KL散度惩罚项不同,我们使用以下无偏估计器(舒尔曼,2020年)来估计KL散度:
D K L [ π θ ∥ π r e f ] = π r e f ( o i , r ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , r ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 \mathbb{D}_{KL}\left[\pi_{\theta} \| \pi_{ref}\right]=\frac{\pi_{ref}\left(o_{i, r} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-\log\frac{\pi_{ref}\left(o_{i, r} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-1 DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,r∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,r∣q,oi,<t)−1
该估计值保证为正。
算法流程:

PPO知识点
强化学习全面知识点参考:https://blog.csdn.net/weixin_44986037/article/details/147685319
https://blog.csdn.net/weixin_44986037/category_12959317.html
PPO的网络模型结构(优势估计)
若使用在策略与价值函数之间共享参数的神经网络架构,则需使用一个结合了策略替代项与价值函数误差项的损失函数。
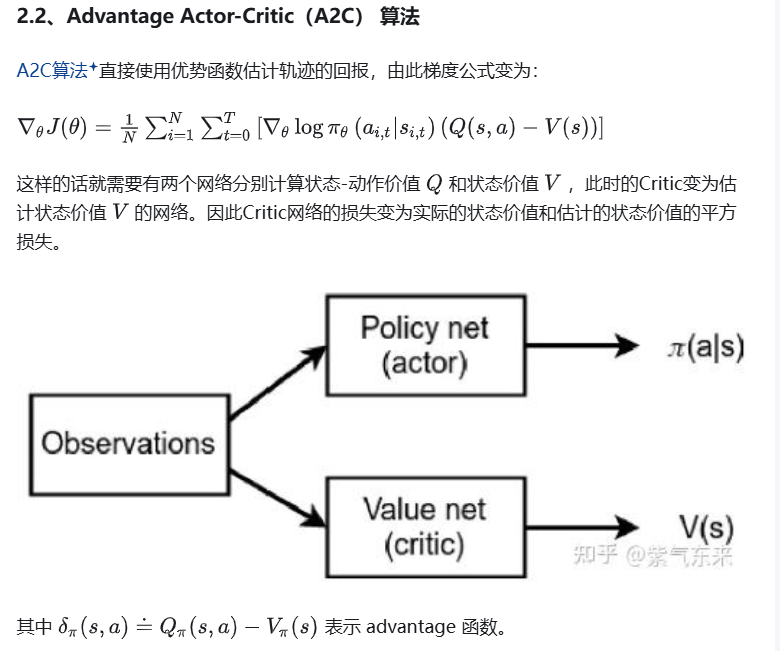
在PPO(Proximal Policy Optimization)算法中,网络模型的数量为两个,分别是 Actor网络 和 Critic网络。而 GAE(Generalized Advantage Estimation) 是一种用于计算优势函数(Advantage Function)的方法,并不引入额外的网络模型。以下是详细说明:
1. PPO的网络模型结构
PPO基于 Actor-Critic 架构,包含以下两个核心网络:
-
Actor网络(策略网络)
• 功能:生成动作概率分布 π ( a ∣ s ) \pi(a|s) π(a∣s),指导智能体行为。
• 结构:多层感知机(MLP)或Transformer,输出层为动作空间的概率分布。- 输入:当前状态 s s s。
- 输出:动作概率分布(离散动作空间)或动作分布参数(连续动作空间,如高斯分布的均值和方差)。
- 作用:决定智能体在特定状态下选择动作的策略(策略优化的核心)。
-
Critic网络(价值网络)
• 功能:估计状态价值函数 V ( s ) V(s) V(s),用于计算优势函数 A t A_t At。
• 结构:与Actor类似,但输出层为标量值(状态价值)。- 输入:当前状态 s s s。
- 输出:状态价值 V ( s ) V(s) V(s),即从当前状态开始预期的累积回报。
- 作用:评估状态的好坏,辅助Actor网络更新策略(通过优势函数的计算)。
-
变体与优化
• 共享参数:部分实现中,Actor和Critic共享底层特征提取层以减少参数量。
• GRPO变体:如DeepSeek提出的GRPO算法,去除Critic网络,通过组内奖励归一化简化计算,但标准PPO仍保留双网络结构。
共享编码层:
在实际实现中,Actor和Critic网络的底层特征提取层(如卷积层、Transformer层等)可能共享参数,以减少计算量并提高特征复用效率。例如,在图像输入场景中,共享的CNN层可以提取通用的视觉特征,然后分别输出到Actor和Critic的分支。
PPO基于 Actor-Critic 架构,A2C网络结构:
参考:https://zhuanlan.zhihu.com/p/450690041
GRPO和PPO网络结构:
图 4 |PPO 和我们的 GRPO 示范。GRPO 放弃了价值模型,而是根据组分数估计基线,从而显著减少了训练资源。
由于PPO中使用的价值函数通常与策略模型规模相当,这会带来巨大的内存和计算负担。此外,在强化学习训练过程中,价值函数在优势值计算中被用作基线以减少方差。而在大语言模型的环境中,奖励模型通常只给最后一个令牌分配奖励分数,这可能会使精确到每个令牌的价值函数的训练变得复杂。
为了解决这个问题,如图4所示,我们提出了组相对策略优化(GRPO)。它无需像PPO那样进行额外的价值函数近似,而是使用针对同一问题产生的多个采样输出的平均奖励作为基线。
2. GAE(广义优势估计)原理
1. 优势函数的定义
优势函数 A ( s , a ) A(s, a) A(s,a) 的数学表达式为:
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
- Q π ( s , a ) Q^\pi(s, a) Qπ(s,a):动作值函数,表示在状态 s s s 下执行动作 a a a 后,遵循策略 π \pi π 所能获得的期望累积奖励。
- V π ( s ) V^\pi(s) Vπ(s):状态值函数,表示在状态 s s s 下,遵循策略 π \pi π 所能获得的期望累积奖励(不指定具体动作)。
- 意义:若 A ( s , a ) > 0 A(s, a) > 0 A(s,a)>0,说明执行动作 a a a 相比于当前策略的平均表现更优;若 A ( s , a ) < 0 A(s, a) < 0 A(s,a)<0,则说明该动作不如当前策略的平均水平。
2.GAE(广义优势估计)
GAE是PPO中用于估计优势函数的核心技术,通过平衡偏差与方差优化策略梯度更新。其核心结构包括以下要点:
-
多步优势加权
GAE通过指数衰减加权不同步长的优势估计(如TD残差)构建综合优势值,公式为:
A t GAE = ∑ l = 0 ∞ ( γ λ ) l δ t + l A_t^{\text{GAE}} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} AtGAE=l=0∑∞(γλ)lδt+l
其中, δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)为时序差分误差。 γ \gamma γ(折扣因子)控制长期回报衰减, λ \lambda λ(GAE参数)调节偏差-方差权衡。 -
偏差-方差平衡机制
• λ ≈ 0 \lambda \approx 0 λ≈0:退化为单步TD残差(高偏差、低方差)• λ ≈ 1 \lambda \approx 1 λ≈1:接近蒙特卡洛估计(低偏差、高方差)
通过调节 λ \lambda λ,GAE在两者间取得最优折衷。
-
与TD-λ的区别
GAE将TD-λ的资格迹思想引入策略梯度框架,直接服务于优势函数计算,而非传统的价值函数更新。
参考:https://blog.csdn.net/animate1/article/details/146100100

2、关键技术与方法
-
大规模数学语料构建(DeepSeekMath Corpus):
- 数据来源:从Common Crawl中通过迭代筛选获取,以OpenWebMath为种子数据,用fastText分类器识别数学网页,经4轮筛选得到 35.5M网页、120B tokens,含英/中多语言内容,规模是Minerva所用数学数据的7倍、OpenWebMath的9倍。
- 去污染:过滤含基准测试题的文本(10-gram精确匹配),避免数据泄露。
- 质量验证:在8个数学基准测试中,基于该语料训练的模型性能显著优于MathPile、OpenWebMath等现有语料,证明其高质量和多语言优势。
-
模型训练流程:
- 预训练:
- 基于代码模型 DeepSeek-Coder-Base-v1.5 7B 初始化,训练数据含 56%数学语料、20%代码、10%自然语言 等,总 500B tokens。
- 基准表现:MATH基准 36.2%(超越Minerva 540B的35%),GSM8K 64.2%。
- 监督微调(SFT):
- 使用 776K数学指令数据(链思维CoT、程序思维PoT、工具推理),训练后模型在MATH达 46.8%,超越同规模开源模型。
- 强化学习(RL):Group Relative Policy Optimization (GRPO):
- 创新点:无需独立价值函数,通过组内样本平均奖励估计基线,减少内存消耗,支持过程监督和迭代RL。
- 效果:MATH准确率提升至 51.7%,GSM8K从82.9%提升至88.2%,CMATH从84.6%提升至88.8%,超越7B-70B开源模型及多数闭源模型(如Inflection-2、Gemini Pro)。
- 预训练:
3、核心实验结果
-
数学推理性能:
基准测试 DeepSeekMath-Base 7B DeepSeekMath-Instruct 7B DeepSeekMath-RL 7B GPT-4 Gemini Ultra MATH (Top1) 36.2% 46.8% 51.7% 52.9% 53.2% GSM8K (CoT) 64.2% 82.9% 88.2% 92.0% 94.4% CMATH (中文) - 84.6% 88.8% - - - 关键优势:在不依赖外部工具和投票技术的情况下,成为首个在MATH基准突破50%的开源模型,自一致性方法(64样本)可提升至60.9%。
-
泛化与代码能力:
- 通用推理:MMLU基准得分 54.9%,BBH 59.5%,均优于同类开源模型。
- 代码任务:HumanEval(零样本)和MBPP(少样本)表现与代码模型DeepSeek-Coder-Base-v1.5相当,证明代码预训练对数学推理的促进作用。
4、结论与未来方向
-
核心贡献:
- 证明公开网络数据可构建高质量数学语料,小模型(7B)通过优质数据和高效算法可超越大模型(如Minerva 540B)。
- 提出GRPO算法,在减少训练资源的同时显著提升数学推理能力,为RL优化提供统一范式。
- 验证代码预训练对数学推理的积极影响,填补“代码是否提升推理能力”的研究空白。
-
局限:
- 几何推理和定理证明能力弱于闭源模型,少样本学习能力不足(与GPT-4存在差距)。
- arXiv论文数据对数学推理提升无显著效果,需进一步探索特定任务适配。
-
未来工作:
- 优化数据筛选流程,构建更全面的数学语料(如几何、定理证明)。
- 探索更高效的RL算法,结合过程监督和迭代优化,提升模型泛化能力。
关键问题与答案
1. DeepSeekMath在数据处理上的核心创新点是什么?
答案:通过 迭代筛选+多语言数据 构建高质量数学语料。以OpenWebMath为种子,用fastText分类器从Common Crawl中筛选数学网页,经4轮迭代获得120B tokens,涵盖英/中多语言内容,规模远超现有数学语料(如OpenWebMath的9倍),且通过严格去污染避免基准测试数据泄露。
2. GRPO算法相比传统PPO有何优势?
答案:GRPO通过 组内相对奖励估计基线 替代独立价值函数,显著减少训练资源消耗。无需额外训练价值模型,直接利用同一问题的多个样本平均奖励计算优势函数,同时支持过程监督(分步奖励)和迭代RL,在MATH基准上比PPO更高效,准确率提升5.9%(46.8%→51.7%)且内存使用更优。
3. 代码预训练对数学推理能力的影响如何?
答案:代码预训练能 显著提升数学推理能力,无论是工具使用(如Python编程解题)还是纯文本推理。实验表明,基于代码模型初始化的DeepSeekMath-Base在GSM8K+Python任务中得分66.9%,远超非代码模型(如Mistral 7B的48.5%),且代码与数学混合训练可缓解灾难性遗忘,证明代码中的逻辑结构和形式化推理对数学任务有迁移优势。
相关文章:
)
23、DeepSeekMath论文笔记(GRPO)
DeepSeekMath论文笔记 0、研究背景与目标1、GRPO结构GRPO结构PPO知识点**1. PPO的网络模型结构****2. GAE(广义优势估计)原理****1. 优势函数的定义**2.GAE(广义优势估计) 2、关键技术与方法3、核心实验结果4、结论与未来方向关键…...
)
Python自动化-python基础(下)
六、带参数的装饰器 七、函数生成器 运行结果: 八、通过反射操作对象方法 1.添加和覆盖对象方法 2.删除对象方法 通过使用内建函数: delattr() # 删除 x.a() print("通过反射删除之后") delattr(x, "a") x.a()3 通过反射判断对象是否有指定…...

用Python绘制动态彩色ASCII爱心:技术深度与创意结合
引言 在技术博客的世界里,代码不仅仅是解决问题的工具,更可以是表达创意的媒介。今天我将分享一个独特的Python爱心代码项目,它结合了数学之美、ASCII艺术和动态效果,展示了Python编程的无限可能。这个项目不仅能运行展示出漂亮的…...

【C++】红黑树
1.红黑树的概念 是一种二叉搜索树,在每个节点上增加一个存储位表示节点的颜色,Red或black,通过对任何一条从根到叶子的路径上各个结点着色方式的限制,确保没有一条路径会比其他路径长出俩倍,是接近平衡的。 2.红黑树…...

链表头插法的优化补充、尾插法完结!
头插法的优化补充 这边我们将考虑到可以将动态创建链表,和插入新链表到链表头前方,成为新链表头的方法分开,使其自由度上升,在创建完链表后,还可以添加链表元素到成为新的链表头。 就是说可以单独的调用这个insertHea…...
)
Java多线程(超详细版!!)
Java多线程(超详细版!!) 文章目录 Java多线程(超详细版!!)1. 线程 进程 多线程2.线程实现2.1线程创建2.1.1 继承Thread类2.1.2 实现runnable接口2.1.2.1 思考:为什么推荐使用runnable接口?2.1.2.1.1 更高的…...

超详细fish-speech本地部署教程
本人配置: windows x64系统 cuda12.6 rtx4070 一、下载fish-speech模型 注意:提前配置好git,教程可在自行搜索 git clone https://gitclone.com/github.com/fishaudio/fish-speech.git cd fish-speech 或者直接进GitHub中下载也可以 …...

Flink和Spark的选型
在Flink和Spark的选型中,需要综合考虑多个技术维度和业务需求,以下是在项目中会重点评估的因素及实际案例说明: 一、核心选型因素 处理模式与延迟要求 Flink:基于事件驱动的流处理优先架构,支持毫秒级低延迟、高吞吐的…...

解锁 DevOps 新境界 :使用 Flux 进行 GitOps 现场演示 – 自动化您的 Kubernetes 部署
前言 GitOps 是实现持续部署的云原生方式。它的名字来源于标准且占主导地位的版本控制系统 Git。GitOps 的 Git 在某种程度上类似于 Kubernetes 的 etcd,但更进一步,因为 etcd 本身不保存版本历史记录。毋庸置疑,任何源代码管理服务…...

【从零实现JsonRpc框架#1】Json库介绍
1.JsonCpp第三方库 JSONCPP 是一个开源的 C 库,用于解析和生成 JSON(JavaScript Object Notation)数据。它提供了简单易用的接口,支持 JSON 的序列化和反序列化操作,适用于处理配置文件、网络通信数据等场景。 2.Jso…...

使用FastAPI和React以及MongoDB构建全栈Web应用02 前言
Who this book is for 本书适合哪些人阅读 This book is designed for web developers who aspire to build robust, scalable, and efficient web applications. It caters to a broad spectrum of developers, from those with foundational knowledge to experienced prof…...

JavaScript中的数据类型
目录 前言 基本类型 Number 特殊的数值NaN Infinity和-Infinity String Boolean Undefined null Symbol Undefined和Null的区别 引用类型 Object(对象) Array(数组) Function(函数) 函数声…...

AI 助力,轻松进行双语学术论文翻译!
在科技日新月异的今天,学术交流中的语言障碍仍然是科研工作者面临的一大挑战。尤其是对于需要查阅大量外文文献的学生、科研人员和学者来说,如何高效地理解和翻译复杂的学术论文成为了一大难题。然而,由Byaidu团队推出的开源项目PDFMathTrans…...

第3.2.3节 Android动态调用链路的获取
3.2.3 Android App动态调用链路 在Android应用中,动态调用链路指的是应用在运行时的调用路径。这通常涉及到方法调用的顺序和调用关系,特别是在应用的复杂逻辑中,理解这些调用链路对于调试和性能优化非常重要。 1,动态调用链路获…...

【Android】文件分块上传尝试
【Android】文件分块上传 在完成一个项目时,遇到了需要上传长视频的场景,尽管可以手动限制视频清晰度和视频的码率帧率,但仍然避免不了视频大小过大的问题,且由于服务器原因,网络不太稳定。这个时候想到了可以将文件分…...

大模型中的三角位置编码实现
Transformer中嵌入表示 位置编码的实现 import torch import math from torch import nn# 词嵌入位置编码实现 class EmbeddingWithPosition(nn.Module):"""vocab_size:词表大小emb_size: 词向量维度seq_max_len: 句子最大长度 (人为设定,例如GPT2…...

深入详解人工智能数学基础——微积分中的自动微分及其在PyTorch中的实现原理
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

【Linux学习笔记】系统文件IO之重定向原理分析
【Linux学习笔记】系统文件IO之重定向原理分析 🔥个人主页:大白的编程日记 🔥专栏:Linux学习笔记 文章目录 【Linux学习笔记】系统文件IO之重定向原理分析前言一. 系统文件I/01.1 一种传递标志位的方法1.2 hello.c写文件:1.3 he…...

《React Native与Flutter:社交应用中用户行为分析与埋点统计的深度剖析》
React Native与Flutter作为两款备受瞩目的跨平台开发框架,正深刻地影响着应用的构建方式。当聚焦于用户行为分析与埋点统计时,它们各自展现出独特的策略与工具选择,这些差异和共性不仅关乎开发效率,更与社交应用能否精准把握用户需…...

Cesium高度参考系统
🌍 Cesium高度参考系统趣味探索 🚀 高度参考系统形象比喻 想象一下,你正在玩一个积木游戏: CLAMP_TO_GROUND:积木被"强力胶水"粘在桌面上,无论桌面高低起伏如何 RELATIVE_TO_GROUND:积木放在"微型支架"上,始终保持离桌面固定距离 NONE:积木漂…...
机顶盒遇到海思摄像头)
海纳思(Hi3798MV300)机顶盒遇到海思摄像头
海纳思机顶盒遇到海思摄像头,正好家里有个海思Hi3516的摄像头模组开发板,结合机顶盒来做个录像。 准备工作 海纳斯机顶盒摄像机模组两根网线、两个电源、路由器一块64G固态硬盘 摄像机模组和机顶盒都接入路由器的LAN口,确保网络正常通信。 …...

[python] 类
一 介绍 具有相同属性和行为的事物的通称,是一个抽象的概念 三要素: 类名,属性,方法 格式: class 类名: 代码块 class Pepole:name "stitchcool"def getname(self):return self.name 1.1 创建对象(实例化) 格式: 对象名 类名() p1 Pepole()…...

Python中的事件循环是什么?事件是怎么个事件?循环是怎么个循环
在Python异步编程中,事件循环(Event Loop)是核心机制,它通过单线程实现高效的任务调度和I/O并发处理。本文将从事件的定义、循环的运行逻辑以及具体实现原理三个维度展开分析。 一、事件循环的本质:协程与任务的调度器…...

单片机-STM32部分:11、ADC
飞书文档https://x509p6c8to.feishu.cn/wiki/OclUwlkifiRKR2k6iLbczn5tn8g STM32的ADC是一种逐次逼近型模拟数字转换器。 是用于将模拟形式的连续信号转换为数字形式的离散信号的一类设备。 逐次逼近型ADC的原理图下: STM32f103系列有3个ADC,精度为12…...

【含文档+PPT+源码】基于微信小程序的社区便民防诈宣传系统设计与实现
项目介绍 本课程演示的是一款基于微信小程序的社区便民防诈宣传系统设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套…...

Laravel 安全:批量赋值 fillable 与 guarded
Laravel 的模型中有两个 protected 字段 fillable 与 guarded,注意:必须是 protected 以上开放程度。 我们经常通过提交表单进行数据的增删改,为了方便的进行数据批量修改操作 Laravel 提供了批量赋值机制: 假如我们想要在数据库…...

[杂谈随感-13]: 人的睡眠,如何布置床的位置比较有安全?感?
睡眠环境中的床位布置直接影响心理安全感与睡眠质量,需从空间防御性、人体感知机制及环境心理学多维度综合设计。 以下基于科学原理与实践案例,系统解析床位布置的核心策略: 一、空间防御性布局:构建心理安全边界 背靠实体墙&a…...

协议路由与路由协议
协议路由”和“路由协议”听起来相似,但其实是两个完全不同的网络概念。下面我来分别解释: 一、协议路由(Policy-Based Routing,PBR) ✅ 定义: 协议路由是指 根据预设策略(策略路由࿰…...

内网穿透系列三:开源本地服务公网映射工具 tunnelmole
以下是对 tunnelmole 简要介绍: tunnelmole 是一款开源的内网穿透工具,一行命令就能把本地http服务映射成公网可访问的链接提供公共免费的网络服务,直接下载运行命令即可使用,也支持自行配置搭建私有客户端、服务端参考开源地址&…...

发行基础:本地化BUG导致审核失败
1、早上收到邮件,Steam客服说本地化功能找不到,无法切换多国语言,所以正式版V1.0程序未通过。 大脑瞬间有要爆炸的感觉,测试后发现V1以及demo都存在同样问题。 属于重大BUG,需要立即解决,最高优先级。 2、…...

QB/T 1649-2024 聚苯乙烯泡沫塑料包装材料检测
聚苯乙烯泡沫塑料包装材料是指以可发行聚苯乙烯珠粒为原料,经加热预发泡后在模具中加热成型而制得,具有闭孔结构的聚苯乙烯泡沫塑料包装材料。 QB/T 1649-2024聚苯乙烯泡沫塑料包装材料检测项目: 测试项目 测试标准 外观 QB/T 1649 气味…...

【Day 24】HarmonyOS端云一体化开发:云函数
一、端云开发核心架构 1. 技术栈对比 维度传统开发模式HarmonyOS端云一体化方案优势 开发工具需独立配置前后端环境DevEco Studio统一开发端云代码降低60%环境搭建时间部署流程手动部署服务器与数据库一键部署至AGC Serverless免运维,自动弹性伸缩通信安全需自行实…...
强化学习——RLHF及其变种)
大模型(LLMs)强化学习——RLHF及其变种
大模型(LLMs)强化学习——RLHF及其变种面 一、介绍一下 LLM的经典预训练Pipeline?二、预训练(Pre-training)篇 具体介绍一下 预训练(Pre-training)?三、有监督微调(Sup…...

20250510解决NanoPi NEO core开发板在Ubuntu core22.04.3系统下适配移远的4G模块EC200A-CN的问题
1、h3-eflasher-friendlycore-jammy-4.14-armhf-20250402.img.gz 在WIN10下使用7-ZIP解压缩/ubuntu20.04下使用tar 2、Win32DiskImager.exe 写如32GB的TF卡。【以管理员身份运行】 3、TF卡如果已经做过会有3个磁盘分区,可以使用SD Card Formatter/SDCardFormatterv5…...

WinCC V7.2到V8.0与S71200/1500系列连接通讯教程以及避坑点
声明:WinCC与PLC连接详细指导与注意避坑点,部分图片和描述来源于网络,如有冒犯,请联系本人删除。 1.环境介绍 自WinCC V7.2版本起,软件新增加了 "SIMATIC S7-1200, S7-1500 Channel"通道,用于WinCC与 S7-1…...

WPF 性能 UI 虚拟化 软件开发人员的思考
UI 虚拟化是 WPF 采用的一项技术,框架会仅创建用户可见的 UI 元素。例如,如果 ListView 中有 1000 个文本块控件,但您只能查看其中的 10 个,那么 VisualTree 中也只会显示 10 个文本块。向下滚动时,不再可见的元素将被…...
)
服务器综合实验(实战详解)
该文章的目录部分 实验内容 实验完成步骤 虚拟机准备 配置两个虚拟机的本地仓库 虚拟机A: 虚拟机B: 配置SSH公钥互信 虚拟机A: 编辑 虚拟机B: 提供基于bind的DNS服务 虚拟机A: 项目需求1: …...

【动态导通电阻】软硬开关下GaN器件的动态RDSON
2019年,浙江大学的Rui Li、Xinke Wu等人基于双脉冲和多脉冲测试方法,研究了在硬开关和软开关条件下商用氮化镓(GaN)功率器件的动态导通电阻(R DSON )特性。实验结果表明,不同GaN器件在硬开关和软开关条件下的动态R DSON 表现出不同的行为,这些行为受关断电压和频率的影…...

Java基础 5.10
1.方法重写课堂练习 package com.logic.override_; //编写一个Person类 包括属性/private(name, age) 构造器 方法say(返回自我介绍的字符串) //编写一个Student类 继承Person类 增加id score 属性/private 以及构造器 //定义say方法(返回自我介绍的信息) //在main中 分别创建…...

通信原理绪论
(I)信息量:第j条消息中包含的信息定义为:I(j) 消息是信息的表现形式 消息是信息的一种抽象和本质内容 消息中所含的信息量是该消息出现概率的函数,即 I I[P(x)] P(x)越小,I越…...

Maven 插件配置分层架构深度解析
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

jMeter压测环境部署JDK+Groovy+JMeter+Proto+IntelliJ IDEA
为确保 Groovy、JDK 和 JMeter 三者的版本兼容性,需遵循以下核心原则和步骤: 一、版本兼容性对照表 组件推荐版本范围关键兼容规则JDKJava 8/11/17 (LTS)- JMeter 5.6 支持 Java 11/17GroovyGroovy 3.0.7 或 4.0- Groovy 3.x 支持 Java 8-17 - Groovy 4…...

c#建筑行业财务流水账系统软件可上传记账凭证财务管理系统签核功能
# financial_建筑行业 建筑行业财务流水账系统软件可上传记账凭证财务管理系统签核功能 # 开发背景 软件是给岳阳客户定制开发一款建筑行业流水账财务软件。提供工程签证单、施工日志、人员出勤表等信息记录。 # 财务管理系统功能描述 1.可以自行设置记账科目,做凭…...
)
深度解析 MySQL 与 Spring Boot 长耗时进程:从故障现象到根治方案(含 Tomcat 重启必要性分析)
一、典型故障现象与用户痛点 在高并发业务场景中,企业级 Spring Boot 应用常遇到以下连锁故障: 用户侧:网页访问超时、提交表单无响应,报错 “服务不可用”。运维侧:监控平台报警 “数据库连接池耗尽”,To…...

一种运动平台扫描雷达超分辨成像视场选择方法——论文阅读
一种运动平台扫描雷达超分辨成像视场选择方法 1. 专利的研究目标与意义1.1 研究目标1.2 实际意义2. 专利的创新方法与技术细节2.1 核心思路与流程2.1.1 方法流程图2.2 关键公式与模型2.2.1 回波卷积模型2.2.2 最大后验概率(MAP)估计2.2.3 统计约束模型2.2.4 迭代优化公式2.3 …...

【程序员AI入门:开发】11.从零构建智能问答引擎:LangChain + RAG 实战手册
1、技术选型 组件推荐方案说明文本嵌入模型sentence-transformers/all-MiniLM-L6-v2轻量级且效果较好的开源模型向量数据库FAISS高效的本地向量检索库大语言模型GPT-3.5/开源LLM(如ChatGLM3)根据资源选择云端或本地模型文档处理框架LangChain简化RAG流程…...

《深入理解Linux网络》笔记
《深入理解Linux网络》笔记 前言参考 前言 前段时间看了《深入理解Linux网络》这本书,虽然有些地方有以代码充篇幅的嫌疑,但总体来说还是值得一看的。在这里简单记录一下笔记,记录下对网络新的理解。 内核是如果接受网络包的? 如…...

【计算机视觉】优化MVSNet可微分代价体以提高深度估计精度的关键技术
优化MVSNet可微分代价体以提高深度估计精度的关键技术 1. 代价体基础理论与分析1.1 标准代价体构建1.2 关键问题诊断 2. 特征表示优化2.1 多尺度特征融合2.2 注意力增强匹配 3. 代价体构建优化3.1 自适应深度假设采样3.2 可微分聚合操作改进 4. 正则化与优化策略4.1 多尺度代价…...
【附百度网盘链接】)
致远A8V5-9.0安装包(包含信创版)【附百度网盘链接】
A8适用于中大型企业,基于"以人为中心"的产品理念,致力于为企业构建和完善“数字智能”的协同运营体系,以组织模型为基础,连接各项工作和业务,聚合信息、资源和能力,实现组织内和跨组织的高效协同…...

terminal 共享工具ttyd
ttyd 是一个非常轻量的工具,它可以将你的终端(如 bash)通过 Web 页面共享出去,适合教学、演示、远程协作等场景,而且 支持 macOS、ARM64、Linux 等平台。 ⸻ ✅ 一、ttyd 简介 • 将 shell 包装成 WebSocket 服务&am…...