李沐《动手学深度学习》 | 多层感知机
文章目录
- 感知机模型
- 《深度学习入门》的解释
- 训练感知机
- 损失函数的选择
- 感知机的收敛定理:什么时候能够停下来,是不是真的可以停下来
- 感知机的不足
- 多层感知模型
- 案例引入
- 隐藏层
- 从线性到非线性
- 单隐藏层-单分类案例
- 多隐藏层
- 激活函数
- softmax函数溢出的问题
- 多层感知机从零开始实现
- 初始化模型参数
- 激活函数:ReLU函数
- 模型
- 损失函数
- 训练
- 报错`module 'd2l.torch' has no attribute 'train_ch3'`
- 多层感知机的简洁实现
- 代码
- Q&A解疑
感知机模型
感知机是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别。
感知机旨在求出将输入空间中的实例划分为两类的分离超平面。如果训练数据集是线性可分的,则感知机一定能求得分离超平面。如果是非线性可分的数据,则无法获得超平面。为了找出这个超平面,也就是确定感知机模型的参数和w,b。
算法描述
给定输入向量x,权重向量w,和偏移标量b感知机输出 o = σ ( < w , x > + b ) σ ( x ) = { 1 i f x > 0 − 1 o t h e r w i s e o=\sigma (<w,x>+b) \;\;\;\; \sigma(x) = \begin{cases} 1 & if\;x>0\\ -1 &otherwise \end{cases} o=σ(<w,x>+b)σ(x)={1−1ifx>0otherwise
< w , x > <w,x> <w,x>表示w和x做内积,感知机是个二分类问题, x > 0 x>0 x>0取1,其余情况取-1.
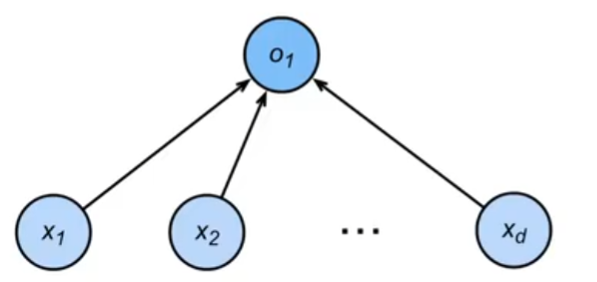
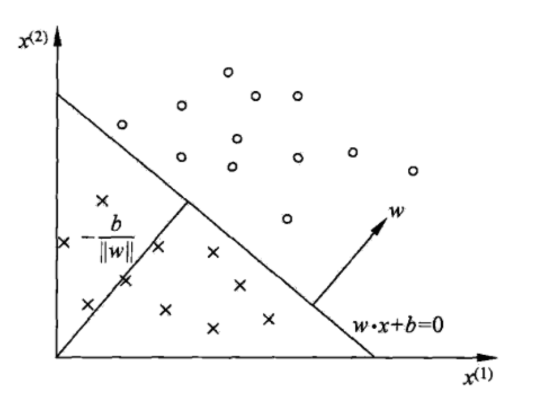
对于特征空间中有一个超平面 w x + b = 0 wx+b=0 wx+b=0,其中 w w w是超平面的法向量, b b b是超平面的截距。这个超平面将特征空间分为两部分,位于两部分的特征向量被分为正负两类,因此称超平面S为分离超平面。
- 正类区域: w ⋅ x + b > 0 w⋅x+b>0 w⋅x+b>0
- 负类区域: w ⋅ x + b < 0 w⋅x+b<0 w⋅x+b<0
法向量 w w w 始终垂直于超平面,指向超平面的“正方向”。
调整 b b b 可以平移超平面,使其靠近或远离原点。
《深度学习入门》的解释
将输入想成不同的信号,每个神经元会计算传送过来的信号总和,只有当这个总和超过某个界限值 θ \theta θ时,才会被激活。
比如 w 1 x 1 + w 2 x 2 ≤ θ w_1x_1+w_2x_2\leq \theta w1x1+w2x2≤θ将 θ \theta θ移动后使用 b = − θ b=-\theta b=−θ表示原来的式子 b + w 1 x 1 + w 2 x 2 ≤ 0 b+w_1x_1+w_2x_2\leq 0 b+w1x1+w2x2≤0
o = σ ( < w , x > + b ) σ ( x ) = { 1 i f x > 0 − 1 o t h e r w i s e o=\sigma (<w,x>+b) \;\;\;\; \sigma(x) = \begin{cases} 1 & if\;x>0\\ -1 &otherwise \end{cases} o=σ(<w,x>+b)σ(x)={1−1ifx>0otherwise
激活函数: σ \sigma σ函数将输入信号的总和转换为输出信号
激活函数的作用:决定如何来激活信号的总和
:
每个神经元对应一个偏置:每个神经元的计算都需独立调节其激活阈值(偏置)。
权重控制输入信号的重要性,偏置调整神经元被激活的容易程度。
训练感知机
假设当前是第i个样本, y i y_i yi是该样本的真是标号,假设+1和-1, y ^ = < w , x i > + b \hat y = <w,x_i>+b y^=<w,xi>+b表示线性模型预测的结果 y ^ \hat y y^。
分类判断:如果真实值 y i y_i yi和 y ^ \hat y y^异号,说明感知机模型预测的结果错误。此时需要更新参数w与b,使用该错误样本来更新权重 w = w + y i x i w=w+y_ix_i w=w+yixi,标量偏差 b = b + y i b=b+y_i b=b+yi。
终止条件:所有的类都分类正确。

这个算法参数更新部分实际上是使用的梯度下降算法,在这里批量大小为1也就是每一次拿一个样本去算梯度。
损失函数的选择
核心:最小化误分类样本的损失,修改参数向正确分类方向更新
李沐视频里介绍的损失函数
损失函数(单样本)为 l ( y , x , w ) = m a x ( 0 , − y < w , x > ) l(y,x,w)=max(0,-y<w,x>) l(y,x,w)=max(0,−y<w,x>),如果分类正确了预测值和真实值一致 − y < w , x > -y<w,x> −y<w,x>的结果为负数,那么max取0;如果分类错误,预测值和真实值不一致 − y < w , x > -y<w,x> −y<w,x>的结果是正数,那么max取 − y < w , x > -y<w,x> −y<w,x>。
李航书中介绍的损失函数
损失函数的一个自然选择是误分类点的总数,但是这样的损失函数不是参数w,b的连续可导函数,不能求导优化。
损失函数的另一个选择是误分类点到超平面S的总距离。
- 一点到超平面的距离公式: d = ∣ w ⋅ x 0 + b ∣ ∣ ∣ w ∣ ∣ d=\frac{|w·x_0+b|}{||w||} d=∣∣w∣∣∣w⋅x0+b∣、
- 函数距离(Functional Distance)是点 x 0 x_0 x0 到超平面 S : w ⋅ x + b = 0 S:w⋅x+b=0 S:w⋅x+b=0的 未规范化距离: 函数距离 = w ⋅ x 0 + b 函数距离=w⋅x_0+b 函数距离=w⋅x0+b,距离为正号,位于超平面的正上方;距离为符号位于超平面的负方向侧。绝对值越大,表示离超平面越远,分类置信度越高。
- 几何距离是物理意义上的实际距离(垂直距离): d = ∣ w ⋅ x 0 + b ∣ ∣ ∣ w ∣ ∣ d=\frac{|w·x_0+b|}{||w||} d=∣∣w∣∣∣w⋅x0+b∣
- 假设点 x 0 x_0 x0 沿法向量方向投影到超平面 S S S 上的点为 x ′ x′ x′,放缩的方向是 w ∣ ∣ w ∣ ∣ \frac{w}{||w||} ∣∣w∣∣w,移动的距离就是待求的几何距离d。可以得到公式 x ′ = x 0 − d w ∣ ∣ w ∣ ∣ x^′=x_0−d\frac{w}{||w||} x′=x0−d∣∣w∣∣w,这里是加距离还是减距离是看 x 0 x_0 x0位于超平面的哪一侧。
- 将 x ′ x′ x′代入超平面方程就可以解出 d = ∣ w ⋅ x 0 + b ∣ ∣ ∣ w ∣ ∣ d=\frac{|w·x_0+b|}{||w||} d=∣∣w∣∣∣w⋅x0+b∣
- 对于误分类的数据 ( x i , y i ) (x_i,y_i) (xi,yi),有 − y i ( w ⋅ x i + b ) > 0 -y_i(w·x_i+b)>0 −yi(w⋅xi+b)>0,当预测值大于0时 y i = − 1 y_i=-1 yi=−1,当预测值小于0时 y i = 1 y_i=1 yi=1
误差分类点 x i x_i xi到超平面S的距离是 d = − y i ( w ⋅ x 0 + b ) ∣ ∣ w ∣ ∣ d=\frac{-y_i(w·x_0+b)}{||w||} d=∣∣w∣∣−yi(w⋅x0+b)
- 假设超平面S的误分类点集合为M,那么所有误分类点到超平面S的总距离为 − 1 ∣ ∣ w ∣ ∣ ∑ x i ∈ M ( − y i ( w ⋅ x 0 + b ) ) -\frac{1}{||w||} \sum_{x_i \in M}(-y_i(w·x_0+b)) −∣∣w∣∣1∑xi∈M(−yi(w⋅x0+b))
- 不考虑 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1,得到感知机的损失函数 − ∑ x i ∈ M ( − y i ( w ⋅ x 0 + b ) ) -\sum_{x_i \in M}(-y_i(w·x_0+b)) −∑xi∈M(−yi(w⋅x0+b))
感知机的收敛定理:什么时候能够停下来,是不是真的可以停下来
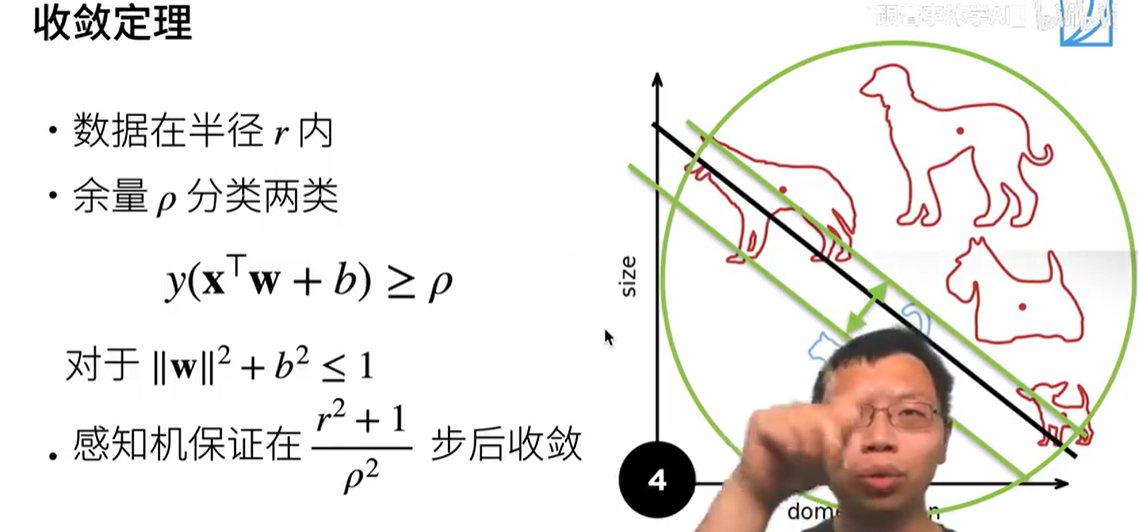
收敛定理:若训练数据集线性可分,则感知机学习算法在有限次迭代后,必定收敛到一个能够将训练数据完全正确分类的超平面。
假设数据在一个半径r的区域内,且存在完美超平面 y ( X T w + b ) ≥ ρ > 0 y(X^Tw+b)\geq \rho \gt 0 y(XTw+b)≥ρ>0, ρ \rho ρ表示余量,该公式的意思是存在完美超平面使得所有样本分类正确且存在余量。
该分界面的参数满足条件 ∣ ∣ w ∣ ∣ 2 + b 2 ≤ 1 ||w||^2+b^2 \leq 1 ∣∣w∣∣2+b2≤1,感知机保证在 r 2 + 1 ρ 2 {\frac{r^2+1}{\rho^2}} ρ2r2+1步后收敛。数据越“容易分开”( ρ ρ ρ 越大)或越“紧凑”( r r r 越小),收敛速度越快。
感知机的不足
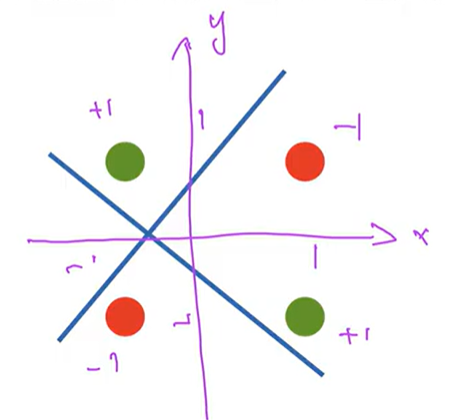
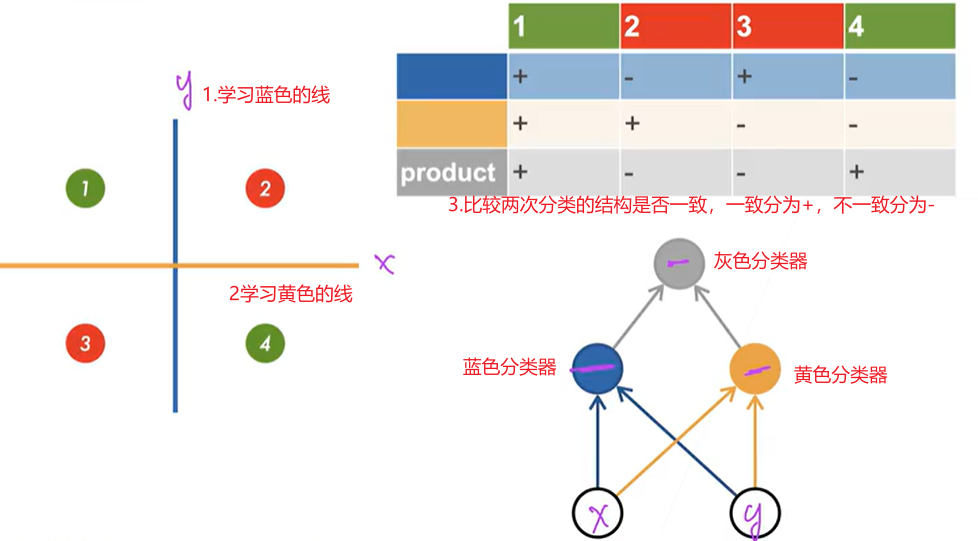
缺点:感知机不能拟合XOR函数,只能产生线性分割面(一条线)
XOR函数是指当输入的x和y都是1(-1)时,输出-1类;如果x和y不相同,则输出+1类。在下图中,紫色坐标轴下统一颜色的小球是一类。
感知机对于二维输入的分割面是一条线,无论如何切割都没有办法分割不同类的样本。
多层感知模型
多层感知机本质:使用隐藏层和激活函数来得到非线性模型
案例引入
前面有讲过感知机模型的缺点是不能拟合XOR函数,只能产生线性分割面,那么如何学习XOR呢?
案例:学习XOR
要学习非线性可分问题,需考虑使用多层功能神经元。输出层与输入层之间的一层神经元,被成为隐含层,隐含层和输出层神经元都是拥有激活函数的功能神经元。
**做法:**在网络中加入一个或多个隐藏层来突破线性模型的限制,使其可以处理更普遍的函数关系
隐藏层
多层感知机是一种前馈人工神经网络**,**由多个神经元层(输入层、隐藏层、输出层)组成,能够学习复杂的非线性关系。
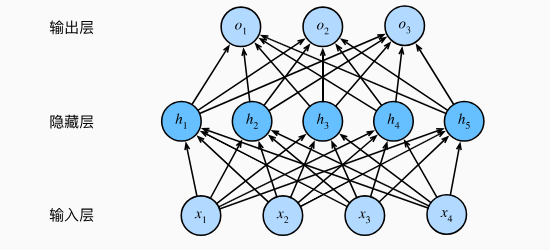
以下是一个单隐藏机的多层感知机,这个多层感知机有4个输入,3个输出,其隐藏层包含5个隐藏单元。这个多层感知机中的层数为2, 输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算。 注意,这两个层都是全连接的。 每个输入都会影响隐藏层中的每个神经元, 而隐藏层中的每个神经元又会影响输出层中的每个神经元。
我们可以把前 L − 1 L−1 L−1层看作表示,把最后一层看作线性预测器。
- 前 L-1 层:负责对输入数据进行特征提取和表示学习(Representation Learning),通过非线性变换将原始数据映射到高维特征空间。
- 第 L 层(最后一层):基于前 L-1 层提取的特征,进行线性预测(如分类或回归),直接输出最终结果。
多层前馈神经网络:
- 多层:由多个层级组成,包括 输入层、隐藏层(至少一层)和 输出层。
- 前馈(Feedforward):数据从输入层单向传递到输出层,没有循环或反馈连接,与递归神经网络(RNN)不同。
- 神经元(节点):每个层由多个神经元构成,神经元之间通过权重 连接。
从线性到非线性
单层感知机的局限是无法分离分线性空间,而感知机的叠加(多层感知机)可以分离非线性空间。。
- 线性空间:使用一条直线分割的空间
- 非线性空间:实用曲线分割的空间
单隐藏层-单分类案例
输入 x ∈ R n x\in R^n x∈Rn
- 隐藏层:假设隐藏层有m个隐藏单元,所以
输入层->隐藏层有m个标量偏置。隐藏层的权重矩阵 W 1 ∈ R m × n , b 1 ∈ R m W_1\in R^{m \times n},b_1 \in R^m W1∈Rm×n,b1∈Rm。
h = σ ( W 1 x + b 1 ) h=\sigma(W_1x+b_1) h=σ(W1x+b1),其中 σ \sigma σ是按元素的激活函数
- 输出层:单分类的输出层只有一个神经元所以
隐藏层->输出层只有一个标量偏置,输出层权重 w 2 ∈ R m , b 2 ∈ R w_2\in R^m,b_2 \in R w2∈Rm,b2∈R
o = w 2 T h + b 2 o=w^T_2h+b_2 o=w2Th+b2,输出是一个标量
多隐藏层
超参数
- 隐藏层数
- 每层隐藏单元数(一般随深度减少)
深度学习本质就是做压损,所以每一层数据会越来越少,也就是逐层压缩。
一般不会先很狠的压缩数据,再扩充数据。因为这样可能会损失特征。
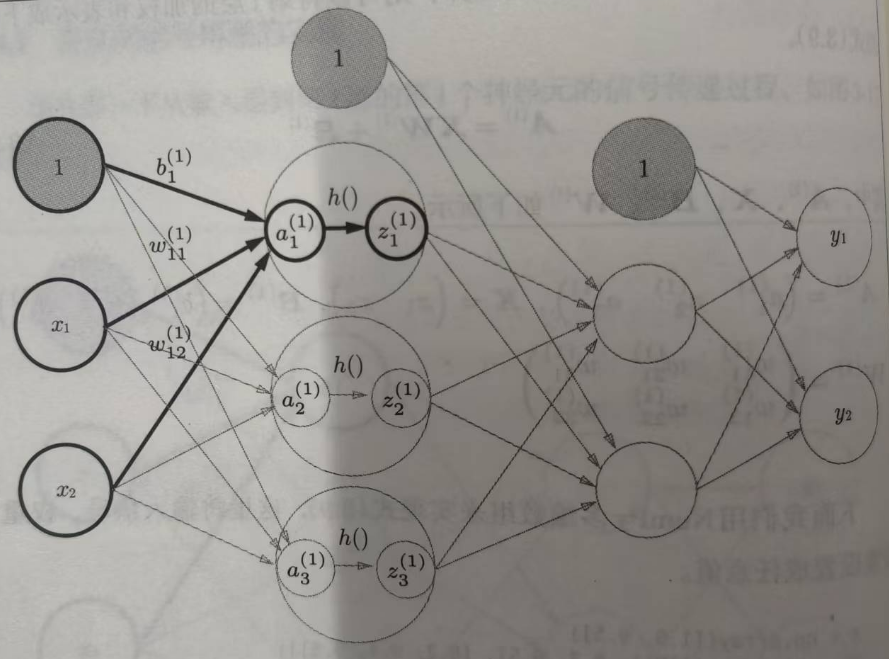
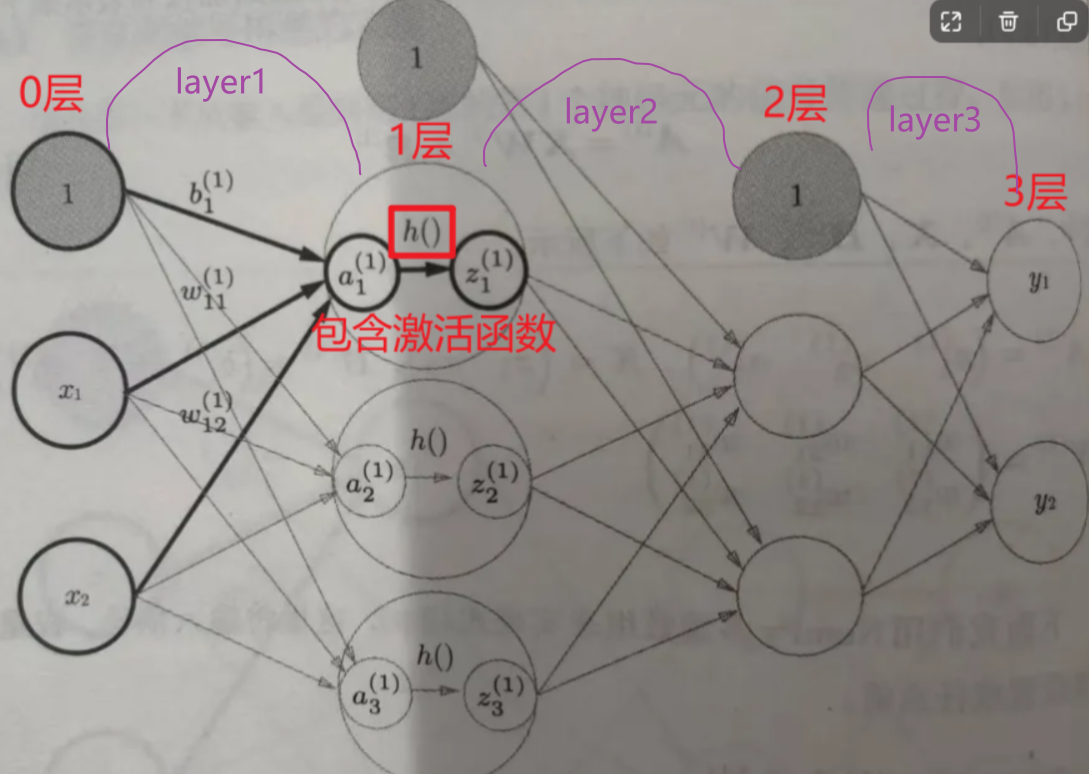
一般图中会省略偏置权重b的表示,下图在每一层的神经元中都增加了表示偏置的神经元1。
以下几个说明需要注意
- 每一层(除去输出层)表示偏置的神经元1只会有一个。
- 偏置权重b的个数取决于后一层神经元的数量(后一层的神经元不包含偏置神经元)
3. w 12 ( 1 ) w^{(1)}_{12} w12(1)表示是第1层(这里是从连接线开始数)的权重,且指向后一层的第1个神经元,来源是前一层的第2个神经元。
4. a 1 ( 1 ) a^{(1)}_1 a1(1)表示第1层的第1个神经元,输入层的神经元一般没有计算功能所以一般是第0层,计算神经网络的总层数也不会计入。 - 第1层的神经元用大圈表示意思是 从输入总和后得到输出 a a a然后利用激活函数 h h h处理输出 a a a得到 z z z用于下一层的输入。
激活函数
神经网络的激活函数必须使用非线性函数问题: 为什么需要非线性的激活函数?
假设 h = W 1 x + b 1 , o = w 2 T h + b 2 h=W_1x+b_1,o=w^T_2h+b_2 h=W1x+b1,o=w2Th+b2则 o = w 2 T W 1 x + b ′ o=w^T_2W_1x+b' o=w2TW1x+b′仍然输出线性,模型的处理能力并没有变强
| 激活函数 | 公式 | 描述 | 使用场景 | 特点 |
|---|---|---|---|---|
| 阶跃函数 | 一旦超过阈值,就切换输出(有点像分段函数) | 感知机中神经元之间的流动的是0或1的二元信号 | ||
| Sigmoid激活函数 | h ( x ) = 1 1 + e x p ( − x ) h(x)=\frac{1}{1+exp(-x)} h(x)=1+exp(−x)1 | sigmoid函数: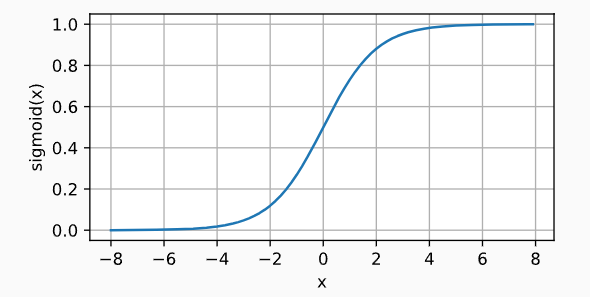 sigmoid导数: 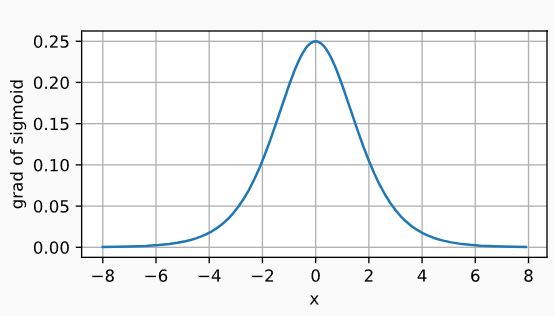 | 将输入投影到(0,1) 神经网络中流动的是连续的实数值信号 | |
| ReLU函数 | x > 0 x>0 x>0输出该值, x ≤ 0 x\leq 0 x≤0输出0 h ( x ) = { x i f x > 0 0 o t h e r w i s e h(x) = \begin{cases} x & if\;x>0\\ 0 &otherwise \end{cases} h(x)={x0ifx>0otherwise | ReLu函数: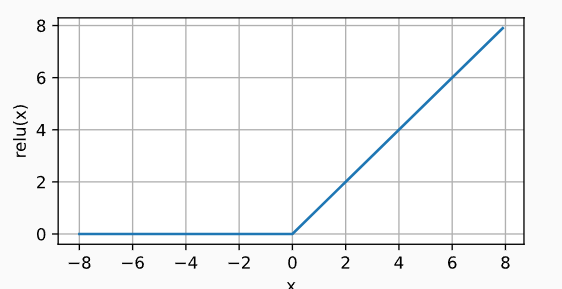 ReLuh导数: 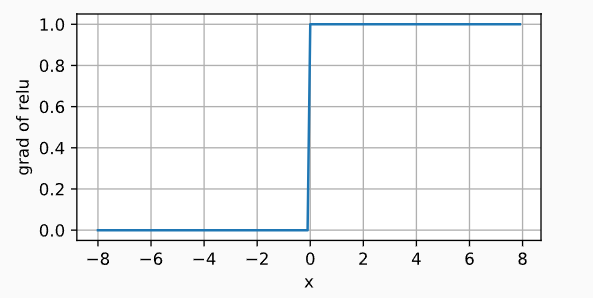 | 最常用的激活函数 | |
| softmax函数 | y i = e x p ( o i ) ∑ k e x p ( o k ) y_i=\frac{exp(o_i)}{\sum_k exp(o_k)} yi=∑kexp(ok)exp(oi) | 多分类问题 分类问题的输出层适合用softmax函数 | 1. 函数输出(0.0,1.0)之间的实数,输出值总数为1。 2. 使用sigmoid函数之后(单调递增的函数),原本输出元素之间的关系也不会改变(大的置信度转换为大的概率)。所以在推理预测阶段一般会省略输出层的softmax操作 | |
| tanh激活函数 | t a n h ( x ) = 1 − e x p ( − 2 x ) 1 + e x p ( − 2 x ) tanh(x)=\frac{1-exp(-2x)}{1+exp(-2x)} tanh(x)=1+exp(−2x)1−exp(−2x) | tanh函数: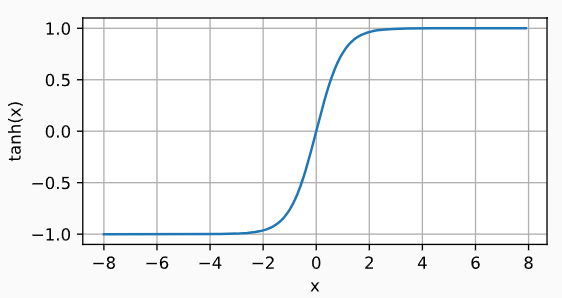 tanh导数: tanh导数: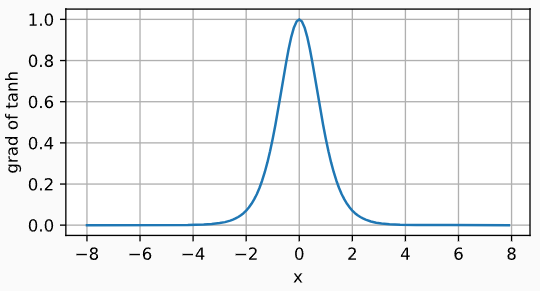 | 将输入投影到(-1,1) |
softmax函数溢出的问题
在softmax回归这一章节,其实有介绍过softmax的数值稳定法。这里再介绍一下如何防止溢出。
y i = e x p ( o i ) ∑ k e x p ( o k ) = C e x p ( o i ) C ∑ k e x p ( o k ) = e x p ( o i + l o g C ) ∑ k e x p ( o k + l o g C ) = e x p ( o i + C ′ ) ∑ k e x p ( o k + C ′ ) y_i=\frac{exp(o_i)}{\sum_k exp(o_k)} = \frac{Cexp(o_i)}{C\sum_k exp(o_k)} = \frac{exp(o_i+logC)}{\sum_k exp(o_k+logC)} = \frac{exp(o_i+C')}{\sum_k exp(o_k+C')} yi=∑kexp(ok)exp(oi)=C∑kexp(ok)Cexp(oi)=∑kexp(ok+logC)exp(oi+logC)=∑kexp(ok+C′)exp(oi+C′)
在进行softmax的指数函数运算时,加上(减去)某个常数并不会改变运算的结果,这里的 C ′ C' C′可以是任何值,但是为了防止溢出一般会使用输入信号中的最大值 C ′ = m a x ( o k ) C'=max(o_k) C′=max(ok)。
稳定版的softmax函数 y i = e x p ( o i + m a x ( o k ) ) ∑ k e x p ( o k + m a x ( o k ) ) y_i=\frac{exp(o_i+max(o_k))}{\sum_k exp(o_k+max(o_k))} yi=∑kexp(ok+max(ok))exp(oi+max(ok))
多层感知机从零开始实现
数据获取采用之前的方式
import torch
from torch import nn
from d2l import torch as d2lbatch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
初始化模型参数
Fashion-MNIST中的每个图像由 28 × 28 = 784 28×28=784 28×28=784个灰度像素值组成, 所有图像共分为 10 10 10个类别。忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。
这里我们实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元。这两个参数都是超参数,可以自己设定。
因为内存在硬件中的分配和寻址方式,通常选择2的若干次幂作为层的宽度,会在计算上更高效。这里一共是两层神经网络,一层隐藏层,一层输出层,每一层的权重矩阵和偏置向量都需要记录。
定义输入层->隐藏层信号传递的参数, w 1 w_1 w1的形状是 ( n u m _ i n p u t s , n u m _ h i d d e n s ) = ( 784 , 256 ) (num\_inputs,num\_hiddens)=(784,256) (num_inputs,num_hiddens)=(784,256),隐藏层有256个神经元,所以偏置向量 b 1 b_1 b1的形状为 ( n u m _ h i d d e n s , ) = ( 256 , ) (num\_hiddens,)=(256,) (num_hiddens,)=(256,)
定义隐藏层->输出层信号传递的参数,w_2的形状是(256,10),输出层有10个神经元,所以偏置向量 b 2 b_2 b2的形状为(10,)
# num_hiddens 表示隐藏层的神经元个数256个,也就是隐藏层->输出层的输入由256个
num_inputs, num_outputs, num_hiddens = 784, 10, 256# torch.randn 初始化服从标准正态分布(均值为0,标准差为1)的随机数。
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))params = [W1, b1, W2, b2]
问题1:之前采用的是torch.normal函数,为什么这里采用torch.randn函数
这里本质是一样的,只是用不同的函数生成。
torch.randn(size):生成元素服从 标准正态分布(均值为 0,标准差为 1) 的张量torch.normal:生成元素服从 自定义均值和标准差 的正态分布
问题2:为什么得到的矩阵要乘0.01?
在神经网络中,将权重初始值缩小(例如乘以 0.01) 是常见的初始化策略,其核心目的是 避免激活值在初始阶段进入非线性激活函数的饱和区,从而缓解梯度消失问题,加速模型收敛。
若权重初始值较大,线性变换后的输入z(z = Wx + b) 可能较大,导致激活函数输出进入饱和区,梯度消失,阻碍参数更新。

问题3:为什么李沐视频里说加不加nn.Parameter都可以?
在 PyTorch 中,nn.Parameter 的作用是将一个张量标记为模型的可训练参数,使其能够被优化器自动追踪和更新。
如果代码中显式将张量加入参数列表(如 params = [W1, b1, W2, b2]),即使未使用 nn.Parameter,只要张量的 requires_grad=True,优化器依然可以更新它们的梯度。
W1 = torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01 # 未使用 nn.Parameter
b1 = torch.zeros(num_hiddens, requires_grad=True)
params = [W1, b1, W2, b2] # 手动传递参数给优化器
# 优化器仍会更新 W1 和 b1 的梯度,因为它们的 requires_grad=True。
optimizer = torch.optim.SGD(params, lr=0.1)
激活函数:ReLU函数
这里使用ReLU函数作为激活函数
def relu(X):# 创建与X形状相同的全零张量a = torch.zeros_like(X) # 对X和a逐元素取最大值return torch.max(X, a)
模型
在 PyTorch 中,@ 符号是 矩阵乘法运算符,用于执行两个张量之间的矩阵乘法。
X @ W 等同于 torch.matmul(X, W)。
def net(X):# 先输入拉成一个二维矩阵X = X.reshape((-1, num_inputs))H = relu(X@W1 + b1) return (H@W2 + b2)
损失函数
loss = nn.CrossEntropyLoss(reduction='none')
训练
因为李沐老师模型训练用到了train_ch3函数,这个函数里画图适用于Jupyter,所以开发工具开始使用Jupyter。
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
报错module 'd2l.torch' has no attribute 'train_ch3'
原因:我的版本是1.0.3太新了,在新版本中移除了
**解决办法:**把之前手动定义的函数搬过来
import torch
from torch import nn
from d2l import torch as d2l# 获取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)# 初始化参数
# num_hiddens 表示隐藏层的神经元个数256个,也就是隐藏层->输出层的输入由256个
num_inputs, num_outputs, num_hiddens = 784, 10, 256# torch.randn 初始化服从标准正态分布(均值为0,标准差为1)的随机数。
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))params = [W1, b1, W2, b2]def relu(X):# 创建与X形状相同的全零张量a = torch.zeros_like(X)# 对X和a逐元素取最大值return torch.max(X, a)def net(X):# 先输入拉成一个二维矩阵X = X.reshape((-1, num_inputs))H = relu(X@W1 + b1)return (H@W2 + b2)# 返回y_hat与y元素比较的结果数组
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())# 常用的变量累计类
class Accumulator: #@savedef __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
# 每个epoch的训练过程
def train_epoch(net, train_iter, loss, updater): # @saveif isinstance(net, torch.nn.Module):net.train()metric = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.mean().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2]
# 计算在指定数据集上的精准度,返回准确率
def evaluate_accuracy(net, data_iter): # @saveif isinstance(net, torch.nn.Module):net.eval()metric = Accumulator(2)with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
# 模型的训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))num_epochs, lr = 10, 0.1
loss = nn.CrossEntropyLoss(reduction='none')
updater = torch.optim.SGD(params, lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
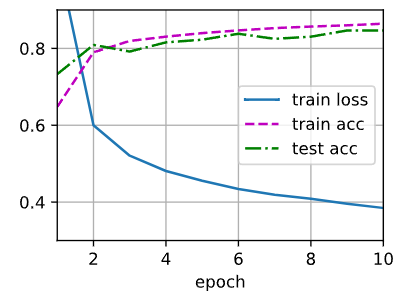
多层感知机模型的观察
损失逐渐减小,但精度并没有比之前好很低(之后内容会探讨这个问题)。
多层感知机的简洁实现
- 神经网络的定义
- 参数的初始化
- 损失函数 ✔
已经使用了pytorch里的nn(Neural Network)的交叉熵损失函数nn.CrossEntropyLoss(reduction='none')
- 优化器 ✔
已经使用了pytorch里的随机梯度下降优化器torch.optim.SGD(params, lr=lr)
- 模型的定义可以采用
nn(Neural Network)模块- 展平层:将输入的数据拉平为
(batch_size, 784)
- 展平层:将输入的数据拉平为
Flatten()默认第一个数保持不变,后面的维度拉平。
2. 隐藏层(全连接层),将 784 维输入映射到 256 维特征空间。然后传递给激活函数处理。
这里256是超参数假设有256个隐藏单元。
3. 最后一层输出层(全连接层),将 256 维特征映射到 10 维输出
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Linear(256, 10))
Flatten函数展平的细节
标准输入形状:(batch_size, channels, height, width),简称 NCHW。
这是 PyTorch 中大多数层(如卷积层、全连接层)的默认预期格式。
nn.Flatten() 默认从 第 1 维开始展平(即保留第 0 维 batch_size)。
输入形状 (256, 1, 28, 28) → 展平后为 (256, 1 * 28 * 28) = (256, 784)。
- 参数初始化
如果模块是 nn.Linear 层,则用均值为 0、标准差为 0.01 的正态分布初始化其权重。
偏置(bias)未显式初始化,默认使用 PyTorch 的默认初始化(通常为零初始化)。
PyTorch 的 nn.Linear 层在初始化时会 根据输入和输出维度自动创建权重矩阵,所以不需要现实化定义维度。
def init_weights(m):if type(m) == nn.Linear:#初始化层:Linear(in_features=784, out_features=256, bias=True), 权重形状:torch.Size([256, 784])#初始化层:Linear(in_features=256, out_features=10, bias=True), 权重形状:torch.Size([10, 256])print(f"初始化层:{m}, 权重形状:{m.weight.shape}")nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)
手动实现与PyTorch全连接层实现的细节区别
- 手动实现:W的形状为
[输入特征维度,输出类别数],模型计算是 X W + b XW+b XW+b - 全连接层的前向传播公式为: 输出 = X ⋅ W T + b 输出=X⋅W^T+b 输出=X⋅WT+b
其实这里都无所谓,手动实现也可以将计算改为 W T W^T WT,只要前后维度是一样的就行。
- 损失函数和优化器
直接使用之前的代码
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
代码
MLP(Multilayer Perceptron)多层感知机 如果效果不好,很容易的转卷积、RN、Transformer,所以MLP经常被使用。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:print(f"初始化层:{m}, 权重形状:{m.weight.shape}")nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)# 返回y_hat与y元素比较的结果数组
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
# 常用的变量累计类
class Accumulator: #@savedef __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
# 每个epoch的训练过程
def train_epoch(net, train_iter, loss, updater): # @saveif isinstance(net, torch.nn.Module):net.train()metric = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.mean().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2]
# 计算在指定数据集上的精准度,返回准确率
def evaluate_accuracy(net, data_iter): # @saveif isinstance(net, torch.nn.Module):net.eval()metric = Accumulator(2)with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
# 模型的训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
Q&A解疑
问题1:神经网络的一层是指什么?
每一个箭头表示可以学习的权重,通常一层需要包含权重+激活函数
问题2:为什么神经网络要增加隐藏层的层数,而不是增加隐藏层的神经元个数
胖神经网络:增加神经元个数 - 容易过拟合
深神经网络:增加层数
这个问题刘宏毅老师课程的《鱼和熊掌可以兼得的机器学习》有讲解过
当参数量一样(未知参数量一样)的时候,Fat+Short的网络和Thin+Tall的网络谁的效果更好?=> 实验表明:Thin+Tall的网络效果更好
deep learing的核心:产生同一个function,使用deep的架构需要的参数量更少,可能需要较少的训练资料就可以了(不容易overfitting)。
问题3:不同任务下的激活函数是不是都不一样?都是通过实验来确定的吗?
激活函数的选择都差不多,远远没有选择隐藏层大小等超参数重要,推荐用ReLu。
相关文章:

李沐《动手学深度学习》 | 多层感知机
文章目录 感知机模型《深度学习入门》的解释训练感知机损失函数的选择感知机的收敛定理:什么时候能够停下来,是不是真的可以停下来感知机的不足 多层感知模型案例引入隐藏层从线性到非线性单隐藏层-单分类案例多隐藏层 激活函数softmax函数溢出的问题 多…...

vue数据可视化开发常用库
一、常用数据可视化库 1. ECharts 特点:功能强大,支持多种图表类型,社区活跃。适用场景:复杂图表、大数据量、3D 可视化。安装:npm install echarts示例:<template><div ref"chart" c…...

CAN转ModbusTCP网关:破解电池生产线设备协议壁垒,实现全链路智能互联
在电池生产的现代工艺中,自动化和信息化水平的提高是提升产能、保障品质与安全的关键。CAN 协议作为一种广泛应用于汽车、工业控制等领域的串行通信协议,它以其高可靠性和强实时性而受到企业的青睐。而在众多工业通讯协议中,ModbusTCP作为一种…...

更新 / 安装 Nvidia Driver 驱动 - Ubuntu - 2
如果按更新 / 安装 Nvidia Driver 驱动 - Ubuntu-CSDN博客中的步骤操作后问题依旧,则查看过程中的提示信息。 如果发现有“Use sudo apt autoremove to remove them.”,则执行: #sudo apt autoremove #nvidia-smi...
处理器上跑通qt开发流程)
技术分享 | 如何在2k0300(LoongArch架构)处理器上跑通qt开发流程
近期迅为售后团队反馈,许多用户咨询:2K0300处理器采用了LA264处理器核,若要在该处理器上运行Qt程序,由于架构发生了变化,其使用方法是否仍与ARM平台保持一致? 单纯回答‘一致’或‘不一致’缺乏说服力&…...

ubuntu 24.04 error: cannot uninstall blinker 1.7.0, record file not found. hint
最近在打python3.12的镜像,安装browser-gym的核心库,编译一个使用browswer agents的环境,然后出现了下面的问题: error: cannot uninstall blinker 1.7.0, record file not found. hint: the package was installed by debian.系…...

学习记录:DAY28
DispatcherController 功能完善与接口文档编写 前言 没什么动力说废话了。 今天来完善 DispatcherController 的功能,然后写写接口文档。 日程 早上:本来只有早八,但是早上摸鱼了,罪过罪过。下午:把 DispatcherContro…...

C# 的异步任务中, 如何暂停, 继续,停止任务
namespace taskTest {using System;using System.Threading;using System.Threading.Tasks;public class MyService{private Task? workTask;private readonly SemaphoreSlim semaphore new SemaphoreSlim(0, 1); // 初始为 0,Start() 启动时手动放行private read…...
(已不推荐使用deprecated,建议使用img、video、audio标签))
html object标签介绍(用于嵌入外部资源通用标签)(已不推荐使用deprecated,建议使用img、video、audio标签)
文章目录 HTML <object> 标签详解基本语法与核心属性关键属性解析1. **data**2. **type**3. **width & height**4. **name** 嵌入不同类型的资源1. **嵌入图像**2. **嵌入音频**3. **嵌入视频**4. **嵌入 PDF** 参数传递与回退内容**参数(<param>&a…...

专题练习1
优化: 找101-200的质数: 开发验证码: 解密数字 抽奖 优化 彩票...

Uniapp编写微信小程序,使用canvas进行绘图
一、canvas文档: https://developer.mozilla.org/zh-CN/docs/Web/API/Canvas_API/Tutorial 二、数据绘制(单位是像素): 1、绘制文本: 文字的长度超过设置的最大宽度,文字会缩在一起 ① 填充文本…...

Java高频基础面试题
Java高频基础面试题 Java基础 Java的特点是什么? 面向对象平台无关性(“一次编写,到处运行”)支持多线程自动内存管理(垃圾回收)安全性丰富的类库 JDK、JRE和JVM的区别 JDK (Java Development Kit): Java…...

U9C-SQL-采购订单视图
U9C-SQL-采购订单视图 SELECTpo.ID,CONVERT ( VARCHAR ( 10 ), po.CreatedOn, 23 ) AS 签订日期,org.Name AS 甲方,po.DocNo AS 单号,item.Code AS 料号,item.Name AS 品名,item.SPECS AS 规格,item.DescFlexField_PrivateDescSeg1 AS 图号,item.DescFlexField_PrivateDescSeg2…...

HTML字符串转换为React元素实现
HTML字符串安全转换为React元素的实现 一、背景介绍 介绍HTML字符串在Web开发中的常见场景。说明React中直接使用HTML字符串的局限性。提出将HTML字符串转换为React元素的需求。 二、首先必备的两个npm库:html-react-parser和dompurify 导入: pnpm i…...

全局异常未能正确捕获到对应的异常
自定义Validation验证器遇到的问题 抛出的异常没有能被指定的TaskValidException.class方法拦截到。故写这个原因 全局异常拦截只能拦截相同的异常。只能通过解析转入自定义的异常。自定义的异常继承的异常要是一家子的。如TaskValidException和ValidationException。这样就能在…...
)
LeetCode 解题思路 47(最长回文子串、最长公共子序列)
解题思路: dp 数组的含义: dp[i][j] 是否为回文子串。递推公式: dp[i][j] s.charAt(i) s.charAt(j) && dp[i 1][j - 1]。dp 数组初始化: 单字符 dp[i][i] true,双字符 dp[i][i 1] s.charAt(i) s.charA…...
)
P11369 [Ynoi2024] 弥留之国的爱丽丝(操作分块,DAG可达性trick)
真的神仙题。感觉学到了很多。 题意: 给你一张 n n n 个结点 m m m 条边的有向图,点编号为 1 , 2 , … , n 1,2,\dots,n 1,2,…,n。每条边的颜色为黑色或白色。一开始所有 m m m 条边都是黑色的。 你需要进行 q q q 次操作,有两种操作…...

NAT穿越
概述 IPSec协商是通过IKE完成--->ISAKMP协议完成--->由UDP封装,源目端口均为500。 NAT--->NAPT,同时转换IP和端口信息。 对端设备会查验收到的数据报文中的源IP和源端口,其中源IP可以设定为NAT转换后的IP,但是源端口无法…...

不黑文化艺术学社首席艺术家孙溟㠭浅析“雪渔派”
孙溟㠭浅析“雪渔派” 何震 字主臣 ,长卿,号雪渔,安徽婺源(今江西)人,是明代著名的篆刻家和书法家,与文彭独树一帜,实现书法与刀法的统一。 云中白鹤 笑谭间气吐霓虹 边款 其篆刻吸…...

【Linux操作系统】第一弹——Linux基础篇
文章目录 💡 一. Linux的基本常识🪔 1.1 linux网络连接三种方式🪔1.2 虚拟机的克隆🪔1.3 虚拟机的快照🪔1.4 虚拟机的迁移和删除🪔1.5 vmtools工具 💡二. Linux的目录结构🪔2.1 Linu…...

“ES7+ React/Redux/React-Native snippets“常用快捷前缀
请注意,这是一个常用的列表,不是扩展提供的所有前缀。最完整和最新的列表请参考扩展的官方文档或在 VS Code 中查看扩展的详情页面。 React (通常用于 .js, .jsx, .ts, .tsx): rfce: React Functional Component with Export Defaultrafce: React Arro…...

selenium替代----playwright
安装 好处特点:这个东西不像selenium需要固定版本的驱动 pip config set global.index-url https://mirrors.aliyun.com/pypi/simplepip install --upgrade pippip install playwright playwright installplaywright install ffmpeg (处理音视频的)验证&#x…...

2025年社交APP安全防御指南:抵御DDoS与CC攻击的实战策略
2025年,社交APP的用户规模与业务复杂度持续增长,但随之而来的DDoS与CC攻击也愈发隐蔽和智能化。攻击者通过AI伪造用户行为、劫持物联网设备,甚至利用区块链漏洞发起混合攻击,对平台稳定性与用户数据安全构成严峻挑战。本文将结合最…...

PHP会话技术
第十六章-PHP会话技术 PHP会话技术是构建动态、个性化Web应用的核心机制之一,它通过跟踪用户在网站上的连续操作状态,实现了网页间的数据持久化交互。无论是电商平台的购物车信息保存、社交媒体的用户登录状态维持,还是表单数据的跨页面传递…...

QT聊天项目DAY10
1.封装redis操作类 头文件 #ifndef REDISMANAGE_H #define REDISMANAGE_H#include "Singletion.h" #include "GlobalHead.h"class RedisManage : public Singletion<RedisManage> {friend class Singletion<RedisManage>; public:~RedisMana…...
)
5.0.5 变换(旋转、缩放、扭曲)
WPF变换可以产生特殊效果,如平移、旋转、扭曲。 变换类 描述TranslateTransform沿着X轴和Y轴平移ScaleTransform 沿着定义的中心点缩放RotateTransform沿着定义的中心点旋转SkewTransform 扭曲元素MatrixTransfrom提供3x3矩阵,用于定义一个自定义变换 1…...

matlab转python
1 matlab2python开源程序 https://blog.csdn.net/qq_43426078/article/details/123384265 2 网址 转换网址:https://app.codeconvert.ai/code-converter?inputLangMatlab&outputLangPython 文件比较网址:https://www.diffchecker.com/text-comp…...

什么是直播美颜SDK?跨平台安卓、iOS美颜SDK开发实战详解
时下,尤其在社交、娱乐、电商等应用场景中,一个流畅且效果自然的美颜功能往往能直接影响用户的留存率和平台的营收。要实现这些效果,美颜SDK是核心工具。那么,什么是直播美颜SDK?它的功能有哪些?如何进行跨…...

大尺寸PCB如何重塑通信与新能源产业格局
在5G通信基站与新能源电站的机房内,一块块面积超过600mm600mm的PCB板正悄然推动着技术革命。作为电子设备的核心载体,大尺寸PCB凭借其高密度集成与复杂工艺,成为通信、能源等领域的“隐形功臣”。以猎板PCB为代表的厂商,凭借宽幅曝…...
)
JavaSE核心知识点02面向对象编程02-04(包和导入)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点02面向对象编程02-04&#…...

【漫话机器学习系列】249.Word2Vec自然语言训练模型
【自然语言处理】用 Word2Vec 将词语映射到向量空间详解 一、背景介绍 在自然语言处理(NLP)领域,我们常常需要将文本信息转化为机器能够理解和处理的形式。传统的方法,如 one-hot编码,虽然简单,但存在严重…...
CSS transition过渡属性
transition 是 CSS 中用于创建平滑动画效果的属性,它允许元素在两个状态之间平滑过渡,而不是立即改变。通过定义过渡的属性、持续时间和速度曲线,你可以实现丰富的交互体验,如悬停效果、状态切换动画等。 核心作用 平滑过渡&…...

U9C对接飞书审批流完整过程
U9C虽然很强大,但是移动办公和审批流功能并不好用,为了弥补U9C这种不足,很多的企业在使用U9C的同时再开通钉钉、飞书、企业微信这种OA管理系统,两套系统并行使用,就需要考虑U9C和OA系统数据同步的问题,最简…...

阿里云 SLS 多云日志接入最佳实践:链路、成本与高可用性优化
作者:裘文成(翊韬) 摘要 随着企业全球化业务的扩展,如何高效、经济且可靠地将分布在海外各地的应用与基础设施日志统一采集至阿里云日志服务 (SLS) 进行分析与监控,已成为关键挑战。 本文聚焦于阿里云高性能日志采集…...

从0开始学习大模型--Day04--大模型的框架以及基本元素
Agent框架与策略分析 计划与执行(planning-and-Execute) 该框架侧重于先规划一系列的行动,然后执行。这个框架可以使大模型能够先综合考虑任务的多个方面,然后按照计划进行行动,比较适合应用在较复杂的项目管理中或者…...

FPGA实战项目2———多协议通信控制器
1. 多协议通信控制器模块 (multi_protocol_controller) 简要介绍 这是整个设计的顶层模块,承担着整合各个子模块的重要任务,是整个系统的核心枢纽。它负责协调 UART、SPI、I2C 等不同通信协议模块以及 DMA 模块的工作,同时处理不同时钟域之间的信号交互,确保各个模块能够…...

strings.Builder 使用详解
目录 1. 官方包 2. 支持版本 3. 官方说明 官方示例 方法 func (b *Builder) Cap() int func (b *Builder) Grow(n int) func (b *Builder) Len() int func (b *Builder) Reset() func (b *Builder) String() string func (b *Builder) Write(p []byte) (int, error)…...

数巅智能携手北京昇腾创新中心深耕行业大模型应用
当前,AI技术正在加速向各行业深度渗透,成为驱动产业转型和社会经济发展的重要引擎。构建开放协作的AI应用生态体系、推动技术和应用深度融合,已成为行业发展的重要趋势。 近日,数巅智能与北京昇腾人工智能计算中心(北京昇腾创新中…...
】第二章:嵌入式系统硬件基础知识——⑤电源及电路设计)
【嵌入式系统设计师(软考中级)】第二章:嵌入式系统硬件基础知识——⑤电源及电路设计
文章目录 7. 嵌入式系统电源分类及管理7.1 嵌入式系统电源分类7.2 电源管理技术7.3 电源完整性设计 8. 电子电路设计8.1 电子电路设计基础知识8.1.1 电子电路设计原理8.1.2 电子电路设计方法及步骤8.1.3 电子电路可靠性设计 8.2 PCB设计基础知识8.2.1 PCB设计原理8.2.2 PCB设计…...

排序算法-希尔排序
希尔排序是插入排序的改进版,通过将原始数组分成多个子序列进行间隔插入排序,逐步缩小间隔直至为1,最终完成整体排序。它也被称为缩小增量排序。 希尔排序步骤 选择增量序列(Gap Sequence):确定一个递减的…...

JAVA继承中变量和方法的存储和方法中访问变量的顺序
一、变量归属与内存位置 static 变量:属于类,只存在一份,保存在方法区(或元空间)。 实例变量(非static):属于对象,每个对象单独一份,保存在堆内存中。 二、…...
)
【PhysUnits】3.3 SI 基础量纲单位(units/base.rs)
一、源码 这段代码定义了一系列基础物理量纲的类型别名,并使用标记 trait Canonical 来表示它们是国际单位制(SI)中的基本单位。 use crate::Dimension; use typenum::{P1, Z0};/// 标记特质,表示基础量纲单位 pub trait Canoni…...

stm32F103芯片 实现PID算法控制温度例程
目录 硬件需求 软件需求 步骤 1. 配置STM32CubeMX 2. 编写PID控制代码 3. 编译和烧录 4. 测试 注意事项 要在STM32F103芯片上实现PID算法控制温度,首先需要确保你有一套完整的硬件和软件开发环境。这里,我将给你一个简化的例程,展示如何使用PID控制算法来调节一个假…...

Java学习手册:微服务设计原则
一、单一职责原则 每个微服务应该专注于一个特定的业务功能,具有清晰的职责边界。这有助于保持服务的简洁性,降低服务之间的耦合度,提高服务的可维护性和可扩展性。例如,可以将用户管理、订单管理、支付管理等功能分别设计为独立…...
(二))
【挑战项目】 --- 微服务编程测评系统(在线OJ系统)(二)
三十二、Swagger介绍&使用 官网:https://swagger.io/ 什么是swagger Swagger是一个接口文档生成工具,它可以帮助开发者自动生成接口文档。当项目的接口发生变更时,Swagger可以实时更新文档,确保文档的准确性和时效性。Swagger还内置了测试功能,开发者可以直接在文档中…...

Unity背景随着文字变化而变化
组件结构: 背景(父)需要添加如下两个组件 根据具体情况选择第一个组件水平还是垂直,一般垂直用的比较多 效果展示: 此时在文本框中改变内容背景图都会随着变化,动态的...

Elasticsearch内存管理与JVM优化:原理剖析与最佳实践
#作者:孙德新 文章目录 一、Elasticsearch缓存分类1、Node Query Cache:2、Shard Request Cache:3、Fielddata Cache: 三、内存常见的问题案例一案例二案例三案例四 四、内参分配最佳实践1、jvm heap分配2、将机器上少于一半的内…...

快速开发-基于Gin框架搭建web应用
一、概述 Go 语言的 Gin 框架是一个用 Go (Golang) 编写的 Web 框架,它旨在提供一种快速、简洁且高效的方式来构建 Web 应用程序。Gin 框架以其高性能和易用性而闻名,非常适合构建 API 服务、Web 服务和其他需要高性能的 Web 应用。 二、Gin框架…...
)
【RAG】RAG系统——langchain 的用法(说人话版与专业版)
说人话版: RAG就是一句话:对数据设置索引,用问题去检索,用llm生成回答 首先,做本地知识库 注意: py 3.10以上 配置环境变量,安装库 load外部数据,存储到本地的一个index里(这是最…...

pycharm无法直接识别wsl
原因是我的2020 无法支持这个版本的wsl 我就换成2024版 添加中可以看到 on wsl 如果你想切到自己创建的虚拟环境 你在下面这个界面选择conda就好 这样就可以切换成你想要的环境了...