【RAG】RAG系统——langchain 的用法(说人话版与专业版)
说人话版:
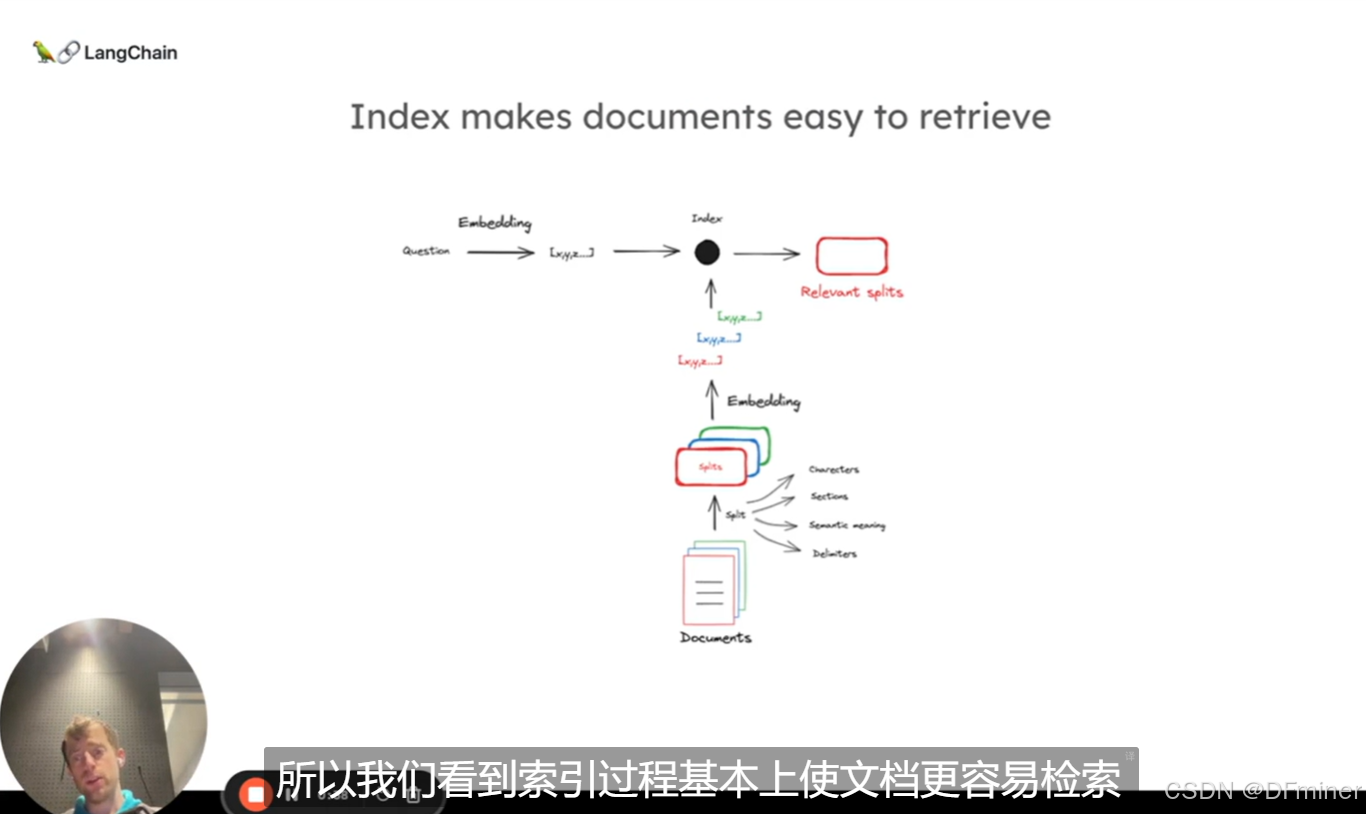
RAG就是一句话:对数据设置索引,用问题去检索,用llm生成回答
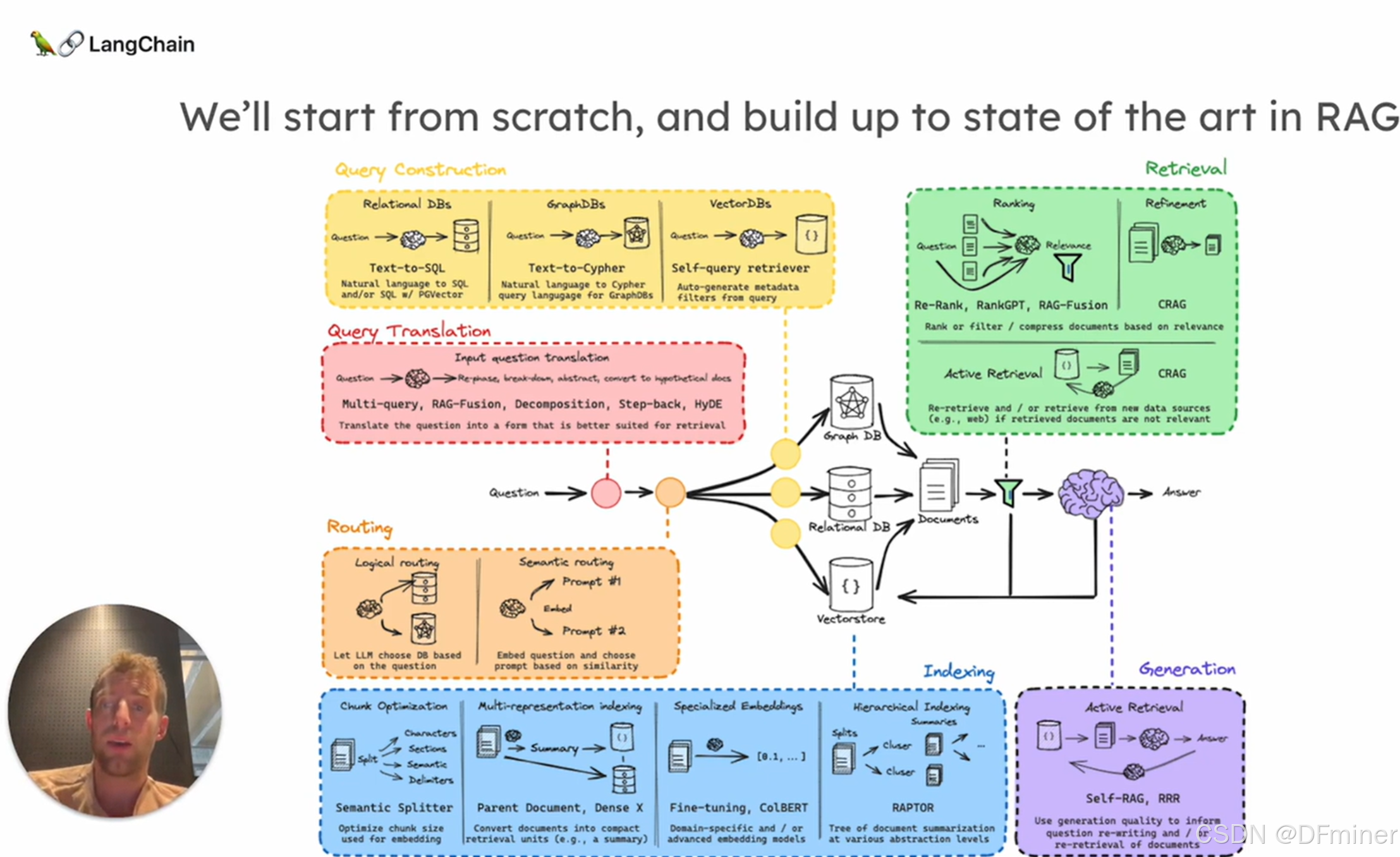

首先,做本地知识库
注意: py 3.10以上
配置环境变量,安装库
load外部数据,存储到本地的一个index里(这是最简单的形式)
然后,对数据做处理,储存好放数据库
对数据做切分 split
然后,做store存储,用Embedding的方式,将切好的数据存到某种数据库,比如向量数据库里
接着,Retrieve 去检索
现在就可以去问问题了
rag系统会先对问题进行处理
(eg...把问题抽象一下,再具体的去数据库检索;把问题用llm重新生成几个语义不变的问题,都去数据库检索;把长问题分解成多个短问题等)主要就是为了能提高与数据库中数据的检索成功率和检索效率。
接着系统会按照用户问题去数据库里面找store好的数据
(eg...文档、摘要、分好的文档、聚类后的摘要、带上下文信息的token级的词向量)的 相似度 ,比如用的k临近算法,SVN
然后按照相关性排个序
最后,写个逻辑,去调大模型回答就好了
再说人话一点:
没问题,你看我这样说怎么样:
一句话概括 RAG: 咱们先给一大堆资料建个“索引”(就像图书馆的书架一样),然后你问问题,我就去这个“索引”里快速找到最相关的几段话,最后让厉害的“聊天机器人”(LLM)根据你问的问题和找到的资料,给你一个靠谱的回答。
咱们一步步来,打造你的“本地知识小助手”:
-
准备好你的“小书库”: 你得先把你的各种资料弄进来,比如你的笔记、PDF 文档、网页文章等等。Langchain 就像一个“搬运工”,能帮你把这些东西都“搬”到电脑里。
-
给你的“小书”分段: 有些“书”(文件)太长了,一下塞给“聊天机器人”它会懵。所以我们要把它们切成一小段一小段的,就像给长文章分段落一样,方便后面查找。
-
给每段“小书”贴标签(Embedding): 光分段还不行,我们得让电脑知道每段话是关于什么的。这就用到一种叫 “Embedding” 的技术,简单来说就是把每段话变成一串数字(就像给书贴上内容标签),意思相近的段落,它们的数字也会比较接近。
-
把“标签”放进“超级书架”(向量数据库): 我们把这些“数字标签”放到一个特别的“书架”里,这个“书架”(向量数据库)的特点就是找东西特别快!你给出一个新的问题(也变成“数字标签”),它能迅速找到和这个问题最相关的那些“书”的“标签”。
-
开始提问,让“小助手”去找答案: 现在你可以问你的“小助手”任何问题了。
-
“小助手”分析你的问题: 它不会直接拿着你的问题就去找,可能会稍微“琢磨”一下你的问题,比如换个说法问,或者把一个复杂的问题拆成几个小问题,这样能更准确地找到相关的资料。
-
“小助手”去“超级书架”里翻书: 它会把你的问题也变成“数字标签”,然后去“超级书架”(向量数据库)里找那些最相似的“书”的“标签”。这就好比在图书馆里,管理员根据你描述的主题,快速找到相关的书籍。
-
找到相关的“书”了! “小助手”会找到和你的问题最相关的几段话。
-
“聊天机器人”读“书”回答问题: 最后,Langchain 会把你的问题和找到的相关段落一起交给厉害的“聊天机器人”(LLM),让它读懂这些信息,然后给你一个清晰、有条理的回答。
更厉害的“小助手”还能做这些:
- 增强“阅读”能力: 用不同的“书本加载器”(比如专门读 PDF 的,读网页的),能处理更多格式的资料。
- 更精细地“切书”: 用不同的“分段方法”,让“小书”的划分更合理。
- 更聪明地“找书”: 用更高级的“检索工具”,比如一次问多个问题,或者先帮你总结一下问题再去找,提高找到有用信息的机会。
- 告诉你答案从哪里来: 有些高级的“小助手”还能告诉你它的回答是根据哪几段“小书”来的,让你更相信它的答案。

专业版:
【RAG】RAG 系统——Langchain 的用法
1. 引言
检索增强生成(Retrieval-Augmented Generation,RAG)是一种强大的自然语言处理(NLP)范式,它通过从外部知识库检索相关文档片段,并将其融入到语言模型的生成过程中,来提高生成文本的质量、相关性和可信度。Langchain 是一个旨在简化 LLM(大型语言模型)应用程序开发的框架,它提供了构建 RAG 系统的各种工具和模块。本文档将深入探讨如何在 Langchain 中使用这些工具来构建高效的 RAG 系统。
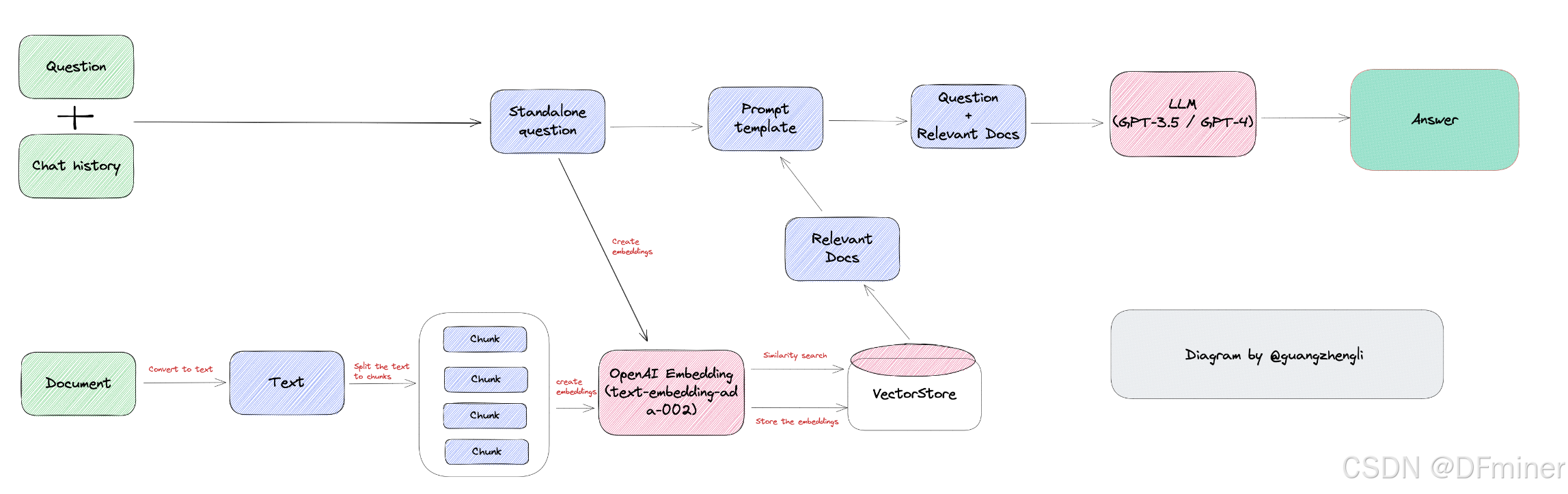
2. RAG 系统的基本流程
一个典型的 RAG 系统包含以下核心步骤:
- 文档加载(Document Loading): 从各种来源(例如,文本文件、PDF、网站、数据库等)加载原始文档数据。
- 文本分割(Text Splitting): 将大型文档分割成更小的、语义相关的文本块(chunks),以便更好地进行检索。
- 向量化嵌入(Vector Embedding): 将分割后的文本块和查询语句转换为向量表示(embeddings),以便在向量空间中进行相似性搜索。
- 向量存储(Vector Store): 将文本块的向量嵌入存储在向量数据库中,以实现高效的检索。
- 检索(Retrieval): 根据用户查询,在向量存储中执行相似性搜索,找到最相关的文本块。
- 生成(Generation): 将检索到的相关文本块与原始用户查询一起输入到语言模型中,生成最终的答案或文本。
3. Langchain 中的 RAG 组件
Langchain 提供了丰富的模块来构建 RAG 系统的各个环节:
3.1 文档加载器(Document Loaders)
Langchain 提供了各种文档加载器,用于从不同的数据源加载文档。例如:
TextLoader: 加载纯文本文件。PyPDFLoader: 加载 PDF 文件。WebBaseLoader: 从 URL 加载网页内容。DirectoryLoader: 加载指定目录下的多个文件。- 还有针对各种数据库、API 和其他文件格式的加载器。
示例代码:
Python
from langchain.document_loaders import TextLoader# 从文本文件加载文档
loader = TextLoader("./my_document.txt")
documents = loader.load()
print(f"加载了 {len(documents)} 个文档。")
print(f"第一个文档的内容:\n{documents[0].page_content[:100]}...")
3.2 文本分割器(Text Splitters)
文本分割器将大型文档分割成更小的块。Langchain 提供了多种分割策略:
CharacterTextSplitter: 基于字符进行分割。RecursiveCharacterTextSplitter: 尝试按特定字符(例如,段落、句子、单词)递归地分割,直到块大小合适。TokenTextSplitter: 基于 token 进行分割。
示例代码:
Python
from langchain.text_splitter import RecursiveCharacterTextSplittertext = """这是一个很长的文档,包含了多个段落。
第一段是关于 Langchain 的介绍。
第二段讨论了 RAG 系统的原理。
第三段将介绍如何在 Langchain 中使用 RAG。"""text_splitter = RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=20,separators=["\n\n", "\n", " ", ""],
)
chunks = text_splitter.split_text(text)
print(f"文档被分割成 {len(chunks)} 个文本块。")
print(f"第一个文本块:\n{chunks[0]}")
3.3 向量嵌入模型(Embeddings)
嵌入模型将文本转换为向量表示。Langchain 集成了多种流行的嵌入模型:
OpenAIEmbeddings: 使用 OpenAI 的嵌入模型(需要 API 密钥)。HuggingFaceEmbeddings: 使用 Hugging Face Transformers 库中的模型。SentenceTransformerEmbeddings: 使用 sentence-transformers 库中的模型。
示例代码:
Python
from langchain.embeddings import OpenAIEmbeddings# 需要设置 OpenAI API 密钥
# export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"embeddings = OpenAIEmbeddings()
text = "这是一个用于测试嵌入的句子。"
vector = embeddings.embed_query(text)
print(f"文本的向量表示(前 5 个维度):\n{vector[:5]}...")
3.4 向量存储(Vector Stores)
向量存储用于存储和索引文本块的向量嵌入,以便进行高效的相似性搜索。Langchain 支持多种向量数据库:
FAISS: 一个高效的相似性搜索库。Chroma: 一个轻量级的嵌入数据库。Pinecone: 一个托管的向量数据库服务。Weaviate: 一个开源的向量数据库。- 还有其他的向量存储集成。
示例代码(使用 FAISS):
Python
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplittertext = """这是一个示例文档,用于演示如何将文本存储到 FAISS 向量存储中。
它可以包含多个段落和句子。"""
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
chunks = text_splitter.split_text(text)
embeddings = OpenAIEmbeddings()
db = FAISS.from_texts(chunks, embeddings)# 保存向量存储
db.save_local("faiss_index")# 加载向量存储
loaded_db = FAISS.load_local("faiss_index", embeddings)# 执行相似性搜索
query = "如何在向量存储中存储文本?"
docs = loaded_db.similarity_search(query)
print(f"与查询相关的文档片段:\n{docs[0].page_content}")
3.5 检索器(Retrievers)
检索器负责根据用户查询从向量存储中检索相关的文档。Langchain 提供了多种检索器:
VectorStoreRetriever: 基于向量存储的相似性搜索。BM25Retriever: 基于 BM25 算法的稀疏检索。MultiQueryRetriever: 生成多个相关查询并检索结果,以提高检索的覆盖率。- 还有其他的自定义检索器。
示例代码(使用 VectorStoreRetriever):
Python
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings# 假设已经加载了向量存储 loaded_dbretriever = loaded_db.as_retriever()
query = "什么是向量嵌入?"
relevant_docs = retriever.get_relevant_documents(query)
print(f"检索到的相关文档数量:{len(relevant_docs)}")
print(f"第一个相关文档的内容:\n{relevant_docs[0].page_content}")
3.6 语言模型(Language Models)
Langchain 集成了各种大型语言模型:
OpenAI: 使用 OpenAI 的语言模型(例如,GPT-3.5, GPT-4)。HuggingFaceHub: 使用 Hugging Face Hub 上的模型。Cohere: 使用 Cohere 的语言模型。- 还有其他的 LLM 集成。
示例代码(使用 OpenAI 的 Chat Model):
Python
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage# 需要设置 OpenAI API 密钥
# export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"llm = ChatOpenAI(model_name="gpt-3.5-turbo")
messages = [HumanMessage(content="请简要介绍一下 Langchain。")]
response = llm(messages)
print(f"LLM 的回复:\n{response.content}")
3.7 提示词模板(Prompt Templates)
提示词模板用于构建发送给语言模型的输入。在 RAG 系统中,提示词通常包含用户查询和检索到的相关上下文。
示例代码:
Python
from langchain.prompts import ChatPromptTemplatetemplate = """请根据以下上下文回答用户的问题:
上下文:{context}
问题:{question}
答案:"""
prompt = ChatPromptTemplate.from_template(template)formatted_prompt = prompt.format_messages(context="Langchain 是一个用于构建 LLM 应用程序的框架。",question="Langchain 的主要用途是什么?",
)print(f"格式化后的提示词:\n{formatted_prompt[0].content}")
3.8 输出解析器(Output Parsers)
输出解析器用于结构化语言模型的输出。
示例代码(简单的文本输出解析器):
Python
from langchain.schema import StrOutputParseroutput_parser = StrOutputParser()
# 在 Chain 中使用
3.9 Chains
Chains 是 Langchain 的核心概念,它将不同的组件(例如,加载器、分割器、嵌入模型、向量存储、检索器、语言模型、提示词模板、输出解析器)连接在一起,形成一个完整的处理流程。对于 RAG 系统,RetrievalQA 或 RetrievalQA.from_chain_type 是一个常用的 Chain 类型。
示例代码(使用 RetrievalQA):
Python
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader# 加载文档
loader = TextLoader("./my_document.txt")
documents = loader.load()# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
chunks = text_splitter.split_documents(documents)# 创建嵌入模型
embeddings = OpenAIEmbeddings()# 创建向量存储
db = FAISS.from_documents(chunks, embeddings)# 创建检索器
retriever = db.as_retriever()# 创建语言模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo")# 创建 RetrievalQA Chain
qa_chain = RetrievalQA.from_llm(llm, retriever=retriever)# 提问
query = "文档中提到了哪些关键技术?"
result = qa_chain({"query": query})
print(f"问题:{query}")
print(f"答案:{result['result']}")
4. 构建更复杂的 RAG 系统
除了基本的 RetrievalQA,Langchain 还支持构建更复杂的 RAG 系统,例如:
- 带引用的 RAG: 返回答案的同时,也提供生成答案所依据的文档片段。可以使用
RetrievalQAWithSourcesChain。 - 多跳问答: 处理需要多个步骤推理的问题。可以使用
GraphCypherQAChain等。 - 上下文压缩: 在将检索到的文档传递给 LLM 之前,对其进行压缩以提高效率和减少噪音。可以使用
ContextCompressor。 - 自定义检索策略: 可以通过继承
BaseRetriever类来实现自定义的检索逻辑。
5. 总结
Langchain 提供了一套强大且灵活的工具,可以帮助开发者快速构建和部署高效的 RAG 系统。通过理解 RAG 的基本流程以及 Langchain 中各个组件的用法,开发者可以根据自己的需求定制出各种复杂的问答、信息检索和文本生成应用。希望本文档能够帮助您入门 Langchain 中的 RAG 系统开发。
6. 进一步学习
- Langchain 官方文档:Introduction | 🦜️🔗 LangChain
- Langchain 检索模块文档:https://python.langchain.com/docs/modules/retrievers/
- Langchain Chains 模块文档:https://python.langchain.com/docs/modules/chains/
另外:
文本加载器——做数据增强 RAG
TextLoader ,CSVLoader等
文档转换器—— 进行拆分
对文本拆分,对代码拆分,对json拆分
当检索到相关的文档10+的时候,设置检索器...
 我们在项目中一般采用什么分割方式?
我们在项目中一般采用什么分割方式?
相关文章:
)
【RAG】RAG系统——langchain 的用法(说人话版与专业版)
说人话版: RAG就是一句话:对数据设置索引,用问题去检索,用llm生成回答 首先,做本地知识库 注意: py 3.10以上 配置环境变量,安装库 load外部数据,存储到本地的一个index里(这是最…...

pycharm无法直接识别wsl
原因是我的2020 无法支持这个版本的wsl 我就换成2024版 添加中可以看到 on wsl 如果你想切到自己创建的虚拟环境 你在下面这个界面选择conda就好 这样就可以切换成你想要的环境了...
★★★★★)
数据结构每日一题day17(链表)★★★★★
题目描述:假设有两个按元素值递增次排列的线性表,均以单链表形式存储。请编与算法将这两个单链表归并为一个按元素值依次递减排列的单链表,并要求利用原来两个单链表的结点存放归并后的单链表。 算法思想: 1.初始化: 创建一个新…...
)
遗传算法(GA)
基本原理 算法介绍 遗传算法(Genetic Algorithm,简称GA)是一种基于自然选择和遗传学原理的搜索和优化技术。它模拟了生物进化过程,通过选择、交叉(重组)和变异等操作,逐步优化问题的解。 遗传…...

EPS三维测图软件
EPS三维测图软件EPS2016...

设计模式-命令模式
写在前面 Hello,我是易元,这篇文章是我学习设计模式时的笔记和心得体会。如果其中有错误,欢迎大家留言指正! 一、什么是命令模式? 命令模式是行为模式中的一种,通过将请求封装成对象,使开发者可…...

深入理解主从数据库架构与主从复制
目录 前言1. 主从数据库概述1.1 什么是主从数据库?1.2 主从数据库的应用场景 2. 主从数据库的工作原理2.1 主从数据库的读写分离2.2 数据同步机制2.3 异步与同步复制模式 3. 主从复制的实现步骤3.1 配置主库3.2 配置从库 4. 主从数据库架构的优缺点4.1 优点4.2 缺点…...

【C】初阶数据结构15 -- 计数排序与稳定性分析
本文主要讲解七大排序算法之外的另一种排序算法 -- 计数排序 目录 1 计数排序 1) 算法思想 2) 代码 3) 时间复杂度与空间复杂度分析 (1) 时间复杂度 (2) 空间复杂度 4) 计…...

@PostConstruct @PreDestroy
PostConstruct 是 Java EE(现 Jakarta EE)中的一个注解,用于标记一个方法在对象初始化完成后立即执行。它在 Spring 框架、Java Web 应用等场景中广泛使用,主要用于资源初始化、依赖注入完成后的配置等操作。 1. 基本作用 执行时…...

2025数维杯数学建模A题完整限量论文:空中芭蕾——蹦床运动的力学行为分析
2025数维杯数学建模A题完整限量论文:空中芭蕾——蹦床运动的力学行为分析 ,先到先得 A题完整论文https://www.jdmm.cc/file/2712067/ 蹦床( Trampoline )是一项运动员利用蹦床的反弹,在空中展示技能 技巧的竞技运动&…...

Kubernetes Gateway API 部署详解:从入门到实战
引言 在 Kubernetes 中管理网络流量一直是一个复杂而关键的任务。传统的 Ingress API 虽然广泛使用,但其功能有限且扩展性不足。Kubernetes Gateway API 作为新一代标准,提供了更强大的路由控制能力,支持多协议、跨命名空间路由和细粒度的流量管理。本文将带你从零开始部署…...

移动设备常用电子屏幕类型对比
概述 LCD 家族 (TN、STN、TFT、IPS、VA)依赖背光,性能差异主要来自液晶排列和驱动方式。OLED 以自发光为核心优势,但成本与寿命限制其普及。E-Paper 专为低功耗静态显示设计,与传统屏幕技术差异显著。 参数LCD&#…...

HarmonyOS开发-组件市场
1. HarmonyOS开发-组件市场 HarmonyOS NEXT开源组件市场是一个独立的插件,需通过DevEco Studio进行安装,可以点击下载,无需解压,直接通过zip进行安装,具体安装和使用方法可参考HarmonyOsNEXT组件市场使用说明。Harmony…...

效果图云渲染:价格、优势与使用技巧
对于做3D设计来说,渲染效果图会占用设计电脑的资源,如果能免去这个环节就好了。用设计电脑渲不仅拖慢电脑速度,遇到紧急情况无法快速渲染出来还可能耽误进度。而云渲染的出现,正是针对这个点——渲的快,价格便宜&#…...

OptiStruct实例:声振耦合超单元应用
如图10-11所示,本例采用一个简化的整车模型,模型分为车身(含声腔)与底盘两部分。首先分别运用CMS与CDS方法对车身(含声腔)模型进行缩聚,生成.h3d格式的CMS超单元和cps超单元,然后进行…...

排序算法-插入排序
插入排序是一种简单直观的排序算法,其核心思想是将未排序部分的元素逐个插入到已排序部分的正确位置,类似于整理扑克牌。 插入排序步骤 初始化:将序列的第一个元素视为已排序部分,其余为未排序部分。 选择元素:从未排…...

Uniapp Android/IOS 获取手机通讯录
介绍 最近忙着开发支付宝小程序和app,下面给大家介绍一下 app 获取通讯录的全部过程吧,也是这也是我app开发中的一项需求吧。 效果图如下 勾选配置文件 使用uniapp开发的童鞋都知道有一个配置文件 manifest.json 简单的说一下,就是安卓/ios/…...

【RAG】index环节中 关于嵌入模型和 ColBERT
1. 什么是嵌入模型?是不是把数据源转换为向量表示的模型? 是的,嵌入模型(Embedding Model)的核心功能就是将各种类型的数据(例如,文本、图像、音频等)转换成低维、稠密的向量表示。…...

一文掌握 LVGL 9 的源码目录结构
文章目录 📂 一文掌握 LVGL 9 的源码目录结构🧭 顶层目录概览📁 1. src/ — LVGL 的核心源码(🔥重点)📁 2. examples/ — API 示例📁 3. demos/ — 综合演示项目📁 4. do…...

ROS1 和 ROS2 在同一个系统中使用
一、环境变量设置 echo "ros noetic(1) or ros2 foxy(2)?" read edition if [ "$edition" -eq "1" ]; thensource /opt/ros/noetic/setup.bash elsesource /opt/ros/foxy/setup.bash fi 二、针对不同的ROS版本创建不同的工作空间work space...

Redis 8.0携新功能,重新开源
01 引言 Redis从7.4版本起,将开源许可证改成 RSALv2(Redis 源代码可用许可证)与 SSPLv1(服务器端公共许可证)的双重授权策略。简单来说,就是不能随意商用。为了抵制Redis,Redis的替代品Valkey、…...

AD原理图复制较多元器件时报错:“InvalidParameter Exception Occurred In Copy”
一、问题描述 AD原理图复制较多元器件时报错:AD原理图复制较多元器件时报错:“InvalidParameter Exception Occurred In Copy”。如下图 二、问题分析 破解BUG。 三、解决方案 1、打开参数配置 2、打开原理图优先项中的通用配置,取消勾选G…...

【wpf】12 在WPF中实现HTTP通信:封装HttpClient的最佳实践
一、背景介绍 在现代桌面应用开发中,网络通信是不可或缺的能力。WPF作为.NET平台下的桌面开发框架,可通过HttpClient轻松实现与后端API的交互。本文将以一个实际的HttpsMessages工具类为例,讲解如何在WPF中安全高效地封装HTTP通信模块。 二、…...

从概念表达到安全验证:智能驾驶功能迎来系统性规范
随着辅助驾驶事故频发,监管机制正在迅速补位。面对能力表达、使用责任、功能部署等方面的新要求,行业开始重估技术边界与验证能力,数字样机正成为企业合规落地的重要抓手。 2025年以来,围绕智能驾驶功能的争议不断升级。多起因辅…...

金贝灯光儿童摄影3大布光方案,解锁专业级童趣写真
随着亲子消费的持续升温,儿童摄影行业对高效、专业、灵活的专业灯光需求日益迫切。为精准解决儿童拍摄中孩子好动难配合、氛围单调、出片效率低下等痛点,深耕影像光源行业三十年,拥有丰富的商业人像摄影灯光解决方案的金贝品牌,近…...

双端口ram与真双端口ram的区别
端口独立性 真双端口RAM:拥有两个完全独立的读写端口(Port A和Port B),每个端口都有自己的地址总线、数据总线、时钟、使能信号和写使能信号。这意味着两个端口可以同时进行读写操作,且互不干扰。 伪双端口RAM&…...

Java设计模式之单例模式:从入门到精通
一、单例模式概述 1.1 什么是单例模式 定义:单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来访问这个实例。 专业解释:单例模式通过限制类的实例化过程,保证在整个应用程序生命周期中,某个类最多只有一个实例存在,…...
)
sqli-labs靶场18-22关(http头)
目录 less18(user-agent) less19(referer) less20(cookie) less21(cookie) less22(cookie) less18(user-agent) 这里尝试了多次…...

【图像大模型】Stable Diffusion Web UI:深度解析与实战指南
Stable Diffusion Web UI:深度解析与实战指南 一、项目概述核心功能 二、项目运行方式与执行步骤1. 环境准备2. 安装步骤在Windows上安装在Linux上安装 3. 使用Web UI 三、执行报错及问题解决方法1. Python版本不兼容2. CUDA未正确安装3. 依赖库安装失败4. 内存不足…...

Linux 学习笔记1
Linux 学习笔记1 一、用户和用户组管理用户组操作用户操作 二、文件权限管理权限查看权限修改归属权修改 三、系统快捷操作四、软件管理包管理工具服务管理 五、文件系统操作软链接 六、时间管理七、网络管理基础命令端口与进程进程管理 八、环境变量基础操作 九、其他重要概念…...

单例模式的两种设计
单例模式确保一个类只有一个实例,并提供一个全局访问点。 1. 饿汉模式 (Eager Initialization) 饿汉模式在程序启动时就创建实例,线程安全。 cpp class EagerSingleton { public:// 删除拷贝构造函数和赋值运算符EagerSingleton(const EagerSingleton…...

【HarmonyOS NEXT+AI】问答05:ArkTS和仓颉编程语言怎么选?
在“HarmonyOS NEXTAI大模型打造智能助手APP(仓颉版)”课程里面,有学员提到了这样一个问题: 鸿蒙的主推开发语言不是ArkTS吗,本课程为什么使用的是仓颉编程语言? 这里就这位同学的问题,统一做下回复,以方便…...

20250509 相对论中的\*\*“无空间”并非真实意义上的虚无,而是时空结构尚未形成\*\*的状态。 仔细解释下这个
相对论中的**“无空间”并非真实意义上的虚无,而是时空结构尚未形成**的状态。 仔细解释下这个 相对论中的“无空间”这一概念,严格来说并非绝对的虚无,而是指在物理学上时空结构尚未形成或无法定义的状态。这种状态通常出现在宇宙起源和黑洞…...

T-SQL在SQL Server中判断表、字段、索引、视图、触发器、Synonym等是否存在
SQL Server创建或者删除表、字段、索引、视图、触发器前判断是否存在。 目录 1. SQL Server创建表之前判断表是否存在 2. SQL Server新增字段之前判断是否存在 3. SQL Server删除字段之前判断是否存在 4. SQL Server新增索引之前判断是否存在 5. SQL Server判断视图是否存…...

C——数组和函数实践:扫雷
此篇博客介绍用C语言写一个扫雷小游戏,所需要用到的知识有:函数、数组、选择结构、循环结构语句等。 所使用的编译器为:VS2022。 一、扫雷游戏是什么样的,如何玩扫雷游戏? 如图,是一个标准的扫雷游戏初始阶段。由此…...

Java中的分布式缓存与Memcached集成实战
一、概述 分布式缓存是提升系统性能和扩展性的关键技术之一。Memcached作为一种高性能的分布式内存对象缓存系统,在许多场景下被广泛使用。本文将深入探讨如何在Java项目中集成Memcached,实现高效的分布式缓存。 二、Memcached简介 Memcached是一种高…...

OpenCV播放摄像头视频
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 播放摄像头视频和播放视频文件类似,也是通过类VideoCapture来实现,只不过调用open的时候传入的是摄像头的索引号。如果计算机安装了一个摄像头,则open的第一个参数通常是0&…...

[计算机科学#13]:算法
【核知坊】:释放青春想象,码动全新视野。 我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!! 内容摘要: 算法是解决问题的系统化步骤,不同的问题…...

git相关
1.将 dev 变基到 origin/master git rebase 是一个本地操作,它只会修改你当前所在分支的提交历史,而不会直接影响远程仓库或任何其他分支。 保持提交历史的线性和整洁: 这是 git rebase 最主要的目的。 想象一下 dev 分支是从 master 分支分…...

Web端项目系统访问页面很慢,后台数据返回很快,网络也没问题,是什么导致的呢?
Web端访问缓慢问题诊断指南(测试工程师专项版) ——从浏览器渲染到网络层的全链路排查方案 一、问题定位黄金法则(前端性能四象限) 1. [网络层] 数据返回快 ≠ 资源加载快(检查Content Download时间) 2. [渲染层] DOM复杂度与浏览器重绘(查看FPS指标) 3. [执行层…...

计算机系统结构-第九章-互联网络 第十章
目录 恒等函数:I(没变) 交换函数:某一位取反 如下 角标为0,第0位取反 均匀洗牌函数、混洗函数Shuffle :σ 左移一位 (左移右边补0,右移左边补0) 蝶式互连函数but…...

H5 移动端适配最佳实践落地指南。
文章目录 前言一、为什么需要移动端适配?二、核心适配方案1. 视口(Viewport)设置2. 三种适配方案 (仅供参考)(1)rem 适配方案(2)vw/vh 适配方案(3)…...

从电动化到智能化,法雷奥“猛攻”中国汽车市场
当前,全球汽车产业正在经历前所未有的变革,外资Tier1巨头开始向中国智能电动汽车市场发起新一轮“猛攻”。 在4月23日-5月2日上海国际车展期间,博世、采埃孚、大陆集团、法雷奥等全球百强零部件厂商纷纷发布战略新品与转型计划。在这其中&am…...

智能网联汽车 “中央计算” 博弈:RTOS 与跨域融合的算力分配挑战
一、引言 随着智能驾驶技术的飞速发展,汽车逐渐从传统的交通工具演变为移动的智能终端。智能网联汽车的核心竞争力日益体现在其强大的计算能力和高效的算力管理上。汽车电子电气架构(EEA)正经历从分布式架构向 “中央计算 区域控制” 架构的…...

springboot 加载 tomcat 源码追踪
加载 TomcatServletWebServerFactory 从 SpringApplication.run()方法进入 进入到 refresh () 方法 选择实现类 ServletWebServerApplicationContext 进入到 AbstractApplicationContext onRefresh() 方法创建容器 找到加载bean 得到 webServer 实例 点击 get…...

AI预测3D新模型百十个定位预测+胆码预测+去和尾2025年5月9日第72弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀6-8个和值,可以做到100-300注左右。 (1)定…...

企业高性能WEB服务器—Nginx
Nginx介绍 Nginx是一款轻量级的网页服务器、反向代理服务器以及电子邮件代理服务器。 具有高并发(特别是静态资源)、占用系统资源少的特性。它不仅是Web服务软件,还具有反向代理负载均衡功能和缓存服务功能 具备如下基本特性 可针对静态资…...

neo4j图数据库基本概念和向量使用
一.节点 1.新建节点 create (n:GroupProduct {name:都邦高保额团意险,description: "保险产品名称"} ) return n CREATE:Neo4j 的关键字,用于创建新节点或关系。 (n:GroupProduct): n 是节点的临时别名(变量名&#…...

安全核查基线-3.用户umask设置策略
在Linux中,umask(用户文件创建掩码)是一个重要的权限管理机制,用于控制新创建的文件和目录的默认权限。umask的值决定了文件或目录的初始权限中哪些权限位会被屏蔽(即不可用)。 1. umask 的作用 文件默认权…...

UE像素流是什么
UE像素流是什么 UE像素流送是一种云渲染技术,由虚幻引擎(UE)提出,用于在浏览器中运行高画质3D应用或游戏。其原理是在远程计算机(可以是云端服务器或本地高性能服务器)上运行UE开发的应用程序,…...