图解gpt之神经概率语言模型与循环神经网络
上节课我们聊了词向量表示,像Word2Vec这样的模型,它确实能捕捉到词语之间的语义关系,但问题在于,它本质上还是在孤立地看待每个词。英文的“Apple”,可以指苹果公司,也可以指水果。这种一词多义的特性,以及词语在上下文中的微妙变化,Word2Vec这种固定向量的表示方式就捉襟见肘了。而且,它还不能处理新词,一旦遇到词表里没有的词,就束手无策。所以,尽管有了词向量,NLP领域在很长一段时间内,也就是所谓的深度学习元年之前,其实并没有迎来真正的突破。
大家看看那些当年最火的AI应用,什么ImageNet图像分类、人脸识别、AlphaGo下围棋,还有后来GAN生成假照片,这些都跟NLP关系不大。这说明什么?说明NLP的技术瓶颈确实存在,尤其是在处理长距离依赖关系和复杂语义方面,当时的模型很难做到。如何让NLP技术真正落地,解决实际问题,成了当时NLP学者们最头疼的问题。
NPLM
就在2003年,约书亚·本希奥及其团队发表了一篇划时代的论文,题目就是《一种神经概率语言模型》。这篇论文的核心思想,就是把神经网络这个强大的工具,引入到语言模型的构建中。这就像在黑暗中看到了一盏明灯,为NLP领域指明了方向,开辟了神经网络在语言处理领域的应用,也为后来的深度学习模型奠定了基础。可以说,NPLM的出现,标志着NLP进入了一个新的阶段。
在NPLM之前,主流的语言模型是啥?N-Gram。简单说,就是数数,看某个词在前几个词出现的频率高不高,然后预测下一个词。这种方法简单粗暴,但遇到问题就来了。比如,如果一个词很少出现,或者两个词之间距离很远,N-Gram就很难准确预测。而NPLM就不一样了,它利用神经网络强大的非线性拟合能力,直接学习词汇之间的概率分布。这就好比,N-Gram是靠经验统计,而NPLM是用神经网络这个大脑去学习规律,自然更强大。当然,代价是计算量也上去了,但效果提升是显著的。
我们来看一下NPLM的内部构造。它主要由三层组成:输入层、隐藏层和输出层。
- 输入层,就是我们熟悉的词嵌入,把离散的词变成连续的向量。
- 隐藏层,这是核心,它通过一个非线性激活函数,比如tanh,来学习词与词之间的复杂关系,捕捉上下文信息。
- 输出层,通常用一个全连接层,再接上一个softmax函数,得到每个词作为下一个词的概率。
理论讲完了,我们来看看怎么一步步实现一个NPLM。
构建实验语料库
sentences = ["我 喜欢 玩具", "我 爱 爸爸", "我 讨厌 挨打"]
词汇表: {'爸爸': 0, '喜欢': 1, '玩具': 2, '讨厌': 3, '挨打': 4, '爱': 5, '我': 6}
生成NPLM训练数据
输入批处理数据: tensor([[6, 3],[6, 1]])
输入批处理数据对应的原始词: [['我', '讨厌'], ['我', '喜欢']]
目标批处理数据: tensor([4, 2])
目标批处理数据对应的原始词: ['挨打', '玩具']
定义NPLM模型
- self.C:一个词嵌入层,用于将输入数据中的每个词转换为固定大小的向量表 示。voc_size表示词汇表大小,embedding_size表示词嵌入的维度。
- self.linear1:第一个线性层,不考虑批次的情况下输入大小为n_step*embedding_size,输出大小 n_hidden。n_step表示时间步数,即每个输入序列的长度;embedding_size表示词嵌入的维度;n_hidden表示隐藏层的大小。
- self.linear2:第二个线性层,不考虑批次的情况下输入大小为n_hidden,输出大小为voc_size。n_hidden表示隐藏层的大小,voc_size表示词汇表大小。
import torch.nn as nn # 导入神经网络模块
# 定义神经概率语言模型(NPLM)
class NPLM(nn.Module):def __init__(self):super(NPLM, self).__init__() self.C = nn.Embedding(voc_size, embedding_size) # 定义一个词嵌入层# 第一个线性层,其输入大小为 n_step * embedding_size,输出大小为 n_hiddenself.linear1 = nn.Linear(n_step * embedding_size, n_hidden) # 第二个线性层,其输入大小为 n_hidden,输出大小为 voc_size,即词汇表大小self.linear2 = nn.Linear(n_hidden, voc_size) def forward(self, X): # 定义前向传播过程# 输入数据 X 张量的形状为 [batch_size, n_step]X = self.C(X) # 将 X 通过词嵌入层,形状变为 [batch_size, n_step, embedding_size]X = X.view(-1, n_step * embedding_size) # 形状变为 [batch_size, n_step * embedding_size]# 通过第一个线性层并应用 ReLU 激活函数hidden = torch.tanh(self.linear1(X)) # hidden 张量形状为 [batch_size, n_hidden]# 通过第二个线性层得到输出 output = self.linear2(hidden) # output 形状为 [batch_size, voc_size]return output # 返回输出结果NPLM((C): Embedding(7, 2)(linear1): Linear(in_features=4, out_features=2, bias=True)(linear2): Linear(in_features=2, out_features=7, bias=True)
)
实例化NPLM模型,训练NPLM模型
import torch.optim as optim # 导入优化器模块
criterion = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.1) # 定义优化器为 Adam,学习率为 0.1
# 训练模型
for epoch in range(5000): # 设置训练迭代次数optimizer.zero_grad() # 清除优化器的梯度input_batch, target_batch = make_batch() # 创建输入和目标批处理数据# input_batch = tensor([[6, 1], [6, 3]]) # target_batch = tensor([2, 4])output = model(input_batch) # 将输入数据传入模型,得到输出结果loss = criterion(output, target_batch) # 计算损失值if (epoch + 1) % 1000 == 0: # 每 1000 次迭代,打印损失值print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数
用NPLM预测新词
# 进行预测
input_strs = [['我', '讨厌'], ['我', '喜欢']] # 需要预测的输入序列
# 将输入序列转换为对应的索引
input_indices = [[word_to_idx[word] for word in seq] for seq in input_strs]# 将输入序列的索引转换为张量
input_batch = torch.LongTensor(input_indices)
# 对输入序列进行预测,取输出中概率最大的类别
predict = model(input_batch).data.max(1)[1]
# 将预测结果的索引转换为对应的词
predict_strs = [idx_to_word[n.item()] for n in predict.squeeze()]
for input_seq, pred in zip(input_strs, predict_strs):print(input_seq, '->', pred) # 打印输入序列和预测结果
回顾一下NPLM,它的贡献是划时代的。它把神经网络带进了NLP领域,开启了深度学习的大门。从此以后,我们不再需要费力地设计各种人工特征,模型可以自动学习。它能处理大规模数据,捕捉到更复杂的语言模式。但是,NPLM本身也有不少局限。它的结构比较浅,表达能力有限,处理不了太长的句子,对长距离依赖关系也不够敏感,训练效率不高,而且死板地依赖于固定词汇表,遇到新词就抓瞎。
RNN
这些局限,正是后来RNN、LSTM等模型要解决的问题。为了解决NPLM的这些问题,特别是处理长句子和捕捉长距离依赖,研究人员提出了循环神经网络,也就是RNN。RNN的核心思想非常巧妙,就是引入了循环。它不像NPLM那样只看固定窗口,而是把前面的信息记住,传递给后面。这样,它就能处理任意长度的序列,并且有能力记住很久以前的信息,从而捕捉到长距离依赖关系。这在处理像文本这样的序列数据时,优势非常明显。我们来看RNN的基本结构。
- 它有一个隐藏层,这个隐藏层的状态是会随着时间步更新的。
- 每个时间步,RNN会接收当前的输入,然后结合上一个时间步的隐藏状态,计算出当前的隐藏状态。
- 这个隐藏状态会同时传递给下一个时间步的RNN单元,以及当前时间步的输出层。
- RNN在每个时间步使用相同的权重(RNN具有参数共享的特性。这意味着在不同时间步,RNN使用相同的权
重矩阵(W_hh,W_xh和W_hy)和偏置(b_h和b_y)进行计算)。这使得它能够处理任意长度的输入序列,非常灵活。
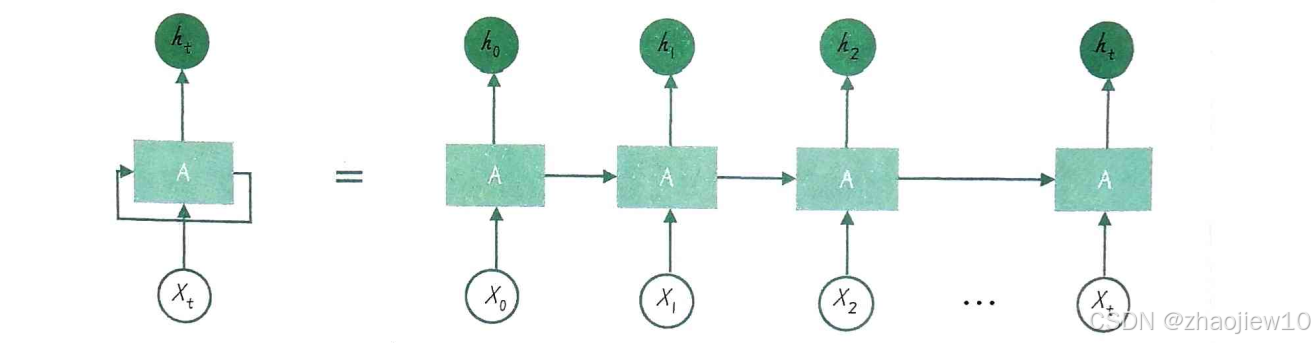
RNN是如何工作的呢?简单来说,就是一步一步地处理序列。
- 每个时间步t,它接收当前的输入x_t,然后用一个公式,把当前的隐藏状态h_t-1和输入x_t结合起来,计算出新的隐藏状态h_t。这个公式通常用tanh激活函数。
- 有了新的隐藏状态h_t,再通过另一个线性变换和softmax函数,得到当前时间步的输出y_t。
- 这个过程是沿着时间序列一步步展开的。
训练RNN时,我们用的是BPTT,也就是通过时间反向传播。RNN采用BPTT算法进行训练。与普通反向传播不同,BPTT算法需要在时间维度上展开RNN,以便在处理时序依赖性时计算损失梯度。因此,BPTT算法可以看作一种针对具有时间结构的数据的反向传播算法。
BPTT算法的关键在于,我们需要将梯度沿着时间步(对于自然语言处理问题来说,时间步就是文本序列的token)反向传播,从输出层一直传播到输入层。具体步骤如下。
- 根据模型的输出和实际标签计算损失。对每个时间步,都可以计算一个损失值,然后对所有时间步的损失值求和,得到总损失。
- 计算损失函数关于模型参数(权重矩阵和偏置)的梯度。这需要应用链式求导法则,分别计算损失函数关于输出层、隐藏层和输入层的梯度。然后将这些梯度沿着时间步传播回去。
- 使用优化算法(如梯度下降法、Adam等)来更新模型参数。这包括更新权重矩阵(W_hh,W_xh和W_hy)和偏置(b_h和b_y)。经过多轮迭代训练,RNN模型的参数不断更新,从而使得模型在处理序列数据时的性能不断提高。
这个算法会把整个序列展开,然后计算梯度,再反向传播回去更新参数。虽然RNN很强大,但也不是完美的。它最大的问题就是梯度消失和梯度爆炸。这导致它在处理很长的序列时,很难记住前面的信息,也就是长距离依赖学不好。另外,RNN是顺序计算的,没法并行计算,效率比较低。
为了解决这些问题,人们又发明了LSTM和GRU。它们都是RNN的变体,但引入了门控机制,就像给信息流动加了开关,可以更好地控制哪些信息需要保留,哪些信息需要遗忘,从而更好地捕捉长距离依赖。
我们来看一个RNN的实战例子。我们还是用刚才那个简单的数据集,但是这次,我们用一个LSTM层来替换掉NPLM里的第一个线性层。这样,我们的模型就变成了:词嵌入层 -> LSTM层 -> 线性层。LSTM层会接收输入序列的词嵌入,然后逐个时间步处理,输出一系列的隐藏状态。我们通常只取最后一个时间步的隐藏状态,作为线性层的输入,来预测下一个词。
import torch.nn as nn # 导入神经网络模块
# 定义神经概率语言模型(NPLM)
class NPLM(nn.Module):def __init__(self):super(NPLM, self).__init__() # 调用父类的构造函数self.C = nn.Embedding(voc_size, embedding_size) # 定义一个词嵌入层# 用 LSTM 层替代第一个线性层,其输入大小为 embedding_size,隐藏层大小为 n_hiddenself.lstm = nn.LSTM(embedding_size, n_hidden, batch_first=True) # 第二个线性层,其输入大小为 n_hidden,输出大小为 voc_size,即词汇表大小self.linear = nn.Linear(n_hidden, voc_size) def forward(self, X): # 定义前向传播过程# 输入数据 X 张量的形状为 [batch_size, n_step]X = self.C(X) # 将 X 通过词嵌入层,形状变为 [batch_size, n_step, embedding_size]# 通过 LSTM 层lstm_out, _ = self.lstm(X) # lstm_out 形状变为 [batch_size, n_step, n_hidden]# !!!只选择最后一个时间步的输出作为全连接层的输入,通过第二个线性层得到输出 output = self.linear(lstm_out[:, -1, :]) # output 的形状为 [batch_size, voc_size]return output # 返回输出结果
这个改动,就是把NPLM变成了一个RNN模型。这个RNN模型主要由几个参数决定:词嵌入的维度,LSTM隐藏层的大小。在PyTorch中,LSTM层的输入是一个形状为 batch_size, seq_length, input_size 的张量,其中 seq_length 是序列长度。还有一个可选的初始隐藏状态 h_0。最关键的是,RNN不再需要像NPLM那样,预先设定一个固定的时间步数 n_step。它可以处理任意长度的序列,这是RNN的一个巨大优势。
刚才我们提到了LSTM的门控机制,这里稍微展开一下。LSTM内部有三个主要的门:输入门、遗忘门和输出门。
- 输入门决定哪些新信息可以加入到细胞状态里
- 遗忘门决定哪些旧的、不重要的信息要从细胞状态里移除
- 输出门决定哪些细胞状态的信息要输出到隐藏状态
通过这些门的精妙配合,LSTM就能有效地记住长期信息,同时忽略短期干扰。这些公式展示了门控机制的计算过程,核心思想就是控制信息的流动。尽管RNN及其变体,特别是LSTM,曾经在NLP领域取得了巨大的成功,甚至可以说是SOTA,但它们仍然存在一些固有的局限性。比如,
- 顺序计算的特性限制了并行计算能力
- 长距离依赖的处理能力在某些情况下仍然不足,可扩展性也受到挑战。
在RNN时代,NLP应用落地整体效果不佳,除了模型本身,也受限于当时数据量、计算资源和优化算法的水平。当然,RNN的出现已经极大地推动了NLP的发展,为后续更强大的模型如Transformer奠定了基础。
相关文章:

图解gpt之神经概率语言模型与循环神经网络
上节课我们聊了词向量表示,像Word2Vec这样的模型,它确实能捕捉到词语之间的语义关系,但问题在于,它本质上还是在孤立地看待每个词。英文的“Apple”,可以指苹果公司,也可以指水果。这种一词多义的特性&…...

Jenkins linux安装
jenkins启动 service jenkins start 重启 service jenkins restart 停止 service jenkins stop jenkins安装 命令切换到自己的下载目录 直接用命令下载 wget http://pkg.jenkins-ci.org/redhat-stable/jenkins-2.190.3-1.1.noarch.rpm 下载直接安装 rpm -ivh jenkins-2.190.3-…...

android 修改单GPS,单北斗,单伽利略等
从hal层入手,代码如下: 各个类型如下: typedef enum {MTK_CONFIG_GPS_GLONASS 0,MTK_CONFIG_GPS_BEIDOU,MTK_CONFIG_GPS_GLONASS_BEIDOU,MTK_CONFIG_GPS_ONLY,MTK_CONFIG_BEIDOU_ONLY,MTK_CONFIG_GLONASS_ONLY,MTK_CONFIG_GPS_GLONASS_BEIDO…...

CNG汽车加气站操作工岗位职责
CNG(压缩天然气)汽车加气站操作工是负责天然气加气设备操作、维护及安全管理的重要岗位。以下是该岗位的职责、技能要求、安全注意事项及职业发展方向的详细说明: *主要职责 加气操作 按照规程为车辆加注CNG,检查车辆气瓶合格证…...

纯Java实现反向传播算法:零依赖神经网络实战
在深度学习框架泛滥的今天,理解算法底层实现变得愈发重要。反向传播(Backpropagation)作为神经网络训练的基石算法,其实现往往被各种框架封装。本文将突破常规,仅用Java标准库实现完整BP算法,帮助开发者: 1) 深入理解…...

springboot3 + mybatis-plus3 创建web项目实现表增删改查
Idea创建项目 环境配置说明 在现代化的企业级应用开发中,合适的开发环境配置能够极大提升开发效率和应用性能。本文介绍的环境配置为: 操作系统:Windows 11JDK:JDK 21Maven:Maven 3.9.xIDE:IntelliJ IDEA…...
)
多模型协同预测在风机故障预测的应用(demo)
数据加载和预处理的真实性: 下面的代码中,DummyDataset 和数据加载部分仍然是高度简化和占位的。为了让这个训练循环真正有效,您必须用您自己的数据加载逻辑替换它。这意味着您需要创建一个 torch.utils.data.Dataset 的子类,它能…...

韩媒聚焦Lazarus攻击手段升级,CertiK联创顾荣辉详解应对之道
近日,韩国知名科技媒体《韩国IT时报》(Korea IT Times)刊文引述了CertiK联合创始人兼CEO顾荣辉教授的专业见解,聚焦黑客组织Lazarus在Web3.0领域攻击手段的持续升级,分析这一威胁的严峻性,并探讨了提升行业…...

5.9-selcct_poll_epoll 和 reactor 的模拟实现
5.9-select_poll_epoll 本文演示 select 等 io 多路复用函数的应用方法,函数具体介绍可以参考我过去写的博客。 先绑定监听的文件描述符 int sockfd socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in serveraddr; memset(&serveraddr, 0, sizeof(struc…...

图上思维:基于知识图的大型语言模型的深层可靠推理
摘要 尽管大型语言模型(LLM)在各种任务中取得了巨大的成功,但它们经常与幻觉问题作斗争,特别是在需要深入和负责任的推理的场景中。这些问题可以通过在LLM推理中引入外部知识图(KG)来部分解决。在本文中&am…...
)
37-智慧医疗服务平台(在线接诊/问诊)
系统功能特点: 技术栈: springBootVueMysql 功能点: 医生端 用户端 管理员端 医生端: 科室信息管理、在线挂号管理、预约体检管理、体检报告管理、药品信息管理、处方信息管理、缴费信息管理、病历信息管理、智能导诊管理、在线接诊患者功能 (和患者1V1沟通) 用户…...

【新品发布】VXI可重构信号处理系统模块系列
VXI可重构信号处理系统模块概述 VXI可重构信号处理系统模块包括了 GPU 模块,CPU 模块,射频模块、IO 模块、DSP模块、高速存储模块、交换模块,采集处理模块、回放处理模块等,全套组件为单体3U VPX架构,可自由组合到多槽…...

React 第三十八节 Router 中useRoutes 的使用详解及注意事项
前言 useRoutes 是 React Router v6 引入的一个钩子函数,允许通过 JavaScript 对象(而非传统的 JSX 语法)定义路由配置。这种方式更适合复杂路由结构,且代码更简洁易维护。 一、基础使用 1.1、useRoutes路由配置对象 useRoute…...

Redhat 系统详解
Red Hat 系统深度解析:从企业级架构到核心组件 一、Red Hat 概述:企业级 Linux 的标杆 Red Hat 是全球领先的开源解决方案供应商,其核心产品 Red Hat Enterprise Linux(RHEL) 是企业级 Linux 的黄金标准。RHEL 以 稳…...

docker常用命令总结
常用命令含义docker info查看docker 服务的信息-------------------------镜像篇docker pull XXX从官网上拉取名为XXX的镜像docker login -u name登录自己的dockerhub账号docker push XXX将XXX镜像上传到自己的dockerhub账户中(XXX的命名必须是用户名/镜像名&#x…...

【el-admin】el-admin关联数据字典
数据字典使用 一、新增数据字典1、新增【图书状态】和【图书类型】数据字典2、编辑字典值 二、代码生成配置1、表单设置2、关联字典3、验证关联数据字典 三、查询操作1、模糊查询2、按类别查询(下拉框) 四、数据校验 一、新增数据字典 1、新增【图书状态…...

component :is是什么?
问: component :is是什么? 是组件? 那我们是不是就不需要自己创建组件了?还是什么意思?component :is和什么功能是类似的,同时和类似功能相比对什么时候用component :is…...

适老化洗浴辅具产业:在技术迭代与需求升级中重塑银发经济新生态
随着中国人口老龄化程度的不断加深,老年群体对于适老化产品的需求日益增长。 适老化洗浴辅具作为保障老年人洗浴安全与舒适的关键产品,其发展状况备受关注。 深入剖析中国适老化洗浴辅具的发展现状,并探寻助力产业发展的有效路径࿰…...

『Python学习笔记』ubuntu解决matplotlit中文乱码的问题!
ubuntu解决matplotlit中文乱码的问题! 文章目录 simhei.ttf字体下载链接:http://xiazaiziti.com/210356.html将字体放到合适的地方 sudo cp SimHei.ttf /usr/share/fonts/(base) zkfzkf:~$ fc-list | grep -i "SimHei" /usr/local/share/font…...

从AI到新能源:猎板PCB的HDI技术如何定义高端制造新标准?
2025年,随着AI服务器、新能源汽车、折叠屏设备等新兴领域的爆发式增长,高密度互连(HDI)电路板成为电子制造业的“必争之地”。HDI板凭借微孔、细线宽和高层间对位精度,能够实现电子设备的高集成化与微型化,…...

汽车制造行业的数字化转型
嘿,大家好!今天来和大家聊聊汽车制造行业的数字化转型,这可是当下非常热门的话题哦! 随着科技的飞速发展,传统的汽车制造行业正经历着一场深刻的变革。数字化技术已经不再是“锦上添花”,而是车企能否在未…...

Redis 常见数据类型
Redis 常见数据类型 一、基本全局命令详解与实操 1. KEYS 命令 功能:按模式匹配返回所有符合条件的键(生产环境慎用,可能导致阻塞)。 语法: KEYS pattern 模式规则: h?llo:匹配 hello, ha…...

【计算机网络-传输层】传输层协议-TCP核心机制与可靠性保障
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:传输层协议-UDP 下篇文章: 网络层 我们的讲解顺序是&…...

对golang中CSP的理解
概念: CSP模型,即通信顺序进程模型,是由英国计算机科学家C.A.R. Hoare于1978年提出的。该模型强调进程之间通过通道(channel)进行通信,并通过消息传递来协调并发执行的进程。CSP模型的核心思想是“不要通过…...

嵌入式openharmony标准系统中HDF框架底层原理分析
1、案例简介 该程序是基于OpenHarmony标准系统编写的基础外设类:简易HDF驱动。 2、基础知识 2.1、OpenHarmony HDF开发简介 HDF(Hardware Driver Foundation)驱动框架,为驱动开发者提供驱动框架能力,包括驱动加载、驱动服务管理、驱动消息机制和配置管理。旨在构建统一…...

238.除自身以外数组的乘积
给你一个数组,求出第 i 个元素以外的数组元素的乘积,不能使用除法,且时间复杂度O(n), 对于一个数,如果知道了前缀元素的乘积和后缀元素的乘积,就知道了这个元素以外的数组元素的乘积,所以现在的问题是如何…...

AI文旅|暴雨打造旅游新体验
今年"五一"假期,全国文旅市场迎来爆发式增长,从丈崖瀑布的磅礴水雾到城市商区的璀璨霓虹,从山野民宿的静谧悠然到主题乐园的欢腾喧嚣,处处人潮涌动。在这火热的景象背后,一股“无形之力”正悄然改变旅游体验…...

学习心得《How Global AI Policy and Regulations Will Impact Your Enterprise》Gartner
AI时代来临,然而与之对应的是海量的数据的安全性和合规性如何保障,如何平衡个人与智能体的利益,恰巧,最近Gartner发布了《How Global AI Policy and Regulations Will Impact Your Enterprise》,我们就其中的观点一起进行探讨。 战略规划假设 我们首先关注的是关键的战略…...

JAVA将一个同步方法改为异步执行
目的: 这么做的目的就是为了使一个高频率执行的方法能不阻塞整个程序,将该方法丢入到线程池中让线程去做异步执行,既提高了程序整体运行速度,也使得在高并发环境下程序能够更加健壮(同步执行可能会使得请求堆积以致系…...

对遗传算法思想的理解与实例详解
目录 一、概述 二、实例详解 1)问题描述与分析 2)初始化种群 3)计算种群适应度 4)遗传操作 5)基因交叉操作 6)变异操作 三、计算结果 四、总结 一、概述 遗传算法在求解最优解的问题中最为常用&a…...
)
数据可视化大屏——物流大数据服务平台(二)
代码分析: 物流大数据平台代码分析 这是一个基于 Bootstrap 和 ECharts 构建的物流大数据平台前端页面,设计采用了经典的三栏布局,主要展示河南省及全国的物流数据可视化内容。下面从多个维度进行分析: 1. 页面结构分析 整体采…...

MindSpore框架学习项目-ResNet药物分类-构建模型
目录 2.构建模型 2.1定义模型类 2.1.1 基础块ResidualBlockBase ResidualBlockBase代码解析 2.1.2 瓶颈块ResidualBlock ResidualBlock代码解释 2.1.3 构建层 构建层代码说明 2.1.4 定义不同组合(block,layer_nums)的ResNet网络实现 ResNet组建类代码解析…...

ChatTempMail - AI驱动的免费临时邮箱服务
在当今数字世界中,保护在线隐私的需求日益增长。ChatTempMail应运而生,作为一款融合人工智能技术的新一代临时邮箱服务,它不仅提供传统临时邮箱的基本功能,还通过AI技术大幅提升了用户体验。 核心功能与特性 1. AI驱动的智能邮件…...
 力扣100 9.找到字符串中所有字母异位词(滑动窗口))
(leetcode) 力扣100 9.找到字符串中所有字母异位词(滑动窗口)
题目 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 数据范围 1 < s.length, p.length < 3 * 104 s 和 p 仅包含小写字母 样例 示例 1: 输入: s "cbaebabacd", p &quo…...

深入了解 Stable Diffusion:AI 图像生成的奥秘
一、引言 AI 艺术与图像生成技术的兴起改变了我们创造和体验视觉内容的方式。在过去几年里,深度学习模型已经能够创造出令人惊叹的艺术作品,这些作品不仅模仿了人类艺术家的风格,甚至还能创造出前所未有的新风格。在这个领域,Sta…...

场外期权平值期权 实值期权 虚值期权有什么区别?收益如何计算?
期权汇 场外期权按价值状态分为平值、虚值、实值期权。 01|实值期权对于看涨期权而言,如果行权价格低于标的市场价格,则该期权处于实值状态;对于看跌期权,如果行权价格高于标的市场价格,则处于实值状态…...

微软系统 红帽系统 网络故障排查:ping、traceroute、netstat
在微软(Windows)和红帽(Red Hat Enterprise Linux,RHEL)等系统中,网络故障排查是确保系统正常运行的重要环节。 ping、traceroute(在Windows中为tracert)和netstat是三个常用的网络…...

HOT 100 | 【子串】76.最小覆盖子串、【普通数组】53.最大子数组和、【普通数组】56.合并区间
一、【子串】76.最小覆盖子串 1. 解题思路 定义两个哈希表分别用于 t 统计字符串 t 的字符个数,另一个sub_s用于统计字符串 t 在 s 的子串里面字符出现的频率。 为了降低时间复杂度,定义一个变量t_count用于统计 t 哈希表中元素的个数。哈希表sub_s是一…...

基于CNN的猫狗图像分类系统
一、系统概述 本系统是基于PyTorch框架构建的智能图像分类系统,专门针对CIFAR-10数据集中的猫(类别3)和狗(类别5)进行分类任务。系统采用卷积神经网络(CNN)作为核心算法,结合图形用…...

《时序数据库全球格局:国产与国外主流方案的对比分析》
引言 时序数据库(Time Series Database, TSDB)是专门用于存储、查询和分析时间序列数据的数据库系统,广泛应用于物联网(IoT)、金融、工业监控、智能运维等领域。近年来,随着大数据和物联网技术的发展&…...

力扣-2.两数相加
题目描述 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数都…...

富乐德传感技术盘古信息 | 锚定“未来工厂”新坐标,开启传感器制造行业数字化转型新征程
在数字化浪潮下,制造业正经历深刻变革。 传感器作为智能制造的核心基础部件,正面临着质量精度要求升级、交付周期缩短、成本管控严苛等多重挑战。传统依赖人工纸质管理、设备数据孤岛化的生产模式,已成为制约高端传感器制造突破“高精度、高…...

RT-Thread 深入系列 Part 2:RT-Thread 内核核心机制深度剖析
摘要: 本文从线程管理、调度器原理、中断处理与上下文切换、IPC 同步机制、内存管理五大核心模块出发,深入剖析 RT-Thread 内核实现细节,并辅以源码解读、流程图、时序图与性能数据。 目录 线程管理与调度器原理 1.1 线程控制块(T…...

uni-app,小程序自定义导航栏实现与最佳实践
文章目录 前言为什么需要自定义导航栏?基本实现方案1. 关闭原生导航栏2. 自定义导航栏组件结构3. 获取状态栏高度4. 样式设置 内容区域适配跨平台适配要点iOS与Android差异处理 常见导航栏效果实现1. 透明导航栏2. 滚动渐变导航栏3. 自定义返回逻辑 解决常见问题1. …...

小程序消息订阅的整个实现流程
以下是微信小程序消息订阅的完整实现流程,分为 5个核心步骤 和 3个关键注意事项: 一、消息订阅完整流程 步骤1:配置订阅消息模板 登录微信公众平台进入「功能」→「订阅消息」选择公共模板或申请自定义模板,获取模板IDÿ…...

istio in action之Gateway流量入口与安全
入口网关,简单来说,就是如何让外部世界和我们精心构建的集群内部服务顺畅地对话。在网络安全领域,有一个词叫流量入口,英文叫Ingress。这指的是那些从我们自己网络之外,比如互联网,发往我们内部网络的流量。…...

LeetCode 1722. 执行交换操作后的最小汉明距离 题解
示例: 输入:source [1,2,3,4], target [2,1,4,5], allowedSwaps [[0,1],[2,3]] 输出:1 解释:source 可以按下述方式转换: - 交换下标 0 和 1 指向的元素:source [2,1,3,4] - 交换下标 2 和 3 指向的元…...

区块链详解
1. 引言 1.1 背景 在数字化时代,信息的存储、传输和验证面临诸多挑战,如数据篡改、信任缺失、中心化风险等。区块链技术应运而生,作为一种分布式账本技术,它通过去中心化、去信任化、不可篡改等特性,为解决这些问题提…...

申能集团笔试1
目录 注意 过程 注意 必须开启摄像头和麦克风 只能用网页编程,不能用本地环境 可以用Index进行测试 过程 我还以为是编程,没想到第一次是企业人际关系、自我评价的选择题,哈哈哈有点轻松,哦对他要求不能泄漏题目,…...

机器人手臂的坐标变换:一步步计算齐次矩阵过程 [特殊字符]
大家好!今天我们来学习如何计算机器人手臂的坐标变换。别担心,我会用最简单的方式解释这个过程,就像搭积木一样简单! 一、理解问题 我们有一个机器人手臂,由多个关节组成。每个关节都有自己的坐标系,我们需要计算从世界坐标系(W)到末端执行器(P₃)的完整变换。 二、已…...