高并发内存池(二):项目的整体框架以及Thread_Cache的结构设计
目录
前言
一,项目整体框架设计
二,thread cache结构设计
模拟定长内存池的设计思路
采用一定的对齐规则设计
thread cache大致框架
申请内存Allocate方法
1,thread cache 哈希桶的内存对齐规则
2,内存对齐规则代码实现
3,申请空间Allocate代码
释放内存,还给thread cache管理
前言
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。前面也已经提到过,malloc本身就是一种内存池,malloc申请内存资源的方式已经很优秀了。而这个项目的原型tcmalloc就是在高并发场景下更胜一筹。
所以我们的项目主要处理的是在多线程下申请内存资源,我们的线程池需要考虑几个问题:
- 性能问题
- 多线程环境下,锁竞争问题。
- 内存碎片问题
而malloc也是一个内存池,它解决的问题就是1和3,他不考虑在多线程环境下锁的竞争问题 。通俗的讲,就是在多线程下,调用malloc时都是需要加锁的。
一,项目整体框架设计
高并发内存池(Concurrent Memory Pool)主要由以下3部分组成:
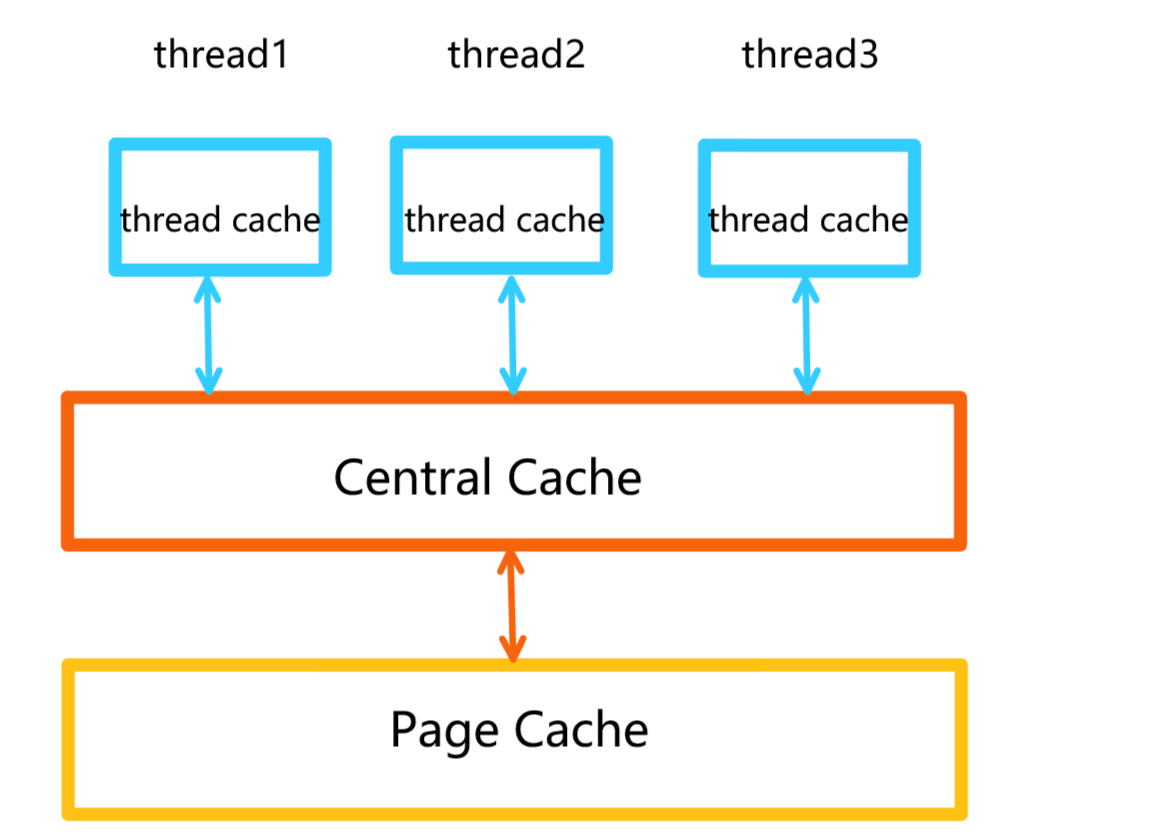
1,thread cache:每个线程独有的,用于小于256KB大小的内存分配。
- 如上图所示,每个线程都有一个自己的thread cache,那么在申请内存时,如果对应的thread cache中有内存,则直接分配,并且该过程是不需要加锁的,因为每个线程 独享一个thread cache。这也就是这个并发线程池高效的地方。
2,Central Cache:中心缓存,该部分是所有线程共享的。
- 当thread cache中没有足够的内存时,会向Central Cache进行申请。如果多个thread cache都需要向Central Cache申请,那么此时就会有多个线程来并发的访问Central Cache,此时就会存在线程安全的问题。所以该部分是需要加锁的。
- 所以在这一层会存在锁竞争的问题,但是后面会讲Central Cache是一个哈希桶的结构,只有当多线程访问同一个桶时,才会需要进行竞争锁的。所以这一层确实会存在锁竞争的问题,但是不会太过激烈,对效率方面影响不大。
- 同时,这一部分还需要完成回收内存的工作。也就是当thread cache中的内存达到一定条件时,会进行回收。这样做就可以避免,有的线程有过剩的内存空间,有的线程申请不到,通俗的说,就是一个人吃的太饱,一个人没得吃,就是为了解决这个问题。
3,Page Cache:页缓存,是Central Cache的下一级缓存。存储的内存是以页为单位的,并且分配内存的时候也是以页为单位的。在操作系统中,一页代表的内存大小是4KB或者8KB。
- 同理,当Central Cache没有内存时,会向Page Cache申请内存,Page Cache会以页为单位进行内存分配。那么当Page Cache的内存也使用完后,就会向操作系统申请。
- Page Cache同样也会回收 Central Cache的内存,当Page Cache内存达到一定条件时,就会将 这部分内存坏给操作系统。
二,thread cache结构设计
thread cache结构,有点类似于我们实现定长内存池的思路。
传送门:高并发内存池(一):项目简介+定长内存池的实现-CSDN博客
thread cahce是哈希桶结构,每个桶上是一个自由链表。每个线程都有一个thread cache对象,这样每个对象在这里申请对象和释放对象时是无锁的。
模拟定长内存池的设计思路
我们之前实现的定长内存池,它是解决固定内存大小的申请,我们在对内存资源进行管理的时候,使用的是一个自由链表,该自由链表管理的内存块是固定大小的,意思是该自由链表上的内存块要么都是 10字节的,要么都是20字节的等等。
而现在我们实现的高并发内存池,是要支持任意内存大小的申请,借鉴定长内存池的设计思路,我们可以使用多个自由链表来管理,说着太抽象,看图理解:
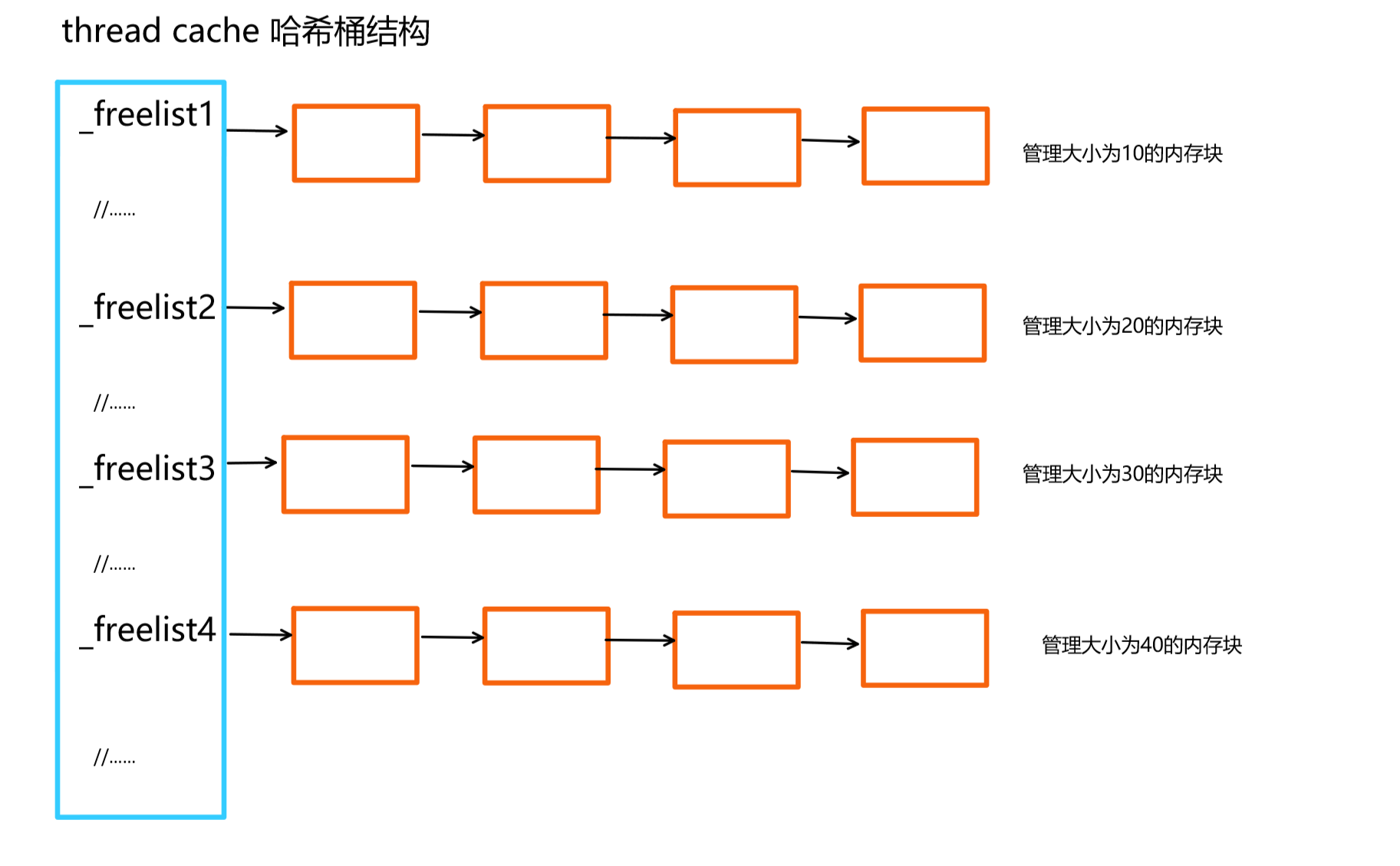
首先在上面提到过,thread cache的内存分配最大是256KB的,也就是256*1024=262114字节,也就是需要创建26万多个自由链表,然后每个链表管理对应内存块大小的管理。这种方法可行,当我想申请任意大小的内存时,都可以给我,但是可行性不高。
采用一定的对齐规则设计
在实现该部分的时候,可以进行一定的空间浪费,采取一定的对齐规则。比如,当申请1-8字节的内存大小时,都分配8字节的内存大小。这样就会存在一定的空间浪费,这种问题叫做内碎片问题。(内存对齐规则会在下面申请资源部分讲解)
对齐规则的定义:数据在内存中的起始地址必须满足特定数值的整数倍要求,这种约束称为对齐规则。
总结一下:
- 内碎片问题:比如由于对齐规则,我申请到了16字节,但是我只用12个字节,就会导致剩下的4个自己浪费,这是内碎片问题。
- 外碎片问题:是一段连续的空间,被切成好多块分出去,只有部分还回来了,但是它们不连续。导致下次再申请的时候,可能申请不成功。
thread cache大致框架
thread cache是一个哈希桶结构,每个桶是一个自由链表。
- 当一个线程申请内存时,假设申请的内存大小是n字节,首先找到对应 的thread cache,然后根据申请的内存大小n找到对应的哈希桶,也就是找到了对应的自由链表,如果自由链表不为空,头删即可;如果为空,找下一层Central Cache申请;
- 同理,当释放内存时,根据内存大小找到对应的哈希桶,也就是对应的自由链表,头插即可,当该自由链表的长度达到一定条件时,将这部分还给Central Cache;
对于自由链表会频繁的进行头删和头插 ,我们可以先封装一下,提供push和pop接口,封装好后下一层Central Cache也会使用。
//封装一下
//求一个内存块的前4个或者8个字节
void*& NextObj(void* obj)
{return *(void**)obj;
}//自由链表
class FreeList
{
public://头插void push(void* obj){//让 obj的前4个或者8个字节指向_freelist/**(void**)obj = _freelist;*/NextObj(obj) = _freelist;_freelist = obj;}//头删void* pop(){void* obj = nullptr;//void* next = *(void**)_freelist;//保存_freelist的下一个内存块地址void* next = NextObj(_freelist);obj = _freelist;_freelist = next;return obj;}
private:void* _freelist=nullptr;
};thread cache大致框架
//thread_cache设计
class threadCache
{
public://申请空间void* Allocate(size_t size);//释放obj,大小为sizevoid Deallocate(void* obj, size_t size);//......private:FreeList _freelists[];
};申请内存Allocate方法
1,thread cache 哈希桶的内存对齐规则
所谓内存对齐,就是当我申请一个大小为n的空间时,实际分配给我的是空间大小为m,这就是按照m字节对齐。
首先,这个项目最低的内存对齐规则是8,因为我们使用自由链表管理的时候,需要在内存块的头上 填充一个指针的大小,指针的大小在32位环境下是4字节,在64位环境下是8字节,所以最低是按照8字节对齐的。
- 按照8字节对齐的thread cache,如下图。当我想申请的内存小于等于8Byte时,就从第一个桶中获取。如果大于8字节小于等于16字节,就从第二个桶中获取。如果大于16,小于等于24,就从第三个 桶中获取。依次类推......
- 这种方案需要的哈希桶总数:总的字节数256*1024=262114,哈希桶个数262114/8=32768。一共需要3万多个哈希桶,还是太多了。
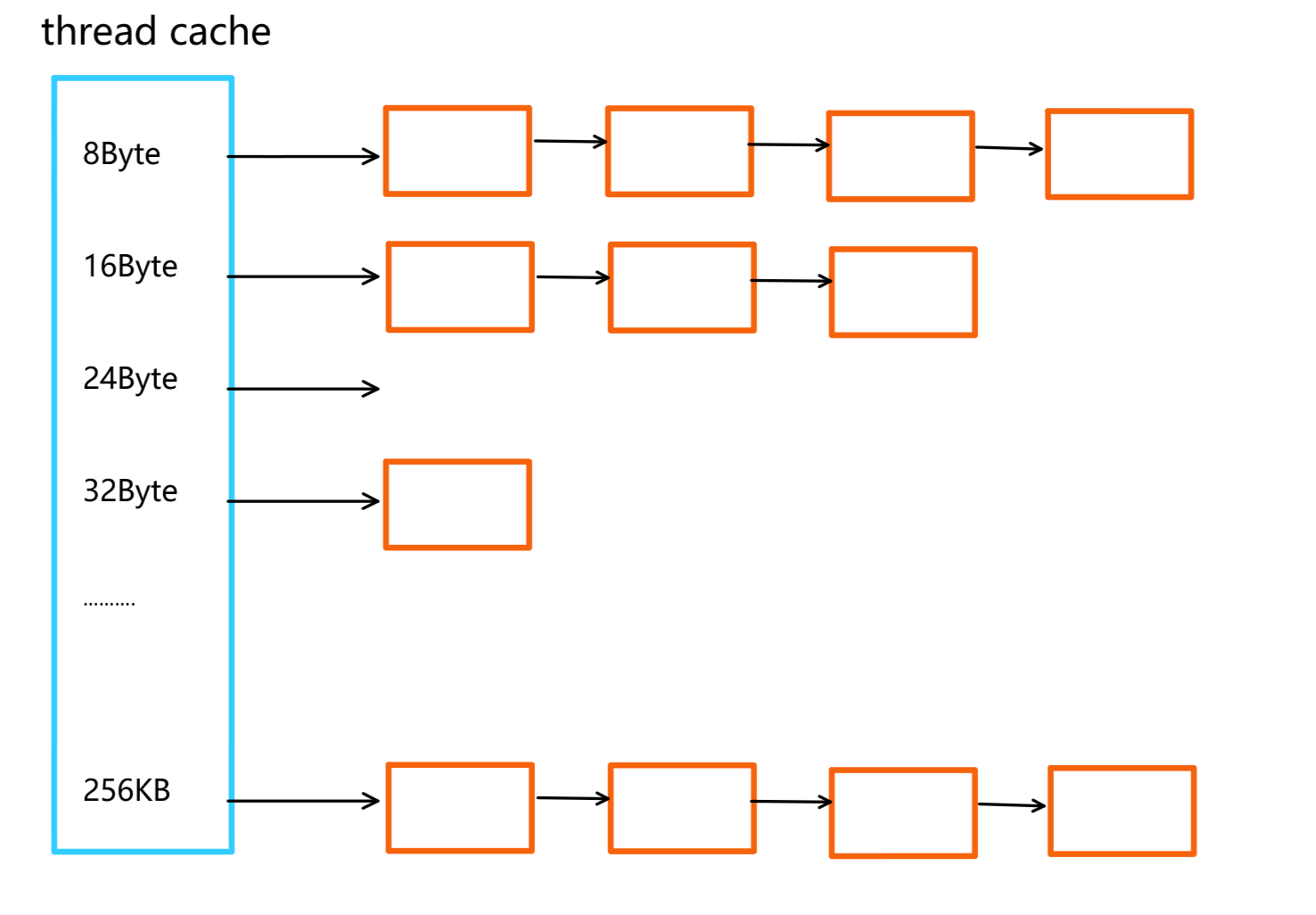
上面的方案,当申请一块大小为n的内存时,我们是无脑的按照8字节的对齐规则。
为了减少哈希桶的个数,对于申请的内存块大小n,我们可以根据n的范围,按照不同的内存对齐规则。n在某一个区间,采用这个区间的对齐规则。
对齐规则如下:
申请的空间大小 对齐规则
【1,128】 8Byte对齐
【128+1,1024】 16Byte对齐
【1024+1,8*1024】 128Byte对齐
【8*1024+1,64*1024】 1024Byte对齐
【64*1024+1,256*1024】 8*1024Byte对齐
申请的空间大小为n,n在[1,128]范围时,采用8字节对齐规则。在[128+1,1024]范围时采用16Byte对齐规则。 依次类推......
哈希桶个数的计算:
【1,128】,按照8字节对齐,需要的哈希桶个数128/8=16
【128+1,1024】,按照16字节对齐,需要的哈希桶个数(1024-128)/16=56
【1024+1,8*1024】,按照128字节对齐,需要的哈希桶个数(8*1024-1024)/128=56
【8*1024+1,64*1024】,按照1024字节对齐,需要的哈希桶个数(64*1024-8*1024)/1024=56
【64*1024+1,256*1024】,按照8*1024字节对齐,需要的哈希桶个数(256*1024-64*1024)/(8*1024)=24
综上一共需要16+56+56+56+24=208,只需要208个哈希桶。
这样设计的好处还有一个,就是可以将内存资源的浪费占比控制在10%左右。因为采取一定的对齐规则,就会不可避免的造成内碎片问题,产生内存资源浪费的问题。
浪费占比=浪费的字节数/实际申请的字节数
证明:
对于第一个哈希桶而言,浪费占比肯定很大,但是从第二个桶开始,可以将浪费占比控制在10%左右。
就比如对于【128+1,1024】区间,采用16字节对齐。假设现在想申请129的字节,按照16字节对齐规则,实际会分配144字节,此时会浪费15个字节,那么此时的浪费占比就是15/144=0.10416666,接近10%。
这种情况浪费的字节数是15,是最多的,同时申请的字节数是129,是这个区间最小的一个。意味着如果是其他情况,申请的字节数肯定更多(大于129),浪费的字节数肯定小于等于15,带到公式里就是分子变小,分母变大,那么结果会更小,所以可以将浪费占比控制在10%左右。
所以最终可以得到如下数据,这也就是我们的thread cache的设计规则:
申请的空间大小 对齐规则 对应的哈希桶
【1,128】 8Byte对齐 _freelist[0,16)
【128+1,1024】 16Byte对齐 _freelist[16,72)
【1024+1,8*1024】 128Byte对齐 _freelist[72,128)
【8*1024+1,64*1024】 1024Byte对齐 _freelist[128,184)
【64*1024+1,256*1024】 8*1024Byte对齐 _freelist[184,208)
2,内存对齐规则代码实现
了解到上述的内存对齐规则后,那么我们现在就需要实现两个方法。
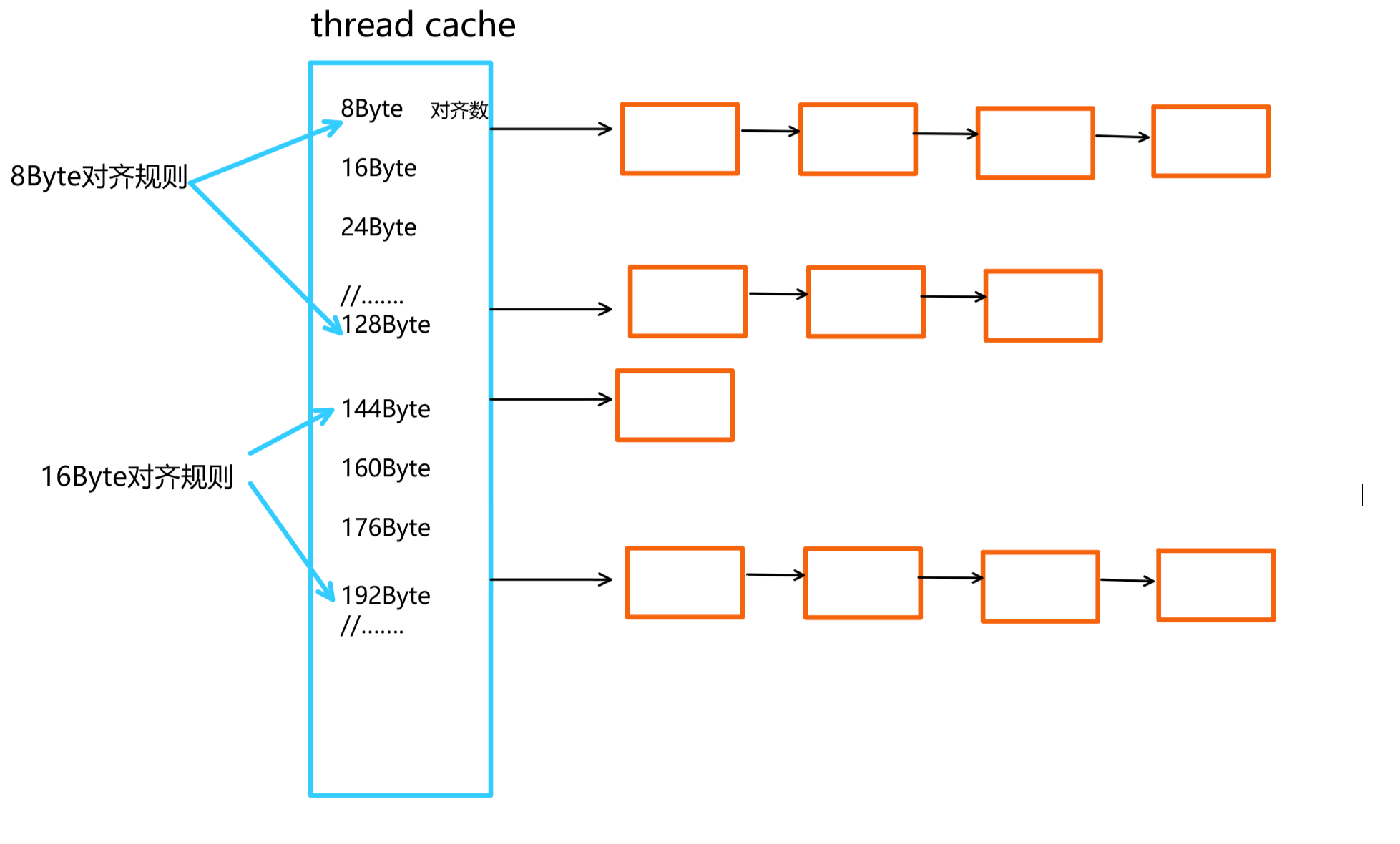
当申请size大小的内存时,我们需要知道该size大小对应的对齐数,以及对应是thread cache的第几个哈希桶。
注意:这里的对齐数不是上面讲的对齐规则。对齐数是实际对齐的字节数。比如我现在想申请大小为12字节的内存,对齐规则是8Byte,实际分配到的是16Byte,对齐数是16字节。以一张图搞定:
实现思路:

//计算对齐数以及第几个哈希桶
struct SizeClass
{//计算对齐数的辅助函数//第一个参数是申请内存的大小//第二个参数是对应的对齐规则static inline size_t _RoundUp(size_t bytes, size_t alginNum){return ((bytes + alginNum - 1) & ~(alginNum - 1));}//计算对齐数static size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if(size<=1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8*1024);}else{assert(false);return -1;}}//版本1 辅助函数//第二个参数是对齐规则//static inline size_t _Index(size_t bytes, size_t alginNum)//{// if (bytes % alginNum == 0)// {// //这里-1是因为下标从1开始// return bytes / alginNum - 1;// }// else// {// return bytes / alginNum;// }//}//版本2辅助函数//第二个参数是对齐规则的指数static inline size_t _Index(size_t bytes, size_t algin_shift){return ((bytes + (1 << algin_shift) - 1) >> algin_shift) - 1;}//计算对应的哈希桶//也就是计算在 _freelist中的下标//bytes为申请的字节数static size_t Index(size_t bytes){//每个区间有多少链(多少桶)//因为在对某一段区间进行计算的时候,求出对应是第几个桶后//我们求的是下标,需要加上前面区间的长度,所以需要记录前一个区间的长度static int group_array[4] = { 16,56,56,56};//第二个参数是对齐规则的指数if (bytes <= 128){//申请[1,128]字节时,对齐规则是8return _Index(bytes, 3);}else if (bytes <= 1024){return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024){return _Index(bytes - 1024, 7) + group_array[0] + group_array[1];}else if (bytes <= 64 * 1024){return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];}else if (bytes <= 156 * 1024){return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];}else{assert(false);return -1;}}
};3,申请空间Allocate代码
//申请空间
void* threadCache::Allocate(size_t size)
{//申请空间的上限是256KBassert(size <= MAX_BYTES);//计算对应的对齐数,以及哈希桶的下标size_t alginSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);//如果对应的哈希桶不为空,则直接从该部分获取if (!_freelists[index].Empty()){//头删即可return _freelists[index].pop();}else{//对应的哈希桶,需要向下一层申请Central Cache//这时候,就需要使用到对齐数alginSize//....return FetchMemoryFromCental(index, alginSize);}
}
释放内存,还给thread cache管理
//释放obj,大小为size
void threadCache::Deallocate(void* obj, size_t size)
{assert(obj);assert(size >0);//找到对应的自由链表,插入即可size_t index = SizeClass::Index(size);_freelists[index].push(obj);
}本节完!
相关文章:
:项目的整体框架以及Thread_Cache的结构设计)
高并发内存池(二):项目的整体框架以及Thread_Cache的结构设计
目录 前言 一,项目整体框架设计 二,thread cache结构设计 模拟定长内存池的设计思路 采用一定的对齐规则设计 thread cache大致框架 申请内存Allocate方法 1,thread cache 哈希桶的内存对齐规则 2,内存对齐规则代码实现 …...

K8S扩缩容及滚动更新和回滚
目录: 1、滚动更新1、定义Deployment配置2、应用更新 2、版本回滚1. 使用kubectl rollout undo命令 3、更新暂停与恢复1、暂停更新2、更新镜像(例如,使用kubectl set image命令)3、恢复更新 4、弹性扩缩容1、扩容命令2、缩容命令3…...

K8S - GitLab CI 自动化构建镜像入门
一、引言 在现代持续交付(CI/CD)体系中,容器镜像的自动化构建与推送已成为交付链条的重要一环。 GitLab CI/CD 作为 GitLab 平台的原生集成功能,提供了声明式、可扩展的流水线机制,使得开发者可以在代码生命周期内实…...

万兴PDF-PDFelement v11.4.13.3417
万兴PDF专家(Wondershare PDFelement)是一款国产PDF文档全方位解决方案.万兴PDF编辑器软件万兴PDF中文版,专注于PDF的创建,编辑,转换,签名,压缩,合并,比较等功能.万兴PDF专业版PDF编辑软件,以简约风格及强大的功能在国外名声大噪,除了传统功能外,还提供OCR扫描,表格识别,创建笔…...

4.2【LLaMA-Factory实战】金融财报分析系统:从数据到部署的全流程实践
【LLaMA-Factory实战】金融财报分析系统:从数据到部署的全流程实践 一、引言 在金融领域,财报分析是投资决策的核心环节。传统分析方法面临信息提取效率低、风险识别不全面等挑战。本文基于LLaMA-Factory框架,详细介绍如何构建一个专业的金…...

Vue Router 3 使用详解:从零构建嵌套路由页面
Vue Router 是 Vue.js 官方的路由管理器,常用于构建单页面应用(SPA)。本文将手把手带你完成 vue-router3.6.5 的基本配置,并实现一个带有嵌套路由的页面结构。本文适用于 Vue 2.x 项目 一、安装 vue-router3.6.5 npm install vue…...

ChatGPT深度研究功能革新:GitHub直连与强化微调
目录 一、ChatGPT深度研究功能迎来革命性更新 1.1 GitHub直连功能详解 1.2 强化微调(RTF)正式发布 二、GitHub直连功能深度体验 2.1 实际应用场景演示 2.2 技术实现原理探讨 三、强化微调技术解析 3.1 RTF技术核心优势 3.2 适用场景分析 四、开发者反馈与行业影响 4…...

【Ansible】模块详解
一、ansible概述 1.1 ansible介绍 Ansible 是一个基于 Python 开发的配置管理和应用部署工具,近年来在自动化管理领域表现突出。它集成了许多传统运维工具的优点,几乎可以实现 Pubbet 和 Saltstack 所具备的功能。 1.2 ansible能做什么 批量处理。An…...

深入理解C/C++内存管理:从基础到高级优化实践
一、内存区域划分与基础管理机制 栈(Stack) 栈由系统自动管理,用于存储函数调用时的局部变量、参数及返回地址。其特点是高效但空间有限(通常1-8MB),遵循后进先出(LIFO)…...

两台服务器之前共享文件夹
本文环境 服务器A:ubuntu24.22系统 IP:10.0.8.1 服务器B:ubuntu24.22系统 IP:10.0.8.10 本操作旨在将服务器B的/opt/files目录共享给服务器A得/opt/files 在 B 服务器上设置共享 安装 NFS 服务: sudo apt -y install nfs-kernel-server编辑/etc/exports文件&…...

stm32之USART
目录 1.引入1.1 通信接口1.2 串口 2.USART2.1 简介2.2 框图2.3 基本机构图2.4 数据帧2.5 波特率发生器2.6 数据包2.6.1 数据模式2.6.2 HEX数据包2.6.3 文本数据包2.6.4 HEX数据包接收2.6.5 文本数据包接收 3.结构体和相关API3.1 结构体3.2 API3.2.1 **初始化相关函数**void USA…...

使用 systemd 管理 Linux 服务:配置与自动重启指南
使用 systemd (推荐,适用于大多数 Linux 发行版) systemd 是现代 Linux 系统中最常用的服务管理器。它能可靠地管理进程,并在进程崩溃时自动重启。 创建 systemd 服务文件: 创建一个文件,例如 /etc/systemd/system/app.service…...

【计算机视觉】Car-Plate-Detection-OpenCV-TesseractOCR:车牌检测与识别
Car-Plate-Detection-OpenCV-TesseractOCR:车牌检测与识别技术深度解析 在计算机视觉领域,车牌检测与识别(License Plate Detection and Recognition, LPDR)是一个极具实用价值的研究方向,广泛应用于智能交通系统、安…...

《Spring Boot 3.0全新特性详解与实战案例》
大家好呀!今天让我们轻松掌握Spring Boot 3.0的所有新特性!🚀 📌 第一章:Spring Boot 3.0简介 1.1 什么是Spring Boot 3.0? Spring Boot 3.0就像是Java开发者的"超级工具箱"🧰&…...

二叉树的深度
二叉树的深度是指从根节点到叶子节点的最长路径上的节点数。 一、最大深度 104. 二叉树的最大深度 - 力扣(LeetCode) 最大深度是指从根节点到最远叶子节点的最长路径上的节点数。 //递归法 /*** Definition for a binary tree node.* public class T…...

科技创业园共享会议室线上预约及智能密码锁系统搭建指南
为科技创业园区的运营管理者,我深知高效利用会议室资源的重要性。2023年第三季度,我们园区启动会议室智能化改造项目,经过三个月的实践,成功将32间共享会议室升级为"线上预约智能门锁"管理模式。现将改造经验分享如下&a…...

自定义prometheus exporter实现监控阿里云RDS
# 自定义 Prometheus Exporter 实现多 RDS 数据采集## 背景1. Prometheus 官网提供的 MySQL Exporter 对于 MySQL 实例只能一个进程监控一个实例,数据库实例很多的情况下,不方便管理。 2. 内部有定制化监控需求,RDS 默认无法实现,…...
)
LeetCode 3342.到达最后一个房间的最少时间 II:dijkstra算法(和I一样)
【LetMeFly】3342.到达最后一个房间的最少时间 II:dijkstra算法(和I一样) 力扣题目链接:https://leetcode.cn/problems/find-minimum-time-to-reach-last-room-ii/ 有一个地窖,地窖中有 n x m 个房间,它们呈网格状排布。 给你一…...

iOS创建Certificate证书、制作p12证书流程
一、创建Certificates 1、第一步得先在苹果电脑上创建一个.certSigningRequest的文件。首先打开钥匙串,使用快捷键【command空格】——输入【钥匙串】回车(找不到就搜一下钥匙串访问使用手册) 2、然后在苹果电脑的左上角菜单栏选择【钥匙串…...
作为全基因组关联分析(GWAS)的表型,其生物学意义和应用价值)
特殊配合力(SCA)作为全基因组关联分析(GWAS)的表型,其生物学意义和应用价值
生物学意义 解析非加性遗传效应 特殊配合力(SCA)主要反映特定亲本组合的杂交优势,由非加性遗传效应(如显性、超显性、上位性)驱动。显性效应涉及等位基因间的显性互作,上位性效应则涉及不同位点间的基因互作。通过SCA-GWAS,可以定位调控这些非加性效应的关键基因组区域…...

Python实例题:Python快速获取斗图表情
目录 Python实例题 题目 python-get-meme-imagesPython 快速获取斗图表情脚本 代码解释 get_meme_images 函数: download_images 函数: 主程序: 运行思路 注意事项 Python实例题 题目 Python快速获取斗图表情 python-get-meme-im…...

探索表访问方法功能:顺序扫描分析
引言 在之前的文章中,我们讨论了 PostgreSQL 表访问方法 API 的基础知识以及堆元组(heap tuple)与元组表槽(Tuple Table Slot,简称 TTS)之间的区别。 本文将深入探讨 PostgreSQL 核心如何通过特定的 API …...
)
RISC-V CLINT、PLIC及芯来ECLIC中断机制分析 —— RISC-V中断机制(一)
在长期的嵌入式开发实践中,对中断机制的理解始终停留在表面层次,特别当开发者长期局限于纯软件抽象层面时,对中断机制的理解极易陷入"知其然而不知其所以然"的困境,这种认知的局限更为明显;随着工作需要不断…...

Idea Code Templates配置
Templates配置 配置位置模板案例 配置位置 Settings->Editor->File and Code Templates模板案例 #if (${PACKAGE_NAME} && ${PACKAGE_NAME} ! "")package ${PACKAGE_NAME};#endimport com.ktools.common.dataprocess.DataProcess; import com.ktools…...

fakebook
解题方法: 一.用御剑扫描后台,查看robot.txt文件,发现是一个/user.php.bak,备份文件,我们访问这个文件 <?phpclass UserInfo {public $name "";public $age 0;public $blog "";public function __co…...

英伟达Blackwell架构重构未来:AI算力革命背后的技术逻辑与产业变革
——从芯片暴力美学到分布式智能体网络,解析英伟达如何定义AI基础设施新范式 开篇:当算力成为“新石油”,英伟达的“炼油厂”如何升级? 2025年3月,英伟达GTC大会上,黄仁勋身披标志性皮衣,宣布了…...

用 Rust 搭建一个优雅的多线程服务器:从零开始的详细指南
嘿,小伙伴们!今天咱们来聊聊怎么用 Rust 搭建一个牛气哄哄的多线程服务器,还能在需要的时候优雅地关机。为啥要用 Rust 呢?因为 Rust 是个超级靠谱的语言,它能保证内存安全,写并发代码的时候不用担心那些让…...

今日行情明日机会——20250509
上证指数今天缩量,整体跌多涨少,走势处于日线短期的高位~ 深证指数今天缩量小级别震荡,大盘股表现更好~ 2025年5月9日涨停股主要行业方向分析 一、核心主线方向 服装家纺(消费复苏出口链驱动) • 涨停家数…...
:HTTP开发实践)
ESP32开发入门(七):HTTP开发实践
一、HTTP协议基础 1.1 什么是HTTP? HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最为广泛的一种网络协议,用于从服务器传输超文本到本地浏览器。它是一种无状态的请求/响应协议,工作…...

【强化学习】强化学习算法 - 马尔可夫决策过程
马尔可夫决策过程 (Markov Decision Process, MDP) 1. MDP 原理介绍 马尔可夫决策过程 (MDP) 是强化学习 (Reinforcement Learning, RL) 中用于对序贯决策 (Sequential Decision Making) 问题进行数学建模的标准框架。它描述了一个智能体 (Agent) 与环境 (Environment) 交互的…...
】)
数据结构【二叉搜索树(BST)】
二叉搜索树 1. 二叉搜索树的概念2. 二叉搜索树的性能分析3.二叉搜索树的插入4. 二叉搜索树的查找5. 二叉搜索树的删除6.二叉搜索树的实现代码7. 二叉搜索树key和key/value使用场景7.1 key搜索场景:7.2 key/value搜索场景: 1. 二叉搜索树的概念 二叉搜索…...

振动临近失效状态,怎么频谱会是梳子?
这是一个破坏性试验的终末期振动波形。左边时域,右边频域。这是咋回事,时域看起来原本很正常的冲击信号,怎么频域是那个鬼样子。 同一组波形,放大后的频域 - 低频部分: 一个解释:...

橡胶制品行业质检管理的痛点 质检LIMS如何重构橡胶制品质检价值链
橡胶制品广泛应用于汽车、医疗、航空等领域,其性能稳定性直接关联终端产品的安全性。从轮胎耐磨性测试到密封件耐腐蚀性验证,每一项检测数据都是企业参与市场竞争的核心筹码。然而,传统实验室管理模式普遍面临设备调度混乱、检测流程追溯断层…...

【CTFSHOW_Web入门】命令执行
文章目录 命令执行web29web30web31web32web33web34web35web36web37web38web39web40web41web42web43web44web45web46web47web48web49web50web51web52web53web54web55web56web57web58web59web60web61web62web63web64web65web66web67web68web69web70web71web72web73web74web75web7…...

三维底座+智能应用,重构城市治理未来
在“数字中国”战略的引领下,住房和城乡建设领域正迎来一场深刻的数字化转型浪潮。2024年《“数字住建”建设整体布局规划》的发布,明确提出以“CIM”(城市信息模型)为核心,构建城市三维数字底座,推动住建行…...

养生:塑造健康生活的良方
养生是一场贯穿生活的自我关爱行动,从饮食、运动、睡眠到心态调节,每一个环节都对健康有着深远影响。以下为你带来全面且实用的养生策略。 饮食养生:科学搭配,呵护肠胃 合理规划三餐,遵循 “早营养、午均衡、晚清淡”…...
)
docker 镜像的导出和导入(导出完整镜像和导出容器快照)
一、导出原始镜像 1. 使用 docker save 导出完整镜像 适用场景:保留镜像的所有层、元数据、标签和历史记录,适合迁移或备份完整镜像环境。 操作命令 docker save -o <导出文件名.tar> <镜像名:标签>示例:docker save -o milvu…...

NestJS 框架深度解析
框架功能分析 NestJS 是一个基于 Node.js 的渐进式框架,专为构建高效、可扩展的服务器端应用程序而设计。其核心理念结合了 面向对象编程(OOP)、函数式编程(FP) 和 函数式响应式编程(FRP)&…...

游戏引擎学习第267天:为每个元素添加裁剪矩形
仓库已满:https://gitee.com/mrxiao_com/2d_game_6 新仓库:https://gitee.com/mrxiao_com/2d_game_7 回顾并为今天的内容定下基调 我们今天的主要目标是对游戏的调试“Top List”进行改进,也就是用来显示游戏中耗时最多的函数或模块的性能分析列表。昨天我们已经实…...

基于阿里云DataWorks的物流履约时效离线分析
基于阿里云DataWorks的物流履约时效离线分析2. 数仓模型构建 ORC和Parquet区别: 压缩率与查询性能 压缩率 ORC通常压缩率更高,文件体积更小,适合存储成本敏感的场景。 Parquet因支持更灵活的嵌套结构,压缩率略…...

web 自动化之 selenium 元素四大操作三大切换等待
文章目录 一、元素的四大操作二、三大切换&等待1、切换窗口:当定位的元素不在当前窗口,则需要切换窗口2、切换iframe:当定位的元素在frame/iframe,则需要切换 一、元素的四大操作 1、输入 2、点击 3、获取文本 4、获取属性 import time…...

前端取经路——性能优化:唐僧的九道心经
大家好,我是老十三,一名前端开发工程师。性能优化如同唐僧的九道心经,是前端修行的精髓所在。在本文中,我将为你揭示从网络传输到渲染优化的九大关键技术,涵盖HTTP协议、资源加载策略、缓存控制等核心难题。通过这些实…...

前端工程化和性能优化问题详解
选自己熟悉的内容当作重难点,最好是前端相关的 以下是面向前端面试官介绍前端工程化和性能优化问题的结构化回答框架,结合行业标准和实战经验进行整合: 一、前端工程化核心解析 定义与目标 前端工程化是通过工具链和规范化流程,将…...

【应急响应】- 日志流量如何分析?
【应急响应】- 日志流量如何下手?https://mp.weixin.qq.com/s/dKl8ZLZ0wjuqUezKo4eUSQ...

8b10b编解码仿真
一、基本概念 8B/10B编码(8-bit to 10-bit encoding)是一种将8位数据(包括数据字符和控制字符)转换为10位符号(Symbol)的编码技术,由IBM工程师Al Widmer和Peter Franaszek于1983年提出。其核心思…...

软件工程之面向对象分析深度解析
前文基础: 1.软件工程学概述:软件工程学概述-CSDN博客 2.软件过程深度解析:软件过程深度解析-CSDN博客 3.软件工程之需求分析涉及的图与工具:软件工程之需求分析涉及的图与工具-CSDN博客 4.软件工程之形式化说明技术深度解…...

常见标签语言的对比
XML、JSON 和 YAML 是常见的数据序列化格式 相同点 结构化数据表示 三者均支持嵌套结构,能描述复杂的数据层级关系(如对象、数组、键值对)。跨平台兼容性 均为纯文本格式,可被多种编程语言解析,适用于跨系统数据交换…...
)
【Linux】环境变量(图文)
目录 一、main函数的参数解释: 1、argc和argc的解释 2、为什么要这样设置? 3、注意: 4、命令行计算器: 二、认识环境变量 三、见见环境变量 1、执行一个程序的前提 2、指令:echo $PATH 3、为什么系统自带的指令…...

基于OpenCV的人脸识别:EigenFaces算法
文章目录 引言一、概述二、代码解析1. 准备工作2. 加载训练图像3. 设置标签4. 准备测试图像5. 创建和训练识别器6. 进行预测7. 显示结果 三、代码要点总结 引言 人脸识别是计算机视觉领域的一个重要应用,今天我将通过一个实际案例来展示如何使用OpenCV中的EigenFac…...

跟我学C++中级篇——STL容器的查找对比
一、C标准库的查找 在C的STL中,对容器或相关序列的查找中,有两种方式,一种是std::find,另外一种是std::search。而且在它们的基础上,还衍生出std::find_if、std::find_if_not、std::find_end等和std::search_n、range…...