pyorch中tensor的理解与操作(一)
tensor 是PyTorch 中一个最基本的数据集合类型, 本文注意针对该结构类型,说明它的存储方式以及主要的操作方法。
tensor其实是一个多维数组(元素的数据类型需一致),类似于 NumPy 的 ndarrays,但可以在 GPU 上运行。张量的维数可以是0,1…,因此这里的张量的意义也包含了数学上的标量(即维度0)、向量(即维度1)、矩阵(即维度2)。
【注】本文示例适用于pytorch2+。
1.内部数据存储理解
在了解tensor的各种方法以前,最好能理解它内部数据的存储方式,这样能更好得理解它的各种行为。
大致上,tensor由meta区和data区两部分构成,meta区保存着tensor的各种信息,如形状(shape)、数据类型(type),底层存储类(Storage)等,底层存储类管理真正的数据存储区。元素有两种存储方式:sparse和dense,sparse用于特殊场景,一般是dense non-overlapping,也就是通常意义下的“逐个元素”存储,存储区是一块内存区域(大小为总元素个数*元素大小)。
数据区保存数据,如何“解释”这些数据,由meta区的信息决定,这是tensor的运作方式。在这种结构下,tensor具有如下性质:
- 如果tensor的shape,stride不同,即使大小相同的存储区域,也可以被“解释”成不同的维度。
- 如果两个tensor的具有相同的数据区,则这两个tensor共享相同的数据,即使它们 “看上去”不同。
- 从时间成本上说,修改或复制meta区的内容比较低,而复制数据区内容则比较高,如果要关注效率,应注意哪些操作复制了数据。
从下面几个方法可以判断两个tensor数据区的“状态”:
- tensor.is_set_to(anothertensor)为true时表明这两个tensor完全一致,共享全部数据
- tensor.data_ptr() 返回底层的存储区指针,此指针相等可以来判断两个tensor数据区相同(反过来不一定成立,即如果一个内存区包含另一个内存区,即使二者不同,数据也是共享的)。
- tensor. untyped_storage()返回底层存储类,通过id操作符来判断两个tensor是否共享底层存储类(如果是则意味着有相同存储区)。
- tensor.equal仅从shape和数据的值来 判断两个tensor是否相等,而不管它们是否是共享数据。
meta区由两个关键属性shape和stride决定存储区数据的“解释”方式。Shape比较好理解,就是各维度大小(各维度下元素的个数,其乘积是总存储区大小)。Stride是各维度下相邻元素的间隔。
例如,假设存储区共24个数,从1到24,shape为(2,3,4),stride为(12,4,1)。从shape角度看(从后到前),每4个元素组成“末级块”,3个“末级块”组成“次末级块”,依次类推;从stride角度看(从后到前),“末级块”中相邻元素的间隔为1,“次末级块”相邻元素的间隔为4,依次类推,如下图所示。
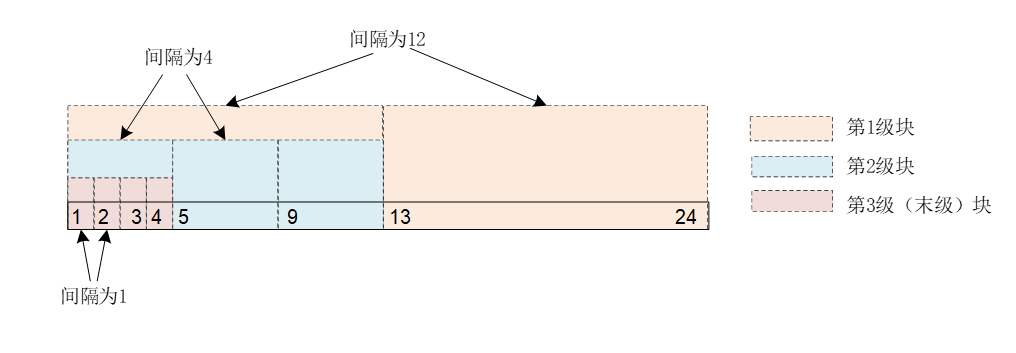
注意,上面示例中,数据是按“行连续”放置(C/C++中数组存放模式,行优先),显而易见,此时shape和stride可以相互推导,且stride呈递减排列,上级是下级的整数倍。然而,某些操作会使数据变得“不连续”,例如transpose(转置),从tensor.is_contiguous()可以返回数据是否按“行连续”放置状态,如果此状态为假,shape和stride变得不能相互推导。
同样对上例,执行
anothertensor=torch.transpose(tensor,1,2)
print(anothertensor.data_ptr(), tensor.data_ptr()
print(anothertensor.shape(), tensor.shape())
print(anothertensor.stride(), tensor.stride())从运行结果,可以看到tensor和anothertensor的数据是共享的,tensor是按“行连续”的,而antothertensor则不是,另外,转置后,shape和stride的第2维与3维交换了,变成shape(2,4,3)和stride(12,1,4),同样可以采用上面的方法进行示意,如下图所示。
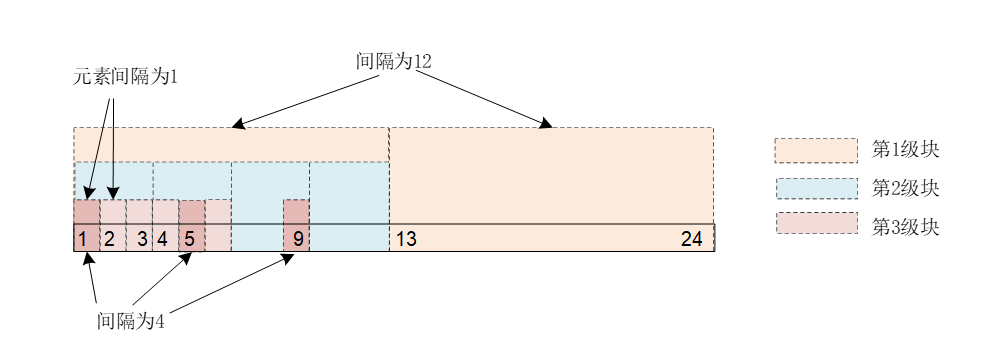
最内层的数据之间间隔为4,由3个数组成,即为[1,5,9],次内层的第2个元素与上个元素的间隔是1,即将第1个元素[1,4,9]中每个整体后移1个间隔,即为[2,6,10],次内层第2个元素为[3,7,11],其余类推。如果按“行连续”,与shape(2,4,3)对应的stride为(12,3,1),显然,按“行连续”与“非行连续”展示存储区的数据,结果是不一样的。
因此,如果数据按“行连续”,根据shape或stride都可以展示数据,如果“不连续”,则要根据shape和stride展示数据。
最后,稍微说一下memory_format,它是tensor.is_contiguous的参数,实际上,tensor.is_contiguous是检查tensor的数据放置模式是否与memory_format一致,缺省时memory_format=torch.contiguous_format,也就是检查是否按行连续。memory_format有4个选项值:
- torch.contiguous_format:也就是通常的按行连续(C语言数组存放模式)
- torch.channels_last: 专门针对“2d图像”数据(4个维度),stride按NHWC顺序。
- torch.channels_last_3d: 专门针对“视频图像”数据(5个维度)stride按NDHWC顺序。
- torch.preserve_format:如果torch.contiguous_format,则不发生变化,否则遵循torch.contiguous_format方式。
其中N:batch,D:Time,H:height,W:width,C:channel
一般情况下,pytorch中图像的存储方式是CHW,其stride为(H*W,W,1),HWC方式与bmp文件格式类似,CHW与HWC如下图所示,HWC的stride为(1,3*W,3),以上假设C=3。
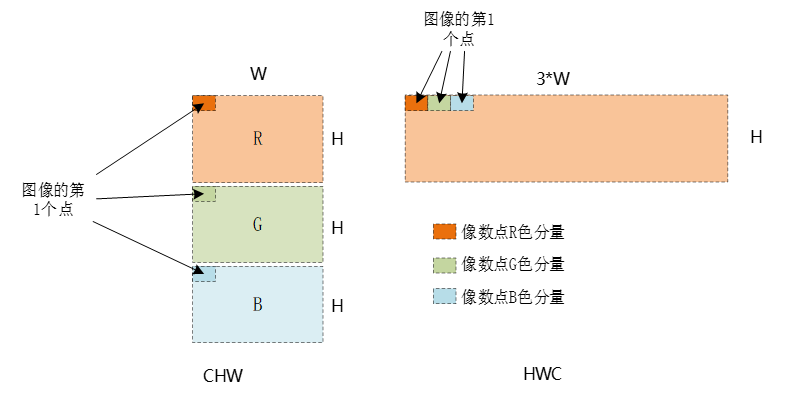
channels_last与channels_last_3d都是针对图像训练数据的,目的是提高运行速度(pytorch,tensorflow都引用了XNNPACK,一个开源的高效的神经网络库,而XNNPACK采用channels_last格式数据)。关于channel_last存储模式,可参考https://pytorch.org/blog/tensor-memory-format-matters/,以及内存模式中数据的表达,可参考https://oneapi-src.github.io/oneDNN/dev_guide_understanding_memory_formats.html
2.tensor的创建
tensor有很多种创建方式,包括创建+不初始元素,创建+按特定方式初始化化元素,从python的list或numpy的narray转换创建等。以下是一些示例。
tensor1 = torch.tensor([[[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]]) #接受从list或tuple的内容创建,1*3*5
tensor2 = torch.Tensor([[[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]]) #接受从list或tuple的内容创建,1*3*5
tensor3 = torch.Tensor(1,3,5) #也接受维度信息,元素随机值,1*3*5,tensor不行
tensor4=torch.tensor(2) #其实是一个标量,0维,值为2,shape为torch.Size([])
tensor5=torch.FloatTensor(2) #1维向量,2个(随机)值tensor6 =torch.empty ((2,3)) # 2*3的矩阵,第1个参数为*size,因而也可写[2,3],或2,3,下同
tensor7 = torch.full((2,3),2) #2*3矩阵,元素都填充为2
tensor8 = torch.ones((2,3)) #相当于full((2,3),1)
tensor9 = torch.zeros ((2,3)) #相当于full((2,3],0)
tensor10= torch.eye(3,2) #创建3*2矩阵,其中包含的2*2方阵为单位阵,不支持3维及以上
tensor11 =torch.rand/randn (2,3) #2*3矩阵,从[0-1]平均/标准正态分布中随机选取数据填充元素tensor12 =torch.as_tensor(anothorarray)
tensor13 =torch.from_numpy(ndarray)
tensor14 = torch.linspace(1,16,16).view(2,4,2) #创建一个数值线性增长(1-16)的2*4*2的Tensor
tensor15 =torch.empty_like /rand_like(anothertensor) / # 与anothertensor的维度相同
tensor16= torch.zeros([2,3],dtype=torch.float64,device=torch.device('cuda:0')) #指定类型和设备在创建过程中,如果tensor的数据来自其它数据源,则应注意tensor数据与这个“数据源”的关系,即这两者的数据是共享还是各自独立。例如,
- tensor1的传入参数是数组,tensor会以“copy”方式创建,二者独立; 注:以torch.tensor()方式创建的tensor总是以“copy”方式创建。
- 采用as_tensor方法,情况比较复杂,首先尝试采用共享,不行的话采用”copy”。
- from_numpy创建的tensor与numpy共享数据。
从已有Tensor创建相同的Tensor有几个方法:
tensor =torch.clone(anothertensor) 或 tensor =anothertensor.clone()
tensor.copy_(anothertensor) 或 tensor = torch.empty_like(anothertensor).copy_( anothertensor)
tensor = anothertensor.detach()clone创建的tensor与源tensor不共享data数据,需要注意,clone被当作一种“运算”(就如同Atensor=Btensor+Ctensor中“+”一样),因而clone的tensor与源tensor通过“计算图”关联(clone的tensor是源tensor某种运算的结果),在反向传播计算时,clone的tensor结果会累积到是源tensor。简单说,就是clone的tensor与源tensor数据独立,反向梯度计算有联系。(关于计算图,参阅下面内容)
copy_在使用之前,tensor需要先创建(第1个示例表示前面已创建,第2个示例中采用了torch.empty_like),然后从anothertensor中“copy”数据,tensor与anothertensor的总数据个数必须一致,但各维度可以不同,它们在操作完成后不再有任何关系。
detach的功能与clone正好相对,detach的tensor与源tensor共享数据,但detach不是一种“运算”,因而二者在反向梯度计算中没有关系,并且detach的tensor会设置其requires_grad为False。
2.tensor信息
创建tensor后或在尤其在调试中,经常需要查看tensor的结构信息,以下是一个查看tenso的信息的方法:
def tensor_info(t):if not isinstance(t,torch.Tensor):return f"not a tensor object:{type(t)}"device=t.device # cpudtype =t.dtypeshape =t.shape # 尺寸ndim =t.ndim #维度nbytes= t.nbytes if hasattr(t,"nbytes") else None # this attribute doesnot exist in low versions itemsize=t.element_size()itemcount=t.nelement() #element count totallyreturn f"device={device}, dtype={dtype}, shape={shape}, ndim={ndim}, nbytes={nbytes}, itemsize={itemsize}, count={itemcount}";特别说明的是tensor的维度信息,有下面两个方法:tensor.size()和tensor.shape,它们返回的是同一个类型torch.Size,注意前者是类的函数,后者是类的属性,如果需要某一维度的大小(示例是第2个维度),调用方法如下:
tensor.size()[1]
tensor.shape[1]相关文章:
)
pyorch中tensor的理解与操作(一)
tensor 是PyTorch 中一个最基本的数据集合类型, 本文注意针对该结构类型,说明它的存储方式以及主要的操作方法。 tensor其实是一个多维数组(元素的数据类型需一致),类似于 NumPy 的 ndarrays,但可以在 GPU …...

用react实现一个简单的三页应用
下面是一个使用 React Router 的简单示例,演示了如何在 React 应用中实现页面之间的导航。 🛠️ 第一步:使用 Vite 创建项目 npm create vitelatest my-router-app -- --template react cd my-router-app npm install🚀 第二步&a…...

OCCT中的布尔运算
OCCT 中的布尔运算是其几何建模的核心功能之一,主要用于实体的合并、切割和相交操作。以下是详细介绍及经典示例程序: 一、OCCT布尔运算的核心类 OCCT 通过 BRepAlgoAPI 命名空间下的类实现布尔运算,主要包括: BRepAlgoAPI_Fus…...

SpringBoot的自动配置和起步依赖原理
关于Spring Boot的自动配置和起步依赖,我想结合最新的实现机制来展开说明。先说自动配置——这是Spring Boot最核心的"约定优于配置"思想的落地体现。举个例子,当我们创建一个新的Spring Boot项目时,只要在pom.xml里添加了spring-b…...

沃伦森电气高压动态无功补偿装置助力企业电能优化
在工业生产的复杂电能环境中,电能质量直接影响企业的生产效率和运营成本。XX光伏科技有限公司作为一家快速发展的制造企业,随着生产规模的不断扩大,其内部电网面临功率因数过低、电压波动频繁等问题,导致供电部门罚款增加、设备故…...

VUE——自定义指令
Vue自定义指令概述 Vue自定义指令可以封装一些 dom 操作,扩展额外功能。它们允许开发者直接对DOM元素进行低层次操作,自定义指令可以响应Vue的响应式系统,从而在数据变化时触发相应的DOM更新。 自定义指令语法 自定义指令的常用钩子函数&am…...

Redis协议与异步方式
1.redis pipeline 通过一次发送多次请求命令,为了减少网络传输时间。 注意:pipeline 不具备事务性。 2.redis 事务 事务:用户定义一系列数据库操作,这些操作视为一个完整的逻辑处理工作单元,要么全部执行,…...

systemd vs crontab:Linux 自动化运行系统的全面对比
在 Linux 系统运维和开发中,任务调度与服务管理 是不可或缺的一环。无论是定期备份、日志轮转,还是启动后台服务,自动化机制都能极大地提高系统的可靠性与效率。两种最常用的自动化工具是: crontab:传统的基于时间的任…...

Centos离线安装mysql、redis、nginx等工具缺乏层层依赖的解决方案
Centos离线安装mysql、redis、nginx等工具缺乏层层依赖的解决方案 引困境yum-utils破局 引 前段时间,有个项目有边缘部署的需求,一台没有的外网的Centos系统服务器,需要先安装jdk,node,mysql,reids…...

观测云:安全、可信赖的监控观测云服务
引言 近日,“TikTok 遭欧盟隐私监管机构调查并处以 5.3 亿欧元”一案,再次引发行业内对数据合规等话题的热议。据了解,仅 2023 年一年就产生了超过 20 亿美元的 GDPR 罚单。这凸显了在全球化背景下,企业在数据隐私保护方面所面临…...

el-table计算表头列宽,不换行显示
1、在utils.js中封装renderHeader方法 2、在el-table-column中引入: 3、页面展示:...

多智能体学习CAMEL-调用api
可选模型范围 在ModelScope中的模型库中选择推理 API-Inference ,里面的模型都可以选择,我们可以体验到最新的使用DeepSeek-R1数据蒸馏出的Llama-70B模型。 1.2.2 使用API调用模型 这里我们使用CAMEL中的ChatAgent模块来简单调用一下模型,…...

奥威BI:AI+BI深度融合,重塑智能AI数据分析新标杆
在数字化浪潮席卷全球的今天,企业正面临着前所未有的数据挑战与机遇。如何高效、精准地挖掘数据价值,已成为推动业务增长、提升竞争力的核心议题。奥威BI,作为智能AI数据分析领域的领军者,凭借其创新的AIBI融合模式,正…...

SM2Utils NoSuchMethodError: org.bouncycastle.math.ec.ECFieldElement$Fp.<init
1,报错图示 2,报错原因: NoSuchMethodError 表示运行时找不到某个方法,通常是编译时依赖的库版本与运行时使用的库版本不一致。 错误中的 ECFieldElement$Fp. 构造函数参数为 (BigInteger, BigInteger),说明代码期望使…...

Spring Boot 中 MongoDB @DBRef注解适用什么场景?
在 Spring Boot 中使用 MongoDB 时,DBRef 注解提供了一种在不同集合(collections)的文档之间建立引用关系(类似于关系型数据库中的外键)的方式。它允许你将一个文档的引用存储在另一个文档中,并在查询时自动…...

PDF生成模块开发经验分享
在日常的项目开发中,PDF文档的生成是一个常见的需求。无论是用于申报单、审批结果通知书还是其他业务相关的文档输出,一个高效且灵活的PDF生成功能都是不可或缺的。本文将基于我使用Java(Spring Boot)和iText库开发PDF生成模块的经…...

Music AI Sandbox:打开你的创作新世界
AI 和音乐人的碰撞 其实,Google 早在 2016 年就启动了一个叫 Magenta 的项目,目标是探索 AI 在音乐和艺术创作上的可能性。一路走来,他们和各种音乐人合作,终于在 2023 年整出了这个 Music AI Sandbox,并且通过 YouTub…...

RISC-V入门资料
以下是获取 RISC-V 相关资料的权威渠道和推荐资源,涵盖技术文档、开发工具、社区支持等: 1. 官方资料 RISC-V 国际基金会官网 https://riscv.org 核心文档:ISA 规范(包括基础指令集(RV32I/RV64I)、扩展指令…...

私服与外挂:刑事法律风险的深度剖析
首席数据官高鹏律师团队编著 在当今数字化时代,网络游戏产业蓬勃发展,然而与之相伴的私服与外挂现象却屡禁不止,且其背后隐藏着严重的刑事法律风险。作为一名律师,有必要在此对私服与外挂相关的刑事问题进行深入解读,以…...
)
sherpa-ncnn:Endpointing(断句规则)
更多内容:XiaoJ的知识星球 目录 1. Endpointing (端点)1.1 规则11.2 规则21.3 规则3 1. Endpointing (端点) 我们有三条端点检测规则。如果激活了其中任何一个,我们假设检测到终端节点。 . 1.1 规则1 规则 1 计算尾随静默的持续时间。如果大于用户指…...

谷云科技iPaaS技术实践:集成平台如何解决库存不准等问题
在当今竞争激烈的商业环境中,电商平台、仓库系统以及门店系统之间的数据不同步问题,如同一颗隐形的 “定时炸弹”,严重威胁着企业的生存与发展。尤其是在库存管理方面,订单系统显示商品已售出,但仓库却无货可发&#x…...
NGINX)
负载均衡算法解析(一)NGINX
文章目录 1. 核心数据结构:算法的基石1.1 负载均衡节点结构:定义服务器实体1.2 关键概念阐述:权重 (Weight) 2. NGINX加权轮询算法旨在解决的具体问题深度分析2.1 应对后端服务器间的负载不均衡问题2.2 后端服务健康状态的动态感知与自适应调…...
——3.3使用广播信道的数据链路层)
计算机网络笔记(十六)——3.3使用广播信道的数据链路层
3.3.1局域网的数据链路层 一、核心逻辑架构(拓扑结构演变) 二、MAC层核心机制 MAC地址结构 以太网帧格式 CSMA/CD工作机制流程 三、关键功能对比表 功能集线器(Hub)交换机(Switch)网桥(Bridge)工作层级物理层数据链路层数据链路层冲突域处理全广播&…...

STM32-模电
目录 一、MOS管 二、二极管 三、IGBT 四、运算放大器 五、推挽、开漏、上拉电阻 一、MOS管 1. MOS简介 这里以nmos管为例,注意箭头方向。G门极/栅极,D漏极,S源极。 当给G通高电平时,灯泡点亮,给G通低电平时&a…...

单片机 + 图像处理芯片 + TFT彩屏 指示灯控件
指示灯控件使用说明 简介 这是一个基于单片机 RA8889/RA6809图形处理芯片的指示灯的控件库,用于在TFT显示屏上显示各种状态的指示灯。该控件支持多种状态显示,包括正常、警告、错误和停止等状态,并支持自定义标签显示。 功能特点 支持多…...

73页最佳实践PPT《DeepSeek自学手册-从理论模型训练到实践模型应用》
这份文档是一份关于 DeepSeek 自学手册的详细指南,涵盖了 DeepSeek V3 和 R1 模型的架构、训练方法、性能表现以及使用技巧等内容。它介绍了 DeepSeek V3 作为强大的 MoE 语言模型在数学、代码等任务上的出色表现以及其训练过程中的创新架构如多头潜在注意力和多 To…...
)
Python自动化-python基础(上)
一.魔法方法 在 Python 中,魔法方法(Magic Methods)是一类特殊的方法,以双下划线 __ 开头和结尾 ,它们在特定的场景下会被 Python 解释器自动调用,用于实现一些内置的操作行为。 1. 初始化与构造相关 __…...

mysql数据库体验
目录 数据库简介 使用数据库 数据库的基本概念 数据 数据库和数据库表 数据库管理系统和数据库系统 数据库系统发展史 经典数据库 网状模型 层次模型 关系模型 当今主流数据库介绍 关系数据库 非关系型库的基本概念 关系数据库的基本结构 主键与外键 主键 外…...

Python开发系统
以下是一个基于Python和OpenCV的简单图像检测系统开发示例,包含目标检测、颜色检测和边缘检测功能: 一、环境搭建 1. 安装依赖 pip install opencv-python numpy matplotlib 2. 准备测试图片 下载示例图片或使用本地图片(如 test.jpg &…...

架空输电线巡检机器人轨迹优化设计
架空输电线巡检机器人轨迹优化 摘要 本论文针对架空输电线巡检机器人的轨迹优化问题展开研究,综合考虑输电线复杂环境、机器人运动特性及巡检任务需求,结合路径规划算法、智能优化算法与机器人动力学约束,构建了多目标轨迹优化模型。通过改进遗传算法与模拟退火算法,有效…...

针对共享内存和上述windows消息机制 在C++ 和qt之间的案例 进行详细举例说明
针对共享内存和上述windows消息机制 在C++ 和qt之间的案例 进行详细举例说明 以下是关于在 C++ 和 Qt 中使用共享内存(QSharedMemory)和 Windows 消息机制(SendMessage / PostMessage)进行跨线程或跨进程通信的详细示例。 🧩 使用 QSharedMemory 进行进程间通信(Qt 示例…...

cursor平替,试试 vscode+cline+openrouter 的方案,还能自定义 mcp-server 教程大纲
一、引言 cursor 工具使用成本高的现状 编程agent好用,解放劳动力,但费用贵 vscodeclineopenrouter Cline 是一款可集成在 IDE 中的 AI 编程助手,支持 OpenAI 和 Ollama 等多种模型,能在 IDE 里自主完成复杂编程任务,…...

Qt实现车载多媒体项目,包含天气、音乐、视频、地图、五子棋功能模块,免费下载源文件!
本文主要介绍项目,项目的结构,项目如何配置,项目如何打包。这篇文章如果对你有帮助请点赞和收藏,谢谢!源代码仅供学习使用,如果转载文章请标明出处!(免费下载源代码)&…...

C++ set替换vector进行优化
文章目录 demo代码解释: 底层原理1. 二叉搜索树基础2. 红黑树的特性3. std::set 基于红黑树的实现优势4. 插入操作5. 删除操作6. 查找操作 demo #include <iostream> #include <set>int main() {// 创建一个存储整数的std::setstd::set<int> myS…...
)
Android学习总结之算法篇八(二叉树和数组)
路径总和 import java.util.ArrayList; import java.util.List;// 定义二叉树节点类 class TreeNode {int val;TreeNode left;TreeNode right;// 构造函数,用于初始化节点值TreeNode(int x) {val x;} }public class PathSumProblems {// 路径总和 I:判…...

正点原子IMX6U开发板移植Qt时出现乱码
移植Qt时出现乱码 1、前言2、问题3、总结 1、前言 记录一下正点原子IMX6U开发板移植Qt时出现乱码的解决方法,方便自己日后回顾,也可以给有需要的人提供帮助。 2、问题 用正点原子IMX6U开发板移植Qt时移植Qt后,sd卡里已经存储了Qt的各种库&…...

算法解密:轮转数组问题全解析
算法解密:轮转数组问题全解析 一、引言 在算法的世界里,数组的操作问题常常考验着我们对数据结构和算法技巧的掌握程度。“轮转数组”问题就是其中一个经典且有趣的题目。它看似简单,却蕴含着多种巧妙的解法。通过深入研究这个问题,我们能更好地理解数组的特性,提升算法思…...

正则化和L1/L2范式
1. 背景与引入 历史与位置 正则化(Regularization)是机器学习中控制模型复杂度、提升泛化能力的核心手段之一。 L2范式(Ridge正则化)最早可追溯至20世纪70年代的Tikhonov正则化,用于解决病态线性方程组问题…...

day05_java中常见的运算符
对字面量或者变量进行操作的符号就是运算符。用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式。 java中常用的运算符有下面几种 算术运算符 代码示例 public class Demo01Operator {public static void main(String[] args) {int a 3;int b 4;System.o…...

Linux_进程退出与进程等待
一、进程退出 退出场景 正常终止:代码执行完毕且结果符合预期(退出码为 0)。异常终止:运行结果错误(退出码非 0)或进程被信号强制终止。(如 SIGINT 或 SIGSEGV)。 退…...
整合配置的详细步骤)
SSM框架(Spring + Spring MVC + MyBatis)整合配置的详细步骤
以下是 SSM框架(Spring Spring MVC MyBatis)整合配置的详细步骤,适用于 Maven 项目。 (一)、pom.xml中添加相关依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"ht…...
)
B. Zero Array(思维)
Problem - 1201B - Codeforces 思路:每次给任意两个不同下表的数减-1,相当于在这个数组总和S上减2,S为奇数则不可能变为0,S为偶数时,一定存在两个序列组成两个S/2,这样每次都是在两个S/2上各减1,…...

FPGA_Verilog实现QSPI驱动,完成FLASH程序固化
FPGA_Verilog实现QSPI驱动,完成FLASH程序固化 操作提要 使用此操作模式实现远程升级的原因是当前的FLASH的管脚直接与FPGA相连接,SPI总线并未直接与CPU相连接,那么则需要CPU下发升级指令与将要升级的文件给FPGA,然后在FPGA内部产…...

前端取经路——框架修行:React与Vue的双修之路
大家好,我是老十三,一名前端开发工程师。在前端的江湖中,React与Vue如同两大武林门派,各有千秋。今天,我将带你进入这两大框架的奥秘世界,共同探索组件生命周期、状态管理、性能优化等核心难题的解决之道。无论你是哪派弟子,掌握双修之术,才能在前端之路上游刃有余。准…...
的存储模型)
【DBMS学习系列】一、DBMS(数据库管理系统)的存储模型
一、前置知识 1.1 什么是OLAP 和 OLTP? On-Line Analytical Processing,简称OLAP(联机分析处理),是一种用于处理大规模数据的技术,它提供了一种灵活的分析和查询方式,能够帮助用户从不同维度来分析和理解业务数据。 On-Line Transaction Processing,简称OLTP(联机事…...

Matlab 镍氢电池模型
1、内容简介 Matlab216-镍氢电池模型 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

39、.NET GC是什么? 为什么需要GC?
.NET GC是什么? .NET GC(Garbage Collector,垃圾回收器)是.NET运行时(CLR)的核心组件,负责自动管理托管堆(Managed Heap)中的内存分配与释放。其核心工作机制包括&#…...

前端缓存踩坑指南:如何优雅地解决浏览器缓存问题?
浏览器缓存,配置得当,它能让页面飞起来;配置错了,一次小小的上线,就能把你扔进线上 bug 的坑里。你可能遇到过这些情况: 部署上线了,结果用户还在加载旧的 JS;接口数据改了…...

XML语言
XML语言 在开始介绍Mybatis之前,先介绍一下XML语言,XML语言发明最初是用于数据的存储和传输,它是由一个一个的标签嵌套而成 <?xml version"1.0" encoding"UTF-8" ?> <outer> <name>阿伟</name&…...

垃圾回收的三色标记算法
目录 1、介绍 1.1、发展 1.2、基本原理 2、执行过程 2.1、初始标记 (Initial Marking) 2.2、并发标记 (Concurrent Marking) 2.3、重新标记 (Remark) 2.4、垃圾清理阶段 3、并发标记 3.1、浮动垃圾 3.2、漏标 前言 三色标记(Tri-color Marking࿰…...