正则化和L1/L2范式
1. 背景与引入
历史与位置
正则化(Regularization)是机器学习中控制模型复杂度、提升泛化能力的核心手段之一。
- L2范式(Ridge正则化)最早可追溯至20世纪70年代的Tikhonov正则化,用于解决病态线性方程组问题,在回归分析中发展为岭回归(Ridge Regression)。
- L1范式(Lasso正则化)由Tibshirani于1996年提出,通过引入稀疏性约束,成为特征选择的经典方法。
两者共同构成正则化理论的基石,广泛应用于回归、分类、深度学习等领域。
实际问题与类比
问题场景:假设你正在设计一个房价预测模型,手头有100个特征(如面积、楼层、周边设施等),但其中部分特征可能是噪声或冗余(如“距离某个路灯的距离”)。直接训练模型可能导致过拟合——模型在训练集上表现很好,但在新数据上失效。
类比:想象你正在整理一个装满物品的背包,但背包容量有限。
- L1范式:强制丢弃不重要的物品(特征),只保留最关键的部分(如“面积”“地段”)。
- L2范式:均匀压缩所有物品的大小(缩小参数值),但不完全丢弃任何物品。
如何选择策略?这取决于你的目标:需要轻装上阵(稀疏性)还是整体减负(稳定性)?
学习目标
学完本章后,你将:
- 理解L1和L2正则化的核心差异(稀疏性 vs. 连续惩罚)。
- 掌握其在模型过拟合、特征选择中的应用逻辑。
- 能针对具体问题选择合适的正则化方法(如高维数据选L1,多共线性选L2)。
2. 核心概念与定义
L1范式(Lasso正则化)
定义:L1范式通过在损失函数中添加权重系数的绝对值之和来约束模型复杂度。
数学表达为:
损失函数 + λ ∑ i = 1 n ∣ w i ∣ \text{损失函数} + \lambda \sum_{i=1}^n |w_i| 损失函数+λ∑i=1n∣wi∣,
其中 λ \lambda λ控制正则化强度, w i w_i wi是模型参数。
核心思想:
L1范式像一个“断舍离”的惩罚机制——对所有权重施加同等力度的压缩,但允许部分权重彻底变为零。这使得模型自动筛选出关键特征,忽略冗余信息。
例子:
想象你有一笔固定的宣传预算,需要分配给多个广告渠道(如电视、社交媒体、户外广告等)。L1范式会逼迫你选择少数几个最有效的渠道集中投放,而直接砍掉其他渠道的预算(权重归零)。
几何意义:
在二维参数空间中,L1正则化的约束区域是一个菱形(顶点在坐标轴上)。优化时,损失函数的等高线更容易与菱形的顶点相交,导致某些权重恰好为零(稀疏性)。
L2范式(Ridge正则化)
定义:L2范式通过在损失函数中添加权重系数的平方和来约束模型复杂度。
数学表达为:
损失函数 + λ ∑ i = 1 n w i 2 \text{损失函数} + \lambda \sum_{i=1}^n w_i^2 损失函数+λ∑i=1nwi2。
核心思想:
L2范式像“雨露均沾”的压缩策略——对所有权重施加与数值大小相关的惩罚,权重越大被压缩得越狠,但永远不会完全归零。
例子:
假设你要给多个员工分配年终奖金,但总预算有限。L2范式会要求你按比例减少每个人的奖金(大额奖金削减更多),但不会让任何人拿零奖金。
几何意义:
L2正则化的约束区域是一个圆形(或球形)。损失函数的等高线更可能与圆周上的某点相切,此时参数值整体缩小但保留非零状态。
关键区别总结
- 稀疏性:L1能产生零权重(特征选择),L2仅缩小权重值。
- 异常值敏感度:L2对大权重惩罚更重,因此对异常值更敏感。
- 解的唯一性:L1可能有多个最优解(如多个特征同等重要),L2解通常是唯一的。
3. 拆解与解读
L1范式(Lasso正则化)
公式拆解:
总损失 = 原始损失函数 + λ ∑ i = 1 n ∣ w i ∣ \text{总损失} = \text{原始损失函数} + \lambda \sum_{i=1}^n |w_i| 总损失=原始损失函数+λi=1∑n∣wi∣
- 原始损失函数:模型的核心任务(如线性回归的均方误差)。
- λ(Lambda):正则化强度系数,决定“断舍离”的力度。
- λ越大,权重压缩越狠,更多特征被舍弃。
- λ=0时,退化为无正则化的原始模型。
- ∑|wᵢ|:所有权重的绝对值之和,直接惩罚参数的大小。
逐层解读:
-
惩罚机制:
- 绝对值的特性是“线性惩罚”——无论权重大小,每增加1单位,惩罚增加1单位。
- 类比:超市购物袋的承重限制(如最多装5kg),无论装书还是棉花,总重量超了就必须减少物品。
-
稀疏性来源:
- 优化时,L1惩罚会迫使部分权重直接降为0(对应特征被剔除)。
- 原因:数学上,绝对值函数在0点处不可导,导致优化路径容易“卡在0点”。
-
λ的作用:
- λ=0:完全信任数据,可能过拟合。
- λ=∞:强制所有权重归零,模型失效。
- 类比:装修预算(λ)越高,能保留的家具越少(特征越精简)。
L2范式(Ridge正则化)
公式拆解:
总损失 = 原始损失函数 + λ ∑ i = 1 n w i 2 \text{总损失} = \text{原始损失函数} + \lambda \sum_{i=1}^n w_i^2 总损失=原始损失函数+λi=1∑nwi2
- 原始损失函数:与L1相同,模型的核心任务。
- λ(Lambda):同样控制惩罚强度,但影响方式不同。
- ∑wᵢ²:权重的平方和,对大权重施加更重的惩罚。
逐层解读:
-
惩罚机制:
- 平方的特性是“非线性惩罚”——权重越大,惩罚增长越快。
- 类比:超速罚款——车速越快(权重越大),罚款(惩罚项)呈指数级增加。
-
权重压缩逻辑:
- 优化时,大权重会被大幅压缩,小权重几乎不受影响。
- 数学推导:梯度更新公式中,L2惩罚项导数为 2 λ w i 2\lambda w_i 2λwi,即权重越大,反向修正越强。
-
λ的作用:
- λ=0:无惩罚,模型可能不稳定(如多重共线性下权重爆炸)。
- λ=∞:所有权重趋近于0,模型失去预测能力。
- 类比:健身教练(λ)越严格,肌肉(权重)被削减得越均匀。
关键联系与对比
-
惩罚项本质:
- L1:最小化权重的“数量”(稀疏性)。
- L2:最小化权重的“规模”(整体稳定性)。
-
优化难度:
- L1:绝对值不可导 → 需使用次梯度或坐标下降法。
- L2:平方连续可导 → 可直接用梯度下降。
-
应用场景:
- L1:高维数据(如基因表达分析),需自动特征选择。
- L2:数据维度低但共线性严重(如经济指标预测),需稳定参数估计。
总结比喻:
- L1是“极简主义者”,追求轻装上阵;
- L2是“平均主义者”,追求均衡压缩。
4. 几何意义与图形化展示
核心思想
L1和L2正则化的几何意义在于其对参数空间的约束形状不同,导致优化问题的解具有不同特性:
- L1正则化:约束区域为菱形(高维为棱形),等高线与菱形顶点相交时产生稀疏解(权重归零)。
- L2正则化:约束区域为圆形(高维为球面),等高线与圆周相切时权重均匀压缩但非零。
图形化展示
Figure-1: L1正则化(Lasso)的几何意义
- 约束条件: ∣ w 1 ∣ + ∣ w 2 ∣ ≤ C |w_1| + |w_2| \leq C ∣w1∣+∣w2∣≤C(菱形)。
- 损失函数等高线:以椭圆表示(如线性回归的均方误差)。
- 关键点:最优解出现在菱形顶点(如 w 1 = 0 w_1=0 w1=0或 w 2 = 0 w_2=0 w2=0),体现稀疏性。
import matplotlib.pyplot as plt
import numpy as np# 参数网格
w1, w2 = np.meshgrid(np.linspace(-2, 2, 400), np.linspace(-2, 2, 400))# L1约束条件:|w1| + |w2| <= C
C = 1.0
l1_constraint = np.abs(w1) + np.abs(w2)# 损失函数(假设为椭圆等高线)
loss = (w1 - 0.5)**2 + (w2 - 0.3)**2# 绘图
plt.figure(figsize=(6, 6))
plt.contourf(w1, w2, l1_constraint, levels=[0, C, 2*C], colors=['#FFD700', '#FFFACD'])
plt.contour(w1, w2, loss, levels=20, cmap='viridis', alpha=0.7)
plt.plot([-C, 0, C, 0, -C], [0, C, 0, -C, 0], 'k--', label='L1 Constraint')
plt.scatter([0], [0], c='red', label='Sparse Solution')
plt.title("Figure-1: L1正则化几何意义")
plt.xlabel('w1')
plt.ylabel('w2')
plt.legend()
plt.grid(True)
plt.show()
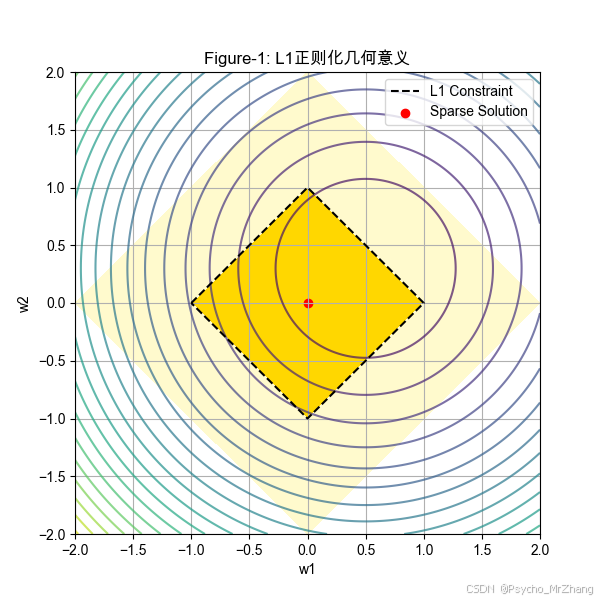
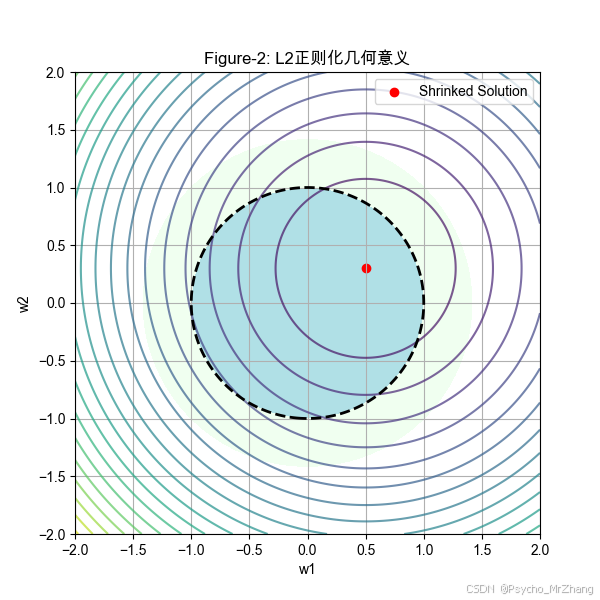
Figure-2: L2正则化(Ridge)的几何意义
- 约束条件: w 1 2 + w 2 2 ≤ C w_1^2 + w_2^2 \leq C w12+w22≤C(圆形)。
- 损失函数等高线:同上。
- 关键点:最优解出现在圆周某点(权重非零),体现均匀压缩特性。
# L2约束条件:w1^2 + w2^2 <= C
C = 1.0
l2_constraint = w1**2 + w2**2# 绘图
plt.figure(figsize=(6, 6))
plt.contourf(w1, w2, l2_constraint, levels=[0, C, 2*C], colors=['#B0E0E6', '#F0FFF0'])
plt.contour(w1, w2, loss, levels=20, cmap='viridis', alpha=0.7)
plt.contour(w1, w2, l2_constraint, levels=[C], colors='k', linestyles='--', linewidths=2)
plt.scatter([0.5], [0.3], c='red', label='Shrinked Solution')
plt.title("Figure-2: L2正则化几何意义")
plt.xlabel('w1')
plt.ylabel('w2')
plt.legend()
plt.grid(True)
plt.show()
图形解读
-
L1正则化(Figure-1):
- 菱形约束的顶点在坐标轴上(如 w 1 = 0 w_1=0 w1=0或 w 2 = 0 w_2=0 w2=0)。
- 损失函数的等高线(椭圆)与菱形相交时,交点常位于顶点,导致某些权重为零(稀疏性)。
-
L2正则化(Figure-2):
- 圆形约束的边界平滑,无尖锐顶点。
- 椭圆等高线与圆周的切点通常不在坐标轴上,权重被压缩但非零。
-
对比总结:
- 形状差异:L1的棱角导致稀疏性,L2的光滑性导致均匀压缩。
- 应用选择:需特征选择(L1),需稳定参数(L2)。
通过上述图形,可直观理解正则化对模型参数的影响机制。
5. 常见形式与变换
L1正则化的常见形式
-
原始损失函数+正则化项
最小化 L ( w ) + λ ∑ i = 1 n ∣ w i ∣ \text{最小化} \quad \mathcal{L}(w) + \lambda \sum_{i=1}^n |w_i| 最小化L(w)+λi=1∑n∣wi∣- 含义:直接在原始损失(如线性回归的均方误差)中添加L1惩罚项。
- 适用场景:梯度下降或坐标下降法优化时常用此形式。
-
约束优化形式
最小化 L ( w ) 满足 ∑ i = 1 n ∣ w i ∣ ≤ C \text{最小化} \quad \mathcal{L}(w) \quad \text{满足} \quad \sum_{i=1}^n |w_i| \leq C 最小化L(w)满足i=1∑n∣wi∣≤C- 含义:将权重约束到L1范数球(菱形区域)内。
- 适用场景:几何分析或拉格朗日乘数法推导时使用。
-
贝叶斯视角下的先验分布
- 含义:L1正则化等价于对权重施加拉普拉斯先验(Laplace Prior)。
- 公式:
p ( w ) ∝ exp ( − λ ∑ i = 1 n ∣ w i ∣ ) p(w) \propto \exp\left(-\lambda \sum_{i=1}^n |w_i|\right) p(w)∝exp(−λi=1∑n∣wi∣) - 适用场景:贝叶斯推断中结合似然函数求后验分布。
L2正则化的常见形式
-
原始损失函数+正则化项
最小化 L ( w ) + λ ∑ i = 1 n w i 2 \text{最小化} \quad \mathcal{L}(w) + \lambda \sum_{i=1}^n w_i^2 最小化L(w)+λi=1∑nwi2- 含义:直接在损失中添加L2惩罚项。
- 适用场景:梯度下降优化时常用,便于自动求导。
-
约束优化形式
最小化 L ( w ) 满足 ∑ i = 1 n w i 2 ≤ C \text{最小化} \quad \mathcal{L}(w) \quad \text{满足} \quad \sum_{i=1}^n w_i^2 \leq C 最小化L(w)满足i=1∑nwi2≤C- 含义:将权重约束到L2范数球(圆形区域)内。
- 适用场景:几何分析或拉格朗日乘数法推导时使用。
-
贝叶斯视角下的先验分布
- 含义:L2正则化等价于对权重施加高斯先验(Gaussian Prior)。
- 公式:
p ( w ) ∝ exp ( − λ ∑ i = 1 n w i 2 ) p(w) \propto \exp\left(-\lambda \sum_{i=1}^n w_i^2\right) p(w)∝exp(−λi=1∑nwi2) - 适用场景:贝叶斯推断中结合似然函数求后验分布。
弹性网络(Elastic Net):L1与L2的混合形式
- 定义:
最小化 L ( w ) + λ 1 ∑ i = 1 n ∣ w i ∣ + λ 2 ∑ i = 1 n w i 2 \text{最小化} \quad \mathcal{L}(w) + \lambda_1 \sum_{i=1}^n |w_i| + \lambda_2 \sum_{i=1}^n w_i^2 最小化L(w)+λ1i=1∑n∣wi∣+λ2i=1∑nwi2 - 含义:同时引入L1和L2惩罚,平衡稀疏性与稳定性。
- 适用场景:
- 高维数据(如基因组学)且特征间存在相关性时。
- 需要特征选择但避免L1对高度相关特征的随机舍弃问题。
形式间的联系
-
拉格朗日乘数法:
- 约束优化形式(如 ∑ ∣ w i ∣ ≤ C \sum |w_i| \leq C ∑∣wi∣≤C)可通过拉格朗日乘数法转化为带正则化项的形式。
- λ \lambda λ与 C C C是对偶关系: λ \lambda λ越大, C C C越小,约束越强。
- 约束优化形式(如 ∑ ∣ w i ∣ ≤ C \sum |w_i| \leq C ∑∣wi∣≤C)可通过拉格朗日乘数法转化为带正则化项的形式。
-
优化算法的选择:
- L1正则化需使用次梯度(Subgradient)或坐标下降法(Coordinate Descent)。
- L2正则化可直接使用梯度下降(连续可导)。
-
贝叶斯视角:
- L1正则化 = 拉普拉斯先验 → 稀疏性。
- L2正则化 = 高斯先验 → 连续收缩。
图形化对比
Figure-1: 不同正则化下的系数收缩路径
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso, Ridge, ElasticNet
from sklearn.datasets import make_regression# 生成合成数据
X, y = make_regression(n_features=10, noise=0.1, random_state=42)# 正则化系数路径
alphas = np.logspace(-4, 1, 100)
lasso_coefs = []
ridge_coefs = []
enet_coefs = []for alpha in alphas:# Lassolasso = Lasso(alpha=alpha)lasso.fit(X, y)lasso_coefs.append(lasso.coef_)# Ridgeridge = Ridge(alpha=alpha)ridge.fit(X, y)ridge_coefs.append(ridge.coef_)# Elastic Net (α=0.5)enet = ElasticNet(alpha=alpha, l1_ratio=0.5)enet.fit(X, y)enet_coefs.append(enet.coef_)# 绘图
plt.figure(figsize=(12, 6))
for i in range(10):plt.plot(alphas, np.array(lasso_coefs)[:, i], c='blue', alpha=0.5)plt.plot(alphas, np.array(ridge_coefs)[:, i], c='red', alpha=0.5)plt.plot(alphas, np.array(enet_coefs)[:, i], c='green', alpha=0.5)plt.xscale('log')
plt.xlabel('正则化强度 λ')
plt.ylabel('系数值')
plt.title("Figure-1: L1(蓝)、L2(红)、Elastic Net(绿)的系数路径对比")
plt.legend(['Lasso', 'Ridge', 'Elastic Net'])
plt.grid(True)
plt.show()
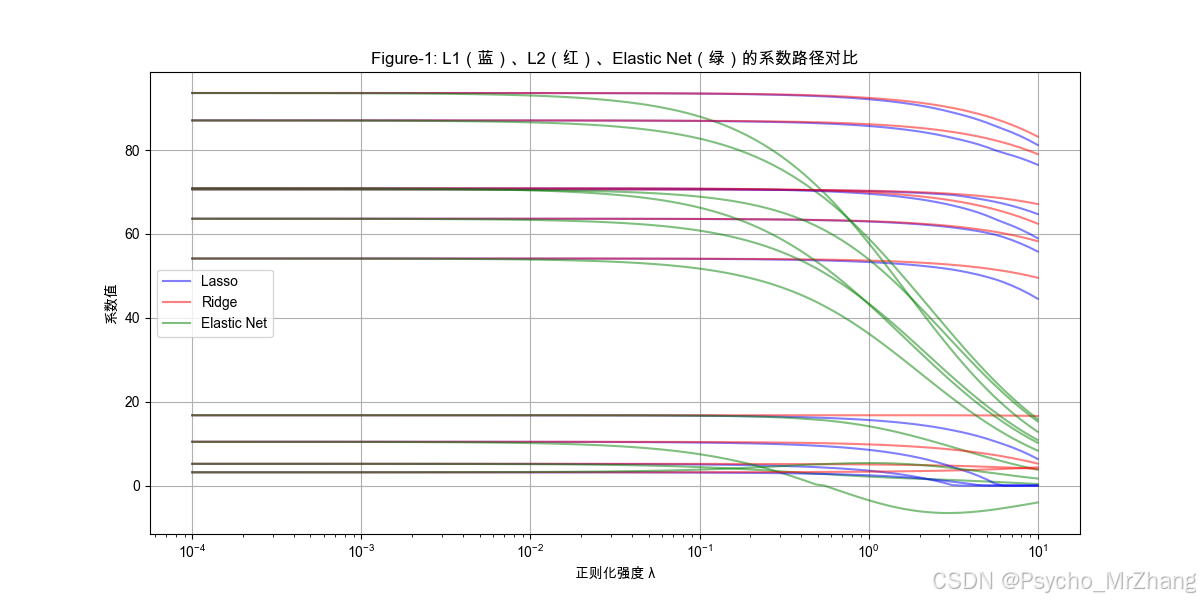
图形解读
- L1正则化(蓝色):随着 λ 增大,部分系数快速趋近于零(稀疏性)。
- L2正则化(红色):所有系数均匀收缩,但不会完全归零。
- Elastic Net(绿色):介于两者之间,部分系数趋零,其余缓慢收缩。
总结
- 形式一致性:
- 所有形式本质是同一问题的不同数学表达(如约束优化与拉格朗日乘数法等价)。
- 适用场景:
- L1:特征选择(如基因表达分析)。
- L2:多重共线性处理(如经济指标预测)。
- Elastic Net:高维且相关性强的特征场景。
- 核心联系:
- 正则化强度 λ 控制模型复杂度,不同形式通过优化算法实现相同目标。
6. 实际应用场景
场景一:基因表达数据分析中的特征选择(L1正则化)
问题背景:
在生物医学研究中,基因表达数据通常包含数万个基因(特征)的表达值,但样本量(如患者数量)往往仅有几十到几百个。直接建模易导致过拟合,需筛选出与疾病关联的关键基因。
解决步骤:
-
数据准备:
- 输入:基因表达矩阵(样本×基因),标签(如癌症类型或生存时间)。
- 预处理:标准化基因表达值,去除批次效应。
-
模型选择:
- 使用 Lasso回归(L1正则化),目标是稀疏化模型,自动选择重要基因。
-
调参与训练:
- 通过交叉验证(如5折CV)选择最优正则化参数 λ \lambda λ。
- 训练模型后,输出非零系数对应的基因作为候选生物标志物。
-
结果验证:
- 在独立测试集上评估模型性能(如分类准确率或生存预测误差)。
- 对筛选出的基因进行生物学功能注释(如GO富集分析)。
图形化展示:
Figure-5: Lasso在基因数据中的特征选择效果
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression# 模拟高维基因数据(n=100, p=5000)
X, y = make_regression(n_samples=100, n_features=5000, n_informative=20, noise=0.1, random_state=42)# Lasso系数路径
alphas = np.logspace(-4, 1, 100)
coefs = []
for alpha in alphas:lasso = Lasso(alpha=alpha)lasso.fit(X, y)coefs.append(lasso.coef_)# 可视化前20个重要基因的系数变化
plt.figure(figsize=(10, 6))
for i in range(20):plt.plot(alphas, np.array(coefs)[:, i], label=f'Gene {i+1}')plt.xscale('log')
plt.xlabel('正则化强度 λ (log scale)')
plt.ylabel('基因系数值')
plt.title("Figure-5: Lasso在高维基因数据中的系数路径(前20个基因)")
plt.legend()
plt.grid(True)
plt.show()
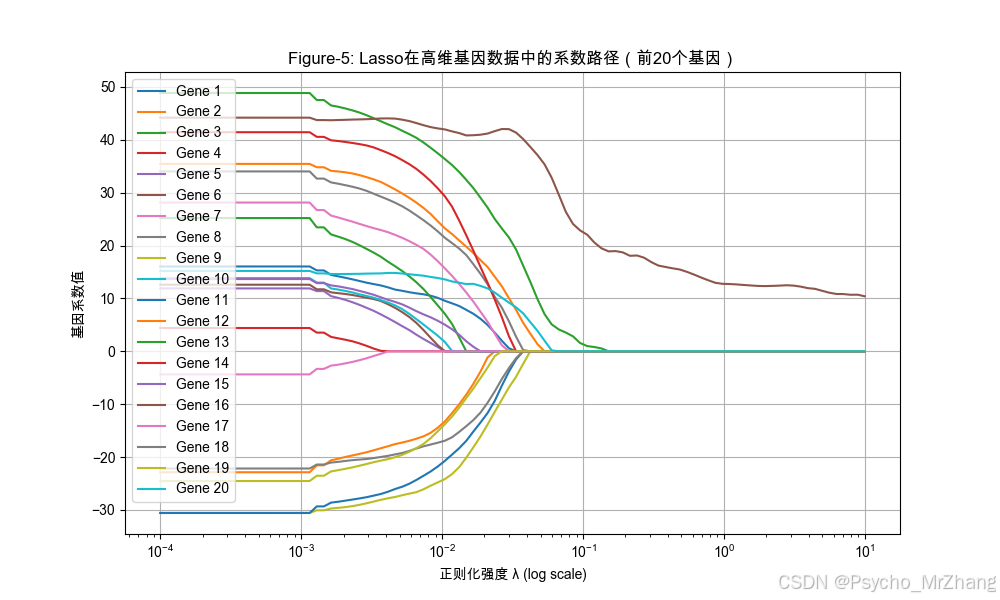
解读:
- 随着 λ \lambda λ增大,多数基因系数趋近于零(被剔除),仅少数关键基因保留非零系数。
- 通过选择合适 λ \lambda λ,可精准定位与目标性状相关的基因。
场景二:房地产价格预测中的多重共线性处理(L2正则化)
问题背景:
在房价预测中,特征如“房间数”和“建筑面积”可能存在高度相关性(共线性),导致线性回归系数不稳定,甚至符号异常(如房间数增加但房价下降)。
解决步骤:
-
数据准备:
- 输入:房价数据集(如波士顿房价),包含房间数、犯罪率、周边学校数量等特征。
- 检测共线性:计算方差膨胀因子(VIF),VIF>10表明严重共线性。
-
模型选择:
- 使用 Ridge回归(L2正则化),通过压缩系数缓解共线性影响。
-
调参与训练:
- 通过交叉验证选择最优 λ \lambda λ。
- 训练模型并检查系数符号是否符合业务逻辑(如房间数对房价的正向影响)。
-
结果对比:
- 对比普通线性回归(OLS)与Ridge回归的系数稳定性(如标准差)。
- 在测试集上比较均方误差(MSE)。
图形化展示:
Figure-6: Ridge回归对共线性特征的压缩效果
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.model_selection import train_test_split
import pandas as pd
# 加载波士顿房价数据
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X, y = data, target# 添加共线性特征(复制一列)
X = np.hstack((X, X[:, [0]])) # 假设第1个特征与其他强相关# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
ols = LinearRegression().fit(X_train, y_train)
ridge = Ridge(alpha=10).fit(X_train, y_train)# 可视化系数对比
plt.figure(figsize=(12, 6))
plt.bar(np.arange(X.shape[1]), ols.coef_, alpha=0.6, label='OLS')
plt.bar(np.arange(X.shape[1]), ridge.coef_, alpha=0.6, label='Ridge')
plt.axhline(0, color='black', linestyle='--')
plt.xlabel('特征索引')
plt.ylabel('系数值')
plt.title("Figure-6: OLS vs Ridge回归系数对比(含共线性特征)")
plt.legend()
plt.grid(True)
plt.show()
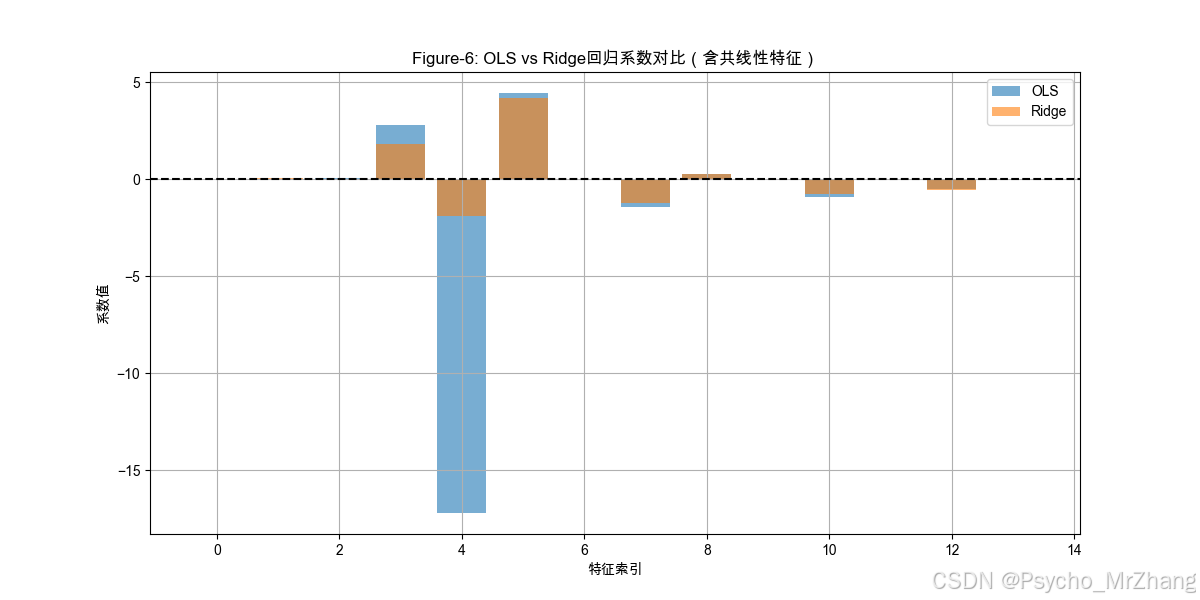
解读:
- OLS系数:共线性特征(如最后1列)系数波动剧烈,甚至出现不合理符号。
- Ridge系数:所有系数被均匀压缩,符号更稳定,避免异常值干扰。
场景三:金融风控中的稀疏信用评分模型(Elastic Net)
问题背景:
在构建信用评分卡时,特征可能既多(如数百个衍生变量)又相关(如收入与资产总额),需同时实现特征选择和稳定性。
解决步骤:
-
数据准备:
- 输入:用户基本信息、征信记录、消费行为等特征。
- 标签:是否违约(0/1)。
-
模型选择:
- 使用 Elastic Net(L1+L2混合正则化),平衡稀疏性与共线性处理。
-
调参与部署:
- 通过网格搜索确定最优 λ \lambda λ和 L1比例(如l1_ratio=0.5)。
- 部署模型生成稀疏评分卡,仅保留关键风险特征(如逾期次数、负债率)。
-
监控与迭代:
- 定期验证模型区分度(AUC)和特征重要性变化。
总结:如何选择正则化方法
| 场景特点 | 推荐方法 | 原因 |
|---|---|---|
| 高维数据(特征 >> 样本) | L1(Lasso) | 自动特征选择,降低复杂度 |
| 多重共线性 | L2(Ridge) | 稳定系数,减少方差 |
| 高维且特征相关 | Elastic Net | 兼顾稀疏性与共线性处理 |
| 需解释性强的模型 | L1或Elastic Net | 稀疏特征更易业务解读 |
7. Python 代码实现
本节通过完整代码实现 L1(Lasso)、L2(Ridge) 和 Elastic Net 正则化的核心功能,并结合可视化展示其对模型系数的影响。
1. L1正则化(Lasso):高维数据特征选择
目标:演示Lasso如何从高维数据中筛选关键特征。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression# 1. 生成高维数据(100个样本,5000个特征,仅20个关键特征)
X, y = make_regression(n_samples=100, n_features=5000, n_informative=20, noise=0.1, random_state=42)# 2. 定义正则化参数路径
alphas = np.logspace(-4, 1, 100) # 对数刻度的α(λ)值
coefs = []# 3. 训练Lasso模型并记录系数
for alpha in alphas:lasso = Lasso(alpha=alpha)lasso.fit(X, y)coefs.append(lasso.coef_)# 4. 可视化前20个特征的系数路径
plt.figure(figsize=(10, 6))
for i in range(20):plt.plot(alphas, np.array(coefs)[:, i], label=f'Feature {i+1}')plt.xscale('log')
plt.xlabel('正则化强度 λ (log scale)')
plt.ylabel('特征系数值')
plt.title("Figure-7: Lasso系数路径(高维数据)")
plt.legend()
plt.grid(True)
plt.show()
代码解释:
- 输入:
X(5000维特征矩阵),y(目标值)。 - 核心逻辑:
- 遍历不同
alpha(λ)值,训练Lasso模型。 - 记录每个特征的系数随正则化强度的变化。
- 遍历不同
- 输出:系数路径图(Figure-7)。
- 结果解读:
- 随着 λ 增大,大部分特征系数趋近于零(被剔除)。
- 关键特征(如 Feature 1~20)保留非零系数,实现自动特征选择。
2. L2正则化(Ridge):多重共线性处理
目标:展示Ridge如何缓解共线性问题。
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split# 1. 加载波士顿房价数据并添加共线性特征
boston = load_boston()
X, y = boston.data, boston.target
X = np.hstack((X, X[:, [0]])) # 复制第一个特征(CRIM)以制造共线性# 2. 划分训练集/测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 训练模型
ols = LinearRegression().fit(X_train, y_train)
ridge = Ridge(alpha=10).fit(X_train, y_train)# 4. 可视化系数对比
plt.figure(figsize=(12, 6))
plt.bar(np.arange(X.shape[1]), ols.coef_, alpha=0.6, label='OLS(普通线性回归)')
plt.bar(np.arange(X.shape[1]), ridge.coef_, alpha=0.6, label='Ridge(L2正则化)')
plt.axhline(0, color='black', linestyle='--')
plt.xlabel('特征索引')
plt.ylabel('系数值')
plt.title("Figure-8: OLS vs Ridge系数对比(含共线性特征)")
plt.legend()
plt.grid(True)
plt.show()
代码解释:
- 输入:
X(含共线性特征的波士顿房价数据),y(房价)。 - 核心逻辑:
- 训练普通线性回归(OLS)和Ridge模型。
- 对比两者的系数稳定性。
- 输出:系数对比图(Figure-8)。
- 结果解读:
- OLS系数:共线性特征(如最后1列)系数波动剧烈,甚至符号异常。
- Ridge系数:所有系数被均匀压缩,符号合理且稳定。
3. Elastic Net:混合正则化
目标:展示Elastic Net在高维且特征相关场景下的优势。
from sklearn.linear_model import ElasticNet# 1. 使用与Lasso相同的高维数据
# 2. 定义混合正则化参数
alphas = np.logspace(-4, 1, 100)
l1_ratio = 0.5 # L1占比
enet_coefs = []# 3. 训练Elastic Net模型
for alpha in alphas:enet = ElasticNet(alpha=alpha, l1_ratio=l1_ratio)enet.fit(X, y)enet_coefs.append(enet.coef_)# 4. 可视化前20个特征的系数路径
plt.figure(figsize=(10, 6))
for i in range(20):plt.plot(alphas, np.array(enet_coefs)[:, i], label=f'Feature {i+1}')plt.xscale('log')
plt.xlabel('正则化强度 λ (log scale)')
plt.ylabel('特征系数值')
plt.title("Figure-9: Elastic Net系数路径(混合正则化)")
plt.legend()
plt.grid(True)
plt.show()
代码解释:
- 输入:
X(高维数据),y(目标值)。 - 核心逻辑:
- 遍历不同
alpha值,训练Elastic Net模型(L1占比50%)。 - 记录系数变化。
- 遍历不同
- 输出:系数路径图(Figure-9)。
- 结果解读:
- 系数路径介于Lasso和Ridge之间:部分特征被彻底剔除,其余缓慢收缩。
- 适用于高维且特征相关的场景(如基因组学、金融风控)。
总结:代码与理论的对应关系
| 理论概念 | 代码实现方式 | 图形化展示 |
|---|---|---|
| 稀疏性 | Lasso系数路径趋零 | Figure-7 |
| 共线性处理 | Ridge系数压缩与稳定性 | Figure-8 |
| 混合正则化 | Elastic Net的L1+L2组合 | Figure-9 |
| 参数选择 | np.logspace遍历α值 | 所有系数路径图 |
通过上述代码,可直观验证L1、L2及其混合形式在不同场景下的效果。
8. 总结与拓展
核心知识点回顾
-
L1正则化(Lasso):
- 通过惩罚权重绝对值之和实现稀疏性,自动筛选关键特征。
- 适用于高维数据(如基因组学、文本分类)和特征选择场景。
-
L2正则化(Ridge):
- 通过惩罚权重平方和抑制大系数,缓解多重共线性问题。
- 适用于低维但特征相关性强的数据(如经济指标预测)。
-
弹性网络(Elastic Net):
- L1与L2的混合形式,平衡稀疏性与稳定性,适合高维且特征相关的复杂场景。
-
几何意义:
- L1约束区域为菱形(顶点在坐标轴),导致稀疏解;
- L2约束区域为圆形(光滑边界),导致均匀压缩。
-
优化差异:
- L1不可导 → 需使用次梯度或坐标下降法;
- L2可导 → 可直接用梯度下降优化。
进一步学习方向
-
非凸正则化方法:
- L0正则化:直接惩罚非零系数数量(计算困难,NP难问题)。
- SCAD(平滑剪切绝对偏差):非凸惩罚项,在大系数时减少偏差。
-
贝叶斯视角下的正则化:
- 理解L1/L2正则化与先验分布的关系(拉普拉斯 vs. 高斯先验)。
- 学习变分推断(Variational Inference)在贝叶斯正则化中的应用。
-
深度学习中的正则化:
- Dropout:通过随机丢弃神经元实现隐式正则化。
- 权重衰减(Weight Decay):等价于L2正则化,在优化器中直接实现(如AdamW)。
-
动态正则化技术:
- 自适应正则化:根据数据分布自动调整惩罚强度(如AdaReg)。
- 早停(Early Stopping):通过监控验证集损失间接实现正则化。
-
高阶应用场景:
- 稀疏信号恢复(如压缩感知):L1正则化用于从少量测量中重建信号。
- 图像去噪与分割:结合L1/L2正则化优化图像处理模型。
推荐学习资源
- 书籍:
- 《统计学习基础》(The Elements of Statistical Learning):深入解析正则化理论。
- 《深度学习》(Deep Learning by Ian Goodfellow):涵盖正则化在神经网络中的应用。
- 课程:
- Andrew Ng的《机器学习》课程(Coursera):实践L1/L2正则化案例。
- Google的《机器学习速成班》:代码实战正则化技巧。
- 论文:
- Tibshirani (1996) Regression Shrinkage and Selection via the Lasso
- Zou & Hastie (2005) Regularization and variable selection via the Elastic Net
深度思考问题
-
稀疏性代价:
- L1正则化可能导致重要但微弱的特征被剔除,如何改进?(提示:SCAD、Adaptive Lasso)
-
正则化与泛化:
- 为什么正则化能提升模型泛化能力?是否所有场景都适用?
-
高维灾难:
- 当特征维度远大于样本量时,L1正则化的有效性是否依赖于特征间的独立性?
-
非参数模型的正则化:
- 如何在决策树(如XGBoost)或神经网络中隐式实现正则化?
通过以上总结与拓展,可进一步深化对正则化技术的理解,并探索其在复杂问题中的应用潜力。
9. 练习与反馈
本节提供分层练习题,涵盖 基础理解、提高应用 和 挑战分析,帮助巩固L1/L2正则化的核心概念与实践技巧。
基础题:概念辨析
1. 判断题
- (1) L1正则化通过惩罚权重的平方和实现稀疏性。
- (2) L2正则化对大权重的惩罚比小权重更重。
- (3) Elastic Net是L1和L2正则化的线性组合。
- (4) 在多重共线性场景下,Ridge回归的系数稳定性优于普通线性回归。
答案与提示:
- (1) ❌ 错误。L1正则化惩罚权重的绝对值之和,L2惩罚平方和。
- (2) ✅ 正确。L2的平方特性导致大权重被更强压缩。
- (3) ✅ 正确。Elastic Net公式为 λ 1 ∥ w ∥ 1 + λ 2 ∥ w ∥ 2 2 \lambda_1 \|w\|_1 + \lambda_2 \|w\|_2^2 λ1∥w∥1+λ2∥w∥22。
- (4) ✅ 正确。Ridge通过压缩系数缓解共线性导致的波动。
2. 简答题
- Q1:为什么L1正则化能实现特征选择,而L2不能?
- Q2:在优化过程中,L1正则化为何可能导致解不唯一?
参考答案:
- A1:
- L1正则化的约束区域为菱形,损失函数等高线与菱形顶点相交时,部分权重被强制归零(稀疏性)。
- L2正则化约束区域为圆形,交点通常不在坐标轴上,权重仅被压缩而非归零。
- A2:
- 当多个特征高度相关时,L1正则化可能随机选择其中一个特征保留,其余归零,导致解不唯一(如两个特征完全共线时)。
提高题:数学与代码应用
3. 数学推导
- Q3:写出L2正则化线性回归的损失函数,并推导其梯度下降更新公式。
答案:
- 损失函数:
L ( w ) = 1 2 N ∥ y − X w ∥ 2 2 + λ 2 ∥ w ∥ 2 2 \mathcal{L}(w) = \frac{1}{2N} \|y - Xw\|^2_2 + \frac{\lambda}{2} \|w\|_2^2 L(w)=2N1∥y−Xw∥22+2λ∥w∥22 - 梯度推导:
∇ w L = 1 N X T ( X w − y ) + λ w \nabla_w \mathcal{L} = \frac{1}{N} X^T (Xw - y) + \lambda w ∇wL=N1XT(Xw−y)+λw - 更新公式:
w t + 1 = w t − η ( 1 N X T ( X w t − y ) + λ w t ) w_{t+1} = w_t - \eta \left( \frac{1}{N} X^T (Xw_t - y) + \lambda w_t \right ) wt+1=wt−η(N1XT(Xwt−y)+λwt)
4. 代码实践
- Q4:使用
sklearn的Lasso和Ridge模型,对比它们在 含噪声特征的数据集 上的表现。- 数据生成:100个样本,10个特征(其中5个与目标无关,随机噪声)。
- 评价指标:测试集MSE、非零系数数量。
代码框架:
from sklearn.linear_model import Lasso, Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 生成数据
X, y = make_regression(n_samples=100, n_features=10, n_informative=5, noise=0.5, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Lasso模型
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
lasso_mse = mean_squared_error(y_test, lasso.predict(X_test))
print(f"Lasso Test MSE: {lasso_mse:.2f}, 非零系数: {np.sum(lasso.coef_ != 0)}")# Ridge模型
ridge = Ridge(alpha=0.1)
ridge.fit(X_train, y_train)
ridge_mse = mean_squared_error(y_test, ridge.predict(X_test))
print(f"Ridge Test MSE: {ridge_mse:.2f}, 非零系数: {np.sum(ridge.coef_ != 0)}")
预期结果:
- Lasso的非零系数数量 ≈ 5(筛选出关键特征),Ridge所有系数非零。
- Lasso的测试MSE可能低于Ridge(因去除了噪声特征干扰)。
挑战题:综合分析
5. 场景分析
- Q5:某电商平台需构建点击率(CTR)预测模型,特征包括用户历史行为(如浏览时长、点击次数)和商品属性(如价格、类别)。
- 问题:特征维度高达10万(稀疏One-Hot编码),且部分特征高度相关(如“用户浏览同类商品次数”与“总浏览次数”)。
- 任务:选择合适的正则化方法并解释理由,设计实验验证效果。
参考思路:
- 方法选择:
- Elastic Net:L1处理高维稀疏特征(自动选择关键行为/属性),L2缓解特征相关性(如浏览次数间的共线性)。
- 实验设计:
- 划分训练集/测试集,对比Lasso、Ridge、Elastic Net的AUC指标。
- 可视化各模型的特征系数分布,观察稀疏性和共线性处理效果。
- 调整Elastic Net的L1比例(如l1_ratio=0.5),分析对性能的影响。
6. 深度思考
- Q6:L1正则化的稀疏性可能导致重要但微弱的特征被剔除(如基因数据中低表达但关键的基因)。
- 如何改进L1正则化以缓解这一问题?
- 提示:查阅 Adaptive Lasso 或 SCAD正则化 的原理与实现。
参考方向:
- Adaptive Lasso:为每个权重分配自适应惩罚权重(如 λ ∣ w i ∣ / ∣ w ^ i ∣ γ \lambda |w_i| / |\hat{w}_i|^\gamma λ∣wi∣/∣w^i∣γ, w ^ i \hat{w}_i w^i为初始估计),小系数受惩罚更轻。
- SCAD:非凸惩罚项,在系数较大时减少惩罚强度,避免过度压缩。
反馈与答疑
-
常见疑问:
- Q: 为什么L2正则化无法进行特征选择?
A: L2惩罚项 w i 2 w_i^2 wi2在 w i = 0 w_i=0 wi=0处导数为0,优化时权重趋近于零但不会精确为零。 - Q: 如何选择L1/L2/Elastic Net?
A:- 高维稀疏数据 → L1(Lasso);
- 共线性问题 → L2(Ridge);
- 高维且相关 → Elastic Net。
- Q: 为什么L2正则化无法进行特征选择?
-
进一步讨论:
- 尝试在代码练习中调整正则化强度(alpha),观察系数路径变化。
- 探索
scikit-learn的ElasticNetCV自动交叉验证调参功能。
相关文章:

正则化和L1/L2范式
1. 背景与引入 历史与位置 正则化(Regularization)是机器学习中控制模型复杂度、提升泛化能力的核心手段之一。 L2范式(Ridge正则化)最早可追溯至20世纪70年代的Tikhonov正则化,用于解决病态线性方程组问题…...

day05_java中常见的运算符
对字面量或者变量进行操作的符号就是运算符。用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式。 java中常用的运算符有下面几种 算术运算符 代码示例 public class Demo01Operator {public static void main(String[] args) {int a 3;int b 4;System.o…...

Linux_进程退出与进程等待
一、进程退出 退出场景 正常终止:代码执行完毕且结果符合预期(退出码为 0)。异常终止:运行结果错误(退出码非 0)或进程被信号强制终止。(如 SIGINT 或 SIGSEGV)。 退…...
整合配置的详细步骤)
SSM框架(Spring + Spring MVC + MyBatis)整合配置的详细步骤
以下是 SSM框架(Spring Spring MVC MyBatis)整合配置的详细步骤,适用于 Maven 项目。 (一)、pom.xml中添加相关依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"ht…...
)
B. Zero Array(思维)
Problem - 1201B - Codeforces 思路:每次给任意两个不同下表的数减-1,相当于在这个数组总和S上减2,S为奇数则不可能变为0,S为偶数时,一定存在两个序列组成两个S/2,这样每次都是在两个S/2上各减1,…...

FPGA_Verilog实现QSPI驱动,完成FLASH程序固化
FPGA_Verilog实现QSPI驱动,完成FLASH程序固化 操作提要 使用此操作模式实现远程升级的原因是当前的FLASH的管脚直接与FPGA相连接,SPI总线并未直接与CPU相连接,那么则需要CPU下发升级指令与将要升级的文件给FPGA,然后在FPGA内部产…...

前端取经路——框架修行:React与Vue的双修之路
大家好,我是老十三,一名前端开发工程师。在前端的江湖中,React与Vue如同两大武林门派,各有千秋。今天,我将带你进入这两大框架的奥秘世界,共同探索组件生命周期、状态管理、性能优化等核心难题的解决之道。无论你是哪派弟子,掌握双修之术,才能在前端之路上游刃有余。准…...
的存储模型)
【DBMS学习系列】一、DBMS(数据库管理系统)的存储模型
一、前置知识 1.1 什么是OLAP 和 OLTP? On-Line Analytical Processing,简称OLAP(联机分析处理),是一种用于处理大规模数据的技术,它提供了一种灵活的分析和查询方式,能够帮助用户从不同维度来分析和理解业务数据。 On-Line Transaction Processing,简称OLTP(联机事…...

Matlab 镍氢电池模型
1、内容简介 Matlab216-镍氢电池模型 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

39、.NET GC是什么? 为什么需要GC?
.NET GC是什么? .NET GC(Garbage Collector,垃圾回收器)是.NET运行时(CLR)的核心组件,负责自动管理托管堆(Managed Heap)中的内存分配与释放。其核心工作机制包括&#…...

前端缓存踩坑指南:如何优雅地解决浏览器缓存问题?
浏览器缓存,配置得当,它能让页面飞起来;配置错了,一次小小的上线,就能把你扔进线上 bug 的坑里。你可能遇到过这些情况: 部署上线了,结果用户还在加载旧的 JS;接口数据改了…...

XML语言
XML语言 在开始介绍Mybatis之前,先介绍一下XML语言,XML语言发明最初是用于数据的存储和传输,它是由一个一个的标签嵌套而成 <?xml version"1.0" encoding"UTF-8" ?> <outer> <name>阿伟</name&…...

垃圾回收的三色标记算法
目录 1、介绍 1.1、发展 1.2、基本原理 2、执行过程 2.1、初始标记 (Initial Marking) 2.2、并发标记 (Concurrent Marking) 2.3、重新标记 (Remark) 2.4、垃圾清理阶段 3、并发标记 3.1、浮动垃圾 3.2、漏标 前言 三色标记(Tri-color Marking࿰…...

紫禁城多语言海外投资理财返利源码带前端uniapp纯工程文件
测试环境:Linux系统CentOS7.6、宝塔、PHP7.2、MySQL5.6,根目录public,伪静态thinkphp,开启ssl证书 语言:中文简体、英文、越南语、马来语、日语、巴西语、印尼语、泰语 前端是uniapp的源码,我已经把nmp给你…...

深入剖析 I/O 复用之 select 机制
深入剖析 I/O 复用之 select 机制 在网络编程中,I/O 复用是一项关键技术,它允许程序同时监控多个文件描述符的状态变化,从而高效地处理多个 I/O 操作。select 作为 I/O 复用的经典实现方式,在众多网络应用中扮演着重要角色。本文…...

Android开发报错解决
Android开发报错解决 组件相关文件相关权限相关代码相关程序报错IDE相关版本对应框架okhttp请求失败 Roomno such table cocos2d 组件相关 使用gravity属性让文字居中是,需把该属性放在text属性上面ScrollView只能容纳一个子视图 文件相关 放在drawble下的图片资源…...

Linux 网络命名空间:从内核资源管理到容器网络隔离
1. 网络命名空间是什么? 网络命名空间(Network Namespace) 是 Linux 内核提供的一种网络资源隔离机制,用于为进程或容器创建完全独立的网络环境。它并非物理或虚拟的网络接口(如网卡、veth pair 等),而是一个虚拟容器,包含以下资源的独立实例: 网络接口(物理或虚拟)…...

VNC windows连接ubuntu桌面
✅ 步骤 1:安装 VNC 服务器 首先,我们需要在 Winux 系统上安装一个 VNC 服务器。这里我们使用 tigervnc 作为例子,它是一个常用的 VNC 服务器软件。 打开终端并更新你的软件包: sudo apt update安装 tigervnc 服务器:…...

Elastic:如何构建由 AI 驱动的数字客户体验策略
作者:来自 Elastic Elastic Platform Team 客户通过多个数字渠道与企业和组织互动 —— 从网站和应用程序到聊天机器人和电子邮件。这些接触点构成了数字客户体验(DCX)。无缝的数字客户体验能显著提升客户满意度,进而带动更高的收…...

安防多协议接入/视频汇聚平台EasyCVR助力工地/工程/建筑施工领域搭建视频远程监控系统
一、摄像机安装方案 1)安装位置选择:摄像机安装需避开强振源与电磁干扰区,兼顾建筑外观,隐蔽安装。其防护罩应巧妙遮蔽视角,增强安防威慑。电梯轿厢内的摄像机,建议藏于吊顶。连接摄像机的视频、电源及…...

《100天精通Python——基础篇 2025 第16天:异常处理与调试机制详解》
目录 一、认识异常1.1 为什么要使用异常处理机制?1.2 语法错误1.3 异常错误1.4 如何解读错误信息 二、异常处理2.1 异常的捕获2.2 Python内置异常2.3 捕获多个异常2.4 raise语句与as子句2.5 使用traceback查看异常2.6 try…except…else语句2.7 try…except…finally语句--捕获…...

Ceph PG unfound/lost 问题排查与解决
Ceph PG unfound/lost 问题排查与解决 背景现象排查过程经验总结参考命令结语 背景 Ceph 集群出现 HEALTH_ERR,提示有 PG 对象丢失(unfound),并且 repair 无法自动修复。 现象 ceph health detail 显示: HEALTH_ERR …...

LeetCode热题100--54.螺旋矩阵--中等
1. 题目 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5] 示例 2: 输入:ma…...

【嵌入式开发-CAN】
嵌入式开发-CAN ■ CAN简介 ■ CAN简介...

SQLite3介绍与常用语句汇总
SQLite3简介 SQLite3是一款轻量级的、基于文件的开源关系型数据库引擎,由 D. Richard Hipp 于 2000 年首次发布。它遵循 SQL 标准,但与传统的数据库系统不同,SQLite 并不运行在独立的服务器进程中,而是作为一个嵌入式数据库引擎直…...

uniapp中score-view中的文字无法换行问题。
项目场景: 今天遇到一个很恶心的问题,uniapp中的文字突然无法换行了。得..就介样 原因分析: 提示:经过一fan研究后发现 scroll-view为了能够横向滚动设置了white-space: nowrap; 强制不换行 解决起来最先想到的是,父…...

[学习]RTKLib详解:ephemeris.c与rinex.c
文章目录 RTKLib详解:ephemeris.c与rinex.cPART A: ephemeris.c一、代码整体作用与工作流程分析1.1 整体作用1.2 工作流程 二、核心函数说明2.1 alm2pos (Almanac to Position)2.2 eph2clk (Ephemeris to Clock)2.3 eph2pos (Ephemeris to Position)2.4 geph2pos (G…...

JDBC:java与数据库连接,Maven,MyBatis
JDBC 是使用Java语言操作关系型数据库的一套API JDBC是接口,用其实现一系列不同种类关系型数据库的实现类 JDBC本质: 官方(sun公司)定义的一套操作所有关系型数据库的规则,即接口 各个数据库厂商去实现这套接口,提供数据库驱动jar包 我…...

代码随想录第39天:单调栈
一、每日温度(Leetcode 739) 思路: 栈里存放的是**“还没等到升温的日子”**的索引; 每遇到一个新的温度: 检查是否比栈顶的温度高; 如果高了,说明升温来了,栈顶元素可以出栈&…...

如何在vite构建的vue项目中从0到1配置postcss-pxtorem
1. 安装postcss-pxtorem和autoprefixer yarn add postcss-pxtorem autoprefixer2. 在vite.config.ts中写入 import { defineConfig } from "vite"; import vue from "vitejs/plugin-vue"; import postcssPxtorem from "postcss-pxtorem"; impo…...

基于51单片机的自动洗衣机衣料材质proteus仿真
地址:https://pan.baidu.com/s/13d2bJ6vKh8ZLuDBZnI0VGw 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C51 是一款常用的 8 位单片机,由 Atmel 公司(现已被 Microchip 收…...

永久免费的小工具,内嵌微软接口
有时候我们制作短视频,需要为视频添加声音,但部分配音软件要收费。不过别担心,今天给大家推荐一款超实用的免费文字转语音软件,完全无需担忧费用问题! 01 软件介绍 这款软件就是Read Aloud,具有以下特点&a…...

C++漫步结构与平衡的殿堂:AVL树
文章目录 1.AVL树的概念2.AVL树的结构3.AVL树的插入4.AVL树的旋转4.1 左单旋4.2 右单旋4.3 右左双旋4.4 左右双旋 5.AVL树的删除6.AVL树的高度7.AVL树的平衡判断希望读者们多多三连支持小编会继续更新你们的鼓励就是我前进的动力! 二叉搜索树有其自身的缺陷…...

MIST:一键解锁 macOS 历史版本,旧系统安装不再难!
在 Mac 电脑的使用过程中,你是否遇到过这些困扰?为了运行一款经典设计软件,新系统却无法兼容;或是想给老旧 Mac 设备升级,却找不到适配的系统版本。而 App Store 里,旧版 macOS 安装包就像 “隐藏副本”&am…...

mac连接lniux服务器教学笔记
从你的检查结果看,容器内已经安装了 XFCE 桌面环境(xfce.desktop 和 xubuntu.desktop 的存在说明桌面环境已存在)。以下是针对 Docker 容器环境的远程桌面配置方案: 一、容器内快速配置远程桌面(XFCE VNC)…...

网站公安备案流程及审核时间
在中国,网站运营除了需要 ICP备案(工信部备案),还需完成 公安备案(公安机关互联网站安全备案)。以下是详细流程及审核时间说明: 一、公安备案流程 1. 备案对象 所有在中国境内运营的网站&#…...

python学生作业提交管理系统-在线作业提交系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...

从颜料混色到网络安全:DH算法的跨界智慧
一、颜料混色的秘密 想象一下,你和朋友各自有一罐私密的颜料,但你们想共同调出一种只有彼此知道的新颜色,而旁观者即使看到你们的操作也无法复现。奇怪的是,你们全程没有直接交换颜料,却能达成共识——这就是**迪菲-赫…...

初学者的AI智能体课程:构建AI智能体的十堂课
初学者的AI智能体课程:构建AI智能体的十堂课 在人工智能(AI)领域,AI智能体正在逐渐发挥其不容忽视的作用。自动化的智能体不仅仅在理论上广泛讨论,更加在实际应用中开辟了一片新的天地。那么如何动手开发属于自己的AI智能体呢?Microsoft提供的AI智能体入门课正是为此而设…...
)
数据结构 - 8( AVL 树和红黑树 10000 字详解 )
一:二叉搜索树 1.1 回顾二叉搜索树 我们在树的章节中学习了二叉搜索树的概念。二叉搜索树满足以下性质:如果它的左子树存在,则左子树所有节点的值均小于根节点的值;如果右子树存在,则右子树所有节点的值均大于根节点…...

Tcp 通信简单demo思路
Server 端 -------------------------- 初始化部分 ------------------------------- 1.创建监听套接字: 使用socket(协议家族,套接字的类型,0) 套接字类型有 SOCK_STREAM:表示面向连接的套接字(Tcp协议)&…...
,自定义放置位置)
Cesium 导航控件(指南针 + 缩放按钮),自定义放置位置
Cesium 导航控件(指南针 缩放按钮) Cesium 导航控件(指南针 缩放按钮)的功能实现,从技术角度来看,可以整理出一整套实现流程和技术结构。这套流程结合了以下几个核心技术点: 1、整体功能目标 …...

MySQL的索引和事务
目录 1、索引 1.1 查看索引 1.2 创建索引 1.3 删除索引 1.4 索引的实现 2、事务 1、索引 索引等同于目录,属于针对查询操作的一个优化手段,可以通过索引来加快查询的速度,避免针对表进行遍历。 主键、unique和外键都是会自动生成索引的…...

【Fifty Project - D25】
今日完成记录 TimePlan完成情况9:00 - 11:30大论文修改修改情况书小论文修改√16:00 - 17 :00Leetcode√ Leetcode 每日一题 到达最后一个房间的最小时间II:和昨天的每日一题大致一样,增加一个条件&…...

pip下载tmp不够
问题描述 今天遇到一个小问题,在用pip安装的时候提示 ERROR: Could not install packages due to an OSError: [Errno 28] No space left on device 但我们单位用于生产环境的机器磁盘都是基本是论TB的,怎么会不够呢? 原因分析:…...

一种机载扫描雷达实时超分辨成像方法——论文阅读
一种机载扫描雷达实时超分辨成像方法 1. 专利的研究目标与产业意义1.1 研究目标与实际问题1.2 产业意义2. 专利的创新方法:滑窗递归优化与实时更新2.1 核心模型与公式2.2 与传统方法对比优势3. 实验设计与验证3.1 仿真参数3.2 实验结果4. 未来研究方向与挑战4.1 学术挑战4.2 技…...
)
nginx 会话保持(cookie的配置)
nginx会话保持主要有以下几种实现方式。 1. ip_hash ip_hash使用源地址哈希算法,将同一客户端的请求总是发往同一个后端服务器,除非该服务器不可用。 ip_hash语法: upstream backend { ip_hash; server backend1.example.com; server backend2.example.com; …...

nginx 实现动静分离
环境 : 三个机器,准备一个nginx代理 两个http 分别处理动态和静态 知识点--expires expires功能说明---(为客户端配置缓存时间) nginx缓存的设置可以提高网站性能,对于网站的图片,尤其是新闻网站,图片一旦发布,改动的可能是非常小的,为了减小对服务器请求的压力,提高…...

k8s的pod挂载共享内存
k8s的pod挂载共享内存,限制不生效问题: 注:/dev/shm 是 Linux 系统中用于共享内存的特殊路径。通过将 emptyDir 的 medium 设置为 Memory,可以确保 /dev/shm 正确地挂载到一个基于内存的文件系统,从而实现高效的共享内…...

Java高频面试之并发编程-14
hello啊,各位观众姥爷们!!!本baby今天又来报道了!哈哈哈哈哈嗝🐶 面试官:指令重排有限制没有?happens-before 又是什么? 在并发编程中,指令重排(…...