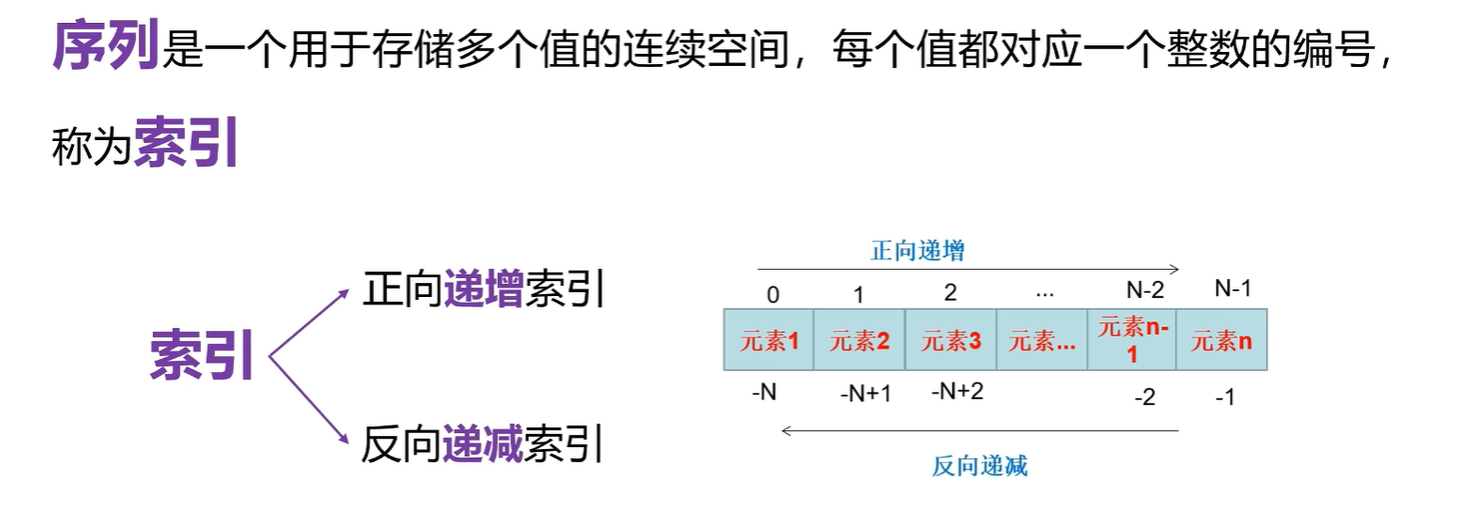
python基础:序列和索引-->Python的特殊属性
一.序列和索引
1.1 用索引检索字符串中的元素
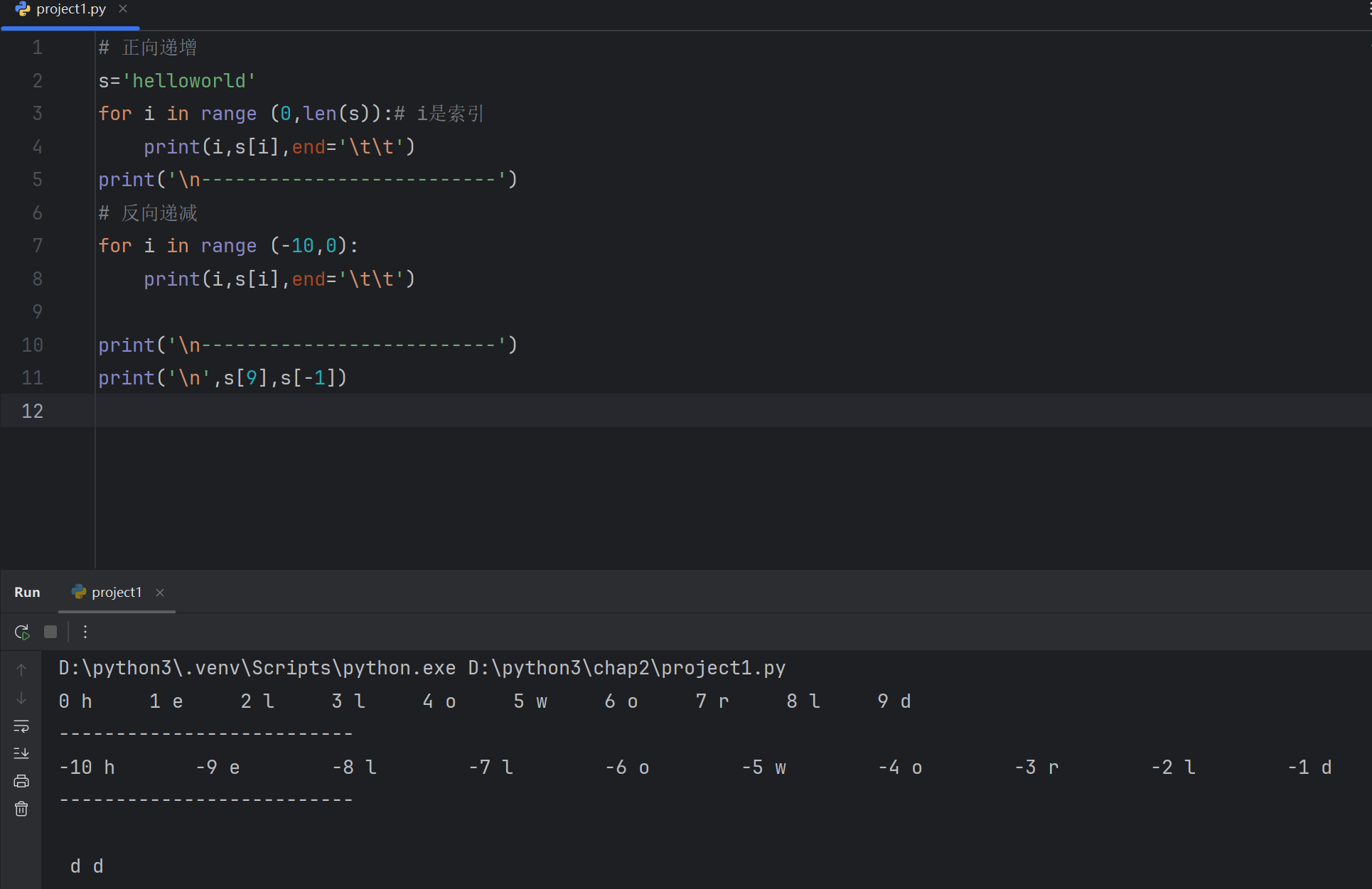
# 正向递增
s='helloworld'
for i in range (0,len(s)):# i是索引print(i,s[i],end='\t\t')
print('\n--------------------------')
# 反向递减
for i in range (-10,0):print(i,s[i],end='\t\t')print('\n--------------------------')
print('\n',s[9],s[-1])
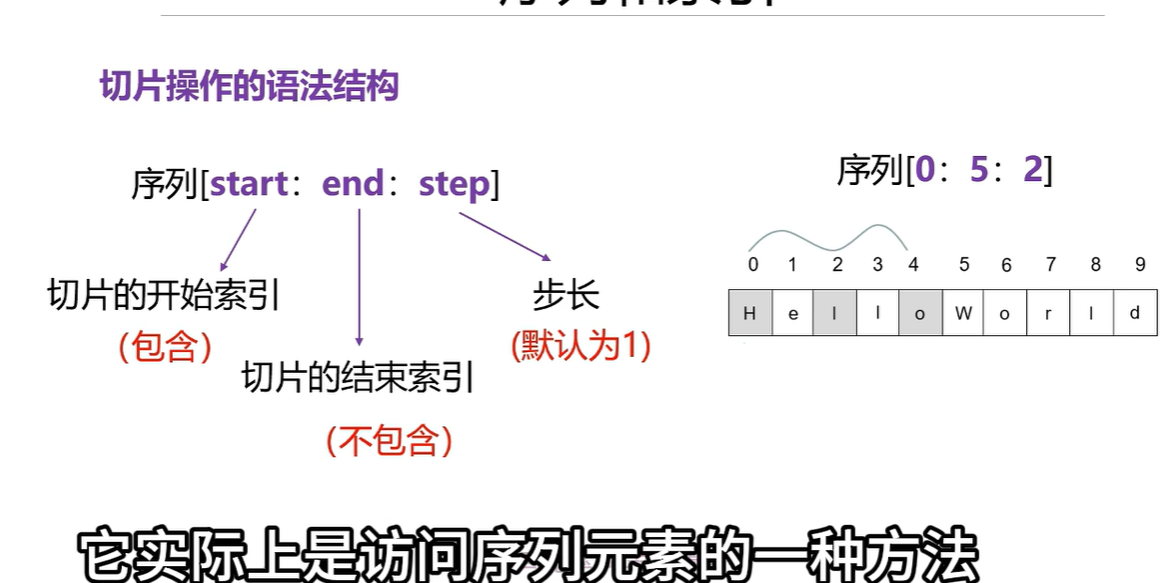
1.2通过切片操作可以获取一个新的序列(从0开始切到五不包含5,步长为2)
s='hello'
s2='world'
print(s+s2)#产生一个新的字符串序列
# 序列的相乘操作
print(s*5)
print('-'*40)
1.3序列的箱操作和函数的使用
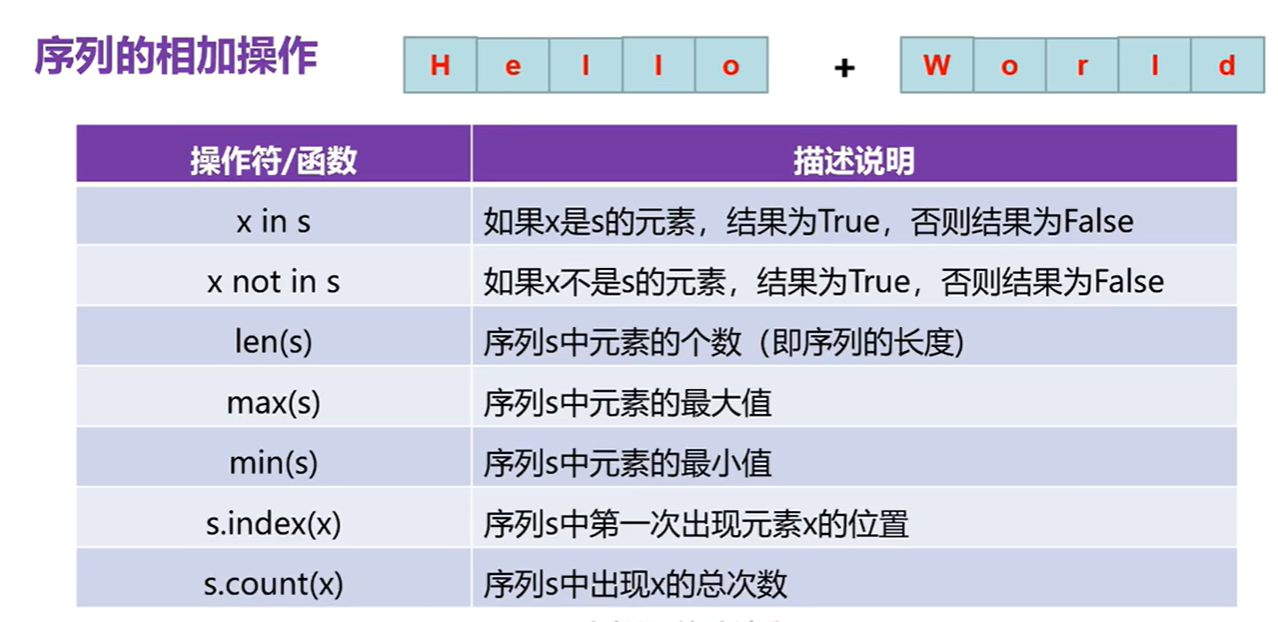
s='helloworld'
print('e在helloworld中存在吗',('e'in s))
print('e在helloworld中存在吗',('v'in s))#not in的使用
print('e在helloworld中存在吗',('e'not in s))# not in的使用
print('e在helloworld中存在吗',('v'not in s))#内置函数的使用
print('len()',len(s))
print('min(s)',min(s))
print('max(s)',max(s))# 序列对象的方法,使用序列的方法,打点调用
print('s.index():',s.index('o'))#o在s中第一次出现的索引位置4
print('s.count():',s.count('o'))#统计o在字符串之间的位置
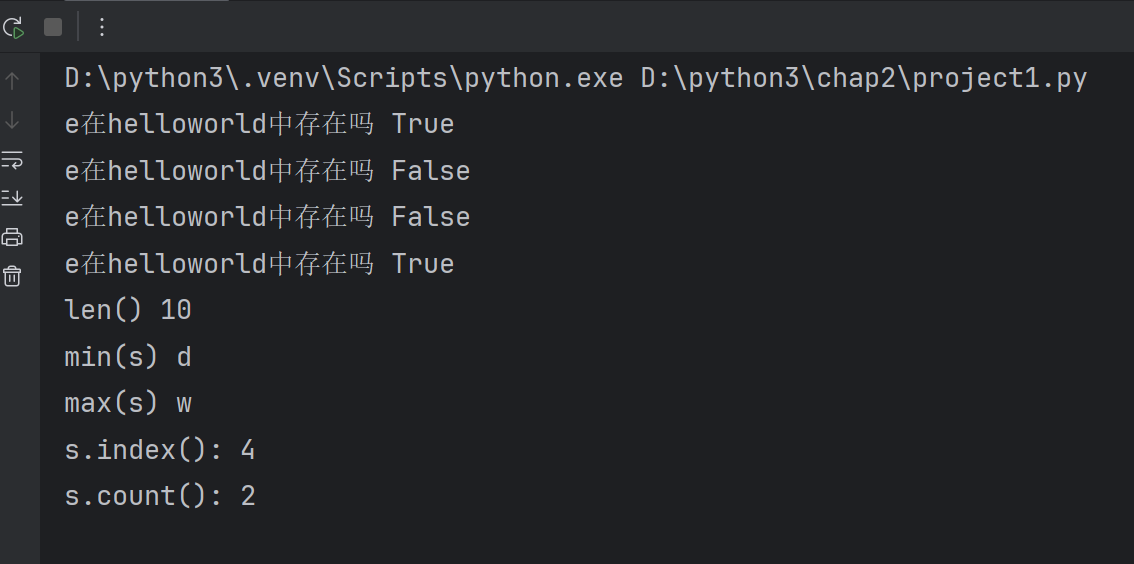
二.列表的基本操作

列表名是自己取的变量名,列表与字符串一样,都是序列中的一种

lst=['hello','world',98,100.5]
print(lst)
# 可以使用内置的函数list()创建列表
lst2=list('helloworld')
lst3=list(range(1,10,2))#从1开始到10结束,步长为2,不包含10,1、3、5、7、9
print(lst2)
print(lst3)#列表是序列中的一种,对列表的操作符,运算符,函数均可操作
print(lst+lst2+lst3)# 序列中的相加操作
print(lst*3)#序列的相乘操作
print(len(lst))
print(max(lst3))
print(min(lst3))print(lst2.count('o'))#统计o的个数
print(lst2.index('o'))# o在列表lst2中第一次的位置# 列表的删除操作
lst4=[10,20,30,40,50]
print(lst4)
# 删除列表
del lst4
#print(lst4)
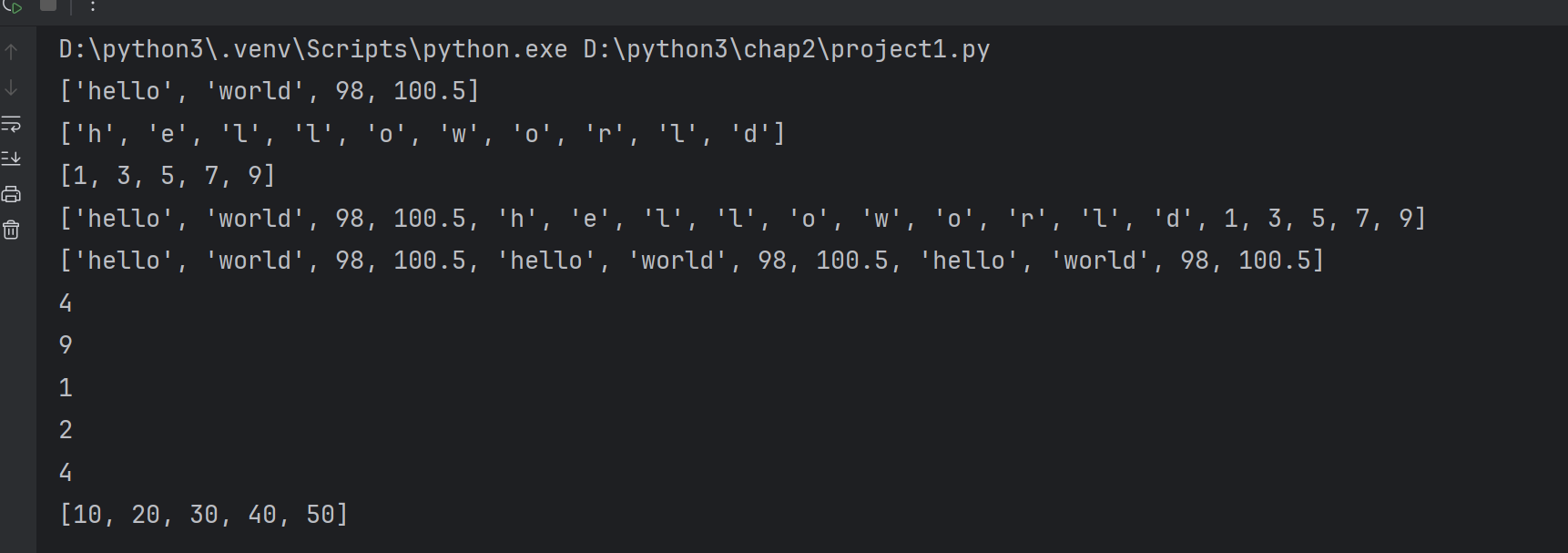

列表的遍历操作
lst=['hello','world','python','php']
# for循环遍历元素
for item in lst:print(item)# 使用for循环,range()函数,len()函数,根据索引进行遍历
for i in range(0,len(lst)):print(i,'--->',lst[i])# 第三种遍历方式 enumerate()函数
for index,item in enumerate(lst):print(index,item)# index是序号,不是索引 元素
#手动修改序号的起始值
for index,item in enumerate(lst,start=1):#直接写1,start不写也可以print(index,item)
2.1列表特有操作

列表的相关操作
lst=['hello','world','python']
print('原列表',lst,id(lst))
#增加元素的操作
lst.append('sql')
print('增加元素之后',lst,id(lst))#使用insert(index,x)在指定的index位置上插入元素x
lst.insert(1,100)
print(lst)#列表元素的删除操作
lst.remove('python')
print('删除元素之后的列表',lst,id(lst))#使用pop(index)根据索引将元素取出,然后再删除
print(lst.pop(1))
print(lst)#清除列表中所有的元素clear()
# lst.clear()
# print(lst,id(lst))#列表的反向
lst.reverse()#不会产生新的列表,在原列表的基础上进行的
print(lst)# 列表的拷贝,将产生的一个新的列表对象
new_lst=lst.copy()
print(lst,id(lst))
print(new_lst,id(new_lst))#列表元素的修改操作
#根据索引进行修改元素
lst[1]='mysql'
print(lst)
ctrl+?:注释
列表的排序操作
lst=[4,56,3,78,40,56,89]
print('原列表',lst)#排序,默认是升序
lst.sort()#排序是在原列表的基础上进行的,不会产生新的列表
print(lst)
print('升序',lst)#排序,降序
lst.sort(reverse=True)#大的在前小的在后
print('降序',lst)print('------------------------------')
lst2=['banana','apple','Cat','Orange']
print('原列表',lst2)
#升序排序,先排大写,再排小写 大写A 65,小写a 97
lst2.sort()#默认升序
print('升序',lst2)#降序,先排小写,后排大写
lst2.sort(reverse=True)
print('降序:',lst2)# 忽略大小写进行比较
lst2.sort(key=str.lower)# 参数不加括号,调用加括号
print(lst2)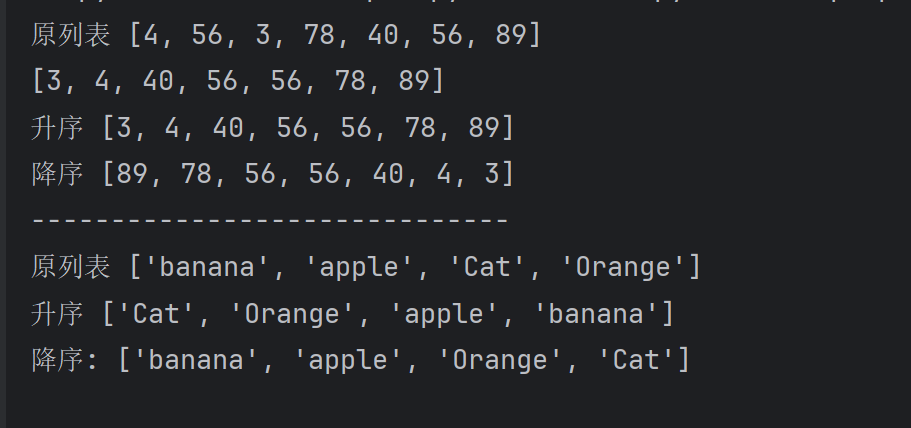
列表的排序sorted
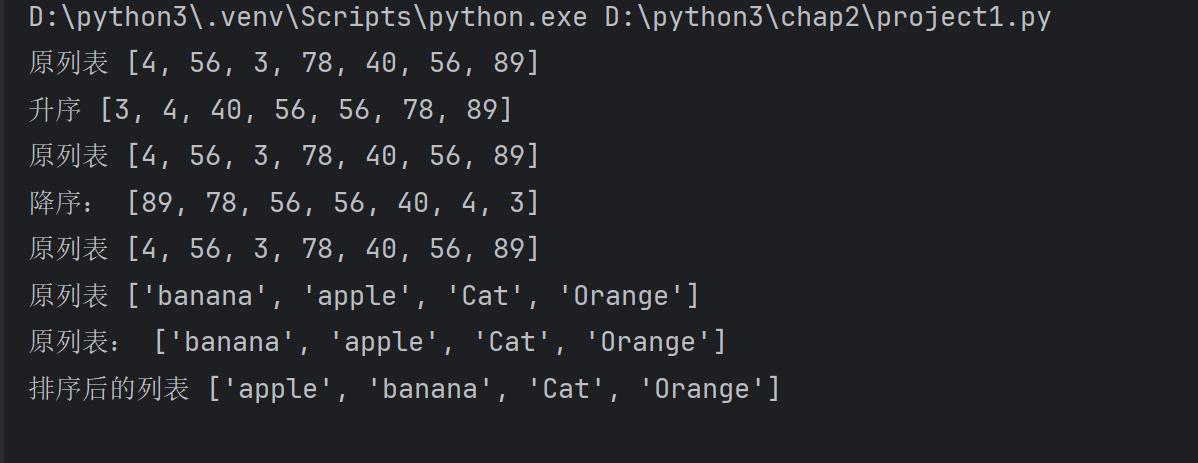
lst=[4,56,3,78,40,56,89]
print('原列表',lst)#排序
asc_lst=sorted(lst)
print('升序',asc_lst)
print('原列表',lst)#降序
desc_lst=sorted(lst,reverse=True)
print('降序:',desc_lst)
print('原列表',lst)lst2=['banana','apple','Cat','Orange']
print('原列表',lst2)#忽略大小写进行排序
new_lst2=sorted(lst2,key=str.lower)
print('原列表:',lst2)
print('排序后的列表',new_lst2)#默认升序
2.2 列表的生成式及二维列表
2.2.1一维列表

列表生成式的使用
import random
lst=[item for item in range(1,11)]
print(lst)lst=[item*item for item in range(1,11)]
print(lst)lst=[random.randint(1,100) for _ in range(1,11)]
print(lst)# 从列表中选择符合条件的元素组成新的列表
lst=[i for i in range(10) if i%2==0 ]
print(lst)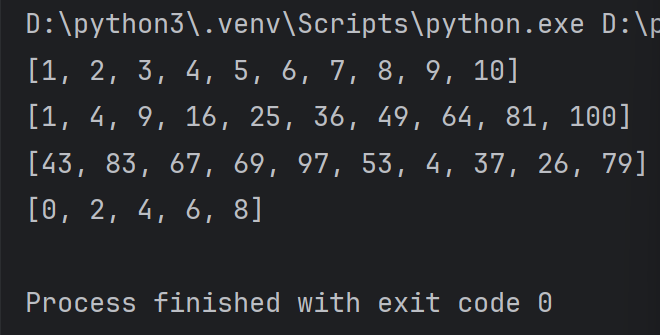
2.2.2 二维列表
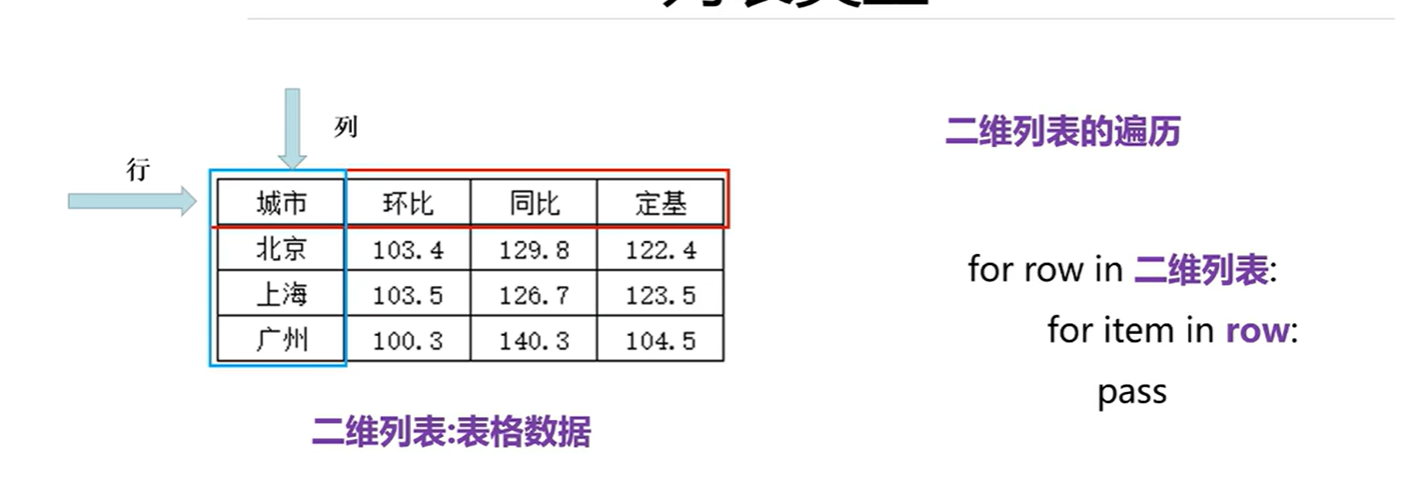
二维列表的遍历及列表生成式
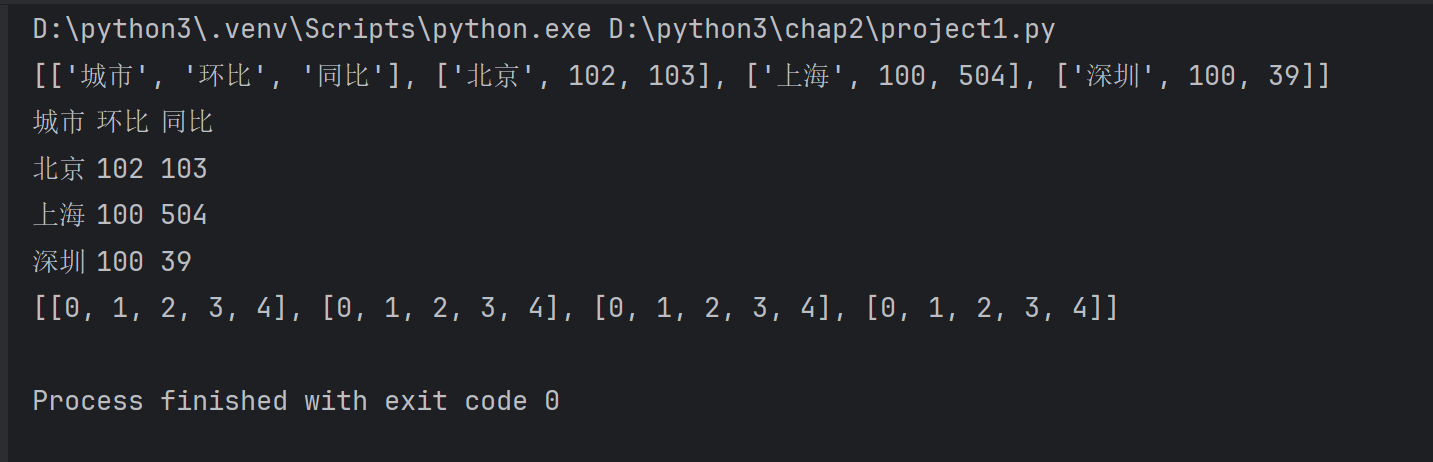
# 创建二维列表
lst=[['城市','环比','同比'],['北京',102,103],['上海',100,504],['深圳',100,39]
]
print(lst)#遍历二维列表使用双层for循环
for row in lst:#行for item in row:#列print(item,end='\t')print()#换行#列行生成式生成一个4行5列的二维列表
lst2=[[j for j in range(5)]for i in range(4)]
print(lst2)
2.3元组的创建与删除

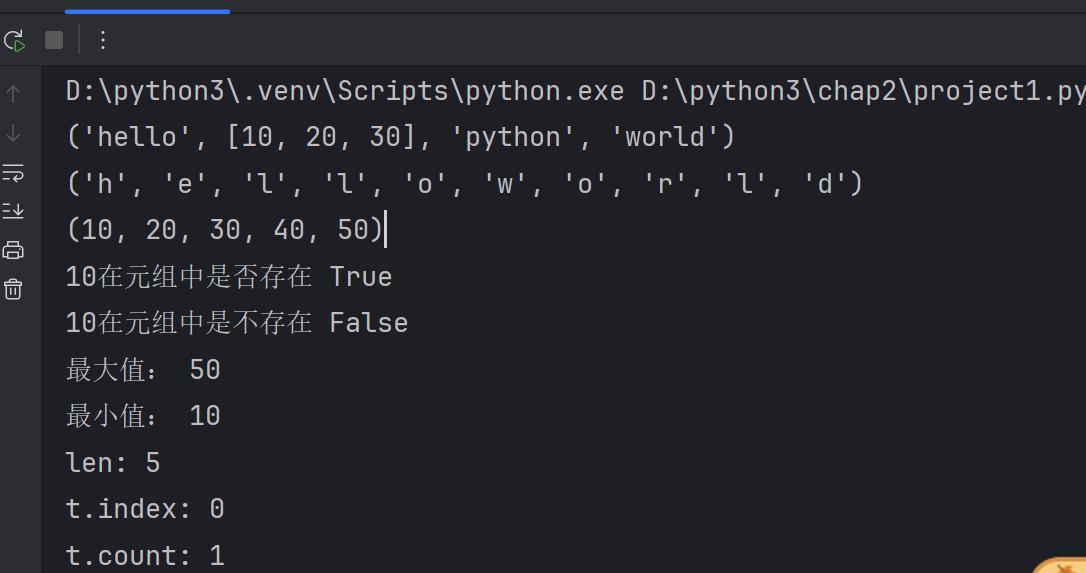
# 使用小括号创建元组
t=('hello',[10,20,30],'python','world')
print(t)# 使用内置函数tuple()创建元组
t=tuple('helloworld')
print(t)t=tuple([10,20,30,40,50])
print(t)print('10在元组中是否存在',(10 in t))
print('10在元组中是不存在',(10 not in t))
print('最大值:',max(t))
print('最小值:',min(t))
print('len:',len(t))
print('t.index:',t.index(10))
print('t.count:',t.count(10))#如果元组中只有一个元素
t=(10)
print(t,type(t))#如果元组只有一个元素,逗号不能省略
y=(10,)
print(y,type(y))#元组的删除
del t
#print(t)
2.4 元组元素的遍历和访问
t=('python','hello','world')
# 根据索引访问元组
print(t[0])
t2=t[0:3:2]#元组支持切片操作
print(t2)#元组的遍历
for item in t:print(item)# for+range()+len()
for i in range(len(t)):print(i,t[i])# 索引 根据索引获取到的元素# 使用enumerate
for index,item in enumerate(t):print(index,'----->',item)for index,item in enumerate(t,start=11): #序号从11开始print(index,'----->',item)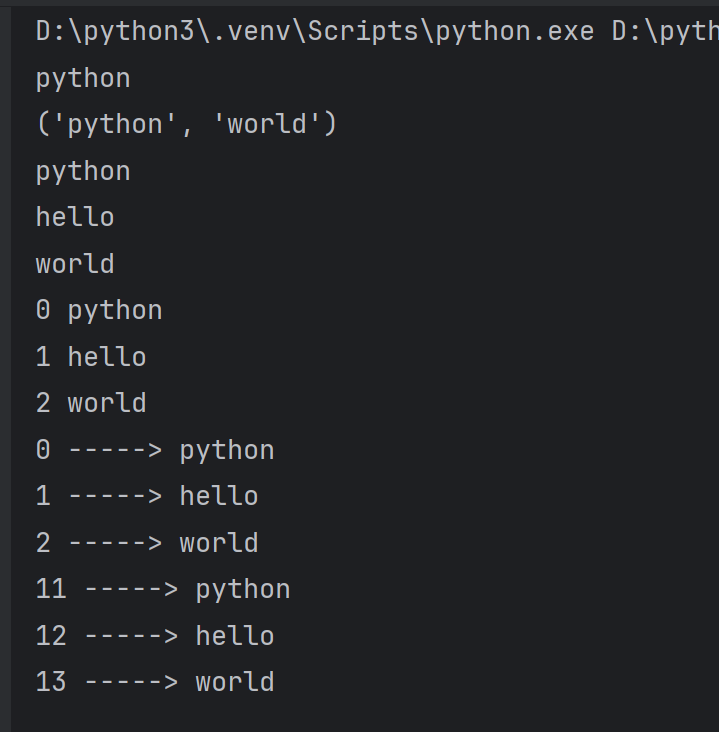
2.5 元组生成式
t=(i for i in range(1,4))
print(t)#t是生成器对象
# t=tuple(t)
# print(t)
#遍历
#for item in t:
# print(item)
print(t.__next__())
print(t.__next__())
print(t.__next__())t=tuple(t)
print(t)# 使用__next__()方法已经把生成器中的元素取出来了,里面没有元素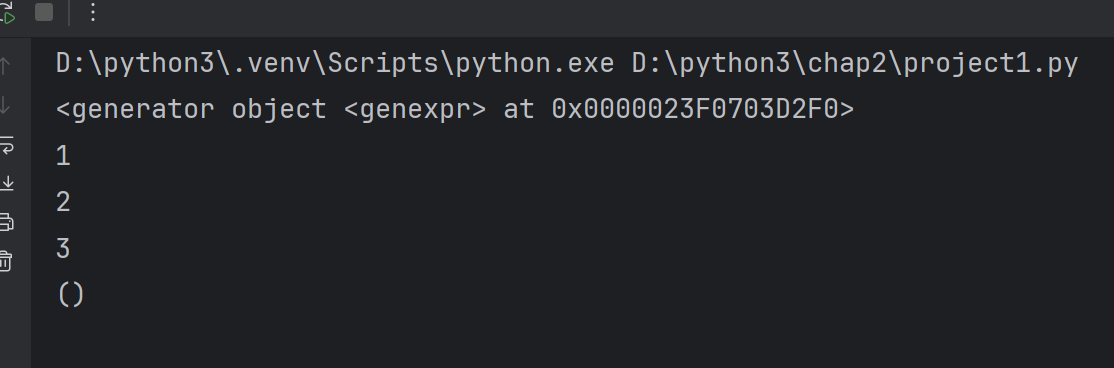
2.6 字典类型


2.6.1 字典的创建与删除
# 1.创建字典
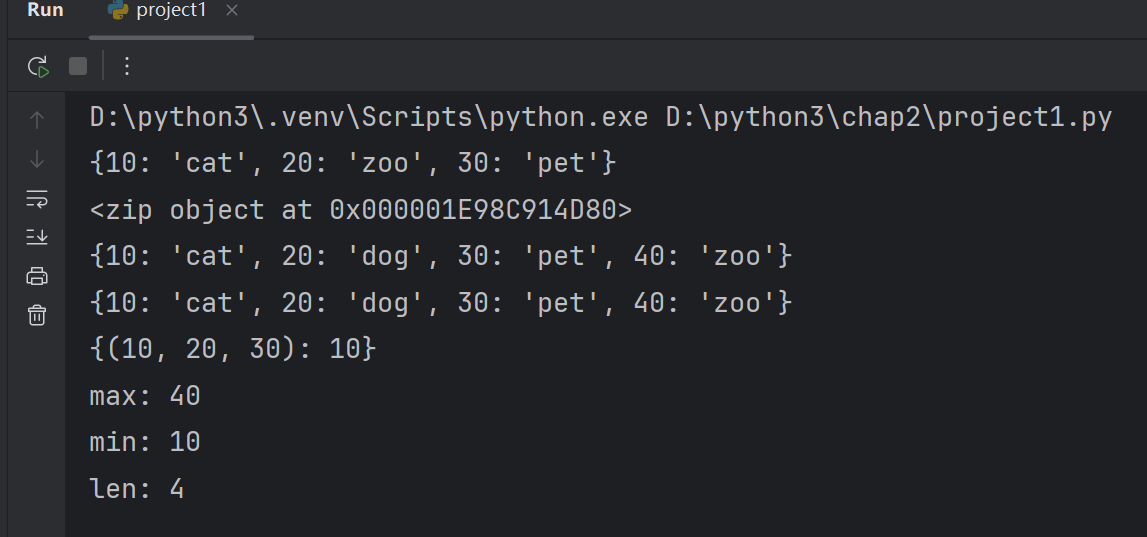
d={10:'cat',20:'dog',30:'pet',20:'zoo'}
print(d)# key相同时,value值进行覆盖# 2.zip函数
lst1=[10,20,30,40]
lst2=['cat','dog','pet','zoo','car']
zipobj=zip(lst1,lst2)
print(zipobj)#<zip object at 0x0000020A30625500>(zip映射对象,看不到里面内容)
#print(list(zipobj))zipobj映射对象里面的内容已经转成列表类型,不能再转成字典了
d=dict(zipobj)
print(d)#使用参数创建字典
d=dict(zip(lst1,lst2))# 左侧cat是key,右侧是value
print(d)t=(10,20,30)
print({t:10})# t是key,10是value,元组是可以作为字典中的key# lst=[10,20,30]#列表和元组目前的区别只是创建符号,元组使用小括号,列表使用方括号
# print(lst:10) SyntaxError: invalid syntax
#列表不可以去作为字典当中的键,列表是可变数据类型#字典属于序列
print('max:',max(d))
print('min:',min(d))
print('len:',len(d))#长度计算式字典当中元素的个数#字典的删除
del d
#print(d)删除之后就不能再使用了
字典中的key是无序的,解释器是帮忙处理了,所以有序
2.6.2 字典元素的访问和遍历

d={'hello':10,'world':20,'python':30}
# 访问字典中的元素
# 1.使用d[key]
print(d['hello'])
# 2. d.get(key)
print(d.get('hello'))# 二者之间是有区别的,如果key不存在,d[key]报错。get(key)
#print(d.['java']) SyntaxError: invalid syntax
print(d.get('java'))#None
print(d.get('java','不存在'))#字典的遍历
for item in d.items():print(item) # key=value组成的一个元组类型# 在使用for循环遍历时,分别获取key,value
for key,value in d.items():print(key,'----->',value)
2.6.3字典操作及相关方法
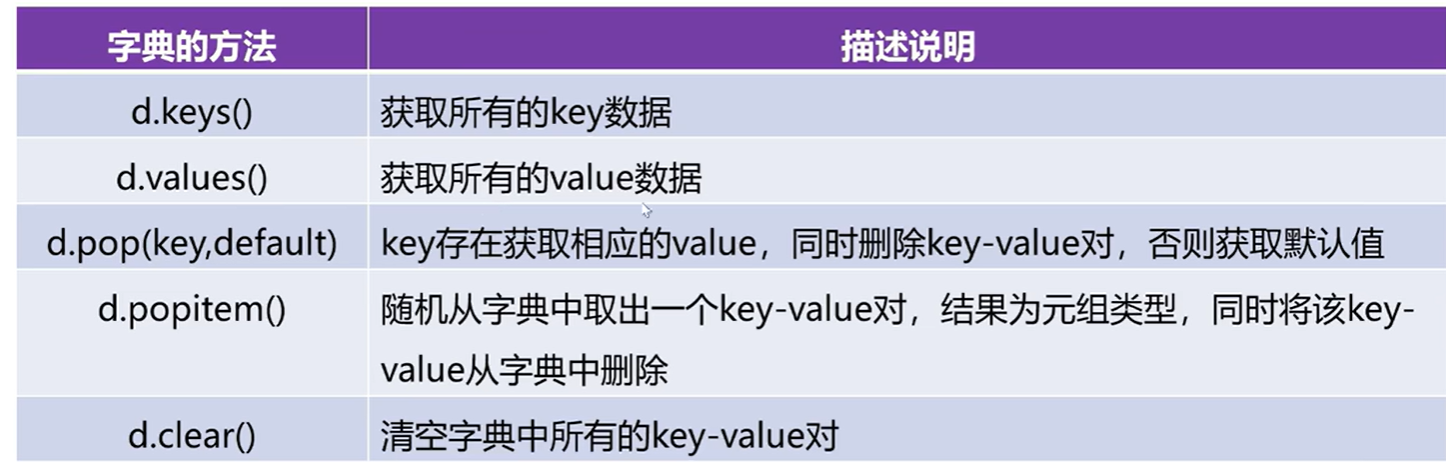
d={1001:'李梅',1002:'王华',1003:'张峰'}
print(d)# 向字典中添加元素
d[1004]='张丽丽'#直接使用赋值运算符向字典中添加元素
print(d)#获取字典中所有的key
keys=d.keys()
print(keys)#dict_keys([1001, 1002, 1003, 1004])
print(list(keys))#转成列表类型查看元素 方括号
print(tuple(keys))# 转成元组类型查看元素 小括号#获取字典中所有的value
values=d.values()
print(values)#dict_values(['李梅', '王华', '张峰', '张丽丽'])
print(list(values))#转成列表类型
print(tuple(values))#转成元组类型# 如果将字典中的数据转成key-value的形式,以元组的方式进行展现
lst=list(d.items())
print(lst)#映射的结果d=dict(list)#转成字典类型
print(d)#使用pop函数
print(d.pop(1001))
print(d)print(d.pop(1008,'不存在'))# 随机删除
print(d.popitem())
print(d)# 清空字典中所有的元素
d.clear()
print(d)
# python中一切皆对象,每个对象都有一个布尔值
print(bool(d))#空字典的布尔值为False
2.6.4 字典生成式

import random
d={ item:random.randint(1,100) for item in range(1,4) }#item(0 1 2 3)做键
#item:random.randint(1,100) 1-100之间随机数做值
print(d)#创建两个列表
lst=[1001,1002,1003]
lst2=['张三','王五','李四']#第一个列表元素做键,第二个元素列表做值
d={key:value for key,value in zip(lst,lst2)}
print(d)
2.7.1集合的创建与删除

#{}直接创建集合
s={10,20,30,40}
print(s)#集合只能存储不可变数据类型
#s={[10,20],[30,40]} 列表不能进行hash的类型
print(s)#使用set()创建集合
s=set()#创建一个空集合,空集合的布尔值是false
print(s)
s={} #创建的是集合还是字典呢?字典
print(s,type(s))#dicts=set('helloworld')
print(s)s2=set([10,20,30])
print(s2)s3=set(range(1,10))
print(s3)#集合属于序列的一种
print('max',max(s3))
print('min',min(s3))
print('len',len(s3))print('9在集合中存在吗',(9 in s3))
print('9在集合中不存在吗',(9 not in s3))# 集合的删除操作
del s3
#print(s3)#未定义
2.7.2集合类型

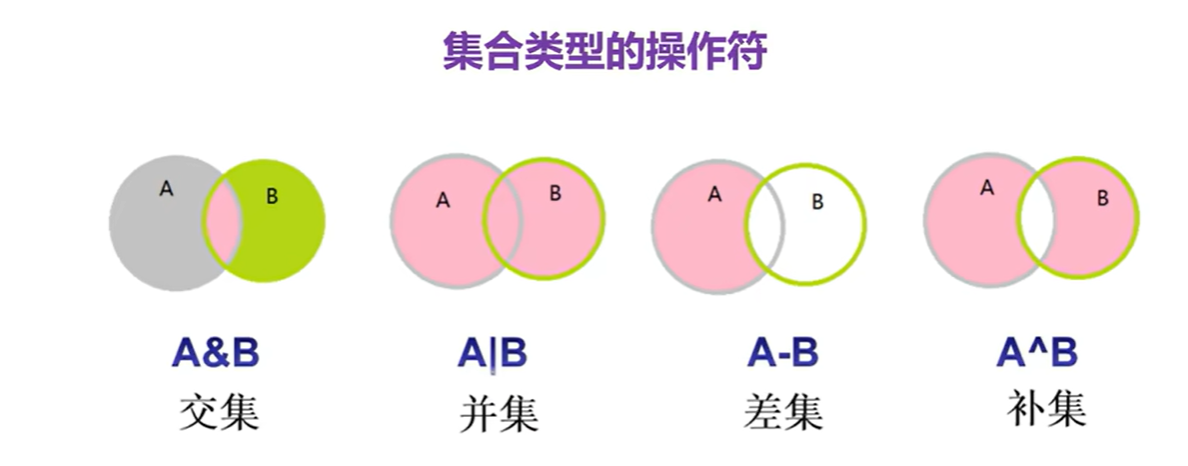
集合的操作符
A={10,20,30,40,50}
B={30,50,88,76,20}
# 交集操作
print(A&B)#两个集合中共有的部分
#并集
print(A|B)
#差集
print(A-B)#补集操作:得到不相交的部分
print(A^B)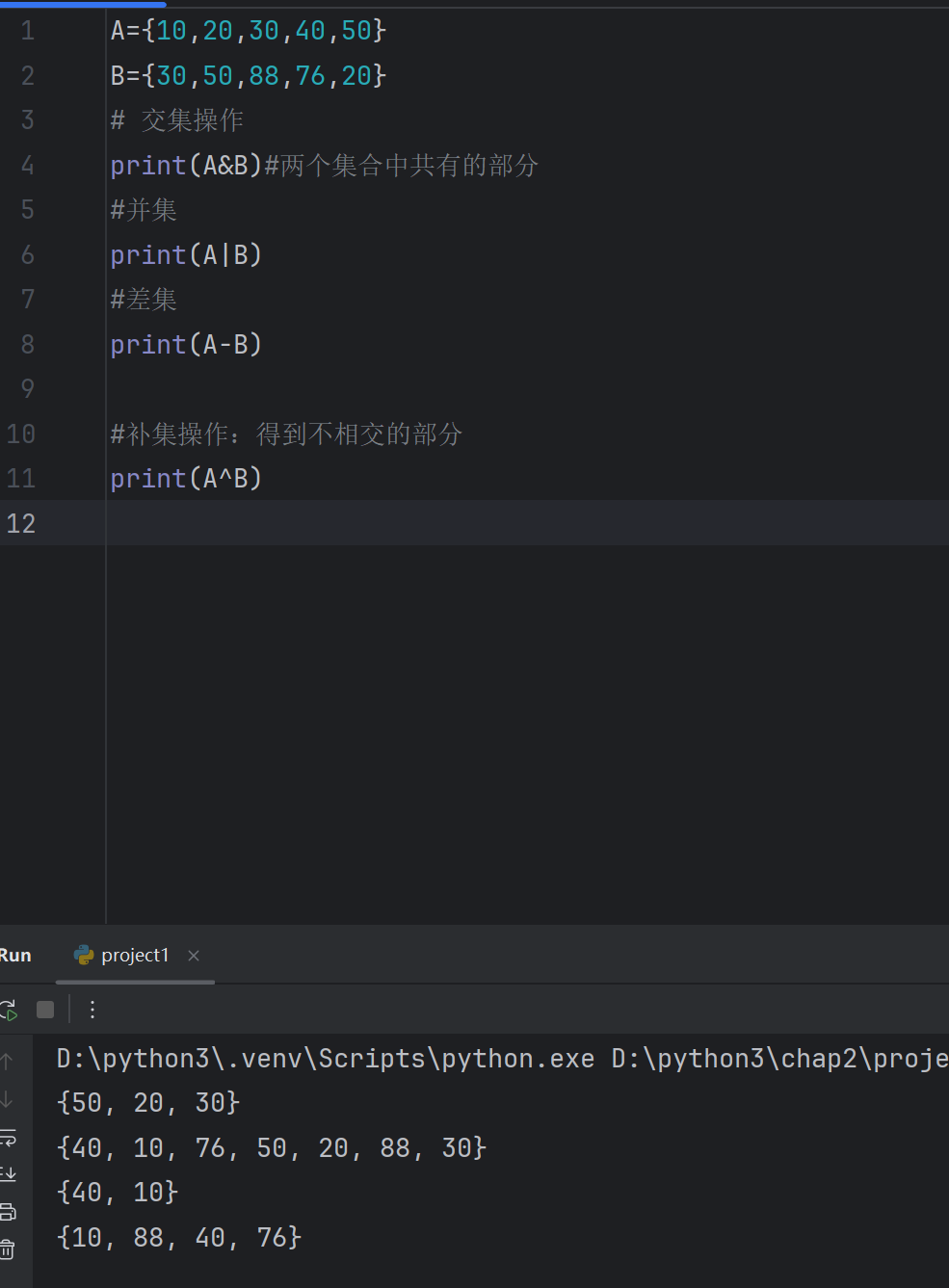
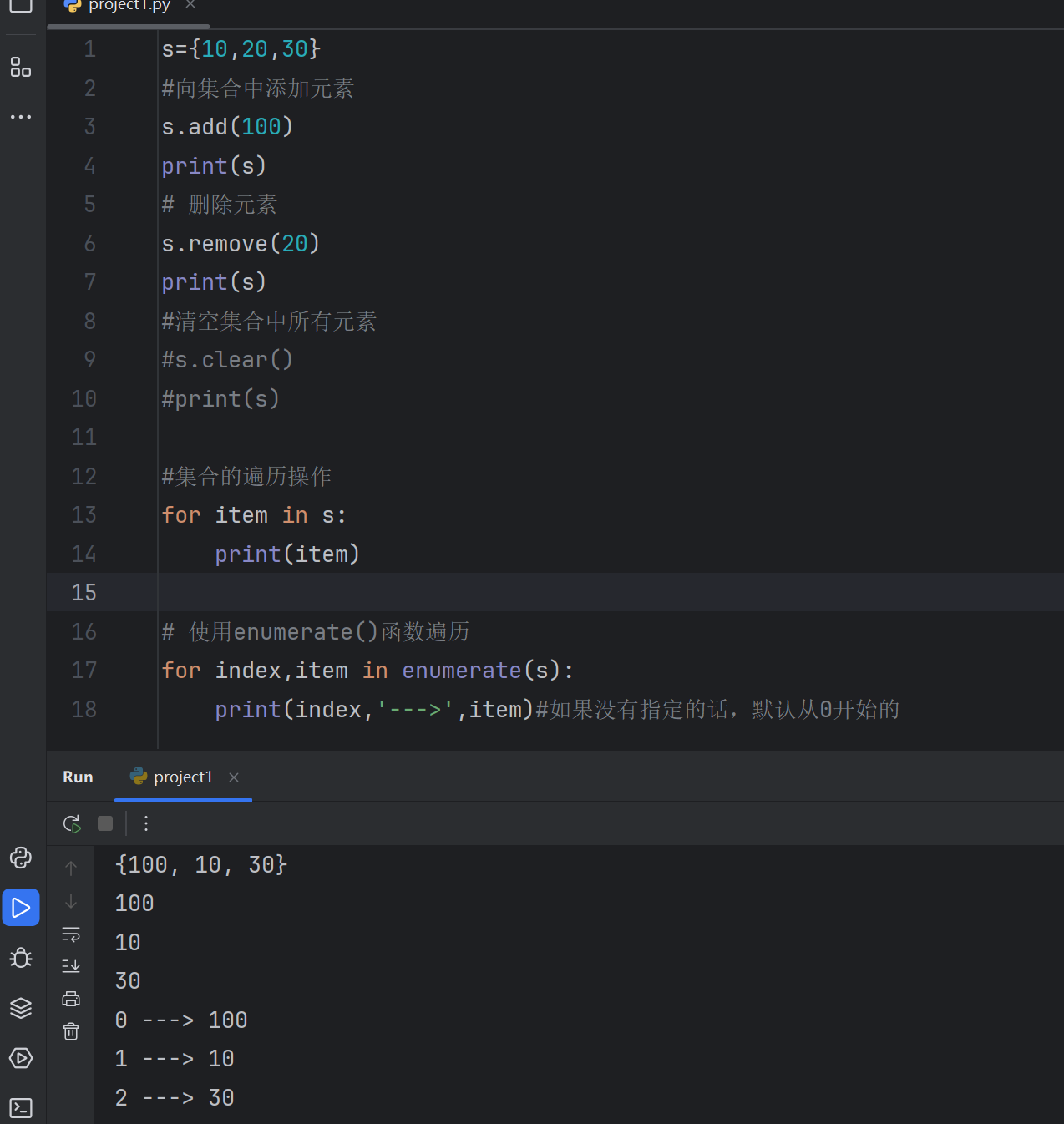
2.7.3 集合的操作方法及集合的遍历:集合的遍历可以使用for与enumerate函数来进行

s={10,20,30}
#向集合中添加元素
s.add(100)
print(s)
# 删除元素
s.remove(20)
print(s)
#清空集合中所有元素
#s.clear()
#print(s)#集合的遍历操作
for item in s:print(item)# 使用enumerate()函数遍历
for index,item in enumerate(s):print(index,'--->',item)#如果没有指定的话,默认从0开始的#集合的生成式
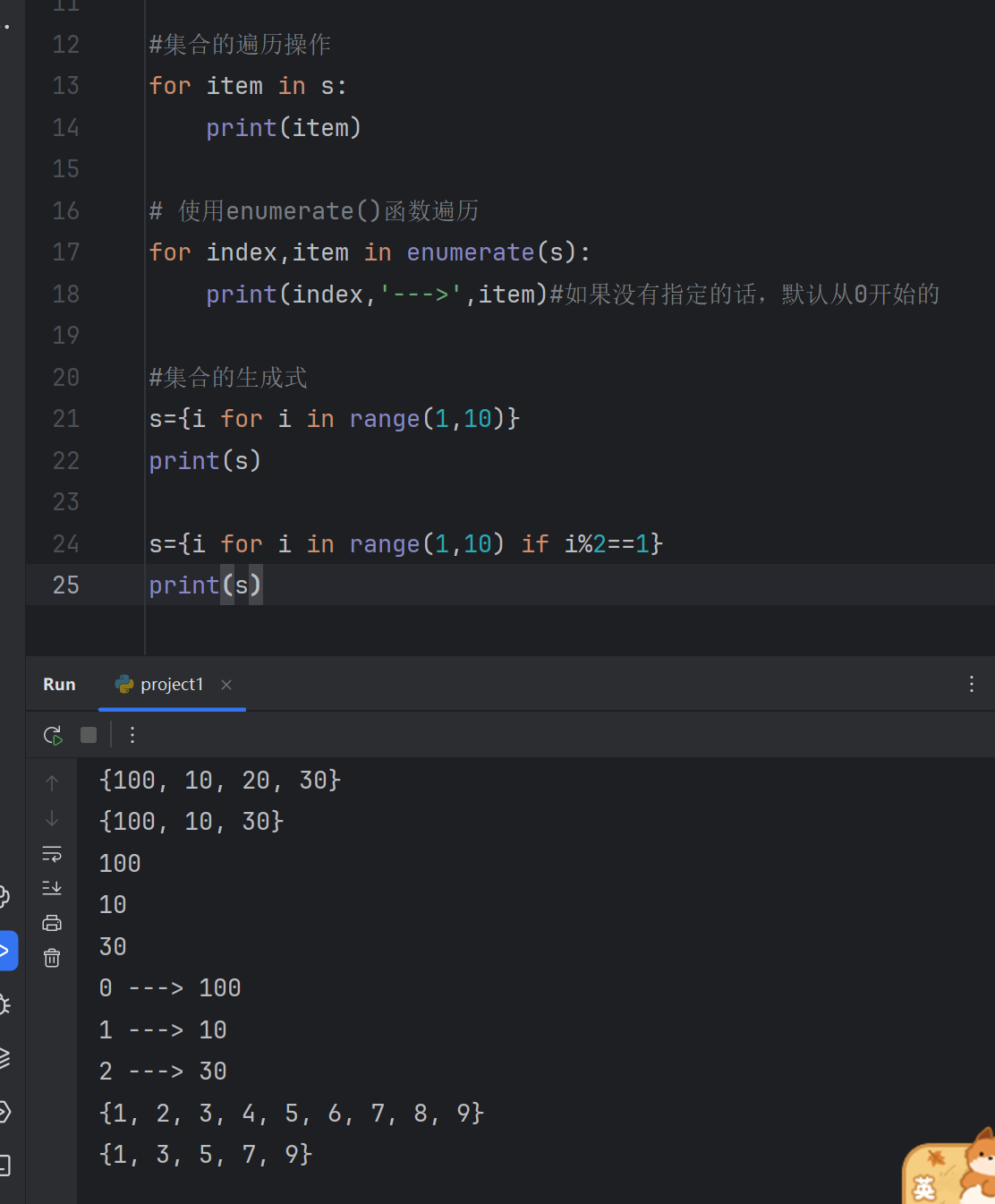
s={i for i in range(1,10)}
print(s)s={i for i in range(1,10) if i%2==1}
print(s)
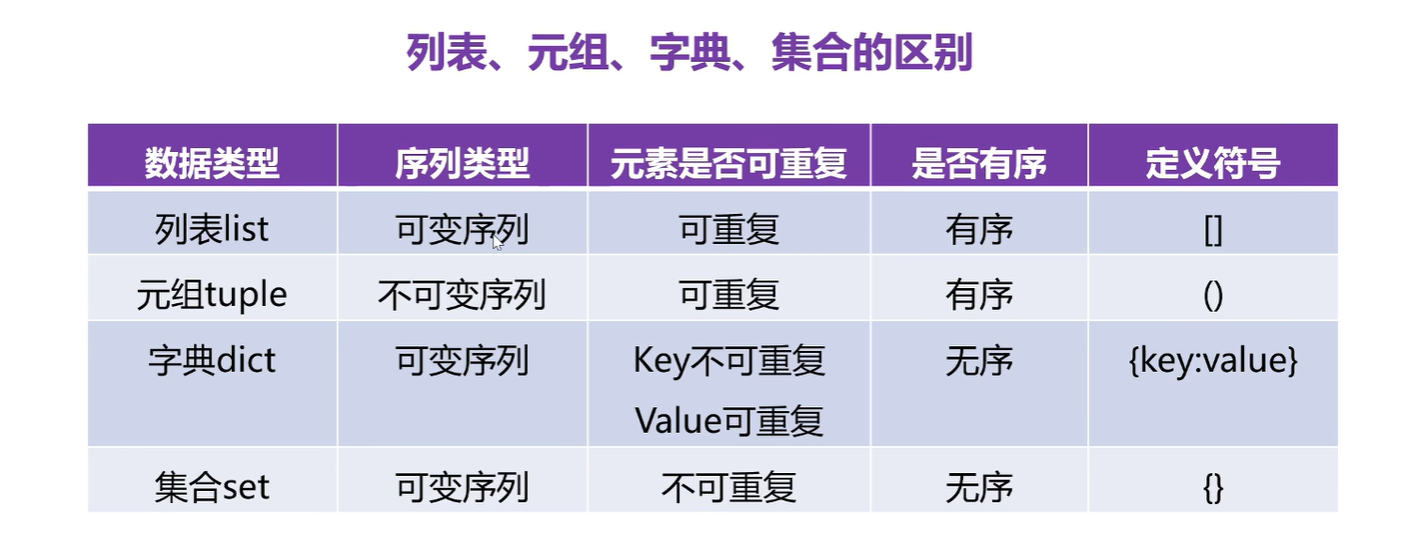
列表是插入顺序。元组是唯一不可变数据类型,使用()定义。字典是无序的,因为底层用到了hash表,定义符号用{}。
2.8 python3.11新特性

2.8.1 结构的模式匹配
data=eval(input('请输入要匹配的数据'))
match data:case {'name':'yy','age':22}:print('字典')case [10,20,30]:print('列表')case (10,20,40):print('元组')case _:print('相当于多重if中的else')
#如果是输入helloworld,helloworld未定义,“helloworld”当去掉一对引号,还带有一对引号
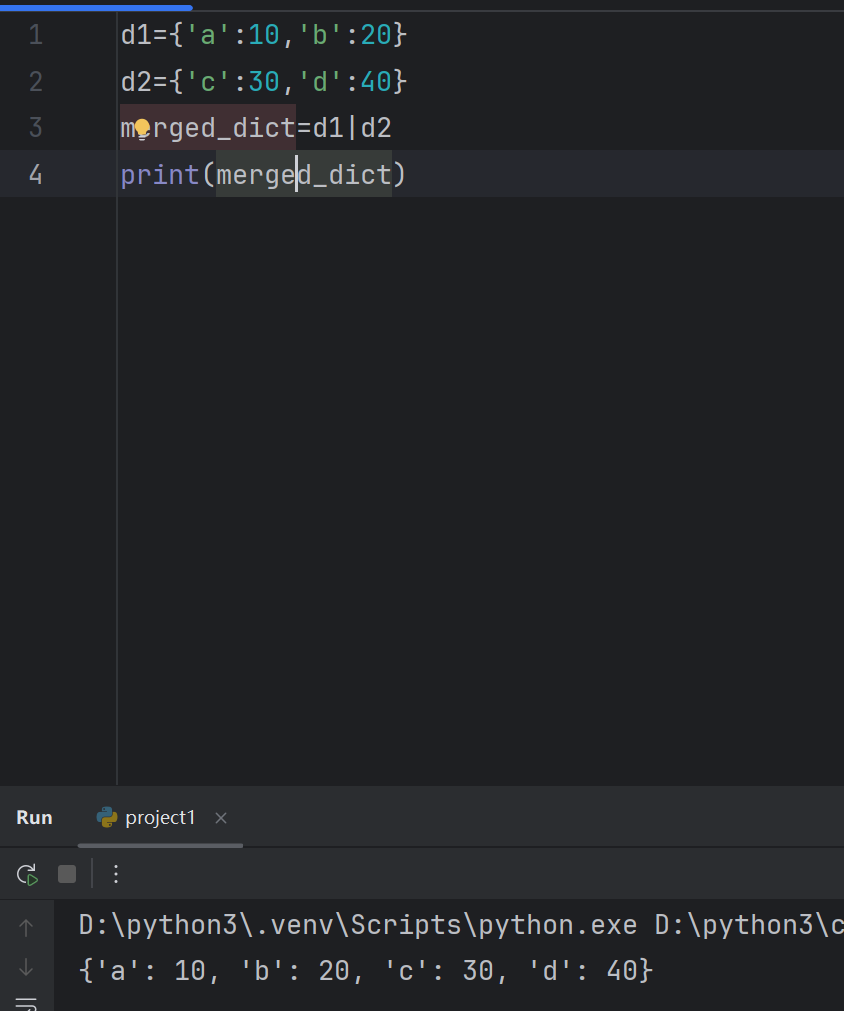
2.8.2 合并字典运算符
d1={'a':10,'b':20}
d2={'c':30,'d':40}
merged_dict=d1|d2
print(merged_dict)
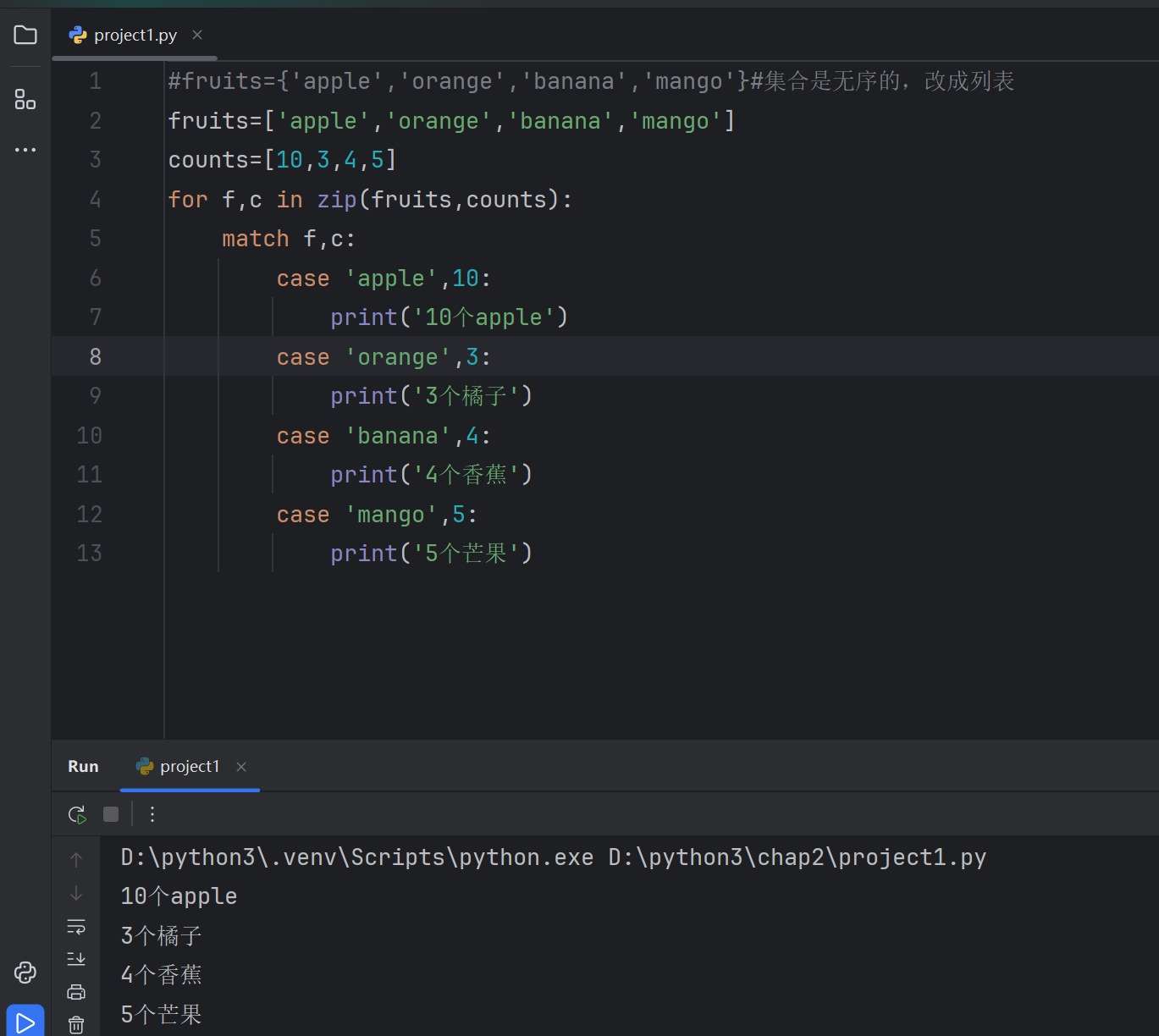
2.8.3同步迭代
#fruits={'apple','orange','banana','mango'}#集合是无序的,改成列表
fruits=['apple','orange','banana','mango']
counts=[10,3,4,5]
for f,c in zip(fruits,counts):match f,c:case 'apple',10:print('10个apple')case 'orange',3:print('3个橘子')case 'banana',4:print('4个香蕉')case 'mango',5:print('5个芒果')
本章总结
列表是无序序列。

在元组中只有一个函数的时候,逗号不能省略。创建字典的方式使用{}直接创建,使用内置函数创建,第一种得到zip对象,需要进行类型转换。第二种左边是键,右边是值。字典是可变数据类型,具有查询的方法
get()获取单个值,keys()获取所有键,values获取所有的值,items获取所有的键值对


列表中有四个元素,向列表中添加一个元组‘hello,world’,将元组作为一个元素添加到列表当中

d是一个字典,d2和d指向同一个内存空间,把b的值修改为100,d2也是100

在字典中的键是不可变数据类型,1是整数,不可变数据类型。元组是不可变数据类型做键可以,字符串是不可变数据类型做键可以,列表是可变数据类型,不能做字典中的键

第四个元素是列表,是整体作为一个元素添加进来
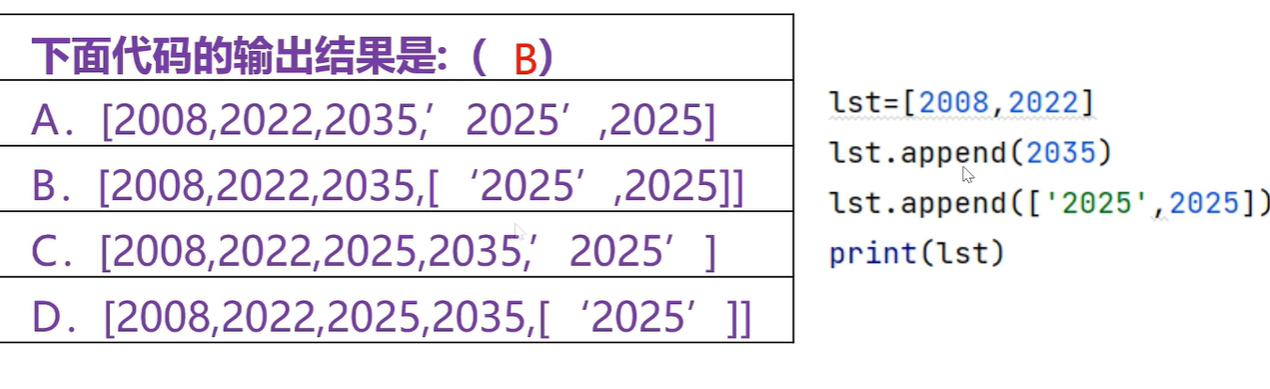

在索引为2的位置添加20

reverse没有返回值



章节习题

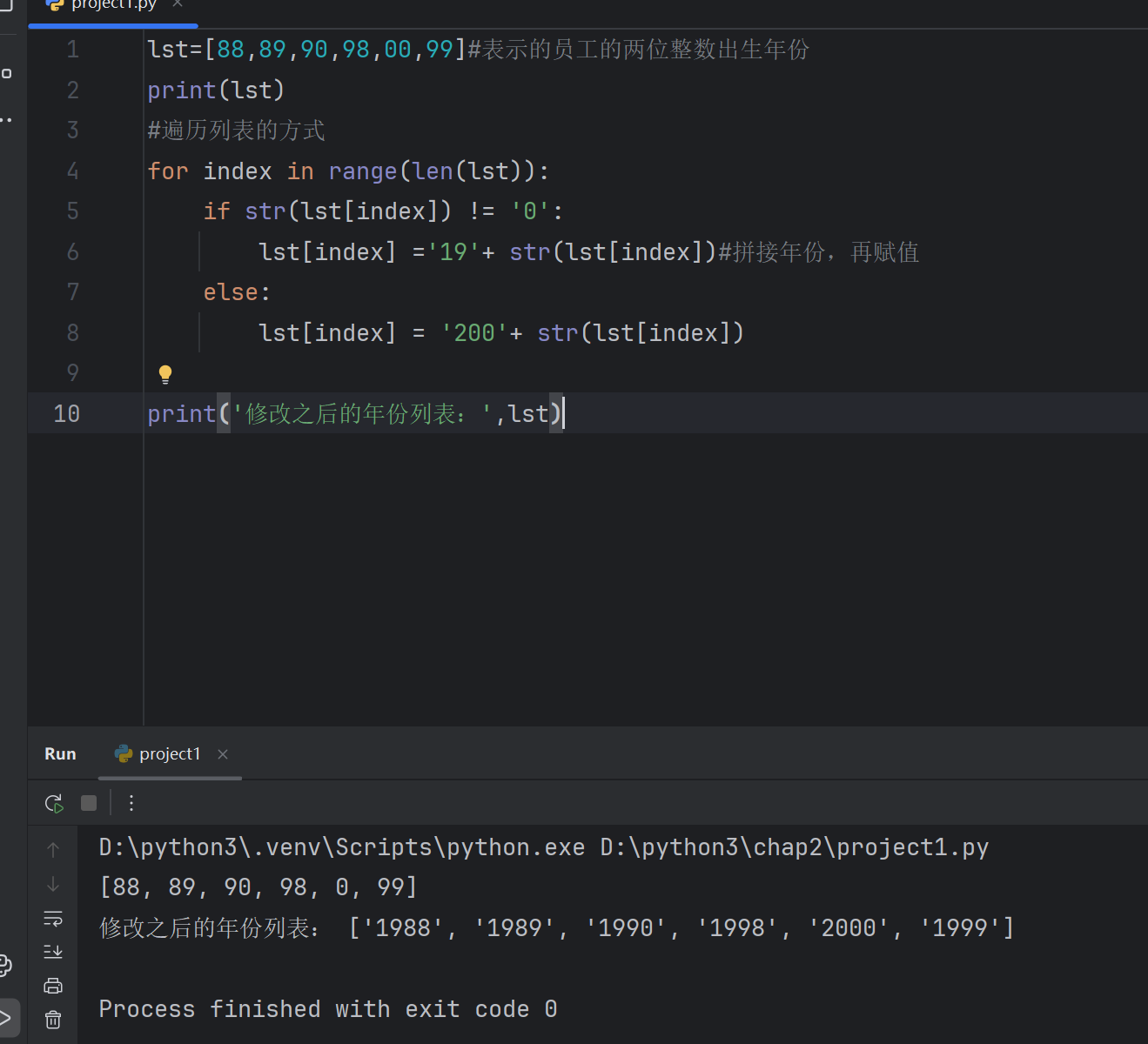
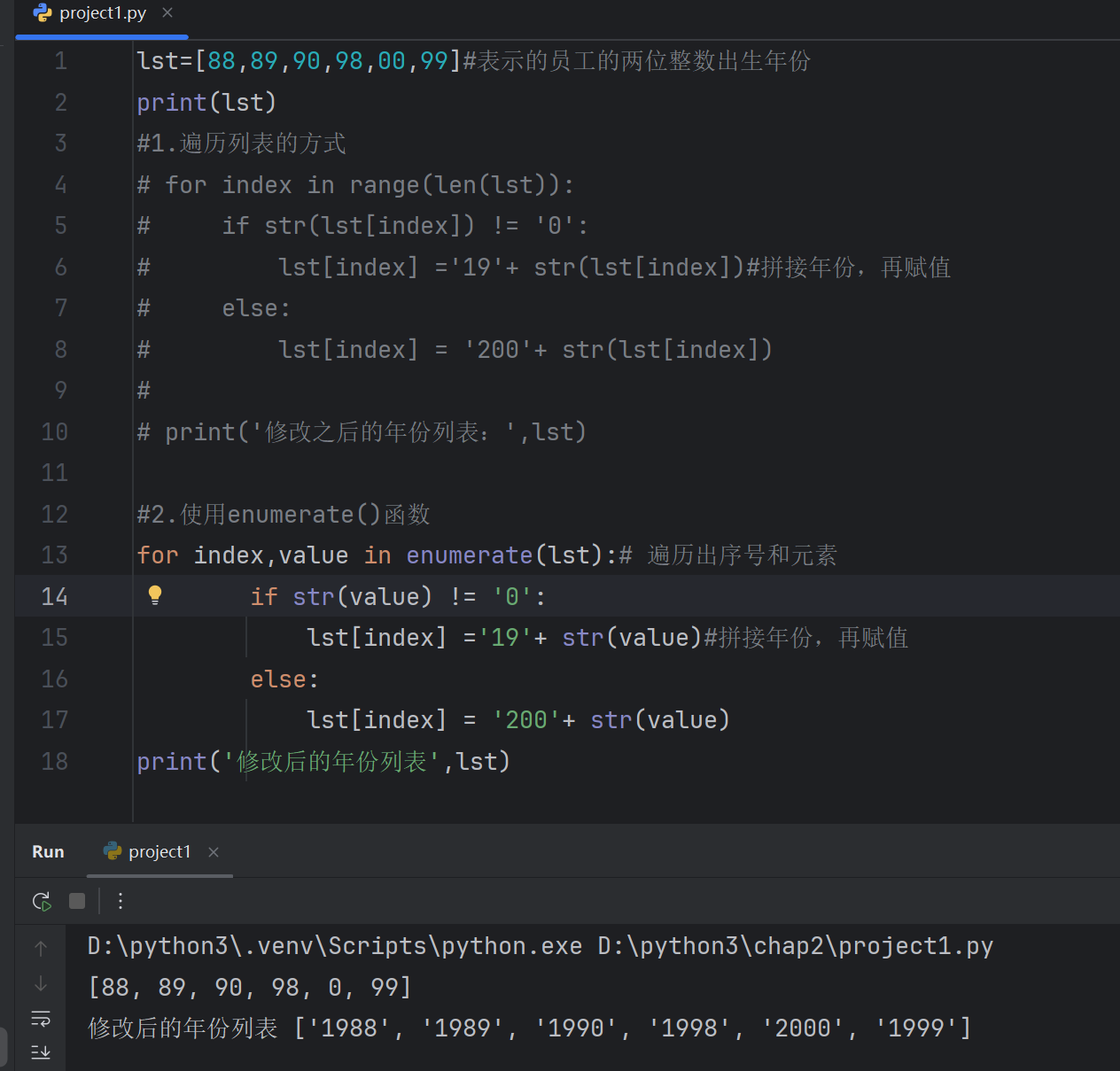
lst=[88,89,90,98,00,99]#表示的员工的两位整数出生年份
print(lst)
#遍历列表的方式
for index in range(len(lst)):if str(lst[index]) != '0':lst[index] ='19'+ str(lst[index])#拼接年份,再赋值else:lst[index] = '200'+ str(lst[index])print('修改之后的年份列表:',lst)
lst=[88,89,90,98,00,99]#表示的员工的两位整数出生年份
print(lst)
#1.遍历列表的方式
# for index in range(len(lst)):
# if str(lst[index]) != '0':
# lst[index] ='19'+ str(lst[index])#拼接年份,再赋值
# else:
# lst[index] = '200'+ str(lst[index])
#
# print('修改之后的年份列表:',lst)#2.使用enumerate()函数
for index,value in enumerate(lst):# 遍历出序号和元素if str(value) != '0':lst[index] ='19'+ str(value)#拼接年份,再赋值else:lst[index] = '200'+ str(value)
print('修改后的年份列表',lst)
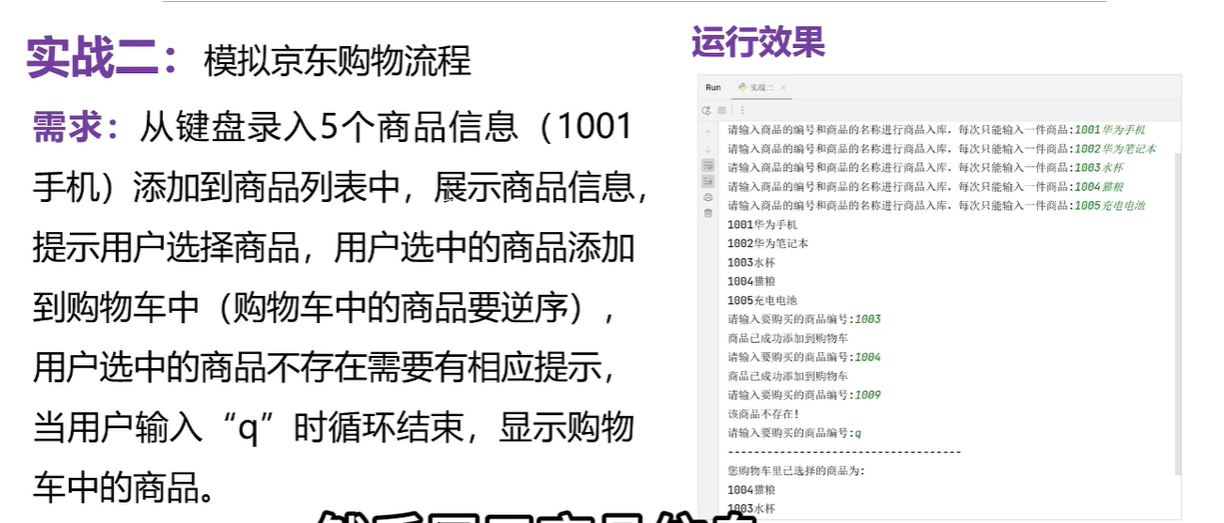
# 创建一个空列表:用于存储入库的商品信息
lst=[]
for i in range(5):#5次赋值goods=input('请输入商品的编号和商品的名称进行商品入库,每次只能输入一次商品')lst.append(goods)
#输入所有的商品信息
for item in lst:print(item)#创建一个空列表,用于存储购物车中的商品
cart=[]
while True:flag=False#代表没有商品的情况num=input('请输入要购买的商品编号:')# 遍历商品列表,查询一下购买的商品是否存在for item in lst:if num==item[0:4]:#前四位是商品编号(切片操作,切到3不包含四)flag=True#代表商品已找到cart.append(item)# 添加到商品当中print('商品已成功添加到购物车')break#退出的是for循环if not flag and num!='q':# not flag 等价于flag==Falseprint('商品不存在')if num=='q':break#退出的是while循环
print('-'*50)
print('您的购物车里已选择的商品为:')
cart.reverse()
for item in cart:print(item)

模拟12306车票订票流程
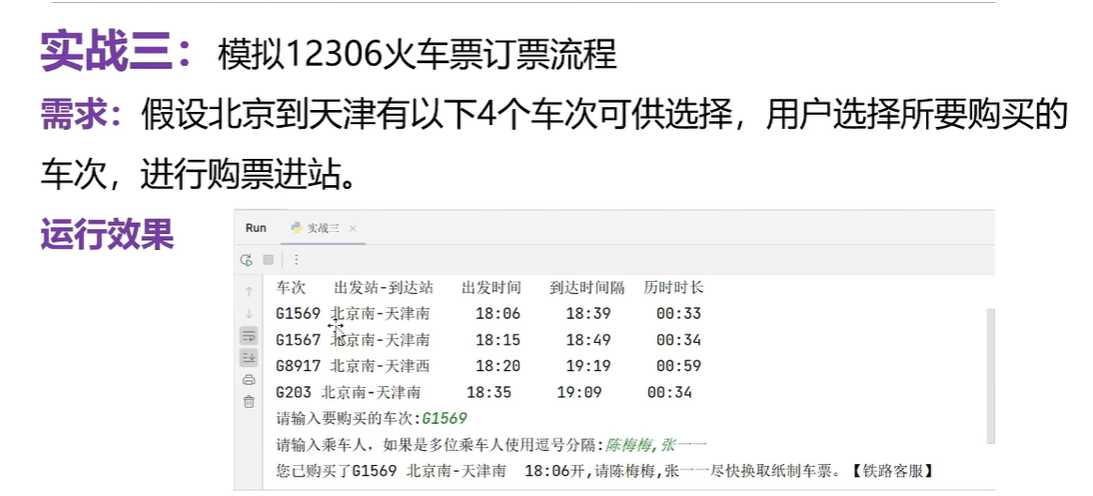
# 创建字典用于存储车票信息,使用车次做key,使用其他信息做value
dict_ticket={'G1569':['北京南-天津南','18:06','18:39','00:33'],'G1567':['北京南-天津南','18:15','18:49','00:34'],'G8917':['北京南-天津南','18:20','18:19','00:59'],'G203':['北京南-天津南','18:35','19:09','00:34'],
}
print('车次 出发站 出发时间 到达时间 历时时长')
#遍历字典中的元素
for key in dict_ticket.keys():print(key,end=' ')#为什么不换行,因为车次和车次的详细信息在一行显示# 根据key获取出来的值是一个列表for item in dict_ticket.get(key):#根据键获取值print(item,end='\t\t ')# 换行print()# 输入用户的购票车次
train_no=input('请输入要购买的车次')
# 根据key获取值
info=dict_ticket.get(train_no,'车次不存在') # info是一个列表类型
#判断车次不存在
if info!='车次不存在':person=input('请输入乘车人,如果多位乘车人使用逗号分隔:')# 获取车次的出发站--到达站,还有出发时间s=info[0]+' '+info[1]+'开'print('您已购买了'+train_no+' '+s+person+'尽快换取纸制车式')
else:print('对不起,选择的车次可能不存在')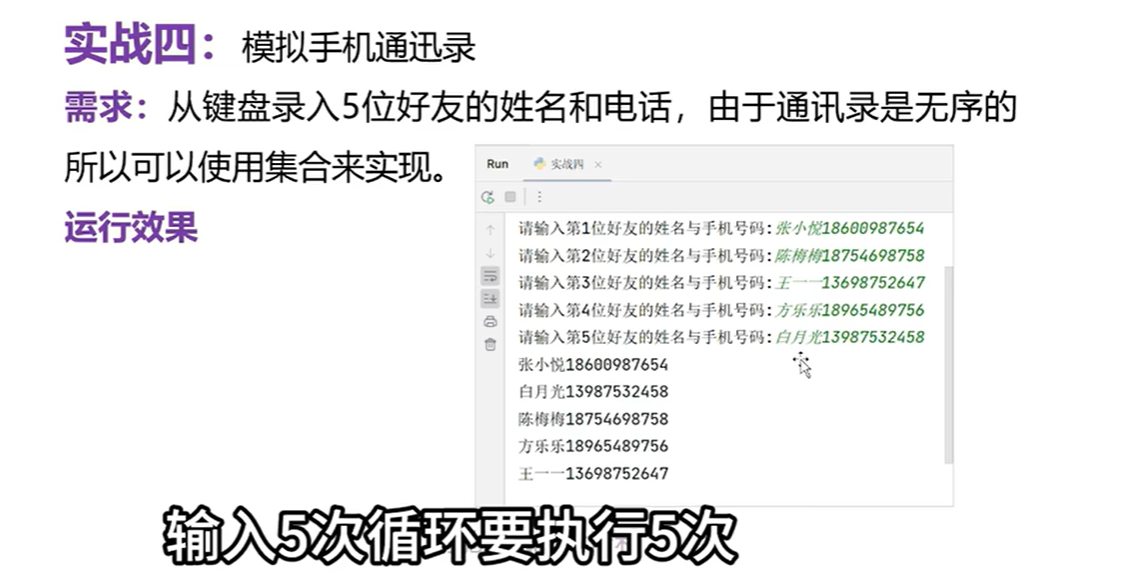
# 创建一个空集合
s=set()
# 录入5位好友的姓名和手机号
for i in range(1,6):info=input(f'请输入第{i}位好友的姓名和手机号:')#添加到集合当中s.add(info)
# 遍历集合
for item in s:print(item)
三、字符串及正则表达式

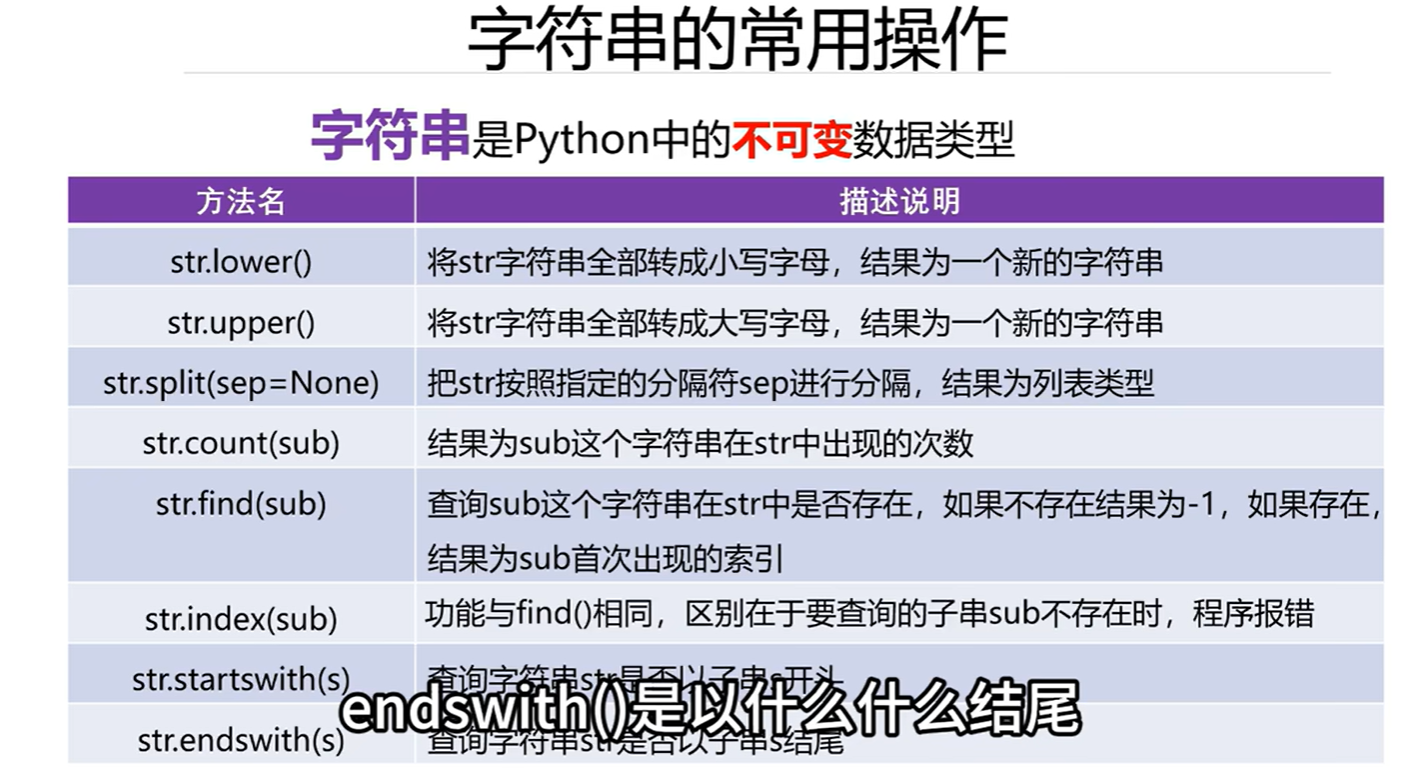
3.1 字符串的常用方法1
# 大小写转换
s1='HelloWorld'
new_s2=s1.lower()
print(s1,new_s2)new_s3=s1.upper()
print(new_s3)#字符串的分隔
e_mail='hh@123.com'
lst=e_mail.split('@')
print('邮箱名:',lst[0],'邮件服务器域名:',lst[1])print(s1.count('o'))#o在字符串s1中出现了两次#检索操作
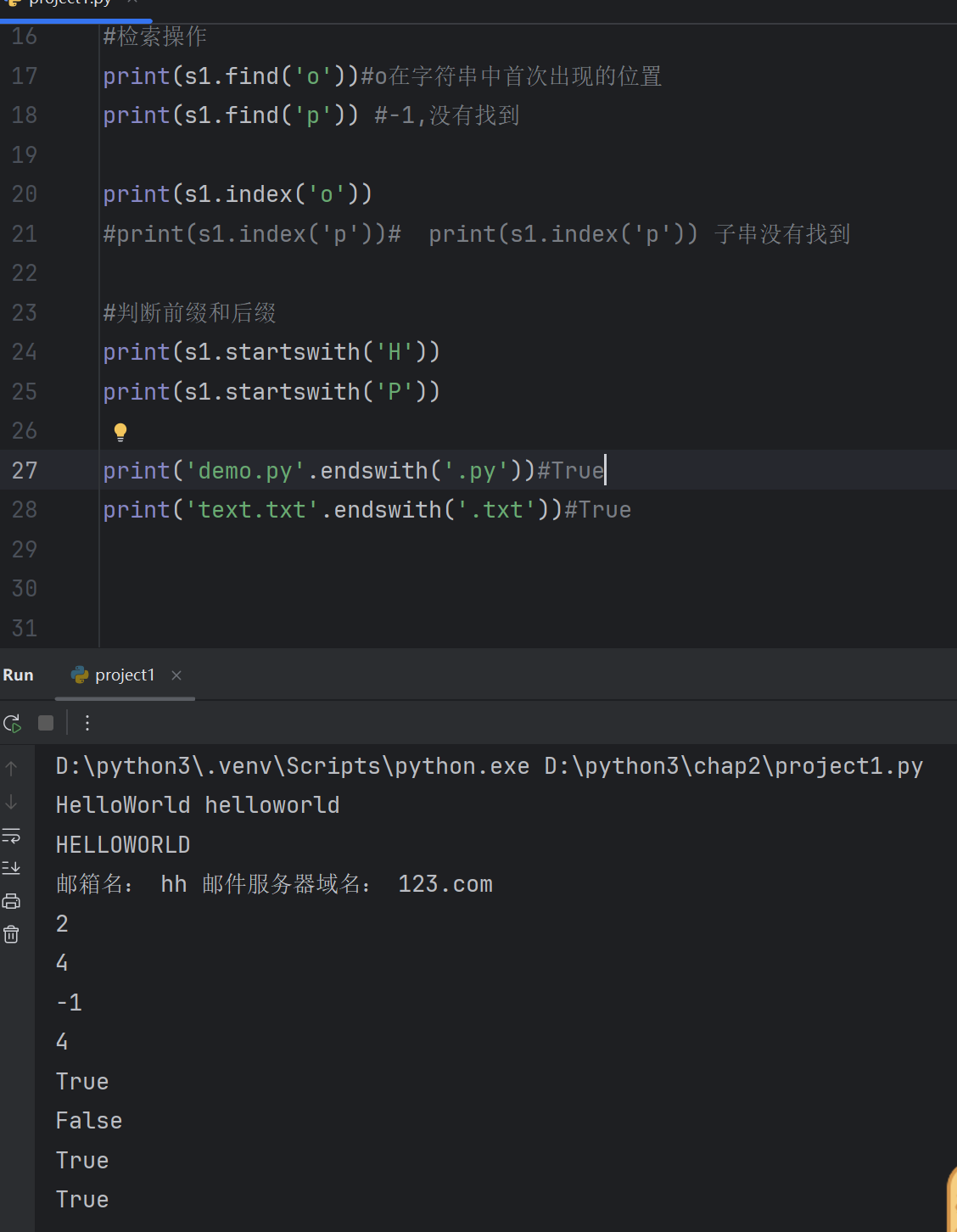
print(s1.find('o'))#o在字符串中首次出现的位置
print(s1.find('p')) #-1,没有找到print(s1.index('o'))
#print(s1.index('p'))# print(s1.index('p')) 子串没有找到#判断前缀和后缀
print(s1.startswith('H'))
print(s1.startswith('P'))print('demo.py'.endswith('.py'))#True
print('text.txt'.endswith('.txt'))#True

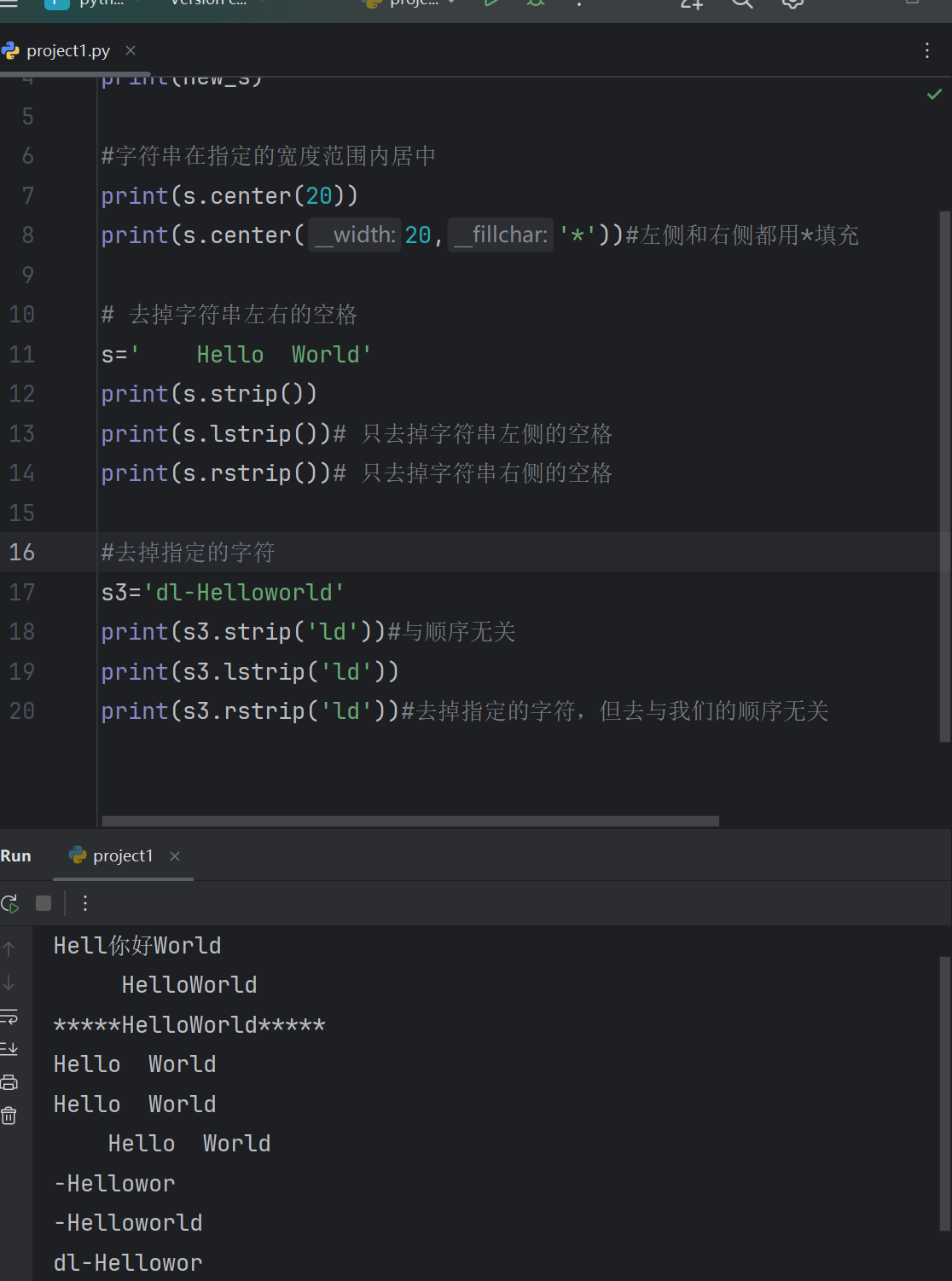
3.2 字符串的常用方法2
s='HelloWorld'
# 字符串的替换
new_s=s.replace('o','你好',1)#最后一个参数是替换次数,默认全部替换
print(new_s)#字符串在指定的宽度范围内居中
print(s.center(20))
print(s.center(20,'*'))#左侧和右侧都用*填充# 去掉字符串左右的空格
s=' Hello World'
print(s.strip())
print(s.lstrip())# 只去掉字符串左侧的空格
print(s.rstrip())# 只去掉字符串右侧的空格#去掉指定的字符
s3='dl-Helloworld'
print(s3.strip('ld'))#与顺序无关
print(s3.lstrip('ld'))
print(s3.rstrip('ld'))#去掉指定的字符,但去与我们的顺序无关
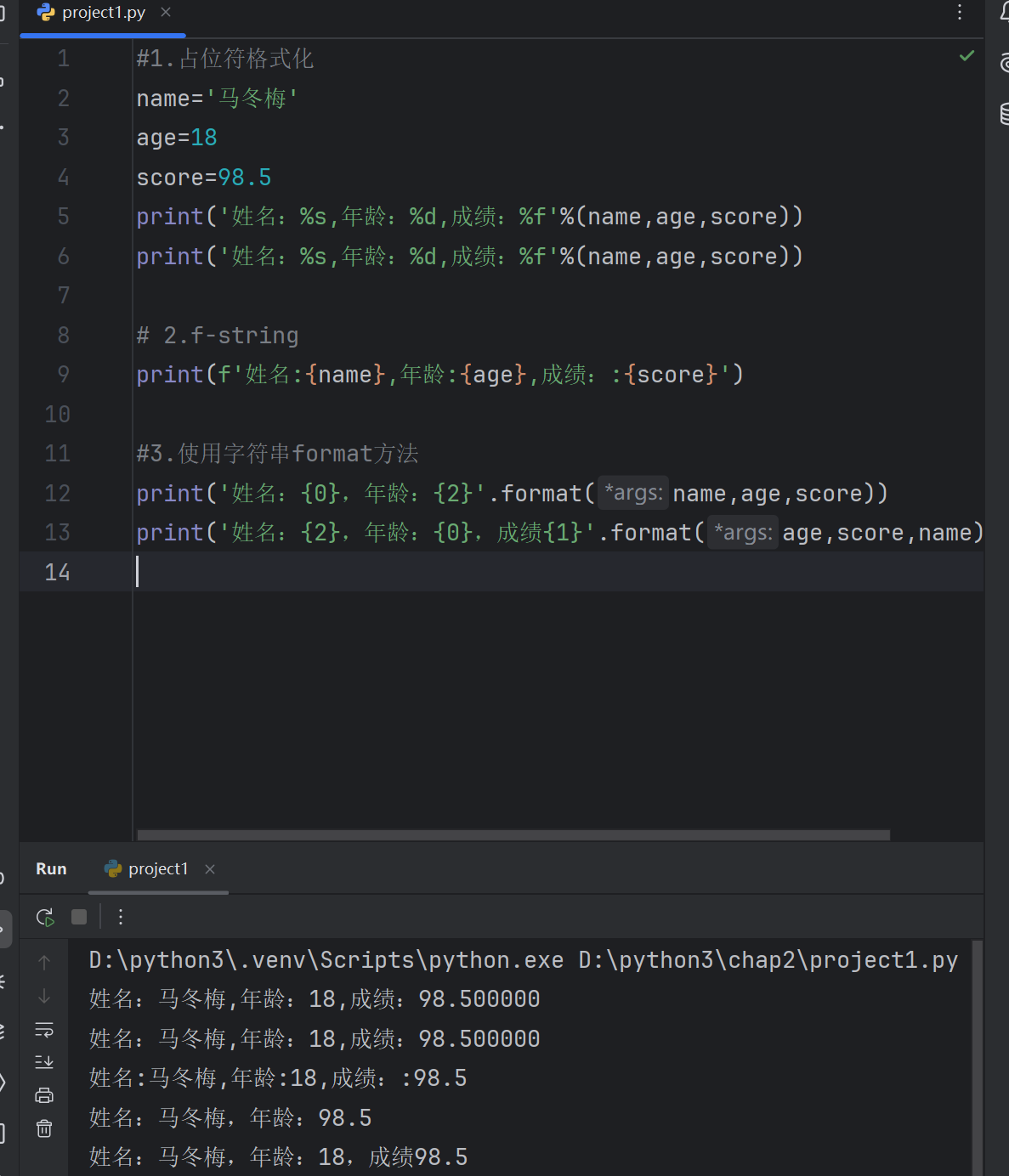
3.3格式化字符串的方式

#1.占位符格式化
name='马冬梅'
age=18
score=98.5
print('姓名:%s,年龄:%d,成绩:%f'%(name,age,score))
print('姓名:%s,年龄:%d,成绩:%f'%(name,age,score))# 2.f-string
print(f'姓名:{name},年龄:{age},成绩::{score}')#3.使用字符串format方法
print('姓名:{0},年龄:{2}'.format(name,age,score))
print('姓名:{2},年龄:{0},成绩{1}'.format(age,score,name))

3.4 mat的格式控制
s='helloworld'
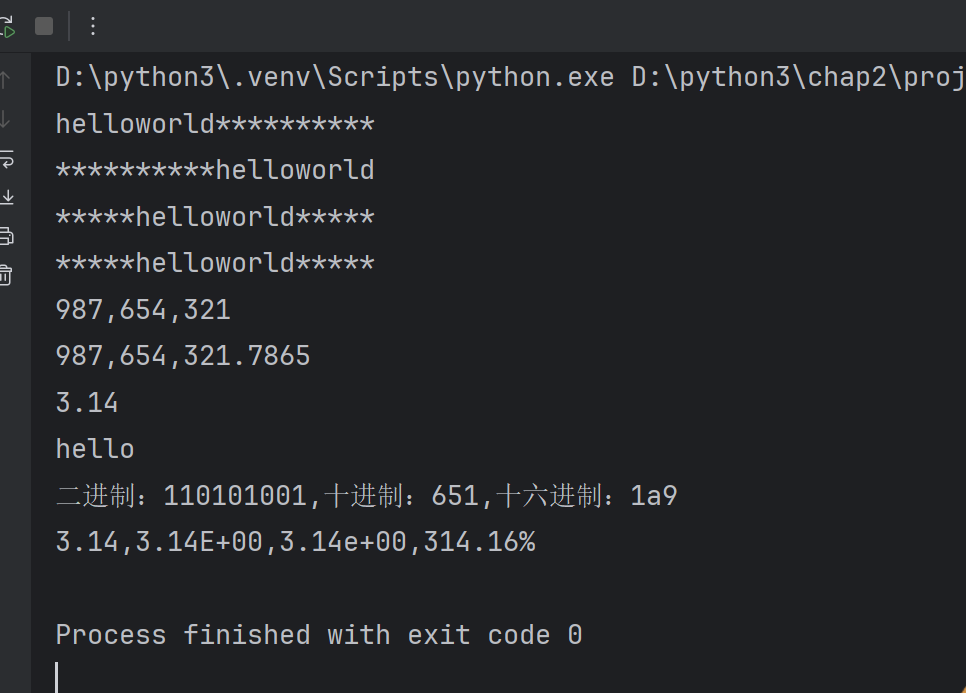
print('{0:*<20}'.format(s))#字符串的显示宽度为20,左对齐,空白部分使用*号填充
print('{0:*>20}'.format(s))
print('{0:*^20}'.format(s))#居中对齐
print(s.center(20,'*'))# 千位分隔符(只适用于整数和浮点数)
print('{0:,}'.format(987654321))
print('{0:,}'.format(987654321.7865))#浮点数小数部分的精度
print('{0:.2f}'.format(3.1415))# 字符串类型,显示的是最大的显示长度
print('{0:.5}'.format('helloworld')) # hello#整数类型
a=425
print('二进制:{0:b},十进制:{0:o},十六进制:{0:x}'.format(a))# 浮点数类型
b=3.1415926
print('{0:.2f},{0:.2E},{0:.2e},{0:.2%}'.format(b))
3.5 字符串的编码和解码

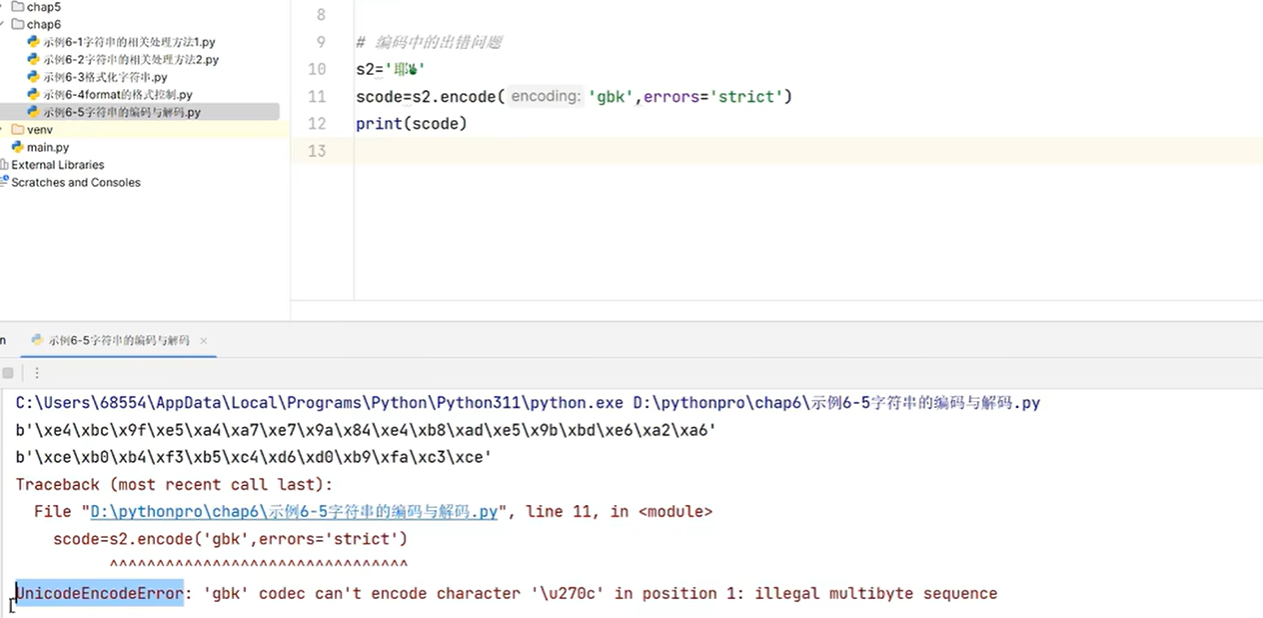
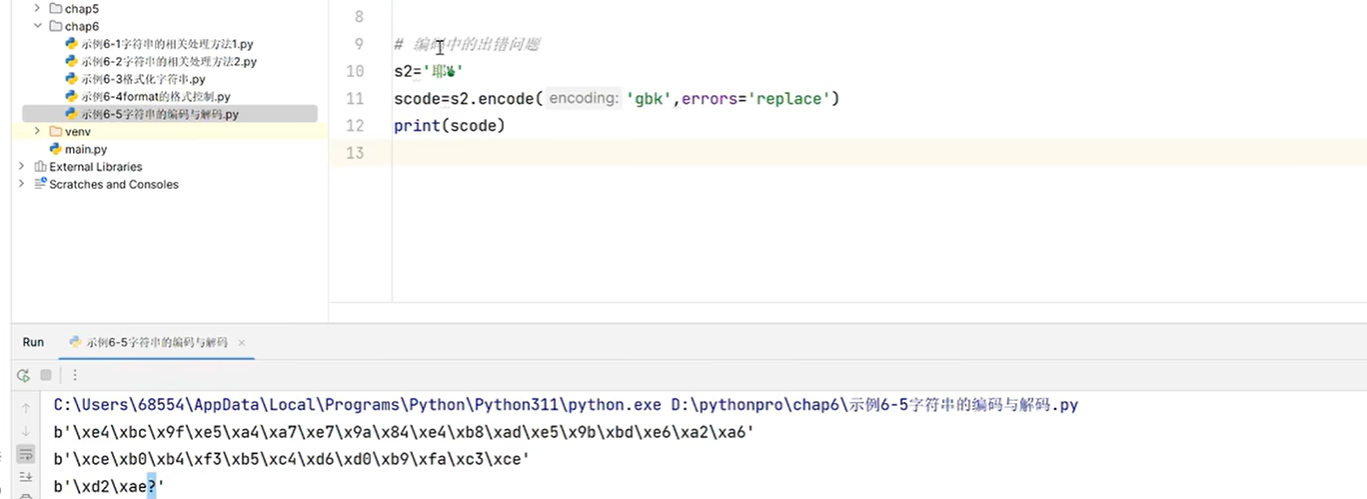
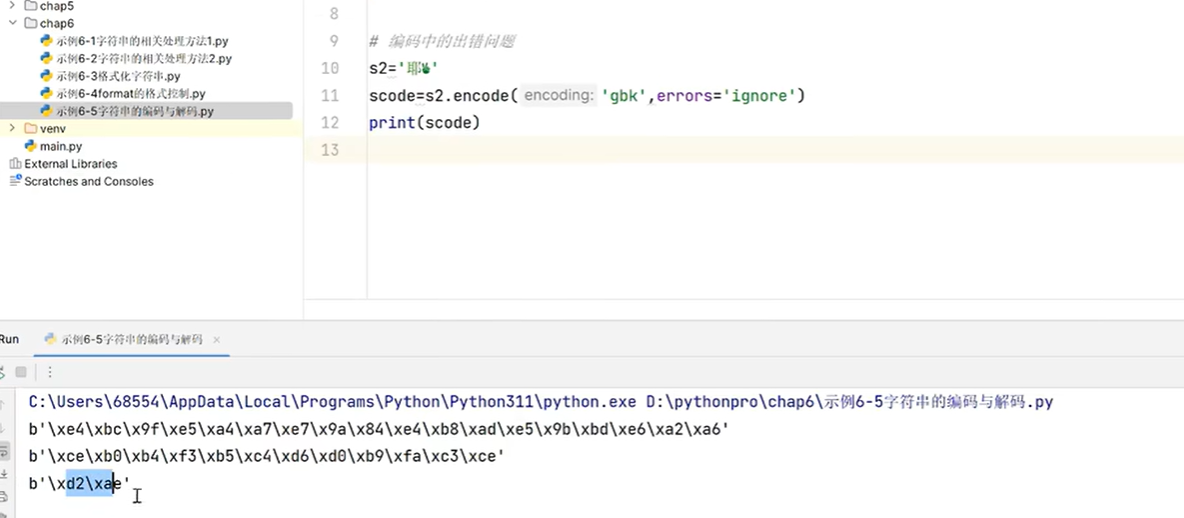
s='伟大的中国梦'
# 编码 str->bytes
scode=s.encode(errors='replace')# 默认utf-8,因为utf-8中文占3个字符
print(scode)scode_gbk=s.encode('gbk',errors='replace')#gbk中文占2个字符
print(scode_gbk)# 解码过程bytes->str
print(bytes.decode(scode_gbk,'gbk'))
print(bytes.decode(scode,'utf-8'))
3.6 数据验证的方法
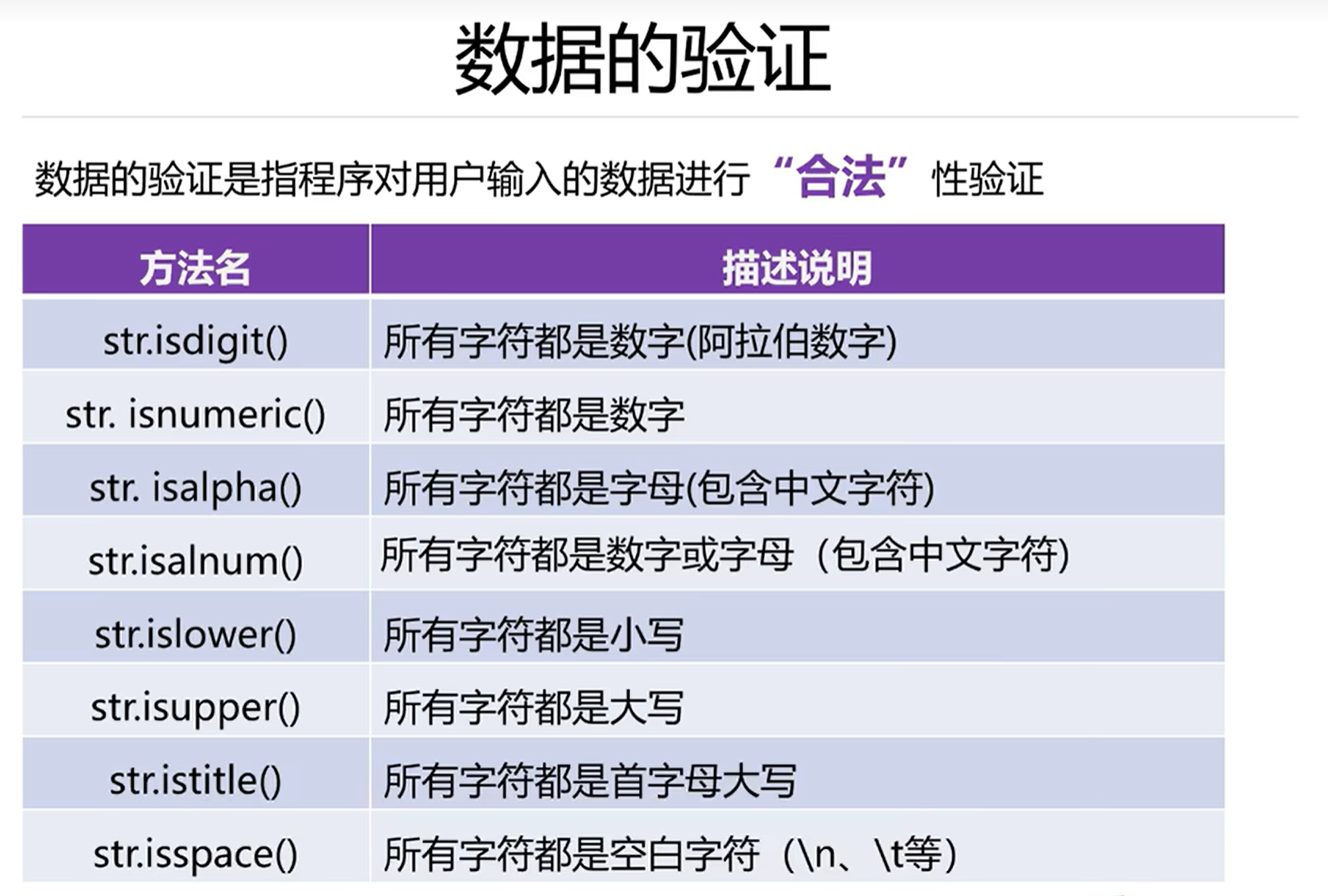
from curses.ascii import isdigit
#isdigit()十进制的阿拉伯数字
print('123',isdigit())#True
print('一二三',isdigit()) #False
print('0b1010',isdigit()) #False
print('IIIIII',isdigit()) #False
print('-'*50)# 所有字符都是数字
print('123'.isnumeric()) #True
print('一二三'.isnumeric()) #True
print('0b1010'.isnumeric()) #False
print('IIIIII'.isnumeric()) #True
print('壹贰叁'.isnumeric()) #True
print('-'*50)#所有的字符都是字母(包含中文字符)
print('hello你好'.isalpha()) #True
print('hello你好123'.isalpha()) #False
print('hello你好一二三'.isalpha()) #True
print('hello你好IIIIII'.isalpha()) #False
print('-'*50)# 所有字符都是数字或字母
print('hello你好'.isalnum()) #True
print('hello你好123'.isalnum()) #True
print('hello你好一二三'.isalnum()) #True
print('hello你好IIIIII'.isalnum()) #True
print('hello你好壹贰叁'.isalnum()) #True
print('-'*50)
#判断字符的大小写
print('HelloWorld'.islower())#False
print('helloworld'.islower())#True
print('hello你好'.islower())#True
# 所有字符都是首字母大写
print('Hello'.istitle())#True
print('HelloWorld'.istitle())#False
print('Helloworld'.istitle())#True
print('Hello World'.istitle())#True
print('Hello world'.istitle())#False# 判断是否都是空白字符
print('-'*50)
print('\t'.isspace())#True
print(' '.isspace())#True
print('\n'.isspace())#True
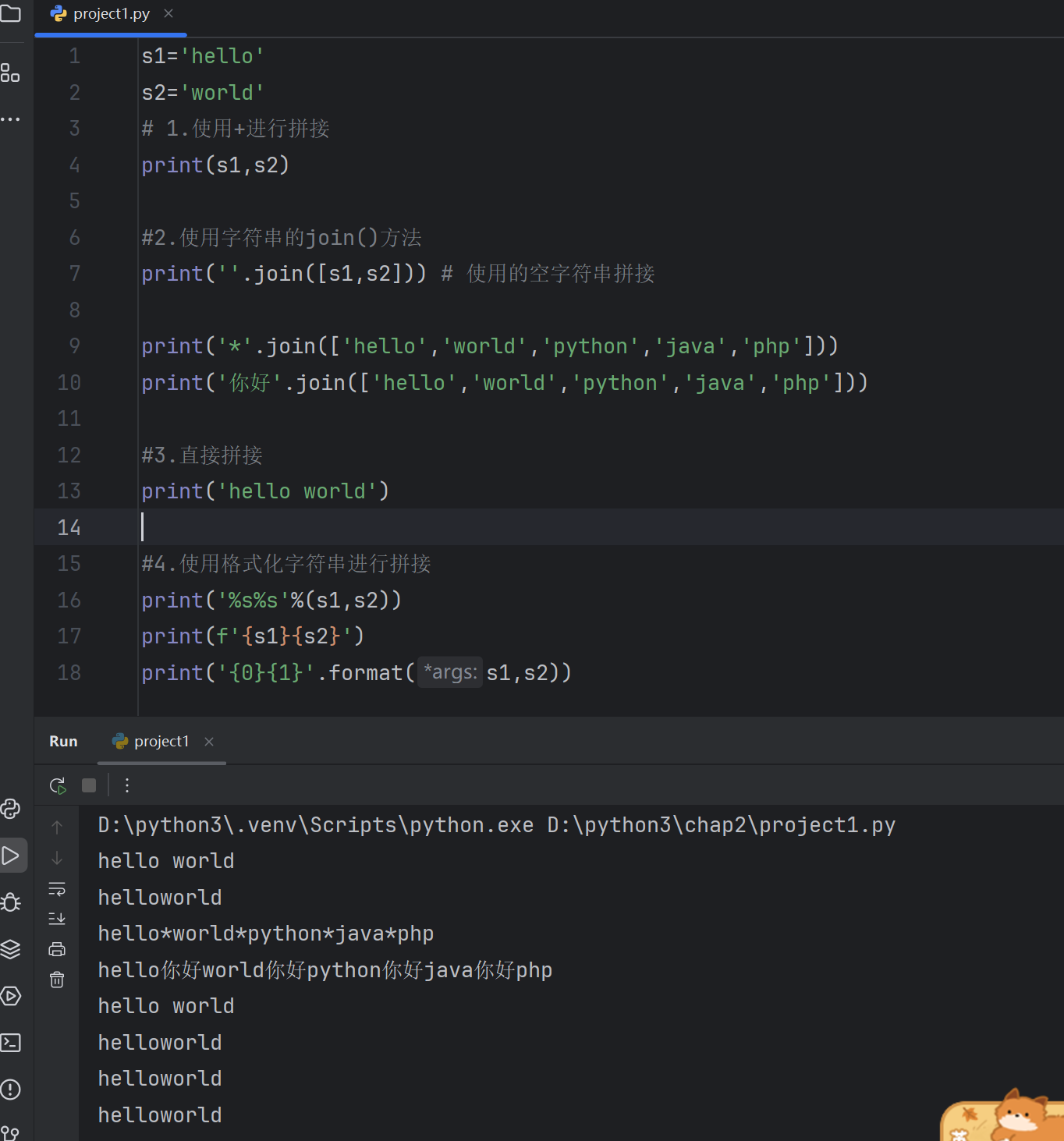
3.7 字符串的拼接处理

s1='hello'
s2='world'
# 1.使用+进行拼接
print(s1,s2)#2.使用字符串的join()方法
print(''.join([s1,s2])) # 使用的空字符串拼接print('*'.join(['hello','world','python','java','php']))
print('你好'.join(['hello','world','python','java','php']))#3.直接拼接
print('hello world')#4.使用格式化字符串进行拼接
print('%s%s'%(s1,s2))
print(f'{s1}{s2}')
print('{0}{1}'.format(s1,s2))
字符串的去重操作
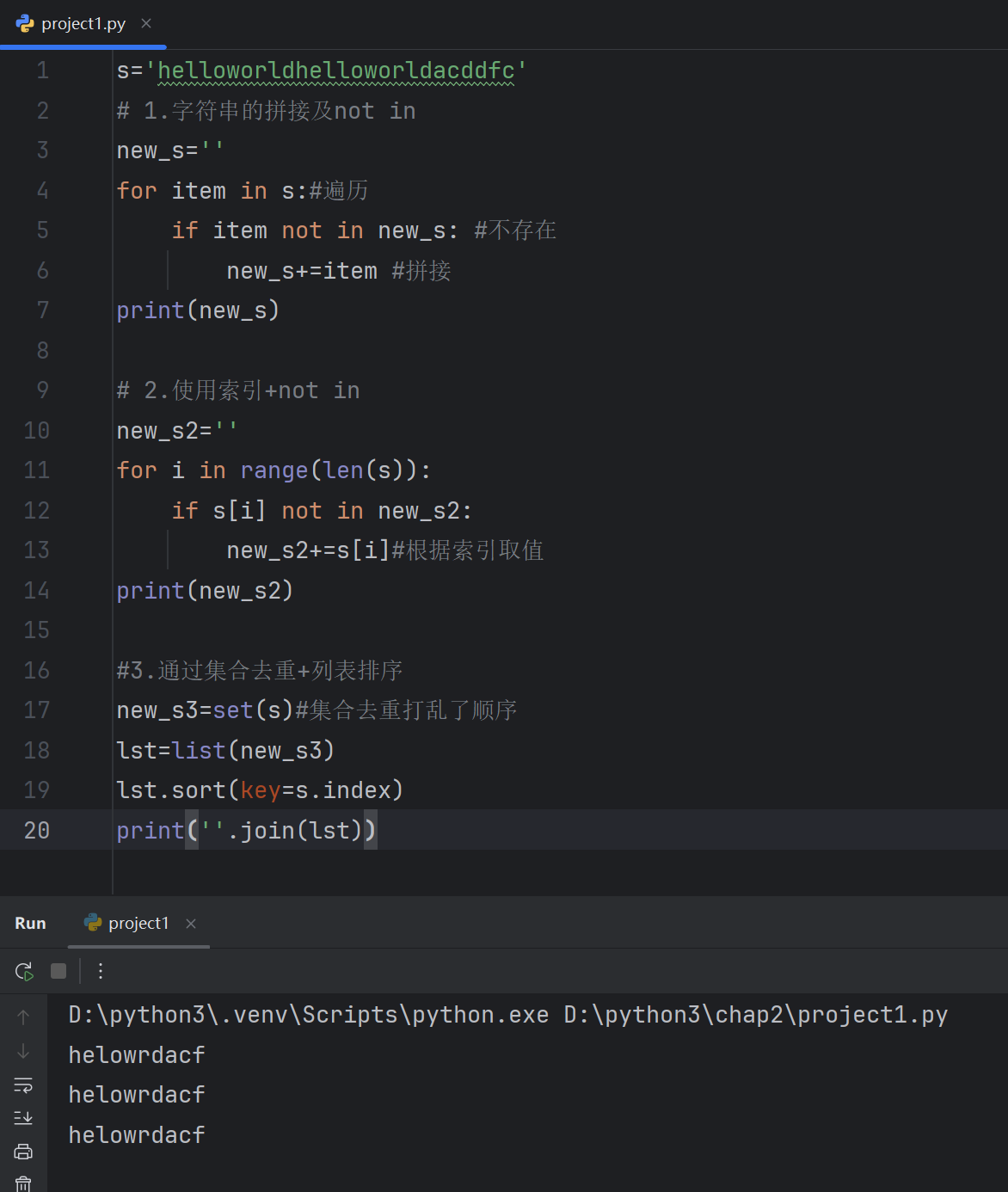
s='helloworldhelloworldacddfc'
# 1.字符串的拼接及not in
new_s=''
for item in s:#遍历if item not in new_s: #不存在new_s+=item #拼接
print(new_s)# 2.使用索引+not in
new_s2=''
for i in range(len(s)):if s[i] not in new_s2:new_s2+=s[i]#根据索引取值
print(new_s2)#3.通过集合去重+列表排序
new_s3=set(s)#集合去重打乱了顺序
lst=list(new_s3)
lst.sort(key=s.index)
print(''.join(lst))
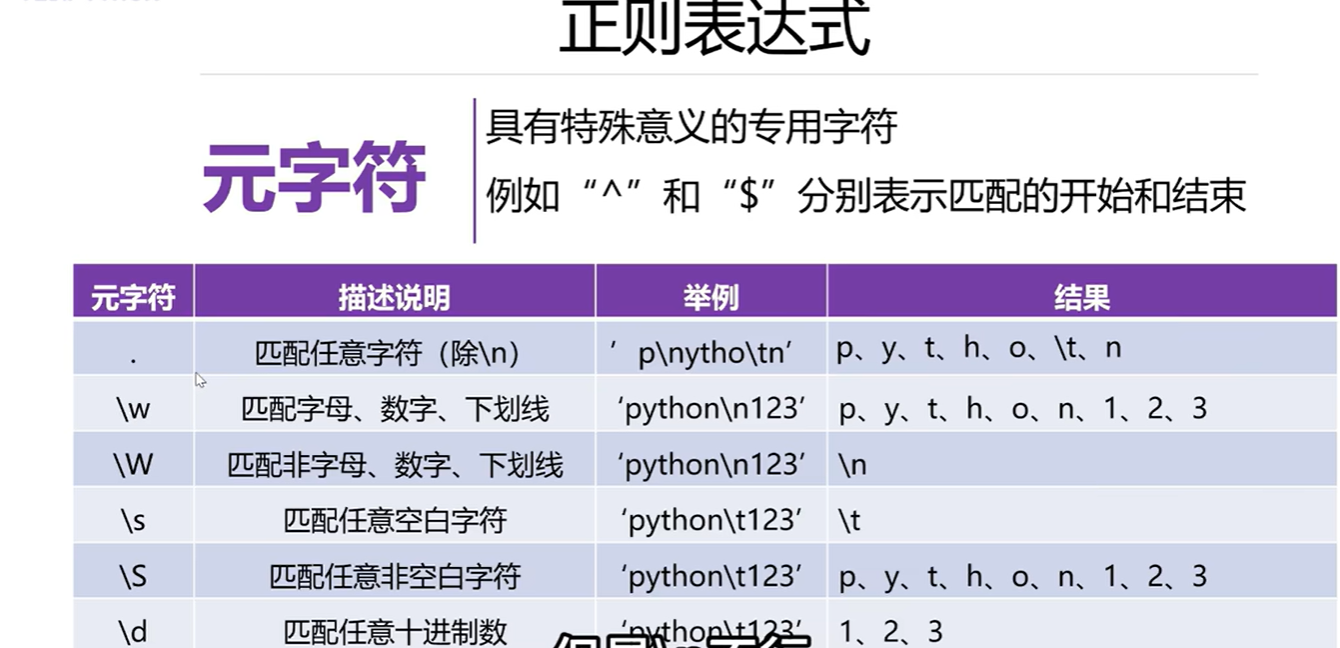
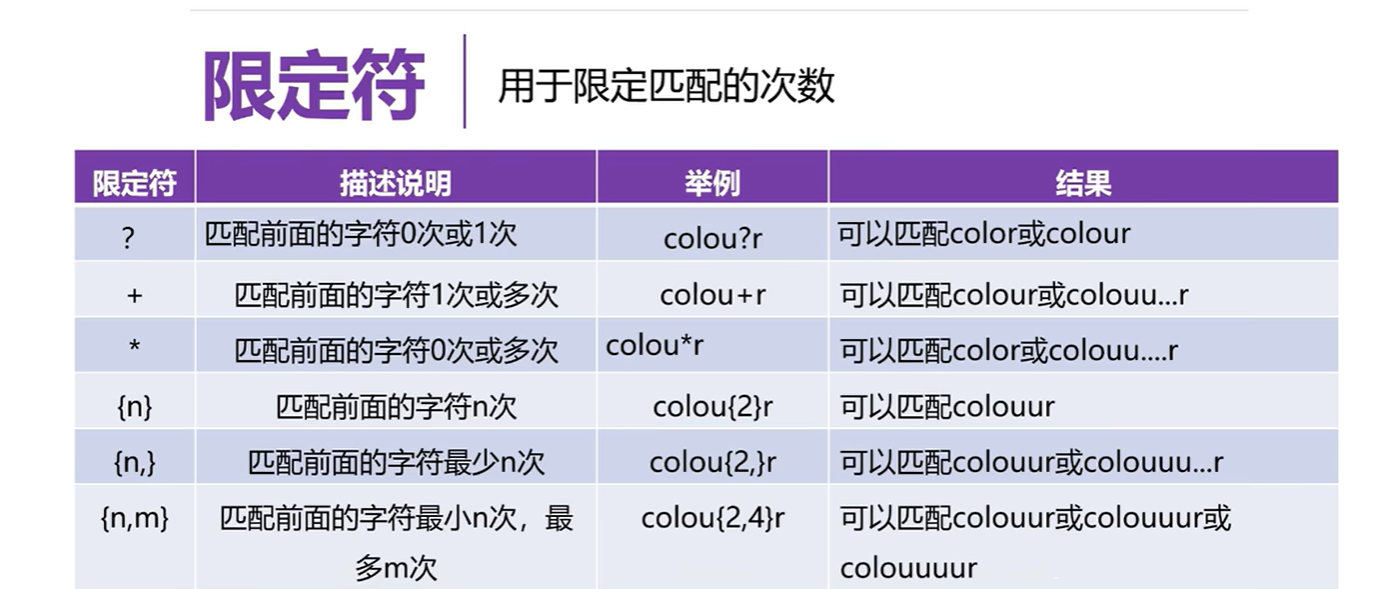
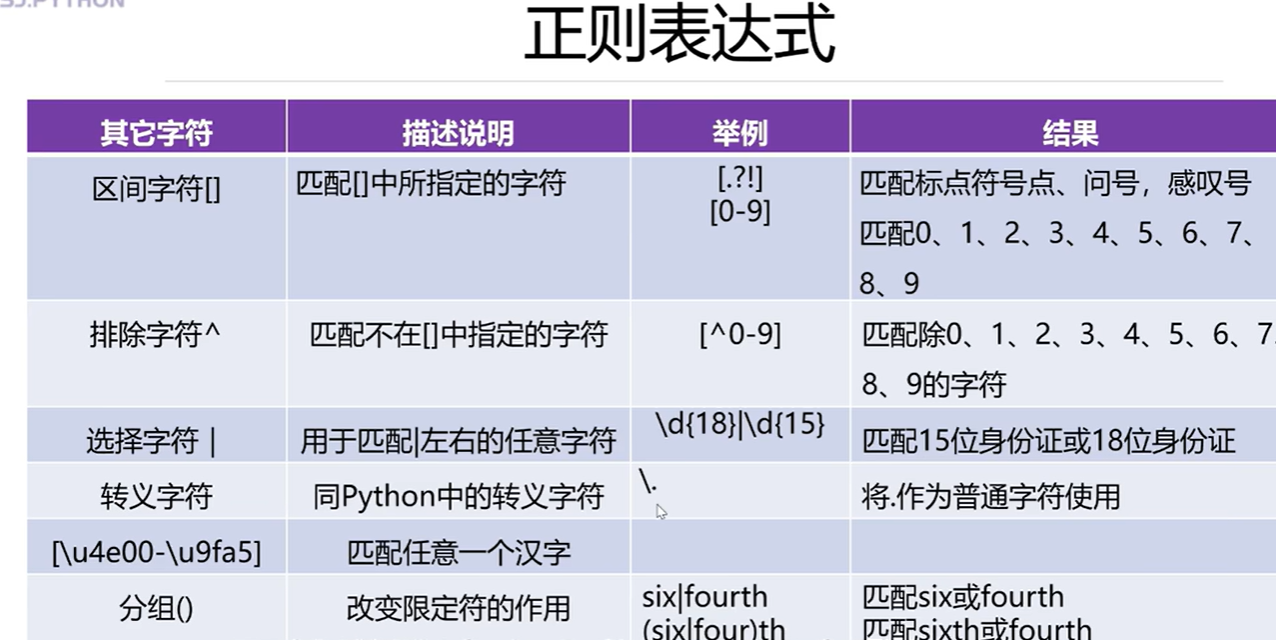
3.8 正则表达式
3.9 re模块中的match函数的使用
import re # 导入
pattern='\d\.\d+'# +限定符, 0-9出现1次或多次
s='I study Python 3.11 every day'match=re.match(pattern,s,re.I)#忽略大小写
print(match)#从头开始匹配,所以是None
s2='3.11Python I study Python 3.11 every day'
match2=re.match(pattern,s2,re.I)
print(match2)#\d是一个数字,没有写次数,就是1次,.作为普通字符,.后面还要0-9的数字,就是1-多次,找的是2次print('匹配的起始位置:',match2.start())
print('匹配值的结束位置',match2.end())
print('匹配区间的位置元素',match2.span())# 元组
print('待匹配的字符串',match2.string)
print('匹配的数据',match2.group())
3.9re模块中的search函数和findall函数的使用
import re # 导入
pattern='\d\.\d+'# +限定符, 0-9出现1次或多次
s='I study Python 3.11 every day Python 2.7 I love you'
match=re.search(pattern,s)#用pattern这个规则在s中查找
print(match)s2='4.10 Python I study every day'
s3='I study every day'
match2=re.search(pattern,s2)
match3=re.search(pattern,s3)
print(match2)
print(match3)
#输出内容用match.group
print(match.group())
print(match2.group())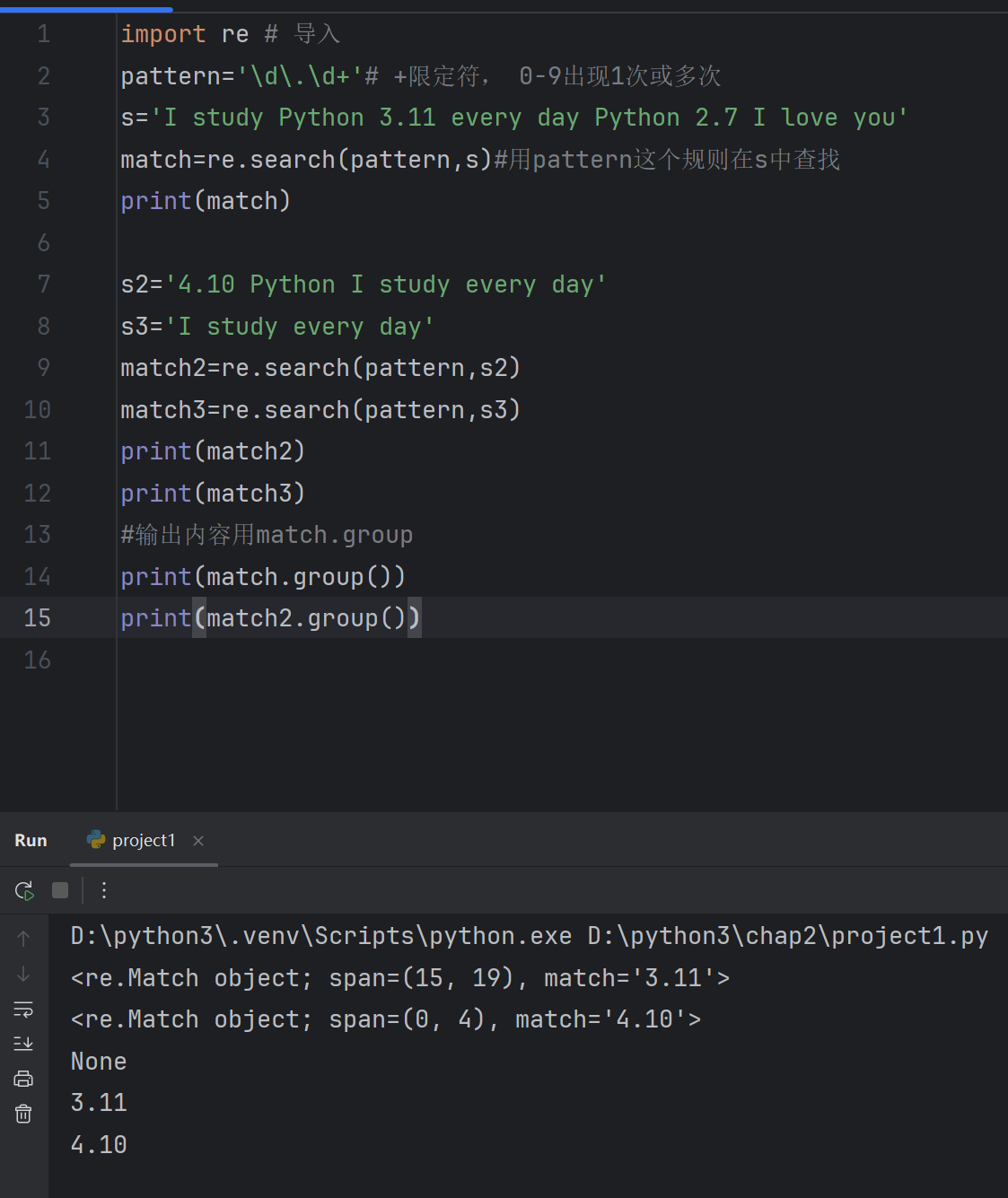
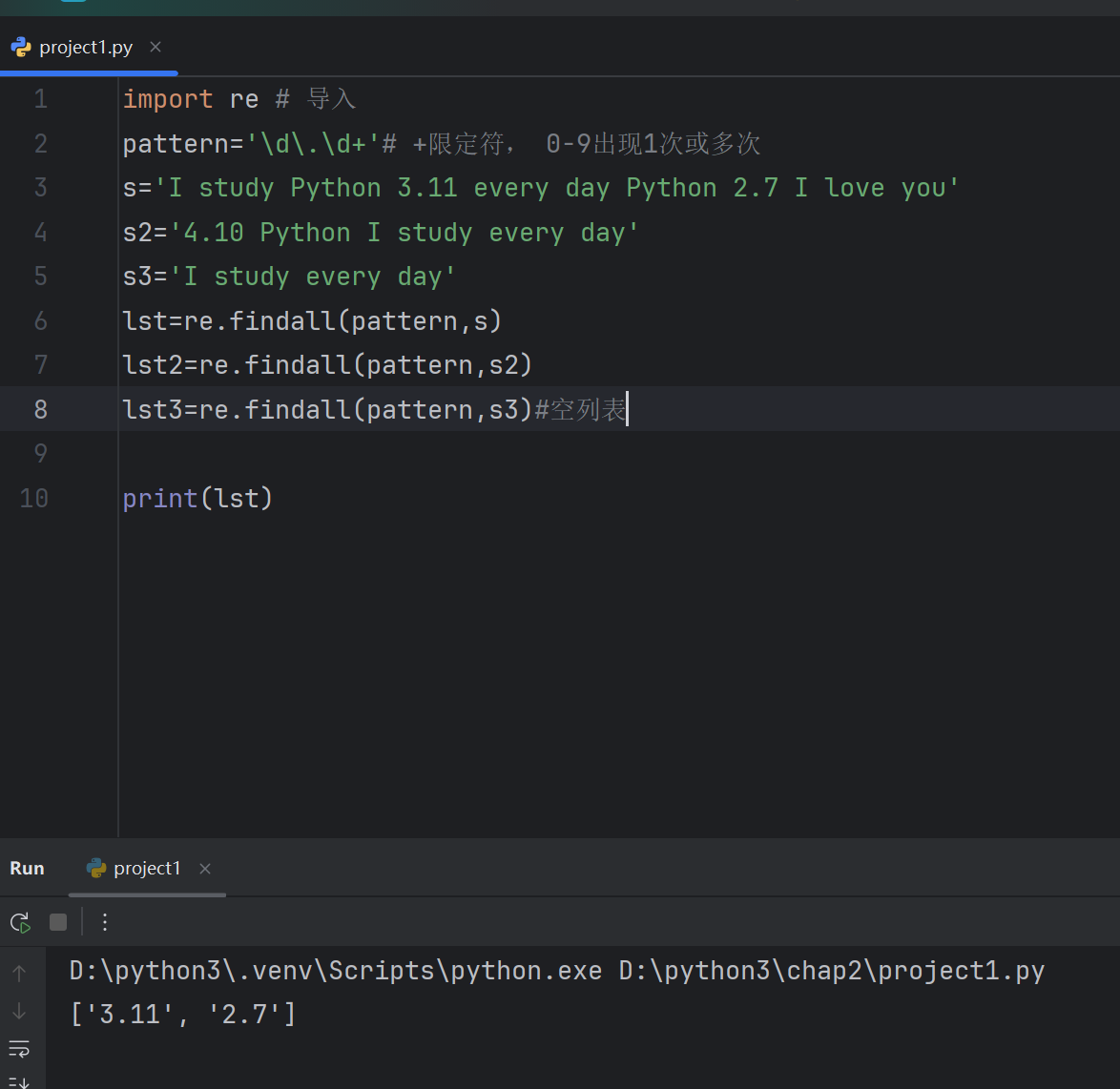
import re # 导入
pattern='\d\.\d+'# +限定符, 0-9出现1次或多次
s='I study Python 3.11 every day Python 2.7 I love you'
s2='4.10 Python I study every day'
s3='I study every day'
lst=re.findall(pattern,s)
lst2=re.findall(pattern,s2)
lst3=re.findall(pattern,s3)#空列表print(lst)
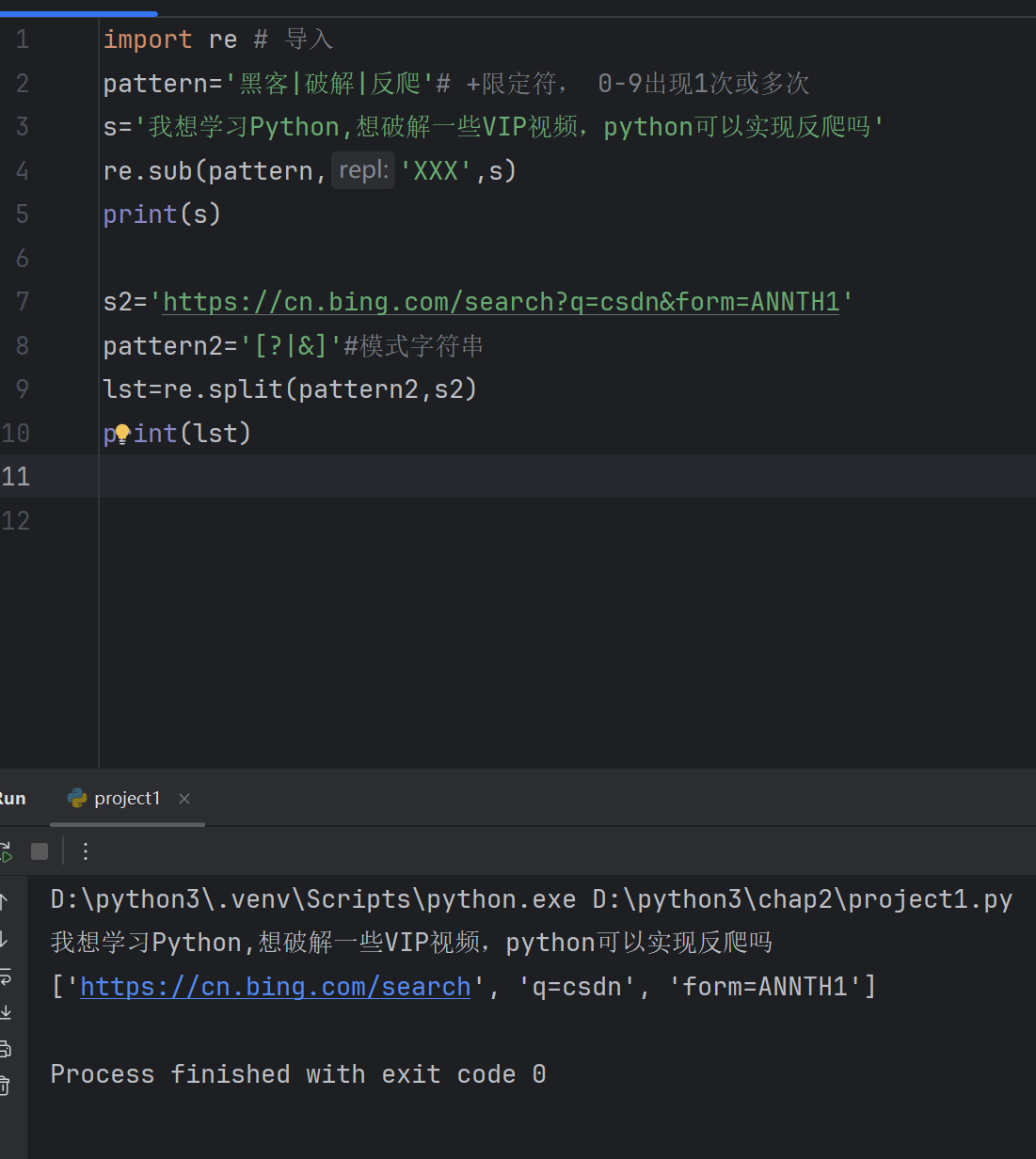
3.10 re模块的sub函数和spilt函数的使用
import re # 导入
pattern='黑客|破解|反爬'# +限定符, 0-9出现1次或多次
s='我想学习Python,想破解一些VIP视频,python可以实现反爬吗'
re.sub(pattern,'XXX',s)
print(s)s2='https://cn.bing.com/search?q=csdn&form=ANNTH1'
pattern2='[?|&]'#模式字符串
lst=re.split(pattern2,s2)
print(lst)
本章总结:
lower和upper结果是一个新的字符串对象
spilt结果是一个列表类型
字符串判断的方法结果是一个bool类型
replace可以指定替换的次数,如果不指定默认会替换全部

match是从字符串的开头,search是查找到第一个,findall查找所有,subn替换,spilt分隔

章节习题
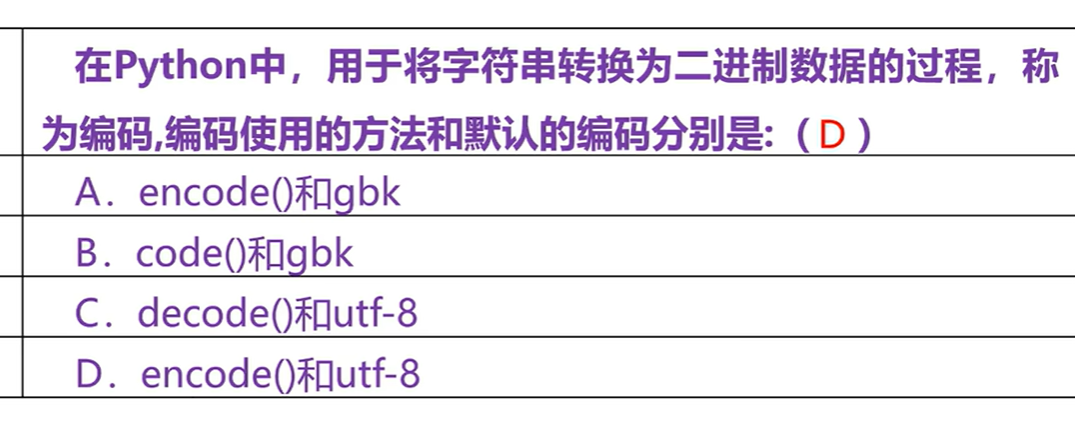
英文占一个字节,中文在utf-8占3个字节

如果不写编码格式就按utf-8编写
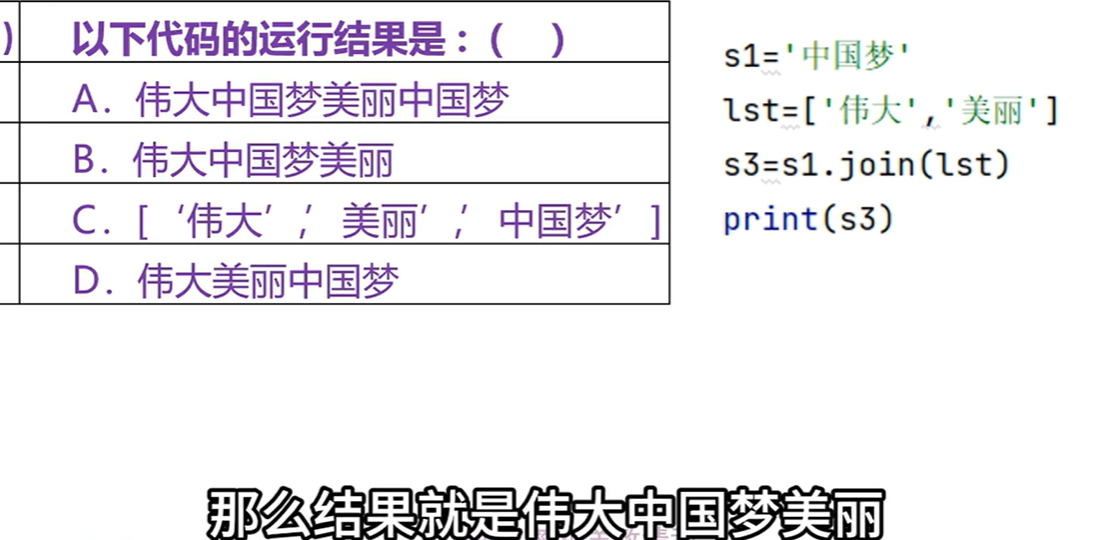
字符串第一个转成小写再连接剩余部分

spilt结果是列表,将ab去掉

index是起始索引,不是全部索引,find查不到是-1,index会报错

lower转小写,upper转大写,strip去掉左右空格或者特殊字符,spilt()分隔不符合要求的

\d 0-9的数字出现8次

小写w是字母、数字、下划线,+是出现的一个次数一到多次,s是待匹配的字符串,re.search使用这个模式字符串到s中查找,只查找到符合条件的第一个

spilt结果是列表类型

章节习题
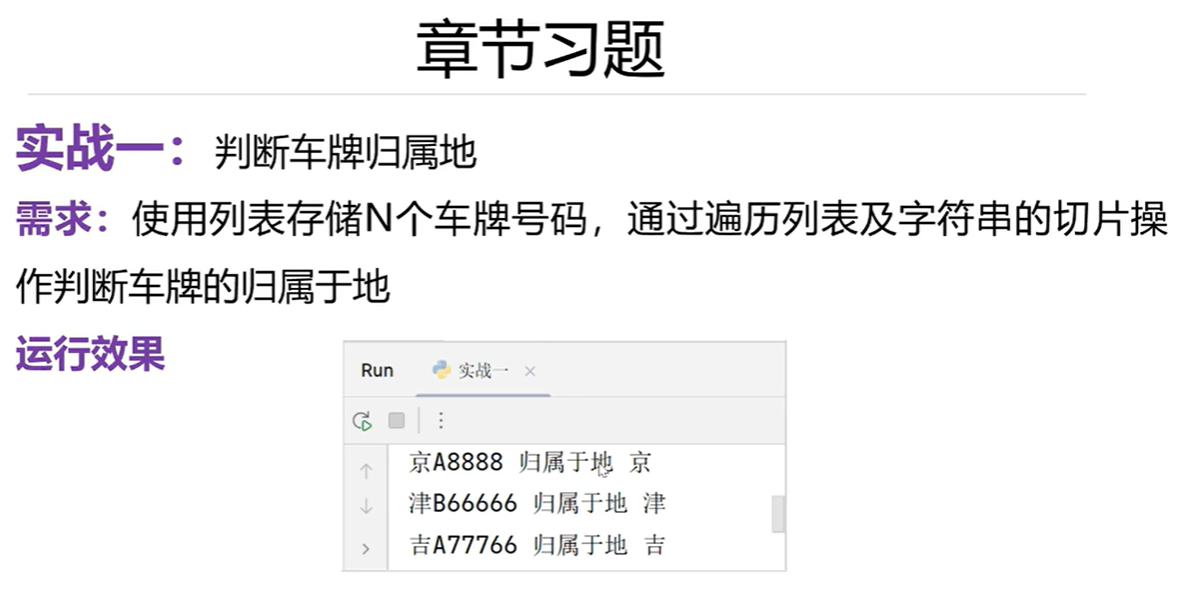
lst=['京A8888','津B6666','吉A777666']
for item in lst:item[0:1]#归属地是车牌第一个字,使用切片操作0:切一个,0-1不包含索引为1area=item[0:1]print(item,'归属地:',area)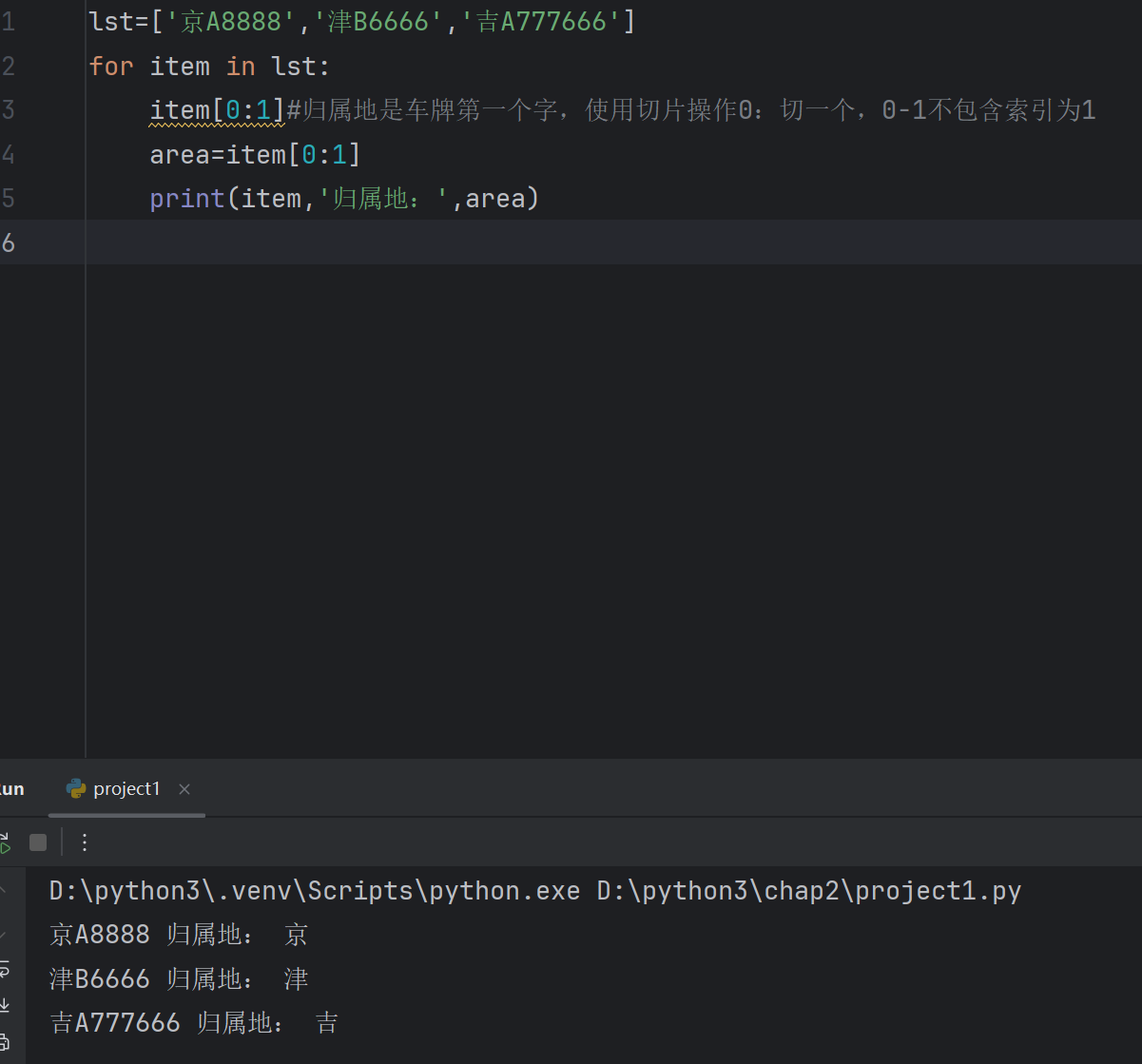
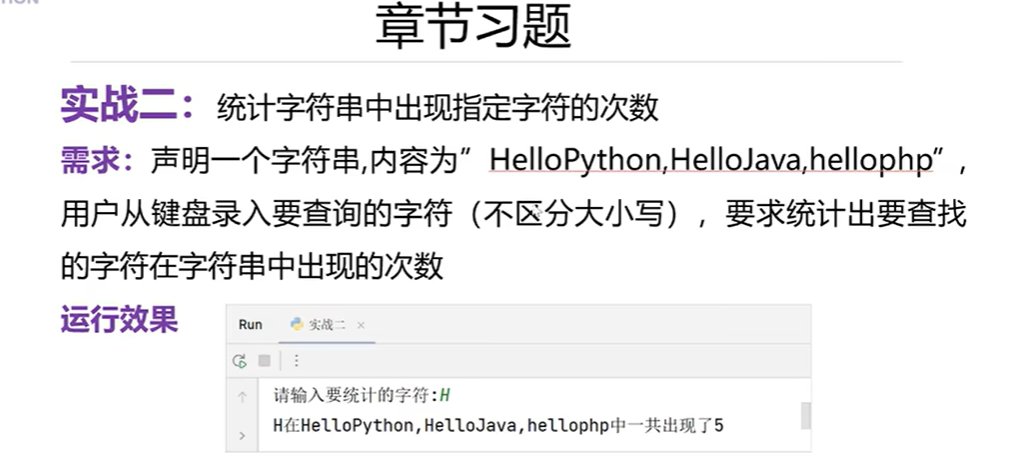
s='HelloPython,HelloJava,hellophp'
word=input('请输入要统计的字符')
print('{0}在{1}一共出现了{2}'.format(word,s,s.upper().count(word)))#字符串的格式化
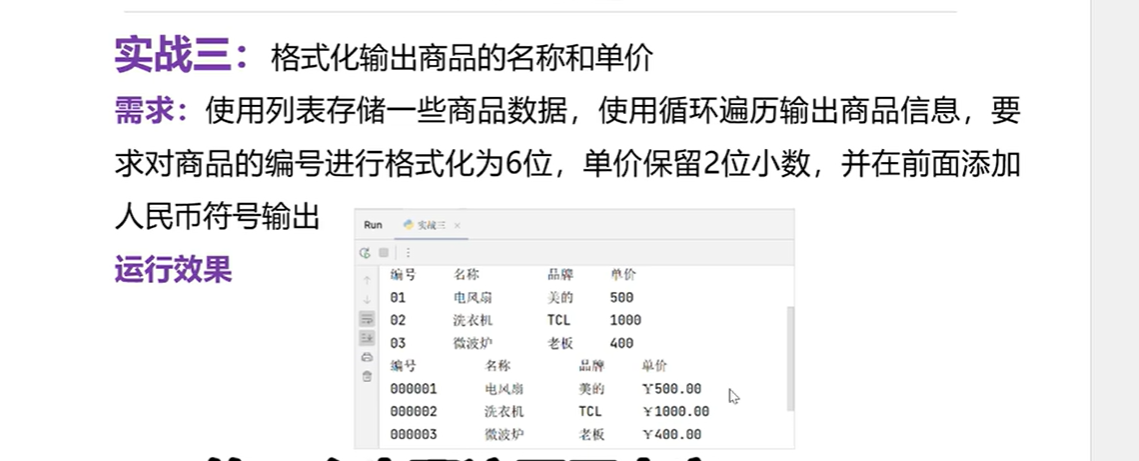
lst=[['01','电风扇','美的',500],['02','洗衣机','TCL',1000],['03','微波炉','老板',500]
]
print('编号\t\t名称\t\t\t品牌\t\t单价')
for item in lst:#item是元素,继续遍历for i in item:print(i,end='\t\t')print()#换行
#格式化
for item in lst:item[0]='0000'+item[0]item[3]='Y{0:.2f}'.format(item[3])#0是索引位置,:是引导符,.2f保留两位小数
print()
print('编号\t\t\t名称\t\t\t品牌\t\t单价')
for item in lst:#item是元素,继续遍历for i in item:print(i,end='\t\t')print()#换行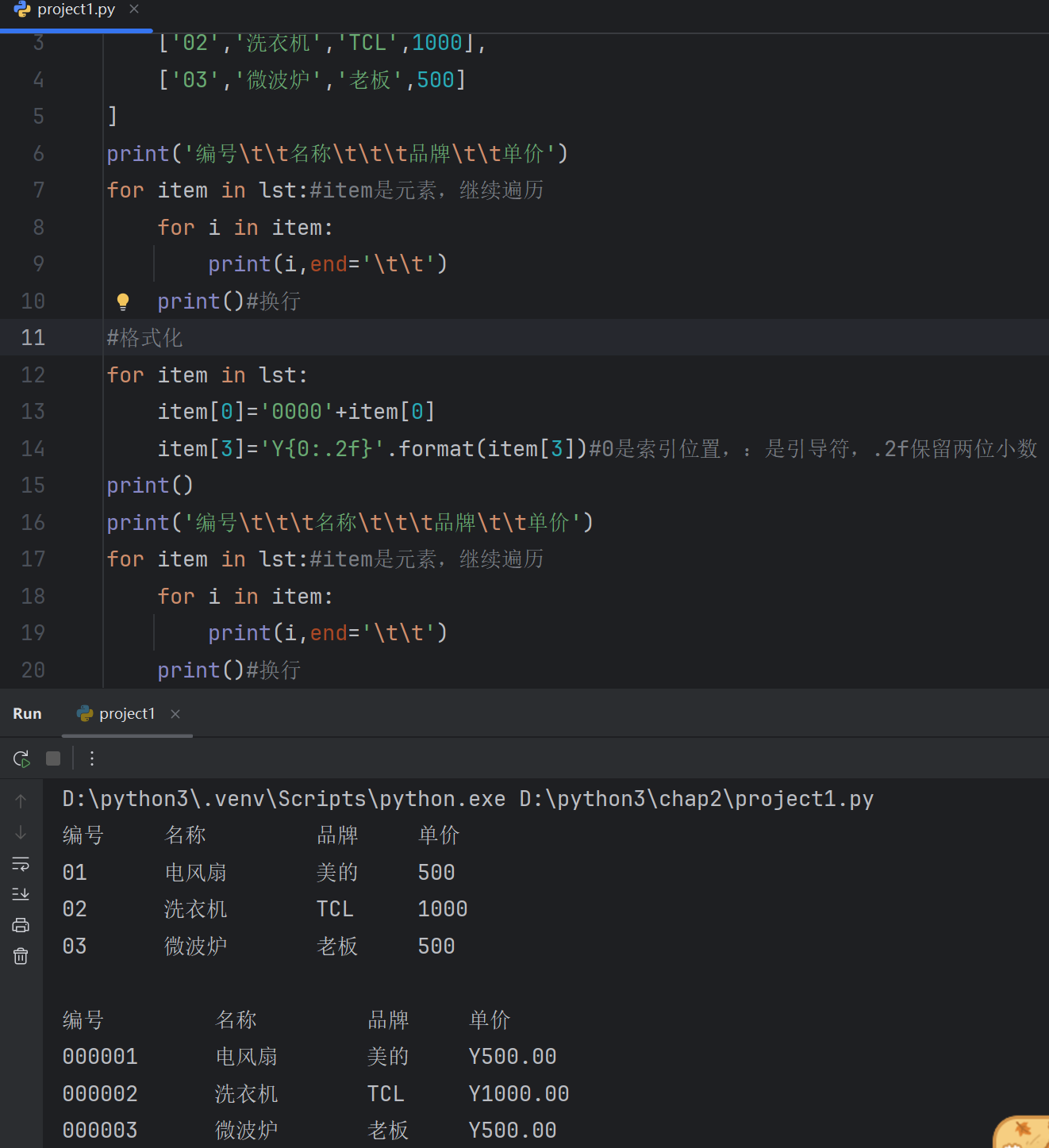
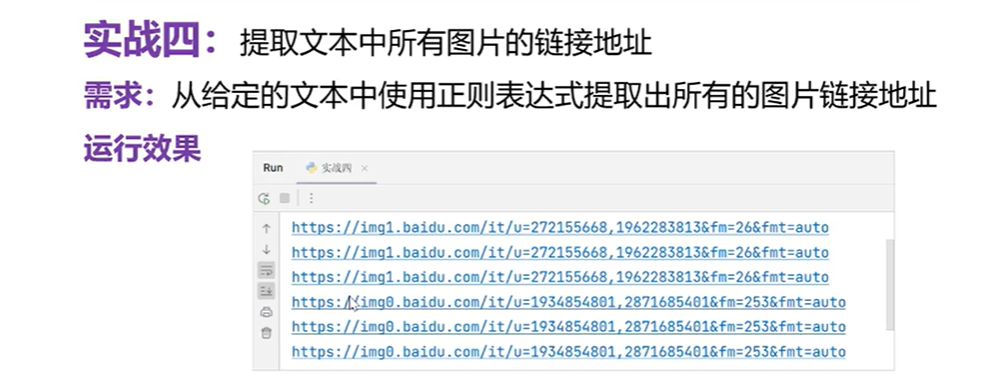
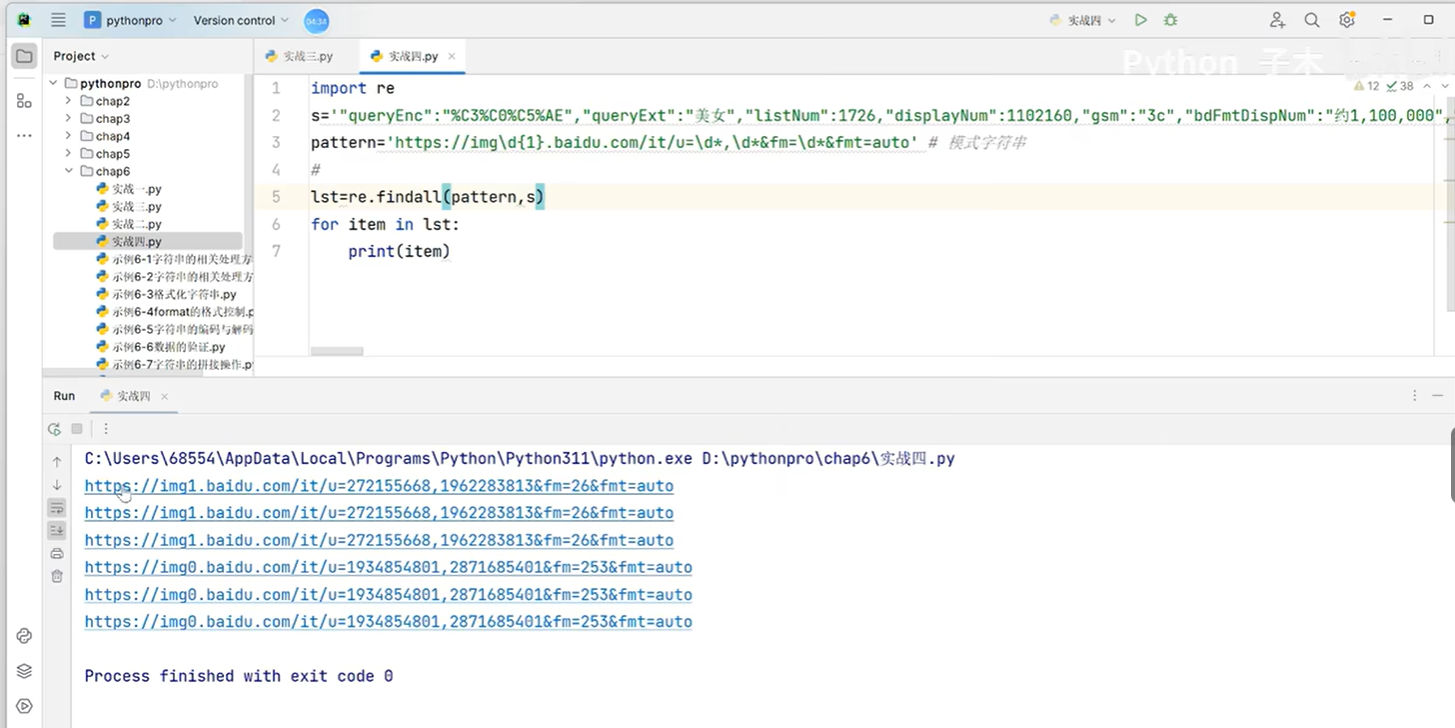
整数的正则表达式是\d,出现几次:{1}。*代表0或者多次
findall结果是列表
四、bug的由来和分类



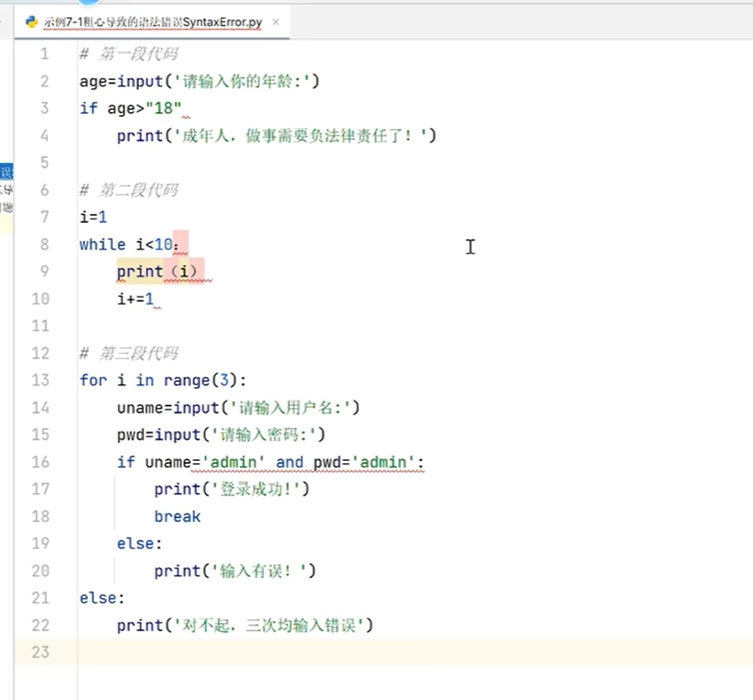
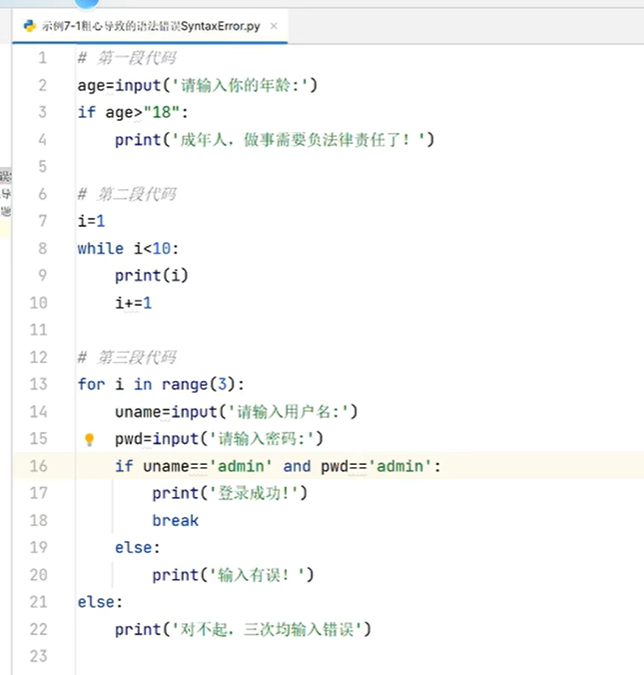
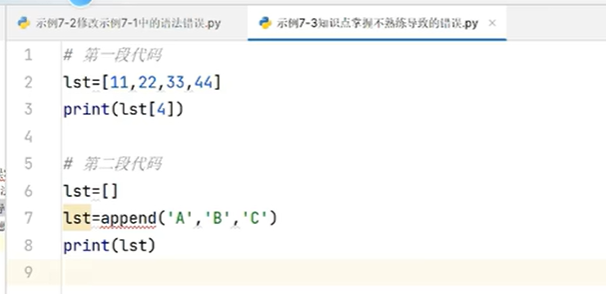
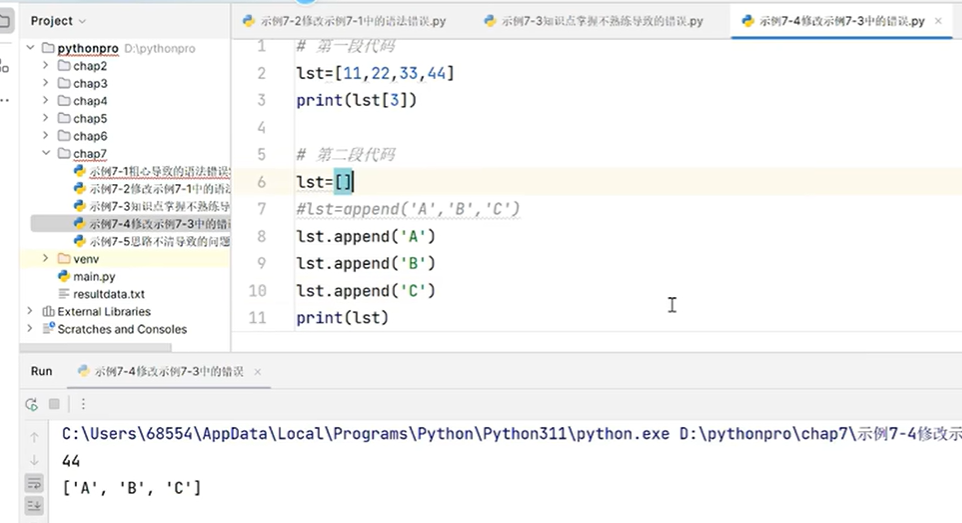
正向递增索引:索引的范围是0—>N-1,append是列表的调用方法,打点调用
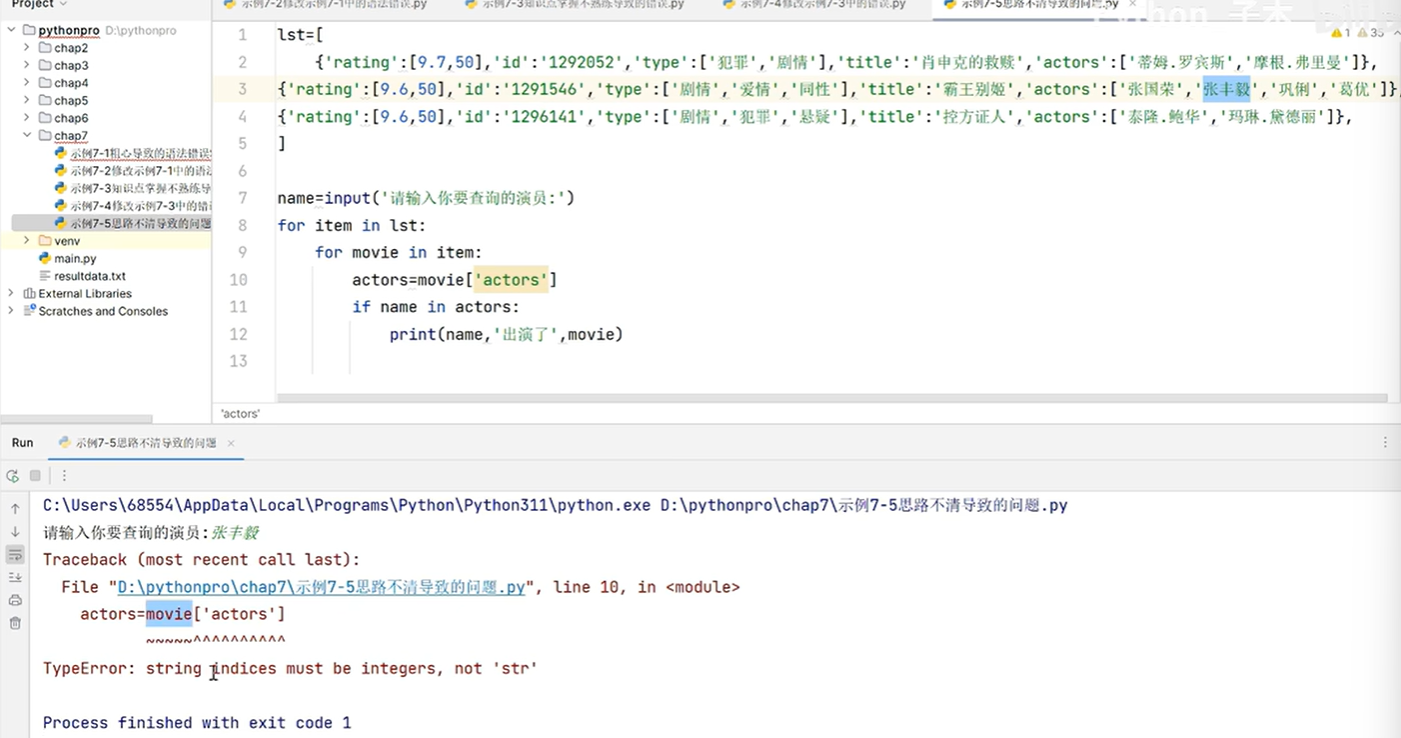
字符串的切片是整数
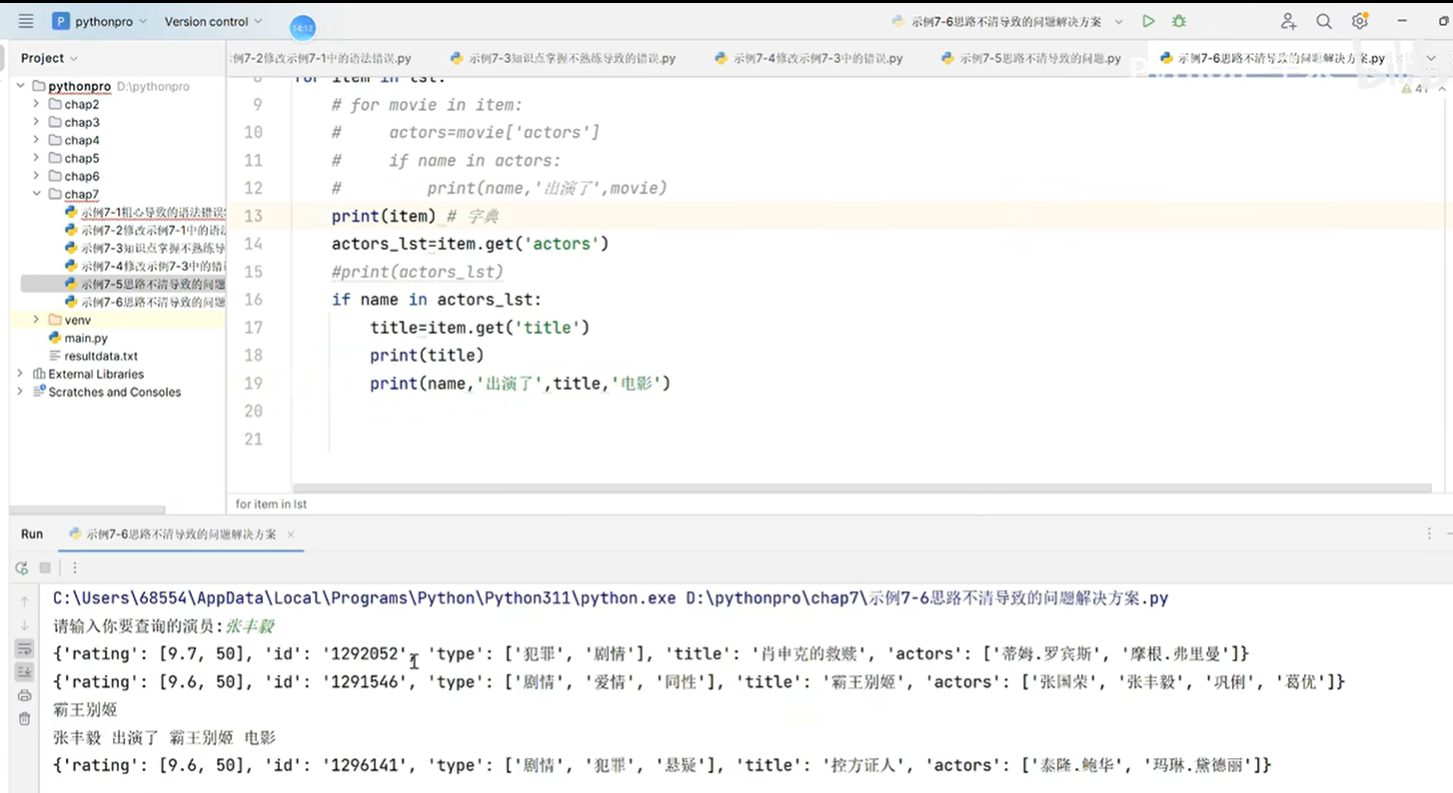
4.1 Python中异常处理机制

try:num1 = int(input("输入一个整数:"))num2 = int(input("输入另一个整数:"))result = num1 / num2print('结果', result)
except ZeroDivisionError:print('除数为0')
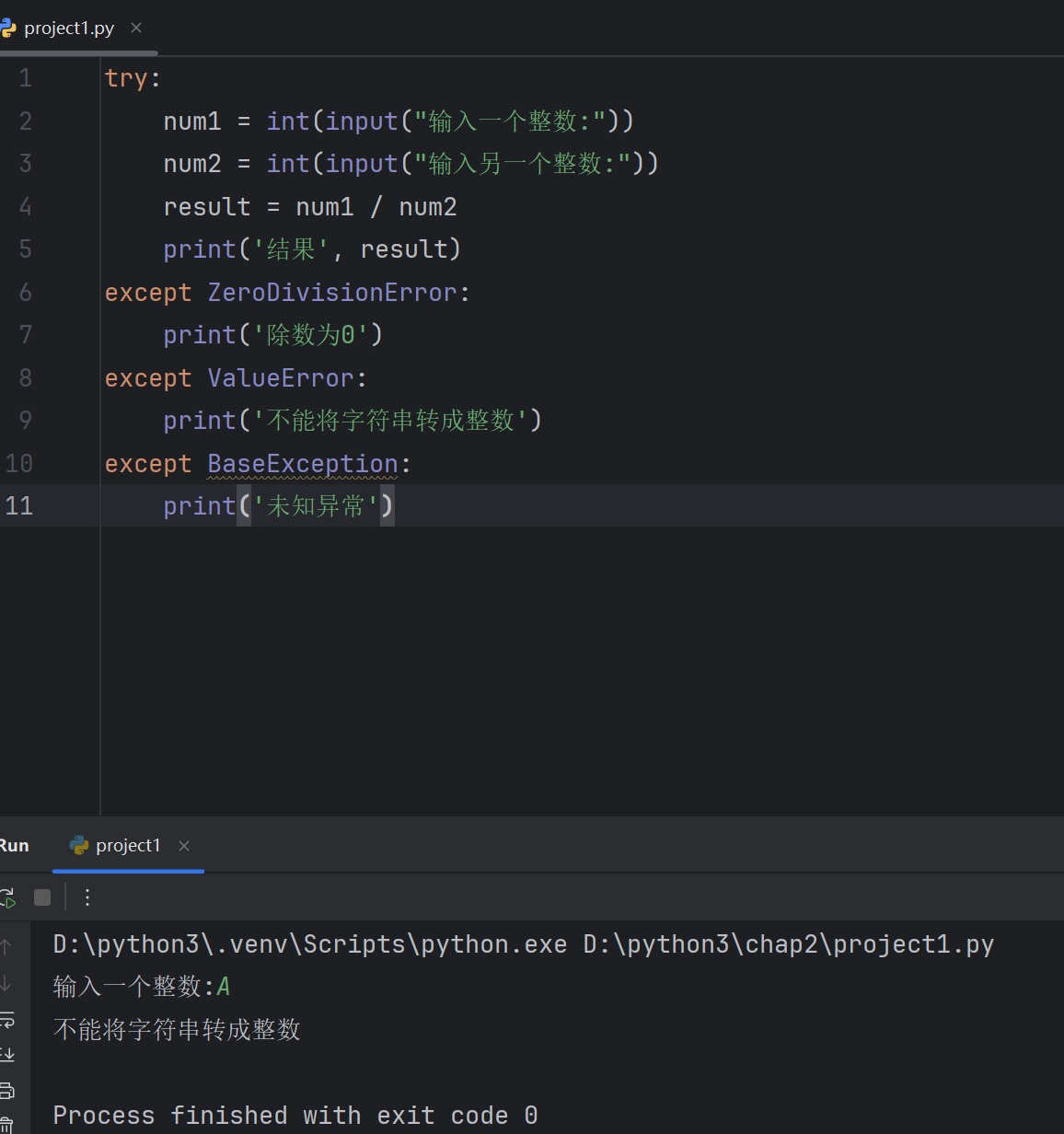
4.2多个except结构
try:num1 = int(input("输入一个整数:"))num2 = int(input("输入另一个整数:"))result = num1 / num2print('结果', result)
except ZeroDivisionError:print('除数为0')
except ValueError:print('不能将字符串转成整数')
except BaseException:print('未知异常')

finally无论程序是否异常都会执行的代码
try:num1 = int(input("输入一个整数:"))num2 = int(input("输入另一个整数:"))result = num1 / num2print('结果', result)
except ZeroDivisionError:print('除数为0')
except ValueError:print('不能将字符串转成整数')
except BaseException:print('未知异常')
else:print('结果:',result)
finally:print('程序执行结束')
4.3 raise关键字的使用

try:gender=input("Enter your gender: ")if gender!="Male"and gender!="Female":raise Exception('性别只能是男或者女')#第三行判断条件为True,会抛出异常对象else:print('您的性别是',gender)
except Exception as e:print(e)
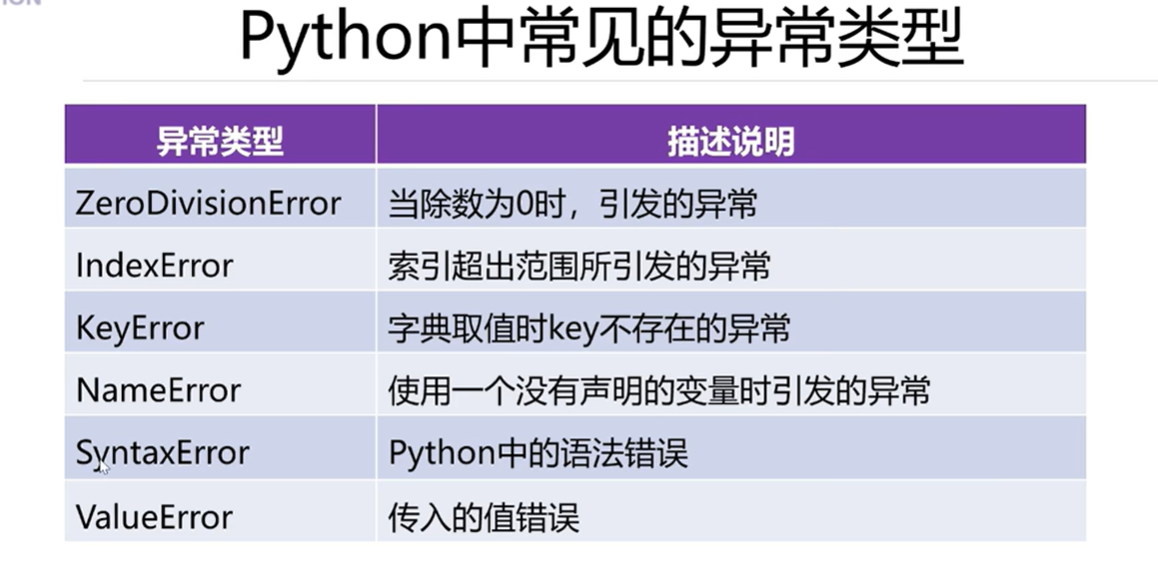
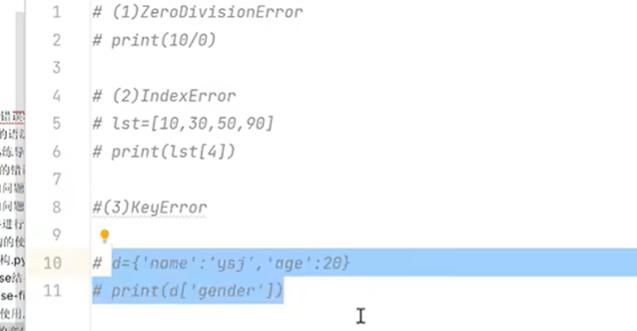
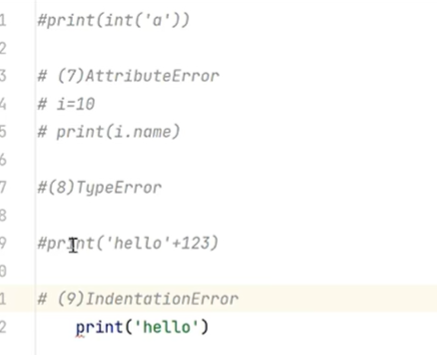
4.4 python中常用的异常类型


4.5 PyCharm的程序调试
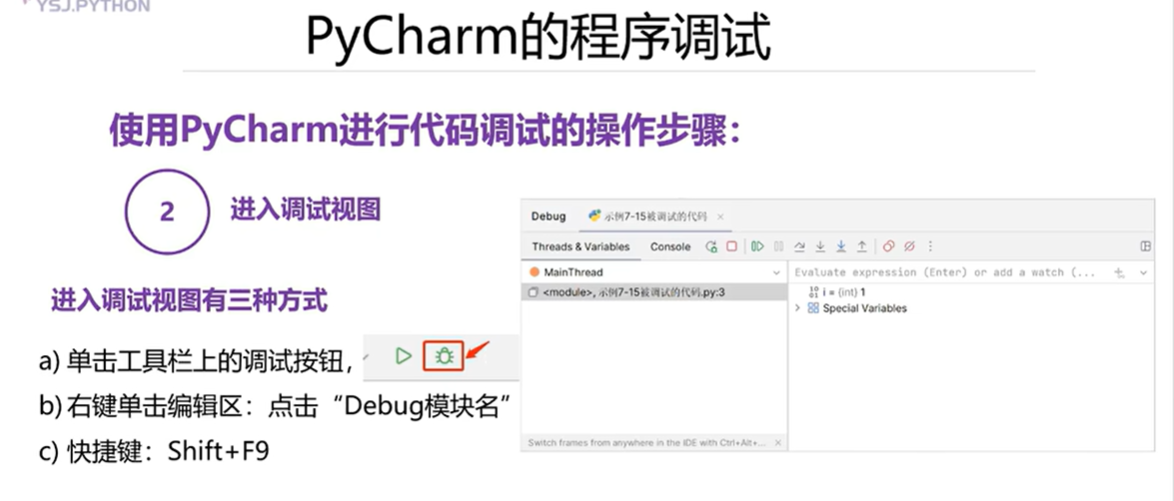
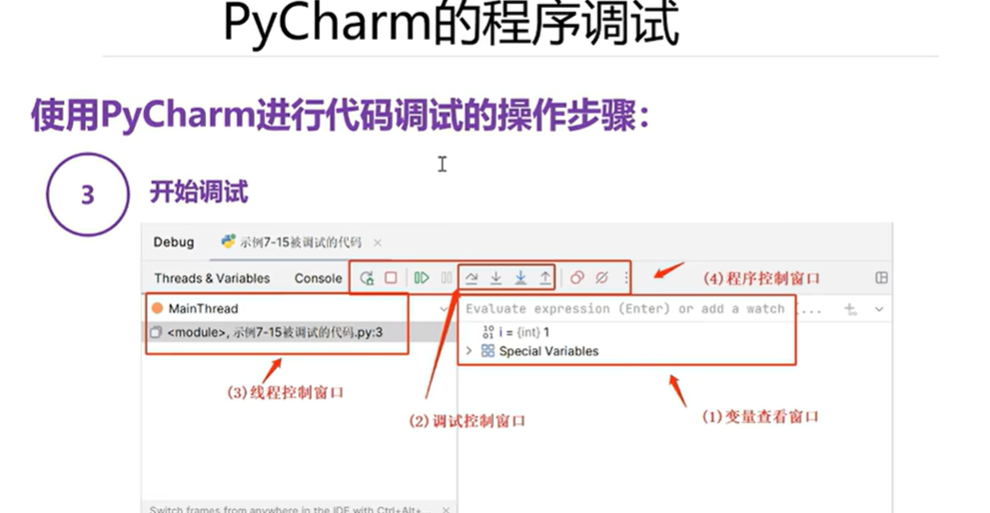
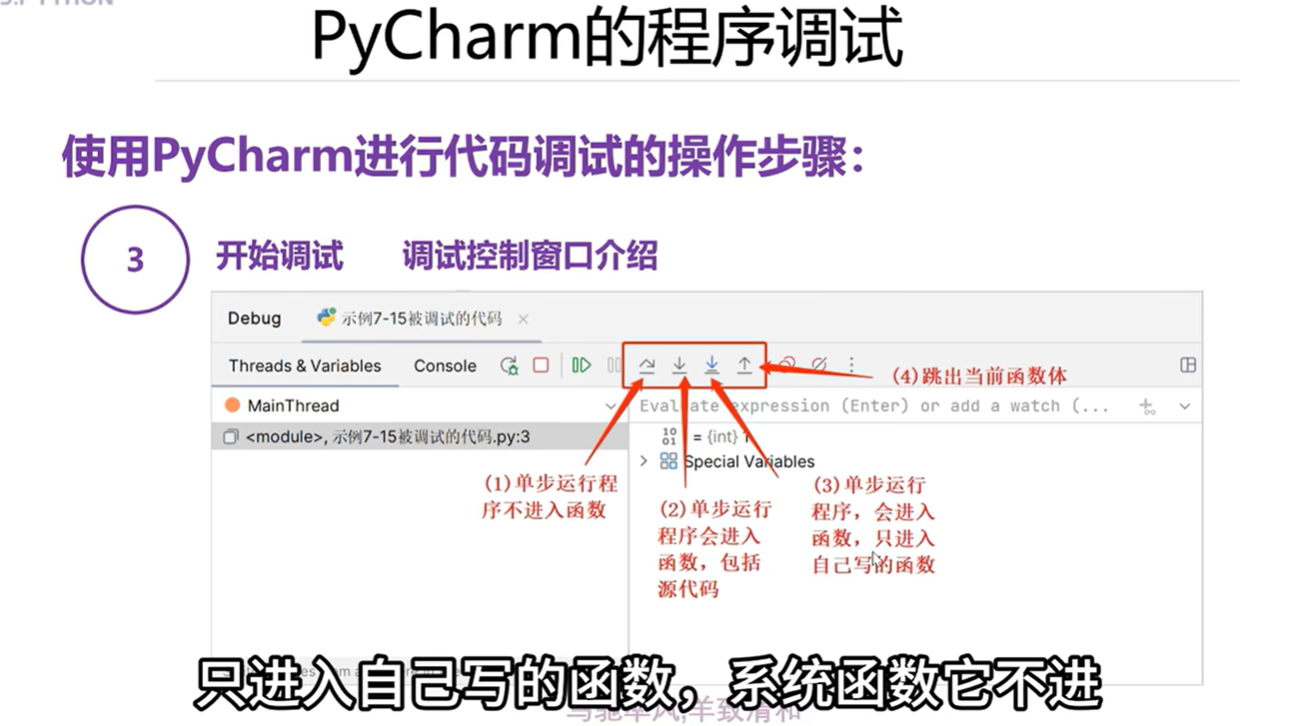
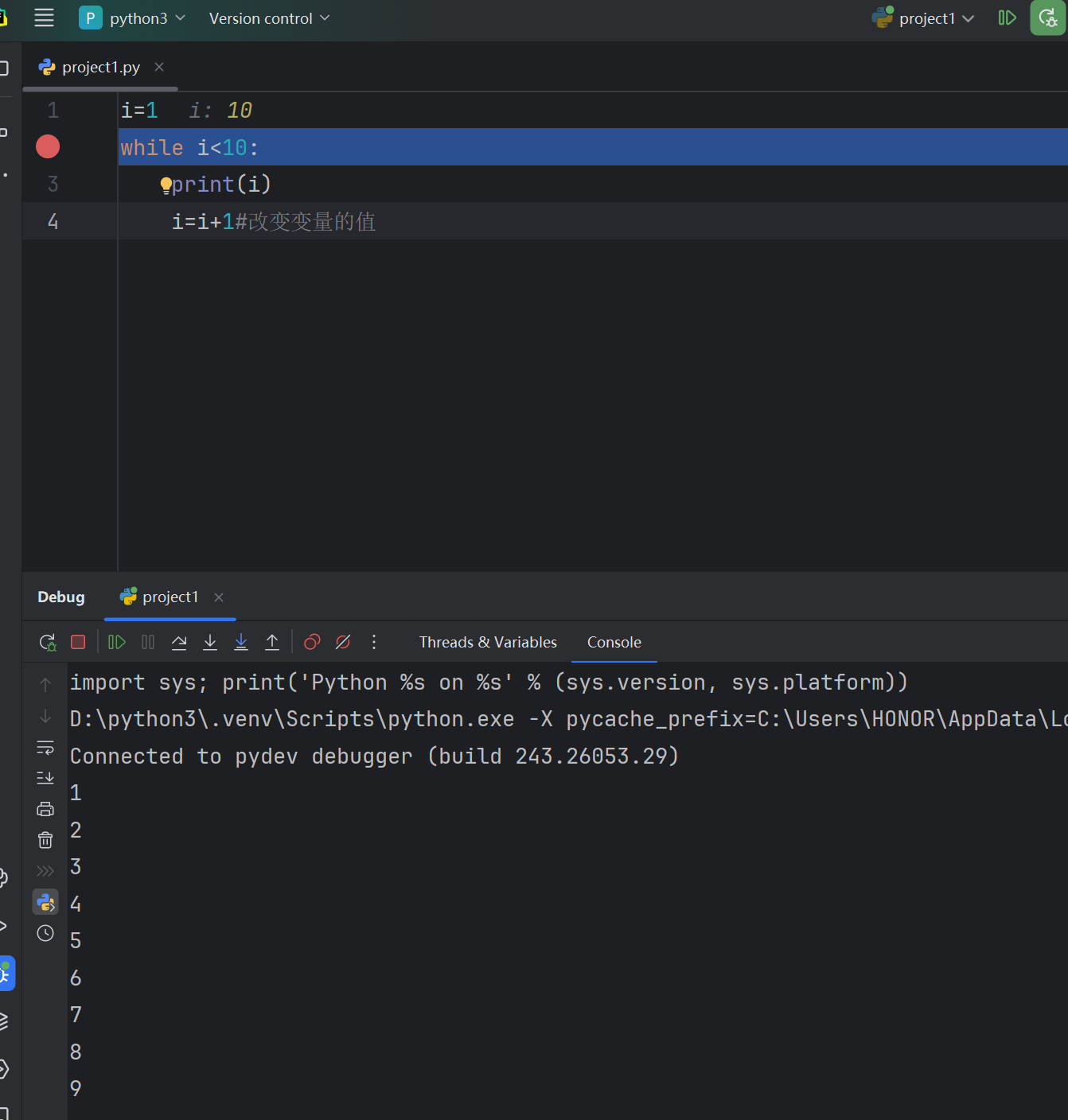
本章总结

如果没有出现异常执行try-else结构,在最后一个结果中,没有异常执行try-else-finally,出现异常执行try-except-finally

设置断点:在变量定义,循环处





finally无论是否异常都会执行




章节习题
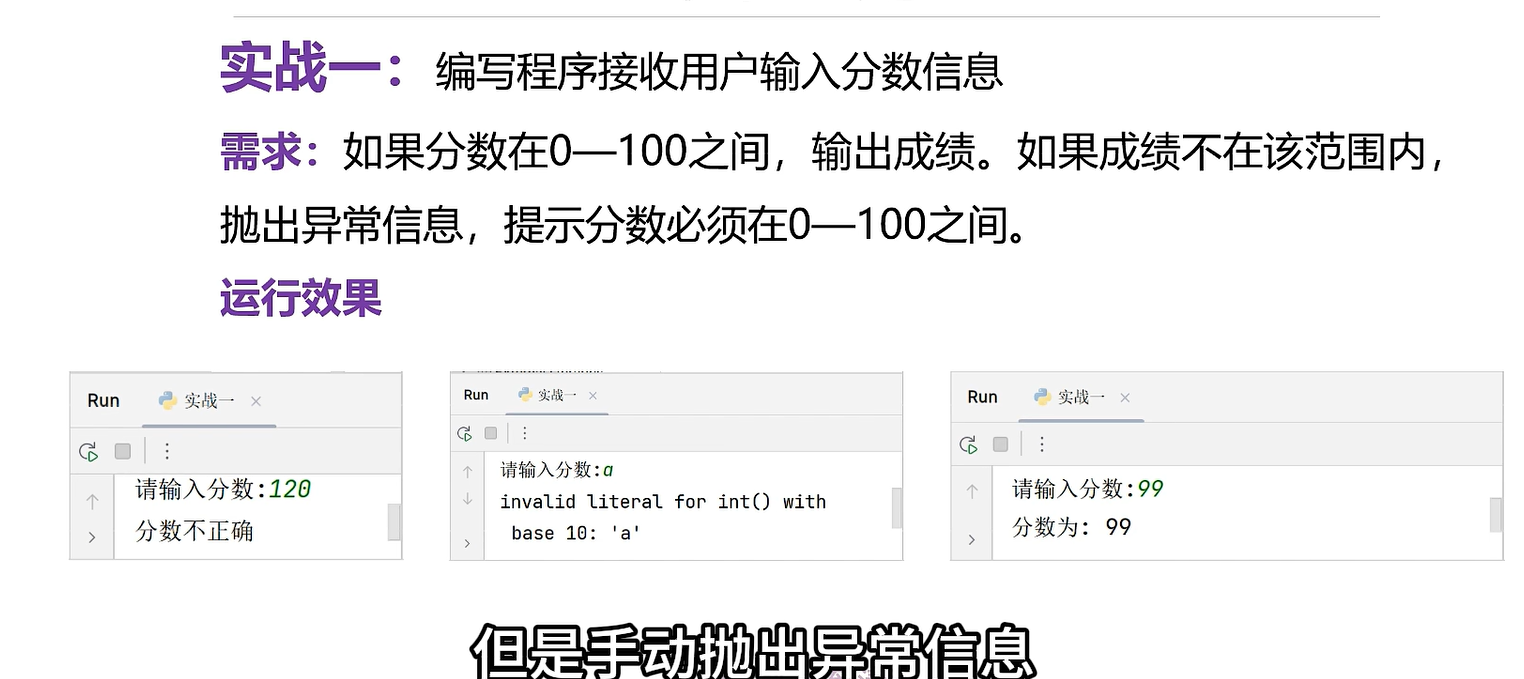
try:score=eval(input("Enter your score: "))if 0<=score<=100:print("Your score is:",score)else:raise Exception('分数不正确')
except Exception as e:print(e)
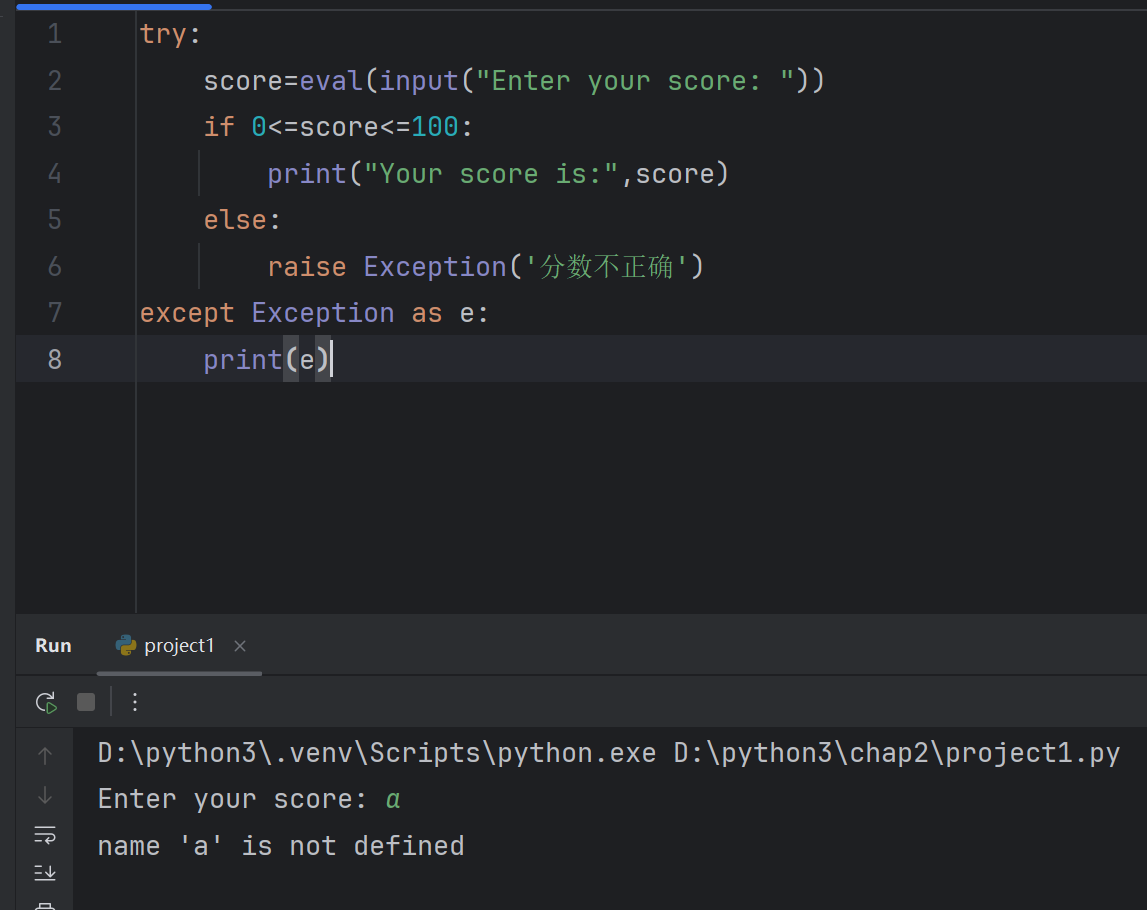
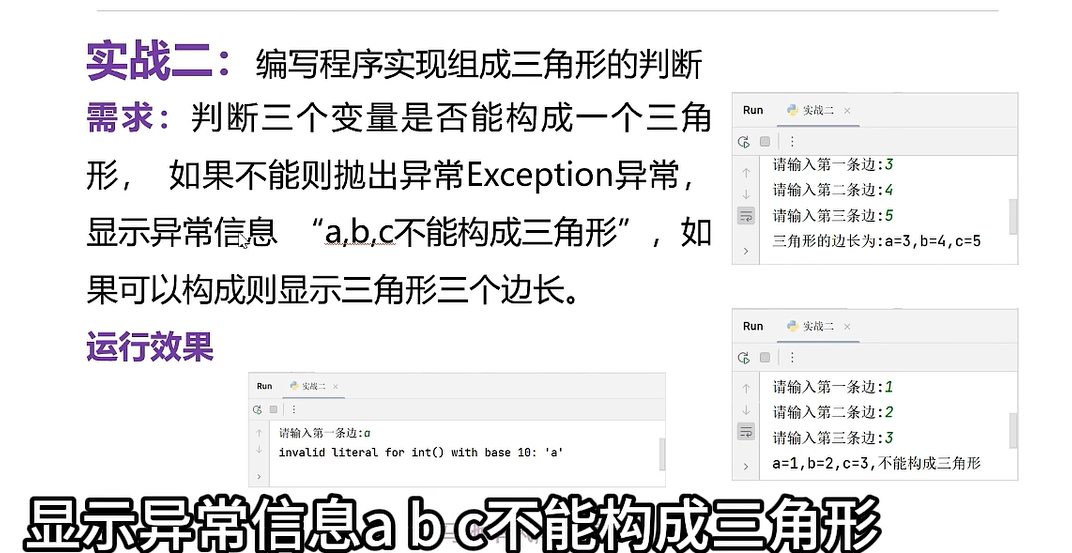
try:a = int(input("请输入第一条边: "))b = int(input("请输入第二条边: "))c = int(input("请输入第三条边: "))if a+b>c and b+c>a:print(f'三角形的边长:,{a},{b},{c}')else:raise Exception(f'{a},{b},{c},不能构成三角形')# 格式化处理
except Exception as e:print(e)
五、函数及常用的内置函数


def get_sum(num):#num叫做形式参数(函数定义处)s=0for i in range(1,num+1):s=s+iprint(f'1到{num}之间的累加和为:{s}')#函数的调用处
get_sum(10)#1-10之间的累加和 10是实际参数值
get_sum(100)#1-100之间的累加和 100是实际参数值
get_sum(1000)#1-100之间的累加和 1000是实际参数值


函数的参数传递-位置参数和关键字参数

def happy_birthday(name,age):print('祝'+name+'生日快乐')print(str(age)+'生日快乐')#调用
happy_birthday('张三',18)#调用时调用的参数个数和顺序必须与定义的参数的个数和顺序相同关键字传参
def happy_birthday(name,age):print('祝'+name+'生日快乐')print(str(age)+'生日快乐')
#关键字传参
happy_birthday(age=18,name='张三')
#happy_birthday(age=18,name1='张三')
#定义形参为name,TypeError: happy_birthday() got an unexpected keyword arguhappy_birthday('陈梅梅',age=18)#正常执行,位置传参,也可以使用关键字传参#happy_birthday(name='陈梅梅',18)#SyntaxError: positional argument follows keyword argument
#位置参数在前,关键字传参在后,不然会报错5.1 函数的参数传递–默认值参数

def happy_birthday(name='张三',age=18):print('祝'+name+'生日快乐')print(str(age)+'生日快乐')#调用
happy_birthday()#不用传参
happy_birthday('陈梅梅')#位置传参
happy_birthday(age=19)#关键字传参(函数调用处传参),name采用默认值#happy_birthday(19)# 19会赋值给哪个变量,如果使用位置传参的方式,19被传给了name
def fun(a,b=20):pass#def fun2(a=20,b):# 语法报错,当位置参数和默认参数(在函数定义时)同时存在的时候,位置参数在后会报错# pass# 当位置参数和关键字参数同时存在,应该遵循位置参数在前,默认参数在后5.2 函数的参数传递–可变参数

# 个数可变的位置参数
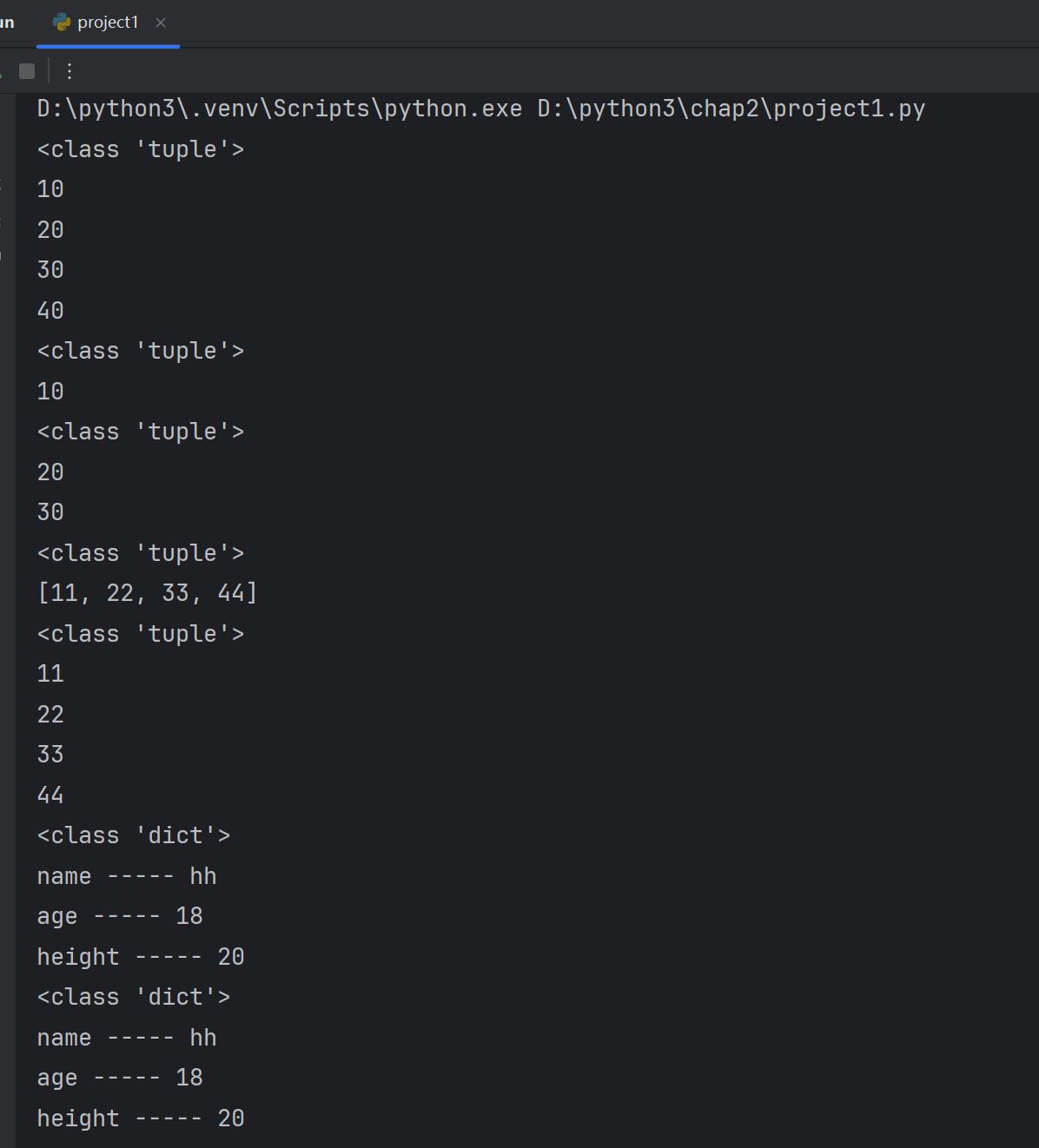
def fun(*data):print(type(data))for item in data:print(item)#调用
fun(10,20,30,40)
fun(10)
fun(20,30)
fun([11,22,33,44])#实际传递的是一个参数
#在调用时,参数前加一颗星,分将列表进行解包
fun(*[11,22,33,44])#个数可变的关键字参数
def fun2(**kwpara):#定义需要两颗星print(type(kwpara))for key,value in kwpara.items():print(key,'-----',value)#调用
fun2(name='hh',age=18,height=20)#关键字参数d={'name':'hh','age':18,'height':20}
#fun2(d)#不可以将字典传入做参数, fun2() takes 0 positional arguments but 1 was given
fun2(**d)# 如果参数是字典,前面加上两颗星进行系列解包
5.3 函数的返回值

# 函数的返回值
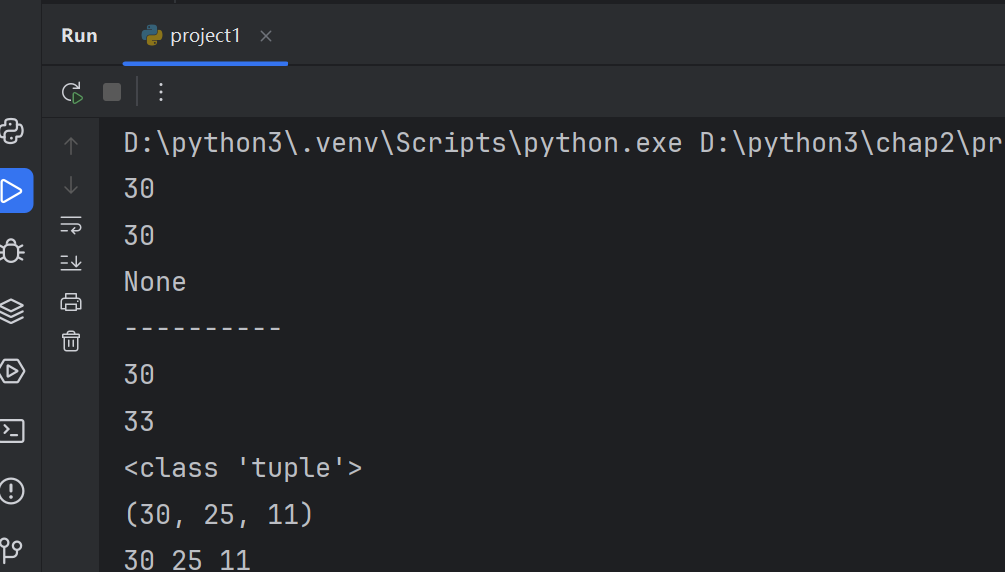
def calc(a,b):print(a+b)calc(10,20)
print(calc(10,20))#Nonedef calc2(a,b):s=a+breturn s #将s返回函数的调用处处理print('-'*10)
get_s=calc2(10,20)#存储到变量当中
print(get_s)get_s2=calc2(calc2(10,20),3)#先去执行calc2(10,20),返回结果是30,再去执行calc2(30,30)
print(get_s2)#返回值可以是多个
def get_sum(num):s=0#累加和for i in range(1,num+1):s=s+iodd_sum=0#奇数和even_sum=0#偶数和for i in range(1,num+1):if i%2==0:odd_sum=odd_sum+ielse:even_sum=even_sum+is+=1return odd_sum,even_sum,s#三个值result=get_sum(10)
print(type(result))
print(result)#系列解包赋值
a,b,c=get_sum(10)
print(a,b,c)
5.4 变量的作用域

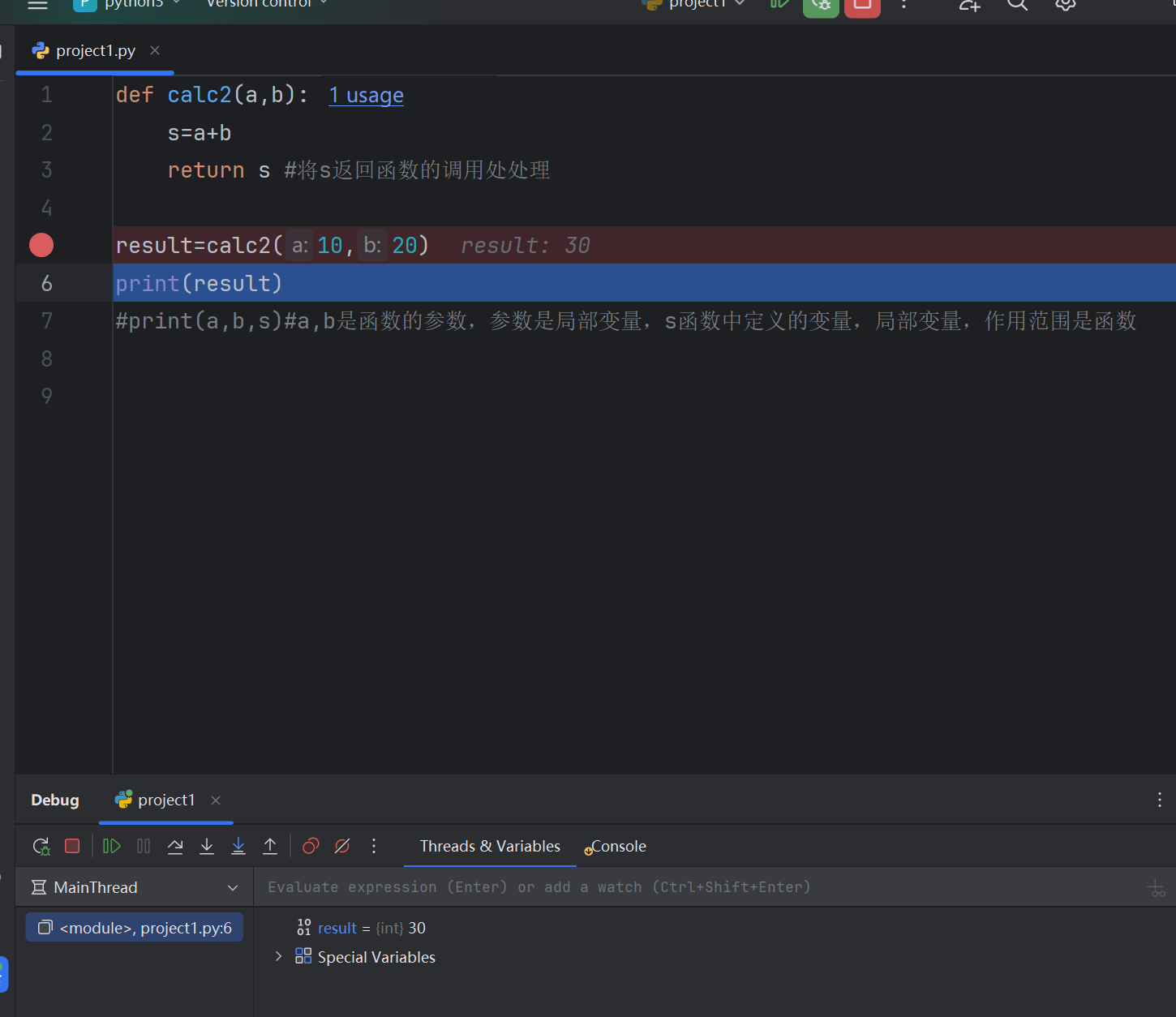
def calc2(a,b):s=a+breturn s #将s返回函数的调用处处理result=calc2(10,20)
print(result)
#print(a,b,s)#a,b是函数的参数,参数是局部变量,s函数中定义的变量,局部变量,作用范围是函数
a=100#全局变量
def calc(x,y):return a+x+y
print(a)
print(calc(10,20))
print('-'*30)def calc2(x,y):a=200#局部变量,局部变量的名称和全局变量的名称相同return a+x+y# a是局部变量还是全局变量?局部变量,当全局变量和局部变量名称相同时,局部变量的优先级高
print(calc2(10,20))
print(a)
print('-'*30)
def calc3(x,y):global s#s是在函数中定义的变量,但是使用了global关键字声明,这个变量s变成了全局变量s=300# 声明和赋值,必须分开执行return s+x+yprint(calc3(10,20))
print(s)
print('-'*30)
5.5 匿名函数的使用

from ctypes import HRESULTdef calc(a,b):return a+b
print(calc(10,20))
#匿名函数
s=lambda a,b:a+b#s表示的是一个匿名函数
print(type(s))
#调用匿名函数
print(s(10,20))
print('*'*50)#
lst=[10,20,30,40,50]
for i in range(len(lst)):# i表示索引print(lst[i])
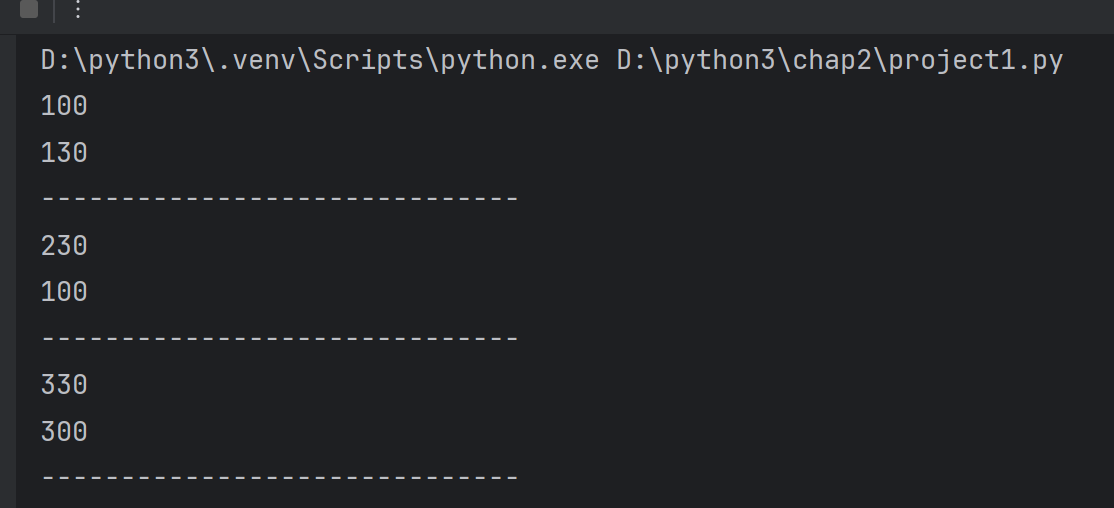
print()for i in range(len(lst)):result=lambda x:x[i]#根据索引取值,result的是函数(function)类型,x是形式参数print(result(lst))# lst是实际参数student_scores=[#列表,列表里面四个元素{'name':'张三','score':98},{'name':'李四','score':96},{'name':'王五','score':98},{'name':'赵六','score':65}
]
# 对列表进行排序,排序规则:字典中的成绩
student_scores.sort(key=lambda x:x.get('score'), reverse=True)#x是字典,降序、
print(student_scores)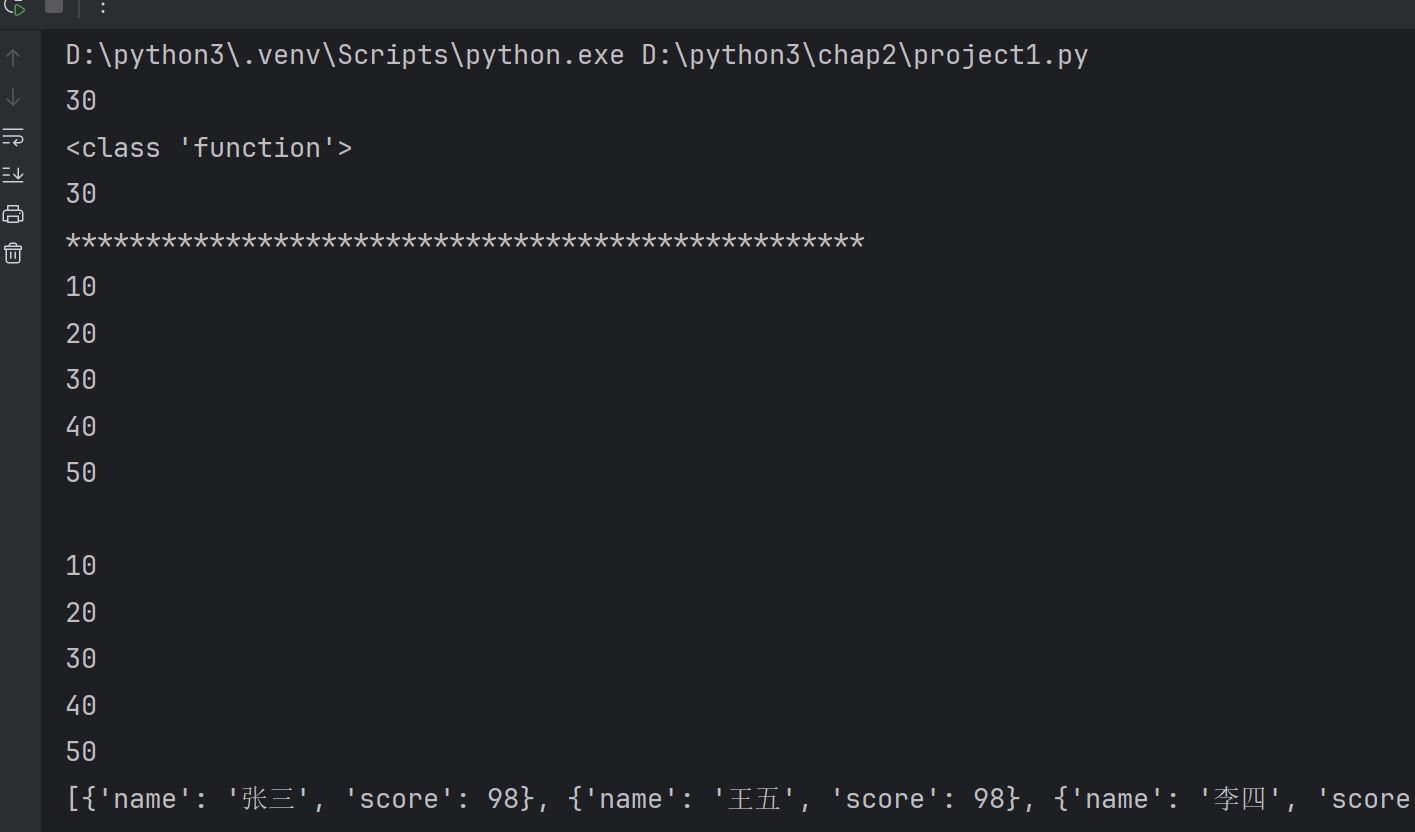
5.6 函数的递归操作

def fac(n):#n的阶乘 N!=N*(N-1)!....1! N=5if n == 1:return 1else:return n * fac(n - 1)# 自己调用自己
print(fac(5))
5.7斐波那契数列
递归每调一次会开辟一个栈

def fac(n):if n == 1 or n == 2:return 1else:return (n - 1)+fac(n-2)print(fac(9))
for i in range(1,9):print(fac(i),end="\t")#不换行
print()
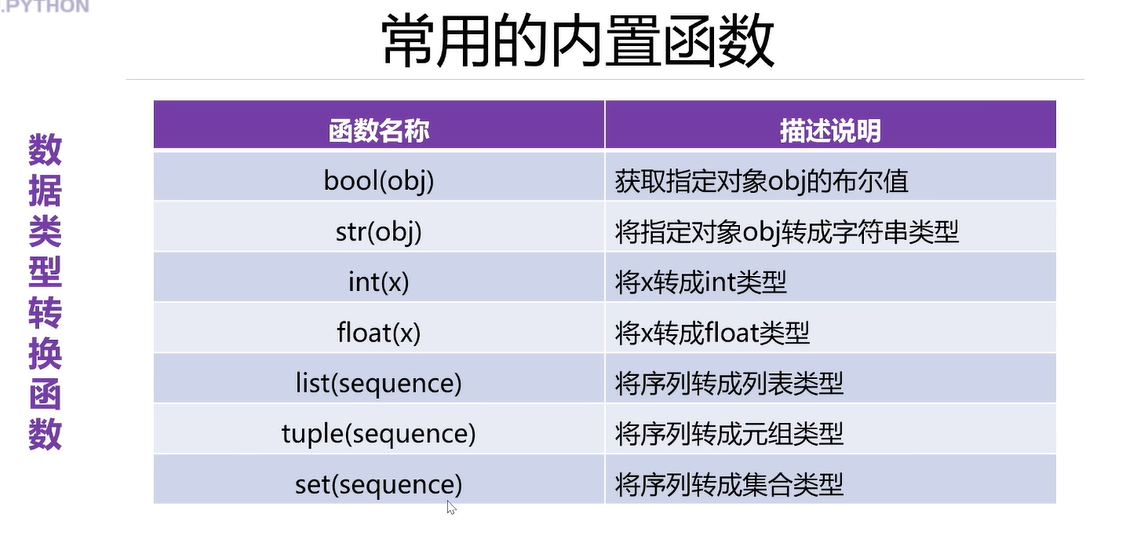
5.8常用的内置函数–类型转换函数
还有转成字典类型的dict
print('非空字符串的布尔值',bool('hello'))
print('空字符串布尔值',bool(''))# 空字符串不是空格字符串
print('空列表布尔值',bool([]))
print('空列表布尔值',bool(list()))
print('空元组布尔值',bool(()))
print('空元组布尔值',bool(tuple()))
print('空集合布尔值',bool(set()))
print('空字典布尔值',bool({}))
print('空字典布尔值',bool(dict()))
print('-'*30)
print('非0数值型布尔值',bool(123))
print('整数0的布尔值',bool(0))
print('浮点数0.0的布尔值',bool(0.0))#将其他类型转成字符型
lst=[10,20,30]
print(type(lst),lst)
print()
s=str(lst)
print(type(s),s)# float类型和str类型转成int类型
print('-'*30,'float类型和str类型转成int类型','-'*30)
print(int(98.7)+int('90'))
# 注意事项
#print(int('98.7'))#ValueError: invalid literal for int() with base 10: '98.7'
#字符串里面的浮点串不可以转
#print(int('a'))ValueError: invalid literal for int() with base 10: 'a'
print('-'*30,'int,str类型转成float类型','-'*30)
print(float(98.7)+float('3.14'))
s='hello'
print(list(s))
seq=range(1,10)#
print(tuple(seq))#创建元组
print(set(seq))#添加到集合中
print(list(seq))
print('-'*30)
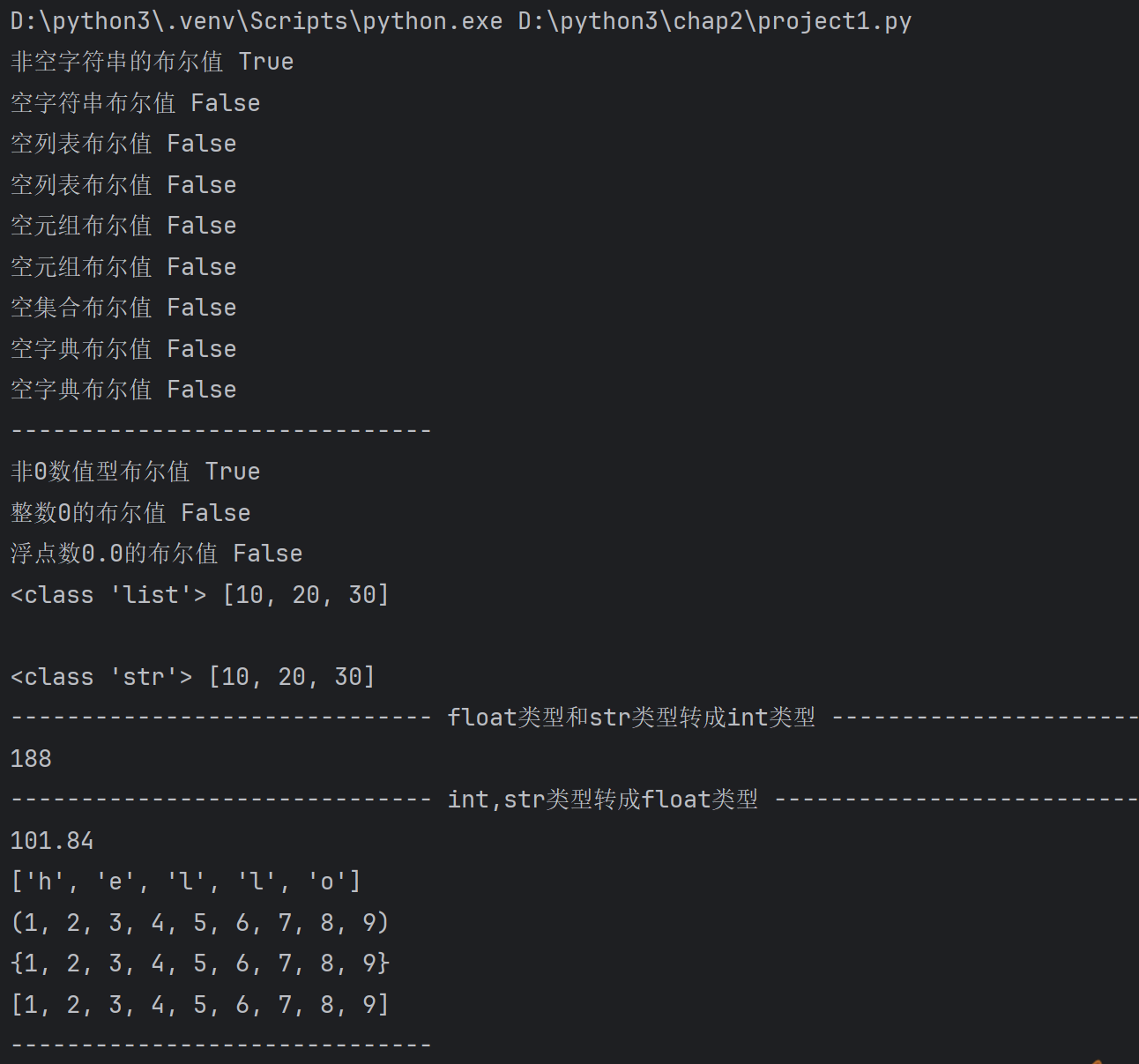
常见的内置函数–数学函数
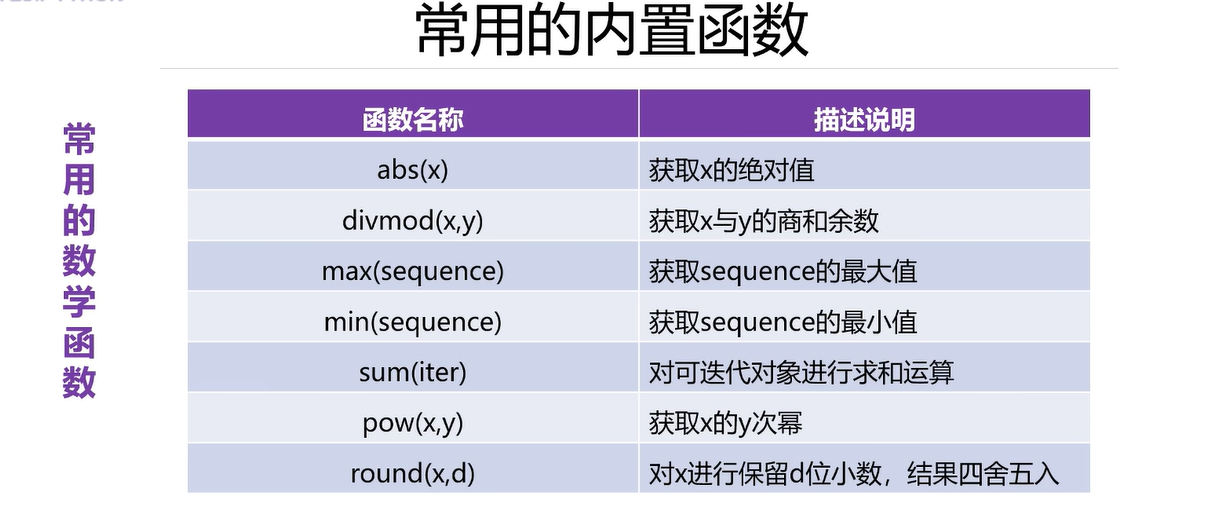
print('绝对值',abs(100),abs(-100),abs(0))
print('商和余数',divmod(13,4))
print('最大值',max('hello'))
print('最大值',max([10,4,56,78,4]))
print('最小值',min('hello'))
print('最小值',min([10,4,56,78,4]))
print('求和',sum([10,34,45]))
print('x的y次幂',pow(2,3))#四舍五入
print(round(3.1415926))# round函数只有一个参数,保留整数
print(round(3.9415926))#4
print(round(3.1415926,2))# 2表示保留两位小数
print(round(314.15926,-1))# 314 ,-1位,个位进行四舍五入
print(round(314.15926,-2))# 300 ,-2位,十位进行四舍五入
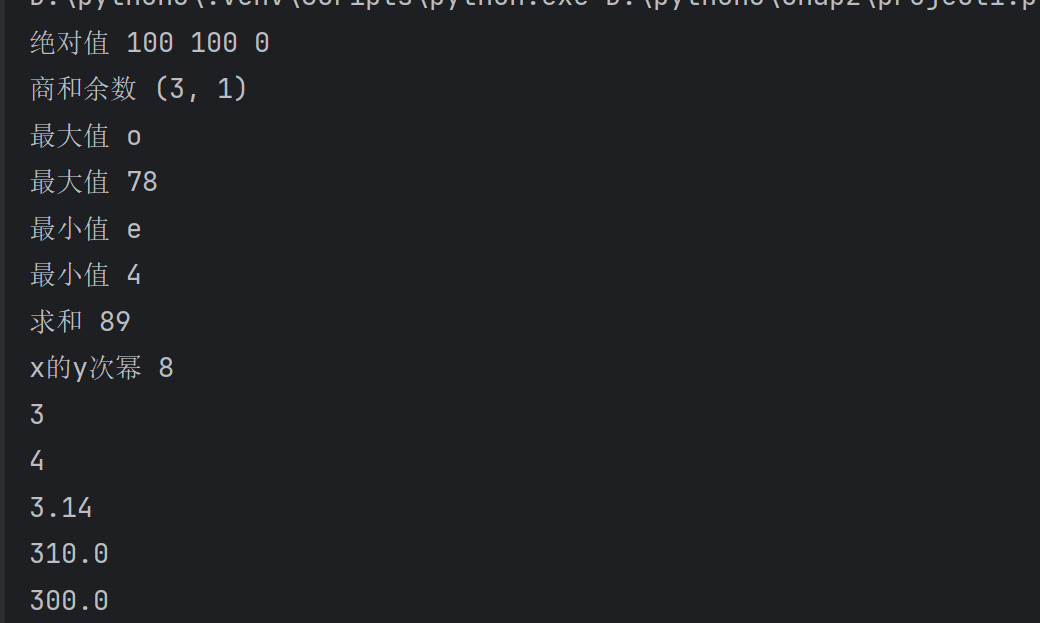
5.9 迭代器操作函数
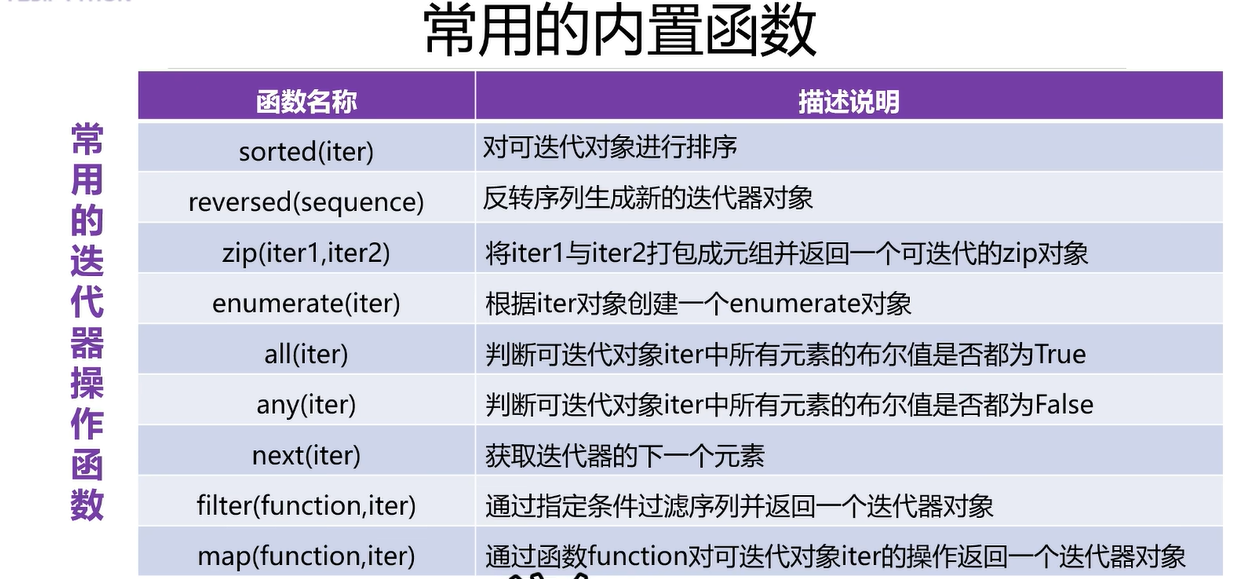
lst=[54,66,43,65,88]
#1.排序
asc_lst=sorted(lst)#升序
desc_lst=sorted(lst,reverse=True)#降序
print('原列表',lst)
print('升序',asc_lst)
print('降序',desc_lst)# 2.reversed反向
new_lst=reversed(lst)
print(type(new_lst))#<class 'list_reverseiterator'> 迭代器对象,结果不是列表
print(list(new_lst))# 3.zip
x=['a','b','c','d','e']
y=[10,20,30,40,50]
zipobj=zip(x,y)
print(type(zipobj))#<class 'zip'>
#print(list(zipobj))# 4.enumerate
enum=enumerate(y,start=1)
print(type(enum))#<class 'enumerate'>
print(tuple(enum))#转成元组#5.all
lst2=[10,20,'',30]
print(all(lst2))#空字符串布尔值是false
print(all(lst))# 6.any
print(any(lst))#True#7.
print(next(zipobj))
print(next(zipobj))
print(next(zipobj))#filter和map第一个参数都是函数
def fun(num):return num*2==1#可能是True,Falseobj=filter(fun,range(10))#函数作为参数
# 将range(10),0-9的整数都执行一次fun操作
print(list(obj))# [1,3,5,7,9]def upper(x):return x.upper()new_lst2=['hello','world','python']
obj=map(upper,new_lst2)
print(list(obj))#迭代器对象要转成列表或元组5.10 其他内置函数的使用
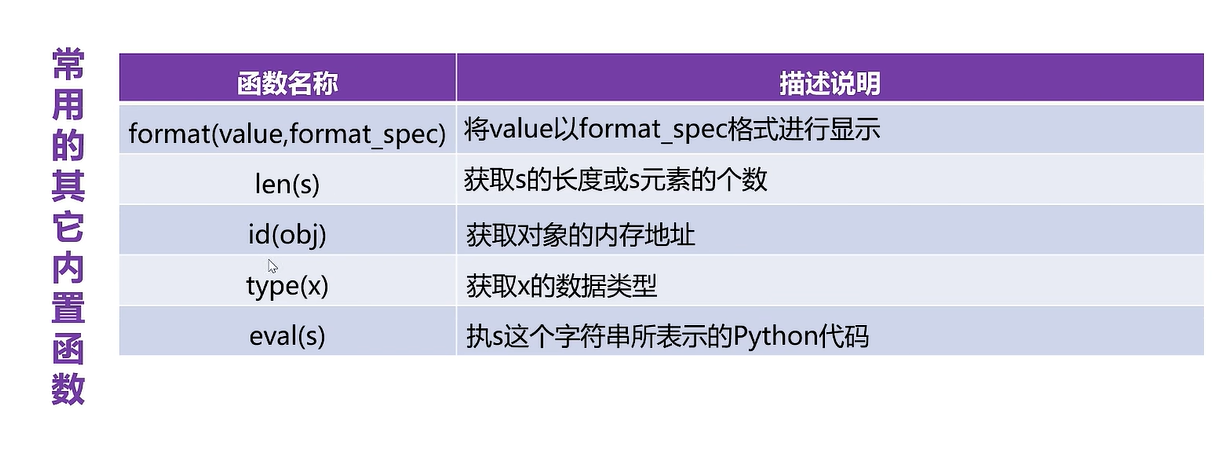
#format()
print(format(3.14,'20'))#默认右对齐
print(format('hello','20'))#默认左对齐
print(format('hello','*<20'))#<左对齐,*表示的填充符,20表示的是显示的宽度
print(format('hello','*^20'))print(format(3.1415926,'.2f'))#3.14
print(format(20,'b'))
print(format(20,'o'))
print(format(20,'x'))
print(format(20,'X'))print('-'*40)
print(len('helloworld'))
print(len([10,20,30,40,50]))print('-'*40)
print(id(10))#查看内存地址
print(id('helloworld'))#查看内存地址
print(type('hello'),type(10))#查看内存地址print(eval('10+30'))
print(eval('10>30'))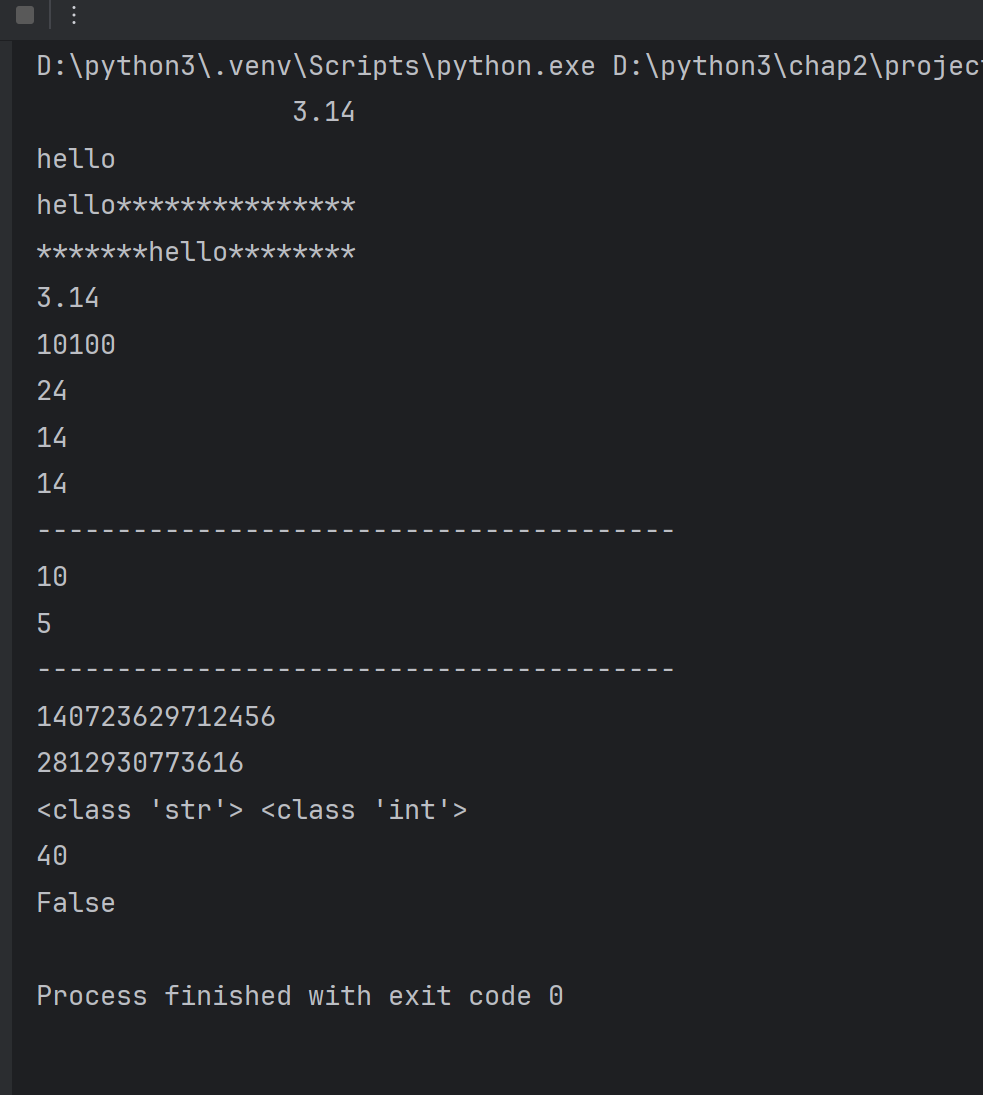
本章总结



章节习题
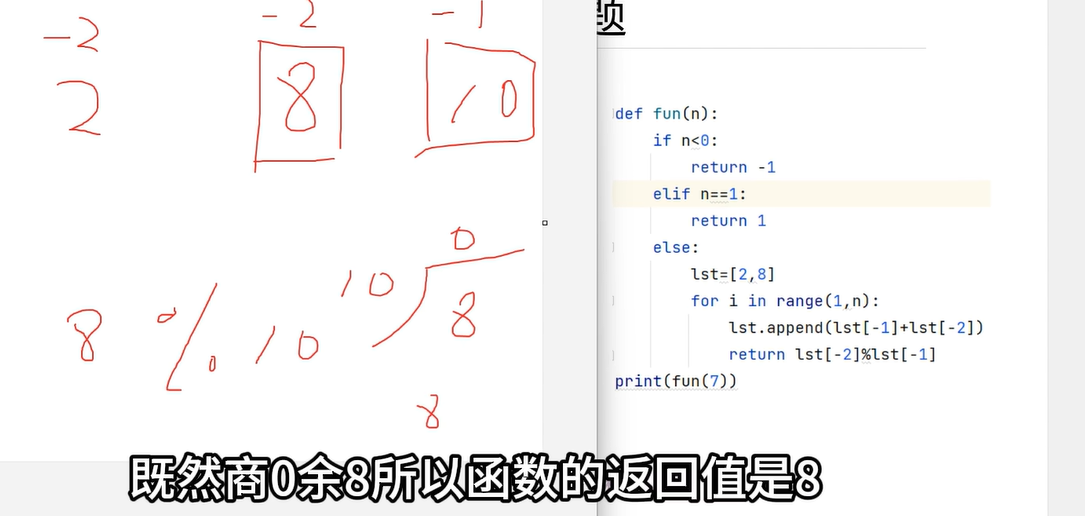
列表用的是-1就是反向递减,8的索引是-1,2的索引是-2,现在有三个元素:2 8 10

函数的返回值可有可无

当全局和局部相同,局部更具有优先级


将第四个元素添加到列表
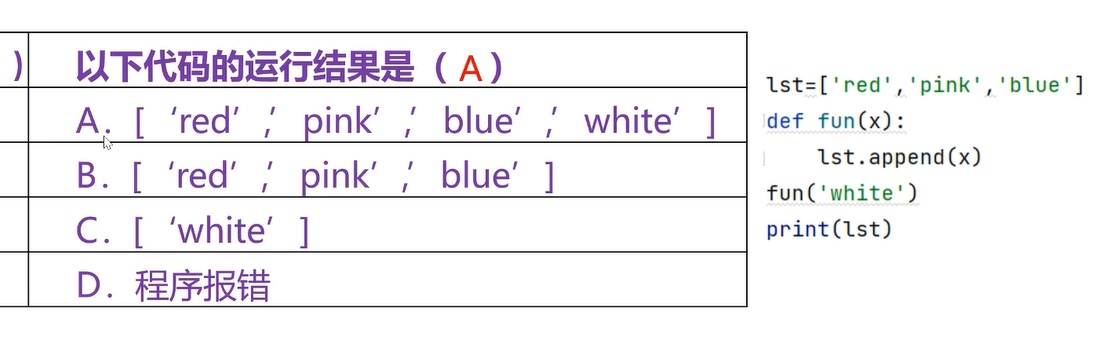
每递归一次规模缩小

3是作为参数传进来的

第一个最内部无返回值
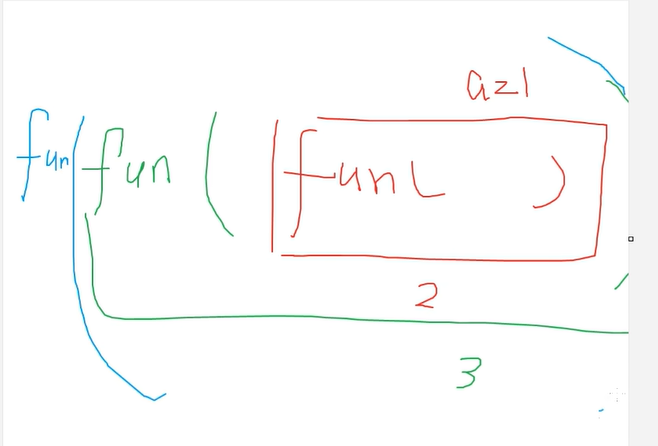

没有返回值类型,结果就是没有

参数可有可无也可以多个

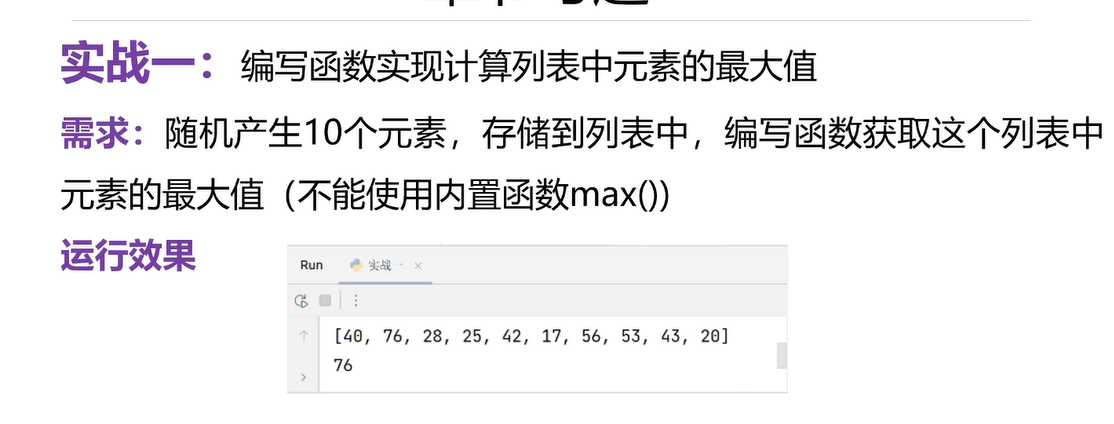
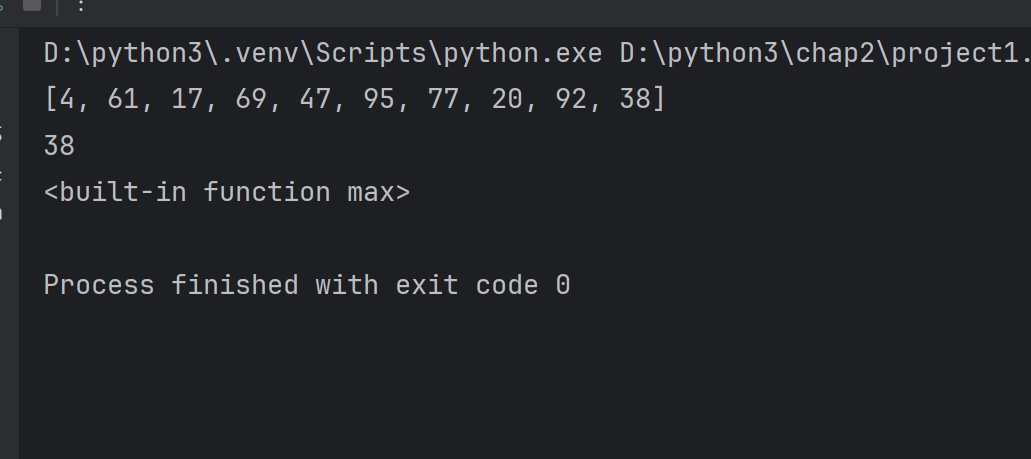
import random
def get_max(lst):x=lst[0]# x存储是元素的最大值#遍历for x in range(1,len(lst)):if lst[x] > x:x=lst[x]# 对最大值进行赋值return x#调用
lst=[random.randint(1,100) for item in range(10)]
print(lst)
#计算列表元素的最大值
print(get_max(lst))
print(max)
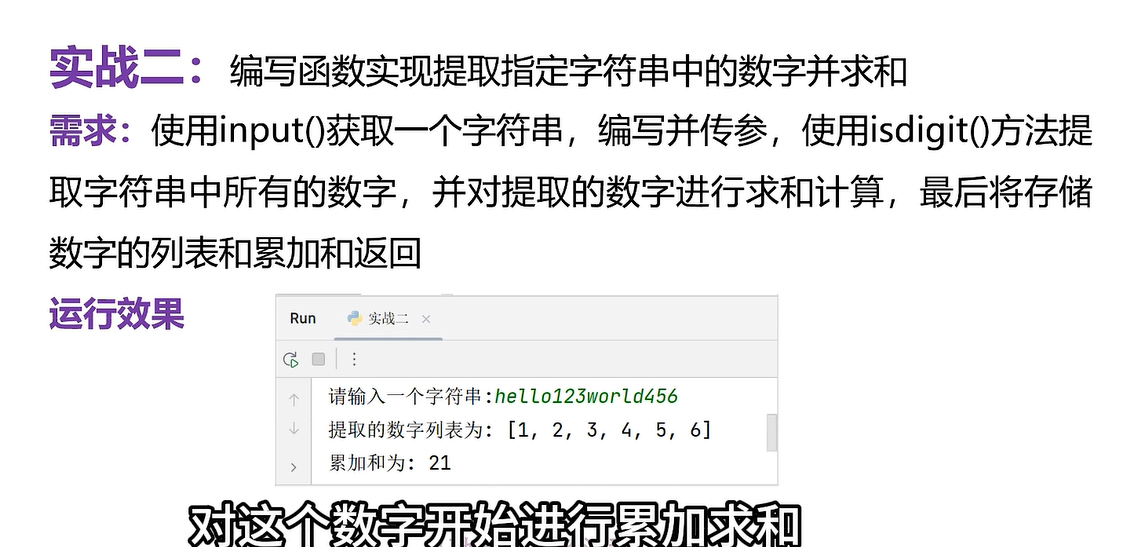
def get_digit(x):s=0 #存储累加和lst=[]#存储提取出来的数字for item in x:if item.isdigit():# 如果是数字lst.append(int(item))#求和s=sum(lst)return lst,s#准备函数的调用
s=input('请输入一个字符串:')
#调用
lst,x=get_digit(s)
print('提取的数字列表为:',lst)
print('累加和为',x)
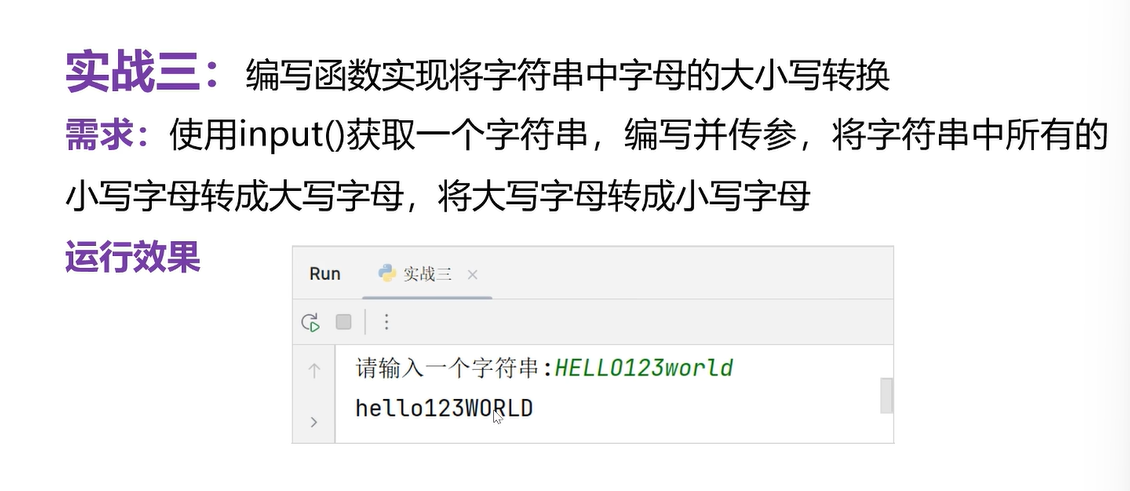
def lower_upper(x):# x是一个字符串,形式参数lst=[]for item in x:if 'A' <= item <= 'Z':lst.append(chr(ord(item)+32))#ord()将字母转成unicode码整数,加上32,chr()整数转成字符elif 'a' <= item <= 'z':lst.append(chr(ord(item)-32))else:lst.append(item)return ''.join(lst)# 准备调用
s=input('请输入一个字符串')
new_s=lower_upper(s)# 函数的调用
print(new_s)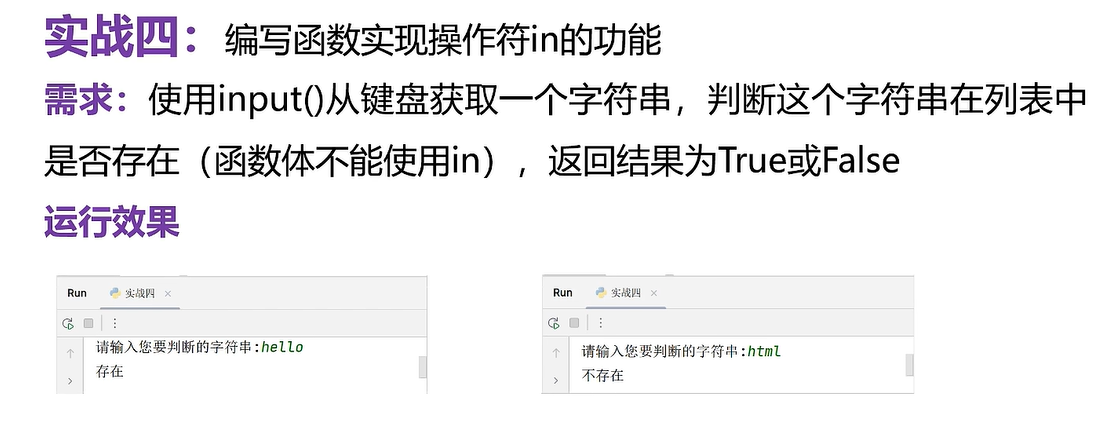
def get_find(s,lst):for item in lst:if s in item:return Truereturn False
lst=['hello','world','python']
s=input('请输入您要判断的字符串')
result=get_find(s,lst)
print('存在'if result else '不存在')# if...else的简写,三元运算符 if result==True if result利用到对象的布尔值六、面向过程和面向对象两大编程思想



6.1 自定义类和创建自定义类的对象

查看对象的数据类型
a=10
b=8.8
s='hello'
print(type(a))
print(type(b))
print(type(s))
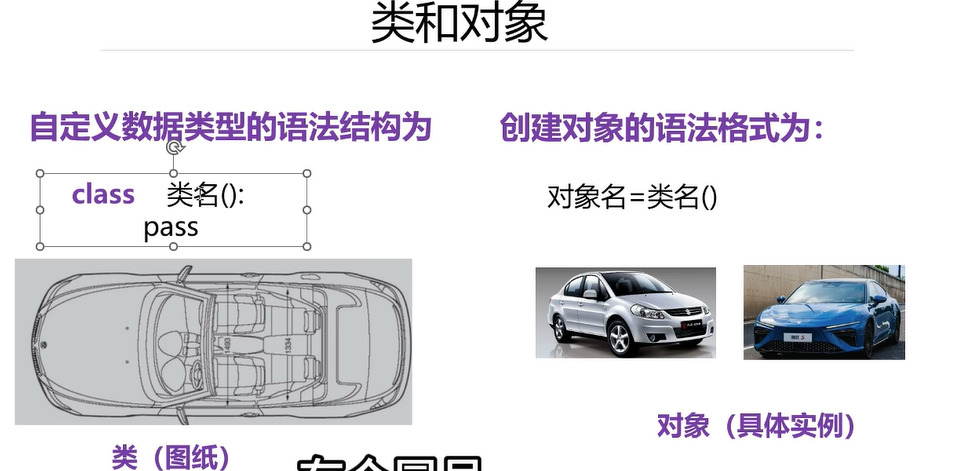
类名大写,冒号可省略,类是抽象的模版,对象是具体的事例
自定义数据类型
#编写一个person
class Person:def __init__(self, name, age):self.name = nameself.age = age# 编写一个Student类
class Student:def __init__(self, name, age):self.name = nameself.age = age
创建自定义类型的对象:
#编写一个person
class Person:pass# 编写一个Student类
class Student:pass#创建一个Person类型对象
per=Person()#per就是Person类型的对象
stu=Student()#stu就是Student类型的对象
print(type(per))
print(type(stu))
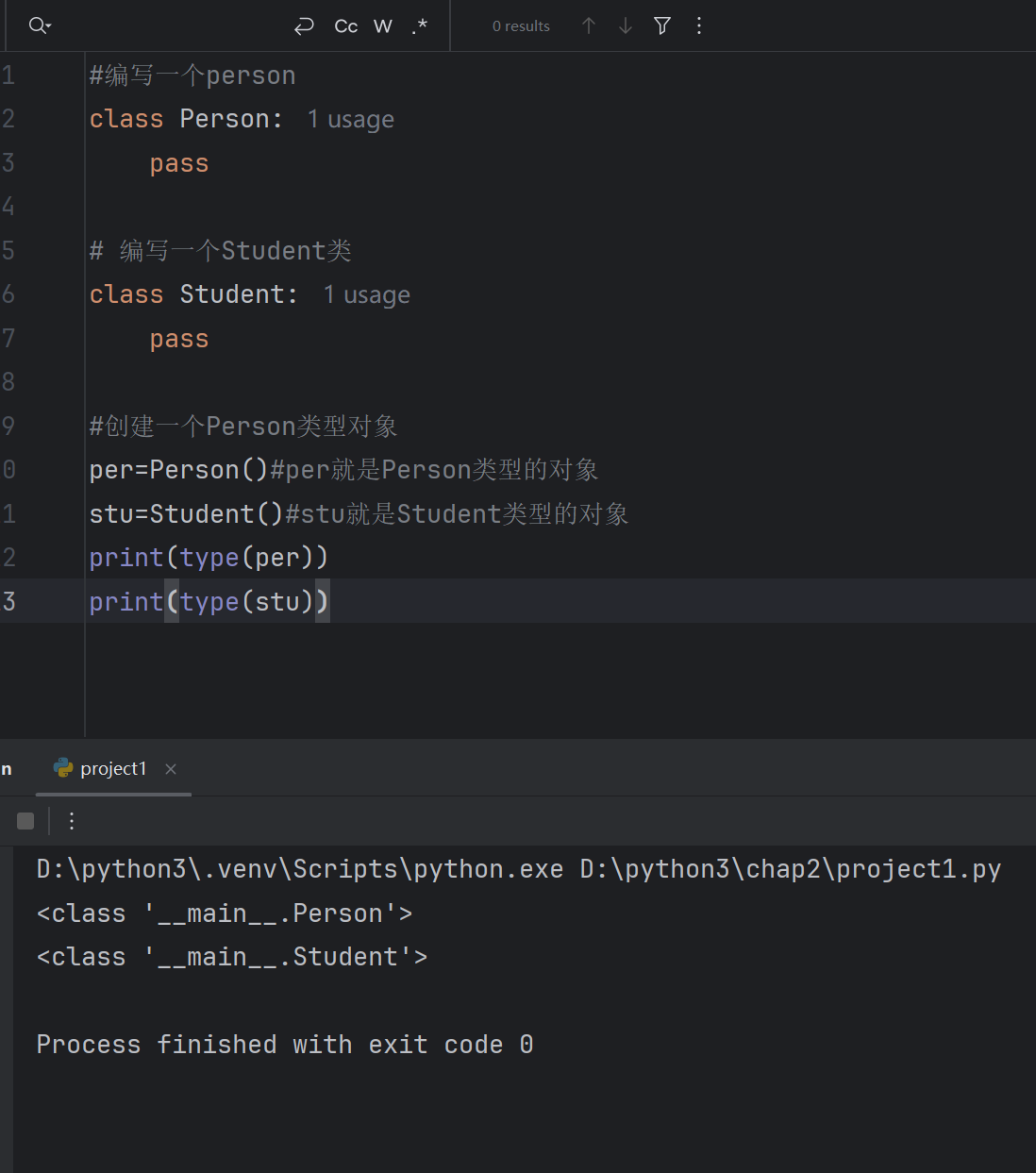

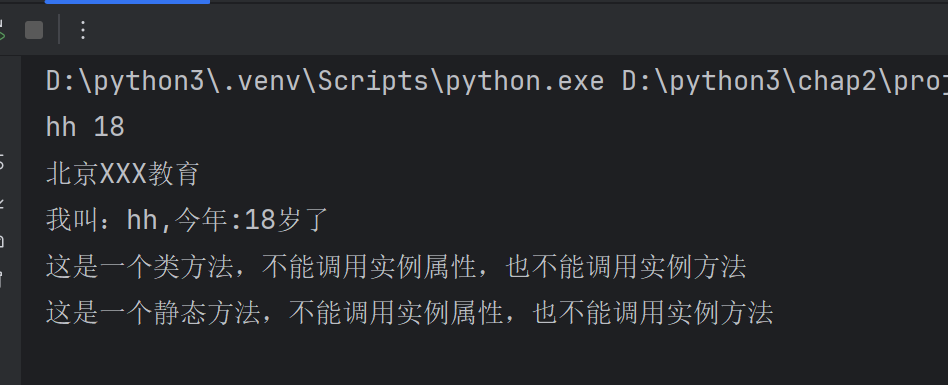
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.xm=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')#静态方法@staticmethoddef sm():#print(self.name)#self.show()print('这是一个静态方法,不能调用实例属性,也不能调用实例方法')@classmethoddef cm(cls):print('这是一个类方法,不能调用实例属性,也不能调用实例方法')#self.show()#print(self.name)
类方法,类属性,静态方法都是使用类名调用,和实例有关都是使用对象进行打点调用
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.name=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')#静态方法@staticmethoddef sm():#print(self.name)#self.show()print('这是一个静态方法,不能调用实例属性,也不能调用实例方法')@classmethoddef cm(cls):print('这是一个类方法,不能调用实例属性,也不能调用实例方法')#self.show()#print(self.name)# 创建类的对象
stu=Student('hh',18)#传了两个参数,因为__init__方法中,有两个参数,self,是自带的参数,无需手动传入
#实例属性,使用对象名打点调用
print(stu.name,stu.age)
#类属性,直接使用类名,打点调用
print(Student.school)
#实例方法,使用对象名进行打点调用
stu.show()
#类方法,@classmethod进行修饰的方法,直接使用类名打点调用
Student.cm()#静态方法 @staticmethod进行修饰的方法,直接使用类名打点调用
Student.sm()
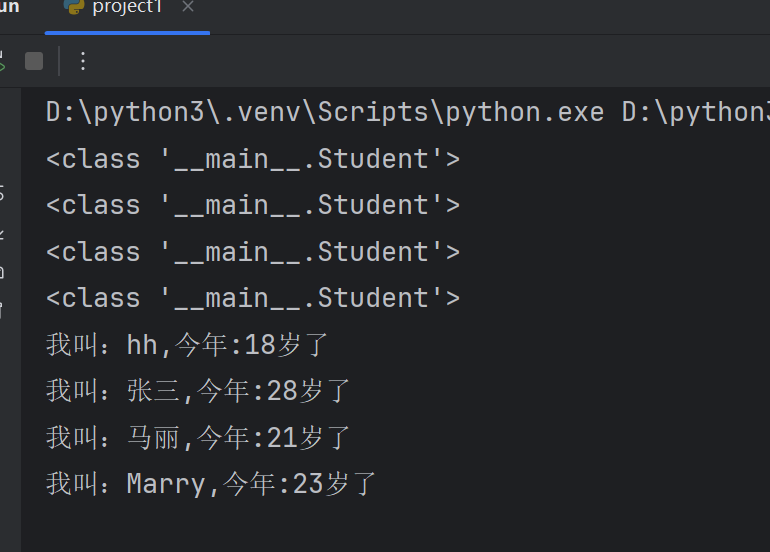
6.2 使用类模版创建N多个对象
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.name=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')#根据图纸创建多个对象
stu=Student('hh',18)
stu2=Student('张三',28)
stu3=Student('马丽',21)
stu4=Student('Marry',23)print(type(stu))
print(type(stu2))
print(type(stu3))
print(type(stu4))Student.school='派森教育'#给类属性赋值#将学生对象存储到列表中
lst=[stu,stu2,stu3,stu4]#列表当中的元素是Student类型的对象
for item in lst:# item是列表中的元素,是Student类型的对象item.show()# 对象名打点调用实例方法
6.3 动态绑定属性和方法
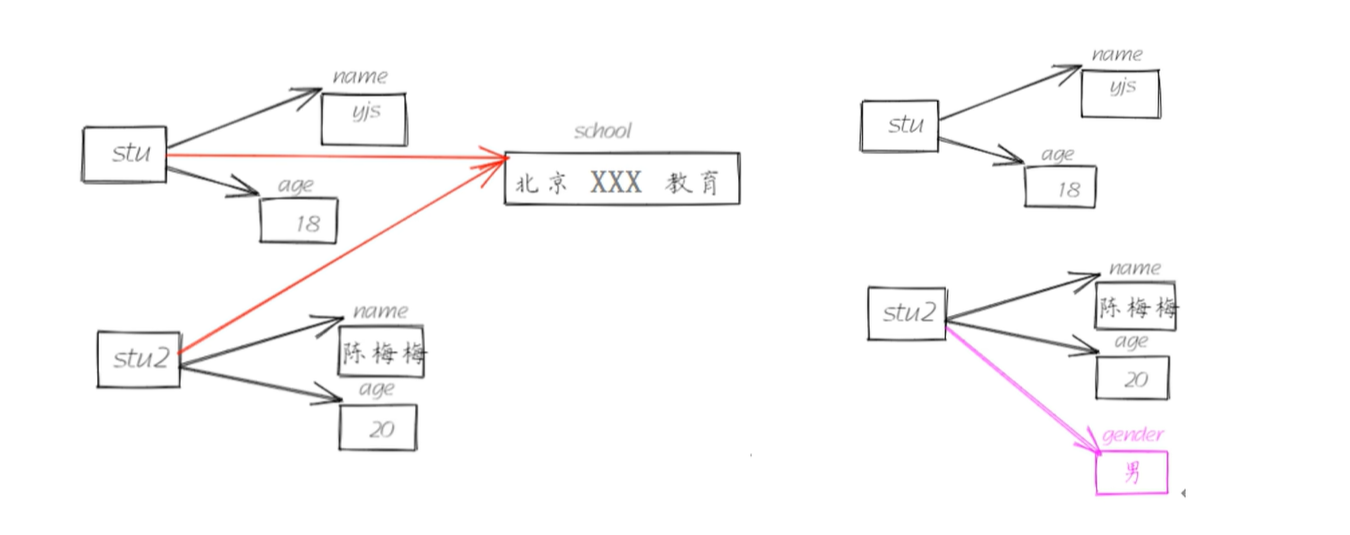
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.name=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')# 创建两个Student类型对象
stu=Student('张三',18)
stu2=Student('王五',19)
print(stu.name,stu.age)
print(stu2.name,stu2.age)#为stu2动态绑定一个实例属性
stu2.gender='男'
print(stu2.name,stu2.age,stu2.gender)
#print(stu.gender)#AttributeError: 'Student' object has no attribute 'gender',没有这个属性,没有给stu绑定# 动态绑定方法
def introduce():print('我是一个普通函数,我被动态绑定成了stu2对象方法')
stu2.fun=introduce#函数的赋值
# fun是stu2对象的方法
#调用(实例方法打点调用)
stu2.fun()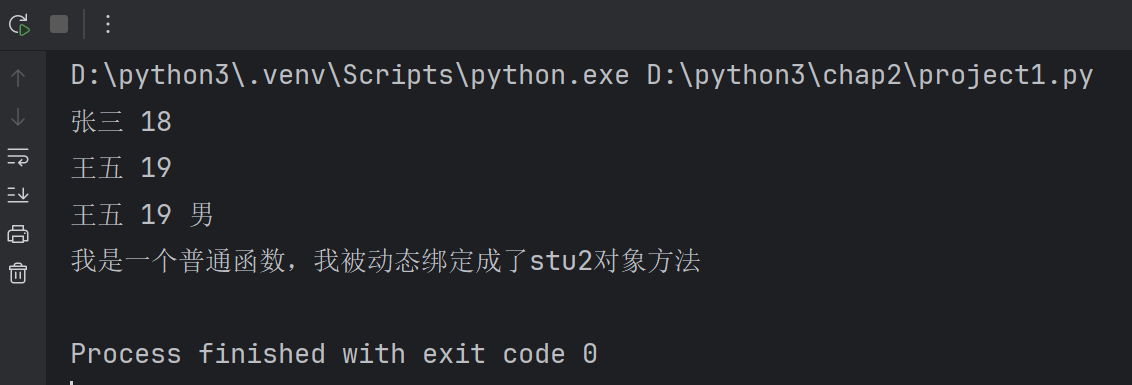
6.4 Python中的权限控制


特殊的:双下划线
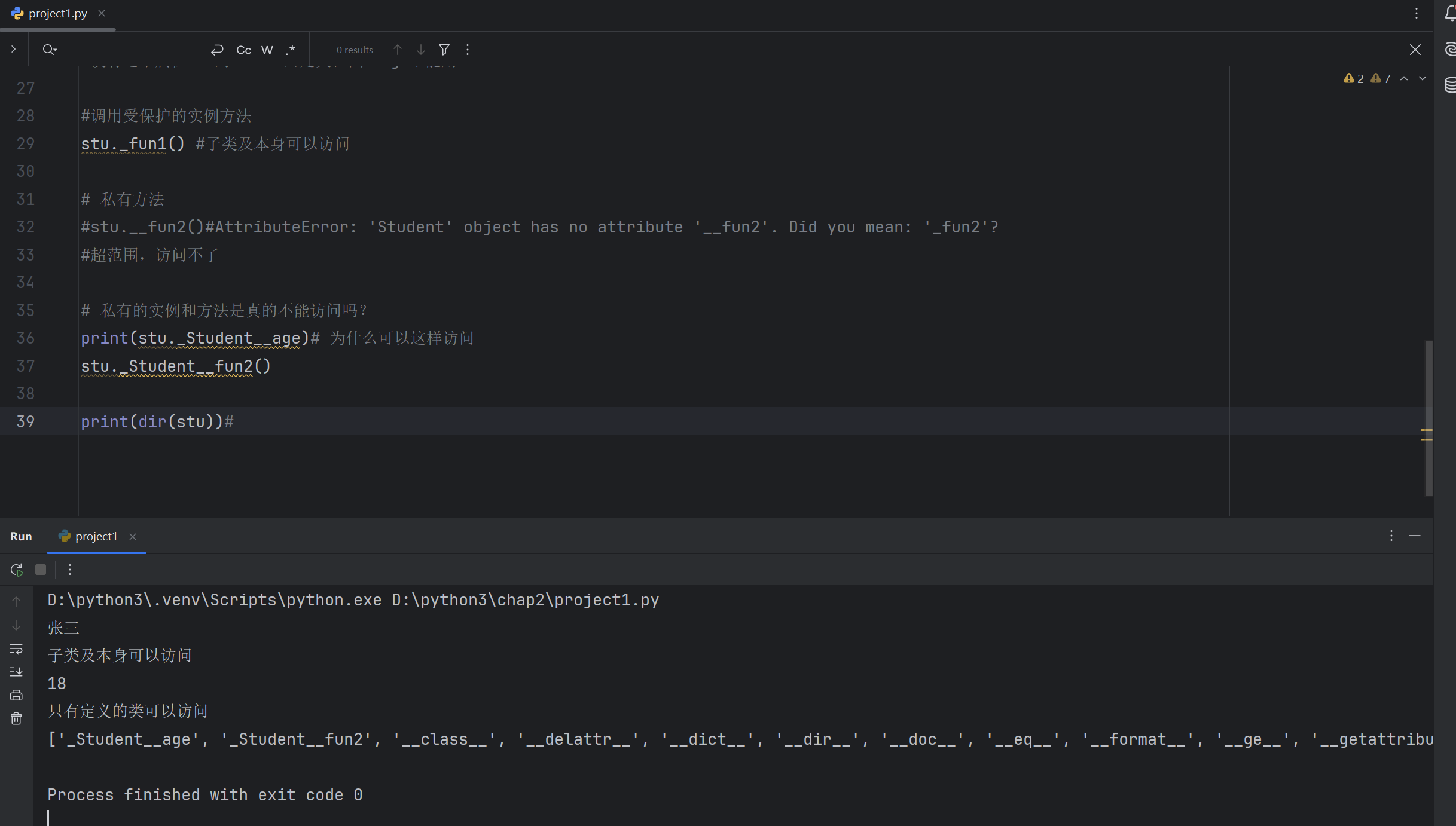
class Student():#首尾双下划线def __init__(self, name,age, gender):self._name = name # self._name受保护的,只能本类和子类访问self.__age = age#self.__age表示私有,只能类本身去访问self.gender=gender# 普通的实例属性,类的内部,外部,及子类都可以访问def _fun1(self):# 受保护的print('子类及本身可以访问')def __fun2(self):# 私有的print('只有定义的类可以访问')def show(self):# 普通的实例方法self._fun1() #类本身访问受保护的方法self.__fun2() #类本身访问私有方法print(self._name)#受保护的实例属性print(self.__age)#私有的实例属性# 创建一个学生类的对象
stu=Student('张三',18 ,'男')#类的外部
print(stu._name)
#print(stu.__age)#AttributeError: 'Student' object has no attribute '__age'. Did you mean: '_name'?
#没有这个属性:出了class的定义范围,age不能用#调用受保护的实例方法
stu._fun1() #子类及本身可以访问# 私有方法
#stu.__fun2()#AttributeError: 'Student' object has no attribute '__fun2'. Did you mean: '_fun2'?
#超范围,访问不了# 私有的实例和方法是真的不能访问吗?
print(stu._Student__age)# 为什么可以这样访问
stu._Student__fun2()print(dir(stu))#
6.5 属性的设置
可以将方法转换成属性使用,访问的时候只能访问属性,不能修改属性的值,可以使用setter方法去修改
class Student():def __init__(self, name,gender):self.name = name#普通实例属性self.__gender=gender#self.__gender是私有的实例属性# 使用@property(属性) 修饰方法,将方法转成属性使用@propertydef gender(self):return self.__gender# 将我们的gender这个属性设置为可写属性@gender.setterdef gender(self,value):if value != '男'and value!='女':print('性别有误,已将性别默认为男')self.__gender='男'else:self.__gender=valuestu=Student('陈梅梅','女')
print(stu.name,'的性别是:',stu.gender)#stu.gender就会去执行syu.gender()
#尝试修改属性值
#stu.gender='男'AttributeError: property 'gender' of 'Student' object has no setterstu.gender='其他'
print(stu.name,'性别是:',stu.gender)

6.6 继承的概念

class Person:# 默认继承了objectdef __init__(self, name, age):self.name = nameself.age = agedef show(self):print(f'大家好,我叫:{self.name},我今年::{self.age}岁')# Student继承Person类
class Student(Person):# 编写初始化的方法def __init__(self, name, age, stuno):super().__init__(name, age) #调用父类的初始化方法self.stuno = stuno
#Doctor继承Person类
class Doctor(Person):# 编写初始化方法def __init__(self, name, age, department):super().__init__(name, age)self.department = department#创建第一个子类对象
stu=Student('陈梅梅',20,'1001')
stu.show()doctor=Doctor('张一一',32,'外科')
doctor.show()
6.7 Python中的多继承
from tkinter.font import namesclass FatherA():def __init__(self,name):self.name=namedef showA(self):print('父类A中的方法')class FatherB():def __init__(self,age):self.age=agedef showB(self):print('父类B中的方法')class Son(FatherA,FatherB):#编写初始化的方法def __init__(self,name,age,gender): # 需要调用两个父类的初始化方法FatherA.__init__(self,name)FatherB.__init__(self,age)self.gender=genderson=Son('陈梅梅',20,'女')
son.showA()
son.showB()
6.8 方法重写
方法的名称必须和父类中相同
from contextlib import suppressclass Person:# 默认继承了objectdef __init__(self, name, age):self.name = nameself.age = agedef show(self):print(f'大家好,我叫:{self.name},我今年::{self.age}岁')# Student继承Person类
class Student(Person):# 编写初始化的方法def __init__(self, name, age, stuno):super().__init__(name, age) #调用父类的初始化方法self.stuno = stunodef show(self):# 调用父类中的方法super().show()print(f'我来着XXX大学,我的学号是:{self.stuno}')#Doctor继承Person类
class Doctor(Person):# 编写初始化方法def __init__(self, name, age, department):super().__init__(name, age)self.department = departmentdef show(self):print(f'大家好,我叫:{self.name},我今年::{self.age}岁,我的工作科室是:{self.department}')#super().show()#调用父类中show方法#创建第一个子类对象
stu=Student('陈梅梅',20,'1001')
stu.show()#调用子类自己的show方法doctor=Doctor('张一一',32,'外科')
doctor.show()#调用子类自己的show方法
6.9 Python中的多态:值关心对象的行为

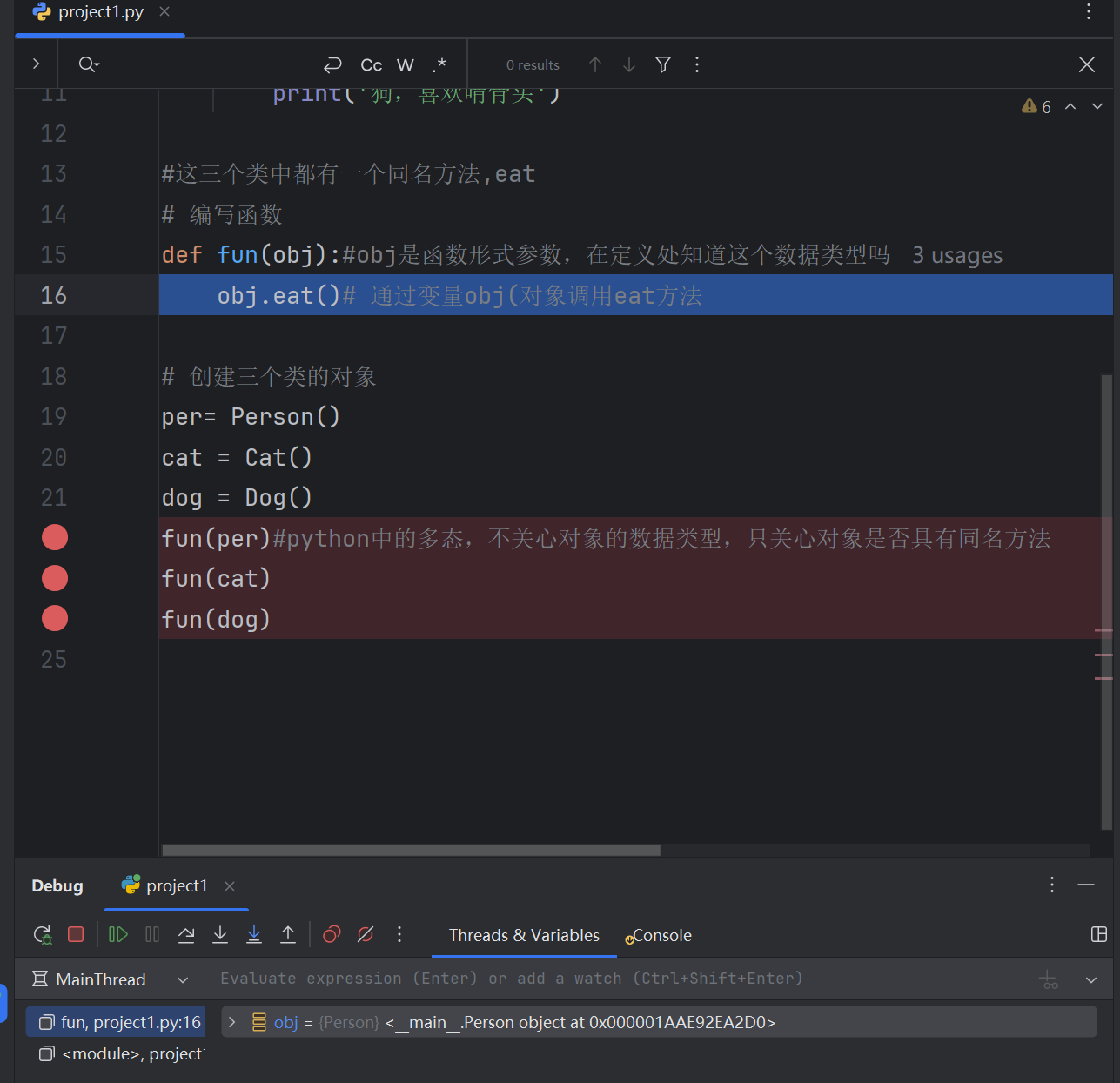
class Person():def eat(self):print("人吃五谷杂粮")class Cat():def eat(self):print('猫,喜欢吃鱼')class Dog():def eat(self):print('狗,喜欢啃骨头')#这三个类中都有一个同名方法,eat
# 编写函数
def fun(obj):#obj是函数形式参数,在定义处知道这个数据类型吗obj.eat()# 通过变量obj(对象调用eat方法# 创建三个类的对象
per= Person()
cat = Cat()
dog = Dog()
fun(per)#python中的多态,不关心对象的数据类型,只关心对象是否具有同名方法
fun(cat)
fun(dog)
6.10 object类
查看对象属性

class Person(object):def __init__(self,name,age):self.name = nameself.age = agedef show(self):print(f'大家好,我叫:{self.name},我今年:{self.age}岁')# 创建Person类的对象
per=Person('陈梅梅',20) #创建对象的时候会自动调用__init__方法()
print(dir(per))
per.show()
# 先new在inital调用
print(per)#自动调用了__str__方法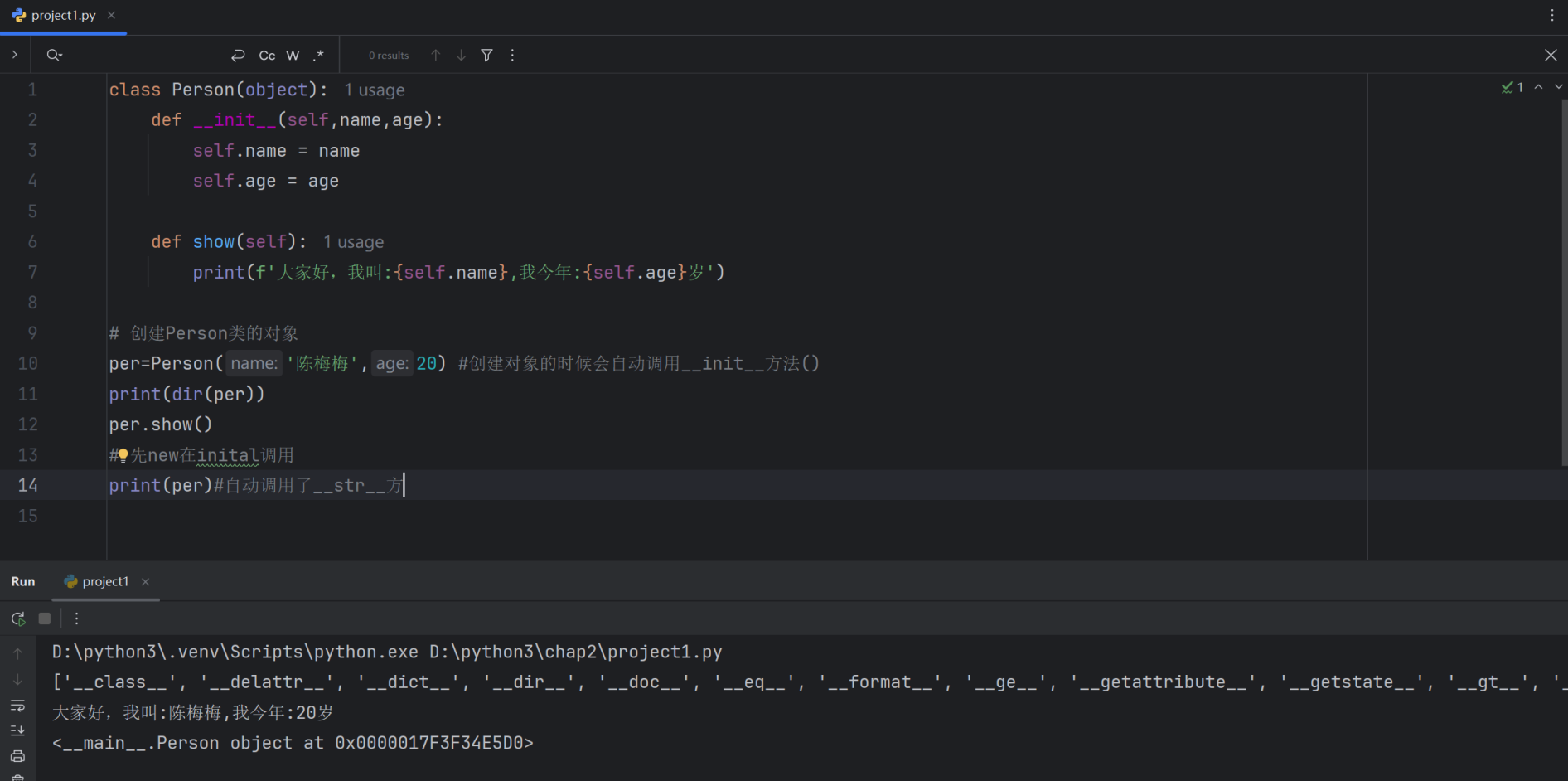
_str_方法重写之前
class Person(object):def __init__(self,name,age):self.name = nameself.age = age# 创建person类的对象
per=Person('陈梅梅',20)
print(per)_str_方法重写之后
class Person(object):def __init__(self,name,age):self.name = nameself.age = age# 方法重写def __str__(self):return '这是一个人类,具有name和age两个实例属性'#返回值是字符串# 创建person类的对象
per=Person('陈梅梅',20)
print(per)# 还是内存地址吗?不是__str__方法中的内容 直接输出对象名,实际上调用__str___方法
print(per.__str__())#手动调用
对象的特殊方法
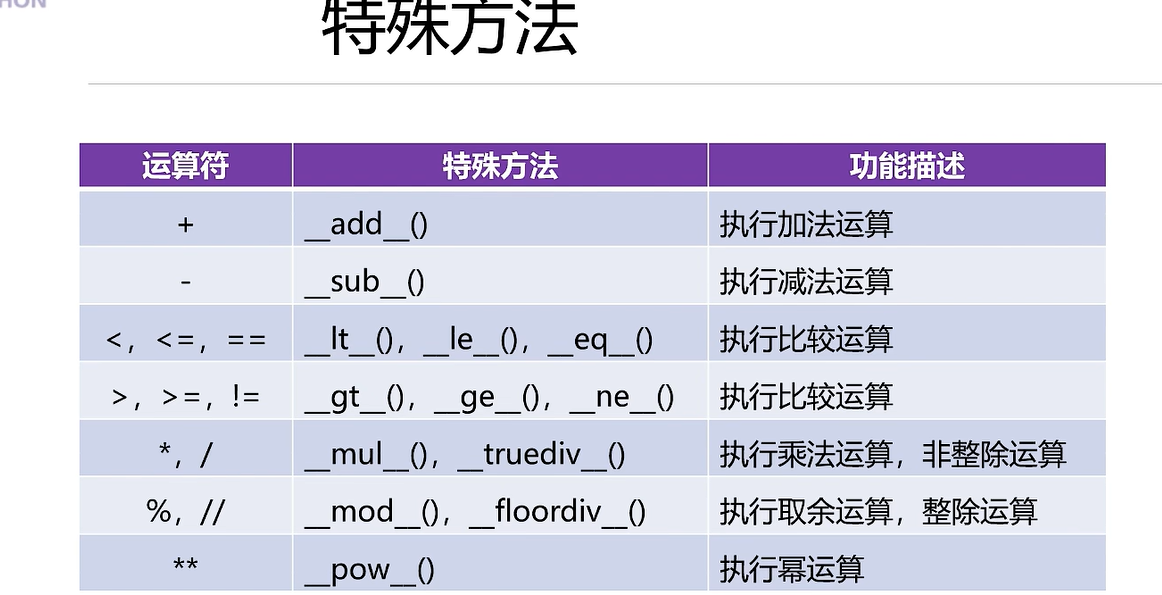
a=10
b=20
print(dir(a))# python中一切皆对象
print(a+b)# 执行加法运算
print(a-b)
print(a.__add__(b))
print(a.__sub__(b)) #执行减法运算
print(f'{a}<{b}吗',a.__lt__(b))
print(f'{a}<={b}吗',a.__le__(b))
print(f'{a}=={b}吗',a.__eq__(b))
print('-'*40)
print(f'{a}>{b}吗',a.__gt__(b))
print(f'{a}>={b}吗',a.__ge__(b))
print(f'{a}!={b}吗',a.__ne__(b))
#
print('-'*40)
print(a.__mul__(b))#乘法
print(a.__truediv__(b))#除法
print(a.__mod__(b))# 取余
print(a.__floordiv__(b))#整除
print(a.__pow__(2))#幂运算
Python的特殊属性
class A:pass
class B:pass
class C(A,B):def __init__(self,name,age):self.name=nameself.age=age# 创建类的对象
a=A()
b=B()
# 创建C类的对象
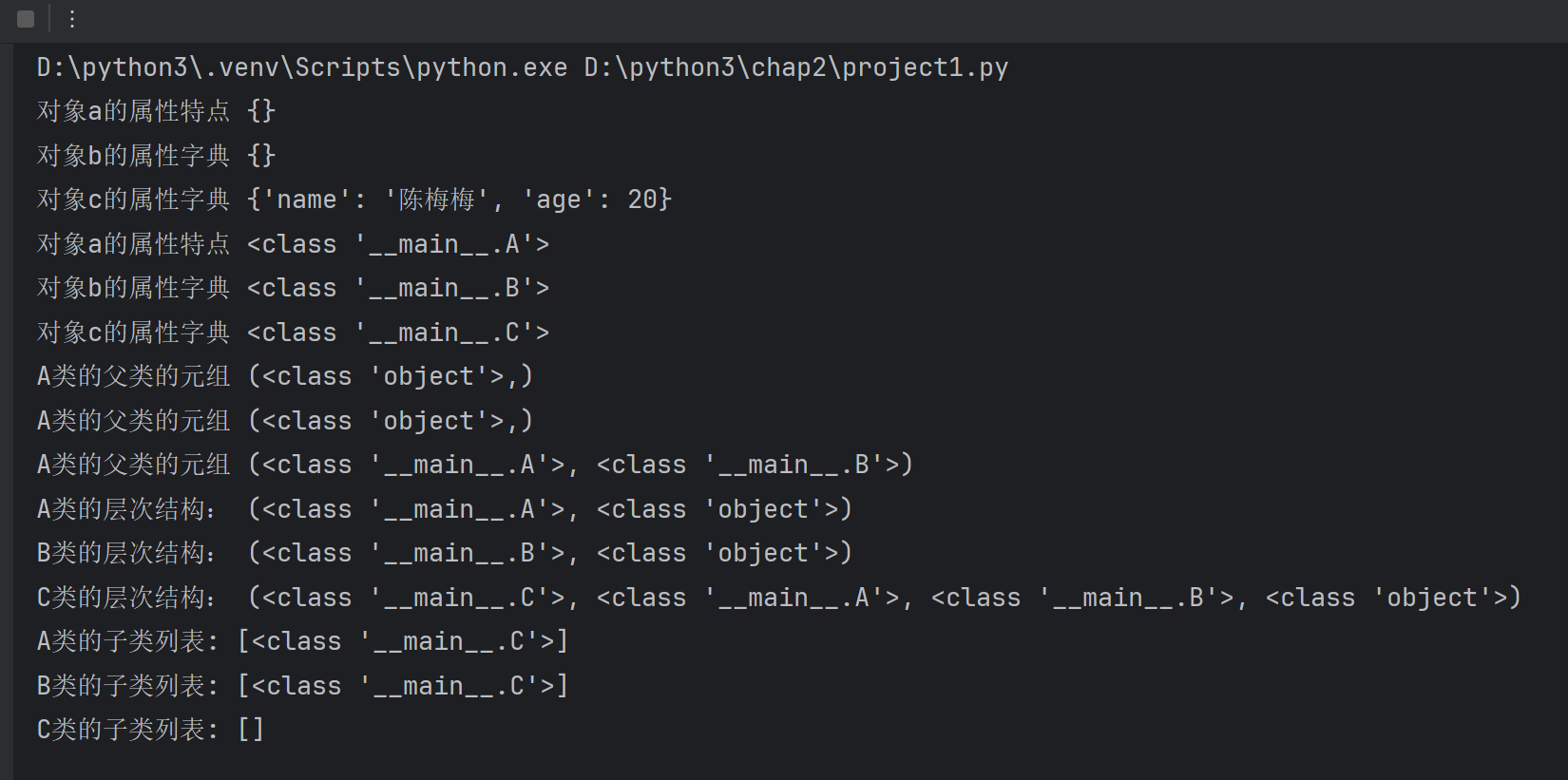
c=C('陈梅梅',20)print('对象a的属性特点',a.__dict__)#对象的属性字典
print('对象b的属性字典',b.__dict__)
print('对象c的属性字典',c.__dict__)print('对象a的属性特点',a.__class__)#对象的属性字典
print('对象b的属性字典',b.__class__)
print('对象c的属性字典',c.__class__)print('A类的父类的元组',A.__bases__)
print('A类的父类的元组',B.__bases__)
print('A类的父类的元组',C.__bases__)#A类,如果继承了N多个父类,结果只显示一个父类print('A类的层次结构:',A.__mro__)
print('B类的层次结构:',B.__mro__)
print('C类的层次结构:',C.__mro__)#C类继承了A类,B类,间接继承了object类#子类的列表
print('A类的子类列表:',A.__subclasses__())#A的子类是C类
print('B类的子类列表:',B.__subclasses__())
print('C类的子类列表:',C.__subclasses__())
相关文章:

python基础:序列和索引-->Python的特殊属性
一.序列和索引 1.1 用索引检索字符串中的元素 # 正向递增 shelloworld for i in range (0,len(s)):# i是索引print(i,s[i],end\t\t) print(\n--------------------------) # 反向递减 for i in range (-10,0):print(i,s[i],end\t\t)print(\n--------------------------) print(…...

在k8s中,如何实现服务的访问,k8s的ip是变化的,怎么保证能访问到我的服务
在K8S中,Pod的IP动态变化确实无法直接通过固定IP限制访问,但可以通过标签(Label)、服务(Service)和网络策略(NetworkPolicy)的组合,实现动态身份识别的访问控制ÿ…...

用NVivo革新企业创新:洞悉市场情绪,引领金融未来
在当今快速变化的商业环境中,理解市场和客户的情感脉动是企业成功的关键。尤其在金融行业,无论是评估经济走势、股票市场波动,还是洞察消费者信心,精准把握隐藏在新闻报道、社交媒体和消费者反馈中的情感倾向至关重要。而NVivo这款…...

如何使用极狐GitLab 软件包仓库功能托管 helm chart?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 Helm charts (BASIC ALL) WARNING:Helm chart 库正在开发中,由于功能有限,尚未准备好用…...
)
Qt 通过控件按钮实现hello world + 命名规范(7)
文章目录 使用编辑框来完成 hello world通过编辑图形化界面方式通过纯代码方式 通过按钮的方式来创建 hello world通过编辑图形化界面方式通过纯代码方式 总结Qt Creator中的快捷键如何使用文档命名规范 简介:这篇文章着重点并不在于创建hello world程序,…...

uniapp index.html怎么改都不生效
打开 manifest.json index.html 模板路径默认为空,所以你改的 index.html 是没用的,uni-app 根本没用这个模板 设置模板后就会生效了...

ABP vNext + gRPC 实现服务间高速通信
ABP vNext gRPC 实现服务间高速通信 💨 在现代微服务架构中,服务之间频繁的调用往往对性能构成挑战。尤其在电商秒杀、金融风控、实时监控等对响应延迟敏感的场景中,传统 REST API 面临序列化负担重、数据体积大、通信延迟高等瓶颈。 本文…...
(新手友好版~))
【JAVA】十三、基础知识“接口”精细讲解!(三)(新手友好版~)
目录 1. Object类 1.1 Object的概念 1.2 Object例子 2. toString 2.1 toString的概念 2.2 为什么要重写toString 2.3 如何重写toString 3. 对象比较equals方法 3.1 equals( ) 方法的概念 3.2 Object类中的默认equals实现 3.3 如何正确重写equals方法 4. hashCode方…...

每周靶点分享:Angptl3、IgE、ADAM9及文献分享:抗体的多样性和特异性以及结构的新见解
本期精选了《脂质代谢的关键调控者Angptl3》《T细胞活化抑制因子VISTA靶点》《文献分享:双特异性抗体重轻链配对设计》三篇文章。以下为各研究内容的概述: 1. 脂质代谢的关键调控者Angptl3 血管生成素相关蛋白3(Angptl3)是血管生…...

网络协议之DHCP和PXE分析
写在前面 本文看下DHCP和PXE相关内容。 1:正文 不知道你自己手动配置过IP地址没有,在Linux的环境中可以通过如下的命令们来进行配置: $ sudo ifconfig eth1 10.0.0.1/24 $ sudo ifconfig eth1 up以及:$ sudo ip addr add 10.0…...

SSH 服务部署指南
本指南涵盖 OpenSSH 服务端的安装、配置密码/公钥/多因素认证,以及连接测试方法。 适用系统:Ubuntu/Debian、CentOS/RHEL 等主流 Linux 发行版。 1. 安装 SSH 服务端 Ubuntu/Debian # 更新软件包索引 sudo apt update# 安装 OpenSSH 服务端 sudo apt i…...
)
表达式求值(算法题)
#include <bits/stdc.h> // 引入常用头文件 using namespace std;stack<int> num; // 存储操作数的栈 stack<char> op; // 存储运算符的栈/* 执行一次运算操作:1. 从num栈弹出两个操作数(n2先弹出,作为右操作数)2. 从op栈弹出运算符…...

IO流--13--MultipartFile
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 MultipartFile1. 概述2. 常用方法解析2.1 getName方法2.2 getOriginalFileName方法2.3 getContentType方法2.4 isEmpty方法2.5 getSize方法2.6 getBytes方法2.7 get…...

leetcode 242. Valid Anagram
题目描述 因为s和t仅仅包含小写字母,所以可以开一个26个元素的数组用来做哈希表。不过如果是unicode字符,那就用编程语言自带的哈希表。 class Solution { public:bool isAnagram(string s, string t) {int n s.size();if(s.size() ! t.size())return …...

内核态函数strlcpy及strscpy以及用户态函数strncpy
一、背景 编写C程序时有一类看似简单实则经常暗藏漏洞的问题就是字符串的处理。对于字符串的处理,常用的函数如strcpy,sprintf,strcat等,这些函数的区别无外乎就是处理\0结尾相关的逻辑。字符串的长度有时候并不能很好确定&#…...

Matlab 车辆四自由度垂向模型平稳性
1、内容简介 Matlab221-车辆四自由度垂向模型平稳性 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略基于Simulink的汽车平顺性仿真_1_杜充 基于Simulink的汽车平顺性仿真分析_谢俊淋...

【hadoop】Sqoop数据迁移工具的安装部署
一、Sqoop安装与配置 步骤: 1、使用XFTP将Sqoop安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz发送到master机器的主目录。 2、解压安装包: tar -zxvf ~/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 3、修改文件夹的名字,将其改为s…...
)
只出现一次的数字(暴力、哈希查重、异或运算)
目录 一.题目 题目解析 题目链接 二.解题过程 俗手(暴力:数组模拟哈希表) 思路 代码示例 提交情况 本手:哈希查重 思路 代码示例 提交情况 妙手:异或运算 思路 代码示例 提交情况 作者的个人gitee 作者…...

Spark缓存
生活中缓存容量受成本和体积限制(比如 CPU 缓存只有几 MB 到几十 MB),但会通过算法(如 “最近最少使用” 原则)智能决定存什么,确保存的是 “最可能被用到的数据”。 1. 为什么需要缓存? 惰性执…...
)
linux中的常用命令(一)
目录 常用的快捷键 1- tab键:命令或者路径提示及补全; 2-ctrlc:放弃当前输入,终止当前任务或程序 3-ctrll;清屏 4-ctrlinsert:复制 5-鼠标右键:粘贴; 6-altc:断开连接/ctrlshift r 重新连接 7-alt1/2/3/等:切换回话窗口 8-上下键…...

Lua学习笔记
文章目录 前言1. Lua的数据类型2. Lua的控制结构2.1 循环2.1.1 for2.1.1.1 数值循环2.1.1.2 迭代循环2.1.2 while2.1.3 repeat-until 2.2 条件语句2.3 函数 3. Lua中的变量作用域 前言 Lua是一种轻量级的、高效的、可扩展的脚本语言,由巴西里约热内卢天主教大学&am…...

5月8日星期四今日早报简报微语报早读
5月8日星期四,农历四月十一,早报#微语早读。 1、外交部回应中美经贸高层会谈:这次会谈是应美方请求举行的; 2、河南许昌官方:胖东来联合京东物流打造的供应链产业基地将于今年投入运营; 3、我国外汇储备…...

P2415 集合求和 详解
此题我认为主要考数学逻辑,这个题目考的是你面对代码时,是否会从中去找规律推导一个数学公式。 先看题目: 此题目与集合有关,所以对于数学基础不好的同学,我会先给你讲一下这个集合的相关知识。 一,首先,…...
和#define ccw 0什么区别)
#define ccw (0)和#define ccw 0什么区别
目录 区别 一般建议 简单总结 #define ccw (0) 和 #define ccw 0 这两者在大多数情况下的功能非常相似,但在细节上有一些区别,主要涉及宏展开时的行为。 区别 #define ccw (0):宏定义的内容是(0),带括…...

跨平台移动开发框架React Native和Flutter性能对比
背景与架构 React Native 和 Flutter 都是跨平台移动开发框架,但它们的性能表现因架构差异而异。React Native 在 2025 年采用了 Bridgeless New Architecture(版本 0.74),使用 JavaScript Interface (JSI) 替代传统的 JavaScrip…...
)
【PhysUnits】2 SI 量纲 实现解析(prefix.rs)
源码 这是一个编译时量纲检查的物理单位库。 //! Physical Units Library with Type-Level Dimension Checking //! 带类型级量纲检查的物理单位库 //! //! This module provides type-safe physical unit representations using Rusts type system //! to enforce dimension…...

新能源汽车赛道变局:传统车企子品牌私有化背后的战略逻辑
2025年5月,一则资本市场动态引发行业震动:某国内头部传统车企宣布拟以每股2.57美元的价格私有化旗下高端新能源品牌,若交易完成,该新能源品牌将正式从纽交所退市。这一决策发生在全球新能源汽车行业经历剧烈洗牌、资本市场估值逻辑…...

[matlab]private和+等特殊目录在新版本matlab中不允许添加搜索路径解决方法
当我们目录包含有private,或者时候matlab搜索目录不让添加,比如截图: 在matlab2018以前这些都可以加进去后面版本都不行了。但是有时候我们必须要加进去才能兼容旧版本matlab库,比如mexopencv库就是这种情况。因此我们必须找到一个办法加进去…...

ImportError: cannot import name ‘Optional‘ from ‘pydantic‘
概览 再使用Optional定义fastapi可选参数时,出现了错误: ImportError: cannot import name Optional from pydantic python version: 3.8 pydantic version: 2.9.2 快速解决方案 Optional导入修改为typing包,如下 from typing import List…...

“水木精灵” 王泫梓妍时尚造型引关注
“水木精灵” 王泫梓妍一组时尚照片曝光,再次展现其独特时尚品味与青春活力。 照片中,王泫梓妍身着白色针织开衫搭配深蓝色牛仔短裙,开衫上精致的水钻装饰与深蓝色海军领增添了细节亮点,牛仔短裙的金色纽扣设计别致,整…...

数据结构-堆排序
1.定义 -堆中每个节点的值都必须大于等于(或小于等于)其左右子节点的值。如果每个节点的值都大于等于其子节点的值,这样的堆称为大根堆(大顶堆);如果每个节点的值都小于等于其子节点的值,称为…...

影响服务器性能的主要因素是什么
在这个数字化高速发展的时代,服务器就像是幕后的超级英雄,默默支撑着我们丰富多彩的网络世界。首先,硬件配置堪称服务器性能的基石。就好比一辆跑车,强大的引擎(CPU)、宽敞的跑道(内存ÿ…...

为什么 MySQL 用 B+ 树作为数据的索引,以及在 InnoDB 中数据库如何通过 B+ 树索引来存储数据以及查找数据
http://www.liuzk.com/410.html 索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据。 索引最形象的比喻就是图书的目录了。注意这里的大量,数据量大了索引才显得有意义,如果我想要在 [1,2,3,4] 中找到 4 这个数据&am…...

若依框架Ruoyi-vue整合图表Echarts中国地图标注动态数据
若依框架Ruoyi-vue整合图表Echarts中国地图 概述创作灵感预期效果整合教程前期准备整合若依框架1、引入china.json2、方法3、data演示数据4、核心代码 完整代码[毫无保留]组件调用 总结 概述 首先,我需要回忆之前给出的回答,确保这次的内容不重复&#…...

可撤销并查集,原理分析,题目练习
零、写在前面 可撤销并查集代码相对简单,但是使用场景往往比较复杂,经常用于处理离线查询,比较经典的应用是结合线段树分治维护动态连通性问题。在一些较为综合的图论问题中也经常出现。 前置知识:并查集,扩展域并查…...
详解)
中介者模式(Mediator Pattern)详解
文章目录 1. 中介者模式概述1.1 定义1.2 基本思想2. 中介者模式的结构3. 中介者模式的UML类图4. 中介者模式的工作原理5. Java实现示例5.1 基本实现示例5.2 飞机空中交通控制示例5.3 GUI应用中的中介者模式6. 中介者模式的优缺点6.1 优点6.2 缺点7. 中介者模式的适用场景8. 中介…...

Java网络编程:深入剖析UDP数据报的奥秘与实践
在浩瀚的计算机网络世界中,数据传输协议扮演着至关重要的角色。其中,用户数据报协议(UDP,User Datagram Protocol)以其独特的“轻量级”和“无连接”特性,在众多应用场景中占据了一席之地。与更为人熟知的传输控制协议(TCP,Transmission Control Protocol)相比,UDP提…...

17.thinkphp的分页功能
一.分页功能 1.不管是数据库操作还是模型操作,都使用paginate()方法来实现(第一种方式); //查找user表所有数据,每页显示5条 returnView::fetch(index, [list > User::paginate(5)]); 页数: 2.创建一个静态模版页面…...

Pandas比MySQL快?
知乎上有人问,处理百万级数据,Python列表、Pandas、Mysql哪个更快? Pands是Python中非常流行的数据处理库,拥有大量用户,所以拿它和Mysql对比也是情理之中。 实测来看,MySQL > Pandas > Python列表…...

问题 | 低空经济未来发展前景机遇及挑战
低空经济 **一、发展前景与机遇**1. **政策红利加速释放,顶层设计逐步完善**2. **技术突破驱动商业化落地**3. **应用场景多元化拓展**4. **万亿级市场潜力** **二、主要挑战**1. **空域管理与安全监管难题**2. **技术瓶颈与产业链短板**3. **法规与标准体系待完善*…...

Matlab 分数阶PID控制
1、内容简介 Matlab218-分数阶PID控制 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

如何对 Oracle 日志文件进行校验
目录 一、基本概述 二、基础知识 1、工具介绍 (1)BBED (2)dump 2、数据解析 (1)BLOCK 0 (2)BLOCK 1 (3)Block n( >=2 ) (4)redo record header (5)redo change 1)redo change header 2)redo change length list (6)Example 三、参考代码…...

从零开始用 AI 编写一个复杂项目的实践方法论
从零开始用 AI 编写一个复杂项目的实践方法论 这篇文章我用ai润色了一下,但是初稿是完全由我个人整理的逻辑思路,不是完全由ai生成的。其中内容也确实是我在实践中遇到问题、解决问题、总结出来的经验。 在从零开发一个复杂项目时,直接把目标…...
:部署Prometheus与Node Exporter)
k8s监控方案实践(一):部署Prometheus与Node Exporter
k8s监控方案实践(一):部署Prometheus与Node Exporter 文章目录 k8s监控方案实践(一):部署Prometheus与Node Exporter一、Prometheus简介二、PrometheusNode Exporter实战部署1. 创建Namespace(p…...

2.5 特征值与特征向量
本章围绕特征值、特征向量及其应用展开,是线性代数的核心章节之一。以下从四个核心考点系统梳理知识体系: 考点一:矩阵的特征值与特征向量 1. 计算方法 具体矩阵: 解特征方程 ∣ λ E − A ∣ 0 |\lambda E - A| 0 ∣λE−A∣…...

从简历筛选到面试管理:开发一站式智能招聘系统源码详解
当下,如何打造一款高效、精准的一站式智能招聘系统,成为了很多人力资源科技公司和创业团队关注的焦点。在这篇文章中,将带你深入了解如何从零开始开发一款智能招聘系统源码,涵盖从简历筛选到面试管理的全流程。 一、招聘系统的核心…...
)
10.进程控制(下)
一、进程程序替换(重点) 在程序替换过程中,并没有创建新的进程,只是把当前进程的代码和数据用新程序的代码和数据进行覆盖式的替换。 1)一旦程序替换成功,就去执行新代码了,后序代码不执行 2&am…...

【Python 字符串】
Python 中的字符串(str)是用于处理文本数据的基础类型,具有不可变性、丰富的内置方法和灵活的操作方式。以下是 Python 字符串的核心知识点: 一、基础特性 定义方式: s1 单引号字符串 s2 "双引号字符串" s…...
补充)
最新CDGP单选题(第四章)补充
31、 [单选] 企业数据模型主题域的识别准则必须在整个企业模型中保持一致,以下哪项是常用的主题域识别准则: A:使用规范化规则,从系统组合中分离主题域...
)
Cursor降智找不到文件(Cursor降智)
文章目录 明明提供了上下文,却找不到文件! 明明提供了上下文,却找不到文件! 解决办法,删除codebase index,最好再把那个Index new folders by default给设置为Disabled。 这样设置貌似就不会出现找不到文件…...