使用Scrapeless Scraping Browser的自动化和网页抓取最佳实践
引言:人工智能时代浏览器自动化和数据收集的新范式
随着生成性人工智能、人工智能代理和数据密集型应用程序的快速崛起,浏览器正在从传统的“用户互动工具”演变为智能系统的“数据执行引擎”。在这一新范式中,许多任务不再依赖单一的API端点,而是通过自动化的浏览器控制来处理复杂的页面交互、内容抓取、任务编排和上下文检索。
从电商网站的价格比较和地图截图到搜索引擎结果解析和社交媒体内容提取,浏览器正成为人工智能获取现实世界数据的重要接口。然而,现代网络结构的复杂性、强大的反机器人措施和高并发需求给传统解决方案(如本地Puppeteer/Playwright实例或代理轮换策略)带来了重大技术和操作挑战。
引入无爬虫抓取浏览器——一个专为大规模自动化构建的先进云端浏览器平台。它克服了关键技术障碍,如反抓取机制、指纹检测和代理维护。此外,它提供了云原生并发调度、人类行为模拟和结构化数据提取,使其成为下一代自动化系统和数据管道的重要基础设施组成部分。
本文探讨无爬虫抓取浏览器的核心能力及其在浏览器自动化和网络抓取中的实际应用。通过分析当前行业趋势和未来方向,我们旨在为开发者、产品构建者和数据团队提供全面且系统的指南。
一、背景:我们为什么需要无爬虫抓取浏览器?
1.1 浏览器自动化的演变
在人工智能驱动的自动化时代,浏览器不再仅仅是人机交互的工具——它们已成为获取结构化和非结构化数据的基本执行端点。在许多现实场景中,API要么不可用,要么受到限制,因此必须通过浏览器模拟人类行为进行数据收集、任务执行和信息提取。
常见用例包括:
- 电商网站上的价格比较:价格和库存数据通常以异步方式在浏览器中加载。
- 解析搜索引擎结果页面:内容必须通过滚动和点击页面元素完全加载。
- 多语言网站、遗留系统和内联网平台:通过API无法访问数据。
传统的抓取解决方案(例如,本地运行的Puppeteer/Playwright或代理轮换设置)通常在高并发下表现不佳,频繁遭到反机器人封锁,并且维护成本高。无爬虫抓取浏览器凭借其云原生部署和真实浏览器行为模拟,为开发者提供了一个高可用、可靠的浏览器自动化平台——为人工智能自动化系统和数据工作流提供了关键基础设施。
1.2 反机器人机制的挑战
与此同时,随着反机器人技术的发展,传统爬虫工具越来越多地被目标网站标记为机器人流量,导致IP被封和访问限制。常见的反抓取机制包括:
- 浏览器指纹识别:通过用户代理、画布渲染、TLS握手等检测异常访问模式。
- CAPTCHA验证:要求用户证明自己是人类。
- IP黑名单:阻止过于频繁访问的IP。
- 行为分析算法:检测不寻常的鼠标移动、滚动速度和交互逻辑。
无爬虫抓取浏览器通过精确的浏览器指纹定制、内置的CAPTCHA解决方案和灵活的代理支持,有效克服了这些挑战,成为下一代自动化工具的核心基础设施。
二、无爬虫的核心能力
无爬虫抓取浏览器提供强大的核心能力,向用户提供稳定、高效和可扩展的数据交互功能。以下是其主要功能模块和技术细节:
2.1 真实浏览器环境
无爬虫建立在Chromium引擎之上,提供一个完整的浏览器环境,能够模拟真实用户行为。主要功能包括:
- TLS指纹伪造:伪造TLS握手参数以绕过传统反机器人机制。
- 动态指纹混淆:调整用户代理、屏幕分辨率、时区等,使每个会话看起来非常人性化。
- 本地化支持:自定义语言、地区和时区设置,使与目标网站的交互更自然。
深度定制浏览器指纹
无爬虫提供全面的浏览器指纹定制,允许用户创建更“真实”的浏览环境:
- 用户代理控制:在浏览器 HTTP 请求中定义 User-Agent 字符串,包括浏览器引擎、版本和操作系统。
- 屏幕分辨率映射:设置
screen.width和screen.height的返回值,以模拟常见的显示尺寸。 - 平台属性锁定:在 JavaScript 中指定
navigator.platform的返回值,以模拟操作系统类型。 - 本地化环境仿真:完全支持自定义本地化设置,影响内容渲染、时间格式和网站上的语言首选项检测。
2.2 基于云的部署和可扩展性
Scrapeless 完全部署在云端,并提供以下优势:
- 无需本地资源:减少硬件成本,提高部署灵活性。
- 全球分布的节点:支持大规模并发任务,克服地理限制。
- 高并发支持:支持从 50 到无限的并发会话——适合从小任务到复杂自动化工作流程的所有场景。
性能比较
与传统工具如 Selenium 和 Playwright 相比,Scrapeless 在高并发场景中表现优异。以下是一个简单的比较表:
| 特性 | Scrapeless | Selenium | Playwright |
|---|---|---|---|
| 并发支持 | 无限制(企业级定制) | 有限 | 中等 |
| 指纹定制 | 先进 | 基本 | 中等 |
| CAPTCHA 解决能力 | 内置(98% 成功率) 支持 reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDome 等 | 外部依赖 | 外部依赖 |
同时,Scrapeless 在高并发场景中表现优于其他竞争产品。以下是从不同维度总结的能力:
| 特性 / 平台 | Scrapeless | Browserless | Browserbase | HyperBrowser | Bright Data | ZenRows | Steel.dev |
|---|---|---|---|---|---|---|---|
| 部署方式 | 基于云的 | 基于云的 Puppeteer 容器 | 多浏览器云集群 | 基于云的无头浏览器平台 | 云部署 | 浏览器 API 接口 | 浏览器云集群 + 浏览器 API |
| 并发支持 | 50 到无限 | 3–50 | 3–50 | 1–250 | 根据计划最多可达无限 | 多达 100(商业计划) | 无官方数据 |
| 反检测能力 | 免费的 CAPTCHA 识别与绕过,支持 reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDome 等 | CAPTCHA 绕过 | CAPTCHA 绕过 + 隐私模式 | CAPTCHA 绕过 + 隐私 + 会话管理 | CAPTCHA 绕过 + 指纹伪造 + 代理 | 自定义浏览器指纹 | 代理 + 指纹识别 |
| 浏览器运行成本 | 每小时 $0.063 – $0.090(包括免费 CAPTCHA 绕过) | 每小时 $0.084 – $0.15(按单位) | 每小时 $0.10 – $0.198(包括 2–5GB 免费代理) | 每月 $30–$100 | 每小时 ~$0.10 | 每小时 ~$0.09 | 每小时 $0.05 – $0.08 |
| 代理成本 | 每 GB $1.26 – $1.80 | 每 GB $4.3 | 每 GB $10(超出免费配额) | 无官方数据 | 每 GB $9.5(标准);每 GB $12.5(优质域名) | 每 GB $2.8 – $5.42 | 每 GB $3 – $8.25 |
2.3 CAPTCHA 自动解决和事件监控机制
Scrapeless 提供先进的 CAPTCHA 解决方案,并通过 Chrome DevTools Protocol (CDP) 扩展一系列自定义功能,以增强浏览器自动化的可靠性。
CAPTCHA 解决能力
Scrapeless 可以自动处理主流 CAPTCHA 类型,包括:reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDome 等等。
事件监控机制
Scrapeless 提供了三个核心事件用于监控 CAPTCHA 解决过程:
| 事件名称 | 描述 |
|---|---|
| Captcha.detected | 检测到 CAPTCHA |
| Captcha.solveFinished | CAPTCHA 已解决 |
| Captcha.solveFailed | CAPTCHA 解决失败 |
事件响应数据结构
| 字段 | 类型 | 描述 |
|---|---|---|
| type | 字符串 | CAPTCHA 类型(例如:recaptcha, turnstile) |
| success | 布尔值 | 解决结果 |
| message | 字符串 | 状态信息(例如:“NOT_DETECTED”,“SOLVE_FINISHED”) |
| token? | 字符串 | 成功时返回的令牌(可选) |
2.4 强大的代理支持
Scrapeless 提供一个灵活可控的代理集成系统,支持多种代理模式:
- 内置住宅代理:支持全球 195 个国家/地区的地理代理,开箱即用。
- 自定义代理(高级订阅):允许用户连接到他们自己的代理服务,该服务不包括在 Scrapeless 的代理计费中。
2.5 会话重放
会话重放是 Scrapeless 抓取浏览器最强大的功能之一。它允许您逐页重放会话,以检查执行的操作和网络请求。
3. 代码示例:Scrapeless 集成和使用
3.1 使用 Scrapeless 抓取浏览器
Puppeteer 示例
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=your-scrapeless-api-key&session_ttl=180&proxy_country=ANY';(async () => {const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});const page = await browser.newPage();await page.goto('https://www.scrapeless.com');console.log(await page.title());await browser.close();
})();Playwright 示例
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=your-scrapeless-api-key&session_ttl=180&proxy_country=ANY';(async () => {const browser = await chromium.connectOverCDP(connectionURL);const page = await browser.newPage();await page.goto('https://www.scrapeless.com');console.log(await page.title());await browser.close();
})();3.2 Scrapeless 抓取浏览器指纹参数示例代码
以下是一个简单的示例代码,展示如何通过 Puppeteer 和 Playwright 集成 Scrapeless 的浏览器指纹自定义功能:
Puppeteer 示例
const puppeteer = require('puppeteer-core');// 自定义浏览器指纹
const fingerprint = {userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',platform: 'Windows',screen: {width: 1280, height: 1024},localization: {languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',}
}const query = new URLSearchParams({token: 'APIKey', // 必需session_ttl: 180,proxy_country: 'ANY',fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;(async () => {const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});const page = await browser.newPage();await page.goto('https://www.scrapeless.com');const info = await page.evaluate(() => {return {screen: {width: screen.width,height: screen.height,},userAgent: navigator.userAgent,timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,languages: navigator.languages};});console.log(info);await browser.close();
})();Playwright 示例
const { chromium } = require('playwright-core');// custom browser fingerprint
const fingerprint = {userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',platform: 'Windows',screen: {width: 1280, height: 1024},localization: {languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',}
}const query = new URLSearchParams({token: 'APIKey', // requiredsession_ttl: 180,proxy_country: 'ANY',fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;(async () => {const browser = await chromium.connectOverCDP(connectionURL);const page = await browser.newPage();await page.goto('https://www.scrapeless.com');const info = await page.evaluate(() => {return {screen: {width: screen.width,height: screen.height,},userAgent: navigator.userAgent,timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,languages: navigator.languages};});console.log(info);await browser.close();
})();3.3 CAPTCHA事件监控示例
以下是使用Scrapeless监控CAPTCHA事件的完整代码示例,展示如何实时监控CAPTCHA的解决状态:
// 监听CAPTCHA解决事件
const client = await page.createCDPSession();client.on('Captcha.detected', (result) => {console.log('检测到CAPTCHA:', result);
});await new Promise((resolve, reject) => {client.on('Captcha.solveFinished', (result) => {if (result.success) resolve();});client.on('Captcha.solveFailed', () =>reject(new Error('CAPTCHA解决失败')));setTimeout(() =>reject(new Error('CAPTCHA解决超时')),5 * 60 * 1000);
});掌握Scrapeless Scraping Browser的核心功能和优势后,我们不仅可以更好地理解其在现代网页爬虫中的价值,还可以更有效地利用其性能优势。为了帮助开发人员更高效和安全地自动化和爬取网站,我们将探讨如何在特定用例中应用Scrapeless Scraping Browser,基于常见场景。
4. 使用Scrapeless Scraping Browser的自动化和网页爬虫最佳实践
法律免责声明和预防措施
本教程涵盖了流行的网页爬虫技术,用于教育目的。与公共服务器的互动需要谨慎和尊重,以下是一些应避免的事项:
- 不要以可能损害网站的速度进行爬取。
- 不要爬取不公开的数据。
- 不要存储受GDPR保护的欧盟公民的个人信息。
- 不要重新使用整个公共数据集,这在某些国家可能是非法的。
理解Cloudflare保护
- 什么是Cloudflare?
Cloudflare是一个集成了内容分发网络(CDN)、DNS加速和安全保护的云平台。网站使用Cloudflare来缓解分布式拒绝服务(DDoS)攻击(即由于多个访问请求导致网站离线),并确保使用它的网站始终在线。
以下是一个简单的示例,用于理解Cloudflare的工作原理:
当您访问启用Cloudflare的网站(例如example.com)时,您的请求首先到达Cloudflare的边缘服务器,而不是源服务器。Cloudflare将根据多条规则判断是否允许您的请求继续,例如:
- 是否可以直接返回缓存页面;
- 是否需要通过CAPTCHA测试;
- 是否会阻止您的请求;
- 请求是否会被转发到实际的网站服务器(源)。
如果您被识别为合法用户,Cloudflare将转发请求到源服务器并将内容返回给您。此机制极大增强了网站的安全性,但也为自动访问带来了重大挑战。
绕过Cloudflare是许多数据收集任务中的技术难题之一。接下来,我们将深入探讨为何绕过Cloudflare是困难的。
- 绕过Cloudflare保护的挑战
绕过Cloudflare并不容易,尤其是在启用高级反机器人特性(如机器人管理、托管挑战、Turnstile验证、JS挑战等)时。许多传统的爬虫工具(如Selenium和Puppeteer)在请求甚至未发出之前,就因明显的指纹特征或不自然的行为模拟而被检测和阻止。
虽然有一些专门设计用于绕过Cloudflare的开源工具(例如FlareSolverr, undetected-chromedriver),但这些工具通常寿命较短。一旦它们被广泛使用,Cloudflare会迅速更新其检测规则以阻止它们。这意味着,要以持续和稳定的方式绕过Cloudflare的保护机制,团队通常需要内部开发能力以及持续的资源投入以进行维护和更新。
以下是绕过Cloudflare保护的主要挑战:
-
严格的浏览器指纹识别:Cloudflare会检测请求中的指纹特征,例如用户代理、语言设置、屏幕分辨率、时区和Canvas/WebGL渲染。如果检测到异常的浏览器或自动化行为,它会阻止请求。
-
复杂的 JS 挑战机制:Cloudflare 动态生成 JavaScript 挑战(如 CAPTCHA、延迟重定向、逻辑计算等),而自动化脚本通常难以正确解析或执行这些复杂的逻辑。
-
行为分析系统:除了静态指纹外,Cloudflare 还分析用户行为轨迹,如鼠标移动、在页面上停留的时间、滚动动作等。这需要在模拟人类行为方面具备高精度。
-
速率和并发控制:高频率的访问很容易触发 Cloudflare 的速率限制和 IP 阻止策略。代理池和分布式调度必须高度优化。
-
不可见的服务器端验证:由于 Cloudflare 是一个边缘拦截器,许多真实请求在到达源服务器之前就被阻止,从而使传统的数据包捕获分析方法无效。
因此,成功绕过 Cloudflare 需要模拟真实的浏览器行为、动态执行 JavaScript、灵活配置指纹,使用高质量的代理和动态调度机制。
使用 Scrapeless 爬虫浏览器绕过 Idealista 的 Cloudflare 收集房地产数据
在本章中,我们将演示如何使用 Scrapeless 爬虫浏览器构建一个高效、稳定且抗反爬的自动化系统,从 Idealista 这一领先的欧洲房地产平台抓取房地产数据。Idealista 采用了多种保护机制,包括 Cloudflare、动态加载、IP 速率限制和用户行为识别,使其成为一个非常具有挑战性的目标平台。
我们将重点关注以下技术方面:
- 绕过 Cloudflare 验证页面
- 自定义指纹与模拟真实用户行为
- 使用会话重放
- 高并发抓取与多个代理池
- 成本优化
理解挑战:Idealista 的 Cloudflare 保护
Idealista 是南欧领先的在线房地产平台,提供数百万条各种类型房产的列表,包括住宅、公寓和合租房。鉴于其房产数据的高度商业价值,该平台实施了严格的反爬虫措施。
为了抵御自动化抓取,Idealista 部署了 Cloudflare——一种广泛使用的防机器人和安全保护系统,旨在防御恶意机器人、DDoS 攻击和数据滥用。Cloudflare 的反抓取机制主要由以下元素组成:
- 访问验证机制:包括 JS 挑战、浏览器完整性检查和 CAPTCHA 验证,以确定访客是否为真实用户。
- 行为分析:通过鼠标移动、点击模式和滚动速度等行为检测真实用户。
- HTTP 头分析:检查浏览器类型、语言设置和引荐数据,以核实差异。可疑头信息可能暴露伪装成自动化机器人的尝试。
- 指纹检测与阻止:通过浏览器指纹、TLS 指纹和头信息识别由自动化工具(如 Selenium 和 Puppeteer)生成的流量。
- 边缘节点过滤:请求首先进入 Cloudflare 的全球边缘网络,该网络评估请求的风险。只有被认为低风险的请求才会转发到 Idealista 的源服务器。
接下来,我们将详细解释如何使用 Scrapeless 爬虫浏览器绕过 Idealista 的 Cloudflare 保护并成功收集房地产数据。
使用 Scrapeless 爬虫浏览器绕过 Idealista 的 Cloudflare
前提条件
在开始之前,让我们确保我们拥有必要的工具:
-
Python:如果您尚未安装 Python,请下载最新版本并将其安装在您的系统上。
-
所需库:您需要安装几个 Python 库。打开终端或命令提示符并运行以下命令:
pip install requests beautifulsoup4 lxml selenium selenium-wire undetected-chromedriver -
ChromeDriver:下载 ChromeDriver。确保选择与您安装的 Chrome 版本相匹配的版本。
-
Scrapeless 账户:要绕过 Idealista 的机器人保护,您需要一个 Scrapeless 爬虫浏览器账户。您可以 在这里注册 并获得 2 美元的免费试用。
定位数据
我们的目标是提取 Idealista 上每个房产列表的详细信息。我们可以使用浏览器的开发者工具来了解网站的结构并识别需要定位的 HTML 元素。
右键单击页面上的任意位置,选择 检查 以查看页面源代码。
在这篇文章中,我们将重点介绍如何使用以下网址从马德里阿尔卡拉-德-海纳雷斯抓取物业列表:
https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/
我们希望从每个列表中提取以下数据点:
- 标题
- 价格
- 面积信息
- 房产描述
- 图片网址
下面您可以看到带注释的房产列表页面,显示每个房源信息的位置。
通过检查HTML源代码,我们可以识别每个数据点的CSS选择器。CSS选择器是用于选择HTML文档中元素的模式。
通过检查HTML源代码,我们发现每个房产列表都包含在带有类 item 的 <article> 标签内。在每个项目内:
- 标题位于带有类
item-link的<a>标签中。 - 价格位于带有类
item-price的<span>标签中。 - 其他数据点也是如此。
步骤1:使用ChromeDriver设置Selenium
首先,我们需要配置Selenium以使用ChromeDriver。首先设置chrome_options并初始化ChromeDriver。
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):chrome_options = Options()chrome_options.add_argument("--headless")s = Service("替换为您的ChromeDriver路径")driver = webdriver.Chrome(service=s, chrome_options=chrome_options)这段代码导入了必要的模块,包括用于高级浏览器交互的seleniumwire和用于HTML解析的BeautifulSoup。
我们定义了一个函数listings(url),并通过向chrome_options添加--headless参数来配置Chrome在无头模式下运行。然后,使用指定的服务路径初始化ChromeDriver。
步骤2:加载目标网址
接下来,我们加载目标网址并等待页面完全加载。
driver.get(url)time.sleep(8) # 根据网站的加载时间进行调整在这里,driver.get(url)命令指示浏览器导航到指定URL。
我们使用time.sleep(8)使脚本暂停8秒,确保网页完全加载。这个等待时间可以根据网站的加载速度进行调整。
步骤3:解析页面内容
页面加载完成后,我们使用BeautifulSoup解析其内容:
soup = BeautifulSoup(driver.page_source, "lxml")driver.quit()在这里,我们使用driver.page_source获取加载页面的HTML内容,并使用lxml解析器通过BeautifulSoup解析它。最后,我们调用driver.quit()关闭浏览器实例并释放资源。
步骤4:从解析的HTML中提取数据
接下来,我们从解析的HTML中提取相关数据。
house_listings = soup.find_all("article", class_="item")extracted_data = []for listing in house_listings:description_elem = listing.find("div", class_="item-description")description_text = description_elem.get_text(strip=True) if description_elem else "nil"item_details = listing.find_all("span", class_="item-detail")bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]first_image_url = image_urls[0] if image_urls else "nil"listing_info = {"标题": listing.find("a", class_="item-link").get("title", "nil"),"价格": listing.find("span", class_="item-price").get_text(strip=True),"卧室": bedrooms,"面积": area,"描述": description_text,"图片网址": first_image_url,}extracted_data.append(listing_info)在这里,我们查找所有匹配带有类名 item 的article标签的元素,表示各个房产列表。对于每个列表,我们提取其标题、细节(如卧室数量和面积)以及图片网址。我们将这些细节存储在一个字典中,并将每个字典附加到名为extracted_data的列表中。
步骤5:保存提取的数据
最后,我们将提取的数据保存到JSON文件中。
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")json_filename = f"new_revised_data_{current_datetime}.json"with open(json_filename, "w", encoding="utf-8") as json_file:
```json
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)print(f"提取的数据已保存到 {json_filename}")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)这里是完整的代码:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):chrome_options = Options()chrome_options.add_argument("--headless")s = Service("替换为您的ChromeDriver路径")driver = webdriver.Chrome(service=s, chrome_options=chrome_options)driver.get(url)time.sleep(8) # 根据网站的加载时间进行调整soup = BeautifulSoup(driver.page_source, "lxml")driver.quit()house_listings = soup.find_all("article", class_="item")extracted_data = []for listing in house_listings:description_elem = listing.find("div", class_="item-description")description_text = description_elem.get_text(strip=True) if description_elem else "nil"item_details = listing.find_all("span", class_="item-detail")bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]first_image_url = image_urls[0] if image_urls else "nil"listing_info = {"标题": listing.find("a", class_="item-link").get("title", "nil"),"价格": listing.find("span", class_="item-price").get_text(strip=True),"卧室": bedrooms,"面积": area,"描述": description_text,"图片网址": first_image_url,}extracted_data.append(listing_info)current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")json_filename = f"new_revised_data_{current_datetime}.json"with open(json_filename, "w", encoding="utf-8") as json_file:json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)print(f"提取的数据已保存到 {json_filename}")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)绕过机器人检测
如果您在本教程中至少运行过两次脚本,您可能已经注意到出现了一个 CAPTCHA 页面。
Cloudflare 挑战页面最初加载 cf-chl-bypass 脚本并执行 JavaScript 计算,这通常需要大约 5 秒。
Scrapeless 提供了一种简单可靠的方法来访问如 Idealista 等网站的数据,而无需构建和维护自己的抓取基础设施。Scrapeless 抓取浏览器是一种高并发自动化解决方案,专为人工智能打造。它是一种高性能、成本效益高、抗封锁的浏览器平台,旨在大规模数据抓取,并模拟高度人类化的行为。它可以实时处理 reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDome 等,使其成为高效的网络抓取解决方案。
以下是使用 Scrapeless 绕过 Cloudflare 保护的步骤:
步骤 1:准备
1.1 创建项目文件夹
- 创建一个新的项目文件夹,例如
scrapeless-bypass。 - 在终端中导航到该文件夹:
cd path/to/scrapeless-bypass1.2 初始化 Node.js 项目
运行以下命令以创建 package.json 文件:
npm init -y1.3 安装所需依赖项
安装 Puppeteer-core,允许远程连接到浏览器实例:
npm install puppeteer-core如果您的系统上尚未安装 Puppeteer,则安装完整版本:
npm install puppeteer puppeteer-core步骤 2:获取您的 Scrapeless API 密钥
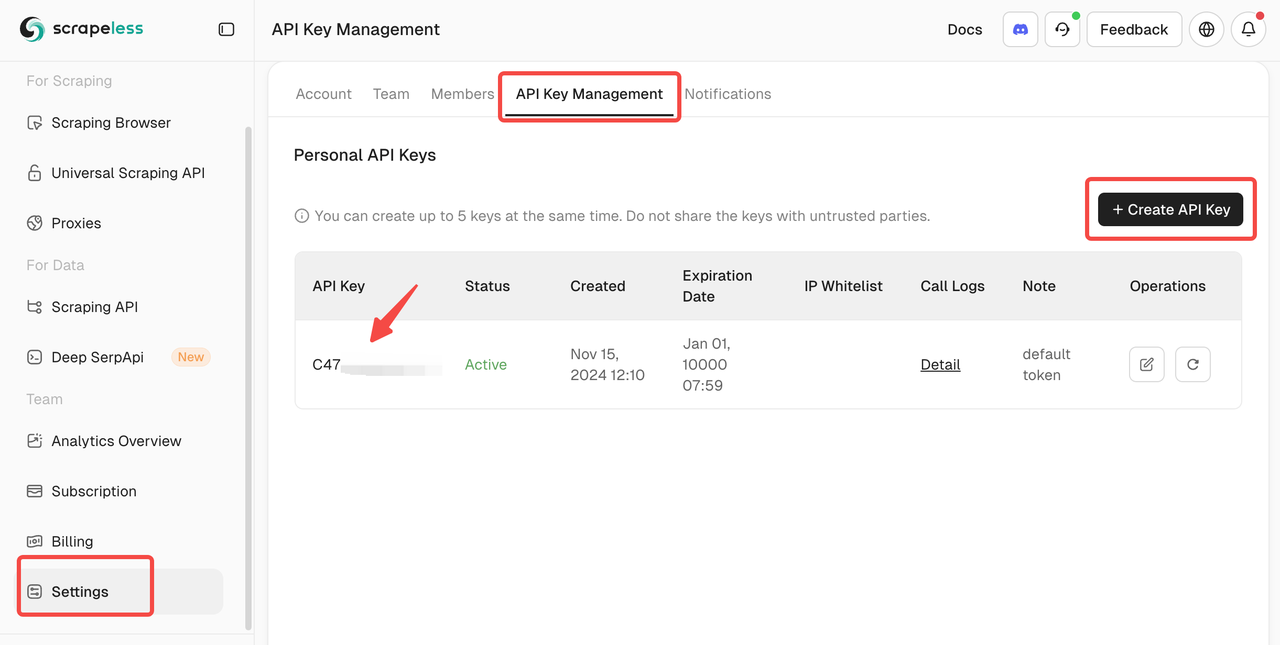
2.1 在 Scrapeless 上注册
- 前往 Scrapeless 并创建一个帐户。
- 导航到 API 密钥管理 部分。
- 生成一个新的 API 密钥并复制它。
步骤 3:连接到 Scrapeless 无浏览器
3.1 获取 WebSocket 连接 URL
Scrapeless 提供 Puppeteer 使用 WebSocket 连接 URL 与云端浏览器进行交互。
格式为:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY将 APIKey 替换为您的实际 Scrapeless API 密钥。
3.2 配置连接参数
token:您的 Scrapeless API 密钥session_ttl:浏览器会话持续时间(以秒为单位),例如180proxy_country:代理服务器的国家代码(例如,GB表示英国,US表示美国)
第4步:编写Puppeteer脚本
4.1 创建脚本文件
在您的项目文件夹中,创建一个名为bypass-cloudflare.js的新JavaScript文件。
4.2 连接到Scrapeless并启动Puppeteer
将以下代码添加到bypass-cloudflare.js中:
import puppeteer from 'puppeteer-core';const API_KEY = 'your_api_key'; // 用实际API密钥替换
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({token: API_KEY, session_ttl: '180', // 浏览器会话持续时间(秒)proxy_country: 'GB', // 代理国家代码proxy_session_id: 'test_session', // 代理会话ID(保持相同IP)proxy_session_duration: '5' // 代理会话持续时间(分钟)
}).toString();const connectionURL = `${host}/browser?${query}`;const browser = await puppeteer.connect({browserWSEndpoint: connectionURL, defaultViewport: null,
});
console.log('连接到Scrapeless');4.3 打开网页并绕过Cloudflare
扩展脚本以打开新页面并导航到Cloudflare保护的网站:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 等待页面元素加载
在继续之前确保绕过Cloudflare保护:
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // 根据需要调整选择器4.5 截取屏幕截图
为验证Cloudflare保护是否已成功绕过,截取页面的屏幕截图:
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('屏幕截图已保存为 challenge-bypass.png');4.6 完整脚本
以下是完整脚本:
import puppeteer from 'puppeteer-core';const API_KEY = 'your_api_key'; // 用实际API密钥替换
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({token: API_KEY,session_ttl: '180',proxy_country: 'GB',proxy_session_id: 'test_session',proxy_session_duration: '5'
}).toString();const connectionURL = `${host}/browser?${query}`;(async () => {try {// 连接到Scrapelessconst browser = await puppeteer.connect({browserWSEndpoint: connectionURL,defaultViewport: null,});console.log('连接到Scrapeless');// 打开新页面并导航到目标网站const page = await browser.newPage();await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });// 等待页面完全加载await page.waitForTimeout(5000); // 如有必要可调整延迟await page.waitForSelector('main.page-content', { timeout: 30000 });// 截取屏幕截图await page.screenshot({ path: 'challenge-bypass.png' });console.log('屏幕截图已保存为 challenge-bypass.png');// 关闭浏览器await browser.close();console.log('浏览器已关闭');} catch (error) {console.error('错误:', error);}
})();第5步:运行脚本
5.1 保存脚本
确保将脚本保存为bypass-cloudflare.js。
5.2 执行脚本
使用Node.js运行脚本:
node bypass-cloudflare.js5.3 预期输出
如果一切设置正确,终端将显示:
连接到Scrapeless
屏幕截图已保存为 challenge-bypass.png
浏览器已关闭challenge-bypass.png文件将出现在您的项目文件夹中,确认Cloudflare保护已成功绕过。
您还可以将Scrapeless抓取浏览器直接集成到您的抓取代码中:
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=C4778985476352D77C08ECB031AF0857&session_ttl=180&proxy_country=ANY';(async () => {const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});const page = await browser.newPage();await page.goto('https://www.scrapeless.com');console.log(await page.title());await browser.close();
})();指纹自定义
在抓取网站数据时——尤其是像Idealista这样的大型房地产平台——即使您成功绕过了Cloudflare挑战,通过Scrapeless,仍然可能由于重复或高频率的访问被标记为机器人。
网站通常使用浏览器指纹识别来检测自动化行为并限制访问。
⚠️ 常见问题
-
多次抓取后响应时间变慢
网站可能会根据IP或行为模式限制请求。 -
页面布局未能渲染
动态内容可能依赖于真实的浏览器环境,导致抓取期间数据缺失或破损。 -
某些地区缺少列表
网站可能会根据可疑的流量模式阻止或隐藏内容。
这些问题通常是由于每个请求的浏览器配置相同造成的。如果您的浏览器指纹保持不变,反机器人系统就容易检测到自动化。
解决方案:使用 Scrapeless 自定义指纹
Scrapeless 抓取浏览器 提供了内置的指纹自定义支持,以模拟真实用户行为并避免被检测。
您可以 随机化或自定义 以下指纹元素:
| 指纹元素 | 描述 |
|---|---|
| 用户代理 | 模拟各种操作系统/浏览器组合(例如,Windows/Mac上的Chrome)。 |
| 平台 | 模拟不同的操作系统(Windows、macOS 等)。 |
| 屏幕大小 | 仿真各种设备分辨率,以避免移动/桌面不匹配。 |
| 本地化 | 与地理位置一致对齐语言和时区。 |
通过旋转或自定义这些值,每个请求看起来更自然——减少被检测的风险,提高数据提取的可靠性。
代码示例:
const puppeteer = require('puppeteer-core');const query = new URLSearchParams({token: 'your-scrapeless-api-key', // 必需session_ttl: 180,proxy_country: 'ANY',// 设置指纹参数userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.6998.45 Safari/537.36',platform: 'Windows',screen: JSON.stringify({ width: 1280, height: 1024 }),localization: JSON.stringify({locale: 'zh-HK',languages: ['zh-HK', 'en-US', 'en'],timezone: 'Asia/Hong_Kong',})
});const connectionURL = `wss://browser.Scrapeless.com/browser?${query.toString()}`;(async () => {const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});const page = await browser.newPage();await page.goto('https://www.Scrapeless.com');console.log(await page.title());await browser.close();
})();会话重放
在自定义浏览器指纹后,页面稳定性显著提高,内容提取变得更加可靠。
然而,在大规模抓取操作期间,意外问题仍可能导致提取失败。为此,Scrapeless 提供了强大的 会话重放 功能。
什么是会话重放?
会话重放详细记录整个浏览器会话,捕捉所有交互,如:
- 页面加载过程
- 网络请求和响应数据
- JavaScript 执行行为
- 动态加载但未解析的内容
为什么使用会话重放?
在抓取复杂网站如 Idealista 时,会话重放可以大大提高调试效率。
| 益处 | 描述 |
|---|---|
| 精确问题追踪 | 快速识别失败的请求,无需猜测 |
| 无需重新运行代码 | 直接从重放中分析问题,而不是重新运行抓取器 |
| 改善协作 | 与团队成员共享重放日志以便于故障排除 |
| 动态内容分析 | 理解在抓取过程中动态加载的数据如何表现 |
使用提示
一旦 会话重放 启用,抓取失败或数据看起来不完整时,首先检查重放日志。这有助于您更快地诊断问题,减少调试时间。
代理配置
在抓取 Idealista 时,重要的是要注意该平台对非本地 IP 地址高度敏感——尤其是在访问特定城市的列表时。如果您的 IP 来源于国外,Idealista 可能会:
- 完全阻止请求
- 返回简化或删减版本的页面
- 提供空或不完整的数据,即使没有触发 CAPTCHA
Scrapeless 内置代理支持
Scrapeless 提供 内置代理配置,允许您直接指定地理来源。
您可以通过以下任一方式进行配置:
proxy_country:一个两字母国家代码(例如,西班牙为'ES')proxy_url:您自己的代理服务器 URL
示例用法:
proxy_country: 'ES',高并发
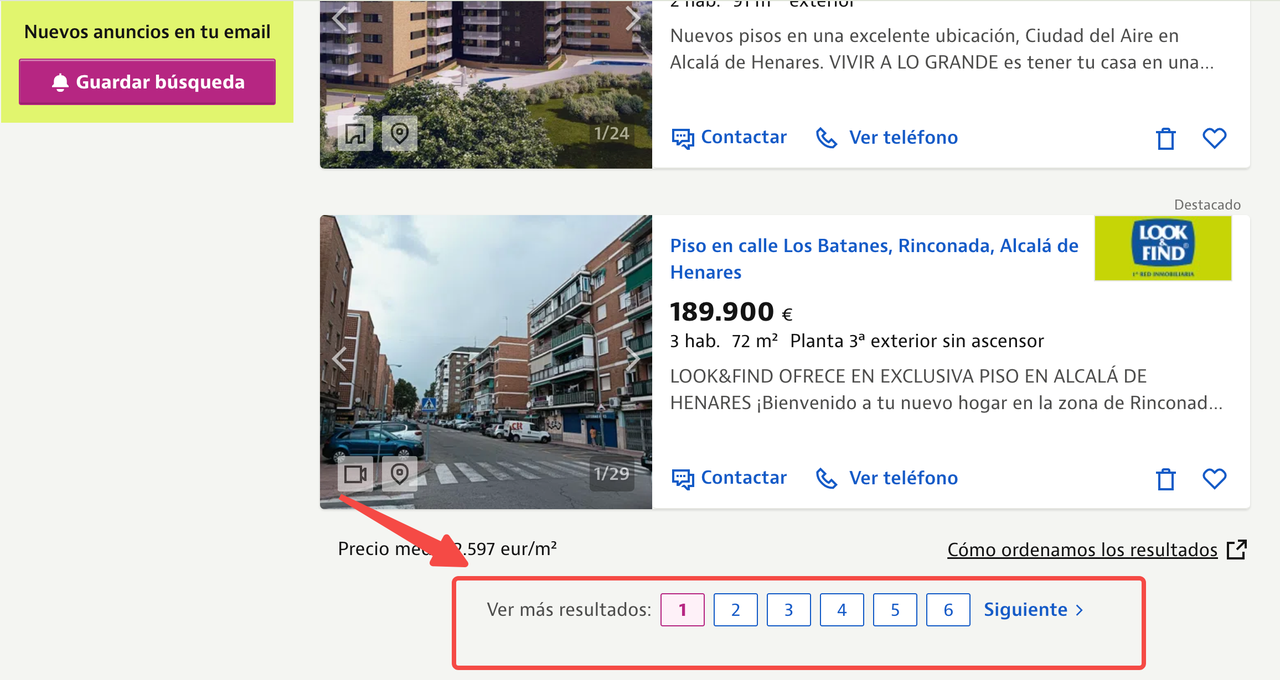
我们刚刚从 Idealista 抓取的页面——阿尔卡拉·德·埃纳雷斯房产列表——有多达 6 页的列表。
当您研究行业趋势或收集竞争营销策略时,可能需要每天从 20+ 个城市 抓取房地产数据,涵盖 数千个页面。在某些情况下,您甚至可能需要每小时刷新这些数据。
高并发要求
为高效处理这种容量,请考虑以下要求:
- 多个并发连接:无需长时间等待即可从数百个页面抓取数据。
- 自动化工具:使用Scrapeless Scraping Browser或类似工具,这些工具能够处理大规模的并发请求。
- 会话管理:保持持久会话,以避免过多的验证码或IP封锁。
无痛扩展性
Scrapeless专门为高并发抓取设计。它提供:
- 并行浏览器会话:同时处理多个请求,使您能够在多个城市快速抓取大量数据。
- 低成本、高效抓取:并行抓取降低了每页抓取的成本,同时优化了吞吐量。
- 绕过高流量反机器人防御:即使在高负荷抓取期间,也能自动处理验证码和其他验证系统。
提示:确保您的请求间隔合理,以模拟人类的浏览行为,防止Idealista的速率限制或封禁。
扩展性与成本效率
常规的Puppeteer在高效扩展会话和与排队系统集成方面表现不佳。然而,Scrapeless Scraping Browser支持从数十个并发会话到无限并发会话的无缝扩展,确保即使在高峰任务负载期间也零排队时间和零超时。
以下是各种高并发抓取工具的比较。即使使用Scrapeless的高并发浏览器,您也无需担心成本——实际上,它可以帮助您节省近**50%**的费用。
工具比较
| 工具名称 | 小时费率 (美元/小时) | 代理费用 (美元/GB) | 并发支持 |
|---|---|---|---|
| Scrapeless | $0.063 – $0.090/小时 (取决于并发性和使用情况) | $1.26 – $1.80/GB | 50 / 100 / 200 / 400 / 600 / 1000 / 无限制 |
| Browserbase | $0.10 – $0.198/小时 (包含2-5GB免费代理) | $10/GB(超出免费分配后) | 3(基础) / 50(高级) |
| Brightdata | $0.10/小时 | $9.5/GB(标准);$12.5/GB(高级域名) | 无限 |
| Zenrows | $0.09/小时 | $2.8 – $5.42/GB | 高达100 |
| Browserless | $0.084 – $0.15/小时 (基于使用单位计费) | $4.3/GB | 3 / 10 / 50 |
提示:如果您需要大规模抓取和高并发支持,Scrapeless提供最佳的性价比。
网络抓取的成本控制策略
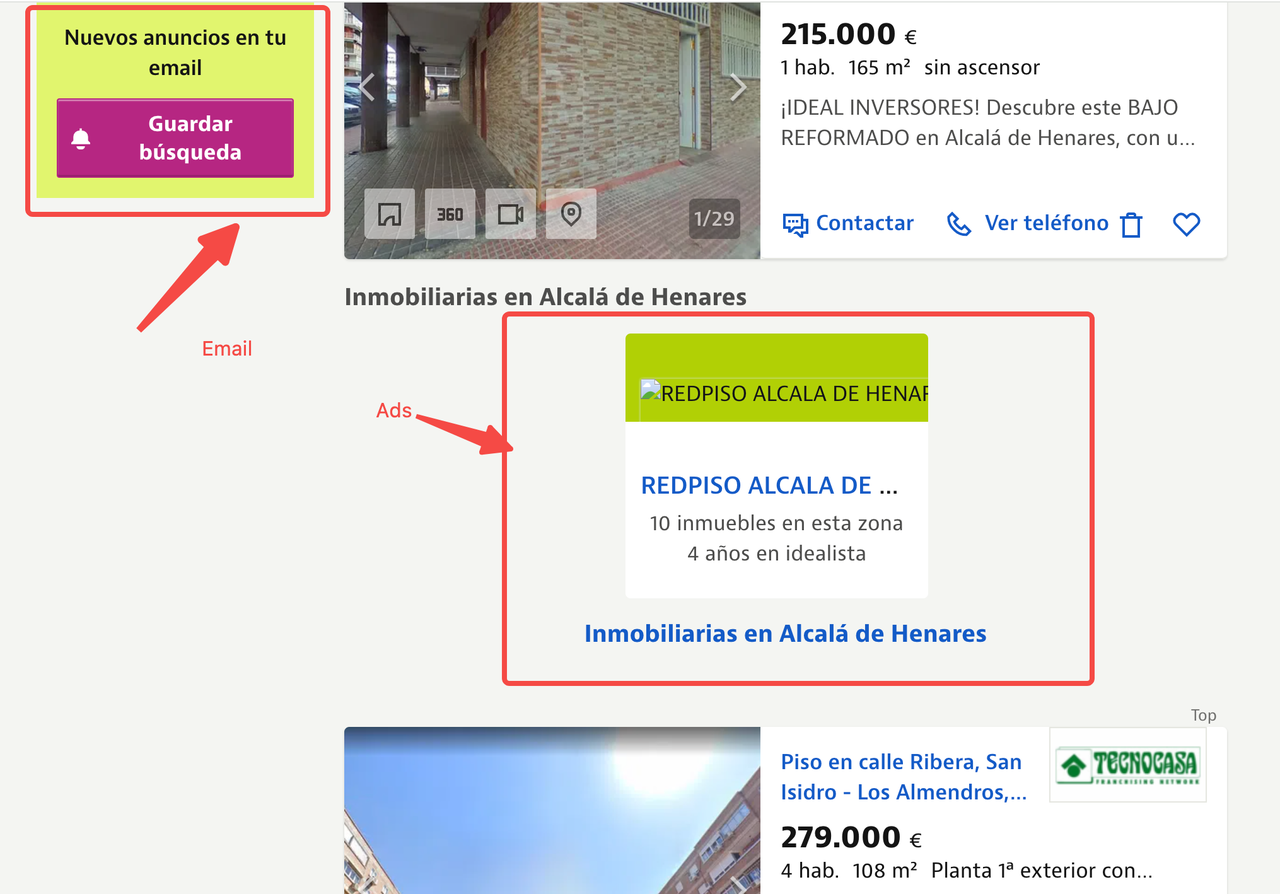
细心的用户可能已经注意到,我们抓取的Idealista页面通常包含大量高清地产图片、互动地图、视频演示和广告脚本。尽管这些元素对最终用户友好,但对数据提取而言是不必要的,并显著增加了带宽消耗和成本。
为了优化流量使用,我们建议用户采用以下策略:
- 资源拦截:拦截不必要的资源请求以减少流量消耗。
- 请求URL拦截:根据URL特征拦截特定请求,以进一步减少流量。
- 模拟移动设备:使用移动设备配置来获取更轻的页面版本。
详细策略
1. 资源拦截
启用资源拦截可以显著提高抓取效率。通过配置Puppeteer的setRequestInterception函数,我们可以阻止图像、媒体、字体和样式表等资源的加载,从而避免下载大量内容。
2. 请求URL过滤
通过检查请求URL,我们可以过滤掉与数据提取无关的无效请求,如广告服务和第三方分析脚本。这降低了不必要的网络流量。
3. 模拟移动设备
模拟移动设备(例如,将用户代理设置为iPhone)允许您获取更轻的、经过移动优化的页面版本。这会导致加载的资源更少,从而加快抓取过程。
要获取更多信息,请参考Scrapeless官方文档
示例代码
以下是使用Scrapeless Cloud Browser + Puppeteer的示例代码,展示如何结合这三种策略进行优化资源抓取:
import puppeteer from 'puppeteer-core';const scrapelessUrl = 'wss://browser.scrapeless.com/browser?token=your_api_key&session_ttl=180&proxy_country=ANY';async function scrapeWithResourceBlocking(url) {const browser = await puppeteer.connect({browserWSEndpoint: scrapelessUrl,defaultViewport: null});const page = await browser.newPage();// Enable request interceptionawait page.setRequestInterception(true);// Define resource types to blockconst BLOCKED_TYPES = new Set(['image','font','media','stylesheet',]);// Intercept requestspage.on('request', (request) => {if (BLOCKED_TYPES.has(request.resourceType())) {request.abort();console.log(`Blocked: ${request.resourceType()} - ${request.url().substring(0, 50)}...`);} else {request.continue();}});await page.goto(url, {waitUntil: 'domcontentloaded'});// Extract dataconst data = await page.evaluate(() => {return {title: document.title,content: document.body.innerText.substring(0, 1000)};});await browser.close();return data;
}// Usage
scrapeWithResourceBlocking('https://www.scrapeless.com').then(data => console.log('Scraping result:', data)).catch(error => console.error('Scraping failed:', error));通过这种方式,您不仅可以节省高额的流量费用,还能在确保数据质量的同时提高爬取速度,从而改善系统的整体稳定性和效率。
5. 安全和合规建议
在使用Scrapeless进行数据爬取时,开发人员应注意以下事项:
- 遵守目标网站的
robots.txt文件及相关法律法规:确保您的爬取活动是合法的,并尊重网站的指南。 - 避免过度请求,导致网站停机:注意爬取频率,以防止服务器过载。
- 不爬取敏感信息:不要收集用户隐私数据、支付信息或任何其他敏感内容。
6. 结论
在大数据时代,数据收集已成为各行业数字化转型的关键基础。尤其是在市场情报、电子商务价格比较、竞争分析、金融风险管理和房地产分析等领域,对数据驱动决策的需求愈加迫切。然而,随着网络技术的持续演变,特别是动态加载内容的广泛使用,传统网页爬虫逐渐显露出其局限性。这些局限性不仅使爬取变得更加困难,而且导致反爬机制的升级,提高了网页爬取的门槛。
随着网络技术的进步,传统爬虫已无法满足复杂爬取需求。以下是一些主要挑战及相应解决方案:
- 动态内容加载:基于浏览器的爬虫通过模拟真实浏览器对JavaScript内容的渲染,确保能够爬取动态加载的网页数据。
- 反爬机制:通过使用代理池、指纹识别、行为模拟等技术,我们可以绕过传统爬虫常触发的反爬机制。
- 高并发爬取:无头浏览器支持高并发任务部署,配合代理调度,以满足大规模数据爬取的需求。
- 合规问题:通过使用合法的API和代理服务,可以确保爬取活动遵循目标网站的条款。
因此,基于浏览器的爬虫已成为行业的新趋势。这项技术不仅通过真实浏览器模拟用户行为,还灵活应对现代网站的复杂结构和反爬机制,为开发人员提供更稳定和高效的爬取解决方案。
Scrapeless抓取浏览器顺应这一技术趋势,通过结合浏览器渲染、代理管理、反检测技术和高并发任务调度,帮助开发人员在复杂的在线环境中高效稳定地完成数据爬取任务。它通过几个核心优势提高爬取效率和稳定性:
-
高并发浏览器解决方案:Scrapeless支持大规模的高并发任务,能够快速部署数千个爬取任务,以满足长期爬取需求。
-
反检测即服务:内置的验证码解决器和可定制的指纹帮助开发人员绕过指纹和行为识别机制,大大降低被封禁的风险。
-
可视化调试工具 - 会话重放:通过回放爬取过程中的每次浏览器交互,开发人员可以轻松调试和诊断爬取过程中的问题,特别是处理复杂页面和动态加载内容时。
-
合规性和透明性保障:Scrapeless强调合规的数据爬取,支持遵守网站的
robots.txt规则,并提供详细的爬取日志,以确保用户的数据爬取活动符合目标网站的政策。 -
灵活的可扩展性:Scrapeless与Puppeteer无缝集成,使用户能够自定义其抓取策略,并与其他工具或平台连接,实现一站式的数据抓取和分析工作流程。
无论是抓取电子商务平台以进行价格比较,提取房地产网站数据,还是应用于金融风险监测和市场情报分析,Scrapeless为各种行业提供高效、智能和可靠的解决方案。
通过本文涵盖的技术细节和最佳实践,您现在了解如何利用Scrapeless进行大规模数据抓取。无论是处理动态页面、提取复杂的交互数据、优化流量使用,还是克服反抓取机制,Scrapeless都能帮助您快速高效地实现抓取目标。
相关文章:

使用Scrapeless Scraping Browser的自动化和网页抓取最佳实践
引言:人工智能时代浏览器自动化和数据收集的新范式 随着生成性人工智能、人工智能代理和数据密集型应用程序的快速崛起,浏览器正在从传统的“用户互动工具”演变为智能系统的“数据执行引擎”。在这一新范式中,许多任务不再依赖单一的API端点…...

电子电气架构 --- 如何有助于提安全性并减少事故
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

【训练】Qwen2.5VL 多机多卡 Grounding Box定位
之前的相关文章: 【深度学习】LLaMA-Factory微调sft Qwen2-VL进行印章识别 https://www.dong-blog.fun/post/1661 使用LLaMA-Factory微调sft Qwen2-VL-7B-Instruct https://www.dong-blog.fun/post/1762 构建最新的LLaMA-Factory镜像 https://www.dong-blog.f…...

MYSQL的行级锁到底锁的是什么东西
MySQL 的行级锁是一种锁机制,它允许数据库在执行并发操作时,锁定表中的某一行数据而不是整张表。行级锁通过限制对特定行的访问,允许其他线程并发地访问表中的其他行,从而提高并发性和性能。 行级锁的锁定对象 行级锁锁定的是 行…...

图神经网络中的虚拟节点
1.虚拟节点 当我们使用节点来构成图结构时, regular node: 常规的节点即代表了某一个局部特征, 即局部节点特征。 virtual node: 普通的节点不同,有时会需要这样的一种特征, 该特征代表了该样本的全局信息࿰…...

关于多版本CUDA共存的研究,是否能一台机子装两个CUDA 版本并正常切换使用
我发现了一个很有意思的事 我装了11.8cuda再装12.3cuda结果我的11.8cuda还在,没被替换掉或者删掉 然后我打开我的环境发现它的环境除了cuda_path都没改 这样我就有个大胆的想法,如果我把cuda path换成11.8路径那是不是就能切换了 而且cuda_path 和 cuda_…...

el-table与echarts图形实现滚动联动
el-table与echarts图形滚动联动 效果图 实现思路 设计图滚动条位于表格下方,且echarts滚动不易获取当前展示数据到左侧的距离 故:通过监听表格的滚动实现联动 为了保持echarts的横坐标和表格的列基本保持对齐,用tdWidth标识单列表格的宽度…...

【Git】【commit】查看未推送的提交查看指定commit的修改内容合并不连续的commit
文章目录 1. 查看未推送的提交方法一 :git status方法二:git log方法三:git cherry方法四:git rev-list 2. 查看指定commit的修改方法一:git show方法二:git log方法三:git diff 3. 合并不连续的…...

C++GO语言微服务基础技术①
目录 01-项目简介 02-单体式架构 03-微服务优缺点 04-单体式和微服务区别 05-RPC简介 06-RPC使用步骤 07-注册RPC服务函数接口 08-绑定服务和调用方法函数接口 09-rpc服务端和客户端编码实现 10-json的rpc 11-rpc的封装 12-rpc封装小结 01-项目简介 # 单体式和微服…...

AI CUBE 使用指南 目标检测格式范例 AI cube 报错数据集不合规范,请清洗数据集
血的教训:labels.txt里面放1 2 3 4 ..也可以英文,不能有中文 教程:K230 借助 AICube部署AI 视觉模型 YOLO等教程_嘉楠 ai cube多标签分类-CSDN博客 | 目标检测范例: 不清楚不是数字行不行 这个id可以英文,你…...

vue中scss使用js的变量
一、前言 在项目开发中,很多时候会涉及到scss样式变量,正常定义方式 $primary-color: rgb(188, 0, 194);;使用时直接使用即可:color: $primary-color。但是,如果,这些变量是在js中定义的怎么办 二、实现 …...
)
QtGUI模块功能详细说明, 字体和文本渲染(四)
目录 一. 窗口和屏幕管理 二. 绘图和渲染 三. 图像处理 四. 字体和文本 1、核心概念 1.1、字体 (Font) 1.2、字形 (Glyph) 1.3、字符 (Character) 1.4、文本布局 (Text Layout) 1.5、文本渲染 (Text Rendering) 1.6、度量 (Metrics) 2、字体管理 2.1、QFont&#…...
)
计算机学习路线与编程语言选择(信息差)
——授人以鱼不如授人以渔 面向岗位学习!到招聘网站看看有哪些岗位,看一看岗位职责、要求 牛客网(计算机实习工作最好的网站) boss直聘 确定岗位后(如前端、后端),岗位需要什么语言…...

多环串级PID
文章目录 为什么要多环程序主函数内环外环 双环PID调参内环Kp调法Ki调法 外环Kp 以一定速度到达指定位置封装 为什么要多环 单环只能单一控制速度或者位置,如果想要同时控制多个量如速度,位置,角度,就需要多个PID 速度环一般PI…...

编写大模型Prompt提示词方法
明确目标和任务 // 调用LLM进行分析const prompt 你是一名严格而友好的英语口语评分官,专业背景包括语音学(phonetics)、二语习得(SLA)和自动语音识别(ASR)。你的任务是: ① 比对参…...

使用chrome浏览器截长图
如何使用chrome浏览器截长图: 使用chrome截取完整网页图片 第一步、按F12,开发者模式的布局按下图布局 第二步、按ctrlshiftp组合键,搜索“截图” ,然后自动截图保存在下载目录(右上角)了。...
))
【MySQL】第二弹——MySQL表的增删改查(CURD))
文章目录 🎓一. CRUD🎓二. 新增(Create)🎓三. 查询(Rertieve)📖1. 全列查询📖2. 指定列查询📖3. 查询带有表达式📖4. 起别名查询(as )📖 5. 去重查询(distinct)📖6. 排序…...

Android NDK版本迭代与FFmpeg交叉编译完全指南
在Android开发中,使用NDK(Native Development Kit)进行原生代码开发是一项常见需求,特别是当我们需要集成FFmpeg这样的多媒体处理库时。本文将深入分析Android NDK的版本迭代分界线,详细讲解FFmpeg交叉编译的注意事项,并提供完整的…...

【Linux网络】Socket-UDP相关函数
socket() 函数 这个函数的作用是创建一个 Socket 文件描述符,在客户端和服务器都可以使用。 #include <sys/socket.h> int socket(int domain, int type, int protocol);参数: domain:指定协议族,例如 AF_INET 代表 IPv4 …...

最优化方法Python计算:有约束优化应用——线性Lasso回归预测器
实际应用中,特征维度 n n n通常远大于样本容量 m m m( n ≪ m n\ll m n≪m),这种高维小样本场景下特征数据可能含有对标签数据 y i y_i yi的取值不必要的成分,甚至是噪声。此时,我们希望回归模型中的优化…...

基础算法 —— 二分算法 【复习总结】
1. 简介 1.1 原理 二分算法,顾名思义,关键在于二分,当我们求解的目标具有二段性时,我们就可以使用二分算法: 先根据待查找区间中点位置,判断结果会在左侧还是右侧,接下来,舍弃一半…...

计算机网络常识:缓存、长短连接 网络初探、URL、客户端与服务端、域名操作 tcp 三次握手 四次挥手
缓存: 缓存是对cpu,内存的一个节约:节约的是网络带宽资源 节约服务器的性能 资源的每次下载和请求都会造成服务器的一个压力 减少网络对资源拉取的延迟 这个就是浏览器缓存的一个好处 表示这个html页面的返回是不要缓存的 忽略缓存 需要每次…...
,MIPI DSI)
OpenHarmony平台驱动开发(九),MIPI DSI
OpenHarmony平台驱动开发(九) MIPI DSI 概述 功能简介 DSI(Display Serial Interface)是由移动行业处理器接口联盟(Mobile Industry Processor Interface (MIPI) Alliance)制定的规范,旨在降…...

经济体制1
一.计划经济体制与市场经济体制 1.计划经济又称指令型经济,是对生产和资源分配以及产品消费事先进行计划的经济体制。 市场经济体制是指依靠市场手段对资源进行配置的经济体制 注意: 计划与市场都是调节经济的手段,都属于资源配…...
)
Spring AI 入门(持续更新)
介绍 Spring AI 是 Spring 项目中一个面向 AI 应用的模块,旨在通过集成开源框架、提供标准化的工具和便捷的开发体验,加速 AI 应用程序的构建和部署。 依赖 <!-- 基于 WebFlux 的响应式 SSE 传输 --> <dependency><groupId>org.spr…...

[ctfshow web入门] web58
信息收集 if(isset($_POST[c])){$c $_POST[c];eval($c); }else{highlight_file(__FILE__); }这麽简单? 解题 好吧,还是我想得太简单了 把system禁用了。不是参数过滤,而是直接禁用,不管是间接还是直接调用system都不行&#x…...

Python量化交易Backtrader技术指标的实现
一、Backtrader技术指标概览 (一)Backtrader内置指标的优势 Backtrader内置的技术指标具有以下优势: 多样性:涵盖了常见的移动平均线、相对强弱指数(RSI)、布林带等多种指标,满足了不同交易者的需求。易用性:通过简单的函数调用即可在策略中添加和使用这些指标,无需…...

蓝桥杯第十六届c组c++题目及个人理解
本篇文章只是部分题目的理解,代码和思路仅供参考,切勿当成正确答案,欢迎各位小伙伴在评论区与博主交流! 题目:2025 题目解析 核心提取 要求的数中至少有1个0、2个2、1个5 代码展示 #include<iostream> #incl…...

ARM 芯片上移植 Ubuntu 操作系统详细步骤
一、准备工作 (一)硬件准备 ARM 开发板:确保 ARM 开发板的型号与 Ubuntu 官方支持的 ARM 架构兼容,常见的 ARM 架构有 ARMv7、ARMv8 等。例如树莓派系列开发板,广泛用于 ARM 系统移植,其采用 ARM 架构。存…...

能耗优化新引擎:EIOT平台助力企业降本增效
安科瑞顾强 数字化转型的背景下,能源管理正加速向智能化、远程化方向演进。安科瑞电气推出的EIOT托管平台及ADW300系列4G无线计量仪表,通过云端技术与无线通信的深度融合,为用户打造了高效、便捷的远程能源监测与管理体系,助力企…...

录播课视觉包装与转化率提升指南
1. 封面设计黄金法则 1.1 程序员审美三要素 极客风配色方案 主色:深空灰(#2D2D2D) 代码蓝(#007BFF) 点缀色:终端绿(#28A745) 警告黄(#FFC107) 信息密度控制 核心标语≤9字(如:"3天攻克分布式事务") 技…...

Solidity语言基础:区块链智能合约开发入门指南
一、Solidity概述 Solidity是以太坊生态系统中最重要的智能合约编程语言,由Gavin Wood于2014年提出。作为面向合约的高级语言,它结合了JavaScript、Python和C的语法特点,专为在以太坊虚拟机(EVM)上运行而设计。 核心…...

QMK开发环境搭建指南:Eclipse和VS Code详解
QMK开发环境搭建指南:Eclipse和VS Code详解 前言 各位键盘DIY爱好者们,今天跟大家分享如何搭建QMK固件开发环境。无论你是想定制自己的客制化键盘固件,还是对开源键盘固件开发感兴趣,这篇教程都能帮你搞定开发环境配置。本文将详…...

Python pandas 向excel追加数据,不覆盖之前的数据
最近突然看了一下pandas向excel追加数据的方法,发现有很多人出了一些馊主意; 比如用concat,append等方法,这种方法的会先将旧数据df_1读取到内存,再把新数据df_2与旧的合并,形成df_new,再覆盖写入,消耗和速…...

spring中RequestContextHolder
1、在 Spring 框架中, RequestAttributes attributes RequestContextHolder.getRequestAttributes(); 是获取当前请求上下文的核心方法。以下是其关键要点及注意事项: 一、核心机制 作用原理 通过 ThreadLocal 存储当前线程的请求属性对象 …...

Kotlin 遍历
在 Kotlin 中,遍历(迭代)是操作集合、数组、范围(Range)等数据结构的常见需求。Kotlin 提供了多种遍历方式,语法简洁且功能强大。以下是不同场景下的遍历方法总结,附代码示例: 一、…...

Ubuntu Linux系统配置账号无密码sudo
在Linux系统中,配置无密码sudo可以通过修改sudoers文件来实现。以下是具体的配置步骤 一、编辑sudoers文件 输入sudo visudo命令来编辑sudo的配置文件。visudo是一个专门用于编辑sudoers文件的命令,它会在保存前检查语法错误,从而防止可能的…...

C# NX二次开发:判断两个体是否干涉和获取系统日志的UFUN函数
大家好,今天要讲关于如何判断两个体是否干涉和获取系统日志的UFUN函数。 (1)UF_MODL_check_interference:这个函数的定义为根据单个目标体检查每个指定的工具体是否有干扰。 Defined in: uf_modl.h Overview Checks each sp…...

若依项目图片显示问题
图片显示异常问题 路径配置问题:前端图片路径配置错误,最初使用相对路径且未从根目录开始解析,导致浏览器根据当前页面 URL 解析路径出错。例如在用户信息展示页面,若当前页面 URL 为http://localhost:8088/user/profileÿ…...

线索二叉树
一 概念 线索二叉树(Threaded Binary Tree)是一种对二叉树的优化结构,主要解决传统二叉树遍历时需要借助栈或递归(额外空间开销)的问题。通过利用节点中的空指针(nullptr)存储遍历过程中的前驱…...

Git查看某个commit的改动
在Git中查看特定commit的改动有多种方法,下面是几种常用的命令行方式: 1. 使用 git show 命令 这是最常用的方法,直接显示某个commit的详细信息和改动: git show <commit-hash> 例如: git show abc1234 也可…...

es 里的Filesystem Cache 理解
文章目录 背景问题1,Filesystem Cache 里放的是啥问题2,哪些查询它们会受益于文件系统缓存 问题3 查询分析 背景 对于es 优化来说常常看到会有一条结论给,给 JVM Heap 最多不超过物理内存的 50%,且不要超过 31GB(避免…...

2025年3月电子学会等级考试五级题——4、收费站在哪里
文章目录 题目代码公式小结 题目 4、收费站在哪里 在一条高速公路上,如果已知 n 座收费站的位置 x1,x2,… ,xn(不妨假设 0x1 ≤ x2 ≤ … ≤ xn),就很容易算出一共有 n(n-1)/2 个距离的值。而比较困难的问题是,在收集…...

深入探索 JavaScript 中的模块对象
引言 在现代 JavaScript 开发中,模块化编程是一项至关重要的技术。它允许开发者将代码拆分成多个独立的模块,每个模块专注于单一功能,从而提高代码的可维护性、可测试性和复用性。而模块对象则是模块化编程中的核心概念之一,它为…...

R1-Searcher:用强化学习解锁大语言模型检索新能力!
R1-Searcher:用强化学习解锁大语言模型检索新能力! 大语言模型(LLMs)发展迅猛,却常因依赖内部知识而在复杂问题上“栽跟头”。今天解读的论文提出R1-Searcher框架,通过强化学习提升LLMs检索能力。它表现超…...

LangChain框架-PromptTemplate 详解
摘要 本文聚焦于 LangChain 框架中PromptTemplate提示词模板模块的深度解析,主要参考langchain_core.prompts源码模块与官方文档。系统梳理 LangChain 对提示词模板的封装逻辑与设计思路,旨在帮助读者构建全面、深入的知识体系,为高效运用LangChain 框架的提示词模板开发应用…...
)
【Java ee 初阶】文件IO和操作(下)
书接上文 文本操作的方法 String[] list() 返回 File 对象代表的目录下的所有文件名 File[] listFiles() 返回 File 对象代表的目录下的所有文件,以 File 对象表示 此处是针对File对象打印得到的效果(调用了File的toString) boolean …...
InputChannel)
Android7 Input(六)InputChannel
概述: 本文讲述Android Input输入框架中 InputChannel的功能。从前面的讲述,我们知道input系统服务最终将输入事件写入了InputChannel,而input属于system_server进程,App属于另外一个进程,当Input系统服务想要把事件传递给App进行…...

【Java ee初阶】初始网络
一、IP地址 概念 IP地址主要用于标识网络主机、其他网络设备(如路由器)的网络地址。简单说,IP地址用于定位主机的网络地址。 就像我们发送快递一样,需要知道对方的收货地址,快递员才能将包裹送到目的地。 格式 IP…...

LabVIEW 2019 与 NI VISA 20.0 安装及报错处理
在使用 Windows 11 操作系统的电脑上,同时安装了 LabVIEW 2019 32 位和 64 位版本的软件。此前安装的 NI VISA 2024 Q1 版,该版本与 LabVIEW 2019 32 位和 64 位不兼容,之后重新安装了 NI VISA 20.0。从说明书来看,NI VISA 20.0 …...