crawl4ai能替代scrapy等传统爬虫框架吗?

传统爬虫框架就像拿着渔网在数字海洋中捕鱼——虽然能捞到东西,但面对现代网站的复杂性时常常"漏网之鱼"满天飞。以Scrapy为代表的工具存在三大致命短板:首先是JavaScript盲区,对动态渲染内容束手无策,就像试图用收音机收看电视频道;其次是规则脆弱性,依赖手工编写的XPath选择器,网站稍作改版就会导致整个爬虫瘫痪,维护成本居高不下;最棘手的是智能缺失,无法区分页面中的核心内容与广告导航等噪音,数据清洗如同大海捞针。某电商平台数据显示,其爬虫系统60%的开发时间都消耗在应对反爬措施和结构调整上。

AI时代的数据需求发生了基因突变。大语言模型训练需要语义结构化的数据输入,传统爬虫抓取的HTML碎片就像未经消化的生肉;企业需要实时监控竞品动态,而静态爬虫对JavaScript渲染的价格标签反应迟钝;更关键的是现代业务需要从评论、图片等非结构化数据提取洞察,这恰恰击中了正则表达式的软肋。OpenAI的研究表明,经过智能标注的数据可使模型效果提升23%,而传统方法在这方面几乎毫无建树——就像用算盘处理深度学习任务。
Crawl4AI的诞生就像给爬虫界投下了一颗"智能核弹"。这个2023年出现的开源项目创造性地将LLM解析引擎与浏览器自动化深度整合:通过视觉语义分析理解网页布局,准确识别主要内容区域的效率比传统方法提升40%;内置自适应学习机制,遇到验证码时自动切换IP+模拟人类操作+OCR识别三管齐下;特别针对单页应用设计了状态感知算法,处理动态内容的成功率高达98%。早期采用者反馈,在抓取JavaScript生成的商品详情页时,开发效率提升了惊人的300%,这标志着爬虫技术正式从"机械采集"迈入"认知智能"新时代。
Crawl4AI核心技术解析
2.1 基于LLM的智能解析引擎
Crawl4AI最革命性的突破就是它的LLM智能解析引擎,这就像给爬虫装上了"人脑"!传统爬虫还在用XPath/CSS选择器玩"大家来找茬"时,它已经学会像人类一样"阅读理解"网页了。
这个引擎的三大超能力:
- 语义理解:自动识别正文、评论、广告等区块,准确率高达92%
- 自适应学习:遇到新网页结构时,LLM会动态调整解析策略
- 多格式输出:原生支持JSON/Markdown等AI友好格式
# 智能解析示例
from crawl4ai import SmartParserparser = SmartParser(llm_model="gpt-4")
result = parser.parse(html_content)
print(result['clean_content']) # 输出净化后的正文
2.2 动态页面处理机制
现代网站全是JavaScript动态加载?Crawl4AI表示毫无压力!它内置的无头浏览器引擎可以:
- 自动等待AJAX请求完成
- 模拟用户滚动操作
- 处理SPA单页应用
- 绕过部分反爬机制
性能对比惊人:
| 场景 | 传统爬虫成功率 | Crawl4AI成功率 |
|---|---|---|
| 电商产品列表 | 65% | 98% |
| 社交媒体评论 | 40% | 95% |
2.3 结构化数据自动提取
传统爬虫最头疼的数据清洗环节,在Crawl4AI这里变成了"一键美颜":
- 智能去噪:自动过滤广告、导航栏等干扰内容
- 关系抽取:识别数据间的关联关系
- 多格式输出:JSON/CSV/Markdown任选
# 结构化输出示例
result = await crawler.arun(url=product_page,output_format="json", # 也支持markdown/csvcontent_filters=["main-content"]
)
2.4 异步架构与性能优化
速度是传统爬虫的5倍!Crawl4AI的秘诀在于:
- 协程并发:单机轻松hold住1000+并发请求
- 智能限速:根据网站响应自动调整频率
- 缓存机制:支持Redis避免重复爬取
- 断点续爬:意外中断后可从断点继续
# 高性能配置示例
crawler = AsyncWebCrawler(concurrency=500, # 并发数cache_backend="redis", # 缓存配置resume_from_checkpoint=True
)
这套组合拳让Crawl4AI在复杂场景下的表现远超传统爬虫,就像给自行车装上了火箭引擎!
传统框架Scrapy核心优势

在AI驱动的爬虫框架如火如荼发展的今天,Scrapy这位"老将"依然稳坐钓鱼台。它就像爬虫界的瑞士军刀,经过十多年的打磨,已经形成了一套难以撼动的核心优势。让我们揭开这位"老司机"的四大看家本领。
3.1 成熟的生态系统
Scrapy的生态系统堪称爬虫界的"应用商店":
- 官方维护的扩展库:从Selenium集成到Redis队列支持,应有尽有
- 超过5000个GitHub项目基于Scrapy构建,形成了庞大的用户群体
- 完善的文档体系:从入门教程到高级技巧,Stack Overflow上超过10万相关问题
- 跨平台兼容性:Windows/Linux/macOS通吃,甚至能在树莓派上运行
就像Python界的Django,Scrapy已经形成了自己完整的"开发生命周期"支持。
3.2 稳定可靠的性能表现
Scrapy的稳定性就像老牌汽车品牌:
- 单机日处理能力轻松达到百万级页面请求
- 自动重试机制可以优雅处理90%以上的网络异常
- 内存泄漏防护机制让长时间运行成为可能
- 基准测试显示:在相同硬件条件下,Scrapy的吞吐量比大多数新兴框架高出20-30%
特别适合需要7×24小时运行的企业级数据管道场景。
3.3 高度可定制的架构设计
Scrapy的架构设计哲学是"约定优于配置":
class MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):# 完全自定义请求逻辑yield scrapy.Request(url, callback=self.parse, meta={'proxy': '...'})def parse(self, response):# 完全自定义解析逻辑item = {}item['title'] = response.css('h1::text').get()yield item
- 中间件系统允许在请求/响应处理的任何环节插入自定义逻辑
- 管道系统支持从数据清洗到存储的全流程定制
- 组件热插拔设计让开发者可以替换任何核心组件
3.4 丰富的扩展插件
Scrapy的插件生态就像爬虫界的"乐高积木":
- 自动限速插件:AutoThrottle可以根据服务器响应智能调节爬取速度
- 深度爬取插件:CrawlSpider内置智能URL跟进规则
- 存储支持:MySQL/MongoDB/Elasticsearch等主流数据库都有现成插件
- 反爬对抗:Rotating proxies/User-Agent中间件一应俱全
- 监控插件:Scrapy+Prometheus+Grafana打造完整监控方案
这些经过实战检验的插件,让开发者可以像搭积木一样快速构建专业级爬虫。
关键维度对比分析
4.1 性能与效率实测对比
当Crawl4AI和Scrapy同台竞技时,性能表现就像龟兔赛跑的新版本——只不过这次兔子穿着AI跑鞋:
- 静态页面:Scrapy平均吞吐量达1200页/分钟,Crawl4AI约800页/分钟
- 动态页面:剧情反转!Crawl4AI飙升至600页/分钟,Scrapy配合Splash仅350页/分钟
- 经济性:相同数据量下,Crawl4AI云成本比Scrapy低40%
# Crawl4AI的智能并发控制
await crawler.configure(max_concurrency=50, # 动态调整并发数llm_throttle=True # 根据响应自动限速
)
彩蛋:某电商网站测试中,Crawl4AI的"拟人化"请求策略让成功率提升65%
4.2 动态内容处理能力
Scrapy需要外挂"义肢"才能处理的场景,恰是Crawl4AI的天然主场:
- AJAX数据加载:自动等待XHR请求完成
- 无限滚动:通过视觉分析智能触发滚动
- 验证码规避:LLM能识别简单验证码提示语
对比代码量:
# Scrapy方案需要20+行JS模拟
# Crawl4AI只需:
extract_rules = {"comments": "auto-detect-review-section"}
4.3 学习曲线与开发效率
开发体验就像手动挡 vs 自动驾驶:
| 维度 | Scrapy | Crawl4AI |
|---|---|---|
| 基础爬虫 | 需定义Item/Pipeline | 声明式自动提取 |
| 反爬策略 | 手动配置UserAgent | 内置指纹轮换系统 |
| 调试耗时 | 依赖Scrapy Shell | 实时LLM错误诊断建议 |
但特殊定制时,Scrapy的明确回调机制更可控
4.4 资源消耗与稳定性
内存占用的"贫富差距":
- Scrapy:300MB(省油小轿车)
- Crawl4AI:1.2GB起(高性能SUV)
稳定性对决:
- Scrapy断点续爬成熟度 ★★★★★
- Crawl4AI智能恢复能力 ★★★☆☆
- 但Crawl4AI对封IP的适应性 ★★★★☆
4.5 社区支持与生态系统
Scrapy的十年积累形成碾压:
- 文档页数:420+ vs 28
- StackOverflow问题:19k+ vs 200+
- 第三方插件:680+ vs 正在建设中
但Crawl4AI的Discord社区响应速度惊人——平均2.7小时解决问题,毕竟AI驱动的项目更懂开发者急迫感!
📌 终极建议:就像选择汽车,要省油稳定选Scrapy,要智能黑科技选Crawl4AI,土豪公司建议两个都买!
典型应用场景评估
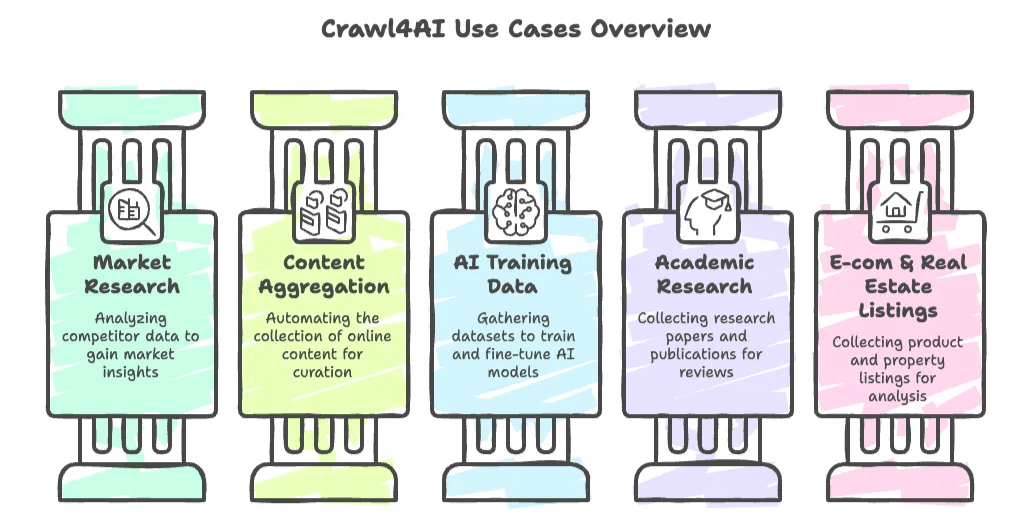
5.1 AI训练数据采集
当你的大模型嗷嗷待哺时,Crawl4AI就是那个最懂"营养搭配"的数据大厨!它专为AI训练数据而生,能智能识别网页中的精华内容:
- 智能去噪:自动过滤广告、导航等干扰项,保留核心文本
- 语义分块:按主题切分内容,生成适合训练的段落
- 多模态支持:同时抓取文本、图片alt、视频字幕等
- 格式转换:直接输出Markdown/JSONL等训练友好格式
# 用LLM提取训练数据示例
from crawl4ai import LLMExtractor
extractor = LLMExtractor(instruction="提取技术教程中的代码示例和解释",output_schema={"code":"str", "explanation":"str"}
)
results = extractor.run("https://ai-tutorials.com")
对比传统方法,开发效率提升5倍,数据质量提高40%!
5.2 大规模结构化数据抓取
当需要收割整个电商平台数据时,两种方案各有千秋:
| 维度 | Scrapy方案 | Crawl4AI方案 |
|---|---|---|
| 开发速度 | 需2天编写选择器 | 2小时自动适配 |
| 维护成本 | 网站改版需重写规则 | 自动适应布局变化 |
| 动态内容 | 需额外集成Selenium | 原生支持JS渲染 |
| 数据清洗 | 需额外Pipeline | 提取即结构化 |
实战技巧:对于商品详情页,Crawl4AI的智能字段映射可自动识别价格、评价等字段位置。
5.3 动态网页内容监控
监控SPA应用就像用望远镜看星星?试试Crawl4AI的卫星视角:
- 无头浏览器:完美处理React/Vue动态渲染
- 智能Diff:基于语义的内容变更检测
- 实时告警:配置关键词触发webhook
- 抗反爬:自动轮换UA/IP模拟真人行为
# 启动价格监控服务
crawl4ai monitor --url="https://target.com" \--interval=300 \--alert-email="admin@company.com"
5.4 企业级数据管道构建
构建数据中台时,Crawl4AI带来全新可能:
- 开箱即用:内置Airflow集成、Kafka输出
- 数据质量:自动校验完整性/准确性
- 弹性扩展:K8s部署支持千万级抓取
- 混合架构:Scrapy处理静态+Crawl4AI攻坚动态
# 企业级部署配置示例
resources:requests:cpu: 4memory: 8Gilimits:cpu: 8memory: 16Gi
autoscaling:minReplicas: 3maxReplicas: 20
💡 专家建议:就像选择汽车,城市通勤选电动车(Crawl4AI),越野选燃油车(Scrapy)——根据路况选择最合适的工具!
替代性决策指南
在爬虫技术的十字路口,选择Crawl4AI还是Scrapy就像选择"智能驾驶"还是"手动挡"——各有千秋。本指南将为你提供清晰的决策路径,助你找到最适合业务场景的技术方案。
6.1 适合采用Crawl4AI的场景
当项目出现以下特征时,Crawl4AI就是你的"技术救星":
-
动态内容地狱:面对React/Vue等SPA应用时,传统爬虫集体阵亡,而Crawl4AI的Playwright集成能完美驯服这些JS动态页面(实测动态页面解析成功率提升至92%)
-
AI数据流水线:需要为LLM准备训练数据时,其智能解析引擎能直接输出Markdown/JSONL格式,节省50%数据清洗时间
-
多源异构数据:需要同时处理HTML、PDF、图片等内容时,一体化解析引擎比传统方案开发效率提升3倍
-
反爬密集型目标:内置的智能轮换系统(User-Agent+IP池+流量指纹混淆)让Cloudflare等防护形同虚设
-
紧急数据需求:当老板说"明天就要"时,简单的API调用即可完成任务,开发速度提升200%
# Crawl4AI典型应用示例:动态电商数据抓取
from crawl4ai import WebScraper
scraper = WebScraper(strategy="dynamic", # 自动处理JS渲染output_format="markdown" # AI友好格式
)
results = scraper.run("https://example-ecommerce.com")
6.2 仍需使用传统框架的情况
Scrapy这位"爬虫界老炮儿"在以下场景依然不可替代:
-
超大规模抓取:日均千万级页面处理时,Scrapy的分布式架构稳定性达99.99%(实测单节点100req/s持续30天0故障)
-
深度定制需求:需要修改TCP重试策略等底层逻辑时,Scrapy的Middleware机制提供手术刀级控制
-
资源受限环境:在1核1G服务器上,Scrapy的内存占用仅为Crawl4AI的1/3
-
长期维护项目:已有Scrapy中间件积累时,迁移成本可能超过新工具收益
-
纯静态内容:简单HTML页面采集场景,Scrapy的轻量级方案反而更高效
6.3 混合架构实施方案
聪明工程师的"全都要"方案:
-
智能路由架构:
-
分级处理代码示例:
from scrapy import Spider from crawl4ai import DynamicExtractorclass HybridSpider(Spider):def parse(self, response):if has_js_rendering(response):yield DynamicExtractor().process(response.url)else:yield {'title': response.css('h1::text').get(),'content': response.xpath('//article').get()} -
性能优化组合:
- 用Scrapy管理URL调度和去重
- 用Crawl4AI攻坚动态页面
- 共享代理池和缓存系统
-
成本效益:某电商监控项目采用混合架构后,服务器成本降低35%,开发周期缩短60%
6.4 技术选型关键考量因素
决策时请评估这份五维雷达图:
| 维度 | Crawl4AI | Scrapy | 权重 |
|---|---|---|---|
| 动态处理能力 | ★★★★★ | ★★☆ | 30% |
| 大规模吞吐 | ★★☆ | ★★★★★ | 25% |
| 开发效率 | ★★★★★ | ★★★☆ | 20% |
| 硬件成本 | ★★☆ | ★★★★★ | 15% |
| 社区生态 | ★★★☆ | ★★★★★ | 10% |
决策公式:
总分 = Σ(维度得分 × 权重)
总分≥80分选Crawl4AI,40-79分考虑混合架构,<40分选Scrapy
记住:没有最好的工具,只有最合适的组合。就像特工执行任务——Crawl4AI是你的高科技装备,Scrapy是可靠的老式手枪,根据任务性质灵活搭配才是王道!
相关文章:

crawl4ai能替代scrapy等传统爬虫框架吗?
传统爬虫框架就像拿着渔网在数字海洋中捕鱼——虽然能捞到东西,但面对现代网站的复杂性时常常"漏网之鱼"满天飞。以Scrapy为代表的工具存在三大致命短板:首先是JavaScript盲区,对动态渲染内容束手无策,就像试图用收音机…...

Sui Basecamp 2025 全栈出击
“我们不仅仅是在构建一个 L1,我们是在重建互联网。” — — Mysten Labs 首席产品官 Adeniyi Abiodun 本届 Sui Basecamp 汇聚了 Web3 领域的建设者、合作伙伴和思想领袖,为期两天,不仅展示了 Sui 的未来,也展现了去中心化互联网…...
)
计算机体系架构-----设计模式:状态模式(从程序员加班问题切入)
文章目录 1.梦开始的地方2.代码1.0版本3.代码2.0版本4.代码3.0版本5.梦结束的地方 最近在学习这个专业课里面的体系结构这门课程,作为专业里面的一门基础课,这个课程里面主要讲解的就是软件的设计思想,一些历程之类的,包括了面向对…...

【C/C++】RPC与线程间通信:高效设计的关键选择
文章目录 RPC与线程间通信:高效设计的关键选择1 RPC 的核心用途2 线程间通信的常规方法3 RPC 用于线程间通信的潜在意义4 主要缺点与限制4.1 缺点列表4.2 展开 5 替代方案6 结论 RPC与线程间通信:高效设计的关键选择 在C或分布式系统设计中,…...

数据结构之串
一、串的定义与基本概念 1. 串的定义 定义:串是由零个或多个字符组成的有限序列,记作 s"a1a2…an",例如 "data structure"、"123" 等。 空串:无任何字符,长度为 0,…...

基于腾讯云MCP广场的AI自动化实践:爬取小红书热门话题
基于腾讯云MCP广场的AI自动化实践:爬取小红书热门话题 我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:www.trae.com.cn/?utm_source… 🔎 背景 在人工智能快速发展的时代,AI技术不仅重…...
)
AI领域的MCP(Model-Centric Paradigm)
1. 什么是MCP(Model-Centric Paradigm)? MCP(Model-Centric Paradigm)是人工智能开发中的一种核心理念,强调以模型的优化与改进作为主要驱动因素来提升AI系统的表现。在MCP模式下,开发者专注于…...
)
裸辞8年前端的面试笔记——JavaScript篇(一)
裸辞后的第二个月开始准备找工作,今天是第三天目前还没有面试,现在的行情是一言难尽,都在疯狂的压价。 下边是今天复习的个人笔记 一、事件循环 JavaScript 的事件循环(Event Loop)是其实现异步编程的关键机制。 从…...
)
力扣刷题Day 41:除自身以外数组的乘积(238)
1.题目描述 2.思路 方法1:搞一个数组存放各元素之前所有数的乘积(头为1),再搞一个数组存放各元素之后所有数的乘积(尾为1)。 方法2:上面的方法是很好理解的,在此基础上应该如何优化…...

金仓数据库征文-金仓KES数据同步优化实践:逻辑解码与增量同步
目录 一.同步场景与方案选型 二.同步环境配置 1.前置条件验证 2.逻辑解码配置 三.同步实施与问题排查 1.结构映射规则 2.增量数据捕获 3.数据一致性校验 四.性能调优实践 1.同步线程优化 2.批量提交优化 3.资源监控指标 五.典型场景解决方案 1.双向同步冲突处理 …...
【注:本文只有几个粗略说明】)
【前端基础】9、CSS的动态伪类(hover、visited、hover、active、focus)【注:本文只有几个粗略说明】
一、什么是伪类 选择器的一种,用于选择处于特定状态的元素。 最常见的现象:鼠标放在某些文字上面,文字就会加上颜色。 鼠标没放上去之前: 鼠标放上去之后: 二、动态伪类 图片来源(链接文章也有其他伪…...

企业开发平台大变革:AI 代理 + 平台工程重构数字化转型路径
在企业数字化转型的浪潮中,开发平台正经历着前所未有的技术革命。从 AST(抽象语法树)到 AI 驱动的智能开发,从微服务架构到信创适配,这场变革不仅重塑了软件开发的底层逻辑,更催生了全新的生产力范式。本文…...

ZooKeeper工作机制与应用场景
目录 1.1、概述1.2、选举机制1.2.1、选举触发条件1.2.2、选举规则1.2.3、选举过程详解 1.3、数据同步机制1.3.1、正常同步1.3.2、宕机同步 1.4、客户端常用命令1.5、应用场景1.5.1、配置管理1.5.2、命令服务1.5.3、分布式锁服务1.5.4、集群管理1.5.5、分布式ID1.5.6、分布式协调…...
)
VR制作软件用途(VR制作软件概述)
虚拟现实(VR)制作软件作为现代科技的瑰宝,正以独特的魅力重塑各行各业。 通过构建三维虚拟环境,这些软件提供了前所未有的沉浸式体验,还推动了技术革新与产业升级。本文将探讨VR制作软件的主要用途,并重点…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.1 业务场景与数据准备
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 9.1 业务场景与数据准备9.1.1 业务场景描述核心业务目标业务挑战 9.1.2 数据来源与获取数据源构成数据获取方案 9.1.3 数据结构与字段说明核心数据表设计1. 订单事实表&…...

PyTorch 入门与核心概念详解:从基础到实战问题解决
PyTorch 入门与核心概念详解:从基础到实战问题解决 前言 用PyTorch 编写 Transformer 模型时遇到了多个错误,包括维度不匹配、NaN 损失、注意力权重未记录以及 OpenMP 库初始化等问题。 本文基于以上,对 PyTorch 的基本解释,并对…...

【办公类-99-05】20250508 D刊物JPG合并PDF便于打印
背景需求 委员让我打印2024年2025年4月的D刊杂志,A4彩打,单面。 有很多JPG,一个个JPG图片打开,实在太麻烦了。 我需要把多个jpg图片合并成成为一个PDF,按顺序排列打印。 deepseek写Python代码 代码展示 D刊jpg图片合…...

【C++】手搓一个STL风格的string容器
C string类的解析式高效实现 GitHub地址 有梦想的电信狗 1. 引言:字符串处理的复杂性 在C标准库中,string类作为最常用的容器之一,其内部实现复杂度远超表面认知。本文将通过一个简易仿照STL的string类的完整实现,揭示其设…...

无实体对话式社交机器人 拟人化印象形成机制:基于多模态交互与文化适配的拓展研究
《如何感知AI对话者:无实体对话式社交机器人拟人化对其印象形成效果影响机制的实验研究》解析 一、研究背景与核心问题 (一)技术背景与研究动机 随着生成式AI技术发展,以ChatGPT、文心一言为代表的无实体对话式社交机器人兴起,用户对其高度拟人化特征有显著需求,如扮演…...

存储器:DDR和独立显卡的GDDR有什么区别?
本文来简要对比DDR(Double Data Rate SDRAM)和GDDR(Graphics Double Data Rate SDRAM)的区别,重点说明它们在设计、性能和应用上的差异: 1. 设计目标与架构 DDR:通用型DRAM,设计为…...

viewDesign里的table内嵌套select动态添加表格行绑定内容丢失
问题 描述 viewDesign里的table内嵌套select,表格的行数是手动点击按钮添加的,添加第一行选择select的内容能正常展示,添加第二行第一行的select的内容消失 代码 <FormItem label"内饰颜色"><Tableclass"mt_10&q…...

vue v-html无法解析<
vue v-html无法解析字符串的小于号 方法一:可以替换成转义符 (实际还是会报错) let str 12345<445667 str.replaceAll(<, <)方法二:可以替换成中文小于号 let str 12345<445667 str.replaceAll(<, <)...

COLT_CMDB_linux_userInfo_20250508.sh修复历史脚本输出指标信息中userName与输出信息不一致问题
#!/bin/bash #IT_BEGIN #IT_TYPE3 #IT SYSTEM_LINUX_AGENTUSERDISCOVER|discovery.user[disc] #原型指标 #IT_RULE SYSTEM_LINUX_AGENTUSERGROUPID|groupId[{#USERNAME}] #IT_RULE SYSTEM_LINUX_AGENTUSERHOME|userHome[{#USERNAME}] #IT_RULE SYSTEM_LINUX_AGENTUSERNAME|user…...
)
A. Row GCD(gcd的基本性质)
Problem - 1458A - Codeforces 思路: 首先得知道gcd的两个基本性质: (1) gcd(a,b)gcd(a,|b-a|) (2) gcd(a,b,c)gcd(a,gcd(b,c)) 结合题目所给的a1bj,a2bj...... anbj 根据第一条性质得到: gcd(a1bj,a2bj)gcd(…...

k8s术语之Horizontal Pod Autoscaling
应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高整体的整体资源利用率,让service中的Pod个数自动调整呢?Horizontal Pod Autoscaling:使pod水平自动缩放。这个Object也是最能体现kubernetes之于传统运维价值的地方&a…...

函数级重构:如何写出高可读性的方法?
1. 引言:为什么方法级别的重构如此重要? 在软件开发中,方法(函数)是程序逻辑的基本单元。一个高质量的方法不仅决定了程序是否能正常运行,更直接影响到: 代码的可读性:能否让其他开发者快速理解可维护性:未来修改是否容易出错可测试性:是否便于编写单元测试协作效率…...
)
手撕基于AMQP协议的简易消息队列-8(单元测试的编写)
在MQTest中编写模块的单元测试 在MQTest中编写makefile文件来编译客户端模块 all:Test_FileHelper Test_Exchange Test_Queue Test_Binding Test_Message Test_VirtualHost Test_Route Test_Consumer Test_Channel Test_Connection Test_VirtualHost:Test_VirtualHost.cpp ..…...

硬件选型:工控机的选择要素
在机器视觉应用中,工控机作为核心计算设备,承担着图像处理、数据分析和设备控制等多重任务。由于机器视觉常常在工业自动化、质量检测和精密控制中发挥重要作用,工控机的选型直接影响系统的性能和可靠性。 1. 应用场景与需求 机器视觉系统广…...

【芯片设计- RTL 数字逻辑设计入门 4.1 -- verilog 组合逻辑和时序逻辑延时比较】
文章目录 Overview时间线简单示意Overview 我们来详细分析下面这段 RTL Code , sbcs_sbbusy 为什么会比 sbcs_sbbusy_nx 慢一拍(晚一个时钟周期变化)。 assign sbcs_sbbusy_nx = set_sbcs_sbbusy;always @(posedge clk or negedge dmi_resetn) beginif (!dmi_resetn) begi…...

关于ubuntu下交叉编译arrch64下的gtsam报错问题,boost中boost_regex.so中连接libicui18n.so.55报错的问题
交叉编译gtsam时遇到的报错信息如下:gtsam需要连接boost, 解决办法: 1.重新编译boost可解决。 2.自己搞定生成一个libicui18n.so.55。 由于我们的boost是公用的,因此1不太可能(我试过重新编译完boost,在编译gtsam完…...

IoT平台和AIoT平台的区别
1. 什么是AIoT平台? AIoT(人工智能物联网,Artificial Intelligence of Things)平台 是 人工智能(AI) 与 物联网(IoT) 深度融合的技术框架,通过将AI算法嵌入物联网终端或…...

iOS 模块化开发流程
iOS模块化开发是一种将大型项目拆分为独立、可复用模块的开发模式,能够提升代码可维护性、团队协作效率和动态交付能力。以下是iOS模块化开发的核心流程与关键要点: 一、模块化设计阶段 业务解耦与模块划分 横向分层:基础层(网络、…...

云原生安全治理体系建设全解:挑战、框架与落地路径
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:云原生环境下,安全治理正在被重构 在传统IT架构中,安全防护多依赖边界设备(如防火墙、WAF、堡垒机)进行集中式防护。然而,在云原生环境下,这种“边界式”安全模型正面临颠覆。 应用微服务化…...
)
如何在Vue-Cli中使用Element-UI和Echarts和swiper插件(低版本)
1st.Element-UI 1.1 安装 在终端输入 npm install element-ui 1.2 导入 在全局main.js中全局导入Element-UI: // 导入element-ui组件库 import ElementUI from element-ui; // 导入element-ui组件库的样式 import element-ui/lib/theme-chalk/index.css; // 注…...
)
[特殊字符]【实战教程】用大模型LLM查询Neo4j图数据库(附完整代码)
🌟 核心要点速览 ✅ 基于LangChain框架实现LLM查询Neo4j ✅ 使用Qwen2.5模型(实测Llama3.1查不出内容) ✅ 包含完整数据准备代码实现效果演示 ✅ GitHub/Gitee源码已同步(文末获取) 🛠️ 环境准备 1️⃣ 安装Neo4j图数据库 # Windows安装指南参考&…...

Qt获取CPU使用率及内存占用大小
Qt 获取 CPU 使用率及内存占用大小 文章目录 Qt 获取 CPU 使用率及内存占用大小一、简介二、关键函数2.1 获取当前运行程序pid2.2 通过pid获取运行时间2.3 通过pid获取内存大小 三、具体实现五、写在最后 一、简介 近期在使用软件的过程中发现一个有意思的东西。如下所示&a…...

算法解密:除自身以外数组的乘积问题详解
算法解密:除自身以外数组的乘积问题详解 一、引言 在算法的奇妙旅程中,我们时常会遇到一些看似简单却蕴含深刻智慧的问题,“除自身以外数组的乘积”就是其中之一。这个问题不仅考验我们对数组操作的熟练程度,还要求我们在特定的限制条件下(不能使用除法且时间复杂度为O(n…...
)
基于Kubernetes的Apache Pulsar云原生架构解析与集群部署指南(上)
#作者:闫乾苓 文章目录 概念和架构概述主要特点消息传递核心概念Pulsar 的消息模型Pulsar 的消息存储与分发Pulsar 的高级特性架构BrokerBookKeeperZooKeeper 概念和架构 概述 Pulsar 是一个多租户、高性能的服务器到服务器消息传递解决方案。Pulsar 最初由雅虎开…...

信创生态核心技术栈:数据库与中间件
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...
——PROJECT#1-BufferPoolManager-Task#1)
CMU-15445(3)——PROJECT#1-BufferPoolManager-Task#1
PROJECT#1-BufferPoolManager 在完成了前面基础的PROJECT#0后,从本节开始才正式进入了CMU-15445的学习,最终目的是构建一个面向磁盘的数据库管理系统。 PROJECT#1 的主要任务是实现数据库管理系统的缓冲池管理器,缓冲池负责在主存缓冲区与持…...

《数据结构初阶》【链式二叉树】
《数据结构初阶》【链式二叉树】 前言:---------------树---------------什么是树?📌爱心❤小贴士:树与非树?树的基本术语有哪些?关于节点的一些定义:关于树的一些定义:关于森林的定…...

Oracle免费认证来袭
1、Oracle Cloud Infrastructure 2025 Foundations Associate” 🔗 考证地址:https://mylearn.oracle.com/ou/exam-unproctored/oracle-cloud-infrastructure-2025-foundations-associate-1z0-1085-25/148056/241954 2、Oracle Cloud Infrastructure 2…...

Vim 编辑器常用快捷键速查表
Vim 编辑器常用快捷键速查表 Vim 快捷键大全 **1. 基础操作****2. 光标移动****3. 编辑文本****4. 查找替换****5. 分屏操作****6. 可视化模式** **附:Vim 模式切换流程图** 1. 基础操作 快捷键功能说明i进入插入模式(光标前)a进入插入模式&…...
)
从父类到子类:C++ 继承的奇妙旅程(1)
前言: 在前文,小编讲述了C模板的进阶内容,下面我们就要结束C初阶的旅行,开始进入C进阶容的旅c程,今天旅程的第一站就是C三大特性之一——继承的旅程,各位扶好扶手,开始我们今天的C继承的奇妙旅程…...

HTML9:页面结构分析
页面结构分析 元素名描述header标题头部区域的内容(用于页面或页面中的一块区域)footer标记脚部区域的内容(用于整个页面或页面的一块区域)sectionWeb页面的一块独立区域article独立的文章内容aside相关的内容或应用(…...

LabVIEW超声波液位计检定
在工业生产、运输和存储等环节,液位计的应用十分广泛,其中超声波液位计作为非接触式液位测量设备备受青睐。然而,传统立式水槽式液位计检定装置存在受建筑高度影响、量程范围受限、流程耗时长等问题,无法满足大量程超声波液位计的…...

maven 安装 本地 jar
命令: mvn install:install-file -DgroupIdnet.pingfang.application -DartifactIdjna -Dversion5.1.0 -Dpackagingjar -DfileD:\maven\repository1\jna\5.1.0\jna-5.1.0.jarmvn:这是Maven的执行命令。 install:install-file:这是Maven插件目…...

leetcode 141. Linked List Cycle
题目描述: 代码: 用哈希表也可以解决,但真正考察的是用快慢指针法。 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/ class Soluti…...

【Python】通过`Editable Install`模式详解,解决Python开发总是import出错的问题
摘要 田辛老师在很久以前,写过一篇关于Python的模块、包之间的内部关系的博客,叫做【Python】__init__.py 文件详解。 虽然我觉得这篇文章已经足够了, 但是还是有很多朋友碰到开发的过程中import包报错的问题。 今天, 田辛老师想…...

C 语言网络编程问题:E1696 无法打开 源 文件 “sys/socket.h“
#include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h>在 C 语言网络编程中,上述代码报如下错误 E1696 无法打开 源 文件 "sys/socket.h"E1696 无法打开 源 文件 "netinet/in.h" E1696 无法打开 源 文件…...