CMU-15445(3)——PROJECT#1-BufferPoolManager-Task#1
PROJECT#1-BufferPoolManager
在完成了前面基础的PROJECT#0后,从本节开始才正式进入了CMU-15445的学习,最终目的是构建一个面向磁盘的数据库管理系统。
PROJECT#1 的主要任务是实现数据库管理系统的缓冲池管理器,缓冲池负责在主存缓冲区与持久化存储(硬盘)之间来回移动数据的物理页(虚拟内存通过内存交换实现运行内存超过物理内存的大小),同时充当缓存 —— 将频繁使用的页面保留在内存中以加快访问速度,并将未使用或不活跃的页面淘汰回存储设备。
在操作系统中,如果虚拟内存采取内存分页的方式进行管理,那么通常会将整个物理内存通过单位页进行划分,单位页的大小是 4KB,因此本节的缓冲池管理器也同样以 4KB 为单位管理数据。由于 BusTub 中的页大小固定,缓冲池管理器将这些页存储在称为帧的固定大小缓冲区中。
- 页是 4 KB 的逻辑(虚拟)数据,可存储在内存、磁盘或同时存在于两者中;
- 帧是固定长度的 4 KB 内存块(即指向该内存的指针),用于存储单个页的数据,只能存在于内存中。
二者的关系可类比为将(逻辑)页存储在(物理)固定大小的帧中。缓冲池管理器通过帧来管理内存中的页 —— 当需要访问磁盘上的页时,会将页的数据加载到某个空闲的帧中(类似把书从仓库搬到书桌的格子里),方便快速访问。
举个例子:
- 当数据库需要处理一个页时(比如查询某条数据),缓冲池管理器会先检查该页是否已在某个帧中(即是否在内存里):
- 如果在,直接使用帧中的数据(快速访问);
- 如果不在,从磁盘读取该页的数据,放入一个空闲的帧中(类似从仓库搬书到书桌的格子)。
- 当内存不够时,缓冲池会根据策略(如 LRU)淘汰某些帧中的页(把书从格子里放回仓库),腾出空间给新的页。
除了能作为缓存,缓冲池管理器使数据库管理系统能够支持容量超过系统可用内存的数据库,主要就是利用虚拟内存的思想。
操作系统本身就有缓存机制,为什么DBMS还需要使用独立的 Buffer Pool?
形象点来说,数据库的缓冲池就像书店专属的高效展示区,能精准管理热销书、记录修改细节、优化取书流程,比商场共用区域更懂书店的生意(数据库的特殊需求),所以必须自己建而不是 “蹭” 公共区域。
缓冲池其实就是为了减少OS从磁盘进行IO的次数,当 DBMS 请求一个页时,该页的副本会被放入缓冲池的某个帧中,此后,当再次请求该页时,系统会先搜索缓冲池:若页存在于缓冲池中,则直接使用;若不存在,则从磁盘读取副本。如下图:
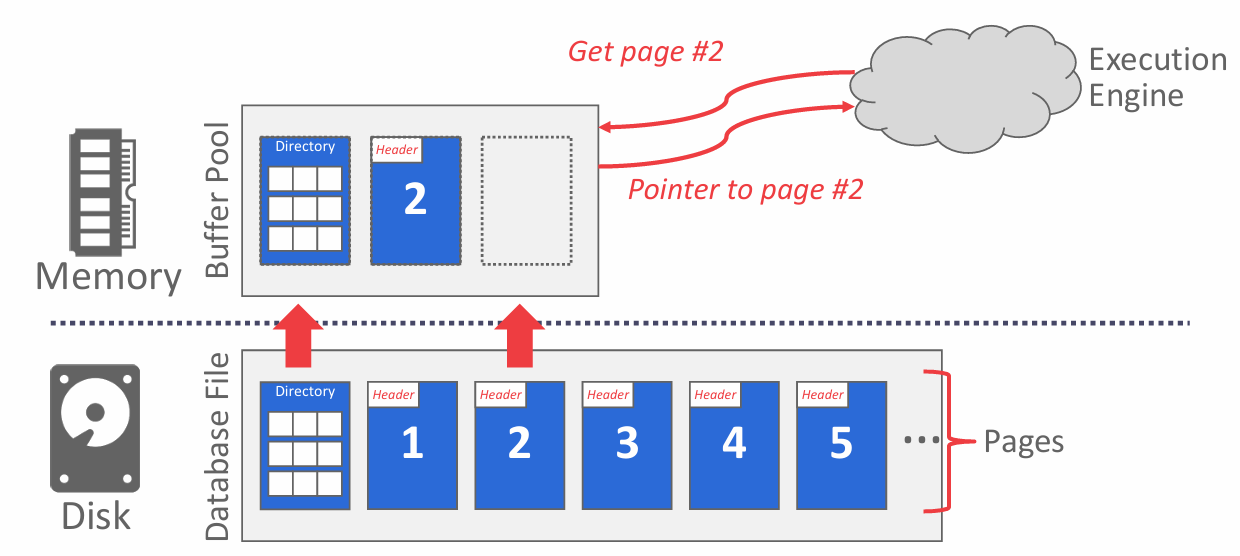
以上的介绍便是PROJECT#1的主要任务,主要通过以下三个TASK实现:
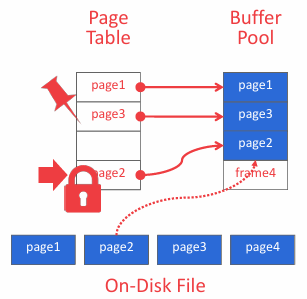
- LRU-K Replacement Policy
- Disk Scheduler
- Buffer Pool Manager
上图中的 Page Table(页表)通过哈希表实现,用于跟踪当前存在于内存中的页,将页 ID 映射到缓冲池中的帧位置(其实和虚拟内存中的页表一个思路,缓冲池的页表不应与页目录混淆,后者是页 ID 到数据库文件中页位置的映射)。LRU-K Replacement Policy 其实就是实现如何通过页表跟踪缓冲池并且记录页面的使用情况进行相应的淘汰过程。
Disk Scheduler 负责缓冲池和硬盘之间的读写,因为页表还维护了每页的额外元数据、dirty-flag 和 pin/reference counter,每当线程修改页面时,dirty-flag 都会由线程设置;且线程在访问页面之前必须递增计数器,如果页面的计数大于零,则不允许存储管理器从内存中淘汰该页面。这些步骤都是需要我们在 Disk Scheduler 实现的,并且需要保证线程安全。
上面两个 TASK 是主要内容的实现,Buffer Pool Manager 则是通过 LRU-K Replacement Policy 和 Disk Scheduler 从磁盘获取数据库页面,并将它们存储在内存中,必要时也可以安排将脏页写回磁盘。
每一个TASK在具体实现的时候介绍。
注意:缓冲池是多线程并发的组件,因此必须要保证线程安全问题,这里可以考虑使用互斥或者原子操作搭配内存序实现。
该课程的讲义ppt可通过以下链接获取:
Kangyupl/CMU15445-slide-and-note - 码云 - 开源中国
Task #1 - LRU-K Replacement Policy
LRU-K Replacement Policy 的任务总结起来就是负责跟踪缓冲池中页面的使用情况,以便在需要为新页面腾出内存空间时,确定应该将哪些页面 / 帧从内存中淘汰并写回到磁盘。
实现该 TASK 需要使用到以下文件:
src/include/buffer/lru_k_replacer.hsrc/buffer/lru_k_replacer.cpp
注意到文件 buffer 下有除 lru_k_replacer.cpp 外名为 lru_replacer.cpp 和 clock_replacer.cpp 的文件,很明显,缓冲区除了LRU-K 外还有 LRU、LFU以及clock 等 Replacement Policy,那为什么这里使用 LRU-K 取代 LRU和CLOCK呢?
LRU 和 LFU 其实是数据库常使用的一种策略,前者基于 “最近最少使用的页面在未来一段时间内也不太可能被使用” 这一假设,它会维护一个页面访问顺序的列表,每当一个页面被访问时,就将其移动到列表头部。当需要淘汰页面时,选择列表尾部(即最近最少使用)的页面进行淘汰。可以参考力扣的题解进行理解:【图解】一张图秒懂 LRU!
Clock 策略是 LRU 的一种近似算法,该策略为每个页面设置一个引用位,初始值为 0。当页面被访问时,引用位被置为 1。系统使用一个类似时钟指针的机制在页面列表中循环扫描,当扫描到一个页面时,如果其引用位为 1,则将其置为 0 并继续扫描;如果引用位为 0,则淘汰该页面。如下图所示:
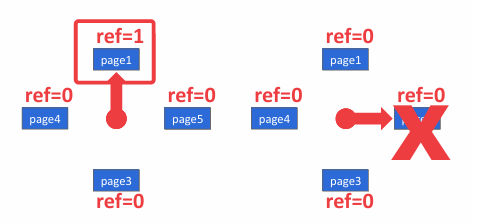
尽管这两种方式都有现有的实现方式,但二者均存在许多问题。比如二者很容易受到 sequential flooding 的影响,比如当进行一次大规模的顺序扫描时,会将大量近期不会再使用的页面加载到缓存中,挤掉原本可能会频繁使用的页面,导致缓存命中率下降。
举例说明:
-
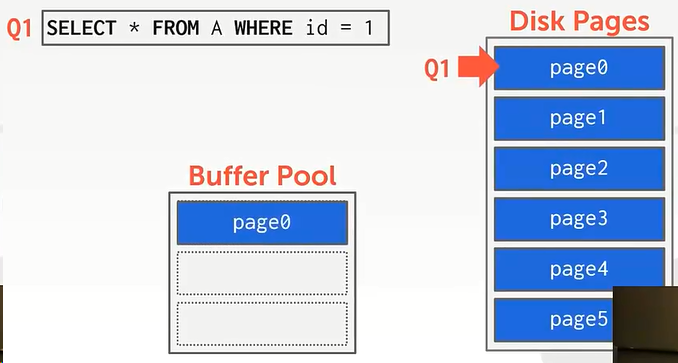
执行Q1,当id=0时,读取了page0,将page0换入到缓冲池:
-
接下来执行Q2,以此读取page1、page2、page3、page … …等等后面的page。

但是在想换入page3的时候,缓冲池空间不够了。如果使用的是LRU算法则会把page0换出。但是我们还要用page0,没有办法,page0只能不断的被换入换出,这样就降低了效率。
可通过以下三种方式解决该问题:
-
LRU-K,也就是在该PROJECT中实现的算法,其中 K 是针对单个页面(page)所对应的缓存数据,需要对其访问次数进行计数(若 K 取值为 2,那就意味着要统计每个页面的最近两次访问情况;若 K 为 3,就是统计最近三次的访问情况)。核心思路是将最近使用过1次的判断标准扩展为最近使用过 K 次,也就是说当某个页面的访问次数还没有达到 K 次时,该页面的访问记录不会被无限地记录下去,把这部分数据存放在一个 “历史队列” 中,临时存放访问次数较少、还不能确定其是否经常被使用的数据;一旦某个页面的访问次数达到了 K 次,就表明这个页面是比较频繁被使用的,是 “热点数据”,此时,会把该数据的索引从 “历史队列” 移动到 “缓存队列”。“缓存队列” 里存放的都是那些经常被访问的数据,当需要淘汰数据时,会优先从 “历史队列” 中选择数据进行淘汰(LRU),当“历史队列”中的数据淘汰完后,通过倒数第 K 次的访问时间与当前时间的距离作为其距离(替换权重)来选择性的将“缓存队列”中的数据淘汰。
举个例子来说,K=2,5个块的访问时间历史如下,时间从1开始,当前时间为12:
块1:1 块2:2 块3:3、6、9、11 块4:4、7、 块5:5、8、10由于访问次数不足K,块1与块2的LRU-K距离为正无穷(+inf);块 3的距离为12-9=3;块4的距离为12-4=8;块5的距离为:12-8=4。如果五个块均可以被替换,那么根据LRU-K算法,块1将最先被替换出去,接着被替换出去的是块2,然后依次是4、5、3。
-
多缓冲区
-
优先级
lru_k_replacer.h
头文件定义了 LRUKNode 和 LRUKReplacer 两个类,前者表示一个页面节点,存储页面的访问历史等信息;后者需要我们实现 LRU-K Replacement Policy,其实就是实现“历史队列”,存放那些使用频率不高的页用于淘汰。源代码如下:
namespace bustub {enum class AccessType { Unknown = 0, Lookup, Scan, Index };class LRUKNode {private:/** History of last seen K timestamps of this page. Least recent timestamp stored in front. */// Remove maybe_unused if you start using them. Feel free to change the member variables as you want.[[maybe_unused]] std::list<size_t> history_;[[maybe_unused]] size_t k_;[[maybe_unused]] frame_id_t fid_;[[maybe_unused]] bool is_evictable_{false};
};class LRUKReplacer {public:explicit LRUKReplacer(size_t num_frames, size_t k);DISALLOW_COPY_AND_MOVE(LRUKReplacer);/*** TODO(P1): Add implementation** @brief Destroys the LRUReplacer.*/~LRUKReplacer() = default;auto Evict() -> std::optional<frame_id_t>;void RecordAccess(frame_id_t frame_id, AccessType access_type = AccessType::Unknown);void SetEvictable(frame_id_t frame_id, bool set_evictable);void Remove(frame_id_t frame_id);auto Size() -> size_t;private:// TODO(student): implement me! You can replace these member variables as you like.// Remove maybe_unused if you start using them.[[maybe_unused]] std::unordered_map<frame_id_t, LRUKNode> node_store_;[[maybe_unused]] size_t current_timestamp_{0};[[maybe_unused]] size_t curr_size_{0};[[maybe_unused]] size_t replacer_size_;[[maybe_unused]] size_t k_;[[maybe_unused]] std::mutex latch_;
};} // namespace bustub
LRUKNode 类代表一个页面节点,存储页面的访问历史和状态信息。简单分析 LRUKNode 的成员信息:
class LRUKNode {private:[[maybe_unused]] std::list<size_t> history_;[[maybe_unused]] size_t k_;[[maybe_unused]] frame_id_t fid_;[[maybe_unused]] bool is_evictable_{false};
};
history_记录该页面最近 K 次访问的时间戳,最旧的时间戳存于列表头部,新时间戳通过push_back存于列表尾部k_明显是 K 值fid_表示缓冲区中帧的 idis_evictable_表示该帧是否可被淘汰
如果我们想要使用该类的某些成员,需要将
[[maybe_unused]]删除
虽然存在其他的策略,比如LRU和时钟,但我们这里仅需要实现LRU-K.同样分析一下 LRUKReplacer 的功能和成员:
[[maybe_unused]] std::unordered_map<frame_id_t, LRUKNode> node_store_;
[[maybe_unused]] size_t current_timestamp_{0};
[[maybe_unused]] size_t curr_size_{0};
[[maybe_unused]] size_t replacer_size_;
[[maybe_unused]] size_t k_;
[[maybe_unused]] std::mutex latch_;
私有成员如上,后续我们需要根据相应情况进行使用和增加。
node_store_是帧 ID 到LRUKNode的映射,其实就是页表Page Table,用于跟踪当前存在于内存中的页,将页映射到缓冲池中的帧位置。current_timestamp_当前的时间戳curr_size_当前可淘汰页的个数,也是size()的返回值,curr_size_在多线程情况下修改可能会造成资源竞争的问题,若使用互斥保护锁粒度过于大,这里可将其类型修改为std::atomic<size_t>,避免资源竞争。replacer_size_表示缓冲池帧的的总上限
分析一下公有函数:
-
explicit LRUKReplacer(size_t num_frames, size_t k):构造函数,以缓冲池的帧数num_frames和K值k作为参数,并且使用宏DISALLOW_COPY_AND_MOVE禁止了LRUKReplacer的拷贝和移动,详细定义如下:#define DISALLOW_COPY(cname) \cname(const cname &) = delete; /* NOLINT */ \auto operator=(const cname &)->cname & = delete; /* NOLINT */#define DISALLOW_MOVE(cname) \cname(cname &&) = delete; /* NOLINT */ \auto operator=(cname &&)->cname & = delete; /* NOLINT */#define DISALLOW_COPY_AND_MOVE(cname) \DISALLOW_COPY(cname); \DISALLOW_MOVE(cname);DISALLOW_COPY_AND_MOVE中结合了DISALLOW_COPY和DISALLOW_MOVE,将给定类的拷贝和移动构造函数和运算符主动delete,仅可以通过公有的构造函数在定义。因为我们使用的是单缓冲池,我们可以使用单例模式优化,将构造函数私有化,避免资源浪费;但是在多缓冲池下就不要使用单例模式了。
-
Evict() -> std::optional<frame_id_t>:淘汰与LRUKReplacer所追踪的其他所有可淘汰帧相比,反向 k 距离最大的帧。若没有可淘汰的帧,则返回std::nullopt。其实就是将“历史队列”中最久未被使用的页淘汰出去。 -
RecordAccess(frame_id_t frame_id):记录给定的帧在当前时间戳已被访问。在缓冲池管理器中固定一个页面后,应调用此方法。其实就是将当前的时间戳存储到给定帧id对应页的history_中,从而记录每次访问的时间戳,进而辅助计算反向 K 距离。 -
Remove(frame_id_t frame_id):清除与一个帧相关的所有访问历史。其实就是当一个页不再需要时,删除与之管理的访问信息,从node_store_删除与frame_id对应的条目,避免无效的访问历史记录干扰 LRU - K 替换策略的决策。Evict 和 Remove 看起来作用很相似,但有很大差别:
Remove:只有在缓冲池管理器中删除一个页面时才会被调用。删除页面的原因可能有很多,比如用户显式删除了某个数据,或者系统进行了一些清理操作等Evict:当缓冲池已满,需要加载新的页面但没有可用的空闲帧时会被调用。此时,Evict方法会根据 LRU-K 选择一个最合适的帧将其中的页数据淘汰到硬盘,以腾出空间来加载新的页面
很明显,前者就是真实删除,该页的数据不再被需要,不仅需要从缓冲区的帧中将该页删除,同时也需要将
LRUKReplacer中记录的信息删除,维护LRUKReplacer中数据的一致性和有效性,避免无效的访问历史记录干扰LRU - K替换策略的决策。而后者的目的是解决缓冲池空间不足的问题,将一个不常用的页面淘汰到磁盘,为新的页面腾出内存空间,保证系统的正常运行,该页的数据并没有被删除,而是暂时移动到了硬盘中。
此外,
Evict()是将反向K距离最大的页淘汰,而Remove是将给定帧id对应的页淘汰,无论它的反向K距离是多少。 -
SetEvictable(frame_id_t frame_id, bool set_evictable):用于控制一个帧是否可被淘汰,同时也会控制LRUKReplacer的大小。其实就是当一个页面的固定计数变为 0 时,将其对应的帧应标记为可淘汰。 -
Size() -> size_t:返回当前LRUKReplacer中可淘汰帧的数量,大小是动态的,其返回值等于当前所有is_evictable_ = true的帧的数量,只有可淘汰的帧才会被纳入 “淘汰候选集”,不可淘汰的帧(如正在被使用的帧)不会被Evict ()方法考虑。
LRUKReplacer 的最大容量与缓冲池的大小相同,包含了缓冲池管理器中所有帧的占位符,无论该帧当前是否可被淘汰,LRUKReplacer都需要跟踪它的访问历史和状态。
LRUKReplacer 的大小由可淘汰帧的数量来表示。LRUKReplacer 初始时不包含任何帧(size() 为0或者说curr_size_是0,即使 node_store_ 中已经为所有帧创建了占位符),只有当一个帧被标记为可淘汰时,LRUKReplacer的大小才会增加。同样,当一个帧被固定或未被使用时,替换器的大小会减小。
当一个帧被用户线程引用的次数变为 0 时(意味着该帧当前未被使用),缓冲池管理器会调用 SetEvictable(frame_id, true),将该帧标记为可淘汰,LRUKReplacer的大小(即可淘汰帧的数量)会增加 1。当帧被重新固定(即被用户线程引用)时,缓冲池管理器会调用 SetEvictable(frame_id, false),将该帧标记为不可淘汰,LRUKReplacer的大小减少 1。
lru_k_replacer.cpp
代码由于课程要求不会公开,这里说一下我实现的思路。
-
首先要在
LRUKReplacer中调用LRUKNode的私有变量,要么对于LRUKNode,实现其构造函数,然后实现一下辅助函数用于设置和返回私有变量:auto GetHistory() -> std::list<size_t> & ;auto GetK() -> size_t ;auto GetFid() -> frame_id_t;auto SetEvictable(bool flag) -> void;auto GetEvictable() -> bool;要么将
LRUKReplacer设为LRUKNode的友元类friend class LRUKReplacer;此外,
LRUKNode除LRUKNode(size_t k, frame_id_t fid)外还需要指定默认构造函数LRUKNode() = default,因为在LRUKReplacer使用std::unordered_map的operator[]时,若指定的键不存在于映射中,会首先调用LRUKNode的默认构造,然后才会报错。要么定义LRUKNode的默认构造,要么使用emplace插入。 -
LRUKReplacer构造函数很简单,将 num_frames 和 k 赋值给对应变量即可。num_frames需要通过static_cast<frame_id_t>转换为frame_id_t。 -
实现
Evict() -> std::optional<frame_id_t>之前,需要先实现一个辅助函数CalculateBackwardKDistance(const LRUKNode& node)计算给定帧id对应页的反向K距离:如果给定LRUKNode的访问记录次数小于K,则返回inf,反之找到倒数第K次的访问时间,然后返回当前时间戳与倒数第K次的访问时间的差。在
Evict()中定义一个比较函数cmp,比较传入两个frame_id_t对应页的优先级关系(反向K距离越大优先级越大,若反向K距离相同则比较最早访问时间,越早访问优先级越高),然后定义一个优先队列std::priority_queue<frame_id_t, std::vector<frame_id_t>, decltype(cmp)>,底层容器使用std::vector方便随机访问,比较函数使用我们定义的cmp,优先级从小到大依次排列。cmp接受两个元素作为参数,并返回一个布尔值。如果比较函数返回true,则第一个元素的优先级低于第二个元素;如果返回false,则第一个元素的优先级高于第二个元素。然后加锁遍历
node_store_,若node的标记is_evictable_为true,则将该node对应的frame_id_t加入到优先队列中进行排序;如果优先队列不为空,则删除
node_store_中优先队列队首元素代表的LRUKNode(经cmp排序后,优先级最大的帧在队首),并修改curr_size_,反之返回std::nullopt。node_store_和curr_size_是需要保护的共享资源,在使用和修改的时候需要注意进行加锁,如果curr_size_的类型被修改为了std::atomic<size_t>则只需要考虑保护node_store_。其实优先队列最好分成“历史队列”和“缓存队列”,前者存放历史记录不满 k 的帧,后者存放历史记录满 k 的帧。
// 历史队列,存放历史记录不满 k 的帧 using HistoryQueueEntry = std::pair<size_t, frame_id_t>; std::priority_queue<HistoryQueueEntry, std::vector<HistoryQueueEntry>, std::greater<>> history_queue_;// 缓存队列,存放历史记录满 k 的帧 using CacheQueueEntry = std::pair<size_t, frame_id_t>; std::priority_queue<CacheQueueEntry, std::vector<CacheQueueEntry>, std::greater<>> cache_queue_; -
RecordAccess(frame_id_t frame_id, [[maybe_unused]] AccessType access_type)主要用于记录给定frame_id对应的页在当前时间戳被访问,同时需要保证frame_id范围在[0, num_frames - 1]中,否则利用已经定义好的宏BUSTUB_ASSERT断言。需要注意,因为有可能在调用
RecordAccess之前系统调用了Evict(),因此即使构造函数中所有可能的帧 ID 预先创建了对应的LRUKNode对象,但有可能在Evict()中将某一个帧id对应的LRUKNode删除,因此我们必须判断node_store_是否存在给定帧id对应的LRUKNode,若没有则创建一个。在
LRUKNode的历史记录中加当前时间戳后(current_timestamp_++),仅需要保存history_中的后 k 个记录,剩余部分需要 pop以节约空间。验证帧id有效性时,需要将 replacer_size_ 的类型强制转换
static_cast<frame_id_t> -
Remove(frame_id_t frame_id)->void需要经过三次验证检查,第一次验证frame_id是否有效(在[0, num_frames - 1]中),第二次需要验证frame_id对应的LRUKNode是否存在,第三次验证帧是否可淘汰,即只有在“历史队列”中的帧才可以淘汰。经过三次验证检查后,帧及其访问历史才会被移除。第一次和第三次检查时通过
BUSTUB_ASSERT来终止程序,而第二次检查不成功会直接 return,不会终止。 -
SetEvictable()和Size()比较简单,前者检查帧id有效性和其对应的页是否存在,并根据标志位相应的增加或删除curr_size_;后者直接返回curr_size_即可。
test
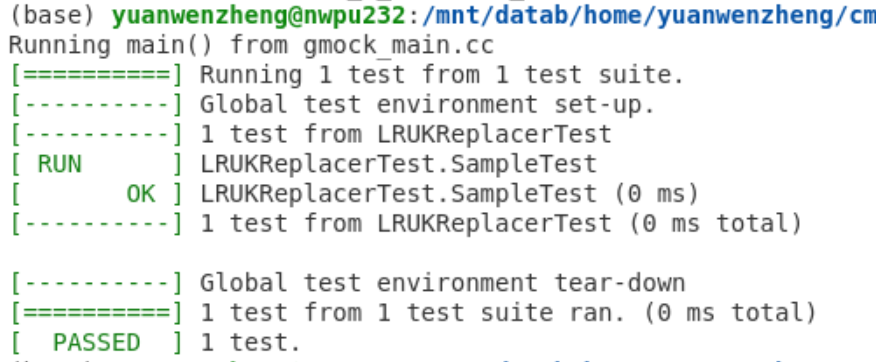
先将 ./test/buffer/lru_k_replacer_test.cpp 下第一个测试函数第二个形参的前缀 DISABLE_ 删除;
然后从根目录cd至build,运行:
make lru_k_replacer_test -j `nproc`
./test/lru_k_replacer_test
参考:
CMU15-445-P1全局思路及详细实现过程(超超超超详细,我奶都能看懂!!!)-CSDN博客
CMU15-445数据库系统:缓存池 - 高志远的个人主页
CMU15445 2024Spring 课程作业_cmu15445 gradescope-CSDN博客
相关文章:
——PROJECT#1-BufferPoolManager-Task#1)
CMU-15445(3)——PROJECT#1-BufferPoolManager-Task#1
PROJECT#1-BufferPoolManager 在完成了前面基础的PROJECT#0后,从本节开始才正式进入了CMU-15445的学习,最终目的是构建一个面向磁盘的数据库管理系统。 PROJECT#1 的主要任务是实现数据库管理系统的缓冲池管理器,缓冲池负责在主存缓冲区与持…...

《数据结构初阶》【链式二叉树】
《数据结构初阶》【链式二叉树】 前言:---------------树---------------什么是树?📌爱心❤小贴士:树与非树?树的基本术语有哪些?关于节点的一些定义:关于树的一些定义:关于森林的定…...

Oracle免费认证来袭
1、Oracle Cloud Infrastructure 2025 Foundations Associate” 🔗 考证地址:https://mylearn.oracle.com/ou/exam-unproctored/oracle-cloud-infrastructure-2025-foundations-associate-1z0-1085-25/148056/241954 2、Oracle Cloud Infrastructure 2…...

Vim 编辑器常用快捷键速查表
Vim 编辑器常用快捷键速查表 Vim 快捷键大全 **1. 基础操作****2. 光标移动****3. 编辑文本****4. 查找替换****5. 分屏操作****6. 可视化模式** **附:Vim 模式切换流程图** 1. 基础操作 快捷键功能说明i进入插入模式(光标前)a进入插入模式&…...
)
从父类到子类:C++ 继承的奇妙旅程(1)
前言: 在前文,小编讲述了C模板的进阶内容,下面我们就要结束C初阶的旅行,开始进入C进阶容的旅c程,今天旅程的第一站就是C三大特性之一——继承的旅程,各位扶好扶手,开始我们今天的C继承的奇妙旅程…...

HTML9:页面结构分析
页面结构分析 元素名描述header标题头部区域的内容(用于页面或页面中的一块区域)footer标记脚部区域的内容(用于整个页面或页面的一块区域)sectionWeb页面的一块独立区域article独立的文章内容aside相关的内容或应用(…...

LabVIEW超声波液位计检定
在工业生产、运输和存储等环节,液位计的应用十分广泛,其中超声波液位计作为非接触式液位测量设备备受青睐。然而,传统立式水槽式液位计检定装置存在受建筑高度影响、量程范围受限、流程耗时长等问题,无法满足大量程超声波液位计的…...

maven 安装 本地 jar
命令: mvn install:install-file -DgroupIdnet.pingfang.application -DartifactIdjna -Dversion5.1.0 -Dpackagingjar -DfileD:\maven\repository1\jna\5.1.0\jna-5.1.0.jarmvn:这是Maven的执行命令。 install:install-file:这是Maven插件目…...

leetcode 141. Linked List Cycle
题目描述: 代码: 用哈希表也可以解决,但真正考察的是用快慢指针法。 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/ class Soluti…...

【Python】通过`Editable Install`模式详解,解决Python开发总是import出错的问题
摘要 田辛老师在很久以前,写过一篇关于Python的模块、包之间的内部关系的博客,叫做【Python】__init__.py 文件详解。 虽然我觉得这篇文章已经足够了, 但是还是有很多朋友碰到开发的过程中import包报错的问题。 今天, 田辛老师想…...

C 语言网络编程问题:E1696 无法打开 源 文件 “sys/socket.h“
#include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h>在 C 语言网络编程中,上述代码报如下错误 E1696 无法打开 源 文件 "sys/socket.h"E1696 无法打开 源 文件 "netinet/in.h" E1696 无法打开 源 文件…...

操作指南*
任务1: 环境搭建 1.1 创建Spring Boot项目 操作步骤: 使用IDEA创建项目: 打开IDEA → File → New → Project选择 Spring Initializr → 设置项目信息(Group、Artifact、Java版本)选择依赖:Spring Web、MySQL Drive…...

VRM Add-on for Blender 学习笔记
VRM Add-on for Blender 使用教程-CSDN博客 VRM Add-on for Blender 是 Blender 的一个官方插件,主要用于 导入和导出 VRM 格式的 3D 模型。VRM(Virtual Reality Model)是一种开放标准的 3D 人形角色模型格式,起源于日本…...

C++ 完美转发
C 完美转发逐步详解 1. 问题背景与核心目标 在 C 模板编程中,若直接将参数传递给其他函数,参数的 值类别(左值/右值)和 类型信息(如 const)可能会丢失。例如: template<typename T> voi…...

学习记录:DAY23
项目开发与学习记录:字段注入优化 前言 我总有一种什么大的要来了的危机感。还是尽快把项目做起来吧,现在全在弄底层的框架。这是一个两天的blog,前一天bug没修好,气到连blog都没写。 日程 5月7日 晚上7点:本来想玩…...
)
Linux 信号(下篇)
Linux 信号-CSDN博客(上篇) 前言:在我上一篇博客写到了信号产生的三种条件分别是键盘组合键、kill命令、系统调用接口; 接下来我要把信号产生剩余的两个条件介绍完毕并理解信号的保存,和信号从产生到保存到处理整个过…...
)
hadoop中的序列化和反序列化(1)
1. 什么是序列化和反序列化 序列化(Serialization) 是将对象的状态信息转换为可以存储或传输的格式的过程。序列化后的对象可以保存到文件中,或者通过网络传输。 反序列化(Deserialization) 是序列化的逆过程&#x…...

linux查java进程CPU高的原因
问题:linux查java进程CPU高的原因 解决:用jdk带的工具分析 被查的java最好也使用jdk启动 systemctl启动的注意要去掉PrivateTmptrue /opt/jdk1.8.0_441/bin/jps -l top -Hp 8156 printf "%x" 8533 /opt/jdk1.8.0_441/bin/jstack 8156 |…...

鸿蒙开发——3.ArkTS声明式开发:构建第一个ArkTS应用
鸿蒙开发——3.ArkTS声明式开发:构建第一个ArkTS应用 一、创建ArkTS工程二、ArkTS工程目录结构(Stage模型)三、构建第一个页面四、构建第二个页面五、实现页面之间的跳转六、模拟器运行 一、创建ArkTS工程 1、若首次打开DevEco Studio,请点击…...

vue3+ts的watch全解!
vue3中的watch只能监听以下四种数据: 1.ref定义的数据 2.reactive定义的数据 3.函数返回一个值(getter函数) 4.一个包含上述内容的数组 通常我们在使用watch的时候,通常会遇到以下几种情况: 情况一: …...

yarn的概述
1.Yarn的定义 2.Yarn的三大组件 3.Yarn的调度策略 1. YARN的定义 YARN(Yet Another Resource Negotiator) 是Hadoop生态系统中的一个资源管理框架,用于管理和调度集群中的计算资源。它允许多个应用程序在同一个集群上高效地运行,…...

C++初阶-string类4
目录 1.String operations 1.1string::c_str 1.2string::data 1.3string::copy 1.4string::find 1.5string::rfind 1.6string::find_first_of 1.7string::find_last_of 1.8string::find_first_not_of和string::find_last_not_of find_first_not_of 功能 典型用途 f…...

HarmonyOS NEXT深度解析:自研框架ArkUI-X的技术革命与跨平台实践
HarmonyOS NEXT~深度解析:自研框架ArkUI-X的技术革命与跨平台实践 引言:ArkUI-X的诞生背景与战略意义 在HarmonyOS NEXT全面摒弃AOSP代码的历史性转折点上,华为推出的ArkUI-X框架标志着国产操作系统研发进入深水区。根据华为202…...
)
CUDA:out of memory的解决方法(实测有效)
一、问题概述 1.问题分析 CUDA out of memory问题通常发生在深度学习训练过程中,当GPU的显存不足以容纳模型、输入数据以及中间计算结果时就会触发。这个问题可能由几个因素引起: 模型和数据规模:深度学习模型尤其是大型模…...

canal mysqltomysql增加同步的库操作
例如增加库 online 1、停止canal.adapter 服务。 ./bin/stop.sh2、备份数据库online,导入目标mysql 备份 mysqldump -h 127.0.0.1 -P 3307 --single-transaction -uroot -p -B online > online.sql导入 mysql -h 127.0.0.1 -P 3308 -uroot -p < onl…...

【AI】模型与权重的基本概念
在 ModelScope 平台上,「模型」和「权重」的定义与工程实践紧密结合,理解它们的区别需要从实际的文件结构和加载逻辑入手。以下是一个典型 ModelScope 模型仓库的组成及其概念解析: 1. ModelScope 模型仓库的典型结构 以 deepseek-ai/deepse…...

k8s 中 deployment 管理的多个 pod 构成集群吗
在 Kubernetes (k8s) 中,通过 Deployment 创建的多个 Pod 本身并不构成一个“集群”,而是属于同一个 工作负载(Workload) 的多个副本实例。它们的角色是 无状态服务副本,而非独立的集群节点。以下是详细解释࿱…...
)
「动态规划」线性DP:股票问题合集 / LeetCode 121|122|123|188 (C++)
目录 概述 Question1 思路 算法过程 Code 复杂度 Question2 思路 解题过程 Code 复杂度 Question3 思路 解题过程 Code 复杂度 Question4 思路 解题过程 Code 复杂度 总结 概述 我们已经了解过了线性DP: 「动态规划」线性DP:最长…...

【Python os模块完全指南】从基础到高效文件操作
目录 🌟 前言🧩 技术背景与价值🚧 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 📚 一、技术原理剖析🎨 核心概念图解💡 核心作用讲解🔑 关键技术模块说明⚖️ 技术选型…...

Ubuntu 安装 Keepalived、LVS
Keepalived Keepalived 是什么(高可用) Keepalived 是一个用于实现 高可用 性(High Availability, HA)的服务,是一款基于 VRRP 协议的高可用软件,常用于主备切换和虚拟IP漂移,在服务故障时自动…...

记录一个rabbitmq因为linux主机名服务无法启动的问题
https://g.co/gemini/share/fb5a55644f6f 过程因为主机名为数字导致之间无法进行网络访问,导致无法开启。修改主机名解决这一问题,debian在系统安装时会指定一个用户名,一般为IP地址的第一块,数字导致了无法访问。 #使用命令查看…...

打造个人知识库,wsl+ollama部署deepseek与vscode集成
目前大模型应用如火如荼,各大LLM如Deepseek也都提供了在线的助手服务,结合mcp-server还可以进一步拓展到本地的工具能力。 但对于一些和本地业务和数据强相关的资料,在线的大模型训练数据集一般并不能涵盖,特别还有一些敏感或对安全要求很高的数据,使用在线大模型并不现实…...

Spring 项目无法连接 MySQL:Nacos 配置误区排查与解决
在开发过程中,我们使用 Nacos 来管理 Spring Boot 项目的配置,其中包括数据库连接配置。然而,在实际操作中,由于一些概念的混淆,我们遇到了一些连接问题。本文将分享我的故障排查过程,帮助大家避免类似的错…...

P值、置信度与置信区间的关系:统计推断的三大支柱
目录 引言一、P值是什么?——假设检验的“证据强度”1.1 定义1.2 判断标准:显著性水平 α \alpha α(阿尔法)1.3 示例说明 二、置信区间与置信度:参数估计的“不确定性范围”2.1 置信区间的定义2.2 置信度的含义 三、显…...

探索智能仓颉:Cangjie Magic开发体验
探索智能仓颉:Cangjie Magic 的开发体验与技术革新 在大型语言模型(LLM)驱动的智能体开发领域,2025年3月开源的 Cangjie Magic 以其独特的原生仓颉语言基因和三大核心技术突破,为开发者提供了一种全新的开发范式。本文将从技术架构、实际应用、开发体验及未来潜力等角度,…...

$在R语言中的作用
在 R 语言中,$ 是一个非常重要的操作符,主要用于访问对象的成员或组件。它的用途非常广泛,不仅限于数据框(data frame),还可以用于列表(list)、环境(environment…...

【Pandas】pandas DataFrame rolling
Pandas2.2 DataFrame Function application, GroupBy & window 方法描述DataFrame.apply(func[, axis, raw, …])用于沿 DataFrame 的轴(行或列)应用一个函数DataFrame.map(func[, na_action])用于对 DataFrame 的每个元素应用一个函数DataFrame.a…...

新疆地区主要灾害链总结
新疆地处亚欧大陆腹地,拥有高山(如天山、昆仑山)、盆地(如塔里木盆地、准噶尔盆地)、沙漠(如塔克拉玛干沙漠)、绿洲、内陆河流和冰川等复杂多样的地貌单元。其气候极端,干旱少雨是常态,但山区夏季暴雨集中、冬季积雪深厚,地质构造活跃,地震风险高。这些特点共同决定…...

在 Vue 2 中使用 qrcode 库生成二维码
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
和休眠(Hibernate))
在 Ubuntu 系统中,挂起(Suspend)和休眠(Hibernate)
在 Ubuntu 系统中,挂起(Suspend)和休眠(Hibernate)是两种常见的电源管理模式。以下是相关命令及说明: --- ### **1. 挂起(Suspend)** 挂起会将当前系统状态保存到内存中࿰…...

什么是声明式UI什么是命令式UI?鸿蒙ArkTS为什么是声明式UI-优雅草卓伊凡
什么是声明式UI什么是命令式UI?鸿蒙ArkTS为什么是声明式UI-优雅草卓伊凡 一、UI编程范式的根本分野 在软件开发领域,用户界面(UI)构建方式经历了三次重大范式转换。作为优雅草科技CTO,卓伊凡在多个操作系统开发实践中发现,UI框架…...

nRF Connect SDK system off模式介绍
目录 概述 1. 软硬件环境 1.1 软件开发环境 1.2 硬件环境 2 System Off 模式 2.1 模式介绍 2.2 注意事项 3 功能实现 3.1 框架结构介绍 3.2 代码介绍 4 功能验证 4.1 编译和下载代码 4.2 测试 4.3 使能CONFIG_APP_USE_RETAINED_MEM的测试 5 main.c的源代码文件…...
)
node.js 实战——餐厅静态主页编写(express+node+ejs+bootstrap)
ejs页面 <!DOCTYPE html> <html> <head><title><% title %></title><link relstylesheet href/stylesheets/style.css/><link relstylesheet href/stylesheets/font-awesome.css/><link relstylesheet href/stylesheets/f…...

晶体布局布线
1Clock时钟电路 时钟电路就是类似像时钟一样准确运动的震荡电路,任何工作都是依照时间顺序,那么产生这个时间的电路就是时钟电路,时钟电路一般是由晶体振荡器、晶振、控制芯片以及匹配电容组成 2.时钟电路布局 晶体电路布局需要优先考虑&…...

数据结构--树
一、树的概念 树是由n(n≥0)个节点组成的有限集合,它满足以下条件: 1. 当n0时,称为空树 2. 当n>0时,有且仅有一个特定的节点称为根节点(root) 3. 其余节点可分为m(m≥0)个互不相交的有限集合,每个集合本身又是一…...

5月7号.
flex布局: 表单标签: 表单标签-表单项:...

Spark 之 YarnCoarseGrainedExecutorBackend
YarnCoarseGrainedExecutorBackend executor ID , 在日志里也有体现。 25/05/06 12:41:58 INFO YarnCoarseGrainedExecutorBackend: Successfully registered with driver 25/05...

Webug4.0靶场通关笔记19- 第24关邮箱轰炸
目录 第24关 邮箱轰炸 1.配置环境 2.打开靶场 3.源码分析 4.邮箱轰炸 (1)注册界面bp抓包 (2)发送到intruder (3)配置position (4)配置payload (5)开…...

机器学习实战:6种数据集划分方法详解与代码实现
在机器学习项目中,合理划分数据集是模型开发的关键第一步。本文将全面介绍6种常见数据格式的划分方法,并附完整Python代码示例,帮助初学者掌握这一核心技能。 一、数据集划分基础函数 1. 核心函数:train_test_split from sklea…...

PostgreSQL 查询历史最大进程数方法
PostgreSQL 查询历史最大进程数方法 PostgreSQL 提供了多种方式来查询数据库的历史最大进程数(连接数)。以下是几种有效的方法: 一、使用统计收集器数据 1. 查看当前统计信息 SELECT max_connections, (SELECT setting FROM pg_settings …...