第5讲、Transformer 编码器(Encoder)处理过程详解
🔍 Transformer 编码器(Encoder)处理过程详解
Transformer Encoder 是一个由 N 层(一般为 6 层)堆叠而成的模块结构。每一层的本质是两个核心子模块:
- 多头自注意力(Multi-Head Self-Attention)
- 前馈神经网络(Feed Forward Network)
每个子模块都通过:
- 残差连接(Residual Connection)
- 层归一化(LayerNorm)
进行包裹与标准化,保持训练稳定性。
🧭 总体流程图解(以一层为例)
嵌入输入│
+───> 位置编码(Position Encoding)│▼
输入表示(X) → ┐│多头自注意力(Self-Attention)│+ Residual + LayerNorm(第一步)▼前馈神经网络(Feed Forward)│+ Residual + LayerNorm(第二步)▼输出 H1(传入下一层)
🧱 输入嵌入层(Input Embedding + Position Encoding)
- 每个输入 token 首先通过词向量矩阵映射为一个固定维度向量(如 512维)。
- 然后加上 位置编码(固定正余弦或可学习向量),使模型具备位置信息。

🧠 第一子模块:多头自注意力 Multi-Head Self-Attention
📌 自注意力(Self-Attention)核心思想:
每个词在计算时都可以关注句中其他所有词,捕捉到全局语义信息。
🧮 计算过程:

✅ 作用:
- 让每个词语动态地感知上下文语义
- 多头机制让模型从多个表示子空间学习依赖关系
🔁 残差连接 + LayerNorm(第一次)
自注意力输出后,加入输入值(残差连接),再做归一化:
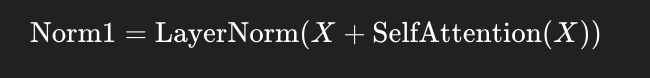
✅ 目的:
- 防止训练过程中的梯度消失
- 保持信息流动稳定
- LayerNorm 保证激活值分布统一,提升收敛速度
🧮 第二子模块:前馈神经网络 Feed Forward
📌 结构:
每个位置上的 token 单独经过一个两层的全连接网络(MLP):
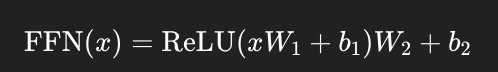
虽然是点对点操作,但提供了非线性特征转换能力。
✅ 特点:
- 输入维度保持不变(如 512 → 2048 → 512)
- 提升模型表达能力与抽象能力
🔁 残差连接 + LayerNorm(第二次)
对 FFN 输出再做一次残差与归一化:

🔄 多层堆叠(Layer Stacking)
Encoder 模块通常堆叠 6 层(或更多),形成深度网络:
Input → EncoderLayer × N → Encoder Output
每层都重复上述两步:自注意力 → FFN,逐层提炼抽象特征。
📤 最终输出
Encoder 最终输出是一个张量:
- 形状为
[batch_size, seq_len, d_model] - 每个 token 都被映射为一个"上下文增强"的向量表示
这个输出将供 Decoder 或下游任务使用(如分类、问答、生成等)。
📌 小结:每一层 Encoder 的设计哲学
| 组件 | 作用 |
|---|---|
| Position Encoding | 弥补无序缺陷,提供位置信息 |
| Self-Attention | 捕捉词与词之间全局依赖 |
| Feed Forward | 增强模型非线性表达能力 |
| Residual Connection | 保持信息路径,减缓梯度消失 |
| LayerNorm | 保证数值稳定,加快训练 |
✅ Encoder 是一个结构精巧的"信息提炼器",将原始嵌入压缩为包含上下文的丰富表示,是 Transformer 模型成功的根本所在。
🧑💻 PyTorch 代码实现与详细讲解
下面以 PyTorch 为例,逐步实现 Transformer 编码器的各个核心模块,并结合代码详细说明其原理与设计。
1. 输入嵌入与位置编码
import torch
import torch.nn as nnclass PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-torch.log(torch.tensor(10000.0)) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0) # [1, max_len, d_model]self.register_buffer('pe', pe)def forward(self, x):# x: [batch_size, seq_len, d_model]x = x + self.pe[:, :x.size(1)]return xclass InputEmbedding(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model)self.pos_encoding = PositionalEncoding(d_model)def forward(self, x):x = self.embedding(x) # [batch, seq_len, d_model]x = self.pos_encoding(x)return x
讲解:
- InputEmbedding 将 token id 映射为向量,并加上位置编码,补充序列顺序信息。
- PositionalEncoding 用正余弦函数实现,保证不同位置有唯一编码。
2. 多头自注意力机制
class MultiHeadSelfAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0self.d_k = d_model // num_headsself.num_heads = num_headsself.qkv_linear = nn.Linear(d_model, d_model * 3)self.out_linear = nn.Linear(d_model, d_model)def forward(self, x, mask=None):batch_size, seq_len, d_model = x.size()qkv = self.qkv_linear(x) # [batch, seq_len, 3*d_model]qkv = qkv.reshape(batch_size, seq_len, 3, self.num_heads, self.d_k)qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch, heads, seq_len, d_k]q, k, v = qkv[0], qkv[1], qkv[2]scores = torch.matmul(q, k.transpose(-2, -1)) / self.d_k ** 0.5 # [batch, heads, seq_len, seq_len]if mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))attn = torch.softmax(scores, dim=-1)context = torch.matmul(attn, v) # [batch, heads, seq_len, d_k]context = context.transpose(1, 2).reshape(batch_size, seq_len, d_model)out = self.out_linear(context)return out
讲解:
- Q、K、V 通过线性变换获得,分多头并行计算注意力。
- 每个头可关注不同子空间的依赖,最后拼接。
- mask 用于屏蔽无效位置(如 padding)。
3. 前馈神经网络
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super().__init__()self.linear1 = nn.Linear(d_model, d_ff)self.relu = nn.ReLU()self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):return self.linear2(self.relu(self.linear1(x)))
讲解:
- 两层全连接+ReLU,提升非线性表达能力。
- 逐位置独立处理,不引入序列间交互。
4. 残差连接与 LayerNorm
class EncoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff):super().__init__()self.self_attn = MultiHeadSelfAttention(d_model, num_heads)self.norm1 = nn.LayerNorm(d_model)self.ffn = FeedForward(d_model, d_ff)self.norm2 = nn.LayerNorm(d_model)def forward(self, x, mask=None):# Self-Attention + Residual + Normattn_out = self.self_attn(x, mask)x = self.norm1(x + attn_out)# FFN + Residual + Normffn_out = self.ffn(x)x = self.norm2(x + ffn_out)return x
讲解:
- 每个子模块后都加残差和 LayerNorm,保证梯度流动和数值稳定。
- 先自注意力,再前馈网络。
5. 编码器整体结构
class TransformerEncoder(nn.Module):def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers):super().__init__()self.embedding = InputEmbedding(vocab_size, d_model)self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])def forward(self, x, mask=None):x = self.embedding(x)for layer in self.layers:x = layer(x, mask)return x # [batch, seq_len, d_model]
讲解:
- 多层 EncoderLayer 堆叠,每层提炼更高层次特征。
- 输出为每个 token 的上下文增强表示。
总结
- 输入嵌入+位置编码:为每个 token 提供唯一、可区分的向量表示。
- 多头自注意力:全局建模 token 间依赖,多头提升表达力。
- 前馈网络:增强非线性特征转换。
- 残差+LayerNorm:稳定训练,防止梯度消失。
- 多层堆叠:逐层抽象,获得丰富的上下文表示。
🧑💻 Streamlit Transformer Encoder 可视化案例(PyTorch版)
完整案例代码
import streamlit as st
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt# 1. 输入嵌入与位置编码
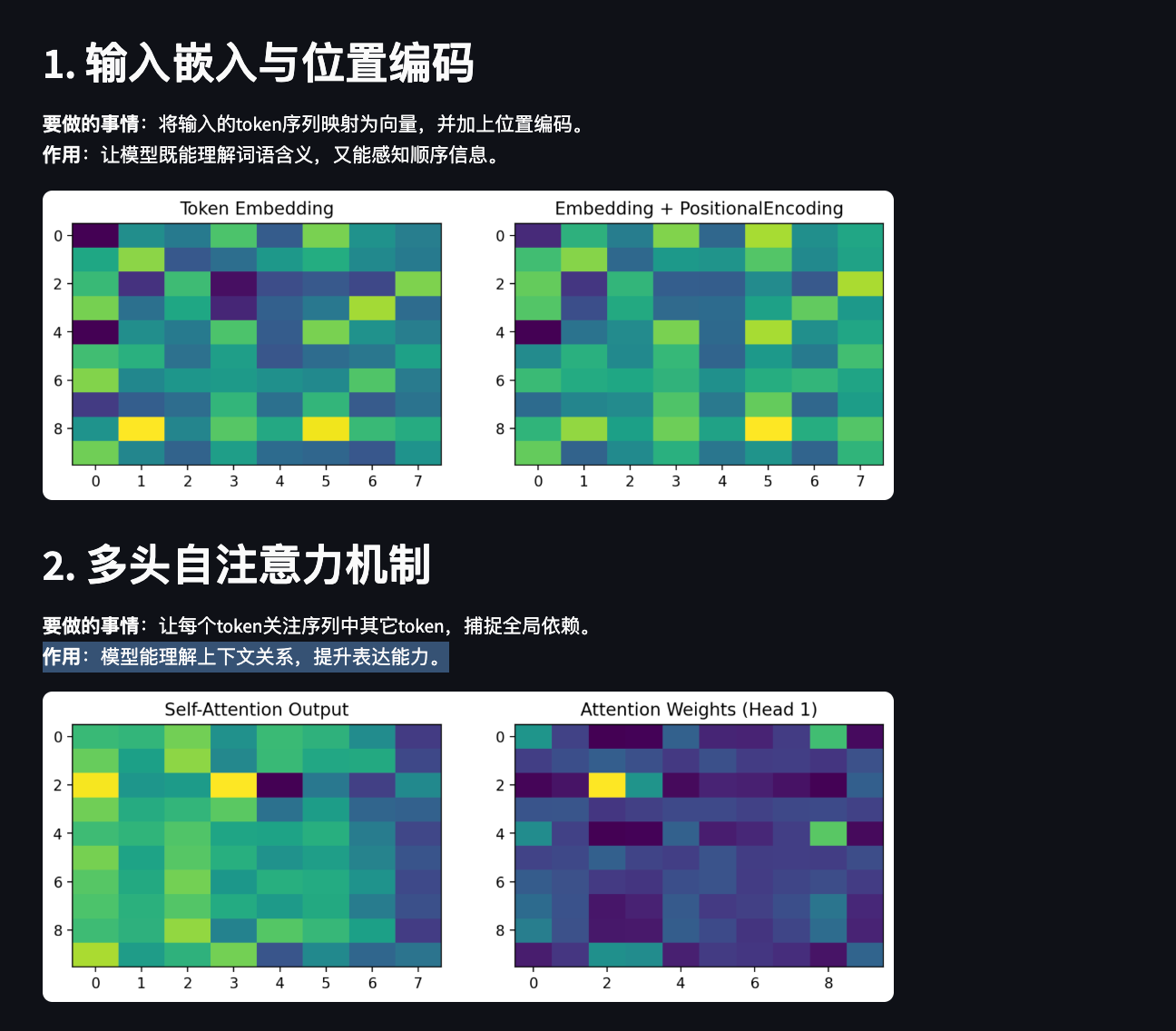
st.header("1. 输入嵌入与位置编码")
st.markdown("""
**要做的事情**:将输入的token序列映射为向量,并加上位置编码。
**作用**:让模型既能理解词语含义,又能感知顺序信息。
""")class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=50):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.pe = pe.unsqueeze(0) # [1, max_len, d_model]def forward(self, x):return x + self.pe[:, :x.size(1)]vocab_size, d_model, seq_len = 20, 8, 10
embedding = nn.Embedding(vocab_size, d_model)
pos_encoding = PositionalEncoding(d_model, max_len=seq_len)tokens = torch.randint(0, vocab_size, (1, seq_len))
embed = embedding(tokens)
embed_pos = pos_encoding(embed)fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ax[0].imshow(embed[0].detach().numpy(), aspect='auto')
ax[0].set_title("Token Embedding")
ax[1].imshow(embed_pos[0].detach().numpy(), aspect='auto')
ax[1].set_title("Embedding + PositionalEncoding")
st.pyplot(fig)# 2. 多头自注意力
st.header("2. 多头自注意力机制")
st.markdown("""
**要做的事情**:让每个token关注序列中其它token,捕捉全局依赖。
**作用**:模型能理解上下文关系,提升表达能力。
""")class MultiHeadSelfAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0self.d_k = d_model // num_headsself.num_heads = num_headsself.qkv_linear = nn.Linear(d_model, d_model * 3)self.out_linear = nn.Linear(d_model, d_model)def forward(self, x):batch_size, seq_len, d_model = x.size()qkv = self.qkv_linear(x)qkv = qkv.reshape(batch_size, seq_len, 3, self.num_heads, self.d_k)qkv = qkv.permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]scores = torch.matmul(q, k.transpose(-2, -1)) / np.sqrt(self.d_k)attn = torch.softmax(scores, dim=-1)context = torch.matmul(attn, v)context = context.transpose(1, 2).reshape(batch_size, seq_len, d_model)out = self.out_linear(context)return out, attnmhsa = MultiHeadSelfAttention(d_model, num_heads=2)
attn_out, attn_weights = mhsa(embed_pos)fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ax[0].imshow(attn_out[0].detach().numpy(), aspect='auto')
ax[0].set_title("Self-Attention Output")
ax[1].imshow(attn_weights[0][0].detach().numpy(), aspect='auto')
ax[1].set_title("Attention Weights (Head 1)")
st.pyplot(fig)# 3. 前馈神经网络
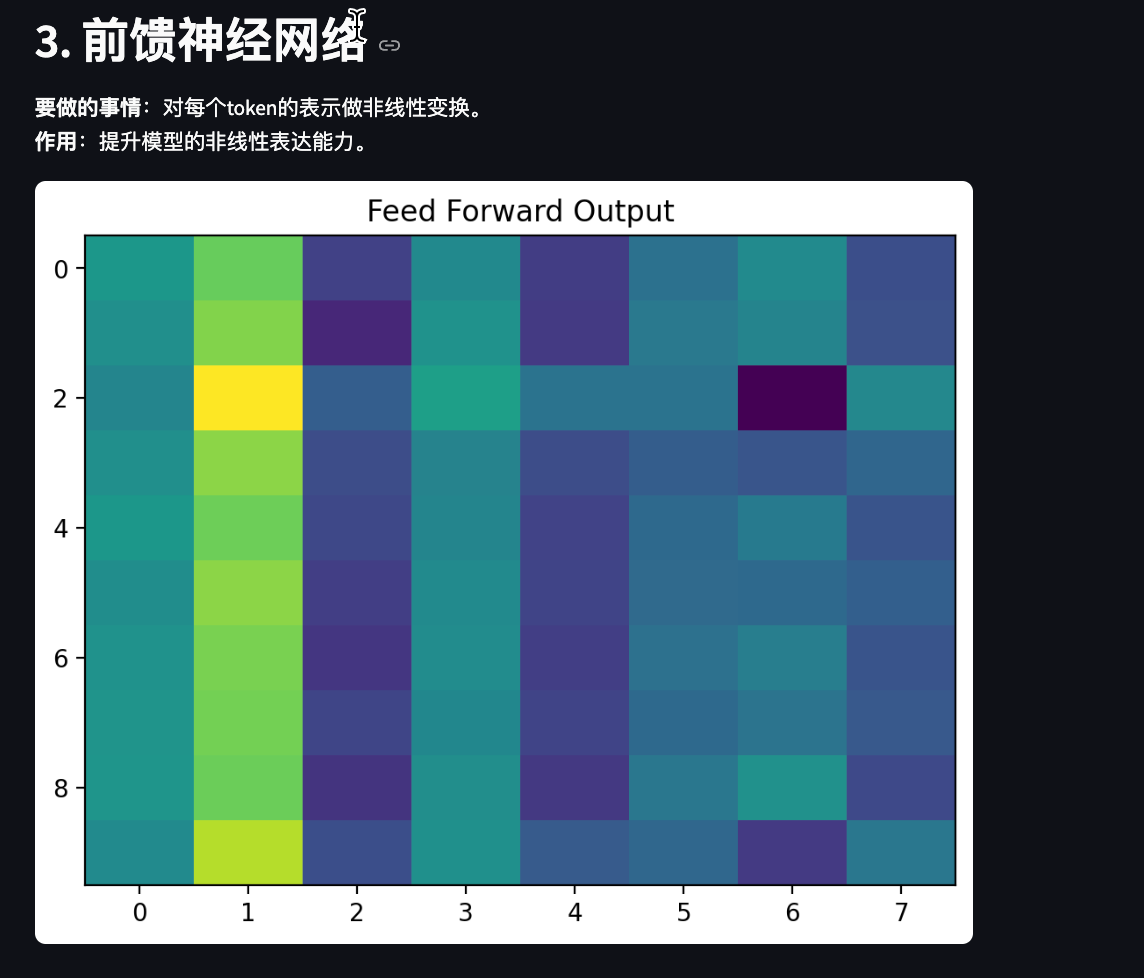
st.header("3. 前馈神经网络")
st.markdown("""
**要做的事情**:对每个token的表示做非线性变换。
**作用**:提升模型的非线性表达能力。
""")class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super().__init__()self.linear1 = nn.Linear(d_model, d_ff)self.relu = nn.ReLU()self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):return self.linear2(self.relu(self.linear1(x)))ffn = FeedForward(d_model, d_ff=16)
ffn_out = ffn(attn_out)fig, ax = plt.subplots()
ax.imshow(ffn_out[0].detach().numpy(), aspect='auto')
ax.set_title("Feed Forward Output")
st.pyplot(fig)# 4. 残差连接与LayerNorm
st.header("4. 残差连接与LayerNorm")
st.markdown("""
**要做的事情**:每个子模块后加残差和归一化。
**作用**:防止梯度消失,提升训练稳定性。
""")layernorm = nn.LayerNorm(d_model)
residual_out = layernorm(embed_pos + attn_out)fig, ax = plt.subplots()
ax.imshow(residual_out[0].detach().numpy(), aspect='auto')
ax.set_title("Residual + LayerNorm Output")
st.pyplot(fig)# 5. 多层堆叠
st.header("5. 多层堆叠")
st.markdown("""
**要做的事情**:重复上述结构,逐层提炼特征。
**作用**:获得更丰富的上下文表示。
""")
st.markdown("(此处可用多层循环堆叠,原理同上,略)")
st.success("案例演示完毕!你可以修改参数、输入等,观察每一步的可视化效果。")
相关文章:
第5讲、Transformer 编码器(Encoder)处理过程详解
🔍 Transformer 编码器(Encoder)处理过程详解 Transformer Encoder 是一个由 N 层(一般为 6 层)堆叠而成的模块结构。每一层的本质是两个核心子模块: 多头自注意力(Multi-Head Self-Attention…...

Flutter Drawer 详解
目录 一、引言 二、Drawer 的基本用法 三、主要属性 四、常见问题与解决方案 4.1 手势冲突处理 4.2 多级导航管理 4.3 响应式布局适配 五、最佳实践建议 5.1 性能优化 5.2 无障碍支持 5.3 跨平台适配 六、结论 相关推荐 一、引言 在移动应用开发中,侧边…...

游戏引擎学习第263天:添加调试帧滑块
运行游戏,开始今天的开发工作。 我们继续游戏代码基础上进行重构,目标是实现更多的性能分析界面功能,尤其是调试用的用户界面。 目前运行游戏并打开性能分析窗口后,发现界面功能上还有不少缺陷。现在的界面可以向下钻取查看具体…...

Hadoop客户端环境准备
hadoop集群我们配置好了,要与它进行交互,我们还需要准备hadoop的客户端。要分成两步:下载hadoop包、配置环境变量。 1. 找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0&#…...

当“信任”遇上“安全”:如何用Curtain Logtrace记录文件操作活动 守护团队与数据的双重底线?
你是否也有过这样的担忧? 团队成员在处理敏感数据时是否遵守了公司规范? 某份被篡改或外泄的文档,到底发生了什么? 为了数据安全而频繁加密、限制下载,却反过来打击了员工的工作积极性…… 如何在不伤害团队信任的…...

如何进行室内VR全景拍摄?
如何进行室内VR全景拍摄? 室内VR全景拍摄作为先进的视觉技术,能够为用户提供沉浸式的空间体验。本文介绍如何进行室内VR全景拍摄,并阐述众趣科技在这一领域的技术支持和服务优势。 室内VR全景拍摄基础 1. 室内VR全景拍摄概述 室内VR全景拍…...

一文走进GpuGeek | conda常用命令
conda 常用命令 查看conda版本 conda --version 查看conda信息 conda info 更新conda自身到最新版本,同时也会更新其它包 conda update conda conda更新指定包,这里更新通过conda安装的zlib包 conda update zlib 列出所有虚拟环境 conda env li…...
)
Consumer Group的作用是什么?Rebalance的触发条件有哪些? (实现消费者负载均衡;消费者加入/离开、订阅Topic变化等)
好的,我现在需要回答用户关于Kafka Consumer Group和Rebalance的问题。首先,用户问的是Consumer Group的作用以及Rebalance的触发条件。根据之前的对话历史,用户已经了解了Kafka的基本组件、消息保留策略、顺序性保证等,现在的问题…...

【计算机视觉】OpenCV实战项目:Long-Exposure:基于深度学习的长时间曝光合成技术
Long-Exposure:基于深度学习的长时间曝光合成技术 项目概述与技术背景项目核心功能技术原理 环境配置与安装硬件要求建议详细安装步骤可选组件安装 实战应用指南1. 基础使用:视频转长曝光2. 高级模式:自定义光轨合成3. 批量处理模式 技术实现…...

CentOS 7 安装OpenJDK 17 JRE
CentOS 7 自带的java 版本为:java version "1.8.0_311", 有些软件的运行需要更高的java版本。CentOS 7 自带的默认仓库里 没有 OpenJDK 17,但是 Adoptium 项目(前身 AdoptOpenJDK)提供了稳定的 OpenJDK 17 版…...
C++函数模板与类模板初阶讲解)
C++从入门到实战(十三)C++函数模板与类模板初阶讲解
C从入门到实战(十三)C函数模板与类模板初阶讲解 前言一、为什么需要模板1. 函数重载的问题2. 泛型编程和模板的作用 二、函数模板2.1 函数模板格式2.2 函数模板的原理2.3 函数模板的实例化(1)隐式实例化:(2…...

CentOS服务器中如何解决内存泄漏问题?
内存泄漏并不是“爆炸性内存飙升”,而是程序申请了内存但没有释放,造成系统可用内存逐渐减少,直到用光。 表现形式: 系统空闲内存越来越少;swap频繁被占用;某些服务响应变慢甚至挂掉;重启服务后内存才释放。 内存泄漏的根源在哪…...

【Java项目脚手架系列】第三篇:Spring MVC基础项目脚手架
【Java项目脚手架系列】第三篇:Spring MVC基础项目脚手架 前言 在前面的文章中,我们介绍了Maven基础项目脚手架和JavaWeb基础项目脚手架。今天,我们将介绍Spring MVC项目脚手架,这是一个用于快速搭建Web应用的框架。 什么是Spr…...

chili3d调试笔记12 deepwiki viewport svg雪碧图 camera three.ts
xiangechen/chili3d | DeepWiki viewport阅读 🧠deep 我要把模型投影成dxf导出有什么办法 引用lookat 截图是如何实现的 明天接着搞 ---------------------------------------------------------------- 截图没什么用 搞个工程图模块可能才行 一个文件一行 忘…...
)
tinyrenderer笔记(Shader)
tinyrenderer个人代码仓库:tinyrenderer个人练习代码 前言 现在我们将所有的渲染代码都放在了 main.cpp 中,然而在 OpenGL 渲染管线中,渲染的核心逻辑是位于 shader 中的,下面是 OpenGL 的渲染管线: 蓝色是我们可以自…...
】第1章:Linux 系统基础知识)
【奔跑吧!Linux 内核(第二版)】第1章:Linux 系统基础知识
笨叔 陈悦. 奔跑吧 Linux 内核(第2版) [M]. 北京: 人民邮电出版社, 2020. 文章目录 Linux 系统的发展历史Linux 发行版Red Hat LinuxDebian LinuxSuSE Linux优麒麟 Linux Linux 内核介绍宏内核和微内核Linux 内核概貌 Linux 系统的发展历史 Linux 系统诞…...

Spring + Shiro 整合的核心要点及详细实现说明
在 Spring 项目中集成 Apache Shiro 可以实现轻量级的安全控制(认证、授权、会话管理等)。以下是 Spring Shiro 整合的核心要点及详细实现说明: 一、Spring 与 Shiro 整合的核心组件 组件作用ShiroFilterFactoryBean创建 Shiro 过…...

已经写好论文的AI率降低
视频演示 https://www.bilibili.com/video/BV1v4VpzgEdc 提示词 你是我专门请来的“降维写作助手”,专门干一件事:把 AI 写得太“像 AI”的文字改得更像人写的。我们主要是处理论文、创作类内容,目标就是:不让检测工具一眼识破…...

AI教你学VUE——Deepseek版
一、基础阶段:打好Web开发基础 HTML/CSS基础 学习HTML标签语义化、CSS布局(Flex/Grid)、响应式设计(媒体查询、REM/VW单位)。资源推荐: MDN Web文档(免费):HTML | CSS实战…...
)
卷积神经网络基础(五)
6.3 Softmax-with-Loss 层 我们最后介绍输出层的softmax函数,之前我们知道softmax函数会将输入值正规化之后再输出。在手写数字识别的例子中,softmax层的输出如下: 输入图像通过Affi ne层和ReLU层进行转换,10个输入通过Softmax层…...

Go语言——string、数组、切片以及map
一、string、数组、切片代码 package mainimport "fmt"// 定义结构体 type student struct {id intname stringage intscore float32 }func main() {// 使用var声明切片var slice1 []intslice1 append(slice1, 1)slice1 append(slice1, 2)slice1 append(sl…...

线性回归有截距
In [ ]: ∑ i 1 m ( y i − x i T w ) 2 \sum _{i1}^{m}(y_{i}-x_{i}^{T}w)^{2} i1∑m(yi−xiTw)2 w ^ ( X T X ) − 1 X T y \hat {w}(X^{T}X)^{-1}X^{T}y w^(XTX)−1XTy In [ ]: 1 #如果有截距,求解时,需要梯度下降法求解w 和b …...

【基础】Python包管理工具uv使用全教程
一、uv简介 uv 是由 Astral(前身为 Basis)团队开发的 Python 包安装器和解析器,完全使用 Rust 语言编写。与传统 Python 工具不同,uv 将多个工具的功能整合到一个高性能的解决方案中,旨在提供更现代、更高效的 Python…...
事务(transaction)-上
事务概述 食物是一个最小的工作单元。在数据库当中,事务表示一件完整的事儿。一个业务的完成可能需要多条DML语句共同配合才能完成,例如转账业务,需要执行两条DML语句,先更新张三账户的余额,再更新李四账户的余额&…...

Python训练打卡Day17
无监督算法中的聚类 知识点 聚类的指标聚类常见算法:kmeans聚类、dbscan聚类、层次聚类三种算法对应的流程 实际在论文中聚类的策略不一定是针对所有特征,可以针对其中几个可以解释的特征进行聚类,得到聚类后的类别,这样后续进行解…...

【爬虫】码上爬第6题-倚天剑
堆栈入手: 全部复制的话,注意修改一些必要在地方: 通过s函数来获取请求头的加密参数 通过xxxxoooo来获取解密后的数据 js代码关键点: python代码我推荐使用这个网站: Convert curl commands to code 根据生成的代码…...

自定义SpringBoot Starter-笔记
SpringBoot Starter的介绍参考: Spring Boot Starter简介-笔记-CSDN博客。这里介绍如何自定义一个springBoot Starter。 1. 项目结构 创建一个 Maven 项目,结构如下: custom-spring-boot-starter-demo/ ├── custom-hello-jdk/ # jdk模…...

一周学会Pandas2 Python数据处理与分析-Pandas2数据类型转换操作
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Pandas 提供了灵活的方法来处理数据类型转换,以下是常见操作及代码示例: 1. 查看数据类型 …...

Java中常见的问题
1. SSO中的Cookie/Token生成与安全传递 生成Cookie/Token: Cookie:服务器通过Set-Cookie响应头生成,包含用户ID、过期时间等,需设置HttpOnly和Secure属性防止XSS和中间人攻击。Token(如JWT):使…...

【JEECG】BasicTable内嵌Table表格错位
功能说明: 解决代码生成后,本地内嵌Table表格样式错位。 优化前: 优化后: 解决方法: 对应的List.vue页面增加css样式调整。 <style lang"less" scoped>//内嵌表格margin边距覆盖:deep(.ant-table-…...

人工智能 计算智能模糊逻辑讲解
引言 在计算智能(Computational Intelligence)领域,模糊逻辑(Fuzzy Logic)作为一种处理不确定性与模糊性信息的数学工具,自 1965 年由洛夫特扎德(Lotfi Zadeh)提出以来,…...

基于SSM实现的健身房系统功能实现一
一、前言介绍: 1.1 项目摘要 随着社会的快速发展和人们健康意识的不断提升,健身行业也在迅速扩展。越来越多的人加入到健身行列,健身房的数量也在不断增加。这种趋势使得健身房的管理变得越来越复杂,传统的手工或部分自动化的管…...

spring详解-循环依赖的解决
Spring循环依赖 重点提示: 本文都快写完了,发现“丈夫” 的英文是husband… 在“②有AOP循环依赖” 改过来了,前面用到的位置太多了就没改。我是说怎么idea的hansband英文下面怎么有波浪线。各位能够理解意思就行,英文拼写不要过…...

【大模型面试每日一题】Day 10:混合精度训练如何加速大模型训练?可能出现什么问题?如何解决?
【大模型面试每日一题】Day 10:混合精度训练如何加速大模型训练?可能出现什么问题?如何解决? 📌 题目重现 🌟🌟 面试官:混合精度训练如何加速大模型训练?可能出现什么问…...

[学习]RTKLib详解:rtkcmn.c与rtkpos.c
文章目录 Part A、Rrtkcmn.c一、总体功能二、关键API列表三、核心算法实现四、函数功能与参数说明1. uniqnav2. lsq3. filter4. matmul5. satazel6. ionmapf7. geodist8. timeadd9. dgetrf_ / dgetri_(LAPACK接口) 五、工作流程说明4.1 模块在RTKLib中的…...

cookie/session的关系
什么是cookie,session 我们平时去医院看病时,从进医院那一刻,我们最开始要做的就是挂号(需要我们填写表格,记录一些核心信息,医生会把这些信息录入电脑,并给我办一个就诊卡,卡里面只…...
进程间通信(IPC),管道)
Linux(十四)进程间通信(IPC),管道
一、进程间通信 (一)系统介绍进程间通信 进程间通信(IPC)介绍 小编插入的这篇文章详细介绍了进程间通信的一些内容,大家可以一起学习。 (二)进程间通信的方法 1、管道 2、信号量 3、共享…...

Nmap 工具的详细使用教程
Nmap(Network Mapper)是一款开源且功能强大的网络扫描和安全审计工具。它被广泛用于网络发现、端口扫描、操作系统检测、服务版本探测以及漏洞扫描等。 官方链接: Nmap 官方网站: https://nmap.org/Nmap 官方文档 (英文): https://nmap.org/book/man.h…...

Vue 自定义指令输入校验过滤
/*** 过滤字符串* param {*} filterCharRule* param {*} newVal* returns*/ function filterCharForValue(filterCharRule, newVal) {if(!filterCharRule || !newVal) returnconst isArray filterCharRule instanceof Arrayconst isRegExp filterCharRule instanceof RegExpi…...
基于qt5.15.2+mingw64+opengl实现纹理贴图)
OpenGl实战笔记(2)基于qt5.15.2+mingw64+opengl实现纹理贴图
一、作用原理 1、作用:将一张图片(纹理)映射到几何体表面,提升视觉真实感,不增加几何复杂度。 2、原理:加载图片为纹理 → 上传到 GPU;为顶点设置纹理坐标(如 0~1 范围)&…...
)
tinyrenderer笔记(透视矫正)
tinyrenderer个人代码仓库:tinyrenderer个人练习代码 引言 还要从上一节知识说起,在上一节中我为了调试代码,换了一个很简单的正方形 obj 模型,配上纹理贴图与法线贴图进行渲染,得了下面的结果: what&…...

c++类【发展】
类的静态成员(用static声明的成员),在声明之外用例单独的语句进行初始化,初始化时,不再需要用static进行限定。在方法文件中初始化。以防重复。 特殊成员函数 复制构造函数: 当使用一个对象来初始化另一个对象…...

玛格丽特鸡尾酒评鉴,玛格丽特酒的寓意和象征
玛格丽特鸡尾酒会有独特的风味,而且还会有一个比较吸引人的背后故事。在目前的鸡尾酒界就会占据着很重要的地位,不仅是味蕾的盛宴,同样也会拥有深厚的情感。 玛格丽特由龙舌兰酒、柠檬汁和君度橙酒调制而成,将三者巧妙地结合在一起…...

关于Java多态简单讲解
面向对象程序设计有三大特征,分别是封装,继承和多态。 这三大特性相辅相成,可以使程序员更容易用编程语言描述现实对象。 其中多态 多态是方法的多态,是通过子类通过对父类的重写,实现不同子类对同一方法有不同的实现…...

SecureCrt设置显示区域横列数
1. Logical rows //逻辑行调显示区域高度的 一般超过50就全屏了 2. Logical columns //逻辑列调显示区域宽度的 3. Scrollback buffer //缓冲区大小...
)
【PhysUnits】1 SI Prefixes 实现解析(prefix.rs)
一、源码 // prefix.rs //! SI Prefixes (国际单位制词头) //! //! 提供所有标准SI词头用于单位转换,仅处理10的幂次 //! //! Provides all standard SI prefixes for unit conversion, handling only powers of 10.use typenum::{Z0, P1, P2, P3, P6, P9, P12, …...

【Python】--实现多进程
import multiprocessing import time # 1.定义好函数 # codeing def coding():for i in range(10):print(f正在编写第{i}行代码)time.sleep(0.2)# music def music():for i in range(10):print(f正在听第{i}首歌曲)time.sleep(0.2)单任务 # 单任务--时间为4s多 if __name__ _…...
)
计算机视觉与深度学习 | 基于数字图像处理的裂缝检测与识别系统(matlab代码)
🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅 基于数字图像处理的裂缝检测与识别系统 🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦**系统架构设计****1. 图像预处理**目标:消除噪声+增强裂缝特征**2. 图像分割**目标:提取裂缝区域**3. 特征…...

嵌入式MCU语音识别算法及实现方案
在嵌入式MCU(微控制器单元)中实现语音识别,由于资源限制(如处理能力、内存、功耗等),通常需要轻量级算法和优化技术。以下是常见的语音识别算法及实现方案: 一、传统语音识别算法 动态时间规整&…...

【C++核心技术深度解析:从继承多态到STL容器 】
一、C继承机制:代码复用与层次设计 1. 继承基础概念 什么是继承? 继承是面向对象编程的核心机制,通过class Derived : public Base让子类(派生类)复用父类(基类)的属性和方法,同时…...