Python训练打卡Day17
无监督算法中的聚类
知识点
- 聚类的指标
- 聚类常见算法:kmeans聚类、dbscan聚类、层次聚类
- 三种算法对应的流程
实际在论文中聚类的策略不一定是针对所有特征,可以针对其中几个可以解释的特征进行聚类,得到聚类后的类别,这样后续进行解释也更加符合逻辑。
聚类的流程
- 标准化数据
- 选择合适的算法,根据评估指标调参( )
- 将聚类后的特征添加到原数据中
- 原则t-sne或者pca进行2D或3D可视化
KMeans 和层次聚类的参数是K值,选完k指标就确定DBSCAN 的参数是 eps 和min_samples,选完他们出现k和评估指标
以及层次聚类的 linkage准则等都需要仔细调优。
除了经典的评估指标,还需要关注聚类出来每个簇对应的样本个数,避免太少没有意义。
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaled#聚类评估指标
1.轮廓系数(Silhouette Score)
定义:轮廓系数衡量每个样本与其所属簇的紧密程度以及与最近其他簇的分离程度。
取值范围:轮廓系数越接近1,表示样本与其所属簇内其他样本很近,与其他簇很远,聚类效果越好。轮廓系数越接近-1,表示样本与其所属簇内样本较远,与其他簇较近,聚类效果越差(可能被错误分类)。轮廓系数接近 0,表示样本在簇边界附近,聚类效果无明显好坏。
选择轮廓系数最高的 `k` 值作为最佳簇数量
2. CH 指数 (Calinski-Harabasz Index)
定义:CH 指数是簇间分散度与簇内分散度之比,用于评估簇的分离度和紧凑度。
取值范围:CH 指数越大,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。没有固定的上限,值越大越好。选择 CH 指数最高的 `k` 值作为最佳簇数量。
3. DB 指数 (Davies-Bouldin Index)
定义:DB 指数衡量簇间距离与簇内分散度的比值,用于评估簇的分离度和紧凑度
取值范围:DB 指数越小,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。没有固定的上限,值越小越好。选择 DB 指数最低的 `k` 值作为最佳簇数量。
轮廓系数:可以比喻为一个人在聚会中,和同组的人是否亲近,而与其他组的人是否疏远。如果这个人在自己组里很合群,且离其他组的人很远,那么他的轮廓系数就高,说明分组合理。
CH指数:可以用班级之间的比较。比如,每个班级内部的学生成绩比较接近(紧凑),而不同班级之间的平均成绩差异较大(分离),这样CH指数就高,说明分班效果好。
DB指数:可以想象成不同岛屿之间的距离和
K-means算法
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = []
silhouette_scores = []
ch_scores = []
db_scores = []for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans_labels = kmeans.fit_predict(X_scaled)inertia_values.append(kmeans.inertia_) # 惯性(肘部法则)silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()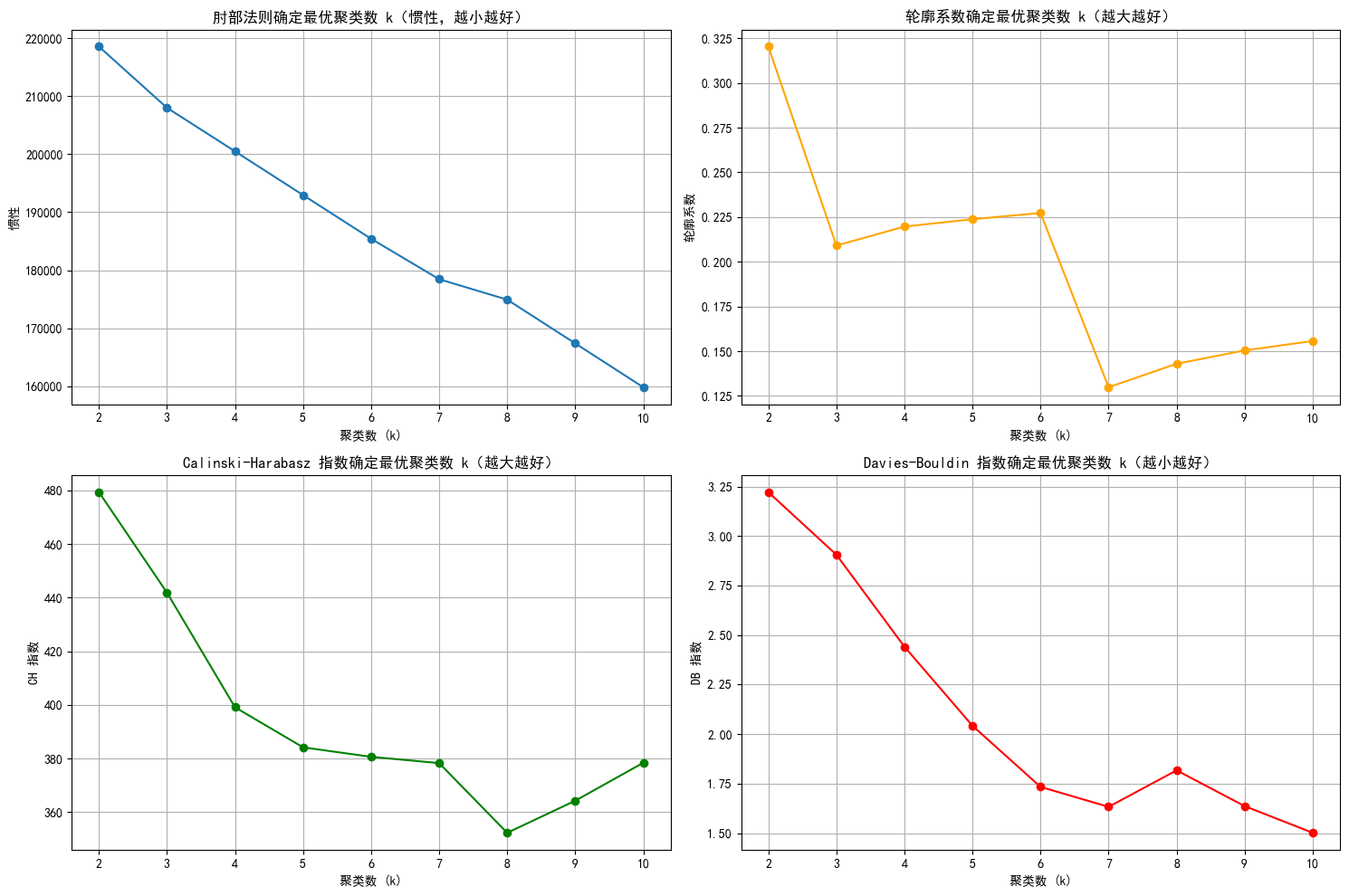
1. 肘部法则图: 找下降速率变慢的拐点,这里都差不多
2. 轮廓系数图:找局部最高点,这里选6不能选7
3. CH指数图: 找局部最高点,这里选7之前的都还行
4. DB指数图:找局部最低点,这里选6 7 9 10都行
综上,选择6比较合适。
# 提示用户选择 k 值
selected_k = 6# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())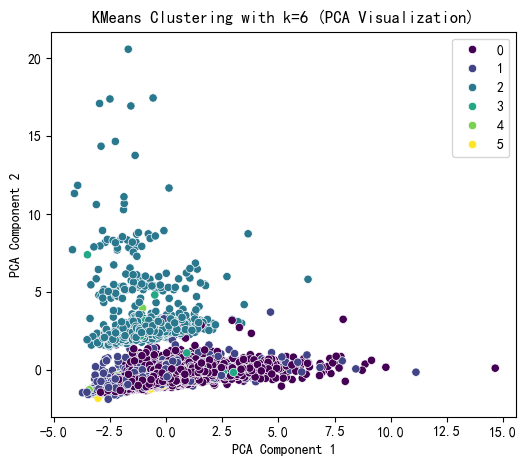
DBCSAN聚类算法
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)results_df# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()
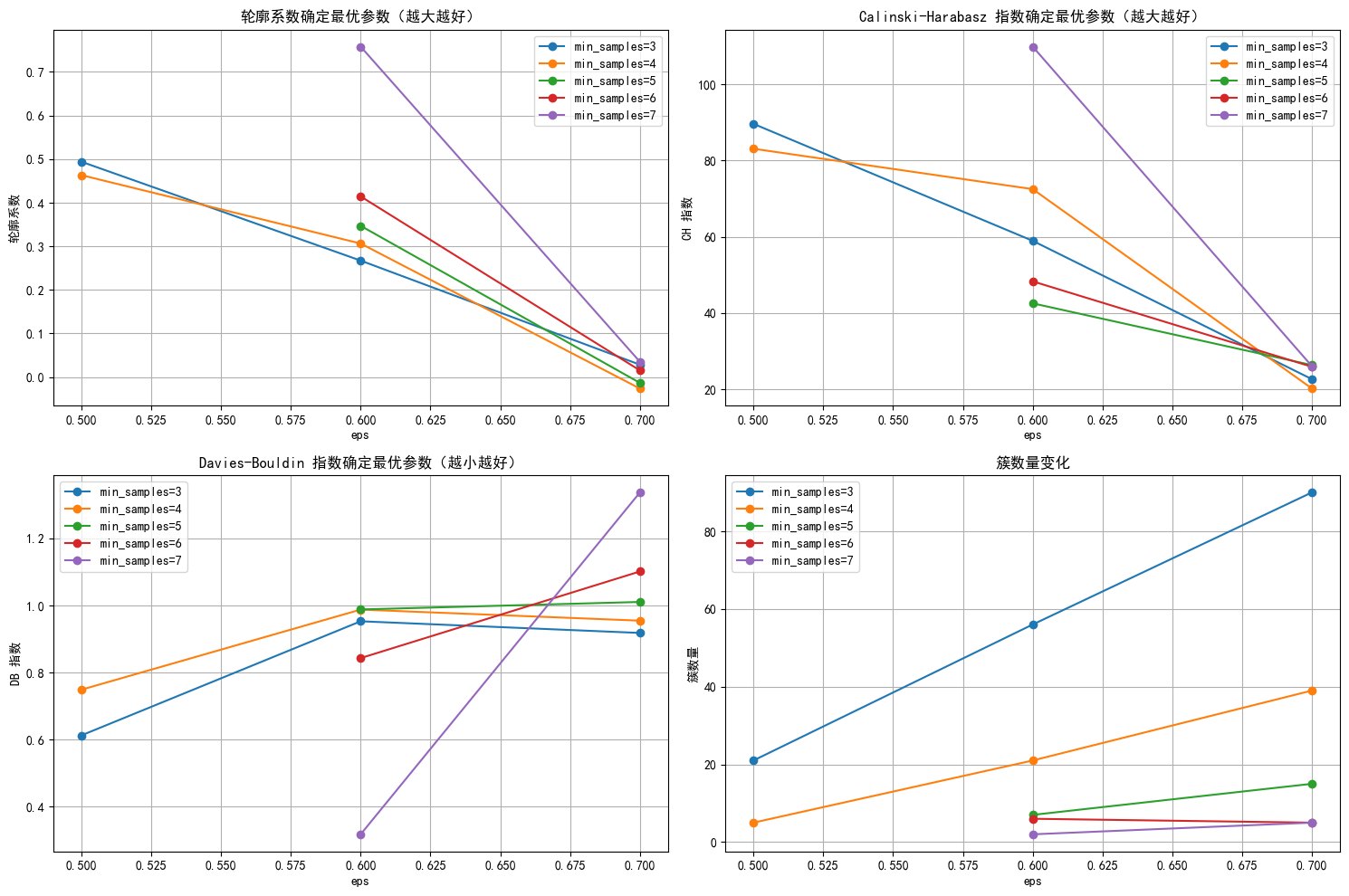
# 选择 eps 和 min_samples 值(根据图表选择最佳参数)
selected_eps = 0.6 # 根据图表调整
selected_min_samples = 6 # 根据图表调整# 使用选择的参数进行 DBSCAN 聚类
dbscan = DBSCAN(eps=selected_eps, min_samples=selected_min_samples)
dbscan_labels = dbscan.fit_predict(X_scaled)
X['DBSCAN_Cluster'] = dbscan_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# DBSCAN 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=dbscan_labels, palette='viridis')
plt.title(f'DBSCAN Clustering with eps={selected_eps}, min_samples={selected_min_samples} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 DBSCAN 聚类标签的分布
print(f"DBSCAN Cluster labels (eps={selected_eps}, min_samples={selected_min_samples}) added to X:")
print(X[['DBSCAN_Cluster']].value_counts())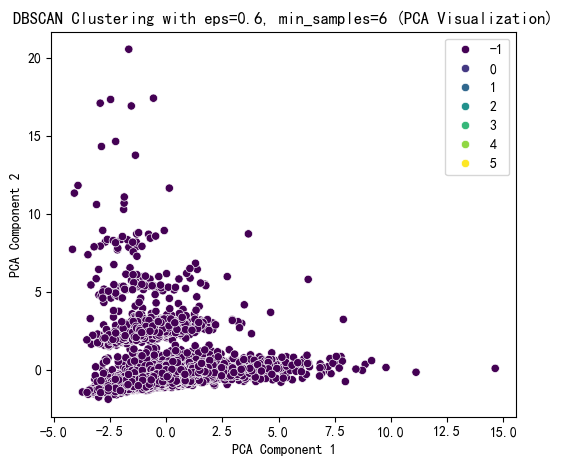
根据代码运行结果可以判断算法合不合适。
层次聚类
import numpy as np
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 评估不同 n_clusters 下的指标
n_clusters_range = range(2, 11) # 测试簇数量从 2 到 10
silhouette_scores = []
ch_scores = []
db_scores = []for n_clusters in n_clusters_range:agglo = AgglomerativeClustering(n_clusters=n_clusters, linkage='ward') # 使用 Ward 准则合并簇agglo_labels = agglo.fit_predict(X_scaled)# 计算评估指标silhouette = silhouette_score(X_scaled, agglo_labels)ch = calinski_harabasz_score(X_scaled, agglo_labels)db = davies_bouldin_score(X_scaled, agglo_labels)silhouette_scores.append(silhouette)ch_scores.append(ch)db_scores.append(db)print(f"n_clusters={n_clusters}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# 绘制评估指标图
plt.figure(figsize=(15, 5))# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()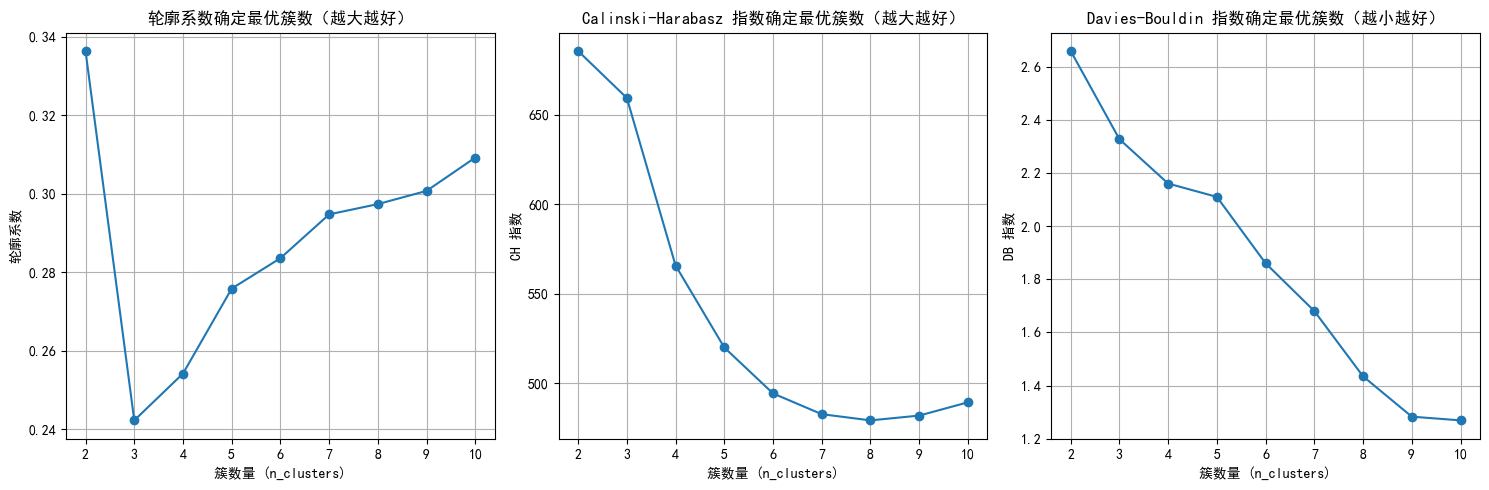
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts())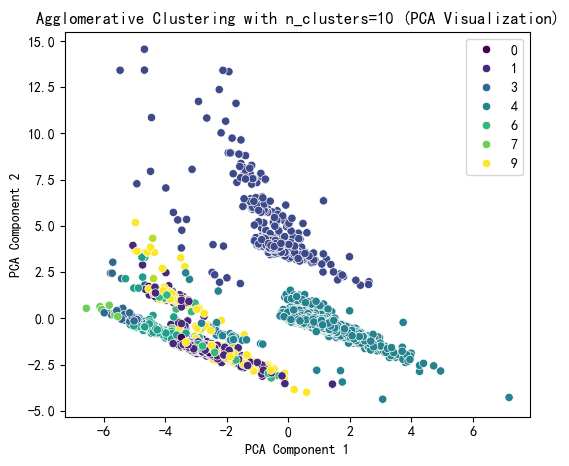
# 层次聚类的树状图可视化
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt# 假设 X_scaled 是标准化后的数据
# 计算层次聚类的链接矩阵
Z = hierarchy.linkage(X_scaled, method='ward') # 'ward' 是常用的合并准则# 绘制树状图
plt.figure(figsize=(10, 6))
hierarchy.dendrogram(Z, truncate_mode='level', p=3) # p 控制显示的层次深度
# hierarchy.dendrogram(Z, truncate_mode='level') # 不用p这个参数,可以显示全部的深度
plt.title('Dendrogram for Agglomerative Clustering')
plt.xlabel('Cluster Size')
plt.ylabel('Distance')
plt.show()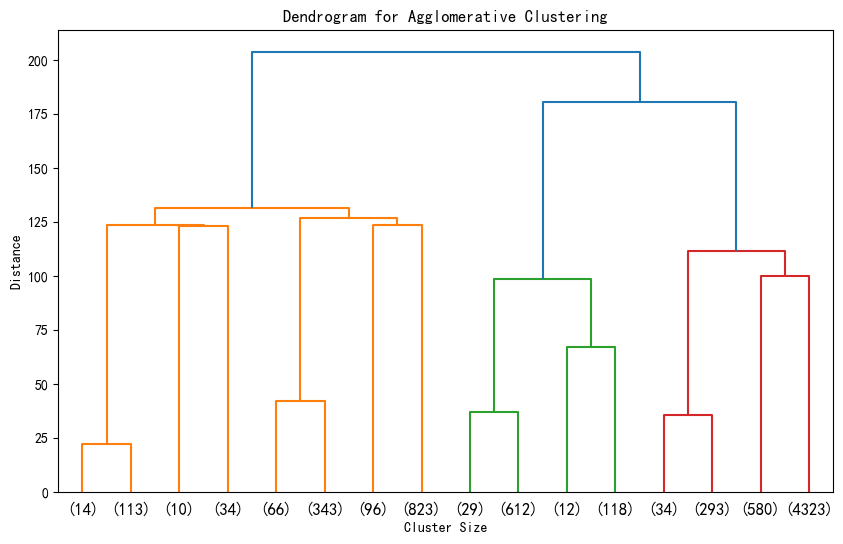
1. 横坐标代表每个簇对应样本的数据,这些样本数目加一起是整个数据集的样本数目。这是从上到下进行截断,p=3显示最后3层,不用p这个参数会显示全部。
2. 纵轴代表距离 ,反映了在聚类过程中,不同样本或簇合并时的距离度量值。距离越大,意味着两个样本或簇之间的差异越大;距离越小,则差异越小。
总结:
1. 聚类算法的原理
- 核心思想:把相似的东西分到同一组,不相似的隔开,不需要提前知道分组规则(无监督学习)。
- 生活比喻:
- 图书馆整理书籍:没有标签分类,管理员根据书名、主题自动把相似的书放在同一书架。
- 超市整理货架:把饮料、零食、日用品分开摆放,顾客一眼能找到同类商品。
- 关键问题:
- 什么是“相似”?→ 用距离(如欧氏距离)或密度衡量。
- 分多少组?→ 有些算法需指定组数(如K-means),有些自动判断(如DBSCAN)。
2. K-means算法
- 核心思想:“物以类聚,人以群分”,先随便画几个圈,不断调整圈的位置,直到圈内人最亲密。
- 通俗比喻:
- 披萨店分区:老板想给不同区域的客人送不同口味的披萨。
- 随机选几个中心点(比如东区、西区、南区)。
- 每个客人选择离自己最近的中心点,形成临时分组。
- 根据每个组的客人位置,重新计算中心点(比如东区客人往北移了,中心点也北移)。
- 重复调整,直到中心点不再变化。
- 披萨店分区:老板想给不同区域的客人送不同口味的披萨。
- 优缺点:
- ✅ 简单高效,适合均匀分布的球形数据。
- ❌ 要提前指定分组数(K值),对异常值敏感(比如有个客人住在荒郊野外,影响中心点)。
3. DBSCAN算法
- 核心思想:“抱团取暖,远离孤岛”,通过密度找核心人群,边缘和孤立的点直接忽略。
- 通俗比喻:
- 岛屿探险:
- 核心点:人群密集的岛屿(周围有足够多的邻居)。
- 边界点:住在岛屿边缘的人(依赖核心点存在)。
- 噪声点:海上孤零零的漂流者(没人搭理)。
- 规则:从一个核心点出发,把周围可达的邻居(包括其他核心点)拉进同一群岛。
- 岛屿探险:
- 优缺点:
- ✅ 能发现任意形状的簇(比如长条形的河流居民区),自动过滤噪声。
- ❌ 对密度参数敏感(比如“多少人才算密集?”需要手动调参)。
4. 层次聚类
- 核心思想:“合并小团体,形成大组织”,像搭积木一样逐层构建分组关系。
- 通俗比喻:
- 自底向上(聚合式):
- 每个人自成一组。
- 找距离最近的两个组合并(比如张三和李四)。
- 重复合并,直到所有人在一个大组。
结果形成“树状图”(类似家族族谱)。
- 自顶向下(分裂式):
- 所有人先在一个大组。
- 不断分裂成更小的组,直到每人单独一组。
- 自底向上(聚合式):
- 优缺点:
- ✅ 不需要指定分组数,可视化直观(树状图)。
- ❌ 计算量大(数据多时很慢),一旦合并/分裂不可逆。
@浙大疏锦行
相关文章:

Python训练打卡Day17
无监督算法中的聚类 知识点 聚类的指标聚类常见算法:kmeans聚类、dbscan聚类、层次聚类三种算法对应的流程 实际在论文中聚类的策略不一定是针对所有特征,可以针对其中几个可以解释的特征进行聚类,得到聚类后的类别,这样后续进行解…...

【爬虫】码上爬第6题-倚天剑
堆栈入手: 全部复制的话,注意修改一些必要在地方: 通过s函数来获取请求头的加密参数 通过xxxxoooo来获取解密后的数据 js代码关键点: python代码我推荐使用这个网站: Convert curl commands to code 根据生成的代码…...

自定义SpringBoot Starter-笔记
SpringBoot Starter的介绍参考: Spring Boot Starter简介-笔记-CSDN博客。这里介绍如何自定义一个springBoot Starter。 1. 项目结构 创建一个 Maven 项目,结构如下: custom-spring-boot-starter-demo/ ├── custom-hello-jdk/ # jdk模…...

一周学会Pandas2 Python数据处理与分析-Pandas2数据类型转换操作
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Pandas 提供了灵活的方法来处理数据类型转换,以下是常见操作及代码示例: 1. 查看数据类型 …...

Java中常见的问题
1. SSO中的Cookie/Token生成与安全传递 生成Cookie/Token: Cookie:服务器通过Set-Cookie响应头生成,包含用户ID、过期时间等,需设置HttpOnly和Secure属性防止XSS和中间人攻击。Token(如JWT):使…...

【JEECG】BasicTable内嵌Table表格错位
功能说明: 解决代码生成后,本地内嵌Table表格样式错位。 优化前: 优化后: 解决方法: 对应的List.vue页面增加css样式调整。 <style lang"less" scoped>//内嵌表格margin边距覆盖:deep(.ant-table-…...

人工智能 计算智能模糊逻辑讲解
引言 在计算智能(Computational Intelligence)领域,模糊逻辑(Fuzzy Logic)作为一种处理不确定性与模糊性信息的数学工具,自 1965 年由洛夫特扎德(Lotfi Zadeh)提出以来,…...

基于SSM实现的健身房系统功能实现一
一、前言介绍: 1.1 项目摘要 随着社会的快速发展和人们健康意识的不断提升,健身行业也在迅速扩展。越来越多的人加入到健身行列,健身房的数量也在不断增加。这种趋势使得健身房的管理变得越来越复杂,传统的手工或部分自动化的管…...

spring详解-循环依赖的解决
Spring循环依赖 重点提示: 本文都快写完了,发现“丈夫” 的英文是husband… 在“②有AOP循环依赖” 改过来了,前面用到的位置太多了就没改。我是说怎么idea的hansband英文下面怎么有波浪线。各位能够理解意思就行,英文拼写不要过…...

【大模型面试每日一题】Day 10:混合精度训练如何加速大模型训练?可能出现什么问题?如何解决?
【大模型面试每日一题】Day 10:混合精度训练如何加速大模型训练?可能出现什么问题?如何解决? 📌 题目重现 🌟🌟 面试官:混合精度训练如何加速大模型训练?可能出现什么问…...

[学习]RTKLib详解:rtkcmn.c与rtkpos.c
文章目录 Part A、Rrtkcmn.c一、总体功能二、关键API列表三、核心算法实现四、函数功能与参数说明1. uniqnav2. lsq3. filter4. matmul5. satazel6. ionmapf7. geodist8. timeadd9. dgetrf_ / dgetri_(LAPACK接口) 五、工作流程说明4.1 模块在RTKLib中的…...

cookie/session的关系
什么是cookie,session 我们平时去医院看病时,从进医院那一刻,我们最开始要做的就是挂号(需要我们填写表格,记录一些核心信息,医生会把这些信息录入电脑,并给我办一个就诊卡,卡里面只…...
进程间通信(IPC),管道)
Linux(十四)进程间通信(IPC),管道
一、进程间通信 (一)系统介绍进程间通信 进程间通信(IPC)介绍 小编插入的这篇文章详细介绍了进程间通信的一些内容,大家可以一起学习。 (二)进程间通信的方法 1、管道 2、信号量 3、共享…...

Nmap 工具的详细使用教程
Nmap(Network Mapper)是一款开源且功能强大的网络扫描和安全审计工具。它被广泛用于网络发现、端口扫描、操作系统检测、服务版本探测以及漏洞扫描等。 官方链接: Nmap 官方网站: https://nmap.org/Nmap 官方文档 (英文): https://nmap.org/book/man.h…...

Vue 自定义指令输入校验过滤
/*** 过滤字符串* param {*} filterCharRule* param {*} newVal* returns*/ function filterCharForValue(filterCharRule, newVal) {if(!filterCharRule || !newVal) returnconst isArray filterCharRule instanceof Arrayconst isRegExp filterCharRule instanceof RegExpi…...
基于qt5.15.2+mingw64+opengl实现纹理贴图)
OpenGl实战笔记(2)基于qt5.15.2+mingw64+opengl实现纹理贴图
一、作用原理 1、作用:将一张图片(纹理)映射到几何体表面,提升视觉真实感,不增加几何复杂度。 2、原理:加载图片为纹理 → 上传到 GPU;为顶点设置纹理坐标(如 0~1 范围)&…...
)
tinyrenderer笔记(透视矫正)
tinyrenderer个人代码仓库:tinyrenderer个人练习代码 引言 还要从上一节知识说起,在上一节中我为了调试代码,换了一个很简单的正方形 obj 模型,配上纹理贴图与法线贴图进行渲染,得了下面的结果: what&…...

c++类【发展】
类的静态成员(用static声明的成员),在声明之外用例单独的语句进行初始化,初始化时,不再需要用static进行限定。在方法文件中初始化。以防重复。 特殊成员函数 复制构造函数: 当使用一个对象来初始化另一个对象…...

玛格丽特鸡尾酒评鉴,玛格丽特酒的寓意和象征
玛格丽特鸡尾酒会有独特的风味,而且还会有一个比较吸引人的背后故事。在目前的鸡尾酒界就会占据着很重要的地位,不仅是味蕾的盛宴,同样也会拥有深厚的情感。 玛格丽特由龙舌兰酒、柠檬汁和君度橙酒调制而成,将三者巧妙地结合在一起…...

关于Java多态简单讲解
面向对象程序设计有三大特征,分别是封装,继承和多态。 这三大特性相辅相成,可以使程序员更容易用编程语言描述现实对象。 其中多态 多态是方法的多态,是通过子类通过对父类的重写,实现不同子类对同一方法有不同的实现…...

SecureCrt设置显示区域横列数
1. Logical rows //逻辑行调显示区域高度的 一般超过50就全屏了 2. Logical columns //逻辑列调显示区域宽度的 3. Scrollback buffer //缓冲区大小...
)
【PhysUnits】1 SI Prefixes 实现解析(prefix.rs)
一、源码 // prefix.rs //! SI Prefixes (国际单位制词头) //! //! 提供所有标准SI词头用于单位转换,仅处理10的幂次 //! //! Provides all standard SI prefixes for unit conversion, handling only powers of 10.use typenum::{Z0, P1, P2, P3, P6, P9, P12, …...

【Python】--实现多进程
import multiprocessing import time # 1.定义好函数 # codeing def coding():for i in range(10):print(f正在编写第{i}行代码)time.sleep(0.2)# music def music():for i in range(10):print(f正在听第{i}首歌曲)time.sleep(0.2)单任务 # 单任务--时间为4s多 if __name__ _…...
)
计算机视觉与深度学习 | 基于数字图像处理的裂缝检测与识别系统(matlab代码)
🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅🍅 基于数字图像处理的裂缝检测与识别系统 🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦🥦**系统架构设计****1. 图像预处理**目标:消除噪声+增强裂缝特征**2. 图像分割**目标:提取裂缝区域**3. 特征…...

嵌入式MCU语音识别算法及实现方案
在嵌入式MCU(微控制器单元)中实现语音识别,由于资源限制(如处理能力、内存、功耗等),通常需要轻量级算法和优化技术。以下是常见的语音识别算法及实现方案: 一、传统语音识别算法 动态时间规整&…...

【C++核心技术深度解析:从继承多态到STL容器 】
一、C继承机制:代码复用与层次设计 1. 继承基础概念 什么是继承? 继承是面向对象编程的核心机制,通过class Derived : public Base让子类(派生类)复用父类(基类)的属性和方法,同时…...

【C/C++】new关键字解析
📘 C 中 new 关键字详解笔记 🔹 什么是 new? new 是 C 中用于动态内存分配的关键字,它在堆内存中为对象或变量分配空间,并返回对应类型的指针。 与 C 语言中的 malloc 相比,new 更安全、更方便ÿ…...

C++高性能内存池
目录 1. 项目介绍 1. 这个项目做的是什么? 2. 该项目要求的知识储备 2. 什么是内存池 1. 池化技术 2. 内存池 3. 内存池主要解决的问题 4.malloc 3. 先设计一个定长的内存池 4.高并发内存池 -- 整体框架设计 5. 高并发内存池 -- thread cache 6. 高并发内存池 -- …...

chili3d调试笔记12 deepwiki viewport
xiangechen/chili3d | DeepWiki viewport阅读 🧠deep 我要把模型投影成dxf导出有什么办法 引用lookat 截图是如何实现的 明天接着搞 ----------------------------------------------------------------...

前端取经路——JavaScript修炼:悟空的九大心法
大家好,我是老十三,一名前端开发工程师。JavaScript如同孙悟空的七十二变,变化多端却又充满威力。本篇文章我将带你攻克JS中最令人头疼的九大难题,从闭包陷阱到原型链继承,从异步编程到性能优化。每个难题都配有实战代…...

从零实战:在Xilinx Zynq PS端移植VxWorks 6.9系统
一、环境准备与工具链搭建 1.1 硬件配置清单 开发板: Zynq-7000系列(推荐ZedBoard或ZCU102)调试工具: USB-JTAG调试器(如Xilinx Platform Cable USB II)存储介质: SD卡(建议Class 10以上)1.2 软件环境 工具版本作用Vivado2022.1FPGA硬件设计Vitis2022.1系统集成开发Wind…...

网工实验——RIP配置
网络拓扑图 配置 1.为每台设备配置ip地址 AR4 <Huawei>u t m <Huawei>sys [Huawei]sysname AR4 [AR4]int g0/0/0 [AR4-GigabitEthernet0/0/0]ip address 172.16.1.1 24 [AR4-GigabitEthernet0/0/0]q#下面配置换回口,模拟网 [AR4]int LoopBack 0 [AR4…...

前端流行框架Vue3教程:14. 组件传递Props效验
(4) 组件传递Props效验 Vue组件可以更细致地声明对传入的props的校验要求 ComponentA.vue <script> import ComponentB from ./ComponentB.vue; export default {components: {ComponentB},data() {return {title: 标题}} } </script> <template><h3&g…...

电子电器架构 --- 网关ECU中采用多CPU解决方案来实现网关功能
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

关于tftpboot的用法
TFTPBOOT 是一个常用于嵌入式系统或网络设备中的命令,用于通过 TFTP 协议从网络上启动操作系统镜像或引导文件。这个命令通常在设备启动时执行,允许设备通过网络从 TFTP 服务器下载启动镜像或其他必要的文件,而不需要从本地存储中启动。 一般…...

团队协作的润滑剂——GitHub与协作流程
各位代码界的社交恐惧症患者们,今天我们要聊的是如何假装自己很会团队协作——使用GitHub!这就像程序员版的"相亲平台",只不过在这里,你展示的不是自拍和收入,而是代码和commit记录(后者往往更令…...

数据库复习
DML操作包括: SELECT INSERT UPDATE DELETE MERGE 返回字符串长度:length() 查询记录:SELECT 增(INSERT)、删(DELETE)、改(UPDATE)、查(SELECT&#…...

AI与机器学习、深度学习在气候变化预测中的应用与实践
前言: 全球气候变化是现代社会面临的最重要的环境挑战之一,影响了气温、降水、海平面、农业、生态系统等多个方面。气候变化的驱动因素主要包括温室气体排放、气溶胶浓度、火灾频发、海冰融化、叶绿素变化、农业变化和生态环境变化等。这些因素在全球范围…...

Laravel 12 基于 EMQX 实现 MQTT 消息发送与接收
Laravel 12 基于 EMQX 实现 MQTT 消息发送与接收 要在 Laravel 12 中实现基于 EMQX 的 MQTT 消息发送与接收,你可以按照以下步骤操作: 1. 安装必要的依赖包 首先安装 MQTT 客户端库: composer require php-mqtt/client2. 配置 EMQX 连接 …...

论广告系统对存算分离架构的应用
辅助论点 辅助论点一:存算分离架构起源于数据库领域,并不是在线系统。 存算分离的架构源于Google的Spanner数据库,这个数据库采用了KV做存储层,OLAP做计算层的分离式设计,其目的是能快速伸缩计算资源,且节…...
)
create-vue搭建Vue3项目(Vue3学习2)
一、认识create-vue image.png 二、create-vue搭建Vue3项目 image.png image.png 依次执行npm install 和npm run dev即可运行项目 image.png image.png © 著作权归作者所有,转载或内容合作请联系作者 喜欢的朋友记得点赞、收藏、关注哦!!ÿ…...

NHDEEP档案管理系统功能介绍
NHDEEP档案管理系统单机版专注于提高档案管理效率,无需网络连接即可独立运作,确保数据的安全与私密性。无论是机关单位的常规档案工作,还是工程、基建项目的特殊档案管理需求,系统都能提供全面的解决方案。系统支持信创环境。 核心…...

【C++】C++中的命名/名字/名称空间 namespace
C中的命名/名字/名称空间 namespace 1、问题引入2、概念3、作用4、格式5、使用命名空间中的成员5.1 using编译指令( 引进整个命名空间) ---将这个盒子全部打开5.2 using声明使特定的标识符可用(引进命名空间的某个成员) ---将这个盒子中某个成员的位置打…...

游戏引擎学习第260天:在性能分析器中实现钻取功能
昨天那个帧内存满之后触发段错误实在没找到什么原因导致的 继续研究一下为什么导致的 内存不够进来释放frame 释放frame 应该会给DebugState->FirstFreeStoredEvent 赋值吧 这段宏定义: #define FREELIST_DEALLOCATE(Pointer, FreeListPointer) \if(Pointer) {…...

人工智能100问☞第15问:人工智能的常见分类方式有哪些?
目录 一、通俗解释 二、专业解析 三、权威参考 人工智能的常见分类方式包括:按智能水平(弱人工智能、通用人工智能、超级人工智能)、按技术原理(生成式AI、判别式AI、强化学习)、按功能目标(生成内容、优化决策)、按应用领域(自然语…...
)
JavaSE核心知识点01基础语法01-04(数组)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点01基础语法01-04࿰…...
的运营实力与服务解析)
抖音代播领航者——品融电商(PINKROON)的运营实力与服务解析
抖音代播领航者——品融电商(PINKROON)的运营实力与服务解析 在兴趣电商高速发展的背景下,杭州品融品牌管理有限公司(PINKROON)凭借其全域增长方法论与抖音生态的深度布局,成为众多品牌首选的抖音代播服务商…...

LeetCode 790 多米诺和托米诺平铺 题解
对于本题不去看LeetCode的评论区和题解很难想到如何去dp,毕竟就算再怎么枚举也很难找到适用于面向结果的规律。所以对于题解我建议大家还是去看一下灵神给的题解,以下是灵神汇总的图,如果能看懂的话,对于解决题目有很大的帮助。 根…...
)
力扣-hot100 (缺失的第一个正数)
41. 缺失的第一个正数 困难 给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。 示例 1: 输入:nums [1,2,0] 输出:3 解释ÿ…...
)
Electrolink信息泄露(CVE-2025-28228)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...