Diffusion Transformer(DiT)
扩散模型的核心思想:Diffusion Models是一种受到非平衡热力学启发的生成模型,其核心思想是通过模拟扩散过程来逐步添加噪声到数据中,并随后学习反转这个过程以从噪声中构建出所需的数据样本。
DiT的架构:DiT架构基于Latent Diffusion Model(LDM)框架,采用Vision Transformer(ViT)作为主干网络,并通过调整ViT的归一化来构建可扩展的扩散模型。如下图所示:

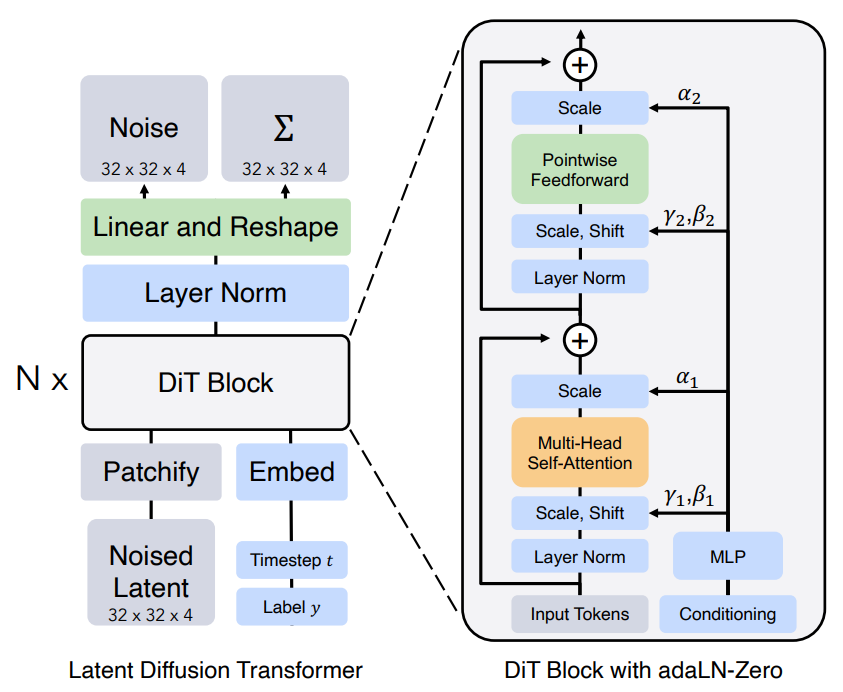
The Diffusion Transformer (DiT) architecture
- Diffusion Model 是基础理论框架(如DDPM)。
- LDM 是 Diffusion Model 的高效改进版,引入 潜在空间(Latent Space) 降低计算成本。
- DiT 是新一代架构,用 Transformer 替代 UNet,代表扩散模型的未来方向(如SD3、Sora)。
处理过程
DiT的处理过程主要包括以下几个阶段:
- 数据准备和预处理:将输入的图像或视频数据转换为模型可以处理的格式。例如,对于图像,会将其切分成固定大小的patches(小块),然后将这些patches转换为特征向量;对于视频,先通过视频压缩网络(视频编码器)将视频数据压缩到一个低维度潜在空间中,得到视频内容的紧凑表征,再将压缩后的视频表征分解成一系列的时空补丁,这些补丁被视为Transformer模型的输入tokens。
- 噪声引入:在数据预处理后的特征向量上逐步引入噪声,形成一个噪声增加的扩散过程。这个过程通常遵循一定的数学分布,如高斯分布,噪声的程度由一个时间步长变量 t t t控制。在 t = 0 t = 0 t=0时, x 0 x_0 x0代表原始图像或视频的潜在表示;随着 t t t逐渐增大,数据中的噪声逐渐增多,到 t = 1000 t = 1000 t=1000时, x 1000 x_{1000} x1000几乎是纯噪声。
- 模型训练:使用引入了噪声的特征向量作为输入,训练DiT模型。模型的目标是学习如何逆转噪声增加的过程,即从噪声数据恢复出原始数据。DiT接受带有噪声的补丁和相应的条件信息(如文本提示)作为输入,通过训练学习去除噪声并恢复出原始的“干净”补丁。在训练过程中,通常会使用损失函数来衡量模型预测的噪声与实际添加的噪声之间的差异,然后通过优化算法来调整模型的参数,以最小化损失函数。
- 图像或视频生成:在模型训练完成后,可以通过输入噪声数据(或随机生成的噪声)到模型中,经过模型的处理后生成新的图像或视频。具体来说,从纯噪声开始,按照一定的采样策略,逐步利用模型去除噪声,生成接近原始数据的样本。例如,从一个随机的噪声向量开始,通过多次迭代,每次迭代都根据当前的噪声状态和模型的参数来预测下一个更接近“干净”状态的向量,最终得到生成的图像或视频的潜在表示。如果是视频生成,还需要将恢复的“干净”时空补丁重新组合成连贯的视频。
- 输出调整:生成的图像或视频内容可以根据需要调整大小和格式,以适应不同的分辨率、持续时间和宽高比需求。例如,调整图像的分辨率以适配不同的显示设备,或者调整视频的时长和宽高比以满足特定的应用场景。
上述过程既包含训练,也包含推理。具体如下:
- 训练:上述内容中的“数据准备和预处理”“噪声引入”以及“模型训练”步骤属于训练过程。在训练阶段,模型通过学习大量带有噪声的数据以及相应的条件信息,来掌握去除噪声、恢复原始数据的能力,不断调整自身的参数以最小化损失函数,从而逐渐优化模型的性能。
- 推理:“图像或视频生成”和“输出调整”步骤属于推理过程。在推理阶段,模型利用训练好的参数,对输入的噪声数据(或随机生成的噪声)进行处理,逐步生成新的图像或视频,并根据实际需求对生成的结果进行调整。
详细步骤
Diffusion Transformers (DiTs) 是一种结合了扩散模型和Transformer架构的新型生成模型,其处理过程主要分为以下几个关键步骤:
1. 输入预处理(Patchify)
Patchify是将空间输入转换为序列化Token的核心预处理层。
DiT基于Vision Transformer (ViT)架构,首先将输入的潜在表示(latent representation)分割成不重叠的图像块(patches)。
- 输入图像 x ∈ R H × W × C x \in \mathbb{R}^{H \times W \times C} x∈RH×W×C 被划分为非重叠的 P × P P \times P P×P patches,展平为序列 z ∈ R N × ( P 2 ⋅ C ) z \in \mathbb{R}^{N \times (P^2 \cdot C)} z∈RN×(P2⋅C),其中 N = H W P 2 N = \frac{HW}{P^2} N=P2HW 是Token数量。
- 每个Patch通过线性投影(learnable projection)映射为隐向量(即Token),类似ViT。
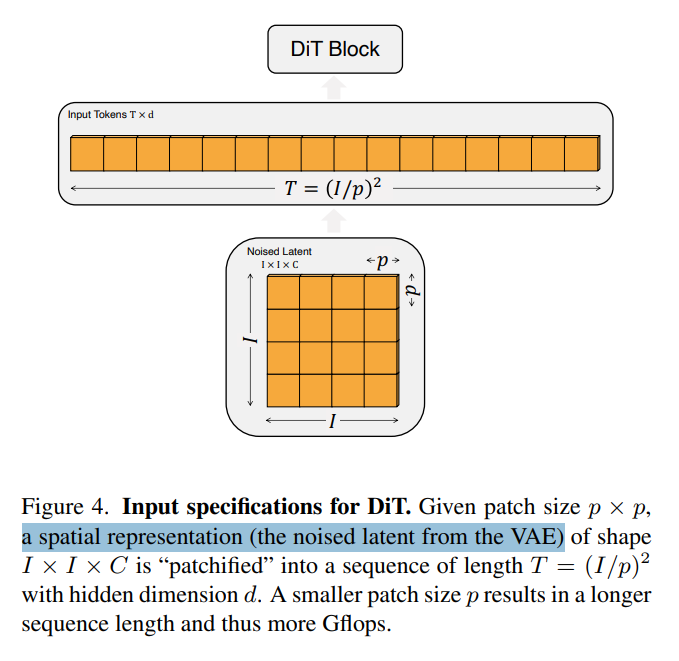
shape I × I × C :VAE编码器输出的空间表示(noised latent)通常具有固定的形状。对于输入为 256 × 256 × 3 256×256×3 256×256×3的RGB图像,经过VAE编码器压缩后,输出的潜在空间表示zzz的形状为 32 × 32 × 4 32×32×4 32×32×4 。
输入处理:
DiT的输入是一个空间表示 z z z(对于256×256×3的图像, z z z的形状为32×32×4)。DiT的第一层是 “Patchify”,它将空间输入转换为由 T T T个Token组成的序列,每个Token的维度为 d d d。具体实现方式是对输入中的每个Patch进行线性嵌入(Linear Embedding)。
位置编码:
在Patchify之后,我们对所有输入Token应用标准的ViT频率位置编码(正弦-余弦版本)。
Token数量 T T T与Patch大小 p p p的关系:
- Patchify生成的Token数量 T T T由超参数 p p p(Patch大小)决定。
- 如图4所示, p p p减半会使 T T T变为原来的4倍,从而导致Transformer的总计算量(GFLOPs)至少增加4倍。
- 但需要注意的是,调整 p p p不会显著影响下游模型的参数量,因为参数主要取决于隐藏层维度 d d d和网络深度。
DiT设计中的 p p p选择:
在DiT的设计空间中,我们测试了 p = 2 , 4 , 8 p=2, 4, 8 p=2,4,8三种不同的Patch大小,以权衡计算效率和模型性能。
关键点总结
- Patchify的作用:将空间输入(32×32×4)转换为Token序列( T T T个,维度 d d d)。
- p p p的影响:
- 计算量(GFLOPs): p p p越小, T T T越大,计算量显著增加( T ∝ 1 / p 2 T \propto 1/p^2 T∝1/p2)。
- 参数量:不受 p p p影响,主要由Transformer结构决定。
- DiT实验设定:测试 p = 2 , 4 , 8 p=2,4,8 p=2,4,8,以优化计算与性能的平衡。
(注:数学公式和术语保持原样,如 T T T、 p p p、GFLOPs等,确保技术准确性。)
2. 位置编码与条件嵌入
-
位置编码:采用ViT中的正弦-余弦位置编码,为token序列添加空间位置信息,确保模型能理解图像块的空间关系。
-
条件嵌入:扩散模型需要 时间步 t t t 和类别标签 c c c 等条件信息。DiT通过以下方式融合条件:
- 自适应层归一化(adaLN):根据条件动态调整归一化参数。
- 交叉注意力机制:将条件信息作为额外的token序列,通过注意力机制与图像token交互。
- 时间步 t t t:通过正弦位置编码或可学习嵌入(如MLP)转换为向量 t e m b t_{emb} temb。
- 条件信息(如类别标签、文本描述):通过额外的嵌入层编码为 c e m b c_{emb} cemb。
这些嵌入可能通过拼接或相加合并到图像Token中。
3. Transformer块处理
DiT的核心是由多个Transformer块堆叠而成,每个块包含:
- 多头自注意力(Multiple Self-Attention):捕捉图像块之间的全局依赖关系,例如生成图像时协调不同区域的一致性。
- 前馈神经网络(FFN):对注意力输出进行非线性变换,增强表达能力。
- 条件控制:通过adaLN-Zero等机制,将时间步和类别标签信息注入每一层,指导去噪过程。
DiT的Transformer层在ViT基础上扩展,关键设计包括:
-
自适应层归一化(AdaLN)
- 替代标准LayerNorm,将时间步 t e m b t_{emb} temb 和条件 c e m b c_{emb} cemb 动态注入归一化层:
AdaLN ( z ) = γ ( t e m b , c e m b ) ⋅ z − μ ( z ) σ ( z ) + β ( t e m b , c e m b ) \text{AdaLN}(z) = \gamma(t_{emb}, c_{emb}) \cdot \frac{z - \mu(z)}{\sigma(z)} + \beta(t_{emb}, c_{emb}) AdaLN(z)=γ(temb,cemb)⋅σ(z)z−μ(z)+β(temb,cemb)
其中 γ , β \gamma, \beta γ,β 由时间/条件嵌入通过MLP生成。
- 替代标准LayerNorm,将时间步 t e m b t_{emb} temb 和条件 c e m b c_{emb} cemb 动态注入归一化层:
-
多头自注意力(MSA)与MLP
- 标准Transformer结构,但可能引入交叉注意力(Cross-Attention)处理条件信息(如文本描述)。
-
Token交互与输出
- 所有Token通过多层Transformer块交互,最终输出预测的噪声 ϵ θ \epsilon_\theta ϵθ 或去噪后的图像 x 0 x_0 x0。
4. 噪声预测与反向扩散 (Transformer decoder)
- 训练阶段:DiT学习预测前向扩散过程中添加的噪声 ϵ θ ( z t , t , c ) \epsilon_\theta(z_t, t, c) ϵθ(zt,t,c),损失函数为噪声预测的MSE和协方差的KL散度。
- 采样阶段:(和推理可互换,均指模型生成数据的去噪过程)
- 从随机噪声 z T z_T zT开始,逐步迭代去噪。
- 每一步通过DiT预测噪声 ϵ θ ( z t , t , c ) \epsilon_\theta(z_t, t, c) ϵθ(zt,t,c),并更新潜在表示 z t − 1 z_{t-1} zt−1。
- 最终得到去噪后的潜在表示 z 0 z_0 z0,通过VAE解码器生成高质量图像。
5. 可扩展性与性能
DiT通过增加Transformer的深度、宽度或输入token数量(减小patch大小)提升模型复杂度(GFLOPs),实验表明更高的GFLOPs通常对应更低的FID(图像质量更高)。例如,DiT-XL/2在ImageNet 256×256任务中达到FID 2.27,超越传统U-Net架构的扩散模型。
总结
DiT通过Transformer的全局注意力机制和ViT的patch处理方式,解决了传统U-Net在长距离依赖和扩展性上的局限,成为扩散模型的新范式。其处理过程结合了条件控制、噪声预测和逐步去噪,适用于图像、视频等多种生成任务。
以下是针对论文中Diffusion Transformers (DiTs) 处理过程的详细解析,结合其架构设计目标和实现方法:
详细步骤2
1. 核心设计目标
- 保持Transformer的原始架构:DiT旨在尽可能遵循标准Transformer(如ViT)的设计,以保留其可扩展性(scaling properties)。
- 适配扩散模型:将Transformer作为扩散模型(DDPM)的主干,替代传统U-Net,专注于图像(空间数据)的生成任务。
2. 前向传播(Forward Pass)流程
输入处理
-
Patchify(图像分块)
- 输入图像 x ∈ R H × W × C x \in \mathbb{R}^{H \times W \times C} x∈RH×W×C 被划分为非重叠的 P × P P \times P P×P patches,展平为序列 z ∈ R N × ( P 2 ⋅ C ) z \in \mathbb{R}^{N \times (P^2 \cdot C)} z∈RN×(P2⋅C),其中 N = H W P 2 N = \frac{HW}{P^2} N=P2HW 是Token数量。
- 每个Patch通过线性投影(learnable projection)映射为隐向量(即Token),类似ViT。
-
时间步与条件嵌入
- 时间步 t t t:通过正弦位置编码或可学习嵌入(如MLP)转换为向量 t e m b t_{emb} temb。
- 条件信息(如类别标签、文本描述):通过额外的嵌入层编码为 c e m b c_{emb} cemb。
- 这些嵌入可能通过拼接或相加合并到图像Token中(具体设计见下文)。
Transformer块设计
DiT的Transformer层在ViT基础上扩展,关键设计包括:
-
自适应层归一化(AdaLN)
- 替代标准LayerNorm,将时间步 t e m b t_{emb} temb 和条件 c e m b c_{emb} cemb 动态注入归一化层:
AdaLN ( z ) = γ ( t e m b , c e m b ) ⋅ z − μ ( z ) σ ( z ) + β ( t e m b , c e m b ) \text{AdaLN}(z) = \gamma(t_{emb}, c_{emb}) \cdot \frac{z - \mu(z)}{\sigma(z)} + \beta(t_{emb}, c_{emb}) AdaLN(z)=γ(temb,cemb)⋅σ(z)z−μ(z)+β(temb,cemb)
其中 γ , β \gamma, \beta γ,β 由时间/条件嵌入通过MLP生成。
- 替代标准LayerNorm,将时间步 t e m b t_{emb} temb 和条件 c e m b c_{emb} cemb 动态注入归一化层:
-
多头自注意力(MSA)与MLP
- 标准Transformer结构,但可能引入交叉注意力(Cross-Attention)处理条件信息(如文本描述)。
-
Token交互与输出
- 所有Token通过多层Transformer块交互,最终输出预测的噪声 ϵ θ \epsilon_\theta ϵθ 或去噪后的图像 x 0 x_0 x0。
输出头
- 预测的Token序列通过线性投影还原为Patch,再重组为图像空间格式。
3. DiT Design Space
论文中提到的DiT架构设计空间包含以下关键选择:
-
Token生成方式
- 标准ViT的线性投影 vs. 更复杂的嵌入(如卷积Patch嵌入)。
-
条件注入机制
- AdaLN(动态调节归一化参数)
- 交叉注意力(将条件作为额外的Key-Value对)
- Token拼接(直接拼接条件Token到图像Token序列)
-
Transformer块变体
- 基础块(标准MSA+MLP)
- 引入窗口注意力(Window Attention)以降低计算成本
- 使用Flash Attention优化长序列处理
-
噪声预测目标
- 直接预测噪声 ϵ \epsilon ϵ(DDPM默认)
- 预测原始数据 x 0 x_0 x0(简化目标)
4. 训练与推理对比
| 阶段 | 输入 | 输出 | 关键操作 |
|---|---|---|---|
| 训练 | 噪声图像 x t x_t xt + 时间步 t t t + 条件 | 预测噪声 ϵ \epsilon ϵ | 反向传播优化AdaLN和注意力权重 |
| 推理 | 纯噪声 x T x_T xT + 时间步 t t t + 条件 | 去噪图像 x t − 1 x_{t-1} xt−1 | 逐步迭代,依赖采样器(DDIM/DDPM) |
5. 图示说明(参考论文Figure 3)
- 输入层:图像 → Patchify → 线性投影 → Token序列。
- 条件融合:时间步和条件嵌入通过AdaLN或交叉注意力注入。
- Transformer堆叠:多个块处理Token序列,输出预测结果。
- 输出层:Token → 图像空间重建。
6. 关键创新点
- 架构简洁性:直接复用ViT,避免复杂设计(如U-Net的编码-解码结构)。
- 可扩展性:模型性能随参数量和数据规模稳定提升(符合Transformer的Scaling Law)。
- 条件灵活性:支持多种条件输入(文本、类别、掩码等)。
总结
DiT的处理过程通过Patch化输入、Transformer主干和动态条件注入,将扩散模型的去噪任务转化为序列预测问题。其设计保留了ViT的优雅性,同时通过AdaLN等机制适配生成任务,成为扩散模型领域的高效架构。
LDMs
(Latent Diffusion Models, LDMs)
核心思想:直接在高分辨率像素空间训练扩散模型计算成本过高。LDMs 在 DiTs 的架构中扮演着基础框架与效率优化核心的角色,潜在扩散模型(LDMs)采用两阶段方法解决该问题:
潜在扩散模型(Latent Diffusion Models, LDMs)通过两阶段训练策略显著降低了计算成本,同时保持了生成图像的高质量。以下是其核心流程和技术细节:
1. 两阶段训练流程
-
阶段一:预训练自动编码器(VAE)
使用变分自编码器(VAE)将高分辨率图像 x ∈ R H × W × 3 x \in \mathbb{R}^{H \times W \times 3} x∈RH×W×3压缩为低维潜在表示 z = E ( x ) ∈ R h × w × c z = E(x) \in \mathbb{R}^{h \times w \times c} z=E(x)∈Rh×w×c(如 64 × 64 × 4 64 \times 64 \times 4 64×64×4),其中 E E E为编码器, D D D为解码器。此阶段通过感知损失(如LPIPS)和对抗损失优化,确保潜在空间保留语义信息并支持高质量重建。 -
阶段二:潜在空间扩散训练
在冻结的VAE编码器基础上,训练扩散模型(如U-Net)对潜在表示 z z z进行去噪。目标函数为:
L L D M = E z , t , ϵ [ ∥ ϵ − ϵ θ ( z t , t ) ∥ 2 ] L_{LDM} = \mathbb{E}_{z,t,\epsilon} \left[ \|\epsilon - \epsilon_\theta(z_t, t)\|^2 \right] LLDM=Ez,t,ϵ[∥ϵ−ϵθ(zt,t)∥2]
其中 ϵ θ \epsilon_\theta ϵθ为噪声预测网络, t t t为时间步。相比像素空间扩散,计算量减少64倍(如 51 2 2 → 6 4 2 512^2 \rightarrow 64^2 5122→642)。
2. 关键优势
- 计算效率:潜在空间操作大幅降低内存和计算需求(如Stable Diffusion的U-Net仅需处理 64 × 64 × 4 64 \times 64 \times 4 64×64×4张量),使高分辨率生成(如1024×1024)可在消费级GPU上实现。
- 条件生成灵活性:通过交叉注意力机制注入文本、边界框等条件(如CLIP文本编码器),支持多模态控制生成。
- 质量与速度平衡:DDIM等采样器允许跳过中间步骤(10-50步),加速推理而不显著降低质量。
3. 与像素空间扩散的对比
| 特性 | 潜在扩散模型 (LDM) | 像素空间扩散模型 |
|---|---|---|
| 计算复杂度 | 低(潜在空间操作) | 高(直接处理像素) |
| 训练数据维度 | 压缩后潜在表示(如64×64×4) | 原始图像(如512×512×3) |
| 典型应用 | Stable Diffusion, DALL·E 2 | 早期DDPM, Imagen |
| 重建依赖 | 需预训练VAE | 无需额外编码器 |
4. 应用与扩展
- 文本到图像:如Stable Diffusion结合CLIP文本编码器生成符合描述的图像。
- 超分辨率与修复:在潜在空间进行局部编辑或分辨率提升。
- 架构创新:DiT(Diffusion Transformer)等将Transformer引入潜在扩散,进一步优化长程依赖建模。
LDMs通过分离压缩与生成阶段,实现了效率与质量的平衡,成为当前生成式AI的主流框架。
潜在扩散模型(LDMs)在推理阶段的流程可分为以下步骤,结合了潜在空间操作与条件控制的高效生成:
LDMs在推理阶段的流程
1. 条件输入编码(如适用)
- 文本/图像条件处理:若需条件生成(如文本描述),输入条件 y y y(如CLIP文本编码)通过专用编码器 τ θ \tau_\theta τθ映射为中间表示,用于后续交叉注意力控制。
2. 潜在空间噪声采样
- 初始噪声生成:从标准高斯分布采样潜在噪声 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(0, I) zT∼N(0,I),维度为 h × w × c h \times w \times c h×w×c(如 64 × 64 × 4 64 \times 64 \times 4 64×64×4),远低于原始像素空间。
3. 迭代去噪(逆向扩散)
- U-Net/Transformer去噪:通过时间步 t = T t=T t=T到 t = 1 t=1 t=1的迭代,模型预测噪声并更新潜在表示:
z t − 1 = 1 α t ( z t − 1 − α t 1 − α ˉ t ϵ θ ( z t , t , τ θ ( y ) ) ) + σ t ϵ z_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( z_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_\theta(z_t, t, \tau_\theta(y)) \right) + \sigma_t \epsilon zt−1=αt1(zt−1−αˉt1−αtϵθ(zt,t,τθ(y)))+σtϵ
其中 ϵ θ \epsilon_\theta ϵθ为去噪网络(如U-Net或DiT), α t \alpha_t αt为噪声调度系数。 - 条件注入:通过交叉注意力机制将 τ θ ( y ) \tau_\theta(y) τθ(y)与 z t z_t zt融合,动态指导生成内容。
4. 潜在空间解码
- VAE解码:最终去噪的潜在表示 z 0 z_0 z0通过冻结的VAE解码器 D D D重建为像素空间图像:
x = D ( z 0 ) x = D(z_0) x=D(z0)
解码器保留训练阶段的权重,确保高分辨率细节还原。
5. 后处理(可选)
- 超分辨率或修复:部分流程可能叠加额外模块(如ESRGAN)进一步提升输出质量。
关键优化技术
- 采样加速:采用DDIM等非马尔可夫采样器,允许跳步生成(如20步替代1000步)。
- 显存效率:潜在空间操作降低显存占用约64倍,支持高分辨率生成(如1024×1024)。
LDMs通过分离压缩与生成阶段,在保证质量的同时显著提升推理效率,成为Stable Diffusion等工具的核心框架。
LDMs在训练阶段的流程
潜在扩散模型(LDMs)的训练流程分为两个核心阶段,结合了自编码器预训练与潜在空间扩散模型优化,具体如下:
1. 预训练自编码器(VAE)
- 目标:学习图像的高效低维表示(潜在空间 z z z),降低后续扩散模型的计算复杂度。
- 步骤:
- 数据压缩:编码器 E E E将图像 x x x映射到潜在空间 z = E ( x ) z = E(x) z=E(x),维度通常为 64 × 64 × 4 64 \times 64 \times 4 64×64×4(远低于原始像素空间)。
- 重建训练:解码器 D D D从 z z z重建图像 x ^ = D ( z ) \hat{x} = D(z) x^=D(z),最小化重建损失(如MSE或感知损失):
L V A E = E x ∼ p ( x ) ∥ x − D ( E ( x ) ) ∥ 2 \mathcal{L}_{VAE} = \mathbb{E}_{x \sim p(x)} \|x - D(E(x))\|^2 LVAE=Ex∼p(x)∥x−D(E(x))∥2 - 冻结参数:训练完成后, E E E和 D D D的参数固定,仅用于后续潜在空间的编码与解码。
2. 训练潜在扩散模型(DM)
- 目标:在潜在空间 z z z中学习扩散与去噪过程,生成高质量潜在表示。
- 步骤:
- 潜在变量加噪:对 z 0 = E ( x ) z_0 = E(x) z0=E(x)按时间步 t t t添加高斯噪声,生成 z t z_t zt:
z t = α t z 0 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) z_t = \sqrt{\alpha_t} z_0 + \sqrt{1-\alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) zt=αtz0+1−αtϵ,ϵ∼N(0,I)
其中 α t \alpha_t αt为噪声调度系数(如线性或余弦调度)。 - 噪声预测:U-Net或Transformer模型 ϵ θ \epsilon_\theta ϵθ预测噪声 ϵ ^ \hat{\epsilon} ϵ^,输入为 z t z_t zt和时间步 t t t(嵌入为高维向量)。
- 条件控制(可选):若需文本/图像条件 y y y,通过交叉注意力机制融合 τ θ ( y ) \tau_\theta(y) τθ(y)与 z t z_t zt:
Attention ( Q , K , V ) = softmax ( Q K T d ) V , Q = W Q φ i ( z t ) , K , V = W K , W V τ θ ( y ) \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V, \quad Q = W_Q \varphi_i(z_t), \ K,V = W_K, W_V \tau_\theta(y) Attention(Q,K,V)=softmax(dQKT)V,Q=WQφi(zt), K,V=WK,WVτθ(y) - 优化目标:最小化预测噪声与真实噪声的差异:
L L D M = E z 0 , ϵ , t ∥ ϵ − ϵ θ ( z t , t , τ θ ( y ) ) ∥ 2 \mathcal{L}_{LDM} = \mathbb{E}_{z_0, \epsilon, t} \|\epsilon - \epsilon_\theta(z_t, t, \tau_\theta(y))\|^2 LLDM=Ez0,ϵ,t∥ϵ−ϵθ(zt,t,τθ(y))∥2
通过梯度下降更新 ϵ θ \epsilon_\theta ϵθ参数。
- 潜在变量加噪:对 z 0 = E ( x ) z_0 = E(x) z0=E(x)按时间步 t t t添加高斯噪声,生成 z t z_t zt:
3. 关键设计
- 两阶段解耦:VAE与DM独立训练,避免联合优化的复杂性。
- 计算效率:潜在空间操作减少约64倍计算量,支持高分辨率生成。
- 条件扩展性:交叉注意力机制支持多模态控制(文本、布局等)。
总结
LDMs通过分离感知压缩(VAE)与语义生成(DM),在降低计算需求的同时保持生成质量。其训练流程的核心是潜在空间的高效扩散建模,为Stable Diffusion等应用奠定基础。
时间步
在扩散模型(Diffusion Models)和 Diffusion Transformers (DiTs) 中,时间步(timestep) 是一个核心概念,用于控制数据在扩散过程中的加噪(前向过程)和去噪(逆向过程)的进度。以下是详细解释:
1. 时间步的定义
- 时间步 t t t 是一个离散变量,表示扩散过程中的第 t t t 步(通常从 t = 0 t=0 t=0 到 t = T t=T t=T)。
- t = 0 t=0 t=0:对应原始数据(如图像 x 0 x_0 x0)。
- t = T t=T t=T:对应完全噪声(纯高斯噪声 x T x_T xT)。
- 在训练和推理中,时间步决定了当前数据 x t x_t xt 的噪声程度,并指导模型如何逐步去噪。
2. 时间步的作用
(1) 前向扩散过程(加噪)
- 在训练时,时间步 t t t 用于控制噪声的添加量。
例如,扩散公式:
x t = α t x 0 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t} x_0 + \sqrt{1-\alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) xt=αtx0+1−αtϵ,ϵ∼N(0,I)- α t \alpha_t αt 是一个与 t t t 相关的调度参数(如线性、余弦等),随 t t t 增大而减小,噪声逐渐增强。
- 时间步 t t t 决定了当前噪声强度和数据破坏程度。
(2) 逆向去噪过程(生成)
- 在推理时,模型需要根据时间步 t t t 预测如何从 x t x_t xt 去噪到 x t − 1 x_{t-1} xt−1。
- 时间步 t t t 告诉模型当前处于生成过程的哪个阶段(早期需粗粒度去噪,晚期需细粒度修正)。
- 例如,DiT 通过时间步嵌入(timestep embedding)将 t t t 编码为向量,输入Transformer以调节去噪行为。
3. 时间步的表示方法
时间步 t t t 通常通过以下方式输入模型:
(1) 正弦位置编码(Sinusoidal Embedding)
- 类似Transformer的位置编码,将离散的 t t t 映射为连续向量:
Embedding ( t ) = [ sin ( ω 1 t ) , cos ( ω 1 t ) , . . . , sin ( ω d t ) , cos ( ω d t ) ] \text{Embedding}(t) = [\sin(\omega_1 t), \cos(\omega_1 t), ..., \sin(\omega_d t), \cos(\omega_d t)] Embedding(t)=[sin(ω1t),cos(ω1t),...,sin(ωdt),cos(ωdt)]
其中 ω i \omega_i ωi 是预设的频率参数。
(2) 可学习的嵌入(MLP投影)
- 通过一个小型MLP将 t t t 映射为高维向量:
t e m b = MLP ( t ) t_{emb} = \text{MLP}(t) temb=MLP(t)
(DiT论文中常用此方法)
(3) 自适应归一化(AdaLN)
- 在DiT中,时间步嵌入 t e m b t_{emb} temb 可能用于动态调节层归一化(LayerNorm)的参数:
AdaLN ( z ) = γ ( t e m b ) ⋅ z − μ ( z ) σ ( z ) + β ( t e m b ) \text{AdaLN}(z) = \gamma(t_{emb}) \cdot \frac{z - \mu(z)}{\sigma(z)} + \beta(t_{emb}) AdaLN(z)=γ(temb)⋅σ(z)z−μ(z)+β(temb)
其中 γ , β \gamma, \beta γ,β 由时间步生成。
4. 为什么需要时间步?
- 动态调节去噪行为:
- 不同时间步需要不同的去噪策略(早期去噪强度大,后期微调细节)。
- 条件生成控制:
- 时间步作为条件输入,确保模型在生成过程中“知道”当前进度。
- 与噪声调度解耦:
- 时间步与噪声调度参数(如 α t \alpha_t αt)绑定,但模型只需学习时间步的映射,无需显式处理调度逻辑。
5. 在DiT中的具体应用
以DiT为例:
- 输入阶段:
- 时间步 t t t 被编码为向量 t e m b t_{emb} temb,与图像Patch Token拼接或相加。
- Transformer处理:
- 通过AdaLN或交叉注意力,将 t e m b t_{emb} temb 注入每一层,动态调节特征归一化。
- 输出阶段:
- 模型根据 t t t 预测当前步的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 或直接预测 x 0 x_0 x0。
6. 时间步与噪声调度的关系
- 时间步 t t t 是离散索引,而噪声调度(如 α t , β t \alpha_t, \beta_t αt,βt)是连续函数。
- 例如,在DDPM中:
[
\alpha_t = \prod_{s=1}^t (1 - \beta_s), \quad \beta_t \text{为预设的噪声方差表}
]
模型通过 t t t 隐式地关联到调度参数,无需直接学习它们。
总结
时间步是扩散模型中协调加噪与去噪进度的“时钟”,在DiT中通过嵌入向量融入Transformer,使模型能够动态适应不同阶段的生成需求。它是连接扩散理论(噪声调度)与深度学习架构(如Transformer)的关键桥梁。
相关文章:
Diffusion Transformer(DiT)
扩散模型的核心思想:Diffusion Models是一种受到非平衡热力学启发的生成模型,其核心思想是通过模拟扩散过程来逐步添加噪声到数据中,并随后学习反转这个过程以从噪声中构建出所需的数据样本。 DiT的架构:DiT架构基于Latent Diffu…...

多模态理论知识
说一下多模态的定义? 多模态是指使用多种不同类型的媒体和数据输入,例如文本、图像、音频、视频等,它们之间存在关联或者对应关系。 这些不同类型的媒体和数据输入可以在不同的层面上传达信息并表达意义。多模态数据的处理需要融合不同类型的信息&…...

Nginx 安全防护与HTTPS部署
目录 一、核心安全配置 1、隐藏版本号 2、限制危险请求方法 3、请求限制(CC攻击防御) (1)使用Nginx的limit_req模块限制请求速率 (2)压力测试验证 4、防盗链 (1)修改 Window…...

Python爬虫+代理IP+Header伪装:高效采集亚马逊数据
1. 引言 在当今大数据时代,电商平台(如亚马逊)的数据采集对于市场分析、竞品监控和价格追踪至关重要。然而,亚马逊具有严格的反爬虫机制,包括IP封禁、Header检测、验证码挑战等。 为了高效且稳定地采集亚马逊数据&am…...

效率提升利器:解锁图片处理新姿势
今天我给大家分享一款超实用的图片压缩软件,好用程度超出想象!该软件身形 “轻盈”,仅 648KB,启动后能迅速上手。 01 软件介绍 这款软件就是PicSizer,具有以下特点: 支持windows系统 体积小,绿…...

【强化学习】什么是强化学习?2025
1. 强化学习简介 一句话总结:强化学习(Reinforcement Learning, RL)是一种机器学习范式,强调智能体(agent)通过与环境(environment)的交互,以试错(trial‑an…...

富文本编辑器的第三方库ProseMirror
如果0-1的开发一个富文本编辑器,成本还是非常高的,里面很多坑要踩,市面上很多库可以帮助我们搭建一个富文本编辑器,ProseMirror就是其中最流行的库之一。 认识ProseMirror ProseMirror 提供了一套工具和概念,用于构建…...

理解IP四元组与网络五元组:网络流量的“身份证”
理解IP四元组与网络五元组:网络流量的“身份证” 在现代网络通信中,IP四元组和网络五元组是流量识别、连接追踪、安全策略等核心的基础概念。理解这些“元组”不仅能够帮助我们更好地设计网络架构、排查故障,还能为安全与运维策略的落地提供…...

ROS2:话题通信CPP语法速记
目录 发布方实现流程重点代码 订阅方实现流程重点代码 参考代码示例发布方代码订阅方代码 发布方实现流程 包含头文件(rclcpp.hpp与[interfaces_pkg].hpp)初始化ROS2客户端(rclcpp::init)自定义节点类(创建发布实例,伺…...

码蹄集——直线切平面、圆切平面
MT1068 直线切平面 思路: 则 #include<bits/stdc.h> using namespace std;int main( ) {int n;cin>>n;cout<<n*(n1)/21;return 0; } MT1069圆切平面 n个圆最多把平面分成几部分?输入圆的数量N,问最多把平面分成几块。比如…...

2025年游戏行业DDoS攻防指南:智能防御体系构建与实战策略
2025年,游戏行业在全球化扩张与技术创新浪潮中,正面临前所未有的DDoS攻击威胁。攻击规模从T级流量到AI驱动的精准渗透,攻击手段从传统网络层洪水到混合型应用层打击,防御体系已从“被动应对”转向“智能博弈”。本文将结合最新攻击…...

LightGBM算法原理及Python实现
一、概述 LightGBM 由微软公司开发,是基于梯度提升框架的高效机器学习算法,属于集成学习中提升树家族的一员。它以决策树为基学习器,通过迭代地训练一系列决策树,不断纠正前一棵树的预测误差,逐步提升模型的预测精度&a…...

Nvidia发布Parakeet V2,一款新的开源自动语音识别模型
Nvidia 发布 Parakeet V2,一款新的开源自动语音识别 AI,核心亮点:一秒钟转录一小时的音频;Open ASR 上的顶级模型,击败了 ElevenLabs 的 Scribe 和 OpenAI 的 Whisper;6.05% 的单词错误率;CC-BY…...
** 和 **存储过程(Stored Procedure)原理及优化建议)
浅析MySQL 的 **触发器(Trigger)** 和 **存储过程(Stored Procedure)原理及优化建议
MySQL 的 触发器(Trigger) 和 存储过程(Stored Procedure) 是数据库中用于实现业务逻辑的重要机制,它们的原理和使用方式不同,适用于不同的场景。 一、基本概念与原理 特性触发器(Trigger)存储过程(Stored Procedure)定义在表上定义,当特定事件(INSERT/UPDATE/DELE…...

网页版部署MySQL + Qwen3-0.5B + Flask + Dify 工作流部署指南
1. 安装MySQL和PyMySQL 安装MySQL # 在Ubuntu/Debian上安装 sudo apt update sudo apt install mysql-server sudo mysql_secure_installation# 启动MySQL服务 sudo systemctl start mysql sudo systemctl enable mysql 安装PyMySQL pip install pymysql 使用 apt 安装 My…...

人工智能与智能合约:如何用AI优化区块链技术中的合约执行?
引言:科技融合的新风口 区块链和人工智能,是当前最受瞩目的两大前沿技术。一个以去中心化、可溯源的机制重构信任体系,另一个以智能学习与决策能力重塑数据的价值。当这两项技术相遇,会碰撞出什么样的火花? 智能合约作…...

如何提升丢包网络环境下的传输性能:从 TCP 到 QUIC,再到 wovenet 的实践
在现代互联网环境中,稳定、可靠的网络连接对各种在线应用至关重要。然而,理想情况往往难以实现,特别是在以下一些典型场景中,网络丢包(packet loss) 常常发生: 一、常见的网络丢包场景 跨境通…...

Python 中的数据结构介绍
Python 是一种功能强大的编程语言,它内置了多种数据结构,以便用户能够方便、高效地存储、处理和访问数据。数据结构是组织和存储数据的方式,不同的数据结构适用于不同的应用场景。掌握 Python 中的基本数据结构,可以使代码更加简洁…...

数据中台架构设计
数据中台分层架构 数据采集层 数据源类型:业务系统(ERP、CRM)、日志、IoT 设备、第三方 API 等。采集方式: 实时采集:Kafka、Flink CDC(变更数据捕获)。离线采集:Sqoop、DataX&…...

基于SpringBoot网上书店的设计与实现
pom.xml配置文件 1. 项目基本信息(没什么作用) <groupId>com.spring</groupId> <!--项目组织标识,通常对应包结构--> <artifactId>boot</artifactId> <!--项目唯一标识--> <version>0.0.1-SNAPSHOT</ve…...

Vue3路由模式为history,使用nginx部署上线后刷新404的问题
一、问题 在使用nginx部署vue3的项目后,发现正常时可以访问的,但是一旦刷新,就是出现404的情况 二、解决方法 1.vite.config.js配置 在vite.config.js中加入以下配置 export default defineConfig(({ mode }) > {const isProduction …...

从单机到生产:Kubernetes 部署方案全解析
🚀 从单机到生产:Kubernetes 部署方案全解析 🌐 Kubernetes(k8s)是当今最流行的容器编排系统,广泛应用于开发、测试和生产环境。但不同的使用场景对集群规模、高可用性和资源需求有不同的要求。本文将带你…...

redis大全
1 redis安装和简介 基于ubuntu系统的安装 sudo apt update sudo apt install redis##包安装的redis 没有默认配置文件 启动 redis-server /path/to/your/redis.confredis-cliRedis 默认是没有设置用户和密码的,即可以无密码访问 设置密码的方法:可以通…...

C#经典算法面试题
C#经典算法面试题 递归算法 C#递归算法计算阶乘的方法 一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且0的阶乘为1。自然数n的阶乘写作n!。1808年,基斯顿卡曼引进这个表示法。 原理:亦即n!=123…(n-1)n。阶乘亦可以递归方式定义:0!=1,n!=(n-1)!n。…...

cephadm部署ceph集群
一、什么是Ceph? ceph是一个统一的、分布式的存储系统,设计初衷式提供较好的性能(io)、可靠性(没有单点故障)和可扩展性(未来可以理论上无限扩展集群规模),这三点也是集群架构所追求的。 “统一的”:意味着Ceph可以一套存储系统同时提供对象存储、块存…...

c#OdbcDataReader的数据读取
先有如下c#示例代码: string strconnect "DSNcustom;UIDsa;PWD123456;" OdbcConnection odbc new OdbcConnection(strconnect); odbc.Open(); if (odbc.State ! System.Data.ConnectionState.Open) { return; } string strSql "select ID from my…...

代码随想录训练营第十八天| 150.逆波兰表达式求值 239.滑动窗口最大值 347.前k个高频元素
150.逆波兰表达式求值: 文档讲解:代码随想录|150.逆波兰表达式求值 视频讲解:栈的最后表演! | LeetCode:150. 逆波兰表达式求值_哔哩哔哩_bilibili 状态:已做出 思路: 这道题目是让我们按照逆波…...

数据中台产品功能介绍
在数字化转型浪潮中,数据中台作为企业数据管理与价值挖掘的核心枢纽,整合分散数据资源,构建统一的数据管理与服务体系。本数据中台产品涵盖数据可视化、数据建设、数据治理、数据采集开发和系统管理五大平台,以丰富且强大的功能模…...

第四章-初始化Direct3D
首先我们需要一个错误检测和抛出机制 inline std::string ToString(const HRESULT& result) {char buffer[256];sprintf_s(buffer, "error code : 0x%08X\n", result);return std::string(buffer); }class MyException : public std::runtime_error { public:My…...

实操3:6位数码管
文章目录 文章介绍仿真图原来的仿真代码教学用开发板段选和位选对应引脚思考题实物图 文章介绍 对应“案例5_3: 6位数码管显示0或者1【静态显示】” 跳转链接 要求:实现开发板的6位数码管同时显示0或者1 仿真图 原来的仿真代码 #include<reg52.h> // 头文件…...
)
常识补充(NVIDIA NVLink技术:打破GPU通信瓶颈的革命性互联技术)
文章目录 **引言:为什么需要NVLink?**1. NVLink技术概述1.1 什么是NVLink?1.2 NVLink的发展历程 2. NVLink vs. PCIe:关键对比2.1 带宽对比2.2 延迟对比 3. NVLink的架构与工作方式3.1 点对点直连(P2P)3.2 …...
)
openwrt 使用quilt 打补丁(patch)
1,引入 本文简单解释如何在OpenWRT下通过quilt命令打补丁--patch,也可查看openwrt官网提供的文档 2,以下代码通过编译net-snmp介绍 ① 执行编译命令之后,进入build_dir的net-snmp-5.9.1目录下,改目录即为snmp最终编译的目录了 /…...

NVIDIA Halos:智能汽车革命中的全栈式安全系统
高级辅助驾驶行业正面临一个尴尬的"安全悖论"——传感器数量翻倍的同时,事故率曲线却迟迟不见明显下降。究其原因,当前行业普遍存在三大技术困局: 碎片化安全方案 传统方案就像"打补丁",激光雷达厂商只管点云…...

k8s术语之service
Kubernetes在设计之初就充分考虑了针对容器的服务发现与负载均衡机制,提供了Service资源,并通过kube-proxy配合cloud provider 来适应不同的用于场景。随着kubernetes用户的激增,用户场景的不断丰富,又产生了一些新的负载均衡机制…...

C/C++工程中的Plugin机制设计与Python实现
C/C工程中的Plugin机制设计与Python实现 1. Plugin机制设计概述 在C/C工程中实现Plugin机制通常需要以下几个关键组件: Plugin接口定义:定义统一的接口规范动态加载机制:运行时加载动态库注册机制:Plugin向主程序注册自己通信机…...

RNN 与 CNN:深度学习中的两大经典模型技术解析
在人工智能和深度学习领域,RNN(Recurrent Neural Network,循环神经网络) 和 CNN(Convolutional Neural Network,卷积神经网络) 是两种非常重要的神经网络结构。 它们分别擅长处理不同类型的数据,在自然语言处理、计算机视觉等多个领域中发挥着关键作用。 本文将从原理…...

多模态训练与微调
1.为什么多模态模型需要大规模预训练? 多模态模型需要大规模预训练的原因包括: (1)数据丰富性:大规模预训练可以暴露模型于丰富的数据,提升其泛化能力。 (2)特征提取:通过预训练,模型能够学习到有效的特…...

【HDLBits刷题】Verilog Language——1.Basics
目录 一、题目与题解 1.Simple wire(简单导线) 2.Four wires(4线) 3.Inverter(逆变器(非门)) 4.AND gate (与门) 5. NOR gate (或非门&am…...

基于深度学习的图像识别技术:从原理到应用
前言 在当今数字化时代,图像识别技术已经渗透到我们生活的方方面面,从智能手机的人脸解锁功能到自动驾驶汽车对交通标志的识别,再到医疗影像诊断中的病变检测,图像识别技术正以其强大的功能和广泛的应用前景,改变着我们…...
)
【coze】手册小助手(提示词、知识库、交互、发布)
【coze】手册小助手(提示词、知识库、交互、发布) 1、创建智能体2、添加提示词3、创建知识库4、测试智能体5、添加交互功能6、发布智能体 1、创建智能体 2、添加提示词 # 角色 你是帮助用户搜索手册资料的AI助手 ## 工作流程 ### 步骤一:查询知识库 1.每…...
的中2班幼儿偏好性测试(HTML))
【教学类-34-11】20250506异形拼图块(圆形、三角、正方,椭圆/半圆)的中2班幼儿偏好性测试(HTML)
背景介绍 最近在写一份工具运用报告,关于剪纸难度的。所以设计了蝴蝶描边系列和异形凹凸角拼图。 【教学类-102-20】蝴蝶三色图作品2——卡纸蝴蝶“满格变形图”(滴颜料按压对称花纹、原图切边后变形放大到A4横版最大化)-CSDN博客文章浏览阅读609次,点赞8次,收藏3次。【…...

Debian系统上PostgreSQL15版本安装调试插件及DBeaver相应配置
PostgreSQL所在Debian Linux服务器安装插件程序 在PostgreSQL数据库服务器Debian系统上执行以下命令,安装插件pldebugger: sudo apt install postgresql-15-pldebugger #上面这一条命令运行完好像pgsql服务自动重启了,看日志的样子是这样的,…...

GD32F470+CH395Q
tcp_client配置 第一步:资料下载 以太网协议栈芯片 CH395 - 南京沁恒微电子股份有限公司 第二步:准备工程 (1) 首先准备一个编译无报错、可以正常打印和延时的工程文件,官方例程采用STM32F1芯片,但本文…...

解决Hyper-V无法启动Debian 12虚拟机
问题 有时,我们会想要在Hyper-V中运行Debian12。我们想利用该系统的ISO镜像文件安装一个全新的虚拟机。 然而,当我们在Hyper-V中创建了一个2代虚拟机、添加了Debian 12的网络安装(Netinst)ISO作为最先启动的介质时,Hy…...

linux redis 设置密码以及redis拓展
redis拓展:http://pecl.php.net/package/redis 在服务器上,这里以linux服务器为例,为redis配置密码。 需要永久配置密码的话就去redis.conf的配置文件中找到requirepass这个参数,如下配置: 修改redis.conf配置文件 # requirepass …...

uniapp app 端获取陀螺仪数据的实现攻略
在 uniapp 开发中,uni.startGyroscope在 app 端并不被支持,这给需要获取陀螺仪数据的开发者带来了挑战。不过,借助 Native.js,我们能调用安卓原生代码实现这一需求。接下来,就为大家详细介绍实现步骤,并附上…...
)
第三节:Vben Admin 最新 v5.0 对接后端登录接口(下)
文章目录 前言一、处理请求头Authorization二、/auth/user/info 接口前端接口后端接口三、/auth/codes 接口1.前端2.后端四、测试接口前言 上一节内容,实现了登录的/auth/login 接口,但是登陆没有完成,还需要完成下面两个接口。才能完成登录。 一、处理请求头Authorizatio…...

标题:基于自适应阈值与K-means聚类的图像行列排序与拼接处理
摘要: 本文提出了一种基于自适应阈值和K-means聚类的图像行列排序与拼接方法。通过对灰度图像的自适应二值化处理,计算并分析图像的左右边距,从而确定图像的行数与列数。通过对图像进行特征提取,并使用K-means聚类进行排序&#…...

修改磁盘权限为管理员
1.右击需要修改的磁盘,点击属性 然后一路点击确定 已经修改好了...

P1782 旅行商的背包 Solution
Description 有一个体积为 C C C 的背包和若干种物品. 前 n n n 种物品,第 i i i 种体积为 v i v_i vi,价值 w i w_i wi,有 d i d_i di 件. 后 m m m 种物品,每种对应一个函数 f ( x ) a i x 2 b i x c i f(x)a…...