多模态理论知识
说一下多模态的定义?
多模态是指使用多种不同类型的媒体和数据输入,例如文本、图像、音频、视频等,它们之间存在关联或者对应关系。 这些不同类型的媒体和数据输入可以在不同的层面上传达信息并表达意义。多模态数据的处理需要融合不同类型的信息, 从而实现更加全面和准确的分析、理解和推断。
多模态的常用方法有哪些?
多模态技术是一种融合多种不同类型的媒体和数据输入,从而实现更加全面和准确的分析、理解和推断的技术。 多模态的常用方法包括数据融合、多模态深度学习、多模态特征提取、多模态数据可视化和多模态信息检索。
- 数据融合:将不同来源、不同类型的数据结合起来,以获得更全面、准确的信息。数据融合可以采用多种方法,如加权平均、贝叶斯估计、神经网络等。
- 多模态深度学习:使用深度学习方法,结合多种不同类型的数据(如图像、文本、语音等)进行学习和分析。多模态深度学习可以采用多种架构, 如卷积神经网络(CNN)、循环神经网络(RNN)、自编码器(AE)等。
- 多模态特征提取:从多种不同类型的数据中提取特征,以用于后续分析和处理。多模态特征提取可以采用多种方法, 如主成分分析(PCA)、线性判别分析(LDA)、多维尺度分析(MDS)等。
- 多模态数据可视化:将多种不同类型的数据以图形化的方式展示出来,以便于分析和理解。多模态数据可视化可以采用多种方法, 如热力图、散点图、折线图等。
- 多模态信息检索:使用多种不同类型的数据(如文本、图像、音频等)进行信息检索。多模态信息检索可以采用多种方法, 如基于内容的检索(CBIR)、基于实例的检索(IBR)等。 这些多模态技术方法可以单独使用,也可以结合使用,以获得更好的性能和效果
多模态技术主要在哪些AI领域得到了广泛的应用?
多模态技术主要在以下领域得到了广泛的应用:
- 视觉问答(Visual Question Answering,VQA):利用图像和自然语言结合的方式来回答关于图像的问题。这需要将图像和问题融合,以便使用多模态模型来解决。
- 智能对话(Intelligent Dialog):在智能对话中,模型需要能够理解自然语言,同时在对话中可能涉及图像或其他类型信息。
- 图像描述(Image Captioning):将图像和自然语言结合在一起,为图像生成相应的文字描述。
- 图像生成(Image Generation):使用多模态数据(如图像和文本)进行图像生成任务。
- 情感分析(Sentiment Analysis):使用多模态数据(如文本和音频)进行情感分析任务。
- 语音识别(Speech Recognition):使用多模态数据(如音频和文本)进行语音识别任务。
- 视频生成(Video Generation):使用多模态数据(如图像和文本)进行视频生成任务。
- 视频理解(Video Understanding):使用多模态数据(如图像、文本和音频)进行视频理解任务。
- 图像检索(Image Retrieval):使用多模态数据(如图像和文本)进行图像检索任务。
- 语音检索(Speech Retrieval):使用多模态数据(如音频和文本)进行语音检索任务。
- 视频检索(Video Retrieval):使用多模态数据(如视频和文本)进行视频检索任务。
多模态技术有哪些挑战?
多模态技术面临的挑战包括:
- 数据稀疏性(Data Sparseness):由于不同模态的数据量差异巨大,导致在训练和推理过程中需要进行大量的数据预处理和数据增强。
- 模态间的不匹配(Modality Mismatch):不同模态的数据之间存在差异和差异性,这需要使用多模态模型来处理。
- 模态间的干扰(Modality Interference):不同模态的数据之间存在干扰和冲突,这需要使用多模态模型来处理。
- 模态间的转换(Modality Conversion):不同模态的数据之间需要进行转换和整合,这需要使用多模态模型来处理。
- 模态间的融合(Modality Fusion):不同模态的数据之间需要进行融合和整合,这需要使用多模态模型来处理。
什么是词嵌入?
词嵌入是将每个单词映射到一个固定长度的向量,使得在模型中能够进行数学运算。这种技术有助于模型理解和生成自然语言。
描述预训练(Pre-training)和微调(Fine-tuning)的区别?
- 预训练是对模型进行初步的训练,使其具备一般化的知识或能力。
- 微调则是在预训练的基础上,对模型进行进一步的调整,以适应特定的任务或领域。这两种方法常用于提高模型的性能和适应性。
Transformer模型有哪些优势,以及如何使用Transformer进行多模态学习?
在多模态学习中,Transformer模型的主要优势包括:
- 并行计算:自注意力机制允许模型在处理多模态数据时进行并行计算,大大提高了计算效率。
- 长程依赖:与传统的RNN模型相比,Transformer模型通过自注意力机制能够捕捉不同位置之间的依赖关系,避免了长序列数据处理中的梯度消失或爆炸问题。
- 空间信息处理:与CNN模型相比,Transformer模型能够考虑空间信息的关系,从而更好地处理多模态数据。
如何使用Transformer进行多模态学习?
- 使用Transformer作为编码器,将不同模态的数据进行编码和融合。
- 使用Transformer作为解码器,对融合后的数据进行解码和生成。
- 使用Transformer的注意力机制,建立不同模态之间的交互和依赖关系。
在多模态Transformer模型中,编码器和解码器都由多个Transformer层组成。对于纯视觉、纯文本和视觉文本混合的任务,编码器的输入会有所不同。 例如,对于视觉文本任务(如视觉问答),编码器的输入可能是图像编码器和文本编码器的输出拼接,因为这类任务需要同时考虑图像和文本信息。 解码器的输入也会根据具体任务而变化,例如,对于检测任务,解码器产生的每个向量都会产生一个输出,包括类别和边界框。
请描述多模态大模型的一般架构?
多模态大模型的一般架构通常包括视觉编码器、连接器和语言模型(LLM)。连接器用于将视觉和文本模态的嵌入维度进行对齐,以便在序列长度维度上进行连接。 这种架构使得模型能够有效地处理和融合来自不同模态的信息。
请描述多模态大模型中的连接器?
连接器是用于将视觉和文本模态的嵌入维度进行对齐的模块。连接器的主要作用是将不同模态的嵌入维度进行对齐,以便在序列长度维度上进行连接。 连接器通常包括线性变换、非线性激活函数和归一化层等操作。连接器的设计和选择对多模态大模型的性能和效果有重要影响。
随着多模态大模型技术的发展,AI范式正经历着深刻变革,主要体现在哪几个方面?
AI范式正经历着深刻变革,主要体现在以下几个方面:
- 从单模态到多模态的范式转变:大模型通常要处理多种类型的数据输入,如图像、视频、文本、语音等,因此在模型结构和训练方法上更加复杂和灵活。 这种从单模态到多模态的范式转变使得AI系统能够更好地理解和处理多种数据类型,从而更好地完成多种任务。
- 从预测到生成的范式转变:大模型通常基于生成模型构建,可以在没有明确标签或答案的情况下生成新的数据,例如文本、图像和音频等。 这种从预测到生成的范式转变使得AI系统具备了更强的创造力和想象力,能够更好地完成一些具有创新性和创造性的任务。
- 从单任务到多任务的范式转变:大模型通常具有良好的泛化能力和可迁移性,能够同时处理多个任务。 这种从单任务到在务的范式转变使得AI系统能够更好地适应多变的应用场景,并具备更强的普适性和通用性.
- 从感知到认知的范式转变:一些多模态大模型具备自我学习和改进的能力,能够不断提高其性能逐渐通近AGI目标。
- 从大模型到超级智能体的转变:ChatGPT 诞生后,AI 具备了和人类进行多轮对话的能力,并且能针对相应问题给出具体回答与建议。 随后,各个领域推出“智能副驾驶(Copilot)”,如 Microsoft 365 Copilot、GitnmbCopilot、Adobe Fireny 等, 让AI成为办公、代码、设计等场景的“智能副驾驶”。如果说 Copilot 是“副驾驶”,那么 Agent 则可以算得上一个初级的“主驾驶”。 Agent可以通过和环境进行交互,感知信息并做出对应的思考和行动。Agent的最终发展目标就是实现 AGI。
多模态基础模型旨在解决哪三个代表性问题?
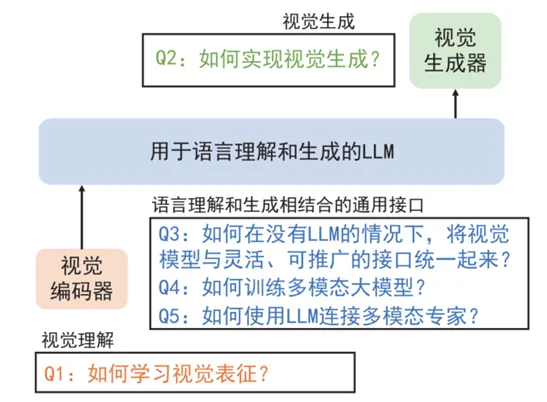
多模态基础模型旨在解决以下三个代表性问题:
- 视觉理解:学习通用的视觉表征对于构建视觉基础模型至关重要,其原因在于预训练一个强大的视觉骨干模型是所有计算机视觉下游任务的基础, 包括从图像级别(如图像分类、检索和字幕生成)到区域级别(如检测和定位)再到像素级别(如分割)的任务。
- 视觉生成:由于大规模的图像文本数据的出现,基础图像生成模型得以构建。其中的关键技术包括矢量量化VAE、扩散模型和自回归模型。
- 语言理解和生成相结合的通用接口:多模态基础模型是为特定目的设计的,用于解决一组特定的计算机视觉问题或任务。 通用模型的出现为AI智能体(AI Agent)奠定了基础。
从算法层面介绍DPO和PPO有什么区别?
PPO (Proximal Policy Optimization): PPO 是一种强化学习算法,采用了策略优化方法。它的目标是通过限制策略更新的幅度来避免策略剧烈变化,减小策略崩溃的风险。具体做法是通过剪裁损失函数,确保策略变化在一个较小的范围内,从而提高训练的稳定性。PPO 的核心是引入了一种近端目标函数,利用优势函数更新策略,兼顾了策略的探索和收敛。
DPO (Direct Policy Optimization): DPO 是一种最近提出的算法,旨在简化传统强化学习中的策略优化问题。它的主要思想是通过直接最小化目标函数来优化策略,而不是像 PPO 一样通过对数比率和剪裁损失函数来进行策略更新。DPO 采用了更直接的优化方式,简化了策略更新的过程。
区别:
策略更新: PPO 通过限制策略变化幅度(例如剪裁)来实现稳定训练,而 DPO 更倾向于直接优化目标函数。
稳定性和效率: PPO 通常能够保持较高的稳定性,但训练效率可能较低;DPO 则更高效,但可能在一定程度上牺牲了训练的稳定性。
介绍BatchNorm和LayerNorm,为什么transformer是LayerNorm?
BatchNorm (Batch Normalization): 主要用于卷积神经网络中,通过对 mini-batch 的每个维度进行标准化,减少内部协变量偏移,提高训练的稳定性。
LayerNorm (Layer Normalization): 主要用于 RNN 和 Transformer 等序列模型中,它对整个层进行标准化,独立于 mini-batch,确保在不同时间步和序列长度下具有一致的归一化效果。
Transformer 的输入是序列数据,不同的批次可能会有不同的长度和特征分布,使用 LayerNorm 可以更好地处理这些变化,同时适应不同时间步的归一化需求。
PostNorm和PreNorm这两个技术有什么优缺点?
PostNorm: 在注意力层和前馈网络之后进行归一化。这种方式能让主干网络更强大,但归一化的影响在模型早期阶段相对较弱。
PreNorm: 在注意力层和前馈网络之前进行归一化,可以增强模型的稳定性,尤其是在训练初期。但随着网络深度增加,归一化可能会影响表示能力的提升。
优缺点: PostNorm: 优点是后期训练效果较好,缺点是前期训练不够稳定。
PreNorm: 优点是前期训练更稳定,缺点是模型可能会陷入局部最优解。
详细描述一下sft过程的细节?
**SFT(Supervised Fine-Tuning)**的过程通常包括以下几个步骤:
数据准备:收集高质量的标注数据集,确保数据能够代表目标任务的特征和分布。
初始模型加载:使用预训练的模型作为基础,这通常是一个大型的预训练语言模型。
模型训练:
输入输出对:将标注数据转化为输入和期望输出对,以便模型进行学习。
损失函数计算:使用交叉熵等损失函数评估模型输出与实际标注之间的差距。
反向传播:根据损失函数的反馈更新模型参数,以最小化输出与实际标注之间的误差。
验证与评估:在验证集上评估模型的性能,调整超参数以提高效果。
迭代优化:根据评估结果进行多轮迭代,直到模型在特定任务上达到预期效果。
Decoder-Only和Encoder-Decoder模型相比有什么优势?在训练和推理效率上有什么区别?
Decoder-Only模型:结构较为简洁,通常只由一个解码器组成。模型参数较少,相比于Encoder-Decoder模型在训练和推理上可能更高效。在自回归生成任务中表现优异,比如语言模型生成文本。
训练效率:
Decoder-Only 模型:在训练过程中,由于模型仅处理解码器部分,参数较少,训练效率较高。
Encoder-Decoder 模型:由于需要同时训练编码器和解码器部分,模型的参数量通常较大,因此训练效率相对较低。
推理效率: Decoder-Only 模型:推理过程中模型依赖先前生成的标记,因此推理时间较长,尤其在生成长文本时。
Encoder-Decoder 模型:推理时编码器只需处理一次输入,但解码器部分的推理仍然逐步进行,因此总的来说推理时间也较长,但对于复杂任务而言,效率可能更好。
介绍常见的位置编码,其特点是什么?
绝对位置编码: 固定正弦-余弦位置编码:最早由 Transformer 引入,使用不同频率的正弦和余弦函数将位置信息编码到每个标记中。 特点:固定不变,无需训练;能够保留序列顺序信息。
相对位置编码: 相对位置编码:相对于其他标记的位置信息,而不是绝对位置。常用于改进 Transformer 模型,如 Transformer-XL。 特点:在处理长序列时表现更好,能够捕捉到序列中不同位置之间的关系。
Learnable Position Encoding(可学习位置编码): 特点:直接在模型中引入可训练的参数来表示位置编码,允许模型自己学习最优的位置信息表示。
多模态大模型微调过程中如何避免灾难性遗忘?
在微调大模型的过程中,确实可能会遇到灾难性遗忘的问题,即模型在优化某一特定任务时,可能会忘记之前学到的其他重要信息或能力。为了缓解这种情况,可以采用以下几种策略:
(1)重新训练:通过使用所有已知数据重新训练模型,可以使其适应数据分布的变化,从而避免遗忘。
(2)增量学习:增量学习是一种在微调过程中逐步添加新数据的方法。通过增量学习,大模型可以在不忘记旧知识的情况下学习新数据。
(3)知识蒸馏:知识蒸馏是一种将老模型的知识传递给新模型的方法。通过训练一个教师模型来生成数据标注或权重,然后将标注或权重传递给新模型进行训练,可以避免灾难性遗忘。
(4)正则化技术:限制模型参数的变化范围,从而减少遗忘,使得大模型在微调过程中保持稳定性。
(5)使用任务相关性数据:如果可能的话,尽量使用与原始任务相关或相似的数据进行微调。这样,模型在优化新任务时,更容易与先前学到的知识建立联系。
如何有效地将不同模态的数据对齐或融合到同一维度?
多模态数据融合是指将来自不同传感器或来源的多种类型的数据(如图像、文本、语音等)结合起来进行分析和理解的过程。在多模态数据融合中,对齐问题是一个重要的挑战,因为不同模态的数据可能存在表示形式、尺度、时序等方面的差异。
以下是一些常见的方法来解决多模态数据融合中的对齐问题:
- 特征提取和对齐:对于每个模态的数据,可以通过特定的特征提取方法提取出高级语义特征。然后,可以使用对齐技术(如配准、对齐变换)来将不同模态的特征映射到一个共享的特征空间,从而实现模态之间的对齐。
- 时间对齐:对于时序模态数据(如视频、语音),时间对齐是十分重要的。可以使用时间对齐方法(如动态时间规整DTW)来将不同模态的时序数据进行对齐,确保它们在相同的时间尺度上进行融合。
- 基于图模型的方法:可以构建图模型来描述多模态数据之间的相互关系,然后使用图匹配和图割等技术来进行数据对齐和融合。图模型的节点可以表示不同的模态,边可以表示模态之间的相似性或相关性。
- 神经网络方法:深度学习的方法在多模态数据融合中也取得了很好的效果。可以使用神经网络架构,如多视图网络、多模态融合网络等,来学习模态间的对齐和表达,从而实现多模态数据的融合。
在多模态大模型中,如何进行参数高效微调以提高模型性能?
参数高效微调是一种通过少量参数调整来适应新任务的方法,旨在减少微调过程中的计算成本和过拟合风险。具体方法包括在每层网络中加入可训练的token,达到接近全量微调的效果。例如,Lora微调通过将权重矩阵分解成两个低值矩阵,使得微调时只需更新少量的参数。此外,还可以引入文本和图像的promot,通过三种chromes训练模型,效果显著提升。这种方法可以在保持大部分模型参数不变的情况下,显著提高模型在新任务上的性能。
多模态大模型中一般使用哪些损失函数?
多模态大模型中常用的损失函数包括均方误差(MSE)、交叉熵损失、**均绝对误差(MAE)**等。这些损失函数在多模态任务中发挥着重要作用,如图像-文本检索、图像描述生成等。以下是对这些损失函数的详细说明以及相关工作中的应用实例:
常用损失函数
- 均方误差(MSE):用于回归问题,计算预测值与实际值之间差值的平方和的平均值。对较大误差较为敏感,适用于需要精确预测的场景。
- 交叉熵损失:广泛用于分类问题,衡量预测概率分布与实际标签之间的差异。特别适用于多类分类任务,能够提供清晰的梯度信号,有助于防止过拟合。
- 均绝对误差(MAE):对异常值的敏感度较低,适用于存在较多异常值的数据集。
相关工作中的应用实例
- BLIP系列模型:在BLIP系列模型中,使用了图像-文本对比损失(ITC)来对齐视觉和语言表示,以及图像-文本匹配损失(ITM)来区分正负图像-文本对。
- MMPareto算法:该算法在多模态学习中引入了帕累托积分,通过考虑梯度的方向和大小,确保最终梯度的方向对所有学习目标都是通用的,从而增强泛化能力。
均方误差在多模态大模型中的定义是什么?
均方误差(Mean Squared Error, MSE)在多模态大模型中是一种常用的损失函数,用于衡量模型预测值与实际值之间的差异。它的定义和计算方法如下:
均方误差的定义
均方误差是预测误差的平方和的平均值,用于评估模型的预测性能。
均方误差的计算公式
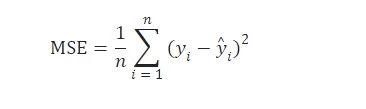
其中, n n n 是样本数量, y i y_i yi 是实际值, y ^ i \hat{y}_i y^i 是预测值。
均方误差在多模态大模型中的应用
在多模态大模型中,均方误差常用于回归任务,如图像重建、语音识别等,通过最小化均方误差来优化模型参数,提高模型的预测精度。
均方误差对大误差较为敏感,这使得它在需要精确预测的场景中非常有用,但也需要注意对异常值的处理。
CLIP模型的损失函数如何设计?
CLIP(Contrastive Language-Image Pre-training)模型是一种基于对比学习的图像-文本预训练模型,其损失函数的设计旨在将图像和文本映射到同一个嵌入空间中,使得匹配的图像-文本对在嵌入空间中更接近,而不匹配的对更远离。以下是CLIP模型中常用的损失函数及其设计思路:
一、图像-文本对比损失(Image-Text Contrastive Loss, ITC)
定义:
ITC损失通过对比正样本(匹配的图像-文本对)和负样本(不匹配的图像-文本对)来拉近正样本之间的距离,并推远负样本之间的距离。
公式:
L I T C = − log exp ( v i ⋅ t i / τ ) ∑ j = 1 N exp ( v i ⋅ t j / τ ) \mathcal{L}_{ITC} = -\log \frac{\exp(\mathbf{v}_i \cdot \mathbf{t}i / \tau)}{\sum{j=1}^N \exp(\mathbf{v}_i \cdot \mathbf{t}_j / \tau)} LITC=−log∑j=1Nexp(vi⋅tj/τ)exp(vi⋅ti/τ)
其中, v i \mathbf{v}_i vi 是图像 i的嵌入向量, t i \mathbf{t}_i ti 是文本 t 的嵌入向量, τ \tau τ 是温度参数, N N N 是负样本的数量。
设计思路:
- 对比学习:通过对比正负样本,使得匹配的图像-文本对在嵌入空间中更接近,而不匹配的对更远离。
- 温度参数: τ \tau τ 控制对比学习的敏感度,较小的 τ \tau τ 会使得模型更加关注于区分相似和不相似的样本。
二、图像-文本匹配损失(Image-Text Matching Loss, ITM)
定义:
ITM损失用于区分正样本和负样本,通常是一个二分类任务,判断一个图像-文本对是否匹配。
公式:
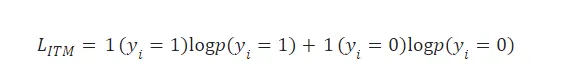
其中, y i y_i yi 是标签(1 表示匹配,0 表示不匹配), p ( y i = 1 ) p(y_i = 1) p(yi=1) 是模型预测匹配的概率。
设计思路:
- 二分类任务:通过训练一个二分类器来判断图像-文本对是否匹配,从而增强模型的判别能力。
- 辅助任务:ITM损失作为一个辅助任务,可以帮助模型更好地学习图像和文本之间的对应关系。
综合损失函数
在实际应用中,CLIP模型通常会综合使用上述损失函数,以全面优化模型的性能:
L = L I T C + λ 1 L I T M + λ 2 L R e c \mathcal{L} = \mathcal{L}{ITC} + \lambda_1 \mathcal{L}{ITM} + \lambda_2 \mathcal{L}_{Rec} L=LITC+λ1LITM+λ2LRec
其中, λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 是超参数,用于平衡不同损失函数的贡献。
CLIP模型的损失函数设计通过对比学习和匹配损失,有效地将图像和文本映射到同一嵌入空间中,从而提高了模型在图像-文本检索和任务中的性能。
多模态大语言模型(MLLMs)中幻觉现象的主要来源是什么?
幻觉现象在多模态大语言模型(MLLMs)中的主要来源包括数据、模型、训练和推理四个方面。
- 数据:数据的质量、数量和统计偏差可能导致幻觉。例如,数据集的噪声、缺乏多样性以及对象共现偏差都会影响模型的表现。
- 模型:模型的架构和组件(如视觉模型、语言模型和对齐接口)的弱点可能导致幻觉。视觉模型的感知能力不足、语言模型的知识先验以及弱对齐接口都是潜在的原因。
- 训练:训练目标和方法的选择不当也可能导致幻觉。例如,仅使用自回归下一个标记预测损失可能不足以处理视觉内容的复杂空间结构。
- 推理:在生成过程中,随着序列长度的增加,模型可能会更多地关注先前生成的文本标记,而忽略视觉内容,从而导致幻觉。
目前评估MLLMs幻觉现象的基准有哪些?这些基准在评估不同类型幻觉时的侧重点是什么?
目前用于评估多模态大语言模型(MLLMs)中幻觉的标准基准和指标包括:
- CHAIR:用于评估图像描述任务中的对象幻觉,通过计算生成文本中实际存在于图像中的单词比例。
- POPE:将幻觉评估转化为二元分类任务,通过简单的“是或否”问题来评估对象幻觉。
- MME:一个综合评估基准,涵盖感知和认知能力的多个子任务,包括对象存在、计数、位置和颜色等。
- CIEM:使用自动管道生成的数据进行幻觉评估,重点在于对象存在幻觉。
- AMBER:支持生成任务和判别任务的评估,结合CHAIR和F1分数形成综合评分。
这些基准和指标各有侧重,评估维度也不同,提供了对MLLMs幻觉现象的多角度分析。
缓解MLLMs幻觉现象的方法有哪些?
缓解MLLMs中幻觉现象的方法可以从数据、模型、训练和推理四个方面入手:
- 数据:**引入负样本、反事实数据和减少现有数据集中的噪声和错误。**例如,LRV-Instruction通过包含正负指令样本来增强视觉指令调优的鲁棒性。
- 模型:提升视觉编码器的分辨率和多样性,引入专用模块来控制参数知识的程度。例如,HallE-Switch通过对比学习增强视觉和文本表示的对齐。
- 训练:使用辅助监督信号、强化学习和无监督学习等方法。例如,MOCHa框架通过多目标奖励函数引导强化学习过程,减少幻觉。
- 推理:采用对比解码、引导解码和后处理校正等方法。例如,VCD通过对比原始和失真视觉输入的输出分布来抑制统计偏差和语言先验。
多模态大语言模型(MLLMs)中幻觉现象的具体类型有哪些?
幻觉现象在多模态大语言模型(MLLMs)中主要表现为对象幻觉,具体可以分为以下三类:
- 类别幻觉:模型识别出图像中不存在的对象类别或错误的对象类别。例如,模型描述图像中存在“一些长椅和一个篱笆”,而实际上图像中没有这些对象。
- 属性幻觉:模型正确识别了对象类别,但对对象的属性描述错误。例如,模型描述图像中的花朵为“粉红色的花朵”,而实际上花朵的颜色并不准确。
- 关系幻觉:模型正确识别了对象及其属性,但对象之间的关系描述不准确。例如,模型描述图像中的人物“站在她周围观看”,而实际上人物在图像中的位置关系并不如此。
数据集的质量和多样性对MLLMs的幻觉现象有何影响?
数据集的质量和多样性对MLLMs的幻觉现象有显著影响:
- 数据质量:低质量的数据集包含噪声、不准确的标注或不完整的图像,可能导致模型在训练过程中学习到错误的信息,从而在生成文本时产生幻觉。
- 数据多样性:缺乏多样性的数据集可能导致模型在处理未见过的场景或对象时表现不佳,容易产生幻觉。例如,训练数据中缺乏否定指令或拒绝回答的样本,可能导致模型在面对否定问题时倾向于回答“是”。
如何通过改进模型架构来减少MLLMs中的幻觉现象?
改进模型架构可以从以下几个方面入手:
- 增强视觉编码器:使用更高分辨率的视觉编码器或引入多种视觉编码器(如CLIP和DINO的混合特征)来提高模型的视觉感知能力。
- 引入专用模块:设计专门的“开关”模块(如HallE-Switch)来控制模型在生成详细描述时的参数知识程度,减少基于语言知识的幻觉。
- 多任务学习:通过多任务学习框架整合多种视觉和语言任务,增强模型的跨模态理解能力。
在训练过程中,如何有效地利用辅助监督信号来减少幻觉?
在训练过程中,可以通过以下方法利用辅助监督信号来减少幻觉:
- 关系关联指令(RAI-30k):构建一个细粒度的视觉指令数据集,每个指令与关系标注相关联,使用掩码预测损失来引导模型关注图像中的关键实例。
- 对比学习:通过对比学习增强视觉和文本表示的对齐,使用幻觉样本作为负例,拉近非幻觉文本和视觉样本的距离。
在推理阶段,如何通过后处理校正来减少MLLMs中的幻觉?
在推理阶段,可以通过以下方法进行后处理校正来减少幻觉:
(1)Woodpecker:提取生成文本中的关键概念,通过视觉内容验证这些概念,检测并修正幻觉内容。 (2)LURE:使用一个专门的幻觉修正器模型,将潜在的幻觉描述转换为准确的描述。训练数据集包含图像和幻觉描述,目标是将幻觉描述修正为准确描述。
跨模态对比学习原理与挑战有哪些
跨模态对比学习的核心思想是通过拉近语义相关的多模态数据表示,同时推开无关数据表示,从而学习一个统一的特征空间。在这个过程中,模型需要处理来自不同模态的正样本对(如对应的图像-文本对)和负样本对。通过精心设计的损失函数(如InfoNCE),模型可以逐步优化特征表示,使得相关内容在特征空间中的距离更近,无关内容的距离更远。
在技术实现层面,跨模态对比学习面临着几个主要挑战。首先是模态差异问题,不同模态数据(如图像和文本)具有完全不同的统计特性和结构,需要设计合适的特征提取和对齐方法。其次是负样本选择的问题,有效的负样本对模型学习至关重要,但在实践中往往难以获得高质量的负样本。最后是训练稳定性问题,不同模态的训练进度可能不一致,需要精心设计优化策略来保持平衡。
为了应对这些挑战,研究者提出了多种解决方案。在架构设计上,采用多层次的特征对齐和自适应融合机制;在优化策略上,引入硬负样本挖掘和动态队列维护;在正则化方面,结合特征归一化和对比正则项等技术。这些方案的组合使用,能够显著提升跨模态对比学习的效果。实践表明,良好的跨模态对比学习不仅能够提升模型的表示能力,还能增强模型在各种下游任务中的泛化性能。
在多模态模型中如何有效处理模态缺失(Modal-Missing)问题
模态缺失是多模态系统中的一个普遍挑战,其解决方案需要考虑数据的完整性和模型的鲁棒性。最基础的处理方法是模态补全,通过生成模型或自编码器来重建缺失的模态信息。这种方法虽然直观,但生成的数据质量往往难以保证,可能引入额外的噪声。近年来,一些研究通过对抗学习来提升生成质量,但计算开销较大。
更实用的方法是设计鲁棒的特征学习策略。通过在训练阶段随机丢弃某些模态的信息,强制模型学习更加鲁棒的特征表示。这种方法不仅能够处理测试阶段的模态缺失问题,还能提升模型对不完整数据的适应能力。另一个重要的技术方向是知识蒸馏,通过将完整模态训练的教师模型知识迁移到处理单一模态的学生模型中,实现在模态缺失情况下的高效推理。
最新的研究还探索了自适应融合机制,根据可用模态的质量和完整性动态调整处理策略。这种方法通过注意力机制或门控单元来控制不同模态特征的权重,能够更好地适应实际应用中的各种模态缺失场景。在实践中,这些方法往往需要结合使用,并根据具体应用场景和资源约束选择合适的策略组合。
相关文章:

多模态理论知识
说一下多模态的定义? 多模态是指使用多种不同类型的媒体和数据输入,例如文本、图像、音频、视频等,它们之间存在关联或者对应关系。 这些不同类型的媒体和数据输入可以在不同的层面上传达信息并表达意义。多模态数据的处理需要融合不同类型的信息&…...

Nginx 安全防护与HTTPS部署
目录 一、核心安全配置 1、隐藏版本号 2、限制危险请求方法 3、请求限制(CC攻击防御) (1)使用Nginx的limit_req模块限制请求速率 (2)压力测试验证 4、防盗链 (1)修改 Window…...

Python爬虫+代理IP+Header伪装:高效采集亚马逊数据
1. 引言 在当今大数据时代,电商平台(如亚马逊)的数据采集对于市场分析、竞品监控和价格追踪至关重要。然而,亚马逊具有严格的反爬虫机制,包括IP封禁、Header检测、验证码挑战等。 为了高效且稳定地采集亚马逊数据&am…...

效率提升利器:解锁图片处理新姿势
今天我给大家分享一款超实用的图片压缩软件,好用程度超出想象!该软件身形 “轻盈”,仅 648KB,启动后能迅速上手。 01 软件介绍 这款软件就是PicSizer,具有以下特点: 支持windows系统 体积小,绿…...

【强化学习】什么是强化学习?2025
1. 强化学习简介 一句话总结:强化学习(Reinforcement Learning, RL)是一种机器学习范式,强调智能体(agent)通过与环境(environment)的交互,以试错(trial‑an…...

富文本编辑器的第三方库ProseMirror
如果0-1的开发一个富文本编辑器,成本还是非常高的,里面很多坑要踩,市面上很多库可以帮助我们搭建一个富文本编辑器,ProseMirror就是其中最流行的库之一。 认识ProseMirror ProseMirror 提供了一套工具和概念,用于构建…...

理解IP四元组与网络五元组:网络流量的“身份证”
理解IP四元组与网络五元组:网络流量的“身份证” 在现代网络通信中,IP四元组和网络五元组是流量识别、连接追踪、安全策略等核心的基础概念。理解这些“元组”不仅能够帮助我们更好地设计网络架构、排查故障,还能为安全与运维策略的落地提供…...

ROS2:话题通信CPP语法速记
目录 发布方实现流程重点代码 订阅方实现流程重点代码 参考代码示例发布方代码订阅方代码 发布方实现流程 包含头文件(rclcpp.hpp与[interfaces_pkg].hpp)初始化ROS2客户端(rclcpp::init)自定义节点类(创建发布实例,伺…...

码蹄集——直线切平面、圆切平面
MT1068 直线切平面 思路: 则 #include<bits/stdc.h> using namespace std;int main( ) {int n;cin>>n;cout<<n*(n1)/21;return 0; } MT1069圆切平面 n个圆最多把平面分成几部分?输入圆的数量N,问最多把平面分成几块。比如…...

2025年游戏行业DDoS攻防指南:智能防御体系构建与实战策略
2025年,游戏行业在全球化扩张与技术创新浪潮中,正面临前所未有的DDoS攻击威胁。攻击规模从T级流量到AI驱动的精准渗透,攻击手段从传统网络层洪水到混合型应用层打击,防御体系已从“被动应对”转向“智能博弈”。本文将结合最新攻击…...

LightGBM算法原理及Python实现
一、概述 LightGBM 由微软公司开发,是基于梯度提升框架的高效机器学习算法,属于集成学习中提升树家族的一员。它以决策树为基学习器,通过迭代地训练一系列决策树,不断纠正前一棵树的预测误差,逐步提升模型的预测精度&a…...

Nvidia发布Parakeet V2,一款新的开源自动语音识别模型
Nvidia 发布 Parakeet V2,一款新的开源自动语音识别 AI,核心亮点:一秒钟转录一小时的音频;Open ASR 上的顶级模型,击败了 ElevenLabs 的 Scribe 和 OpenAI 的 Whisper;6.05% 的单词错误率;CC-BY…...
** 和 **存储过程(Stored Procedure)原理及优化建议)
浅析MySQL 的 **触发器(Trigger)** 和 **存储过程(Stored Procedure)原理及优化建议
MySQL 的 触发器(Trigger) 和 存储过程(Stored Procedure) 是数据库中用于实现业务逻辑的重要机制,它们的原理和使用方式不同,适用于不同的场景。 一、基本概念与原理 特性触发器(Trigger)存储过程(Stored Procedure)定义在表上定义,当特定事件(INSERT/UPDATE/DELE…...

网页版部署MySQL + Qwen3-0.5B + Flask + Dify 工作流部署指南
1. 安装MySQL和PyMySQL 安装MySQL # 在Ubuntu/Debian上安装 sudo apt update sudo apt install mysql-server sudo mysql_secure_installation# 启动MySQL服务 sudo systemctl start mysql sudo systemctl enable mysql 安装PyMySQL pip install pymysql 使用 apt 安装 My…...

人工智能与智能合约:如何用AI优化区块链技术中的合约执行?
引言:科技融合的新风口 区块链和人工智能,是当前最受瞩目的两大前沿技术。一个以去中心化、可溯源的机制重构信任体系,另一个以智能学习与决策能力重塑数据的价值。当这两项技术相遇,会碰撞出什么样的火花? 智能合约作…...

如何提升丢包网络环境下的传输性能:从 TCP 到 QUIC,再到 wovenet 的实践
在现代互联网环境中,稳定、可靠的网络连接对各种在线应用至关重要。然而,理想情况往往难以实现,特别是在以下一些典型场景中,网络丢包(packet loss) 常常发生: 一、常见的网络丢包场景 跨境通…...

Python 中的数据结构介绍
Python 是一种功能强大的编程语言,它内置了多种数据结构,以便用户能够方便、高效地存储、处理和访问数据。数据结构是组织和存储数据的方式,不同的数据结构适用于不同的应用场景。掌握 Python 中的基本数据结构,可以使代码更加简洁…...

数据中台架构设计
数据中台分层架构 数据采集层 数据源类型:业务系统(ERP、CRM)、日志、IoT 设备、第三方 API 等。采集方式: 实时采集:Kafka、Flink CDC(变更数据捕获)。离线采集:Sqoop、DataX&…...

基于SpringBoot网上书店的设计与实现
pom.xml配置文件 1. 项目基本信息(没什么作用) <groupId>com.spring</groupId> <!--项目组织标识,通常对应包结构--> <artifactId>boot</artifactId> <!--项目唯一标识--> <version>0.0.1-SNAPSHOT</ve…...

Vue3路由模式为history,使用nginx部署上线后刷新404的问题
一、问题 在使用nginx部署vue3的项目后,发现正常时可以访问的,但是一旦刷新,就是出现404的情况 二、解决方法 1.vite.config.js配置 在vite.config.js中加入以下配置 export default defineConfig(({ mode }) > {const isProduction …...

从单机到生产:Kubernetes 部署方案全解析
🚀 从单机到生产:Kubernetes 部署方案全解析 🌐 Kubernetes(k8s)是当今最流行的容器编排系统,广泛应用于开发、测试和生产环境。但不同的使用场景对集群规模、高可用性和资源需求有不同的要求。本文将带你…...

redis大全
1 redis安装和简介 基于ubuntu系统的安装 sudo apt update sudo apt install redis##包安装的redis 没有默认配置文件 启动 redis-server /path/to/your/redis.confredis-cliRedis 默认是没有设置用户和密码的,即可以无密码访问 设置密码的方法:可以通…...

C#经典算法面试题
C#经典算法面试题 递归算法 C#递归算法计算阶乘的方法 一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且0的阶乘为1。自然数n的阶乘写作n!。1808年,基斯顿卡曼引进这个表示法。 原理:亦即n!=123…(n-1)n。阶乘亦可以递归方式定义:0!=1,n!=(n-1)!n。…...

cephadm部署ceph集群
一、什么是Ceph? ceph是一个统一的、分布式的存储系统,设计初衷式提供较好的性能(io)、可靠性(没有单点故障)和可扩展性(未来可以理论上无限扩展集群规模),这三点也是集群架构所追求的。 “统一的”:意味着Ceph可以一套存储系统同时提供对象存储、块存…...

c#OdbcDataReader的数据读取
先有如下c#示例代码: string strconnect "DSNcustom;UIDsa;PWD123456;" OdbcConnection odbc new OdbcConnection(strconnect); odbc.Open(); if (odbc.State ! System.Data.ConnectionState.Open) { return; } string strSql "select ID from my…...

代码随想录训练营第十八天| 150.逆波兰表达式求值 239.滑动窗口最大值 347.前k个高频元素
150.逆波兰表达式求值: 文档讲解:代码随想录|150.逆波兰表达式求值 视频讲解:栈的最后表演! | LeetCode:150. 逆波兰表达式求值_哔哩哔哩_bilibili 状态:已做出 思路: 这道题目是让我们按照逆波…...

数据中台产品功能介绍
在数字化转型浪潮中,数据中台作为企业数据管理与价值挖掘的核心枢纽,整合分散数据资源,构建统一的数据管理与服务体系。本数据中台产品涵盖数据可视化、数据建设、数据治理、数据采集开发和系统管理五大平台,以丰富且强大的功能模…...

第四章-初始化Direct3D
首先我们需要一个错误检测和抛出机制 inline std::string ToString(const HRESULT& result) {char buffer[256];sprintf_s(buffer, "error code : 0x%08X\n", result);return std::string(buffer); }class MyException : public std::runtime_error { public:My…...

实操3:6位数码管
文章目录 文章介绍仿真图原来的仿真代码教学用开发板段选和位选对应引脚思考题实物图 文章介绍 对应“案例5_3: 6位数码管显示0或者1【静态显示】” 跳转链接 要求:实现开发板的6位数码管同时显示0或者1 仿真图 原来的仿真代码 #include<reg52.h> // 头文件…...
)
常识补充(NVIDIA NVLink技术:打破GPU通信瓶颈的革命性互联技术)
文章目录 **引言:为什么需要NVLink?**1. NVLink技术概述1.1 什么是NVLink?1.2 NVLink的发展历程 2. NVLink vs. PCIe:关键对比2.1 带宽对比2.2 延迟对比 3. NVLink的架构与工作方式3.1 点对点直连(P2P)3.2 …...
)
openwrt 使用quilt 打补丁(patch)
1,引入 本文简单解释如何在OpenWRT下通过quilt命令打补丁--patch,也可查看openwrt官网提供的文档 2,以下代码通过编译net-snmp介绍 ① 执行编译命令之后,进入build_dir的net-snmp-5.9.1目录下,改目录即为snmp最终编译的目录了 /…...

NVIDIA Halos:智能汽车革命中的全栈式安全系统
高级辅助驾驶行业正面临一个尴尬的"安全悖论"——传感器数量翻倍的同时,事故率曲线却迟迟不见明显下降。究其原因,当前行业普遍存在三大技术困局: 碎片化安全方案 传统方案就像"打补丁",激光雷达厂商只管点云…...

k8s术语之service
Kubernetes在设计之初就充分考虑了针对容器的服务发现与负载均衡机制,提供了Service资源,并通过kube-proxy配合cloud provider 来适应不同的用于场景。随着kubernetes用户的激增,用户场景的不断丰富,又产生了一些新的负载均衡机制…...

C/C++工程中的Plugin机制设计与Python实现
C/C工程中的Plugin机制设计与Python实现 1. Plugin机制设计概述 在C/C工程中实现Plugin机制通常需要以下几个关键组件: Plugin接口定义:定义统一的接口规范动态加载机制:运行时加载动态库注册机制:Plugin向主程序注册自己通信机…...

RNN 与 CNN:深度学习中的两大经典模型技术解析
在人工智能和深度学习领域,RNN(Recurrent Neural Network,循环神经网络) 和 CNN(Convolutional Neural Network,卷积神经网络) 是两种非常重要的神经网络结构。 它们分别擅长处理不同类型的数据,在自然语言处理、计算机视觉等多个领域中发挥着关键作用。 本文将从原理…...

多模态训练与微调
1.为什么多模态模型需要大规模预训练? 多模态模型需要大规模预训练的原因包括: (1)数据丰富性:大规模预训练可以暴露模型于丰富的数据,提升其泛化能力。 (2)特征提取:通过预训练,模型能够学习到有效的特…...

【HDLBits刷题】Verilog Language——1.Basics
目录 一、题目与题解 1.Simple wire(简单导线) 2.Four wires(4线) 3.Inverter(逆变器(非门)) 4.AND gate (与门) 5. NOR gate (或非门&am…...

基于深度学习的图像识别技术:从原理到应用
前言 在当今数字化时代,图像识别技术已经渗透到我们生活的方方面面,从智能手机的人脸解锁功能到自动驾驶汽车对交通标志的识别,再到医疗影像诊断中的病变检测,图像识别技术正以其强大的功能和广泛的应用前景,改变着我们…...
)
【coze】手册小助手(提示词、知识库、交互、发布)
【coze】手册小助手(提示词、知识库、交互、发布) 1、创建智能体2、添加提示词3、创建知识库4、测试智能体5、添加交互功能6、发布智能体 1、创建智能体 2、添加提示词 # 角色 你是帮助用户搜索手册资料的AI助手 ## 工作流程 ### 步骤一:查询知识库 1.每…...
的中2班幼儿偏好性测试(HTML))
【教学类-34-11】20250506异形拼图块(圆形、三角、正方,椭圆/半圆)的中2班幼儿偏好性测试(HTML)
背景介绍 最近在写一份工具运用报告,关于剪纸难度的。所以设计了蝴蝶描边系列和异形凹凸角拼图。 【教学类-102-20】蝴蝶三色图作品2——卡纸蝴蝶“满格变形图”(滴颜料按压对称花纹、原图切边后变形放大到A4横版最大化)-CSDN博客文章浏览阅读609次,点赞8次,收藏3次。【…...

Debian系统上PostgreSQL15版本安装调试插件及DBeaver相应配置
PostgreSQL所在Debian Linux服务器安装插件程序 在PostgreSQL数据库服务器Debian系统上执行以下命令,安装插件pldebugger: sudo apt install postgresql-15-pldebugger #上面这一条命令运行完好像pgsql服务自动重启了,看日志的样子是这样的,…...

GD32F470+CH395Q
tcp_client配置 第一步:资料下载 以太网协议栈芯片 CH395 - 南京沁恒微电子股份有限公司 第二步:准备工程 (1) 首先准备一个编译无报错、可以正常打印和延时的工程文件,官方例程采用STM32F1芯片,但本文…...

解决Hyper-V无法启动Debian 12虚拟机
问题 有时,我们会想要在Hyper-V中运行Debian12。我们想利用该系统的ISO镜像文件安装一个全新的虚拟机。 然而,当我们在Hyper-V中创建了一个2代虚拟机、添加了Debian 12的网络安装(Netinst)ISO作为最先启动的介质时,Hy…...

linux redis 设置密码以及redis拓展
redis拓展:http://pecl.php.net/package/redis 在服务器上,这里以linux服务器为例,为redis配置密码。 需要永久配置密码的话就去redis.conf的配置文件中找到requirepass这个参数,如下配置: 修改redis.conf配置文件 # requirepass …...

uniapp app 端获取陀螺仪数据的实现攻略
在 uniapp 开发中,uni.startGyroscope在 app 端并不被支持,这给需要获取陀螺仪数据的开发者带来了挑战。不过,借助 Native.js,我们能调用安卓原生代码实现这一需求。接下来,就为大家详细介绍实现步骤,并附上…...
)
第三节:Vben Admin 最新 v5.0 对接后端登录接口(下)
文章目录 前言一、处理请求头Authorization二、/auth/user/info 接口前端接口后端接口三、/auth/codes 接口1.前端2.后端四、测试接口前言 上一节内容,实现了登录的/auth/login 接口,但是登陆没有完成,还需要完成下面两个接口。才能完成登录。 一、处理请求头Authorizatio…...

标题:基于自适应阈值与K-means聚类的图像行列排序与拼接处理
摘要: 本文提出了一种基于自适应阈值和K-means聚类的图像行列排序与拼接方法。通过对灰度图像的自适应二值化处理,计算并分析图像的左右边距,从而确定图像的行数与列数。通过对图像进行特征提取,并使用K-means聚类进行排序&#…...

修改磁盘权限为管理员
1.右击需要修改的磁盘,点击属性 然后一路点击确定 已经修改好了...

P1782 旅行商的背包 Solution
Description 有一个体积为 C C C 的背包和若干种物品. 前 n n n 种物品,第 i i i 种体积为 v i v_i vi,价值 w i w_i wi,有 d i d_i di 件. 后 m m m 种物品,每种对应一个函数 f ( x ) a i x 2 b i x c i f(x)a…...

Acrel-EIoT 能源物联网云平台在能耗监测系统中的创新设计
摘要 随着能源管理的重要性日益凸显,能耗监测系统成为实现能源高效利用的关键手段。本文详细介绍了基于安科瑞Acrel-EIoT能源物联网云平台的能耗监测系统的设计架构与应用实践。该平台采用分层分布式结构,涵盖感知层、网络层、平台层和应用层࿰…...