多模态核心模型
1.BLIP的原理?
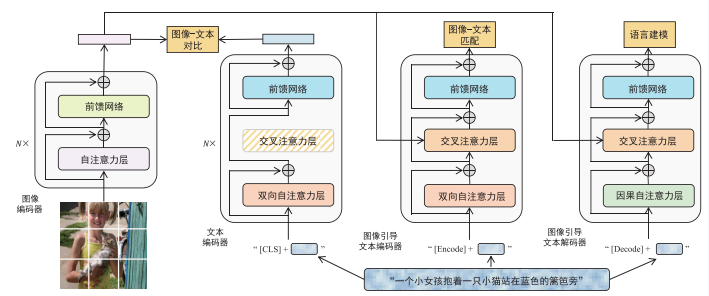
BLIP是一种统一视觉语言理解和生成的预训练模型。BLIP的特点在于它采用了一种编码器-解码器混合架构(MED),并且引入了CapFilt机制来提高数据质量和模型性能。BLIP的主要组成部分包括:
- MED架构:包括单模态编码器、图像引导的文本编码器和图像引导的文本解码器,这使得BLIP能够同时处理理解和生成任务。
- 预训练目标:BLIP在预训练期间联合优化了三个目标,包括图文对比学习、图文匹配和图像条件语言建模。
- CapFilt机制:包括Captioner和Filter两个模块,Captioner用于生成图像的文本描述,而Filter用于从生成的描述中去除噪声,从而提高数据集的质量。
2.CLIP的原理?
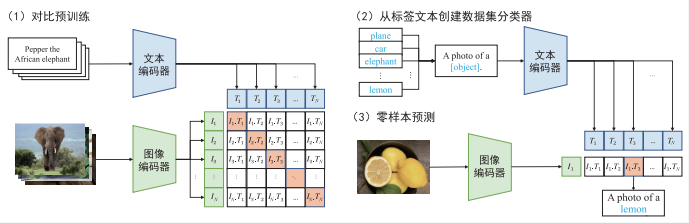
CLIP是由OpenAI提出的一种多模态预训练模型,它通过对比学习的方式,使用大规模的图像和文本数据对来进行预训练。CLIP模型包括两个主要部分:
Text Encoder:用于提取文本的特征,通常采用基于Transformer的模型。
Image Encoder:用于提取图像的特征,可以采用CNN或基于Transformer的Vision Transformer。 CLIP的训练过程涉及将文本特征和图像特征进行对比学习,使得模型能够学习到文本和图像之间的匹配关系。CLIP能够实现zero-shot分类,即在没有特定任务的训练数据的情况下,通过对图像进行分类预测其对应的文本描述。
3.为什么StableDiffusion使用CLIP而不使用BLIP?
CLIP是通过对比学习的方式训练图像和文本的编码器,使得图像和文本之间的语义空间能够对齐。CLIP的架构和训练方式可能更适合Stable Diffusion模型的目标,即生成与文本描述相匹配的高质量图像。
BLIP由于其图像特征受到了图文匹配(ITM)和图像条件语言建模(LM)的影响,可以理解为其图像特征和文本特征在语义空间不算对齐的。
最大区别:损失函数,CLIP和BLIP针对任务不同,不同任务不同损失函数。
4.BLIP2的工作有哪些创新点?
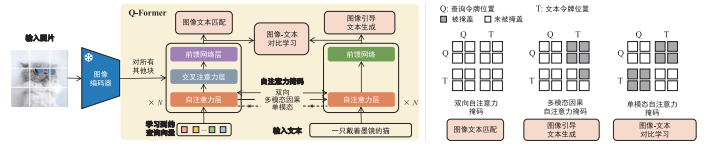
BLIP-2 使用 Q-Former 作为可训练的模块,用于连接冻结的图像编码器和冻结的 LLM。它从图像编码器中提取固定数量的输出特征,这些特征与输入图像的分辨率无关。Q-Former 由两个 Transformer 子模块组成,它们共享相同的自注意力层。
- (1)图像 Transformer 与冻结的图像编码器进行交互,进行视觉特征提取。
- (2)文本 Transformer 既可以作为文本编码器,也可以作为文本解码器。
BLIP-2 创建了一组可学习的输入到图像 Transformer 的查询嵌入。查询通过自注意力层交互,并通过交叉注意力层(每隔一个 Transformer 块插入一个)与冻结的图像特征进行交互,还可以通过相同的自注意力层与文本进行交互。根据不同的预训练任务, BLIP-2 应用不同的自注意力掩码控制查询-文本交互。
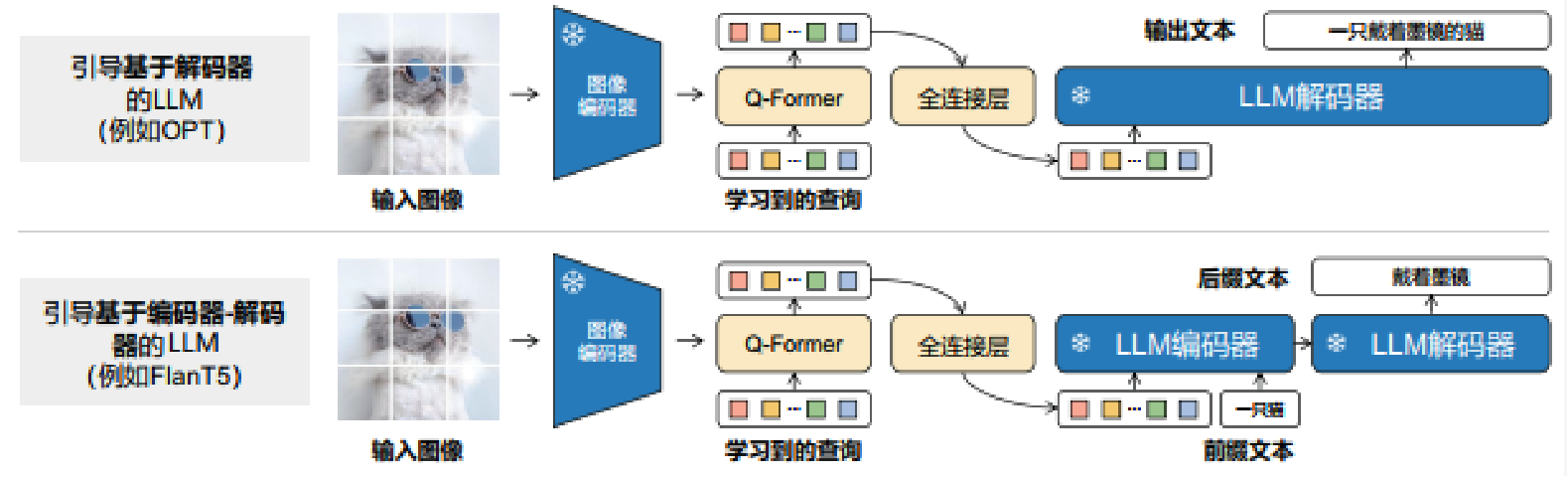
在生成学习阶段, BLIP-2 将带有冻结的图像编码器的 Q-Former 连接到冻结的 LLM,以利用 LLM 的生成能力。BLIP-2 先使用全连接层将输出查询表示 Z 线性投影到与 LLM 的文本表示相同的维度。然后,在输入文本表示之前添加投影的查询表示。它们作为软性的视觉提示,将 LLM 置于由 Q-Former 提取的视觉特征上。由于 Q-Former 已经被预训练以提取语言信息的视觉特征,有效地充当了信息瓶颈,馈送最有用的信息给 LLM,同时删除不相关的视觉信息。这减轻了 LLM 学习视觉-语言对齐的负担,缓解了灾难性遗忘问题。
对于基于解码器的 LLM, BLIP-2 使用语言建模损失进行预训练,冻结 LLM 的任务是在Q-Former 提取的视觉特征的条件下生成文本。对于基于编码器-解码器的 LLM, BLIP-2 使用前缀语言建模损失进行预训练,将文本分为两部分:前缀文本与视觉特征连接在一起,作为 LLM编码器的输入;后缀文本作为 LLM 解码器的生成目标。
5.解释自监督学习中对比学习的原理,并举例说明其在图像特征提取中的应用?
对比学习的原理,其核心在于通过优化一个目标函数,来促使模型学会区分数据中的相似与不同。具体来说,这一过程涉及两个关键步骤:首先是最大化正样本间的相似度,正样本通常指的是来自同一数据点的不同视角或变换,例如,在图像领域,可以通过对同一张图片进行不同的裁剪、旋转或颜色调整来生成正样本。这样做的好处是,模型能够学会忽略那些不重要的变化,专注于学习数据本质的特征。
接下来是最小化负样本间的相似度。负样本通常是指来自不同数据点的样本。在对比学习中,通过确保模型能够区分这些不同的数据点,模型能够学会为每个数据点生成独特的特征表示。这种方法的有效性在于,它迫使模型去关注数据中的关键差异,而不是表面的、无关紧要的变化。
以图像特征提取为例,对比学习特别有效。在这一领域,对比学习通过将图像与其经过增强的版本视为正样本,而将其他图像的增强版本视为负样本,来训练模型。这种方法使得模型能够学习到具有高度区分度的特征表示。例如,SimCLR(Simple Contrastive Learning of Representations)模型是一个典型的对比学习框架。它首先使用数据增强技术生成图像的多个副本,然后通过对比损失函数来训练模型,使模型能够学会区分不同的图像。
6.说明解释BLIP-2的查询Transformer如何解决模态差距问题?
BLIP-2(Bridging the Language-Image Pre-training Gap)的查询Transformer是一种多模态预训练模型,旨在解决语言和图像之间的模态差距问题。该模型通过结合视觉和文本信息来提高跨模态的理解和生成能力。以下是BLIP-2的查询Transformer如何解决模态差距问题的详细解释:
(1). 多模态预训练 BLIP-2采用多模态预训练的方法,通过同时处理图像和文本数据来学习跨模态的表示。具体来说,模型在预训练阶段使用大规模的图像-文本对,通过对比学习和生成任务来学习通用的跨模态表示。
(2). 查询Transformer架构 BLIP-2的核心是一个查询Transformer模型,该模型结合了视觉和文本信息。查询Transformer的架构允许模型在处理图像和文本时动态地关注相关的信息。
(2.1) 视觉编码器 视觉编码器负责将图像转换为视觉特征向量。BLIP-2使用预训练的视觉模型(如ResNet或ViT)来提取图像特征。
(2.2) 文本编码器 文本编码器负责将文本转换为文本特征向量。BLIP-2使用BERT或RoBERTa等预训练的语言模型来提取文本特征。
(2.3) 查询Transformer 查询Transformer结合了视觉和文本特征,通过自注意力机制和跨模态注意力机制来动态地关注相关的信息。具体来说,模型在处理每个查询时,可以同时考虑图像和文本中的相关信息,从而减少模态之间的差距。
(3). 对比学习 BLIP-2使用对比学习来进一步减少模态差距。具体来说,模型通过比较正样本(匹配的图像-文本对)和负样本(不匹配的图像-文本对)来学习跨模态的表示。这种方法有助于模型学习到更鲁棒的跨模态特征。
(4). 生成任务 BLIP-2还包括生成任务,如图像描述生成和文本条件下的图像生成。这些生成任务有助于模型更好地理解图像和文本之间的关系,从而进一步减少模态差距。
(5). 解决模态差距的具体方法
- 跨模态注意力机制:查询Transformer通过跨模态注意力机制,使得模型在处理图像和文本时可以动态地关注相关的信息,从而减少模态之间的差距。
- 对比学习:通过比较正样本和负样本,模型学习到更鲁棒的跨模态特征,从而减少模态差距。
- 生成任务:生成任务帮助模型更好地理解图像和文本之间的关系,从而进一步减少模态差距。
7.LLaMA-AdapterV2如何通过早期融合策略提高视觉指令跟随能力?
早期融合策略 ●策略描述:早期融合策略指的是在模型的早期层就融合视觉信息,这样可以在模型的训练过程中充分利用视觉知识,提高对视觉指令的理解和响应能力。 ●对视觉指令跟随能力的影响:通过在模型的早期层融合视觉信息,LLaMA-Adapter V2 能够更有效地处理视觉指令,从而提高其视觉指令跟随能力。 LLaMA-Adapter V2 的其他改进 ●偏差调整:通过解锁更多可学习的参数,如范数、偏差和比例,来增强 LLaMA Adapter 的性能,这些参数将指令遵循能力分布到整个 LLaMA 模型中。 ●联合训练范式:优化不相交的可学习参数组,引入图像-文本对和指令跟随数据的联合训练范式,缓解图文对齐和指令跟随任务之间的干扰。
8.SAM如何通过可提示的分割任务实现强大的泛化能力?
SAM(Segment Anything Model) 是一种基于提示的可分割模型,它通过以下方式实现强大的泛化能力: ●通用掩码预测器:SAM 采用一个通用的掩码预测器,可以处理任何类别的分割任务,而不需要为每个类别单独训练模型。 ●提示机制:SAM 允许用户通过简单的点击或框选来提供分割提示,这使得模型能够适应各种复杂的分割场景。 ●大规模预训练:SAM 在大规模数据集上进行预训练,学习到丰富的视觉特征和上下文信息,从而提高了模型的泛化能力。 ●微调能力:尽管 SAM 在预训练阶段已经具备了强大的泛化能力,但用户还可以根据特定任务对模型进行微调,以进一步提高性能。
9.PaLM-E如何将连续传感器模态直接融入语言模型中,实现具身智能?
PaLM-E(Pathways Language Model with Embodied) 是一种将连续传感器模态直接融入语言模型的具身智能模型,其实现方式如下: ●多模态表示:PaLM-E 将视觉、听觉等连续传感器模态的信息编码成向量表示,并与文本信息一起输入到模型中。 ●统一编码空间:通过统一的编码空间,PaLME 能够在文本和传感器模态之间建立联系,使得模型能够理解和生成与传感器数据相关的文本。 ●强化学习:PaLM-E 使用强化学习算法来优化模型在具身环境中的行为,从而实现更智能的交互和决策。
10.CLIP的对比学习机制如何实现跨模态对齐?
CLIP通过双塔结构实现跨模态对比学习,其视觉编码器和文本编码器分别将图像和文本映射到共享的嵌入空间。模型在大规模图文对数据集上训练,目标是最小化匹配图文对的余弦相似度,同时最大化非匹配对的相似度差异。通过对称交叉熵损失函数优化,CLIP学习到模态无关的语义表征,使图像和文本在嵌入空间中高度对齐。该机制无需人工标注的类别标签,仅依赖自然语言监督即可实现零样本迁移能力。
11.GPT-4V的多模态推理机制有何创新?
GPT-4V通过扩展Transformer架构实现多模态联合推理,其核心在于统一处理文本、图像和其他模态的输入。模型采用分阶段训练策略:首先预训练视觉编码器提取图像特征,再与文本标记共同输入语言模型进行跨模态注意力计算。创新性地引入动态路由机制,根据输入模态类型自动选择专家模块,并通过门控网络融合多模态特征。推理时支持交错式多模态输入,通过自回归生成实现复杂跨模态任务(如视觉问答、图文推理等)。
12.ImageBind如何实现六模态联合嵌入?
ImageBind通过自监督学习构建跨六种模态(图像、文本、音频、深度、IMU、热成像)的统一嵌入空间。其关键技术包括模态间对比学习损失和层次化对齐策略:利用图像作为枢纽模态,强制其他模态特征与图像特征对齐;同时引入模态间相关性矩阵,学习不同模态的语义关联强度。模型采用共享的Transformer编码器提取特征,并通过可学习的模态适配器将异构数据映射到相同维度。该架构支持零样本跨模态检索和生成任务。
13.多模态融合层的设计原则有哪些?
多模态融合层的设计需遵循三原则:1)层次化交互,通过浅层特征拼接、中层注意力融合和深层联合推理实现渐进式信息整合;2)动态门控机制,根据输入内容自适应调整各模态贡献权重;3)跨模态注意力,使用交叉注意力模块建立模态间细粒度关联。先进方法如Gated Multimodal Unit通过门控网络控制信息流,而Multimodal Transformer通过多头交叉注意力实现模态间双向交互。
14.Sora模型的视频生成技术有何突破?
Sora基于扩散Transformer架构实现高保真视频生成,其创新点包括时空分离注意力机制和因果卷积模块。模型将视频分解为时空补丁,通过分层扩散过程逐步去噪:首先生成关键帧,再插值中间帧保证时序连贯性。引入3D位置编码捕获时空依赖关系,并结合物理引擎模拟真实运动轨迹。训练采用大规模视频文本对数据集,通过CLIP嵌入实现细粒度语义控制,支持生成分辨率达1024×1024、时长超1分钟的高质量视频。
15.多模态大模型的高效训练策略有哪些?
高效训练策略包含四方面:1)混合精度训练,使用FP16/FP8精度减少显存占用,配合梯度缩放保持数值稳定性;2)模态异步训练,对计算密集型模态(如视觉)采用参数冻结或延迟更新;3)数据并行优化,对文本模态采用ZeRO-3分片,视觉模态采用张量并行;4)课程学习策略,先训练单模态基础能力,再逐步增加跨模态任务复杂度。实验表明,这些策略可降低40%训练成本且保持模型性能。
16.3D-LLM如何处理三维点云数据?
3D-LLM采用分层特征提取架构处理点云数据:首先通过体素化将无序点云转换为规则网格,使用3D稀疏卷积提取局部几何特征;接着通过图注意力网络建模点间拓扑关系;最后将全局特征与文本嵌入对齐。创新性地引入可微的神经渲染模块,将3D特征投影到2D视图以实现与视觉语言模型的兼容。训练时采用多任务学习,联合优化点云重建、跨模态检索和三维问答任务。
17.多模态指令微调的关键技术是什么?
多模态指令微调需解决三大挑战:
1)指令多样性,通过模板引擎生成涵盖跨模态推理、生成、编辑等任务的百万级指令数据;
2)模态对齐增强,采用对比损失函数约束生成结果与多模态输入的语义一致性;
3)混合专家系统,针对不同任务类型动态路由至专用处理模块。关键技术包括Chain-of-Modality提示技术,引导模型显式分解跨模态推理步骤,以及多粒度奖励模型实现强化学习优化。
18.跨模态检索的评估指标有哪些?
跨模态检索主要评估指标包括:
1)Recall@K,衡量前K个结果中包含正确结果的比例;
2)Mean Reciprocal Rank(MRR),计算首个正确结果的倒数排名均值;
3)Normalized Discounted Cumulative Gain(NDCG),考虑结果排序相关性的加权评分;
4)Cross-modal Semantic Consistency,通过预训练模型计算图文嵌入的余弦相似度分布。新兴指标如Modality-Aware F1 Score,综合评估多模态查询中各模态贡献的平衡性。
19.小型视觉语言模型(sVLM)的主要架构分类及各自的优势?
sVLM主要分为三类架构,其特点与优势如下:
| 架构类型 | 代表模型 | 核心创新 | 优势 | 典型应用场景 |
|---|---|---|---|---|
| Transformer-based | TinyGPT-V, FastVLM | - 多头自注意力机制实现跨模态交互- 轻量化设计(如Q-Former投影层压缩视觉token至1个) | - 支持高分辨率输入(如1536×1536图像)- 在VizWiz VQA任务中准确率达87%- FLOPs降低70% | 长文本理解、高精度视觉问答 |
| Mamba-based | VL-Mamba | - 结构化状态空间模型(SSM)实现线性复杂度- 双向扫描(Bidirectional-Scan)机制 | - 科学推理任务速度比Transformer快2.3倍- 动态参数调整过滤60%冗余特征 | 时序推理、数学问题解决 |
| Hybrid | LLaVA-Mini | - 融合CNN局部特征与Transformer全局上下文- EVA-ViT编码器结合LoRA微调 | - 医疗影像分析mIoU达68.3%- 内存占用减少45%(对比纯Transformer) | 医疗影像、细粒度场景理解 |
20.知识蒸馏在sVLM中的作用及实现方式?
作用:
- 将大型教师模型(如CLIP-ViT-L)的知识迁移到轻量级模型,在保持92%精度的同时模型体积缩小76%。
- 提升跨模态注意力对齐能力,减少因参数不足导致的模态鸿沟。
实现方式:
- 特征蒸馏(TinyViT):使用11层教师模型的中间层特征,通过对比损失将512维CLIP嵌入压缩至256维。效果:在ImageNet分类任务中,模型尺寸缩小76%,精度保持92%。
- 注意力蒸馏(MiniGPT-4):冻结Vicuna语言模型,仅训练线性投影层对齐视觉特征。两阶段训练:500万图文对预训练投影层 → 3500条精标数据微调注意力头数(32→16)。
- 动态蒸馏(FastViT):训练时用3×3深度卷积替代自注意力,推理时重构为1×1卷积。效果:ADE20K分割任务推理速度提升2.1倍,内存消耗降低58%。
21.模态预融合modality-pre-fusion在sVLM中的具体应用及优势?
应用案例:
- LLaVA-Mini:
- EVA-ViT编码器在输入阶段将图像块(patch)与文本token混合,通过交叉注意力生成联合表示。
- 效果:在Flickr30K检索任务中,Recall@1提升至58.3%。
- TinyGPT-V:
- Q-Former模块将视觉特征动态路由至语言空间,实现早期模态对齐。
优势:
- 计算延迟降低:预融合后推理FLOPs减少30%(ADE20K实测)。
- 细粒度理解提升:通过早期特征交互捕获模态间隐式关联(如“握住”动作与手部视觉特征的匹配)。
22.TinyGPT-V和MiniGPT-4在架构设计上的主要区别?
| 特性 | TinyGPT-V | MiniGPT-4 |
|---|---|---|
| 视觉编码器 | Mamba架构的VSS模块(动态路由) | ViT-based CLIP编码器 |
| 投影层设计 | 动态路由机制(Dynamic Router) | 静态线性投影 |
| 训练策略 | 单阶段端到端训练 | 两阶段训练(预训练+微调) |
| 内存占用 | 1.8GB(224×224输入) | 3.2GB(同等输入) |
| 典型应用 | 边缘设备实时推理 | 多轮对话场景 |
核心差异:
- 动态路由 vs 静态投影:TinyGPT-V通过可学习的路由策略动态分配视觉特征至语言模型,而MiniGPT-4采用固定投影层。
- 训练效率:TinyGPT-V单阶段训练更快,适合资源受限场景;MiniGPT-4通过两阶段微调提升精度。
23.Mamba-based模型相比Transformer-based模型在效率上的改进?
三大改进点:
- 计算复杂度:Transformer的O(n²) → Mamba的O(n),处理512×512图像时内存占用减少42%。
- 动态特征选择:Cross-Scan机制过滤冗余视觉特征,保留关键信息(如GQA问答任务中准确率提升至63.8%)。
- 硬件加速:CUDA核融合技术将SSM的四个计算步骤合并,在NVIDIA A100上实现12.7K tokens/s吞吐量。科学推理任务(ScienceQA-IMG)推理延迟降至230ms(对比Transformer的600ms)。
24.sVLM在处理多模态任务时面临的主要挑战?
关键挑战:
- 模态鸿沟:文本“狗”与图像中不同品种/姿态的狗语义匹配误差达38%(COCO数据集分析)。
- 时序对齐:视频帧率(30fps)与文本描述的粒度不匹配,长视频处理需15GB显存。
- 多模态幻觉:ActivityNet数据集中13.2%的推理步骤存在视觉误判(如混淆“跑步”与“走路”)。
- 资源约束:边缘设备需在1.8GB内存内完成推理(如TinyGPT-V对224×224图像的支持)。
25.轻量级注意力机制如何优化sVLM的计算效率?
三种主流方法:
- 分组注意力(LLaVA-Mini):将576个视觉token分为8组,每组执行局部自注意力。效果:计算复杂度从O(n²)降至O(n√n),VQA任务保持87%准确率。
- 动态稀疏注意力(TinyGPT-V):每层自动选择Top-k(k=32)关键token,减少计算量。效果:Hateful Memes检测F1值达65.3%,内存消耗减少58%。
- 轴向注意力(DeepSeek-VL2):将注意力矩阵分解为行(Row)与列(Column)注意力,显存占用降低63%。应用场景:4096×4096医学影像处理(GPU显存≤24GB)。
26.如何评估sVLM的性能,常用基准测试有哪些?
评估维度与常用基准:
| 任务类型 | 基准测试 | 评价指标 | 代表模型性能 |
|---|---|---|---|
| 视觉问答(VQA) | VizWiz, Flickr30K | 准确率(Accuracy) | LLaVA-Mini: 87% (VizWiz) |
| 图像分割 | ADE20K, COCO-Stuff | mIoU | TinyGPT-V: 52.3% (ADE20K) |
| 文本生成 | ChatGLM, GPT-4 Prompts | BLEU-4, ROUGE-L | MiniGPT-4: BLEU-4=38.2 |
| 医疗影像 | CheXpert, NIH Chest X-rays | AUC, Sensitivity/Specificity | LLaVA-Mini: mIoU=68.3 (CheXpert) |
27.sVLM在资源受限环境中的应用案例?
典型案例:
- 边缘设备实时推理:TinyGPT-V(1.8GB)在Jetson Xavier上实现25FPS的实时VQA,适用于无人机/智能安防场景。
- 医疗影像分析:LLaVA-Mini结合LoRA微调,在胸部X光片分类任务中达到91.5% AUC(仅需4GB显存)。
- 自动驾驶感知:VL-Mamba通过12.7K tokens/s的吞吐量处理车载摄像头输入,支持10Hz的实时物体检测。
28.sVLM的未来发展方向及潜在研究热点?
六大研究方向:
- 动态模态加权:根据任务自动调节图文对齐强度(如医疗影像中视觉权重提高至0.7)。
- 因果对齐:使用结构因果模型(SCM)识别跨模态混淆变量(如“药物”与“副作用”的因果关系)。
- 知识增强蒸馏:将领域知识(如医学本体SNOMED CT)注入蒸馏过程,提升专业场景性能(AUC提升至0.91)。
- 异构算子融合:结合CNN的局部敏感性与Transformer的全局依赖,设计轻量级混合算子。
- 能效优化:开发FPGA专用量化模块(如4-bit对比学习),功耗降低至7W(较GPU方案下降90%)。
- 多模态持续学习:设计灾难性遗忘防止机制,在EdgeTPU等设备上实现增量式学习(如新增10类物体仅需100样本)。
潜在突破点:
- 时空联合编码:将视频的时序信息与静态图像特征统一建模(如VL-Mamba的Video-of-Thought框架)。
- 鲁棒性增强:通过对抗训练(PGD攻击+BERT-Attack)构建跨模态鲁棒性基准(如AdPO数据集)。
相关文章:

多模态核心模型
1.BLIP的原理? BLIP是一种统一视觉语言理解和生成的预训练模型。BLIP的特点在于它采用了一种编码器-解码器混合架构(MED),并且引入了CapFilt机制来提高数据质量和模型性能。BLIP的主要组成部分包括: MED架构:包括单模态编码器、…...
Kubernetes入门)
Kubernetes笔记(1)Kubernetes入门
Kubernetes入门 一、容器技术二、Kubernetes介绍1. Kubernetes核心资源2. Kubernetes集群架构2.1 Master2.2 Node 一、容器技术 随着技术发展,应用程序的部署经历了从物理机到虚拟机,再到容器的转变。 物理机:物理机会运行多个程序…...
)
【coze】意图识别(售前售后问题、搜索引擎去广告)
【coze】(售前售后问题、搜索引擎去广告) 1、创建意图识别工作流(1)创建工作流(2)添加意图识别节点(3)配置意图识别节点(4)运行看效果(5ÿ…...

Vue3 中用 canvas 封装抽奖转盘组件:设定中奖概率及奖项图标和名称
在 Web 应用开发中,抽奖功能是提升用户参与度的常用手段。使用 Vue3 结合 canvas 技术,我们可以轻松实现一个高度自定义的抽奖转盘组件,不仅能设定中奖概率,还能灵活配置奖项图标和名称。本文将详细介绍该组件的实现原理、步骤&am…...

vue3+vite+AI大模型实现谷歌插件-web诊断
vue3viteAI大模型实现谷歌插件-web诊断 一、前言二、实现思路1、功模块构图2、数据交互图 三、技术栈简介1、Web端2、服务端 四、主要功能实现1、Web端【1】谷歌插件vue全局配置文件【2】加载web诊断工具至当前页面【3】全局捕获异常错误 2、Server端【1】websock管理模块【2】…...

高频PCB设计如何选择PCB层数?
以四层板为例,可以第一层和第二层画信号,作为信号层。 第三层可以走电源,然后第四层走GND 但是更可以第一层和第三层画信号。第二层可以走电源,然后第四层走GND 用中间的电源层以及地层可以起到屏蔽的作用,有效降低寄…...

第100+40步 ChatGPT学习:R语言实现多轮建模
回顾一下什么叫多轮建模: 要综合判断一个模型好不好,一次随机抽样是不行的,得多次抽样建模,看看整体的性能如何才行(特别是对于这种小训练集)。 所以我的思路是,随机抽取训练集和验证集2000次…...

DolphinScheduler-3.2.0集群部署教程
详见: DolphinScheduler-3.2.0集群部署教程Centos7 DolphinScheduler集群部署...
)
如何设计Kafka的高可用跨机房容灾方案?(需要实战,未实战,纯理论)
1. 双活多中心架构设计 startuml 机房A <--> [Kafka Cluster A] : 万兆光纤 机房B <--> [Kafka Cluster B] : 专线网络 机房C <--> [Kafka Cluster C] : VPN隧道[Kafka Cluster A] <-.-> [Kafka Cluster B] : MirrorMaker2双向镜像 [Kafka Cluster B]…...

[人机交互]协作与通信的设计
零.要点 – 解释协作与通信的含义 – 描述人们在协作与通信中使用的社会机制的主要类型 – 概述存在的各种群件系统 – 讨论学科研究和与社交相关的理论,对设计的启示 一.解释协作与通信的含义 1.1什么是通信 通信是个体之间的信息交换的过程 – 按照所 交换信息的…...

LXwhat-嘉立创
一 电路板简介 什么是PCB? 印刷电路板 什么是SMT? 表面贴装技术 有关电路板的几个专业名词 覆铜腐蚀走线多层板 为什么要画电路板? 杜邦线:接线杂乱、虚接、有可能短路洞洞板:考验焊功(虚焊)、异型元器件不适配自己画板:整齐有序、适配异型元器件、紧凑优雅、有成就感(输…...

决 策 树
1 决策树模型 假如你正在运营一家猫咪领养中心,并拥有一些特征数据,你想训练一个分类器来快速判断一只动物是否为猫。这里有十个训练样本,有关于动物耳朵形状、面部形状、是否有胡须的特征,你想要预测这种动物是否为猫࿱…...

ts axios中报 Property ‘code‘ does not exist on type ‘AxiosResponse<any, any>‘
ts语法有严格的格式,如果我们在处理响应数据时,出现了axios响应中非默认字段,就会出现标题那样的警告,我们可以通过创建axios.dt.ts解决这个问题 下面是我在开发中遇到的警告,code并不是axios默认返回的字段࿰…...
)
【AI】用AI将文档、文字一键生成PPT的方法(百度的自由画布版)
前提: 最近看了个书,周末要参加读书会,要分享这本书的内容。一般来说,我都是写好了内容文档,然后在网上找一些模板套上去。 最近发现,有些网站已经可以按照文档,自动生成PPT模板了,里…...

爬虫技术-利用Python和Selenium批量下载动态渲染网页中的标准文本文件
近日工作需要整理信息安全的各项标准文件,这些文件通常发布在在官方网站,供社会各界下载和参考。 这些页面中,标准文本文件常以Word(.doc/.docx)或PDF格式提供下载。由于文件数量庞大,手动逐条点击下载效率…...

CUDA编程 - 如何在 GPU 上使用 C++ 函数重载 - cppOverload
这里写目录标题 一、完整代码与例程目的二、代码拆解与复用 2.1、函数重载: 2.2、函数指针声明: 2.3、函数指针赋值与内核启动: 2.4、CUDA API调用:2.4.1、cudaFuncSetCacheConfig:2.4.2、cud…...

AI教你学VUE——Gemini版
前端开发学习路线图 (针对编程新手,主攻 Vue 框架) 总原则:先夯实基础,再深入框架。 想象一下建房子,地基不牢,上面的高楼(框架)是盖不起来的。HTML、CSS、JavaScript 就是前端的地基。 阶段一…...
)
力扣热题100,力扣49.字母异位词分组力扣128.最长连续序列力扣.盛水最多的容器力扣42.接雨水(单调栈)
目录 力扣49.字母异位词分组 力扣128.最长连续序列 力扣.盛水最多的容器 力扣42.接雨水(单调栈) 1.包的命名规范: java的命名规范 全部采用小写 结尾不能加负数 声明包: 位置必须在首行 类: 字母数字下划线,美元符号 不能数字开头 不能有中文 不能以关键字命名 区…...

react naive 网络框架源码解析
本文取 react native 两个区别很大的版本做分析(0.76.5、0.53.3) 一、0.76.5 版fetch 全流程排查 1、JS 端的实现 随手写一个fetch,点开。 我们这里常用的还是手机端,因此选择 react-native,react-native-windows …...

DID在元宇宙的应用爆发:数字身份资产化与跨平台迁移——解析Decentraland等项目的虚拟身份全链路实现
元宇宙的兴起催生了多维度的数字身份需求,但传统虚拟身份系统受限于中心化架构,面临数据孤岛、身份碎片化、资产归属模糊等核心挑战。本文以Decentraland、The Sandbox、Somnium Space等顶级元宇宙平台为研究对象,探讨去中心化身份࿰…...

MySQL的内置函数与复杂查询
目录 前言 一、聚合函数 1.1日期函数 1.2字符串函数 1.3数学函数 1.4其它函数 二、关键字周边 2.1关键字的生效顺序 2.2数据源 2.3可以使用聚合函数的关键字 前言 在前面几篇文章中,讲解了有关MySQL数据库、数据库表的创建、数据库表的数据操作等等。本文我…...

mysql中select 1 from的作用
在MySQL中,SELECT 1 FROM ... 是一个常见的SQL写法,通常用于以下场景: 1. 作用与原理 SELECT 1 的本质是返回一个常数值(即数字1),且不依赖表中的实际数据。 它的核心作用是快速验证逻辑条件是否成立&…...
、 df (详解)和 free(详解)以及它们的区别)
Linux中 du (详解)、 df (详解)和 free(详解)以及它们的区别
目录 du命令 df命令 free命令 du/df/free区别 Tree du命令 功能:用于计算文件或目录所占用的磁盘空间大小。它会递归地遍历指定目录下的所有文件和子目录,统计它们占用的磁盘块数,从而得出占用的空间大小。常用选项: -h&…...

ETL交通行业案例丨某大型铁路运输集团ETL数据集成实践
在广袤的祖国边疆,一条条钢铁动脉承载着区域经济发展的重要使命。某大型铁路运输集团作为区域交通枢纽的运营主体,管辖着横跨多个省、区的铁路网络,运营里程超3000公里,每日承载着数以万计的客货运输任务。随着"数字中国&quo…...

【数据挖掘】Apriori算法
Apriori算法是经典的关联规则挖掘算法,用于从事务型数据库中发现频繁项集和强关联规则,特别常用于购物篮分析等场景。 🧠 核心思想(Apriori原则) 一个项集是频繁的,前提是它的所有子集也必须是频繁的。 即&…...

7.9/Q1,Charls最新文章解读
文章题目:Association between urbanization levels and frailty among middle-aged and older adults in China: evidence from the CHARLS DOI:10.1186/s12916-025-03961-y 中文标题:中国中老年人城市化水平与虚弱程度之间的关联࿱…...
从入门到登峰-嵌入式Tracker定位算法全景之旅 Part 7 |TinyML 定位:深度模型在 MCU 上的部署
Part 7 |TinyML 定位:深度模型在 MCU 上的部署 本章聚焦如何在 ESP32-S3 平台上,通过 TinyML 将深度学习模型应用到定位场景,包括特征提取、模型剪枝与量化、TensorFlow Lite for Microcontrollers 部署,以及在线微调与自适应策略。 一、为什么要用 TinyML? 非线性特征挖…...
 ABC)
Codeforces Round 1023 (Div. 2) ABC
链接 Dashboard - Codeforces Round 1023 (Div. 2) - Codeforces A 将数组a分成两组,使得gcd(b) ! gcd(c) 思路 gcd(a,b) < min(a,b) 求数组a的max,min 如果数组a都一样无解 (即max min 否则有解:让是max的一组&…...

56. 合并区间
给定若干个区间的集合,将重叠的区间合并后,放入一个数组中返回。 具体思路就是按左端点排序后合并区间,因为按左端点排序后,可以确保每次合并都是以最小元素为合并后区间的起始,并且按左端点排序可以方便合并ÿ…...

Docker安装使用
1.Docker简介 Docker是一个开源的应用容器引擎;是一个轻量级容器技术; Docker支持将软件编译成一个镜像;然后在镜像中各种软件做好配置,将镜像发布出去,其他使用者可以直接使用这个镜像; 运行中的这个镜…...

Linux/AndroidOS中进程间的通信线程间的同步 - POSIX IPC
1 什么是POSIX? POSIX(Portable Operating System Interface)即可移植操作系统接口,它是IEEE为要在各种UNIX操作系统上运行软件,而定义API的一系列标准的总称。以下为你展开介绍: 产生背景:在…...

5.2创新架构
一、MoE(Mixture of Experts,混合专家模型) 了解混合专家模型架构,与 Dense 架构相比有什么优劣 是一种提升大模型推理效率和参数利用率的关键技术 核心思想:在模型中增加多个“专家模块”(Experts&#x…...
显示区域更新)
驱动开发系列57 - Linux Graphics QXL显卡驱动代码分析(四)显示区域更新
一:概述 前面在介绍了显示模式设置(分辨率,刷新率)之后,本文继续分析下,显示区域的绘制,详细看看虚拟机的画面是如何由QXL显卡绘制出来的。 二:相关数据结构介绍 struct qxl_moni…...

疗愈服务预约小程序源码介绍
基于ThinkPHP、FastAdmin和UniApp开发的疗愈服务预约小程序源码,这款小程序在功能设计和用户体验上都表现出色,为疗愈行业提供了一种全新的服务模式。 该小程序源码采用了ThinkPHP作为后端框架,保证了系统的稳定性和高效性。同时,…...

力扣118,1920题解
记录 2525.5.6 题目: 思路: 用一个二维数组dp[numRows][numRows]保存每一次动态规划的结果 1.令dp[0][0]1(第一列) 2.找规律 3.得到如下规律(以下情况均为列数大于1) if(col0){ dp[row][col]1 } else { dp[row][col]dp[row-1][col-1]dp[row-1][col] }…...

电池热管理CFD解决方案,为新能源汽车筑安全防线
在全球能源结构加速转型的大背景下,新能源汽车产业异军突起,成为可持续发展的重要驱动力。而作为新能源汽车 “心脏” 的电池系统,其热管理技术的优劣,直接决定了车辆的安全性、续航里程和使用寿命。电池在充放电过程中会产生大量…...
毛子整洁架构(Domain Layer/Repository Pattern/Result Pattern/Error Pattern))
(一)毛子整洁架构(Domain Layer/Repository Pattern/Result Pattern/Error Pattern)
文章目录 项目地址一、整洁架构概念1.1 各个分层的功能1. Domain核心部件2. Application Layer3. Infrastructure layer3. Presenetation layer1.2 项目数据库二、Domain Layer2.1 Apartments 实体1. Current Value Obj2. Money Value Obj3. Apartment 类2.2 User 实体1. User类…...

XSS ..
Web安全中的XSS攻击详细教学,Xss-Labs靶场通关全教程(建议收藏) - 白小雨 - 博客园跨站脚本攻击(XSS)主要是攻击者通过注入恶意脚本到网页中,当用户访问该页面时,恶意脚本会在用户的浏览器中执行…...

Github Action部署node项目
Github Action部署node项目 个人学习的时候,作为前端感觉这个CICD基本流程还是有必要了解的,这里记录一下Github Action部署node项目的流程,也算是一个学习的过程 首先肯定是要有一个可运行的node项目 编写部署文件 部署文件放置在.githu…...

高频面试题:设计秒杀系统,用Redis+Lua解决超卖
高频面试题:设计秒杀系统,用RedisLua解决超卖 **1. 问题背景****2. 解决方案:Redis Lua****为什么选择Redis Lua?****核心代码逻辑****Java调用示例(Spring Boot)** **3. 方案优势****4. 面试回答话术***…...

2、Kafka Replica机制与ISR、HW、LEO、AR、OSR详解
Kafka 作为分布式高可用消息队列,其副本(Replica)机制是实现高可靠性和数据一致性的核心。本文将系统介绍 Kafka 的 Replica 机制,并详细解释 ISR、HW、LEO、AR、OSR 等关键概念。 一、Kafka Replica机制概述 在分布式系统中&am…...

生成式 AI:从工具革命到智能体觉醒,2025 年的质变与突破
在上海胸科医院的手术室里,一束全息投影正精准勾勒出患者肺部的三维血管模型。主刀医生手持机械臂的瞬间,AI 导航系统已同步完成 200 次路径演算,将毫米级误差控制在 0.3 毫米以内 —— 这个真实发生在 2025 年的临床场景,标志着生…...
)
安卓基础(拖拽)
当用户长按或拖拽某个视图(如按钮、图片)时,需要提供视觉反馈(即阴影)。这行代码通常在拖拽事件的处理逻辑中,例如: view.setOnLongClickListener(v -> {// 创建拖拽阴影DragShadowBuilder …...

IoTDB磁盘I/O性能监控与优化指南
一、磁盘I/O性能观测核心指标 在现代计算机系统中,磁盘I/O性能对整体系统表现至关重要。为有效监控和优化磁盘I/O性能,需关注以下核心指标: I/O读写延迟:衡量从发起I/O请求到接收响应的时间间隔。IOPS(Input/O…...

java每日精进 5.06【框架之功能权限】
0.概述 0.1 整体架构概述 这个RBAC权限系统基于Spring Security和Token认证机制,主要包含以下核心组件: 用户-角色-菜单的多对多关系模型 基于Token的认证流程 细粒度的权限控制(菜单权限、按钮权限) 灵活的权限配置方式 1…...

静态NAT
实验需求 PC1和PC2通过静态NAT去访问服务器 实验拓扑 图13-1 静态NAT 实验步骤 步骤1:IP地址的配置 PC1的配置 PC2的配置 R1的配置 <Huawei>system-view [Huawei]undo info-center enable [Huawei]sysname R1 [R1]interface g0/0/0 [R1-GigabitEt…...

RabbitMQ-api开发
前言 MQ就是接收并转发消息 核心概念 admin是用户 每个虚拟机上都有多个交换机 快速入门 引入依赖 <dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>5.22.0</version></dependen…...
 ; MachineTree getMachineTree() const; 区别?)
const MachineTree getMachineTree() ; MachineTree getMachineTree() const; 区别?
这两个函数声明在语法和语义上有明显的区别,它们的用途和行为也不同。让我们逐一分析它们的区别: 1. const MachineTree &getMachineTree(); 这个函数声明表示: 返回类型:const MachineTree &,即返回一个 M…...

使用DevTools工具调试前端页面,便捷脚本,鸿蒙调试webView
参考官方文章 便捷脚本 创建文本,复制修改后缀为bat 建立bat文件 echo off setlocal enabledelayedexpansion:: Initialize port number and PID list set PORT9222 set PID_LIST:: Get the list of all forwarded ports and PIDs for /f "tokens2,5 delims…...

浏览器存储 Cookie,Local Storage和Session Storage
什么是Cookie? 存储容量:一般限制在 4KB 以内。数据有效期:可以设置过期时间,若未设置,则在浏览器关闭时失效。数据共享:在同一域名下,不同页面可以共享cookie数据。并且在每次 HTTP 请求时&am…...