决 策 树
1 决策树模型
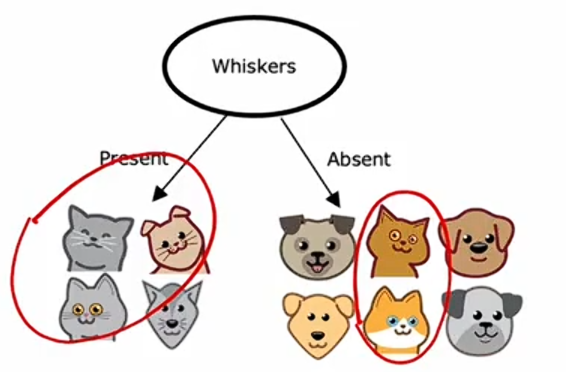
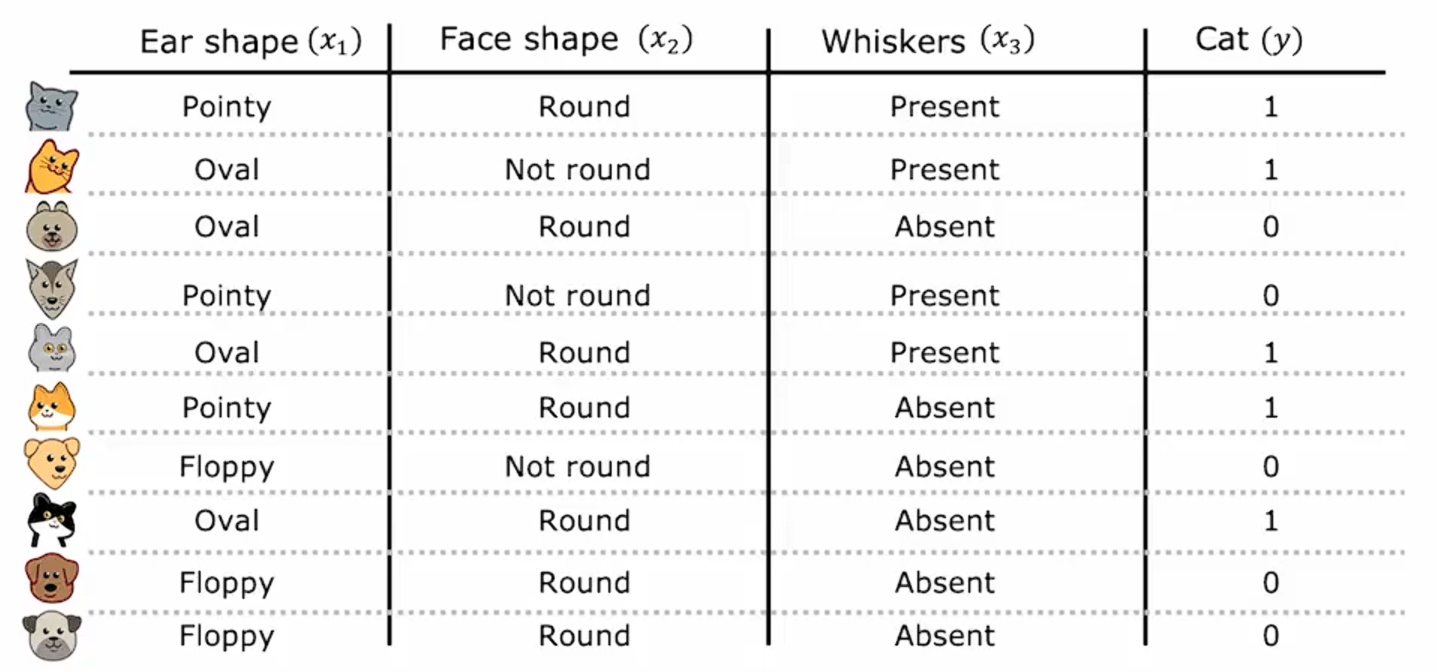
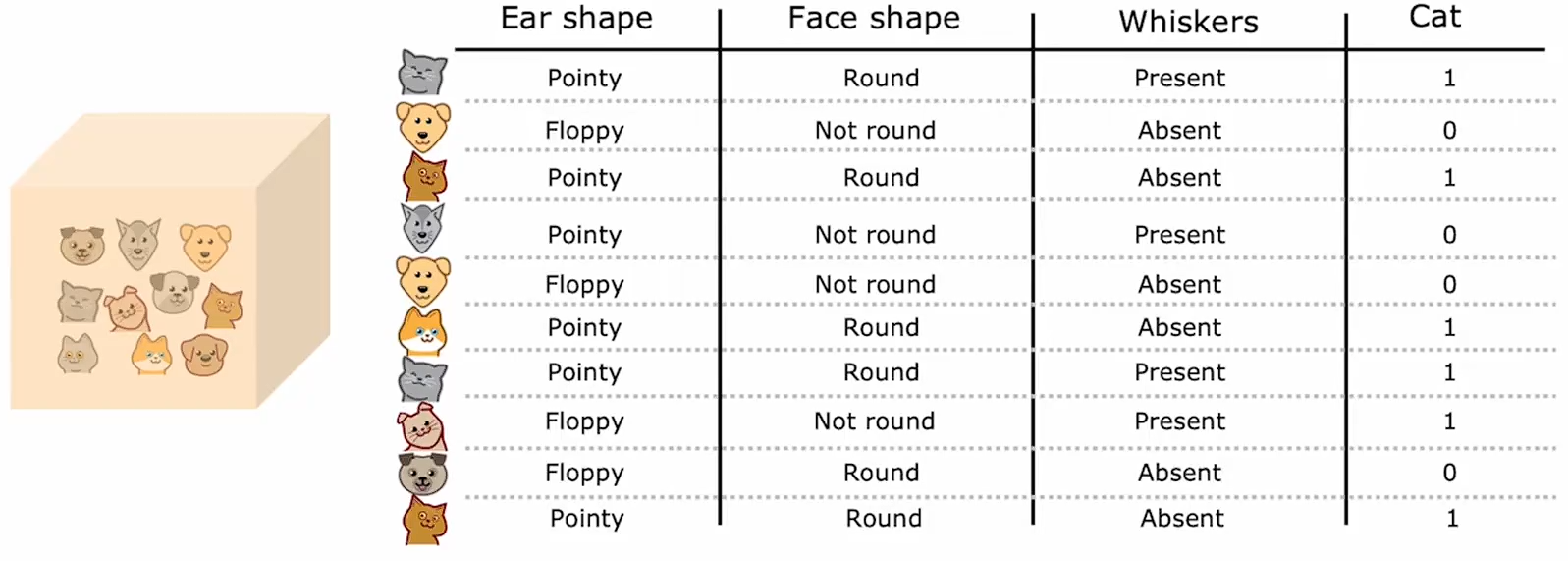
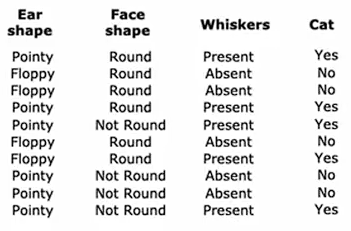
假如你正在运营一家猫咪领养中心,并拥有一些特征数据,你想训练一个分类器来快速判断一只动物是否为猫。这里有十个训练样本,有关于动物耳朵形状、面部形状、是否有胡须的特征,你想要预测这种动物是否为猫?
第一个样本:有尖耳朵圆脸有胡须,它是一只猫;第二个样本:有耷拉的耳朵,脸型不圆,有胡须,它是一只猫;其他的样本也如此......
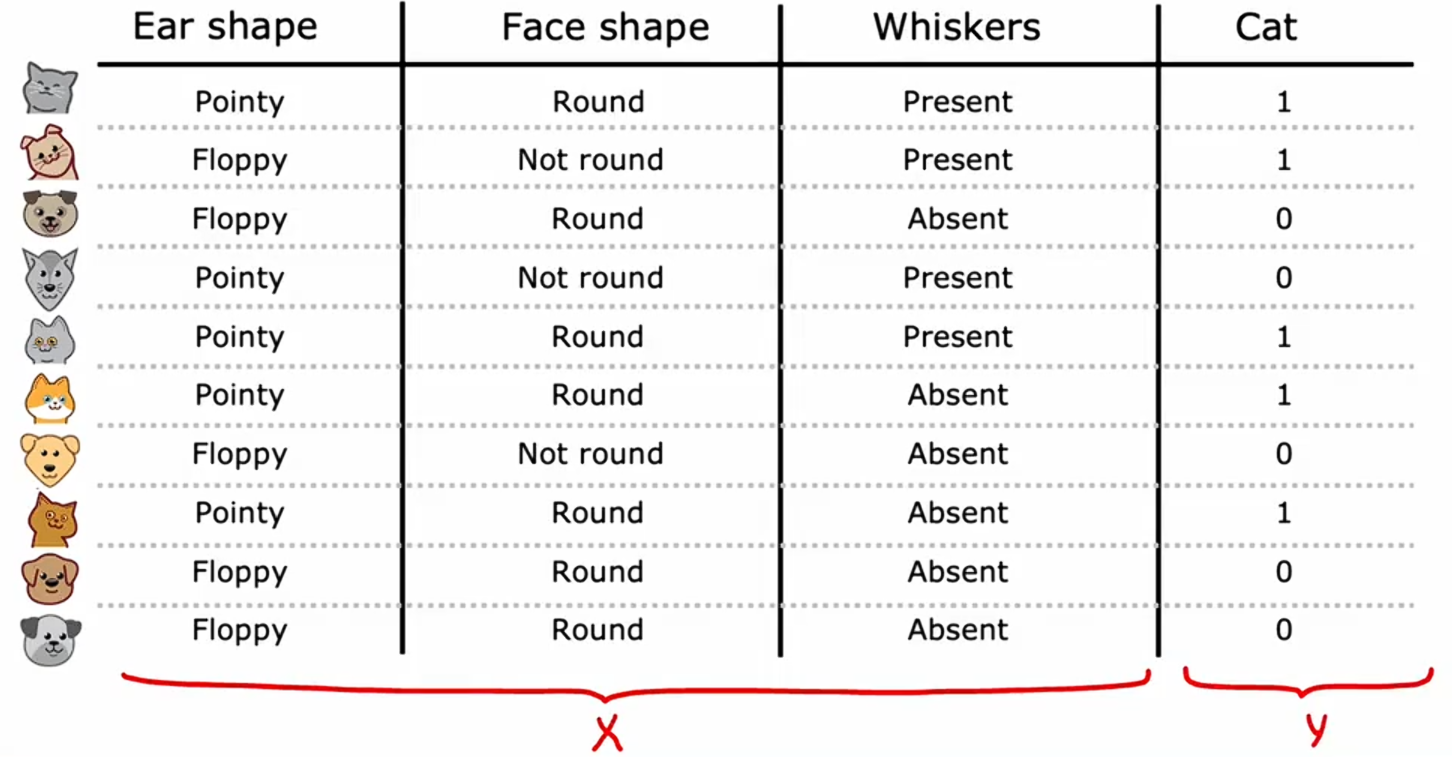
这个数据集中有五只猫和五只狗。 输入特征x是耳朵形状、面部形状、是否有胡须;预测y是否是一只猫,1表示是猫,0表示不是猫。目前每个特征仅取两个可能值:是尖耳朵或者不是尖耳朵;是圆脸或者不是圆脸;有胡子或没有胡子。
什么是决策树?
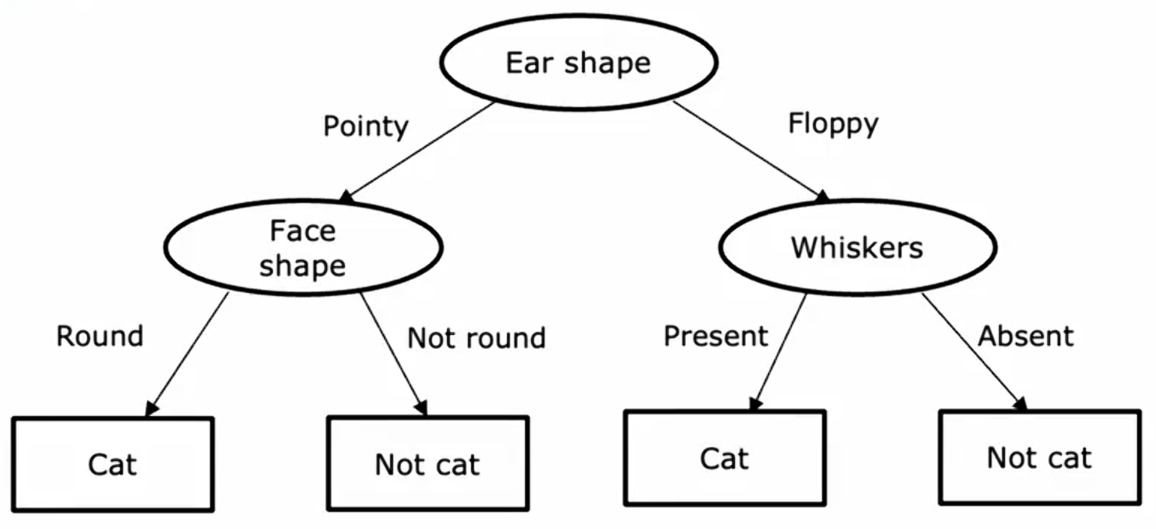
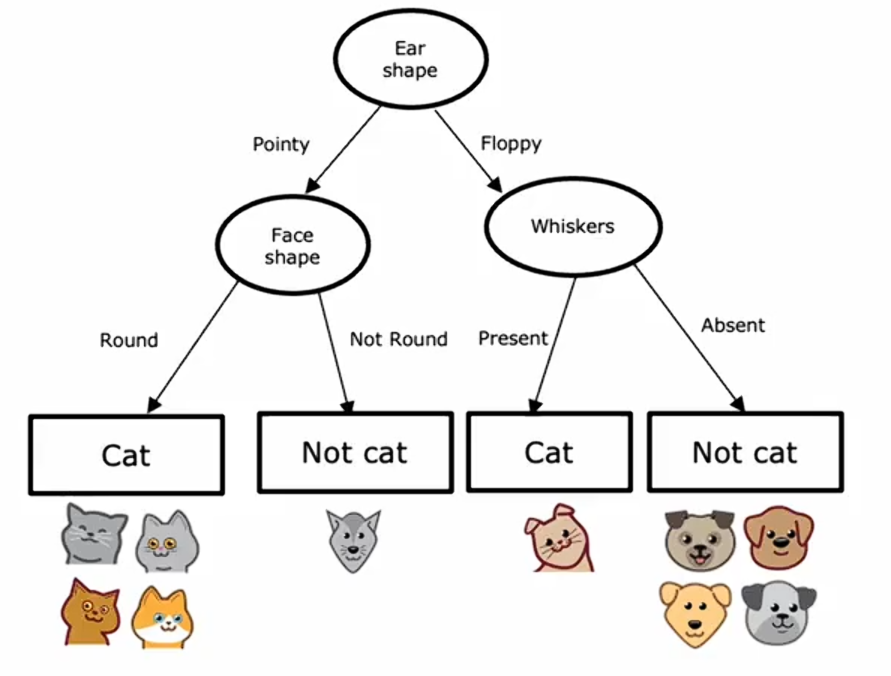
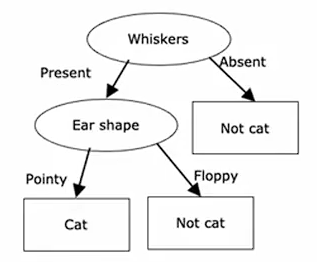
这是一个示例模型,你可能在刚刚看到的数据集上训练决策树学习算法后得到它,学习算法输出的模型看起来像一棵树,这样的模型就是计算机科学家所说的树。
每一个矩形或者椭圆形在树中被称为一个结点。如果你有一个新的测试样本,动物耳朵形状是尖的,脸型是圆的,而且有胡须,这个模型做出分类决策的方式是:从树的根节点开始,查看其中写入的特征,即耳朵形状,根据这个例子的耳朵形状,要么向左走,要么向右走,这个例子的耳朵形状值是尖的,因此我们将沿着树的左侧分支向下;接着看这个例子的脸型,结果是圆的,继续沿着左箭头往下走,算法将推断它是一只猫。
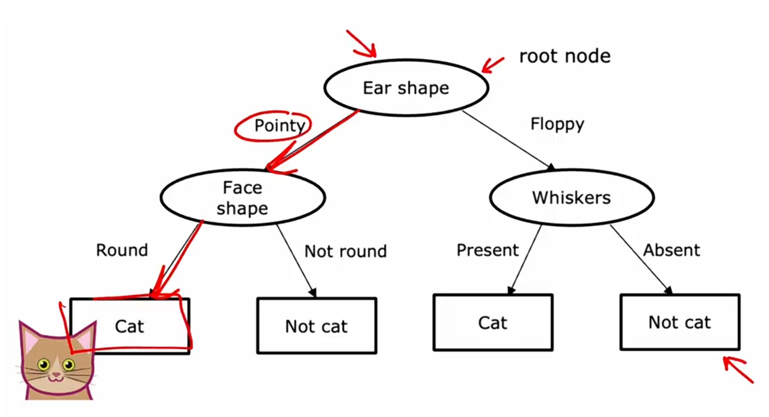
这是一个特定的决策树模型。为了引入更多术语,树中最顶层的结点称为根结点;所有的椭圆形节点称为决策节点,因为它们查看特定特征,然后根据该特征的值决定是向左还是向右沿着树向下移动;底部的矩形节点被称为叶节点,它们做出预测。
对于同一个示例,可能有不同的决策树模型:
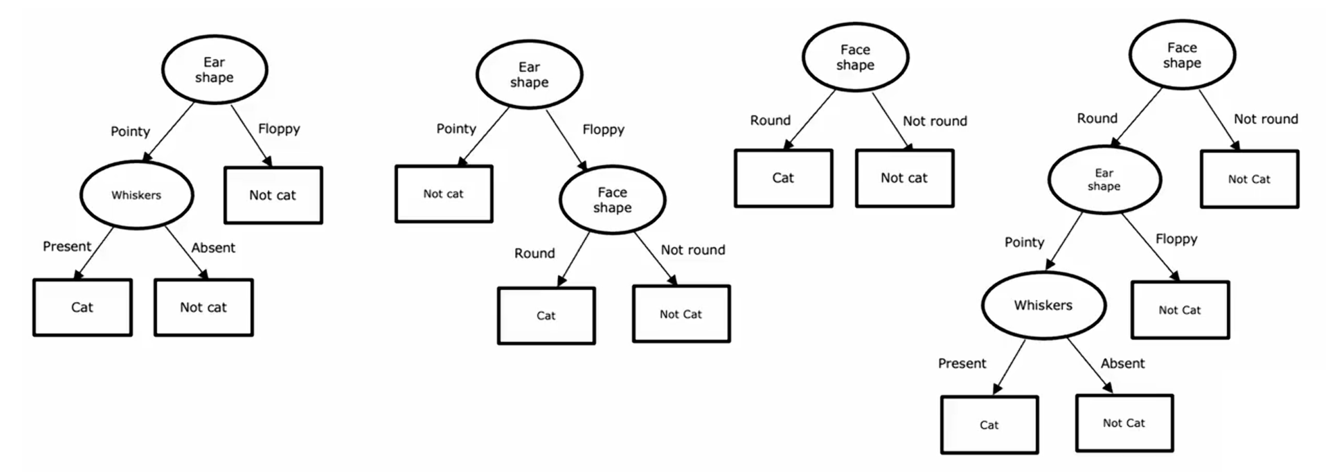
在这些不同的决策树中,有些在训练集上表现好,有些则在验证集和测试集上表现好。决策树学习算法的任务是从所有可能的决策树中尝试挑选出一个在训练集上表现良好的树。在理想情况下,模型也能很好的泛化到新数据,比如你的验证集和测试集。
2 学习过程
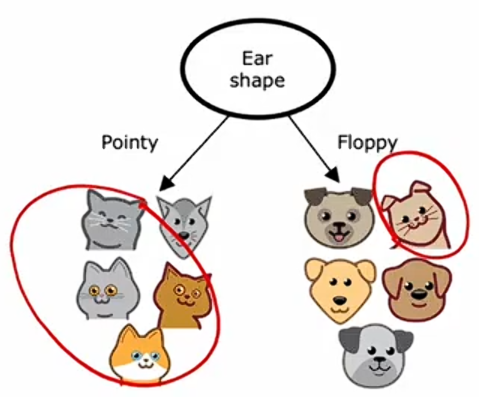
给定一个包含猫和狗的十个训练集样本,决策树学习的第一步是决定在根节点使用什么特征,假设我们决定选择耳朵形状特征作为决策树模型的根节点,这意味着,我们将查看所有的训练样本,根据耳朵形状进行初步的分类。
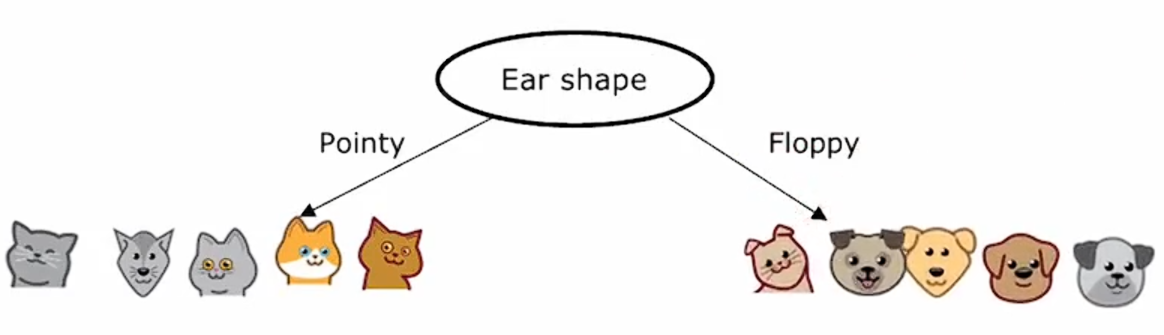
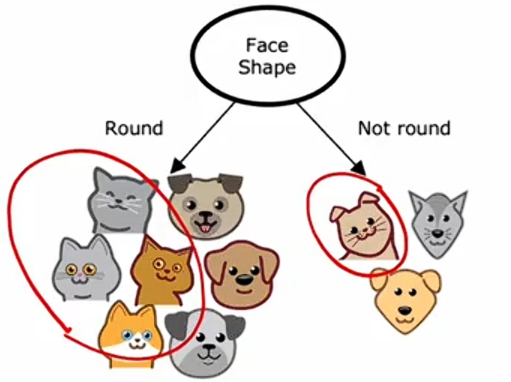
第二步是关注决策树的左侧部分来决定想要在哪个特征上进行分割,假设你决定使用脸型特征,将这五个例子根据脸型值分成两个子集。
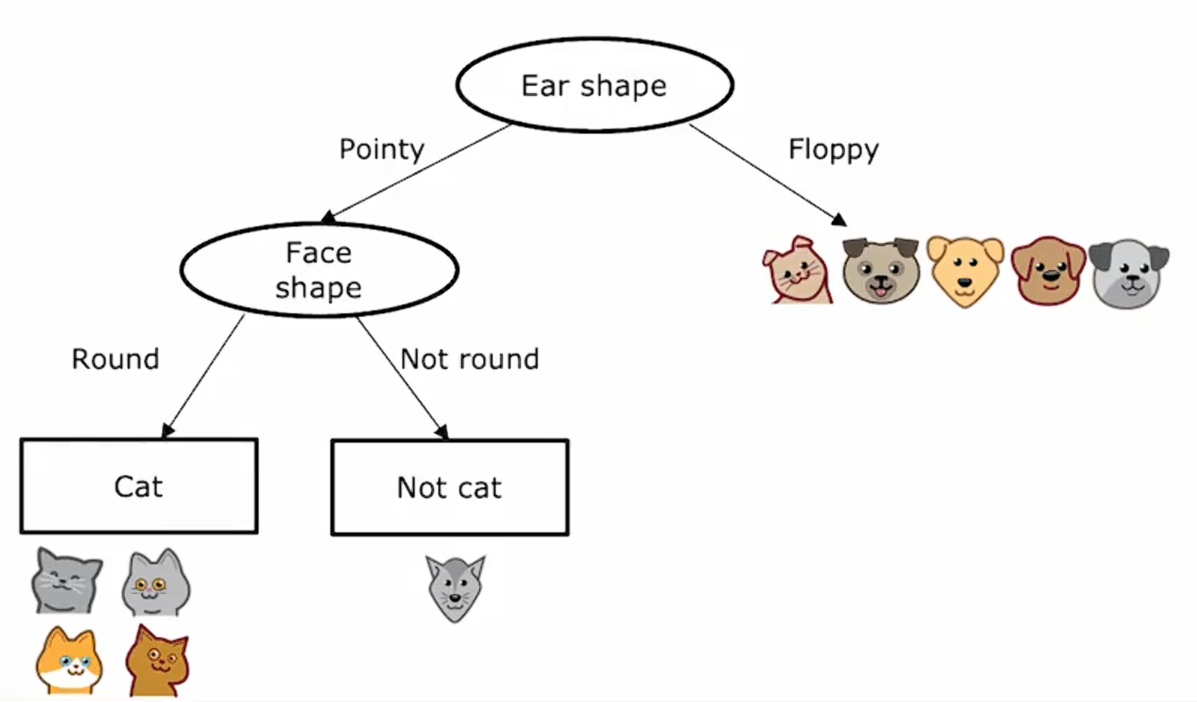
最后,我们注意到左侧的四个例样本都是猫,右侧的样本不是猫。创建一个叶节点,表示对到达该节点的样本进行的预测。
上述就是在决策树的左侧部分完成的操作,在决策树的右侧部分可以通过类似的过程对样本进行预测。
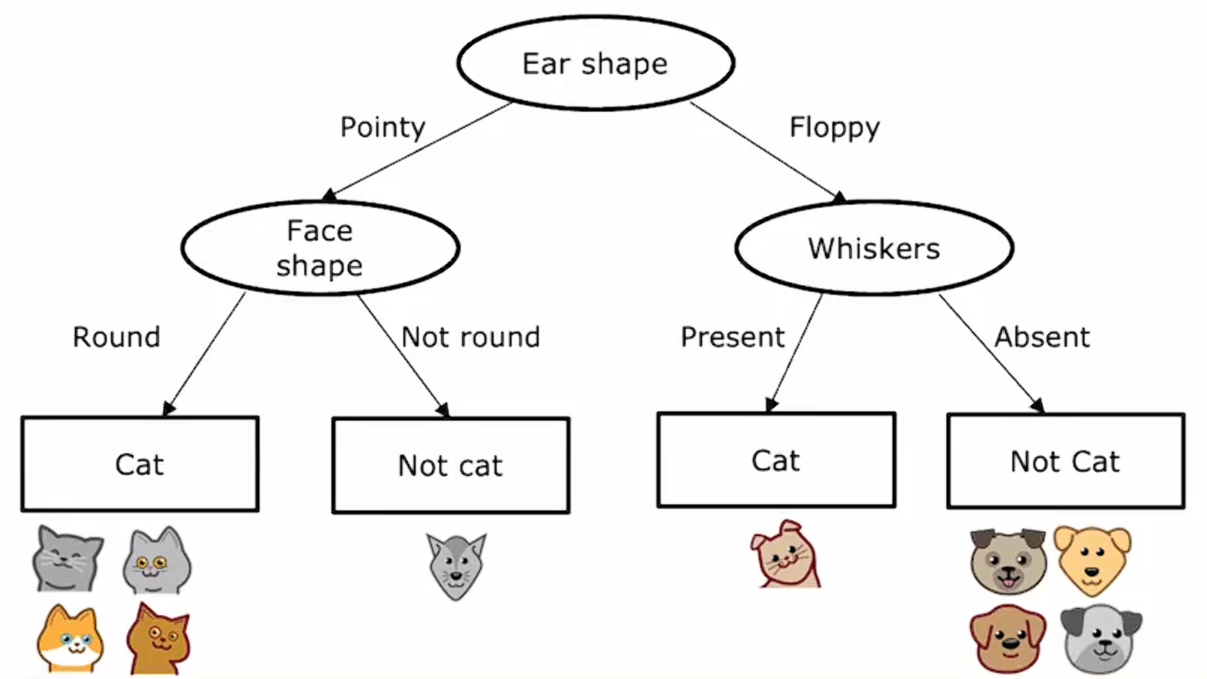
以上就是构建决策树的过程。在算法的各个步骤中,我们不得不做出几个关键决策,我们一起讨论下这些关键决策是什么?
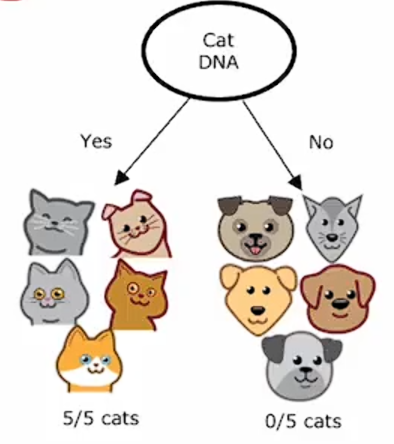
第一个关键决策是如何选择在每个节点上用于分割的特征。在根节点以及决策树的左分支和右分支上,我们必须判断该节点上是否有少数几个包含猫和狗混合的示例,你是想根据耳型特征,面部特征还是胡须特征进行分割?决策树需要在一个能最大化纯度的特征上进行分割,也就是尽可能得到全是猫或全是狗的子集。假设我们有一个特征是用来检测是否有猫的DNA,通过这个特征进行分割,导致左分支全是预测为猫,右分支全部预测不是猫,则说这两个左右子集都是完全纯净的。即左右分支都只有一个类别,要么全是猫,要么全不是猫。如果我们有这个特征,猫DNA是很好用的特征。
但根据我们实际拥有的特征,如果我们按照耳朵形状划分,这会导致左分支有五个是猫,右分支的五个样本有一个是猫;按照脸型划分,左分支的七个样本有四个是猫,右分支的三个样本中有一个是猫;按照是否有胡须划分,导致左边四个例子中有三个猫,右边六个例子中有两个是猫。
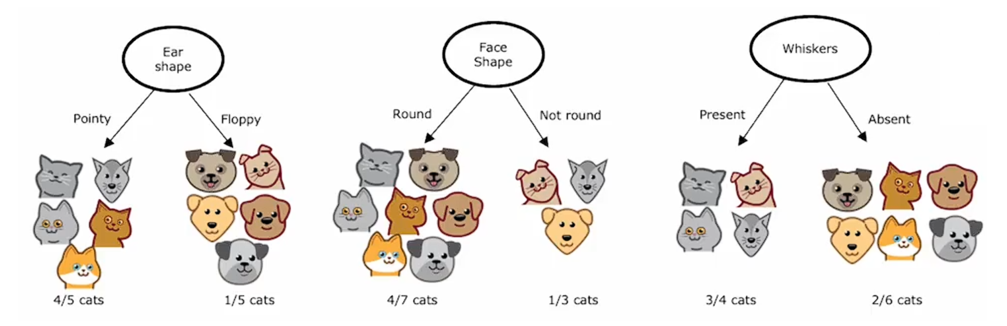
决策树学习算法必须在耳朵形状,面部形状和胡须之间做出选择,如果能得到高度纯净的子集,那么就可以在大多数情况下都能够正确的预测是猫或非猫。
构建决策树时,你需要做出的第二个关键决定是确定何时停止分割。刚才我们使用的标准是:直到我知道要么100%全是猫,要么是100%全是狗,而没有猫。
你也可以在不再导致树超过最大深度时停止分割,你允许树达到的最大深度是一个你可以直接指定的参数。在决策树中,节点的深度定义为:从根节点到该特定节点所需的跳数。限制决策树深度的原因之一,是为了确保树不会变得过于庞大和难以管理。其次,通过保持树的规模较小,可以减少过拟合的风险。
另一个你可能用来决定停止分割的标准是:纯度分数提升低于某个阈值。如果分割一个节点,导致纯度的提升很小,或者你发现实际上导致杂质增加,可能就会停止分割。这既是为了保证树比较小,也是为了降低过拟合的风险。
如果一个节点下的样本数量低于某个阈值,也可能会停止分裂。比如在根节点,根据脸型特征进行分割,那么右分支将只有三个训练样本,其中一只猫,两只狗。
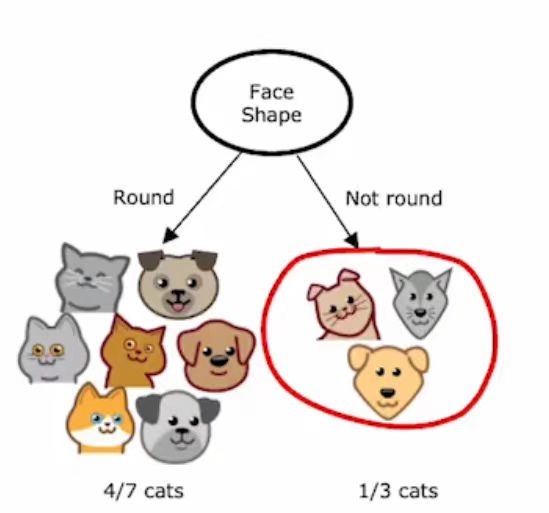
如果不再分割这仅有的三个样本,那么将创建一个决策节点。由于这里主要是狗,将做出不是猫的预测。
3 衡量纯度
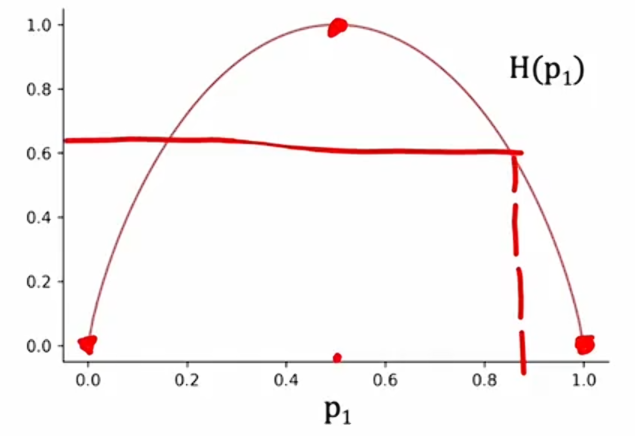
在这里,我们将探讨如何衡量一组样本的纯度。如果样本都是单一类别的猫,那么这是非常纯的;如果都不是猫,那也是非常纯的;但如果介于两者之间,我们该如何衡量这组样本的纯度呢?我们来看一下熵的定义,它是衡量一组数据不纯度的指标。
假如给定六个样本,其中有三个是猫,三个是狗,定义为猫样本所占的比例。

在这个里例子中中,。我们将使用一个称为熵的函数来测量一组样本的杂志,它看起来像这样:
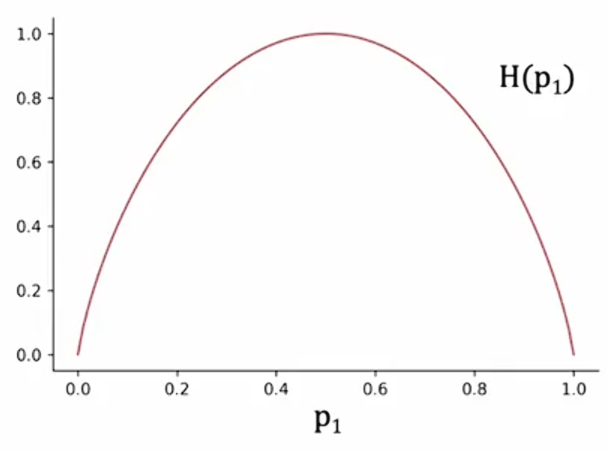
横轴是,表示样本中猫的比例;纵轴是熵的值。子啊上面的例子中,
,熵
。你可能注意到,当你的样本集是50-50时,此时处于这条曲线的最高点,因此当你的样本集是50-50时,它最不纯,杂质为一或熵为一;相比之下,如果你的样本集全是猫或没有猫,那么熵为零。
我们再通过几个例子来进一步理解熵及其工作原理。
当有五只猫和一只狗时, 此时
此时,熵
。
如果全是猫: ,此时
,此时,熵
。
我们看到,当从六个样本中有三只是猫到六个样本全是猫,杂志从1减少到0。换句话说,当从猫和狗各占一半的混合到全是猫时,纯度增加了。
当六个样本中,有两只猫和四只: ,此时
,此时,熵
。这实际上相当不纯,因为它=更接近50-50的混乱比例。
如果六个样本全是狗: ,此时
,此时,熵
,所以杂质为0。
现在我们来看下熵函数的实际方程。
是含有猫的样本比例,所以如果样本中有
是猫,那么必然有
不是猫。定义
为非猫的样本比例,即
。
熵函数
4 选择分割:信息增益
在构建决策树时,我们决定在节点上根据哪个特征进行分割的方式,将基于哪种特征选择能最大程度的减少熵或减少杂质或最大化纯度。
在决策树学习中熵的减少被称为信息增益。在这里,我们一起学习如何计算信息增益,从而决定在决策树的每个节点上使用哪些特征来进行分割。
让我们以刚才构建的用于识别猫与非猫的决策树根节点使用什么特征为例。如果我们根据它们的耳朵形状特征,在根节点进行分割,我们会在左分支得到五个样本,右分支得到五个样本。在左边的五个样本中,有四个样本是猫,所以,右边的五个样本中,有一个样本是猫,
。
如果将熵函数应用于这个左侧数据子集和右侧数据子集,我们会发现,左侧的杂质程度,右侧的杂质程度
。这将是我们根据耳朵形状特征进行分割时,左右分支的熵。
另一种选择是,根据脸形特征进行分割。那么,左分支的七个样本中有四个是猫,所以,右分支的三个样本有一个是猫,
,所以它们的熵分别为:
,
。
如果根据胡须是否存在进行分割:在这种情况下,左侧的,右侧的
,此时它们的熵分别为
,
。
我们需要回答的关键问题是:在根节点使用这三个特征时,哪一种效果最好?事实证明,与其查看这些熵值并进行比较,不如对它们进行加权平均。 如果一个节点中有很多样本并且熵值很高,这比一个只有少数样本且熵值很高的节点更糟糕。因为熵作为衡量不纯度的指标,在面对一个非常大且不纯的数据集时,相较于仅有少量样本会更糟。
与这些分割中的每一个相关联的是两个数字:左侧分支的熵和右侧分支的熵。为了从中选择,我们喜欢将这两个数字合并成一个单一的数字,我们可以通过取加权平均来结合这两个数字。
在取耳朵形状作为分割的例子中,十个样本有五个进入了左分支,因此我们可以计算加权平均为;对于脸部形状进行分割的例子:十个样本有七个进入了左分支,因此我们可以计算加权平均为
;对于是否有胡须的例子中:十个样本有四个进入了左分支,因此我们可以计算加权平均为
。我们将通过计算这三个数字,并选择其中最低的一个来确定分割方式,因为这会给我们提供具有最低平均加权熵的左右子分支。
在决策树的构建方式中,我们实际上要对这些公式再做一次改动,以遵循决策树构建的惯例,但这实际上不会改变最终的选择结果。
我们将计算与完全不分割相比的熵减少量。在开始时根节点有十个样本,其中猫和狗各有五个样本,因此,在根节点,根节点的熵
。
我们实际用于选择分割的公式不是左右子分支的加权熵,而是根节点的熵。
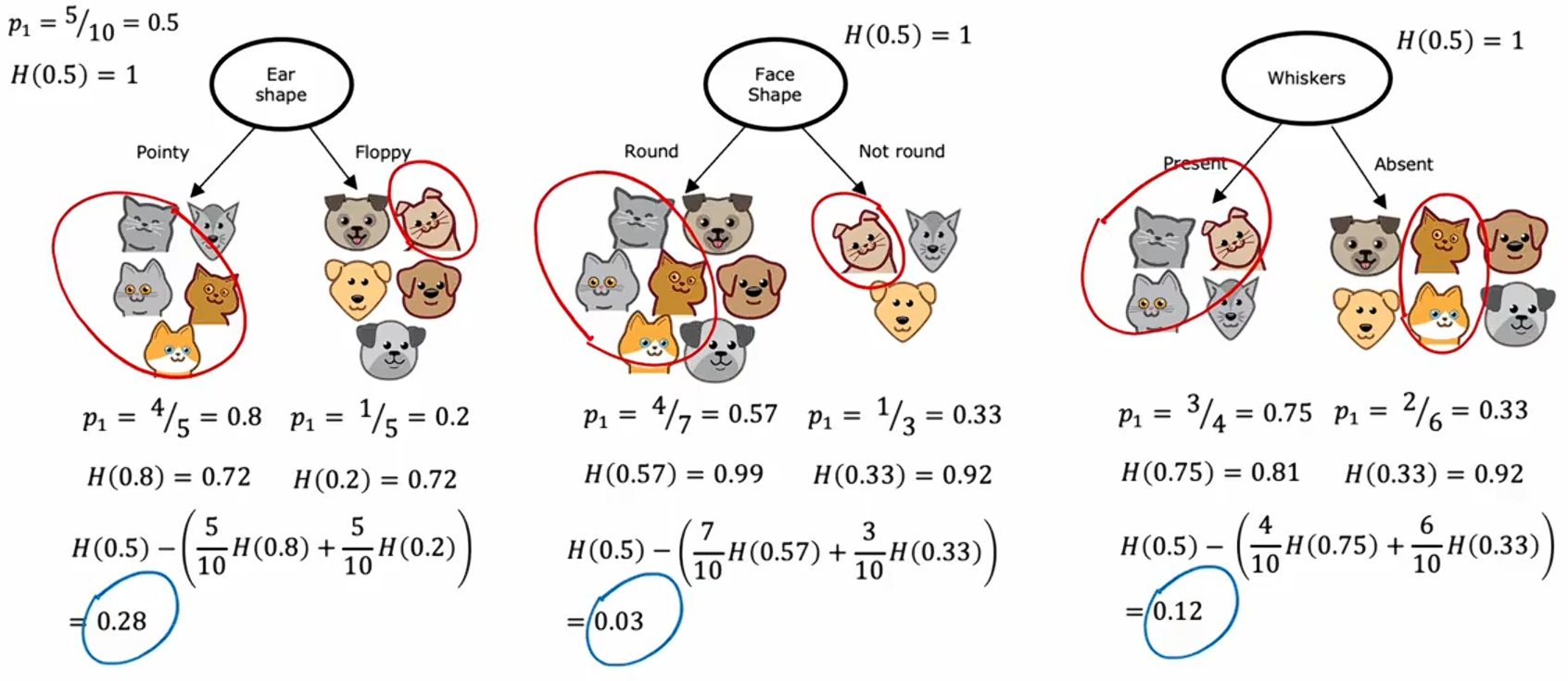
计算所得的0.28、0.03/0.12被称为信息增益。因为熵在根节点处为一,通过分割得到了一个较低的熵值,这两个值之间的差异就是熵的减少,例如在用耳形进行分割的情况下,这个减少量为0.28。
我们为什么要费心计算熵的减少,而不是仅仅计算左右子分支的熵呢?事实证明,决定何时不再进一步分割的停止标准之一是:熵的减少是否太小,在这种情况下,仅仅增加树的大小是不必要的,并且通过分割可能会增加过拟合的风险,因此如果熵的减少太小或者低于某一个阈值,就不用费心去继续分割了。
在这个例子中,对耳朵形状进行分割导致熵的减少最大,因此,我们选择在根节点上,根据耳朵形状特征进行分割。
为根节点所有样本进入左分支的比例;
为根节点所有样本进入右分支的样本比例;
等于左子树中具有正标签(即猫)的样本比例;
等于右子树中具有正标签(即猫)的样本比例;
为根节点中正例的比例。
现在我们写一下计算信息增益的通用公式,以耳形特征分割为例,;
;
;
;
。信息增益被定义为
的熵,也就是根节点的熵。信息增益=
。
有了这个熵的定义,你就可以计算与选择节点上任何特定特征进行分割相关的信息增益,然后在所有可能的分割中选择能给你带来最高信息增益的分支,这将有希望增加你在决策树左右分支上获得的数据集的纯度。
5 整合
从所有训练样本开始,在树的根节点处计算所有可能特征的信息增益,并选择能提供最高信息增益的特征进行分割。选择了这个特征后,根据所选特征将数据集分成两个子集,构建左右分支,根据这个特征的值,将训练样本送到左分支或右分支;不断重复在树的左右分支进行分割的过程,直到满足停止标准。停止标准是:当一个节点100%是某一个类时;进一步分割节点会导致树超过设置的最大深度;额外分割的信息增益小于阈值;节点中的样本数量低于阈值。
让我们来看一个该过程运作的示例。
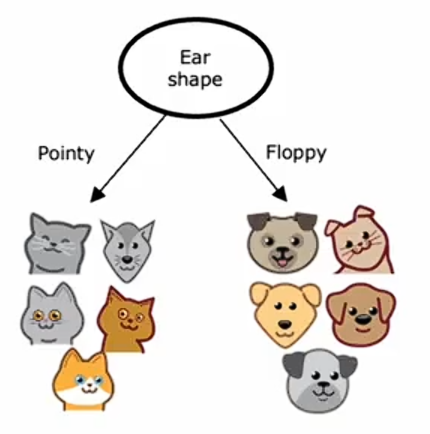
我们从根节点开始所有样本,并根据计算三个特征的信息增益,知道耳形是最佳的分裂特征,基于此,我们创建左右分支,并将具有尖耳与垂耳的数据子集分别发送到左右分支。
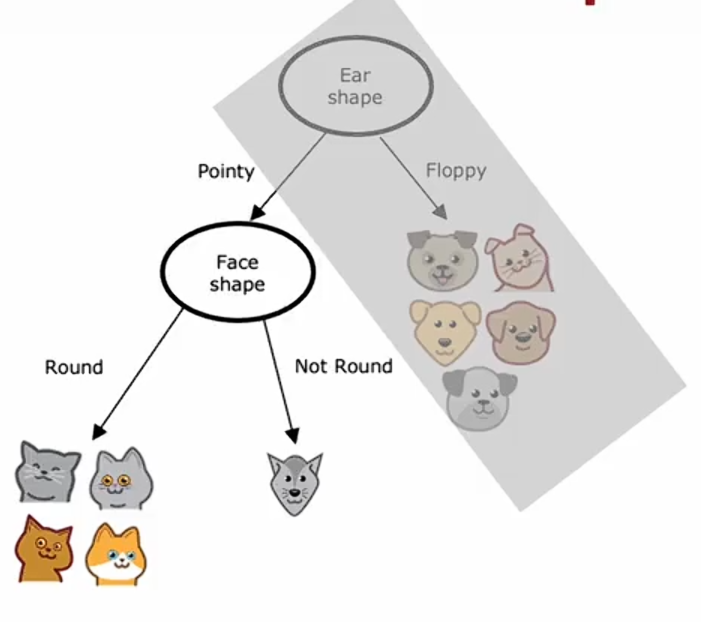
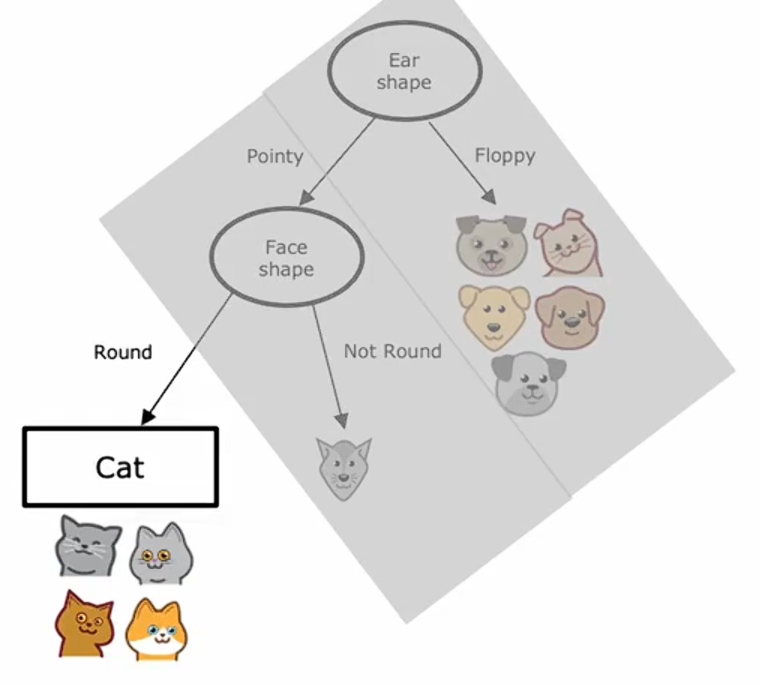
现在我们只看左分支的样本。这里有五个样本,我们的停止标准是直到节点中所有样本都属于单一类别,就是要么全部都是猫,要么全部都是狗。我们查看该节点,并检查它是否满足停止标准,检查后发现,它并不满足,所以下一步是选择一个特征进行分割,然后我们逐一检查每一个特征,并计算每个特征的信息增益,就好像这个节点训练了一个决策树的新根节点。我们将计算使用胡须特征的信息增益,以及在面部形状特征上分割的信息增益,结果是面部特征具有最高的信息增益,所以我们将在面部形状上进行分割,这将使我们能够按照以下方式构建左右分支 :
对于左分支,我们检查停止分裂的标准,发现样本全是猫,此时停止条件满足,我们创建一个叶节点,预测为猫。
对于右分支,我们发现全是狗,满足停止标准,设置叶节点,预测不是猫。
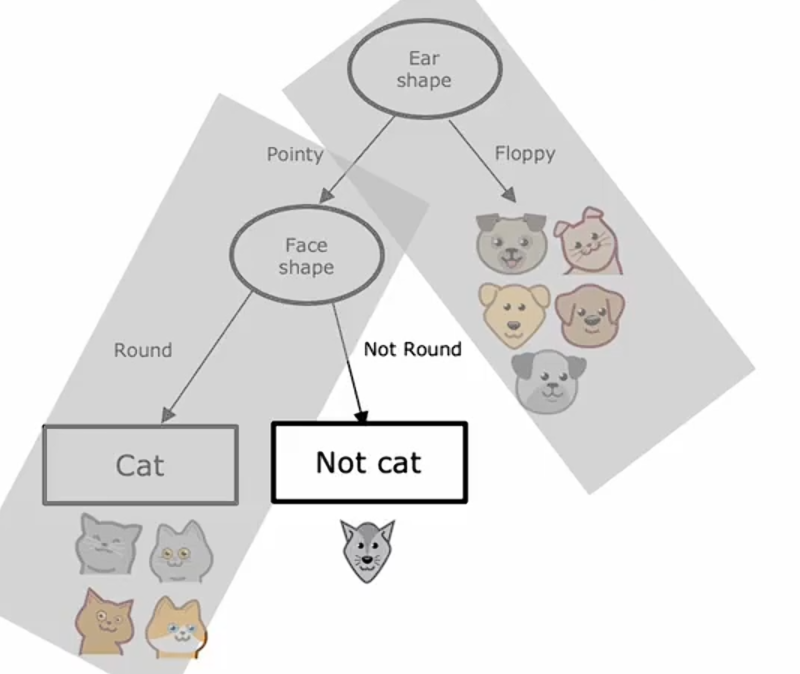
构建完左子树后,我们看一看右子树。首先我们看一下是否满足停止分割的标准,发现并不满足停止标准将继续分割。
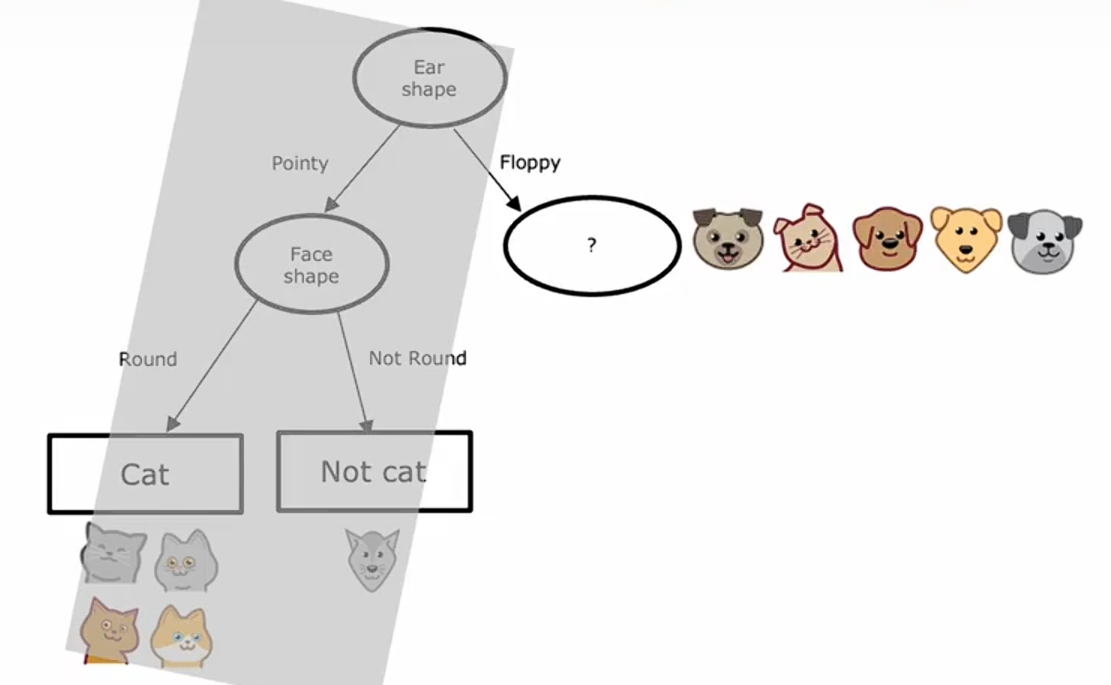
事实上,构建右分支的过程非常类似于从头开始训练决策树学习算法,其中你的数据集仅包含这五个训练样本,再一次计算所有可能用于分割的特征的信息增益,你发现胡须特征的信息增益最高,将这五个样本根据是否有胡须分割:
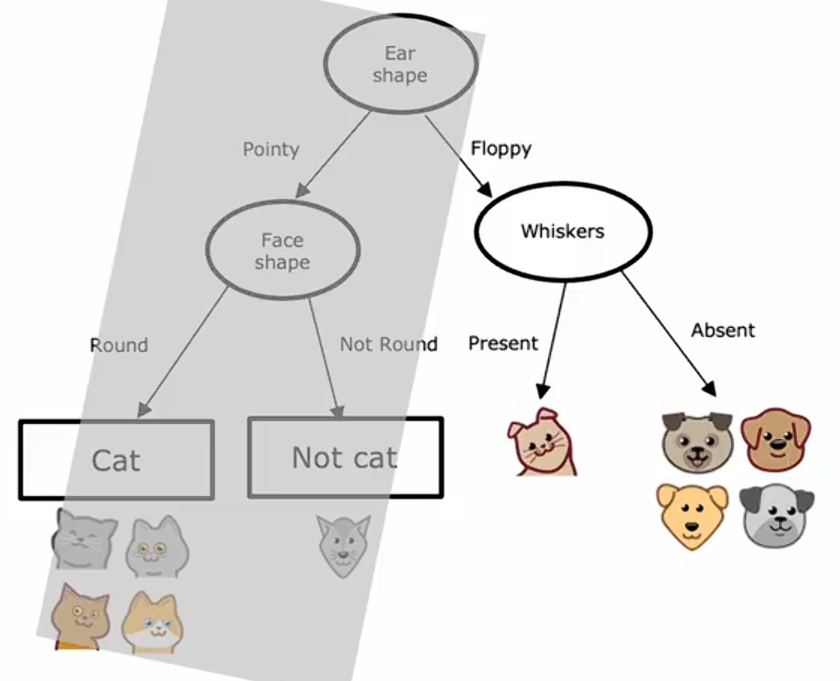
检查发现左右分支已经满足停止标准,最终得到预测为猫和非猫的叶节点,此时完成构建决策树的整体流程。
注意到在决定了根节点的分割方式后,我们构建左子树的方法是在五个样本子集上构建一个决策树,构建右子树的方法也是在五个样本的子集上建一个决策树。在计算机科学中,这是递归算法的一个例子,这意味着,在根节点构建决策树的方式,就是在左右分支中构建其他较小的决策树。
6 使用独热编码的分类特征
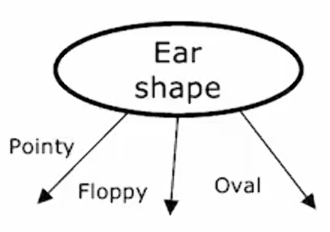
在我们目前看到的例子中,每一个特征只能取两个可能值中的一个,耳朵形状是尖的或者是耷拉的;脸型是圆的或不是圆的;有胡须或者没有胡须。但如果你有特征可以取两个以上的离散值,我们可以使用独热编码来解决这类特征。
这是宠物领养中心应用程序的新训练集,除了耳朵形状特征具有三个可选值外,其余特征都是两个可选值。耳朵形状有:尖的、耷拉的、椭圆的。这意味着,当你根据这个特征进行分割时,最终会创建数据的三个子集,并为这棵树创建三个分支。
在这里介绍一种可以取多个值的方法--独热编码法,而不是使用可以取三个可能值的耳型特征。我们将创建三个新特征,其中一个特征是,这只动物是否有尖耳朵;第二个特征是它们是否有垂耳;第三个特征是它们是否有椭圆耳朵。
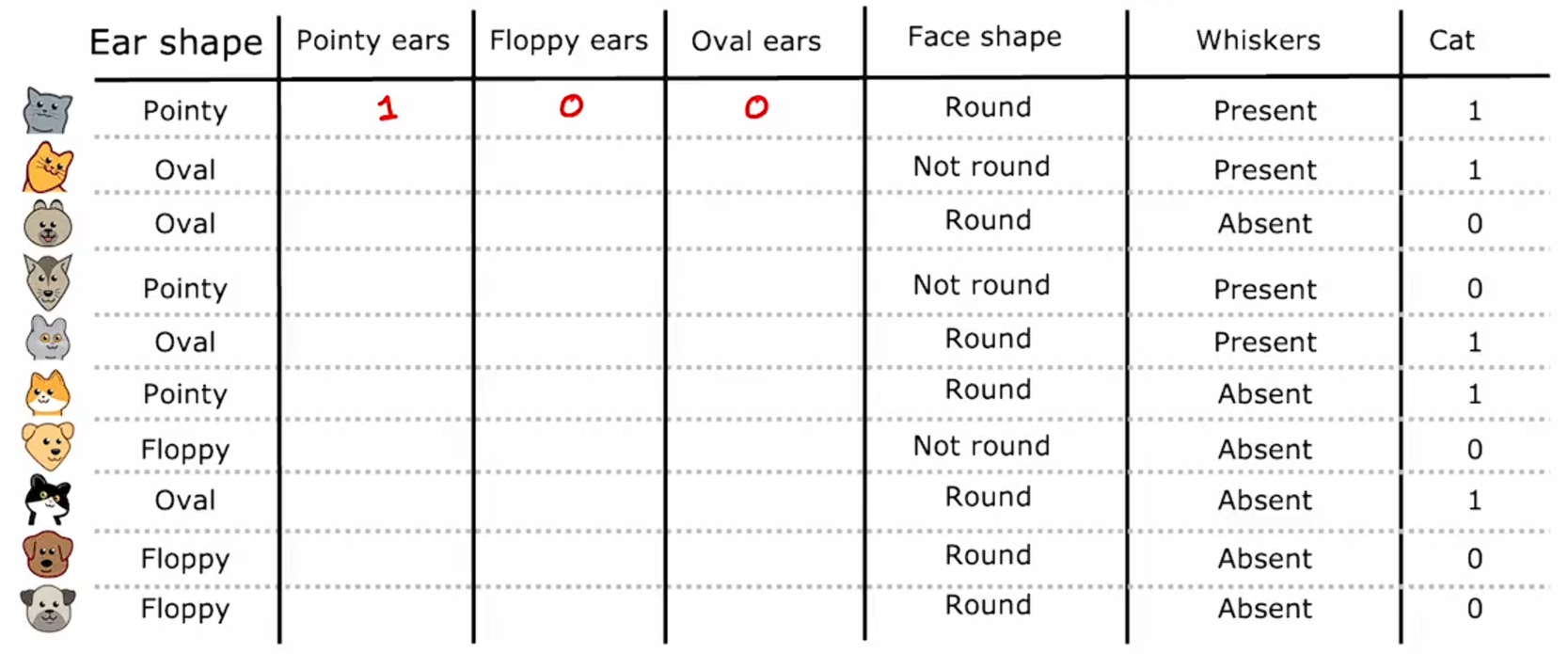
例如:对于第一个例子,我们之前将耳朵形状描述为尖的,现在则改说这种动物在尖耳特征上的值为1,而在垂耳和椭圆形耳特征上的值为0。
对于第二个例子,我们之前说它有椭圆形的耳朵,现在我们说它在尖耳和垂耳特征上的值为0,在椭圆形耳的特征上为1。
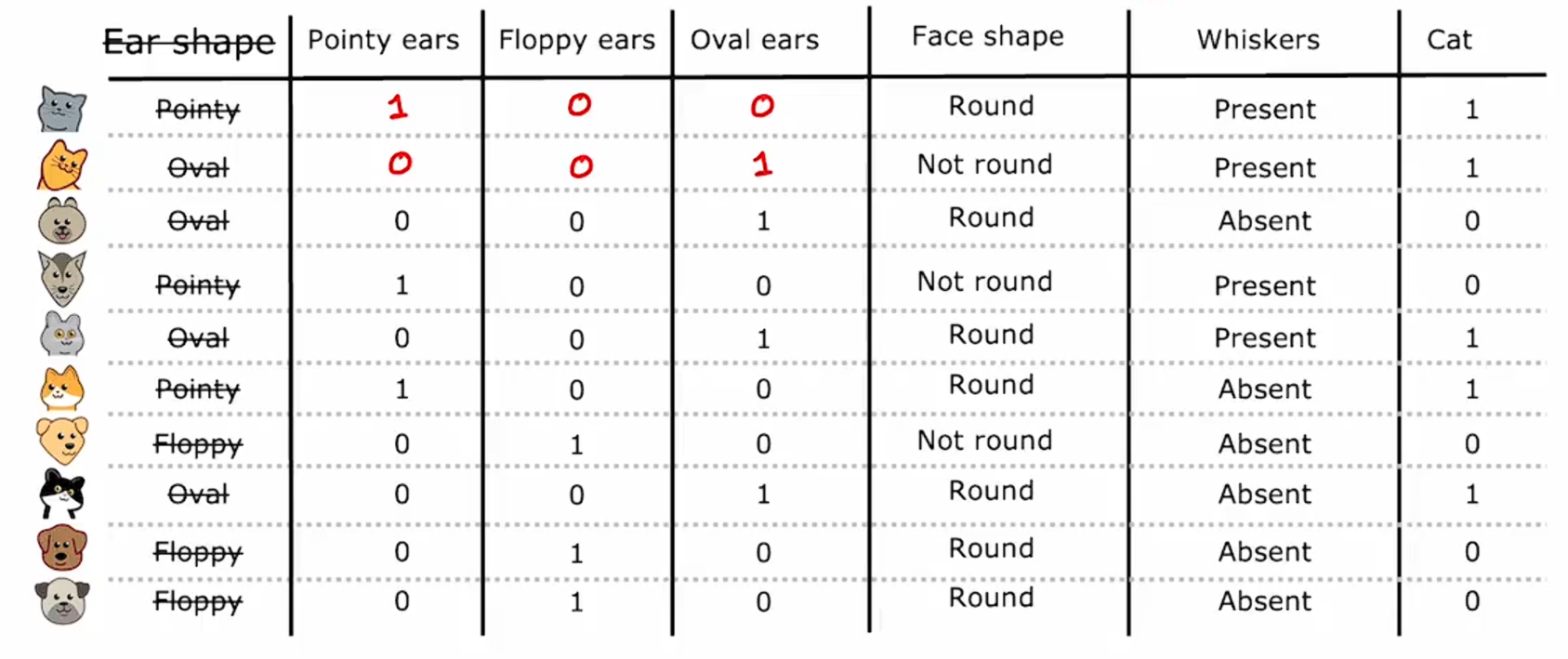
数据集中的其他样本也是按照这样的方式进行说明:
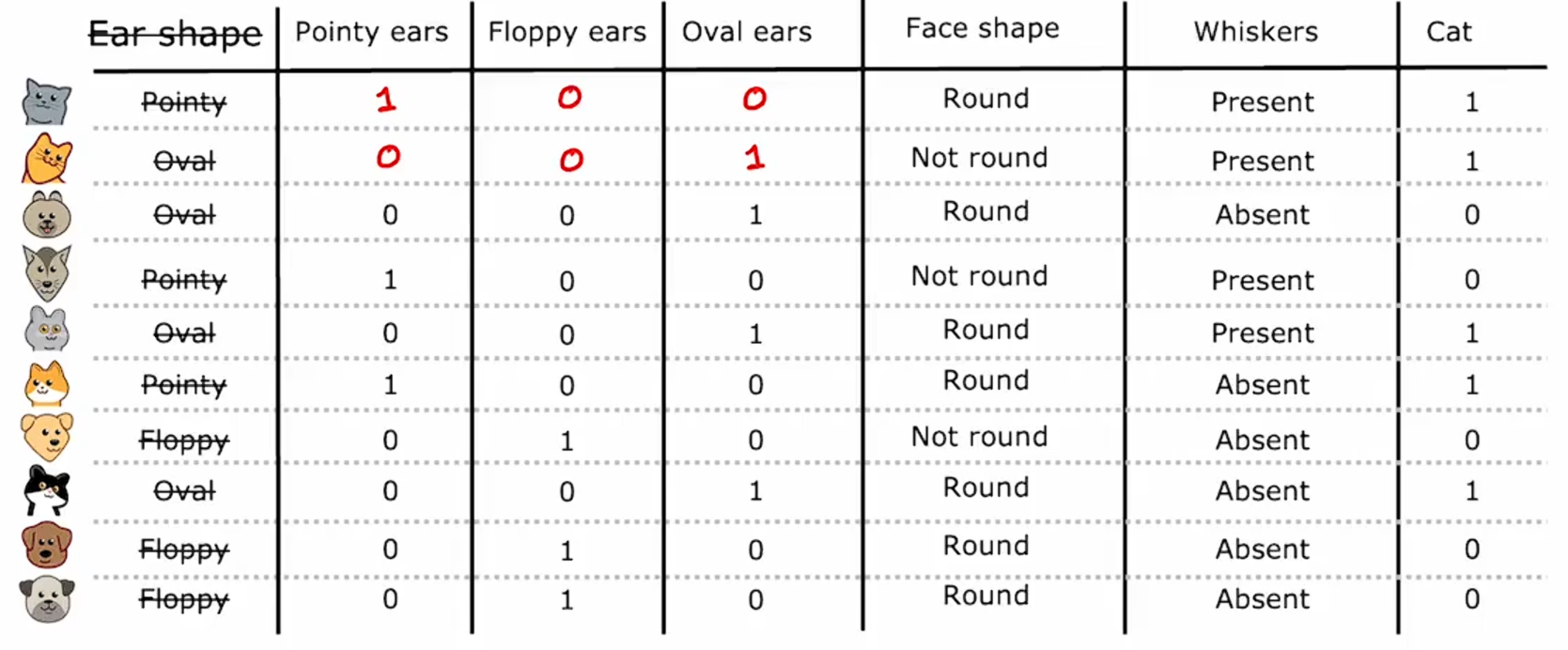
因此,我们不是让一个特征承担三个可能的值,而是构建了三个新特征,每个特征只能取两个可能的值之一,即0或1。
稍微详细一点来说,如果一个分类特征可以取k个可能的值,那么我们可以通过创建k个可能取0或1的二元特征来替换它。比如,在上面的耳形特征的例子中,如果你看到有一个值等于1,就说明它具有该种特征。
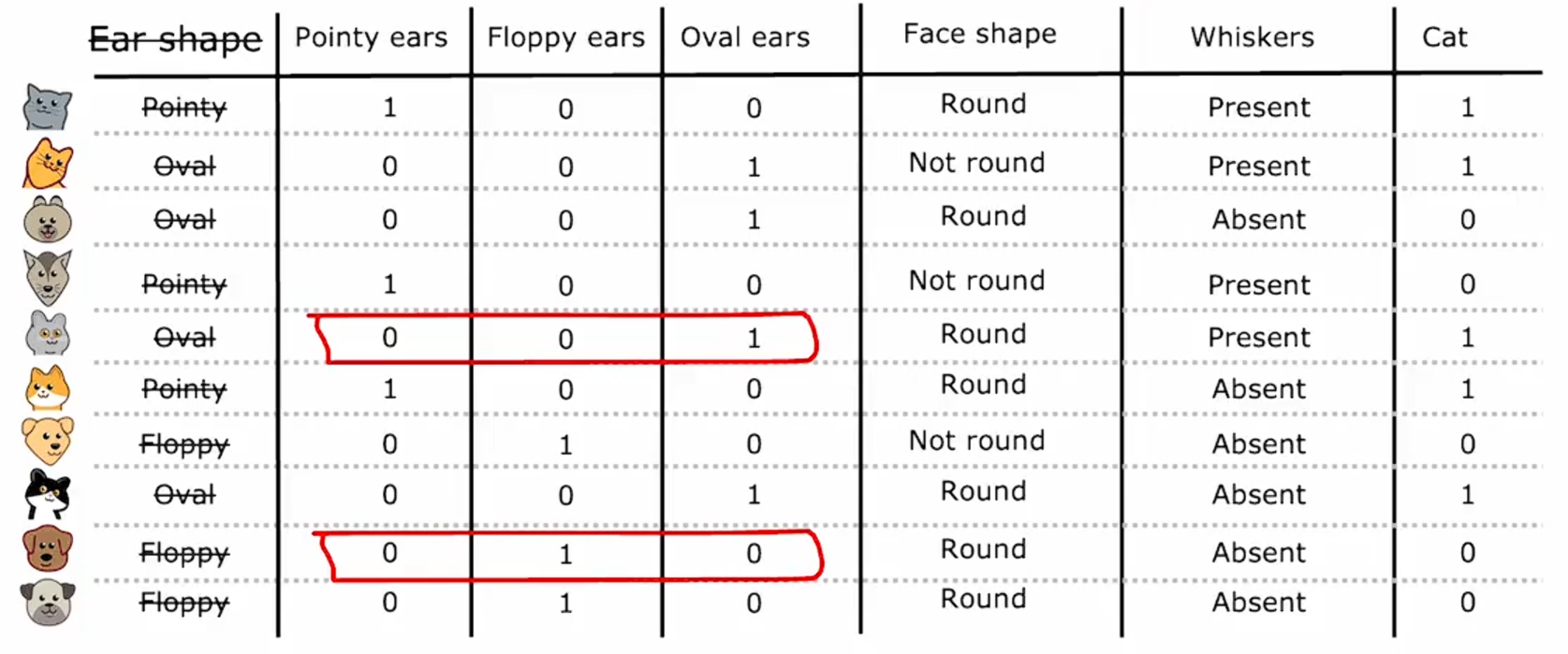
通过这种特征选择,我们现在回到了原始设置,其中每个特征仅取两个可能值之一,因此我们之前看到的决策树学习算法将适用于此数据,无需进一步修改。
7 连续值特征
在这里我们看看如何修改决策树,使其不仅适用于离散值特征,还能处理连续值特征。让我们从一个例子开始,我修改了猫领养中心的数据集,增加了一个新特征,即动物的体重。
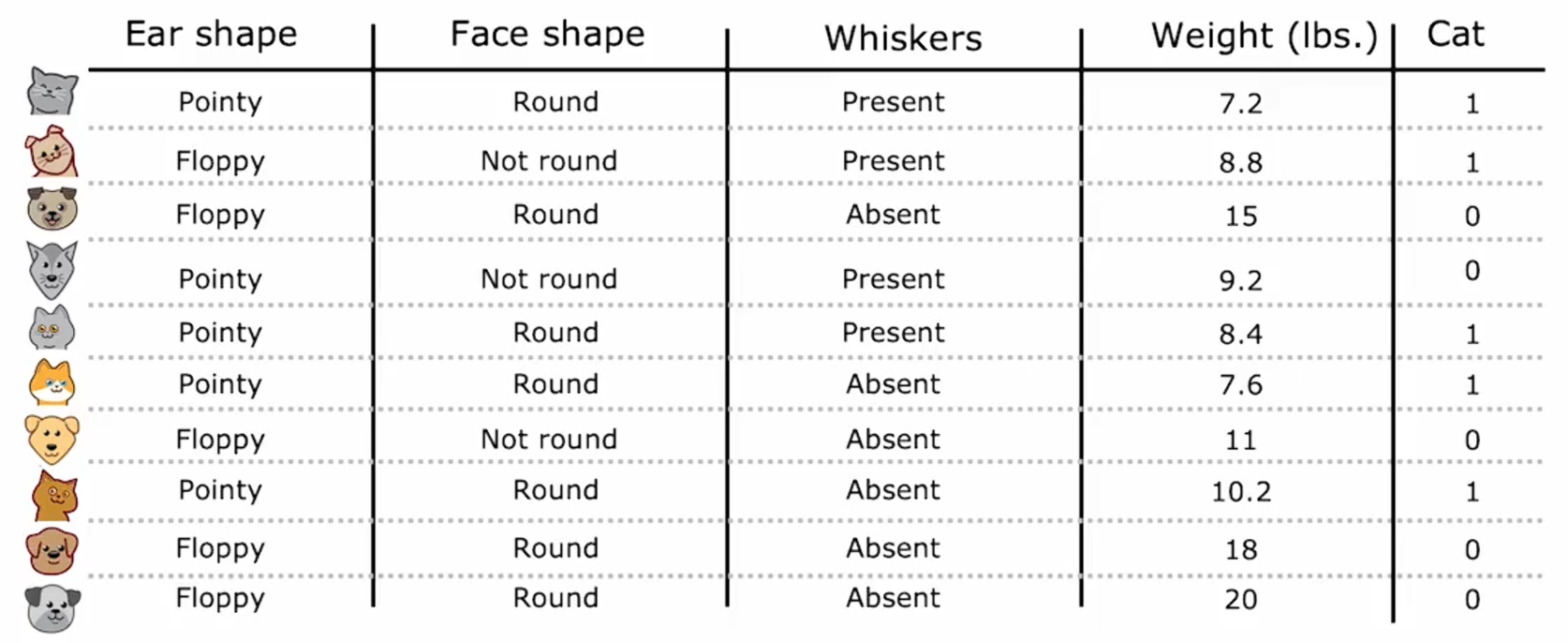
在平均体重上,猫比狗稍微轻一些,尽管有些猫比某些狗还要重;但是动物的体重是决定它是否是猫的一个有用特征,那么,你如何让决策树使用这样的特征呢?
决策树学习算法跟之前一样,只不过现在不在仅限于根据耳朵形状、面部形状和胡须进行约束分割,而是在此基础上增加了体重特征。
如果在体重特征上分割比在其他特征上分割能带来更好的信息增益,那么你可以在体重特征上进行分割,但是你要怎么在体重特征上进行分割呢?
这是一个图标,横轴表示体重,纵轴表示动物类别:
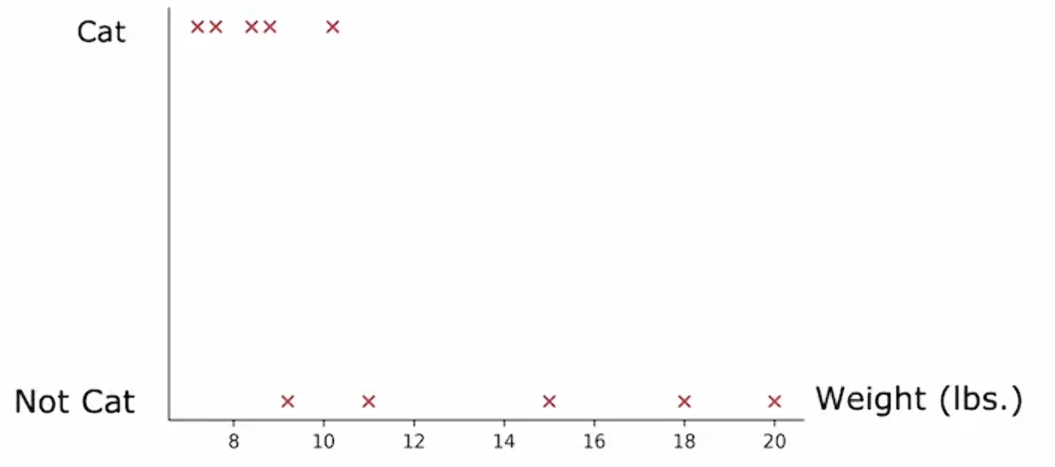
如果根据体重是否≤8来划分样本,那么你将会把这个数据集分为两个子集,左边的子集有两只猫,右边的子集有三只猫和五只狗。
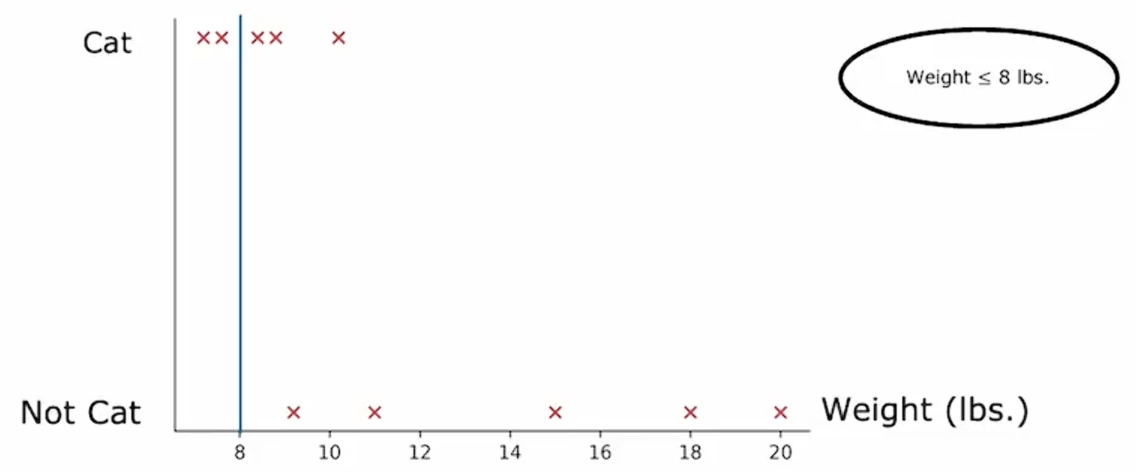
如果你要计算体重≤8时的信息增益:,我们也可以尝试其他值。
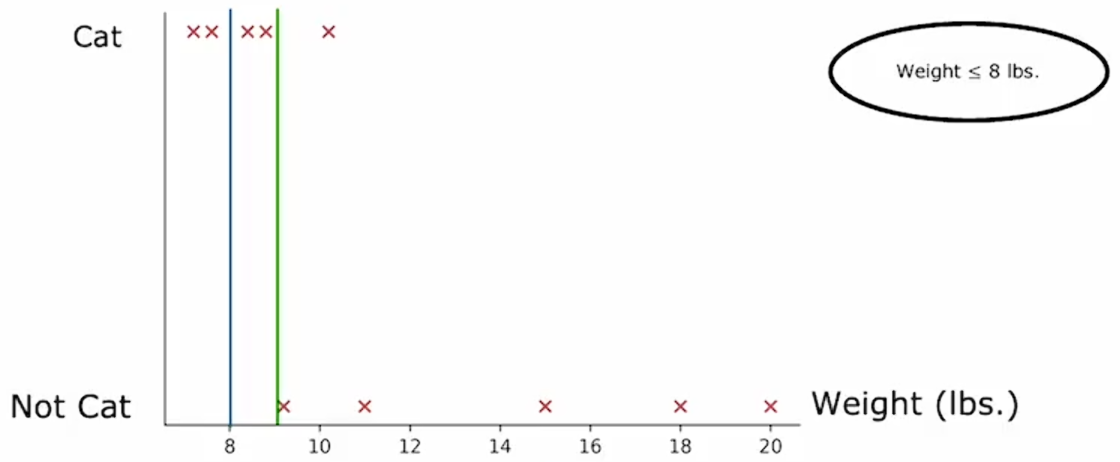
当按体重≤9划分时:信息增益为:
尝试另一个值13,计算的信息增益为0.4。
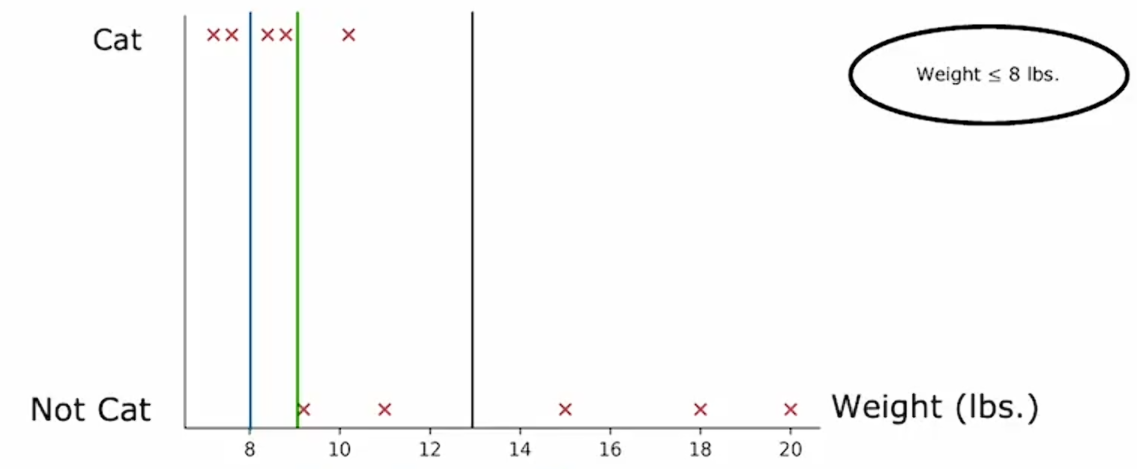
更一般的情况下,我们实际上不仅会尝试这三个值,还会尝试沿x轴的多个值的信息增益。一般的做法是,根据特征的值对所有样本进行排序,取排序后训练列表中所有中间点的值作为阈值。最后,如果根据此阈值进行分割所获得的信息增益优于根据其他特征进行分割的信息增益,那么就决定在该特征上分割节点。
8 回归树
之前我们只讨论了决策树作为分类算法,在这里,我们将把决策树推广为回归算法,以便我们能够预测一个数值。这里所使用的例子是之前拥有的三个特征x,以此来预测动物的体重y。
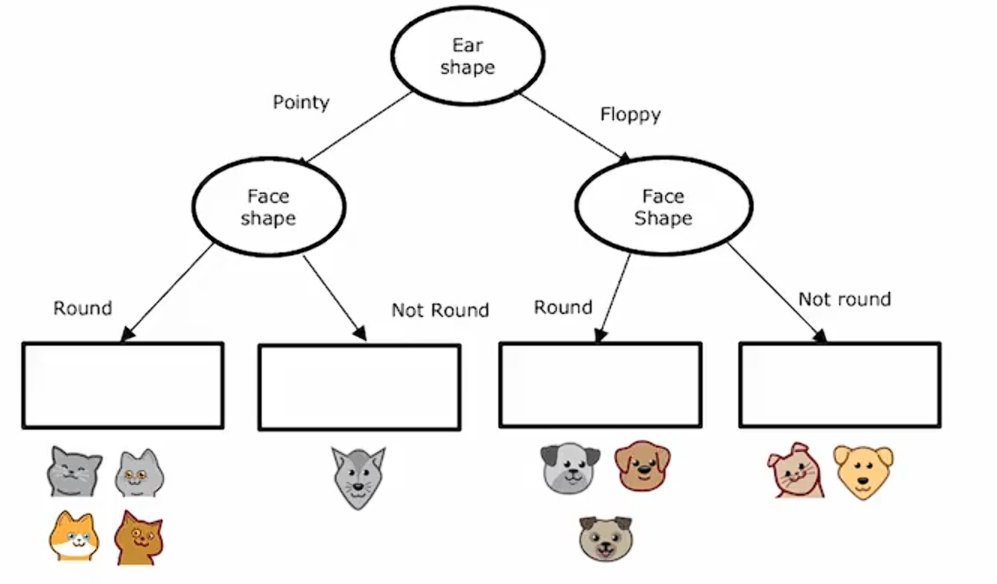
这里已经为回归问题构建了一棵树,其中根节点根据耳朵形状进行分割,左右子树分别根据脸型进行分割,需要在此说明的是,决策树在左右两侧分支上选择相同特征进行分割是没有任何问题的。
如果在训练期间,你决定了这样子分割,那么在根节点就会相应的动物,体重如下图标注。
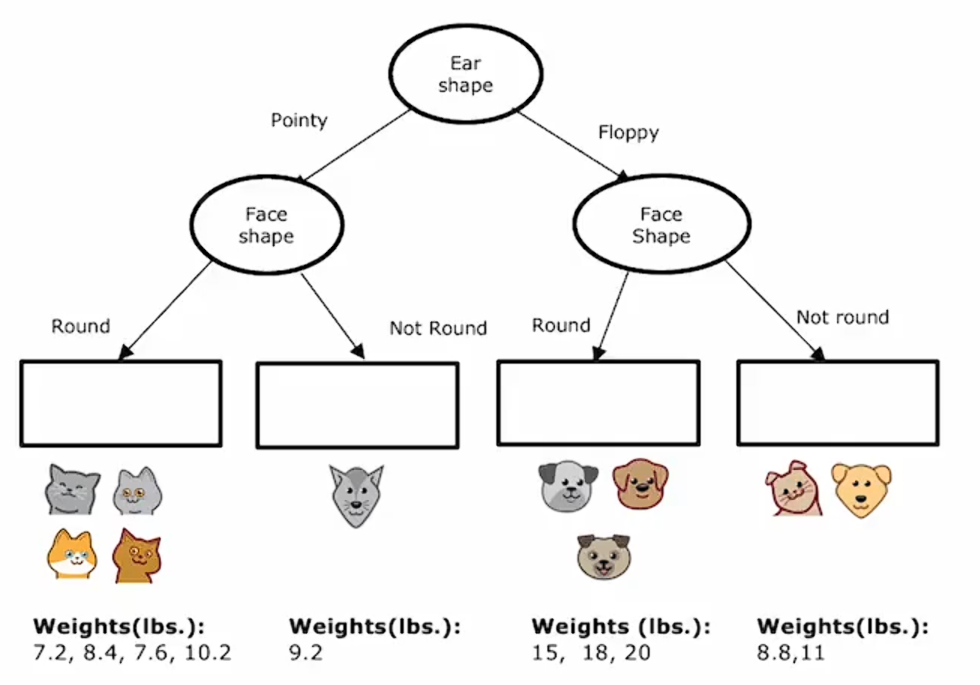
所以我们需要为这个决策树填入的最后一件事是:如果有一个测试样本到达这个节点,对于具有尖耳朵和圆脸形状的动物,我们应该预测的体重是什么?决策树将基于训练样本中体重的平均值进行预测。
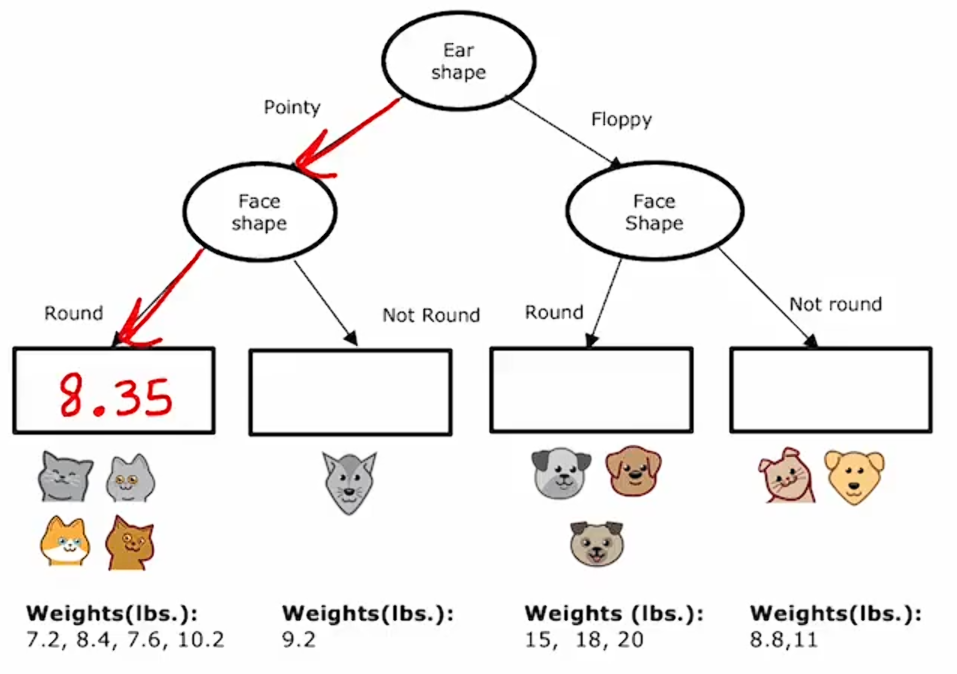
如果一只动物有尖耳朵且脸型不圆,那么它将预测体重为9.2,因为这是下面这只动物的重量。
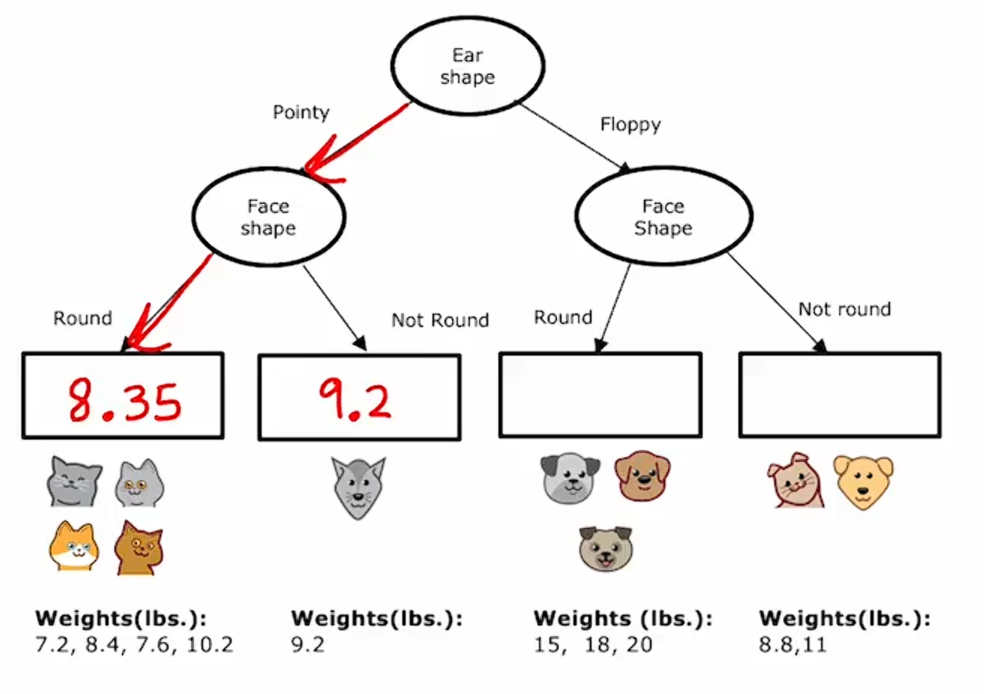
同时,对于其他两个也是如此:
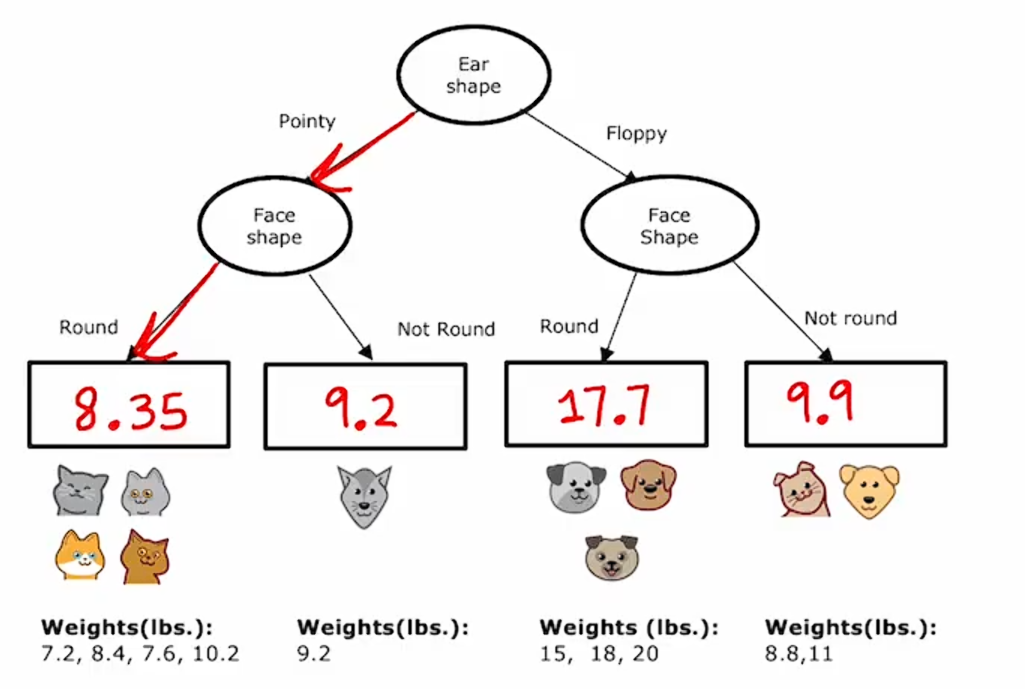
这个模型要做的是给定一个新的测试样本,按照决策节点一路向下,直到到达一个叶节点,然后预测该叶节点的值,这个值是刚刚通过训练期间到达同一叶节点的动物平均体重计算出来的 。
如果你要从头开始使用这个数据集构建一个决策树来预测体重。在根节点上,你可以根据耳朵形状进行分割,得到树的左右分支,并且左右分支各有五只动物,具有以下体重:
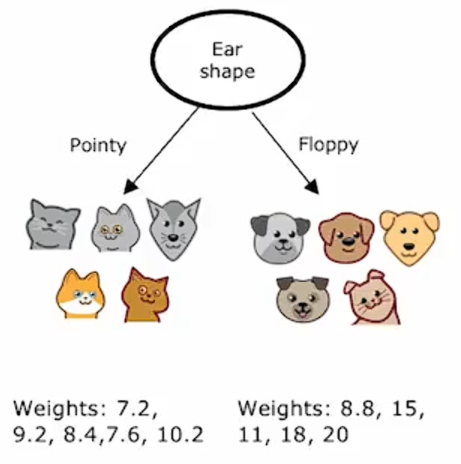
选择以脸型进行分割,也会得到结果:
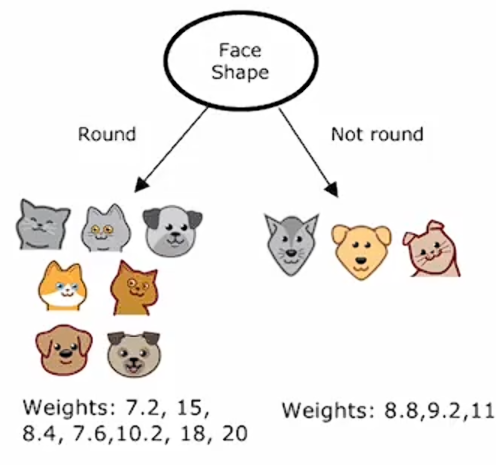
根据是否有胡须进行分割也是如此:
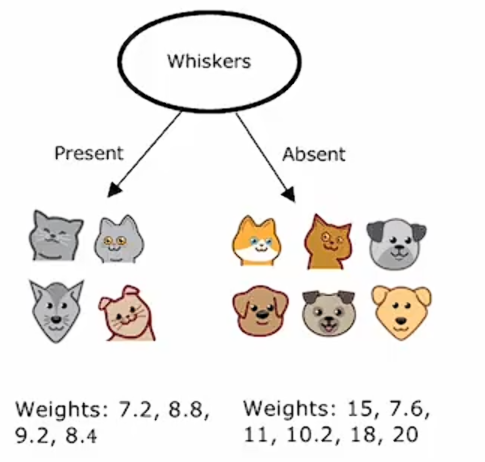
那么问题来了:在根节点上有这三个可能的分割,那么我们该选择哪一个来对动物的体重做出最佳预测呢?在构建回归树时,我们不是试图减少熵(分类问题中衡量不纯度的指标),而是试图减少每个数据子集中值y的方差。因此,我们评估这种分割质量的方法,我们将像之前一样计算。为根节点所有样本进入左分支的比例;
为根节点所有样本进入右分支的样本比例。
对于根据耳朵形状进行分割的样例中,左子树的方差的1.47,右子树的方差是21.87,,
。
。
这个加权平均方差在决策树中,扮演着与加权平均熵相似的角色。我们也可以用这样的方式对其他可能的特征分割进行计算。
选择分割的一个好方法是直接选择加权方差最低的值,类似于我们在计算信息增益,测量了熵的减少;对于回归树,我们同样会类似的测量方差的减少。事实证明,如果你查看训练集中的所有样本,并计算它们的方差,方差结果是20.51。因为根节点是相同的十个样本,因此在所有根节点中都是同一个方差值,因此,我们实际上要计算的是根节点的方差,即用20.51减去之前算出的加权方差。
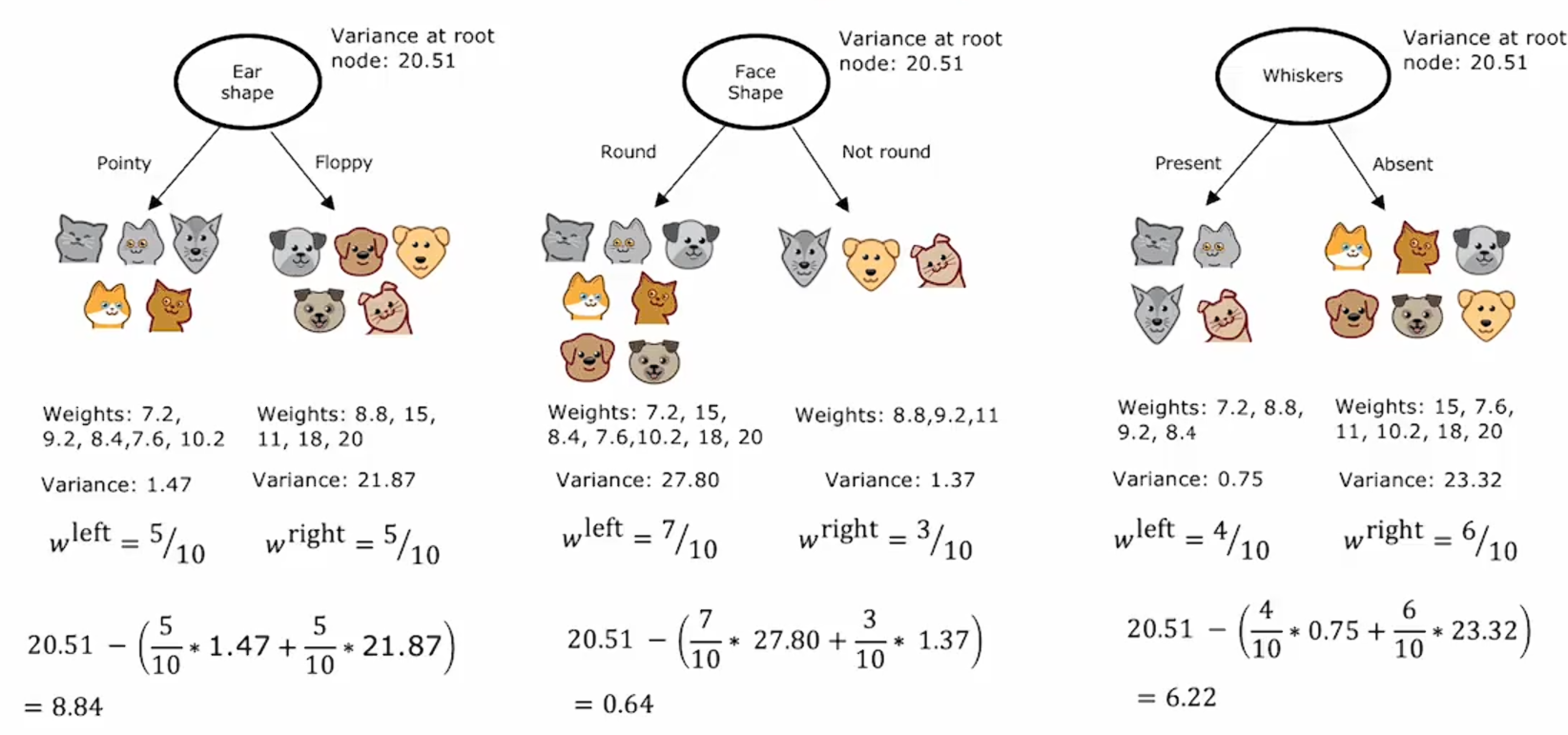
在这里,我们选择能最大减少方差的特征,也就是为什么选择用耳朵形状作为分割的原因。
9 使用多个决策树
以我们一直在使用的例子为例,根节点上最佳的特征分割是耳朵形状,这会导致数据划分成左右两个子集,然后在这两个数据子集上进一步构建子树。但事实证明,如果你改变其中一个训练样本,比如将一只猫的特征从尖耳、圆脸,没有胡须,改为垂耳、圆脸、有胡须。仅仅通过改变这一个训练样本,最高信息增益的特征分割就变成了胡须特征而不是耳型特征,左右子树上得到的数据子集也完全不同。随着你继续递归运行决策树学习算法,你会在左右子树上构建出完全不同的子树。

因此,仅仅改变一个训练样本,就会导致算法在根节点上产生不同的分割,从而得到完全不同的树,这使得该算法鲁棒性不好。这就是为什么在使用决策树时,你通常会得到更好的结果。也就是说,如果你训练的不是单一的决策树,而是一整批不同的决策树,你会得到更准确的预测,这就是我们所说的树集成,它是多个树的集合。
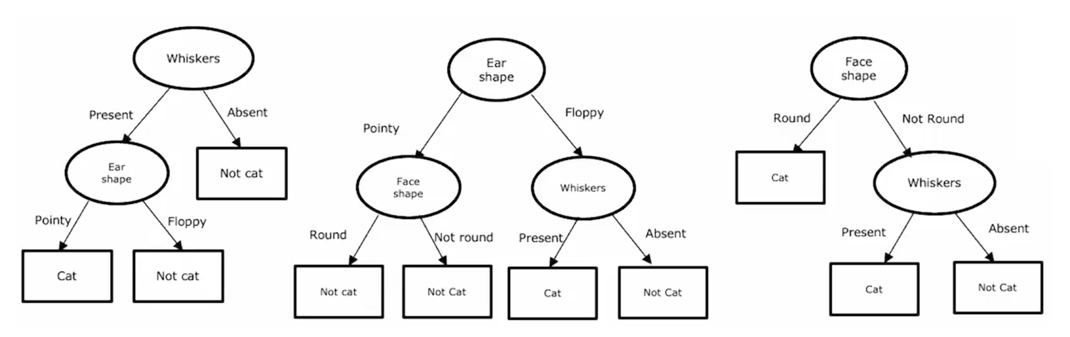
如果你有这样一个由三棵树组成的集成,每一种都可能是区分猫与非猫的一种合理方式。当用一个新的测试样本进行分类,那么你要做的就是,让样本通过这三棵树,并让他们投票决定最终的预测结果。
比如这个测试例子中的动物有尖尖的耳朵,不是圆脸有胡须,因此第一棵树会预测它是一只猫;第二棵树预测它不是猫;第三棵树预测它是猫。

这三棵树做出了不同的预测,因此我们要做的就是让他们投票。这三棵树预测中的多数投票结果是猫,这也恰好是正确的预测。
我们使用树集成的原因是:通过拥有许多决策树并让它们投票,使得你的整体算法对任何单一树的行为不那么敏感,从而让你的整体算法更具有鲁棒性。
10 有放回抽样
为了构建一个数集成,我们需要一种称为有放回抽样的技术。
为了说明有放回抽样的工作原理,在这里展示一个使用红色,蓝色,绿色和蓝色四种颜色代币的有放回抽样演示。

把这四种颜色代币放入一个黑袋子里,从中抽取代币,记录颜色,再把代币放回黑袋子,抽取代币,记录颜色,经过几次这样的操作,假设得到的代币颜色顺序是绿色、黄色、蓝色、蓝色。

如果你重复这个有放回抽样过程多次,你可能会得到其他的抽样顺序,比如:



这里的有放回部分是关键,因为如果每次抽样时不放回代币,那么从装有四个代币的袋子中抽取代币时,总是会得到四个相同的代币。抽取后放回是为了确保不会每次都只得到相同的四个代币。
有抽取采样的方法应用于构建树集成的方式如下:我们将构建多个与原始训练集略有不同的随机训练集,比如取十个猫和狗的样本,将这十个训练样本放入一个理论袋中,用这个理论袋创建一个与原始数据集大小相同的新随机训练集,然后从理论袋中随机挑选一个训练样本,记录后放回袋子,然后再随机挑选一个训练样本,重复这样的动作,直到最后你得到了十个训练样本,其中可能有一些是重复的,但这没有关系。
你可能注意到这个训练集并不包含所有的十个原始训练样本,这没有关系,这是有放回抽样过程的一部分。
11 随机森林算法
现在我们有了一个方法:通过有放回抽样创建新训练集。这些训练集与原始训练集有些相似,但也相当不同,我们可以用此来构建我们的第一个树集成算法。在这里,我们将讨论随机森林算法,这是一种非常强大的树集成算法,它的效果远远优于使用单一决策树。
如果你有一个大小为m的训练集,那么你可以将这十个训练样本放入虚拟袋中以生成一个也有十个样本的新训练集,然后在这个数据集上训练一个决策树,假如下面是使用有放回抽样生成的数据集。
如果仔细观察,你可能会注意到一些训练样本是重复的,这没有关系。如果你在这个训练集上训练决策树算法,你会得到这颗决策树:
完成一次后,我们将再次重复这个过程:使用有放回抽样生成另一个大小为十的新随机样本:
然后在这个新数据集上训练决策树,你可能会得到一棵不同的决策树:
你可能会这样做B次, B是你想构建的树的数量,一般推荐的范围是在64到128之间。假如构建了大约100棵不同的树后,当你试图进行预测,你会让这些树全部投票来决定最终的正确预测。事实证明,将B设置的很大永远不会损坏性能,但超过某个点后收益会递减;当B远大于100时,性能并不会显著提高,反而会显著减慢计算速度。这种特定的树集成实例,有时也称为袋装决策树。这指的是将你的训练样本放入虚拟袋中。
这个算法有一个修改版本,它实际上会使效果更好。这个修改将袋装决策树算法变成了随机森林算法。关键思想是:即使使用这种有放回抽样过程,有时最终会在根结点和根结点附近的节点上总是使用相同的分割。因此对算法进行了一次修改,以进一步尝试在每个节点随机化特征选择,这可能导致生成的树集彼此之间更加不同,从而在投票时得到更准确的预测。通常的做法是,在每个节点选择一个特征进行分割时,如果有n个特征可用,我们会选择一个随机子集k(k<n),并允许算法仅从该k个特征的子集中选择。
换句话说,你会选择k个特征作为允许的特征,然后从这些k个特征中选择信息增益最高的特征作为分割选择。当n很大时,例如n是几十,几百甚至更大,一般选择的。
在我们的例子中,我们只有三个特征,这种技术更多的应用于具有更多特征的大规模问题。通过进一步改变算法,你最终会得到随机森林算法,它通常比单个决策树表现的更好,并且更具有鲁棒性。
思考为什么这比单个决策树更鲁棒的一种方式是:有放回抽样过程导致算法探索了许多数据的微小变化,并且训练了不同的决策树,平均了有放回抽样过程导致的所有数据变化。因此,这意味着对训练集的任何微小改变,都不太可能对随机森林算法的总体输出产生巨大影响。
12 XGBoost
到目前为止,最常用的决策树集成或决策树的实现方式是一种称为XGBoost的算法,它运行速度快,开源实现易于使用,并且在许多机器学习竞赛和商业应用中取得了巨大成功。我们已经看到了一种对袋装决策树算法的修改,可以使它工作的更好。
我们再次写下之前的算法:给定一个大小为m的训练集,重复B次有放回采样来创建一个新的训练集,然后在新训练集上训练决策树。但这里我们要改变算法:在每次循环中,除了第一次之外,在采样时,不是从所有m个等概率的样本中以1/m的概率选取,而是更有可能选择那些先前训练的决策树表现不佳的误分类样本。
在培训和教育中有一个概念叫做刻意练习。比如说如果你正在学习弹钢琴,并且你试图掌握一首钢琴曲,一遍又一遍的练习整个曲子是相当耗时的,如果你将注意力集中在练习中演奏的不够好的那一部分,反复练习这些小部分,你会发现这是一种更有效的学习弹钢琴的方法。
因此,这种提升的想法是类似的,我们查看训练好的决策树,看看我们仍然没有做好的部分,然后再构建下一颗决策树时,更多的关注那些处理的不够好的样本。因此,我们不再查看所有的训练样本,而是更多的关注那些表现不佳的样本,并生成新的决策树,让集成中的下一颗决策树,尝试在这些样本上做的更好。
因此,更详细来说,我们将查看刚刚构建的这棵树,并回到原始的训练集逐一查看所有的样本,并观察这棵学习到的决策树对所有样本的预测结果。第四列是决策树的预测,分类正确就打勾,分类错误就打叉。
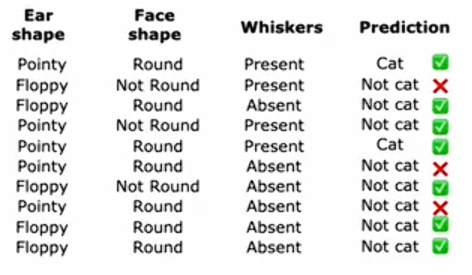
在第二次循环中要做的是:使用有放回抽样来生成另一个包含十个样本的训练集,每次从这十个样本中选择一个时,我们将更有可能选择这三个误分类样本中的一个。因此,这通过类似于刻意练习的过程,使第二个决策树更多地关注算法仍然没有做好的样本。
提升过程将总共执行b次 ,在每次迭代中,将查看从第一棵树到第b-1棵树的集成模型在哪些方面尚未表现良好,当构建第b棵树时,将会有更高的概率选择集成中先前构建的树仍然表现不佳的样本。
XGBoost有很好的默认分割标准和停止分割标准。XGBoost一项创新在于,它内置了正则化功能,以防止过拟合。这在机器学习竞赛中非常有用,比如在名为kaggle的竞赛平台。XGBoost通常是一种极具竞争力的算法。事实上,XGBoost和深度学习算法似乎是赢得许多这类比赛的两种算法。
实际上XGBoost不是通过有放回抽样,而是为不同的训练样本分配不同的权重,所以它实际上不需要生成大量随机选择的训练集,这使得它比使用有放回抽样程序还要稍微高效一些。
13 何时使用决策树
决策树和树集成通常在表格数据(也称结构化数据)上表现良好。这意味着,如果你的数据集看起来像一个巨大的电子表格,那么决策树就值得考虑。例如,在房价预测应用中,我们有一个数据集,它的特征是房屋的大小、卧室数量、楼层数和房屋年龄。这种数据存储在电子表格中,具有分类或连续值特征,并且适用于分类或回归任务,即预测离散类别或预测数值。所有这些问题都是决策树擅长处理的。
相比之下,不建议在非结构化数据上使用决策树和树集成,这些数据如图像、视频、音频和文本,你不太可能以电子表格格式存储。神经网络往往在非结构化数据任务上表现更好。
决策树和树集成的一个巨大优势,是它们可以非常快速的训练。如果你的模型需要花费数小时来训练,那么这将限制你改进算法性能的速度;但由于决策树和树集成通常训练速度较快,这使得你可以更有效的改进学习算法的性能。最后,小型决策树可能是人类可解释的。如果你正在训练一个单一的决策树,并且该决策树只有几十个节点,你可能能够画出该决策树,以理解它如何做出决策。
决策树的可解释性,有时被夸大了,如果当你构建一个包含100棵树的集成,并且每棵树有数百个节点时,查看这个集成以弄清楚它在做什么确实变得困难,可能需要一些单独的可视化技术。
如果你决定使用决策树或树集成,你可能会在大多数应用中使用XGBoost。树集成的一个缺点是它比单一决策树更昂贵。因此如果你的计算预算非常有限,你可以使用单一决策树;除此之外,使用树集成或XGBoost。
不过神经网络的一个缺点是它可能比决策树慢,大型网络的训练可能需要花费很长时间。神经网络的其他好处包括它适用于迁移学习。这一点非常重要,因为在许多只有少量数据集的应用中,能够使用迁移学习并在更大的数据集上进行预训练,这对获得竞争性能至关重要。
最后如果你正在构建一个由多个机器学习模型协同工作的系统,将多个神经网络串联起来并进行训练,可能比多个决策树更容易。
相关文章:

决 策 树
1 决策树模型 假如你正在运营一家猫咪领养中心,并拥有一些特征数据,你想训练一个分类器来快速判断一只动物是否为猫。这里有十个训练样本,有关于动物耳朵形状、面部形状、是否有胡须的特征,你想要预测这种动物是否为猫࿱…...

ts axios中报 Property ‘code‘ does not exist on type ‘AxiosResponse<any, any>‘
ts语法有严格的格式,如果我们在处理响应数据时,出现了axios响应中非默认字段,就会出现标题那样的警告,我们可以通过创建axios.dt.ts解决这个问题 下面是我在开发中遇到的警告,code并不是axios默认返回的字段࿰…...
)
【AI】用AI将文档、文字一键生成PPT的方法(百度的自由画布版)
前提: 最近看了个书,周末要参加读书会,要分享这本书的内容。一般来说,我都是写好了内容文档,然后在网上找一些模板套上去。 最近发现,有些网站已经可以按照文档,自动生成PPT模板了,里…...

爬虫技术-利用Python和Selenium批量下载动态渲染网页中的标准文本文件
近日工作需要整理信息安全的各项标准文件,这些文件通常发布在在官方网站,供社会各界下载和参考。 这些页面中,标准文本文件常以Word(.doc/.docx)或PDF格式提供下载。由于文件数量庞大,手动逐条点击下载效率…...

CUDA编程 - 如何在 GPU 上使用 C++ 函数重载 - cppOverload
这里写目录标题 一、完整代码与例程目的二、代码拆解与复用 2.1、函数重载: 2.2、函数指针声明: 2.3、函数指针赋值与内核启动: 2.4、CUDA API调用:2.4.1、cudaFuncSetCacheConfig:2.4.2、cud…...

AI教你学VUE——Gemini版
前端开发学习路线图 (针对编程新手,主攻 Vue 框架) 总原则:先夯实基础,再深入框架。 想象一下建房子,地基不牢,上面的高楼(框架)是盖不起来的。HTML、CSS、JavaScript 就是前端的地基。 阶段一…...
)
力扣热题100,力扣49.字母异位词分组力扣128.最长连续序列力扣.盛水最多的容器力扣42.接雨水(单调栈)
目录 力扣49.字母异位词分组 力扣128.最长连续序列 力扣.盛水最多的容器 力扣42.接雨水(单调栈) 1.包的命名规范: java的命名规范 全部采用小写 结尾不能加负数 声明包: 位置必须在首行 类: 字母数字下划线,美元符号 不能数字开头 不能有中文 不能以关键字命名 区…...

react naive 网络框架源码解析
本文取 react native 两个区别很大的版本做分析(0.76.5、0.53.3) 一、0.76.5 版fetch 全流程排查 1、JS 端的实现 随手写一个fetch,点开。 我们这里常用的还是手机端,因此选择 react-native,react-native-windows …...

DID在元宇宙的应用爆发:数字身份资产化与跨平台迁移——解析Decentraland等项目的虚拟身份全链路实现
元宇宙的兴起催生了多维度的数字身份需求,但传统虚拟身份系统受限于中心化架构,面临数据孤岛、身份碎片化、资产归属模糊等核心挑战。本文以Decentraland、The Sandbox、Somnium Space等顶级元宇宙平台为研究对象,探讨去中心化身份࿰…...

MySQL的内置函数与复杂查询
目录 前言 一、聚合函数 1.1日期函数 1.2字符串函数 1.3数学函数 1.4其它函数 二、关键字周边 2.1关键字的生效顺序 2.2数据源 2.3可以使用聚合函数的关键字 前言 在前面几篇文章中,讲解了有关MySQL数据库、数据库表的创建、数据库表的数据操作等等。本文我…...

mysql中select 1 from的作用
在MySQL中,SELECT 1 FROM ... 是一个常见的SQL写法,通常用于以下场景: 1. 作用与原理 SELECT 1 的本质是返回一个常数值(即数字1),且不依赖表中的实际数据。 它的核心作用是快速验证逻辑条件是否成立&…...
、 df (详解)和 free(详解)以及它们的区别)
Linux中 du (详解)、 df (详解)和 free(详解)以及它们的区别
目录 du命令 df命令 free命令 du/df/free区别 Tree du命令 功能:用于计算文件或目录所占用的磁盘空间大小。它会递归地遍历指定目录下的所有文件和子目录,统计它们占用的磁盘块数,从而得出占用的空间大小。常用选项: -h&…...

ETL交通行业案例丨某大型铁路运输集团ETL数据集成实践
在广袤的祖国边疆,一条条钢铁动脉承载着区域经济发展的重要使命。某大型铁路运输集团作为区域交通枢纽的运营主体,管辖着横跨多个省、区的铁路网络,运营里程超3000公里,每日承载着数以万计的客货运输任务。随着"数字中国&quo…...

【数据挖掘】Apriori算法
Apriori算法是经典的关联规则挖掘算法,用于从事务型数据库中发现频繁项集和强关联规则,特别常用于购物篮分析等场景。 🧠 核心思想(Apriori原则) 一个项集是频繁的,前提是它的所有子集也必须是频繁的。 即&…...

7.9/Q1,Charls最新文章解读
文章题目:Association between urbanization levels and frailty among middle-aged and older adults in China: evidence from the CHARLS DOI:10.1186/s12916-025-03961-y 中文标题:中国中老年人城市化水平与虚弱程度之间的关联࿱…...
从入门到登峰-嵌入式Tracker定位算法全景之旅 Part 7 |TinyML 定位:深度模型在 MCU 上的部署
Part 7 |TinyML 定位:深度模型在 MCU 上的部署 本章聚焦如何在 ESP32-S3 平台上,通过 TinyML 将深度学习模型应用到定位场景,包括特征提取、模型剪枝与量化、TensorFlow Lite for Microcontrollers 部署,以及在线微调与自适应策略。 一、为什么要用 TinyML? 非线性特征挖…...
 ABC)
Codeforces Round 1023 (Div. 2) ABC
链接 Dashboard - Codeforces Round 1023 (Div. 2) - Codeforces A 将数组a分成两组,使得gcd(b) ! gcd(c) 思路 gcd(a,b) < min(a,b) 求数组a的max,min 如果数组a都一样无解 (即max min 否则有解:让是max的一组&…...

56. 合并区间
给定若干个区间的集合,将重叠的区间合并后,放入一个数组中返回。 具体思路就是按左端点排序后合并区间,因为按左端点排序后,可以确保每次合并都是以最小元素为合并后区间的起始,并且按左端点排序可以方便合并ÿ…...

Docker安装使用
1.Docker简介 Docker是一个开源的应用容器引擎;是一个轻量级容器技术; Docker支持将软件编译成一个镜像;然后在镜像中各种软件做好配置,将镜像发布出去,其他使用者可以直接使用这个镜像; 运行中的这个镜…...

Linux/AndroidOS中进程间的通信线程间的同步 - POSIX IPC
1 什么是POSIX? POSIX(Portable Operating System Interface)即可移植操作系统接口,它是IEEE为要在各种UNIX操作系统上运行软件,而定义API的一系列标准的总称。以下为你展开介绍: 产生背景:在…...

5.2创新架构
一、MoE(Mixture of Experts,混合专家模型) 了解混合专家模型架构,与 Dense 架构相比有什么优劣 是一种提升大模型推理效率和参数利用率的关键技术 核心思想:在模型中增加多个“专家模块”(Experts&#x…...
显示区域更新)
驱动开发系列57 - Linux Graphics QXL显卡驱动代码分析(四)显示区域更新
一:概述 前面在介绍了显示模式设置(分辨率,刷新率)之后,本文继续分析下,显示区域的绘制,详细看看虚拟机的画面是如何由QXL显卡绘制出来的。 二:相关数据结构介绍 struct qxl_moni…...

疗愈服务预约小程序源码介绍
基于ThinkPHP、FastAdmin和UniApp开发的疗愈服务预约小程序源码,这款小程序在功能设计和用户体验上都表现出色,为疗愈行业提供了一种全新的服务模式。 该小程序源码采用了ThinkPHP作为后端框架,保证了系统的稳定性和高效性。同时,…...

力扣118,1920题解
记录 2525.5.6 题目: 思路: 用一个二维数组dp[numRows][numRows]保存每一次动态规划的结果 1.令dp[0][0]1(第一列) 2.找规律 3.得到如下规律(以下情况均为列数大于1) if(col0){ dp[row][col]1 } else { dp[row][col]dp[row-1][col-1]dp[row-1][col] }…...

电池热管理CFD解决方案,为新能源汽车筑安全防线
在全球能源结构加速转型的大背景下,新能源汽车产业异军突起,成为可持续发展的重要驱动力。而作为新能源汽车 “心脏” 的电池系统,其热管理技术的优劣,直接决定了车辆的安全性、续航里程和使用寿命。电池在充放电过程中会产生大量…...
毛子整洁架构(Domain Layer/Repository Pattern/Result Pattern/Error Pattern))
(一)毛子整洁架构(Domain Layer/Repository Pattern/Result Pattern/Error Pattern)
文章目录 项目地址一、整洁架构概念1.1 各个分层的功能1. Domain核心部件2. Application Layer3. Infrastructure layer3. Presenetation layer1.2 项目数据库二、Domain Layer2.1 Apartments 实体1. Current Value Obj2. Money Value Obj3. Apartment 类2.2 User 实体1. User类…...

XSS ..
Web安全中的XSS攻击详细教学,Xss-Labs靶场通关全教程(建议收藏) - 白小雨 - 博客园跨站脚本攻击(XSS)主要是攻击者通过注入恶意脚本到网页中,当用户访问该页面时,恶意脚本会在用户的浏览器中执行…...

Github Action部署node项目
Github Action部署node项目 个人学习的时候,作为前端感觉这个CICD基本流程还是有必要了解的,这里记录一下Github Action部署node项目的流程,也算是一个学习的过程 首先肯定是要有一个可运行的node项目 编写部署文件 部署文件放置在.githu…...

高频面试题:设计秒杀系统,用Redis+Lua解决超卖
高频面试题:设计秒杀系统,用RedisLua解决超卖 **1. 问题背景****2. 解决方案:Redis Lua****为什么选择Redis Lua?****核心代码逻辑****Java调用示例(Spring Boot)** **3. 方案优势****4. 面试回答话术***…...

2、Kafka Replica机制与ISR、HW、LEO、AR、OSR详解
Kafka 作为分布式高可用消息队列,其副本(Replica)机制是实现高可靠性和数据一致性的核心。本文将系统介绍 Kafka 的 Replica 机制,并详细解释 ISR、HW、LEO、AR、OSR 等关键概念。 一、Kafka Replica机制概述 在分布式系统中&am…...

生成式 AI:从工具革命到智能体觉醒,2025 年的质变与突破
在上海胸科医院的手术室里,一束全息投影正精准勾勒出患者肺部的三维血管模型。主刀医生手持机械臂的瞬间,AI 导航系统已同步完成 200 次路径演算,将毫米级误差控制在 0.3 毫米以内 —— 这个真实发生在 2025 年的临床场景,标志着生…...
)
安卓基础(拖拽)
当用户长按或拖拽某个视图(如按钮、图片)时,需要提供视觉反馈(即阴影)。这行代码通常在拖拽事件的处理逻辑中,例如: view.setOnLongClickListener(v -> {// 创建拖拽阴影DragShadowBuilder …...

IoTDB磁盘I/O性能监控与优化指南
一、磁盘I/O性能观测核心指标 在现代计算机系统中,磁盘I/O性能对整体系统表现至关重要。为有效监控和优化磁盘I/O性能,需关注以下核心指标: I/O读写延迟:衡量从发起I/O请求到接收响应的时间间隔。IOPS(Input/O…...

java每日精进 5.06【框架之功能权限】
0.概述 0.1 整体架构概述 这个RBAC权限系统基于Spring Security和Token认证机制,主要包含以下核心组件: 用户-角色-菜单的多对多关系模型 基于Token的认证流程 细粒度的权限控制(菜单权限、按钮权限) 灵活的权限配置方式 1…...

静态NAT
实验需求 PC1和PC2通过静态NAT去访问服务器 实验拓扑 图13-1 静态NAT 实验步骤 步骤1:IP地址的配置 PC1的配置 PC2的配置 R1的配置 <Huawei>system-view [Huawei]undo info-center enable [Huawei]sysname R1 [R1]interface g0/0/0 [R1-GigabitEt…...

RabbitMQ-api开发
前言 MQ就是接收并转发消息 核心概念 admin是用户 每个虚拟机上都有多个交换机 快速入门 引入依赖 <dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>5.22.0</version></dependen…...
 ; MachineTree getMachineTree() const; 区别?)
const MachineTree getMachineTree() ; MachineTree getMachineTree() const; 区别?
这两个函数声明在语法和语义上有明显的区别,它们的用途和行为也不同。让我们逐一分析它们的区别: 1. const MachineTree &getMachineTree(); 这个函数声明表示: 返回类型:const MachineTree &,即返回一个 M…...

使用DevTools工具调试前端页面,便捷脚本,鸿蒙调试webView
参考官方文章 便捷脚本 创建文本,复制修改后缀为bat 建立bat文件 echo off setlocal enabledelayedexpansion:: Initialize port number and PID list set PORT9222 set PID_LIST:: Get the list of all forwarded ports and PIDs for /f "tokens2,5 delims…...

浏览器存储 Cookie,Local Storage和Session Storage
什么是Cookie? 存储容量:一般限制在 4KB 以内。数据有效期:可以设置过期时间,若未设置,则在浏览器关闭时失效。数据共享:在同一域名下,不同页面可以共享cookie数据。并且在每次 HTTP 请求时&am…...
)
校内周赛题(思维题)
这次周赛的题目没有什么很难的代码实现,基本上都是对思路的把握。 与君共勉🌹 选取x个数,看能不能使得这x个数相加的结果是奇数。 如果x是偶数,他的分布肯定是一个奇数一个偶数若干个两两配对的奇数若干个两两配对的偶数。 如果…...

在 GitLab 中部署Python定时任务
在 GitLab 中部署定时任务(如每天早8点运行Python脚本并存储结果)可以通过 GitLab CI/CD 结合 计划任务(Scheduled Pipelines) 实现。以下是详细步骤和准备工作: 1. 准备工作 (1) 项目结构准备 确保项目包含: Python脚本(如 main.py):执行核心算法逻辑。 结果存储模…...

学习黑客Windows权限体系
已思考 24 秒 借着 Week 2 Day 4 的号角,我们把权限系统这条「双持长枪」摆上擂台:一边是 Windows DACL/icacls,另一边是 Linux sudoers。你将看到二者在授权语法、常见配置漏洞与提权打法上的一一对照——尤其关注 可写服务(Wr…...

DXFViewer进行中2 -> 直线 解析+渲染 ✅已完成
DXFViewer进行中 : ->封装OpenGL -> 解析DXF直线-CSDN博客https://blog.csdn.net/qq_25547755/article/details/147723906 上篇博文 解析dxf直线635条 1. DXFViewer.h #pragma once #include "Application.h" #include <stdio.h> #inc…...

当智能科技遇上医疗行业会帮助疫苗如何方便管理呢?
随着科技的发展,智能科技在医疗行业的应用日益广泛,在疫苗管理方面,温湿度监控设备的安装可以简化管理流程,提高监测效率,降低疫苗损坏的风险。 疫苗管理面临着诸多挑战和需求。疫苗的存储、运输、接种等环节都…...

Excel 数据 可视化 + 自动化!Excel 对比软件
各位Excel小能手们!你们有没有过要对比两个Excel表格数据差异,却看得眼睛都花了的经历?其实啊,现在有专门的Excel文件比较软件能帮咱解决这大难题。这软件就是用来快速找出两个或多个Excel表格数据不同之处,还能把修改…...
)
Selenium模拟人类行为,操作网页的方法(全)
看到有朋友评论问,用selenium怎么模仿人类行为,去操作网页的页面呢? 我想了想,这确实是一个很大的点,不应该是一段代码能解决的, 就像是,如果让程序模拟人类的行为。例如模拟人类买菜,做饭&am…...

LVS负载均衡群集解析:理解LVS-NAT的工作原理
目录 一、LVS群集应用基础 1.群集技术概述 2.LVS虚拟服务器 3.NFS共享存储服务 二、案例:地址转换模式(LVS-NAT) 1.资源清单 2.修改主机名 3.配置负载调度器(LVS上) 4.配置节点服务器(web1、web2) 5.测试LVS…...

Leetcode Hot 100最长连续序列
题目描述 思路 思路1 我们对数组进行排序,通过遍历数组,如果前一个数组的值1等于当前数组的值,计数count,如果中断了,计算当前最大连续长度的值ans,并且统计值count重新置为1,最后返回count与…...

【东枫科技】代理英伟达产品:交换机系统
文章目录 总体详细:NVIDIA Spectrum SN5000详细:NVIDIA Spectrum SN2100详细:NVIDIA Spectrum SN4700详细:NVIDIA Spectrum SN2010详细:NVIDIA Spectrum SN4600详细:NVIDIA Spectrum SN3700详细:…...

[前端]Javascript获取元素宽度
元素宽度属性对比示意图 ---------------------------------- | 外边距(margin) | -------------------------------- | | 边框(border) | | | -------------------------- | | | …...