python打卡day17
知识点
- 聚类的指标
- 聚类常见算法:kmeans聚类、dbscan聚类、层次聚类
- 三种算法对应的流程
实际在论文中聚类的策略不一定是针对所有特征,可以针对其中几个可以解释的特征进行聚类,得到聚类后的类别,这样后续进行解释也更加符合逻辑。
聚类的流程
- 标准化数据------聚类前的一般操作
- 选择合适的算法,根据评估指标调参( )
- 将聚类后的特征添加到原数据中
- 原则t-sne或者pca进行2D或3D可视化
- KMeans 和层次聚类的参数是K值,选完k指标就确定
- DBSCAN 的参数是 eps 和 min_samples,选完他们出现k和评估指标
- 以及层次聚类的 linkage 准则等都需要仔细调优。
- 除了经典的评估指标,还需要关注聚类出来每个簇对应的样本个数,避免太少没有意义。
作业: 对心脏病数据集进行聚类。
聚类评估指标
1. 轮廓系数 (Silhouette Score)
定义:轮廓系数衡量每个样本与其所属簇的紧密程度以及与最近其他簇的分离程度。取值范围:[-1, 1]
- 轮廓系数越接近 1,表示样本与其所属簇内其他样本很近,与其他簇很远,聚类效果越好。
- 轮廓系数越接近-1,表示样本与其所属簇内样本较远,与其他簇较近,聚类效果越差(可能被错误分类)。
- 轮廓系数接近 0,表示样本在簇边界附近,聚类效果无明显好坏。
2. CH 指数 (Calinski-Harabasz Index)
定义:CH 指数是簇间分散度与簇内分散度之比,用于评估簇的分离度和紧凑度。取值范围:[0, +∞)
- CH 指数越大,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。
- 没有固定的上限,值越大越好。
3. DB 指数 (Davies-Bouldin Index)
定义:DB 指数衡量簇间距离与簇内分散度的比值,用于评估簇的分离度和紧凑度。取值范围:[0, +∞)
- DB 指数越小,表示簇间分离度越高,簇内紧凑度越高,聚类效果越好。
- 没有固定的上限,值越小越好。
以班级类比通俗理解一下,轮廓系数看个人是否融入班级(-1到1,越大越好);CH指数比班级间差距(越大分班越合理);DB指数查班级紧密度(越小越好)。
聚类常见算法
1、KMeans聚类----就像用圆规画分组的圈子,简单但不够灵活。
KMeans 是一种基于距离的聚类算法,需要预先指定聚类个数,即 `k`。其核心步骤如下:
1. 随机选择 `k` 个样本点作为初始质心(簇中心)。
2. 计算每个样本点到各个质心的距离,将样本点分配到距离最近的质心所在的簇。
3. 更新每个簇的质心为该簇内所有样本点的均值。
4. 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数为止。
确定簇数的方法:肘部法
通过计算不同 `k` 值下的簇内平方和(Within-Cluster Sum of Squares, WCSS),绘制 `k` 与 WCSS 的关系图。在图中找到“肘部”点,即 WCSS 下降速率明显减缓的 `k` 值,通常认为是最佳簇数。这是因为增加 `k` 值带来的收益(WCSS 减少)在该点后变得不显著。
说人话就是画折线图,横轴是组数,纵轴是组内紧密程度,选"拐弯"的点
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 k 值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = [] # 存每个k值的组内紧凑程度(越小越好)
silhouette_scores = [] # 存轮廓系数(-1到1,越大越好)
ch_scores = [] # 存CH指数(越大越好)
db_scores = [] # 存DB指数(越小越好)for k in k_range:kmeans = KMeans(n_clusters=k, random_state=42) # 创建KMeans模型,设置当前要测试的k值kmeans_labels = kmeans.fit_predict(X_scaled) # 执行聚类,得到每个点的分组标签inertia_values.append(kmeans.inertia_) # 惯性(肘部法则),组内紧密程度silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数silhouette_scores.append(silhouette)ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数ch_scores.append(ch)db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数db_scores.append(db)print(f"k={k}, 惯性: {kmeans.inertia_:.2f}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")# -------- 打印结果 ----------
k=2, 惯性: 218529.50, 轮廓系数: 0.320, CH 指数: 479.34, DB 指数: 3.222
k=3, 惯性: 207982.87, 轮廓系数: 0.209, CH 指数: 441.88, DB 指数: 2.906
k=4, 惯性: 200477.28, 轮廓系数: 0.220, CH 指数: 399.12, DB 指数: 2.441
k=5, 惯性: 192940.36, 轮廓系数: 0.224, CH 指数: 384.19, DB 指数: 2.042
k=6, 惯性: 185411.81, 轮廓系数: 0.227, CH 指数: 380.64, DB 指数: 1.733
k=7, 惯性: 178444.49, 轮廓系数: 0.130, CH 指数: 378.31, DB 指数: 1.633
k=8, 惯性: 174920.27, 轮廓系数: 0.143, CH 指数: 352.31, DB 指数: 1.817
k=9, 惯性: 167383.96, 轮廓系数: 0.150, CH 指数: 364.27, DB 指数: 1.636
k=10, 惯性: 159824.84, 轮廓系数: 0.156, CH 指数: 378.43, DB 指数: 1.502# 绘制评估指标图
plt.figure(figsize=(15, 10))# 肘部法则图(Inertia)
plt.subplot(2, 2, 1)
plt.plot(k_range, inertia_values, marker='o')
plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('惯性')
plt.grid(True)# 轮廓系数图
plt.subplot(2, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o', color='orange')
plt.title('轮廓系数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 3)
plt.plot(k_range, ch_scores, marker='o', color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 4)
plt.plot(k_range, db_scores, marker='o', color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()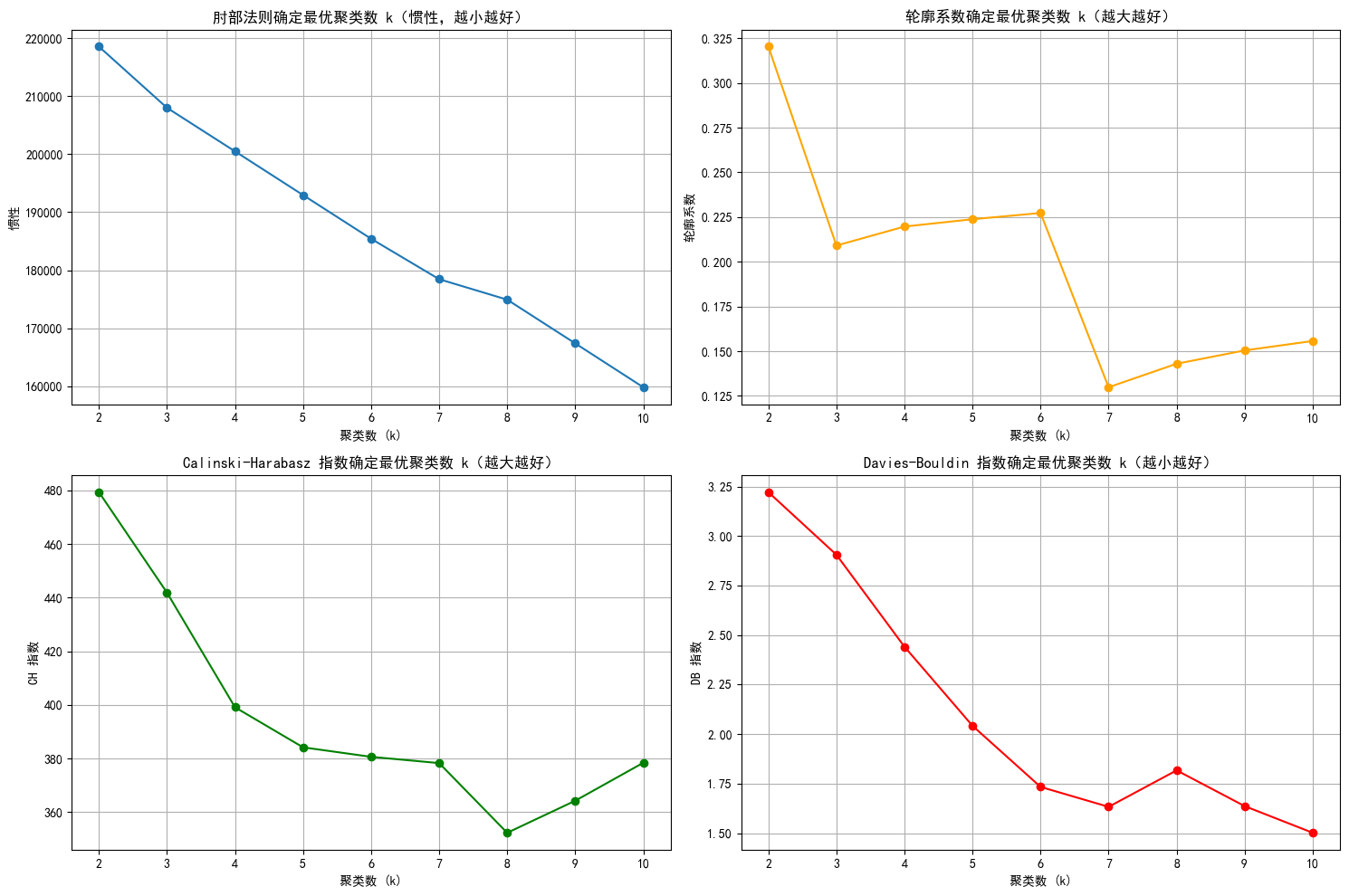
1. 肘部法则图: 找下降速率变慢的拐点,这里都差不多
2. 轮廓系数图:找局部最高点,这里选6不能选7
3. CH指数图: 找局部最高点,这里选7之前的都还行
4. DB指数图:找局部最低点,这里选6 7 9 10都行
综上,k = 6比较合适,下面进行聚类结果的可视化(聚类➡降维➡画图)
问题来了,为什么要降维?因为原始数据可能有几十个特征(维度),无法直接画在2D平面上。PCA就像"投影仪",把高维数据投影到最重要的两个方向上。
# 提示用户选择 k 值
selected_k = 6# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled) # 得到每个数据点的分组标签
X['KMeans_Cluster'] = kmeans_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled) # 压缩后的数据,形状从[n个样本, m个特征]变成[n个样本, 2]# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
# 所有点的横坐标(PCA第一维),所有点的纵坐标(PCA第二维),用颜色区分不同聚类组
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())# ---------- 打印结果 ------------
KMeans Cluster labels (k=6) added to X:
KMeans_Cluster
0 5205
1 1220
2 903
3 128
4 34
5 10
dtype: int64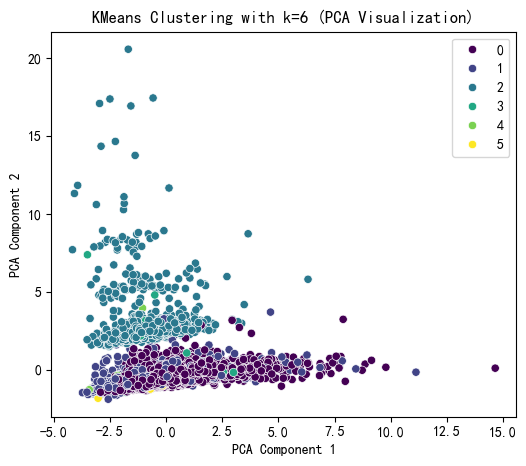
通俗理解全过程
- 分组:像把全班同学按相似性分成几个小组(KMeans)
- 拍合照:让所有人站到操场拍2D照片(PCA降维)
- 穿队服:给不同组的人穿不同颜色衣服(hue颜色区分)
- 点名:统计每个组有多少人(value_counts)
2.DBSCAN聚类
DBSCAN 是一种基于密度的聚类算法,自动发现紧密相连的数据点群,并排除噪声,无需预设K值,但要找出最佳的eps和min_samples
步骤如下:
- 随机选一个未访问的点
- 检查它半径范围里的邻居:如果邻居数 ≥ min_samples(最小邻居数) → 标记为核心点,创建一个新簇,并递归扩散找所有密度相连的点;否则 → 暂时标记为噪声(可能后续被其他簇吸收为边界点)
- 重复直到所有点被访问
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 eps 和 min_samples 下的指标
# eps这个参数表示邻域的半径,min_samples表示一个点被认为是核心点所需的最小样本数。
# min_samples这个参数表示一个核心点所需的最小样本数。eps_range = np.arange(0.3, 0.8, 0.1) # 测试 eps 从 0.3 到 0.7
min_samples_range = range(3, 8) # 测试 min_samples 从 3 到 7
results = []for eps in eps_range:for min_samples in min_samples_range:dbscan = DBSCAN(eps=eps, min_samples=min_samples)dbscan_labels = dbscan.fit_predict(X_scaled)# 计算簇的数量(排除噪声点 -1)n_clusters = len(np.unique(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)# 计算噪声点数量n_noise = list(dbscan_labels).count(-1)# 只有当簇数量大于 1 且有有效簇时才计算评估指标if n_clusters > 1:# 排除噪声点后计算评估指标mask = dbscan_labels != -1if mask.sum() > 0: # 确保有非噪声点silhouette = silhouette_score(X_scaled[mask], dbscan_labels[mask])ch = calinski_harabasz_score(X_scaled[mask], dbscan_labels[mask])db = davies_bouldin_score(X_scaled[mask], dbscan_labels[mask])results.append({'eps': eps,'min_samples': min_samples,'n_clusters': n_clusters,'n_noise': n_noise,'silhouette': silhouette,'ch_score': ch,'db_score': db})print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, "f"轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")else:print(f"eps={eps:.1f}, min_samples={min_samples}, 簇数: {n_clusters}, 噪声点: {n_noise}, 无法计算评估指标")# 将结果转为 DataFrame 以便可视化和选择参数
results_df = pd.DataFrame(results)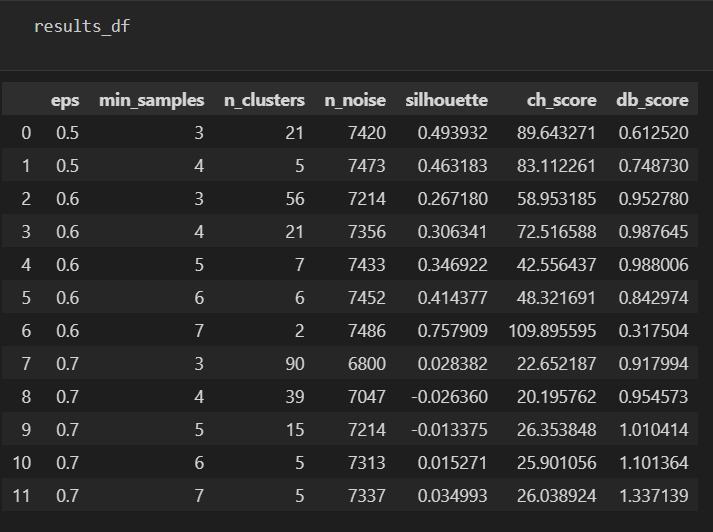
看表还是不明确,还是来画折线图一下找找最佳参数吧:
# 绘制评估指标图,增加点论文中的工作量
plt.figure(figsize=(15, 10))
# 轮廓系数图
plt.subplot(2, 2, 1)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples] # plt.plot(subset['eps'], subset['silhouette'], marker='o', label=f'min_samples={min_samples}')
plt.title('轮廓系数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('轮廓系数')
plt.legend()
plt.grid(True)# CH 指数图
plt.subplot(2, 2, 2)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['ch_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Calinski-Harabasz 指数确定最优参数(越大越好)')
plt.xlabel('eps')
plt.ylabel('CH 指数')
plt.legend()
plt.grid(True)# DB 指数图
plt.subplot(2, 2, 3)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['db_score'], marker='o', label=f'min_samples={min_samples}')
plt.title('Davies-Bouldin 指数确定最优参数(越小越好)')
plt.xlabel('eps')
plt.ylabel('DB 指数')
plt.legend()
plt.grid(True)# 簇数量图
plt.subplot(2, 2, 4)
for min_samples in min_samples_range:subset = results_df[results_df['min_samples'] == min_samples]plt.plot(subset['eps'], subset['n_clusters'], marker='o', label=f'min_samples={min_samples}')
plt.title('簇数量变化')
plt.xlabel('eps')
plt.ylabel('簇数量')
plt.legend()
plt.grid(True)plt.tight_layout()
plt.show()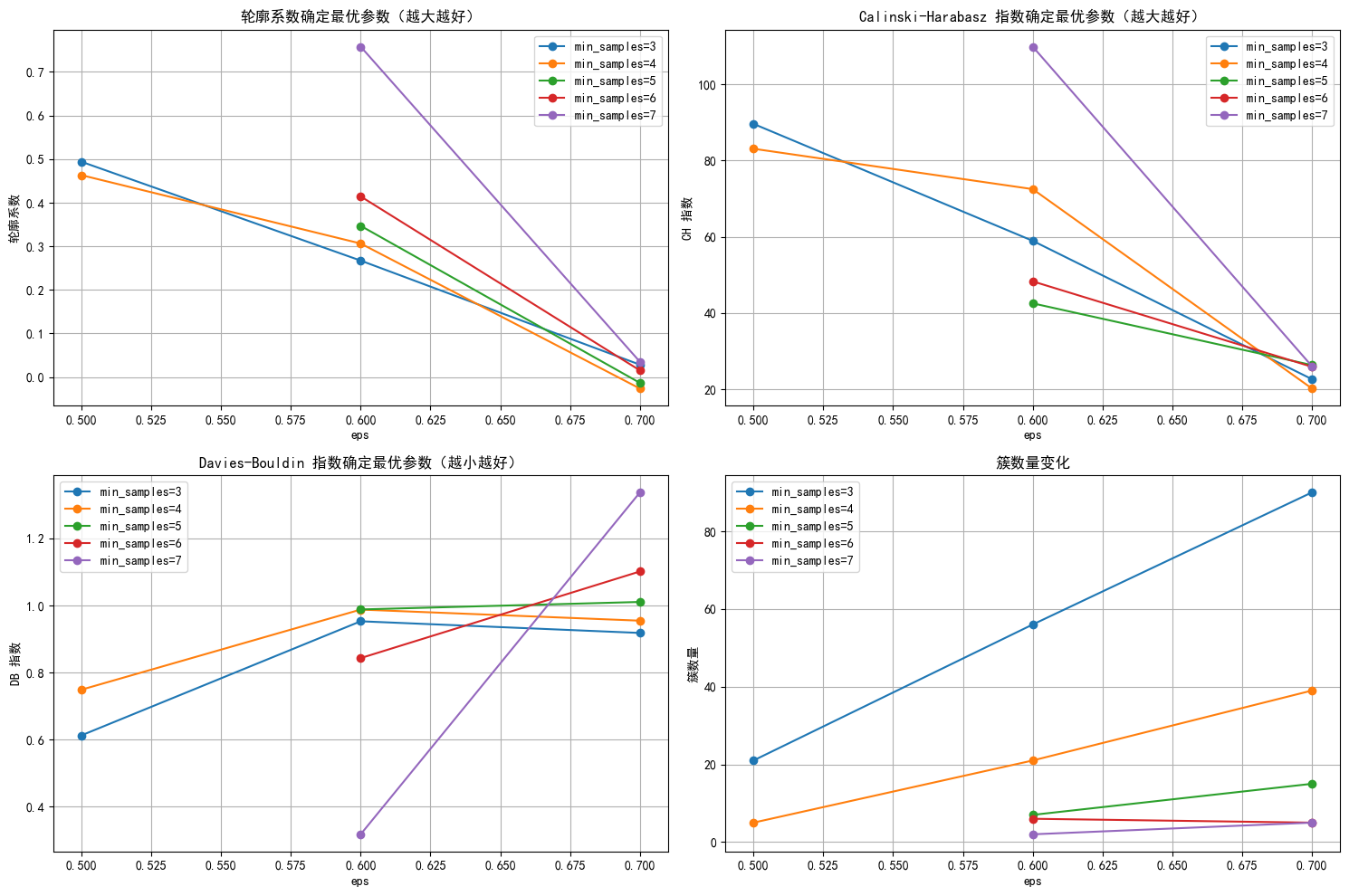
看图是eps=0.6, min_samples=7最佳,但将这个参数组合带入算法进行聚类之后分出来的簇只有两类,并且少数簇中的样本数很少,有点失败
3.层次聚类
层次聚类是一种自底向上的聚类方法,初始时每个样本是一个簇,然后逐步合并最相似的簇,直到达到指定的簇数量或满足停止条件,需要指定簇数量(类似于 KMeans)。就像"家族族谱生成器":
- 从每个人独立开始(每个样本是一个簇)
- 逐步合并最相似的两个人/家族(合并最近簇)
- 直到合并到指定数量的大家族(预设的n_clusters)
import numpy as np
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
import seaborn as sns# 评估不同 n_clusters 下的指标
n_clusters_range = range(2, 11) # 测试簇数量从 2 到 10
silhouette_scores = []
ch_scores = []
db_scores = []for n_clusters in n_clusters_range:agglo = AgglomerativeClustering(n_clusters=n_clusters, linkage='ward') # 使用 Ward 准则合并簇agglo_labels = agglo.fit_predict(X_scaled)# 计算评估指标silhouette = silhouette_score(X_scaled, agglo_labels)ch = calinski_harabasz_score(X_scaled, agglo_labels)db = davies_bouldin_score(X_scaled, agglo_labels)silhouette_scores.append(silhouette)ch_scores.append(ch)db_scores.append(db)print(f"n_clusters={n_clusters}, 轮廓系数: {silhouette:.3f}, CH 指数: {ch:.2f}, DB 指数: {db:.3f}")
# -------- 打印结果 ----------
n_clusters=2, 轮廓系数: 0.336, CH 指数: 685.66, DB 指数: 2.659
n_clusters=3, 轮廓系数: 0.242, CH 指数: 659.40, DB 指数: 2.327
n_clusters=4, 轮廓系数: 0.254, CH 指数: 565.74, DB 指数: 2.160
n_clusters=5, 轮廓系数: 0.276, CH 指数: 519.91, DB 指数: 2.110
n_clusters=6, 轮廓系数: 0.284, CH 指数: 494.24, DB 指数: 1.860
n_clusters=7, 轮廓系数: 0.295, CH 指数: 482.64, DB 指数: 1.680
n_clusters=8, 轮廓系数: 0.297, CH 指数: 479.17, DB 指数: 1.435
n_clusters=9, 轮廓系数: 0.301, CH 指数: 481.85, DB 指数: 1.283
n_clusters=10, 轮廓系数: 0.309, CH 指数: 489.27, DB 指数: 1.269# 绘制评估指标图
plt.figure(figsize=(15, 5))# 轮廓系数图
plt.subplot(1, 3, 1)
plt.plot(n_clusters_range, silhouette_scores, marker='o')
plt.title('轮廓系数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('轮廓系数')
plt.grid(True)# CH 指数图
plt.subplot(1, 3, 2)
plt.plot(n_clusters_range, ch_scores, marker='o')
plt.title('Calinski-Harabasz 指数确定最优簇数(越大越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('CH 指数')
plt.grid(True)# DB 指数图
plt.subplot(1, 3, 3)
plt.plot(n_clusters_range, db_scores, marker='o')
plt.title('Davies-Bouldin 指数确定最优簇数(越小越好)')
plt.xlabel('簇数量 (n_clusters)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()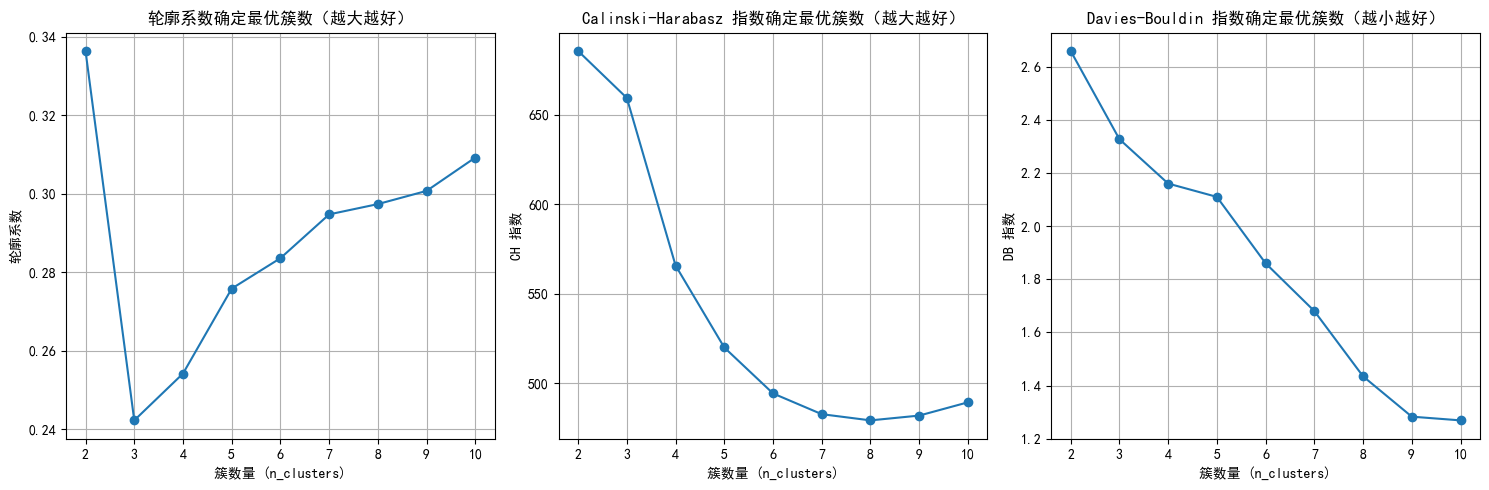
看图簇数就选10吧,带入聚类算法进行可视化
# 提示用户选择 n_clusters 值(这里可以根据图表选择最佳簇数)
selected_n_clusters = 10 # 示例值,根据图表调整# 使用选择的簇数进行 Agglomerative Clustering 聚类
agglo = AgglomerativeClustering(n_clusters=selected_n_clusters, linkage='ward')
agglo_labels = agglo.fit_predict(X_scaled)
X['Agglo_Cluster'] = agglo_labels# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# Agglomerative Clustering 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=agglo_labels, palette='viridis')
plt.title(f'Agglomerative Clustering with n_clusters={selected_n_clusters} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 Agglomerative Clustering 聚类标签的分布
print(f"Agglomerative Cluster labels (n_clusters={selected_n_clusters}) added to X:")
print(X[['Agglo_Cluster']].value_counts())
# ---------- 打印结果 -----------
Agglomerative Cluster labels (n_clusters=10) added to X:
Agglo_Cluster
4 5230
1 778
2 771
9 409
5 127
6 96
0 37
3 34
7 10
8 8
dtype: int64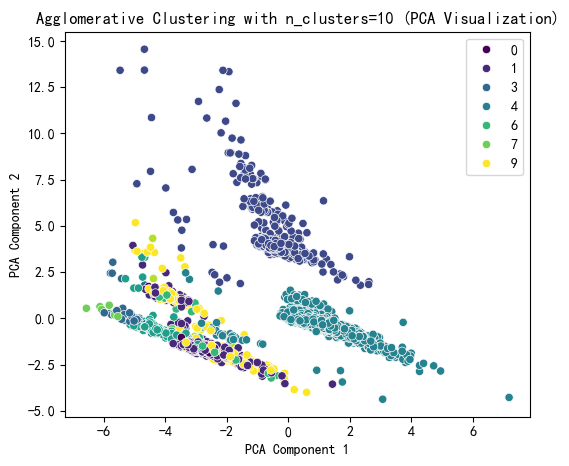
另外提一下,层次聚类还有另一种可视化方法-------树状图
# 层次聚类的树状图可视化
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt# 假设 X_scaled 是标准化后的数据
# 计算层次聚类的链接矩阵
Z = hierarchy.linkage(X_scaled, method='ward') # 'ward' 是常用的合并准则# 绘制树状图
plt.figure(figsize=(10, 6))
hierarchy.dendrogram(Z, truncate_mode='level', p=3) # p 控制显示的层次深度
# hierarchy.dendrogram(Z, truncate_mode='level') # 不用p这个参数,可以显示全部的深度
plt.title('Dendrogram for Agglomerative Clustering')
plt.xlabel('Cluster Size')
plt.ylabel('Distance')
plt.show()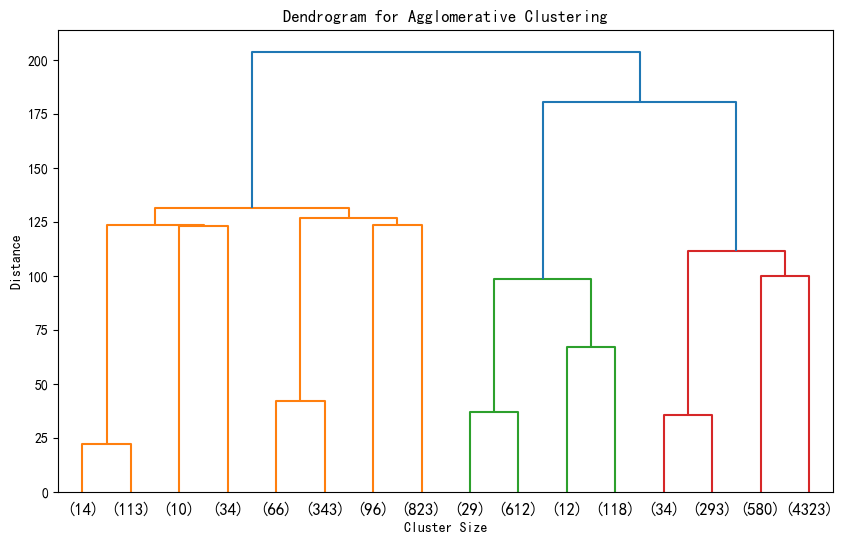
1. 横坐标代表每个簇对应样本的数据,这些样本数目加一起是整个数据集的样本数目。这是从上到下进行截断,p=3显示最后3层,不用p这个参数会显示全部。
2. 纵轴代表距离 ,反映了在聚类过程中,不同样本或簇合并时的距离度量值。距离越大,意味着两个样本或簇之间的差异越大;距离越小,则差异越小。
@浙大疏锦行
相关文章:

python打卡day17
聚类的基础知识 知识点 聚类的指标聚类常见算法:kmeans聚类、dbscan聚类、层次聚类三种算法对应的流程 实际在论文中聚类的策略不一定是针对所有特征,可以针对其中几个可以解释的特征进行聚类,得到聚类后的类别,这样后续进行解释也…...

洛谷---P1629 邮递员送信
题目描述 有一个邮递员要送东西,邮局在节点 1。他总共要送 n−1 样东西,其目的地分别是节点 2 到节点 n。由于这个城市的交通比较繁忙,因此所有的道路都是单行的,共有 m 条道路。这个邮递员每次只能带一样东西,并且运…...
)
第11次:用户注册(简要版)
1、定义模板 在templates文件夹下边新建register.html,代码如下: <html lang"en"> <head><meta charset"UTF-8"><title>注册</title> </head> <body><!--{%是模板标签, …...

【IP101】图像特征提取技术:从传统方法到深度学习的完整指南
🌟 特征提取魔法指南 🎨 在图像处理的世界里,特征提取就像是寻找图像的"指纹",让我们能够识别和理解图像的独特性。让我们一起来探索这些神奇的特征提取术吧! 📚 目录 基础概念 - 特征的"体…...

对windows的简单介绍
目录 一、Windows 操作系统概述 1. 定义与定位 2. 核心目标 二、历史与版本演变 1. 早期阶段(1985–1995) 2. NT 内核时代(1996–2009) 3. 现代操作系统(2012–至今) 三、系统架构与技术特性 1. 内…...
生产进度)
Waymo公司正在加快其位于亚利桑那州新工厂的无人驾驶出租车(robotaxi)生产进度
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
)
JavaSE核心知识点01基础语法01-03(流程控制:顺序、分支、循环)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点01基础语法01-03࿰…...

信息论01:从通信到理论的飞跃
信息论01:从通信到理论的飞跃 1. 信息论的诞生与发展 1.1 前信息论时代(1920s之前) 信息与消息的混淆:传统认知中将信息等同于消息本身先驱者奠基: 哈里奈奎斯特 (1924):提出《影响电报速度的某些因素》…...

Pandas 的透视与逆透视
目录 1. 透视 1.1 pivot 1.2 pivot_table 2.逆透视 1. 透视 透视是长表变宽表。 pivot() 和 pivot_table()两个函数都可以做到,后者可以聚合前者不行。 特性df.pivot()df.pivot_table()重复值处理要求索引和列的组合唯一,否则报错 ValueError允许…...

AI大模型驱动的智能座舱研发体系重构
随着AI大模型(如LLM、多模态模型)的快速发展,传统智能座舱研发流程面临巨大挑战。传统座舱研发以需求驱动、功能固定、架构封闭为特点,而AI大模型的引入使得座舱系统向自主决策、动态适应、持续进化的方向发展。 因此思考并提出一…...

【东枫科技】代理英伟达产品:DPU
NVIDIA BlueField-3 DPU 400Gb/s 基础设施计算平台 NVIDIA BlueField -3 数据处理单元 (DPU) 是第三代基础设施计算平台,使企业能够构建从云端到核心数据中心再到边缘的软件定义、硬件加速的 IT 基础设施。借助 400Gb/s 以太网或 NDR 400Gb/s InfiniBand 网络连接…...

【KWDB 创作者计划】一文掌握KWDB的时序表管理
前言 本文是在对时序数据库有一定了解,并且KWDB的数据库操作了解后进行学习的文章安排,如果对时序数据库与KWDB的数据库操作还不怎么了解的可以查阅官网的文档进行提前学习,当有了这些基础后,本文就是对时序数据表的一个管理操作…...
》阅读笔记:p9-p9)
《算法导论(第4版)》阅读笔记:p9-p9
《算法导论(第4版)》学习第 6 天,p9-p9 总结,总计 1 页。 一、技术总结 1. data structure A data structure is a way to store and organize data in order to facilitate access and modifications(数据结构是一种存储和组织数据的方式,…...

Facebook隐私保护措施的优缺点解析
在这个数字化的时代,隐私保护已成为公众关注的热点话题。Facebook,作为全球最大的社交媒体平台之一,其隐私保护措施自然也受到了广泛的关注和讨论。本文将对Facebook的隐私保护措施进行解析,探讨其优点与缺点,并探讨如…...

深入了解linux系统—— 进程地址空间
前言 程序地址空间 在之前,我们学习C/C时,多多少少都看过这样的一张图 我们现在通过下面这一段代码看一下: #include <stdio.h> #include <unistd.h> #include <stdlib.h> int g_unval; int g_val 100; int main(int…...

电动加长杆金属硬密封法兰式蝶阀泄漏等级解析:水、蒸汽、油品介质的可靠选择-耀圣
电动加长杆金属硬密封法兰式蝶阀泄漏等级解析:水、蒸汽、油品介质的可靠选择 在工业流体控制领域,电动金属硬密封蝶阀凭借其卓越的密封性能和耐高温高压特性,成为水、蒸汽、油品等介质的核心控制设备。其泄漏等级作为衡量阀门性能的关键指标…...

win11共享打印机主机设置
1.首先打开设置,选择打印机和扫描仪点击打印机属性,将共享窗口的共享这台打印机和在客户端计算机上呈现打印作业这两项勾选上。 2.通过cmd命令 gpedit.msc 打开本地组策略编辑器。 3.网络访问选择仅来宾 4.将账户来宾状态选择启用 5.将拒绝从网络访问这台…...
查看流程办理进度图)
Flowable7.x学习笔记(二十)查看流程办理进度图
前言 本文是基于继承Flowable的【DefaultProcessDiagramCanvas】和【DefaultProcessDiagramGenerator】实现的自定义流程图生成器,通过自定义流程图生成器可以灵活的指定已经执行过的节点和当前正在活跃的节点样式,比如说已经执行完成的节点我们标绿&…...

【计算机网络 第8版】谢希仁编著 第四章网络层 地址类题型总结
小结 个人觉得地址类在网络层算好做的题,这部分知识本身并不多,理解到位了就是2进制和10进制的换算题了。而且这种题给你一小时例题和标答,肯定自己都能悟出来。但是计网网络层的整体我感觉很散,老师讲的也乱七八糟的,…...
的CT重建算法)
一种基于条件生成对抗网络(cGAN)的CT重建算法
简介 简介:该文提出了一种基于条件生成对抗网络(cGAN)的CT重建算法,通过引入CBAM注意力机制增强网络对关键特征的提取能力,有效解决了CT成像中因噪声干扰导致的重建精度下降问题。实验采用固体火箭发动机模拟件数据集,将正弦图分为五组并添加不同程度的噪声进行训练。结…...
上部署OpenStack的完整指南 ——基于Yoga版本的全流程实践)
欧拉系统(openEuler)上部署OpenStack的完整指南 ——基于Yoga版本的全流程实践
(资源区里有上传的配置好的openstack镜像) 一、环境规划与前置准备 1. 硬件与节点规划升级 存储节点(可选):若需Cinder后端,建议配置SSDHDD混合存储网络拓扑强化: 管理网络:启用V…...

oceanbase不兼容SqlSugarCore的问题
问题发现 C#程序使用SqlSugarCore5.1.4.166进行数据库操作,而且项目需要在多台服务器上面部署,结果发现A服务器部署运行没有问题, B服务器部署却报错:SqlSugar.SqlSugarException:Connect timeout expired. 但是我们的C#代码是一…...

深入理解分布式锁——以Redis为例
一、分布式锁简介 1、什么是分布式锁 分布式锁是一种在分布式系统环境下,通过多个节点对共享资源进行访问控制的一种同步机制。它的主要目的是防止多个节点同时操作同一份数据,从而避免数据的不一致性。 线程锁: 也被称为互斥锁(…...
1 - 搭建环境)
OrangePi Zero 3学习笔记(Android篇)1 - 搭建环境
目录 1. 下载安装Ubuntu22.04 1.1 安装增强功能 1.2 设置共享文件夹 1.3 创建AOSP.vdi 1.4 更新相关软件包 2. 解压AOSP源代码 3. 编译代码 3.1 编译uboot/Linux 3.2 编译AOSP源代码 3.3 内存问题调试记录 3.3.1 查看具体什么问题 3.3.2 关闭dex2oat(无…...
)
RabbitMq(尚硅谷)
RabbitMq 1.RabbitMq异步调用 2.work模型 3.Fanout交换机(广播模式) 4.Diret交换机(直连) 5.Topic交换机(主题交换机,通过路由匹配) 6.Headers交换机(头交换机) 6…...

OpenAI的“四面楚歌”:从营利到非营利,一场关于AGI控制权的革命
引言 当“奥特曼妥协”与“四面楚歌”并置时,OpenAI的这次重大调整,仿佛在科技史上投下一颗震撼弹。这家曾因“拒绝盈利”而备受争议的人工智能公司,如今却在资本与理想之间艰难抉择——放弃营利性转型,回归非营利初心。这不仅是对…...

[250505] Arch Linux 正式登陆 Linux 的 Windows 子系统
目录 Arch Linux 正式登陆 Windows Subsystem for Linux (WSL) Arch Linux 正式登陆 Windows Subsystem for Linux (WSL) Arch Linux 社区与 Microsoft 合作,正式宣布 Arch Linux 现已提供官方的 Windows Subsystem for Linux (WSL) 镜像。这意味着 Windows 用户现…...

MySQL 日期格式化:DATE_FORMAT 函数用法
MySQL 日期格式化:DATE_FORMAT 函数用法 在 MySQL 中,DATE_FORMAT() 函数用于将日期或时间值格式化为指定的字符串格式。 正确语法 DATE_FORMAT(date, format)常用格式说明符 说明符描述%Y四位数的年份(例如:2023)…...

java springboot解析出一个图片的多个二维码
引入 <dependencies><!-- ZXing --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.4.1</version></dependency><dependency><groupId>com.google.zxing…...
)
【四川省专升本计算机基础】第一章 计算机基础知识(上)
前言 对计算机专业的同学来说这门课程可能很简单,容易拿高分(125分以上),但也可能很容易大意丢分。因为本门课程人称:背多分。大意丢分者的心态觉得计算机基础都学过,内容很简单,最后才开始背计…...

406错误,WARN 33820 --- [generator] [nio-8080-exec-4] .w.s.m.s.DefaultHa
在接口调用过程中,后端出现.w.s.m.s.DefaultHandlerExceptionResolver : Resolved [org.springframework.web.HttpMediaTypeNotAcceptableException: No acceptable representation]错误。检查了一个小时才发现我返回的对象没有写getter方法, 当Spring B…...

基于STM32、HAL库的SST26VF064B NOR FLASH存储器驱动应用程序设计
一、简介: SST26VF064B是Microchip公司生产的一款64Mbit(8MB)串行闪存器件,采用SPI接口通信,具有以下特点: 工作电压:2.7-3.6V 最高104MHz时钟频率 统一4KB扇区结构 快速擦除和编程时间 低功耗特性 支持标准SPI、Dual SPI和Quad SPI模式 二、硬件接口: STM32L4引脚SST26V…...

美信监控易:全栈式自主可控的底层架构优势
在当今数字化时代,企业的运维管理面临着越来越多的挑战。为了确保业务的稳定运行,企业需要一款高效、可靠的运维管理软件。北京美信时代的美信监控易运维管理软件,以其全栈式自主可控的底层架构优势,成为了运维团队的理想选择。 …...

Class AB OPA corner 仿真,有些corenr相位从0开始
Class AB OPA做 STB 仿真时,会遇到有些corner(c0_0、c0_4、c0_5)相位从0开始的情况。 首先应该去检查电路,电路里是否有正反馈;排除没有正反馈后,考虑是图中的红框中的线性跨导环中的Vds 太大导致了碰撞电离导致的。 查找了网上…...

【JEECG】BasicTable单元格编辑,插槽添加下拉组件样式错位
1.功能说明 BasicTable表格利用插槽,添加组件实现单元格编辑功能,选择组件下拉框错位 2.效果展示 3.解决方案 插槽内组件增加::getPopupContainer"getPopupContainer" <template #salesOrderProductStatus"{ column, re…...

第十五届蓝桥杯单片机国赛-串口解析
串口通信像是蓝桥杯单片机组国赛中一个若隐若现的秘境,总在不经意间为勇者们敞开大门。然而,初次探索这片领域的冒险者,常常会被其神秘莫测的特性所震慑,黯然退场(编不下去了,直接进入正题)。 附…...

Flutter开发HarmonyOS实战-鸿蒙App商业项目
Flutter开发HarmonyOS实战内容介绍: Flutter开发HarmonyOS 鸿蒙App商业项目(小米商城APP)实战视频教程 Flutter开发鸿蒙APP是在《FlutterGetx仿小米商城》项目基础之上讲解的,调试Flutter HarmonyOS应用需要有HarmonyOS Next的手机…...

【回眸】香橙派Zero2 超声波模块测距控制SG90舵机转动
前言 知识准备 超声波模块时序图 gettimeofday()函数作用 gettimeofday()函数原型 tv结构体 获取当前系统时间与格林威治时间的时间差 获取香橙派数10万秒花费的时间 使用超声波模块获取到障碍物距离 SG90舵机模块 舵机模块的作用 舵机模块方波时序图 舵机模块工作原…...

RabbitMQ 添加新用户和配置权限
以下是关于使用 sudo rabbitmqctl add_user 命令创建新用户的详细示例,同时包含创建用户后进行权限设置、角色设置等相关操作的示例。 1. 前提条件 确保你的 RabbitMQ 服务已经正常运行,并且你具有执行 sudo 命令的权限。 2. 创建新用户 假设我们要创…...

【前缀和】矩阵区域和
文章目录 1314. 矩阵区域和解题思路1314. 矩阵区域和 1314. 矩阵区域和 给你一个 m x n 的矩阵 mat 和一个整数 k ,请你返回一个矩阵 answer ,其中每个 answer[i][j] 是所有满足下述条件的元素 mat[r][c] 的和: i - k <= r <= i + k, j - k <= c <= j + k …...

编程日志4.25
栈的stl模板 可直接用<stack>库进行调用 #include<iostream> #include<stack>//栈的模板库 using namespace std; int main() { stack<int> intStk;//整数 栈 stack<double> doubleStk;//浮点数 栈 intStk.push(1); intStk.pu…...

【中间件】brpc之工作窃取队列
文章目录 BRPC Work Stealing Queue1 核心功能2 关键数据结构2.1 队列结构2.2 内存布局优化 3 核心操作3.1 本地线程操作(非线程安全)3.2 窃取操作(线程安全) 4 设计亮点4.1 无锁原子操作4.2 环形缓冲区优化4.3 线程角色分离 5 性…...

用OMS从MySQL迁移到OceanBase,字符集utf8与utf8mb4的差异
一、问题背景 在一次从MySQL数据库迁移到OceanBase的MySQL租户过程中,出现了一个转换提示: [WARN][CONVER] he table charset:utf8->utf8mb4, 你可能会担心这种转换可能导致字符集不兼容的问题。但通过查阅相关资料可知,utf8m…...

知乎前端面试题及参考答案
Webpack 和 Vite 的区别是什么? 构建原理: Webpack 是基于传统的打包方式,它会将所有的模块依赖进行分析,然后打包成一个或多个 bundle。在开发过程中,当代码发生变化时,需要重新构建整个项目,构建速度会随着项目规模的增大而变慢。Vite 利用了浏览器对 ES 模块的支持,…...

项目中为什么选择RabbitMQ
当被问及为什么选择某种技术时,应该结合开发中的实际情况以及类似的技术进行分析,适合的技术才是最好的。 在项目中为什么选择RabbitMQ 作为消息中间件,主要可以基于以下几方面进行分析: 1. 可靠性 消息持久化:Rabbi…...

深入解析二维矩阵搜索:LeetCode 74与240题的两种高效解法对比
文章目录 [toc]**引言** **一、问题背景与排序规则对比****1. LeetCode 74. 搜索二维矩阵****2. LeetCode 240. 搜索二维矩阵 II** **二、核心解法对比****方法1:二分查找法(适用于LeetCode 74)****方法2:线性缩小搜索范围法&…...

Qt案例 以单线程或者单生产者多消费者设计模式实现QFTP模块上传文件夹功能
前文:Qt案例 使用QFtpServerLib开源库实现Qt软件搭建FTP服务器,使用QFTP模块访问FTP服务器 已经介绍了Qt环境下搭建FTP服务器或者使用QFTP上传的方式示例, 这里主要介绍下使用QFTP模块上传整个文件夹的案例示例。 目录导读 前因后果单线程处理1.定义FTPFolderUpload 继承 QT…...

含锡废水回收率提升技术方案
一、预处理环节优化 物理分离强化 采用双层格栅系统(孔径1mm0.5mm)拦截悬浮物,配套旋流分离器去除密度>2.6g/cm的金属颗粒,使悬浮物去除率提升至85%。增设pH值智能调节模块,通过在线pH计联动碳酸钠/氢氧化钠投加系…...
)
第八章,STP(生成树协议)
广播风暴----广播帧在二层环路中形成逆时针或顺时针的转动的环路,并且无限循环,最终导致设备宕机,网络瘫痪。 MAC地址表的翻摆(漂移)----同一个数据帧,顺时针接收后将记录MAC地址及接口的对应信息ÿ…...

《面向对象程序设计-C++》实验五 虚函数的使用及抽象类
程序片段编程题 1.【问题描述】 基类shape类是一个表示形状的抽象类,area( )为求图形面积的函数。请从shape类派生三角形类(triangle)、圆类(circles)、并给出具体的求面积函数。注:圆周率取3.14 #include<iostream> #in…...