基于计算机视觉的试卷答题区表格识别与提取技术
基于计算机视觉的试卷答题区表格识别与提取技术
摘要
本文介绍了一种基于计算机视觉技术的试卷答题区表格识别与提取算法。该算法能够自动从试卷图像中定位答题区表格,执行图像方向矫正,精确识别表格网格线,并提取每个答案单元格。本技术可广泛应用于教育测评、考试管理系统等场景,极大提高答卷处理效率。
关键技术
- 表格区域提取与分割
- 图像二值化预处理
- 多尺度形态学操作
- 水平线与竖线精确检测
- 单元格定位与提取
1. 系统架构
我们设计的试卷答题区表格处理工具由以下主要模块组成:
- 答题区定位:从整张试卷图像中提取右上角的答题区表格
- 图像预处理:进行二值化、去噪等操作以增强表格线条
- 表格网格识别:精确检测水平线和竖线位置
- 单元格提取:根据网格线交点切割并保存各个答案单元格
处理流程:
输入图像 -> 答题区定位 -> 方向矫正 -> 图像预处理 ->
网格线检测 -> 单元格提取 -> 输出结果
2. 核心功能实现
2.1 答题区表格定位
我们假设答题区通常位于试卷右上角,首先提取该区域并应用轮廓检测算法:
# 提取右上角区域(答题区域通常在试卷右上角)
x_start = int(width * 0.6)
y_start = 0
w = width - x_start
h = int(height * 0.5)# 提取区域
region = img[y_start:y_start + h, x_start:x_start + w]
接着使用形态学操作提取线条并查找表格轮廓:
# 转为灰度图并二值化
gray = cv2.cvtColor(region, cv2.COLOR_BGR2GRAY)
binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY_INV, 11, 2)# 使用形态学操作检测线条
horizontal_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_h, iterations=2)
vertical_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_v, iterations=2)
2.2 图像预处理
为了增强表格线条特征,我们执行以下预处理步骤:
# 高斯平滑去噪
blurred = cv2.GaussianBlur(gray, (5, 5), 0)# 自适应阈值二值化
binary = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 21, 5)# 形态学操作填充小空隙
kernel = np.ones((3, 3), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)
2.3 表格网格线识别
这是本算法的核心部分,我们分别检测水平线和竖线:
2.3.1 水平线检测
使用形态学开运算提取水平线,然后计算投影找到线条位置:
horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (horizontal_size, 1))
horizontal_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, horizontal_kernel, iterations=2)# 提取水平线坐标 - 基于行投影
h_coords = []
h_projection = np.sum(horizontal_lines, axis=1)
for i in range(1, len(h_projection) - 1):if h_projection[i] > h_projection[i - 1] and h_projection[i] > h_projection[i + 1] and h_projection[i] > width // 5:h_coords.append(i)
2.3.2 竖线检测
竖线检测采用多尺度策略,使用不同大小的结构元素,提高检测的鲁棒性:
# 使用不同大小的结构元素进行竖线检测
vertical_kernels = [cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 12)), # 细线cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 8)), # 中等cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 4)) # 粗线
]# 合并不同尺度的检测结果
vertical_lines = np.zeros_like(binary_image)
for kernel in vertical_kernels:v_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, kernel, iterations=1)vertical_lines = cv2.bitwise_or(vertical_lines, v_lines)
2.4 表格竖线位置精确校正
由于竖线检测可能存在偏左问题,我们实现了复杂的位置校正算法:
# 竖线位置修正:解决偏左问题 - 检测实际线条中心位置
v_coords_corrected = []
for idx, v_coord in enumerate(v_coords_detected):# 第2-11根竖线特殊处理if 1 <= idx <= 10: # 第2-11根竖线search_range_left = 2 # 左侧搜索范围更小search_range_right = 12 # 右侧搜索范围大幅增大else:search_range_left = 5search_range_right = 5# 在搜索范围内找到峰值中心位置# 对于特定竖线,使用加权平均来偏向右侧if 1 <= idx <= 10:window = col_sum[left_bound:right_bound+1]weights = np.linspace(0.3, 2.0, len(window)) # 更强的右侧权重weighted_window = window * weightsmax_pos = left_bound + np.argmax(weighted_window)# 强制向右偏移max_pos += 3else:max_pos = left_bound + np.argmax(col_sum[left_bound:right_bound+1])
2.4.1 不等间距网格处理
我们根据实际表格特点,处理了第一列宽度与其他列不同的情况:
# 设置第一列的宽度为其他列的1.3倍
first_column_width_ratio = 1.3# 计算除第一列外每列的宽度
remaining_width = right_bound - left_bound
regular_column_width = remaining_width / (expected_vlines - 1 + (first_column_width_ratio - 1))
2.5 单元格提取与保存
根据检测到的网格线,我们提取出每个单元格:
# 提取单元格的过程
cell_img = image[y1_m:y2_m, x1_m:x2_m].copy()# 保存单元格图片
cell_filename = f'cell_0{q_num:02d}.png'
cell_path = os.path.join(output_dir, cell_filename)
cv2.imwrite(cell_path, cell_img)
3. 技术创新点
- 多尺度形态学操作:使用不同尺寸的结构元素检测竖线,提高了检测的鲁棒性
- 表格线位置动态校正:针对不同位置的竖线采用不同的校正策略,解决了竖线偏左问题
- 不等间距网格处理:通过特殊计算处理第一列宽度不同的情况,更好地适应实际试卷样式
- 加权峰值搜索:使用加权策略进行峰值搜索,提高了线条中心位置的准确性
4. 使用示例
4.1 基本用法
from image_processing import process_image# 处理单张图像
input_image = "./images/1.jpg"
output_dir = "./output"
image_paths = process_image(input_image, output_dir)print(f"处理成功: 共生成{len(image_paths)}个单元格图片")
4.2 批量处理
我们还提供了批量处理多张试卷图像的功能:
# 批量处理目录中的所有图像
for img_file in image_files:img_path = os.path.join(images_dir, img_file)output_dir = os.path.join(output_base_dir, f"result_{img_name}")image_paths = process_image(img_path, output_dir)
4.3 完整代码
"""
试卷答题区表格处理工具
1. 从试卷提取答题区表格
2. 对表格进行方向矫正
3. 切割表格单元格并保存所有25道题的答案单元格
"""
import os
import cv2
import numpy as np
import argparse
import sys
import time
import shutilclass AnswerSheetProcessor:"""试卷答题区表格处理工具类"""def __init__(self):"""初始化处理器"""passdef process(self, input_image_path, output_dir):"""处理试卷答题区,提取表格并保存单元格Args:input_image_path: 输入图像路径output_dir: 输出单元格图像的目录Returns:处理后的图片路径列表,失败时返回空列表"""os.makedirs(output_dir, exist_ok=True)temp_dir = os.path.join(os.path.dirname(output_dir), f"temp_{time.strftime('%Y%m%d_%H%M%S')}")os.makedirs(temp_dir, exist_ok=True)try:# 1. 提取答题区表格table_img, _ = self._extract_answer_table(input_image_path, temp_dir)if table_img is None:print("无法提取答题区表格")return []# 保存提取的原始表格图像# original_table_path = os.path.join(output_dir, "original_table.png")# cv2.imwrite(original_table_path, table_img)# 2. 矫正表格方向corrected_table = self._correct_table_orientation(table_img)# cv2.imwrite(os.path.join(output_dir, "corrected_table.png"), corrected_table)# 3. 提取表格单元格image_paths = self._process_and_save_cells(corrected_table, temp_dir, output_dir)# 4. 清理临时目录shutil.rmtree(temp_dir, ignore_errors=True)return image_pathsexcept Exception as e:print(f"处理失败: {str(e)}")shutil.rmtree(temp_dir, ignore_errors=True)return []def _extract_answer_table(self, image, output_dir):"""提取试卷答题区表格"""# 读取图像if isinstance(image, str):img = cv2.imread(image)if img is None:return None, Noneelse:img = image# 调整图像大小以提高处理速度max_width = 1500if img.shape[1] > max_width:scale = max_width / img.shape[1]img = cv2.resize(img, None, fx=scale, fy=scale)# 获取图像尺寸height, width = img.shape[:2]# 提取右上角区域(答题区域通常在试卷右上角)x_start = int(width * 0.6)y_start = 0w = width - x_starth = int(height * 0.5)# 提取区域region = img[y_start:y_start + h, x_start:x_start + w]# 转为灰度图并二值化gray = cv2.cvtColor(region, cv2.COLOR_BGR2GRAY)binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY_INV, 11, 2)# 检测表格线kernel_h = cv2.getStructuringElement(cv2.MORPH_RECT, (max(25, w // 20), 1))kernel_v = cv2.getStructuringElement(cv2.MORPH_RECT, (1, max(25, h // 20)))horizontal_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_h, iterations=2)vertical_lines = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel_v, iterations=2)# 合并线条grid_lines = cv2.add(horizontal_lines, vertical_lines)# 膨胀线条kernel = np.ones((3, 3), np.uint8)dilated_lines = cv2.dilate(grid_lines, kernel, iterations=1)# 查找轮廓contours, _ = cv2.findContours(dilated_lines, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 筛选可能的表格轮廓valid_contours = []for contour in contours:x, y, w, h = cv2.boundingRect(contour)area = cv2.contourArea(contour)if area < 1000:continueaspect_ratio = float(w) / h if h > 0 else 0if 0.1 <= aspect_ratio <= 3.0:valid_contours.append((x, y, w, h, area))if valid_contours:# 选择面积最大的轮廓valid_contours.sort(key=lambda c: c[4], reverse=True)x, y, w, h, _ = valid_contours[0]# 调整回原图坐标x_abs = x_start + xy_abs = y_start + y# 提取表格区域并加一些padding确保完整padding = 10x_abs = max(0, x_abs - padding)y_abs = max(0, y_abs - padding)w_padded = min(width - x_abs, w + 2 * padding)h_padded = min(height - y_abs, h + 2 * padding)table_region = img[y_abs:y_abs + h_padded, x_abs:x_abs + w_padded]return table_region, (x_abs, y_abs, w_padded, h_padded)# 如果未找到有效轮廓,返回预估区域x_start = int(width * 0.75)y_start = int(height * 0.15)w = int(width * 0.2)h = int(height * 0.4)x_start = max(0, min(x_start, width - 1))y_start = max(0, min(y_start, height - 1))w = min(width - x_start, w)h = min(height - y_start, h)return img[y_start:y_start + h, x_start:x_start + w], (x_start, y_start, w, h)def _correct_table_orientation(self, table_img):"""矫正表格方向(逆时针旋转90度)"""if table_img is None:return Nonetry:return cv2.rotate(table_img, cv2.ROTATE_90_COUNTERCLOCKWISE)except Exception as e:print(f"表格方向矫正失败: {str(e)}")return table_imgdef _process_and_save_cells(self, table_img, temp_dir, output_dir):"""处理表格并保存单元格"""try:# 预处理图像binary = self._preprocess_image(table_img)# cv2.imwrite(os.path.join(output_dir, "binary_table.png"), binary)# 检测表格网格h_lines, v_lines = self._detect_table_cells(binary, table_img.shape, output_dir)# 如果未检测到足够的网格线if len(h_lines) < 2 or len(v_lines) < 2:print("未检测到足够的表格线")return []# 可视化并保存表格网格self._visualize_grid(table_img, h_lines, v_lines, output_dir)# 提取并直接保存单元格image_paths = self._extract_and_save_cells(table_img, h_lines, v_lines, output_dir)return image_pathsexcept Exception as e:print(f"表格处理错误: {str(e)}")return []def _preprocess_image(self, image):"""表格图像预处理"""if image is None:return None# 转为灰度图if len(image.shape) == 3:gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)else:gray = image.copy()# 高斯平滑blurred = cv2.GaussianBlur(gray, (5, 5), 0)# 自适应阈值二值化binary = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 21, 5)# 进行形态学操作,填充小空隙kernel = np.ones((3, 3), np.uint8)binary = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)return binarydef _detect_table_cells(self, binary_image, image_shape, output_dir):"""检测表格网格,基于图像真实表格线精确定位"""height, width = image_shape[:2]# 1. 先检测水平线horizontal_size = width // 10horizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (horizontal_size, 1))horizontal_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, horizontal_kernel, iterations=2)# 提取水平线坐标h_coords = []h_projection = np.sum(horizontal_lines, axis=1)for i in range(1, len(h_projection) - 1):if h_projection[i] > h_projection[i - 1] and h_projection[i] > h_projection[i + 1] and h_projection[i] > width // 5:h_coords.append(i)# 使用聚类合并相近的水平线h_coords = self._cluster_coordinates(h_coords, eps=height // 30)# 2. 确保我们至少有足够的水平线定义表格区域if len(h_coords) < 2:print("警告: 水平线检测不足,无法确定表格范围")h_lines = [(0, int(y), width, int(y)) for y in h_coords]v_lines = []return h_lines, v_lines# 获取表格垂直范围h_coords.sort()table_top = int(h_coords[0])table_bottom = int(h_coords[-1])# 3. 增强竖线检测 - 使用多尺度检测策略# 使用不同大小的结构元素进行竖线检测vertical_kernels = [cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 12)), # 细线cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 8)), # 中等cv2.getStructuringElement(cv2.MORPH_RECT, (1, (table_bottom - table_top) // 4)) # 粗线]# 合并不同尺度的检测结果vertical_lines = np.zeros_like(binary_image)for kernel in vertical_kernels:v_lines = cv2.morphologyEx(binary_image, cv2.MORPH_OPEN, kernel, iterations=1)vertical_lines = cv2.bitwise_or(vertical_lines, v_lines)# 只关注表格区域内的竖线table_region_v = vertical_lines[table_top:table_bottom, :]# 计算列投影col_sum = np.sum(table_region_v, axis=0)# 4. 更精准地寻找竖线位置# 使用自适应阈值计算local_max_width = width // 25 # 更精细的局部最大值搜索窗口threshold_ratio = 0.15 # 降低阈值以捕获更多可能的竖线# 自适应阈值计算threshold = np.max(col_sum) * threshold_ratio# 扫描所有列查找峰值v_coords_raw = []i = 0while i < len(col_sum):# 查找局部范围内的峰值local_end = min(i + local_max_width, len(col_sum))local_peak = i# 找到局部最大值for j in range(i, local_end):if col_sum[j] > col_sum[local_peak]:local_peak = j# 如果局部最大值大于阈值,认为是竖线if col_sum[local_peak] > threshold:v_coords_raw.append(local_peak)# 跳过已处理的区域i = local_peak + local_max_width // 2else:i += 1# 5. 去除过于接近的竖线(可能是同一条线被重复检测)v_coords_detected = self._cluster_coordinates(v_coords_raw, eps=width // 50) # 使用更小的合并阈值# 6. 检查找到的竖线数量expected_vlines = 15 # 预期应有15条竖线print(f"初步检测到竖线数量: {len(v_coords_detected)}")# 7. 处理识别结果if len(v_coords_detected) > 0:# 7.1 获取表格的左右边界v_coords_detected.sort() # 确保按位置排序# 竖线位置修正:解决偏左问题 - 检测实际线条中心位置v_coords_corrected = []for idx, v_coord in enumerate(v_coords_detected):# 在竖线坐标附近寻找准确的线条中心# 对于第2-11根竖线,使用更大的搜索范围向右偏移if 1 <= idx <= 10: # 第2-11根竖线search_range_left = 2 # 左侧搜索范围更小search_range_right = 12 # 右侧搜索范围大幅增大else:search_range_left = 5search_range_right = 5left_bound = max(0, v_coord - search_range_left)right_bound = min(width - 1, v_coord + search_range_right)if left_bound < right_bound and left_bound < len(col_sum) and right_bound < len(col_sum):# 在搜索范围内找到峰值中心位置# 对于第2-11根竖线,使用加权平均来偏向右侧if 1 <= idx <= 10:# 计算加权平均,右侧权重更大window = col_sum[left_bound:right_bound+1]weights = np.linspace(0.3, 2.0, len(window)) # 更强的右侧权重weighted_window = window * weightsmax_pos = left_bound + np.argmax(weighted_window)# 强制向右偏移2-3像素max_pos += 3max_pos = min(right_bound, max_pos)else:max_pos = left_bound + np.argmax(col_sum[left_bound:right_bound+1])v_coords_corrected.append(max_pos)else:v_coords_corrected.append(v_coord)# 使用修正后的坐标v_coords_detected = v_coords_correctedleft_bound = v_coords_detected[0] # 最左边的竖线right_bound = v_coords_detected[-1] # 最右边的竖线# 7.2 计算理想的等距离竖线位置,但使第一列宽度比其他列宽ideal_vlines = []# 设置第一列的宽度为其他列的1.5倍first_column_width_ratio = 1.3# 计算除第一列外每列的宽度remaining_width = right_bound - left_boundregular_column_width = remaining_width / (expected_vlines - 1 + (first_column_width_ratio - 1))# 设置第一列ideal_vlines.append(int(left_bound))# 设置第二列位置ideal_vlines.append(int(left_bound + regular_column_width * first_column_width_ratio))# 设置剩余列for i in range(2, expected_vlines):ideal_vlines.append(int(left_bound + regular_column_width * (i + (first_column_width_ratio - 1))))# 7.3 使用修正后的列位置v_coords = ideal_vlines# 进一步向右偏移第2-11根竖线(总共15根)for i in range(1, 11):if i < len(v_coords):v_coords[i] += 3 # 向右偏移3像素else:# 如果没有检测到竖线,使用预估等距离print("未检测到任何竖线,使用预估等距离")left_bound = width // 10right_bound = width * 9 // 10# 计算除第一列外每列的宽度first_column_width_ratio = 1.5remaining_width = right_bound - left_boundregular_column_width = remaining_width / (expected_vlines - 1 + (first_column_width_ratio - 1))# 设置列位置v_coords = []v_coords.append(int(left_bound))v_coords.append(int(left_bound + regular_column_width * first_column_width_ratio))for i in range(2, expected_vlines):v_coords.append(int(left_bound + regular_column_width * (i + (first_column_width_ratio - 1))))# 8. 检验最终的竖线位置是否合理if len(v_coords) == expected_vlines:# 计算相邻竖线间距spacings = [v_coords[i + 1] - v_coords[i] for i in range(len(v_coords) - 1)]avg_spacing = sum(spacings[1:]) / len(spacings[1:]) # 不计入第一列的宽度# 检查是否有间距异常的竖线(除第一列外)for i in range(1, len(spacings)):if abs(spacings[i] - avg_spacing) > avg_spacing * 0.2: # 如果间距偏差超过20%print(f"警告: 第{i + 1}和第{i + 2}竖线之间间距异常, 实际:{spacings[i]}, 平均:{avg_spacing}")# 如果是最后一个间距异常,可能是最后一条竖线位置不准if i == len(spacings) - 1:v_coords[-1] = v_coords[-2] + int(avg_spacing)print(f"修正最后一条竖线位置: {v_coords[-1]}")# 9. 转换为线段表示h_lines = [(0, int(y), width, int(y)) for y in h_coords]v_lines = [(int(x), int(table_top), int(x), int(table_bottom)) for x in v_coords]# 10. 强制补充缺失的水平线 - 期望有5条水平线(4行表格)if len(h_lines) < 5 and len(h_lines) >= 2:h_lines.sort(key=lambda x: x[1])top_y = int(h_lines[0][1])bottom_y = int(h_lines[-1][1])height_range = bottom_y - top_y# 计算应有的4等分位置expected_y_positions = [top_y + int(height_range * i / 4) for i in range(1, 4)]# 添加缺失的水平线new_h_lines = list(h_lines)for y_pos in expected_y_positions:# 检查是否已存在接近该位置的线exist = Falsefor line in h_lines:if abs(line[1] - y_pos) < height // 20:exist = Truebreakif not exist:new_h_lines.append((0, int(y_pos), width, int(y_pos)))h_lines = new_h_lines# 11. 最终排序h_lines = sorted(h_lines, key=lambda x: x[1])v_lines = sorted(v_lines, key=lambda x: x[0])print(f"最终水平线数量: {len(h_lines)}")print(f"最终竖线数量: {len(v_lines)}")# 12. 计算并打印竖线间距,用于检验均匀性if len(v_lines) > 1:spacings = []for i in range(len(v_lines) - 1):spacing = v_lines[i + 1][0] - v_lines[i][0]spacings.append(spacing)avg_spacing = sum(spacings[1:]) / len(spacings[1:]) # 不计入第一列的宽度print(f"竖线平均间距: {avg_spacing:.2f}像素")print(f"竖线间距: {spacings}")return h_lines, v_linesdef _cluster_coordinates(self, coords, eps=10):"""合并相近的坐标"""if not coords:return []coords = sorted(coords)clusters = []current_cluster = [coords[0]]for i in range(1, len(coords)):if coords[i] - coords[i - 1] <= eps:current_cluster.append(coords[i])else:clusters.append(int(sum(current_cluster) / len(current_cluster)))current_cluster = [coords[i]]if current_cluster:clusters.append(int(sum(current_cluster) / len(current_cluster)))return clustersdef _visualize_grid(self, image, h_lines, v_lines, output_dir):"""可视化检测到的网格线并保存结果图像"""# 复制原图用于绘制result = image.copy()if len(result.shape) == 2:result = cv2.cvtColor(result, cv2.COLOR_GRAY2BGR)# 绘制水平线for line in h_lines:x1, y1, x2, y2 = linecv2.line(result, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)# 绘制垂直线for line in v_lines:x1, y1, x2, y2 = linecv2.line(result, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2)# 绘制交点for h_line in h_lines:for v_line in v_lines:y = h_line[1]x = v_line[0]cv2.circle(result, (int(x), int(y)), 3, (0, 255, 0), -1)# 只保存grid_on_image.pngif output_dir:cv2.imwrite(os.path.join(output_dir, "grid_on_image.png"), result)def _extract_and_save_cells(self, image, h_lines, v_lines, output_dir, margin=3):"""提取单元格并保存到输出目录"""height, width = image.shape[:2]# 确保线条按坐标排序h_lines = sorted(h_lines, key=lambda x: x[1])v_lines = sorted(v_lines, key=lambda x: x[0])# 保存图片路径image_paths = []# 检查线条数量是否足够if len(h_lines) < 4 or len(v_lines) < 10:print(f"警告: 线条数量不足(水平线={len(h_lines)}, 垂直线={len(v_lines)})")if len(h_lines) < 2 or len(v_lines) < 2:print("错误: 线条数量太少,无法提取任何单元格")return image_paths# 记录表格结构print(f"表格结构: {len(h_lines)}行, {len(v_lines) - 1}列")# 创建题号到行列索引的映射question_mapping = {}# 第2行是1-13题(列索引从1开始,0列是题号列)for i in range(1, 14):if i < len(v_lines):question_mapping[i] = (1, i)# 第4行是14-25题(列索引从1开始,0列是题号列)for i in range(14, 26):col_idx = i - 13 # 14题对应第1列,15题对应第2列,...if col_idx < len(v_lines) and 3 < len(h_lines):question_mapping[i] = (3, col_idx)# 提取每道题的单元格saved_questions = []for q_num in range(1, 26):if q_num not in question_mapping:print(f"题号 {q_num} 没有对应的行列索引映射")continuerow_idx, col_idx = question_mapping[q_num]if row_idx >= len(h_lines) - 1 or col_idx >= len(v_lines) - 1:print(f"题号 {q_num} 的行列索引 ({row_idx}, {col_idx}) 超出表格范围")continuetry:# 获取单元格边界x1 = int(v_lines[col_idx][0])y1 = int(h_lines[row_idx][1])x2 = int(v_lines[col_idx + 1][0])y2 = int(h_lines[row_idx + 1][1])# 打印单元格信息用于调试if q_num in [1, 4, 13, 14, 25]: # 打印关键单元格的位置信息print(f"题号 {q_num} 单元格: x1={x1}, y1={y1}, x2={x2}, y2={y2}, 宽={x2 - x1}, 高={y2 - y1}")# 添加边距,避免包含边框线x1_m = min(width - 1, max(0, x1 + margin))y1_m = min(height - 1, max(0, y1 + margin))x2_m = max(0, min(width, x2 - margin))y2_m = max(0, min(height, y2 - margin))# 检查单元格尺寸if x2_m <= x1_m or y2_m <= y1_m or (x2_m - x1_m) < 5 or (y2_m - y1_m) < 5:print(f"跳过无效单元格: 题号 {q_num}, 尺寸过小")continue# 提取单元格cell_img = image[y1_m:y2_m, x1_m:x2_m].copy()# 检查单元格是否为空图像if cell_img.size == 0 or cell_img.shape[0] == 0 or cell_img.shape[1] == 0:print(f"跳过空单元格: 题号 {q_num}")continue# 保存单元格图片cell_filename = f'cell_0{q_num:02d}.png'cell_path = os.path.join(output_dir, cell_filename)cv2.imwrite(cell_path, cell_img)# 添加到路径列表和已保存题号列表image_paths.append(cell_path)saved_questions.append(q_num)except Exception as e:print(f"提取题号 {q_num} 时出错: {str(e)}")print(f"已保存 {len(saved_questions)} 个单元格,题号: {sorted(saved_questions)}")return image_pathsdef process_image(input_image_path, output_dir):"""处理试卷答题区,提取表格并保存单元格"""processor = AnswerSheetProcessor()return processor.process(input_image_path, output_dir)def main():"""主函数:解析命令行参数并执行处理流程"""# 解析命令行参数parser = argparse.ArgumentParser(description='试卷答题区表格处理工具')parser.add_argument('--image', type=str, default="./images/12.jpg", help='输入图像路径')parser.add_argument('--output', type=str, default="./output", help='输出目录')args = parser.parse_args()# 检查图像是否存在if not os.path.exists(args.image):print(f"图像文件不存在: {args.image}")return 1# 确保输出目录存在os.makedirs(args.output, exist_ok=True)print(f"开始处理图像: {args.image}")print(f"输出目录: {args.output}")# 处理图像try:image_paths = process_image(args.image, args.output)if image_paths:print(f"处理成功: 共生成{len(image_paths)}个单元格图片")print(f"所有结果已保存到: {args.output}")return 0else:print("处理失败")return 1except Exception as e:print(f"处理过程中发生错误: {str(e)}")return 1if __name__ == "__main__":sys.exit(main())5. 应用场景
- 考试批阅系统:大规模考试的答题卡批阅
- 教育测评平台:智能化教育测评系统
- 试卷数字化处理:将纸质试卷转换为电子数据
- 教学检测系统:快速评估学生答题情况
6. 算法效果展示

上图是测试的试卷图片,要求提取出填写的答题区。

上图展示了表格网格识别的效果,蓝色线条表示竖线,红色线条表示水平线,绿色点表示线条交点。
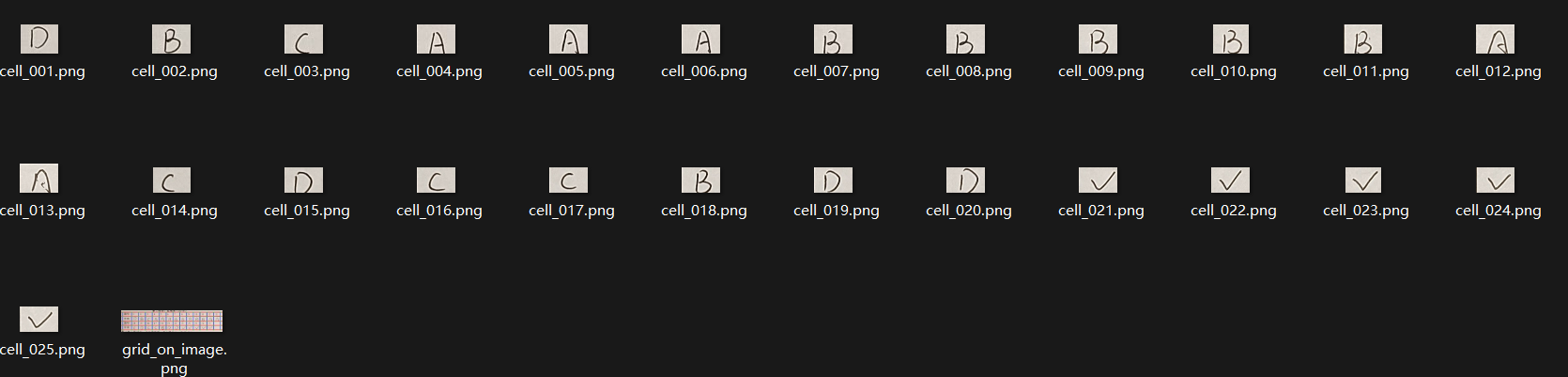
上图是从试卷中提取出的答案单元格。
7. 总结与展望
本文介绍的试卷答题区表格识别技术,通过计算机视觉算法实现了高效准确的表格定位和单元格提取。该技术有以下优势:
- 高精度:采用多尺度策略和位置校正算法,提高了表格线识别的精度
- 高适应性:能够处理不同样式的试卷答题区
- 高效率:自动化处理流程大幅提高了试卷处理效率
未来我们将继续优化算法,提高对更复杂表格的识别能力,并结合OCR技术实现答案内容的自动识别。
参考资料
- OpenCV官方文档: https://docs.opencv.org/
- 数字图像处理 - 冈萨雷斯
- 计算机视觉:算法与应用 - Richard Szeliski
相关文章:

基于计算机视觉的试卷答题区表格识别与提取技术
基于计算机视觉的试卷答题区表格识别与提取技术 摘要 本文介绍了一种基于计算机视觉技术的试卷答题区表格识别与提取算法。该算法能够自动从试卷图像中定位答题区表格,执行图像方向矫正,精确识别表格网格线,并提取每个答案单元格。本技术可…...

Java面试全栈解析:Spring Boot、Kafka与Redis实战揭秘
《Java面试全栈解析:Spring Boot、Kafka与Redis实战揭秘》 【面试现场】 面试官:(推了推眼镜)小张,你简历里提到用Spring Boot开发过微服务系统,能说说自动配置的实现原理吗? 程序员࿱…...

打成jar 包以后,运行时找不到文件路径?
报错信息: FileNotFoundException。。。。。。。 原因: 打成jar包后,路径src/*可能都找不到了。 使用命令,查看jar包内的结构及文件路径: tar -tf XX.jar 你会看到目录结构: META-INF/ META-INF/MANIFEST.MF main/ ma…...

C++复习2
set、map、multiset、multimap CSTL包含了序列式容器和关联式容器: 序列式容器里面存储的是元素本身,其底层为线性序列的数据结构。比如:vector,list,deque,forward_list(C11)等。 关联式容器里面存储的是…...

el-row el-col
参考layout布局 Element - The worlds most popular Vue UI frameworkElement,一套为开发者、设计师和产品经理准备的基于 Vue 2.0 的桌面端组件库https://element.eleme.cn/#/zh-CN/component/layout#row-attributes 一行可以看做24个 Element UI 中的 el-row 是…...

【旅游网站设计与实现】基于SpringBoot + Vue 的前后端分离项目 | 万字详细文档 + 源码 + 数据库 + PPT
一、项目简介 旅游网站管理系统以信息化为核心,结合用户体验和系统管理功能,为旅游爱好者和管理者提供全面的服务平台。通过系统,用户可以浏览线路、收藏心仪旅游产品、下单订购,管理员则可在后台完成旅游线路管理、用户管理、订…...

On the Biology of a Large Language Model——论文学习笔记——拒答和越狱
本文仍然是对Anthropic团队的模型解释工作 On the Biology of a Large Language Model 的学习笔记。 前几篇课见我的主页中相同标题的几篇文章 本篇主要关注的是该博客中的Refusal和 Life of a Jailbreak这两部分的内容。 一句话总结 在这两部分中,作者展示了以下…...

使用OpenCV 和Dlib 实现表情识别
文章目录 引言1.代码主要概述2.代码解析2.1 面部特征计算函数(1) 嘴部宽高比(MAR)(2) 嘴宽与脸颊宽比值(MJR)(3) 眼睛纵横比(EAR)(4) 眉毛弯曲比(EBR) 2.2 自定义函数显示中文2.3 表情分类逻辑2.4 实时视频处理 3.系统特点4.总结 引言 面部表情是人类情感交流的重要方式&#…...

Matplotlib 饼图
pie():绘制饼图 Matplotlib 直方图 我们也可以结合 Pandas 来绘制直方图 除了数据框之外,我们还可以使用 Pandas 中的 Series 对象绘制直方图。只需将数据框中的列替换为 Series 对象 Matplotlib imshow() imshow() 可以显示灰度图像 imshow() 可以显示彩…...

区块链交易所开发:开启数字交易新时代
区块链交易所开发:开启数字交易新时代 ——2025年技术革新与万亿级市场的破局指南 一、区块链交易所的颠覆性价值 1️⃣ 去中心化革命终结数据霸权 区块链交易所通过分布式账本技术,将交易数据存储于全网节点,彻底消除中心化服务器宕机、跑路…...

ChatGPT对话导出工具-轻松提取聊天记录导出至本地[特殊字符]安装指南
1、edge浏览器安装tampermonkey插件 Edge浏览器安装:https://microsoftedge.microsoft.com/addons/detail/%E7%AF%A1%E6%94%B9%E7%8C%B4/iikmkjmpaadaobahmlepeloendndfphd 其他浏览器安装:https://www.tampermonkey.net/index.php?browserchrome 2、…...
 优化方案)
k8s node soft lockup (内核软死锁) 优化方案
在 Kubernetes 环境中,Node 节点的内核软死锁(soft lockup)是一个严重的稳定性问题,可能导致节点无响应、Pod 调度失败甚至数据丢失。以下是针对该问题的优化策略和解决方案: 一、临时缓解措施 1. 调整内核 watchdog…...
)
【LDM】视觉自回归建模:通过Next-Scale预测生成可扩展图像(NeurIPS2024最佳论文阅读笔记与吃瓜)
【LDM】视觉自回归建模:通过Next-Scale预测生成可扩展图像(NeurIPS2024最佳论文阅读笔记与吃瓜) 《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》 视觉自回归建模:通过Next-Scale预测…...

计算机网络-传输层
一、概述 1、逻辑通信:对等层之间的通信好像是沿着水平方向传送的,但两个对等层之间并没有一条水平方向的物理连接。 2、复用与分用 2.1传输层 复用:发送方不同的应用进程可以使用同一传输层协议传送数据 分用:接收方的传输层…...

MacOS+VSCODE 安装esp-adf详细流程
安装python3,省略vscode安装ESP-IDF插件,选择v5.2.5 版本,电脑需要能够访问github,esp-idf安装后的默认目录是: /Users/***/esp/v5.2.5/esp-idf# 启动***为省略名称在/Users/***/esp/ 目录下使用git clone 下载 esp-adf # 国内用…...
)
2025年5月HCIP题库(带解析)
某个ACL规则如下:则下列哪些IP地址可以被permit规则匹配: rule 5 permit ip source 10.0.2.0 0.0.254.255 A、10.0.4.5 B、10.0.5.6 C、10.0.6.7 D、10.0.2.1 试题答案:A;C;D 试题解析: 10.0.2.000001010.00000000.00000010.0000000…...

【Linux系统】vim编辑器的使用
文章目录 一、vim编辑器的简单介绍二、vim的一键化配置方案(目前只支持 Centos7 x86_64)三、vim编辑器在各模式下的操作1.vim的使用 以及 各模式间的切换2.普通模式(Normal Mode,初始默认处于该模式)3.替换模式&#x…...

网站主机控制面板深度解析:cPanel、Plesk 及其他主流选择
网站主机控制面板深度解析:cPanel、Plesk 及其他主流选择 在网站管理和服务器维护的领域,一个强大且易用的控制面板至关重要。它们能够将复杂的技术命令转化为直观的图形界面,极大简化了网站管理员的工作。本文将为您详细介绍市面上几款主流…...

【程序员AI入门:应用】7.LangChain是什么?
LangChain作为当前最热门的AI应用开发框架,正在重塑大语言模型(LLM)的应用生态。其核心价值在于解耦LLM能力与工程实现,构建起连接智能模型与现实世界的"神经网络"。 一、核心定位:AI应用的"操作系统&q…...

jenkins访问端口调整成80端口
使用 Nginx 反向代理解决以上问题,这样可以: 1. 保持 Jenkins 在其他端口(博主使用8090端口) 稳定运行 2. 通过 Nginx 将 80 端口的请求转发到 Jenkins 3. 更安全,因为 Jenkins 不需要直接监听 80 端口 4. 后续如果…...

如何从服务器日志中分析是否被黑客攻击?
一、关键日志文件定位与攻击特征分析 1. 核心日志文件路径 Web 服务器日志: Nginx:/var/log/nginx/access.log(访问日志)、/var/log/nginx/error.log(错误日志) Apache:/var/log/apache2/…...

[250504] Moonshot AI 发布 Kimi-Audio:开源通用音频大模型,驱动多模态 AI 新浪潮
目录 Moonshot AI 发布 Kimi-Audio:开源音频基础模型,赋能音频理解、生成与对话新时代核心能力与特性技术基础开放资源与评估行业意义 Moonshot AI 发布 Kimi-Audio:开源音频基础模型,赋能音频理解、生成与对话新时代 Moonshot A…...
图像与通道拼接函数-----对图像进行几何变换函数remap())
OpenCV 图形API(77)图像与通道拼接函数-----对图像进行几何变换函数remap()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对图像应用一个通用的几何变换。 函数 remap 使用指定的映射对源图像进行变换: dst ( x , y ) src ( m a p x ( x , y ) , m a p y…...

理清缓存穿透、缓存击穿、缓存雪崩、缓存不一致的本质与解决方案
在构建高性能系统中,缓存(如Redis) 是不可或缺的关键组件,它大幅减轻了数据库压力、加快了响应速度。然而,在高并发环境下,缓存也可能带来一系列棘手的问题,如:缓存穿透、缓存击穿、…...

Jetpack Compose 自定义 Slider 完全指南
自定义 Compose Slider 在 Jetpack Compose 中,你可以通过多种方式自定义 Slider 组件。以下是一些常见的自定义方法: 基本自定义 var sliderPosition by remember { mutableStateOf(0f) }Slider(value sliderPosition,onValueChange { sliderPosit…...
)
荣耀A8互动娱乐组件部署实录(终章:后台配置系统与整体架构总结)
作者:被配置文件的“开关参数”折磨过无数次的运维兼后端工 一、后台系统架构概述 荣耀A8组件后台采用 PHP 构建,配合 MySQL 数据库与 Redis 缓存系统,整体结构遵循简化版的 MVC 模式。后台主要实现以下核心功能: 系统参数调控与配置热更新 用户管理(封号、授权、角色) …...

本地文件批量切片处理与大模型精准交互系统开发指南
本地文件批量切片处理与大模型精准交互系统开发指南 一、系统架构设计 #mermaid-svg-yCbT2xBukW6iX98y {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-yCbT2xBukW6iX98y .error-icon{fill:#552222;}#mermaid-svg-y…...
)
homebrew安装配置Python(MAC版)
Mac系统自带python路径为: /System/Library/Frameworks/Python.framework/Versionbrew 安装 Python3 在终端输入以下命令: brew search python3 # 查看支持安装的版本 brew install python3就可以轻松easy安装python了,安装完成后提示 查看 pyth…...

STM32--RCC--时钟
教程 系统时钟 RCC RCC(Reset and Clock Control)是STM32微控制器中管理时钟和复位系统的关键外设模块,负责整个芯片的时钟树配置和复位控制。 RCC主要功能 时钟系统管理: 内部/外部时钟源选择 时钟分频/倍频配置 各外设时钟门…...

深度学习在油气地震资料反卷积中的应用
深度学习在油气地震资料反卷积中的应用 基本原理 在油气地震勘探中,反卷积(Deconvolution)是一种重要的信号处理技术,用于提高地震资料的分辨率。传统方法(如维纳滤波、预测反卷积等)存在对噪声敏感、假设条件严格等局限。深度学习方法通过数据驱动的方…...

实现滑动选择器从离散型的数组中选择
1.使用原生的input 详细代码如下: <template><div class"slider-container"><!-- 滑动条 --><inputtype"range"v-model.number"sliderIndex":min"0":max"customValues.length - 1"step&qu…...

基于 GO 语言的 Ebyte 勒索软件——简要分析
一种新的勒索软件变种,采用Go 语言编写,使用ChaCha20进行加密,并使用ECIES进行安全密钥传输,加密用户数据并修改系统壁纸。其开发者EvilByteCode曾开发过多种攻击性安全工具,现已在 GitHub 上公开 EByte 勒索软件。尽管该勒索软件声称仅用于教育目的,但滥用可能会导致严重…...

学习人工智能开发的详细指南
一、引言 人工智能(AI)开发是一个充满挑战与机遇的领域,它融合了数学、计算机科学、统计学、认知科学等多个学科的知识。随着大数据、云计算和深度学习技术的快速发展,AI已经成为推动社会进步和产业升级的关键力量。本文将为初学…...

使用图像生成式AI和主题社区网站助力运动和时尚品牌的新产品设计和市场推广的点子和实现
通过构建针对公司产品线的专有图像生成式AI模型,用户可以将自己对于产品的想法和偏好,变成设计发布到社区空间中与社区分享,也可以通过在产品经典款或使用社区空间中其它人的创作来重新设计。组织大型市场推广活动来宣传DIY设计理念ÿ…...

POI创建Excel文件
文章目录 1、背景2、创建表格2.1 定义表头对象2.2 Excel生成器2.3 创建模板2.4 处理Excel表头2.5 处理Excel内容单元格样式2.6 处理单个表头 3、追加sheet4、静态工具5、单元测试6、完整代码示例 1、背景 需求中有需要用户自定义Excel表格表头,然后生成Excel文件&a…...

CentOS虚拟机固定ip以及出现的问题
1.打开终端,进入网卡配置目录: cd etc/sysconfig/network-scripts 2.找到网卡配置文件,我这里是 ifcfg-ens32(替换成你自己的文件) 4.进入ifcfg-ens32,注释IPV6,修改别的参数如下图 TYPEEther…...

【Python】常用命令提示符
Python常用的命令提示符 一、Python环境基础命令【Windows】 于Windows环境下,针对Python,在CMD(命令提示符)常用的命令以及具体用法,怎么用; 主要包含:运行脚本、包管理、虚拟环境、调试与…...

Java引用RabbitMQ快速入门
这里写目录 Java发送消息给MQ消费者接收消息实现一个队列绑定多个消费者消息推送限制 Fanout交换机路由的作用Direct交换机使用案例 Java发送消息给MQ public void testSendMessage() throws IOException, TimeoutException {// 1.建立连接ConnectionFactory factory new Conn…...

USB接口的PCB设计
目录 USB接口简介 USB3.0接口 USB接口的电路设计 USB接口的PCB设计 USB接口简介 USB(通用串行总线)接口是一种广泛应用于电子设备的标准连接技术,自1996年由英特尔、微软等公司联合推出以来,逐步取代了传统串口、并口等复杂接…...

星纪魅族新品发布会定档5月13日,Note 16系列战神归来
5 月 13 日,星纪魅族将举办 Note 16 系列新品线上发布会。届时,国民严选魅族 Note 16 系列将战神归来,刷新用户对“高性价比科技”的想象,开启一场关乎「国民 AI 科技平权」的革新盛宴。 无创意不魅族,花式创意邀请即日…...

Jenkins+Newman实现接口自动化测试
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、是什么Newman Newman就是纽曼手机这个经典牌子,哈哈,开玩笑啦。。。别当真,简单地说Newman就是命令行版的Postman&…...

window 显示驱动开发-线程和同步级别为零级
在零级线程处理和同步中,WDDM 允许以可重入的方式对显示微型端口驱动程序进行零级 DxgkDdi*Xxx 调用。 也就是说,多个线程可以通过调用零级 DDI 同时进入驱动程序。 驱动程序应预期系统中的任何线程会传入,并应相应地保护该线程的数据。 尽…...

RabbitMQ ①-MQ | Linux安装RabbitMQ | 快速上手
MQ MQ(Message Queue)即消息队列,是一种应用间通信的一种方式。消息队列是一种异步通信方式,生产者(Producer)将消息放入队列,消费者(Consumer)从队列中取出消息进行消费…...
)
tinyrenderer笔记(Shadow Mapping)
tinyrenderer个人代码仓库:tinyrenderer个人练习代码 前言 阴影是光线被阻挡的结果;当光源的光线由于其他物体的阻挡而无法到达物体表面时,该物体就会产生阴影。阴影能使场景看起来更真实,并让观察者获得物体之间的空间位置关系。…...
)
【quantity】1 SI Prefixes 实现解析(prefix.rs)
一、源码 // prefix.rs //! SI Prefixes (国际单位制词头) //! //! 提供所有标准SI词头用于单位转换,仅处理10的幂次 //! //! Provides all standard SI prefixes for unit conversion, handling only powers of 10.use typenum::{Z0, P1, P2, P3, P6, P9, P12, …...

如何开发一个笑话管理小工具
前言 笔者曾经开发过一个可以对笑话浏览、收藏、分类、编辑上传的小工具(笔者开发后台,另外一个朋友负责小程序前台开发),如今所租用的服务器到期了,特此记录一下。 数据层 部署数据库 # 拉取Mysql镜像 docker pull…...
Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究 引言与背景 深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测…...

深入浅出iOS性能优化:打造极致用户体验的实战指南
前言 在当今移动应用竞争激烈的时代,性能优化已经成为iOS开发中不可或缺的重要环节。一个性能优秀的应用不仅能给用户带来流畅的使用体验,还能减少设备资源消耗,延长电池寿命,提高用户留存率。本文将深入探讨iOS性能优化的各个方…...

Spring AI 与大语言模型工具调用机制详细笔记
一、基本概念 大语言模型(LLM)工具调用机制是一种允许AI模型与外部系统交互的技术框架,它使模型能够在对话过程中请求调用预定义的函数或服务。这种机制极大地扩展了大模型的能力边界,使其不再局限于静态知识,而是能够…...

数据清洗-电商双11美妆数据分析
1.数据读取(前八行) 2.数据清洗 2.1 因为数据中存在重复跟空值,将数据进行重复值处理 (删除重复值) 2.2 缺失值处理 存在的缺失值很可能意味着售出的数量为0或者评论的数量为0,所以我们用0来填补缺失值 2…...