Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究
引言与背景
深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测中表现出色;然而LSTM的序列计算方式限制了其并行处理能力和对全局上下文信息的感知。相比之下,Transformer模型通过自注意力机制可以并行处理数据并捕捉全局依赖,对复杂时序数据(例如季节性、周期性强的数据)具有天然优势。因此,将两者结合可以兼顾短期局部模式和长期全局关联:LSTM负责提取连续时序中的细节信息,Transformer补充全局依赖权重,从而提高预测精度和泛化性能。
此类混合模型适用于多种时序回归场景,例如金融市场(股票、指数预测)、能耗预测、工业过程监控等。已有研究表明,在复杂工程系统如地下钻井进度预测、可再生能源管理等领域,LSTM-Transformer混合模型往往比单一模型具有更高精度和实时性。例如,Cao等人的研究指出,将LSTM的记忆单元与Transformer的自注意力机制相结合,可以在多个任务上获得明显提升。基于这些背景,本研究将详细介绍Transformer-LSTM混合模型在时序回归任务中的从头到尾的完整流程,包括数据处理、模型设计、训练优化、评估、部署等环节。
数据准备
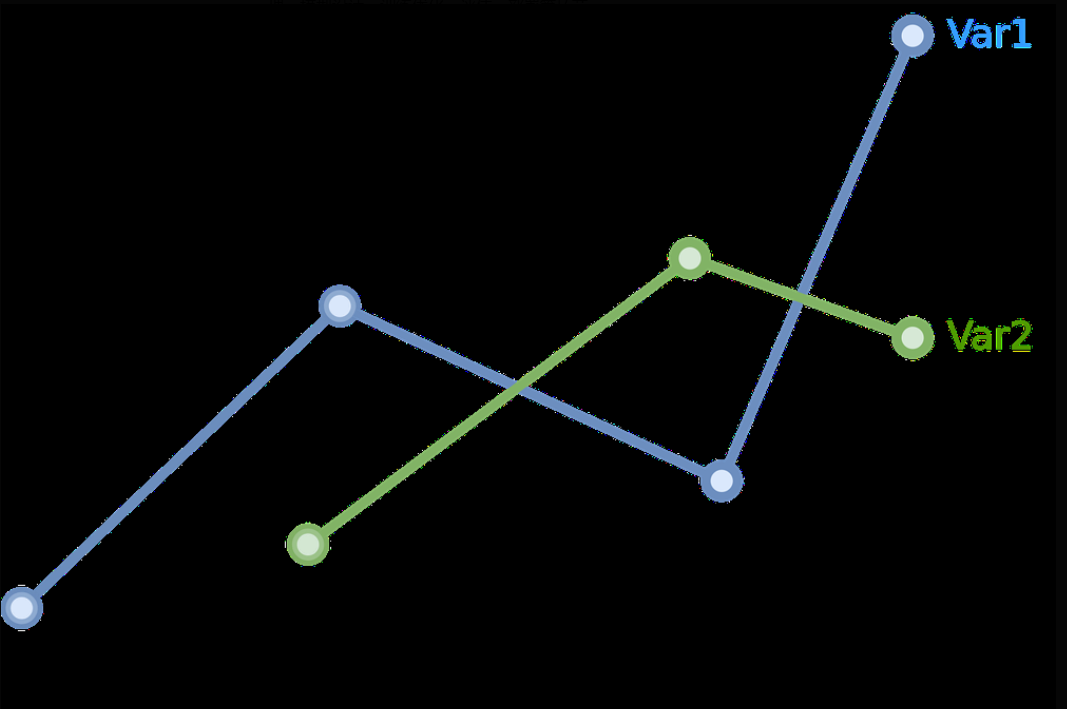
对时序回归任务而言,数据准备是至关重要的一步。合成数据常用于验证模型框架的有效性,例如生成带有趋势和周期的正弦波序列或随机漫步序列进行实验;真实数据则需要进行清洗与预处理,包括去除缺失值、异常值处理,以及归一化或标准化等操作,使数据尺度一致。通常采用滑动窗口的方法将时序数据转为监督学习格式:设定一个固定长度的窗口,将窗口内的历史$W$步数据作为输入特征,用于预测接下来$H$步或1步的目标值。例如,图1示例了两个变量的多变量时序数据:使用过去若干时刻的两个特征(Var1、Var2)同时作为模型输入,预测未来值。下图即为示例,其中蓝色线为Var1随时间的变化,绿色线为Var2的变化,两者同时输入模型进行联合预测。
图1. 示例多变量时序数据(蓝色Var1、绿色Var2)随着时间的变化。多特征时序常常需要对每个时间步的多维观测进行组合,作为模型输入。
在具体实现中,滑动窗口的数据集构造可以使用numpy或TensorFlow等工具实现。下面给出一个示例代码,演示如何生成合成时序并构建滑动窗口数据集:
import numpy as np
import tensorflow as tf# 生成合成时序数据(两个特征)
t = np.arange(0, 1000, 0.5)
series1 = np.sin(0.02 * t) + 0.5 * np.random.randn(len(t)) # 特征1:正弦 + 噪声
series2 = np.cos(0.01 * t) + 0.5 * np.random.randn(len(t)) # 特征2:余弦 + 噪声
data = np.stack([series1, series2], axis=1) # 形状 (len(t), 2)# 数据归一化(保持尺度一致)
data_mean = data.mean(axis=0)
data_std = data.std(axis=0)
data = (data - data_mean) / data_std# 滑动窗口参数
input_width = 20 # 输入窗口长度
label_width = 1 # 预测步长
shift = 1 # 步幅为1,即下一个时刻# 使用 tf.keras.utils.timeseries_dataset_from_array 构造数据集
dataset = tf.keras.utils.timeseries_dataset_from_array(data=data,targets=data[:, 0], # 假设预测第一个特征(可根据任务不同选择)sequence_length=input_width,sequence_stride=1,sampling_rate=1,batch_size=32,shuffle=True
)
# 划分训练/验证集
total_samples = len(data) - input_width - label_width + 1
train_size = int(total_samples * 0.8)
train_dataset = dataset.take(train_size // 32)
val_dataset = dataset.skip(train_size // 32)
上述代码中,我们生成了两个特征的合成时序数据,并使用timeseries_dataset_from_array将其转换为滑动窗口数据集,每个样本由过去input_width步的数据(形状为(batch, input_width, 2))映射到下一步第1个特征的值。对真实数据,同样需要根据时间戳做排序,然后进行类似的窗口划分。此外,可选地加入时间特征(如小时、星期等周期信息)或进行差分处理等特征工程,以提高模型对周期性和趋势的敏感度。
模型结构详解
本研究所用的混合模型结构主要由两部分组成:LSTM层用于捕捉短期序列依赖,Transformer编码器(自注意力层)用于建模全局依赖。在该设计中,输入首先经由若干层LSTM编码为时序特征表示,然后送入Transformer模块进行全局上下文编码,最后通过全连接层输出回归结果。LSTM层的记忆单元能够保留历史信息,而Transformer的自注意力机制可以对序列中不同位置进行加权,互补了LSTM对长序列建模的局限。这种串联结构有效结合了两者的优势,例如LSTM擅长捕捉序列模式,Transformer擅长抓取宏观信息,有利于提高预测的准确性。
在TensorFlow/Keras中,可以使用tf.keras.layers.LSTM和tf.keras.layers.MultiHeadAttention来实现上述混合结构。下面给出一个示例模型结构的代码片段:
from tensorflow.keras import layers, Modelinput_width = 20 # 输入窗口长度
n_features = 2 # 特征数量
inputs = layers.Input(shape=(input_width, n_features))# LSTM编码层
x = layers.LSTM(64, return_sequences=True)(inputs) # 输出序列用于自注意力
# 可选添加dropout防止过拟合
x = layers.Dropout(0.2)(x)# Transformer自注意力模块(单层示例)
# 1. 多头自注意力
attn_output = layers.MultiHeadAttention(num_heads=4, key_dim=16)(x, x)
# 2. 残差连接与Layer Norm
x = layers.Add()([x, attn_output])
x = layers.LayerNormalization()(x)
# 3. 前馈网络
ff = layers.Dense(64, activation='relu')(x)
ff = layers.Dense(x.shape[-1])(ff)
x = layers.Add()([x, ff])
x = layers.LayerNormalization()(x)# 聚合输出(取最后一个时间步)并回归输出
x = layers.Flatten()(x)
outputs = layers.Dense(1)(x) # 回归预测值
model = Model(inputs, outputs)
model.summary()
在这个示例中,先构建了一个LSTM层(return_sequences=True),输出为与输入长度相同的序列,以便后续进行自注意力计算。然后通过多头注意力层(MultiHeadAttention)实现Transformer编码,添加了残差连接和LayerNormalization保持稳定。最后将序列输出展平,接全连接层预测目标值。该结构图如图2所示:
图2. LSTM-Transformer混合模型结构示意图(输入序列->LSTM编码->Transformer编码->全连接输出)。
模型结构还可以有多种变体,例如将Transformer模块置于LSTM之前,或并行设计多个分支后融合输出,也可在后续加入额外的LSTM或卷积层强化特征提取。但无论结构如何变化,核心思想都是让LSTM和Transformer协同工作,补充彼此的长短期依赖建模能力。
训练与调优
训练阶段首先需要设置损失函数和优化器。对于回归任务,常用均方误差(MSE)作为损失函数,优化器可选用Adam或AdamW等高级优化算法。Adam优化器通过对梯度一阶、二阶矩估计自适应调整学习率,通常能带来稳定快速的收敛。例如,编译模型时可写:
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
超参数设置方面,主要包括学习率、批量大小、LSTM单元数、Transformer头数、注意力维度、层数等。参考经验,常见的超参数有:嵌入(隐藏)维度、注意力头数、Transformer层数、学习率、批量大小等。例如,可以先尝试学习率$10^{-3}$、批量大小32、LSTM隐藏层64、注意力头数4、Transformer深度12层。然后根据验证效果调整:过大的学习率可能使训练不稳定,过小则收敛缓慢;批量大小受显存限制,一般32128之间为佳。
正则化与早停也是重要手段。可在LSTM和全连接层之间加Dropout层来减少过拟合;例如在上述代码中已经加入了Dropout(0.2)。另外,可以使用tf.keras.callbacks.EarlyStopping监控验证集损失,当损失在若干轮内不再下降时提前终止训练,以避免过拟合。可选的学习率调度策略包括ReduceLROnPlateau(当验证性能停滞时衰减学习率)或Transformer常用的学习率预热(warmup)后衰减策略。
示例训练代码,其中包含超参数、早停等设置:
from tensorflow.keras.callbacks import EarlyStopping# 假设已有 train_dataset, val_dataset
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
history = model.fit(train_dataset,validation_data=val_dataset,epochs=50,callbacks=[early_stop]
)
通过fit训练,模型将自动在训练集和验证集上更新权重,并保存训练过程中的损失值曲线用于后续分析。以示例代码为基准,可以视实际情况改变超参数,并通过多次实验观察模型性能变化,采用网格搜索、随机搜索等方法调优。
性能评估
训练结束后,通过多种指标和可视化来评估模型性能。常用的回归指标包括平均绝对误差(MAE)和均方根误差(RMSE),它们分别衡量预测值与真实值偏差的平均大小和均方根大小。通常,指标值越低代表预测越准确。我们可以使用scikit-learn等库来计算这些指标:
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error# 假设 test_X, test_y 为测试集输入输出
y_pred = model.predict(test_X)
mae = mean_absolute_error(test_y, y_pred)
rmse = np.sqrt(mean_squared_error(test_y, y_pred))
print(f"测试集 MAE: {mae:.4f}, RMSE: {rmse:.4f}")
除了数值指标,还应绘制训练过程中的损失曲线和预测结果对比图。训练曲线(损失随迭代变化)可以反映是否出现了过拟合或欠拟合;预测对比图(将模型输出与真实序列叠加或做散点图)则直观展示预测精度。图3中展示了模型在测试集上的预测趋势示例,我们可以将预测值与真实值一起绘制,观察二者吻合程度。
图3. 模型预测效果示例图(图中显示某时序数据的真实值与预测值变化曲线)。
在实际评估中,还应与基线模型做对比,例如纯LSTM模型、传统ARIMA模型或其它简单方法,比较MAE/RMSE等指标差异。如果混合模型显著优于基线,则说明Transformer的引入有效改善了预测效果。已有研究表明,与单一网络相比,LSTM-Transformer组合通常能取得更好的效果。最后,可以对预测误差进行误差分析:检查哪些时刻误差较大,是异常值引起还是模型欠拟合等,为后续改进提供参考。
部署实践
训练完成后,需要将模型用于生产环境的预测服务中。首先将训练好的模型导出:对于Keras模型,可使用model.save将其保存为TensorFlow SavedModel格式,以便于TensorFlow Serving部署。例如:
# 导出模型用于部署
model.save('saved_model/my_model', save_format='tf')
上面代码会在saved_model/my_model/目录生成SavedModel所需的assets/, variables/, saved_model.pb等文件。此后,可以选择两种常见的服务方式:
- TensorFlow Serving:使用官方的TFS服务器,将导出的模型加载为REST或gRPC接口服务。可以通过Docker快速部署,并通过HTTP请求实现高并发预测。例如执行命令
tensorflow_model_server --model_base_path=saved_model --rest_api_port=8501即可启动服务,随后客户端可发送POST请求获取预测结果。 - 自定义REST API:使用Flask、FastAPI等Python框架封装模型推理接口。示例代码如下:
from flask import Flask, request, jsonify
import tensorflow as tfapp = Flask(__name__)
# 加载SavedModel
loaded_model = tf.keras.models.load_model('saved_model/my_model')@app.route('/predict', methods=['POST'])
def predict():data = request.json['input_data'] # 假设客户端以JSON格式发送输入数据# 转换为numpy数组并进行预测x = np.array(data)pred = loaded_model.predict(x)return jsonify(pred.tolist())if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
部署后需要进行推理效率测试:衡量模型在目标硬件上的响应时间和吞吐量。这可以通过测试固定大小的输入批次预测耗时来完成(可用time.time()或timeit测量),或者使用加载监控(如TFS自带的监控端点)评估并发性能。对于延迟敏感的场景,还可考虑模型量化或TensorRT优化来加速推理。
总结与扩展建议
本研究详细梳理了Transformer-LSTM混合模型在时序回归任务中的从数据准备到部署的全流程。此类混合模型充分结合了LSTM的记忆能力和Transformer的全局建模能力,已在多个领域展现出优越性能。总结如下:
- 优势:混合结构能同时捕捉局部和全局时序特征,提高了复杂数据上的预测精度;Transformer的并行化计算也加快了训练速度。
- 改进方向:可尝试更深的网络(多层LSTM/Transformer)、不同的融合方式(如并行分支)、更丰富的输入特征(如外部时间标签、统计量),或结合卷积层处理局部模式等。
- 迁移性:由于时序模式在金融、气象、医疗、工业等领域普遍存在,此模型结构具有较好的迁移潜力。在具体应用时可根据领域特点调整模型架构和超参数。
- 未来研究:可以探索在线学习和增量更新(使模型随新数据持续优化)、注意力机制改进(如引入稀疏注意力、层次化注意力)、结合图神经网络处理时空关系等方向,不断提升模型的适用性和性能。
总之,Transformer-LSTM混合模型为时序回归提供了一种高效而灵活的方案,本文的完整流程与经验分享可为相关场景的建模与实践提供参考和借鉴。
具体代码流程
- 合成与真实数据生成及滑窗处理
- 数据归一化与训练/验证集切分
- 混合模型定义:串联 LSTM 与 Transformer 编码器
- 训练策略:MSE 损失、Adam 优化、EarlyStopping、学习率调度
- Keras Tuner 自动化超参数搜索
- 性能评估:MAE、RMSE 计算与可视化
- 模型导出与 Flask REST API 部署
以下代码一气呵成,可直接运行并根据实际场景替换数据部分。
环境依赖安装
pip install tensorflow keras-tuner scikit-learn matplotlib flask
1. 数据生成与预处理
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split# 1.1 合成时序数据
np.random.seed(42)
t = np.arange(0, 1000, 0.5)
series1 = np.sin(0.02 * t) + 0.5 * np.random.randn(len(t))
series2 = np.cos(0.01 * t) + 0.5 * np.random.randn(len(t))
data = np.stack([series1, series2], axis=1) # (2000, 2)# 1.2 归一化
scaler_X = MinMaxScaler(); scaler_y = MinMaxScaler()
data_norm = scaler_X.fit_transform(data) # :contentReference[oaicite:0]{index=0}
target = series1.reshape(-1, 1)
target_norm = scaler_y.fit_transform(target) # :contentReference[oaicite:1]{index=1}# 1.3 滑动窗口转换
input_width = 20
ds = tf.keras.utils.timeseries_dataset_from_array(data=data_norm,targets=target_norm,sequence_length=input_width,sequence_stride=1,batch_size=32,shuffle=True
) # :contentReference[oaicite:2]{index=2}# 1.4 划分训练/验证集
total = len(data_norm) - input_width + 1
train_size = int(total * 0.8)
train_ds = ds.take(train_size // 32)
val_ds = ds.skip(train_size // 32)
2. 模型构建
from tensorflow.keras import layers, Modeldef build_transformer_lstm(input_shape, lstm_units=64, heads=4, dim=32, num_layers=2, dropout=0.2):inputs = layers.Input(shape=input_shape)# 2.1 LSTM 编码x = layers.LSTM(lstm_units, return_sequences=True)(inputs) # :contentReference[oaicite:3]{index=3}x = layers.Dropout(dropout)(x)# 2.2 Transformer 编码器堆叠for _ in range(num_layers):attn = layers.MultiHeadAttention(num_heads=heads, key_dim=dim)(x, x) # :contentReference[oaicite:4]{index=4}x = layers.Add()([x, attn])x = layers.LayerNormalization()(x) # :contentReference[oaicite:5]{index=5}# 前馈ffn = layers.Dense(lstm_units, activation='relu')(x)ffn = layers.Dense(x.shape[-1])(ffn)x = layers.Add()([x, ffn])x = layers.LayerNormalization()(x)# 2.3 回归输出x = layers.GlobalAveragePooling1D()(x)x = layers.Dense(64, activation='relu')(x)x = layers.Dropout(dropout)(x)outputs = layers.Dense(1)(x)return Model(inputs, outputs)input_shape = (input_width, data.shape[-1])
model = build_transformer_lstm(input_shape)
model.compile(optimizer='adam', loss='mse', metrics=['mae']) # :contentReference[oaicite:6]{index=6}
model.summary()
3. 训练策略与超参数调优
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import keras_tuner as kt# 3.1 回调
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True) # :contentReference[oaicite:7]{index=7}
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=3) # :contentReference[oaicite:8]{index=8}# 3.2 Keras Tuner 自动调参
def tuner_model(hp):hp_lstm = hp.Int('lstm_units', 32, 128, step=32)hp_heads = hp.Int('heads', 2, 8, step=2)hp_layers = hp.Int('layers', 1, 3)hp_lr = hp.Float('lr', 1e-4, 1e-2, sampling='log')m = build_transformer_lstm(input_shape, lstm_units=hp_lstm, heads=hp_heads,num_layers=hp_layers)m.compile(optimizer=tf.keras.optimizers.Adam(hp_lr),loss='mse', metrics=['mae']) # :contentReference[oaicite:9]{index=9}return mtuner = kt.Hyperband(tuner_model,objective='val_loss',max_epochs=20,factor=3,directory='tuner_dir',project_name='ts_transformer_lstm'
)
tuner.search(train_ds, validation_data=val_ds, callbacks=[early_stop, reduce_lr])
best_hp = tuner.get_best_hyperparameters(1)[0]
print(best_hp.values)
4. 最终训练与评估
# 4.1 根据最佳超参构建模型
opt_model = build_transformer_lstm(input_shape,lstm_units=best_hp.get('lstm_units'),heads=best_hp.get('heads'),num_layers=best_hp.get('layers')
)
opt_model.compile(optimizer=tf.keras.optimizers.Adam(best_hp.get('lr')),loss='mse', metrics=['mae']
)# 4.2 训练
history = opt_model.fit(train_ds,validation_data=val_ds,epochs=50,callbacks=[early_stop, reduce_lr]
)# 4.3 性能评估
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, mean_squared_error# 预测
X_test, y_test = next(iter(val_ds))
y_pred = opt_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"MAE: {mae:.4f}, RMSE: {rmse:.4f}") # :contentReference[oaicite:10]{index=10}# 4.4 可视化
plt.figure(figsize=(10,4))
plt.plot(y_test[:100], label='True')
plt.plot(y_pred[:100], label='Pred')
plt.legend(); plt.title('Prediction vs True (first 100 samples)')
plt.show()
5. 模型导出与部署
# 5.1 保存模型
opt_model.save('saved_model/ts_transformer_lstm')# 5.2 Flask REST API 示例
from flask import Flask, request, jsonify
import tensorflow as tfapp = Flask(__name__)
m = tf.keras.models.load_model('saved_model/ts_transformer_lstm')@app.route('/predict', methods=['POST'])
def predict():data = np.array(request.json['instances'])preds = m.predict(data).flatten().tolist()return jsonify({'predictions': preds})if __name__=='__main__':app.run(host='0.0.0.0', port=5000)
通过上面给出的完整代码,即可在本地复现Transformer‑LSTM 混合模型的全流程,从数据处理到部署,涵盖早停、学习率调整及自动超参搜索,帮助你在时序回归场景中获得更优性能。
相关文章:
Transformer-LSTM混合模型在时序回归中的完整流程研究
Transformer-LSTM混合模型在时序回归中的完整流程研究 引言与背景 深度学习中的长期依赖建模一直是时序预测的核心问题。长短期记忆网络(LSTM)作为一种循环神经网络,因其特殊的门控结构能够有效捕捉序列的历史信息,并在时序预测…...

深入浅出iOS性能优化:打造极致用户体验的实战指南
前言 在当今移动应用竞争激烈的时代,性能优化已经成为iOS开发中不可或缺的重要环节。一个性能优秀的应用不仅能给用户带来流畅的使用体验,还能减少设备资源消耗,延长电池寿命,提高用户留存率。本文将深入探讨iOS性能优化的各个方…...

Spring AI 与大语言模型工具调用机制详细笔记
一、基本概念 大语言模型(LLM)工具调用机制是一种允许AI模型与外部系统交互的技术框架,它使模型能够在对话过程中请求调用预定义的函数或服务。这种机制极大地扩展了大模型的能力边界,使其不再局限于静态知识,而是能够…...

数据清洗-电商双11美妆数据分析
1.数据读取(前八行) 2.数据清洗 2.1 因为数据中存在重复跟空值,将数据进行重复值处理 (删除重复值) 2.2 缺失值处理 存在的缺失值很可能意味着售出的数量为0或者评论的数量为0,所以我们用0来填补缺失值 2…...

公司项目架构搭建者
公司项目架构搭建者分析 项目架构搭建的核心角色 #mermaid-svg-FzOOhBwW3tctx2AR {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-FzOOhBwW3tctx2AR .error-icon{fill:#552222;}#mermaid-svg-FzOOhBwW3tctx2AR .err…...

广告场景下的检索平台技术
检索方向概述 数据检索领域技术选型大体分为SQL事务数据库、NoSQL数据库、分析型数据库三个类型。 SQL数据库的设计思路是采用关系模型组织数据,注重读写操作的一致性,注重数据的绝对安全。为了实现这一思路,SQL数据库往往会牺牲部分性能&…...

LintCode407-加一,LintCode第479题-数组第二大数
第407题: 描述 给定一个非负数,表示一个数字数组,在该数的基础上1,返回一个新的数组。 该数字按照数位高低进行排列,最高位的数在列表的最前面. 样例 1: 输入:[1,2,3] 输出:[1,2,4] 样例 …...

网络安全的范式革命:从被动防御到 AI 驱动的主动对抗
当黑客利用生成式 AI 在 30 秒内生成 10 万组钓鱼邮件,当恶意代码学会根据网络环境自主进化,传统网络安全防线正面临前所未有的挑战。2025 年,全球网络安全领域正在经历一场从 “被动挨打” 到 “主动出击” 的革命性转变,AI 与量…...

内网im软件,支持企业云盘的协同办公软件推荐
BeeWorks不仅是一个即时通讯工具,更是一个综合性的企业管理平台。其云盘功能支持大容量文件存储,便企业集中管理文件。并且具备在线协同编辑的能力,这使得企业在文件管理和团队协作方面更加高效和便捷。以下是BeeWorks在企业云盘和在线协同编…...
——多态)
JAVA SE(9)——多态
1.多态的概念&作用 多态(Polymorphism)是面向对象编程的三大基本特性之一(封装和继承已经讲过了),它允许不同类的对象对同一消息做出不同的响应。具体来说,多态允许基类/父类的引用指向派生类/子类的对象(向上转型…...
:从原理到高频面试题)
单调栈算法精解(Java实现):从原理到高频面试题
在算法与数据结构的领域中,单调栈(Monotonic Stack)凭借其独特的设计和高效的求解能力,成为解决特定类型问题的神兵利器。它通过维护栈内元素的单调性,能将许多问题的时间复杂度从暴力解法的\(O(n)\)优化至\(O(n)\)&am…...

密码工具类-生成随机密码校验密码强度是否满足要求
生成随机密码 符合密码强度的密码要求: 至少有一个大写字母至少有一个小写字母至少有一个数字至少有一个特殊字符长度满足要求(通常为8-16位) // 大写字母private static final String UPPERCASE "ABCDEFGHIJKLMNOPQRSTUVWXYZ";…...

什么是进程,如何管理进程
基本概念(什么是进程?) 课本概念:程序的一个执行实例,正在执行的程序等内核观点:担当分配系统资源(CPU时间,内存)的实体。 描述进程-PCB 进程信息被放在一个叫做进程控…...

小刚说C语言刷题—1044 -找出最经济型的包装箱型号
1.题目描述 已知有 A,B,C,D,E五种包装箱,为了不浪费材料,小于 10公斤的用 A型,大于等于 10公斤小于 20 公斤的用 B型,大于等于 20公斤小于 40 公斤的用 C型,大于等于 40…...

用 GRPO 魔法点亮Text2SQL 的推理之路:让模型“思考”得更像人类
推理能力(Chain of Thought, CoT)可以帮助模型逐步解释其思考过程,从而提高Text-to-SQL 生成的准确性和可解释性。本文探讨了如何将一个标准的 7B 参数的大型语言模型(Qwen2.5-Coder-7B-Instruct)转变为一个能够为Text…...

k8s service的类型
service和Pods service通过使用labels指向pods,而不是指向deployments或者replicasets。这种设计的灵活性极高,因为创建pods的方式有很多,而Service不需要关心pods通过那种方式创建 不使用service(首先看不使用service的情况) 如下…...

机器学习 day6 -线性回归练习
题目: 从Kaggle的“House Prices - Advanced Regression Techniques”数据集使用Pandas读取数据,并查看数据的基本信息。选择一些你认为对房屋价格有重要影响的特征,并进行数据预处理(如缺失值处理、异常值处理等)。…...

机器学习-简要与数据集加载
一.机器学习简要 1.1 概念 机器学习即计算机在数据中总结规律并预测未来结果,这一过程仿照人类的学习过程进行。 深度学习是机器学习中的重要算法的其中之一,是一种偏近现代的算法。 1.2 机器学习发展历史 从上世纪50年代的图灵测试提出、塞缪尔开发…...

HTTP请求与前端资源未优化的系统性风险与高性能优化方案
目录 前言一、未合并静态资源:HTTP请求的隐形杀手1.1 多文件拆分的代价1.2 合并策略与工具链实践 二、未启用GZIP压缩:传输流量的浪费2.1 文本资源的压缩潜力2.2 服务端配置与压缩算法选择 三、未配置浏览器缓存:重复请求的根源3.1 缓存失效的…...
)
黑马点评day04(分布式锁-setnx)
4、分布式锁 4.1 、基本原理和实现方式对比 分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。 分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程并行&#x…...

哈尔滨服务器租用
选择一家正规的本地服务商,能够直接促进您网站今后的发展、确保您企业的信息化进程安全、高效。擦亮您的慧眼,用我的经验告诉您该怎么选择服务商。。。。。。。。综合我们为数据客户服务的经验,选择服务器租用、服务提供商客户所需要关注的主…...
)
企业级RAG架构设计:从FAISS索引到HyDE优化的全链路拆解,金融/医疗领域RAG落地案例与避坑指南(附架构图)
本文较长,纯干货,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。 一. RAG技术概述 1.1 什么是RAG? RAG(Retrieval-Augmented Generation,检索增强生成) 是…...

js获取uniapp获取webview内容高度
js获取uniapp获取webview内容高度 在uni-app中,如果你想要获取webview的内容高度,可以使用uni-app提供的bindload事件来监听webview的加载,然后通过调用webview的invokeMethod方法来获取内容的高度。 以下是一个示例代码: <te…...

AI量化解析:从暴跌5%到飙涨3%—非线性动力学模型重构黄金极端波动预测框架
AI分析:假期效应褪去,金价回调背后的市场逻辑 五一假期期间,全球贵金属市场经历显著波动。5月1日,现货黄金单日跌幅达5.06%,价格从历史高位回落至3200美元/盎司附近,国内金饰价格同步回调,主流…...
辅助管理工具)
Python之pip图形化(GUI界面)辅助管理工具
Python之pip图形化(GUI界面)辅助管理工具 pip 是 Python 的包管理工具,用于安装、管理、更新和卸载 Python 包(模块)。用于第三方库的安装和管理过程,是 Python 开发中不可或缺的工具。 包的安装、更新、…...

数字传播生态中开源链动模式与智能技术协同驱动的品牌认知重构研究——基于“开源链动2+1模式+AI智能名片+S2B2C商城小程序”的场景化传播实践
摘要:在数字传播碎片化与用户注意力稀缺的双重挑战下,传统品牌认知构建模式面临效率衰减与情感黏性缺失的困境。本文以“开源链动21模式AI智能名片S2B2C商城小程序”的协同创新为切入点,构建“技术赋能-场景重构-认知强化”的分析框架。通过对…...

小芯片大战略:Chiplet技术如何重构全球半导体竞争格局?
在科技飞速发展的今天,半导体行业作为信息技术的核心领域之一,其发展速度和创新水平对全球经济的发展具有举足轻重的影响。然而,随着芯片制造工艺的不断进步,传统的单片集成方式逐渐遇到了技术瓶颈,如摩尔定律逐渐逼近…...

链表的面试题3找出中间节点
来来来,接着继续我们的第三道题 。 解法 暴力求解 快慢指针 https://leetcode.cn/problems/middle-of-the-linked-list/submissions/ 这道题的话,思路是非常明确的,就是让你找出我们这个所谓的中间节点并且输出。 那这道题我们就需要注意…...

Java泛型深度解析与电商场景应用
学海无涯,志当存远。燃心砺志,奋进不辍。 愿诸君得此鸡汤,如沐春风,事业有成。 若觉此言甚善,烦请赐赞一枚,共励学途,同铸辉煌! 泛型的工作原理可能包括类型擦除、参数化类型、类型边…...
)
C语言 指针(7)
目录 1.函数指针变量 2.函数指针数组 3.转移表 1.函数指针变量 1.1函数指针变量的创建 什么是函数指针变量呢? 根据前面学习整型指针,数组指针的时候,我们的类比关系,我们不难得出结论: 函数指针变量应该是用来…...

go 编译报错:build constraints exclude all Go files
报错信息: package command-line-arguments imports github.com/amikos-tech/chroma-go imports github.com/amikos-tech/chroma-go/pkg/embeddings/default_ef imports github.com/amikos-tech/chroma-go/pkg/tokenizers/libtokenizers: …...

Android Service 从 1.0 到 16 的演进史
一、Android 1.0(API 1) - 服务的诞生 核心特性: 基础服务组件:作为四大组件之一,Service 用于在后台执行长时间运行的任务,不提供 UI 界面。 启动方式:通过 startService() 启动独立运行的服…...

如何保障服务器租用中的数据安全?
网络科技和互联网的飞速发展,让用户越来越依赖与网络业务,各个行业开展了不同的线上服务,租用服务器已经成为必不可少的组成部分,能够为企业带来便捷,但是数据安全也是不可忽视的,为了能够保护服务器中数据…...

python校园二手交易管理系统-闲置物品交易系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...

消除AttributeError: module ‘ttsfrd‘ has no attribute ‘TtsFrontendEngine‘报错输出的记录
#工作记录 尝试消除 消除“模块ttsfrd没有属性ttsfrontendengine”的错误的记录 报错摘录: Traceback (most recent call last): File "F:\PythonProjects\CosyVoice\webui.py", line 188, in <module> cosyvoice CosyVoice(args.model_di…...

MD2card + Deepseek 王炸组合 一键制作小红书知识卡片
本文目录 MD2Card介绍使用示例deepseek 提示词输出结果MD2Card 制作小红书卡片 MD2Card介绍 MD2Card 是一个免费的 Markdown 转知识卡片工具,支持一键生成小红书风格海报、社交媒体文案排版,让创作者轻松制作精美的图文内容。支持多种主题风格、长文自动…...
)
Relay算子注册(在pytorch.py端调用)
1. Relay算子注册 (C层) (a) 算子属性注册 路径: src/relay/op/nn/nn.cc RELAY_REGISTER_OP("hardswish").set_num_inputs(1).add_argument("data", "Tensor", "Input tensor.").set_support_level(3).add_type_rel("Identity…...

基于RT-Thread的STM32F4开发第二讲第一篇——ADC
文章目录 前言一、RT-Thread工程创建二、ADC工程创建三、ADC功能实现1.ADC.c2.ADC.h3.mian.c 四、效果展示和工程分享总结 前言 ADC是什么不多讲了,前面裸机操作部分有很多讲述。我要说的是RT-Thread对STM32的ADC外设的适配极其不好,特别是STM32G4系类&…...

py实现win自动化自动登陆qq
系列文章目录 py实现win自动化自动登陆qq 文章目录 系列文章目录前言一、上代码?总结 前言 之前都是网页自动化感觉太容易了,就来尝尝win自动化,就先写了一个qq登陆的,这个是拿到className 然后进行点击等。 一、上代码…...

Axure : 列表分页、 列表翻页
文章目录 引言I 列表分页操作说明II 列表翻页操作说明引言 列表分页实现思路:局部变量、 中继器设置每页项目数 I 列表分页 操作说明 在列表元件底部添加一个分页下拉控件,分别为10,20,30,40,50; 将列表转换为动态面板,将设置面板大小勾选取消 给分页大小下拉控件添加…...

大学之大:隆德大学2025.5.6
隆德大学:北欧学术明珠的八百年传承与创新 一.前身历史:从中世纪神学院到现代综合大学的蜕变 隆德大学的历史可追溯至1425年,由丹麦国王埃里克七世在瑞典南部城市隆德创立的“神学与教会法研究院”。这所中世纪学府最初以培养天主教神职人员…...

每日算法-250506
每日算法学习记录 - 250506 今天记录了三道算法题的解题过程和思路,分享给大家。 3192. 使二进制数组全部等于 1 的最少操作次数 II 题目 思路 贪心 解题过程 我们从左到右遍历数组。使用一个变量 ret 来记录已经执行的操作次数。 对于当前元素 nums[i]&#x…...

【免费试用】LattePanda Mu x86 计算模块套件,专为嵌入式开发、边缘计算与 AI 模型部署设计
本次活动为载板设计挑战,旨在激发创意与技术实践能力,鼓励电子工程师、创客、学生及开发者围绕指定LattePanda Mu进行功能丰富、应用多样的载板开发设计。参赛用户将有机会展示硬件设计能力,并通过作品解决实际问题或构建创新项目。本次挑战活…...

用于备份的git版本管理指令
一、先下载一个git服务器软件并安装,创建一个git服务器进行备份的版本管理。 下列指令用于git常用备份: 1、强制覆盖远程仓库: git push --force origin master 2、重新指向新仓库: git remote set-url origin http://192.168.1.2…...

STM32H743单片机实现ADC+DMA多通道检测
在stm32cubeMX上配置ADCDMA实现多通道检测功能 DMA配置 生成代码,HAL_ADC_Start_DMA开始DMA读取ADC值,HAL_ADC_Stop_DMA关闭DMA读取 void Start_ADC2_DMA(void) {/* 初始化后校准ADC */HAL_ADCEx_Calibration_Start(&hadc2, ADC_CALIB_OFFSET, ADC_…...
媒体投稿技能)
(提升)媒体投稿技能
1\前期策划与准备 精准定位目标受众,分析内容偏好与活跃媒体基于目标受众,确定发稿核心主题与内容方向 2\内容创作与素材 撰写稿件注重标题吸引力,确保内容逻辑清晰价值突出。素材整合准备高质量的配图、视频 3\内部审核与优化 对稿件内…...

2025年提交App到Appstore从审核被拒到通过的经历
今年3月份提交一个App到Appstore,感觉比以前要严格了很多,被拒了多次才通过。 如果周末提交审核会非常非常,所以最好选择周一之周四的中午提交。 第一次提交被拒,原因为 Guideline 2.1 - Performance - App Completeness Guidel…...
 SkyWalking--分布式链路追踪系统/分布式的应用性能管理工具)
63.微服务保姆教程 (六) SkyWalking--分布式链路追踪系统/分布式的应用性能管理工具
SkyWalking—分布式链路追踪系统/分布式的应用性能管理工具(APM) 一、为什么要用SkyWalking 对于一个有很多个微服务组成的微服务架构系统,通常会遇到一些问题,比如: 如何串联整个调用链路,快速定位问题如何缕清各个微服务之间的依赖关系如何进行各个微服务接口的性能分…...

vue3 computed方法传参数
我们对computed的基础用法不陌生,比如前端项目中经常会遇到数据处理的情况,我们就会选择computed方法来实现。但大家在碰到某些特殊场景,比如在template模板中for循环遍历时想给自己的计算属性传参,这个该怎么实现呢,很…...

Linux中为某个进程临时指定tmp目录
起因: 在linux下编译k8s,由于编译的中间文件太多而系统的/tmp分区设置太小,导致编译失败,但自己不想或不能更改/tmp分区大小,所以只能通过其他方式解决。 现象: tmp分区大小: 解决方法&#x…...