通过 ModernBERT 实现零样本分类的性能提升
文本分类 是机器学习中最基础的任务之一,拥有悠久的研究历史和深远的实用价值。更重要的是,它是许多实际项目中不可或缺的组成部分,从搜索引擎到生物医学研究都离不开它。文本分类方法被广泛应用于科学论文分类、用户工单分类、社交媒体情感分析、金融研究中的公司分类等领域。让我们再拓展一下这个任务的范畴到序列分类,这个领域的应用场景和影响力会更加广泛,从 DNA 序列分类到 RAG 管道,后者是当前聊天机器人系统中保证高质量和时效性输出的最常用方式。
近年来,自回归语言模型 的进步为许多 零样本分类 任务(包括文本分类)开辟了新天地。虽然这些模型展示出了惊人的多功能性,但它们往往难以严格遵循指令,并且在训练和推理方面都可能存在计算效率问题。
交叉编码器 作为 自然语言推理(NLI)模型是另一种常用于零样本分类和 检索增强生成(RAG)管道的方法。该方法通过将待分类的序列作为 NLI 的前提,并为每个候选标签构造一个假设来进行分类。总的来说,这种方法在处理大量类别时会遇到效率挑战,因为它采用的是成对处理方式。此外,它在理解跨标签信息方面的能力有限,这可能会影响预测质量,尤其是在复杂的场景中。
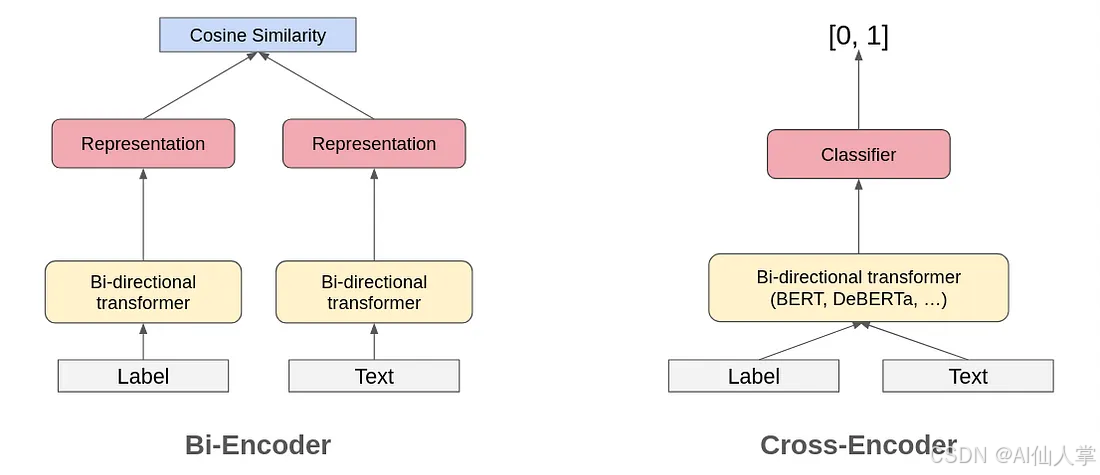
双编码器与交叉编码器架构对比
Word2Vec 的嵌入式方法被认定为文本分类的一种潜在方法,特别是在零样本设置下。使用句子编码器能够更好地理解句子和文本的语义,这使得使用句子嵌入进行文本分类的想法变得显而易见。Sentence Transformers 的出现进一步提高了嵌入的质量,使得即使不进行微调也能使用它们进行分类任务成为可能。SetFit —— 一项基于 Sentence Transformers 的工作,使得即使在每个标签只有少量示例的情况下也能获得良好的性能。尽管基于嵌入的方法效率高且在许多语义任务中表现良好,但在涉及逻辑和语义约束的复杂场景中常常表现不佳。
本文介绍的一种新的文本分类方法,该方法基于 GLiNER 架构,特别适用于 序列分类 任务。旨在在复杂模型的准确性与嵌入式方法的效率之间取得平衡,同时保持良好的 零样本 和 少样本 能力。
GLiClass 架构
我们的架构引入了一种新颖的 序列分类 方法,该方法能够在保持计算效率的同时实现标签与输入文本之间的丰富交互。该实现由几个关键阶段组成,这些阶段协同工作以实现卓越的分类性能。
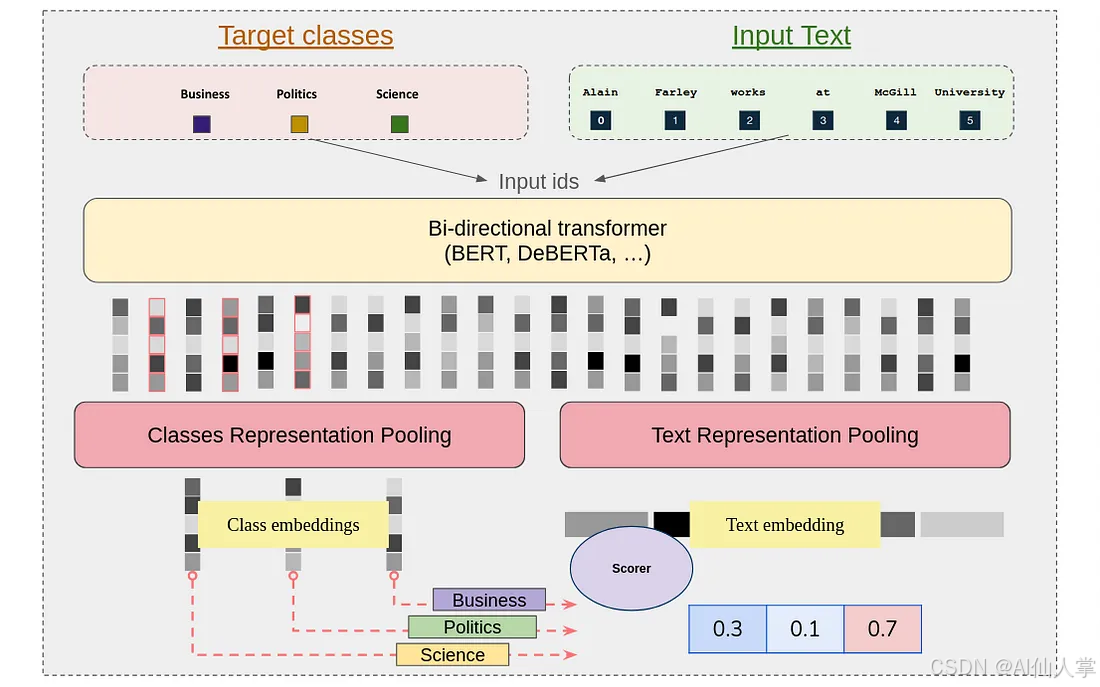
GLiClass 架构
输入处理与标签整合
该过程始于标签整合机制。我们在每个类别标签前添加一个特殊标记 <
上下文表示学习
在分词之后,合并后的输入 ID 会通过双向 Transformer 架构(如 BERT 或 DeBERTa)进行处理。这个阶段至关重要,因为它能够实现三种不同的上下文理解:
- 标签间交互:标签之间可以共享信息,使模型能够理解标签关系和层次结构
- 文本-标签交互:输入文本可以直接影响标签表示
- 标签-文本交互:标签信息可以指导文本的解读
这种多向信息流动代表了对传统交叉编码器架构的重大优势,后者通常仅限于文本-标签对交互,而忽略了宝贵的标签间关系。
表示池化
在获得上下文化表示后,我们采用不同的池化机制来分别处理标签和文本,以提取变压器输出中的基本信息。我们的实现支持多种池化策略:
- 首个 token 池化:利用首个 token 的表示
- 平均池化:对所有 token 进行平均
- 注意力加权池化:应用学习到的注意力权重
- 自定义池化策略:针对特定分类需求进行调整
池化策略的选择可以根据分类任务的具体要求和输入数据的性质进行优化。
评分机制
最后阶段涉及计算合并表示之间的兼容性分数。我们通过灵活的评分框架实现这一点,该框架可以适应各种方法:
- 简单点积评分:对于许多应用来说既高效又有效
- 神经网络评分:用于具有挑战性的场景的更复杂评分函数
- 任务特定评分模块:针对特定分类需求进行定制
这种模块化评分方法使架构能够适应不同的分类场景,同时保持计算效率。
如何使用模型
Hugging Face 上开源了这个模型。
要使用它们,首先安装 gliclass 包:
pip install gliclass
然后你需要初始化一个模型和一个管道:
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizermodel = GLiClassModel.from_pretrained("knowledgator/gliclass-modern-base-v2.0-init")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-modern-base-v2.0-init")pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
这是如何执行推理:
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:print(result["label"], "=>", result["score"])
如何微调
首先,你需要准备如下格式的训练数据:
[{"text": "Some text here!","all_labels": ["sport", "science", "business", …],"true_labels": ["other"]}, …
]
下面是你需要的导入需求:
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"from datasets import load_dataset, Dataset, DatasetDict
from sklearn.metrics import classification_report, f1_score, precision_recall_fscore_support, accuracy_score
import numpy as np
import random
from transformers import AutoTokenizer
import torch
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from gliclass.data_processing import GLiClassDataset, DataCollatorWithPadding
from gliclass.training import TrainingArguments, Trainer
然后,我们初始化模型和分词器:
device = torch.device('cuda:0') if torch.cuda.is_available else torch.device('cpu')
model_name = 'knowledgator/gliclass-base-v1.0'
model = GLiClassModel.from_pretrained(model_name).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
然后,我们指定训练参数:
max_length = 1024
problem_type = "multi_label_classification"
architecture_type = model.config.architecture_type
prompt_first = model.config.prompt_firsttraining_args = TrainingArguments(output_dir='models/test',learning_rate=1e-5,weight_decay=0.01,others_lr=1e-5,others_weight_decay=0.01,lr_scheduler_type='linear',warmup_ratio=0.0,per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=8,evaluation_strategy="epoch",save_steps = 1000,save_total_limit=10,dataloader_num_workers=8,logging_steps=10,use_cpu = False,report_to="none",fp16=False,
)
当你以正确的格式准备好了数据集后,我们需要初始化 GLiClass 数据集和数据收集器:
train_dataset = GLiClassDataset(train_data, tokenizer, max_length, problem_type, architecture_type, prompt_first)
test_dataset = GLiClassDataset(train_data[:int(len(train_data)*0.1)], tokenizer, max_length, problem_type, architecture_type, prompt_first)data_collator = DataCollatorWithPadding(device=device)
当一切就绪后,我们可以开始训练:
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,tokenizer=tokenizer,data_collator=data_collator,
)
trainer.train()
在仓库中查看更多示例:https://github.com/Knowledgator/GLiClass/blob/main/finetuning.ipynb
关键应用场景
GLiClass 在广泛的自然语言处理任务中展示了卓越的多功能性,使其在研究和实际应用中都具有极高的价值。
多类分类
该架构高效地处理大规模分类任务,单次处理最多可处理 100 个不同类别。这一能力对于文档分类、产品分类和内容标签系统等需要多个详细类别的应用特别有价值。
主题分类
GLiClass 在识别和分类文本主题方面表现出色,特别适用于:
- 学术论文分类
- 新闻文章分类
- 内容推荐系统
- 研究文档组织
情感分析
该架构有效捕捉细微的情感和观点内容,支持:
- 社交媒体情感跟踪
- 客户反馈分析
- 产品评论分类
- 品牌感知监控
事件分类
GLiClass 在识别和分类文本中的事件方面表现出强大的能力,支持:
- 新闻事件分类
- 社交媒体事件检测
- 历史事件分类
- 时间线分析和组织
基于提示的约束分类
该系统提供灵活的基于提示的分类与自定义约束,支持:
- 引导分类任务
- 上下文感知分类
- 自定义分类规则
- 动态类别适配
自然语言推理
GLiClass 支持关于文本关系的复杂推理,促进:
- 文本蕴含检测
- 矛盾识别
- 语义相似性评估
- 逻辑关系分析
检索增强生成 (RAG)
良好的架构泛化性以及对自然语言推理任务的支持使其成为 RAG 管道中重排序的理想选择。此外,GLiClass 的效率使其更具竞争力,尤其是与交叉编码器相比。
这一全面的应用范围使 GLiClass 成为现代自然语言处理挑战的多功能工具,在各种分类任务中提供灵活性和精确性。
基准测试结果
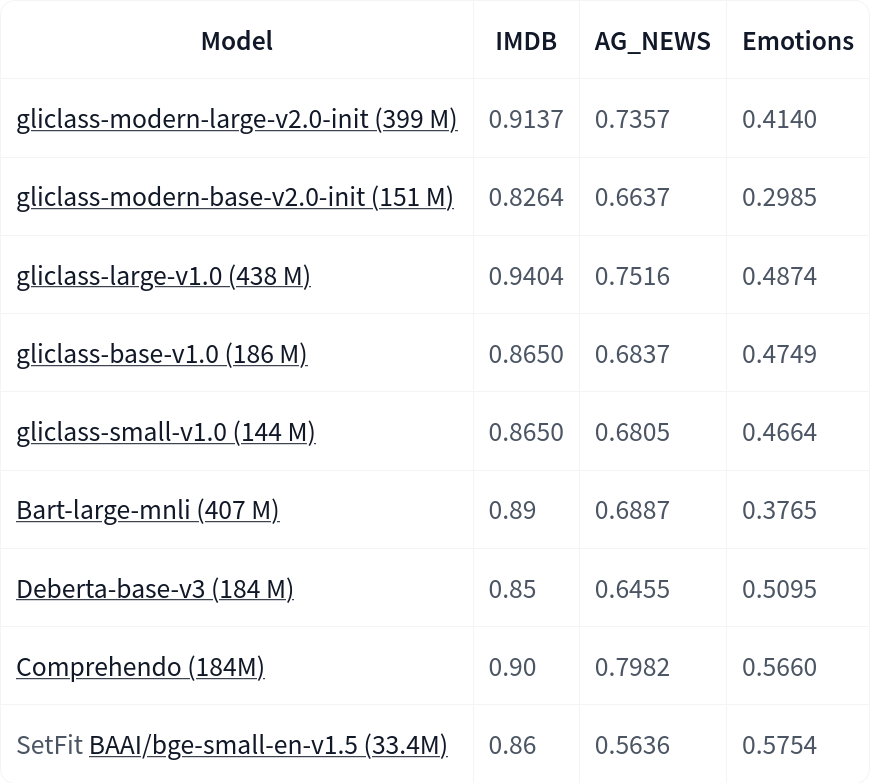
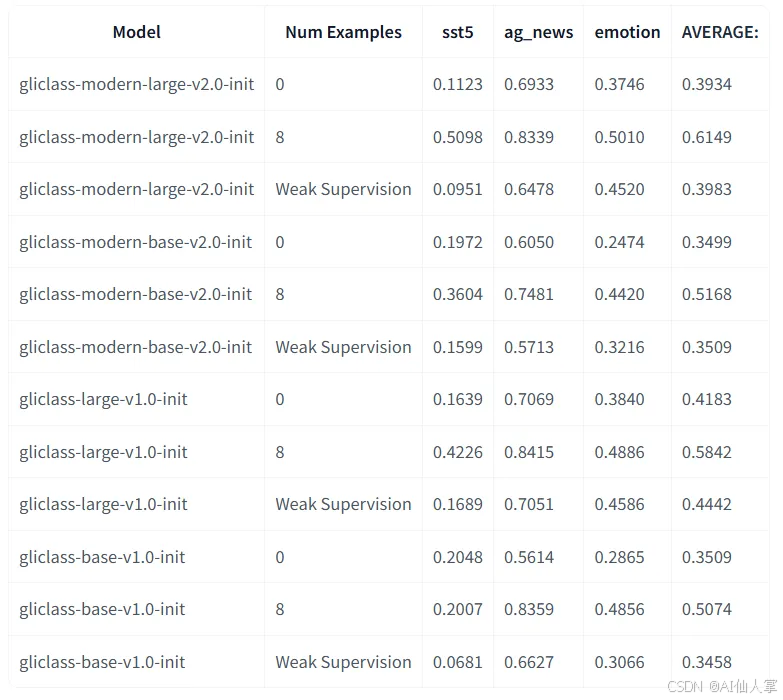
我们发布了一个基于 ModernBERT 的新 GLiClass 模型,与旧模型如 DeBERTa 相比,它提供了更长的上下文长度支持(高达 8k 个 token)和更快的推理速度。我们在多个 文本分类数据集 上对我们的 GLiClass 模型进行了基准测试。
以下是 F1 分数在几个 文本分类数据集 上的表现。所有测试模型都没有在这些数据集上进行微调,并且在 零样本设置 下进行了测试。
以下是对 ModernBERT GLiClass 与其他 GLiClass 模型的更全面比较:
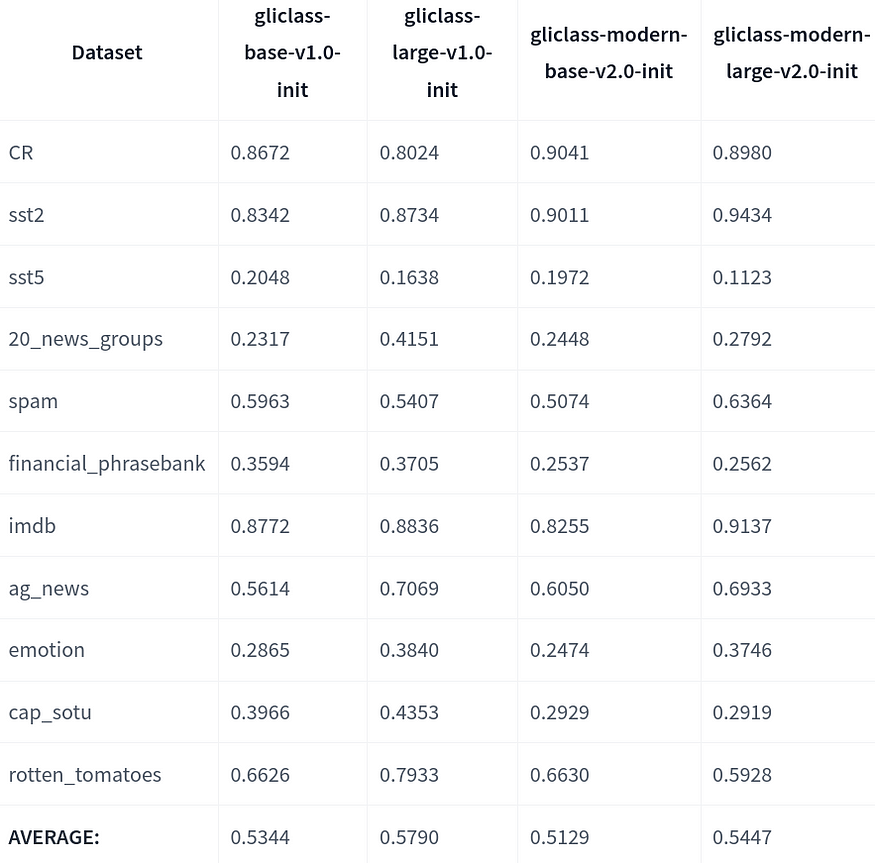
我们研究了如果我们对少量 每个标签的示例 进行 微调,性能会如何增长。此外,我们测试了一种简单的方法,当我们不提供真实文本而是提供给定文本主题的通用短描述时,我们称之为 弱监督。令人惊讶的是,对于像“emotion”这样的某些数据集,它显著提高了性能。
结论
GLiClass 代表了文本分类领域的重大进步,提供了一种强大而高效的解决方案,弥合了复杂 Transformer 模型的准确性与嵌入式方法的简单性之间的差距。通过利用一种新颖的架构,该架构促进了输入文本和标签之间的丰富交互,GLiClass 在零样本和少样本分类任务中实现了卓越的性能,同时保持了计算效率,即使面对大型标签集也是如此。它能够捕捉跨标签依赖关系,适应各种分类场景,并与现有的 NLP 管道无缝集成,使其成为从情感分析和主题分类到检索增强生成和自然语言推理等各种应用的多功能工具。
使用生成式语言模型进行零样本分类:https://github.com/Knowledgator/unlimited_classifier
相关文章:

通过 ModernBERT 实现零样本分类的性能提升
文本分类 是机器学习中最基础的任务之一,拥有悠久的研究历史和深远的实用价值。更重要的是,它是许多实际项目中不可或缺的组成部分,从搜索引擎到生物医学研究都离不开它。文本分类方法被广泛应用于科学论文分类、用户工单分类、社交媒体情感分…...

【AI】Ubuntu 22.04 4060Ti 16G vllm-api部署Qwen3-8B-FP8
下载模型 # 非常重要,否则容易不兼容报错 pip install modelscope -U cd /data/ai/models modelscope download --model Qwen/Qwen3-8B-FP8 --local_dir ./Qwen3-8B-FP8 安装vllm 创建虚拟环境 mkdir vllm cd vllm/ python -m venv venv ource venv/bin/activat…...

QML ProgressBar控件详解
在 QML 中,ProgressBar 是一个常用的进度条控件,用于显示任务的完成进度。以下是 ProgressBar 的详细用法,包括基本用法、自定义样式、动态绑定数据等。 1. 基本用法 1.1 最简单的 ProgressBar import QtQuick.Controls 2.15ProgressBar {w…...
*详细教程*)
STM32教程:串口USART通讯协议原理及分析(基于STM32F103C8T6最小系统板标准库开发)*详细教程*
前言: 本文主要介绍了单片机的通讯协议和STM32的串口USART通讯的原理及分析。 通信的目的 将一个设备的数据传送到另一个设备,扩展硬件系统。 通信协议 指定通信的规则,通信双方按照协议规则进行数据收发。 STM32常见通讯协议 各通讯特点 USART: TX(发送)、RX(接…...

EDA文件
不同的EDA软件使用不同的文件扩展名和格式,以下是主流工具对应的文件类型: EDA软件文件扩展名说明Altium Designer.PcbDocAltium专属格式,需用原软件打开,可导出为Gerber或STEP文件用于生产。KiCad.kicad_pcbKiCad项目文件&#…...

【C/C++】构造函数与析构函数
📘 C 构造函数与析构函数详解笔记 🧠 为什么需要构造函数与析构函数? 在 C 中,对象创建和销毁过程如果仅靠手动赋值和清理非常容易出错。为此,语言提供了构造函数和析构函数: 构造函数:用于在…...

在Unity AR应用中实现摄像头切换功能
本教程将详细讲解如何在Unity AR Foundation项目中实现前后摄像头切换功能,并提供完整的代码解析。我们将使用AR Foundation的核心组件和简单的UI交互来实现这一功能。 第一部分:环境准备 1.1 所需组件 Unity 2019.4或更高版本 AR Foundation 4.0+ ARCore XR Plugin(Andro…...
深度学习)
Pycharm(十九)深度学习
一、深度学习概述 1.1 什么是深度学习 深度学习是机器学习中的一种特殊方法,它使用称为神经网络的复杂结构,特别是“深层”的神经网络,来学习和做出预测。深度学习特别适合处理大规模和高维度的数据,如图像、声音和文本。深度学习、机器学习和人工智能之间的关系如下图所…...

状态模式 VS 策略模式
在软件开发的世界里,设计模式如同工匠手中的精良工具,能帮助开发者打造出结构清晰、易于维护和扩展的软件系统。状态模式和策略模式便是其中两个常用却容易让人混淆的设计模式。接下来,我们会详细剖析它们的区别、适用场景,并给出…...

如何在 Ubuntu 24.04 本地安装 DeepSeek ?
在本地 Ubuntu 系统上安装 DeepSeek 可以让您在本地使用高级 AI 功能,从而消除对云服务的依赖需求。 What is DeepSeek? DeepSeek 是一个先进的开源人工智能模型,专为自然语言理解和生成而设计。它提供了类似ChatGPT的强大功能。 Prerequisites: A …...
)
云计算训练营笔记day02(Linux、计算机网络、进制)
Linux 是一个操作系统 Linux版本 RedHat Rocky Linux CentOS7 Linux Ubuntu Linux Debian Linux Deepin Linux 登录用户 管理员 root a 普通用户 nsd a 打开终端 放大: ctrl shift 缩小: ctrl - 命令行提示符 [rootlocalhost ~]# ~ 家目录 /root 当前登录的用户…...

数据库实验10 函数存储
数据库实验10 一、实验目的 掌握函数和存储过程的定义方法,包括标量函数、表值函数、存储过程的语法结构。理解函数和存储过程的作用及原理,区分标量函数与表值函数的应用场景,掌握存储过程的参数传递、逻辑控制和错误处理机制。能够熟练运…...

SQL Server执行安装python环境
安装注意事项 启用python脚本支持 sp_configure external scripts enabled, 1; RECONFIGURE; 安装后接受 Python EULA协议 接受python授权 setup.exe /qs /ACTIONInstall /FEATURESSQL_INST_MR /INSTANCENAME您的实例名 /IACCEPTROPENLICENSETERMS1 /IACCEPTPYTHONLICENSETE…...
)
ActiveMQ 安全机制与企业级实践(二)
四、企业级实践案例分析 4.1 案例背景介绍 某大型电商企业拥有复杂的分布式系统,涵盖订单管理、库存管理、物流配送、用户服务等多个核心业务模块。在业务快速发展过程中,系统间的通信量呈爆发式增长,为了实现系统的高效解耦和异步通信&…...
)
ActiveMQ 安全机制与企业级实践(一)
一、引言 在当今数字化时代,企业级应用的架构愈发复杂,各个系统之间的通信和协作变得至关重要。消息队列作为一种高效的异步通信机制,在企业级应用集成中扮演着关键角色。ActiveMQ 作为一款广泛使用的开源消息中间件,以其丰富的功…...

【Python pass 语句】
在 Python 中,pass 语句是一个特殊的空操作(no-op)语句,它的核心作用是保持程序结构的完整性,同时不执行任何实际操作。以下是详细说明: 一、基础特性 语法占位符:当语法上需要一条语句&#x…...

Maven依赖未生效问题
在你描述的情况下,测试类无法找到 Maven 依赖的 jar 包,可能由以下原因导致: 依赖未正确添加到 pom.xml 检查 pom.xml 文件中是否正确添加了 Elasticsearch 和 JUnit 等相关依赖。例如,对于 Elasticsearch 的 TransportClient 相关…...

NGINX `ngx_http_auth_request_module` 模块详解基于子请求的认证授权方案
一、背景介绍 在 Web 系统中,我们常常需要根据外部服务(例如单点登录、API 网关、权限中心)的结果来判断用户是否有权限访问某个资源。NGINX 提供的 ngx_http_auth_request_module 模块,正是为这种场景而生。它允许通过向后端发送…...
)
Qwen3简要介绍(截止20250506)
Qwen3是阿里云推出的一个大语言模型系列,它在多个方面进行了升级和优化。以下是Qwen3的一些主要特点: 模型规模多样:Qwen3提供了一系列不同规模的模型,包括稠密模型(0.6B、1.7B、4B、8B、14B、32B)以及专家…...
:移动应用商业模式的深度剖析与实战要点)
精益数据分析(42/126):移动应用商业模式的深度剖析与实战要点
精益数据分析(42/126):移动应用商业模式的深度剖析与实战要点 在创业和数据分析的学习之路上,我们持续探索不同商业模式的奥秘,今天聚焦于移动应用商业模式。我希望和大家一起进步,深入解读《精益数据分析…...

2025.5.6总结
昨天12:30睡觉,结果翻来覆去睡不着,两点半左右才睡着。看了一下最近的睡眠打卡,平均入睡时间是凌晨12:30。 自五一一个人过了5天,我才明白,人是需要社交的,只有在社交中才能找到自我…...

UE5 脚部贴地不穿过地板方案
UE自带的IK RIG和ControlRig技术 【UE5】角色脚部IK——如何让脚贴在不同斜度的地面(设置脚的旋转)_哔哩哔哩_bilibili 实验后这个还是有一部分问题,首先只能保证高度不能穿过,但是脚步旋转还是会导致穿模 IK前,整个模型在斜坡上会浮空 参考制作:https://www.youtube.com/w…...
系统设计方案)
Spring AI 函数调用(Function Call)系统设计方案
一、系统概述与设计目标 1.1 核心目标 从零构建一个灵活、安全、高效的函数调用系统,使大语言模型能够在对话中调用应用程序中的方法,同时保持良好的开发体验和企业级特性。 1.2 主要功能需求 支持通过注解将普通Java方法标记为可被AI调用的函数自动生成符合LLM要求的函数…...

Jupyter Notebook为什么适合数据分析?
Jupyter Notebook 是一款超实用的 Web 应用程序,在数据科学、编程等诸多领域都发挥着重要作用。它最大的特点就是能让大家轻松创建和共享文学化程序文档。这里说的文学化程序文档,简单来讲,就是把代码、解释说明、数学公式以及数据可视化结果…...

Leetcode Hot 100字母异位词分词
题目描述 思路 根据题意,我们可以得知我们需要将字符统计数一样的字符串,放在一起,并以列表进行返回。因此我们可以通过一个哈希表,把统计相同的放在一起,最终返回即可 代码 class Solution:def groupAnagrams(self…...

用python实现鼠标监听与手势交互
摘要 本文探讨了一种基于Python的数学函数可视化系统的设计与实现,该系统整合了Pynput鼠标事件监听机制、Matplotlib绘图引擎以及PyQt5图形用户界面框架。系统通过人机交互方式实现了函数图像的直观构建与可视化表达,支持多种函数类型的参数化建模与实时…...

UE5 GAS开发P47 游戏标签
FGameplayTag 是 Unreal Engine 中用于标记游戏对象的系统。它允许开发者为游戏对象分配标签,以便在游戏中对其进行分类、识别和操作。 FGameplayTag 结构用于表示单个游戏标签,而 FGameplayTagContainer 则用于表示一组游戏标签。 这些标签可以用于诸…...
)
C# 实现PLC数据自动化定时采集与存储(无需界面,自动化运行)
C# 实现PLC数据自动化定时采集与存储(无需界面,自动化运行) 在平时开发中,我们时常会遇到需要后台静默运行的应用场景,这些程序不需要用户的直接操作或界面展示,而是专注于定时任务的执行。比如说…...

Java实现堆排序算法
1. 堆排序原理图解 堆排序是一种基于二叉堆(通常使用最大堆)的排序算法。其核心思想是利用堆的性质(父节点的值大于或等于子节点的值)来高效地进行排序。堆排序分为两个主要阶段:建堆和排序。 堆排序步骤: …...

封装axios,实现取消请求
封装axios import axios from axios// 创建自定义的请求类 class CancelableRequest {constructor() {this.controller new AbortController()}abort() {this.controller.abort()} }// 创建 axios 实例 const service axios.create({baseURL: process.env.VUE_APP_BASE_API,…...

在 Laravel 12 中实现 WebSocket 通信
在 Laravel 12 中实现 WebSocket 通信主要有两种主流方案:官方推荐的 Laravel Reverb 和 第三方库(如 Soketi/Pusher 或 Workerman/Swoole)。以下是详细实现步骤: 一、官方方案:Laravel Reverb(推…...

iPhone或iPad想要远程投屏到Linux系统电脑,要怎么办?
苹果手机自带AirPlay投屏功能,对于苹果电脑,自然可以随时投屏。但如果电脑是Linux系统,而且还想要远程投屏呢?这时候要怎么将iPhone或iPad投屏到Linux电脑? 方法很简单,用AirDroid Cast的网页版即可。 步骤…...

Ubuntu 22.04 安装配置远程桌面环境指南
在云服务器或远程主机上安装图形化桌面环境,可以极大地提升管理效率和用户体验。本文将详细介绍如何在 Ubuntu 22.04 (Jammy Jellyfish) 系统上安装和配置 Xfce4 桌面环境,并通过 VNC 实现远程访问。 系统环境 操作系统:Ubuntu 22.04 LTS (Jammy Jellyfish)架构:AMD64安装…...

【Redis | 基础总结篇 】
目录 前言: 1.Redis的介绍: 2.Redis的类型与命令: 3.Redis的安装: 3.1.Windows版本 3.2.Linux版本 4.在java中使用Redis: 4.1.介绍 4.2.Jedis 4.3.Spring Data Redis 前言: 本篇主要讲述了Redis的…...

如何通过外网访问内网?对比5个简单的局域网让互联网连接方案
在实际应用中,常常需要从外网访问内网资源,如远程办公访问公司内部服务器、在家访问家庭网络中的设备等。又或者在本地内网搭建的项目应用需要提供互联网服务。以下介绍几种常见的外网访问内网、内网提供公网连接实现方法参考。 一、公网IP路由器端口映…...

iMeta | 临床研究+scRNA-seq的组合思路 | 真实世界新辅助研究,HER2⁺就一定受益?单细胞揭示真正的“疗效敏感克隆”
👋 欢迎关注我的生信学习专栏~ 如果觉得文章有帮助,别忘了点赞、关注、评论,一起学习 近年来,临床医学与单细胞组学的结合开启了全新的研究范式,让临床医生能以“显微镜”般的精度,深入理解疾病机制与疗效…...

国标GB28181视频平台EasyCVR安防系统部署知识:如何解决异地监控集中管理和组网问题
在企业、连锁机构及园区管理等场景中,异地监控集中管控与快速组网需求日益迫切。弱电项目人员和企业管理者亟需整合分散监控资源,实现跨区域统一管理与实时查看。 一、解决方案 案例一:运营商专线方案 利用运营商专线,连接各分…...

220V降12V1000mA非隔离芯片WT5110
220V降12V1000mA非隔离芯片WT5110 以下是采用WT5110芯片的非隔离降压电源电路设计,将220V电压转换为12V、1000mA输出: 一、WT5110芯片简介 WT5110是一款用于非隔离降压应用的集成电路,具备宽输入电压范围和高效的转换功能。它可以将高输入电…...

【ES】Elasticsearch字段映射冲突问题分析与解决
在使用Elasticsearch作为搜索引擎时,经常会遇到一些映射(Mapping)相关的问题。本文将深入分析字段映射冲突问题,并通过原生的Elasticsearch API请求来复现和解决这个问题。 问题描述 在实际项目中,我们遇到以下错误: Transport…...

【上位机——MFC】绘图
相关类 CDC类(绘图设备类):封装了各种绘图相关的函数,以及两个非常重要的成员变量m_hDC和m_hAttribDC CPaintDC类,封装了在WM_PAINT消息中绘图的绘图设备 CClientDC类,封装了在客户区绘图的绘图设备 CGdiObject类(绘图对象类) 封…...

【AI】Ubuntu 22.04 evalscope 模型评测 Qwen3-4B-FP8
安装evalscope mkdir evalscope cd evalscope/ python3 -m venv venv source venv/bin/activate pip install evalscope[app,perf] -U -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.compip install tiktoken omegaconf -i https://mirrors.aliyu…...

js var a=如果ForRemove=true,是“normal“,否则为“bold“
你是想根据变量 ForRemove 的布尔值来给变量 a 赋值,如果 ForRemove 为 true,则 a 的值是 "normal",否则为 "bold"。在 JavaScript 里,你可以使用 if...else 语句或者三元运算符来实现。 方法一:…...

JavaScript性能优化实战:从瓶颈分析到解决方案
前言 在当今快节奏的互联网环境中,用户对网站性能的期望日益提高。 JavaScript作为前端开发的核心语言,其性能直接影响用户体验。本文将深入探讨JavaScript代码中常见的性能瓶颈,并结合实际案例分享优化技巧和工具,帮助开发者提升…...

CyberSentinel AI开源程序 是一个自动化安全监控与AI分析系统
一、软件介绍 文末提供程序和源码下载 CyberSentinel AI 开源程序是一个强大的自动化安全监控与AI分析系统,旨在帮助安全研究人员和爱好者 实时追踪最新的安全漏洞 (CVE) 和 GitHub 上的安全相关仓库,并利用 人工智能技术进行深度分析,最终…...
)
C++23 std::generator:用于范围的同步协程生成器 (P2502R2, P2787R0)
文章目录 引言C23新特性概述std::generator基本概念定义作用模板参数 std::generator特性分析与协程的结合范围视图内存管理 std::generator使用示例std::generator的优势与挑战优势挑战 总结 引言 在C的发展历程中,每一个新版本都带来了许多令人期待的新特性和改进…...
下的传感器数据和轨迹信息。)
FoMo 数据集是一个专注于机器人在季节性积雪变化环境中的导航数据集,记录了不同季节(无雪、浅雪、深雪)下的传感器数据和轨迹信息。
2025-05-02,由加拿大拉瓦尔大学北方机器人实验室和多伦多大学机器人研究所联合创建的 FoMo 数据集,目的是研究机器人在季节性积雪变化环境中的导航能力。该数据集的意义在于填补了机器人在极端季节变化(如积雪深度变化)下的导航研…...

Github上如何准确地搜索开源项目
Github上如何准确地搜索开源项目: 因为寻找项目练手是最快速掌握技术的途径,而Github上有最全最好的开源项目。 就像我的毕业设计“机器翻译”就可以在Github上查找开源项目来参考。 以下搜索针对:项目名的关键词,关注数限制&a…...

从 MDM 到 Data Fabric:下一代数据架构如何释放 AI 潜能
从 MDM 到 Data Fabric:下一代数据架构如何释放 AI 潜能 —— 传统治理与新兴架构的范式变革与协同进化 引言:AI 规模化落地的数据困境 在人工智能技术快速发展的今天,企业对 AI 的期望已从 “单点实验” 转向 “规模化落地”。然而&#…...
)
个人Unity自用面经(未完)
目录标题 1.在 2D 平台跳跃游戏项目中,你使用了对象池来生成和回收怪物包含阵亡的动画预制件。在对象池回收对象时,如何确保动画状态被正确重置,避免下次使用时出现异常?2.在僵尸吃脑子模拟项目中,你创建了继承于IAspe…...

【Pandas】pandas DataFrame agg
Pandas2.2 DataFrame Function application, GroupBy & window 方法描述DataFrame.apply(func[, axis, raw, …])用于沿 DataFrame 的轴(行或列)应用一个函数DataFrame.map(func[, na_action])用于对 DataFrame 的每个元素应用一个函数DataFrame.a…...