【AI】Ubuntu 22.04 4060Ti 16G vllm-api部署Qwen3-8B-FP8
下载模型
# 非常重要,否则容易不兼容报错
pip install modelscope -U
cd /data/ai/models
modelscope download --model Qwen/Qwen3-8B-FP8 --local_dir ./Qwen3-8B-FP8安装vllm
创建虚拟环境
mkdir vllm
cd vllm/
python -m venv venv
ource venv/bin/activate
安装vllm
# 安装vLLM框架及ModelScope
pip install modelscope vllm -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com# 安装FlashAttention优化模块
# 安装系统级构建工具
sudo apt-get install build-essential python3-dev
# 安装Python构建工具
pip install setuptools wheel ninja -i https://mirrors.aliyun.com/pypi/simple/# 更新Transformers库
pip install --upgrade transformers -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
启动vllm openapi服务器
vllm serve /data/ai/models/Qwen3-8B-FP8 \
--served-model-name Qwen3-8B-FP8 \
--port 8000 \
--dtype auto \
--gpu-memory-utilization 0.8 \
--max-model-len 4096 \
--tensor-parallel-size 1
启动日志
(venv) yeqiang@yeqiang-Default-string:/data/ai/vllm$ vllm serve /data/ai/models/Qwen3-8B-FP8 --served-model-name Qwen3-8B-FP8 --port 8000 --dtype auto --gpu-memory-utilization 0.8 --max-model-len 4096 --tensor-parallel-size 1
INFO 05-06 20:48:11 [__init__.py:239] Automatically detected platform cuda.
INFO 05-06 20:48:14 [api_server.py:1043] vLLM API server version 0.8.5.post1
INFO 05-06 20:48:14 [api_server.py:1044] args: Namespace(subparser='serve', model_tag='/data/ai/models/Qwen3-8B-FP8', config='', host=None, port=8000, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='/data/ai/models/Qwen3-8B-FP8', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config={}, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', max_model_len=4096, guided_decoding_backend='auto', reasoning_parser=None, logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=None, gpu_memory_utilization=0.8, swap_space=4, kv_cache_dtype='auto', num_gpu_blocks_override=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', cpu_offload_gb=0, calculate_kv_scales=False, disable_sliding_window=False, use_v2_block_manager=True, seed=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config={}, limit_mm_per_prompt={}, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=None, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=None, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', speculative_config=None, ignore_patterns=[], served_model_name=['Qwen3-8B-FP8'], qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, max_num_batched_tokens=None, max_num_seqs=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, num_lookahead_slots=0, scheduler_delay_factor=0.0, preemption_mode=None, num_scheduler_steps=1, multi_step_stream_outputs=True, scheduling_policy='fcfs', enable_chunked_prefill=None, disable_chunked_mm_input=False, scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, additional_config=None, enable_reasoning=False, disable_cascade_attn=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False, dispatch_function=<function ServeSubcommand.cmd at 0x7f2d48275000>)
INFO 05-06 20:48:18 [config.py:717] This model supports multiple tasks: {'generate', 'reward', 'embed', 'score', 'classify'}. Defaulting to 'generate'.
INFO 05-06 20:48:18 [config.py:2003] Chunked prefill is enabled with max_num_batched_tokens=2048.
WARNING 05-06 20:48:18 [fp8.py:63] Detected fp8 checkpoint. Please note that the format is experimental and subject to change.
INFO 05-06 20:48:20 [__init__.py:239] Automatically detected platform cuda.
INFO 05-06 20:48:22 [core.py:58] Initializing a V1 LLM engine (v0.8.5.post1) with config: model='/data/ai/models/Qwen3-8B-FP8', speculative_config=None, tokenizer='/data/ai/models/Qwen3-8B-FP8', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=fp8, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='auto', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=Qwen3-8B-FP8, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 05-06 20:48:22 [utils.py:2522] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7fdf82584790>
INFO 05-06 20:48:22 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-06 20:48:22 [cuda.py:221] Using Flash Attention backend on V1 engine.
WARNING 05-06 20:48:22 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
INFO 05-06 20:48:22 [gpu_model_runner.py:1329] Starting to load model /data/ai/models/Qwen3-8B-FP8...
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:00<00:00, 1.98it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.75it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.78it/s]INFO 05-06 20:48:23 [loader.py:458] Loading weights took 1.18 seconds
WARNING 05-06 20:48:23 [kv_cache.py:128] Using Q scale 1.0 and prob scale 1.0 with fp8 attention. This may cause accuracy issues. Please make sure Q/prob scaling factors are available in the fp8 checkpoint.
INFO 05-06 20:48:23 [gpu_model_runner.py:1347] Model loading took 8.8011 GiB and 1.314728 seconds
INFO 05-06 20:48:30 [backends.py:420] Using cache directory: /home/yeqiang/.cache/vllm/torch_compile_cache/075128b044/rank_0_0 for vLLM's torch.compile
INFO 05-06 20:48:30 [backends.py:430] Dynamo bytecode transform time: 6.33 s
INFO 05-06 20:48:33 [backends.py:136] Cache the graph of shape None for later use
INFO 05-06 20:48:53 [backends.py:148] Compiling a graph for general shape takes 22.83 s
WARNING 05-06 20:48:54 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=6144,K=4096,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
WARNING 05-06 20:48:56 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=4096,K=4096,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
WARNING 05-06 20:48:56 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=24576,K=4096,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
WARNING 05-06 20:48:56 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=4096,K=12288,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
INFO 05-06 20:49:28 [monitor.py:33] torch.compile takes 29.15 s in total
INFO 05-06 20:49:29 [kv_cache_utils.py:634] GPU KV cache size: 11,184 tokens
INFO 05-06 20:49:29 [kv_cache_utils.py:637] Maximum concurrency for 4,096 tokens per request: 2.73x
INFO 05-06 20:49:54 [gpu_model_runner.py:1686] Graph capturing finished in 25 secs, took 2.61 GiB
INFO 05-06 20:49:54 [core.py:159] init engine (profile, create kv cache, warmup model) took 90.51 seconds
INFO 05-06 20:49:54 [core_client.py:439] Core engine process 0 ready.
WARNING 05-06 20:49:54 [config.py:1239] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 05-06 20:49:54 [serving_chat.py:118] Using default chat sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-06 20:49:54 [serving_completion.py:61] Using default completion sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-06 20:49:54 [api_server.py:1090] Starting vLLM API server on http://0.0.0.0:8000
INFO 05-06 20:49:54 [launcher.py:28] Available routes are:
INFO 05-06 20:49:54 [launcher.py:36] Route: /openapi.json, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /docs, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /redoc, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /health, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /load, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /ping, Methods: GET, POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /tokenize, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /detokenize, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/models, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /version, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/completions, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/embeddings, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /pooling, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /score, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/score, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /rerank, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/rerank, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v2/rerank, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /invocations, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /metrics, Methods: GET
INFO: Started server process [201874]
INFO: Waiting for application startup.
INFO: Application startup complete.验证基本服务状态
yeqiang@yeqiang-Default-string:/data/ai/vllm$ curl http://localhost:8000/v1/models
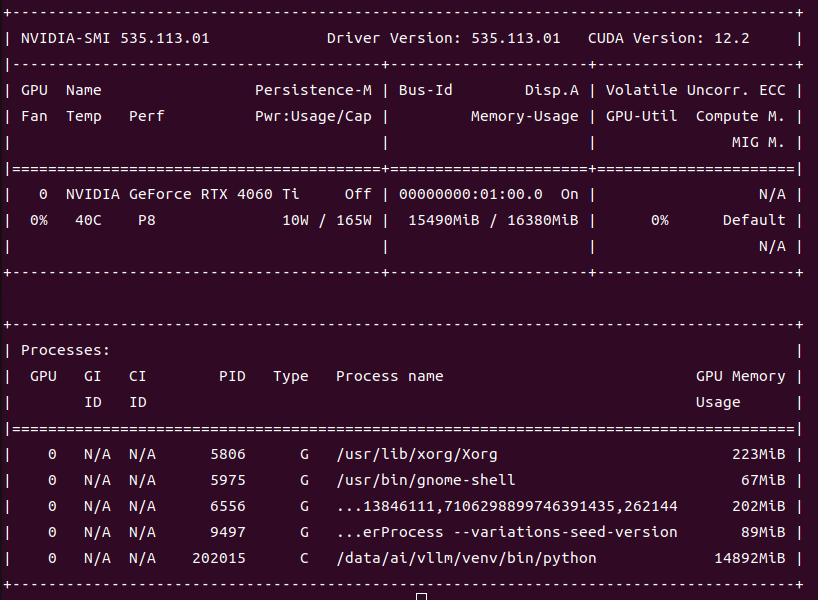
{"object":"list","data":[{"id":"Qwen3-8B-FP8","object":"model","created":1746535967,"owned_by":"vllm","root":"/data/ai/models/Qwen3-8B-FP8","parent":null,"max_model_len":4096,"permission":[{"id":"modelperm-9c2faa75985d4efabc3ddf63942c3f04","object":"model_permission","created":1746535967,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}GPU状态
相关文章:

【AI】Ubuntu 22.04 4060Ti 16G vllm-api部署Qwen3-8B-FP8
下载模型 # 非常重要,否则容易不兼容报错 pip install modelscope -U cd /data/ai/models modelscope download --model Qwen/Qwen3-8B-FP8 --local_dir ./Qwen3-8B-FP8 安装vllm 创建虚拟环境 mkdir vllm cd vllm/ python -m venv venv ource venv/bin/activat…...

QML ProgressBar控件详解
在 QML 中,ProgressBar 是一个常用的进度条控件,用于显示任务的完成进度。以下是 ProgressBar 的详细用法,包括基本用法、自定义样式、动态绑定数据等。 1. 基本用法 1.1 最简单的 ProgressBar import QtQuick.Controls 2.15ProgressBar {w…...
*详细教程*)
STM32教程:串口USART通讯协议原理及分析(基于STM32F103C8T6最小系统板标准库开发)*详细教程*
前言: 本文主要介绍了单片机的通讯协议和STM32的串口USART通讯的原理及分析。 通信的目的 将一个设备的数据传送到另一个设备,扩展硬件系统。 通信协议 指定通信的规则,通信双方按照协议规则进行数据收发。 STM32常见通讯协议 各通讯特点 USART: TX(发送)、RX(接…...

EDA文件
不同的EDA软件使用不同的文件扩展名和格式,以下是主流工具对应的文件类型: EDA软件文件扩展名说明Altium Designer.PcbDocAltium专属格式,需用原软件打开,可导出为Gerber或STEP文件用于生产。KiCad.kicad_pcbKiCad项目文件&#…...

【C/C++】构造函数与析构函数
📘 C 构造函数与析构函数详解笔记 🧠 为什么需要构造函数与析构函数? 在 C 中,对象创建和销毁过程如果仅靠手动赋值和清理非常容易出错。为此,语言提供了构造函数和析构函数: 构造函数:用于在…...

在Unity AR应用中实现摄像头切换功能
本教程将详细讲解如何在Unity AR Foundation项目中实现前后摄像头切换功能,并提供完整的代码解析。我们将使用AR Foundation的核心组件和简单的UI交互来实现这一功能。 第一部分:环境准备 1.1 所需组件 Unity 2019.4或更高版本 AR Foundation 4.0+ ARCore XR Plugin(Andro…...
深度学习)
Pycharm(十九)深度学习
一、深度学习概述 1.1 什么是深度学习 深度学习是机器学习中的一种特殊方法,它使用称为神经网络的复杂结构,特别是“深层”的神经网络,来学习和做出预测。深度学习特别适合处理大规模和高维度的数据,如图像、声音和文本。深度学习、机器学习和人工智能之间的关系如下图所…...

状态模式 VS 策略模式
在软件开发的世界里,设计模式如同工匠手中的精良工具,能帮助开发者打造出结构清晰、易于维护和扩展的软件系统。状态模式和策略模式便是其中两个常用却容易让人混淆的设计模式。接下来,我们会详细剖析它们的区别、适用场景,并给出…...

如何在 Ubuntu 24.04 本地安装 DeepSeek ?
在本地 Ubuntu 系统上安装 DeepSeek 可以让您在本地使用高级 AI 功能,从而消除对云服务的依赖需求。 What is DeepSeek? DeepSeek 是一个先进的开源人工智能模型,专为自然语言理解和生成而设计。它提供了类似ChatGPT的强大功能。 Prerequisites: A …...
)
云计算训练营笔记day02(Linux、计算机网络、进制)
Linux 是一个操作系统 Linux版本 RedHat Rocky Linux CentOS7 Linux Ubuntu Linux Debian Linux Deepin Linux 登录用户 管理员 root a 普通用户 nsd a 打开终端 放大: ctrl shift 缩小: ctrl - 命令行提示符 [rootlocalhost ~]# ~ 家目录 /root 当前登录的用户…...

数据库实验10 函数存储
数据库实验10 一、实验目的 掌握函数和存储过程的定义方法,包括标量函数、表值函数、存储过程的语法结构。理解函数和存储过程的作用及原理,区分标量函数与表值函数的应用场景,掌握存储过程的参数传递、逻辑控制和错误处理机制。能够熟练运…...

SQL Server执行安装python环境
安装注意事项 启用python脚本支持 sp_configure external scripts enabled, 1; RECONFIGURE; 安装后接受 Python EULA协议 接受python授权 setup.exe /qs /ACTIONInstall /FEATURESSQL_INST_MR /INSTANCENAME您的实例名 /IACCEPTROPENLICENSETERMS1 /IACCEPTPYTHONLICENSETE…...
)
ActiveMQ 安全机制与企业级实践(二)
四、企业级实践案例分析 4.1 案例背景介绍 某大型电商企业拥有复杂的分布式系统,涵盖订单管理、库存管理、物流配送、用户服务等多个核心业务模块。在业务快速发展过程中,系统间的通信量呈爆发式增长,为了实现系统的高效解耦和异步通信&…...
)
ActiveMQ 安全机制与企业级实践(一)
一、引言 在当今数字化时代,企业级应用的架构愈发复杂,各个系统之间的通信和协作变得至关重要。消息队列作为一种高效的异步通信机制,在企业级应用集成中扮演着关键角色。ActiveMQ 作为一款广泛使用的开源消息中间件,以其丰富的功…...

【Python pass 语句】
在 Python 中,pass 语句是一个特殊的空操作(no-op)语句,它的核心作用是保持程序结构的完整性,同时不执行任何实际操作。以下是详细说明: 一、基础特性 语法占位符:当语法上需要一条语句&#x…...

Maven依赖未生效问题
在你描述的情况下,测试类无法找到 Maven 依赖的 jar 包,可能由以下原因导致: 依赖未正确添加到 pom.xml 检查 pom.xml 文件中是否正确添加了 Elasticsearch 和 JUnit 等相关依赖。例如,对于 Elasticsearch 的 TransportClient 相关…...

NGINX `ngx_http_auth_request_module` 模块详解基于子请求的认证授权方案
一、背景介绍 在 Web 系统中,我们常常需要根据外部服务(例如单点登录、API 网关、权限中心)的结果来判断用户是否有权限访问某个资源。NGINX 提供的 ngx_http_auth_request_module 模块,正是为这种场景而生。它允许通过向后端发送…...
)
Qwen3简要介绍(截止20250506)
Qwen3是阿里云推出的一个大语言模型系列,它在多个方面进行了升级和优化。以下是Qwen3的一些主要特点: 模型规模多样:Qwen3提供了一系列不同规模的模型,包括稠密模型(0.6B、1.7B、4B、8B、14B、32B)以及专家…...
:移动应用商业模式的深度剖析与实战要点)
精益数据分析(42/126):移动应用商业模式的深度剖析与实战要点
精益数据分析(42/126):移动应用商业模式的深度剖析与实战要点 在创业和数据分析的学习之路上,我们持续探索不同商业模式的奥秘,今天聚焦于移动应用商业模式。我希望和大家一起进步,深入解读《精益数据分析…...

2025.5.6总结
昨天12:30睡觉,结果翻来覆去睡不着,两点半左右才睡着。看了一下最近的睡眠打卡,平均入睡时间是凌晨12:30。 自五一一个人过了5天,我才明白,人是需要社交的,只有在社交中才能找到自我…...

UE5 脚部贴地不穿过地板方案
UE自带的IK RIG和ControlRig技术 【UE5】角色脚部IK——如何让脚贴在不同斜度的地面(设置脚的旋转)_哔哩哔哩_bilibili 实验后这个还是有一部分问题,首先只能保证高度不能穿过,但是脚步旋转还是会导致穿模 IK前,整个模型在斜坡上会浮空 参考制作:https://www.youtube.com/w…...
系统设计方案)
Spring AI 函数调用(Function Call)系统设计方案
一、系统概述与设计目标 1.1 核心目标 从零构建一个灵活、安全、高效的函数调用系统,使大语言模型能够在对话中调用应用程序中的方法,同时保持良好的开发体验和企业级特性。 1.2 主要功能需求 支持通过注解将普通Java方法标记为可被AI调用的函数自动生成符合LLM要求的函数…...

Jupyter Notebook为什么适合数据分析?
Jupyter Notebook 是一款超实用的 Web 应用程序,在数据科学、编程等诸多领域都发挥着重要作用。它最大的特点就是能让大家轻松创建和共享文学化程序文档。这里说的文学化程序文档,简单来讲,就是把代码、解释说明、数学公式以及数据可视化结果…...

Leetcode Hot 100字母异位词分词
题目描述 思路 根据题意,我们可以得知我们需要将字符统计数一样的字符串,放在一起,并以列表进行返回。因此我们可以通过一个哈希表,把统计相同的放在一起,最终返回即可 代码 class Solution:def groupAnagrams(self…...

用python实现鼠标监听与手势交互
摘要 本文探讨了一种基于Python的数学函数可视化系统的设计与实现,该系统整合了Pynput鼠标事件监听机制、Matplotlib绘图引擎以及PyQt5图形用户界面框架。系统通过人机交互方式实现了函数图像的直观构建与可视化表达,支持多种函数类型的参数化建模与实时…...

UE5 GAS开发P47 游戏标签
FGameplayTag 是 Unreal Engine 中用于标记游戏对象的系统。它允许开发者为游戏对象分配标签,以便在游戏中对其进行分类、识别和操作。 FGameplayTag 结构用于表示单个游戏标签,而 FGameplayTagContainer 则用于表示一组游戏标签。 这些标签可以用于诸…...
)
C# 实现PLC数据自动化定时采集与存储(无需界面,自动化运行)
C# 实现PLC数据自动化定时采集与存储(无需界面,自动化运行) 在平时开发中,我们时常会遇到需要后台静默运行的应用场景,这些程序不需要用户的直接操作或界面展示,而是专注于定时任务的执行。比如说…...

Java实现堆排序算法
1. 堆排序原理图解 堆排序是一种基于二叉堆(通常使用最大堆)的排序算法。其核心思想是利用堆的性质(父节点的值大于或等于子节点的值)来高效地进行排序。堆排序分为两个主要阶段:建堆和排序。 堆排序步骤: …...

封装axios,实现取消请求
封装axios import axios from axios// 创建自定义的请求类 class CancelableRequest {constructor() {this.controller new AbortController()}abort() {this.controller.abort()} }// 创建 axios 实例 const service axios.create({baseURL: process.env.VUE_APP_BASE_API,…...

在 Laravel 12 中实现 WebSocket 通信
在 Laravel 12 中实现 WebSocket 通信主要有两种主流方案:官方推荐的 Laravel Reverb 和 第三方库(如 Soketi/Pusher 或 Workerman/Swoole)。以下是详细实现步骤: 一、官方方案:Laravel Reverb(推…...

iPhone或iPad想要远程投屏到Linux系统电脑,要怎么办?
苹果手机自带AirPlay投屏功能,对于苹果电脑,自然可以随时投屏。但如果电脑是Linux系统,而且还想要远程投屏呢?这时候要怎么将iPhone或iPad投屏到Linux电脑? 方法很简单,用AirDroid Cast的网页版即可。 步骤…...

Ubuntu 22.04 安装配置远程桌面环境指南
在云服务器或远程主机上安装图形化桌面环境,可以极大地提升管理效率和用户体验。本文将详细介绍如何在 Ubuntu 22.04 (Jammy Jellyfish) 系统上安装和配置 Xfce4 桌面环境,并通过 VNC 实现远程访问。 系统环境 操作系统:Ubuntu 22.04 LTS (Jammy Jellyfish)架构:AMD64安装…...

【Redis | 基础总结篇 】
目录 前言: 1.Redis的介绍: 2.Redis的类型与命令: 3.Redis的安装: 3.1.Windows版本 3.2.Linux版本 4.在java中使用Redis: 4.1.介绍 4.2.Jedis 4.3.Spring Data Redis 前言: 本篇主要讲述了Redis的…...

如何通过外网访问内网?对比5个简单的局域网让互联网连接方案
在实际应用中,常常需要从外网访问内网资源,如远程办公访问公司内部服务器、在家访问家庭网络中的设备等。又或者在本地内网搭建的项目应用需要提供互联网服务。以下介绍几种常见的外网访问内网、内网提供公网连接实现方法参考。 一、公网IP路由器端口映…...

iMeta | 临床研究+scRNA-seq的组合思路 | 真实世界新辅助研究,HER2⁺就一定受益?单细胞揭示真正的“疗效敏感克隆”
👋 欢迎关注我的生信学习专栏~ 如果觉得文章有帮助,别忘了点赞、关注、评论,一起学习 近年来,临床医学与单细胞组学的结合开启了全新的研究范式,让临床医生能以“显微镜”般的精度,深入理解疾病机制与疗效…...

国标GB28181视频平台EasyCVR安防系统部署知识:如何解决异地监控集中管理和组网问题
在企业、连锁机构及园区管理等场景中,异地监控集中管控与快速组网需求日益迫切。弱电项目人员和企业管理者亟需整合分散监控资源,实现跨区域统一管理与实时查看。 一、解决方案 案例一:运营商专线方案 利用运营商专线,连接各分…...

220V降12V1000mA非隔离芯片WT5110
220V降12V1000mA非隔离芯片WT5110 以下是采用WT5110芯片的非隔离降压电源电路设计,将220V电压转换为12V、1000mA输出: 一、WT5110芯片简介 WT5110是一款用于非隔离降压应用的集成电路,具备宽输入电压范围和高效的转换功能。它可以将高输入电…...

【ES】Elasticsearch字段映射冲突问题分析与解决
在使用Elasticsearch作为搜索引擎时,经常会遇到一些映射(Mapping)相关的问题。本文将深入分析字段映射冲突问题,并通过原生的Elasticsearch API请求来复现和解决这个问题。 问题描述 在实际项目中,我们遇到以下错误: Transport…...

【上位机——MFC】绘图
相关类 CDC类(绘图设备类):封装了各种绘图相关的函数,以及两个非常重要的成员变量m_hDC和m_hAttribDC CPaintDC类,封装了在WM_PAINT消息中绘图的绘图设备 CClientDC类,封装了在客户区绘图的绘图设备 CGdiObject类(绘图对象类) 封…...

【AI】Ubuntu 22.04 evalscope 模型评测 Qwen3-4B-FP8
安装evalscope mkdir evalscope cd evalscope/ python3 -m venv venv source venv/bin/activate pip install evalscope[app,perf] -U -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.compip install tiktoken omegaconf -i https://mirrors.aliyu…...

js var a=如果ForRemove=true,是“normal“,否则为“bold“
你是想根据变量 ForRemove 的布尔值来给变量 a 赋值,如果 ForRemove 为 true,则 a 的值是 "normal",否则为 "bold"。在 JavaScript 里,你可以使用 if...else 语句或者三元运算符来实现。 方法一:…...

JavaScript性能优化实战:从瓶颈分析到解决方案
前言 在当今快节奏的互联网环境中,用户对网站性能的期望日益提高。 JavaScript作为前端开发的核心语言,其性能直接影响用户体验。本文将深入探讨JavaScript代码中常见的性能瓶颈,并结合实际案例分享优化技巧和工具,帮助开发者提升…...

CyberSentinel AI开源程序 是一个自动化安全监控与AI分析系统
一、软件介绍 文末提供程序和源码下载 CyberSentinel AI 开源程序是一个强大的自动化安全监控与AI分析系统,旨在帮助安全研究人员和爱好者 实时追踪最新的安全漏洞 (CVE) 和 GitHub 上的安全相关仓库,并利用 人工智能技术进行深度分析,最终…...
)
C++23 std::generator:用于范围的同步协程生成器 (P2502R2, P2787R0)
文章目录 引言C23新特性概述std::generator基本概念定义作用模板参数 std::generator特性分析与协程的结合范围视图内存管理 std::generator使用示例std::generator的优势与挑战优势挑战 总结 引言 在C的发展历程中,每一个新版本都带来了许多令人期待的新特性和改进…...
下的传感器数据和轨迹信息。)
FoMo 数据集是一个专注于机器人在季节性积雪变化环境中的导航数据集,记录了不同季节(无雪、浅雪、深雪)下的传感器数据和轨迹信息。
2025-05-02,由加拿大拉瓦尔大学北方机器人实验室和多伦多大学机器人研究所联合创建的 FoMo 数据集,目的是研究机器人在季节性积雪变化环境中的导航能力。该数据集的意义在于填补了机器人在极端季节变化(如积雪深度变化)下的导航研…...

Github上如何准确地搜索开源项目
Github上如何准确地搜索开源项目: 因为寻找项目练手是最快速掌握技术的途径,而Github上有最全最好的开源项目。 就像我的毕业设计“机器翻译”就可以在Github上查找开源项目来参考。 以下搜索针对:项目名的关键词,关注数限制&a…...

从 MDM 到 Data Fabric:下一代数据架构如何释放 AI 潜能
从 MDM 到 Data Fabric:下一代数据架构如何释放 AI 潜能 —— 传统治理与新兴架构的范式变革与协同进化 引言:AI 规模化落地的数据困境 在人工智能技术快速发展的今天,企业对 AI 的期望已从 “单点实验” 转向 “规模化落地”。然而&#…...
)
个人Unity自用面经(未完)
目录标题 1.在 2D 平台跳跃游戏项目中,你使用了对象池来生成和回收怪物包含阵亡的动画预制件。在对象池回收对象时,如何确保动画状态被正确重置,避免下次使用时出现异常?2.在僵尸吃脑子模拟项目中,你创建了继承于IAspe…...

【Pandas】pandas DataFrame agg
Pandas2.2 DataFrame Function application, GroupBy & window 方法描述DataFrame.apply(func[, axis, raw, …])用于沿 DataFrame 的轴(行或列)应用一个函数DataFrame.map(func[, na_action])用于对 DataFrame 的每个元素应用一个函数DataFrame.a…...

LearnOpenGL---绘制三角形
绘制三角形 #include <glad/glad.h> #include <GLFW/glfw3.h> #include <iostream>const unsigned int SCR_WIDTH 800; const unsigned int SCR_HEIGHT 600;/// <summary> /// 当用户改变窗口大小时,视口也应该被调整,因此编…...