NoUniqueKey问题和Regular join介绍
问题背景
在flink任务中,遇到了 NoUniqueKey Join的情况,导致了数据膨胀,和下游结果与数据库数据不一致问题
那NoUniqueKey Join为什么会导致问题呢,下面是其中一种场景示例:
为什么会出现 NoUniqueKey :原因有很多,较为常见的是下方示例,我们通常指使用主键作为pk,而往往业务场景使用的是唯一建进行关联和查询,所以pk就丢了(疑问:flink自身不可以透传pk吗),进行关联时就变成了NoUniqueKey
怎么解决(以下方场景示例):
- 查询字段带有 pk 字段
- 提前基于关联字段做group
- 将pk字段改为 left_code
上诉3中时通用方案,尤其针对下面这个常见案列,具体原因还要具体分析
示例
CREATE TABLE left_table (`left_id` BIGINT COMMENT '自增主键',`left_code` STRING COMMENT '唯一建',`left_code` STRING COMMENT 'left_table唯一建',`left_created_at` TIMESTAMP ,`left_updated_at` TIMESTAMP ,PRIMARY KEY (`left_id`) NOT ENFORCED
) WITH (
);CREATE TABLE right_table (`right_id` INT ,`right_code` STRING COMMENT 'left_table唯一建',`left_code` STRING COMMENT 'left_table唯一建',`right_state` STRING COMMENT '状态',`right_created_at` TIMESTAMP COMMENT '创建时间',`right_updated_at` TIMESTAMP COMMENT '更新时间',right_proc_time as proctime(),PRIMARY KEY (`right_id`) NOT ENFORCED
) WITH (
);-- 定义输出表,省略
INSERT INTO print_table
SELECTleft.left_code,left.left_created_at,left.left_updated_at,right.right_code,right.right_created_at,right.right_updated_at
FROM left_table left
JOIN right_table right
ON left.left_code = right.right_code
;它的执行计划中JOIN是:
leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]Regular join 简单介绍
关联逻辑
核心类org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator
private void processElement(RowData input,JoinRecordStateView inputSideStateView,JoinRecordStateView otherSideStateView,boolean inputIsLeft)throws Exception {boolean inputIsOuter = inputIsLeft ? leftIsOuter : rightIsOuter;boolean otherIsOuter = inputIsLeft ? rightIsOuter : leftIsOuter;boolean isAccumulateMsg = RowDataUtil.isAccumulateMsg(input);RowKind inputRowKind = input.getRowKind();input.setRowKind(RowKind.INSERT); // erase RowKind for later state updatingAssociatedRecords associatedRecords =AssociatedRecords.of(input, inputIsLeft, otherSideStateView, joinCondition);if (isAccumulateMsg) { // record is accumulateif (inputIsOuter) { // input side is outerOuterJoinRecordStateView inputSideOuterStateView =(OuterJoinRecordStateView) inputSideStateView;if (associatedRecords.isEmpty()) { // there is no matched rows on the other side// send +I[record+null]outRow.setRowKind(RowKind.INSERT);outputNullPadding(input, inputIsLeft);// state.add(record, 0)inputSideOuterStateView.addRecord(input, 0);} else { // there are matched rows on the other sideif (otherIsOuter) { // other side is outerOuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {RowData other = outerRecord.record;// if the matched num in the matched rows == 0if (outerRecord.numOfAssociations == 0) {// send -D[null+other]outRow.setRowKind(RowKind.DELETE);outputNullPadding(other, !inputIsLeft);} // ignore matched number > 0// otherState.update(other, old + 1)otherSideOuterStateView.updateNumOfAssociations(other, outerRecord.numOfAssociations + 1);}}// send +I[record+other]soutRow.setRowKind(RowKind.INSERT);for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}// state.add(record, other.size)inputSideOuterStateView.addRecord(input, associatedRecords.size());}} else { // input side not outer// state.add(record)inputSideStateView.addRecord(input);if (!associatedRecords.isEmpty()) { // if there are matched rows on the other sideif (otherIsOuter) { // if other side is outerOuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {if (outerRecord.numOfAssociations== 0) { // if the matched num in the matched rows == 0// send -D[null+other]outRow.setRowKind(RowKind.DELETE);outputNullPadding(outerRecord.record, !inputIsLeft);}// otherState.update(other, old + 1)otherSideOuterStateView.updateNumOfAssociations(outerRecord.record, outerRecord.numOfAssociations + 1);}// send +I[record+other]soutRow.setRowKind(RowKind.INSERT);} else {// send +I/+U[record+other]s (using input RowKind)outRow.setRowKind(inputRowKind);}for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}}// skip when there is no matched rows on the other side}} else { // input record is retract// state.retract(record)inputSideStateView.retractRecord(input);if (associatedRecords.isEmpty()) { // there is no matched rows on the other sideif (inputIsOuter) { // input side is outer// send -D[record+null]outRow.setRowKind(RowKind.DELETE);outputNullPadding(input, inputIsLeft);}// nothing to do when input side is not outer} else { // there are matched rows on the other sideif (inputIsOuter) {// send -D[record+other]soutRow.setRowKind(RowKind.DELETE);} else {// send -D/-U[record+other]s (using input RowKind)outRow.setRowKind(inputRowKind);}for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}// if other side is outerif (otherIsOuter) {OuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {if (outerRecord.numOfAssociations == 1) {// send +I[null+other]outRow.setRowKind(RowKind.INSERT);outputNullPadding(outerRecord.record, !inputIsLeft);} // nothing else to do when number of associations > 1// otherState.update(other, old - 1)otherSideOuterStateView.updateNumOfAssociations(outerRecord.record, outerRecord.numOfAssociations - 1);}}}}}主要逻辑实际上就两步:
- 将数据存储于本侧的状态中
- 根据join key去另一侧的状态中获取数据并且match
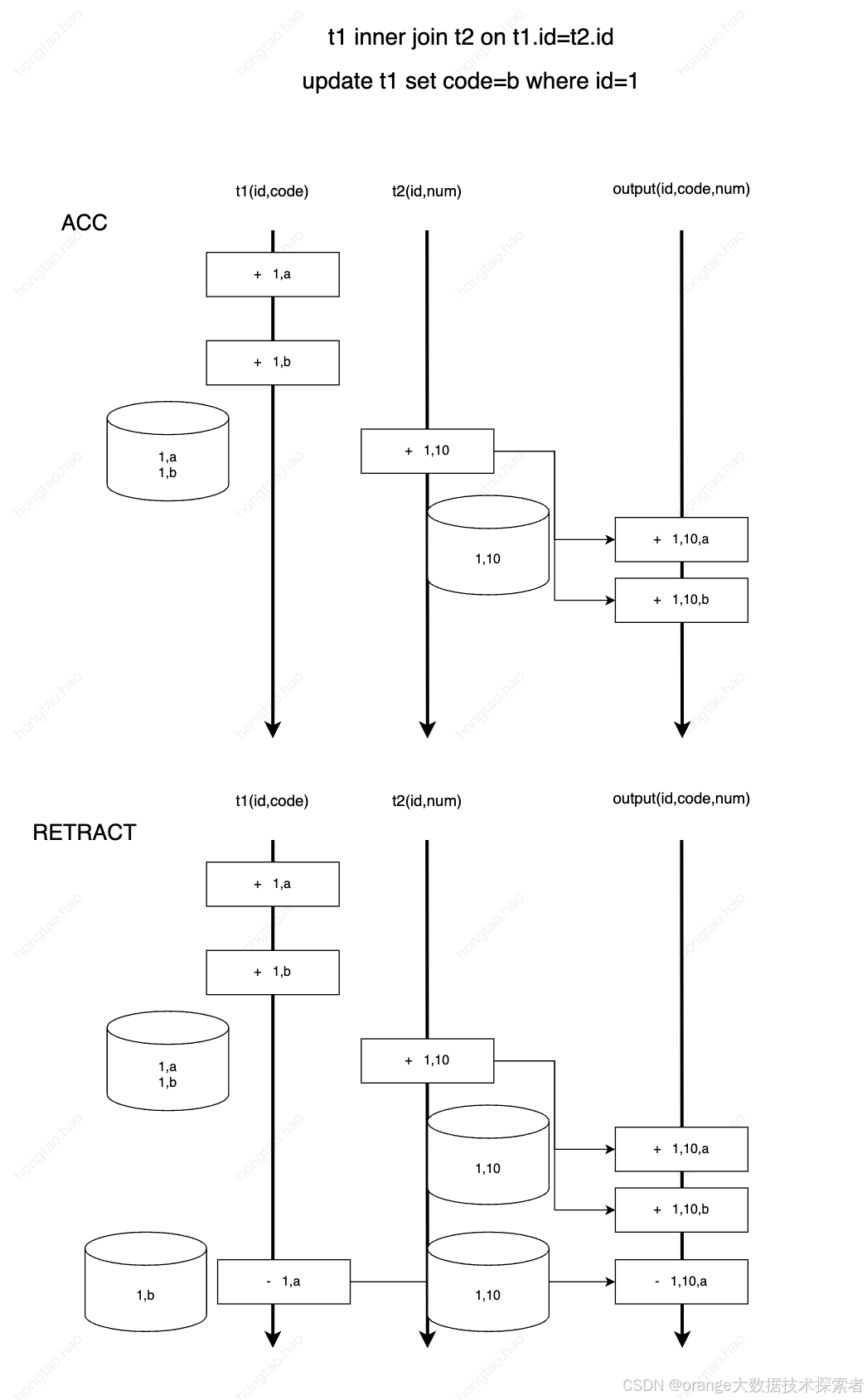
在flinksql对changelog的处理中将数据分为了Accumulate(insert/update_after)和Retract(delete/update_before)两类。
如果该消息类型为Accumulate,则处理逻辑的伪代码如下:
//record is ACC
if input side is outer //本侧是outer joinif no matched row on the other side //另一侧没有匹配记录send +[record + null]state.add(record, 0) // 0 表示另一侧没有关联的记录else // other.size > 0if other side is outerif (associated rows in matched rows == 0)//另一侧之前在本侧没有匹配的记录,所以需要撤回之前的 [null + other]send -[null + other]elseskipendifotherState.update(other, old + 1) //另一侧关联的记录 + 1endifsend +[record, other]s //另一侧有多少匹配的记录就发送多少条state.add(record, other.size) //更新状态endif
else //本侧不是 outer joinstate.add(record)if no matched row on the other side //另一侧没有匹配记录skip //无需输出else // other.size > 0if other size is outerif (associated rows in matched rows == 0) send -[null + other]elseskipendifotherState.update(other, old + 1) //另一侧关联的记录 + 1endifsend +[record + other]s //另一侧有多少匹配的记录就发送多少条endif
endif如果该消息为Retract,则处理逻辑的伪代码如下:
//record is RETRACT
state.retract(record)
if no matched rows on the other side //另一侧没有关联记录if input side is outersend -[record + null]endif
else //另一侧存在关联记录send -[record, other]s //要撤回已发送的关联记录if other side is outerif the matched num in the matched rows == 0, this should never happen!if the matched num in the matched rows == 1, send +[null + other]if the matched num in the matched rows > 1, skipotherState.update(other, old - 1) //另一侧关联的记录数 - 1endif
endifinner join的处理相对简单,重点在于当一侧流来数据去另一侧进行匹配的时候,会获取多少个匹配值,并且由于双流join为了保证join的准确性,需要将左右侧历史数据存放于状态中,因此除了给状态设置ttl,flink本身也对双流join的状态数据结构做了一些设计。
状态存储
根据 JoinInputSideSpec 中输入侧的特点(是否包含唯一键、关联键是否包含唯一键),Flink SQL 设计了几种不同的状态存储结构,即 JoinKeyContainsUniqueKey, InputSideHasUniqueKey 和 InputSideHasNoUniqueKey,分别如下:

public interface JoinRecordStateView {/*** Add a new record to the state view.*/void addRecord(BaseRow record) throws Exception;/*** Retract the record from the state view.*/void retractRecord(BaseRow record) throws Exception;/*** Gets all the records under the current context (i.e. join key).*/Iterable<BaseRow> getRecords() throws Exception;
}这些类都基于JoinRecordStateView进行函数实现:分别是往状态中添加一条记录,往状态中回撤一条记录,获取关联记录。
StreamingJoinOperator中的状态即使用MapState(键控状态),key就是当前关联记录的join key,在不同情况下不同的状态存储结构如下:

根据上面表格,可得出不同的join key和unique key的状态存储情况:
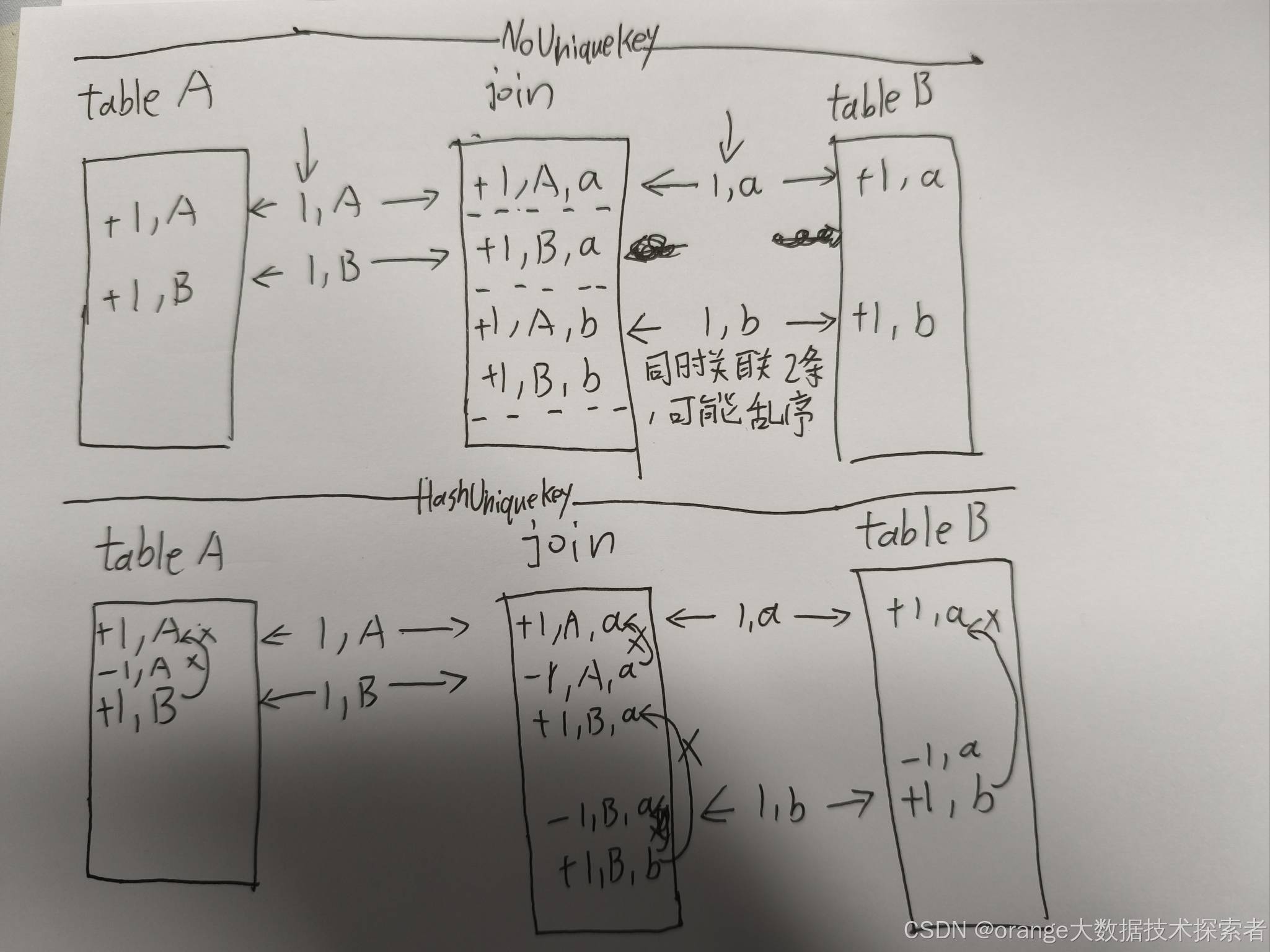
- 如果join key中包含unique key,那么一个join key只是对应一条记录
- 如果join key不包含unique key,那么一个join key 对应多条记录,但这些记录的unique key一定不同
- 如果输入没有unique key,那么只能使用ListState,当然,出于性能考虑flink仍然采用的MapState,只是key值即为记录本身
下图给一个inner join的例子,两侧的状态均为InputSideHasNoUniqueKey
unique key的获取与判断
FlinkSql的解析是在calcite的基础上做了二次开发,Unique key的获取和判断发生在planner的Optimize阶段,即将AST语法树(SqlNode)转化成关系代数式(RelNode)和行表达式(RexNode),然后从RelNode中判断是否有unique key。
核心类:org.apache.flink.table.planner.plan.metadata.FlinkRelMdUpsertKeys和org.apache.flink.table.planner.plan.metadata.FlinkRelMdUniqueKeys
private def getJoinUniqueKeys(joinInfo: JoinInfo,joinRelType: JoinRelType,left: RelNode,right: RelNode,mq: RelMetadataQuery,ignoreNulls: Boolean): JSet[ImmutableBitSet] = {val leftUniqueKeys = mq.getUniqueKeys(left, ignoreNulls)val rightUniqueKeys = mq.getUniqueKeys(right, ignoreNulls)getJoinUniqueKeys(joinRelType, left.getRowType, leftUniqueKeys, rightUniqueKeys,mq.areColumnsUnique(left, joinInfo.leftSet, ignoreNulls),mq.areColumnsUnique(right, joinInfo.rightSet, ignoreNulls))}def getJoinUniqueKeys(joinRelType: JoinRelType,leftType: RelDataType,leftUniqueKeys: JSet[ImmutableBitSet],rightUniqueKeys: JSet[ImmutableBitSet],isLeftUnique: JBoolean,isRightUnique: JBoolean): JSet[ImmutableBitSet] = {// first add the different combinations of concatenated unique keys// from the left and the right, adjusting the right hand side keys to// reflect the addition of the left hand side// NOTE zfong 12/18/06 - If the number of tables in a join is large,// the number of combinations of unique key sets will explode. If// that is undesirable, use RelMetadataQuery.areColumnsUnique() as// an alternative way of getting unique key information.val retSet = new JHashSet[ImmutableBitSet]val nFieldsOnLeft = leftType.getFieldCountval rightSet = if (rightUniqueKeys != null) {val res = new JHashSet[ImmutableBitSet]rightUniqueKeys.foreach { colMask =>val tmpMask = ImmutableBitSet.buildercolMask.foreach(bit => tmpMask.set(bit + nFieldsOnLeft))res.add(tmpMask.build())}if (leftUniqueKeys != null) {res.foreach { colMaskRight =>leftUniqueKeys.foreach(colMaskLeft => retSet.add(colMaskLeft.union(colMaskRight)))}}res} else {null}// determine if either or both the LHS and RHS are unique on the// equi-join columnsval leftUnique = isLeftUniqueval rightUnique = isRightUnique// if the right hand side is unique on its equijoin columns, then we can// add the unique keys from left if the left hand side is not null// generatingif (rightUnique != null&& rightUnique&& (leftUniqueKeys != null)&& !joinRelType.generatesNullsOnLeft) {retSet.addAll(leftUniqueKeys)}// same as above except left and right are reversedif (leftUnique != null&& leftUnique&& (rightSet != null)&& !joinRelType.generatesNullsOnRight) {retSet.addAll(rightSet)}retSet}private def getTableUniqueKeys(relOptTable: RelOptTable): JSet[ImmutableBitSet] = {relOptTable match {case sourceTable: TableSourceTable =>val catalogTable = sourceTable.catalogTablecatalogTable match {case act: CatalogTable =>val builder = ImmutableSet.builder[ImmutableBitSet]()val schema = act.getResolvedSchemaif (schema.getPrimaryKey.isPresent) {// use relOptTable's type which may be projected based on original schemaval columns = relOptTable.getRowType.getFieldNamesval primaryKeyColumns = schema.getPrimaryKey.get().getColumns// we check this because a portion of a composite primary key is not uniqueif (columns.containsAll(primaryKeyColumns)) {val columnIndices = primaryKeyColumns.map(c => columns.indexOf(c))builder.add(ImmutableBitSet.of(columnIndices: _*))}}val uniqueSet = sourceTable.uniqueKeysSet.orElse(null)if (uniqueSet != null) {builder.addAll(uniqueSet)}val result = builder.build()if (result.isEmpty) null else result}case table: FlinkPreparingTableBase => table.uniqueKeysSet.orElse(null)case _ => null}}def getProjectUniqueKeys(projects: JList[RexNode],typeFactory: RelDataTypeFactory,getInputUniqueKeys :() => util.Set[ImmutableBitSet],ignoreNulls: Boolean): JSet[ImmutableBitSet] = {// LogicalProject maps a set of rows to a different set;// Without knowledge of the mapping function(whether it// preserves uniqueness), it is only safe to derive uniqueness// info from the child of a project when the mapping is f(a) => a.//// Further more, the unique bitset coming from the child needsval projUniqueKeySet = new JHashSet[ImmutableBitSet]()val mapInToOutPos = new JHashMap[Int, JArrayList[Int]]()def appendMapInToOutPos(inIndex: Int, outIndex: Int): Unit = {if (mapInToOutPos.contains(inIndex)) {mapInToOutPos(inIndex).add(outIndex)} else {val arrayBuffer = new JArrayList[Int]()arrayBuffer.add(outIndex)mapInToOutPos.put(inIndex, arrayBuffer)}}// Build an input to output position map.projects.zipWithIndex.foreach {case (projExpr, i) =>projExpr match {case ref: RexInputRef => appendMapInToOutPos(ref.getIndex, i)case a: RexCall if ignoreNulls && a.getOperator.equals(SqlStdOperatorTable.CAST) =>val castOperand = a.getOperands.get(0)castOperand match {case castRef: RexInputRef =>val castType = typeFactory.createTypeWithNullability(projExpr.getType, true)val origType = typeFactory.createTypeWithNullability(castOperand.getType, true)if (castType == origType) {appendMapInToOutPos(castRef.getIndex, i)}case _ => // ignore}//rename or castcase a: RexCall if (a.getKind.equals(SqlKind.AS) || isFidelityCast(a)) &&a.getOperands.get(0).isInstanceOf[RexInputRef] =>appendMapInToOutPos(a.getOperands.get(0).asInstanceOf[RexInputRef].getIndex, i)case _ => // ignore}}if (mapInToOutPos.isEmpty) {// if there's no RexInputRef in the projected expressions// return empty set.return projUniqueKeySet}val childUniqueKeySet = getInputUniqueKeys()if (childUniqueKeySet != null) {// Now add to the projUniqueKeySet the child keys that are fully// projected.childUniqueKeySet.foreach { colMask =>val filerInToOutPos = mapInToOutPos.filter { inToOut =>colMask.asList().contains(inToOut._1)}val keys = filerInToOutPos.keysif (colMask.forall(keys.contains(_))) {val total = filerInToOutPos.map(_._2.size).productfor (i <- 0 to total) {val tmpMask = ImmutableBitSet.builder()filerInToOutPos.foreach { inToOut =>val outs = inToOut._2tmpMask.set(outs.get(i % outs.size))}projUniqueKeySet.add(tmpMask.build())}}}}projUniqueKeySet}def getUniqueKeysOnAggregate(grouping: Array[Int]): util.Set[ImmutableBitSet] = {// group by keys form a unique keyImmutableSet.of(ImmutableBitSet.of(grouping.indices: _*))}由于sql场景很多因此文档里只列举几个场景:
- join的uniqueKey需要判断两侧的uniquekey情况并进行组合判断
- scan的uniqueKey由scan的列是否全部包含该table定义中primary key来决定
- 投影的uniqueKey由投影的列是否全部包含输入子Node的unique key来决定
- 聚合的uniqueKey即是group by的unique key
比如上诉案例,两张表uniquekey均为为id,然后对scan后结果做投影,此时投影列不包含子Node unique key,唯一键丢失。
基于上面两个投影做join,因此本次join操作的左侧为no unique key,右侧则有unique key,又由于本次为inner join所以join后的投影也没有unique key
大致可以归纳为以下几个步骤或方法(不仅仅是FlinkSql,所有sql逻辑都这样):
- 静态信息:部分rel节点可以从表的元数据中获取unique key信息,例如table scan(Flink中TableSourceScan)
- 推导:根据输入的uniquekey信息来推导新的unique key,例如投影
- 聚合和分组:在进行聚合操作时,分组的key会形成一个新的unique key
- join:根据join类型和join条件来推导结果的unique key
相关文章:

NoUniqueKey问题和Regular join介绍
问题背景 在flink任务中,遇到了 NoUniqueKey Join的情况,导致了数据膨胀,和下游结果与数据库数据不一致问题 那NoUniqueKey Join为什么会导致问题呢,下面是其中一种场景示例: 为什么会出现 NoUniqueKey :…...

TC8:SOMEIP_ETS_027-028
SOMEIP_ETS_027: echoUINT8 目的 检查method方法echoUINT8的参数及其顺序能够被顺利地发送和接收 说白了就是检查UINT8数据类型参数在SOME/IP协议层的序列化与反序列化是否正常。 UINT8相比于测试用例SOMEIP_ETS_021: echoINT8中的SINT8数据类型来说,属于无符号整数,也就是…...

小微企业SaaS ERP管理系统,SpringBoot+Vue+ElementUI+UniAPP
小微企业的SaaS ERP管理系统,ERP系统源码,ERP管理系统源代码 一款适用于小微企业的SaaS ERP管理系统, 采用SpringBootVueElementUIUniAPP技术栈开发,让企业简单上云。 专注于小微企业的应用需求,如企业基本的进销存、询价&#…...

css filter 常用方法函数和应用实例
1. blur() 模糊 filter: blur(半径);参数:模糊半径(像素),值越大越模糊 示例:filter: blur(5px);2. brightness() 亮度 filter: brightness(百分比); 参数:1原始对比度,0全灰,>…...

chrome inspect 调试遇到的问题
1、oppp 手机打开webview 的时候, 报错这个并没有页面 Offline #V8FIG6SGLN75M7FY Pending authentication: please accept debugging session on the device. 解决方法,保持chrome 浏览器在显示的状态 去设置里开启usb 调试再关闭,反复重…...

Kotlin 中 List 和 MutableList 的区别
在 Kotlin 中,List 和 MutableList 是两种不同的集合接口,核心区别在于可变性。 Kotlin 集合框架的重要设计原则:通过接口分离只读(read - only)和可变(mutable)操作,以提高代码的安…...

openssl 生成自签名证书实现接口支持https
1.下载安装openssl Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions 2.配置环境变量 将 openssl 的目录(D:\tools\openssl\bin)添加到 path 中 3.生成自签名证书 找一个存证书的目录打开powershell 3.1 生成私钥 openssl gen…...

React 中集成 Ant Design 组件库:提升开发效率与用户体验
React 中集成 Ant Design 组件库:提升开发效率与用户体验 一、为什么选择 Ant Design 组件库?二、基础引入方式三、按需引入(优化性能)四、Ant Design Charts无缝接入图标前面提到了利用Redux提供全局维护,但如果在开发时再自己手动封装组件,不仅效率不高,可能开发的组件…...

神经网络:节点、隐藏层与非线性学习
神经网络:节点、隐藏层与非线性学习 摘要: 神经网络是机器学习领域中一种强大的工具,能够通过复杂的结构学习数据中的非线性关系。本文从基础的线性模型出发,逐步深入探讨神经网络中节点和隐藏层的作用,以及它们如何…...

vue+tsc+noEmit导致打包报TS类型错误问题及解决方法
项目场景: 提示:这里简述项目相关背景: 当我们新建vue3项目,package.json文件会自动给我添加一些配置选项,这写选项基本没有问题,但是在实际操作过程中,当项目越来越复杂就会出现问题,本文给大家分享vuetscnoEmit导致打包报TS类型错误问题及…...

Ragflow服务器上部署教程
参考官方文档进行整理 克隆相应代码 git clone https://github.com/infiniflow/ragflow.git修改vm.max_map_count sudo sysctl -w vm.max_map_count262144修改 daemon.json文件 {"registry-mirrors": ["https://docker.m.daocloud.io","https://0…...

Ubuntu 系统中解决 Firefox 中文显示乱码的完整指南
Firefox 是一款流行的网络浏览器,但在 Ubuntu 系统中有时会遇到中文显示乱码的问题。本文将为您提供一个全面的解决方案,帮助您轻松解决这个烦人的问题。 问题概述 在 Ubuntu 系统中使用 Firefox 浏览器时,有时会发现中文字符显示为乱码或方块。这通常是由于缺少合适的中文…...

JVM——垃圾回收
垃圾回收 在Java虚拟机(JVM)的自动内存管理中,垃圾回收(Garbage Collection, GC)是其核心组件之一。它负责回收堆内存中不再使用的对象所占用的内存空间,以供新对象的分配使用。下面我们将深入探讨JVM中的…...

【AI News | 20250506】每日AI进展
AI Repos 1、gitsummarize GitSummarize是一个在线工具,用户只需将GitHub URL中的“hub”替换为“summarize”,即可为任何公开或私有代码库生成交互式文档。该工具利用Gemini分析代码结构,自动生成系统级架构概述、目录和文件摘要、自然语言…...

LabVIEW高冲击加速度校准系统
在国防科技领域,高 g 值加速度传感器广泛应用于先进兵器研制,如深侵彻系统、精确打击弹药及钻地弹药等。其性能指标直接影响研究结果的准确性与可靠性,因此对该传感器进行定期校准意义重大。高冲击加速度校准系统具备多方面功能,适…...

优化算法 - intro
优化问题 一般形式 minimize f ( x ) f(\mathbf{x}) f(x) subject to x ∈ C \mathbf{x} \in C x∈C 目标函数 f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R限制集合例子 C { x ∣ h 1 ( x ) 0 , . . . , h m ( x ) 0 , g 1 ( x ) ≤ 0 , . . . , g r …...

从PotPlayer到专业播放器—基于 RTSP|RTMP播放器功能、架构、工程能力的全面对比分析
从PotPlayer到专业播放器SDK:工程项目怎么选择合适的播放方案? ——基于 RTSP、RTMP 播放器功能、架构、工程能力的全面对比分析 在许多音视频项目早期,我们都听过这句话: “本地测试就用 PotPlayer 播吧,能播就行了…...

EasyRTC嵌入式音视频通信SDK技术,助力工业制造多场景实时监控与音视频通信
一、背景 在数字化时代,实时监控广泛应用于安防、工业、交通等领域。但传统监控系统实时性、交互性欠佳,难以满足需求。EasyRTC作为先进实时通信技术,具有低延迟、高可靠、跨平台特性,能有效升级监控系统。融入EasyRTC后…...

MPay码支付系统第四方聚合收款码多款支付插件个人免签支付源码TP8框架全开源
一、源码描述 这是一套码支付源码(MPay),基于TP8框架,前端layui2.9后端PearAdmin,专注于个人免签收款,通过个人的普通收款码,即可实现收款通知自动回调,支持绝大多数商城系统&#…...

wrod生成pdf。[特殊字符]改背景
import subprocess import os,time from rembg import remove, new_session from PIL import Image import io from docxtpl import DocxTemplate, InlineImage from docx.shared import Inches input_folder ‘tupian’ # 输入文件夹 kouchu_folder ‘kouchu’ # 去背景图像…...
)
动手学深度学习12.1. 编译器和解释器-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:无 本节教材地址:12.1. 编译器和解释器 — 动手学深度学习 2.0.0 documentation 本节…...

数字文明时代开源技术驱动的商业范式重构:基于开源AI大模型、AI智能名片与S2B2C商城小程序源码的协同创新研究
摘要:数字文明时代,数字技术正以指数级速度重构全球经济与社会结构。本文聚焦开源AI大模型、AI智能名片与S2B2C商城小程序源码的协同创新机制,从技术架构、商业逻辑、实践案例三个维度展开系统研究。基于多行业实证数据,揭示开源技…...
)
【Bootstrap V4系列】学习入门教程之 组件-轮播(Carousel)
Bootstrap V4系列 学习入门教程之 组件-轮播(Carousel) 轮播(Carousel)一、How it works二、Example2.1 Slides only 仅幻灯片2.2 With controls 带控制装置2.3 With indicators 带指示器2.4 With captions 带字幕 轮播࿰…...

嵌入式openharmony标准鸿蒙系统驱动开发基本原理与流程
第一:鸿蒙概述 OpenHarmony采用多内核(Linux内核或者LiteOS)设计,支持系统在不同资源容量的设备部署。当相同的硬件部署不同内核时,如何能够让设备驱动程序在不同内核间平滑迁移,消除驱动代码移植适配和维护的负担,是OpenHarmony驱动子系统需要解决的重要问题。 …...

Leetcode 刷题记录 08 —— 链表第二弹
本系列为笔者的 Leetcode 刷题记录,顺序为 Hot 100 题官方顺序,根据标签命名,记录笔者总结的做题思路,附部分代码解释和疑问解答,01~07为C语言,08及以后为Java语言。 01 合并两个有序链表 /*** Definition…...

PaddlePaddle 和PyTorch选择与对比互斥
你遇到的错误信息如下: RuntimeError: (PreconditionNotMet) Tensors dimension is out of bound.Tensors dimension must be equal or less than the size of its memory.But received Tensors dimension is 8, memorys size is 0.[Hint: Expected numel() * Size…...

极新月报·2025.4人工智能投融资观察
“ AI投资从‘量’向‘质’过渡 ” 4月重点关注: 1、四月人工智能领域投融资事件105起,披露金额78.63亿人民币。 2、亿级人民币以上金额的投资事件共20起 。 3、四月人工智能领域出现1起IPO事件。 4、在所有融资事件里,除去股权投资&…...

C++ vector 介绍与使用
目录 1.vector是什么? 2.vector的使用 2.1vector的构造函数 2.2vector iterator 的使用 2.3vector 空间增长问题 2.4vector的增删查改 1.vector是什么? 1. vector是表示可变大小数组的序列容器。 2. 就像数组一样,vector也 采用连续的存储…...

可以下载blender/fbx格式模型网站
glbxz.com glbxz.com可以下载blender/fbx格式模型。当然里面有免费的...

Vi/Vim 编辑器详细指南
Vi/Vim 编辑器详细指南 简介一、模式详解1. 命令模式(Normal Mode)2. 插入模式(Insert Mode)3. 可视模式(Visual Mode)4. 命令行模式(Ex Mode)二、核心操作1. 保存与退出2. 导航与移动3. 编辑与文本操作4. 搜索与替换三、高级技巧1. 多文件与窗口操作2. 宏录制3. 寄存器…...

LeetCode 热题 100 22. 括号生成
LeetCode 热题 100 | 22. 括号生成 大家好,今天我们来解决一道经典的算法题——括号生成。这道题在 LeetCode 上被标记为中等难度,要求生成所有可能的并且有效的括号组合。这是一道非常经典的回溯法题目,非常适合用来练习递归和回溯的技巧。…...

UE5 MetaHuman眼睛变黑
第5个材质MI_EyeOcclusion_Inst修改成透明即可...
)
【C语言】--指针超详解(一)
目录 一.内存和地址 1.1--内存 1.2--如何理解编址 二.指针变量和地址 2.1--取地址操作符(&) 2.2--指针变量和解引用操作符(*) 2.2.1--指针变量 2.2.2--如何理解指针类型 2.2.3--解引用操作符 2.3--指针变量的大小 三.指针变量类型的意义 3.1--从指针的解引用方…...

高频工业RFID读写器-三格电子
高频工业RFID读写器 型号:SG-HF40-485、SG-HF40-TCP 产品功能 高频工业读写器(RFID)产品用在自动化生产线,自动化分拣系统,零部件组装产线等情境下,在自动化节点的工位上部署RFID读写设备,通过与制品的交互…...
显示区域绘制)
驱动开发系列57 - Linux Graphics QXL显卡驱动代码分析(四)显示区域绘制
一:概述 前面在介绍了显示模式设置(分辨率,刷新率)之后,本文继续分析下,显示区域的绘制,详细看看虚拟机的画面是如何由QXL显卡绘制出来的。 二:相关数据结构介绍 struct qxl_moni…...

6.5 行业特定应用:金融、医疗、制造等行业的定制化解决方案
金融、医疗和制造行业作为全球经济支柱,面临数据复杂性、实时性需求和严格合规性的共同挑战,同时各行业因业务特性衍生出独特需求。金融行业需应对市场波动、欺诈风险和多国法规,医疗行业聚焦精准诊断和患者数据隐私,制造业则强调…...

【Linux我做主】深入探讨从冯诺依曼体系到进程
从冯诺依曼体系到进程 从冯诺依曼体系到进程github地址1. 前言2. 计算机硬件2.1 冯诺依曼体系结构2.2 冯诺依曼模型的三大要点2.3 从QQ聊天认识:冯诺依曼体系下数据是如何流动的?发送方数据流动接收方数据流动 3. 计算机软件的根基——操作系统3.1 操作系…...

idea更换jdk版本操作
有时候我们有更换jdk版本的问题,自己电脑可能有多个版本,下面来介绍修改jdk版本修改修改什么地方 1 2 3 4 5 6 再修改pom即可,还有环境变量即可,希望有帮到大家!...

npm install下载插件无法更新package.json和package-lock.json文件的解决办法
经过多番查证,使用npm config ls查看相关配置等方式,最后发现全局的.npmrc文件的配置多写了globaltrue,去掉就好了 如果参数很多,不知道是哪个参数引起的,先只保留registryhttp://xxx/,试试下载࿰…...

机器学习实操 第二部分 神经网路和深度学习 第13章 使用TensorFlow加载和预处理数据
机器学习实操 第二部分 神经网路和深度学习 第13章 使用TensorFlow加载和预处理数据 内容概要 第13章深入探讨了如何使用TensorFlow加载和预处理数据。本章首先介绍了tf.data API,它能够高效地加载和预处理大规模数据集,支持并行文件读取、数据打乱、批…...

WebSoket的简单使用
一、WebSocket简介 1.1、双向通信/全双工 客户端和服务器之间同时双向传输,全双工通信允许客户端和服务器随时互相发送消息,不需等一方发送请求后另一方才进行响应。 适用要低延迟/实时交互的场景,如在线游戏、即时通讯、股票行情等。 1.2…...

01_线性表
一、线性表的顺序存储 逻辑上相邻的数据元素,物理次序也相邻。占用连续存储空间,用“数组”实现,知道初始位置就可推出其他位置。 00_宏定义 // 函数结果状态代码 #define TRUE 1 #define FALSE 0 #define OK 1 #define ERROR 0 #defin…...

STL详解 - map和set
目录 一、关联式容器概述 二、键值对 三、树形结构的关联式容器 (一)set 1. set的介绍 2. set的使用 (1)模板参数列表 (2)构造函数 (3)迭代器函数 (4ÿ…...

SpringBoot 集成滑块验证码AJ-Captcha行为验证码 Redis分布式 接口限流 防爬虫
介绍 滑块验证码比传统的字符验证码更加直观和用户友好,能够很好防止爬虫获取数据。 AJ-Captcha行为验证码,包含滑动拼图、文字点选两种方式,UI支持弹出和嵌入两种方式。后端提供Java实现,前端提供了php、angular、html、vue、u…...

高并发PHP部署演进:从虚拟机到K8S的DevOps实践优化
一、虚拟机环境下的部署演进 1. 低并发场景(QPS<10)的简单模式 # 典型部署脚本示例 ssh userproduction "cd /var/www && git pull origin master" 技术痛点: 文件替换期间导致Nginx返回502错误(统计显示…...

vue引入物理引擎matter.js
vue引入物理引擎matter.js 在 Vue 项目中集成 Matter.js 物理引擎的步骤如下: 1. 安装 Matter.js npm install matter-js # 或 yarn add matter-js2. 创建 Vue 组件 <template><div ref="physicsContainer" class="physics-container"><…...

【实战项目】简易版的 QQ 音乐:一
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:能自我实现简易版的 QQ 音乐。 > 毒鸡汤:有些事情,总是不明白,所以我不会坚持。早安! > 专栏选自:…...
连接HANA数据库)
部署Superset BI(三)连接HANA数据库
metabase和redash都不支持HANA数据库,选择superset就是看重这一点,开始尝试连接HANA数据库。 按Superset的技术文档:pip install hdbcli sqlalchemy-hana or pip install apache-superset[hana] --进入容器 rootNocobase:/usr/superset/supe…...

快速学会Linux的WEB服务
一.用户常用关于WEB的信息 什么是WWW www是world wide web的缩写,及万维网,也就是全球信息广播的意思 通常说的上网就是使用www来查询用户所需要的信息。 www可以结合文字、图形、影像以及声音等多媒体,超链接的方式将信息以Internet传递到世…...

如何搭建spark yarn模式集群的集群
以下是搭建 Spark YARN 模式集群的一般步骤: 准备工作 确保集群中各节点已安装并配置好 Java 环境,且版本符合 Spark 要求。规划好集群中节点的角色,如 Master 节点、Worker 节点等,并确保各节点之间网络畅通,能相互…...