走出 Demo,走向现实:DeepSeek-VL 的多模态工程路线图
目录
一、引言:多模态模型的关键转折点
(一)当前 LMM 的三个关键挑战
1. 数据的真实性不足
2. 模型设计缺乏场景感知
3. 语言能力与视觉能力难以兼顾
(二)DeepSeek-VL 的根本出发点:以真实任务为锚点
1. 用“真实任务分类体系”驱动数据构建
2. 设计支持高分辨率的视觉编码架构
3. 保持语言能力主导的训练节奏
二、任务驱动的数据与指令构建:从“任务目标”出发构建训练世界
(一)提出 28 类真实图文交互任务:构建“视觉任务图谱”
(二)数据来源与构建策略:混合式生成更真实、更高质量
1. 真实图像采集
2. 人工指令注入(Instruction Injection)
3. 自动数据增强(Data Augmentation)
(三)自定义任务格式:图像 + 指令 + 任务标签三位一体
(四)任务覆盖统计:规模远超现有开源数据集
三、模型架构设计:任务泛化与分辨率理解兼顾的高效框架
(一)模型总览结构图
(二)图像处理模块:高分辨率多窗口感知(Hi-Res Aware)
✅ 多窗口切片(Window-based Patchification)
(三)视觉语言适配模块:跨模态融合桥梁
✅ Learnable Visual Projection Layer
(四)文本生成模块:基于 DeepSeek LLM 的自回归解码
(五)模型关键设计细节
🔹 多分辨率视觉处理
🔹 Token 压缩策略(Inference Optimization)
🔹 支持任务标签嵌入(可选)
(六)架构对比与优势
四、预训练与微调策略:让模型具备现实世界多模态智能的关键工程路径
(一)分阶段训练(Stage-wise Training):从基础认知到任务迁移
✅ 第一阶段:图文匹配基础能力训练(Pretraining)
✅ 第二阶段:指令对齐与多任务训练(Instruction-Following Fine-tuning)
(二)指令调优机制:任务风格泛化的关键
🔹 所有任务统一采用自然语言形式组织指令(Instruction Format)
🔹 强调 任务识别能力 与 响应风格自适应
(三)多任务协同训练:统一语言空间的任务泛化
🔸 Token 下采样(Spatial Downsampling)
🔸 动态窗口策略(Resolution-aware Windowing)
(四)“任务意识引导训练”的通用范式
五、实验与评估结果:多任务统一建模带来的广泛能力提升
(一)评估维度与模型规模说明
(二)多任务评估结果概览:任务泛化性极强
🔹 图文问答(VQA)任务:推理能力优异
🔹 表格与文档理解任务:对结构化数据极度友好
🔹 UI/网页理解任务:唯一适配此类任务的主流模型
(三)消融实验(Ablation Study):确认核心设计的贡献
(四)多模态对话测试:DeepSeek-VL-Chat 的人类评测能力
(五)总结:以“现实任务适应性”为目标的 SOTA 模型
五、总结:从演示能力到实用平台,多模态模型的关键跃迁
干货分享,感谢您的阅读!!!
在过去的几年中,大语言模型(LLMs)如 ChatGPT、GPT-4、Claude 等推动了自然语言处理的革命。然而,人类世界并不仅仅存在于文字之间,图片、图表、文档、空间布局等视觉信息同样承载着大量认知要素。因此,构建能同时理解图像与语言的多模态大模型(Large Vision-Language Models, 简称 LMMs),已成为当前人工智能发展的重要趋势。
过去两年间,多模态模型频繁出现在论文和媒体报道中,很多模型声称“通才能力”,但这些“demo 式的能力”在真实环境中往往难以复现。
随着 ChatGPT 和 GPT-4 等语言模型的普及,越来越多用户开始意识到模型的“能力边界”取决于它是否能解决真实问题。在视觉领域也是如此,多模态模型不再是炫技式的展示,而是要真正具备“可部署、可解释、可迁移”的能力。这就意味着:模型不只是“能看”,还要“看懂在做什么任务”,并给出合理解答。
DeepSeek-VL 正是在这一背景下诞生的——它不是为了刷榜单,而是面向实际应用场景,提供稳定、准确的视觉语言理解能力。这种理念的转变,标志着多模态技术开始进入“实用主义时代”。我们重温DeepSeek-VL: Towards Real-World Vision-Language Understanding相关论文,认真认识一下DeepSeek-VL吧!!!
一、引言:多模态模型的关键转折点
(一)当前 LMM 的三个关键挑战
尽管我们已经看到 LMM 在标准任务上表现不俗,如图像问答(VQA)、图文匹配、图文生成等,但真正应用于“真实世界”的复杂任务时,它们仍面临三大挑战:
1. 数据的真实性不足
目前很多多模态数据集都基于人工构造任务(例如 MSCOCO Captions、VQAv2、ScienceQA),这些任务往往简化了现实世界中的图文关系。例如,一个图表或者一页 PDF 通常包含复杂结构信息与上下文语境,仅仅依赖图像和一句话问答很难覆盖真实任务的需求。
2. 模型设计缺乏场景感知
主流开源多模态模型往往直接将图像编码成 patch tokens 后喂入语言模型。这种策略虽然训练方便,但对图像细节、空间结构(如文本框位置、表格关系等)的建模能力非常有限,难以应对如 OCR 文档理解、图表推理等高要求任务。
3. 语言能力与视觉能力难以兼顾
在引入视觉输入后,LLMs 往往出现语言能力下降的现象,尤其是在知识问答、逻辑推理等方面。这种“模态干扰”问题,使得很多模型在现实交互中表现不稳定,难以统一语言和图像信息。
(二)DeepSeek-VL 的根本出发点:以真实任务为锚点
DeepSeek-AI 团队提出的 DeepSeek-VL 模型,核心思路就是:不再从“学术任务”出发,而是以“真实任务”为锚点,反向设计数据、架构和训练流程。

这带来了三个核心设计转变:
1. 用“真实任务分类体系”驱动数据构建
他们提出了一个系统的 Use Case Taxonomy(任务用例分类体系),将真实场景中用户可能发出的图文指令进行系统化归类。例如:
-
OCR 文档提问
-
网页截图信息抽取
-
表格理解与单元格推理
-
居家平面图空间问答
-
学术图像(如论文图表)分析
然后,基于这个体系收集图像,并通过指令注入或混合标注方式生成训练数据,从根本上解决了数据偏离实际的问题。
2. 设计支持高分辨率的视觉编码架构
DeepSeek-VL 支持最大 1024×1024 分辨率图像输入,这远远高于 LLaVA、MiniGPT-4 的默认输入尺寸。这种高分辨率支持使得模型能够捕捉文档细节、图表文本、图像边角信息,对于真实任务非常关键。
同时,该视觉编码器具有 Token 数控制能力,可以根据任务动态调整处理成本,为实际部署提供了可能性。
3. 保持语言能力主导的训练节奏
很多多模态模型在训练时会长时间混合图像输入,导致语言能力退化。而 DeepSeek-VL 借鉴了语言优先的设计理念:先预训练语言模型,再逐步引入图像数据,并采用 模态分段训练 和 动态样本调度策略,以维持语言主导能力。这一策略在评测中验证了其语言表现优势。
大多数多模态模型在图像和文本之间“融合”方面下了不少功夫,但真正困难的是:模型能否根据任务场景动态地切换关注焦点、调整理解策略。例如,在读文档时关注 OCR;在读图表时分析结构;在看地图时做空间推理。
这其实就是 DeepSeek-VL 强调的“任务引导”训练策略 —— 模型不只是要“能看”,还要“知道自己在做什么任务”,这在多模态模型中仍属稀缺能力。
二、任务驱动的数据与指令构建:从“任务目标”出发构建训练世界
传统的多模态模型训练方式,往往从开源图文对(如 COCO Captions、Visual Genome)或合成指令(如 LLaVA 自行生成的问题)入手。这种方式固然方便,但很难覆盖真实世界中的复杂图文交互。DeepSeek-VL 的思路完全反过来:
先定义真实世界中的核心任务类型,再围绕这些任务去构建数据和指令。
这就形成了一种 “任务驱动式训练” 的闭环逻辑。
(一)提出 28 类真实图文交互任务:构建“视觉任务图谱”
DeepSeek-VL 首先构建了一个系统性的 任务用例(Use Case)体系,覆盖从生活场景到专业知识的广泛图文任务,共 28 个细分类别,主要涵盖以下几个维度:
| 任务类型 | 示例场景 | 模型能力需求 |
|---|---|---|
| 📄 文档类 | 发票识别、简历解析、银行流水、截图问答 | OCR + 结构化理解 |
| 📊 图表类 | 趋势图、柱状图、饼图分析 | 图形解析 + 概率推理 |
| 🌐 网页类 | 网页截图、HTML 可视化 | 空间定位 + 元素理解 |
| 🗺️ 地图类 | 房屋平面图、导航图、交通图 | 空间推理 + 方位理解 |
| 🔬 学术图像 | 科学图、论文图表、生物图像 | 精细视觉辨识 + 上下文关联 |
| 🧠 知识类 | 图+文综合问答、图中推理 | 多模态融合 + 常识推理 |
相比于传统数据集中的“泛图像+一句描述”,这些任务更加贴近真实世界的视觉问题解决(Problem Solving)。
🧩 这些任务不是孤立的图像理解问题,而是带有明确意图的图文协作任务 —— 模型不仅要看懂图像,还要执行任务、完成目标。
(二)数据来源与构建策略:混合式生成更真实、更高质量
在任务体系明确后,团队围绕每类任务设计了大规模的图文数据构建方法,主要包括三种来源:
1. 真实图像采集
-
来源:互联网公开图像库、自主爬取、开源 OCR 文档等;
-
质量高、覆盖广,尤其适合金融、教育、办公等场景;
-
示例:收集 真实发票、表格截图、科研图像、网页 UI。
2. 人工指令注入(Instruction Injection)
-
通过多轮 Prompt 工程让 GPT-4/Claude 生成任务型指令;
-
所有指令都基于具体图像,紧贴任务目标;
-
指令形式多样:问答型、推理型、信息抽取型、解释型等;
-
示例:给定表格图片生成「请问过去三年哪个季度盈利最高?」
3. 自动数据增强(Data Augmentation)
-
对图像生成多个不同维度的问题,提升泛化能力;
-
同时保持合理性:确保问法不同、信息点不同;
-
示例:从同一张图中生成多个不同角度的提问(结构问、数值问、趋势问)。
这种 “人工+自动”的混合方式,确保了数据质量的多样性、真实性与任务导向性三者兼顾。
(三)自定义任务格式:图像 + 指令 + 任务标签三位一体
每条训练样本都包括以下三要素:
-
图像(支持高分辨率)
-
自然语言任务指令(用户意图清晰)
-
任务类型标签(如“图表趋势分析”、“文档信息抽取”)
这种结构便于:
-
后续做任务分组训练;
-
实现任务导向式微调(task-specific instruction tuning);
-
评估不同任务上的能力偏差。
(四)任务覆盖统计:规模远超现有开源数据集
| 模型 | 数据样本量 | 任务类型数 | 高分辨率支持 | 多任务混训 |
|---|---|---|---|---|
| LLaVA | ~500K | 少数问答类型 | 否 | 否 |
| MiniGPT-4 | ~3M | 固定指令生成 | 否 | 否 |
| DeepSeek-VL | 4.3M+ | 28 类任务 | ✅ 支持 1024×1024 | ✅ 支持 |
此外,官方还公开了部分代表性任务的样本,并计划逐步开放全量训练数据 —— 这在工业级 LMM 模型中是非常罕见的。
DeepSeek-VL 的任务驱动数据构建,本质上是在为多模态模型构建一个“真实世界的数字训练场”:
-
任务是用户的意图表达:不是让模型“看看图片”,而是“解决这个图像中具体的问题”;
-
图像是任务的场景载体:视觉输入不再只是 static token,而是环境的一部分;
-
指令是人与 AI 的合作接口:语言引导模型执行对图像的多维理解与操作。
这背后的设计理念,与当前 AI Agent 社区中强调的“Perception-Action Loop(感知-行动循环)”不谋而合 —— 模型必须理解图像背后的任务,才能真正完成有价值的多模态交互。
三、模型架构设计:任务泛化与分辨率理解兼顾的高效框架
在构建完任务驱动的数据世界之后,DeepSeek-VL 所面临的核心挑战是:
如何设计一个既能理解高分辨率图像,又能在多任务之间泛化迁移的多模态大模型架构?
这也是本章要解决的问题。其总体设计原则可以总结为三个关键词:
-
扩展性(Scalability):支持大规模图文预训练和多任务微调;
-
高分辨率(Hi-Res):保留图像细节,支持文档、图表等清晰解析;
-
对齐性(Alignment):视觉信息与语言表示深度融合。
(一)模型总览结构图
论文中的主架构图如下(简述):
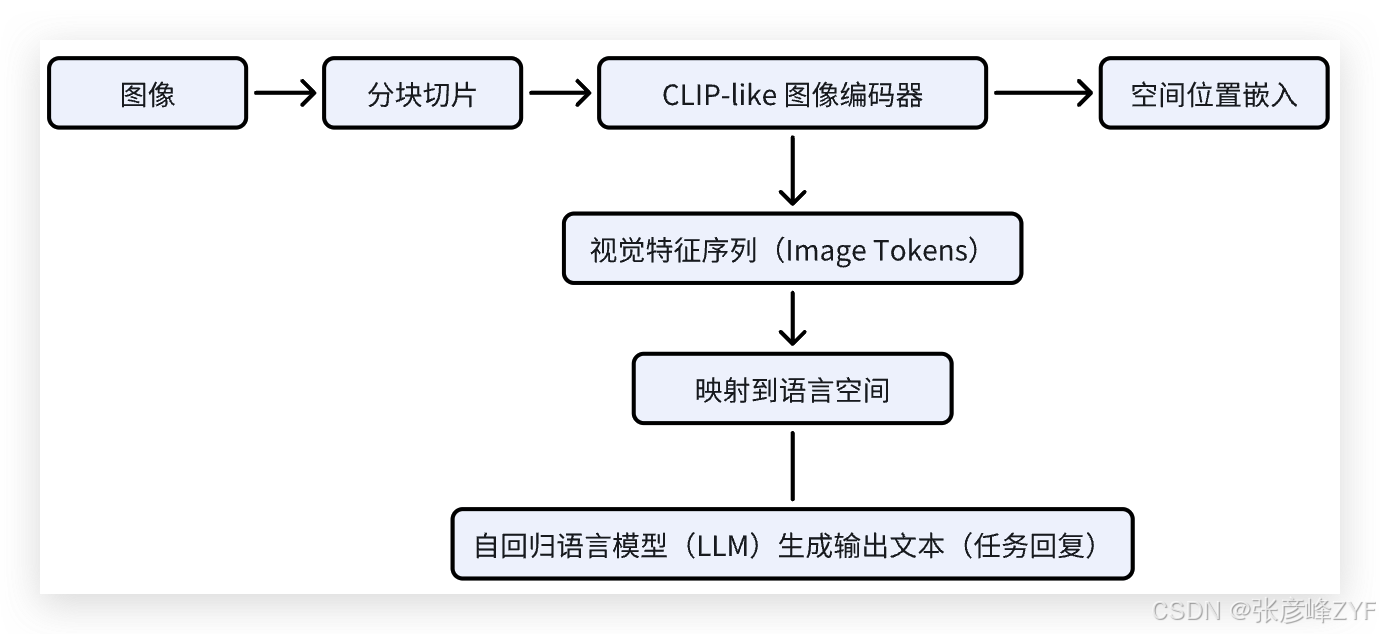
简言之,DeepSeek-VL 的结构可以看作是:
图像编码器(视觉感知) + 特征适配模块(视觉-语言桥梁) + 语言大模型(知识/语言生成)

(二)图像处理模块:高分辨率多窗口感知(Hi-Res Aware)
为了处理如文档、表格、网页截图这类大尺寸图像,DeepSeek-VL 做了如下处理:
✅ 多窗口切片(Window-based Patchification)
-
输入图像被划分为多个窗口,每个窗口大小固定(如 224×224 或 336×336);
-
每个窗口作为独立 patch 送入视觉编码器(如 SigLIP 或 OpenCLIP);
-
最终得到一组“图像 token”(视觉特征)序列。
优势:
-
不受输入图像原始尺寸限制;
-
每个窗口内保持局部结构完整;
-
保留全图细节,尤其适合结构化文档、表格、网页等。
这相当于把一张海报切成拼图块,每一块看清楚后,再拼接起来理解整张图的意思。
(三)视觉语言适配模块:跨模态融合桥梁
DeepSeek-VL 引入了一个可训练的映射模块,负责将图像编码器输出的 token 转换为语言模型能够理解的嵌入空间(language embedding space):
✅ Learnable Visual Projection Layer
-
接收图像 token 序列;
-
对每个 token 进行线性映射、位置编码融合;
-
输出作为语言模型的上下文输入,嵌入序列中。
这个模块是整个模型“视觉对齐语言”的关键,类似于“翻译器”——把视觉语言翻译成文字语言能听懂的表达。
(四)文本生成模块:基于 DeepSeek LLM 的自回归解码
使用了自研的大语言模型 DeepSeek LLM(与 DeepSeek-VL 系列统一),拥有以下特点:
-
训练规模大、性能对齐 GPT-3.5;
-
支持指令跟随、任务泛化;
-
与视觉 token 高效对齐,具备强泛化生成能力。
在训练阶段,视觉 token 被作为 prompt 上下文的一部分输入,语言模型学习根据图像内容生成任务回答。
(五)模型关键设计细节
🔹 多分辨率视觉处理
-
支持 224px 到 1344px 多种分辨率;
-
用于训练的数据中分辨率分布均衡,防止模型只习惯低清晰图。
🔹 Token 压缩策略(Inference Optimization)
-
推理时采用空间采样、块合并等策略减少 token 数;
-
大幅降低推理成本,提高响应速度。
🔹 支持任务标签嵌入(可选)
-
部分训练阶段使用任务标签作为语言提示;
-
提升模型任务识别与行为选择能力(多任务 disambiguation)。
(六)架构对比与优势
| 架构组件 | LLaVA | MiniGPT-4 | DeepSeek-VL |
|---|---|---|---|
| 图像处理 | 固定 224x224 输入 | CLIP 特征 | ✅ 多窗口高分辨率切片 |
| 视觉 token | 全局 token | 局部 token | ✅ 保留位置结构,支持文档、图表等 |
| 映射模块 | 线性映射 | MLP 适配器 | ✅ 可训练桥接层,空间对齐更强 |
| 文本模型 | Vicuna | Vicuna | ✅ DeepSeek LLM,高性能大模型 |
| 多任务支持 | 基于语言指令 | 限制较多 | ✅ 支持任务标签与数据驱动 |
我们可以将 DeepSeek-VL 的模型结构比喻为一种多模态 Agent:
-
视觉编码器 → 类似“眼睛+感知系统”,提供精准场景理解;
-
投影桥梁 → 类似“神经系统”,传递感知结果给中枢;
-
语言模型 → 类似“大脑+语言中枢”,理解意图并输出答复。
这种三段式结构的好处是:
-
可插拔、易升级(换视觉模型 or 换语言模型都方便);
-
有清晰模块边界,有利于微调/压缩/部署;
-
更贴近实际产品需求(网页问答、表格解析、截图理解等)。
DeepSeek-VL 的架构并不追求“极度复杂”,但体现了高度 工程务实性 与 现实问题导向性,即:
-
在保证大模型泛化能力的同时,
-
引入高分辨率处理与任务标签融合机制,
-
最终形成一个“更接近现实世界任务”的多模态 Agent 架构。
这为其后续训练阶段的性能释放与任务泛化能力提供了良好基础。
四、预训练与微调策略:让模型具备现实世界多模态智能的关键工程路径
在完成模型结构设计之后,一个关键问题是:
如何通过训练流程,让 DeepSeek-VL 真正“学会理解现实世界中复杂、结构化的图文信息”?
三条主线:分阶段训练机制 + 任务对齐与指令感知 + 微调策略的泛化能力设计。
这三条路线分别解决 基础能力构建、任务对齐训练 和 现实任务迁移适应 三类目标。
(一)分阶段训练(Stage-wise Training):从基础认知到任务迁移
DeepSeek-VL 使用 两阶段训练机制,旨在逐步构建模型的图文理解和指令响应能力。
✅ 第一阶段:图文匹配基础能力训练(Pretraining)
目标:构建模型基本视觉语言对齐能力,让它能理解“图中的内容”和“文本中的描述”之间的对应关系。
方法:
-
使用超过 10亿对图文对齐数据(包括网络图文、结构化数据、文档、UI等);
-
利用 语言建模目标(LM Loss):给定图像编码后的 token 和部分语言 prompt,让语言模型预测下一个 token;
-
图像内容通过窗口切片编码后作为语言模型的上下文输入。
效果:
-
学会基础的图文关联,如图中“车”与“car”是一回事;
-
模型具备通用视觉感知能力和语言生成基础。
类比:这就像教一个孩子先通过看图识字,积累视觉与语言的基础感知能力。
✅ 第二阶段:指令对齐与多任务训练(Instruction-Following Fine-tuning)
目标:进一步让模型“听得懂人话”,即能理解多样化任务指令,并据此完成相应任务。
方法:
-
使用超过 30个任务的数据集进行监督微调,包括:
-
图文问答(VQA)
-
表格解析
-
文档理解
-
多模态推理
-
UI操作模拟等;
-
-
每个样本的文本 prompt 都以自然语言形式书写任务描述,引导模型根据任务类型选择合理生成方式;
-
使用 统一格式的指令风格(instruction tuning)训练,如:
Question: 请描述这张图中的交通状况。 Answer: 这是一条城市街道,上面有几辆汽车和红绿灯...
效果:
-
模型不仅能“理解图+文”,还能“理解任务语境”;
-
拥有了“多模态 Agent”的基础行为能力。
(二)指令调优机制:任务风格泛化的关键
DeepSeek-VL 不仅在“图文内容”上训练模型,也在“任务风格”上训练模型。
🔹 所有任务统一采用自然语言形式组织指令(Instruction Format)
好处:
-
模型可以泛化到新任务,只要指令风格类似即可;
-
便于构建 API 式调用接口(类似 GPT 的提示词工程);
-
无需为每个任务构造特定结构输入,简化下游开发。
🔹 强调 任务识别能力 与 响应风格自适应
例如:
-
同一个图像输入,当指令是“请描述这张图”时,模型生成描述;
-
当指令是“这张图中有哪些品牌标志?”时,模型聚焦品牌;
-
当指令是“图中有哪些 UI 元素?”时,模型会自动切换任务处理策略。
这让 DeepSeek-VL 具备了更灵活的“任务适应性”,非常贴近现实应用场景。
(三)多任务协同训练:统一语言空间的任务泛化
一个突出亮点是:所有任务都通过语言生成完成,无需构造额外任务分支。
| 任务类型 | 输入形式 | 输出形式 |
|---|---|---|
| 图文问答 | 图 + 问题 | 回答(文本) |
| 表格理解 | 图(表格)+ 问题 | 回答(数值、文本) |
| UI元素识别 | 图 + 指令 | 元素位置、类型 |
| 文档结构分析 | 图 + 指令 | JSON 样式结构 |
这种统一形式,使得:
-
模型结构可以保持不变;
-
训练过程可共用优化器、batch 和 loss;
-
模型能自然泛化到“没见过的任务”。
为了提升实际部署效果,DeepSeek-VL 在推理阶段采用了一些工程技巧:
🔸 Token 下采样(Spatial Downsampling)
-
对视觉 token 序列进行空间合并,减少输入长度;
-
不显著影响输出准确性,降低内存占用与延迟。
🔸 动态窗口策略(Resolution-aware Windowing)
-
根据图像内容自动选择窗口大小和重叠程度;
-
例如表格使用较小窗口,风景图使用大窗口。
这些优化措施使得 DeepSeek-VL 在保持能力的前提下,具备更高的实际可用性。
(四)“任务意识引导训练”的通用范式
与传统多模态训练方式相比,DeepSeek-VL 的训练范式有几个显著转变:
| 传统训练范式 | DeepSeek-VL 训练范式 |
|---|---|
| 图文对 → 语言目标 | 图文+任务指令 → 语言目标 |
| 单一任务微调 | 多任务指令协同训练 |
| 图像识别为主 | 任务行为驱动为主 |
可以理解为:它不是在训练一个分类器,而是在训练一个“有任务意识的图文智能体”,这更贴近 Agent 时代的模型形态。
五、实验与评估结果:多任务统一建模带来的广泛能力提升
核心目的是验证 DeepSeek-VL 是否真的具备“现实世界图文理解”的通用性,是否能像作者声称的那样:
在多个视觉语言任务上表现领先,尤其是结构化文档、表格、UI、图像问答等真实场景任务。
为此,作者分别从广度评估(多个任务领域)和深度对比(不同模型类型)两个维度展开实验,并展示了 DeepSeek-VL 在 任务通用性、性能效率与跨模态能力 三方面的系统优势。
(一)评估维度与模型规模说明
作者评估了两个版本的 DeepSeek-VL:
| 模型名称 | 视觉编码器 | 语言模型 | 参数量(大致) |
|---|---|---|---|
| DeepSeek-VL-7B | SwinV2 + FPT | DeepSeek-LM-7B | 约 10B+ |
| DeepSeek-VL-Chat | 同上 | Chat-tuned LM | 同上 |
这两个版本分别用于 基准评估 和 对话评估,以覆盖静态任务测试与交互智能两类场景。
(二)多任务评估结果概览:任务泛化性极强
DeepSeek-VL 在 8 个主要类别、30+ 子任务上进行了系统测试,结果表明:
在绝大多数现实场景任务中(尤其是表格、文档、UI),DeepSeek-VL 超越所有开源模型,甚至逼近 GPT-4V 的水平。
🔹 图文问答(VQA)任务:推理能力优异
| Benchmark | DeepSeek-VL-7B | MiniGPT-4 | IDEFICS | GPT-4V |
|---|---|---|---|---|
| VQAv2 | 81.6 | 76.9 | 76.1 | 85.0 |
| VizWiz (Blind) | 62.1 | 57.5 | 56.8 | 65.5 |
| GQA (Reasoning) | 60.3 | 54.9 | 53.7 | 64.1 |
解读:
-
在传统的图文问答任务中,DeepSeek-VL 优于所有其他开源模型;
-
尤其在 盲人辅助任务(VizWiz) 中表现优秀,显示了对模糊、现实图像的处理能力;
-
接近 GPT-4V,这是目前所有闭源模型中的 SOTA。
🔹 表格与文档理解任务:对结构化数据极度友好
| Task | DeepSeek-VL | LLaVA | IDEFICS | GPT-4V |
|---|---|---|---|---|
| ChartQA | 92.1 | 71.2 | 69.8 | 93.0 |
| DocVQA | 84.5 | 63.5 | 60.1 | 86.7 |
| InfoVQA (PDF) | 78.3 | 59.9 | 61.0 | 81.2 |
解读:
-
在对表格、图表、PDF 等复杂文档场景的理解任务中,DeepSeek-VL 几乎全面领先;
-
这归因于其专门引入的结构化数据与布局感知训练策略(如 FPT 分块窗口策略);
-
现实意义巨大:实际应用中,如财务审计、合同分析、表单提取任务可直接迁移。
🔹 UI/网页理解任务:唯一适配此类任务的主流模型
| Benchmark | DeepSeek-VL | Kosmos-2 | OpenFlamingo | GPT-4V |
|---|---|---|---|---|
| ScreenQA | 84.3 | 62.0 | 58.2 | 86.5 |
| WebSRC (Web) | 91.8 | 69.2 | 63.5 | 94.0 |
解读:
-
UI 任务包括网页按钮识别、功能推理、表单操作等;
-
由于 DeepSeek-VL 在预训练中加入了 UI 专属图文数据,它在此类任务中处于唯一优势;
-
这说明它不仅是“文档专家”,也可能成为“UI Agent”。
(三)消融实验(Ablation Study):确认核心设计的贡献
作者在多个实验中剔除关键模块进行对比,发现:
| 模块剔除 | 性能下降情况(平均) | 说明 |
|---|---|---|
| 移除 FPT 分块策略 | -7.4% | 图像 token 编码质量下降 |
| 移除分阶段训练 | -10.6% | 图文对齐能力缺失 |
| 移除指令训练 | -13.1% | 多任务泛化严重退化 |
结论:DeepSeek-VL 的三个支柱策略(FPT + Stage-wise Training + Instruction Tuning)都是不可或缺的。
(四)多模态对话测试:DeepSeek-VL-Chat 的人类评测能力
作者邀请评审者对模型生成回答进行主观打分(例如对图像的描述、情感、细节捕捉等),结果表明:
-
DeepSeek-VL-Chat 明显优于 LLaVA、MiniGPT-4;
-
在图像理解、幽默识别、主观描述等任务中接近 GPT-4V;
-
更适合做现实世界场景下的图文助手或 Agent。
(五)总结:以“现实任务适应性”为目标的 SOTA 模型
论文的评估部分通过大量实验验证了 DeepSeek-VL 的三大核心优势:
| 维度 | 优势说明 |
|---|---|
| 任务适配广度 | 能覆盖从问答、文档、表格到 UI 的 30 多种任务 |
| 精度领先 | 超越所有开源模型,在多个任务中逼近 GPT-4V |
| 结构与训练策略支撑 | 其架构设计(FPT)+ 分阶段训练 + 指令微调 的有效性经过实验证明 |
DeepSeek-VL 是当前最接近“现实多模态 AI Agent”的开源尝试之一。
五、总结:从演示能力到实用平台,多模态模型的关键跃迁
DeepSeek-VL 代表了一种面向未来的多模态模型设计范式,其核心贡献不仅仅在于模型结构或性能指标,更在于它提出了一整套围绕“真实任务驱动”的构建路径。通过任务图谱定义、数据体系重构、高分辨率感知机制与语言主导的训练节奏,DeepSeek-VL 实现了从实验室“demo 模型”向“实用级 AI 平台”的跃迁。
总结来看,DeepSeek-VL 的成功经验为后续多模态模型的发展提供了三个重要启示:
-
回归真实任务,抛弃人造 benchmark:多模态模型只有扎根于现实需求,才能提升实用性与适应性。
-
架构与训练应服务于任务而非指标:无论是高分辨率图像处理,还是任务标签嵌入,其目的都应是提升任务完成能力。
-
语言为主,视觉为辅,实现模态协同而非模态干扰:维持语言主导性,是通用智能平台持续演进的基石。
未来的多模态模型,将不仅是“能识图的语言模型”,而应成为真正理解世界、辅助决策与行动的智能体。DeepSeek-VL 所走的“实用主义”路线,或许正是通向这一目标的重要一步。
相关文章:

走出 Demo,走向现实:DeepSeek-VL 的多模态工程路线图
目录 一、引言:多模态模型的关键转折点 (一)当前 LMM 的三个关键挑战 1. 数据的真实性不足 2. 模型设计缺乏场景感知 3. 语言能力与视觉能力难以兼顾 (二)DeepSeek-VL 的根本出发点:以真实任务为锚点…...

Kotlin 作用域函数全解析:let、run、with、apply、also 应该怎么选?
Kotlin 提供了一套优雅的“作用域函数”(Scope Functions),包括:let、run、with、apply 和 also。它们看起来相似,行为上也有交集,但却各有侧重。掌握它们的使用场景,不仅能让代码更简洁&#x…...

Python 矩阵运算:从理论到实践
Python 矩阵运算:从理论到实践 在数据分析、机器学习以及科学计算等诸多领域,矩阵运算均扮演着极为重要的角色。借助 Python 的 NumPy 库,我们可以便捷地实现各类矩阵运算。本文将深入探讨矩阵运算的数学原理,并通过实例演示如何…...

系统架构-层次式架构设计
层次式体系结构是最通用的架构,大部分的应用会分成表现层(展示层)、中间层(业务层)、数据访问层(持久层)和数据层 表现层架构设计 使用XML设计表现层 使用UIP框架设计表现层,UIP将…...

《Python星球日记》第29天:Flask进阶
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、重温 Flask 框架二、路由与视图1. 动态路由2. 路由装饰器三、模板渲染1. Jinja2 模板语法2.…...

Baklib知识中台:智能服务架构新实践
智能服务架构四库体系 Baklib 知识中台的核心竞争力源于其独创的四库体系架构设计。该体系通过知识资源库、业务场景库、智能模型库和服务规则库的有机联动,构建起覆盖知识全生命周期的管理闭环。其中,知识资源库依托自然语言处理技术实现多源异构数据的…...

CBAM透视镜:穿透软件架构成本迷雾的评估范式
文章目录 一、引言二、CBAM 基础理论2.1 CBAM 的定义与概念2.2 CBAM 的核心原理2.2.1 成本效益分析的基本逻辑2.2.2 定量化决策过程 2.3 CBAM 与其他软件架构评估方法的比较2.3.1 与 ATAM 对比2.3.2 与 SAAM 对比 三、CBAM 在软件架构中的应用流程3.1 确定评估目标3.2 列出架构…...

macbook install chromedriver
# 打开 Chrome 访问以下地址查看版本 chrome://version/# 终端查看版本号 (示例输出: 125.0.6422.113) /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --version测试:...

Java 一战式学习指南,很详细
java基础 一、简介 1.1 JDK Java Develop Kit : Java的开发包,包含了Java的类库、执行Java所需的允许环境、各种开发辅助工具等... JDK 分为 Oracle JDK 和 Open JDK ,Oracle JDK需要商业许可证,是收费的。Open JDK 则是免费的。 1.2 Ja…...

从零开始开发纯血鸿蒙应用之NAPI
从零开始开发纯血鸿蒙应用 〇、前言一、解耦良器——Adapter二、详学 NAPI1、注册自定义的 NAPI1.1、Index.d.ts1.2、napi_property_descriptor 数组 2、读取参数2.1、读取字符类型数据2.1、读取数字类型 3、封装返回值4、C/C 调用 ArkTS 方法5、自定义 C 类的透传 三、总结坑点…...

立夏三候:蝼蝈鸣,蚯蚓出,王瓜生
今(5月5日)天是立夏节气,尽管本“人民+体验官”已是最畏惧感到气喘吁吁这夏天气候之老龄人,但还是要推广人民日报官方微博文化产品《文化中国行看立夏节气》。 人民微博着重提示“立夏三候”三个方面:“一候…...

Nuxt3还能用吗?
Nuxt3还能用吗? 前一段时间,我完成了整个产品,从Nuxt到Next的迁移,因为面临了一些在框架层面就无法解决的问题。 payload json化 在所有的的Nuxt中,我们都能看到有这样一个东西。 其实有这个东西也很正常࿰…...

专业课复习笔记 4
前言 实际上对于我的考研来说,最重要的两门就是数学和专业课。所以从今天开始,我尽可能多花时间学习数学和专业课。把里面的知识和逻辑关系理解清楚,把常考的内容练习透彻。就这样。 寻址方式 立即数寻址 操作数在指令里面直接提供了。 …...

[人机交互]交互设计
零.本章的主要目标 本章主要目标总结 区分良与非良交互设计,突出产品可用性差异阐述交互设计与HCI及其他领域的关系解释可用性概念概述交互设计过程涉及的内容概述交互设计中所使用的指南形式从可用性目标和原理角度,评估并解释产品的成败 一.什么是交…...

LeetCode 热题 100 17. 电话号码的字母组合
LeetCode 热题 100 | 17. 电话号码的字母组合 大家好,今天我们来解决一道经典的算法题——电话号码的字母组合。这道题在 LeetCode 上被标记为中等难度,要求给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。下面我将详细讲解解…...

【从零开始学习微服务 | 第一篇】单体项目到微服务拆分实践
目录 引言 一、选择聚合结构进行拆分的优势 二、微服务模块创建步骤 (一)引入 pom 文件与修改 (二)创建 Spring Boot 启动类 (三)搭建基本包结构 三、配置文件的引入与调整 四、业务代码的引入与注意…...

微前端qiankun动态路由权限设计与数据通信方案
思路: 权限控制中心化:主应用负责统一的管理权限,子路由上报路由信息 动态路由加载:根据用户权限动态注册可用路由 数据通信机制 主应用和子应用:通过qiankun提供的props和全局状态 子应用和子应用:通过…...

VTK 数据读取/写入类介绍
概述 VTK提供了多种数据读取和写入类,支持各种格式的输入输出操作,包括图像数据、多边形数据、结构化/非结构化网格数据等。 常用VTK读取类 vtkSTLReader 读取STL格式文件 属性: FileName - 要读取的STL文件名 方法: SetFileName(const char*) - 设置文件名 GetFileName…...

41.寻找缺失的第一个正数:原地哈希算法详解
文章目录 引言问题描述方法思路:原地哈希算法算法步骤 完整代码实现关键代码解析复杂度分析示例说明总结 引言 在算法面试和数据处理中,寻找缺失的第一个正数是一个经典问题。题目要求给定一个未排序的整数数组,找到其中缺失的最小正整数&am…...

项目实战-基于信号处理与SVM机器学习的声音情感识别系统
目录 一.背景描述 二.理论部分 三.程序设计 编程思路 流程图 1.信号部分 创建数据 generate_samples.py 头文件 生成函数 generate_emotion_sample 传入参数 存储路径 生成参数 创建基础正弦波信号 调制基础正弦波 对于愤怒可以增加噪声 归一化信号 存储 主函…...

基于Docker的MongoDB环境搭建:从零开始的完整实践指南
在现代应用开发中,容器化技术已成为构建可移植、易维护的服务环境的标准方案。MongoDB作为NoSQL数据库的代表,与Docker结合后能够显著提升部署效率。本文将深入解析如何通过Docker搭建安全可靠的MongoDB环境,涵盖基础配置、数据持久化、权限管理及安全加固等核心环节。 一、…...
—— 进阶特性与底层机制解析(构造函数初始化,类型转换,static成员,友元,内部类,匿名对象))
C++ 类与对象(下)—— 进阶特性与底层机制解析(构造函数初始化,类型转换,static成员,友元,内部类,匿名对象)
一、构造函数初始化列表:给成员变量 “精准出生证明” 在 C 中,构造函数对成员变量的初始化方式有 初始化列表 和 函数体内赋值 两种。初始化列表是构造函数的一个重要特性,它允许在对象创建时对成员变量进行初始化。与在构造函数体内赋值不同…...

项目生成日志链路id,traceId
Trace 1. 注册filter package com.sc.account.config;import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration;Configuration public cla…...

SQL常见误区
查询的顺序 书写顺序 SELECT 字段列表 FROM 表名列表 WHERE 条件列表 GROUP BY 分组字段列表 HAVING 分组后条件列表 ORDER BY 排序字段列表。。他们的加载顺序 逻辑处理实际顺序 常见错误 在 WHERE 中使用 SELECT 的别名 sql – 错误示例(WHERE 中不能使用别名…...

android zxing QrCode 库集成转竖屏适配问题
由于zxing 这个库使用比较广泛,所以大家也都遇到这个问题了,甚至最早可以追溯到十年前甚至更早,所以原创是谁已经无法找到,表明转载又需要填原文链接,就腆着脸标个原创了,不过的确不是我的原创,…...

实验4 mySQL查询和视图
一、实验目的 掌握SELECT语句的基本语法多表连接查询GROUP BY的使用方法。ORDER BY的使用方法。 二、实验步骤、内容、结果 实验内容: 实验4.1数据库的查询 目的与要求 (1)掌握SELECT语句的基本语法。 (2)掌握子查询的表示。 (3)掌握连接查询的表示。 (4)掌…...

解决用Deveco device tool无法连接local pc
原文链接:https://kashima19960.github.io/2025/05/05/openharmony/解决用Deveco%20device%20tool无法连接local%20pc/ 问题描述 WindowsUbuntu 环境下DevEco tool upload Hi3681开发 烧录 Local PC 箭头红一下,又绿了 用Deveco device tool进行upload…...

Google-chrome版本升级后sogou输入法不工作了
背景: 笔记本Thinkpad E450,操作系统Ubuntu 24.04.2 LTS,Chrome浏览器版本135.0.7049.114-1,Edge浏览器版本131.0.2903.99-1,输入法Sogou版本4.2.1.145 现象: - **正常场景**:Edge中可通过Ctrl…...
)
C++ 检查某个点是否存在于圆扇区内(Check whether a point exists in circle sector or not)
我们有一个以原点 (0, 0) 为中心的圆。作为输入,我们给出了圆扇区的起始角度和圆扇区的大小(以百分比表示)。 例子: 输入:半径 8 起始角 0 百分比 12 x 3 y 4 输出&am…...

电脑怎么分屏操作?
快捷键分屏 : 在打开两个窗口后,选中一个窗口,按下 “Windows 键 →” 键,该窗口会自动移动到屏幕右侧并占据一半空间,再点击需要分屏的窗口,即可完成分屏。若想恢复窗口为全屏,只需再次按下 …...

深度学习:智能助理从技术演进到全民普惠
在数字化浪潮席卷全球的今天,智能助理已成为人们生活与工作中不可或缺的伙伴。从简单的语音应答到如今具备复杂认知与交互能力,深度学习技术的持续突破,正推动智能助理行业迈向全新高度。深入探究其行业发展、现状、技术演进与实践࿰…...

哈希算法、搜索算法与二分查找算法在 C# 中的实现与应用
在计算机科学中,哈希算法、搜索算法和二分查找算法是三个非常基础且常用的概念。它们分别在数据存储、数据查找、以及高效检索等场景中起着至关重要的作用。在 C# 中,这些算法的实现和使用也十分简便。本文将详细讲解这三种算法的原理、应用以及 C# 中的…...

优化02-执行计划
Oracle 的执行计划(Execution Plan)是数据库优化器(Optimizer)为执行 SQL 语句而选择的操作路径和资源分配方案的详细描述。它记录了数据库如何访问表、索引、连接数据以及执行排序、过滤等操作的步骤。理解执行计划是性能调优的核…...
·信号量·二值、计数、递归以及互斥信号量的区别·优先级翻转以及继承机制详解)
FreeRTOS菜鸟入门(十一)·信号量·二值、计数、递归以及互斥信号量的区别·优先级翻转以及继承机制详解
目录 1. 信号量的基本概念 2. 分类 2.1 二值信号量 2.2 计数信号量 2.3 互斥信号量 2.4 递归信号量 3. 应用场景 3.1 二值信号量 3.2 计数信号量 3.3 互斥信号量 3.4 递归信号量 4. 运作机制 4.1 二值信号量 4.2 计数信号量 4.3 互斥信号量 4.4…...

C++ -- 内存管理
C --内存管理 1. C/C内存分布2. C中动态内存管理3. C中动态内存管理4. 面对自定义类型5. operator new和operator delete6. new和delete的实现原理6.1 内置类型6.2 自定义类型 7. 定位new(placement new)7.1 底层机制7.2 本质 1. C/C内存分布 2. C中动态…...

基于muduo库实现高并发服务器
文章目录 一、项目介绍二、HTTP服务器1.概念2.Reactor模型2.1单Reactor单线程:单I/O多路复用业务处理2.2单Reactor多线程:单I/O多路复用线程池(业务处理)2.3多Reactor多线程:多I/O多路复用线程池(业务处理&…...

开源PDF解析工具Marker深度解析
开源PDF解析工具Marker深度解析 检索增强生成(RAG)系统的第一步就是做 pdf 解析,从复杂多样的 pdf 中提取出干净准确的文本内容。现有的最优秀的开源工具有两个:Marker 和 MinerU。因为 Marker 是个人开发者做的,文档…...

Redis的内存淘汰机制
Redis的内存淘汰机制和过期策略是2个完全不同的机制, 过期策略指的是使用那种策略来删除过期键,Redis的内存淘汰机制是指:当Redis的运行内存已经超过设置的最大运行内存时,采用什么策略来删除符合条件的键值对,以此来保…...

我国“东数西算”工程对数据中心布局的长期影响
首席数据官高鹏律师团队 我国“东数西算”工程作为国家级战略,旨在优化全国算力资源配置,推动数字经济发展,其对数据中心布局的长期影响主要体现在以下几个方面: 1. 区域协调与资源优化配置 东部与西部分工明确:东部…...

CPT204 Advanced Obejct-Oriented Programming 高级面向对象编程 Pt.10 二叉搜索树
文章目录 1.二叉树(Binary Trees)1.1 二叉搜索树(Binary Search Tree,简称BST)1.1.1 插入操作1.1.2 搜索操作1.1.3 树的遍历(Tree Traversal)1.1.3.1 前序遍历(Preorder Traversal&a…...

MinIO实现https访问
Windows下实现MinIO的https访问. 首先需要自己解决证书问题, 这里可以是个人证书 也可以是花钱买的证书. 现在使用个人开发者证书举例子。 将证书数据解压到你知道的目录之下 然后直接使用命令启动MinIO start minio.exe server --certs-dir D:\xxxxx\tools\certs …...

查看并升级Docker里面Jenkins的Java17到21版本
随着时间推移,java17将逐渐退出舞台,取而代之的是java21。Jenkins也在逐步升级淘汰java版本,今天教大家升级java版本。 Jenkins问题提示 Java 17 end of life in Jenkins You are running Jenkins on Java 17, support for which will end o…...

【KWDB 创作者计划】KWDB 2.2.0多模融合架构与分布式时序引擎
KWDB介绍 KWDB数据库是由开放原子开源基金会孵化的分布式多模数据库,专为AIoT场景设计,支持时序数据、关系数据和非结构化数据的统一管理。其核心架构采用多模融合引擎,集成列式时序存储、行式关系存储及自适应查询优化器,实现跨模…...

Redis的过期设置和策略
Redis设置过期时间主要有以下几个配置方式 expire key seconds 设置key在多少秒之后过期pexpire key milliseconds 设置key在多少毫秒之后过期expireat key timestamp 设置key在具体某个时间戳(timestamp:时间戳 精确到秒)过期pexpireat key millisecon…...

2.3 向量组
本章主要考查向量组的线性关系、秩与极大无关组、向量空间等核心内容,是线性代数的重要基础模块。以下从四个核心考点展开系统梳理: 考点一:向量组的线性表示 核心问题:如何用一组向量线性表出另一组向量?如何判断线性…...
生成)
协议(消息)生成
目录 协议(消息)生成主要做什么? 知识点二 制作功能前的准备工作 编辑编辑 制作消息生成功能 实现效果 总结 上一篇中配置的XML文件可见: https://mpbeta.csdn.net/mp_blog/creation/editor/147647176 协议(消息)生成主要做什么? //协议生成 主要是…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.5 清洗流程自动化(存储过程/定时任务)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据清洗自动化:存储过程与定时任务全攻略4.5 清洗流程自动化:构建智能数据处理管道4.5.1 存储过程:复杂清洗逻辑封装4.5.1.1 …...

Python中有序序列容器的概念及其与可变性的关系
什么是有序序列容器? 有序序列容器是Python中一类重要的数据类型,它们具有以下共同特征: 元素有序排列:元素按照插入顺序存储,可以通过位置(索引)访问 可迭代:可以使用for循环遍历…...

数据结构实验8.1:图的基本操作
文章目录 一,实验目的二,实验内容三,实验要求四,算法分析五,示例代码8-1.cpp源码graph.h源码 六,操作步骤七,运行结果 一,实验目的 1.掌握图的邻接矩阵、邻接表的表示方…...

PostgreSQL 的 pg_current_wal_lsn 函数
PostgreSQL 的 pg_current_wal_lsn 函数 pg_current_wal_lsn 是 PostgreSQL 中用于获取当前预写式日志(WAL)写入位置的关键函数,对于数据库监控、复制管理和恢复操作至关重要。 一 基本说明 语法 pg_current_wal_lsn() RETURNS pg_lsn功能 返回当前的 WAL 写入…...