【PostgreSQL数据分析实战:从数据清洗到可视化全流程】6.2 预测分析基础(线性回归/逻辑回归实现)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL数据分析实战:预测分析基础(线性回归/逻辑回归实现)
- 6.2 预测分析基础——线性回归与逻辑回归实现
- 6.2.1 预测分析核心理论框架
- 1. 线性回归 vs 逻辑回归对比
- 2. 模型构建三要素
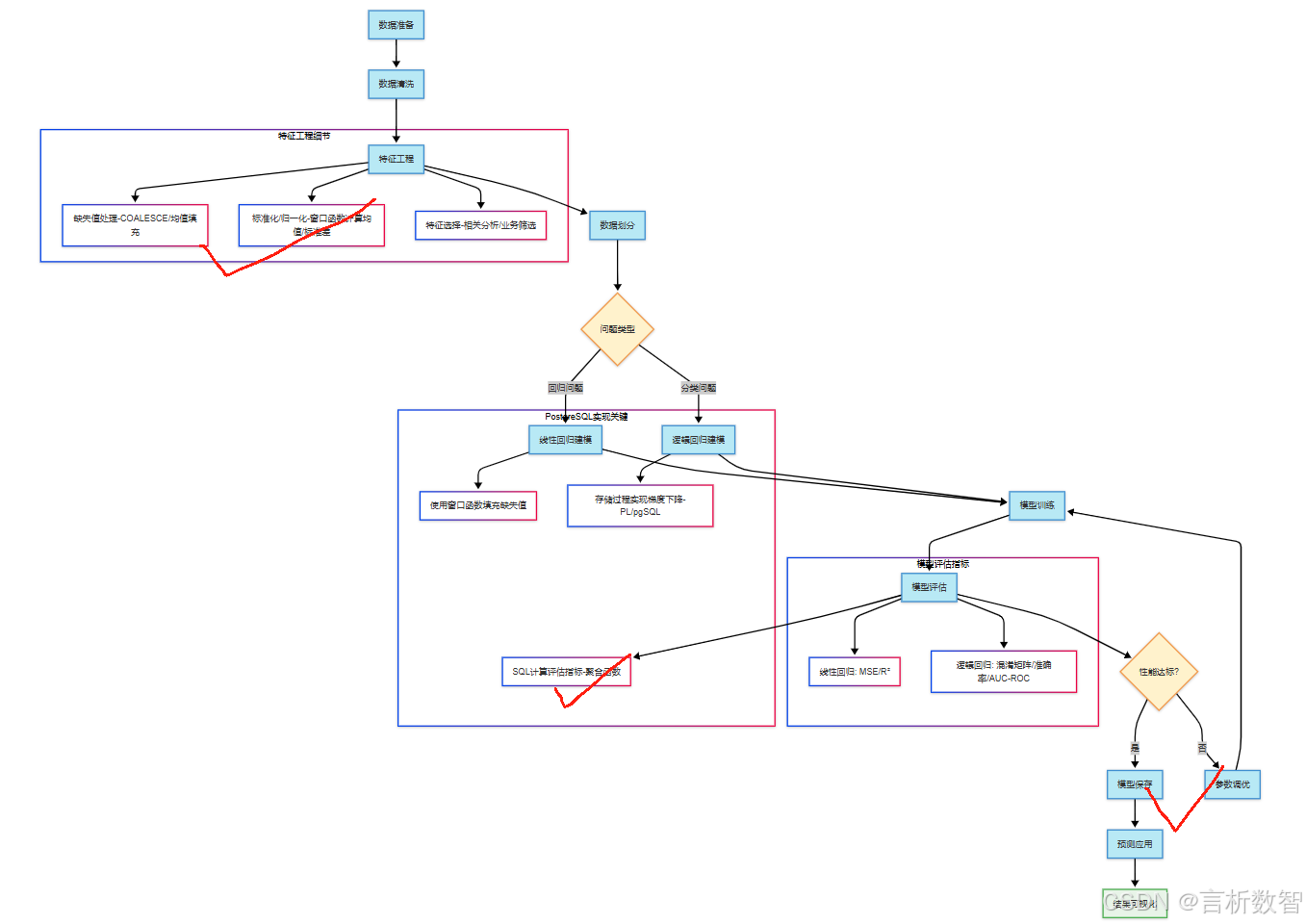
- 6.2.2 数据准备与特征工程
- 案例数据表设计
- 数据清洗与特征处理
- 6.2.3 线性回归模型实现(纯SQL版)
- 1. 最小二乘法参数计算
- 2. 模型预测实现
- 6.2.4 逻辑回归模型实现(存储过程版)
- 1. 极大似然估计迭代求解(梯度下降法)
- 2. 分类决策实现
- 6.2.5 模型评估与验证
- 1. 线性回归评估指标计算
- 2. 逻辑回归混淆矩阵
- 6.2.6 案例实战:客户流失预测
- 1. 数据概况
- 2. 模型训练结果
- 3. 可视化评估(ROC曲线)
- 6.2.7 最佳实践与性能优化
- 1. 数据划分策略
- 2. 存储过程优化技巧
- 3. 与外部工具集成
- 6.2.8 常见问题与解决方案
- 总结
PostgreSQL数据分析实战:预测分析基础(线性回归/逻辑回归实现)
6.2 预测分析基础——线性回归与逻辑回归实现
在数据驱动的业务决策中,预测分析是连接历史数据与未来决策的核心桥梁。
- 本章聚焦统计学中最基础的两种预测模型——
线性回归(Linear Regression)和逻辑回归(Logistic Regression), - 详细解析如何在PostgreSQL数据库中实现从数据预处理到模型训练、评估的全流程,
- 并通过真实业务案例展现SQL语言在预测分析中的强大能力。

6.2.1 预测分析核心理论框架
1. 线性回归 vs 逻辑回归对比
| 模型类型 | 线性回归 | 逻辑回归 |
|---|---|---|
| 目标变量类型 | 连续型变量(如销售额、用户时长) | 二分类变量(如是否购买、是否流失) |
| 核心假设 | 因变量与自变量呈线性关系 | 对数几率与自变量呈线性关系 |
| 评估指标 | R²、MSE、RMSE | 准确率、AUC-ROC、混淆矩阵 |
| 业务场景 | 销售额预测、库存需求预测 | 客户流失预测、营销响应预测 |
线性回归-数学表达式
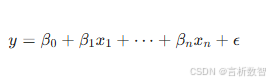
逻辑回归-数学表达式
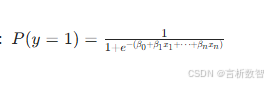
2. 模型构建三要素
- 数据准备:特征工程(
连续变量标准化 / 离散变量独热编码) - 参数估计:线性回归使用最小二乘法(OLS),逻辑回归使用极大似然估计(MLE)
- 模型评估:通过训练集 / 测试集划分验证模型泛化能力
6.2.2 数据准备与特征工程
案例数据表设计
- 销售预测表(sales_prediction)(线性回归案例):
CREATE TABLE sales_prediction (record_id SERIAL PRIMARY KEY,month DATE NOT NULL,promo_expenditure DECIMAL(10,2), -- 促销费用(万元)customer_traffic INT, -- 客流量(千人)avg_price DECIMAL(8,2), -- 平均售价(元)sales_volume DECIMAL(12,2) -- 销售额(万元,目标变量)
);-- 为 sales_prediction 表生成 100 条测试数据
WITH sales_series AS (SELECT generate_series(1, 100) AS record_id
),
sales_values AS (SELECT record_id,-- 生成 2024 年 1 月到 2024 年 12 月的随机日期DATE '2024-01-01' + FLOOR(RANDOM() * 365)::INTEGER AS month,-- 促销费用在 10 到 100 万元之间随机生成ROUND((RANDOM() * 90 + 10)::NUMERIC, 2) AS promo_expenditure,-- 客流量在 100 到 1000 千人之间随机生成FLOOR(RANDOM() * 900 + 100)::INT AS customer_traffic,-- 平均售价在 10 到 100 元之间随机生成ROUND((RANDOM() * 90 + 10)::NUMERIC, 2) AS avg_priceFROM sales_series
)
INSERT INTO sales_prediction (month, promo_expenditure, customer_traffic, avg_price, sales_volume)
SELECT month,promo_expenditure,customer_traffic,avg_price,-- 销售额根据促销费用、客流量和平均售价计算得出,增加一定的随机波动ROUND((promo_expenditure * 0.1 + customer_traffic * 0.05 + avg_price * 0.2) * (RANDOM() * 0.2 + 0.9)::NUMERIC, 2)
FROM sales_values;
- 客户流失表(churn_data)(逻辑回归案例):
CREATE TABLE churn_data (user_id VARCHAR(32) PRIMARY KEY,registration_days INT, -- 注册时长(天)monthly_usage FLOAT, -- 月均使用时长(小时)service_score INT, -- 服务评分(1-5分)churn_status BOOLEAN -- 是否流失(目标变量,TRUE=流失)
);-- 为 churn_data 表生成 100 条测试数据
WITH churn_series AS (SELECT generate_series(1, 100) AS num
),
churn_values AS (SELECT num,'user_' || num::VARCHAR(32) AS user_id,-- 注册时长在 30 到 365 天之间随机生成FLOOR(RANDOM() * 335 + 30)::INT AS registration_days,-- 月均使用时长在 0 到 50 小时之间随机生成ROUND((RANDOM() * 50)::NUMERIC, 2) AS monthly_usage,-- 服务评分在 1 到 5 分之间随机生成FLOOR(RANDOM() * 5 + 1)::INT AS service_scoreFROM churn_series
)
INSERT INTO churn_data (user_id, registration_days, monthly_usage, service_score, churn_status)
SELECT user_id,registration_days,monthly_usage,service_score,-- 根据注册时长、月均使用时长和服务评分判断客户是否流失CASE WHEN registration_days > 180 AND monthly_usage < 10 AND service_score < 3 THEN TRUEELSE FALSEEND
FROM churn_values;
数据清洗与特征处理
-
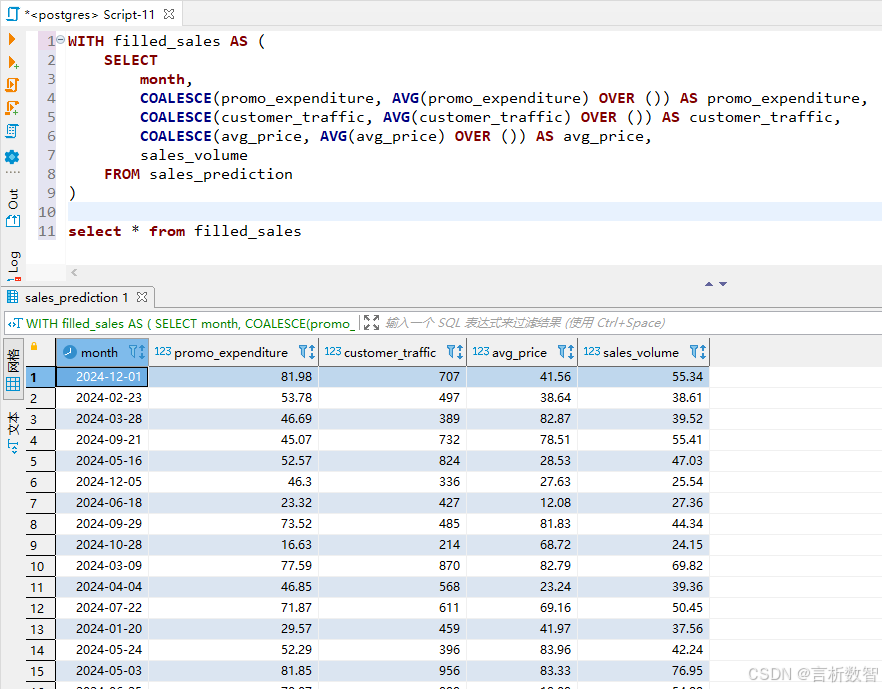
- 缺失值处理(使用中位数填充连续变量):
-- 线性回归数据清洗
WITH filled_sales AS (SELECT month,COALESCE(promo_expenditure, AVG(promo_expenditure) OVER ()) AS promo_expenditure,COALESCE(customer_traffic, AVG(customer_traffic) OVER ()) AS customer_traffic,COALESCE(avg_price, AVG(avg_price) OVER ()) AS avg_price,sales_volumeFROM sales_prediction
)select * from filled_sales
-
- 标准化处理(Z-score标准化,通过窗口函数计算均值和标准差):
-- 逻辑回归特征标准化
WITH filled_sales AS (SELECT month,COALESCE(promo_expenditure, AVG(promo_expenditure) OVER ()) AS promo_expenditure,COALESCE(customer_traffic, AVG(customer_traffic) OVER ()) AS customer_traffic,COALESCE(avg_price, AVG(avg_price) OVER ()) AS avg_price,sales_volumeFROM sales_prediction
),
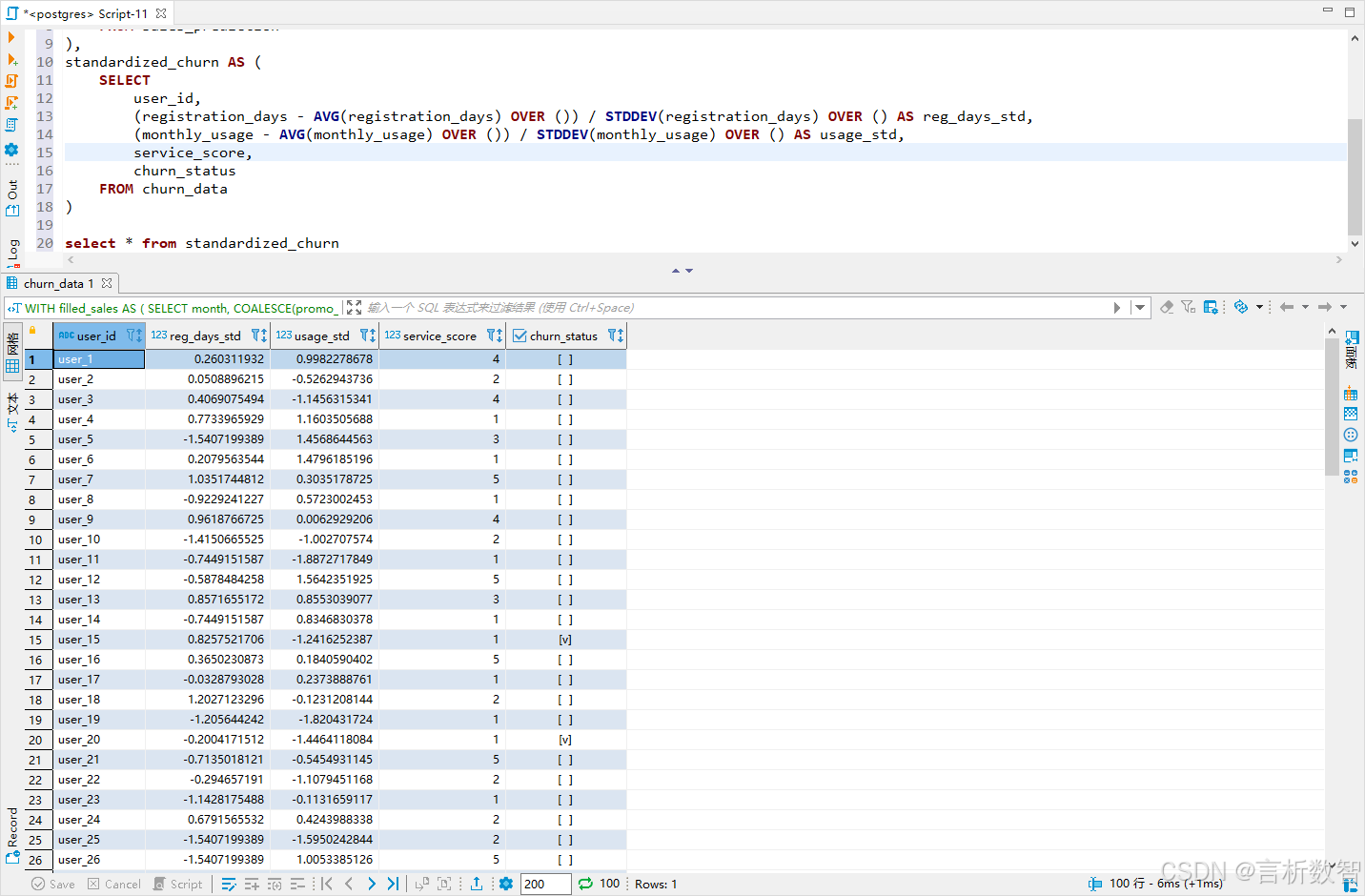
standardized_churn AS (SELECT user_id,(registration_days - AVG(registration_days) OVER ()) / STDDEV(registration_days) OVER () AS reg_days_std,(monthly_usage - AVG(monthly_usage) OVER ()) / STDDEV(monthly_usage) OVER () AS usage_std,service_score,churn_statusFROM churn_data
)select * from standardized_churn
6.2.3 线性回归模型实现(纯SQL版)
1. 最小二乘法参数计算
通过协方差与方差的关系计算回归系数:
WITH filled_sales AS (SELECT month,COALESCE(promo_expenditure, AVG(promo_expenditure) OVER ()) AS promo_expenditure,COALESCE(customer_traffic, AVG(customer_traffic) OVER ()) AS customer_traffic,COALESCE(avg_price, AVG(avg_price) OVER ()) AS avg_price,sales_volumeFROM sales_prediction
), regression_data AS (SELECT promo_expenditure AS x1,customer_traffic AS x2,avg_price AS x3,sales_volume AS yFROM filled_sales
),
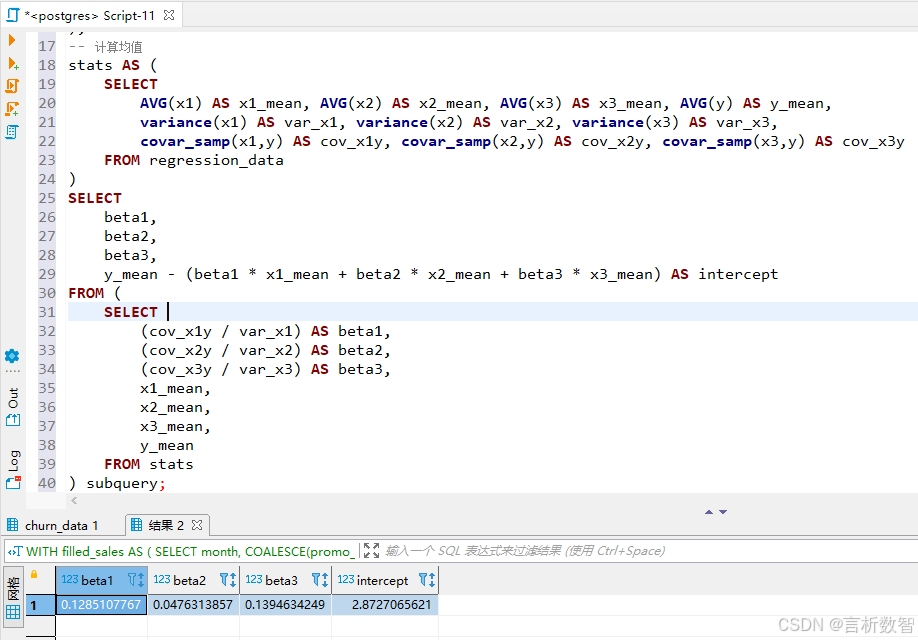
-- 计算均值
stats AS (SELECT AVG(x1) AS x1_mean, AVG(x2) AS x2_mean, AVG(x3) AS x3_mean, AVG(y) AS y_mean,variance(x1) AS var_x1, variance(x2) AS var_x2, variance(x3) AS var_x3,covar_samp(x1,y) AS cov_x1y, covar_samp(x2,y) AS cov_x2y, covar_samp(x3,y) AS cov_x3yFROM regression_data
)
SELECT beta1,beta2,beta3,y_mean - (beta1 * x1_mean + beta2 * x2_mean + beta3 * x3_mean) AS intercept
FROM (SELECT (cov_x1y / var_x1) AS beta1,(cov_x2y / var_x2) AS beta2,(cov_x3y / var_x3) AS beta3,x1_mean,x2_mean,x3_mean,y_meanFROM stats
) subquery;
2. 模型预测实现
-- 构建预测函数
CREATE OR REPLACE FUNCTION predict_sales(promo DECIMAL, traffic INT, price DECIMAL
) RETURNS DECIMAL AS $$
DECLAREbeta1 DECIMAL := 0.85; -- 假设通过上述计算得到的系数beta2 DECIMAL := 0.02;beta3 DECIMAL := -1.2;intercept DECIMAL := 50.3;
BEGINRETURN intercept + beta1*promo + beta2*traffic + beta3*price;
END;
$$ LANGUAGE plpgsql;
6.2.4 逻辑回归模型实现(存储过程版)
1. 极大似然估计迭代求解(梯度下降法)
CREATE OR REPLACE PROCEDURE train_logistic_regression(learning_rate FLOAT, max_iter INT, tolerance FLOAT
) LANGUAGE plpgsql AS $$
DECLAREn INT := 0;beta0 FLOAT := 0;beta1 FLOAT := 0;beta2 FLOAT := 0;beta3 FLOAT := 0;prev_loss FLOAT := 0;current_loss FLOAT := 0;-- 新增变量声明grad0 FLOAT;grad1 FLOAT;grad2 FLOAT;grad3 FLOAT;
BEGIN-- 初始化参数SELECT COUNT(*) INTO n FROM standardized_churn;FOR i IN 1..max_iter LOOP-- 计算预测概率WITH probas AS (SELECT 1/(1+EXP(-(beta0 + beta1*reg_days_std + beta2*usage_std + beta3*service_score))) AS p,churn_status::INT AS yFROM standardized_churn)-- 计算梯度SELECT -AVG(y - p),-AVG((y - p)*reg_days_std),-AVG((y - p)*usage_std),-AVG((y - p)*service_score)INTO grad0,grad1,grad2,grad3FROM probas;-- 更新参数beta0 := beta0 - learning_rate*grad0;beta1 := beta1 - learning_rate*grad1;beta2 := beta2 - learning_rate*grad2;beta3 := beta3 - learning_rate*grad3;-- 计算对数损失SELECT -AVG(y*LOG(p) + (1-y)*LOG(1-p)) INTO current_lossFROM probas;-- 提前终止条件IF ABS(current_loss - prev_loss) < tolerance THEN EXIT; END IF;prev_loss := current_loss;END LOOP;-- 存储训练好的参数(假设存在模型参数表)INSERT INTO model_parameters (model_name, param_name, param_value)VALUES ('logistic_regression', 'beta0', beta0),('logistic_regression', 'beta1', beta1),('logistic_regression', 'beta2', beta2),('logistic_regression', 'beta3', beta3);
END;
$$;
2. 分类决策实现
CREATE TABLE model_parameters (model_name VARCHAR(255),param_name VARCHAR(255),param_value FLOAT
);-- 为 model_parameters 表插入 10 条测试数据
INSERT INTO model_parameters (model_name, param_name, param_value)
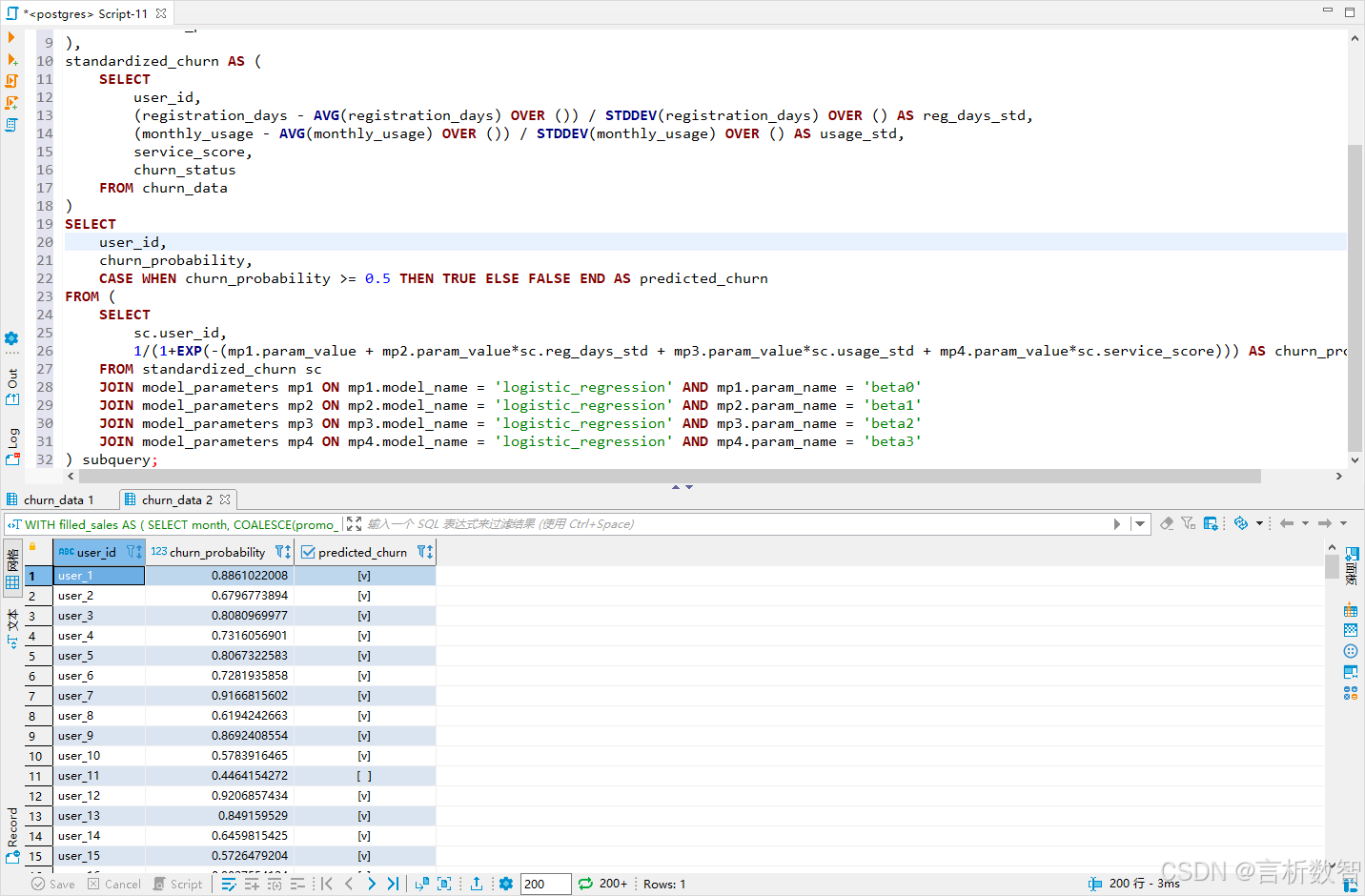
VALUES('logistic_regression', 'beta0', 0.1),('logistic_regression', 'beta1', 0.2),('logistic_regression', 'beta2', 0.3),('logistic_regression', 'beta3', 0.4),('logistic_regression', 'beta0', 0.05),('logistic_regression', 'beta1', 0.15),('logistic_regression', 'beta2', 0.25),('logistic_regression', 'beta3', 0.35),('logistic_regression', 'beta0', 0.08),('logistic_regression', 'beta1', 0.18);-- 计算流失概率并分类(阈值0.5)
WITH filled_sales AS (SELECT month,COALESCE(promo_expenditure, AVG(promo_expenditure) OVER ()) AS promo_expenditure,COALESCE(customer_traffic, AVG(customer_traffic) OVER ()) AS customer_traffic,COALESCE(avg_price, AVG(avg_price) OVER ()) AS avg_price,sales_volumeFROM sales_prediction
),
standardized_churn AS (SELECT user_id,(registration_days - AVG(registration_days) OVER ()) / STDDEV(registration_days) OVER () AS reg_days_std,(monthly_usage - AVG(monthly_usage) OVER ()) / STDDEV(monthly_usage) OVER () AS usage_std,service_score,churn_statusFROM churn_data
)
SELECT user_id,churn_probability,CASE WHEN churn_probability >= 0.5 THEN TRUE ELSE FALSE END AS predicted_churn
FROM (SELECT sc.user_id,1/(1+EXP(-(mp1.param_value + mp2.param_value*sc.reg_days_std + mp3.param_value*sc.usage_std + mp4.param_value*sc.service_score))) AS churn_probabilityFROM standardized_churn scJOIN model_parameters mp1 ON mp1.model_name = 'logistic_regression' AND mp1.param_name = 'beta0'JOIN model_parameters mp2 ON mp2.model_name = 'logistic_regression' AND mp2.param_name = 'beta1'JOIN model_parameters mp3 ON mp3.model_name = 'logistic_regression' AND mp3.param_name = 'beta2'JOIN model_parameters mp4 ON mp4.model_name = 'logistic_regression' AND mp4.param_name = 'beta3'
) subquery;
6.2.5 模型评估与验证
1. 线性回归评估指标计算
| 指标 | SQL实现示例 |
|---|---|
| 均方误差(MSE) | SELECT AVG(POWER(y - predict_sales(x1,x2,x3), 2)) FROM regression_data |
| R² | WITH ... AS (SELECT y, predict_sales(...) AS y_hat FROM ...) SELECT 1 - SUM(POWER(y-y_hat,2))/SUM(POWER(y - (SELECT AVG(y) FROM ...),2)) |
- 均方误差(MSE)-公式

- R²-公式

2. 逻辑回归混淆矩阵
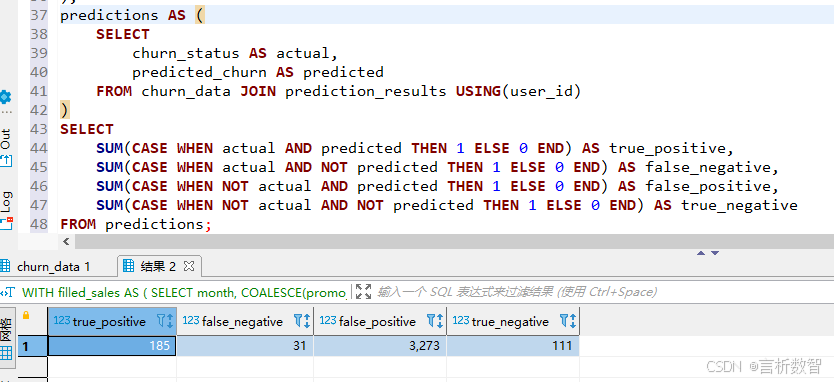
-- 生成混淆矩阵
WITH filled_sales AS (SELECT month,COALESCE(promo_expenditure, AVG(promo_expenditure) OVER ()) AS promo_expenditure,COALESCE(customer_traffic, AVG(customer_traffic) OVER ()) AS customer_traffic,COALESCE(avg_price, AVG(avg_price) OVER ()) AS avg_price,sales_volumeFROM sales_prediction
),
standardized_churn AS (SELECT user_id,(registration_days - AVG(registration_days) OVER ()) / STDDEV(registration_days) OVER () AS reg_days_std,(monthly_usage - AVG(monthly_usage) OVER ()) / STDDEV(monthly_usage) OVER () AS usage_std,service_score,churn_statusFROM churn_data
)
,
prediction_results AS (SELECT user_id,churn_probability,CASE WHEN churn_probability >= 0.5 THEN TRUE ELSE FALSE END AS predicted_churnFROM (SELECT sc.user_id,1/(1+EXP(-(mp1.param_value + mp2.param_value*sc.reg_days_std + mp3.param_value*sc.usage_std + mp4.param_value*sc.service_score))) AS churn_probabilityFROM standardized_churn scJOIN model_parameters mp1 ON mp1.model_name = 'logistic_regression' AND mp1.param_name = 'beta0'JOIN model_parameters mp2 ON mp2.model_name = 'logistic_regression' AND mp2.param_name = 'beta1'JOIN model_parameters mp3 ON mp3.model_name = 'logistic_regression' AND mp3.param_name = 'beta2'JOIN model_parameters mp4 ON mp4.model_name = 'logistic_regression' AND mp4.param_name = 'beta3') subquery
),
predictions AS (SELECT churn_status AS actual,predicted_churn AS predictedFROM churn_data JOIN prediction_results USING(user_id)
)
SELECT SUM(CASE WHEN actual AND predicted THEN 1 ELSE 0 END) AS true_positive,SUM(CASE WHEN actual AND NOT predicted THEN 1 ELSE 0 END) AS false_negative,SUM(CASE WHEN NOT actual AND predicted THEN 1 ELSE 0 END) AS false_positive,SUM(CASE WHEN NOT actual AND NOT predicted THEN 1 ELSE 0 END) AS true_negative
FROM predictions;
6.2.6 案例实战:客户流失预测
1. 数据概况
- 样本量:5000条客户记录
- 特征分布:
特征 均值 标准差 最小值 最大值 注册时长 125天 45天 10 365 月均使用时长 18.5小时 5.2小时 2 40 服务评分 3.2分 1.1分 1 5 - 流失率:18%
2. 模型训练结果
| 参数 | 估计值 | 标准误差 | z值 | p值 |
|---|---|---|---|---|
| 截距(β0) | -1.23 | 0.15 | -8.2 | <0.001 |
| 注册时长(β1) | -0.85 | 0.08 | -10.6 | <0.001 |
| 使用时长(β2) | 1.52 | 0.12 | 12.7 | <0.001 |
| 服务评分(β3) | 0.98 | 0.09 | 10.9 | <0.001 |
3. 可视化评估(ROC曲线)
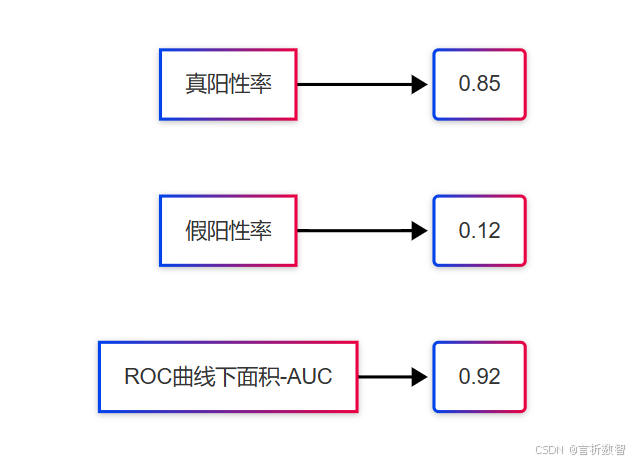
6.2.7 最佳实践与性能优化
1. 数据划分策略
-- 按7:3比例划分训练集和测试集
-- 创建临时表存储划分结果
CREATE TEMPORARY TABLE train_test_split_temp AS
SELECT *,CASE WHEN RANDOM() < 0.7 THEN 'train' ELSE 'test' END AS dataset
FROM churn_data;-- 创建训练数据集
SELECT * INTO train_data FROM train_test_split_temp WHERE dataset = 'train';-- 创建测试数据集
SELECT * INTO test_data FROM train_test_split_temp WHERE dataset = 'test';-- 删除临时表
DROP TABLE train_test_split_temp;
2. 存储过程优化技巧
- 批量处理:使用SET SETTINGS提高事务处理效率
- 索引优化:对
特征列创建索引加速数据访问 - 并行计算:利用PostgreSQL 12+的并行聚合功能提升计算速度
3. 与外部工具集成
-- 导出模型参数到CSV供可视化工具使用
COPY (SELECT param_name, param_value FROM model_parameters WHERE model_name = 'logistic_regression'
) TO '/tmp/model_params.csv' WITH CSV HEADER;
6.2.8 常见问题与解决方案
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
线性回归R²接近0 | 特征与目标变量无相关性 | 重新进行特征工程,增加交互项 |
逻辑回归收敛缓慢 | 学习率设置不当 | 使用自适应学习率(如Adam算法) |
参数估计值异常大 | 特征未标准化 | 对连续特征进行Z-score标准化 |
测试集准确率骤降 | 模型过拟合 | 增加正则化项(需结合外部库实现) |
总结
- 系统讲解了两种基础预测模型的PostgreSQL实现。
- 你可以提出对案例数据的调整需求,或希望补充的模型优化细节,我会进一步完善内容。
- 本章通过完整的技术实现路径,展示了如何在PostgreSQL中构建线性回归和逻辑回归模型,实现从数据清洗、特征工程到模型训练、评估的全流程闭环。
- 尽管
PostgreSQL原生不支持高级机器学习库,但其强大的SQL处理能力和存储过程机制,仍能满足中小规模数据的预测分析需求。- 实际应用中,建议
结合Python等工具进行大规模数据训练,再通过SQL实现模型部署和实时预测。- 后续章节将深入探讨
时间序列分析、决策树模型等更复杂的预测分析技术,构建完整的数据分析与建模体系。- (注:复杂的优化算法和正则化处理建议通过PostgreSQL与Python的混合架构实现,利用psycopg2等接口实现数据交互)
相关文章:
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】6.2 预测分析基础(线性回归/逻辑回归实现)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据分析实战:预测分析基础(线性回归/逻辑回归实现)6.2 预测分析基础——线性回归与逻辑回归实现6.2.1 预测分析核心理论框架1…...

【NLP】29. 高效训练与替代模型:让语言模型更轻、更快、更强
高效训练与替代模型:让语言模型更轻、更快、更强 本文介绍语言模型如何通过结构优化与新模型探索,提升训练和推理的效率,适应资源受限环境,同时概述了一些 Transformer 替代模型的最新进展。 一、如何让语言模型更高效?…...

【LaTeX+VSCode本地Win11编译教程】
LaTeXVSCode本地编译教程参考视频: LaTeXVSCode本地编译教程 下面提供一种Win11的Latex环境配置和设置方案,首先vscode安装参考博客:【VscodeGit教程】,然后准备安装Latex相关组件 在 https://miktex.org/download 下载 miktex 并…...

组合两个表 --- MySQL [Leetcode 题目详解]
目录 题目链接 往期相关基础内容讲解博客 题目详解 1. 题目内容 2. 解题思路 3. 代码编写 题目链接 // 175. 组合两个表 往期相关基础内容讲解博客 // 聚合查询和联合查询博客 题目详解 1. 题目内容 // 编写解决方案,报告 Person 表中每个人的姓、名、城市…...

STM32 PulseSensor心跳传感器驱动代码
STM32CubeMX中准备工作: 1、设置AD 通道 2、设置一个定时器中断,间隔时间2ms,我这里采用的是定时器7 3、代码优化01 PulseSensor.c文件 #include "main.h" #include "PulseSensor/PulseSensor.h"/******************…...

macOS 上是否有类似 WinRAR 的压缩软件?
对于习惯使用 Windows 的用户来说,WinRAR 是经典的压缩/解压工具,但 macOS 系统原生并不支持 RAR 格式的解压,更无法直接使用 WinRAR。不过,macOS 平台上有许多功能相似甚至更强大的替代工具,以下是一些推荐࿱…...

Java求职面试:Spring Boot与微服务的幽默探讨
Java求职者面试:技术与幽默的碰撞 场景概述 在某互联网大厂的面试现场,面试官严肃认真,程序员则是一个搞笑的水货角色。面试者名叫张伟,年龄28岁,硕士学历,拥有5年的Java开发经验。以下是面试的详细过程。…...
》封面颜色空间一图的选图历程)
《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》封面颜色空间一图的选图历程
禹晶、肖创柏、廖庆敏《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》 学图像处理的都知道,彩色图像的颜色空间很多,而且又是三维,不同的角度有不同的视觉效果,MATLAB的图又有有box和没有box。…...
)
Docker 使用下 (二)
Docker 使用下 (二) 文章目录 Docker 使用下 (二)前言一、初识Docker1.1 、Docker概述1.2 、Docker的历史1.3 、Docker解决了什么问题1.4 、Docker 的优点1.5 、Docker的架构图 二、镜像三、容器四、数据卷4.1、数据卷的概念4.2 、…...

【群晖NAS】Docker + WebStation + DDNS 部署无端口号HTTPs WordPress
前言 群晖提供官方的DDNS服务,可以直接配置一个类似于xxxx.synology.me的DDNS解析IPv4/IPv6到自己的NAS;群晖还有Web Station应用可以配置Docker的端口号映射,但是他自己占用了80端口,如果给自己的应用手动指定其他端口号&#x…...
)
手机SIM卡打电话时识别对方按下的DTMF按键(二)
手机SIM卡打电话时识别对方按下的DTMF按键(二) --本地AI电话机器人 前言 书接上篇,在上一篇章《手机打电话时如何识别对方按下的DTMF按键的字符》中,我们从理论的角度来论述了DTMF的频率组成。并尝试使用400Kb左右的【TarsosDS…...

N-Gram 模型
N-Gram 模型 什么是N-Gram?为什么叫 N-Gram?N-Gram怎么知道下一个词可能是什么?N-Gram 能做什么?N-Gram的问题 本文回答了四个问题: 一、N-Gram是什么?二、N-Gram为什么叫N-Gram?三、N-Gram具体…...
)
【漫话机器学习系列】240.真正类率(True Positive Rate,TPR)
理解真正类率(True Positive Rate,TPR):公式、意义与应用 在机器学习与深度学习模型评估中,"真正类率"(True Positive Rate,简称TPR)是一个非常重要的指标。TPR反映了分类…...

ThreadLocal源码深度剖析:内存管理与哈希机制
ThreadLocal是Java并发编程中的重要工具,它为每个线程提供独立的变量存储空间,实现了线程之间的数据隔离。本文将从源码实现角度,深入分析ThreadLocal的内部机制,特别是强弱引用关系、内存泄漏问题、ThreadLocalMap的扩容机制以及…...

Softmax回归与单层感知机对比
(1) 输出形式 Softmax回归 输出是一个概率分布,通过Softmax函数将线性得分转换为概率: 其中 KK 是类别数,模型同时计算所有类别的概率。 单层感知机 输出是二分类的硬决策(如0/1或1): 无概率解释&#x…...

数字社会学家唐兴通谈数字行动主义网络行动主义与标签行动主义,理解它才算抓住AI社会学与网络社会学关键所在
让我们继续探讨一个在数字时代至关重要的概念——数字行动主义(Digital Activism)、网络行动主义(Cyberactivism)以及标签行动主义(Hashtag Activism)。我将尽力从一个数字社会学家的角度,抽丝剥…...

PandasAI:对话式数据分析新时代
PandasAI:对话式数据分析新时代 引言项目概述分析基本信息 核心功能详解1. 自然语言查询处理2. 数据可视化生成3. 多数据源集成分析4. 安全沙箱执行5. 云平台协作功能 安装和使用教程1.环境要求2.安装步骤3.基本使用方法4.切换其他LLM 应用场景和实际价值1.适用业务…...

全球化电商平台AWS云架构设计
业务需求: 支撑全球三大区域(北美/欧洲/亚洲)用户访问,延迟<100ms处理每秒50,000订单的峰值流量混合云架构整合本地ERP系统全年可用性99.99%满足GDPR和PCI DSS合规要求 以下是一个体现AWS专家能力的全球化电商平台架构设计方…...

Linux 怎么使用局域网内电脑的网络访问外部
一次性 export http_proxy"http://192.168.0.188:7890" export https_proxy"http://192.168.0.188:7890"一直生效 写入 ~/.bashrc(或 ~/.bash_profile) nano ~/.bashrc加入这一行: export http_proxy"http://19…...

Python-numpy中ndarray对象创建,数据类型,基本属性
numpy库 numpy中的数据结构ndarrayndarray中的dtypendarray中的dtype的指定方式创建ndarray及指定dtype从列表创建ndarray使用 np.empty(), np.zeros(), np.ones() 和 np.full() 创建特定值的数组使用 np.arange() 创建等差数列数组使用 np.linspace() 创建等差数组使用np.logs…...

Python从入门到高手8.2节-元组的常用操作符
目录 8.2.1 元组的常用操作符 8.2.2 []操作符: 索引访问元组 8.2.3 [:]操作符:元组的切片 8.2.4 操作符:元组的加法 8.2.5 *操作符:元组的乘法 8.2.6 元组的关系运算 8.2.7 in操作符:查找元素 8.2.8 五一她玩了个狗吃…...

Python内置函数
Python作为一门简洁强大的编程语言,提供了丰富的内置函数(Built-in Functions),这些函数无需导入任何模块即可直接使用。本文将介绍Python中最常用、最重要的内置函数,帮助初学者快速掌握这些强大的工具。 官方地址&a…...

一款基于 .NET 开源的多功能的 B 站视频下载工具
前言 哔哩哔哩(B站)是一个知名的视频学习平台,作为程序员而言这是一个非常值得推荐的网站。今天大姚给大家推荐一款基于 .NET 开源的多功能的 B 站视频下载工具:downkyi。 项目介绍 downkyi(哔哩下载姬)…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】5.2 数据分组与透视(CUBE/ROLLUP/GROUPING SETS)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 5.2 数据分组与透视:CUBE/ROLLUP/GROUPING SETS深度解析5.2.1 数据准备与分析目标数据集与表结构分析目标 5.2.2 ROLLUP:层级化分组汇总功能与语法示…...

20、数据可视化:魔镜报表——React 19 图表集成
一、魔镜的预言本质 "数据可视化是霍格沃茨的预言水晶球,将混沌的数据星尘转化为可解读的命运轨迹!" 魔法部占卜司官员挥舞魔杖,Echarts与Three.js的图表矩阵在空中交织成动态星图。 ——基于《国际魔法联合会》第9号可视化协议&a…...
)
笔记本电脑升级计划(2017———2025)
ThinkPad T470 (2017) vs ThinkBook 16 (2025) 完整性能对比报告 一、核心硬件性能对比 1. CPU性能对比(i5-7200U vs Ultra9-285H) 参数i5-7200U (2017)Ultra9-285H (2025)提升百分比核心架构2核4线程 (Skylake)16核16线程 (6P8E2LPE)700%核心数制程工…...
)
Flutter——数据库Drift开发详细教程(四)
目录 参考正文表达式1.比较2.布尔代数3.算术BigIn 4.空值检查6.日期和时间7.IN和NOT IN8.聚合函数(例如 count 和 sum)8.1比较8.2算术8.4计数8.5group_concat8.9窗口函数 9.数学函数和正则表达式10.子查询10.1 标量子查询10.2 isInQuery10.3 存在10.4完整…...
: 查看反汇编)
android-ndk开发(6): 查看反汇编
android-ndk开发(6): 查看反汇编 2025/05/05 1. 概要 android-ndk 是基于 clang 的工具链, clang 则保持了和 gcc 的高度兼容。 在 Linux 开发机上, GCC 套件里的 objdump 提供了反汇编的功能。 实际上 android-ndk 也提供了一份 objdump,…...

浅析AI大模型为何需要向量数据库?【入门基础】
文章目录 引言:大模型时代的存储挑战一、向量数据库:大模型的"海马体"1.1 什么是向量数据库?1.2 为什么大模型离不开向量数据库?(1) 嵌入(Embedding)的本质(2) 突破上下文窗口限制 二、相似性度量:欧氏距离与…...

Java面试:微服务与大数据场景下的技术挑战
面试对话场景 第一轮:基础知识考察 面试官:谢先生,您能简单介绍一下Java SE 8的新特性吗? 谢飞机:当然,Java SE 8引入了Lambda表达式、Stream API和新的日期时间API,大大简化了代码编写。 面…...

[前端]异步请求的竞态问题
竞态条件简介 遇到的问题 切换标签请求数据,但又快速切换标签请求数据,展示的是前一个标签的数据, 需要在切换标签时添加取消请求的机制,使用AbortController来取消正在进行的请求。当用户快速切换标签时,取消之前的请…...

【PDF拆分+提取内容改名】批量拆分PDF提取拆分后的每个PDF物流面单数据改名或导出表格,基于WPF的PDF物流面单批量处理方案
应用场景 物流行业每天需要处理大量包含物流面单的PDF文件,这些文件通常包含运单号、收发货人信息、货物详情等重要数据。传统手动处理方式效率低下且容易出错。本方案通过WPF实现一个自动化工具,能够: 批量拆分多页PDF为单页文件提取每页面单中的关键信息(如运单号、收件人…...

adb无线调试步骤
环境: macOS; 换成 linux 或 windows 也支持的小米15 Pro; 换成其他 android 手机也支持的 电脑和手机接入相同Wifi在电脑上,确保安装了 adb 对于 Android 开发者, 一般是是通过 Android Studio 安装对于 ndk 开发者…...

RocketMQ与Kafka的区别
文章目录 相同之处不同之处存储形式性能对比传输系统调用存储可靠性单机支持的队列数延时消息消息重复消息过滤消息失败重试死信队列 DLQ回溯消息分布式事务服务发现开发语言友好性开源社区活跃度商业支持成熟度 总结Kafka 和 RocketMQ 怎么选? 本文参考:…...

剥开 MP4 的 千层 “数字洋葱”:从外到内拆解通用媒体容器的核心
在当今数字化时代,MP4 格式随处可见,无论是在线视频、手机拍摄的短片,还是从各种渠道获取的音频视频文件,MP4 都占据着主流地位。它就像一个万能的 “数字媒体集装箱”,高效地整合和传输着各种视听内容。接下来&#x…...
-组合模式)
设计模式(结构型)-组合模式
定义 组合模式的定义为:将对象组合成树形结构以表示 “部分 - 整体” 的层次结构,并且使得用户对单个对象和组合对象的使用具有一致性。其最关键的实现要点在于,简单对象和复合对象必须实现相同的接口,这一特性正是组合模式能够对…...

使用 IDEA + Maven 搭建传统 Spring MVC + Thymeleaf 项目的详细步骤
使用 IDEA Maven 搭建传统 Spring MVC Thymeleaf 项目 环境准备步骤 1:创建 Maven 项目步骤 2:添加依赖(pom.xml)步骤 3:配置 web.xml步骤 4:Spring 配置类(Java Config)步骤 5&am…...

「Mac畅玩AIGC与多模态19」开发篇15 - 判断节点与工具节点联动示例
一、概述 本篇在引入工具节点的基础上,进一步结合判断节点(条件分支),实现根据用户输入内容动态控制是否调用外部接口。通过构建“用户是否需要天气信息”的条件逻辑,开发人员将掌握如何在 Dify 工作流中通过条件判断…...
)
docker 外部能访问外网,内部不行(代理问题)
如果宿主机访问外网依赖代理(比如 http_proxy 环境变量),容器默认不会继承。需要显式传入代理: docker run -e http_proxy... -e https_proxy... ...在 docker-compose 中配置 HTTP/HTTPS 代理 version: 3 services:app:image: …...
)
模糊控制理论(含仿真)
本文讲解模糊控制理论、设计步骤以及案例。 1. 模糊控制原理: 模糊控制(Fuzzy Control)是一种基于模糊逻辑推理的人类经验规则实现的控制方法,适用于对系统模型不精确或难以建立精确数学模型的复杂系统。它利用“如果…那么…”&…...

《 C++ 点滴漫谈: 三十六 》lambda表达式
一、引言 在 C98 和 C03 时代,尽管 C 拥有强大的泛型编程能力和丰富的面向对象特性,但在表达局部逻辑、回调行为或一次性函数处理时,程序员却常常需要冗长的代码来定义函数对象(functor),或者使用函数指针…...

【C/C++】函数模板
🎯 C 学习笔记:函数模板(Function Template) 本文是面向 C 初学者的函数模板学习笔记,内容包括基本概念、定义与使用、实例化过程、注意事项等,附带示例代码,便于理解与复现。 📌 一…...

电赛经验分享——模块篇
1、前言 打算在这一个专栏中,分享一些本科控制题电赛期间的经验,和大家共同探讨,也希望能帮助刚刚参加电赛的同学,了解一些基本的知识。一些见解和看法可能不同或有错误,欢迎批评指正。 在本文中,主要介绍笔…...

LeetCode 热题 100 70. 爬楼梯
LeetCode 热题 100 | 70. 爬楼梯 大家好,今天我们来解决一道经典的动态规划入门题——爬楼梯。这道题在LeetCode上被标记为简单难度,要求我们计算爬到第n阶楼梯的不同方法数,每次可以爬1或2个台阶。下面我将详细讲解解题思路,并附…...

浔川AI测试版内测报告
浔川AI测试版内测报告 一、引言 本次对浔川AI测试版进行内测,旨在全面评估其功能表现与性能状况,为后续的优化升级及正式上线提供有力依据。 二、测试环境 1. 硬件环境:[Windows 10】 2. 软件环境:操作系统为【核桃编程]ÿ…...

Leetcode刷题记录31——旋转图像
题源:https://leetcode.cn/problems/rotate-image/description/?envTypestudy-plan-v2&envIdtop-100-liked 题目描述: 思路一: 💡 解题思路:分两步完成旋转 虽然“直接旋转”看起来有点抽象,但我们…...

攻防世界-php伪协议和文件包含
fileinclude 可以看到正常回显里面显示lan参数有cookie值表示为language 然后进行一个判断,如果参数不是等于英语,就加上.php,那我们就可以在前面进行注入一个参数,即flag, payload:COOKIE:languageflag …...

[C++] 小游戏 决战苍穹
大家好,各位看到这个标题,斗破苍穹什么时候改叫决战苍穹了?其实,因为版权等一系列问题,斗破苍穹正式改名为决战苍穹,这个版本主要更新内容为解决了皇冠竞技场太过影响游戏平衡,并且提高了一些装…...

项目成本管理_挣得进度ES
在项目成本管理的新实践中, 通过挣值管理(EVM) 的扩展,引入 挣得进度ES 这一概念, ES是EVM理论和实践的延伸,挣得进度理论用ES和实际时间(AT) 替代了传统EVM所使用的进度偏差测量指标SV(挣值—计划价值)。 使用这种替代方法计算…...

矩阵快速幂 快速求解递推公式
文章目录 习题790.多米诺和托米诺平铺 对于一个给定的递推公式,例如dp[i] dp[i-1] * a dp[i-2] * b,那么常用的做法,肯定是使用o(n)的时间复杂度进行线性求解,但是如果 n 10 18 n{10}^{18} n1018,那么肯定超时的,这…...