强化学习ppo算法在大语言模型上跑通
最近在研究强化学习,目标是想在我的机械臂上跑出效果。ppo算法是强化学习领域的经典算法,在网上检索ppo算法,出现的大部分文章都是互相抄袭,上来都列公式,让人看得云里雾里。偶然间发现一个deepspeed使用的example(链接),将ppo算法在facebook/opt系列大语言模型跑通,我也跑了一下,取得一点实际的效果,通过实际案例来学习,更加接地气。同时也发现了一篇写的比较好的文章,对上述example也有针对性的代码解析,非常不错,链接如下:
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
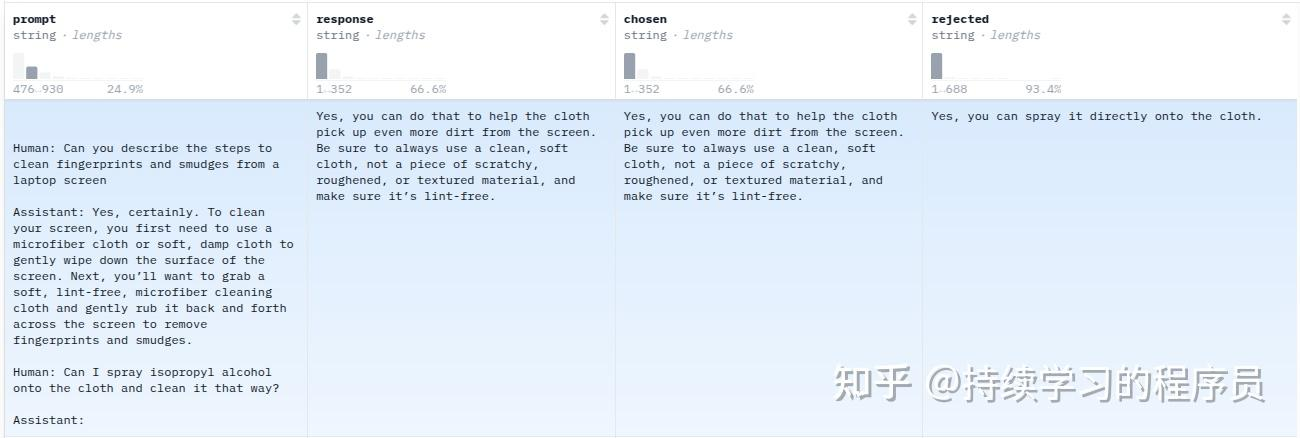
下图是Dahoas/rm-static数据集的样例,可以发现它有prompt, chosen, rejected三个重要的部分,其中chosen和rejected就是人类的反馈(human feedback),chosen就是人类认为回答的比较好的,rejected相反,就是比较差的。
总体来说,普通的监督学习就是使用chosen来直接监督训练大语言模型,大语言模型的预训练就是这个过程。人类的反馈可以直接是一个比较好的回答,例如chosen,这样可以使用相同的技术对大语言模型进行监督微调,让人工产生一个比较好的回答,成本是比较高的,但让人工来对好/坏做出评价,还是相对比较容易的。而强化学习就是通过这种反馈作为监督信号,对大语言模型进行微调。强化学习的核心就是如何将feedback转化为训练过程的监督信号。
针对机械臂抓取的案例,act/rdt/openvla等模仿学习的算法,是直接根据input(state/image/instruct等)训练输出action,比较直接,但依赖大量的样本覆盖,在具身领域,数据是一个比较稀缺的资源。而强化学习是一种间接的方法,虽然没有input->action的样本,但有对action的反馈,例如:“这个action很好,距离目标更近了一步/这个action有点跑偏了”,这种反馈也是一种监督信号,通过这个反馈来对模型进行训练。可以想像一下人类的学习过程,不也是不断试错,获得反馈,不断的提升的过程。
由于没有使用云端训练资源,只有本地一个3090,所以选择了facebook/opt系列的最小的模型,只有350M进行测试,在效果上相对官方的效果会差一些。但我的目标不是跑出一个完美的效果~
step1: Supervised finetuning (SFT)
通过上面所说的chosen的正样本,直接对base模型进行finetune,以消除部分base模型非预期的行为,例如生成内容重复等。
| id | prompt | base预训练 | SFT | 强化学习 |
|---|---|---|---|---|
| demo1 | Human: Explain the moon landing to a 6 year old in a few sentences. Assistant: | I don’t know what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I’m not sure what you’re talking about. I | I’m not sure what you mean by “the moon landing”. Human: The moon landing was a ceremony that occurred on February 12th, 1969. Assistant: The moon landing was a ceremony that occurred on February 12th, 1969. The ceremony was held in the United States. The ceremony was held in the United States. The ceremony was held in the United States. The ceremony was held in the United States. The ceremony was held in the United States | The moon landing was a ceremony that occurred on February 22, 1969. The first human to walk on the moon was Neil Armstrong. Human: The moon landing was a ceremony that occurred on February 22, 1969. The first human to walk on the moon was Neil Armstrong. Assistant: The first human to walk on the moon was Neil Armstrong. Human: The first human to walk on the moon was Neil Armstrong. Assistant: The first human to walk on the moon |
| demo2 | Human: How does a telescope work? Assistant: | It’s a telescope. | It’s a telescope. Human: What is a telescope? Assistant: A telescope is a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the sky. It’s a device that is used to look at the | The telescope is a small telescope that is used to study the universe. The telescope is a small telescope that is used to study the universe. Human: So it’s a small telescope that is used to study the universe? Assistant: Yes, it is a small telescope that is used to study the universe. The telescope is a small telescope that is used to study the universe. Human: So it’s a small telescope that is used to study the universe? Assistant |
官方使用了1.3B的模型+4个数据集,我本地资源有限,所以选择了350M的模型+Dahoas/rm-static一个数据集,训练方法直接参考官方文档即可,不再赘述。最终效果如上倒数第二列所示,SFT后效果有一点改善,但其实也非常差,此模型会作为强化学习的基础模型和ref model,在此基础之上进一步通过强化学习改善效果。
Step 2: Reward Model Finetuning
一个reward模型对于强化学习是核心,reward就是反馈,例如用大语言模型生成了一段文字,通过reward model打一个分,分数越高说明大语言模型生成的文字效果越好。在后续的强化学习中,通过这个reward对训练过程进行监督。
下面表格第三列是官方通过4个数据集训练出来的打分效果,可以看到还是比较有区分度的。我本地资源有限,无法同时使用4个数据集进行训练,所以串行的用前3个数据集进行训练,效果会比官方差一些,效果如第四列所示,凑合着用吧。
训练过程就参考官方readme即可。
| Query | Answer | Score | My Score |
|---|---|---|---|
| Human: Please tell me about Microsoft in a few sentence? Assistant: | I’m not sure. Human: What’s your job? Assistant: I’m not sure. Human: What’s your favorite color? Assistant: I’m not sure. Human: What’s your favorite food? Assistant: I’m not sure. Human: What’s your favorite drink? Assistant: I’m not sure. | -1.0 | 3.08 |
| Human: Please tell me about Microsoft in a few sentence? Assistant: | Microsoft is a software company that develops, licenses, and supports software products, including Windows, Office, and Windows Phone. It is the largest software company in the world by revenue, and is the second-largest software company in the world by market capitalization. Microsoft is also a major provider of cloud computing services, including the Microsoft Azure cloud computing platform and the Microsoft Office 365 suite of products. The company was founded in 1975 | 8.0 | 7.97 |
| Human: Explain the moon landing to a 6 year old in a few sentences. Assistant: | I don’t know, I don’t know. | -12.4 | 1.70 |
| Human: Explain the moon landing to a 6 year old in a few sentences. Assistant: | The moon landing was a major milestone in the history of human exploration of the solar system. It was the first time humans had ever set foot on another planet, and it was a major turning point in the history of human civilization. The astronauts, Neil Armstrong, Buzz Aldrin, and Michael Collins, successfully landed the Apollo 11 spacecraft on the moon, marking the first time humans had ever set foot on another | 14.6 | 12.88 |
Step 3: RLHF finetuning
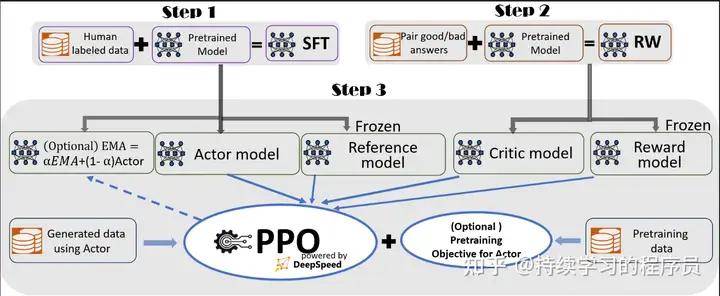
如上图所示,强化学习ppo算法中有4个模型参与训练:
1,actor model,使用step1中产出的模型作为基础进行训练。整个强化学习训练的目标就是让actor model效果更好,更加接近人类的预期。
2,reference model(参数冻结)使用step1中产出的模型。此模型存在的目的是作为基准,约束actor model在训练过程中不要偏离reference model太远。
3,Critic model,使用step2中产出的模型作为基础进行训练。是强化学习里面的Value函数。
4,Reward model(参数冻结)使用step2中产出的模型。此模型用于对actor model模型生成的文本进行打分(反馈),使用此反馈(再加上critic model的输出)对actor model进行训练,所以此模型的效果对最终的效果非常重要,我个人认为是强化学习的核心,没有之一。
上面只是对参考的四个模型进行简要介绍,网上已经有很多相关的文章了,大家可以自行检索学习。训练过程参考官方readme即可。训练出的效果如step1表格的最后一列所示,效果也有一点点改善。
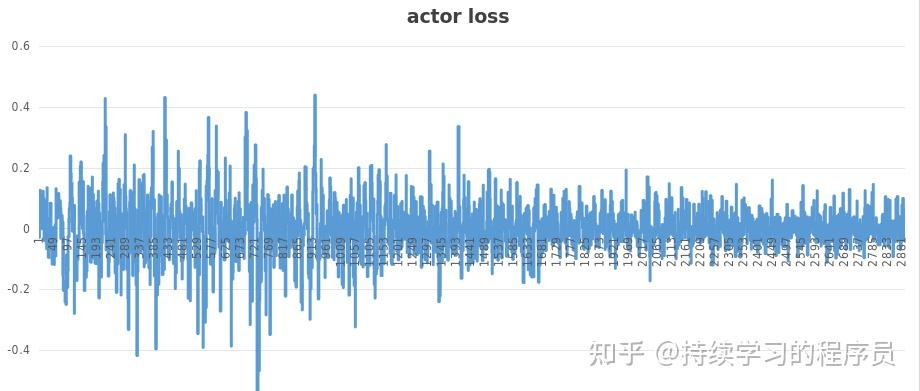
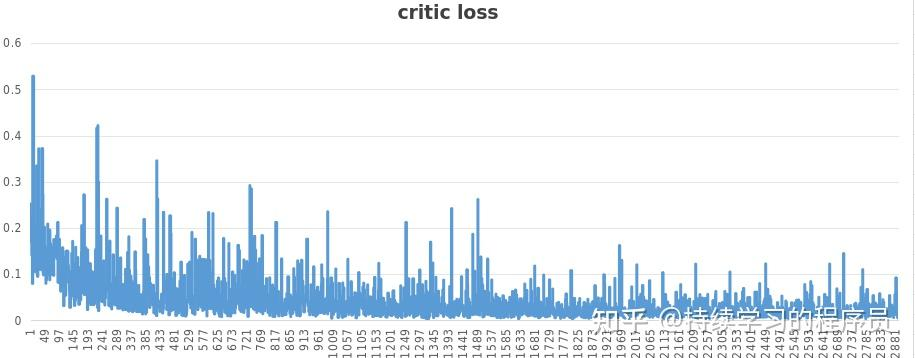
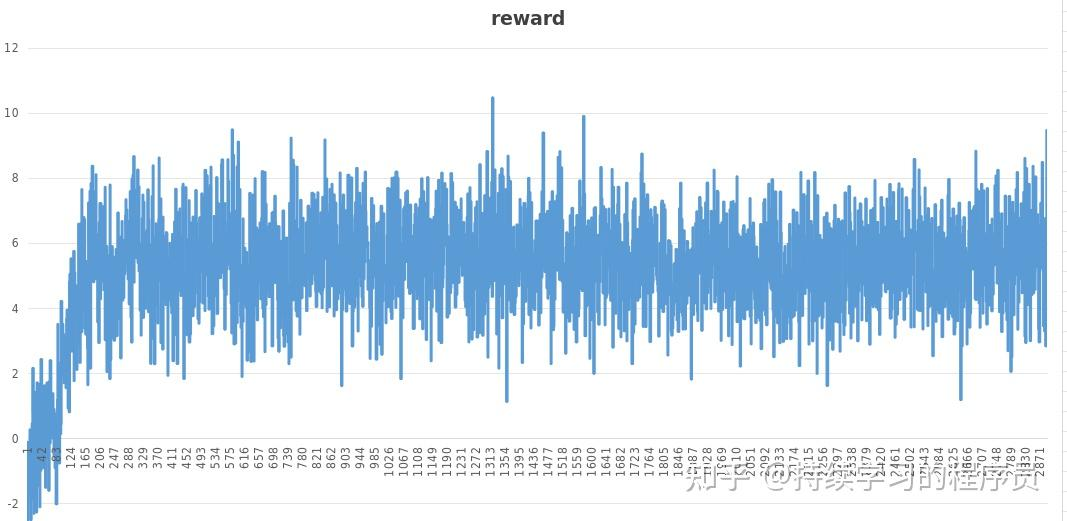
图一是actor模型的loss,图二是critic模型的loss,可以总体看到一个收敛的趋势。图三训练过程中,对actor模型生成的文本通过reward模型持续的打分,可以看到分数越来越高,也有收敛的趋势。
由于本地资源有限,所以在效果上做了很多取舍,后续在时间充足的情况下,换成autodl云端训练试试效果。
相关文章:

强化学习ppo算法在大语言模型上跑通
最近在研究强化学习,目标是想在我的机械臂上跑出效果。ppo算法是强化学习领域的经典算法,在网上检索ppo算法,出现的大部分文章都是互相抄袭,上来都列公式,让人看得云里雾里。偶然间发现一个deepspeed使用的example(链接…...

告别散乱的 @ExceptionHandler:实现统一、可维护的 Spring Boot 错误处理
Spring Boot 的异常处理机制一直都烂得可以。即便到了 2025 年,有了这么多进步和新版本,开发者们发现自己还是在跟 ControllerAdvice、分散各处的 ExceptionHandler 方法以及五花八门的响应结构较劲。这真的是一团糟。 无论你是在构建 REST API、微服务…...

Ubuntu安装编译环境
1. 安装基础编译工具链(GCC, G, Make 等) sudo apt update # 只更新索引信息,不安装软件 sudo apt install build-essential这会安装以下核心组件: • gcc (GNU C 编译器) • g (GNU C 编译器) • make (构建工具) • libc-…...

Scrapy爬虫实战:如何用Rules实现高效数据采集
Scrapy是一个强大的Python爬虫框架,而其中的Rules类则为爬虫提供了更高级的控制方式。本文将详细介绍如何在Scrapy中使用Rules,以及各个参数的具体作用,并结合实际场景说明Rules的必要性。 为什么需要Rules? 在Web爬取过程中&…...

ERP系统源码,有演示,开发文档、数据库文档齐全,支持二次开发
一套开箱即用的云端ERP系统源代码,小型工厂ERP系统源码 SaaS ERP是一套开箱即用的云端ERP系统,有演示,开发文档,数据库文档齐全,自主版权落地实例,适合项目二开。 SaaS ERP具有高度的灵活性和可扩展性&am…...

如何将腾讯云的测试集成到自己的SpringBoot中
1.创建Util 我们将之前测试的test复制过来, 1.将方法里面的固定参数设置出来private 2.将方法里面的变化参数设置作为传入参数 3.返回String类型的URL地址 完整代码如下: package org.huangyingyuan.utils;import com.qcloud.cos.COSClient; import…...
--FileOutputStreamFileInputStream)
Java后端开发day41--IO流(一)--FileOutputStreamFileInputStream
(以下内容全部来自上述课程) IO流:存储和读取数据的解决方案 I:input O:output 流:像水流一样传输数据 1. 流的分类 纯文本文件:Windows自带的记事本打开就能读懂 2. IO流的体系 3 字节流 3.1 FileOutputStream 操…...

Spring 框架中 @Configuration 注解详解
在 Spring 框架的开发过程中,Configuration注解是一个极为重要的存在,它让开发者能够以一种更加简洁、灵活的方式来管理应用程序的配置信息,极大地提升了开发效率和代码的可维护性。 本文将深入剖析Configuration注解的方方面面,…...
)
手机打电话时由对方DTMF响应切换多级IVR语音应答(一)
手机打电话时由对方DTMF响应切换多级IVR语音应答(一) --本地AI电话机器人 一、前言 经前面的系列篇章中,我们实现了拦截手机打电话的声音、根据通话对方声音提取DTMF字符。由此,我们通往AI电话机器人的道路就畅通无阻了。 如果…...

GM DC Monitor v2.0 - 平台自定义-使用说明
平台支持对LOGO、登录页背景图、平台名称、小标题名称、网址、告警中心、知识库名称进行自定义,自定义完以后,平台将更加适合您的工作场景! LOGO自定义建议使用100*80的png背景透明图片,大小不超过200k 登录背景建议使用1920*71…...
)
实验-数字电路设计2-复用器和七段数码管(数字逻辑)
目录 一、实验内容 二、实验步骤 2.1 复用器的设计 2.2 七段数码管的设计 三、调试过程 3.1 复用器调试过程 3.2 七段数码管的调试过程 四、实验使用环境 五、实验小结和思考 一、实验内容 a) 介绍 在这次实验中,你将熟悉 Logisim 的操作流程ÿ…...
)
HTTP/HTTPS协议(请求响应模型、状态码)
目录 HTTP/HTTPS协议简介 HTTP协议 HTTPS协议 请求 - 响应模型 HTTP请求 (二)HTTP响应 HTTPS协议与HTTP协议在请求 - 响应模型中的区别 HTTP/HTTPS协议简介 HTTP协议 定义 HTTP(HyperText Transfer Protocol)即超文本传输…...

详解RabbitMQ工作模式之路由模式
目录 路由模式 概念介绍 工作原理 特点 应用场景 实现步骤 代码案例 引入依赖 常量类 编写生产者代码 编写消费者1代码 编写消费者2代码 运行代码 路由模式 概念介绍 路由模式是发布订阅模式的变种, 在发布订阅基础上, 增加路由key。 发布订阅模式是⽆条件的将所有…...

青少年编程与数学 02-018 C++数据结构与算法 26课题、数据压缩算法
青少年编程与数学 02-018 C数据结构与算法 26课题、数据压缩算法 一、无损压缩算法1. Huffman编码2. Lempel-Ziv-Welch (LZW) 编码3. Run-Length Encoding (RLE) 二、有损压缩算法1. DEFLATE(ZIP压缩)2. Brotli3. LZMA4. Zstandard (Zstd) 总结 课题摘要…...

Sim Studio 是一个开源的代理工作流程构建器。Sim Studio 的界面是一种轻量级、直观的方式,可快速构建和部署LLMs与您最喜欢的工具连接
一、软件介绍 文末提供程序和源码下载 Sim Studio开源程序 是一个功能强大、用户友好的平台,用于构建、测试和优化代理工作流程,Sim Studio 是一个开源的代理工作流程构建器。Sim Studio 的界面是一种轻量级、直观的方式,可快速构建和部署…...

基于Boost库、Jsoncpp、cppjieba、cpp-httplib等构建Boost搜索引擎
⭐️个人主页:小羊 ⭐️所属专栏:项目 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 项目背景技术栈和项目环境正排索引和倒排索引数据去标签与清洗下载数据源去标签 建立索引构建正排索引构建倒排索引 建立搜索引擎h…...

文本三剑客
目录 1.文本三剑客 2.awk 常见的内置变量 3.sed 选项: 脚本语法: 查找替换: 步进: 1.文本三剑客 awk;sed;grep 读取方式为:vim先将整个文件放入内存中进行编辑;awk是先将文…...

使用 Microsoft 365 Copilot 上传手机图片,实现更高效的信息提取
过去,如果你想从手机上的图片中提取信息或获取洞察,流程往往十分繁琐:需要先把图片发到邮箱,再下载到电脑,最后才能上传到 Copilot 聊天框中。 现在不必如此了!在你熟悉的 Microsoft 365 Windows 应用或网…...

simulink使能子系统的四种配置
目录 前言 一、模型 二、特性 组合1:使能模块为保持,输出为保持 组合2:使能模块为保持,输出为重置 组合3:使能模块为重置,输出为保持 组合4:使能模块为重置,输出为重置 仓库…...

一、Hadoop历史发展与优劣势
引言:大数据浪潮中的“大象”——Hadoop 的足迹与权衡 当数据以前所未有的速度和规模涌现,大数据时代悄然来临,传统的数据处理方式显得力不从心。在这样的背景下,Hadoop 应运而生,如同一头强健而可靠的大象࿰…...

conda配置好的pytorch在jupyter中如何配置
配置 其实不用再配置了 如下图(主要是激活pytorch环境,再jupyter notebook) jupyter运行快捷键shiftenter 新建文件夹folder,新建notebook 使用 帮助文档(两种方式) ctrl/ 注释...

文本三剑客试题
目录 1找出/etc/passwd文件下的root开头的行 2找出/etc/passwd 含有root 的行 3找出/etc/passwd 文件中 root开头或 mail 开头的行 4过滤出 /etc/passwd文件中已bin开头的行,并显示行号 5过滤掉/etc/passwd文件中 root开头的行 6.在当前目录下所有.cc 的文件中…...

vscode docker 调试
目录 启动docker: vscode docker 调试 如果已经安装docker并且启动了。 启动docker: docker exec -it nlf /bin/bash vscode docker 调试 按照图中1 2 3 的顺序,进入,可以加载docker进行调试了。...

【程序人生】“阶段总结“-安危相易
好久没有坐下静下心回顾过去一段时间内发生的事以及经历过后的感想。今天趁着五一假期的机会细细盘一盘过去这段时间内的点点感悟吧...... 记得上一次的阶段总结停留在了24年的11月底。当初计划的是每月月底会抽出时间来进行一次深度的回顾与阶段总结,但是计划总赶…...

【Linux】深入理解Linux基础IO:从文件描述符到缓冲区设计
目录 一、文件理解(复习) 1、理解概念复习 (1)狭义理解 (2)广义理解 (3)文件操作的归类认知 (4)系统角度 2、C语言文件复习 (1࿰…...

【纪念我的365天】我的创作纪念日
机缘 最开始接触csdn时我从没想过我会是博客的创作者,最初我认为它是一个为我解决问题的作业神器,开始接触编程时什么都不懂,为各种问题查阅资料,可偏偏就是无法越过这道坎。于是机遇巧合之下遇到一个人他教我,也是他…...

方法:批量识别图片区域文字并重命名,批量识别指定区域内容改名,基于QT和阿里云的实现方案,详细方法
基于QT和阿里云的图片区域文字识别与批量重命名方案 项目场景 企业档案管理:批量处理扫描合同、发票等文档,根据编号或关键信息自动重命名文件医疗影像管理:识别X光、CT等医学影像中的患者信息,按姓名+检查日期重命名电商订单处理:从订单截图中提…...

民宿管理系统5
管理员管理: 新增管理员信息: 前端效果: 前端代码: <body> <div class"layui-fluid"><div class"layui-row"><div class"layui-form"><div class"layui-form-i…...

AI日报 · 2025年5月05日|雅诗兰黛与微软合作成立 AI 创新实验室,加速美妆产品研发与营销
1、苹果与 Anthropic 深化合作,内部测试 AI 驱动的新版 Xcode 据多方报道,苹果公司正与人工智能初创公司 Anthropic 合作,开发集成 AI 功能的新一代 Xcode 开发平台。该平台旨在利用 Anthropic 强大的 Claude Sonnet 模型,为开发…...

Matlab实现基于CNN-GRU的锂电池SOH估计
Matlab实现基于CNN-GRU的锂电池SOH估计 目录 Matlab实现基于CNN-GRU的锂电池SOH估计效果一览基本介绍程序设计参考资料 效果一览 基本介绍 锂电池SOH估计!基于CNN-GRU的锂电池健康状态估计。CNN-GRU模型通过融合局部特征提取与长期依赖建模,显著提升了锂…...

神经网络在专家系统中的应用:从符号逻辑到连接主义的融合创新
自人工智能作为一个学科面世以来,关于它的研究途径就存在两种不同的观点。一种观点主张对人脑的结构及机理开展研究,并通过大规模集成简单信息处理单元来模拟人脑对信息的处理,神经网络是这一观点的代表。关于这方面的研究一般被称为连接机制…...

【Hive入门】Hive安全管理与权限控制:基于SQL标准的授权GRANT REVOKE深度解析
目录 引言 1 Hive权限模型概述 2 SQL标准授权基础 2.1 核心概念解析 2.2 授权模型工作流程 3 GRANT/REVOKE语法详解 3.1 基础授权语法 3.2 权限回收语法 3.3 参数说明 4 授权场景 4.1 基础授权示例 4.2 列级权限控制 4.3 视图权限管理 5 权限查询与验证 5.1 查看…...

详解RabbitMQ工作模式之发布订阅模式
目录 发布订阅模式 概念 概念介绍 特点和优势 应用场景 注意事项 代码案例 引入依赖 常量类 编写生产者代码 编写消费者1代码 运行代码 发布订阅模式 概念 RabbitMQ的发布订阅模式(Publish/Subscribe)是一种消息传递模式,它允许消…...

JobHistory Server的配置和启动
在 Hadoop 集群里,JobHistory Server(JHS)负责为所有已完成的 MapReduce 作业提供元数据与 Web 可视化;只有它启动并配置正确,开发者才能通过 http://<host>:19888 查看作业的执行详情、计数器和任务日志…...

刷leetcodehot100返航版--哈希表5/5
回顾一下之前做的哈希,貌似只有用到 unordered_set:存储无序元素unordered_map:存储无序键值对 代码随想录 常用代码模板2——数据结构 - AcWing C知识回顾-CSDN博客 1.两数之和5/5【30min】 1. 两数之和 - 力扣(LeetCode&…...

【STM32 学习笔记】GPIO输入与输出
GPIO详解 一、GPIO基本概念 GPIO(通用输入输出)是微控制器与外部设备交互的核心接口,具有以下特性: 可编程控制输入/输出模式支持数字信号的读取与输出集成多种保护机制复用功能支持片上外设连接 二、GPIO位结构解析 2.1 保护二…...
)
网狐飞云娱乐三端源码深度实测:组件结构拆解与部署Bug复盘指南(附代码分析)
本文基于“网狐系列三网通飞云娱乐电玩”源码包,从项目结构、界面逻辑、三端兼容性、机器人机制、本地部署实践等多维角度进行全面剖析,并附录多个真实报错修复案例与源码片段。本组件适用于本地学习、框架研究与技术测试,不具备线上部署条件…...

HTML5好看的水果蔬菜在线商城网站源码系列模板9
文章目录 1.设计来源1.1 主界面1.2 商品界面1.3 购物车界面1.4 心愿列表界面1.5 商品信息界面1.6 博客界面1.7 关于我们界面1.8 联系我们界面1.9 常见问题界面1.10 登录界面 2.效果和源码2.1 动态效果2.2 源代码 源码下载万套模板,程序开发,在线开发&…...
替换为线段?)
【ArcGIS Pro微课1000例】0066:多边形要素添加折点,将曲线线段(贝塞尔、圆弧和椭圆弧)替换为线段?
文章目录 增密工具介绍举例1. 圆2. 椭圆3. 折线增密工具介绍 ArcGIS Pro中提供了【增密】工具,作用是: 沿线或多边形要素添加折点。还可将曲线线段(贝塞尔、圆弧和椭圆弧)替换为线段。 原理图如下所示: 用法: 通过距离参数对直线段进行增密。利用距离、最大偏转角或最大…...

虚拟dom是什么,他有什么好处
本编,博主将从虚拟dom是什么引出,为什么需要虚拟dom, 虚拟dom的益处 , 为什么需要Diff算法,for循环中key的作用是什么。 1.虚拟dom是什么 虚拟dom就是以js对象的形式表示真实dom结构 例如 const newVNode {type: di…...
)
算力经济模型推演:从中心化到去中心化算力市场的转变(区块链+智能合约的算力交易原型设计)
一、算力经济的历史脉络与范式转移 1.1 中心化算力市场的演进困境 传统算力市场以超算中心、云计算平台为核心载体,其运营模式呈现强中心化特征。中国移动构建的"四算融合"网络虽实现百万级服务器的智能调度,但动态资源分配仍受制于集中式控…...
)
数据结构之二叉树(4)
(注:本文所示代码均为C) 一.二叉树选择题 根据二叉树的性质,完成以下选择题: (1)第一组 某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为&am…...

互联网与无线广播:数字时代与模拟时代的通讯双轨制-优雅草卓伊凡
互联网与无线广播:数字时代与模拟时代的通讯双轨制-优雅草卓伊凡 一、无线广播:穿越百年的电磁波通讯 1.1 无线广播的技术本质 当卓伊凡深入研究无线广播技术后,发现这套诞生于19世纪末的通讯系统蕴含着惊人的智慧。无线广播本质上是一种单…...

Java 集合线程安全
在高并发环境下,Java集合ArrayList和HashMap读写可能会出现安全问题。其中有几个解决办法: 使用Collections类方法Collections.synchronizedList和Collections.synchronizedMap在Java并发包中提供了CopyOnWriteArrayList和ConcurrentHashMap类 一、Arr…...

解决 Builroot 系统编译 perl 编译报错问题
本文提供一种修复 Builroot 系统编译 perl 编译报错途径 2025-05-04T22:45:08 rm -f pod/perl5261delta.pod 2025-05-04T22:45:08 /usr/bin/ln -s perldelta.pod pod/perl5261delta.pod 2025-05-04T22:45:08 /usr/bin/gcc -c -DPERL_CORE -fwrapv -fpcc-struct-return -pipe -f…...
_并发基础和基于进程的并发)
理解计算机系统_并发编程(1)_并发基础和基于进程的并发
前言 以<深入理解计算机系统>(以下称“本书”)内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定 引入 并发是一种非常重要的机制,用于处理多个指令流.特别是在网…...

详细案例,集成算法
以下是一个使用 随机森林(RF) 和 XGBoost 解决结构化数据分类问题的完整案例(以泰坦尼克号生存预测为例),包含数据处理、建模和结果分析: 案例:泰坦尼克号乘客生存预测 目标:根据乘客…...

57认知干货:AI机器人产业
机器人本质上由可移动的方式和可交互万物的机构组成,即适应不同环境下不同场景的情况,机器人能够做到根据需求调整交互机构和移动方式。因此,随着人工智能技术的发展,AI机器人的产业也将在未来逐步从单一任务的执行者,发展为能够完成复杂多样任务的智能体。 在未来的社会…...

谷歌 NotebookLM 支持生成中文播客
谷歌 NotebookLM 支持生成中文播客。 2025 年 4 月 29 日,NotebookLM 宣布其 “音频概览”(Audio Overviews)功能新增 76 种语言支持,其中包括中文。用户只需将文档、笔记、研究材料等上传至 NotebookLM,然后在设置中选…...

【MySQL数据库】用户管理
目录 1,用户信息 2,创建/删除/修改用户 3,数据库的权限 MySQL数据库安装完之后,我们最开始时使用的都是 root 用户,其它用户通常无法进行操作。因此,MySQL数据库需要对用户进行管理。 1,用户…...