文献总结:TPAMI端到端自动驾驶综述——End-to-End Autonomous Driving: Challenges and Frontiers
端到端自动驾驶综述
- 1. 文章基本信息
- 2. 背景介绍
- 3. 端到端自动驾驶主要使用方法
- 3. 1 模仿学习
- 3.2 强化学习
- 4. 测试基准
- 4.1 真实世界评估
- 4.2 在线/闭环仿真测试
- 4.3 离线/开环测试评价
- 5. 端到端自动驾驶面临的挑战
- 5.1 多模态输入
- 5.2 对视觉表征的依赖
- 5.3 基于模型的强化学习的世界模型复杂性
- 5.4 对多任务学习的依赖
- 5.5 专家模型与策略蒸馏低效
- 5.6 缺乏可解释性
- 5.7 缺乏安全保障
- 5.8 因果混淆
- 5.9 缺乏鲁棒性
- 6. 未来研究方向
- 6.1 零样本与小样本学习
- 6.2 模块化端到端规划
- 6.3 数据引擎
- 6.4 基础模型
- 总结
1. 文章基本信息
| 标题 | End-to-End Autonomous Driving: Challenges and Frontiers |
|---|---|
| 期刊 | IEEE Transcations on Pattern Analysis and Machine Intelligence (IF=20.4) |
| 作者 | Li Chen;Penghao Wu;Kashyap Chitta;Bernhard Jaeger;Andreas Geiger;Hongyang Li |
| 主要单位 | Shanghai AI Laboratory;University of Hong Kong |
| 关键词 | Autonomous driving; end-to-end system design; policy learning; simulation |
| 日期 | 收稿日期: 24 June 2023;接收日期: 22 July 2024 |
| 文章链接 | https://arxiv.org/abs/2306.16927 |
| 项目地址 | https://github.com/OpenDriveLab/End-to-end-Autonomous-Driving |

摘要: 自动驾驶社区见证了端到端自动驾驶算法的快速发展,这种利用原始摄像头输入生成车辆运动规划的方法,代替了集中于单一任务(检测、运动规划)的方法。与模块化流程相比,端到端系统受益于感知和规划的联合特征优化。由于大规模数据集、闭环测试和自动驾驶在挑战场景有效性需求的增加,端到端自动驾驶领域正在呈现一种快速发展的趋势。在这篇综述中,作者提供了超过270篇文献的全面分析,涵盖端到端自动驾驶领域的动机、路线、方法论、挑战和未来发展趋势等多个方面。本文深入探讨了其中的几个挑战,包括多模态、可解释性、因果混淆、鲁棒性和世界模型等等。此外,本文还讨论了基础模型和预训练视觉模型的运用,以及如何在端到端自动驾驶框架中协调这些技术。 |
2. 背景介绍
传统的自动驾驶系统采用模块化的设计策略,这使得自动驾驶系统的感知、预测、规划等功能是单独发展的,最后再整合到自车上。规划或控制模块负责生成方向和加速度输出,在决定驾驶体验方面扮演了一个重要的角色。模块化自动驾驶中大部分规划方法是采用复杂的基于规则的设置方法,在面对实际路况时显得效率低下。因此,采用大规模数据和基于学习的规划成为了发展的可能。
本文定义的端到端自动驾驶系统是指采用原始传感器数据作为输入,采用规划或底层控制作为输出的系统。下图证明了经典算法和端到端框架的区别:
- 模块化的自动驾驶算法:每个子模块生成对应输出,并输入到下一个任务中。如图中所示,感知模块生成3D目标检测框,传入到轨迹预测模块,生成周围车辆的预测轨迹,并转入到规划模块,生成最终的自车规划。
- 端到端自动驾驶算法:输入传感器的图片,通过特征流一步步传到规划,在规划模块计算损失,再通过反向传播将损失函数梯度传递给每一个子模块,以优化各模块的权重。这里只在规划模块计算损失值,不在其他模块产生损失计算。

下图展示了本综述的大纲,通过总结最近文献对端到端自动驾驶的方法、基准、挑战、未来趋势进行了总结。端到端自动驾驶优点:
- 将多个模块融合到一个模型中进行联合训练,减少训练步骤
- 整个系统面向最终任务来优化,增强模型使用性
- 共享主干网络提升计算效率
- 数据驱动优化,来提升系统潜力
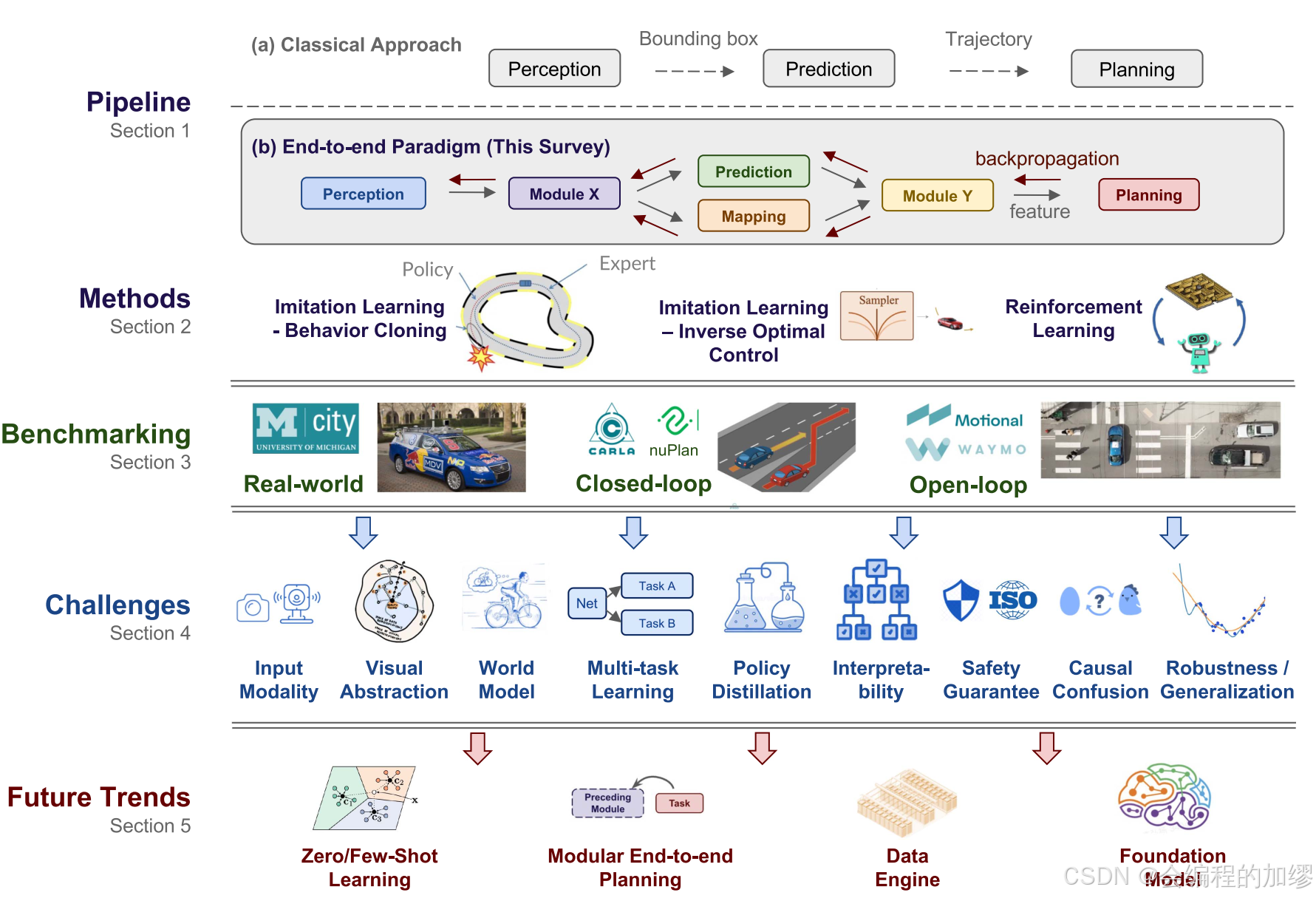
下图按时间顺序整理了端到端自动驾驶算法的关键事件:
-
最早的端到端自动驾驶可以追溯到1988年的ALVINN,其输入是来自摄像头的两个 “视网膜” 图像以及激光测距仪的数据,通过一个简单的神经网络生成方向的输出。
-
2016年,NVIDIA设计了一款端到端的卷积神经网络原型系统,在GPU计算这一时代重新确立了端到端自动驾驶的理念。随着深度神经网络的发展,模仿学习和强化学习在端到端自动驾驶中都取得了显著进展。
-
2019年,LBC提出了策略蒸馏范式,通过模仿表现良好的专家,显著提高了端到端自动驾驶在闭环测试下的性能。
-
2021年,在合理的计算预算范围内,各种传感器配置可用,学者们的注意力集中在纳入更多的模态和先进的架构(如Transformer)上,来捕捉全局上下文和代表性特征,该时期的代表作是TransFuser。结合对模拟环境的更多理解,这些先进设计在CARLA基准测试中显著提升了性能。为了提高自动驾驶系统的可解释性和安全性,该时期的方法引入了各种辅助模块、以更好地监督学习过程或利用注意力可视化技术。
-
2022年,学者们考虑到测试过程中存在很多数据分布不平衡的问题,于是考虑生成安全关键场景数据。同时,具有挑战性的新基准测试CARLA v2成功引入到该领域。
-
2023年,出现了模块化的端到端自动驾驶,旨在提高模型的可解释性,同时,nuPlan也被引入做新基准测试中。
3. 端到端自动驾驶主要使用方法
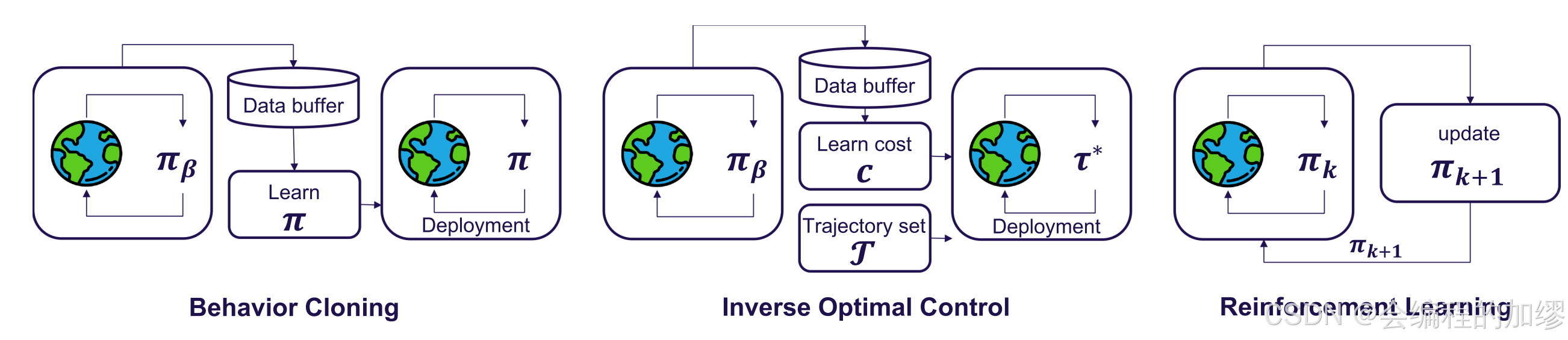
📷 图 3. 端到端自动驾驶方法概述。本图展示了三种流行的范式,包括两种模仿学习框架(行为克隆和逆最优控制),以及在线强化学习。
3. 1 模仿学习
模仿学习(imitation learning, IL),也称为从示范中学习,它训练一个智能体通过模仿专家的行为来学习策略。模仿学习需要一个数据集 D = { ξ i } D=\{ \xi_{i} \} D={ξi} ,其中包含根据专家策略 π β \pi_{\beta} πβ 收集的轨迹,每条轨迹都是一系列状态 - 动作对。模仿学习的目标是学习一个与 π β \pi_{\beta} πβ相匹配的智能体策略 π \pi π。
1)行为克隆(Behavior cloning, BC):在行为克隆中,通过在收集的数据集上进行监督学习,最小化规划损失,从而使智能体的策略与专家的策略相匹配: E ( s , a ) ℓ ( π θ ( s ) , a ) \mathbb{E}_{(s, a)} \ell(\pi_{\theta}(s), a) E(s,a)ℓ(πθ(s),a)。这里, ℓ ( π θ ( s ) , a ) \ell(\pi_{\theta}(s), a) ℓ(πθ(s),a) 表示一个损失函数,用于衡量智能体动作与专家动作之间的差异。
2)逆最优控制(Inverse optimal control):传统的逆最优控制算法从专家演示中学习未知的奖励函数 R ( s , a ) R(s, a) R(s,a) ,其中专家的奖励函数可以表示为特征的线性组合。然而,在连续的、高维的自动驾驶场景中,奖励的定义是隐含的,且难以优化。
3.2 强化学习
强化学习(Reinforcement learning, RL)是一个通过试错进行学习的领域。深度Q网络(Deep Q networks, DQN)在雅达利(Atari)基准测试中成功实现了人类水平的控制,这使得深度强化学习得到了广泛应用。DQN训练一个名为评论家(或Q网络)的神经网络,该网络以当前状态和一个动作为输入,并预测该动作的折扣回报。然后,通过选择预测回报最高的动作来隐式定义策略。
4. 测试基准
4.1 真实世界评估
早期对自动驾驶进行基准测试的尝试涉及到真实世界评估。值得注意的是,美国国防高级研究计划局(DARPA)发起了一系列比赛来推动自动驾驶技术的发展。第一场比赛为能自主导航穿越莫哈韦沙漠240公里路线的团队提供100万美元奖金,但没有团队成功完成。最后一场系列赛事——DARPA城市挑战赛,要求车辆在96公里的模拟城镇路线中行驶,同时遵守交通规则并避开障碍物。这些比赛促进了自动驾驶领域的重要发展,例如激光雷达传感器的应用。受此启发,密歇根大学建立了MCity,这是一个大型的可控真实世界环境,旨在方便进行自动驾驶汽车的测试。然而,由于缺乏数据和车辆,这类学术项目并未在端到端系统中得到广泛应用。相比之下,有资源部署无人驾驶车队的企业可以依靠真实世界评估来衡量其算法的改进效果。

图片来源:聊聊无人驾驶汽车的发展历史(三)——DARPA无人驾驶挑战赛
4.2 在线/闭环仿真测试
闭环评估涉及构建一个能紧密模拟现实世界驾驶环境的仿真环境。评估工作包括在模拟环境中部署驾驶系统,并衡量其性能。该系统必须在驶向指定目标位置的过程中,安全地在车流中行驶。开发这类模拟器主要涉及四项子任务:参数初始化、交通模拟、传感器模拟和车辆动力学模拟。我们将在下面简要介绍这些子任务,随后总结目前可用于闭环基准测试的开源模拟器。
1)参数初始化:模拟具有高度可控环境的优势,可控的内容包括天气、地图、三维资产,以及诸如交通场景中物体布局之类的底层属性。尽管功能强大,但这些参数的数量众多,从而带来了一个具有挑战性的设计问题。目前的模拟器通过两种方式来解决这一问题:程序生成与数据驱动。
2)交通模拟:交通模拟涉及在环境中生成虚拟实体并为其定位,同时让它们具有逼真的运动状态。这些实体通常包括车辆(如汽车、摩托车、自行车等)和行人。交通模拟器必须考虑速度、加速度、制动、障碍物以及其他实体的行为所产生的影响。此外,必须定期更新交通信号灯的状态,以模拟真实的城市驾驶情况。目前有两种流行的交通模拟方法:基于规则的方法和数据驱动的方法。
3)传感器模拟:对于评估端到端自动驾驶系统而言,传感器模拟至关重要。这包括生成模拟的原始传感器数据,比如驾驶系统在模拟器中从不同视角接收到的摄像头图像或激光雷达扫描数据。这一过程需要考虑噪声和遮挡情况,以便对自动驾驶系统进行真实的评估。关于传感器模拟,主要有以下两大思路分支:基于图形的和数据驱动的。
4)车辆动力学模拟:驾驶模拟的最后一个方面是要确保模拟车辆的运动符合物理上的合理性。大多数现有的公开可用模拟器使用高度简化的车辆模型,例如独轮车模型或自行车模型。然而,为了使算法能够顺利地从模拟环境转移到现实世界中,纳入更精确的车辆动力学物理建模至关重要。例如,CARLA采用了多体系统方法,将车辆表示为由四个车轮支撑的多个弹性质量块的组合。
5)目前主要的两个测试模拟器为CARLA和nuPlan,部分测试场景已经被现有算法很好的解决,所以这些模拟器的维护方也推出了一些比较用挑战性的场景,涉及泛化性、unseen scenes等
📊用于自动驾驶闭环评估且带有活跃基准测试的开源模拟器

4.3 离线/开环测试评价
开环评估主要是根据预先记录的专家驾驶行为来评估一个系统的性能。这种方法需要评估数据集,其中包括
(1)传感器读数
(2)目标位置,
(3)相应的未来驾驶轨迹
以传感器输入和目标位置作为输入,通过将系统预测的未来轨迹与驾驶记录中的轨迹进行比较来衡量性能。系统的评估依据是其轨迹预测与人类真实情况的匹配程度,以及其他辅助指标,比如与其他智能体发生碰撞的概率。
开环评估的优点在于,使用真实的交通和传感器数据很容易采集,因为它不需要模拟器。然而,其关键缺点是它无法衡量系统在实际部署测试中所遇到的真实分布情况下的性能。在测试过程中,驾驶系统可能会偏离专家的驾驶路径,而验证系统从这种偏离中恢复的能力是至关重要的。
此外,在多模式场景中,预测轨迹与记录轨迹之间的距离并不是一个理想的衡量指标。例如,在并入转弯车道的情况下,立即并入或稍后并入这两种选择都可能是合理的,但开环评估会对数据中未观察到的那种选择进行扣分。因此,除了衡量碰撞概率和预测误差之外,还提出了一些指标来更全面地涵盖交通违规、行驶进展以及驾驶舒适性等方面。
5. 端到端自动驾驶面临的挑战
5.1 多模态输入
1)感知与多传感器融合。尽管早期的研究成果通过单目摄像头成功实现了车道跟随功能,但这种单一的输入模态无法应对复杂的场景。因此,对于如今的自动驾驶汽车,已经引入了图4中所示的各种传感器。特别是,来自摄像头的RGB图像能够复现人类感知世界的方式,具有丰富的语义细节;激光雷达或立体摄像头则能提供精确的三维空间信息。像毫米波雷达和事件相机这样的新兴传感器在捕捉物体的相对运动方面表现出色。此外,来自速度计和惯性测量单元(IMU)的车辆状态信息,以及导航指令,也是引导驾驶系统的其他输入信息。然而,不同的传感器具有不同的视角、数据分布,并且价格差异巨大,这就给有效地设计传感器布局以及将它们融合起来以实现自动驾驶中的互补带来了挑战。
2)语言作为输入:人类驾驶时既依靠视觉感知,也依靠内在知识,二者共同构成了因果行为。在与自动驾驶相关的领域,比如具身人工智能中,将自然语言作为细粒度的知识和指令来控制视觉运动智能体方面,已经取得了显著进展。然而,与机器人应用相比,驾驶任务更为直接,无需进行任务分解,而且户外环境要复杂得多,存在高度动态的智能体,但可供作为参照的明显标志物却很少。
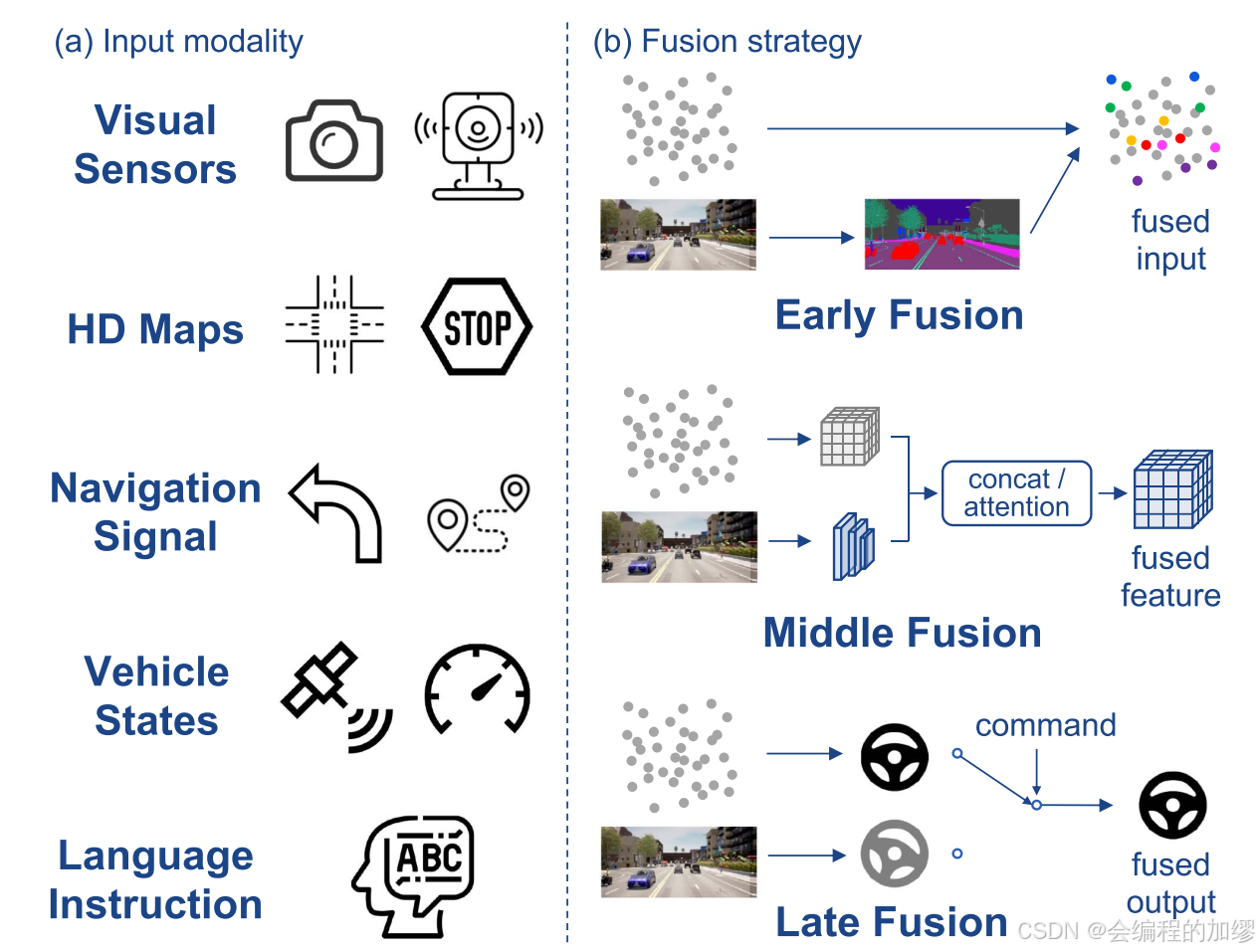
📷 图4展示了输入模态和融合策略的示例。我们以点云和图像为例来描述各种融合策略。(不同模态)具有鲜明的特征,这给有效的传感器融合带来了挑战。
5.2 对视觉表征的依赖
端到端自动驾驶系统大致分为两个阶段:将状态编码为潜在特征表示,然后利用中间特征对驾驶策略进行解码。在城市驾驶中,与诸如电子游戏这类常见的策略学习基准相比,输入状态,即周围环境和自身状态,要更加多样化且维度更高,这可能会导致表征与制定策略所需的关注区域之间不匹配。因此,设计 “优质” 的中间感知表征,或者首先使用代理任务对视觉编码器进行预训练是有帮助的。这能使网络有效地提取对驾驶有用的信息,从而为后续的策略制定阶段提供便利。此外,这还可以提高强化学习方法的样本效率。
1)表征设计:简单的表征是通过各种主干网络提取的。经典的卷积神经网络(CNN)仍然占据主导地位,它在平移等变性和高效性方面具有优势。经过深度预训练的卷积神经网络显著提升了感知能力和下游任务的性能。相比之下,基于Transformer的特征提取器在感知任务中展现出了强大的可扩展性,但尚未在端到端驾驶领域被广泛采用。对于驾驶特定的表征,研究人员引入了鸟瞰图(BEV)的概念,在统一的三维空间内融合不同的传感器模态和时间信息。这也便于对下游任务进行适配。此外,基于网格的三维占据(occupancy)表示法被开发出来用于捕捉不规则物体,并在规划过程中用于避免碰撞。然而,与鸟瞰图方法相比,这种密集的表征会带来巨大的计算成本。
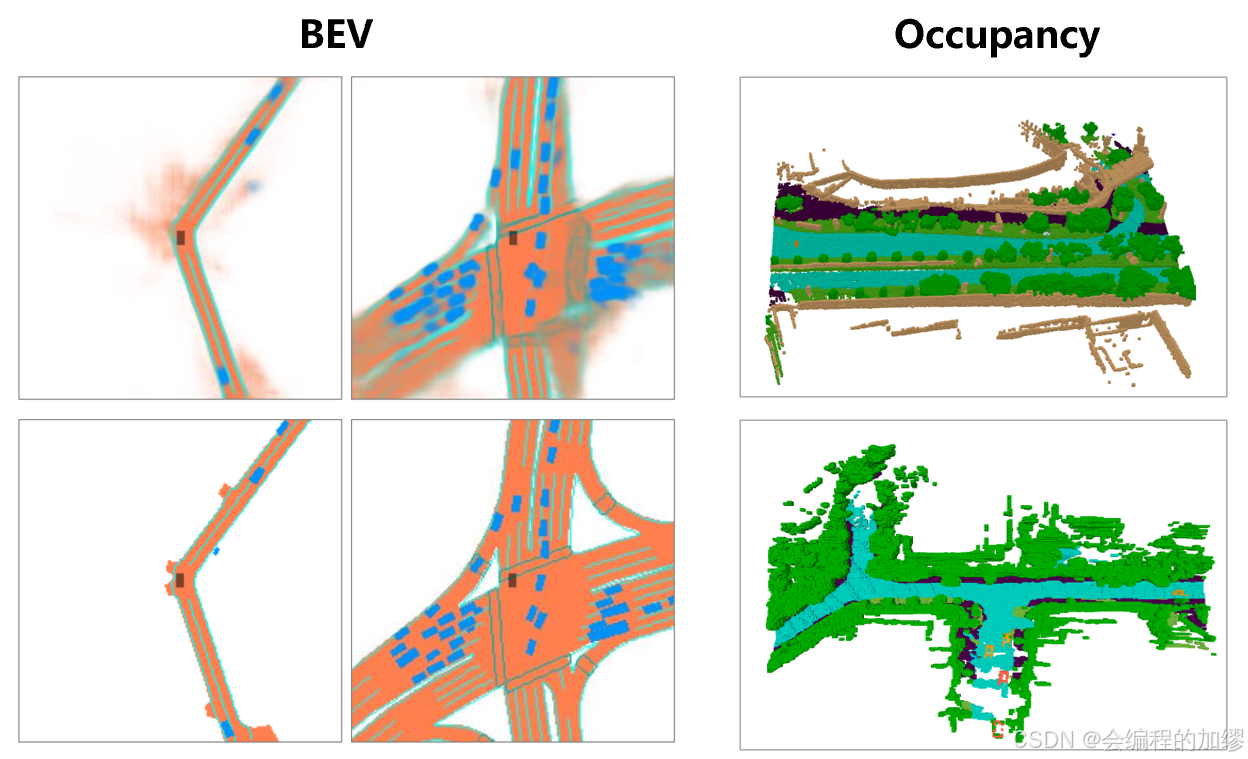
2)表征学习:表征学习通常会纳入某些归纳偏置或先验信息。在学习得到的表征中不可避免地存在可能的信息瓶颈,并且与决策无关的冗余上下文信息可能会被剔除。从大规模无标签数据中进行自监督表征学习以用于策略学习是很有前景的,值得在未来进一步探索。
5.3 基于模型的强化学习的世界模型复杂性
深度强化学习通常存在样本复杂度高的问题,这一问题在自动驾驶领域尤为突出。基于模型的强化学习(model-based reinforcement learning, MBRL)提供了一个很有前景的方向,它允许智能体与学习到的世界模型进行交互,而非与真实环境交互,以此来提高样本效率。基于模型的强化学习方法采用一个明确的世界(环境)模型,该模型由转移动力学和奖励函数组成。这在自动驾驶中特别有用,因为像CARLA这样的模拟器运行相对较慢。
针对端到端自动驾驶的世界模型学习是一个新兴且极具潜力的方向,因为它能大幅降低强化学习的样本复杂度,并且对世界的理解有助于驾驶。然而,由于驾驶环境高度复杂且动态多变,仍需进一步研究来确定哪些内容需要建模,以及如何有效地对世界进行建模。
5.4 对多任务学习的依赖
多任务学习(MTL)是指基于一种共享表征,通过不同的任务头来联合执行多项相关任务。多任务学习具有诸多优势,比如降低计算成本、共享相关领域知识,以及能够利用任务之间的关系来提升模型的泛化能力。因此,多任务学习非常适合端到端的驾驶场景,在这种场景中,最终的策略预测需要对环境有全面的理解。然而,如何选择辅助任务的最佳组合,以及如何对损失进行恰当的加权以实现最佳性能,是一个重大挑战。
5.5 专家模型与策略蒸馏低效
由于模仿学习,或者其主要的子类别——行为克隆,仅仅是模仿专家行为的监督学习,相应的方法通常遵循“teacher-student”范式。这里存在两个主要挑战:(1)“teature”,例如由CARLA提供的人工设计的专家自动驾驶程序,尽管能够获取周围智能体的真实状态和地图信息,但并非是完美的驾驶者。(2)“student”仅通过记录的带有传感器输入的输出来接受监督,这要求他们同时从零开始提取感知特征并学习策略。
尽管人们付出了巨大努力来设计一个强大的专家模型,并在不同层面上进行知识迁移,但“teacher-student”范式仍然存在知识蒸馏效率低下的问题。例如,拥有特殊信息的智能体能够获取交通信号灯的真实状态,而交通信号灯在图像中是小目标物体,因此很难提炼出相应的特征。结果是,视觉运动智能体与拥有特殊信息的智能体相比,表现出较大的性能差距。这也可能会给“student”智能体带来因果关系上的混淆。值得探索的是,如何从机器学习中的通用蒸馏方法中获得更多启发,以缩小这种差距。
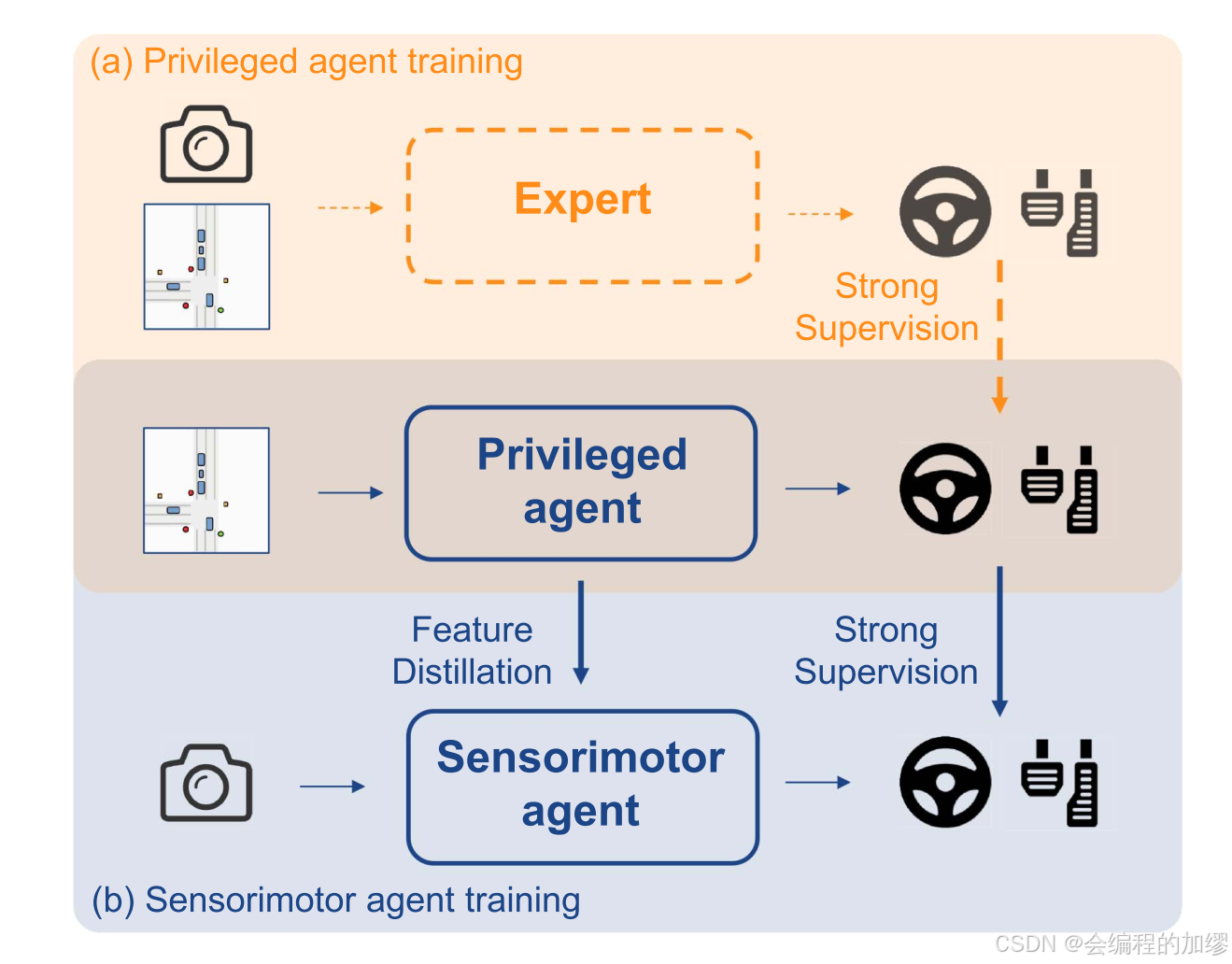
📷 图5. 策略蒸馏。(a) 特权智能体通过获取特权真实信息来学习稳健的策略。图中专家用虚线标注,表明如果特权智能体通过强化学习进行训练,专家并非必需。(b) 感觉运动智能体通过特征蒸馏和输出模仿两种方式来模仿特权智能体。
5.6 缺乏可解释性
可解释性在自动驾驶领域中起着至关重要的作用。它能让工程师更好地调试系统,从社会层面为系统性能提供保障,并且有助于提高公众对自动驾驶的接受度。对于通常被称为“黑箱”的端到端驾驶模型而言,实现其可解释性不仅更为关键,而且极具挑战性。下图展示了用于端到端自动驾驶的集中方法,包括注意力可视化、引入可解释化任务、融合规则和成本的学习、基于自然语言的学习和不确定性建模。
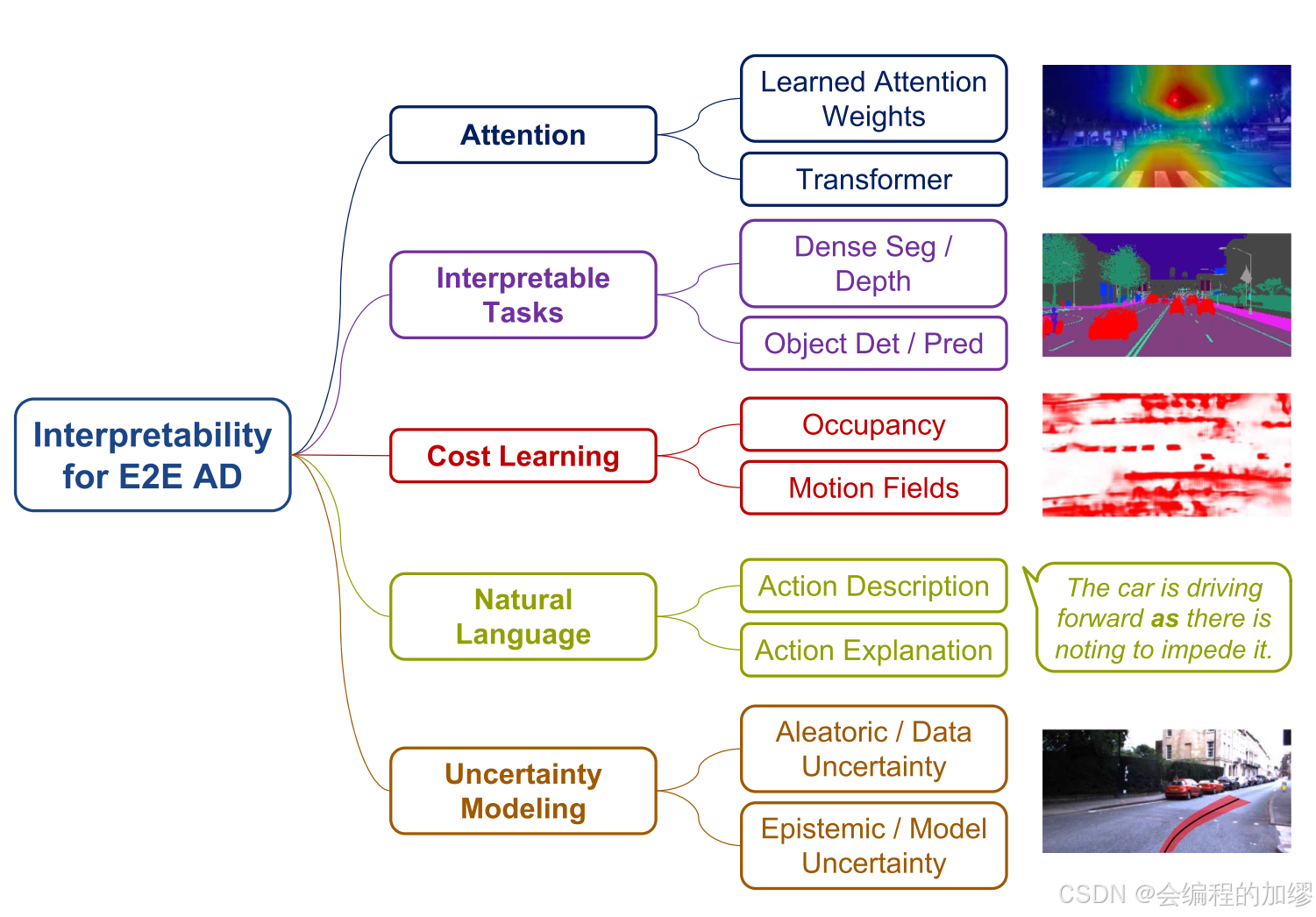
📷图6. 不同可解释性形式的总结。它们有助于人们理解端到端模型的决策过程以及输出的可靠性。
5.7 缺乏安全保障
在现实世界场景中部署自动驾驶系统时,确保安全至关重要。然而,与传统的基于规则的方法不同,端到端框架基于学习的本质使得其在安全性方面从根本上缺乏精确的数学推导证明。然而,需要注意的是,模块化驾驶系统已经在其运动规划或速度预测模块中纳入了特定的与安全相关的约束条件或优化措施,以确保安全性。这些机制有可能经过调整后作为后处理步骤或安全检查集成到端到端模型中,从而提供额外的安全保障。
5.8 因果混淆
近二十年来,模仿学习中的因果关系混淆一直是一个长期存在的挑战。最早报道这种现象的是勒昆(LeCun)等人。他们使用单个输入帧来进行转向预测,以避免出现这种外推情况。尽管这种方法比较简单,但在当前最先进的模仿学习(IL)方法中,它仍是一种首选的解决方案。遗憾的是,使用单个帧很难提取周围行为体的运动情况。因果关系混淆的另一个来源是速度测量。图7展示了一辆在红灯前等待的汽车的例子。这辆汽车的动作与其速度可能高度相关,因为在很多帧画面中,它的速度为零且动作是刹车。只有当交通信号灯从红灯变为绿灯时,这种相关性才会被打破。
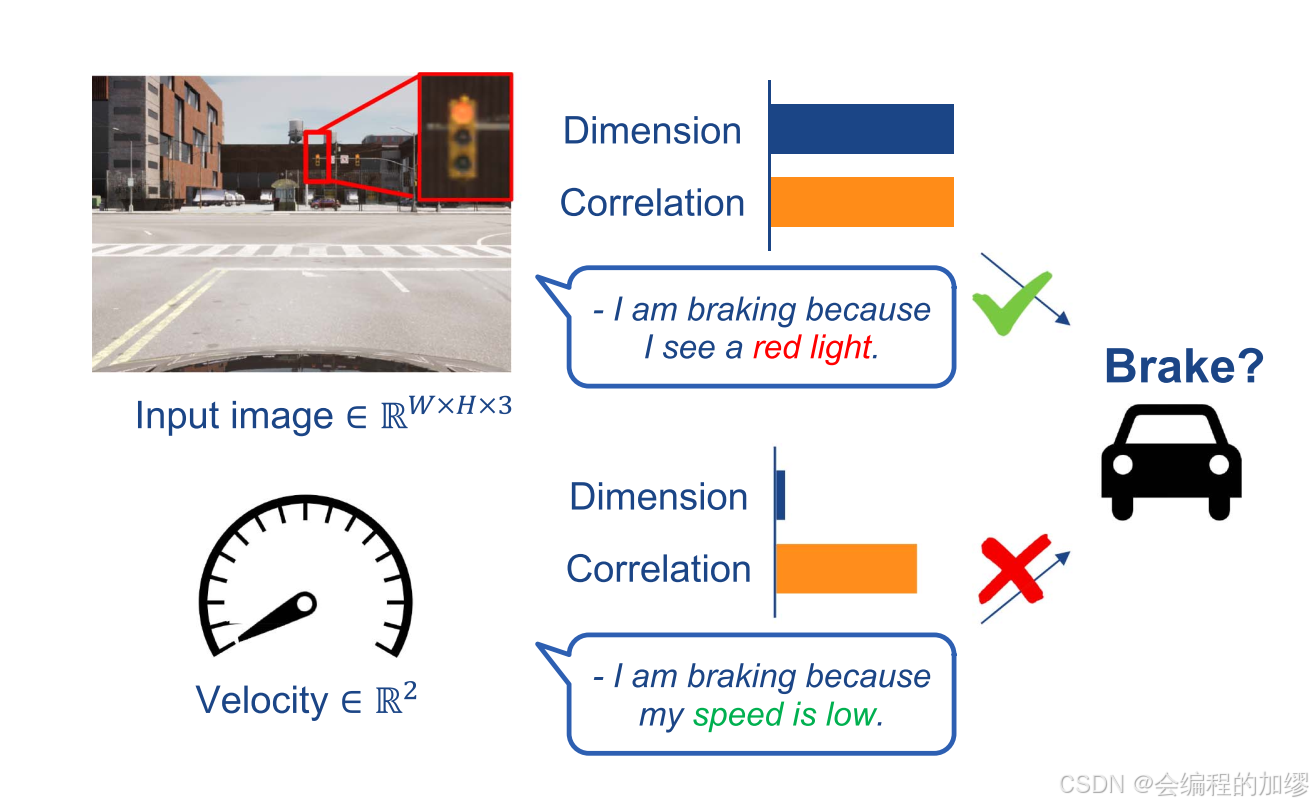
📷 图7. 因果混淆。汽车当前的行为与速度或汽车过去的轨迹等低维虚假特征密切相关。端到端模型可能会依赖这些特征,从而导致因果混淆。
5.9 缺乏鲁棒性
1)长尾分布:长尾分布问题的一个重要方面是数据集不均衡,即少数类别占据了大多数,如图8(a)所示。这对模型推广到多样化环境构成了巨大挑战。各种方法通过数据处理来缓解这一问题,包括过采样、欠采样以及数据增强。此外,基于加权的方法也被广泛使用。
2)协变量偏移:正如在模仿学习中所讨论的,行为克隆面临的一个重要挑战是协变量偏移。专家策略下的状态分布与经过训练的智能体策略下的状态分布有所不同,这就导致当将经过训练的智能体部署到未曾见过的测试环境中,或者当其他智能体的反应与训练时不同时,会产生复合误差。这可能会使经过训练的智能体处于专家训练分布之外的状态,从而导致严重的失败。图8(b)展示了一个相关示例。
3)域适应:域适应(DA)是一种迁移学习,其中目标任务与源任务相同,但域不同。在此,我们讨论这样的场景:源域有可用的标签,而目标域没有标签或者只有少量可用的标签。
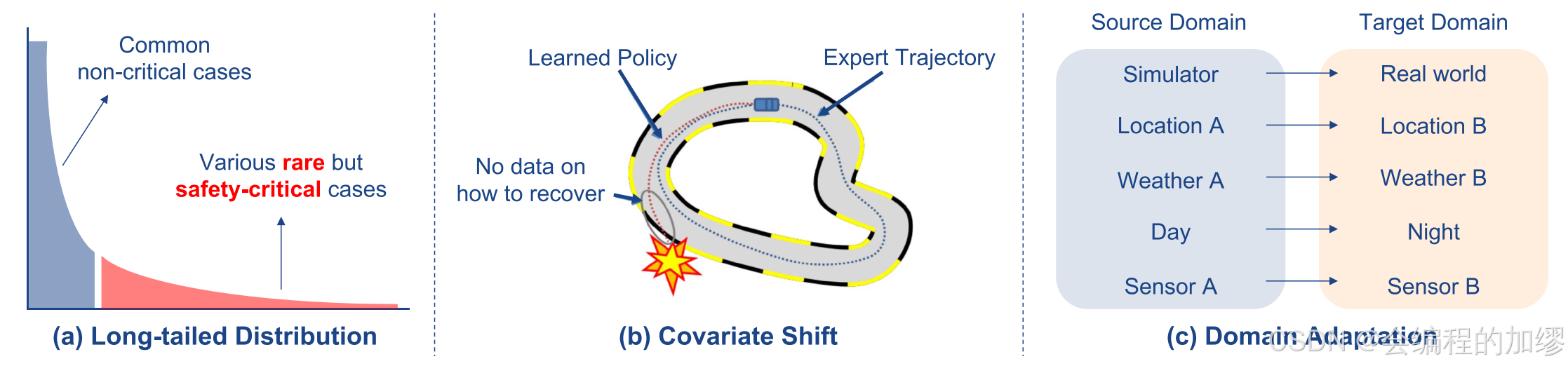
📷 图8. 稳健性方面的挑战。与数据集分布差异相关的主要泛化问题有三个,即长尾分布与普通情况、专家演示与测试场景,以及位置、天气等方面的领域转移。
6. 未来研究方向
6.1 零样本与小样本学习
自动驾驶模型最终不可避免地会遇到超出训练数据分布范围的现实世界场景。这就引出了一个问题:我们是否能够成功地让模型适应一个未曾见过的目标领域,而在这个领域中只有有限的标记数据,甚至没有标记数据。对于端到端驾驶领域而言,将这一任务形式化,并融入来自零样本/少样本学习文献中的技术,是实现这一目标的关键步骤。
6.2 模块化端到端规划
模块化端到端规划框架在优化多个模块的同时,将最终的规划任务置于优先地位,这种框架具有可解释性的优势。最近的文献都提倡这种框架,并且某些行业解决方案(如特斯拉、Wayve等)也融入了类似的理念。在设计这些可微感知模块时,会出现一些关于损失函数选择的问题,比如在目标检测中三维边界框的必要性,在静态场景感知中,是选择鸟瞰图(BEV)分割还是车道拓扑结构,或者是在模块数据有限的情况下的训练策略等问题。
6.3 数据引擎
大规模且高质量的数据对于自动驾驶的重要性,怎么强调都不为过。建立一个配备自动标注流水线的数据引擎,能够极大地推动数据和模型的迭代发展。用于自动驾驶的数据引擎,尤其是模块化端到端规划系统,需要借助大型感知模型,以自动化的方式简化高质量感知标签的标注流程。它还应该支持挖掘困难/极端情况、场景生成和编辑,以便进行数据驱动评估,并提高数据的多样性以及模型的泛化能力。一个数据引擎将使自动驾驶模型能够持续地改进。
6.4 基础模型
近期,在语言领域和视觉领域的基础模型方面取得的进展已经证明,大规模的数据和模型容量能够释放人工智能在高级推理任务中的巨大潜力。微调或提示学习的范式、以自监督重建或对比对等形式的优化方法,都适用于端到端的驾驶领域。然而,我们认为直接将大型语言模型(LLMs)应用于驾驶可能会存在问题。自动驾驶智能体的输出需要稳定且准确的测量结果,而语言模型的生成式输出旨在表现得像人类一样,却并不太在意其准确性。开发一个“基础”驾驶模型的可行解决方案是训练一个世界模型,该模型能够在二维、三维或潜在空间中预测环境合理的未来状况。为了在诸如规划等下游任务中表现良好,对于该模型而言,需要优化的目标必须足够完善,不能仅仅局限于帧级别的感知。
总结
⭐ Research Question
本文主要提出并回答了下面三个研究问题:
- 端到端自动驾驶主要的技术路线是什么?
- 目前端到端自动驾驶面临着什么样的困难与挑战?
- 未来可能的发展方向是什么?
总结: 本文通过文献综述的方式,梳理了目前端到端自动驾驶常用的一些技术路线及方法:模仿学习与强化学习。同时,详细地总结了端到端自动驾驶面临着的挑战,包括传感器输入模态、视觉表征、可解释性、因果混淆、数据泛化性与鲁棒性等。并且指明了未来可能的4个发展方向,包括端到端自动驾驶中的零样本与小样本学习、模块化端到端规划、数据引擎以及基础模型的运用。 |
相关文章:

文献总结:TPAMI端到端自动驾驶综述——End-to-End Autonomous Driving: Challenges and Frontiers
端到端自动驾驶综述 1. 文章基本信息2. 背景介绍3. 端到端自动驾驶主要使用方法3. 1 模仿学习3.2 强化学习 4. 测试基准4.1 真实世界评估4.2 在线/闭环仿真测试4.3 离线/开环测试评价 5. 端到端自动驾驶面临的挑战5.1 多模态输入5.2 对视觉表征的依赖5.3 基于模型的强化学习的世…...

二极管反向恢复的定义和原理
二极管的反向恢复定义 二极管的反向恢复是指二极管从正向导通状态切换到反向阻断状态时,电流从正向变为负向并最终回到零所需的时间。具体过程如下: 正向导通:当二极管正向偏置时,电流可以顺利通过,此时二极管处于导…...
的猫狗图像分类实践)
# 基于词袋模型(BoW)的猫狗图像分类实践
基于词袋模型(BoW)的猫狗图像分类实践 在计算机视觉领域,图像分类是一项基础且重要的任务。本文将介绍如何使用词袋模型(Bag of Words, BoW)结合支持向量机(SVM)实现猫狗图像分类。通过详细的代…...

Vscode+git笔记
1.U是untracked m是modify modified修改了的。 2.check out 查看观察 3 status changed 暂存区 4.fetch v 取来拿来 5.orangion 起源代表远程分支 git checkout就是可以理解为进入的意思。...

生成式 AI 的未来
在人类文明的长河中,技术革命始终是推动社会跃迁的核心引擎。从蒸汽机解放双手,到电力点亮黑夜,再到互联网编织全球神经网络,每一次技术浪潮都在重塑人类的生产方式与认知边界。而今天,生成式人工智能(Generative AI)正以一种前所未有的姿态登上历史舞台——它不再局限于…...
)
进程间通信(IPC)
进程间通信(IPC)是操作系统中非常重要且基础的概念,涉及到不同进程之间如何交换数据和同步操作。下面我会一个一个地详细讲解这几种常见的IPC方式:管道(包含匿名管道和有名管道)、消息队列、共享内存、信号量、Socket通信,内容尽量用通俗易懂的语言,并结合具体原理、优…...

C语言奇幻指南:宏、头文件与变量的秘密世界
🌟 C语言奇幻指南:宏、头文件与变量的秘密世界 🌟 一、写一个“比小”宏:三目运算符的魔法 目标:定义一个宏,返回两个参数中较小的值。 代码: #define MIN(a, b) ((a) < (b) ? (a) : (b))…...

【开源免费】二维码批量识别-未来之窗——C#-仙盟创梦IDE
二维码批量识别工具,借助先进图像识别技术,能快速准确读取大量二维码信息。适用于物流与供应链管理,如库存盘点和货物追踪;可用于资产管理,像固定资产盘点与设备巡检;还能助力数据收集与市场调研࿰…...

n8n工作流自动化平台的实操:解决中文乱码
解决问题: 通过ftp读取中文内容的文件,会存在乱码,如下图: 解决方案 1.详见《安装 iconv-lite》 2.在code节点,写如下代码: const iconv require(iconv-lite);const items $input.all(); items.forEa…...

MCP 探索:MCP 集成的相关网站 Smithery、PulseMCP 等
简简单单 Online zuozuo :本心、输入输出、结果 文章目录 MCP 探索:MCP 集成的相关网站 Smithery、PulseMCP 等前言一、MCP 集成基础二、利用热门资源平台集成三、集成常见 MCP 服务四、管理集成的 MCP 能力五、集成示例借鉴六、数据交互与安全管理MCP 探索:MCP 集成的相关网…...

linux的时间轮
时间轮:高效管理海量定时任务的利器 1. 引言:为什么需要时间轮? 在许多应用场景中,我们都需要管理大量的定时任务,例如: 网络连接的超时检测。分布式系统中的心跳检测。缓存条目的过期淘汰。需要延迟执行…...
——进一步完善内核)
《操作系统真象还原》第十二章(2)——进一步完善内核
文章目录 前言可变参数的原理实现系统调用write更新syscall.h更新syscall.c更新syscall-init.c 实现printf编写stdio.h编写stdio.c 第一次测试main.cmakefile结果截图 完善printf修改main.c 结语 前言 上部分链接:《操作系统真象还原》第十二章(1&#…...

MIT6.S081-lab8前置
MIT6.S081-lab8前置 注:本部分除了文件系统还包含了调度的内容。 调度 调度涉及到保存寄存器,恢复寄存器,就这一点而言,和我们的 trap 很像,但是实际上,我们实现并不是复用了 trap 的逻辑,我…...

Java从入门到精通 - Java语法
Java 语法 此笔记参考黑马教程,仅学习使用,如有侵权,联系必删 文章目录 Java 语法01 变量详解1. 变量里的数据在计算机中的存储原理1.1 二进制1.2 十进制转二进制的算法1.3 计算机中表示数据的最小单元总结1.4 字符在计算机中是如何存储的呢…...
 BCD)
【CF】Day50——Codeforces Round 960 (Div. 2) BCD
B. Array Craft 题目: 思路: 有点意思的构造 首先题目告诉我们 y < x,这是一个重要的条件 我们先来考虑简单情况,假如可以放0进去,那么我们只需要在 y ~ x 之间全放 1 ,其余都是 0 即可,但…...

MySQL 日期加减函数详解
MySQL 日期加减函数详解 1. DATE_ADD 函数 基本语法 DATE_ADD(date, INTERVAL expr unit)功能 在指定日期/时间上添加一个时间间隔 参数说明 date:要处理的日期/时间值(可以是DATE, DATETIME或TIMESTAMP类型)expr:要添加的间…...

NV189NV195美光固态闪存NV197NV199
NV189NV195美光固态闪存NV197NV199 在存储技术持续迭代的2025年,美光固态闪存NV189、NV195、NV197、NV199系列凭借其差异化的性能定位,正在重新定义数据存储的边界。本文将从技术参数、场景适配、行业价值等维度,为不同领域的专业人士提供深度…...

C语言-回调函数
回调函数 通过函数指针调用函数,而这个被调用的函数称为回调函数 回调函数是C语言中一种强大的机制,允许将函数作为参数传递给其他函数,从而在特定时机由后者调用。它的核心在于函数指针的使用 以下是回调函数的使用例子 先创建好一个函数…...

启发式算法-蚁群算法
蚁群算法是模拟蚂蚁觅食行为的仿生优化算法,原理是信息素的正反馈机制,蚂蚁通过释放信息素来引导同伴找到最短路径。把问题的元素抽象为多条路径,每次迭代时为每只蚂蚁构建一个解决方案,该解决方案对应一条完整的路径,…...

DeepSeek与MySQL:开启数据智能新时代
目录 一、引言:技术融合的力量二、DeepSeek 与 MySQL:技术基石2.1 DeepSeek 技术探秘2.2 MySQL 数据库深度解析 三、DeepSeek 与 MySQL 集成:从理论到实践3.1 集成原理剖析3.2 集成步骤详解 四、应用案例:实战中的价值体现4.1 电商…...
)
Modbus 通讯协议(超详细,简单易懂)
目录 一、协议中的寄存器定义 二、协议概述 三、使用串口的Modbus 报文帧 编辑 3.1、Modbus ASCII 模式 3.2、Modbus RTU 模式 3.3、功能码概要 3.4、Modbus 报文分析 四、什么是RS-485 RS-232? 一、协议中的寄存器定义 阅读 Modbus 协议时会发现它的概念别扭…...
)
单细胞测序试验设计赏析(一)
单细胞测序试验设计赏析(一) 单细胞测序试验设计中,单细胞测序技术通常会结合其它的技术来共同说明问题,或者结合年龄、性别等临床数据,进行分层分析说明问题以下以发表文章来进行一定的分析。 Single-cell RNA seque…...

ES6入门---第二单元 模块三:对象新增、
一:对象简洁语法: 1、变量简洁 <script>let name Strive;let age 18;let json {name, //name:name,age //age:age};console.log(json);</script> 2、函数简洁 let json {name, //name:name,age, //age:age/* showA:functi…...

多元随机变量协方差矩阵
主要记录多元随机变量数字特征相关内容。 关键词:多元统计分析 二元随机变量(X, Y) 说明:可以理解变量中的 X为身高、Y为体重 总体协方差 σ X Y c o v ( X , Y ) E [ ( X − μ X ) ( Y − μ Y ) ] E ( X Y ) − μ X μ Y \sigma_{XY}cov(X, Y)E[…...

计算机网络-同等学力计算机综合真题及答案
计算机网络-同等学力计算机综合真题及答案 (2003-2024) 2003 年网络 第二部分 计算机网络(共 30 分) (因大纲变动因此 2004 年真题仅附真题,不作解析。) 一、填空题(共 10 分&#…...
与工具条制作(Toolbar))
[案例二] 菜单条制作(Menuscript)与工具条制作(Toolbar)
最近五一正好毕业论文盲审,抽时间研究一下菜单条制作(Menuscript)与工具条制作(Toolbar)的制作,在NX二次开发中唐康林老师已经讲的很详细了,在这里只对视频中的内容进行总结,并且根据自己的想法进行补充。在里海博主的直播教学中发现一个很有趣的NX图标工具,本人大概做了一…...

bellard.org : QuickJS 如何使用 qjs 执行 js 脚本
参阅上一篇:Fabrice Bellard(个人网站:bellard.org)介绍 Fabrice Bellard(个人网站:bellard.org)是计算机领域最具影响力的程序员之一,其贡献跨越多个技术领域并持续推动开…...

计组复习笔记 3
前言 继续做例题。昨天做到第一个就把我难住了。可恶。 4.1 地址码越长,操作码越短。因为两者加起来是指令字,指令字的大小一般是固定的。扩展编码按照操作码从短到长进行编码。算了先放一下。我先看一下别的复习资料。等会儿再看这个题。 鼓励自己 …...

GCD 深入解析:从使用到底层实现
前言 Grand Central Dispatch (GCD) 是 Apple 基于 C 语言开发的一套完整的并发编程框架。它不仅仅是一个简单的线程管理工具,而是一个高度优化的并发编程解决方案。GCD 的设计理念是将并发编程的复杂性封装在框架内部,为开发者提供简单易用的接口。本文…...

JavaScript中的AES加密与解密:原理、代码与实战
前言 关于有js加密、js解密,js业务相关,找jsjiami官网站长v。 另外前段时间做了个单子跑单了,出售TEMU助手。eller点kuajingmaihuo点com的全自动化助手,可以批量合规,批量实拍图,批量资质上传等。 一、A…...
 堆指令部件模块实验)
计算机组成原理实验(7) 堆指令部件模块实验
实验七 堆指令部件模块实验 一、实验目的 1、掌握指令部件的组成方式。 2、熟悉指令寄存器的打入操作,PC计数器的设置和加1操作,理解跳转指令的实现过程。 二、实验要求 按照实验步骤完成实验项目,掌握数据打入指令寄存器IR1、PC计数器的…...

Windows系统下Node.js环境部署指南:使用nvm管理多版本
Windows系统下Node.js环境部署指南:使用nvm管理多版本 一、Node.js介绍二、为什么需要nvm?三、安装前的准备工作1. 本次环境说明2. 卸载现有Node.js(如有) 三、nvm-windows安装步骤1. 下载安装包2. 安装过程3. 验证安装 四、使用n…...

数据结构*队列
队列 什么是队列 是一种线性的数据结构,和栈不同,队列遵循“先进先出”的原则。如下图所示: 在集合框架中我们可以看到LinkedList类继承了Queue类(队列)。 普通队列(Queue) Queue中的方法 …...

C语言蓝桥杯真题代码
以下是不同届蓝桥杯C语言真题代码示例,供参考: 第十三届蓝桥杯省赛 C语言大学B组 真题:卡片 题目:小蓝有很多数字卡片,每张卡片上都是数字1-9。他想拼出1到n的数列,每张卡片只能用一次,求最大的…...

Sharding-JDBC分库分表中的热点数据分布不均匀问题及解决方案
引言 在现代分布式应用中,使用Sharding-JDBC进行数据库的分库分表是提高系统性能和扩展性的常见策略。然而,在实际应用中,某些特定的数据(如最新订单、热门商品等)可能会成为“热点”,导致这些部分的数据处…...

Dagster中的Ops与Assets:数据管道构建的两种选择
Dagster是一个强大的数据编排平台,它提供了多种工具来帮助数据工程师构建可靠的数据管道。在Dagster中,Ops和Assets是两种核心概念,用于定义数据处理逻辑。本文将全面介绍Ops的概念、特性及其使用方法,特别补充了Op上下文和Op工厂…...

thonny提示自动补全功能
THONNY IDE 自动补全功能配置 在 Thonny IDE 中启用和优化自动补全功能可以显著提升编程体验。为了确保该功能正常工作,需要确认几个设置选项。 配置自动补全 Thonyy IDE 的自动补全默认情况下是开启的。如果发现自动补全未按预期运行,可以通过调整首选…...

PyTorch_阿达玛积
阿达玛积指的是矩阵对应位置的元素相乘,可以使用乘号运算符,也可以使用mul函数来完成计算。 代码 import torch import numpy as np # 1. 使用 mul 函数 def test01():data1 torch.tensor([[1, 2], [3, 4]])data2 torch.tensor([[5, 6], [7, 8]])dat…...

蓝桥杯 摆动序列
摆动序列 原题目链接 题目描述 如果一个序列的奇数项都比前一项大,偶数项都比前一项小,则称为一个摆动序列。 即对于任意整数 i(i ≥ 1)满足: a₂ᵢ < a₂ᵢ₋₁,a₂ᵢ₊₁ > a₂ᵢ 小明想知道&…...

AI 与生物技术的融合:开启精准医疗的新纪元
在科技飞速发展的今天,人工智能(AI)与生物技术的融合正在成为推动医疗领域变革的重要力量。精准医疗作为现代医学的重要发展方向,旨在通过深入了解个体的基因信息、生理特征和生活方式,为患者提供个性化的治疗方案。AI…...

三、shell脚本--运算符与表达式:让脚本学会“思考”
一、算术运算符:加减乘除取模 在我们写shell脚本时,做点基本的数学运算还是经常需要的。常用的算术运算符跟我们平时学的一样: : 加- : 减* : 乘 (小提示:有时候在某些命令里可能需要写成 \*)/ : 除 (在 Shell 里通常是取整数部分…...

c++ 指针参数传递的深层原理
指针参数传递的深层原理 理解为什么可以修改指针指向的内容但不能直接修改指针本身,需要深入理解指针在内存中的表示方式和函数参数传递机制。 1. 指针的内存表示 指针本质上是一个变量,它存储的是另一个变量的内存地址。在内存中: 假设有…...

【查看.ipynp 文件】
目录 如何打开 .ipynb 文件? 如果确实是 .ipynp 文件: .ipynp 并不是常见的 Jupyter Notebook 文件格式。通常,Jupyter Notebook 文件的扩展名是 .ipynb(即 Interactive Python Notebook)。如果你遇到的是 .ipynb 文…...

C++ 简单工厂模式详解
简单工厂模式(Simple Factory Pattern)是最简单的工厂模式,它不属于GoF 23种设计模式,但它是工厂方法模式和抽象工厂模式的基础。 概念解析 简单工厂模式的核心思想是: 将对象的创建逻辑集中在一个工厂类中 客户端不…...

ubuntu使用apt安装软件
1、使用apt list |grep jdk查看要安装的软件 此处以jdk为例 2、执行名称:安装指定版本的软件 sudo apt install openjdk-11-jdk...
和LCD(液晶显示器)区别)
TFT(薄膜晶体管)和LCD(液晶显示器)区别
TFT(薄膜晶体管)和LCD(液晶显示器)是显示技术中常见的术语,二者既有联系又有区别。以下是它们的核心区别和关系: 1. 基本概念 LCD(液晶显示器) LCD是一种利用液晶材料特性控制光线通…...

【文献阅读】中国湿地随着保护和修复的反弹
一、研究背景 滨海湿地是全球最具生态价值的生态系统之一,广泛分布在河口、潮间带、泻湖和盐沼等地带,在调节气候、水质净化、生物栖息以及防止海岸侵蚀等方面发挥着关键作用。然而,近年来滨海湿地正面临严峻威胁,全球估计约有50%…...

用Ensaio下载GIS数据
文章目录 简介重力场绘制 简介 Ensaio在葡萄牙语中是随笔的意思,是一个用于下载开源数据集的python库。其底层基于Pooch来下载和管理数据。 Ensaio可通过pip或者conda来安装 pip isntall ensaio conda install ensaio --channel conda-forge由于这个库功能较为单…...

【算法基础】递归算法 - JAVA
一、递归基础 1.1 什么是递归算法 递归算法是一种通过函数调用自身来解决问题的方法。简单来说,就是"自己调用自己"。递归将复杂问题分解为同类的更简单子问题,直到达到易于直接解决的基本情况。 1.2 递归的核心要素 递归算法由两个关键部…...

连续变量与离散变量的互信息法
1. 互信息法简介 互信息(Mutual Information, MI) 是一种衡量两个变量之间相互依赖程度的统计量,它来源于信息论。互信息可以用于评估特征与目标变量之间的相关性,无论这些变量是连续的还是离散的。互信息法是一种强大的特征选择…...