day 11 超参数调整
一、内参与外参(超参数)
内参是模型为了适应训练数据而自动调整的,是模型内部与训练数据紧密相关的因素,不同的训练数据会导致模型学习到不同的参数值,这些参数在模型训练完成后就固定下来。
超参数是在模型训练前需要人为设定的参数,比如决策树模型中的最大深度,一个叶节点的最小样本数等,这些参数控制着模型的结构、训练过程以及学习方式,合适的超参数可以让模型更好的拟合数据,提高泛化能力。超参数不依赖于具体的训练数据实例,但是会影响模型对训练数据的学习效果,通常需要一些技巧,如网格搜索、随机搜索、交叉验证等方法。
模型 = 算法 + 实例化设置的外参(超参数)+训练得到的内参
二、调参方法
调参可以分成 2 步,第一步调参来找到每个模型综合性能最好的参数,对比选出最好的模型, 第二部再根据最好的模型来调整阈值。
网格搜索(GridSearch):
网格搜索是对用户指定的多个参数的所有组合进行遍历搜索。例如,对于一个有两个超参数 param1 和 param2 的模型,param1 有 [a, b, c] 三种取值,param2 有 [x, y] 两种取值,网格搜索会对 (a, x)、(a, y)、(b, x)、(b, y)、(c, x)、(c, y) 这六种参数组合都进行尝试,找到的是局部最优解。
调参过程:定义模型→定义参数网格(每个点对应一组参数取值)→初始化网格搜索→训练集进行网格搜索,输出最佳参数→使用最佳参数训练模型 →在测试集上进行预测,计算准确率
贝叶斯优化:
用已有的参数 - 性能数据,不断更新对目标函数的认知,在考虑各种参数组合使目标函数变好可能性(概率)的基础上,平衡探索新参数和利用已知好参数,逐步找到最优参数组合,比网格搜索更高效,尤其在参数空间较大时,能快速收敛到较优解。
朴素贝叶斯模型:
就是基于贝叶斯原理,利用训练集中已知的标签结果,去计算样本在具有某些特征值时属于不同类别的概率大小 。
随机搜索:
从参数空间中随机选择一定数量的参数组合进行实验。例如,在一个较大的参数空间中,随机抽取 100 组参数组合来训练模型并用交叉验证评估性能,然后从这 100 个结果中选择最优的参数组合。相比暴力搜索,随机搜索计算效率更高,能在较短时间内探索较大的参数空间。但由于是随机采样,不能保证找到真正的全局最优解,只是有较大概率找到接近全局最优的解。
调参过程的局限性:
调参范围有限:在调参时,我们通常会根据经验设定一个参数搜索范围。但这个范围可能没有包含真正能使模型在所有数据上都达到最佳性能的参数值。例如,在调整决策树的最大深度参数时,设定搜索范围是 1 到 10,可能真正最优的深度是 15,由于没有在这个范围内搜索,导致选出的参数不是全局最优,在测试集上不能发挥最佳性能。
调参方法的误差:调参方法本身可能存在一定误差。例如使用网格搜索方法调参,它是在给定的参数网格点上进行搜索,找到验证集上表现最好的参数组合。但这种离散的搜索方式可能无法精确找到全局最优解,只是在网格点中找到相对较好的参数,这就可能导致在测试集上的结果不如预期。
三、为什么划分验证集?
若验证集与训练集题目类型高度相似,模型在验证集表现好,可能只是记住了特定题型解法,产生 “模型有效” 的假象(即过拟合)。当测试集加入线性代数这类全新内容,模型因未在训练和验证阶段接触相关题型,无法将已有知识迁移应用,导致表现不佳,体现出模型缺乏泛化能力。
训练集用于训练模型,验证集用于在模型训练过程中调整超参数,测试集用于评估模型最终的泛化性能(泛化能力指的是模型对未见过的数据进行准确预测的能力)。
四、有无办法不划分验证集也能避免偶然性?
交叉验证(cross val):
目的:是为了让评估指标变得更可信(可能因划分方式的随机性,导致验证集不能很好地代表整体数据特征,它与最终的测试集无关)。
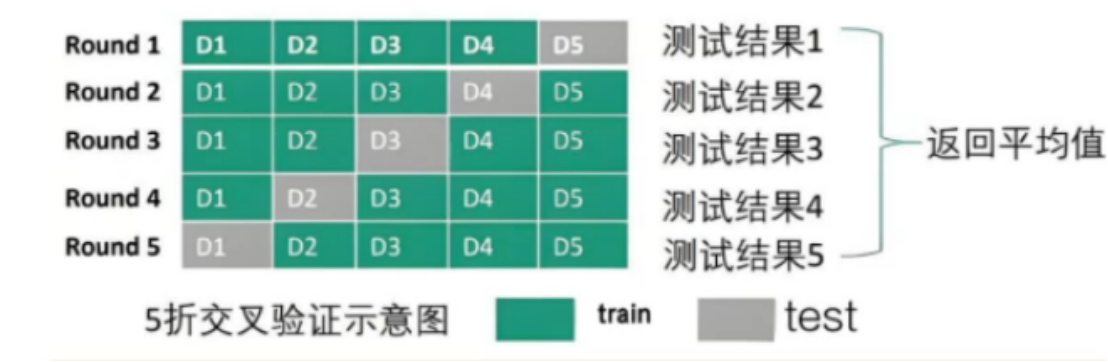
过程:n折交叉验证需要n倍的时间。交叉验证过程中,将数据集分成多个子集,多次训练和评估模型。每次使用不同子集作为训练集和测试集,得到一组性能指标(如准确率、召回率等),然后计算这些指标的平均值,能反映模型在不同数据划分下的平均表现。
例如在 5 折交叉验证中,模型在 5 个不同的数据子集组合上进行训练和测试,最终得到的准确率平均值,能让我们了解模型在整体数据集上相对稳定的性能水平,一定程度上体现了模型的泛化能力,即对新数据的适应能力。
交叉验证的 K 折划分是将数据集无重叠地分成 K 个子集,每次训练和测试使用不同的 K - 1 折训练集和 1 折测试集组合,其重点在于全面地用不同数据部分评估模型。

验证过程:定义模型(使用默认参数)→进行n折交叉验证→输出每折准确率→输出平均准确率
所以如果不做交叉验证,就需要划分验证集和测试集,但是很多调参方法中都默认有交叉验证,所以实际中可以省去划分验证集和测试集的步骤。
五、基准模型
基准模型是在特定任务或数据集上,选择的一个相对简单、易于理解和实现的模型。它代表了在该任务上的一种基础性能水平。比如在预测房价的回归任务里,简单的线性回归模型可以充当基准模型;或者首先运行一个使用默认参数的 RandomForestClassifier,记录其性能作为比较的基准。
作用:
将新模型与基准模型对比,能清晰看出新模型是否取得了真正的进步。例如,研究一种新的深度学习架构用于手写数字识别,通过与传统的 K - 近邻算法(基准模型)对比准确率,判断新架构是否有效。
通过基准模型在数据集上的表现,可以初步了解该数据集的难度。如果基准模型表现很差,说明数据集可能具有高度复杂性,或者数据存在噪声、标注错误等问题。比如在一个文本情感分类任务中,简单的朴素贝叶斯基准模型准确率很低,这就暗示数据集的文本特征可能复杂多变,或者标注质量有待提高。
在探索多种模型解决问题时,先建立基准模型可以快速获得一个基础性能,避免一开始就投入大量时间和资源到复杂模型中。如果复杂模型提升效果不明显,就可以考虑调整策略,而不是盲目追求模型复杂度。例如,在尝试用深度神经网络解决一个问题前,先使用简单的决策树模型作为基准,若决策树已能满足需求,就无需再耗费资源搭建复杂的神经网络。
六、整个流程
预处理代码:
import pandas as pd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#随机森林分类器
from sklearn.ensemble import RandomForestClassifier
# 用于评估分类器性能的指标
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
#用于生成分类报告和混淆矩阵
from sklearn.metrics import classification_report, confusion_matrix
#用于忽略警告信息
import warnings
warnings.filterwarnings("ignore") # 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('data.csv') # 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码
data = pd.get_dummies(data, columns=['Purpose'])
# 重新读取数据,用来做列名对比
data2 = pd.read_csv("data.csv")
# 新建一个空列表,用于存放独热编码后新增的特征名
list_final = []
# 这里打印出来的就是独热编码后的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i)
# 将bool类型转换为数值
for i in list_final:data[i] = data[i].astype(int) # Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True)
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() # 连续特征用众数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] data[feature].fillna(mode_value, inplace=True)
划分训练集、验证集和测试集 :
# train_test_split函数只能划分一次,需要调用两次。
from sklearn.model_selection import train_test_split
# 提取特征与标签
X = data.drop(['Credit Default'], axis=1)
y = data['Credit Default']
# 按照8:2划分训练集与临时集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42)
# 将临时数据集的50%作为测试集,最终按8:1:1的比例划分为训练集、验证集和测试集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
# 查看划分后的结构
print("Data shapes:")
print("X_train:", X_train.shape)
print("y_train:", y_train.shape)
print("X_val:", X_val.shape)
print("y_val:", y_val.shape)
print("X_test:", X_test.shape)
print("y_test:", y_test.shape)
# 输出:
Data shapes:
X_train: (6000, 31)
y_train: (6000,)
X_val: (750, 31)
y_val: (750,)
X_test: (750, 31)
y_test: (750,)评估基准模型:
# 默认参数的随机森林
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
# 记录调参时长
import time
# 记录开始时间
start_time = time.time()
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# 记录结束时间
end_time = time.time() print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))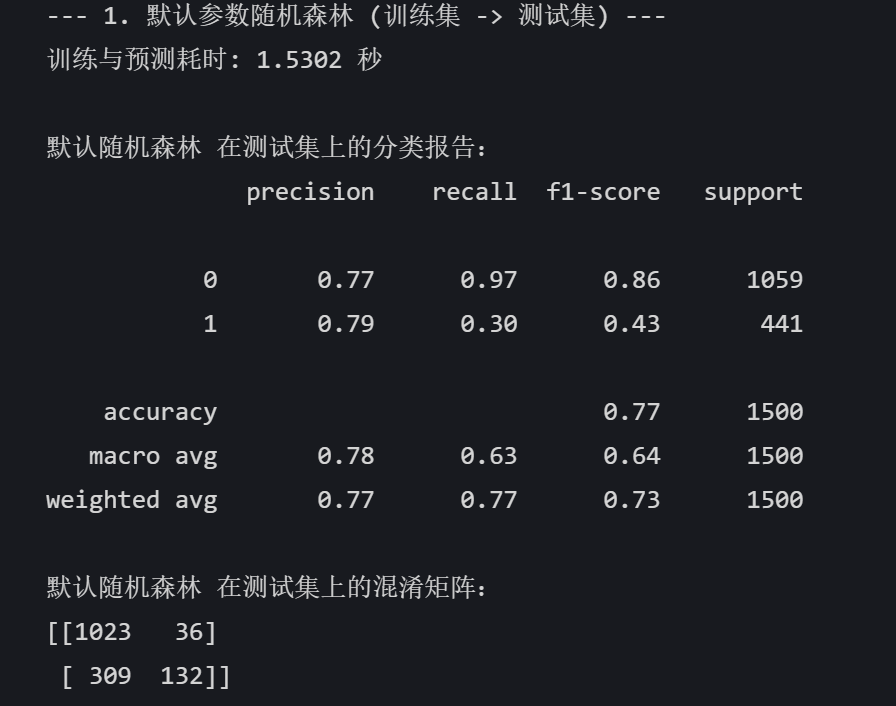
网格搜索:
print("\n--- 2. 网格搜索优化随机森林 (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV# 定义要搜索的参数网格
param_grid = {'n_estimators': [50, 100, 200], # 集成模型中树的数量'max_depth': [None, 10, 20, 30], # 每棵树的最大深度,限制树的复杂度,防止过拟合'min_samples_split': [2, 5, 10], # 在树的节点上进行划分时,所需的最小样本数'min_samples_leaf': [1, 2, 4] # 一个叶节点所需的最小样本数
}# 创建网格搜索对象
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42), # 随机森林分类器param_grid=param_grid, # 参数网格cv=5, # 5折交叉验证n_jobs=-1, # 使用所有可用的CPU核心进行并行计算scoring='accuracy') # 使用准确率作为评分标准# 在训练集上进行网格搜索(模型实例化和训练的方法都被封装在这个网格搜索对象里了)
start_time = time.time()
grid_search.fit(X_train, y_train)
end_time = time.time()print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_
best_pred = best_model.predict(X_test) print("\n网格搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))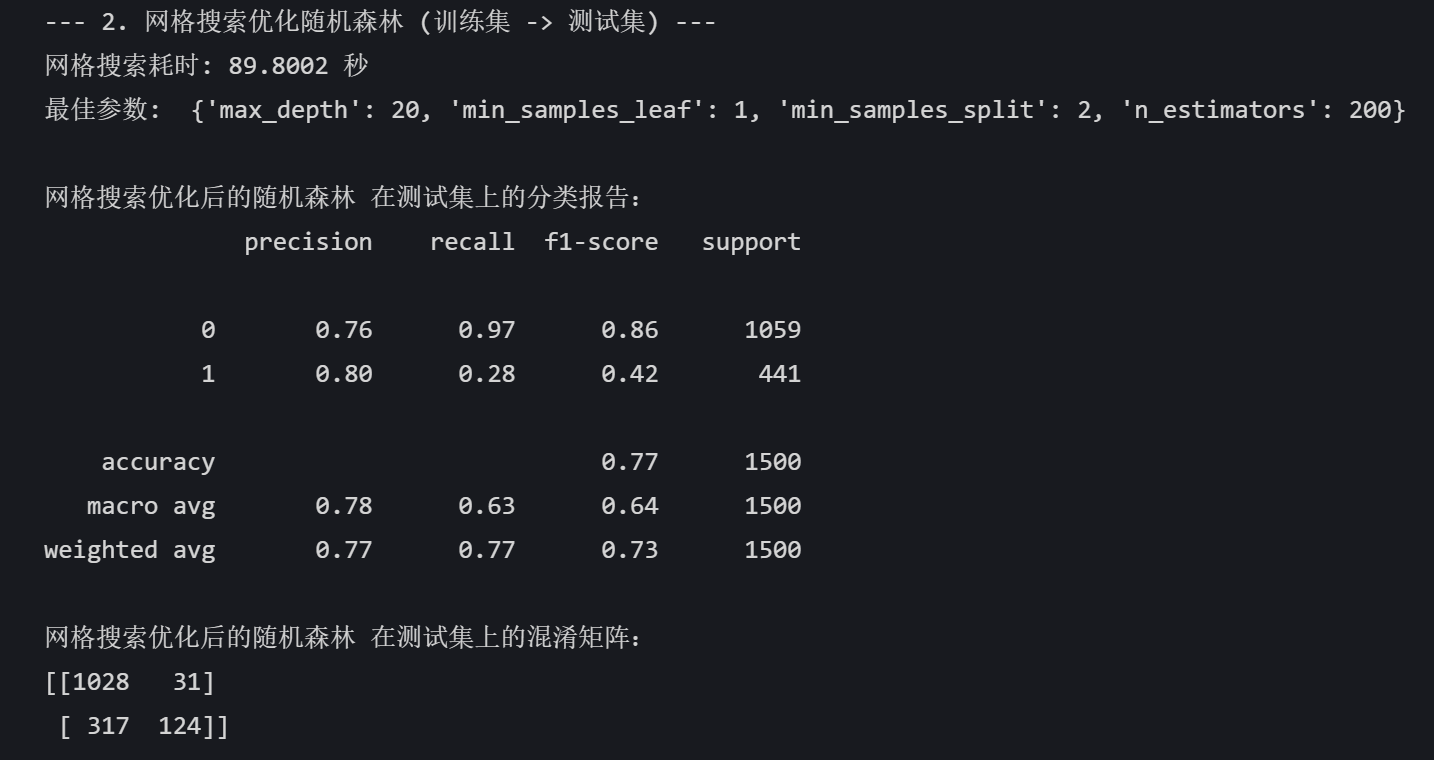
贝叶斯优化简单方法:
准备工作:贝叶斯优化需要安装scikit-optimize这个库(在Anaconda Prompt中)
pip install scikit-optimize -i https://pypi.tuna.tsinghua.edu.cn/simple
print("\n--- 3. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time# 定义要搜索的参数空间
search_space = {'n_estimators': Integer(50, 200),'max_depth': Integer(10, 30),'min_samples_split': Integer(2, 10),'min_samples_leaf': Integer(1, 4)
}# 创建贝叶斯优化搜索对象
bayes_search = BayesSearchCV(estimator=RandomForestClassifier(random_state=42),search_spaces=search_space, # 超参数搜索空间n_iter=32, # 迭代次数,可根据需要调整cv=5, # 5折交叉验证,这个参数是必须的n_jobs=-1, # 设置为 -1 表示使用所有可用的 CPU 核心进行并行计算scoring='accuracy' # 分类问题中常用的评估指标
)# 在训练集上进行贝叶斯优化搜索
start_time = time.time()
bayes_search.fit(X_train, y_train)
end_time = time.time()print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))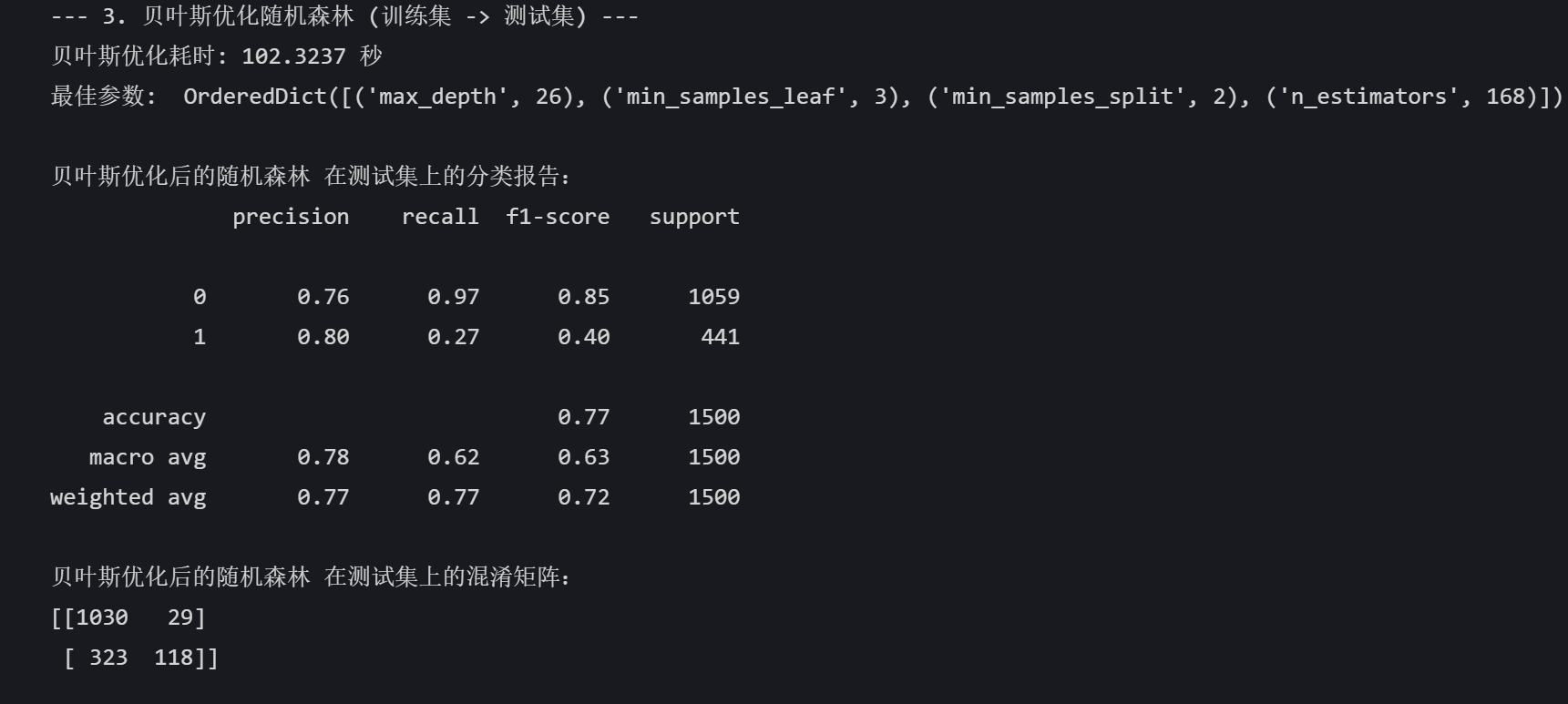
贝叶斯优化另一方法:
上面的代码比较简洁美观,和网格搜索的代码书写风格高度一致。下面介绍一种贝叶斯优化方法的其他实现代码,它允许用户自定义目标函数,像通过 rf_eval 函数定义基于随机森林超参数计算交叉验证平均准确率的目标函数,极大增强了适配不同任务与评估标准的能力。同时,可不依赖交叉验证,只需修改评估指标即可,为用户提供更自由的评估途径。此外,借助 verbose 参数,设置后能输出中间过程信息,便于了解优化进展,监测算法是否正常收敛。
# 导入必要的库
print("\n--- 4. 贝叶斯优化随机森林 (训练集 -> 测试集) ---")
from bayes_opt import BayesianOptimization
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np# 定义目标函数 rf_eval
def rf_eval(n_estimators, max_depth, min_samples_split, min_samples_leaf):
# 将传入的超参数转换为整数类型,因为贝叶斯优化可能会传入浮点数n_estimators = int(n_estimators)max_depth = int(max_depth)min_samples_split = int(min_samples_split)min_samples_leaf = int(min_samples_leaf)
# 使用传入的超参数初始化一个随机森林分类器model = RandomForestClassifier(n_estimators=n_estimators,max_depth=max_depth,min_samples_split=min_samples_split,min_samples_leaf=min_samples_leaf,random_state=42)
# 对模型进行5折交叉验证,以准确率作为评估指标,返回平均值scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')return np.mean(scores)# 定义参数搜索空间 pbounds_rf
pbounds_rf = {'n_estimators': (50, 200),'max_depth': (10, 30),'min_samples_split': (2, 10),'min_samples_leaf': (1, 4)
}# 创建贝叶斯优化对象 optimizer_rf
optimizer_rf = BayesianOptimization(f=rf_eval, # 指定目标函数,即贝叶斯优化要最大化的函数。 pbounds=pbounds_rf, # 指定超参数的搜索空间random_state=42,verbose=2 # 设置详细程度,2 表示在每次迭代时打印详细信息,包括超参数组合和目标函数值。
)# 运行贝叶斯优化
start_time = time.time()
optimizer_rf.maximize(init_points=5, # 开始优化前,先随机采样 5 组超参数进行评估,这些样本点用于初始化概率模型。n_iter=32 # 在每次迭代中,根据之前的结果选择一组新的超参数进行评估。
)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", optimizer_rf.max['params'])# 使用最佳参数进行预测与评估
best_params = optimizer_rf.max['params']
# 使用最佳超参数初始化一个新的随机森林分类器 best_model。
best_model = RandomForestClassifier(n_estimators=int(best_params['n_estimators']),max_depth=int(best_params['max_depth']),min_samples_split=int(best_params['min_samples_split']),min_samples_leaf=int(best_params['min_samples_leaf']),random_state=42
)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))@浙大疏锦行
相关文章:

day 11 超参数调整
一、内参与外参(超参数) 内参是模型为了适应训练数据而自动调整的,是模型内部与训练数据紧密相关的因素,不同的训练数据会导致模型学习到不同的参数值,这些参数在模型训练完成后就固定下来。 超参数是在模型训练前需…...

纯Java实现STDIO通信的MCP Server与客户端验证
在 MCP 协议中通过 STDIO(标准输入/输出)通信 是一种进程间通信(IPC)方式,服务器与客户端通过标准输入(stdin)和标准输出(stdout)交换数据。 关于STDIO 详细介绍以及如何基于Spring Boot项目实现 STDIO 的MCP服务器 以及如何调用和验证服务器可以参考: 基于Spring …...

Vue3学习笔记2——路由守卫
路由守卫 全局 router.beforeEach((to, from, next) > {})router.afterEach((to, from, next) > {}) 组件内守卫 beforeRouteEnter((to, from, next) > {})beforeRouteUpdate((to, from, next) > {})beforeRouteLeave((to, from, next) > {}) 路由独享 be…...
-加载、控制)
Three.js在vue中的使用(二)-加载、控制
在 Vue 中使用 Three.js 加载模型、控制视角、添加点击事件是构建 3D 场景的常见需求。下面是一个完整的示例,演示如何在 Vue 单文件组件中实现以下功能: 使用 GLTFLoader 加载 .glb/.gltf 模型添加 OrbitControls 控制视角(旋转、缩放、平移…...

【堆】最大堆、最小堆以及GO语言的实现
堆是计算机科学中一种特别的完全二叉树结构,在优先队列、图算法和排序算法中有广泛应用。本文将从概念、原理和实现等方面详细介绍堆这一重要的数据结构。 1. 堆的基本概念 1.1 什么是堆? 堆(Heap)是一种特殊的完全二叉树&…...

动态规划之路劲问题3
解析题目: 跟之前路径题目大概一样,从左上角到右下角,每一步只能向下或者向右,而且每次走出来血量必须大于0(注意这一点,否则容易导致每次出来可能小于0就可能错) 算法分析: 状态…...

学习黑客网络安全法
在正式“开荒”各种黑客工具前,Day 4 的任务是给自己装上一副合规与伦理的“护身铠”。这一小时你将弄懂——做渗透想合法必须先拿授权、哪些法律条款碰不得、等保 2.0 与关基条例为何对企业像副“主线任务”;同时动手把这些要点制成一张“法律速查卡”&…...

节流 和 防抖的使用
节流(Throttle)是一种常用的性能优化技术,用于限制函数的执行频率,确保在一定时间内只执行一次。它常用于处理浏览器事件(如滚动、窗口调整大小、鼠标移动等),以避免因事件触发过于频繁而导致的…...

关于项目中优化使用ConcurrentHashMap来存储锁对象
方案介绍 在开发用户创建私有空间功能时,我们的规则是一个用户最多只能创建一个私有空间。 在最初方案中,我是采用字符串常量池的方式存储锁对象useID。通过intern方法保证 同一用户ID的锁 唯一性。这一方案存在的问题是: 随着userId越来越…...

Java 网络安全新技术:构建面向未来的防御体系
一、Java 安全架构的演进与挑战 1.1 传统安全模型的局限性 Java 平台自 1995 年诞生以来,安全机制经历了从安全管理器(Security Manager)到 Java 平台模块系统(JPMS)的演进。早期的安全管理器通过沙箱模型限制不可信…...

【在Spring Boot中集成Redis】
在Spring Boot中集成Redis 依赖在application.yml中配置Redis服务地址创建Redis配置类缓存工具类使用 依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency&…...

昇腾的昇思MindSpore是什么?跟TensorFlow/PyTorch 等第三方框架有什么区别和联系?【浅谈版】
昇腾的昇思 MindSpore 是华为自主研发的全场景深度学习框架,旨在覆盖从科研到工业落地的全流程,支持云、边缘、手机等多种硬件场景的部署。它与 TensorFlow、PyTorch 等第三方框架既有相似性,也有明显差异。 一、昇思 MindSpore 的核心特点 全…...
)
MySQL进阶(三)
五、锁 1. 概述 锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢)。 在数据库中,除传统的计算资源(如 CPU、RAM、I/O 等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发…...

Java面试趣事:从死循环到分段锁
互联网大厂Java开发岗终面现场 面试官(推了推黑框眼镜):马小帅是吧?先说下HashMap扩容机制? 马小帅(抓耳挠腮):这我知道!默认初始容量16,默认负载因子0.75..…...

健康养生新主张
健康养生并非遥不可及的高深学问,摒弃中医理念,从生活细节入手,同样能实现身心的良好养护,开启活力满满的生活。 水是生命之源,科学饮水对养生意义重大。每天饮用 1500 - 2000 毫升的水,可维持身体正常的…...
)
合成复用原则(CRP)
非常好!你已经学习了好几个设计原则,现在我们来讲解合成复用原则(Composite Reuse Principle, CRP)——它和继承是常被比较的一对“重用方式”。 🧠 一句话定义 合成复用原则(CRP):尽…...

基于PyTorch的食物图像分类实战:从数据处理到模型训练
基于PyTorch的食物图像分类实战:从数据处理到模型训练 在深度学习领域,图像分类是一个经典且应用广泛的任务。无论是在电商平台的商品分类、医疗影像诊断,还是在农业作物识别等场景中,图像分类模型都发挥着重要作用。本文将以食物…...

在pycharm profession 2020.3将.py程序使用pyinstaller打包成exe
一、安装pyinstaller 在pycharm的项目的Terminal中运行pip3 install pyinstaller即可。 安装后在Terminal中输入pip3 list看一下是否成功 二、务必在在项目的Terminal中输入命令打包,命令如下: python3 -m PyInstaller --noconsole --onefile xxx.py …...

基于Springboot旅游网站系统【附源码】
基于Springboot旅游网站系统 效果如下: 系统登陆页面 系统主页面 景点信息推荐页面 路线详情页面 景点详情页面 确认下单页面 景点信息管理页面 旅游路线管理页面 研究背景 随着互联网技术普及与在线旅游消费习惯的深化,传统旅游服务模式面临效率低、…...
详细讲解Linux权限概念)
Linux操作系统从入门到实战(五)详细讲解Linux权限概念
Linux操作系统从入门到实战(五)详细讲解Linux权限概念 前言一、Linux中两种用户1.1 超级用户(root)1.2 普通用户1.3 切换用户命令 二、Linux权限管理2.1 文件访问者的分类:谁能访问文件?2.2 文件类型2.3 基…...

[方法论]软件工程中的设计模式:从理论到实践的深度解析
文章目录 软件工程中的设计模式:从理论到实践的深度解析引言:为什么需要设计模式?第一部分:设计模式的核心原则1. SOLID 原则(面向对象设计的五大基石)2. 其他关键思想 第二部分:创建型模式&…...

测试基础笔记第十八天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、web自动化1.xpath定位1.属性定位2.属性与逻辑结合3.属性和层级结合 2.常见元素定位方法(面试题)3.常见元素定位失败原因4.cookie1.验证码…...
)
深度学习系统学习系列【2】之人工神经网络(ANN)
文章目录 说明人工神经网络概述基本单位(神经元模型)神经元基本模型线性模型与激活函数多层神经网络人工神经网络的注意内容 人工神经网络的阶段划分训练阶段输入、输出数据量化的设计权值向量W和偏置b的设计 预测阶段 人工神经网络核心算法梯度下降算法…...

《解锁Windows下GCC升级密码,开启高效编程新旅程》
《解锁Windows下GCC升级密码,开启高效编程新旅程》 为什么要升级 Windows 下的 GCC 版本? 在软件开发的动态领域中,GCC 作为一款卓越的编译器,在 Windows 环境下的升级有着重要意义,其影响深远且广泛。 从性能优化的角度来看,新版 GCC 往往在编译速度上有显著提升。随着…...

**Java面试大冒险:谢飞机的幽默与技术碰撞记**
互联网大厂Java求职者面试:一场严肃与搞笑交织的技术盛宴 场景: 互联网大厂面试间 人物: 面试官: 一位严肃的资深架构师,对技术要求严格。谢飞机: 一位搞笑的程序员,技术实力参差不齐。 第一…...

软件检测价格受多种因素影响,你了解多少?
软件检测价格受到多种因素的影响,这对企业来说至关重要,对开发者来说也至关重要,了解软件检测价格能够让企业和开发者更好地进行预算,能够让企业和开发者更好地进行决策。以下为你深入分析相关内容。 检测范围影响软件检测范围的…...

学习黑客风险Risk
一眼纵览 今天 Day 5 我们用 60 分钟打通「风险管理快闪副本」——先用漫画式视角速读两个国际标准(NIST & ISO/IEC 27005),再把抽象概念变身为炫彩 Risk Heat Map,最后亲手填一张迷你 风险登记簿。学完你将能: 讲…...

scikit-learn在监督学习算法的应用
shiyonguyu大家好,我是我不是小upper!最近行业大环境不是很好,有人苦恼别人都开始着手项目实战了,自己却还卡在 scikit-learn 的代码语法上,连简单的示例运行起来都磕磕绊绊。确实,对很多机器学习初学者来说…...

BG开发者日志505:项目总体情况
1、从2024年12月中旬启动,到4月底gameplay部分开发完毕,已经四个半月过去了。 其中大部分内容是3、4两个月中完成的,量产阶段。 预计6月初参加新品节,6月中旬发售(比原计划7月中旬提前一个月)。 --------…...

MySQL 空值处理函数对比:IFNULL、COALESCE 和 NULLIF
IFNULL、COALESCE 和 NULLIF这三个函数都是 MySQL 中处理 NULL 值的函数,但它们的功能和使用场景有所不同: 1. IFNULL(expr, fallback) 功能:两值处理,专为替换 NULL 设计 如果 expr 不是 NULL,返回 expr如果 expr …...

【2025年】MySQL面试题总结
文章目录 1. MySQL 支持哪些存储引擎?默认使⽤哪个?2. MyISAM 和 InnoDB 有什么区别?3. 事务的四大特性?4. 并发事务带来了哪些问题?5. 不可重复读和幻读有什么区别?6. MySQL 事务隔离级别?默认是什么级别࿱…...
:智能商品推荐 - LLM “猜你喜欢”)
Python 数据智能实战 (10):智能商品推荐 - LLM “猜你喜欢”
写在前面 —— 从协同过滤到语义理解:融合 LLM,打造更懂用户心意的个性化推荐 在之前的篇章里,我们已经见证了 LLM 在用户分群、购物篮分析、流失预测、内容生成等多个电商环节的赋能潜力。今天,我们将聚焦于电商平台的“心脏”之一,也是用户体验和商业转化的核心驱动力…...

2025年 蓝桥杯省赛 Python A 组题目
文章目录 A.偏蓝B.IPv6C.2025图形D.最大数字E.倒水F.拼好数G.登山H.原料采购 近期复盘一下 省赛的题目,正所谓知不足方能进步可以在洛谷找到比赛的题目,不过得注意由于python版本的问题,有些代码想要在洛谷上ac的话,需要对应调整代…...
)
shell(7)
运算符 1.基本介绍 这是shell进行运算的符号,依靠这些标识才能实现我们在脚本中的运算. 2.基本语法 1、$((运算符))或$[运算符]或expr m n 注意: expr运算符间有空格→如果不加空格会被当做一个整体不会进行运算 例子: 3.expr m - n,如果要将expr运算…...

LangChain与MCP:大模型时代的工具生态之争与协同未来
LangChain与MCP:大模型时代的工具生态之争与协同未来 ——从架构差异到应用场景的深度解析 引言 在大模型驱动的AI应用生态中,LangChain与Model Context Protocol (MCP) 代表了两种截然不同的技术路径:前者以灵活的工具链和开发者友好性著称…...

【LLaMA-Factory实战】Web UI快速上手:可视化大模型微调全流程
一、引言 在大模型微调场景中,高效的工具链能显著降低开发门槛。LLaMA-Factory的Web UI(LlamaBoard)提供了低代码可视化平台,支持从模型加载、数据管理到训练配置的全流程操作。本文将结合结构图、代码示例和实战命令,…...

源码编译Qt StateMachine
编译某个项目时报错提示fatal error: QSignalTransition: No such file or directory,是因为qtbase中没有包含StateMachine模块,需要qt/qtscxml.git - SCXML (state machine notation) compiler and related tools 编译安装qtscxml 执行如下步骤&#…...

C++ STL vector高级特性与实战技巧
引言 各位小伙伴们好!上一篇博客我们介绍了vector的基础知识和常见操作,今天我们将更深入地探讨vector的高级特性、内存管理细节以及实战应用技巧。 想象一下vector就像一辆能自动变长的公交车,我们上一篇讲了如何上下车(添加删…...

[Windows] Kazumi番剧采集v1.6.9:支持自定义规则+在线观看+弹幕,跨平台下载
[Windows] Kazumi番剧采集 链接:https://pan.xunlei.com/s/VOPLMhEQD7qixvAnoy73NUK9A1?pwdtu6i# Kazumi是一款基于框架; 开发的轻量级番剧采集工具,专为ACG爱好者设计。通过;自定义XPath规则; 实现精准内容抓取,支持多平台(An…...

二种MVCC对比分析
文章目录 前言MVCCInnodb的MVCC版本链回滚与提交可见性判断 Oracle的MVCC版本链 PostgreSQL的MVCCMVCC实现可见性判断特点 前言 MVCC(多版本并发控制,Multi-Version Concurrency Control)是一种数据库管理系统(DBMS&#x…...

Python蓝桥杯真题代码
以下是一些不同届蓝桥杯Python真题代码示例: 第十四届青少年蓝桥杯python组省赛真题 删除字符串后缀 input_str input("请输入一个字符串:") suffixes (er, ly, ing) for suffix in suffixes: if input_str.endswith(suffix): input_str …...

高中数学联赛模拟试题精选学数学系列第5套几何题
四边形 A B C D ABCD ABCD 的对角线 A C AC AC 与 B D BD BD 互相垂直, 点 M M M, N N N 在直线 B D BD BD 上, 且关于直线 A C AC AC 对称. 设点 M M M 关于直线 A B AB AB, B C BC BC 的对称点分别为 X X X, Y Y Y, 点 N N N 关于直线 C D CD CD, D A DA DA 的…...

【KWDB 创作者计划】Docker单机环境下KWDB集群快速搭建指南
【KWDB 创作者计划】Docker 单机环境下 KaiwuDB集群快速搭建指南 前言一、KWDB介绍1.1 KWDB简介1.2 主要特点1.3 典型应用场景 二、环境介绍2.1 部署环境要求2.2 本地环境规划2.3 本次部署介绍 三、下载容器镜像四、创建相关证书文件4.1 创建部署目录4.2 创建证书文件4.3 查看证…...

基于51单片机和LCD1602、矩阵按键的小游戏《猜数字》
目录 系列文章目录前言一、效果展示二、原理分析三、各模块代码1、LCD16022、矩阵按键3、定时器0 四、主函数总结 系列文章目录 前言 用的是普中A2开发板,用到板上的矩阵按键,还需要外接一个LCD1602液晶显示屏。 【单片机】STC89C52RC 【频率】12T11.05…...

从广义线性回归推导出Softmax:理解多分类问题的核心
文章目录 引言:从回归到分类广义线性模型回顾从二分类到多分类Softmax函数的推导建模多类概率基于最大熵原理具体推导步骤Softmax函数的数学形式 Softmax回归模型参数的可辨识性 最大似然估计与交叉熵损失似然函数交叉熵损失梯度计算 Softmax回归的实现要点数值稳定…...

传奇各版本迭代时间及内容变化,屠龙/嗜魂法杖/逍遥扇第一次出现的时间和版本
【早期经典版本】 1.10 三英雄传说:2001 年 9 月 28 日热血传奇正式开启公测,这是传奇的第一个版本。游戏中白天与黑夜和现实同步,升级慢,怪物爆率低,玩家需要靠捡垃圾卖金币维持游戏开销,遇到高级别法师…...

云计算-私有云-私有云运维开发
三、私有云运维开发(15) 使用自动化运维工具 Ansible 完成系统的自动化部署与管理。 基于 OpenStack APIs 与SDK,开发私有云运维程序 1.OpenStack Python运维开发:实现镜像管理(7分) 编写Python代…...

hadoop存储数据文件原理
Hadoop是一个开源的分布式计算框架,可以用于存储和处理大规模数据集。Hadoop的存储系统基于Hadoop Distributed File System(HDFS),它的主要原理如下: 数据切块:当用户向HDFS中存储一个文件时,该…...

spring2.x详解介绍
一、核心架构升级 Spring 2.x 是 Spring 框架的重要迭代版本(2006-2009年间发布),其核心改进体现在 模块化设计 和 轻量化配置 上。相较于 1.x 版本,2.x 通过以下方式重构了架构: XML Schema 支持:弃用 D…...

探索Grok-3的高级用法:功能与应用详解
引言 随着人工智能技术的迅猛发展,xAI推出的Grok-3模型以其卓越的性能和创新功能,成为AI领域的新标杆。Grok-3不仅在计算能力上实现了十倍提升,还引入了多种高级模式和实时数据处理能力,适用于学术研究、技术分析、市场洞察等多场…...