从广义线性回归推导出Softmax:理解多分类问题的核心
文章目录
- 引言:从回归到分类
- 广义线性模型回顾
- 从二分类到多分类
- Softmax函数的推导
- 建模多类概率
- 基于最大熵原理
- 具体推导步骤
- Softmax函数的数学形式
- Softmax回归模型
- 参数的可辨识性
- 最大似然估计与交叉熵损失
- 似然函数
- 交叉熵损失
- 梯度计算
- Softmax回归的实现要点
- 数值稳定性
- 正则化
- Softmax与逻辑回归的关系
- 一、模型形式等价性证明
- 二、损失函数等价性证明
- 三、几何解释
- 四、实际应用验证
- 五、重要注意事项
- Softmax在神经网络中的应用
- 反向传播中的梯度
- Softmax的变体与扩展
- 实际应用案例
- 总结
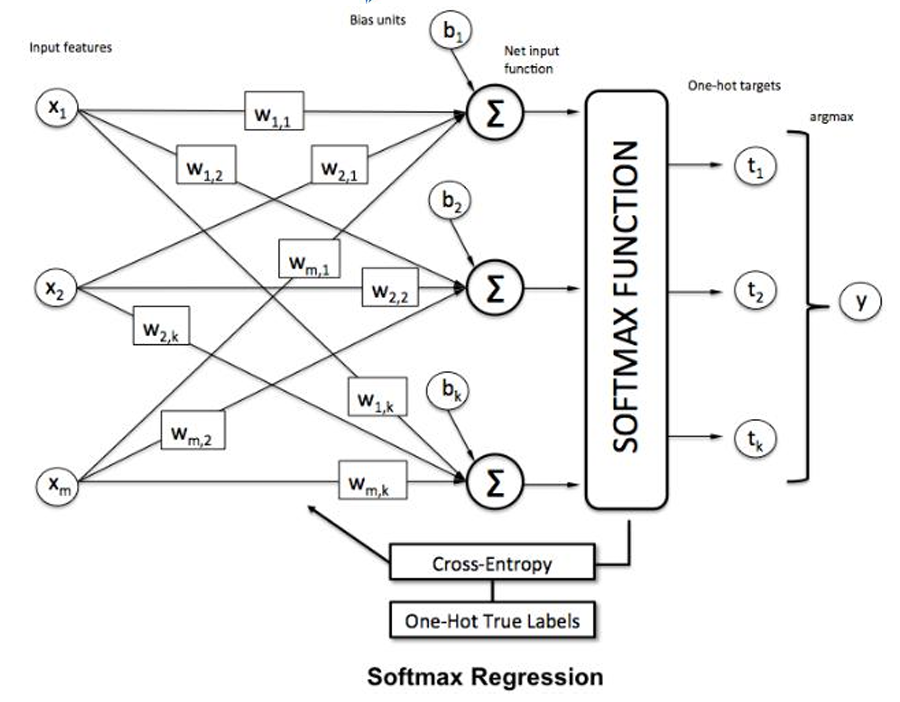
引言:从回归到分类
- 在机器学习领域,回归和分类是两大基本任务。线性回归处理连续值的预测,而当我们面对离散类别预测时,就需要分类模型。Softmax回归(也称为多项逻辑回归)是处理多分类问题的基础模型,它在神经网络中扮演着至关重要的角色,特别是在深度学习的分类任务中。
广义线性模型回顾
- 广义线性模型(GLM) 是线性回归的扩展,它通过连接函数(link function)将线性预测器与响应变量的期望值联系起来,并允许响应变量服从指数族分布。
- 一个广义线性模型由三个部分组成:
- 随机成分:响应变量 Y Y Y服从指数族分布
- 系统成分:线性预测器 η = X β η = Xβ η=Xβ
- 连接函数: g ( E [ Y ∣ X ] ) = η g(E[Y|X]) = η g(E[Y∣X])=η
- 对于线性回归,连接函数是恒等函数,响应变量假设服从高斯分布。而对于分类问题,我们需要不同的连接函数和分布假设。
从二分类到多分类
- 逻辑回归是处理二分类问题的经典方法,它使用sigmoid函数将线性预测器的输出映射到 ( 0 , 1 ) (0,1) (0,1)区间,解释为概率:
P ( Y = 1 ∣ X ) = σ ( X β ) = 1 ( 1 + e ( − X β ) ) P(Y=1|X) = σ(Xβ) = \frac{1}{(1+e^{(-Xβ)})} P(Y=1∣X)=σ(Xβ)=(1+e(−Xβ))1 - 当我们需要处理 K K K个类别 ( K > 2 ) (K>2) (K>2)的分类问题时,就需要将其扩展为多项逻辑回归,即Softmax回归。
Softmax函数的推导
建模多类概率
- 假设我们有K个类别,每个类别都有自己的线性预测器:
η k = X β k , k = 1 , . . . , k η_k = Xβ_k, k=1,...,k ηk=Xβk,k=1,...,k - 我们需要将这些线性预测转换为类别概率,满足:
- 每个概率在0和1之间
- 所有类别概率之和为1
基于最大熵原理
- 从统计力学和信息论的角度,Softmax函数可以看作是最大熵模型在给定约束下的自然结果。我们希望找到在给定特征条件下类别分布的最大熵分布,同时满足特征与类别标签之间的期望约束。
具体推导步骤
-
假设对数几率比是线性的:
l n ( P ( Y = k ∣ X ) P ( Y = K ∣ X ) ) = X β k , k = 1 , . . . , K − 1 ln \frac{(P(Y=k|X)}{P(Y=K|X))} = Xβ_k, k=1,...,K-1 lnP(Y=K∣X))(P(Y=k∣X)=Xβk,k=1,...,K−1
(选择类别K作为基准类别) -
对上述等式取指数:
P ( Y = k ∣ X ) / P ( Y = K ∣ X ) = e ( X β k ) P(Y=k|X)/P(Y=K|X) = e^{(Xβ_k)} P(Y=k∣X)/P(Y=K∣X)=e(Xβk) -
令所有类别的概率和为1:
1 = Σ k = 1 K P ( Y = k ∣ X ) = P ( Y = K ∣ X ) [ 1 + Σ k = 1 K − 1 e ( X β k ) ] 1 = Σ_{k=1}^K P(Y=k|X) = P(Y=K|X) [1 + Σ_{k=1}^{K-1} e^{(Xβ_k)}] 1=Σk=1KP(Y=k∣X)=P(Y=K∣X)[1+Σk=1K−1e(Xβk)] -
解得:
P ( Y = K ∣ X ) = 1 / ( 1 + Σ k = 1 K − 1 e ( X β k ) ) P(Y=K|X) = 1 / (1 + Σ_{k=1}^{K-1} e^{(Xβ_k)}) P(Y=K∣X)=1/(1+Σk=1K−1e(Xβk))
对于k=1,…,K-1:
P ( Y = k ∣ X ) = e X β k P ( Y = k ∣ X ) = e ( X β k ) ( 1 + Σ j = 1 K − 1 e ( X β j ) ) P(Y=k|X) =e^{Xβ_k}P(Y=k|X)= \frac{e^{(Xβ_k)} }{ (1 + Σ_{j=1}^{K-1} e^{(Xβ_j)})} P(Y=k∣X)=eXβkP(Y=k∣X)=(1+Σj=1K−1e(Xβj))e(Xβk) -
为了对称性,我们也可以表示为(这就是Softmax函数):
P ( Y = k ∣ X ) = e ( X β k ) Σ j = 1 K e ( X β j ) P(Y=k|X) = \frac{e^{(Xβ_k) }}{ Σ_{j=1}^K e^{(Xβ_j)}} P(Y=k∣X)=Σj=1Ke(Xβj)e(Xβk)
Softmax函数的数学形式
- Softmax函数定义为:
σ ( z ) i = e ( z i ) Σ j = 1 K e ( z j ) , i = 1 , . . . , K σ(z)_i = \frac{e^{(z_i)}} { Σ_{j=1}^K e^{(z_j)}}, i=1,...,K σ(z)i=Σj=1Ke(zj)e(zi),i=1,...,K - 其中 z z z是输入向量, σ ( z ) i σ(z)_i σ(z)i表示第 i i i个输出元素。
Softmax回归模型
- 将Softmax函数应用于多分类问题,我们得到Softmax回归模型:
P ( Y = k ∣ X ) = e ( X β k ) Σ j = 1 K e ( X β j ) P(Y=k|X) = \frac{e^{(Xβ_k)}}{Σ_{j=1}^K e^{(Xβ_j)}} P(Y=k∣X)=Σj=1Ke(Xβj)e(Xβk) - 模型参数为{β_1,…,β_K},其中每个β_k都是一个与输入特征维度相同的向量。
参数的可辨识性
- 注意:如果将所有β_k加上一个相同的向量c,概率预测不会改变:
P ( Y = k ∣ X ) = e ( X ( β k + c ) ) ∑ j = 1 K e ( X ( β j + c ) ) = e ( X β k ) e ( X c ) ∑ j = 1 K e ( X β j ) e ( X c ) = e ( X β k ) ∑ j = 1 K e ( X β j ) \begin{align*} P(Y=k|X) &= \frac{ e^{ (X(\beta_k + c)) }}{\sum_{j=1}^K e^{(X(\beta_j + c))}} \\ &= \frac{e^{(X\beta_k)} e^{(Xc)}}{\sum_{j=1}^K e^{(X\beta_j)} e^{(Xc)}} \\ &= \frac{e^{(X\beta_k)}}{\sum_{j=1}^K e^{(X\beta_j)}} \end{align*} P(Y=k∣X)=∑j=1Ke(X(βj+c))e(X(βk+c))=∑j=1Ke(Xβj)e(Xc)e(Xβk)e(Xc)=∑j=1Ke(Xβj)e(Xβk)
推导过程说明:
- 第一行:原始Softmax公式,所有参数加上常数向量c
- 第二行:利用指数函数的性质将 e ( X ( β + c ) ) e^{(X(β+c))} e(X(β+c))拆分为 e ( X β ) e ( X c ) e^{(Xβ)}e^{(Xc)} e(Xβ)e(Xc)
- 第三行:分子分母中的exp(Xc)项相互抵消,结果与原始Softmax公式相同
- 因此,模型参数不是唯一可辨识的。通常我们通过设置一个基准类别(如 β K = 0 β_K=0 βK=0)来解决这个问题,这与最初的推导一致。
最大似然估计与交叉熵损失
似然函数
给定训练数据 ( x i , y i ) i = 1 N {(x_i,y_i)}_{i=1}^N (xi,yi)i=1N,似然函数为:
L ( β ) = Π i = 1 N P ( Y = y i ∣ x i ) L(β) = Π_{i=1}^N P(Y=y_i|x_i) L(β)=Πi=1NP(Y=yi∣xi)
对数似然:
l ( β ) = l n L ( β ) = Σ i = 1 N l n P ( Y = y i ∣ x i ) = Σ i = 1 N l n e ( X β k ) ∑ j = 1 K e ( X β j ) = Σ i = 1 N [ X i β y i − l n ( Σ j = 1 K e ( X i β j ) ) ] \begin{align*} l(β) &=lnL(β) \\ &= Σ_{i=1}^N ln P(Y=y_i|x_i) \\ &= Σ_{i=1}^N ln \frac{e^{(X\beta_k)}}{\sum_{j=1}^K e^{(X\beta_j)}} \\ &= Σ_{i=1}^N [X_iβ_{y_i} - ln(Σ_{j=1}^K e^{(X_iβ_j))}] \end{align*} l(β)=lnL(β)=Σi=1NlnP(Y=yi∣xi)=Σi=1Nln∑j=1Ke(Xβj)e(Xβk)=Σi=1N[Xiβyi−ln(Σj=1Ke(Xiβj))]
交叉熵损失
- 最大化似然等价于最小化负对数似然,这定义了我们的损失函数:
J ( β ) = − Σ i = 1 N [ X i β y i − l n ( Σ j = 1 K e ( X i β j ) ) ] = Σ i = 1 N [ − X i β y i + l n ( Σ j = 1 K e ( X i β j ) ) ] \begin{align*} J(β) &= -Σ_{i=1}^N [X_iβ_{y_i} - ln(Σ_{j=1}^K e^{(X_iβ_j))}] \\ &= Σ_{i=1}^N [-X_iβ_{y_i} + ln(Σ_{j=1}^K e^{(X_iβ_j))}] \end{align*} J(β)=−Σi=1N[Xiβyi−ln(Σj=1Ke(Xiβj))]=Σi=1N[−Xiβyi+ln(Σj=1Ke(Xiβj))]
这实际上就是交叉熵损失在多分类情况下的形式。
梯度计算
- 为了使用梯度下降优化参数,我们需要计算损失函数对参数的梯度:
∂ J / ∂ β k = − Σ i = 1 N [ 1 ( y i = k ) − P ( Y = k ∣ x i ) ] X i ∂J/∂β_k = -Σ_{i=1}^N [1(y_i=k) - P(Y=k|x_i)] X_i ∂J/∂βk=−Σi=1N[1(yi=k)−P(Y=k∣xi)]Xi
这个优雅的结果表明,梯度是特征向量在预测误差上的加权和。
Softmax回归的实现要点
数值稳定性
在实际实现中,直接计算 e ( X β ) e^{(Xβ)} e(Xβ)可能会遇到数值上溢或下溢的问题。常见的解决方案是使用以下恒等式:
σ ( z ) i = e ( z i − C ) Σ j e ( z j − C ) σ(z)_i = \frac{e^{(z_i - C)}} {Σ_j e^{(z_j - C)}} σ(z)i=Σje(zj−C)e(zi−C)
其中C通常取 m a x ( z i ) max(z_i) max(zi),保证了数值计算的稳定性。
正则化
为了防止过拟合,通常会在损失函数中加入正则化项,如L2正则化:
J ( β ) + = λ Σ k = 1 K ∣ ∣ β k ∣ ∣ 2 2 J(β) += \frac{λ Σ_{k=1}^K ||β_k||^2}{2} J(β)+=2λΣk=1K∣∣βk∣∣2
Softmax与逻辑回归的关系
- 当K=2时,Softmax回归退化为标准的逻辑回归。可以证明两者在这种情况下是等价的。
一、模型形式等价性证明
-
Softmax回归的一般形式(K类):
P ( Y = k ∣ X ) = e θ k T X ∑ j = 1 K e θ j T X ( k = 1 , . . . , K ) P(Y=k|X) = \frac{e^{\theta_k^T X}}{\sum_{j=1}^K e^{\theta_j^T X}} \quad (k=1,...,K) P(Y=k∣X)=∑j=1KeθjTXeθkTX(k=1,...,K) -
当K=2时的特殊形式:
{ P ( Y = 1 ∣ X ) = e θ 1 T X e θ 1 T X + e θ 2 T X P ( Y = 2 ∣ X ) = e θ 2 T X e θ 1 T X + e θ 2 T X \begin{cases} P(Y=1|X) = \frac{e^{\theta_1^T X}}{e^{\theta_1^T X} + e^{\theta_2^T X}} \\ P(Y=2|X) = \frac{e^{\theta_2^T X}}{e^{\theta_1^T X} + e^{\theta_2^T X}} \end{cases} ⎩ ⎨ ⎧P(Y=1∣X)=eθ1TX+eθ2TXeθ1TXP(Y=2∣X)=eθ1TX+eθ2TXeθ2TX -
参数冗余消除(令β = θ₁ - θ₂):
- 分子分母同除 e θ 1 T X e^{\theta_1^T X} eθ1TX:
P ( Y = 1 ∣ X ) = 1 1 + e ( θ 2 − θ 1 ) T X = 1 1 + e − β T X = σ ( β T X ) P(Y=1|X) = \frac{1}{1 + e^{(\theta_2 - \theta_1)^T X}} = \frac{1}{1 + e^{-\beta^T X}} = \sigma(\beta^T X) P(Y=1∣X)=1+e(θ2−θ1)TX1=1+e−βTX1=σ(βTX) - 这正是sigmoid函数的标准形式
- 分子分母同除 e θ 1 T X e^{\theta_1^T X} eθ1TX:
-
类别对称性:
P ( Y = 2 ∣ X ) = 1 − σ ( β T X ) = σ ( − β T X ) P(Y=2|X) = 1 - \sigma(\beta^T X) = \sigma(-\beta^T X) P(Y=2∣X)=1−σ(βTX)=σ(−βTX)
二、损失函数等价性证明
-
Softmax交叉熵损失(K=2):
L = − ∑ i = 1 N [ y i ln P ( Y = 1 ∣ X i ) + ( 1 − y i ) ln P ( Y = 2 ∣ X i ) ] \mathcal{L} = -\sum_{i=1}^N \left[ y_i \ln P(Y=1|X_i) + (1-y_i) \ln P(Y=2|X_i) \right] L=−i=1∑N[yilnP(Y=1∣Xi)+(1−yi)lnP(Y=2∣Xi)] -
代入概率表达式:
L = − ∑ i = 1 N [ y i ln σ ( β T X i ) + ( 1 − y i ) ln ( 1 − σ ( β T X i ) ) ] \mathcal{L} = -\sum_{i=1}^N \left[ y_i \ln \sigma(\beta^T X_i) + (1-y_i) \ln (1 - \sigma(\beta^T X_i)) \right] L=−i=1∑N[yilnσ(βTXi)+(1−yi)ln(1−σ(βTXi))] -
与逻辑回归损失完全一致:
- 这正是二分类逻辑回归的二元交叉熵损失函数
- 梯度更新规则也完全相同:
∇ β L = ∑ i = 1 N ( σ ( β T X i ) − y i ) X i \nabla_\beta \mathcal{L} = \sum_{i=1}^N (\sigma(\beta^T X_i) - y_i)X_i ∇βL=i=1∑N(σ(βTXi)−yi)Xi
三、几何解释
-
决策边界对比:
- Softmax(K=2): ( θ 1 − θ 2 ) T X = 0 (\theta_1 - \theta_2)^T X = 0 (θ1−θ2)TX=0
- 逻辑回归: β T X = 0 \beta^T X = 0 βTX=0
- 两者定义相同的超平面决策边界
-
参数空间关系:
- Softmax有冗余参数(可设θ₂=0)
- 此时θ₁即对应逻辑回归的β参数
四、实际应用验证
# 用相同数据验证两种模型的等价性
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegression as Softmax2# 生成二分类数据
X = np.random.randn(100, 3)
y = (X[:, 0] > 0).astype(int)# 训练模型
#multi_class='multinomial' 参数在 scikit-learn 1.5 版本中已被弃用,并将在 1.7 版本中移除。
#对于二分类任务,建议直接使用默认的逻辑回归模型(即自动采用 multi_class='ovr)
lr = LogisticRegression( solver='lbfgs').fit(X, y) # Softmax K=2
logit = LogisticRegression().fit(X, y) # 标准逻辑回归# 比较参数(需注意符号方向)
assert np.allclose(lr.coef_[0], logit.coef_[0])
五、重要注意事项
-
参数化差异:
- Softmax默认使用多参数形式(K个参数向量)
- 逻辑回归使用单参数形式(1个参数向量)
-
实现细节:
- 软件包中可能对截距项处理不同
- 类别标签编码方式(0/1 vs 1/2)会影响常数项
-
统计解释:
- 两者都是广义线性模型的特例
- 均采用最大似然估计,具有相同的统计效率
这个证明体系从代数形式、优化目标、几何意义到实际验证四个维度,完整展现了Softmax回归与逻辑回归在二分类场景下的本质一致性。这种等价关系也解释了为什么在神经网络中,二分类输出层可以使用单个sigmoid单元替代Softmax层。
Softmax在神经网络中的应用
- 在深度学习中,Softmax通常作为神经网络的最后一层,用于多分类任务:
- 前面的层学习特征表示
- 最后一层线性变换产生每个类别的"得分"
- Softmax将这些得分转换为概率分布
反向传播中的梯度
在神经网络中,Softmax层与交叉熵损失结合使用时,梯度计算特别简洁:
∂ J / ∂ z i = p i − y i ∂J/∂z_i = p_i - y_i ∂J/∂zi=pi−yi
其中 z i z_i zi是输入到Softmax的得分, p i p_i pi是Softmax输出概率, y i y_i yi是真实标签的one-hot编码。
Softmax的变体与扩展
- 温度参数
- 引入温度参数T控制输出的"尖锐"程度:
σ ( z ) i = e ( z i / T ) Σ j e ( z j / T ) σ(z)_i = \frac{e^{(z_i/T)} }{Σ_j e^{(z_j/T)}} σ(z)i=Σje(zj/T)e(zi/T)
较高的T使分布更均匀,较低的T使分布更集中。
- 稀疏Softmax:通过添加稀疏性约束或使用top-k变体,可以产生稀疏的概率分布。
实际应用案例
- 手写数字识别:在MNIST数据集中,Softmax回归可以直接达到约92%的准确率,作为强大的基线方法。
- 自然语言处理:在语言模型中,Softmax用于预测下一个词的概率分布,尽管对于大词汇表需要采样或层次化技巧。
- 计算机视觉:现代CNN架构通常在最后一层使用Softmax进行图像分类。
总结
- Softmax回归从广义线性模型的角度自然导出,为多分类问题提供了坚实的概率基础。通过最大似然估计,我们得到了广泛使用的交叉熵损失函数。在深度学习中,Softmax作为将原始得分转换为概率分布的标准方法,与神经网络完美结合。理解其数学原理不仅有助于正确应用,还能为模型调试和扩展提供坚实基础。
相关文章:

从广义线性回归推导出Softmax:理解多分类问题的核心
文章目录 引言:从回归到分类广义线性模型回顾从二分类到多分类Softmax函数的推导建模多类概率基于最大熵原理具体推导步骤Softmax函数的数学形式 Softmax回归模型参数的可辨识性 最大似然估计与交叉熵损失似然函数交叉熵损失梯度计算 Softmax回归的实现要点数值稳定…...

传奇各版本迭代时间及内容变化,屠龙/嗜魂法杖/逍遥扇第一次出现的时间和版本
【早期经典版本】 1.10 三英雄传说:2001 年 9 月 28 日热血传奇正式开启公测,这是传奇的第一个版本。游戏中白天与黑夜和现实同步,升级慢,怪物爆率低,玩家需要靠捡垃圾卖金币维持游戏开销,遇到高级别法师…...

云计算-私有云-私有云运维开发
三、私有云运维开发(15) 使用自动化运维工具 Ansible 完成系统的自动化部署与管理。 基于 OpenStack APIs 与SDK,开发私有云运维程序 1.OpenStack Python运维开发:实现镜像管理(7分) 编写Python代…...

hadoop存储数据文件原理
Hadoop是一个开源的分布式计算框架,可以用于存储和处理大规模数据集。Hadoop的存储系统基于Hadoop Distributed File System(HDFS),它的主要原理如下: 数据切块:当用户向HDFS中存储一个文件时,该…...

spring2.x详解介绍
一、核心架构升级 Spring 2.x 是 Spring 框架的重要迭代版本(2006-2009年间发布),其核心改进体现在 模块化设计 和 轻量化配置 上。相较于 1.x 版本,2.x 通过以下方式重构了架构: XML Schema 支持:弃用 D…...

探索Grok-3的高级用法:功能与应用详解
引言 随着人工智能技术的迅猛发展,xAI推出的Grok-3模型以其卓越的性能和创新功能,成为AI领域的新标杆。Grok-3不仅在计算能力上实现了十倍提升,还引入了多种高级模式和实时数据处理能力,适用于学术研究、技术分析、市场洞察等多场…...

PyTorch_张量转换为numpy数组
使用 tensor.numpy 函数可以将张量转换为 ndarray 数组,但是共享内存,可以使用 copy 函数避免共享。共享内存会导致张量或者numpy中的其中一个更改后,另外一个会受到影响。 代码 import torch # 张量转换为 numpy 数组 def test01():data_te…...

什么是“原子变量”?
原子变量(std::atomic)在C++中是一个非常关键的机制,特别是在多线程编程中保持数据安全和避免竞争条件。它的设计目标就是让一段操作在多线程环境下变得“原子性”,即不可被中断,保证操作的完整与一致。 一、什么是“原子变量”? 简单来说: 普通变量:在多线程环境中,…...

[Linux开发工具]gcc/g++
C语言文件编译运行 gcc code.c -o mycode gcc -o mycode code.c 预处理 汇编 编译 链接 预处理(进行宏替换/去注释/条件编译/头文件展开) gcc -E code.c -o code.i -E ->从现在开始进行程序的编译,当我们 的程序预处理完毕后,翻译工作,就停下来 code.i预处理之后的结果 …...

【Mytais系列】Type模块:类型转换
MyBatis 的 类型系统(Type System) 是框架处理 Java 类型与数据库类型之间映射的核心模块,它通过 类型处理器(TypeHandler)、类型别名(TypeAlias) 和 类型转换器 等机制,实现了数据库…...

C++类_虚基类
在 C 里,虚基类是用来解决菱形继承问题的。菱形继承问题是指当一个派生类从两个或更多基类派生,而这些基类又从同一个基类派生时,派生类会包含多份间接基类的数据副本,这可能会引发数据冗余和二义性问题。虚基类可以保证在派生类中…...

【自然语言处理与大模型】使用Xtuner进行模型合并与导出
在上一篇文章中我为大家介绍了Xtuner框架如何进行QLoRA微调,这个框架在微调过后会得到适配器权重文件,它的后缀是.pth。但原模型都是huggingface模型,其后缀是safetensors。所以呢我们在使用这个框架导出模型之前要合并,合并之前要…...

数据结构4.0
大家好,今天是栈的知识点~ 目录 一、栈的概念 1.0 栈的概念 2.0 概念区分 二、栈的方法 1.0 MyStack方法: 2.0 将元素压入栈顶 3.0 移除并返回栈顶元素 4.0 返回栈顶元素但不移除 三、栈的题目 1.0括号匹配 2.0逆波兰表达式求值 3.0 出栈…...

SMT贴片检验标准核心要点与实施规范
内容概要 SMT贴片检验标准是确保电子产品组装质量的核心框架,其核心要点覆盖从原材料到成品的全流程工艺控制。该标准体系以焊点质量、元件定位精度及锡膏印刷检测为技术基线,结合IPC-A-610电子组装验收规范,对PCBA加工中的缺陷类型、判定阈…...

探索 C++23 std::to_underlying:枚举底层值获取的利器
文章目录 引言基本概念作用使用示例与之前方法的对比在 C23 中的意义总结 引言 在 C 的发展历程中,每一个新版本都带来了许多令人期待的新特性和改进,以提升代码的安全性、可读性和可维护性。C23 作为其中的一个重要版本,也不例外。其中&…...
(一))
PyTorch学习之张量(Tensor)(一)
1. 张量的基本概念 1.1. 定义与特性 张量是PyTorch中最基础的数据结构,可视为多维数组的泛化形式,支持标量(0维)、向量(1维)、矩阵(2维)及更高维度的数据存储。其核心特性包括&…...
(support))
理解数学概念——支集(支持)(support)
1. 支集(support)的定义 在数学中,一个实函数 f 的支集(support)是函数的不被映射到 0 的元素域(即定义域)的子集。若 f 的(定义)域(domain)是一个拓扑空间(即符合拓扑的集合),则 f 的支集则定义为包含( f 的元素域中)不被映射到0的所有点之最小闭集…...

Python 部分内置函数及其用法详解
在 Python 编程的世界里,内置函数是我们强大的 “工具箱”,它们提供了丰富而便捷的功能,帮助我们高效地完成各种任务。本文将带你深入了解这些常用内置函数及其用法,通过简单易懂的实例,让你轻松掌握它们。 一、数据类…...

[蓝桥杯真题题目及解析]2025年C++b组
移动距离(填空)** 小明初始在二维平面的原点,他想前往坐标 (233,666)。在移动过程中,他只能采用以下两种移动方式,并且这两种移动方式可以交替、不限次数地使用: 水平向右移动,即沿着 x 轴正方…...

yolov5 train笔记4 roboflow
How to Train a YOLOv5 Model On a Custom Dataset Sign in to Roboflow https://www.youtube.com/watch?vr3Ke7ZEh2Qo 他的ai懂中文的 还是得训练,明天再搞 https://www.youtube.com/watch?vEmYCpbFQ5wo&t2s 很香但是我没有马内...

工作记录 2015-06-01
工作记录 2015-06-01 序号 工作 相关人员 1 修改了FnetFax 修改了iConverter 修改了iCDA 郝 FNSR识别引擎 统计了最近几个星期0223医院的打字和录音的时间比。上周的比值是3.42,是近8个星期中最低的值。和05/03/2015 - 05/09/2015的3.74相比,下降…...

创意Python爱心代码分享
在代码的世界里,程序员以独特方式书写浪漫。他们精心打造的一个个 demo,宛如熠熠星辰。这些 demo 不仅是技术结晶,更饱含对编程的热爱与执着。从简洁的算法示例到复杂的系统雏形,每一行代码都凝聚着思考与智慧。它们被无私分享&am…...
、LSH、K-means)
【RAG】向量?知识库的底层原理:向量数据库の技术鉴赏 | HNSW(导航小世界)、LSH、K-means
一、向量化表示的核心概念 1.1 特征空间与向量表示 多维特征表示:通过多个特征维度(如体型、毛发长度、鼻子长短等)描述对象,每个对象对应高维空间中的一个坐标点,来表示狗这个对象,这样可以区分出不同种…...

降维大合集
1. 主成分分析(PCA,Principal Component Analysis) 基本原理 PCA 是一种线性降维方法,其核心思想是: 找到数据中方差最大的方向(称为主成分),并将数据投影到这些方向上。 利用正交变…...

AWS上构建基于自然语言和LINDO API的线性规划与非线性规划的优化计算系统
我想要实现一个通过使用C#、Semantic Kernel库、OpenAI GPT 4的API和附件文档里提到的LINDO API 15.0实现通过中文自然语言提示词中包含LATEX代码输入到系统,通过LINDO API 15.0线性规划与非线性规划的优化计算程序输出计算结果和必要步骤的应用,结果用中…...

26考研 | 王道 | 计算机网络 | 第三章 数据链路层
26考研 | 王道 | 第三章 数据链路层 数据链路层所处的地位 数据链路层 使用 物理层 提供的“比特传输”服务数据链路层 为 网络层 提供服务,将网络层的 IP数据报(分组)封装成帧,传输给下一个相邻结点物理链路:传输介质…...

学习黑客资产威胁分析贴
第一天作业: 完成作业奖励: 🎁 奖励 1 ── Week 2《Web 渗透手册》预览 Day主题关键目标练手靶场 / 工具1HTTP 基础 & Burp 入门抓包、改包、重放PortSwigger Academy:“HTTP basics”2SQL 注入原理手工注入 sqlmapDVWA →…...
)
CSS元素动画篇:基于当前位置的变换动画(合集篇)
CSS元素动画篇:基于当前位置的变换动画(合集篇) 前言位移效果类元素动画水平抖动效果效果预览代码实现 垂直抖动效果效果预览代码实现 摇头动画效果效果预览代码实现 点头动画效果效果预览代码实现 旋转效果类元素动画摇摆动画效果效果预览代…...

Spring 容器相关的核心注解
以下是 Spring 容器中用于 Bean 管理、依赖注入、配置控制 的关键注解,按功能分类说明: 1. Bean 声明与注册 注解作用示例Component通用注解,标记一个类为 Spring Bean(自动扫描注册) Compo…...
)
经典算法 最小生成树(prim算法)
最小生成树 题目描述 给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环,边权可能为负数。 求最小生成树的树边权重之和。如果最小生成树不存在,则输出 impossible。 给定一张边带权的无向图 G (V, E),其中:…...

机器学习中的分类和回归问题
1. 分类问题 机器学习中的分类问题是一种监督学习任务,其核心目标是将数据样本分配到预定义的离散类别中,例如判断邮件是否为垃圾邮件、识别图像中的物体类型等。 分类通过已知标签的训练数据(如带类别标注的样本)学习特征与类别…...

pip命令
安装&卸载 -- 安装numpy pip install numpy1.26.4 -- 从索引安装(自定义源) pip install package_name --index-url https://custom_url -- 安装本地文件或目录 pip install /path/to/package.whl pip install D:\Downloads\transformers-4.40.0-py…...

n8n工作流自动化平台的实操:Cannot find module ‘iconv-lite‘
解决问题: 1.在可视化界面,执行const iconv require(iconv-lite);,报Cannot find module iconv-lite [line 2]错误; 查看module的路径 进入docker容器 #docker exec -it n8n /bin/sh 构建一个test.js,并写入如何代码 vi tes…...

AIGC时代——语义化AI驱动器:提示词的未来图景与技术深潜
文章目录 一、技术范式重构:从指令集到语义认知网络1.1 多模态语义解析器的进化路径1.2 提示词工程的认知分层 二、交互革命:从提示词到意图理解2.1 自然语言交互的认知进化2.2 专业领域的认知增强 三、未来技术图谱:2025-2030演进路线3.1 20…...

基于Springboot高校网上缴费综合务系统【附源码】
基于Springboot高校网上缴费综合务系统 效果如下: 系统登陆页面 个人中心页面 论坛交流页面 发表评论页面 付款页面 教师缴费页面 新增缴费类型页面 审核页面 研究背景 随着高校信息化建设进程的加速,传统手工缴费模式因效率低、错误率高、管理成本高…...

返回倒数第k个节点题解
这题要用到快慢指针的思想。 1.定义两个指针,一个快指针,一个慢指针,初始都指向头结点 2.先让快指针往后走k步,也就是移动k个节点,这个时候快指针比慢指针领先k 3.现在让快慢指针同时往后移动,两指针之间…...

《操作系统精髓与设计原理》第4章课后题答案-线程、对称多处理器和微内核
1.表3.5列出了在一个没有线程的操作系统中进程控制块的基本元素。对于多线程系统,这些元素中哪些可能属于线程控制块,哪些可能属于进程控制块? 对于不同的系统来说通常是不同的,但一般来说,进程是资源的所有者…...

《ATPL地面培训教材13:飞行原理》——第4章:亚音速气流
翻译:刘远贺;工具:Cursor & Claude 3.7;过程稿 第4章:亚音速气流 目录 翼型术语气流基础二维气流总结习题答案 翼型术语 翼型 一种能够以较高效率产生升力的特殊形状。 弦线 连接翼型前缘和后缘曲率中心的直…...

5月3日星期六今日早报简报微语报早读
5月3日星期六,农历四月初六,早报#微语早读。 1、五一假期多地政府食堂对外开放:部分机关食堂饭菜“秒没”; 2、2025年五一档电影新片票房破3亿; 3、首日5金!中国队夺得跳水世界杯总决赛混合团体冠军&…...

2024 虚拟电厂与大电网三道防线的关系探讨【附全文阅读】
本文围绕虚拟电厂与大电网三道防线展开探讨。大电网三道防线包括第一道防线的预防性控制和继电保护、第二道防线的稳控系统、第三道防线的失步解列及频率电压紧急控制装置 ,新型电力系统建设对第三道防线带来频率稳定等挑战。当前新型配电网第三道防线建设存在问题&…...

【c++】模板详解
目录 泛型编程模板的使用函数模板函数模板的本质函数模板的实例化显式实例化隐式实例化 函数模板的模板参数的匹配原则 类模板类模板的本质类模板的实例化 非类型模板参数模板特化函数模板特化类模板特化类模板全特化类模板偏特化(半特化) 模板分离编译t…...

【Linux】驱动开发方法
使用Petalinux学习驱动开发时的一些经验。 部分图片和经验来源于网络,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 目录 1 基础——字符设备驱动 1.1 分配设备号(驱动入口使用)…...

BUUCTF——禁止套娃
BUUCTF——禁止套娃 进入靶场 一个近乎空白的页面 看一下框架 没什么有用的信息,扫个目录吧 只扫出来给flag.php,但是0B,估计又是个空网站 拼接访问一下 果然又是什么都没有 没有突破口 githack找找看看也没有源码吧 <?php include …...

Spring MVC @RequestBody 注解怎么用?接收什么格式的数据?
RequestBody 注解的作用 RequestBody 将方法上的参数绑定到 HTTP 请求的 Body(请求体)的内容上。 当客户端发送一个包含数据的请求体(通常在 POST, PUT, PATCH 请求中)时,RequestBody 告诉 Spring MVC 读取这个请求体…...
)
线性DP(动态规划)
线性DP的概念(视频) 学习线性DP之前,请确保已经对递推有所了解。 一、概念 1、动态规划 不要去看网上的各种概念,什么无后效性,什么空间换时间,会越看越晕。从做题的角度去理解就好了,动态规划…...

Qt中实现工厂模式
在Qt中实现工厂模式可以通过多种方式,具体选择取决于需求和场景。以下是几种常见的实现方法: 1. 简单工厂模式通过一个工厂类根据参数创建不同对象。cppclass Shape {public: virtual void draw() 0; virtual ~Shape() default;};class Circle : publ…...

基于 Dify + vLLM插件 + Qwen3 构建问答机器人Docker版
前提条件 硬件要求: 推荐 NVIDIA GPU (至少 16GB 显存,Qwen3 可能需要更多) 至少 32GB 内存 足够的存储空间 (Qwen3 模型文件较大) 软件要求: Docker 和 Docker Compose Python 3.8 CUDA 和 cuDNN (与你的 GPU 兼容的版本) 安装步骤…...

【Linux】Linux应用开发小经验
基于Petalinux工具链的Linux应用开发小经验,未完待续... 部分图片和经验来源于网络,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 目录…...

第39课 绘制原理图——绘制命令在哪里?
绘制原理图符号的命令在哪里? 在新建完原理图之后,我们就可以在原理图上绘制各种相关的符号了。 我们基本会从以下的两个地方,找到绘制各种符号的命令: 菜单栏中的“放置”菜单; 悬浮于设计窗口中的快速工具条 在初…...

第十四篇:系统分析师第三遍——15章
目录 一、目标二、计划三、完成情况四、意外之喜(最少2点)1.计划内的明确认知和思想的提升标志2.计划外的具体事情提升内容和标志 五、总结六、后面准备怎么做? 一、目标 通过参加考试,训练学习能力,而非单纯以拿证为目的。 1.在复习过程中&…...