Linux操作系统系统编程:x86-64架构下的系统调用
在Linux操作系统里,系统编程如同精密仪器的核心部件,掌控着系统运行的关键。而 x86-64 架构下的系统调用,更是连接用户空间程序与内核的关键桥梁。你可以把用户空间的程序想象成一个个 “工匠”,它们有着各式各样的需求,比如读取文件数据、展示图像、与其他程序交流信息等。但用户空间就像被一道无形的屏障围住,“工匠们” 无法直接触碰内核掌管的磁盘、内存、网络接口等底层资源。这时,系统调用就如同 “工匠们” 手中的神奇工具,当他们发出特定指令,就能突破屏障,让内核这位 “大管家” 提供相应服务。
从计算机发展历程看,系统调用一直在不断革新。早期操作系统资源有限,系统调用种类和功能少,程序与内核交互简单。随着硬件性能提升、软件场景变复杂,x86-64 架构持续演进,系统调用机制也在优化,指令集、参数传递方式不断改进,与内核功能深度融合,推动着 Linux 系统编程不断进步。当下,不管是数据中心的高性能应用,还是手持设备里的便捷 APP,高效的系统调用机制都是背后的有力支撑。理解 x86-64 架构下的系统调用,不仅是掌握 Linux 系统编程的关键,更是开启现代计算机高效运行奥秘的钥匙。现在,就让我们一起深入探索 x86-64 架构下系统调用的精妙之处 。
一、x86-64系统调用初相识
在计算机的世界里,系统调用可谓是连接用户程序与操作系统内核的桥梁,有着不可或缺的地位。它是操作系统提供给用户程序的一组 “特殊接口”,用户程序能够借助这些接口,请求内核提供各种服务,像文件操作、进程管理、内存分配等等。可以说,系统调用是操作系统内核向外提供服务的主要途径,也是用户程序与操作系统交互的关键方式。
系统调用与常规函数调用不同,因为被调用的代码位于内核中。需要特殊指令来使处理器执行从用户态切换到特权态(ring 0)。此外,调用的内核代码通过系统调用号来标识,而不是函数地址。
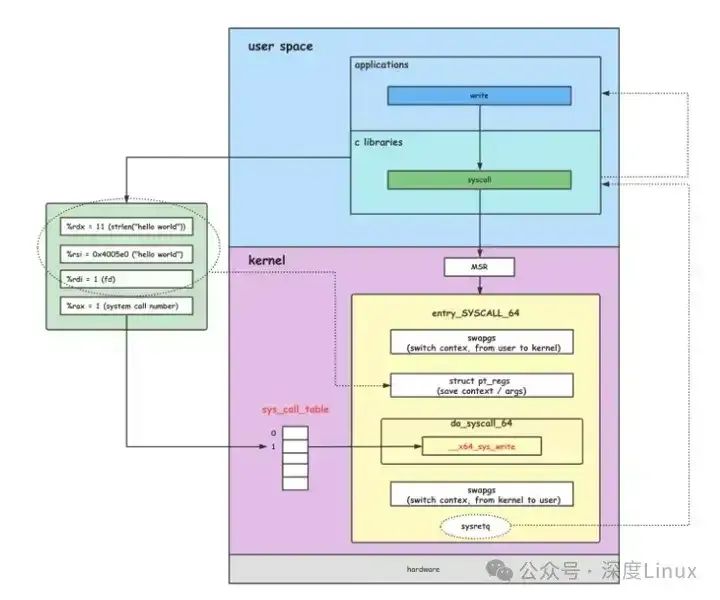
当用户空间程序需要执行一个系统调用时,它会使用特定的指令(例如x86架构中的syscall指令)触发从用户态到内核态的切换。在进行切换时,处理器会将当前的上下文保存起来,包括寄存器状态和程序计数器等。然后,处理器会跳转到预定义的系统调用入口点,该入口点由系统调用号标识。
在内核中,系统调用表(system call table)维护了系统调用号与相应内核函数的映射关系。当处理器进入内核态并跳转到系统调用入口点时,内核会根据系统调用号找到对应的内核函数来执行相应的操作。内核函数完成后,处理器将恢复之前保存的上下文,并返回到用户空间程序继续执行。
通过使用系统调用号而不是函数地址,内核能够提供一种标准化的、跨平台的系统调用接口。不同的系统调用由唯一的系统调用号进行标识,这样用户空间程序可以使用相同的系统调用号在不同的操作系统上进行系统调用,而无需关心具体的内核实现;Linux 应用程序要与内核通信,需要通过系统调用。系统调用,相当于用户空间和内核空间之间添加了一个中间层。
因此,系统调用的机制涉及从用户态到内核态的切换、系统调用号的标识和匹配,以及内核中相应的处理逻辑,以实现用户空间程序与内核的交互,系统调用作用:
-
内核将复杂困难的逻辑封装起来,用户程序通过系统来操作硬件,极大简化了用户程序开发。
-
降低用户程序非法操作的风险,保证操作系统能安全,稳定地工作。
-
系统有效地分离了用户程序和内核开发。
-
通过接口访问黑盒操作,使得程序有更好的移植性。
而 x86-64 系统调用,指的是在 x86-64 架构的计算机系统中,用户空间程序与内核进行交互的主要机制。x86-64 是一种广泛应用的计算机硬件架构,包括我们日常使用的桌面电脑、服务器等,很多都是基于这个架构。在这个架构下的系统调用,有着特定的实现方式和规则。
或许你会好奇,x86-64 系统调用与我们平常熟悉的函数调用有啥不一样呢?从本质上来说,普通函数调用是在用户空间内进行的,执行过程相对简单。当我们在程序里调用一个普通函数时,程序直接跳转到函数的代码处执行,执行完毕后再返回调用点继续执行后续代码,整个过程都在用户空间,不会涉及到系统内核。比如说,在 C 语言中调用一个自定义的函数add(int a, int b),计算两个整数的和,这就是一个普通函数调用:
#include <stdio.h>int add(int a, int b) {return a + b;
}int main() {int result = add(3, 5);printf("结果是: %d\n", result);return 0;
}在这个例子里,add函数在用户空间执行,调用和返回都很直接。
但 x86-64 系统调用可就复杂多了。由于它涉及到用户空间程序请求内核服务,所以需要进行特权级别的切换,从用户态切换到内核态。简单来讲,用户态下程序的操作权限有限,而内核态下程序拥有更高的权限,可以访问系统的关键资源和执行特权指令。当进行系统调用时,程序需要通过特定的指令(比如syscall指令)来触发从用户态到内核态的切换,然后内核根据系统调用号找到对应的内核函数进行执行,执行完毕后再切换回用户态,并返回结果给用户程序。这就好比你要进入一个高级机密区域(内核态)获取某些重要资源(执行内核服务),必须先经过严格的身份验证(特权级切换),才能进入并获取所需。
二、x86-64 系统调用原理
2.1系统调用流程
为了更直观地理解 x86-64 系统调用的工作过程,我们通过一个详细的流程图表(如下)和具体的程序实例来深入剖析。就以一个简单的文件读取程序为例,看看它是如何进行系统调用的。
假设我们有一个用 C 语言编写的简单文件读取程序:
#include <stdio.h>int main() {FILE *file = fopen("test.txt", "r");if (file == NULL) {perror("无法打开文件");return 1;}char buffer[100];size_t bytes_read = fread(buffer, 1, sizeof(buffer), file);if (bytes_read > 0) {printf("读取的内容: %s\n", buffer);}fclose(file);return 0;
}在这个程序中,当执行fopen函数时,实际上它会调用底层的系统调用open来打开文件。具体过程如下:
-
用户空间程序发起系统调用请求:程序执行到fopen函数时,它会向操作系统发起打开文件的请求,这就触发了系统调用。
-
设置系统调用号和参数到寄存器:根据 x86-64 的调用约定,会将系统调用号(比如open系统调用在 x86-64 系统中的调用号是 2)存入%rax寄存器,将文件名(这里是test.txt)的地址存入%rdi寄存器,将打开文件的模式(这里是只读模式"r"对应的标志)存入%rsi寄存器。
-
执行 syscall 指令:当所有参数设置好后,程序执行syscall指令,这个指令是触发系统调用的关键,它会引发处理器从用户态切换到内核态。
-
处理器切换到内核态:syscall指令执行后,处理器的特权级别提升,从用户态进入内核态,此时程序可以访问内核的资源和执行特权指令。
-
内核根据系统调用号查找对应的内核函数:内核接收到系统调用请求后,会从%rax寄存器中读取系统调用号,然后在内核的系统调用表中查找对应的内核函数。比如对于open系统调用号 2,内核会找到对应的sys_open函数。
-
执行内核函数:内核调用sys_open函数,该函数会进行一系列的操作,如检查文件权限、查找文件的 inode 等,最终完成文件的打开操作,并返回一个文件描述符。
-
内核函数执行完毕,返回结果到寄存器:sys_open函数执行完成后,会将结果(文件描述符或者错误码)存入%rax寄存器。
-
处理器切换回用户态:内核处理完系统调用后,通过特定的机制(如sysret指令)将处理器的特权级别从内核态降回用户态。
-
用户空间程序从寄存器获取结果:用户空间程序继续执行,从%rax寄存器中获取系统调用的结果。如果%rax的值是一个有效的文件描述符,那么fopen函数就可以继续进行后续的文件读取操作;如果%rax的值是一个错误码,那么fopen函数会根据错误码进行相应的错误处理,比如在程序中通过perror函数输出错误信息。
2.2调用约定深度剖析
参数传递规则:依据 x86-64 ABI(应用二进制接口)文档,在进行系统调用时,参数的传递有着明确的规则。参数 1 对应%rdi寄存器,参数 2 对应%rsi寄存器,参数 3 对应%rdx寄存器,参数 4 对应%r10寄存器,参数 5 对应%r8寄存器,参数 6 对应%r9寄存器 。例如,在前面提到的open系统调用中,文件名作为参数 1,就会被传递到%rdi寄存器;打开文件的模式作为参数 2,会被传递到%rsi寄存器。
并且,系统调用的参数数量限制为 6 个,如果需要传递更多参数,可能需要将多个参数打包成一个结构体,通过内存传递。同时,参数类型限制为INTEGER和MEMORY。INTEGER类型指的是可以存放在通用寄存器中的整型数据,比如int、long等;MEMORY类型则是指通过内存(堆栈)来传递和返回的数据类型,像结构体、数组等。
系统调用号作用:系统调用号在 x86-64 系统调用中起着至关重要的作用。它通过%rax寄存器传递,是内核识别系统调用的唯一标识。每一个系统调用在内核中都有一个对应的系统调用号,就如同函数指针一样,引导程序找到对应的内核函数执行。比如,在 Linux 系统中,write系统调用的系统调用号是 1,exit系统调用的系统调用号是 60。
当用户空间程序发起系统调用时,将相应的系统调用号存入%rax寄存器,内核接收到系统调用请求后,首先从%rax寄存器读取系统调用号,然后根据这个调用号在内核的系统调用表中查找对应的内核函数。系统调用表是一个存储着系统调用号和对应内核函数指针的数组,通过系统调用号作为索引,内核可以快速定位到要执行的内核函数,从而实现对用户请求的处理。
系统调用指令解析:syscall指令是 x86-64 系统调用的核心指令,它的执行过程相当复杂。当程序执行syscall指令时,首先会保存返回地址到%rcx寄存器,这个返回地址就是syscall指令的下一条指令的地址,以便系统调用完成后能够返回正确的位置继续执行用户程序。接着,syscall指令会替换指令指针寄存器%rip,将其值替换为 IA32_LSTAR MSR(模型特定寄存器)中存储的地址,这个地址指向内核中系统调用处理程序的入口。
同时,syscall指令还会保存标志寄存器%rflags到%r11寄存器,并使用 IA32_FMASK MSR 对%rflags进行掩码操作 ,以确保在特权级切换过程中标志位的正确处理。之后,syscall指令会加载新的CS(代码段寄存器)和SS(堆栈段寄存器)选择子,其值来源于 IA32_STAR MSR 的特定比特位。通过这一系列操作,syscall指令实现了从用户态到内核态的快速切换,使得程序能够进入内核执行系统调用对应的内核函数。
2.3返回值与错误码
当系统调用执行完毕,从内核返回用户空间时,%rax寄存器保存着系统调用的结果。如果系统调用成功执行,%rax中存储的就是正常的返回值,比如对于open系统调用,如果文件成功打开,%rax中会返回一个有效的文件描述符;对于read系统调用,如果读取文件成功,%rax中会返回实际读取的字节数。然而,如果系统调用过程中发生了错误,%rax的值就会在 -4095 至 -1 之间,这个值表示错误码,并且是实际错误码的相反数(即-errno) 。例如,如果%rax的值为 -1,表示发生了EPERM错误,即操作不被允许;如果%rax的值为 -2,表示发生了ENOENT错误,即文件或目录不存在。
在 C 语言中,我们可以通过errno全局变量来获取具体的错误码,然后通过查阅相关的错误码定义(通常在<errno.h>头文件中),定位具体的错误类型,以便进行相应的错误处理。比如在前面的文件读取程序中,如果fopen函数返回NULL,我们可以通过perror函数输出错误信息,perror函数会根据errno的值查找对应的错误描述并输出,帮助我们快速定位和解决问题。
三、用户空间
我们以一个 Hello world 程序开始,逐步进入系统调用的学习。下面是用汇编代码写的一个简单的程序:
.section .data
msg:.ascii "Hello World!\n"
len = . - msg.section .text
.globl main
main:# ssize_t write(int fd, const void *buf, size_t count)mov $1, %rdi # fdmov $msg, %rsi # buffermov $len, %rdx # countmov $1, %rax # write(2)系统调用号,64位系统为1syscall# exit(status)mov $0, %rdi # statusmov $60, %rax # exit(2)系统调用号,64位系统为60syscall编译并运行:
$ gcc -o helloworld helloworld.s
$ ./helloworld
Hello world!
$ echo $?
0上面这段代码,是直接从我的一篇文章 使用 GNU 汇编语法编写 Hello World 程序的三种方法拷贝过来的。那篇文章里还提到了使用int 0x80软中断和printf函数实现输出的方法,有兴趣的可以去看下。
四、内核空间
用户空间通过 syscall 指令,从用户空间进入内核空间。
4.1内核调试
设置断点。在内核 write 函数名下断点,调试跟踪函数的调用堆栈。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>static ssize_t my_write(struct file *file, const char __user *buf,size_t len, loff_t *offset)
{/* 在这里设置断点 *//* 打印调用堆栈 */dump_stack();/* 写入操作的具体实现 */// ...return len;
}static struct file_operations fops = {.write = my_write,
};static int __init my_init(void)
{/* 注册字符设备驱动程序 */// ...return 0;
}static void __exit my_exit(void)
{/* 注销字符设备驱动程序 */// ...
}module_init(my_init);
module_exit(my_exit);MODULE_LICENSE("GPL");
调试触发断点。查看函数调用堆栈,可以发现 syscall 指令触发 entry_SYSCALL_64 处理函数。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>int main() {pid_t pid = getpid();// 触发系统调用syscall(39, pid, NULL, NULL);return 0;
}以上代码是一个简单的C程序,在执行期间会通过syscall函数触发系统调用。你可以将代码保存为test.c,然后使用gcc进行编译:gcc -o test test.c。
接下来,你可以使用GDB连接到生成的可执行文件并设置断点以及跟踪函数调用堆栈。在终端中输入gdb ./test启动GDB调试器。然后按照以下步骤进行操作:
-
在GDB提示符下输入命令:break main,设置一个断点在程序的main函数处。
-
输入命令: run ,运行程序。
-
当程序运行到syscall指令时,会进入内核并跳转到相应的系统调用处理函数(例如entry_SYSCALL_64)。
-
在entry_SYSCALL_64处理函数处会自动停下,此时你可以使用命令: bt(backtrace) 或者 where 来查看函数调用堆栈信息。
4.2系统调用入口
entry_SYSCALL_64 是 64 位 syscall 指令 入口函数,这个函数通常是由操作系统提供并负责处理所有来自用户空间发起的系统调用请求。具体实现可能因不同的操作系统而有所差异,但其作用都是为了协调用户空间和内核空间之间的交互。在不同的架构或操作系统上,对于syscall指令和相应处理函数名称可能会有所不同。例如,在32位x86架构上使用entry_INT80_32来处理syscall指令。因此,请根据目标平台和操作系统环境选择正确的符号名称和相关文档来进行调试和理解
初始化系统调用。当 linux 内核启动时,MSR 特殊模块寄存器会存储 syscall 指令的入口函数地址;当 syscall 指令执行后,系统从特殊模块寄存器中取出入口函数地址进行调用。
#include <linux/kernel.h>
#include <linux/module.h>MODULE_LICENSE("GPL");// 声明一个简单的系统调用函数
asmlinkage long my_syscall(void)
{printk(KERN_INFO "Hello from custom syscall!\n");return 0;
}// 初始化系统调用表
static void init_syscall_table(void)
{// 获取syscall table地址unsigned long *syscall_table = (unsigned long *)kallsyms_lookup_name("sys_call_table");// 替换对应系统调用函数指针write_cr0(read_cr0() & (~0x10000)); // 关闭写保护syscall_table[__NR_my_syscall] = (unsigned long)my_syscall; // 将自定义系统调用函数指针存储在syscall table中write_cr0(read_cr0() | 0x10000); // 开启写保护
}static int __init my_module_init(void)
{init_syscall_table();printk(KERN_INFO "Custom syscall module loaded\n");return 0;
}static void __exit my_module_exit(void)
{printk(KERN_INFO "Custom syscall module unloaded\n");
}module_init(my_module_init);
module_exit(my_module_exit);入口函数工作流程:
-
程序从用户空间进入内核空间,保存用户态现场,载入内核态的信息,程序工作状态从用户态转变为内核态。
-
根据系统调用号,从系统跳转表中,调用对应的系统调用函数。
-
系统调用函数完成逻辑后,需要从内核空间回到用户空间,程序内核态转变为用户态,需要把之前保存的用户态现场进行恢复。
ENTRY(entry_SYSCALL_64)TRACE_IRQS_OFFsubq $FRAME_SIZE, %rsp /* Reserve space for pt_regs */MOV_LDX(regs, %rsp) /* Save user stack pointer */cmpl $(nr_syscalls),%eax /* syscall number valid? */jae badsys /** Load the syscall table pointer into r10 from a global variable.* We stash it in memory at boot time to workaround boot loader* address randomization.** movl sys_call_table(,%rax,8),%r10** can be replaced with this:** leal sys_call_table(%rip),%r10* movq (%r10,%rax,8),%r10*/.section ".data", "a"sys_call_table:.quad __x64_sys_call_table- sys_call_table.section ".text", "ax"leaq sys_call_table(%rip),%r10 /* Get the syscall table address into r10 */
movq (%r10,%rax,8), %r10 /* Load the corresponding system call handler */在这段代码中,我们可以看到以下几个关键步骤:
-
首先,通过
subq指令为 pt_regs 结构体在用户栈上分配空间,用于保存系统调用的参数和返回值。 -
然后,将用户栈指针
%rsp的值保存到regs寄存器中,以便在系统调用处理函数中可以访问到用户栈上的参数。 -
接下来,通过
cmpl指令检查系统调用号是否有效。如果系统调用号大于等于nr_syscalls(即 sys_call_table 数组的长度),则跳转到badsys标签处进行错误处理。 -
紧接着,使用
leaq和movq指令加载 syscall table 的地址,并从表中获取对应的系统调用处理函数地址,存储在寄存器%r10中。这里有两种不同的实现方式,一种是直接使用全局变量 sys_call_table 获取 syscall table 的地址;另一种是先通过 RIP 相对寻址获取 sys_call_table 地址,并再从表中获取对应的系统调用处理函数地址。
然后,在代码中还有其他一些逻辑和错误处理部分,在此就不一一列举了。
gdb 反汇编查看 entry_SYSCALL_64 函数功能
(1)编译内核并启动调试模式:
make menuconfig # 配置内核选项(可根据需要进行配置)
make -j$(nproc) # 编译内核
sudo gdb vmlinux # 启动 gdb,并加载编译好的内核文件(2)在gdb中设置断点:
break entry_SYSCALL_64 # 在 entry_SYSCALL_64 函数处设置断点(3)启动内核调试:
target remote :1234 # 连接到 QEMU 调试服务器(如果使用 QEMU 进行内核调试)
continue # 继续执行,使程序运行到设置的断点处(4)反汇编查看代码:
disassemble /m entry_SYSCALL_64 # 使用 disassemble 命令反汇编 entry_SYSCALL_64 函数struct pt_regs。程序在系统调用后,从用户空间进入内核空间,保存用户态现场,保存用户态传入参数。
/* arch/x86/include/asm/ptrace.h */
struct pt_regs {
/** C ABI says these regs are callee-preserved. They aren't saved on kernel entry* unless syscall needs a complete, fully filled "struct pt_regs".*/unsigned long r15;unsigned long r14;unsigned long r13;unsigned long r12;unsigned long rbp;unsigned long rbx;
/* These regs are callee-clobbered. Always saved on kernel entry. */unsigned long r11;unsigned long r10; /* 程序传递到内核的第 4 个参数。 */unsigned long r9; /* 程序传递到内核的第 6 个参数。 */unsigned long r8; /* 程序传递到内核的第 5 个参数。 */unsigned long ax; /* 程序传递到内核的系统调用号。 */unsigned long cx; /* 程序传递到内核的 syscall 的下一条指令地址。 */unsigned long dx; /* 程序传递到内核的第 3 个参数。 */unsigned long si; /* 程序传递到内核的第 2 个参数。 */unsigned long di; /* 程序传递到内核的第 1 个参数。 */
/** On syscall entry, this is syscall#. On CPU exception, this is error code.* On hw interrupt, it's IRQ number:*/unsigned long orig_rax; /* 系统调用号。 */
/* Return frame for iretq * 内核态返回用户态需要恢复现场的数据。*/unsigned long ip; /* 保存程序调用 syscall 的下一条指令地址。 */unsigned long cs; /* 用户态代码起始段地址。 */unsigned long flags; /* 用户态的 CPU 标志。 */unsigned long sp; /* 用户态的栈顶地址(栈内存是向下增长的)。 */unsigned long ss; /* 用户态的数据段地址。 */
/* top of stack page */
};4.3do_syscall_64
do_syscall_64 函数是 Linux 内核中的关键函数之一,它的主要功能是处理 64 位系统调用。当用户程序通过软件中断(syscall)发起系统调用请求时,内核会将控制转移到 do_syscall_64 函数来执行相应的操作。
具体而言,do_syscall_64 函数完成以下主要功能:
-
获取系统调用号:从当前进程的 CPU 寄存器或栈中获取系统调用号,以确定用户程序请求执行哪个特定的系统调用。
-
参数传递:根据系统调用约定,从当前进程的寄存器或堆栈中提取相应数量和类型的参数,并将这些参数传递给相应的系统调用处理函数。
-
权限检查:验证当前进程是否有足够权限执行所请求的系统调用。这可能涉及访问权限、资源配额、权限级别等方面的检查。
-
系统调用执行:将控制权转移给与所请求系统调用对应的内核函数,以便在内核模式下执行特定操作。
-
结果返回:如果需要,将系统调用执行结果返回给用户空间,并更新相应寄存器或内存位置以供用户程序读取结果。
ENTRY(entry_SYSCALL_64)...call do_syscall_64 /* returns with IRQs disabled */...
END(entry_SYSCALL_64)/* arch/x86/entry/common.c */
#ifdef CONFIG_X86_64
__visible void do_syscall_64(unsigned long nr, struct pt_regs *regs) {struct thread_info *ti;.../** NB: Native and x32 syscalls are dispatched from the same* table. The only functional difference is the x32 bit in* regs->orig_ax, which changes the behavior of some syscalls.*/nr &= __SYSCALL_MASK;if (likely(nr < NR_syscalls)) {nr = array_index_nospec(nr, NR_syscalls);/* 通过系统调用跳转表,调用系统调用号对应的函数。* 函数返回值保存在 regs->ax 里,最后将这个值,保存到 rax 寄存器传递到用户空间。 */regs->ax = sys_call_table[nr](regs);}syscall_return_slowpath(regs);
}
#endif4.4系统调用表
系统调用表 syscall_64.tbl,建立了系统调用号与系统调用函数名的映射关系。脚本会根据这个表,自动生成相关的映射源码。
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>// 定义系统调用号与函数名的映射数组
static const char *syscall_names[] = {[0] = "sys_read",[1] = "sys_write",[2] = "sys_open",// ...
};int main() {int i;// 遍历系统调用号并打印对应的函数名for (i = 0; i < sizeof(syscall_names) / sizeof(syscall_names[0]); i++) {printf("Syscall number %d: %s\n", i, syscall_names[i]);}return 0;
}4.5系统跳转表(sys_call_table)
运行流程。系统调用的执行流程如下,但是系统调用号、系统跳转表,系统调用函数,这三者是如何关联起来的呢?
系统调用的执行流程如下:
-
用户程序通过编写系统调用号(或者使用对应的库函数)来请求操作系统提供某项服务。
-
当用户程序发起系统调用时,会触发处理器从用户态切换到内核态,进入特权模式。
-
处理器将控制权交给操作系统内核,并传递系统调用号以及其他必要的参数。
-
操作系统内核根据系统调用号在系统调用表中查找相应的处理函数地址。
-
内核跳转到对应的系统调用处理函数,开始执行具体的操作。
-
执行完毕后,将结果返回给用户程序,并再次切换回用户态。
关于系统调用号、系统跳转表和系统调用函数之间的关联:
-
系统调用号:每个系统调用都被赋予一个唯一的编号。例如,在 Linux 中使用 x86_64 架构时,可以在 syscall_64.tbl 文件中找到这些编号定义。它们为每个操作分配了一个特定的数字标识符。
-
系统跳转表:在内核中,有一个称为“system_call”或类似名称的特殊位置存储着一个指向所有系统调用处理函数地址数组(也称为“sys_call_table”)的指针。该数组包含了所有可能存在的系统调用处理函数地址。
-
系统调用函数:每个具体的功能对应一个系统调用函数,它们是内核中的实现代码。这些函数通过在系统跳转表中查找与其对应的位置来进行调用。
当用户程序触发系统调用时,操作系统根据系统调用号从系统跳转表中获取对应的处理函数地址,并执行该函数来完成请求的操作。因此,通过系统调用号和系统跳转表,操作系统能够将用户程序的请求路由到正确的系统调用函数上。
syscall's number -> syscall -> entry_SYSCALL_64 -> do_syscall_64 -> sys_call_table -> __x64_sys_writesys_call_table 的定义。#include <asm/syscalls_64.h> 这行源码对应的文件是在内核编译的时候,通过脚本创建的。
/* include/generated/asm-offsets.h */
#define __NR_syscall_max 547 /* sizeof(syscalls_64) - 1 *//* arch/x86/entry/syscall_64.c */
#define __SYSCALL_64(nr, sym, qual) [nr] = sym,/* arch/x86/entry/syscall_64.c */
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {/** Smells like a compiler bug -- it doesn't work* when the & below is removed.*/[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};Makefile。通过执行 syscalltbl.sh 脚本,解析系统调用文件 syscall_64.tbl 数据,自动生成 syscalls_64.h。
# arch/x86/entry/syscalls/Makefile
syscall64 := $(srctree)/$(src)/syscall_64.tbl
systbl := $(srctree)/$(src)/syscalltbl.sh
quiet_cmd_systbl = SYSTBL $@cmd_systbl = $(CONFIG_SHELL) '$(systbl)' $< $@
syscalltbl.sh
# arch/x86/entry/syscalls/syscalltbl.sh
...
syscall_macro() {abi="$1"nr="$2"entry="$3"# Entry can be either just a function name or "function/qualifier"real_entry="${entry%%/*}"if [ "$entry" = "$real_entry" ]; thenqualifier=elsequalifier=${entry#*/}fiecho "__SYSCALL_${abi}($nr, $real_entry, $qualifier)"
}
...syscalls_64.h 文件内容
/* arch/x86/include/generated/asm/syscalls_64.h */
...
#ifdef CONFIG_X86
__SYSCALL_64(0, __x64_sys_read, )
#else /* CONFIG_UML */
__SYSCALL_64(0, sys_read, )
#endif
#ifdef CONFIG_X86
__SYSCALL_64(1, __x64_sys_write, )
#else /* CONFIG_UML */
__SYSCALL_64(1, sys_write, )
#endif
...三者关系。通过上述操作,sys_call_table 的定义与 syscalls_64.h 文件内容结合起来就是一个完整的数组初始化,将系统调用号,系统调用函数,系统跳转表三者结合起来了。
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {/** Smells like a compiler bug -- it doesn't work* when the & below is removed.*/[0 ... __NR_syscall_max] = &sys_ni_syscall,[0] = __x64_sys_read,[1] = __x64_sys_write,...系统调用函数。现在虽然搞清楚了系统调用的关系,但是还没有发现 __x64_sys_write 这个函数是在哪里定义的。答案就在这个宏 SYSCALL_DEFINE3,将这个宏展开,回头再看上面 gdb 调试断点截断处的那些函数,整个思路就清晰了。
__do_sys_write() (/root/linux-5.0.1/fs/read_write.c:610)
__se_sys_write() (/root/linux-5.0.1/fs/read_write.c:607)
__x64_sys_write(const struct pt_regs * regs) (/root/linux-5.0.1/fs/read_write.c:607)
.../* fs/read_write.c */
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,size_t, count) {return ksys_write(fd, buf, count);
}/* include/linux/syscalls.h */
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)#define SYSCALL_DEFINEx(x, sname, ...) \SYSCALL_METADATA(sname, x, __VA_ARGS__) \__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)/* arch/x86/include/asm/syscall_wrapper.h */
#define __SYSCALL_DEFINEx(x, name, ...) \asmlinkage long __x64_sys##name(const struct pt_regs *regs); \ALLOW_ERROR_INJECTION(__x64_sys##name, ERRNO); \static long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \asmlinkage long __x64_sys##name(const struct pt_regs *regs) \{ \return __se_sys##name(SC_X86_64_REGS_TO_ARGS(x,__VA_ARGS__)); \} \__IA32_SYS_STUBx(x, name, __VA_ARGS__) \static long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \{ \long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \__MAP(x,__SC_TEST,__VA_ARGS__); \__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \return ret; \} \static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__))五、系统调用的定义
read()系统调用是一个很好的初始示例,可以用来探索内核的系统调用机制。它在fs/read_write.c中作为一个简短的函数实现,大部分工作由vfs_read()函数处理。从调用的角度来看,这段代码最有趣的地方是函数是如何使用SYSCALL_DEFINE3()宏来定义的。实际上,从代码中,甚至并不立即清楚该函数被称为什么。
// linux-3.10/fs/read_write.cSYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{struct fd f = fdget(fd);ssize_t ret = -EBADF;if (f.file) {loff_t pos = file_pos_read(f.file);ret = vfs_read(f.file, buf, count, &pos);file_pos_write(f.file, pos);fdput(f);}return ret;
}这些SYSCALL_DEFINEn()宏是内核代码定义系统调用的标准方式,其中n后缀表示参数计数。这些宏的定义(在include/linux/syscalls.h中)为每个系统调用提供了两个不同的输出。
// include/linux/syscalls.h#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)// include/linux/syscalls.h#define SYSCALL_DEFINEx(x, sname, ...) \SYSCALL_METADATA(sname, x, __VA_ARGS__) \__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)SYSCALL_METADATA(_read, 3, unsigned int, fd, char __user *, buf, size_t, count)__SYSCALL_DEFINEx(3, _read, unsigned int, fd, char __user *, buf, size_t, count){struct fd f = fdget_pos(fd);ssize_t ret = -EBADF;/* ... */5.1SYSCALL_METADATA
其中之一是SYSCALL_METADATA()宏,用于构建关于系统调用的元数据,以便进行跟踪。只有在内核构建时定义了CONFIG_FTRACE_SYSCALLS时才会展开该宏,展开后它会生成描述系统调用及其参数的数据的样板定义。(单独的页面详细描述了这些定义。)
SYSCALL_METADATA()宏主要用于在内核中进行系统调用的跟踪和分析。当启用了CONFIG_FTRACE_SYSCALLS配置选项进行内核构建时,宏会展开,并生成一系列用于描述系统调用及其参数的元数据定义。这些元数据包括系统调用号、参数个数、参数类型等信息,用于记录和分析系统调用的执行情况。
通过使用SYSCALL_METADATA()宏,内核能够在编译时生成系统调用的元数据,以支持跟踪工具对系统调用的监控和分析。这些元数据的定义是一种样板代码,提供了系统调用的相关信息,帮助开发人员和调试工具在系统调用层面进行问题排查和性能优化。
5.2__SYSCALL_DEFINEx
__SYSCALL_DEFINEx()部分更加有趣,因为它包含了系统调用的实现。一旦各种宏和GCC类型扩展层层展开,生成的代码包含一些有趣的特性:
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \{ \long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \__MAP(x,__SC_TEST,__VA_ARGS__); \__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \return ret; \} \SYSCALL_ALIAS(sys##name, SyS##name); \static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__))asmlinkage long sys_read(unsigned int fd, char __user * buf, size_t count)__attribute__((alias(__stringify(SyS_read))));static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count);asmlinkage long SyS_read(long int fd, long int buf, long int count);asmlinkage long SyS_read(long int fd, long int buf, long int count){long ret = SYSC_read((unsigned int) fd, (char __user *) buf, (size_t) count);asmlinkage_protect(3, ret, fd, buf, count);return ret;}static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count){struct fd f = fdget_pos(fd);ssize_t ret = -EBADF;/* ... */[root@localhost ~]# uname -r
3.10.0-693.el7.x86_64
[root@localhost ~]# cat /proc/kallsyms | grep '\<sys_read\>'
ffffffff812019e0 T sys_read
[root@localhost ~]# cat /proc/kallsyms | grep '\<SYSC_read\>'
[root@localhost ~]# cat /proc/kallsyms | grep '\<SyS_read\>'
ffffffff812019e0 T SyS_read5.3SYSCALL_ALIAS
SYSCALL_ALIAS宏定义如下:
// file: include/linux/linkage.h
#ifndef SYSCALL_ALIAS
#define SYSCALL_ALIAS(alias, name) asm( \".globl " VMLINUX_SYMBOL_STR(alias) "\n\t" \".set " VMLINUX_SYMBOL_STR(alias) "," \VMLINUX_SYMBOL_STR(name))
#endif宏VMLINUX_SYMBOL_STR定义如下:
// file: include/linux/export.h
/** Export symbols from the kernel to modules. Forked from module.h* to reduce the amount of pointless cruft we feed to gcc when only* exporting a simple symbol or two.** Try not to add #includes here. It slows compilation and makes kernel* hackers place grumpy comments in header files.*/
/* Indirect, so macros are expanded before pasting. */
#define VMLINUX_SYMBOL(x) __VMLINUX_SYMBOL(x)
#define VMLINUX_SYMBOL_STR(x) __VMLINUX_SYMBOL_STR(x)#define __VMLINUX_SYMBOL(x) x
#define __VMLINUX_SYMBOL_STR(x) #x实际效果是给name设置了个别名alias,本例中是给SyS_write设置了别名sys_write。
5.4Syscall table entries
寻找调用sys_read()的函数还有助于了解用户空间如何调用该函数。对于没有提供自己覆盖的"通用"架构,include/uapi/asm-generic/unistd.h文件中包含了一个引用sys_read的条目:
// include/uapi/asm-generic/unistd.h#define __NR_read 63
__SYSCALL(__NR_read, sys_read)这个定义为read()定义了通用的系统调用号__NR_read(63),并使用__SYSCALL()宏以特定于体系结构的方式将该号码与sys_read()关联起来。例如,arm64使用asm-generic/unistd.h头文件填充一个表格,将系统调用号映射到实现函数指针。
然而,我们将集中讨论x86_64架构,它不使用这个通用表格。相反,x86_64架构在arch/x86/syscalls/syscall_64.tbl中定义了自己的映射,其中包含sys_read()的条目:
// arch/x86/syscalls/syscall_64.tbl#
# 64-bit system call numbers and entry vectors
#
# The format is:
# <number> <abi> <name> <entry point>
#
# The abi is "common", "64" or "x32" for this file.
#
0 common read sys_read
1 common write sys_write
2 common open sys_open
3 common close sys_close
4 common stat sys_newstat
......这表明在x86_64架构上,read()的系统调用号为0(不是63),并且对于x86_64的两种ABI(应用二进制接口),即sys_read(),有一个共同的实现。(关于不同的ABI将在本系列的第二部分中讨论。)syscalltbl.sh脚本从syscall_64.tbl表生成arch/x86/include/generated/asm/syscalls_64.h文件,具体为sys_read()生成对__SYSCALL_COMMON()宏的调用。然后,该头文件用于填充syscall表sys_call_table,这是一个关键的数据结构,将系统调用号映射到sys_name()函数。
// arch/x86/syscalls/syscalltbl.sh#!/bin/shin="$1"
out="$2"grep '^[0-9]' "$in" | sort -n | (while read nr abi name entry compat; doabi=`echo "$abi" | tr '[a-z]' '[A-Z]'`if [ -n "$compat" ]; thenecho "__SYSCALL_${abi}($nr, $entry, $compat)"elif [ -n "$entry" ]; thenecho "__SYSCALL_${abi}($nr, $entry, $entry)"fidone
) > "$out"在x86_64架构中,syscalltbl.sh脚本使用syscall_64.tbl表格生成了arch/x86/include/generated/asm/syscalls_64.h文件。其中,对于sys_read()的定义会包含类似以下的代码:
__SYSCALL_COMMON(0, sys_read)这个宏的调用将系统调用号0和sys_read()函数关联起来。然后,arch/x86/include/generated/asm/syscalls_64.h文件会被其他代码引用,用于填充sys_call_table数据结构。
即由一个 Makefile文件中在编译 Linux 系统内核时调用了一个脚本,这个脚本文件会读取 syscall_64.tbl 文件,根据其中信息生成相应的文件 syscall_64.h。
// arch/x86/syscalls/Makefilesyscall64 := $(srctree)/$(src)/syscall_64.tblsystbl := $(srctree)/$(src)/syscalltbl.sh$(out)/syscalls_64.h: $(syscall64) $(systbl)$(call if_changed,systbl)sys_call_table是一个数组,其中每个元素对应一个系统调用号,它将系统调用号映射到相应的sys_name()函数。在这种情况下,sys_read()函数将与系统调用号0关联起来,以便当用户空间发起sys_read()的系统调用请求时,内核可以根据系统调用号从sys_call_table中找到sys_read()函数并执行。这样,内核就能正确处理用户空间对read()的系统调用请求。
六、x86-64系统调用实战演练
6.1汇编代码实操
为了更直观地感受 x86-64 系统调用的实际应用,我们通过具体的汇编代码示例来深入学习。这里以文件读写和进程创建这两个常见的系统调用为例,详细剖析每一行代码的功能和作用。
(1)文件读取汇编代码示例
section .datafilename db 'test.txt', 0 ; 要读取的文件名,以0结尾表示字符串结束buffer times 128 db 0 ; 用于存储读取内容的缓冲区,大小为128字节section .bssfd resq 1 ; 用于保存文件描述符,resq表示预留8字节空间(64位系统)bytes_read resq 1 ; 用于保存实际读取的字节数section .textglobal _start_start:; 打开文件,使用O_RDONLY标志表示只读模式mov rax, 2 ; 将系统调用号2(open系统调用号)存入%rax寄存器mov rdi, filename ; 将文件名的地址存入%rdi寄存器,作为open系统调用的第一个参数mov rsi, 0 ; 将打开文件的标志O_RDONLY(值为0)存入%rsi寄存器,作为第二个参数syscall ; 执行系统调用,触发从用户态到内核态的切换,执行open系统调用mov [fd], rax ; 将open系统调用返回的文件描述符保存到fd变量中; 读取文件内容到缓冲区mov rax, 0 ; 将系统调用号0(read系统调用号)存入%rax寄存器mov rdi, [fd] ; 将文件描述符从fd变量中取出,存入%rdi寄存器,作为read系统调用的第一个参数mov rsi, buffer ; 将缓冲区的地址存入%rsi寄存器,作为read系统调用的第二个参数mov rdx, 128 ; 将读取的最大字节数128存入%rdx寄存器,作为read系统调用的第三个参数syscall ; 执行系统调用,触发read系统调用,从文件中读取内容到缓冲区mov [bytes_read], rax ; 将read系统调用返回的实际读取的字节数保存到bytes_read变量中; 关闭文件mov rax, 3 ; 将系统调用号3(close系统调用号)存入%rax寄存器mov rdi, [fd] ; 将文件描述符从fd变量中取出,存入%rdi寄存器,作为close系统调用的第一个参数syscall ; 执行系统调用,触发close系统调用,关闭文件; 退出程序mov rax, 60 ; 将系统调用号60(exit系统调用号)存入%rax寄存器xor rdi, rdi ; 将退出状态码0存入%rdi寄存器,作为exit系统调用的第一个参数syscall ; 执行系统调用,触发exit系统调用,程序结束在这段代码中,首先定义了要读取的文件名test.txt和用于存储读取内容的缓冲区buffer。然后通过open系统调用打开文件,获取文件描述符并保存。接着使用read系统调用从文件中读取内容到缓冲区,保存实际读取的字节数。最后通过close系统调用关闭文件,并使用exit系统调用退出程序。每一个系统调用都严格按照 x86-64 的调用约定,将系统调用号存入%rax寄存器,将参数依次存入%rdi、%rsi、%rdx等寄存器,通过syscall指令触发系统调用。
(2)进程创建汇编代码示例
section .textglobal _start_start: ; 创建子进程mov rax, 57 ; 将系统调用号57(clone系统调用号,用于创建进程,在Linux中clone可用于创建进程、线程等,这里用于创建进程)存入%rax寄存器xor rdi, rdi ; 将%rdi寄存器清零,作为clone系统调用的第一个参数(这里参数为0,表示使用默认的克隆标志)xor rsi, rsi ; 将%rsi寄存器清零,作为clone系统调用的第二个参数(通常用于传递栈指针,这里为0表示使用默认栈)xor rdx, rdx ; 将%rdx寄存器清零,作为clone系统调用的第三个参数(通常用于传递父进程的标志,这里为0表示默认)xor r10, r10 ; 将%r10寄存器清零,作为clone系统调用的第四个参数(通常用于传递子进程的标志,这里为0表示默认)xor r8, r8 ; 将%r8寄存器清零,作为clone系统调用的第五个参数(通常用于传递新的线程组ID,这里为0表示默认)xor r9, r9 ; 将%r9寄存器清零,作为clone系统调用的第六个参数(通常用于传递新的父进程ID,这里为0表示默认)syscall ; 执行系统调用,触发clone系统调用,创建子进程cmp rax, 0 ; 比较clone系统调用的返回值(%rax寄存器)与0jz child ; 如果返回值为0,说明是子进程,跳转到child标签处执行; 父进程执行的代码mov rax, 60 ; 将系统调用号60(exit系统调用号)存入%rax寄存器xor rdi, rdi ; 将退出状态码0存入%rdi寄存器,作为exit系统调用的第一个参数syscall ; 执行系统调用,触发exit系统调用,父进程结束child:; 子进程执行的代码mov rax, 1 ; 将系统调用号1(write系统调用号)存入%rax寄存器mov rdi, 1 ; 将文件描述符1(标准输出)存入%rdi寄存器,作为write系统调用的第一个参数mov rsi, msg ; 将要输出的消息的地址存入%rsi寄存器,作为write系统调用的第二个参数mov rdx, msg_len ; 将消息的长度存入%rdx寄存器,作为write系统调用的第三个参数syscall ; 执行系统调用,触发write系统调用,子进程向标准输出打印消息mov rax, 60 ; 将系统调用号60(exit系统调用号)存入%rax寄存器xor rdi, rdi ; 将退出状态码0存入%rdi寄存器,作为exit系统调用的第一个参数syscall ; 执行系统调用,触发exit系统调用,子进程结束section .datamsg db 'This is a child process!', 0xa, 0 ; 子进程要输出的消息,0xa表示换行符,0表示字符串结束msg_len equ $ - msg ; 计算消息的长度在这段进程创建的汇编代码中,通过clone系统调用创建一个新的子进程。clone系统调用的参数较多,这里使用默认值,通过将各个参数寄存器清零来实现。clone系统调用返回后,根据返回值判断是父进程还是子进程。如果返回值为 0,则是子进程,子进程会向标准输出打印一条消息,然后退出;如果返回值不为 0,则是父进程,父进程直接退出。同样,每个系统调用都遵循 x86-64 的调用约定,准确设置系统调用号和参数寄存器,通过syscall指令实现系统调用的执行。
6.2C 语言调用示范
在 C 语言中,我们通常不会直接使用系统调用的原始方式(如汇编代码中的方式),而是通过调用 glibc 库函数来间接使用系统调用。glibc(GNU C Library)是 GNU 项目中提供的 C 标准库,它对系统调用进行了封装,提供了更方便、更高级的接口,使得程序员可以更便捷地使用系统调用。下面以open、read、write等函数为例,分析 C 语言中如何调用这些库函数,以及它们内部是如何封装系统调用的。
(1)C语言文件操作示例
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>#define BUFFER_SIZE 128int main() {int fd;char buffer[BUFFER_SIZE];ssize_t bytes_read;// 打开文件,使用O_RDONLY标志表示只读模式fd = open("test.txt", O_RDONLY);if (fd == -1) {perror("无法打开文件");return 1;}// 读取文件内容到缓冲区bytes_read = read(fd, buffer, BUFFER_SIZE);if (bytes_read == -1) {perror("读取文件失败");close(fd);return 1;}// 输出读取到的内容write(1, buffer, bytes_read);// 关闭文件close(fd);return 0;
}在这个 C 语言示例中,首先使用open函数打开文件test.txt,open函数的原型定义在<fcntl.h>头文件中,其函数声明为int open(const char *pathname, int flags, mode_t mode);。第一个参数pathname是要打开的文件名,第二个参数flags用于指定打开文件的模式,这里使用O_RDONLY表示只读模式。如果open函数调用失败,会返回 -1,并设置errno全局变量来表示具体的错误类型,通过perror函数可以输出错误信息。
接着使用read函数从文件中读取内容到缓冲区,read函数的原型定义在<unistd.h>头文件中,声明为ssize_t read(int fd, void *buf, size_t count);。第一个参数fd是文件描述符,即open函数返回的值;第二个参数buf是用于存储读取内容的缓冲区;第三个参数count是要读取的最大字节数。如果read函数调用失败,同样会返回 -1,并设置errno变量。
然后使用write函数将读取到的内容输出到标准输出,write函数的原型为ssize_t write(int fd, const void *buf, size_t count);。第一个参数fd为标准输出的文件描述符(值为 1),第二个参数buf是要输出的内容缓冲区,第三个参数count是要输出的字节数。
最后使用close函数关闭文件,close函数的原型为int close(int fd);,参数fd为要关闭的文件描述符。
从内部实现来看,这些 glibc 库函数实际上是对系统调用的封装。以open函数为例,当我们在 C 语言中调用open函数时,glibc 会将函数调用转换为对应的系统调用。在 x86-64 架构下,它会按照系统调用的调用约定,设置好系统调用号和参数寄存器,然后执行syscall指令,触发系统调用。
例如,对于open系统调用,glibc 会将系统调用号 2 存入%rax寄存器,将文件名的地址存入%rdi寄存器,将打开文件的标志存入%rsi寄存器,然后执行syscall指令。系统调用完成后,glibc 会根据系统调用的返回值进行处理,如果返回错误码,会设置errno全局变量,并返回 -1 给用户程序。同样,read、write、close等函数也都是类似的封装方式,通过这种方式,glibc 为程序员提供了更简洁、更易用的接口,隐藏了系统调用的底层细节 。
七、x86-64系统调用常见问题与优化策略
7.1常见问题诊断
在使用 x86-64 系统调用时,可能会遭遇各种棘手的问题,这些问题倘若不能及时解决,就会对程序的正常运行和性能产生严重影响。
参数传递错误是较为常见的问题之一。比如,在进行文件读取系统调用时,如果错误地将文件名传递到了本该存放文件描述符的寄存器,就会导致系统调用失败。假设在一个文件读取的汇编代码中,原本应该将文件描述符存入%rdi寄存器,却错误地存入了文件名:
; 错误示例
mov rax, 0 ; read系统调用号
mov rdi, filename ; 错误地将文件名存入%rdi寄存器,应该存入文件描述符
mov rsi, buffer
mov rdx, 128
syscall解决这类问题,需要仔细检查系统调用的参数传递,严格按照 x86-64 的调用约定,将参数准确无误地传递到对应的寄存器中。在编写代码时,可以参考相关的系统调用文档,明确每个参数所对应的寄存器。同时,使用调试工具(如 GDB),在程序运行过程中查看寄存器的值,以确保参数传递正确。比如,在 GDB 中,可以使用info registers命令查看寄存器的值,定位参数传递错误的位置。
系统调用号错误也是一个容易出现的问题。如果传递了错误的系统调用号,内核将无法找到对应的内核函数,从而引发未知行为。例如,将open系统调用号误写成了其他值:
; 错误示例
mov rax, 5 ; 错误的系统调用号,open系统调用号应为2
mov rdi, filename
mov rsi, 0
syscall为了避免这类错误,在编写代码时,要确保使用正确的系统调用号。可以查阅相关的操作系统文档或头文件,获取准确的系统调用号。在 Linux 系统中,系统调用号的定义通常可以在/usr/include/asm/unistd_64.h头文件中找到。并且,在程序中使用宏定义来表示系统调用号,这样不仅可以提高代码的可读性,还能减少因手写系统调用号而导致的错误。例如:
; 正确示例,使用宏定义表示系统调用号
%define SYS_OPEN 2
mov rax, SYS_OPEN
mov rdi, filename
mov rsi, 0
syscall7.2性能优化策略
系统调用涉及用户态和内核态的切换,这个过程会带来一定的开销,包括保存和恢复寄存器状态、切换页表等。因此,优化系统调用的性能对于提高程序的整体效率至关重要。
减少系统调用次数是一个有效的优化策略。以文件读写操作为例,如果需要读取大量的数据,频繁地进行小数据量的系统调用会导致较高的开销。假设我们要读取一个大文件的内容,如果每次只读取 10 个字节,然后进行一次系统调用,那么对于一个 1MB 大小的文件,就需要进行 10 万次系统调用,这会产生大量的上下文切换开销。
// 低效的文件读取方式,频繁进行系统调用
#include <stdio.h>int main() {FILE *file = fopen("large_file.txt", "r");if (file == NULL) {perror("无法打开文件");return 1;}char buffer[10];while (fread(buffer, 1, 10, file) > 0) {// 处理读取到的数据}fclose(file);return 0;
}为了优化性能,可以采用批量操作数据的方式,一次性读取较大的数据块,减少系统调用的次数。比如将缓冲区大小设置为 1024 字节,这样读取 1MB 大小的文件只需要进行约 1000 次系统调用,大大降低了上下文切换的开销。
// 优化后的文件读取方式,批量读取数据
#include <stdio.h>int main() {FILE *file = fopen("large_file.txt", "r");if (file == NULL) {perror("无法打开文件");return 1;}char buffer[1024];while (fread(buffer, 1, 1024, file) > 0) {// 处理读取到的数据}fclose(file);return 0;
}合理选择系统调用函数也能提高效率。不同的系统调用函数在功能和性能上可能存在差异,应根据具体需求选择最合适的系统调用。例如,在创建进程时,如果只是简单地创建一个子进程并等待其结束,可以使用fork和wait系统调用;但如果需要创建一个新的进程,并在新进程中执行一个新的程序,那么就应该使用execve系统调用。
如果在需要执行新程序的情况下错误地使用了fork,就无法达到预期的效果,还可能导致性能问题。同时,了解系统调用函数的底层实现和性能特点,可以帮助我们在编写程序时做出更优的选择。比如,一些系统调用函数可能会涉及到复杂的内核操作,而另一些则相对简单,我们可以根据实际需求选择更高效的函数。
相关文章:

Linux操作系统系统编程:x86-64架构下的系统调用
在Linux操作系统里,系统编程如同精密仪器的核心部件,掌控着系统运行的关键。而 x86-64 架构下的系统调用,更是连接用户空间程序与内核的关键桥梁。你可以把用户空间的程序想象成一个个 “工匠”,它们有着各式各样的需求࿰…...

linux下如何在一个录目中将一个文件复制到另一个录目,删除目录
一.文件复制到另一个目录 在Linux系统中,要将一个文件从一个目录复制到另一个目录,你可以使用cp命令。下面是一些基本的用法: 1. 使用绝对路径 如果你知道文件的绝对路径和目标目录的绝对路径,你可以直接使用cp命令。例如&…...

用Selenium开启自动化网页交互与数据抓取之旅
用Selenium开启自动化网页交互与数据抓取之旅 在当今数字化时代,数据的价值不言而喻,而网页作为海量数据的重要载体,如何高效获取其中的关键信息成为众多开发者和数据爱好者关注的焦点。Selenium这一强大工具,为我们打开了自动化…...

RabbitMQ的交换机
一、三种交换机模式 核心区别对比 特性广播模式(Fanout)路由模式(Direct)主题模式(Topic)路由规则无条件复制到所有绑定队列精确匹配 Routing Key通配符匹配…...
)
多模态大语言模型arxiv论文略读(五十五)
MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation ➡️ 论文标题:MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation ➡️ 论文作者:Kunpeng Song, Yizhe Zhu, Bingchen Liu, Qing Yan, Ahmed Elgammal, Xiao…...
:投稿相关网址)
TMI投稿指南(四):投稿相关网址
TMI官网:https://ieeetmi.org/ 模版选择器:选择合适的latex模版 IEEE-Template Selector 评审过程状态查看:ScholarOne Manuscripts AE assigns reviewers:副编辑已经开始选择和邀请审稿人,但同意审稿…...
)
Oracle无法正常OPEN(三)
在Oracle数据库中,如果几个数据文件丢失,导致数据库无法启动,报错“ORA-01157: cannot identify/lock data file 2 - see DBWR trace file”,如果没有物理备份的情况下,位于丢失数据文件的数据是无法找回的,…...

SQL语句练习 自学SQL网 在查询中使用表达式 统计
目录 Day 9 在查询中使用表达式 Day 10 在查询中进行统计 聚合函数 Day 11 在查询中进行统计 HAVING关键字 Day12 查询执行顺序 Day 9 在查询中使用表达式 SELECT id , Title , (International_salesDomestic_sales)/1000000 AS International_sales FROM moviesLEFT JOIN …...

当LLM遇上Agent:AI三大流派的“复仇者联盟”
你一定听说过ChatGPT和DeepSeek,也知道它们背后的LLM(大语言模型)有多牛——能写诗、写代码、甚至假装人类。但如果你以为这就是AI的极限,那你就too young too simple了! 最近,**Agent(智能体&a…...

模拟开发授权平台
这次只是实现应用的curd和公私钥的校验以及第三方的通知dmeo项目,大家可以拓开视野来编写 进入主题 项目链接:桌角的眼镜/develop_auth_platform 直接下拉并运行就行 回调应用代码在test包中 回调应用测试代码 package mainimport ("encoding/…...
:Pandas 文本数据处理)
python数据分析(八):Pandas 文本数据处理
Pandas 文本数据处理全面指南 1. 引言 在数据分析中,文本数据是常见的数据类型之一。Pandas 提供了强大的字符串处理方法,可以方便地对文本数据进行各种操作。本文将详细介绍 Pandas 中的文本处理功能,包括字符串连接(cat)、分割(split)、替…...

Spring AI:简化人工智能功能应用程序开发
Spring AI:简化人工智能功能应用程序开发 一、项目简介 Spring AI 项目致力于简化包含人工智能功能的应用程序的开发工作,并且不会引入不必要的复杂性。该项目从著名的 Python 项目(如 LangChain 和 LlamaIndex)中获取灵感&#…...

【算法基础】三指针排序算法 - JAVA
一、基础概念 1.1 什么是三指针排序 三指针排序是一种特殊的分区排序算法,通过使用三个指针同时操作数组,将元素按照特定规则进行分类和排序。这种算法在处理包含有限种类值的数组时表现出色,最经典的应用是荷兰国旗问题(Dutch …...

从实列中学习linux shell9 如何确认 服务器反应迟钝是因为cpu还是 硬盘io 到底是那个程序引起的。cpu负载多高算高
在 Linux 系统中,Load Average(平均负载) 是衡量系统整体压力的关键指标,但它本身没有绝对的“高/低”阈值,需要结合 CPU 核心数 和 其他性能指标 综合分析。以下是具体判断方法: 一、Load Average 的基本含义 定义:Load Average 表示 单位时间内处于可运行状态(R)和不…...
)
[面试]SoC验证工程师面试常见问题(三)
SoC验证工程师面试常见问题(三) 在 SoC 验证工程师的面试中,面试官可能会要求候选人现场编写 SystemVerilog、UVM (Universal Verification Methodology) 或 SystemC 代码,以评估其编程能力、语言掌握程度以及解决实际验证问题的能力。这种随机抽题写代码的环节通常…...
【附全文阅读】)
架构进阶:深入学习企业总体架构规划(Oracle 战略专家培训课件)【附全文阅读】
本文主要讨论了企业总体技术架构规划的重要性与实施建议。针对Oracle战略专家培训课件中的内容,文章强调了行业面临的挑战及现状分析、总体技术架构探讨、SOA集成解决方案讨论与问题解答等方面。文章指出,为了消除信息孤岛、强化应用系统,需要…...

stm32教程:软件I2C通信协议 代码模板提供
早上好啊大伙,这一期也是stm32的基础教学,这一期说的是 —— I2C通信协议。 文章目录 一、I2C协议概述二、物理层特性硬件结构速率模式 三、协议层机制起始与停止信号数据帧结构应答机制时钟同步与仲裁 四、通信协议1. 起始信号(START Condit…...

Java零基础入门Day4:数组与二维数组详解
一、为什么需要数组? 当程序需要处理批量同类型数据时,使用多个变量存储会非常繁琐。例如存储70个学生姓名时,需定义70个变量,而数组可以简化这一过程,提高代码可维护性。 示例:变量存储的弊端 String n…...
)
一条 SQL 查询语句是如何执行的(MySQL)
第一讲:一条 SQL 查询语句是如何执行的 总览图示 MySQL 查询的执行流程可以大致分为以下步骤(如图所示): 连接器(Connection)查询缓存(Query Cache,MySQL 8.0 已废弃)…...

IntelliJ IDEA
文章目录 一、集成开发环境(IDE, Integrated Development Environment)二、IntelliJ IDEAIDEA 安装 三、IDEA 管理 Java 程序的结构四、IDEA 开发 HelloWorld 程序 一、集成开发环境(IDE, Integrated Development Environment) 把代码编写,编译,执行等多…...

详细说明StandardCopyOption.REPLACE_EXISTING参数的作用和使用方法
StandardCopyOption.REPLACE_EXISTING 是 Java java.nio.file.StandardCopyOption 枚举类中的一个常量,它主要用于在文件复制或移动操作中处理目标文件已存在的情况。下面详细介绍其作用和使用方法。 作用 在使用 java.nio.file.Files 类的 copy() 或 move() 方法时…...

Linux 下使用tcpdump进行网络分析原
简介 tcpdump 是一个命令行数据包分析器,可实时捕获和检查网络流量。它通常用于网络故障排除、性能分析和安全监控。 安装 Debian/Ubuntu sudo apt update && sudo apt install tcpdump -yCentOS/RHEL sudo yum install tcpdump -ymacOS brew install…...

人车交叉作业防撞系统介绍
一、技术原理与核心功能 UWB脉冲测距技术 系统基于UWB技术,通过纳秒级非正弦窄脉冲(脉冲宽度0.21.5ns)实现实时测距,精度可达1030厘米。 工作原理:人员佩戴防撞标签(A)与车载基站(B&…...

移动端开发中设备、分辨率、浏览器兼容性问题
以下是针对移动端开发中设备、分辨率、浏览器兼容性问题的 系统化解决方案,按开发流程和技术维度拆解,形成可落地的执行步骤: 一、基础环境适配:从「起点」杜绝兼容性隐患 1. Viewport 元标签标准化 <meta name"viewpor…...
)
Git 基本操作(二)
目录 撤销修改操作 情况一 情况二 情况三 删除文件 升级git 撤销修改操作 在日常编码过程中,有些时候,我们可能写着写着发现目前的版本的代码越写越挫,越不符合标准,想让我们当前的文件去恢复到上一次提交的版本…...

多模态大模型轻量化探索-开源SmolVLM模型架构、数据策略及其衍生物PDF解析模型SmolDocling
在《多模态大模型轻量化探索-视觉大模型SAM的视觉编码器》介绍到,缩小视觉编码器的尺寸,能够有效的降低多模态大模型的参数量。再来看一个整体的工作,从视觉侧和语言模型侧综合考量模型参数量的平衡模式,进一步降低参数量…...

gRPC学习笔记记录以及整合gin开发
gprc基础 前置环境准备 grpc下载 项目目录下执行 go get google.golang.org/grpclatestProtocol Buffers v3 https://github.com/protocolbuffers/protobuf/releases/download/v3.20.1/protoc-3.20.1-linux-x86_64.zip go语言插件: go install google.golang.…...

Linux diff 命令使用详解
简介 Linux 中的 diff 命令用于逐行比较文件。它以各种格式报告差异,广泛应用于脚本编写、开发和补丁生成。 基础语法 diff [OPTION]... FILES常用选项 -i:忽略大小写 -u:打印输出时不包含任何多余的上下文行 -c:输出不同行周…...
——密码学基础)
非对称加密算法(RSA、ECC、SM2)——密码学基础
对称加密算法(AES、ChaCha20和SM4)Python实现——密码学基础(Python出现No module named “Crypto” 解决方案) 这篇的续篇,因此实践部分少些; 文章目录 一、非对称加密算法基础二、RSA算法2.1 RSA原理与数学基础2.2 RSA密钥长度…...

【安装指南】Chat2DB-集成了AI功能的数据库管理工具
一、Chat2DB 的介绍 Chat2DB 是一款开源的、AI 驱动的数据库工具和 SQL 客户端,提供现代化的图形界面,支持 MySQL、Oracle、PostgreSQL、DB2、SQL Server、SQLite、H2、ClickHouse、BigQuery 等多种数据库。它旨在简化数据库管理、SQL 查询编写、报表生…...

【C++】认识map和set
目录 前言: 一:认识map和set 二:map和set的使用 1.set的使用 2.map的使用 三:map的insert方法返回值 四:map的[ ]的使用 五:multiset和multimap 六:map和set的底层数据结构 七&#x…...

LWIP带freeRTOS系统移植笔记
以正点原子学习视频为基础的文章 LWIP带freeRTOS系统移植 准备资料/工程 1、lwIP例程1 lwIP裸机移植 工程 , 作为基础工程 改名为LWIP_freeRTOS_yizhi工程 2、lwIP例程6 lwIP_FreeRTOS移植 工程 3、freeRTO源码 打开https://www.freertos.org/网址下载…...

【MinerU技术原理深度解析】大模型时代的文档解析革命
目录 一、MinerU概述 获取MinerU 二、核心功能与技术亮点 1. 多模态解析能力 2. 高效预处理能力 3. 多场景适配性 4. API服务 三、技术架构解析 3.1 概述 1. 模块化处理流程 2. 关键模型与技术 3.2 核心组件技术原理 3.2.1 布局检测(Layout Detection) 3.2.2 公式…...

rabbitMQ如何确保消息不会丢失
rabbitmq消息丢失的三种情况 生产者将消息发送到RabbitMQ的过程中时,消息丢失。消息发送到RabbitMQ,还未被持久化就丢失了数据。消费者接收到消息,还未处理,比如服务宕机导致消息丢失。 解决方案 生产者发送过程中,…...
(文末有下载方式))
数字智慧方案5970丨智慧农业大数据服务建设方案(69页PPT)(文末有下载方式)
详细资料请看本解读文章的最后内容。 资料解读:智慧农业大数据服务建设方案 在当今数字化时代,农业领域也正经历着深刻变革,智慧农业大数据服务建设方案应运而生。这一方案对推动农业现代化进程意义非凡,下面让我们深入剖析其核心…...

英一真题阅读单词笔记 22-23年
2022年真题阅读单词 2022 年 Text 1 第一段 1 complain [kəmˈpleɪn] v. 抱怨,投诉;诉说(病痛) 2 plastic [ˈplstɪk] n. 塑料;信用卡 a. 造型的,塑造的;塑料制的 3 durable [ˈd…...

Java大师成长计划之第10天:锁与原子操作
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在多线程编程中,锁与原子…...
)
2025大模型安全研究十大框架合集(10份)
2025大模型安全研究十大框架合集的详细介绍: Anthropic AI信任研究框架 Anthropic于2024年10月更新的《安全责任扩展政策》(RSP),提出了一个灵活的动态AI风险治理框架。该框架规定当AI模型达到特定能力时,将自动升级安全措施,如…...

溯因推理思维——AI与思维模型【92】
一、定义 溯因推理思维模型是一种从结果出发,通过分析、推测和验证,寻找导致该结果的可能原因的思维方式。它试图在已知的现象或结果基础上,逆向追溯可能的原因,构建合理的解释框架,以理解事物的本质和内在机制。 二、由来 溯因推理的思想可以追溯到古希腊哲学家亚里士…...

系统架构设计师:设计模式——结构型设计模式
一、结构型设计模式 结构型设计模式涉及如何组合类和对象以获得更大的结构。结构型类模式采用继承机制来组合接口或实现。一个简单的例子是采用多重继承方法将两个以上的类组合成一个类,结果这个类包含了所有父类的性质。 这一模式尤其有助于多个独立开发的类库协…...

接口测试实战指南:从入门到精通的质量保障之道
为什么接口测试如此重要? 在当今快速迭代的软件开发环境中,接口测试已成为质量保障体系中不可或缺的一环。据统计,有效的接口测试可以发现约70%的系统缺陷,同时能将测试效率提升3-5倍。本指南将从实战角度出发,系统性…...

对第三方软件开展安全测评,如何保障其安全使用?
对第三方软件开展安全测评,能够精准找出软件存在的各类安全隐患,进而为软件的安全使用给予保障。此次会从漏洞发现、风险评估、测试环境等多个方面进行具体说明。 漏洞发现情况 在测评过程中,我们借助专业技术与工具,对第三方软…...

计算方法实验四 解线性方程组的间接方法
【实验性质】 综合性实验。 【实验目的】 掌握迭代法求解线性方程组。 【实验内容】 应用雅可比迭代法和Gauss-Sediel迭代法求解下方程组: 【理论基础】 线性方程组的数值解法分直接算法和迭代算法。迭代法将方程组的求解转化为构造一个向量序列&…...

Qt 中基于 QTableView + QSqlTableModel 的分页搜索与数据管理实现
Qt 中基于 QTableView QSqlTableModel 的分页搜索与数据管理实现 一、组件说明 QTableView:一个基于模型的表格视图控件,支持排序、选择、委托自定义。QSqlTableModel:与数据库表直接绑定的模型类,可用于展示和编辑数据库表数据…...

云计算-容器云-服务网格Bookinfo
服务网格:创建 Ingress Gateway 将 Bookinfo 应用部署到 default 命名空间下,请为 Bookinfo 应用创建一个网 关,使外部可以访问 Bookinfo 应用。 上传ServiceMesh.tar.gz包 [rootk8s-master-node1 ~]# tar -zxvf ServiceMesh.tar.gz [rootk…...

PostgreSQL自定义函数
自定义函数 基本语法 //建一个名字为function_name的自定义函数create or replace function function_name() returns data_type as //returns 返回一个data_type数据类型的结果;data_type 是返回的字段的类型;$$ //固定写法......//方法体$$ LANGUAGE …...

学习记录:DAY22
我的重生开发之旅:优化DI容器,git提交规范,AOP处理器,锁与并发安全 前言 我重生了,重生到了五一开始的一天。上一世,我天天摆烂,最后惨遭实习生优化。这一世,我要好好内卷… 今天的…...

HarmonyOS NEXT第一课——HarmonyOS介绍
一、什么是HarmonyOS 万物互联时代应用开发的机遇、挑战和趋势 随着万物互联时代的开启,应用的设备底座将从几十亿手机扩展到数百亿IoT设备。全新的全场景设备体验,正深入改变消费者的使用习惯。 同时应用开发者也面临设备底座从手机单设备到全场景多设…...

数据库系统概论|第五章:数据库完整性—课程笔记1
前言 在前文介绍完数据库标准语言SQL之后,大家已经基本上掌握了关于数据库编程的基本操作,那我们今天将顺承介绍关于数据库完整性的介绍,数据库的完整性是指数据的正确性和相容性。数据的完整性是为了防止数据库中存在不符合语义的数据&…...

开源无人机地面站QGroundControl安卓界面美化与逻辑优化实战
QGroundControl作为开源无人机地面站软件,其安卓客户端界面美化与逻辑优化是提升用户体验的重要工程。 通过Qt框架的界面重构和代码逻辑优化,可以实现视觉升级与性能提升的双重目标。本文将系统讲解QGC安卓客户端的二次开发全流程,包括开发环境搭建、界面视觉升级、多分辨率…...