pytest——参数化
之前有说过,通过pytest测试框架标记参数化功能可以实现数据驱动测试。数据驱动测试使用的文件主要有以下类型:
- txt 文件
- csv 文件
- excel 文件
- json 文件
- yaml 文件
- ....
本文主要讲的就是以上几种文件类型的读取和使用
一.txt 文件读取使用
首先创建一个 txt 文件,文件内容为:
张三,男,2024-09-10
李四,女,2022-09-10
王五,男,2090-09-10
然后读取文件内容
def get_txt_data():with open(r"D:\python_project\API_Auto\API3\data\txt_data", encoding="utf-8") as file:content = file.readlines()# print(content)# 去掉数据后面的换行符list_data = []list_data1 = []for i in content:list_data.append(i.strip())# 将数据分割for i in list_data:list_data1.append(i.split(","))return list_data1
这样就得到了 符合参数化要求的参数,对读取的内容进行使用:
@pytest.mark.parametrize(("name", "gender", "data"), get_txt_data())
def test_txt_func(name, gender, data):print(f'输入名字:{name}')print(f'输入性别 :{gender}')print(f'输入日期:{data}')
输出为:
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... [['张三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]
collected 3 itemstestcases/test_ddt.py::test_txt_func[张三-男-2024-09-10] 输入名字:张三
输入性别 :男
输入日期:2024-09-10
PASSED
testcases/test_ddt.py::test_txt_func[李四-女-2022-09-10] 输入名字:李四
输入性别 :女
输入日期:2022-09-10
PASSED
testcases/test_ddt.py::test_txt_func[王五-男-2090-09-10] 输入名字:王五
输入性别 :男
输入日期:2090-09-10
PASSED============================== 3 passed in 0.06s ==============================
Report successfully generated to .\reportProcess finished with exit code 0
二.csv 文件读取使用
首先创建一个csv文件,内容为:
1,2,3 1,3,3 2,2,4
然后读取文件内容
import csvdef get_csv_data():list1 = []f = csv.reader(open(r"D:\python_project\API_Auto\API3\data\x_y_z.csv", encoding="utf-8"))for i in f:# list1.append(i.strip())# [int(element) for element in i], 列表推导式,它的作用是对 i 中的每个元素进行遍历,并将每个元素从字符串(str)转换为整数(int)a = [int(element) for element in i]list1.append(a)return list1
然后使用读取到的数据
@pytest.mark.parametrize(("x", "y", "z"), get_csv_data()
)
def test_csv_func(x, y, z):assert x * y == z
输出为:
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... [['张三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]
collected 3 itemstestcases/test_ddt.py::test_csv_func[1-2-3] FAILED
testcases/test_ddt.py::test_csv_func[1-3-3] PASSED
testcases/test_ddt.py::test_csv_func[2-2-4] PASSED================================== FAILURES ===================================
____________________________ test_csv_func[1-2-3] _____________________________x = 1, y = 2, z = 3@pytest.mark.parametrize(("x", "y", "z"), get_csv_data())def test_csv_func(x, y, z):
> assert x * y == z
E assert (1 * 2) == 3testcases\test_ddt.py:21: AssertionError
----------------------------- Captured log setup ------------------------------
WARNING pytest_result_log:plugin.py:122 ---------------Start: testcases/test_ddt.py::test_csv_func[1-2-3]---------------
---------------------------- Captured log teardown ----------------------------
WARNING pytest_result_log:plugin.py:128 ----------------End: testcases/test_ddt.py::test_csv_func[1-2-3]----------------
=========================== short test summary info ===========================
FAILED testcases/test_ddt.py::test_csv_func[1-2-3] - assert (1 * 2) == 3
========================= 1 failed, 2 passed in 0.13s =========================
Report successfully generated to .\reportProcess finished with exit code 0
三.excel 文件读取使用
首先创建一个excel文件,文件内容为:
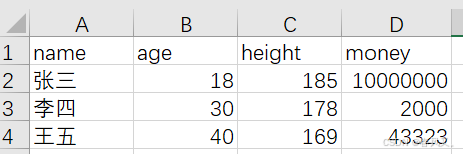
然后在读取Excel数据内容前,要针对不同版本使用不同的第三方库
- xls
- office 2003版本
- 安装:xlrd第三库
- 必须指定版本
- pip install xlrd==1.2.0
- office 2003版本
- xlsx
- office 2016版本
- 安装:openpyxl第三方库
- 默认安装最新的版本库即可
- pip install openpyxl
- office 2016版本
安装完后,读取 数据:
import xlrd# # 读取excel 文件数据获取xls文件对象
# xls = xlrd.open_workbook(r'D:\python_project\API_Auto\API3\data\test.xlsx')
#
# # 获取excel 中的sheet 表,0代表第一张 表的索引、
# sheet = xls.sheet_by_index(0)
#
# # 输出数据列
# print(sheet.ncols)
#
# # 输出数据行
# print(sheet.nrows)
#
# # 读取具体某一行内容,0代表第一行数据索引
# print(sheet.row_values(1))
#def get_excel_data(path):list_excel = []xls = xlrd.open_workbook(path)# 获取excel 中的sheet 表,0代表第一张 表的索引、sheet = xls.sheet_by_index(0)for i in range(sheet.nrows):list_excel.append(sheet.row_values(i))# 删除表头数据list_excel.pop(0)# print(list_excel)return list_excel
使用读取到的数据:
@pytest.mark.parametrize(("name", "age", "height", "money"), get_excel_data(r"D:\python_project\API_Auto\API3\data\test.xlsx")
)
def test_excel_func(name, age, height, money):print(f"name是{name},age是{age},height是{height},money是{money}")
输出结果为 :
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... collected 3 itemstestcases/test_ddt.py::test_excel_func[张三-18.0-185.0-10000000.0] name是张三,age是18.0,height是185.0,money是10000000.0
PASSED
testcases/test_ddt.py::test_excel_func[李四-30.0-178.0-2000.0] name是李四,age是30.0,height是178.0,money是2000.0
PASSED
testcases/test_ddt.py::test_excel_func[王五-40.0-169.0-43323.0] name是王五,age是40.0,height是169.0,money是43323.0
PASSED============================== 3 passed in 0.09s ==============================
Report successfully generated to .\reportProcess finished with exit code 0
四.json 文件的读取使用
首先创建一个json文件,内容为:
[[1,2,3],[4,2,6],[7,8,9] ]
然后读取文件内容
def get_json_data(path):with open(path, encoding="utf-8") as file:content = file.read()# print(eval(content))# print(type(eval(content)))# eval() : 去掉最外层的引号return eval(content)
对读取到的内容进行使用:
@pytest.mark.parametrize(("x", "y", "z"), get_json_data(r'D:\python_project\API_Auto\API3\data\json.json')
)
def test_json_func(x, y, z):assert x + y == z
输出结果为:
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... collected 3 itemstestcases/test_ddt.py::test_json_func[1-2-3] PASSED
testcases/test_ddt.py::test_json_func[4-2-6] PASSED
testcases/test_ddt.py::test_json_func[7-8-9] FAILED================================== FAILURES ===================================
____________________________ test_json_func[7-8-9] ____________________________x = 7, y = 8, z = 9@pytest.mark.parametrize(("x", "y", "z"), get_json_data(r'D:\python_project\API_Auto\API3\data\json.json'))def test_json_func(x, y, z):
> assert x + y == z
E assert (7 + 8) == 9testcases\test_ddt.py:35: AssertionError
----------------------------- Captured log setup ------------------------------
WARNING pytest_result_log:plugin.py:122 --------------Start: testcases/test_ddt.py::test_json_func[7-8-9]---------------
---------------------------- Captured log teardown ----------------------------
WARNING pytest_result_log:plugin.py:128 ---------------End: testcases/test_ddt.py::test_json_func[7-8-9]----------------
=========================== short test summary info ===========================
FAILED testcases/test_ddt.py::test_json_func[7-8-9] - assert (7 + 8) == 9
========================= 1 failed, 2 passed in 0.14s =========================
Report successfully generated to .\reportProcess finished with exit code 0
五.yaml 文件读取使用
1.yaml数据读写
序列化:内存中数据,转化为文件
反序列化:将文件转化为内存数据 需要操作yaml文件,安装第三方库
pip install pyyaml
2.序列化 将yaml 数据写入文件中
"""
YAML 是一个可读性 高,用来达标数据序列化的格式基本语法格式:1.区分大小写2.使用缩进表示层级 关系3.缩进不能 使用 tab 建,只能使用空格4.缩进的空格数不重要,只要相同 层级的元素左对齐即可5.可以使用 注释符号 #yaml 序列化 常用数据类型:1.对象(python中的 字段,键值对)2.数组(python 中的列表 )3.纯量:单个的、不可再分值4.布尔值5.空值YAML 数据读写:序列化:将内存 中数据转化为文件反序列化 :将文件转化为内存数据需要安装第三方库:pip install pyyaml
"""data = {'数字': [1, 2, 3, 4, -1],'字符串': ["a", "@#", "c"],'空值': None,'布尔值': [True, False],'元组': (1, 2, 3)
}import yaml# 将 python 数据类型,转换为yaml 格式
yaml_data = yaml.safe_dump(data, # 要转化的数据内容allow_unicode=True, # 允许unicode 字符,中文原样显示sort_keys=False # 不进行排序,原样输出
)# 序列化 将yaml 数据写入文件中
f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "w", encoding="utf-8")
f.write(yaml_data)
f.close()
3.反序列化 读取yaml 文件中的数据
# 反序列化 读取yaml 文件中的数据
f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "r", encoding="utf-8")
s = f.read()
data_yaml = yaml.safe_load(s)
print(data_yaml)4.写入一个大列表里面嵌套小列表
# 写入一个大列表里面嵌套小列表list1 = [['张三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]yaml_data = yaml.safe_dump(list1, # 要转化的数据内容allow_unicode=True, # 允许unicode 字符,中文原样显示sort_keys=False # 不进行排序,原样输出
)# 序列化 将yaml 数据写入文件中
f = open(r"D:\python_project\API_Auto\API3\data\yaml1.yaml", "w", encoding="utf-8")
f.write(yaml_data)
f.close()完整代码为:
data = {'数字': [1, 2, 3, 4, -1],'字符串': ["a", "@#", "c"],'空值': None,'布尔值': [True, False],'元组': (1, 2, 3)
}import yamldef get_yaml_data():# 将 python 数据类型,转换为yaml 格式yaml_data = yaml.safe_dump(data, # 要转化的数据内容allow_unicode=True, # 允许unicode 字符,中文原样显示sort_keys=False # 不进行排序,原样输出)# 序列化 将yaml 数据写入文件中f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "w", encoding="utf-8")f.write(yaml_data)f.close()# 反序列化 读取yaml 文件中的数据f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "r", encoding="utf-8")s = f.read()data_yaml = yaml.safe_load(s)print(data_yaml)# 写入一个大列表里面嵌套小列表list1 = [['张三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]yaml_data = yaml.safe_dump(list1, # 要转化的数据内容allow_unicode=True, # 允许unicode 字符,中文原样显示sort_keys=False # 不进行排序,原样输出)# 序列化 将yaml 数据写入文件中f = open(r"D:\python_project\API_Auto\API3\data\yaml1.yaml", "w", encoding="utf-8")f.write(yaml_data)f.close()# 反序列化 读取yaml 文件中的数据f = open(r"D:\python_project\API_Auto\API3\data\yaml1.yaml", "r", encoding="utf-8")s = f.read()data_yaml1 = yaml.safe_load(s)print(data_yaml1)return data_yaml1
使用读取到的数据:
@pytest.mark.parametrize(("x"), get_yaml_data()
)
def test_yaml_func(x):for i in x:print(i)
输出为 :
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... {'数字': [1, 2, 3, 4, -1], '字符串': ['a', '@#', 'c'], '空值': None, '布尔值': [True, False], '元组': [1, 2, 3]}
[['张三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]
collected 3 itemstestcases/test_ddt.py::test_yaml_func[x0] 张三
18.0
185.0
10000000.0
PASSED
testcases/test_ddt.py::test_yaml_func[x1] 李四
30.0
178.0
2000.0
PASSED
testcases/test_ddt.py::test_yaml_func[x2] 王五
40.0
169.0
43323.0
PASSED============================== 3 passed in 0.10s ==============================
Report successfully generated to .\reportProcess finished with exit code 0
相关文章:

pytest——参数化
之前有说过,通过pytest测试框架标记参数化功能可以实现数据驱动测试。数据驱动测试使用的文件主要有以下类型: txt 文件 csv 文件excel 文件json 文件yaml 文件.... 本文主要讲的就是以上几种文件类型的读取和使用 一.txt 文件读取使用 首先创建一个 …...

第7篇:RESTful API设计与安全防护
在前后端分离架构中,RESTful API是系统交互的核心通道。本文将从接口规范设计到安全防护,全面讲解如何在EggJS中构建安全、规范、易用的API系统,并提供完整的解决方案和最佳实践。 一、标准化API接口规范设计 1. RESTful设计原则 核心要素&…...

CSS 架构与命名规范
CSS 架构与命名规范:BEM、SMACSS 与 OOCSS 实战 引言 在前端开发中,随着项目规模的扩大,CSS 代码往往会变得难以维护和扩展。无组织的样式表会导致命名冲突、权重覆盖问题和样式继承混乱,这些问题在团队协作的大型项目中尤为明显…...

实验二 软件白盒测试
实验二 软件白盒测试 某工资计算程序功能如下:若雇员月工作小时超过40小时,则超过部分按原小时工资的1.5倍的加班工资来计算。若雇员月工作小时超过50小时,则超过50的部分按原小时工资的3倍的加班工资来计算,而40到50小时的工资仍…...

【数据结构】String字符串的存储
目录 一、存储结构 1.字符串常量池 2.字符串哈希表 2.1结构 2.2基础存储单位 2.2.1键对象 2.2.2值对象 二、存储过程 1.搜索 2.创建 三、存储位置 四、存储操作 1.new新建 2.intern入池 这是String类的详解:String类变量 一、存储结构 1.字符串常量池…...
)
LLMs Tokenizer Byte-Pair Encoding(BPE)
1 Byte-Pair Encoding(BPE) 如何构建词典? 准备足够的训练语料;以及期望的词表大小;将单词拆分为字符粒度(字粒度),并在末尾添加后缀“”,统计单词频率合并方式:统计每一个连续/相邻字节对的出现频率,将最高频的连续字…...

npm,yarn,pnpm,cnpm,nvm,npx包管理器常用命令
前端比较主流的包管理器主要有三个npm,yarn,pnpm 多层级依赖,通常发生在依赖之间存在复杂的版本要求时 包 A 依赖于包 B1.0.0 包 B 依赖于包 C2.0.0 另一个包 D 也依赖于 C3.0.0 一、NPM (Node Package Manager) https://www.npmjs.cn/…...

使用mybatis实例类和MySQL表的字段不一致怎么办
在 MyBatis 中,当 Java 实体类的属性名与数据库表的字段名不一致时,会导致查询结果无法正确映射。以下是几种常见解决方案及代码示例: 1. 使用 resultMap 显式映射(推荐) 场景:字段名与属性名差异较大&…...

阿里发布新一代通义千问 Qwen3模型
近日,阿里巴巴发布了新一代通义千问 Qwen3 模型,一举登顶全球最强开源模型。 这是国内首个“混合推理模型”,将“快思考”与“慢思考”集成进同一个模型,大大节省算力消耗。 旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等…...

React pros比较机制
将 count1作为prop传递给Memoson组件 引用类型情况 虽然list值没有发生变化,但是仍旧重新渲染 解决方法使用useMemo()函数,传递一个空依赖项 // 传递数据为引用类型 比较的是引用 // 使用useMemo函数改写、const list useMemo(()>{return [1,2,3]},[…...
审批我的待办)
Flowable7.x学习笔记(十七)审批我的待办
前言 前文完成了我的待办的查询功能,本文就在此基础上从源码解读到完成审批任务的功能,审批界面我就先不带表单,直接单纯审批通过,这里需要注意的事,审批的表单其实每个节点都可能需要不同的表单内容,后续要…...

HTTP 状态码详解:用途与含义
HTTP 状态码详解:用途与含义 HTTP 状态码详解:用途与含义1. (2xx)成功类200 OK201 Created204 No Content206 Partial Content 2. (3xx)重定向类301 Moved Permanently302 Found(临时重定向&…...

AI日报 · 2025年05月02日 | 再见GPT-4!OpenAI CEO 确认 GPT-4 已从 ChatGPT 界面正式移除
1、OpenAI CEO 确认 GPT-4 已从 ChatGPT 界面正式移除 在处理 GPT-4o 更新问题的同时,OpenAI CEO Sam Altman 于 5 月 1 日在 X 平台发文,正式确认初代 GPT-4 模型已从 ChatGPT 主用户界面中移除。此举遵循了 OpenAI 此前公布的计划,即在 4 …...

ppt设计美化公司_杰青_长江学者_优青_青年长江学者_万人计划青年拔尖人才答辩ppt模板
WordinPPT / 持续为双一流高校、科研院所、企业等提供PPT制作系统服务。 / 近期PPT美化案例 - 院士增选、科学技术奖、杰青、长江学者特聘教授、校企联聘长江、重点研发、优青、青长、青拔.. 杰青(杰出青年科学基金) 支持已取得突出成果的45岁以下学…...

文章四《深度学习核心概念与框架入门》
文章4:深度学习核心概念与框架入门——从大脑神经元到手写数字识别的奇幻之旅 引言:给大脑装个"GPU加速器"? 想象一下,你的大脑如果能像智能手机的GPU一样快速处理信息会怎样?这正是深度学习的终极目标&…...

HTML5+JavaScript实现连连看游戏之二
HTML5JavaScript实现连连看游戏之二 以前一篇,见 https://blog.csdn.net/cnds123/article/details/144220548 连连看游戏连接规则: 只能连接相同图案(或图标、字符)的方块。 连线路径必须是由直线段组成的,最多可以有…...
---java版)
2025年- H19-Lc127-48.旋转矩阵(矩阵)---java版
1.题目描述 2.思路 画出矩阵,新的旋转矩阵的列坐标等于原始矩阵的矩阵长度-i-1(也就是减去当前遍历的i),前后对调。然后新的旋转矩阵的横坐标,是原始矩阵的列坐标。 3.代码实现 public class H48 {public void rota…...

深入理解 MyBatis 代理机制
在 Java 开发领域,MyBatis 是一款优秀的持久层框架,它极大地简化了数据库操作,提高了开发效率。其中,代理机制作为 MyBatis 的核心特性之一,在连接 Java 代码与数据库操作中发挥着关键作用。本文将深入探讨 MyBatis 代…...

游戏引擎学习第254天:重新启用性能分析
运行游戏并尝试让性能分析系统恢复部分功能 我们现在的调试系统这几天基本整理得差不多了,因此我们打算开始清理一些功能,比如目前虽然已经在收集性能分析数据,但我们没有办法查看或有效利用这些信息。今天的计划可能会围绕这方面展开&#…...

性能测试工具篇
文章目录 目录1. JMeter介绍1.1 安装JMeter1.2 打开JMeter1.3 JMeter基础配置1.4 JMeter基本使用流程1.5 JMeter元件作用域和执行顺序 2. 重点组件2.1 线程组2.2 HTTP取样器2.3 查看结果树2.4 HTTP请求默认值2.5 JSON提取器2.6 用户定义的变量2.7 JSON断言2.8 同步定时器&#…...

【Hive入门】Hive性能调优之Join优化:深入解析MapJoin与Sort-Merge Join策略
目录 前言 1 Hive Join操作基础 1.1 Join操作的类型与挑战 1.2 Hive Join执行机制 2 MapJoin优化策略 2.1 MapJoin原理 2.2 MapJoin适用场景 2.3 MapJoin关键参数 3 Sort-Merge Join优化策略 3.1 Sort-Merge Join原理 3.2 Sort-Merge Join优势 3.3 关键配置参数 3…...

【Unity】使用XLua实现C#访问Lua文件
先引入XLua文件中的Plugins和XLua文件夹于Unity项目的Asset文件中 XLua_github链接 建立Lua虚拟机:LuaEnv luaEnv new LuaEnv(); 关闭虚拟机,及时释放资源:luaEnv.Dispose(); Resources文件夹下加载lua文件(假设文件路径为Resour…...

AXI中的out of order和interleaving的定义和两者的差别?
AXI中的out of order和interleaving的定义和两者的差别 摘要:在 AXI (Advanced eXtensible Interface) 协议中,Out-of-Order 和 Interleaving 是两个与事务处理顺序和数据传输相关的概念,它们都与 AXI 协议支持的多事务并发处理能力有关&…...

生产级RAG系统一些经验总结
本文将探讨如何使用最新技术构建生产级检索增强生成(RAG)系统,包括健壮的架构、向量数据库(Faiss、Pinecone、Weaviate)、框架(LangChain、LlamaIndex)、混合搜索、重排序器、流式数据接入、评估策略以及实际部署技巧。 引言:检索增强生成的力量 大型语…...

sftp连接报错Received message too long 168449893
sftp连接报错Received message too long 168449893 一、openEuler传文件报错二、分析问题三、解决问题endl 一、openEuler传文件报错 [rootRocky9-12 ~]# scp apache-tomcat-10.1.33.tar.gz root10.0.0.14:Authorized users only. All activities may be monitored and report…...

Java中修饰类的关键字
Java中修饰类的关键字 在web编程课上,老师提问了Java中各种修饰类的关键字的用途和区别,一时间我头脑空白,现在课后重新梳理一遍Java中修饰类的各种关键字的区别和用法。在Java编程中,修饰类的关键字起着至关重要的作用ÿ…...

2025年人工智能火爆技术总结
2025年人工智能火爆技术总结: 生成式人工智能 生成式人工智能可生成高质量的图像、视频、音频和文本等多种内容。如昆仑万维的SkyReels-V2能生成无限时长电影,其基于扩散强迫框架,结合多模态大语言模型和强化学习等技术,在运动动…...

脑机接口技术:开启人类与机器的全新交互时代
在科技飞速发展的今天,人类与机器的交互方式正经历着前所未有的变革。从最初的键盘鼠标,到触摸屏,再到语音控制,每一次交互方式的升级都极大地提升了用户体验和效率。如今,脑机接口(Brain-Computer Interfa…...

Arduino程序函数详解与实际案例
一、Arduino程序的核心架构与函数解析 Arduino程序的核心由两个函数构成:setup() 和 loop()。这两个函数是所有Arduino代码的骨架,它们的合理使用决定了程序的结构和功能。 1.1 setup() 函数:初始化阶段 setup() 函数在程序启动时仅执行一次,用于完成初始化配置,例如设置…...

2025年RAG技术发展现状分析
2025年,大模型RAG(检索增强生成)技术经历了快速迭代与深度应用,逐渐从技术探索走向行业落地,同时也面临安全性和实用性的新挑战。以下是其发展现状的综合分析: 一、技术架构的持续演进 从单一到模块化架构 …...

C++11新特性_范围-based for 循环
based for 循环介绍 范围 - based for 循环(Range-based for loop)是 C11 引入的一种新的 for 循环语法,它可以更简洁地遍历容器和数组。 遍历数组:定义了一个整数数组 arr,使用范围 - based for 循环 for (int num :…...

小牛电动:荣登央视舞台,引领智能出行新潮流
在这个科技飞速发展的时代,出行方式也在不断地变革与创新。而在两轮电动车领域,有一个品牌凭借其卓越的技术、独特的设计和优质的服务脱颖而出,那就是小牛电动。近日,小牛电动荣登央视舞台,成为备受瞩目的焦点…...
-基础)
Three.js在vue中的使用(一)-基础
Three.js 是一个基于 WebGL 的 JavaScript 3D 图形库,它简化了在网页中创建和渲染 3D 场景的复杂性。Three.js 提供了丰富的功能,如光照、材质、几何体、动画、控制器等,使得开发者可以快速构建交互式的 3D 应用。 🧠 Three.js 原理概述 1. WebGL 基础 Three.js 底层使用…...

开发板型号 ESP32-DevKitC-32模块型号 ESP32-WROOM-32 和主控芯片 ESP32-D0WDQ6-V3
以下是关于开发板型号 ESP32-DevKitC-32、模块型号 ESP32-WROOM-32 和主控芯片 ESP32-D0WDQ6-V3 的详细介绍: 开发板型号:ESP32-DevKitC-32 概述:ESP32-DevKitC 是乐鑫推出的一款基于 ESP32 模组的小型开发板,板上模组的绝大部…...

【C语言练习】015. 声明和初始化指针
015. 声明和初始化指针 015. 声明和初始化指针1. 声明指针示例1:声明一个指向整数的指针2. 初始化指针示例2:将指针初始化为`NULL`示例3:将指针初始化为某个变量的地址示例4:将指针初始化为动态分配的内存地址3. 使用指针访问和修改变量的值示例5:使用指针访问和修改变量的…...

手撕哈希表
引入:unordered_set /map是什么? 库里面除开set和map,还有unordered_set 和 unordered_map,区别在于: ①:set和map的底层结构是红黑树,而unordered_set和unordered_map的底层是哈希表 ②&…...

编程题python常用技巧-持续
1.字典 1.1排序 在Python中,要按照字典的值进行排序,可以按照以下步骤操作: 方法说明 获取键值对列表:使用 dict.items() 获取字典的键值对视图。排序键值对:使用 sorted() 函数,并通过 key 参…...

大模型蒸馏技术
提问:请写一篇关于蒸馏大模型的详细解说(论文),要求配有图并不少于8000字。 Deepseek: 大模型蒸馏技术:原理、方法与产业实践 ——基于知识压缩与效率优化的深度解析 目录 引言:大模型时代的…...

深入理解C语言中的整形提升与算术转换
深入理解C语言中的整形提升与算术转换 一.整形提升:概念与原理 在C语言中,整形提升(Integer Promotion)是一个重要但容易被忽视的概念。它指的是在表达式中,任何小于int类型的整型(如char、short…...

企业经营系统分类及功能详解
近年来互联网行业下行,招聘少,要求离谱,年龄学历背景已经卡的死死的,技术再突出也没用。 但对于软件开发来说,互联网只是一小部分,企业级系统软件开发,虽然不如互联网大起大落,但重…...

IRF2.0IRF3.1
1、IRF3定义 IRF3是一种能够提高网络接入层的接入能力和管理效率的纵向网络整合虚拟化技术,采用IEEE 802.1BR标准协议实现。IRF3将多台PEX设备(Bridge Port Extender)连接到父设备(Parent device)上,将每台…...

【C++】类和对象【中下】
目录 一、类与对象1、运算符重载1.2 赋值运算符重载1.3 <<运算符和>>运算符1.4 前置与后置 2、 const成员函数3、取地址运算符重载 个人主页<—请点击 C专栏<—请点击 一、类与对象 本期的主题是一步步完善日期类的编写,将要讲解的知识融入在代…...

ThreadLocal详解
什么是 ThreadLocal? ThreadLocal 是 Java 中的一个工具类,用于为每个线程提供独立的变量副本,使得每个线程可以独立操作自己的变量,避免多线程环境下的数据竞争问题。它的核心思想是线程封闭(Thread Confi…...

Vue3 + OpenLayers 企业级应用进阶
1. 企业级架构设计 1.1 微前端架构集成 // src/micro-frontend/map-container.ts import { Map } from ol; import { registerMicroApps, start } from qiankun;export class MapMicroFrontend {private map: Map;private apps: any[];constructor(map: Map) {this.map map;…...

如何提升自我执行力?
提升个人执行力是一个系统性工程,需要从目标管理、习惯养成、心理调节等多方面入手。 以下是具体方法,结合心理学和行为科学原理,帮助你有效提升执行力: 一、明确目标:解决「方向模糊」问题 1. 用SMART原则设定目标 …...

L3-041 影响力
下面给出基于“切比雪夫距离”(Chebyshev 距离)之和的高效 O(nm) 解法。核心思想是把 ∑ u 1 n ∑ v 1 m max ( ∣ u − i ∣ , ∣ v − j ∣ ) \sum_{u1}^n\sum_{v1}^m\max\bigl(|u-i|,|v-j|\bigr) u1∑nv1∑mmax(∣u−i∣,∣v−j∣) 拆成两个…...

【ESP32】st7735s + LVGL使用-------图片显示
【ESP32】st7735s + LVGL使用-------图片显示 1、文件准备2、工程搭建3、代码编写4、应用部分5、函数调用6、显示效果移植部分参考这个博客: 【ESP32】st7735s + LVGL移植 1、文件准备 本次图片放在内部存储,先使用转换工具将要显示的图片转换好。 文件名保存为xx.c,xx这…...
,FEDERATED存储引擎(介绍,操作),不同存储引擎的特性图)
MERGE存储引擎(介绍,操作),FEDERATED存储引擎(介绍,操作),不同存储引擎的特性图
目录 MERGE存储引擎(合并) 介绍 创建表 语法 示例 查看.mrg文件 操作 查询结果 示例 重建逻辑表 FEDERATED存储引擎 结盟 介绍 编辑 应用场景 操作 开启 创建表 对本地表进行数据插入 EXAMPLE存储引擎 不同存储引擎的特性编辑 MERGE存储引擎(合并) 介绍…...

初学者如何学习AI问答应用开发范式
本文是根据本人2年大模型应用开发5年小模型开发经验,对AI问答应用的开发过程进行总结。 技术范式 现在超过80%的AI问答是 提示词 大模型, 然后就是RAG 方案,这两种无疑是主流方案。 1、提示词大模型 适合于本身业务不超过大模型的知识范围…...
))
GESP2024年6月认证C++八级( 第二部分判断题(1-5))
判断题2: #include <iostream> #include <iomanip> using namespace std;int main() {double a 1e308;double b 1e-10;double orig_a a, orig_b b;a a b;b a - b;a a - b;cout << fixed << setprecision(20);cout << "…...