近端策略优化PPO详解:python从零实现
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
引言
近端策略优化(Proximal Policy Optimization,简称 PPO)是一种最先进的策略梯度算法,已经成为许多强化学习任务的首选,尤其是在连续控制领域。它在信任区域策略优化(Trust Region Policy Optimization,简称 TRPO)的基础上进行了改进,但使用了更简单的机制——主要是截断代理目标函数——来限制策略更新并确保学习过程稳定。这使得 PPO 更容易实现和调整,同时通常能够达到与 TRPO 相当甚至更好的性能。
PPO 是什么?
PPO 是一种在线策略、演员-评论家算法。和其他策略梯度方法一样,它直接学习一个策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)。它的关键特性包括:
- 演员-评论家结构:它使用两个网络:一个演员(策略网络 π θ \pi_\theta πθ)用于选择动作,一个评论家(价值网络 $ V_\phi $)用于评估状态并帮助估计优势。
- 在线策略数据收集:它使用当前策略收集经验轨迹。
- 截断代理目标函数:与 TRPO 的复杂 KL 约束和二阶优化不同,PPO 使用一个更简单的一阶目标函数,通过惩罚策略概率比 r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st) 的大幅变化来限制策略更新。这种截断机制有效地将新策略保持在旧策略附近。
- 多次更新周期:PPO 通常对同一个数据批次进行多次梯度更新,与那些在一次更新后就丢弃数据的方法(例如 REINFORCE 或标准 A2C)相比,显著提高了样本效率。
PPO 的优势:相比 TRPO 和普通策略梯度
- 简单性:PPO 的截断目标函数比 TRPO 的 FVP、CG 和线搜索更容易实现,它使用标准的随机梯度上升法。
- 稳定性:截断机制提供了与 TRPO 信任区域类似的稳定性,防止了普通策略梯度中可能出现的破坏性大策略更新。
- 效率:通常比普通策略梯度更样本高效,因为它对每个批次进行多次更新,而且每次更新的计算速度通常比 TRPO 更快。
- 性能:在广泛的基准测试中,尤其是在连续控制任务中,PPO 能够取得最先进的结果。
PPO 的应用场景
PPO 是目前最流行和广泛使用的强化学习算法之一:
- 连续控制:机器人仿真(MuJoCo)、运动控制、操作任务。
- 视频游戏:需要复杂策略的游戏(例如 Dota 2、星际争霸)。
- 大型语言模型对齐:在基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,简称 RLHF)中,用于微调像 ChatGPT 这样的大型语言模型(LLM)。
- 通用强化学习基准测试:通常作为新算法开发的强基线。
PPO 适用于以下情况:
- 需要稳定和鲁棒的学习过程。
- 实现简单性比 TRPO 的理论保证更重要。
- 动作空间是离散的或连续的。
- 可以进行在线策略交互。
- 需要相对较好的样本效率(与其他在线策略方法相比)。
PPO 的数学基础
策略梯度回顾与代理目标函数
回顾 TRPO 的代理目标函数,使用重要性采样:
L θ o l d ( θ ) = E t [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A ^ t ] = E t [ r t ( θ ) A ^ t ] L_{\theta_{old}}(\theta) = \mathbb{E}_{t} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} \hat{A}_t \right] = \mathbb{E}_{t} [ r_t(\theta) \hat{A}_t ] Lθold(θ)=Et[πθold(at∣st)πθ(at∣st)A^t]=Et[rt(θ)A^t]
其中 $ r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} $ 是概率比,$ \hat{A}t $ 是在旧策略 $ \pi{\theta_{old}} $ 下估计的优势。
大策略更新的问题
直接用大步长最大化 L θ o l d ( θ ) L_{\theta_{old}}(\theta) Lθold(θ) 可能会出问题,因为如果 r t ( θ ) r_t(\theta) rt(θ) 变得非常大或非常小,更新就会变得不稳定。TRPO 通过 KL 约束解决了这个问题。
PPO 的截断代理目标函数( L C L I P L^{CLIP} LCLIP)
PPO 引入了一种更简单的方法来阻止大的比率 $ r_t(\theta) $,通过截断目标函数:
L C L I P ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \quad \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right] LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
这里:
- ϵ \epsilon ϵ 是一个小的超参数(例如 0.1 或 0.2),定义了截断范围。
- clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) clip(rt(θ),1−ϵ,1+ϵ) 将比率 r t ( θ ) r_t(\theta) rt(θ) 限制在区间 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 内。
- $\min $ 函数取原始目标 ( r t ( θ ) A ^ t ) (r_t(\theta) \hat{A}_t) (rt(θ)A^t) 和截断版本 ( clip ( . . . ) A ^ t ) (\text{clip}(...) \hat{A}_t) (clip(...)A^t) 的最小值。
直觉理解:
- 如果 A ^ t > 0 \hat{A}_t > 0 A^t>0(动作比平均水平更好):目标函数随着 r t ( θ ) r_t(\theta) rt(θ) 的增加而增加(使动作更有可能发生)。然而,当 $r_t(\theta) $ 超过 $ 1 + \epsilon$ 时,增加会被限制,防止由于这个单一的好动作而导致过于大的更新。
- 如果 $ \hat{A}_t < 0 $(动作比平均水平更差):目标函数随着 r t ( θ ) r_t(\theta) rt(θ) 的增加而减少(使动作更不可能发生)。当 r t ( θ ) r_t(\theta) rt(θ) 低于 1 − ϵ 1 - \epsilon 1−ϵ 时,截断项 clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) clip(rt(θ),1−ϵ,1+ϵ) 开始起作用。取 min \min min 确保我们使用的是使目标函数更小(更不负面或更正面)的项,有效地限制了在一步中减少这个动作概率的程度。
本质上,截断机制消除了策略在单次更新中基于当前优势估计而发生剧烈变化( r t r_t rt 远离 1.0)的动机。
价值函数损失($ L^{VF} $)
像许多演员-评论家方法一样,PPO 训练一个价值网络 V ϕ ( s ) V_\phi(s) Vϕ(s) 来估计状态值,主要用于计算优势。价值网络通过最小化其预测值与某个目标值(通常是经验回报或 GAE 优势 + 旧价值)之间的平方误差来训练:
L V F ( ϕ ) = E t [ ( V ϕ ( s t ) − V t t a r g ) 2 ] L^{VF}(\phi) = \mathbb{E}_t [(V_\phi(s_t) - V_t^{targ})^2] LVF(ϕ)=Et[(Vϕ(st)−Vttarg)2]
其中 V t t a r g V_t^{targ} Vttarg 可以是折扣回报 $G_t $ 或 $ \hat{A}t^{GAE} + V{\phi_{old}}(s_t)$。
可选:熵奖励($ S $)
为了鼓励探索并防止过早收敛到次优的确定性策略,通常会添加一个熵奖励到目标函数中。目标是最大化策略熵 H ( π θ ( ⋅ ∣ s t ) ) H(\pi_\theta(\cdot|s_t)) H(πθ(⋅∣st))。
S [ π θ ] ( s t ) = E a ∼ π θ ( ⋅ ∣ s t ) [ − log π θ ( a ∣ s t ) ] S[\pi_\theta](s_t) = \mathbb{E}_{a \sim \pi_\theta(\cdot|s_t)} [-\log \pi_\theta(a|s_t)] S[πθ](st)=Ea∼πθ(⋅∣st)[−logπθ(a∣st)]
PPO 的综合目标函数
最终的目标函数通常将策略代理损失、价值函数损失和熵奖励结合起来:
L P P O ( θ , ϕ ) = E t [ L C L I P ( θ ) − c 1 L V F ( ϕ ) + c 2 S [ π θ ] ( s t ) ] L^{PPO}(\theta, \phi) = \mathbb{E}_t [ L^{CLIP}(\theta) - c_1 L^{VF}(\phi) + c_2 S[\pi_\theta](s_t) ] LPPO(θ,ϕ)=Et[LCLIP(θ)−c1LVF(ϕ)+c2S[πθ](st)]
其中 $ c_1 $ 和 $ c_2 $ 是系数(超参数)。通常,策略和价值损失会使用各自的梯度进行优化,尽管它们可以共享较低层的网络。
优势估计:GAE
PPO 通常使用广义优势估计(Generalized Advantage Estimation,简称 GAE),与 TRPO 中的使用方式相同,以获得稳定且低方差的优势估计 A ^ t \hat{A}_t A^t。
A ^ t G A E = ∑ l = 0 ∞ ( γ λ ) l δ t + l , 其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \hat{A}^{GAE}_t = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}, \quad \text{其中} \quad \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) A^tGAE=l=0∑∞(γλ)lδt+l,其中δt=rt+γV(st+1)−V(st)
多次更新周期
PPO 的一个关键特性是对同一个收集到的经验批次进行多次梯度下降步骤(周期)。这提高了样本效率。截断机制防止策略在多次更新中偏离 π θ o l d \pi_{\theta_{old}} πθold,即使使用相同的旧数据进行更新。
PPO 的逐步解释
- 初始化:策略网络 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)(演员)、价值网络 V ( s ; ϕ ) V(s; \phi) V(s;ϕ)(评论家)、超参数( γ , λ , ϵ , c 1 , c 2 \gamma, \lambda, \epsilon, c_1, c_2 γ,λ,ϵ,c1,c2,学习率,周期数,批次大小/每次迭代的步数)。
- 每次迭代:
a. 收集轨迹:使用当前策略 π θ o l d = π ( ⋅ ∣ ⋅ ; θ ) \pi_{\theta_{old}} = \pi(\cdot | \cdot; \theta) πθold=π(⋅∣⋅;θ),收集一批轨迹(状态、动作、奖励、结束标志、下一个状态,以及对数概率 $ \log \pi_{\theta_{old}}(a_t|s_t) $)。
b. 估计价值和优势:计算所有状态的 V ( s t ; ϕ ) V(s_t; \phi) V(st;ϕ)。使用收集到的数据和当前价值网络计算 GAE 优势 $ \hat{A}_t $ 和目标回报 V t t a r g = A ^ t + V ( s t ; ϕ ) V_t^{targ} = \hat{A}_t + V(s_t; \phi) Vttarg=A^t+V(st;ϕ)。
c. 优化(多次周期):对于 K 个周期:
i. 遍历收集到的批次(可能使用小批次)。
ii. 对于每个小批次:
- 计算策略比率 r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) = exp ( log π θ ( a t ∣ s t ) − log π θ o l d ( a t ∣ s t ) ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} = \exp(\log \pi_\theta(a_t|s_t) - \log \pi_{\theta_{old}}(a_t|s_t)) rt(θ)=πθold(at∣st)πθ(at∣st)=exp(logπθ(at∣st)−logπθold(at∣st))。
- 计算截断代理目标 L C L I P L^{CLIP} LCLIP。
- 计算价值函数损失 L V F L^{VF} LVF。
- (可选)计算熵奖励 S S S。
- 计算综合损失(例如, L = − L C L I P + c 1 L V F − c 2 S L = -L^{CLIP} + c_1 L^{VF} - c_2 S L=−LCLIP+c1LVF−c2S)。
- 使用综合损失或单独的损失对 θ \theta θ 和 ϕ \phi ϕ 进行梯度下降步骤。 - 重复:直到收敛。
PPO 的关键组成部分
策略网络(演员)
- 参数化随机策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ),输出动作概率或分布的参数。
价值网络(评论家)
- 参数化状态价值函数 V ( s ; ϕ ) V(s; \phi) V(s;ϕ),用于 GAE。
- 通过均方误差损失进行训练。
轨迹收集(在线策略)
- 使用当前策略 π θ o l d \pi_{\theta_{old}} πθold 收集经验批次。
- 存储状态、动作、奖励、结束标志以及 log π θ o l d ( a ∣ s ) \log \pi_{\theta_{old}}(a|s) logπθold(a∣s)。
优势估计(GAE)
- 计算方差降低的优势估计 A ^ t \hat{A}_t A^t。
截断代理目标函数
- PPO-Clip 的核心。限制概率比率 r t ( θ ) r_t(\theta) rt(θ) 的影响,防止过大的策略更新。
价值函数更新
- 根据观察到的回报/优势更新评论家网络。
多次周期和小批次
- 通过多次梯度更新重用收集到的数据,提高样本效率。
- 小批次可以进一步稳定周期内的训练。
超参数
- 截断范围( ϵ \epsilon ϵ):控制新策略与旧策略的最大偏离程度(例如 0.1、0.2)。
- GAE Lambda( λ \lambda λ):控制优势估计中的偏差-方差权衡(例如 0.95、0.97)。
- 折扣因子( γ \gamma γ):标准的强化学习折扣因子(例如 0.99)。
- 学习率:演员和评论家优化器的学习率(通常使用 Adam 优化器)。
- 周期数(K):对数据批次进行迭代的次数(例如 4、10)。
- 小批次大小:在周期内使用的小批次大小。
- 价值损失系数($c_ $):价值损失项的权重(例如 0.5、1.0)。
- 熵系数( c 2 c_2 c2):熵奖励的权重(例如 0.01、0.001)。
PPO 与大型语言模型(LLM)——基于人类反馈的强化学习(RLHF)
PPO 已经成为通过一种称为基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,简称 RLHF)的技术,将大型语言模型(LLM)与人类偏好对齐的核心算法。这解决了仅仅预测下一个标记(标准监督学习)并不能保证 LLM 的输出是有帮助的、无害的和诚实的问题。
对齐问题
通过在海量互联网文本上训练的 LLM 可以生成流畅且知识渊博的回应,但它们也可能产生不理想的输出(有毒、有偏见、事实错误、无帮助)。我们希望引导 LLM 生成人类更偏好的回应。
基于人类反馈的强化学习(RLHF)
RLHF 通常是一个三阶段的过程:
-
监督微调(SFT):从一个预训练的基础 LLM 开始。在一个人类策划的高质量的提示-回应对数据集上进行微调。这使模型适应期望的风格和领域(例如,指令遵循、聊天)。
-
奖励模型(RM)训练:
- 使用 SFT 模型生成多个回应。
- 人类标注者根据期望的标准(有帮助、无害等)对这些回应进行从最好到最差的排名。
- 训练一个单独的模型(通常是另一个 LLM,从 SFT 模型或其较小变体初始化)来预测这些人类偏好分数。输入是提示-回应对,输出是一个标量奖励信号。
-
基于 RL 的微调(PPO):
- 使用 SFT 模型作为初始策略。
- 使用 PPO 进一步微调这个策略。
- 演员:正在调整的 LLM。
- 状态:输入提示(上下文)。
- 动作空间:LLM 可以生成的词汇表中的标记。
- 动作:生成序列中的下一个标记。
- 策略 π θ \pi_\theta πθ:LLM 本身,定义了给定上下文下下一个标记的概率分布。
- 环境:从提示开始,逐标记生成完整回应的过程。
- 奖励:在生成完整回应后,奖励模型提供一个标量奖励,表示对该整个回应的预测质量/偏好。
- PPO 更新:PPO 使用经验(提示、生成的回应、RM 奖励)来更新 LLM(演员)的参数 $ \theta $,以最大化来自 RM 的预期奖励。
PPO 在 RLHF 中的作用
在 RLHF 阶段:
- PPO 优化 LLM 策略 π θ \pi_\theta πθ。
- 轨迹包括给定提示(状态)生成标记序列(动作)。
- 优势函数 A ^ t \hat{A}_t A^t 依赖于 RM 的奖励以及可能用于估计中间状态(标记序列)的预期 RM 奖励的价值函数(评论家)。
- 策略更新旨在增加导致 RM 高奖励的标记序列的概率。
RLHF 的目标函数与 PPO
在 RLHF 中,通常会在 PPO 目标中添加一个 KL 散度惩罚项。这防止了微调后的 LLM ( π θ \pi_\theta πθ) 与原始 SFT 模型 ($ \pi_{ref} $) 偏离太多,确保它保留了语言能力,而不是过度适应奖励模型(奖励欺骗)。
Objective R L H F = E ( s , a ) ∼ π θ [ R R M ( s , a ) − β D K L ( π θ ( ⋅ ∣ s ) ∣ ∣ π r e f ( ⋅ ∣ s ) ) ] \text{Objective}_{RLHF} = \mathbb{E}_{(s,a) \sim \pi_\theta} [ R_{RM}(s, a) - \beta D_{KL}(\pi_\theta(\cdot|s) || \pi_{ref}(\cdot|s)) ] ObjectiveRLHF=E(s,a)∼πθ[RRM(s,a)−βDKL(πθ(⋅∣s)∣∣πref(⋅∣s))]
这里,$ R_{RM} $ 是奖励模型的奖励,而 $ \beta $ 控制 KL 惩罚项的强度。PPO 用于优化这个综合目标(最大化 RM 奖励,同时保持与参考策略的接近)。截断代理目标 L C L I P L^{CLIP} LCLIP 通过优势估计隐式地包含奖励项,而 KL 惩罚项则显式地添加。
为什么使用 PPO 来对齐 LLM?
- 稳定性:微调大型模型的计算成本很高;稳定的更新对于防止性能崩溃至关重要。
- 相对样本效率:尽管仍然是在线策略,但每个数据批次的多次更新使得它比单次更新的方法(例如 REINFORCE)更有效地利用了昂贵的采样过程(生成文本并获取 RM 分数)。
- 简单性和可扩展性:与 TRPO 相比,更容易实现和扩展到分布式系统。
面临的挑战
- 奖励模型的质量:整个过程依赖于能够准确反映真实人类偏好的奖励模型。
- 奖励欺骗:LLM 可能找到利用奖励模型的方法,以获得高分,而不是真正提高质量。
- 计算成本:RLHF 极其计算密集。
- 超参数调整:需要仔细调整 PPO 和 RLHF 特定的参数(例如 β \beta β)。
总之,PPO 提供了稳定且相对高效的强化学习优化引擎,用于在 RLHF 流程中基于学习到的人类偏好模型微调大型 LLM。
实践示例:自定义网格世界
我们再次使用自定义网格世界来说明 PPO 的实现机制,保持与之前笔记本的一致性。
环境描述:(与之前相同)
- 网格大小:10x10。
- 状态:
[row/9, col/9] - 动作:4 个离散动作(上、下、左、右)。
- 起点:(0, 0),终点:(9, 9)。
- 奖励:+10(到达终点),-1(碰到墙壁),-0.1(每步)。
- 终止条件:到达终点或达到最大步数。
设置环境
导入库(与 TRPO 相同)。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque
from itertools import count
from typing import List, Tuple, Dict, Optional, Callable
import copy # 用于存储旧策略网络参数# 导入 PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")# 设置随机种子以确保可重复性
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)%matplotlib inline
使用设备:cpu
创建自定义环境
重新使用 GridEnvironment 类。
# 自定义网格世界环境(与之前的笔记本相同)
class GridEnvironment:"""一个简单的 10x10 网格世界环境。状态:(行, 列),表示为归一化向量 [row/9, col/9]。动作:0(上),1(下),2(左),3(右)。奖励:到达终点 +10,碰到墙壁 -1,每步 -0.1。"""def __init__(self, rows: int = 10, cols: int = 10) -> None:self.rows: int = rowsself.cols: int = colsself.start_state: Tuple[int, int] = (0, 0)self.goal_state: Tuple[int, int] = (rows - 1, cols - 1)self.state: Tuple[int, int] = self.start_stateself.state_dim: int = 2self.action_dim: int = 4self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}def reset(self) -> torch.Tensor:self.state = self.start_statereturn self._get_state_tensor(self.state)def _get_state_tensor(self, state_tuple: Tuple[int, int]) -> torch.Tensor:norm_row = state_tuple[0] / (self.rows - 1) if self.rows > 1 else 0.0norm_col = state_tuple[1] / (self.cols - 1) if self.cols > 1 else 0.0normalized_state: List[float] = [norm_row, norm_col]return torch.tensor(normalized_state, dtype=torch.float32, device=device)def step(self, action: int) -> Tuple[torch.Tensor, float, bool]:if self.state == self.goal_state:return self._get_state_tensor(self.state), 0.0, Truedr, dc = self.action_map[action]current_row, current_col = self.statenext_row, next_col = current_row + dr, current_col + dcreward: float = -0.1hit_wall: bool = Falseif not (0 <= next_row < self.rows and 0 <= next_col < self.cols):next_row, next_col = current_row, current_colreward = -1.0hit_wall = Trueself.state = (next_row, next_col)next_state_tensor: torch.Tensor = self._get_state_tensor(self.state)done: bool = (self.state == self.goal_state)if done:reward = 10.0return next_state_tensor, reward, donedef get_action_space_size(self) -> int:return self.action_dimdef get_state_dimension(self) -> int:return self.state_dim
实例化并测试环境。
custom_env = GridEnvironment(rows=10, cols=10)
n_actions_custom = custom_env.get_action_space_size()
n_observations_custom = custom_env.get_state_dimension()print(f"自定义网格环境:")
print(f"大小:{custom_env.rows}x{custom_env.cols}")
print(f"状态维度:{n_observations_custom}")
print(f"动作维度:{n_actions_custom}")
start_state_tensor = custom_env.reset()
print(f"示例状态张量 (0,0):{start_state_tensor}")
自定义网格环境:
大小:10x10
状态维度:2
动作维度:4
示例状态张量 (0,0):tensor([0., 0.])
实现 PPO 算法
定义演员(策略网络)和评论家(价值网络),计算 GAE 以及 PPO 更新函数。
定义演员网络
与 TRPO/REINFORCE 中使用的策略网络相同。
# 定义策略网络(演员)
class PolicyNetwork(nn.Module):""" PPO 的 MLP 演员网络 """def __init__(self, n_observations: int, n_actions: int):super(PolicyNetwork, self).__init__()self.layer1 = nn.Linear(n_observations, 128)self.layer2 = nn.Linear(128, 128)self.layer3 = nn.Linear(128, n_actions)def forward(self, x: torch.Tensor) -> Categorical:"""前向传播,返回一个 Categorical 分布。"""if not isinstance(x, torch.Tensor):x = torch.tensor(x, dtype=torch.float32, device=device)elif x.dtype != torch.float32:x = x.to(dtype=torch.float32)if x.dim() == 1:x = x.unsqueeze(0)x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))action_logits = self.layer3(x)return Categorical(logits=action_logits)
定义评论家网络
与 TRPO 中使用的价值网络相同。
# 定义价值网络(评论家)
class ValueNetwork(nn.Module):""" PPO 的 MLP 评论家网络 """def __init__(self, n_observations: int):super(ValueNetwork, self).__init__()self.layer1 = nn.Linear(n_observations, 128)self.layer2 = nn.Linear(128, 128)self.layer3 = nn.Linear(128, 1)def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播,返回估计的状态价值。"""if not isinstance(x, torch.Tensor):x = torch.tensor(x, dtype=torch.float32, device=device)elif x.dtype != torch.float32:x = x.to(dtype=torch.float32)if x.dim() == 1:x = x.unsqueeze(0)x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))state_value = self.layer3(x)return state_value
计算广义优势估计(GAE)
重新使用 TRPO 中的 GAE 函数。
# 定义 compute_gae 函数(当前缺失)
def compute_gae(rewards: torch.Tensor, values: torch.Tensor, next_values: torch.Tensor, dones: torch.Tensor, gamma: float, lambda_gae: float, standardize: bool = True) -> torch.Tensor:"""计算广义优势估计(GAE)。"""advantages = torch.zeros_like(rewards)last_advantage = 0.0for t in reversed(range(len(rewards))):mask = 1.0 - dones[t]delta = rewards[t] + gamma * next_values[t] * mask - values[t]advantages[t] = delta + gamma * lambda_gae * last_advantage * masklast_advantage = advantages[t]if standardize:mean_adv = torch.mean(advantages)std_adv = torch.std(advantages) + 1e-8advantages = (advantages - mean_adv) / std_advreturn advantages
PPO 更新步骤
这个函数执行 PPO 的核心更新,对收集到的批次进行多次周期的迭代,计算截断代理目标和价值损失,并更新演员和评论家网络。
def update_ppo(actor: PolicyNetwork,critic: ValueNetwork,actor_optimizer: optim.Optimizer,critic_optimizer: optim.Optimizer,states: torch.Tensor,actions: torch.Tensor,log_probs_old: torch.Tensor,advantages: torch.Tensor,returns_to_go: torch.Tensor,ppo_epochs: int,ppo_clip_epsilon: float,value_loss_coeff: float,entropy_coeff: float) -> Tuple[float, float, float]: # 返回平均损失"""对收集到的批次进行多次周期的 PPO 更新。参数:- actor, critic:网络。- actor_optimizer, critic_optimizer:优化器。- states, actions, log_probs_old, advantages, returns_to_go:批次数据张量。- ppo_epochs (int):优化周期数。- ppo_clip_epsilon (float):截断参数 epsilon。- value_loss_coeff (float):价值损失的系数。- entropy_coeff (float):熵奖励的系数。返回:- Tuple[float, float, float]:周期内的平均策略损失、价值损失和熵。"""total_policy_loss = 0.0total_value_loss = 0.0total_entropy = 0.0# 将优势和旧对数概率分离——它们在更新过程中被视为常量advantages = advantages.detach()log_probs_old = log_probs_old.detach()returns_to_go = returns_to_go.detach()for _ in range(ppo_epochs):# --- 演员(策略)更新 ---# 评估当前策略policy_dist = actor(states)log_probs_new = policy_dist.log_prob(actions)entropy = policy_dist.entropy().mean() # 熵用于探索奖励# 计算比率 $ r_t(\theta) $ratio = torch.exp(log_probs_new - log_probs_old)# 计算代理目标surr1 = ratio * advantagessurr2 = torch.clamp(ratio, 1.0 - ppo_clip_epsilon, 1.0 + ppo_clip_epsilon) * advantages# PPO 截断策略损失(负值是因为优化器最小化)# 我们添加熵奖励(最大化熵 -> 最小化负熵)policy_loss = -torch.min(surr1, surr2).mean() - entropy_coeff * entropy# 优化演员actor_optimizer.zero_grad()policy_loss.backward()actor_optimizer.step()# --- 评论家(价值)更新 ---# 预测价值values_pred = critic(states).squeeze()# 价值损失(均方误差)value_loss = F.mse_loss(values_pred, returns_to_go)# 优化评论家critic_optimizer.zero_grad()# 在反向传播前对价值损失进行缩放(value_loss_coeff * value_loss).backward()critic_optimizer.step()# 累积损失以便记录total_policy_loss += policy_loss.item() # 记录负截断目标 + 熵奖励total_value_loss += value_loss.item()total_entropy += entropy.item()# 计算周期内的平均损失avg_policy_loss = total_policy_loss / ppo_epochsavg_value_loss = total_value_loss / ppo_epochsavg_entropy = total_entropy / ppo_epochsreturn avg_policy_loss, avg_value_loss, avg_entropy
运行 PPO 算法
设置超参数,初始化网络和优化器,并运行 PPO 训练循环。
超参数设置
定义 PPO 的超参数。
# PPO 在自定义网格世界的超参数
GAMMA_PPO = 0.99 # 折扣因子
GAE_LAMBDA_PPO = 0.95 # GAE 的 lambda 参数
PPO_CLIP_EPSILON = 0.2 # PPO 截断 epsilon
ACTOR_LR = 3e-4 # 演员学习率
CRITIC_LR_PPO = 1e-3 # 评论家学习率
PPO_EPOCHS = 10 # 每次迭代的优化周期数
VALUE_LOSS_COEFF = 0.5 # 价值损失的系数
ENTROPY_COEFF = 0.01 # 熵奖励的系数
STANDARDIZE_ADV_PPO = True # 是否标准化优势NUM_ITERATIONS_PPO = 150 # PPO 迭代次数(策略更新)
STEPS_PER_ITERATION_PPO = 1000 # 每次迭代收集的步数
MAX_STEPS_PER_EPISODE_PPO = 200 # 每个回合的最大步数
初始化
初始化演员、评论家及其优化器。
# 重新实例化环境
custom_env: GridEnvironment = GridEnvironment(rows=10, cols=10)
n_actions_custom: int = custom_env.get_action_space_size()
n_observations_custom: int = custom_env.get_state_dimension()# 初始化演员和评论家
actor_ppo: PolicyNetwork = PolicyNetwork(n_observations_custom, n_actions_custom).to(device)
critic_ppo: ValueNetwork = ValueNetwork(n_observations_custom).to(device)# 初始化优化器
actor_optimizer_ppo: optim.Adam = optim.Adam(actor_ppo.parameters(), lr=ACTOR_LR)
critic_optimizer_ppo: optim.Adam = optim.Adam(critic_ppo.parameters(), lr=CRITIC_LR_PPO)# 用于绘图的列表
ppo_iteration_rewards = []
ppo_iteration_avg_ep_lens = []
ppo_iteration_policy_losses = []
ppo_iteration_value_losses = []
ppo_iteration_entropies = []
训练循环
PPO 训练循环:收集数据,计算优势/回报,对演员和评论家进行多次周期的更新。
print("开始在自定义网格世界中训练 PPO...")# --- PPO 训练循环 ---
for iteration in range(NUM_ITERATIONS_PPO):# --- 1. 收集轨迹(采样阶段) ---# 将数据临时存储在列表中batch_states_list = []batch_actions_list = []batch_log_probs_old_list = []batch_rewards_list = []batch_values_list = []batch_dones_list = []episode_rewards_in_iter = []episode_lengths_in_iter = []steps_collected = 0while steps_collected < STEPS_PER_ITERATION_PPO:state = custom_env.reset()episode_reward = 0.0episode_steps = 0done = Falsefor t in range(MAX_STEPS_PER_EPISODE_PPO):# 采样动作并获取价值估计with torch.no_grad():policy_dist = actor_ppo(state)value = critic_ppo(state).squeeze()action_tensor = policy_dist.sample()action = action_tensor.item()log_prob = policy_dist.log_prob(action_tensor)# 与环境交互next_state, reward, done = custom_env.step(action)# 存储数据batch_states_list.append(state)batch_actions_list.append(action)batch_log_probs_old_list.append(log_prob)batch_values_list.append(value)batch_rewards_list.append(reward)batch_dones_list.append(float(done))state = next_stateepisode_reward += rewardsteps_collected += 1episode_steps += 1if done or steps_collected >= STEPS_PER_ITERATION_PPO:episode_rewards_in_iter.append(episode_reward)episode_lengths_in_iter.append(episode_steps)breakif steps_collected >= STEPS_PER_ITERATION_PPO:break# --- 结束采样 ---# 计算 GAE 的 next_values# 对于非终止状态,next_value 是下一个状态的价值# 对于终止状态,next_value 是 0next_values = []with torch.no_grad():for i in range(len(batch_states_list)):if batch_dones_list[i] > 0.5: # 如果 donenext_values.append(torch.tensor(0.0))elif i == len(batch_states_list) - 1: # 批次中的最后一个状态next_state = custom_env.step(batch_actions_list[i])[0] # 获取下一个状态next_values.append(critic_ppo(next_state).squeeze())else: # 未终止,使用批次中的下一个状态的价值next_values.append(batch_values_list[i+1])# 将列表转换为张量states_tensor = torch.stack(batch_states_list).to(device)actions_tensor = torch.tensor(batch_actions_list, dtype=torch.long, device=device)log_probs_old_tensor = torch.stack(batch_log_probs_old_list).squeeze().to(device)rewards_tensor = torch.tensor(batch_rewards_list, dtype=torch.float32, device=device)values_tensor = torch.stack(batch_values_list).to(device)next_values_tensor = torch.stack(next_values).to(device)dones_tensor = torch.tensor(batch_dones_list, dtype=torch.float32, device=device)# --- 2. 估计优势和回报 ---advantages_tensor = compute_gae(rewards_tensor, values_tensor, next_values_tensor, dones_tensor, GAMMA_PPO, GAE_LAMBDA_PPO, standardize=STANDARDIZE_ADV_PPO)returns_to_go_tensor = advantages_tensor + values_tensor# --- 3. 执行 PPO 更新 ---avg_policy_loss, avg_value_loss, avg_entropy = update_ppo(actor_ppo, critic_ppo, actor_optimizer_ppo, critic_optimizer_ppo,states_tensor, actions_tensor, log_probs_old_tensor,advantages_tensor, returns_to_go_tensor,PPO_EPOCHS, PPO_CLIP_EPSILON, VALUE_LOSS_COEFF, ENTROPY_COEFF)# --- 记录 ---avg_reward_iter = np.mean(episode_rewards_in_iter) if episode_rewards_in_iter else np.nanavg_len_iter = np.mean(episode_lengths_in_iter) if episode_lengths_in_iter else np.nanppo_iteration_rewards.append(avg_reward_iter)ppo_iteration_avg_ep_lens.append(avg_len_iter)ppo_iteration_policy_losses.append(avg_policy_loss)ppo_iteration_value_losses.append(avg_value_loss)ppo_iteration_entropies.append(avg_entropy)if (iteration + 1) % 10 == 0:print(f"迭代 {iteration+1}/{NUM_ITERATIONS_PPO} | 平均奖励:{avg_reward_iter:.2f} | 平均长度:{avg_len_iter:.1f} | 策略损失:{avg_policy_loss:.4f} | 价值损失:{avg_value_loss:.4f} | 熵:{avg_entropy:.4f}")print("自定义网格世界训练完成(PPO)。")
开始在自定义网格世界中训练 PPO...
迭代 10/150 | 平均奖励:6.36 | 平均长度:21.3 | 策略损失:-0.0145 | 价值损失:0.9804 | 熵:0.8628
迭代 20/150 | 平均奖励:7.09 | 平均长度:18.9 | 策略损失:-0.0118 | 价值损失:1.0018 | 熵:0.6925
迭代 30/150 | 平均奖励:7.61 | 平均长度:18.5 | 策略损失:-0.0146 | 价值损失:0.9844 | 熵:0.6553
迭代 40/150 | 平均奖励:7.82 | 平均长度:18.2 | 策略损失:-0.0076 | 价值损失:0.9962 | 熵:0.6224
迭代 50/150 | 平均奖励:7.89 | 平均长度:18.2 | 策略损失:-0.0079 | 价值损失:0.9865 | 熵:0.6108
迭代 60/150 | 平均奖励:7.92 | 平均长度:18.2 | 策略损失:-0.0082 | 价值损失:0.9977 | 熵:0.5717
迭代 70/150 | 平均奖励:7.82 | 平均长度:18.2 | 策略损失:-0.0062 | 价值损失:1.0129 | 熵:0.5540
迭代 80/150 | 平均奖励:7.92 | 平均长度:18.2 | 策略损失:-0.0085 | 价值损失:1.0051 | 熵:0.5434
迭代 90/150 | 平均奖励:8.01 | 平均长度:17.9 | 策略损失:-0.0064 | 价值损失:0.9879 | 熵:0.5104
迭代 100/150 | 平均奖励:8.07 | 平均长度:17.9 | 策略损失:-0.0052 | 价值损失:0.9288 | 熵:0.4867
迭代 110/150 | 平均奖励:8.04 | 平均长度:17.9 | 策略损失:-0.0066 | 价值损失:1.0013 | 熵:0.4765
迭代 120/150 | 平均奖励:8.12 | 平均长度:18.2 | 策略损失:-0.0069 | 价值损失:0.9964 | 熵:0.4301
迭代 130/150 | 平均奖励:8.12 | 平均长度:17.9 | 策略损失:-0.0044 | 价值损失:0.9387 | 熵:0.4038
迭代 140/150 | 平均奖励:8.02 | 平均长度:17.9 | 策略损失:-0.0044 | 价值损失:1.0230 | 熵:0.3629
迭代 150/150 | 平均奖励:8.07 | 平均长度:17.9 | 策略损失:-0.0067 | 价值损失:1.0051 | 熵:0.2982
自定义网格世界训练完成(PPO)。
可视化学习过程
绘制 PPO 代理的结果。
# 绘制自定义网格世界中 PPO 的结果
plt.figure(figsize=(20, 8))# 每次迭代的平均奖励
plt.subplot(2, 3, 1)
valid_rewards_ppo = [r for r in ppo_iteration_rewards if not np.isnan(r)]
valid_indices_ppo = [i for i, r in enumerate(ppo_iteration_rewards) if not np.isnan(r)]
plt.plot(valid_indices_ppo, valid_rewards_ppo)
plt.title('PPO 自定义网格:每次迭代的平均奖励')
plt.xlabel('迭代次数')
plt.ylabel('平均奖励')
plt.grid(True)
if len(valid_rewards_ppo) >= 10:rewards_ma_ppo = np.convolve(valid_rewards_ppo, np.ones(10)/10, mode='valid')plt.plot(valid_indices_ppo[9:], rewards_ma_ppo, label='10-次迭代移动平均', color='orange')plt.legend()# 每次迭代的平均回合长度
plt.subplot(2, 3, 2)
valid_lens_ppo = [l for l in ppo_iteration_avg_ep_lens if not np.isnan(l)]
valid_indices_len_ppo = [i for i, l in enumerate(ppo_iteration_avg_ep_lens) if not np.isnan(l)]
plt.plot(valid_indices_len_ppo, valid_lens_ppo)
plt.title('PPO 自定义网格:每次迭代的平均回合长度')
plt.xlabel('迭代次数')
plt.ylabel('平均步数')
plt.grid(True)
if len(valid_lens_ppo) >= 10:lens_ma_ppo = np.convolve(valid_lens_ppo, np.ones(10)/10, mode='valid')plt.plot(valid_indices_len_ppo[9:], lens_ma_ppo, label='10-次迭代移动平均', color='orange')plt.legend()# 每次迭代的评论家(价值)损失
plt.subplot(2, 3, 3)
plt.plot(ppo_iteration_value_losses)
plt.title('PPO 自定义网格:每次迭代的平均价值损失')
plt.xlabel('迭代次数')
plt.ylabel('均方误差损失')
plt.grid(True)
if len(ppo_iteration_value_losses) >= 10:vloss_ma_ppo = np.convolve(ppo_iteration_value_losses, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(vloss_ma_ppo)) + 9, vloss_ma_ppo, label='10-次迭代移动平均', color='orange')plt.legend()# 每次迭代的演员(策略)损失
plt.subplot(2, 3, 4)
# 绘制负损失(因为我们最小化了 -L_clip - 熵)
plt.plot([-l for l in ppo_iteration_policy_losses])
plt.title('PPO 自定义网格:每次迭代的平均策略目标')
plt.xlabel('迭代次数')
plt.ylabel('平均(-策略损失)')
plt.grid(True)
if len(ppo_iteration_policy_losses) >= 10:ploss_ma_ppo = np.convolve([-l for l in ppo_iteration_policy_losses], np.ones(10)/10, mode='valid')plt.plot(np.arange(len(ploss_ma_ppo)) + 9, ploss_ma_ppo, label='10-次迭代移动平均', color='orange')plt.legend()# 每次迭代的熵
plt.subplot(2, 3, 5)
plt.plot(ppo_iteration_entropies)
plt.title('PPO 自定义网格:每次迭代的平均策略熵')
plt.xlabel('迭代次数')
plt.ylabel('熵')
plt.grid(True)
if len(ppo_iteration_entropies) >= 10:entropy_ma_ppo = np.convolve(ppo_iteration_entropies, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(entropy_ma_ppo)) + 9, entropy_ma_ppo, label='10-次迭代移动平均', color='orange')plt.legend()plt.tight_layout()
plt.show()
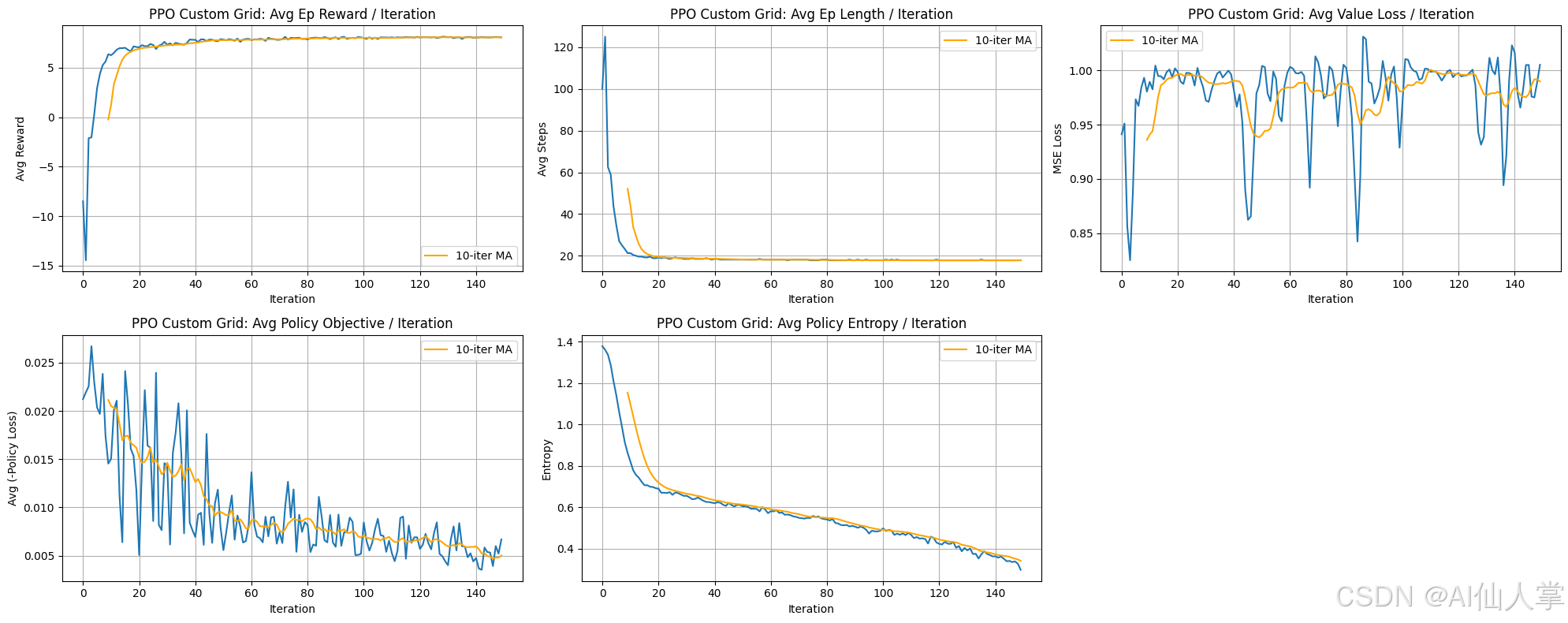
PPO 学习曲线的简洁分析(自定义网格世界):
-
每次迭代的平均奖励:
代理展示了快速且稳定的收敛能力,平均奖励在大约 20 次迭代内迅速增加并接近最优值(约为 8)。与 REINFORCE 相比,曲线的波动更小,这体现了 PPO 通过截断目标函数和演员-评论家结构所获得的稳定性。它在收敛后始终保持较高的水平。 -
每次迭代的平均回合长度:
与奖励曲线类似,回合长度在大约 20 次迭代内迅速下降,并收敛到最优路径长度(大约 18 步)。这表明代理迅速学会了高效的导航策略。在最优长度处的稳定性表明了策略的鲁棒性和收敛性。 -
每次迭代的平均价值损失:
评论家(价值函数)的损失在整个训练过程中有所波动,但平均值在经过初始调整期后保持相对稳定(稳定在大约 0.98-1.00 之间)。这表明评论家能够充分跟踪策略改进下的状态价值,为演员更新提供稳定的优势估计,即使均方误差绝对值没有严格收敛到零。注意:这个绝对值对于典型的均方误差来说似乎有点高,它可能代表了某种略有不同的东西,或者表明需要进行缩放。 -
每次迭代的平均策略目标:
策略损失(表示 PPO 截断代理目标)显示出清晰的下降趋势,尤其是在移动平均线中。这表明策略网络成功地优化了目标函数。尽管仍存在一些波动,但比 REINFORCE 的损失曲线要稳定得多。 -
每次迭代的平均策略熵:
策略熵从高值开始,并随着训练的进行稳步下降,表明策略逐渐变得更加确定性,随着学习的深入,代理对动作的选择更加自信。这种平稳的下降表明了探索和利用之间的平衡得到了适当的控制,没有出现过早的探索崩溃。
总体结论:
PPO 在网格世界中表现出色,能够快速收敛到最优且高效的策略,其收敛速度与 REINFORCE 相当,但在奖励和损失曲线的稳定性方面表现更好。价值函数能够充分学习以支持策略改进,策略熵的下降也符合预期。这些结果展示了 PPO 在平衡探索和利用的同时,能够保持稳定更新的能力。
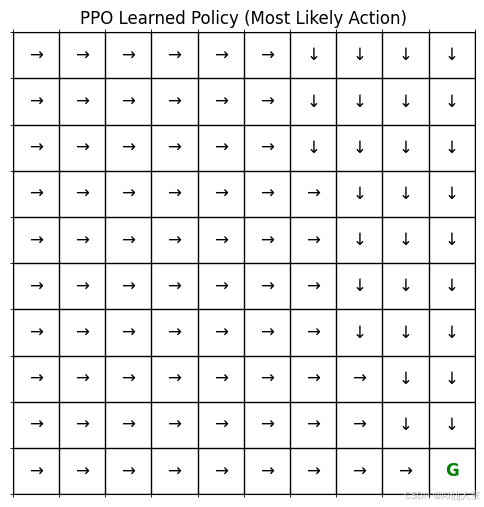
分析学习到的策略(可选可视化)
可视化 PPO 演员网络学习到的策略。
# 重新使用策略绘制函数(适用于任何输出 Categorical 的网络)
def plot_ppo_policy_grid(policy_net: PolicyNetwork, env: GridEnvironment, device: torch.device) -> None:"""绘制从 PPO 策略网络得出的贪婪策略。显示每个状态中最有可能的动作。(与 REINFORCE/TRPO 绘图函数相同)"""rows: int = env.rowscols: int = env.colspolicy_grid: np.ndarray = np.empty((rows, cols), dtype=str)action_symbols: Dict[int, str] = {0: '↑', 1: '↓', 2: '←', 3: '→'}fig, ax = plt.subplots(figsize=(cols * 0.6, rows * 0.6))for r in range(rows):for c in range(cols):state_tuple: Tuple[int, int] = (r, c)if state_tuple == env.goal_state:policy_grid[r, c] = 'G'ax.text(c, r, 'G', ha='center', va='center', color='green', fontsize=12, weight='bold')else:state_tensor: torch.Tensor = env._get_state_tensor(state_tuple)with torch.no_grad():action_dist: Categorical = policy_net(state_tensor)best_action: int = action_dist.probs.argmax(dim=1).item()policy_grid[r, c] = action_symbols[best_action]ax.text(c, r, policy_grid[r, c], ha='center', va='center', color='black', fontsize=12)ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1)ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='black', linestyle='-', linewidth=1)ax.set_xticks([])ax.set_yticks([])ax.set_title("PPO 学习到的策略(最有可能的动作)")plt.show()# 绘制 PPO 演员学习到的策略
print("\n绘制 PPO 学习到的策略:")
plot_ppo_policy_grid(actor_ppo, custom_env, device)
PPO 中常见的挑战及解决方案
挑战:对超参数敏感
- 问题:性能仍然对截断范围( ϵ \epsilon ϵ)、学习率、周期数、小批量大小、GAE 参数( λ \lambda λ)以及系数( c 1 , c 2 c_1, c_2 c1,c2)的选择非常敏感。
- 解决方案:
- 使用标准默认值:从广泛使用的值开始( ϵ = 0.2 \epsilon=0.2 ϵ=0.2, λ = 0.95 \lambda=0.95 λ=0.95,Adam 优化器的学习率约为 3 e − 4 3e-4 3e−4, K ≈ 4 − 10 K \approx 4-10 K≈4−10 个周期,合理的小批量大小)。
- 调整:系统地进行实验,特别是 ϵ \epsilon ϵ 和学习率。较大的 ϵ \epsilon ϵ 允许更大的策略变化,但可能会导致不稳定;较小的 ϵ \epsilon ϵ 更保守。
- 自适应 epsilon/KL:一些 PPO 变体会根据 KL 散度自适应调整 ϵ \epsilon ϵ,而不是使用硬截断。
挑战:样本效率(在线策略)
- 问题:尽管比 REINFORCE/A2C 更样本高效,但由于是在线策略,仍然不如离线策略方法(如 SAC 或 DQN)在样本效率上高,尤其是在可以使用离线策略学习的任务中。
- 解决方案:
- 增加每次迭代的数据量:在更新之前收集更多的步数( S T E P S P E R I T E R A T I O N STEPS_PER_ITERATION STEPSPERITERATION)。
- 增加周期数:对每个批次进行更多的更新( K K K),但要注意过拟合或策略发散。
- 考虑离线策略替代方法:如果交互非常昂贵,可以探索 SAC 或 TD3 等算法。
挑战:价值函数的准确性
- 问题:优势估计的准确性严重依赖于评论家的准确性。如果评论家不准确,可能会导致策略更新效果不佳。
- 解决方案:
- 调整评论家学习:调整评论家学习率、每次策略更新时的评论家更新周期数,或者尝试不同的优化技术。
- 网络架构:确保评论家网络具有足够的容量。
- 共享与独立网络:尝试共享演员和评论家的初始层(可以提高效率)与完全独立的网络(有时可以提供更多的稳定性)。
挑战:实现细节很重要
- 问题:小细节如优势标准化、观察/奖励归一化、学习率调度以及网络初始化等可能会显著影响性能。
- 解决方案:
- 标准化优势:通常有益。
- 归一化观察/奖励:在连续控制任务中,尤其是涉及不同尺度的任务时,通常至关重要。
- 学习率衰减:线性衰减学习率可以提高稳定性。
- 谨慎初始化:使用适当的权重初始化方法(例如正交初始化)。
结论
近端策略优化(PPO)作为一种高效且广泛使用的强化学习算法脱颖而出。通过引入截断代理目标函数,它在 TRPO 这样的信任区域方法的稳定性与一阶优化的简单性之间取得了平衡。其演员-评论家结构,结合广义优势估计和每个数据批次多次更新的能力,使其在样本效率和稳定性方面优于简单的在线策略方法。
PPO 的通用性使其能够适应离散和连续动作空间,并且由于其实现和调整的简单性,使其在 TRPO 相比下成为政策优化家族中一个强大且实用的选择。尽管在线策略学习在样本效率方面仍然存在固有限制,但 PPO 在强化学习领域仍然是一个极具竞争力的算法。
相关文章:

近端策略优化PPO详解:python从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...
:从基础到高性能序列化实战)
C# System.Text.Json终极指南(十):从基础到高性能序列化实战
一、JSON序列化革命:System.Text.Json的架构优势 1.1 核心组件解析 1.2 性能基准测试(.NET 8) 操作Newtonsoft.JsonSystem.Text.Json性能提升简单对象序列化1,200 ns450 ns2.7x大型对象反序列化15 ms5.2 ms2.9x内存分配(1k次操作)45 MB12 MB3.75x二、基础序列化操作精解 …...

Centos7.9 安装mysql5.7
1.配置镜像(7.9的镜像过期了) 2.备份原有的 CentOS 基础源配置文件 sudo cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak 3.更换为国内镜像源 sudo vi /etc/yum.repos.d/CentOS-Base.repo 将文件内容替换为以下内容&am…...

Qt指南针
Qt写的指南针demo. 运行结果 滑动调整指针角度 实现代码 h文件 #ifndef COMPASS_H #define COMPASS_H#include <QWidget> #include <QColor>class Compass : public QWidget {Q_OBJECT// 可自定义属性Q_PROPERTY(QColor backgroundColor READ backgroundColor WRI…...

杜邦分析法
杜邦分析法(DuPont Analysis)是一种用于分析企业财务状况和经营绩效的综合分析方法,由美国杜邦公司在20世纪20年代率先采用,故得名。以下是其相关内容介绍: 核心指标与分解 净资产收益率(ROE):杜邦分析法的核心指标,反映股东权益的收益水平,用以衡量公司运用自有资本…...

给U盘加上图标
电脑插入U盘后,U盘的那个标志没有特色,我们可以换成有意义的照片作为U盘图标,插上U盘就能看到,多么地浪漫。那该如何设置呢?一起来看看吧 选择一张ICO格式的图片到U盘里 PNG转ICO - 在线转换图标文件PNG转ICO - 免费…...

人工智能对未来工作的影响
人工智能对未来工作的影响是多方面的,既包括对就业结构的改变,也涉及工作方式、职业技能需求以及社会政策的调整。以下是对人工智能对未来工作影响的详细分析: 一、就业结构的变革 岗位替代与消失 人工智能技术在许多领域展现出强大的自动化…...

RocketMQ常见面试题一
1. RocketMQ 是什么?它的核心组件有哪些? 答:RocketMQ 是阿里巴巴开源的一款分布式消息中间件,支持高吞吐、低延迟、高可用的消息发布与订阅。 核心组件: NameServer:轻量级注册中心,管理 Broker 的元数据(路由信息),无状态。 Broker:消息存储和转发节点,分为 Mas…...
:初步认识WinDbg和dump文件)
C++调试(壹):初步认识WinDbg和dump文件
目录 1.前言 2.WinDbg是什么? 3.WinDbg安装 4.Dump文件是什么? 5.生成Dump文件的场景 前言 这是一个关于C调试的博客,该系列博客主要是讲解如何使用WinDbg工具结合dump文件调试程序。在日常开发过程中,我们往往无法完…...

centos7 离线安装python3 保留python2
一、事前准备: (1)查看centos具体版本 cat /etc/redhat-releaseCentOS Linux release 7.4.1708 (Core) (2)查看linux中当前python版本 centos7 默认安装python2.7.5 (3)查看python3的依赖&#…...

【dify—9】Chatflow实战——博客文章生成器
目录 一、创建Chatflow 二、创建变量 三、添加时间工具 四、编写提示词 五、回复输出 六、运行 第一部分 安装difydocker教程:【difydocker安装教程】-CSDN博客 第二部分 dock重装教程:【dify—2】docker重装-CSDN博客 第三部分 dify拉取镜像&…...
Java/python/JavaScript/C/C++/GO最佳实现)
华为OD机试真题——斗地主之顺子(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录…...

3.2/Q2,Charls最新文章解读
文章题目:Internet usage elevates elderly obesity: evidence from a difference-in-differences analysis of the broadband China policy DOI:10.1186/s13690-025-01565-9 中文标题:互联网使用导致老年人肥胖:中国宽带政策差异…...

Seata服务端开启事务核心源码解析
文章目录 概述一、doGlobalBegin1.1、createGlobalSession1.2、addSessionLifecycleListener1.3、begin 概述 Seata服务端作为TC角色,用于接收客户端标注了GlobalTransactional也就是TM角色的开启事务,提交/回滚事务请求,维护全局和分支事务的…...

Seata服务端回滚事务核心源码解析
文章目录 前言一、doGlobalRollback3.1、changeGlobalStatus3.2、doGlobalRollback 前言 本篇介绍Seata服务端接收到客户端TM回滚请求,进行处理并且驱动所有的RM进行回滚的源码。 一、doGlobalRollback doGlobalRollback是全局回滚的方法: 首先依旧…...
)
PMP-第九章 项目资源管理(一)
项目资源管理概述 项目资源管理包括识别、获取和管理所需资源以完成项目的各个过程资源主要分为实物资源和人力资源;实物资源包括设备、材料和基础设施等团队资源或人员指的是人力资源团队资源管理与项目干系人管理有重叠的部分,本章重点关注组成项目团…...

【Unity】MVP框架的使用例子
在提到MVP之前,可以先看看这篇MVC的帖子: 【Unity】MVC的简单分享以及一个在UI中使用的例子 MVC的不足之处: 在MVC的使用中,会发现View层直接调用了Model层的引用,即这两个层之间存在着一定的耦合性,而MV…...
 - PWM调制模拟)
Matlab/Simulink - BLDC直流无刷电机仿真基础教程(四) - PWM调制模拟
Matlab/Simulink - BLDC直流无刷电机仿真基础教程(四) - PWM调制模拟 前言一、PWM调制技术基本原理二、仿真模型中加入PWM调制三、逆变电路MOS管添加体二极管四、模拟添加机械负载五、仿真模型与控制框图文章相关模型文件下载链接参考链接 前言 本系列文…...

x86架构详解:定义、应用及特点
一、x86架构的定义 x86 是由Intel公司开发的复杂指令集(CISC)处理器架构,起源于1978年的Intel 8086处理器,后续扩展至32位(IA-32)和64位(x86-64)。其名称来源于早期处理器型号的“8…...

C++学习-入门到精通-【3】控制语句、赋值、自增和自减运算符
C学习-入门到精通-【3】控制语句、赋值、自增和自减运算符 控制语句、赋值、自增和自减运算符 C学习-入门到精通-【3】控制语句、赋值、自增和自减运算符一、什么是算法二、伪代码三、控制结构顺序结构选择结构if语句if...else语句switch语句 循环结构while语句 四、算法详述&a…...

【Bootstrap V4系列】学习入门教程之 页面内容排版
Bootstrap V4 学习入门教程之 页面内容排版 按钮上的指针排版一、Global settings 全局设置二、Headings 标题2.1 Customizing headings 自定义标题2.2 Display headings 显示标题2.3 Lead 引导 三、Blockquotes 块引用3.1 Naming a source 命名源3.2 Alignment 对齐 四、Lists…...
 13980+真车 超跑 大型载具MOD整合包+最新GTA6大型地图MOD 5月最新更新)
GTA5(传承/增强) 13980+真车 超跑 大型载具MOD整合包+最新GTA6大型地图MOD 5月最新更新
1500超跑载具 1000普通超跑 1500真车超跑 各种军载具1000 各种普通跑车 船舶 飞机 1000 人物1500 添加式led载具1000 超级英雄最新版 添加添加式武器MOD1000 添加地图MOD500 添加超跑载具2000 当前共计1.2wMOD 4月2日更新 新增770menyoo地图 当前共计12770 新增48款超级英雄最新…...

目标文件的段结构及核心组件详解
目标文件(如 .o 或 .obj)是编译器生成的中间文件,其结构遵循 ELF(Linux)或 COFF(Windows)格式。以下是其核心段(Section)和关键机制的详细解析: 1. 目标文件的…...

60常用控件_QSpinBox的使用
目录 代码示例:调整麦当劳购物车中的份数 使⽤ QSpinBox 或者 QDoubleSpinBox 表⽰ "微调框", 它是带有按钮的输⼊框. 可以⽤来输⼊整 数/浮点数. 通过点击按钮来修改数值⼤⼩. 由于 SpinBox 和 QDoubleSpinBox ⽤法基本相同, 就只介绍 SpinBox 的…...

数据库Mysql_约束
将失败当作自己的老师,即使他会使自己难堪 ----------陳長生. 1.什么是数据库约束 数据库约束是在数据库中对表中的内容设定条件或者规则,设置了这些规则能使得数据更具体有准确性,可靠性。 2.约束类型 NOT NULL设置列不能为空UNIQUE设置列…...
(包含派生类的默认成员函数,菱形继承等))
C++笔记-继承(下)(包含派生类的默认成员函数,菱形继承等)
一.派生类的默认成员函数 1.14个常见默认成员函数 默认成员函数,默认的意思就是指我们不写,编译器会自动为我们生成一个,那么在派生类中,这几个成员函数是如何生成的呢? 1.派生类的构造函数必须调用基类的构造函数初…...

DeepSeek V3 训练策略:FP8混合精度与多Token预测
近年来,大规模语言模型取得重大突破,但其训练与部署成本也随之攀升。DeepSeek 系列开源模型致力于通过优化模型结构和训练策略来降低成本、提升性能。DeepSeek V3 融合了多种先进技术(如 FP8 低精度训练、DualPipe 双流水线机制、多Token 预测目标等),在保证模型能力的同时…...

开始一个vue项目
一、创建vite项目和配置 1、查看npm版本: npm --version 根据版本选择创建命令 # npm 6.x npm create vitelatest my-vue-product --template vue # npm 7 npm create vitelatest my-vue-product -- --template vue 2、依次执行: npm install n…...

世纪华通:从财报数据看其在游戏领域的成功与未来
引言 日前,世纪华通发布了2024年及2025年第一季度的财务报告。报告显示,公司不仅在过去一年取得了显著的营收增长,而且在国内外市场均有出色表现。特别是《无尽冬日》和《Whiteout Survival》等游戏的成功,为世纪华通带来了巨大的…...

ruoyi-plus Spring Boot + MyBatis 中 BaseEntity 的设计与动态查询实践
一、BaseEntity 设计解析 以下是一个典型的 BaseEntity 设计示例: @Data public class BaseEntity implements Serializable {@Serialprivate static final long serialVersionUID =...

MCP:智能家居的“大脑”,如何引领未来居住革命
MCP:智能家居的“大脑”,如何引领未来居住革命 一、引言:MCP与智能家居的未来 随着智能家居的迅猛发展,越来越多的家庭开始拥有各种智能设备,从智能灯泡、智能门锁到智能音响,每一个设备都在为生活提供便利与舒适。然而,尽管这些设备各自具备了独立的功能,但它们之间往…...
)
[基础]详解C++模板类(完整实例代码)
目录 C模板类:通用编程的基石引言一、模板类的核心作用1.1 代码复用1.2 类型安全1.3 性能优化 二、模板类的进阶用法2.1 多参数模板2.2 非类型参数2.3 成员函数特化 三、实战场景解析3.1 场景一:通用容器开发3.2 场景二:算法抽象3.3 场景三&a…...
:type()函数——获取对象类型或获取一个新的类型对象)
Python 常用内置函数详解(九):type()函数——获取对象类型或获取一个新的类型对象
目录 一、功能二、语法和示例 一、功能 type() 函数有两种形式,当只有一个参数时,用于获取对象的类型;当有多个参数时,用于获取新的类型对象。 二、语法和示例 第一种: type(object)参数说明: 1.object: 对象 2.…...

FreeRTOS任务管理与通信机制详解
1 任务的创建与管理 任务创建 使用 xTaskCreate() 创建任务: BaseType_t xTaskCreate( TaskFunction_t pxTaskCode, // 任务函数(入口) const char * const pcName, // 任务名称(调试用) config…...
redis)
哈希表笔记(二)redis
Redis哈希表实现分析 这份代码是Redis核心数据结构之一的字典(dict)实现,本质上是一个哈希表的实现。Redis的字典结构被广泛用于各种内部数据结构,包括Redis数据库本身和哈希键类型。 核心特点 双表设计:每个字典包含两个哈希表࿰…...

专题二十一:无线局域网——WLAN
一、WLAN简介 WLAN(Wireless Local Area Network )无线局域网,使用的是 IEEE 802.11 标准系列。 标准版本发布年份最大传输速率频段Wi-Fi代数特点/描述IEEE 802.1119971–2 Mbps2.4 GHzWi-Fi 0最早的无线局域网标准,传输速率低&…...

例数据中关键指标对应的SQL查询模板
以下是针对示例数据中关键指标对应的SQL查询模板,包含MySQL和PostgreSQL两种版本: 1. 订单处理系统指标查询 1.1 订单处理成功率 -- MySQL SELECT DATE_FORMAT(created_at, %Y-%m-%d %H:%i:00) AS time_window,COUNT(*) AS total_orders,SUM(CASE WHE…...

【业务领域】电脑主板芯片电路结构
前言 由前几期视频合集(零基础自学计算机故障排除—7天了解计算机开机过程),讲解了POST的主板软启动过程;有不少网友留言、私信来问各种不开机的故障,但大多网友没能能过我们的这合集视频,很好的理清思路,那这样的情况…...

利用无事务方式插入数据库解决并发插入问题
一、背景 由于项目中同一个网元,可能会被多个不同用户操作,而且操作大部分都是以异步子任务形式进行执行,这样就会带来并发写数据问题,本文通过利用无事务方式插入数据库解决并发插入问题,算是解决问题的一种思路&…...
(文末有下载方式))
数字智慧方案6166丨智慧医养结合大数据平台方案(50页PPT)(文末有下载方式)
数字智慧方案6166丨智慧医养结合大数据平台方案 详细资料请看本解读文章的最后内容。 引言 随着人口老龄化的加剧,智慧医养结合的需求日益迫切。本文将对《数字智慧方案6166丨智慧医养结合大数据平台方案》进行详细解读,探讨如何通过大数据和人工智能…...
(文末有下载方式))
数字智慧方案5974丨智慧农业大数据应用平台综合解决方案(79页PPT)(文末有下载方式)
详细资料请看本解读文章的最后内容。 资料解读:智慧农业大数据应用平台综合解决方案 在当今数字化时代,智慧农业成为农业发展的新趋势,对提升农业生产效率、保障农产品质量、推动农业可持续发展意义重大。这份《智慧农业大数据应用平台综合解…...
)
补题( Convolution, 二维卷积求输出矩阵元素和最大值)
来源:https://codeforces.com/gym/105231/problem/H 题目描述: 一、题目分析 本题涉及深度学习中的二维卷积操作。给定一个nm的二维输入矩阵I和一个kl的核矩阵K ,通过特定公式计算得到(n - k 1)(m - l 1)的输出矩阵O ,要求在…...

聊一聊接口测试如何处理鉴权
目录 一、常见鉴权方式及测试方法 1. Basic Auth 2. Token 鉴权 3. OAuth 2.0 4. JWT (JSON Web Token) 5. API Key 6. HMAC 签名 7.Session-Cookie 认证 二、接口测试中的鉴权实践 1. 工具示例(Postman) 2. 代码示例(Python Requ…...

第 2.3 节: 基于 Python 的关节空间与任务空间控制
在机器人控制领域,我们通常关心两个主要的“空间”:关节空间(Joint Space)和任务空间(Task Space,也常称为操作空间 Operational Space)。关节空间描述了机器人各关节的角度或位置集合ÿ…...

[更新完毕]2025东三省A题深圳杯A题数学建模挑战赛数模思路代码文章教学:热弹性物理参数估计
完整内容请看文章最下面的推广群 热弹性物理参数估计 摘要 随着现代电子设备向高性能、微型化方向发展,芯片封装结构面临着日益严峻的热机械可靠性挑战。BGA(球栅阵列)和QFN(四方扁平无引脚)作为两种主流封装形式&am…...

【大模型面试每日一题】Day 5:GQA vs MHA效率对比
【大模型面试每日一题】Day 5:GQA vs MHA效率对比 📌 题目重现 🌟🌟 面试官:最近一些研究(如LLaMA、Mixtral)采用Grouped-Query Attention(GQA)代替传统的Multi-Head A…...

【c语言】字符函数和字符串函数
目录 1.函数介绍 1.1 strlen 1.2 strcpy 1.3 strcat 1.4 strcmp 1.5 strncpy 1.6 strncat 1.7 strncmp 1.8 strstr 1.9 strtok 1.10 strerror 1.11 memcpy 1.12 memmove 1.13 memset 编辑 1.14 memcmp C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有…...
和 Claude 在 Node.js 中构建聊天应用程序)
使用 MCP(模型上下文协议)和 Claude 在 Node.js 中构建聊天应用程序
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 使用 Node.js 中的 MCP(模型上下文协议)构建聊天应用程序 我最近开发了一个简单的聊天应用程序,允许 …...

B站Michale_ee——ESP32_IDF SDK——FreeRTOS_2 队列
一、通过队列传递三种类型数据(整型、结构体、指针) 1.队列简介 FreeRTOS中的队列本质就是一个先入先出的缓冲区(FIFO,First Input First Output) 2.API简介 (1)创建队列的API (…...

小米MiMo:7B模型逆袭AI大模型战场的技术密码
小米MiMo:7B模型逆袭AI大模型战场的技术密码 在大模型竞争愈发激烈的2025年4月30日,小米以一款名为 MiMo-7B 的开源模型强势突围,在数学推理与代码能力评测中表现亮眼,不仅与规模更大的模型正面对抗,甚至超越了 OpenA…...