【笔记】深度学习模型训练的 GPU 内存优化之旅⑤:内存分配篇
开设此专题,目的一是梳理文献,目的二是分享知识。因为笔者读研期间的研究方向是单卡上的显存优化,所以最初思考的专题名称是“显存突围:深度学习模型训练的 GPU 内存优化之旅”,英文缩写是 “MLSys_GPU_Memory_Opt”。该专题下的其他内容:
- 【笔记】深度学习模型训练的 GPU 内存优化之旅①:综述篇
- 【笔记】深度学习模型训练的 GPU 内存优化之旅②:重计算篇
- 【笔记】深度学习模型训练的 GPU 内存优化之旅③:内存交换篇
- 【笔记】深度学习模型训练的 GPU 内存优化之旅④:内存交换与重计算的联合优化篇
本文是该专题下的第 5 篇文章,梳理并分享与内存分配技术相关的高水平论文(截至 2025 年 3 月 19 日,一共 6 篇论文。另外,之前系列中也有关于内存分配技术的论文,这里不再包含),具体内容为笔者的论文阅读笔记。说明:
- 内存分配策略 (memory allocation strategies) 又可分为静态内存分配 (static memory allocation, SMA) 和动态内存分配 (dynamic memory allocation, DMA),关于经典的内存分配策略可以参考:Memory Allocation Strategies - gingerBill;
- 本文二级标题的内容格式为:[年份]_[会刊缩写]_[会刊等级/版本]_[论文标题];
- 笔者不评价论文质量,每篇论文都有自己的侧重,笔者只记录与自己研究方向相关的内容;
- 论文文件在笔者的开源仓库 zhulu506/MLSys_GPU_Memory_Opt 中,如有需要可自行下载;
- 英文论文使用 DeepSeek 进行了翻译,如有翻译不准确的地方还请读者直接阅读英文原文;
文章目录
- 1) 2018_arXiv:1804.10001_v1_Profile-guided memory optimization for deep neural networks
- 2) 2023_NeurIPS_A会_Coop: Memory is not a Commodity
- 3) 2023_ICML_A会_MODeL: Memory Optimizations for Deep Learning
- 4) 2023_arXiv:2310.19295_v1_ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
- 5) 2024_ASPLOS_A会_GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
- 6) 2024_ISMM_内存领域_A Heuristic for Periodic Memory Allocation with Little Fragmentation to Train Neural Networks
1) 2018_arXiv:1804.10001_v1_Profile-guided memory optimization for deep neural networks
因为该工作是在深度学习框架 Chainer 上实现的,为了方便,笔者将其称为 Chainer-Opt。Chainer-Opt 启发了后续很多工作,包括 ROAM、HMO 等。Chainer-Opt 对训练和推理都有效。
动机:尽管扩展神经网络似乎是提高准确性的关键,但这伴随着高昂的内存成本,因为在训练和推理的传播过程中,需要存储权重参数和中间结果(如激活值、特征图等)。这带来了几个不理想的后果。首先,在训练深度神经网络(DNN)时,我们只能使用较小的 mini-batch 以避免内存耗尽的风险,因此收敛速度会变慢。其次,使用如此庞大的 DNN 进行推理可能需要在部署环境中使用大量计算设备。第三,更严重的是,神经网络的设计灵活性受到限制,以便 DNN 能够适应底层设备的内存容量。在 GPU 和边缘设备上,这种高内存消耗问题尤为严重,因为与 CPU 相比,它们的内存容量更小,且扩展性有限。
总结:Chainer-Opt 在一次迭代中分析内存使用情况,并利用该分析结果来确定内存分配方案,从而在后续迭代中最小化峰值内存使用。Chainer-Opt 使用混合整数规划 (mixed integer programming, MIP) 求解小规模动态存储分配问题的最优解。Chainer-Opt 将动态存储分配问题视为二维矩形装箱问题 (two-dimensional rectangle packing problems) 的特例,使用基于 Best-fit 的启发式算法来寻找大规模动态存储分配问题的近似最优解。
摘抄:
- 由于深度神经网络(DNN)消耗大量内存,内存管理的需求逐渐显现。许多深度学习框架(如 Theano、TensorFlow 和 Chainer)采用基于内存池和垃圾回收的动态 GPU 内存分配方式。内存池是由未使用的内存块组成的集合。
- 在接收到 GPU 内存请求时,这些框架会从内存池中找到一个合适大小的内存块,
- 或者如果池中没有合适的块,则从物理内存中分配,并用引用计数对其进行管理。
- 当垃圾回收机制回收该内存块时,该块会返回到内存池。
- 通常,内存分配可以被视为一个二维条带装箱问题(two dimensional strip packing problem, 2SP)。该问题要求在固定宽度的容器内放置一组矩形物品,同时最小化容器的高度。一个内存块可以对应一个矩形物品,其分配时间对应宽度,内存大小对应高度。
图表:
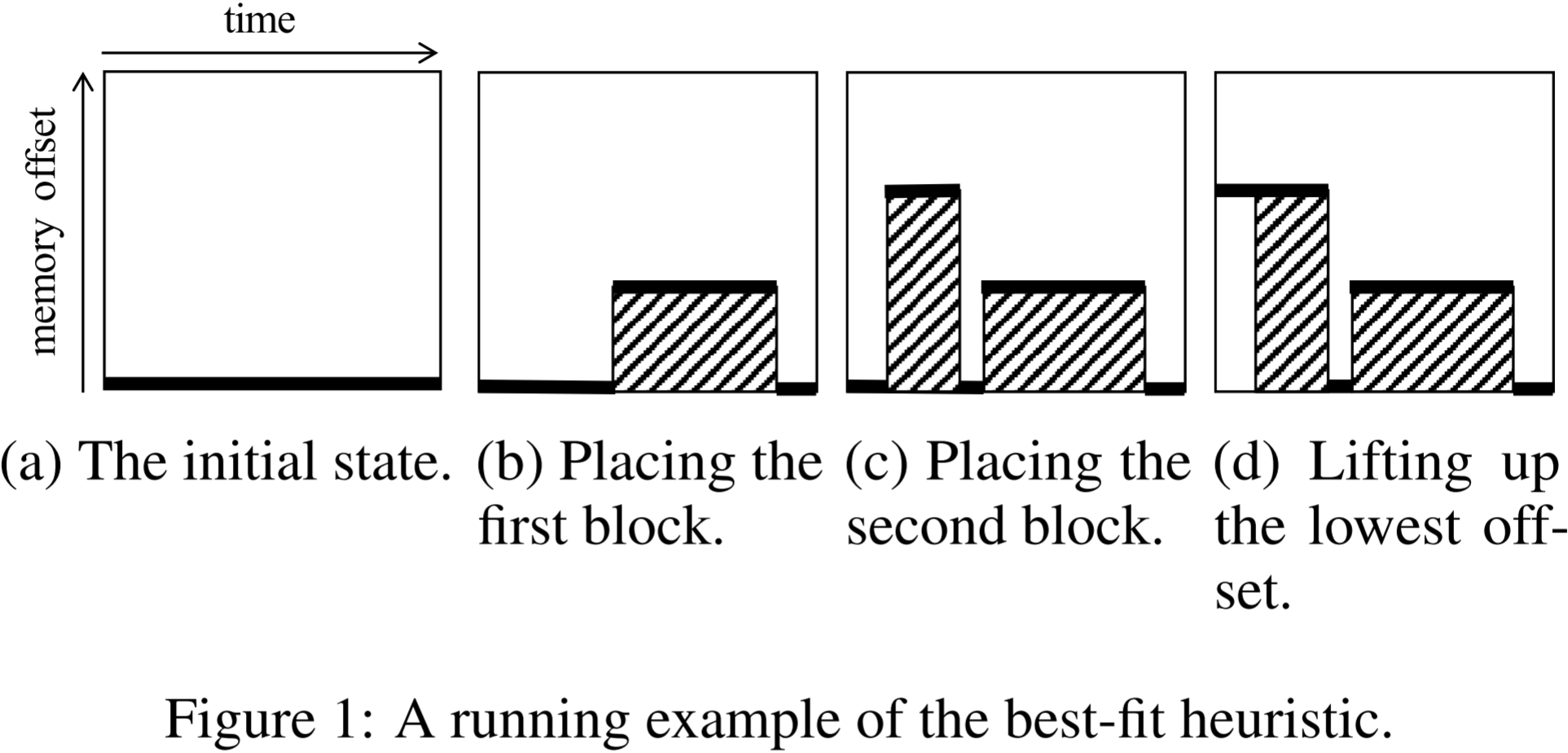
在本文中,我们研究一个特殊情况,即所有内存块的分配时间都是固定的输入。该问题也被称为动态存储分配问题(Dynamic Storage Allocation,DSA),是一个典型的 NP 难问题。
我们的目标是在矩形区域内放置所有内存块,使得顶部的内存块尽可能低。该启发式算法重复执行两个操作,直到所有内存块都被放置完毕:
- 选择一个偏移量 (offset),
- 搜索一个可以放置在该偏移量 (offset) 处且不会与已放置的内存块发生冲突的内存块。
我们通过图 1 所示的示例说明该启发式算法的工作方式。
- 在图 1 中,x 轴和 y 轴分别表示时间和内存偏移量。
- 在算法的初始阶段(图 1a),由于尚未放置任何内存块,因此我们选择偏移量为零。
- 当搜索可放置的内存块时,我们总是在可以放置的候选块中选择生存期最长的一个。在图 1 的示例中,我们选择了生存期最长的内存块并将其放置(图 1b)。
- 放置后,会产生三个候选内存偏移量(图 1 中的粗线,我们称之为偏移线 (offset lines))。当存在多个偏移量时,我们总是选择最小的一个(如果存在多个相同的最小偏移量,则选择最左侧的一个)。
- 接下来,我们为所选的偏移量搜索一个内存块并进行放置(图 1c)。
- 如果没有可放置的内存块,我们会通过与相邻的最低偏移线合并来“抬升”该偏移线(如图 1d 所示,如果相邻偏移线的偏移量相同,则合并所有相邻的线),然后再次选择偏移量并搜索内存块。
该启发式算法的计算时间复杂度在内存块数量的平方范围内。
2) 2023_NeurIPS_A会_Coop: Memory is not a Commodity
Coop 是 Oneflow 在工程实践中针对 DTR 带来的碎片化问题开展的优化,适用于动态计算图,实现了张量分配和张量重计算的协同优化。
动机:现有的张量重计算技术忽略了深度学习框架中的内存系统,并隐含地假设不同地址上的空闲内存块是等价的,但这一假设只有在所有被驱逐的张量是连续的情况下才成立。在这一错误假设下,非连续的张量会被驱逐,驱逐无法形成连续内存的张量会导致内存碎片化。这导致严重的内存碎片化,并增加了潜在重计算的成本。
总结:DTR 会驱逐无法形成连续内存的张量,导致严重的内存碎片化。为了解决该问题,Coop 提出了一种滑动窗口 (sliding window) 算法,确保驱逐的张量在地址上都是连续的。具体地说,Coop 将所有张量按内存地址排序并存储在列表中来跟踪它们的状态,使用两个指针表示滑动窗口的起点和终点,通过在列表中移动窗口,并不断比较窗口内张量的启发式成本总和,找到一组连续的张量,使其总内存大于所需内存且驱逐成本最低,窗口内的张量将被驱逐。另外,为了优化张量内存布局,从而进一步降低重计算成本,Coop 还提出了低成本张量划分 (cheap tensor partitioning) 和可重计算就地操作 (recomputable in-place)。具体地说,Coop 将驱逐成本相近的张量聚类到相同的位置,从而增加了驱逐一组连续低成本张量的可能性。此外,Coop 观察到 in-place 主要发生在不可驱逐的模型参数更新过程中。为了防止这些张量将整个内存池划分成不连续的内存块,Coop 先将参数张量分配到内存池的两端,并在更新时重用其内存,从而最大程度地降低了内存碎片化的发生率。
摘抄:
- 内存分配器(Memory allocator)是深度学习(DL)系统中的重要组成部分。所有已知的 DL 系统(如 PyTorch、TensorFlow 和 MXNet)都配备了专属的内存分配器,以实现细粒度内存管理(fine-grained memory management)并避免与操作系统(OS)通信的开销。相比于先进的 CPU 内存分配器(如 mimalloc 和 jemalloc),DL 框架中的内存分配器设计更为简单。
- 通常,在 DL 框架中,当张量被销毁时,其内存不会归还给 OS,而是被插入到分配器的空闲列表中,并与相邻地址的内存块合并。当用户请求大小为 S S S 的张量内存时,分配器会尝试将该张量放置在大小大于或等于 S S S 的空闲块的最左侧。如果所有空闲块的大小都小于 S S S,则分配器会向 OS 申请新的内存,即使所有空闲块的总大小可能大于 S S S。这些未被利用的空闲块称为内存碎片(memory fragments)。
- 在每次迭代中,由顺序操作生成的张量往往会从内存池的最左侧开始被连续分配。
- 此外,内存分配器可以利用硬件的页表(page table),将非连续的内存块在**虚拟内存(virtual memory)**的视角下重新组合成连续的内存块。研究表明,这种方法能够减少 CPU 端的内存碎片。(但是 NVIDIA GPU 的驱动程序不开源)。
- 内存碎片指的是由于尺寸较小且零散分布,无法用于张量分配的内存块。这一问题影响所有深度神经网络(DNN)训练,但在张量重计算过程中尤为严重,因为重计算会导致更频繁的内存重组。
- 现有张量重计算方法无法解决该问题的根本原因在于,它们并不强调生成连续的空闲内存块。此外,它们的启发式方法往往会使问题更加严重。大多数重计算方法为了减少递归重计算,会惩罚驱逐由顺序操作生成的张量。例如,在 DTR 的启发式方法中,张量的预估开销是基于其邻域计算的(即依赖于当前张量或依赖其重计算的张量)。惩罚顺序张量的驱逐通常会导致生成非连续的空闲内存块,因为顺序张量往往是连续存储的。
图表:
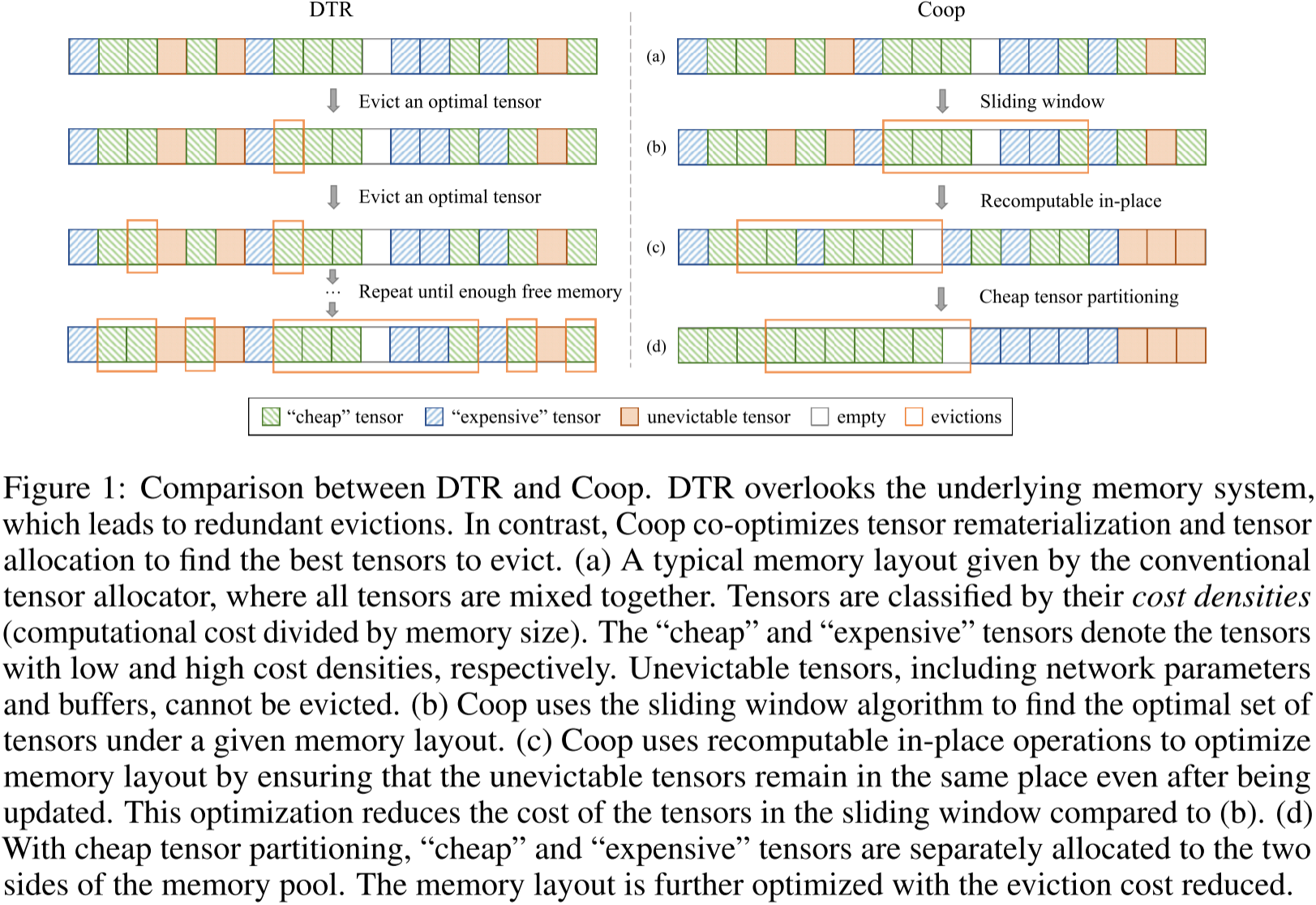
图 1:DTR 与 Coop 的对比。DTR 忽略了底层内存系统,导致冗余的逐出操作。相比之下,Coop 共同优化了张量重计算和张量分配,以找到最优的张量进行逐出。
张量按其成本密度(计算成本除以内存大小)进行分类。“低成本”张量和“高成本”张量分别表示成本密度低和高的张量。不可逐出的张量(包括网络参数和缓冲区)无法被逐出。
(a) 传统张量分配器给出的典型内存布局,其中所有张量混合存储。
(b) Coop 采用滑动窗口算法,在给定的内存布局下找到最优的张量集合。
© Coop 通过可重计算的就地(in-place)操作优化内存布局,确保不可逐出的张量在更新后仍保持原位。这一优化降低了滑动窗口内张量的成本,相较于 (b) 更加高效。
(d) 通过低成本张量划分,“低成本”张量和“高成本”张量分别分配到内存池的两侧。进一步优化内存布局,降低逐出成本。
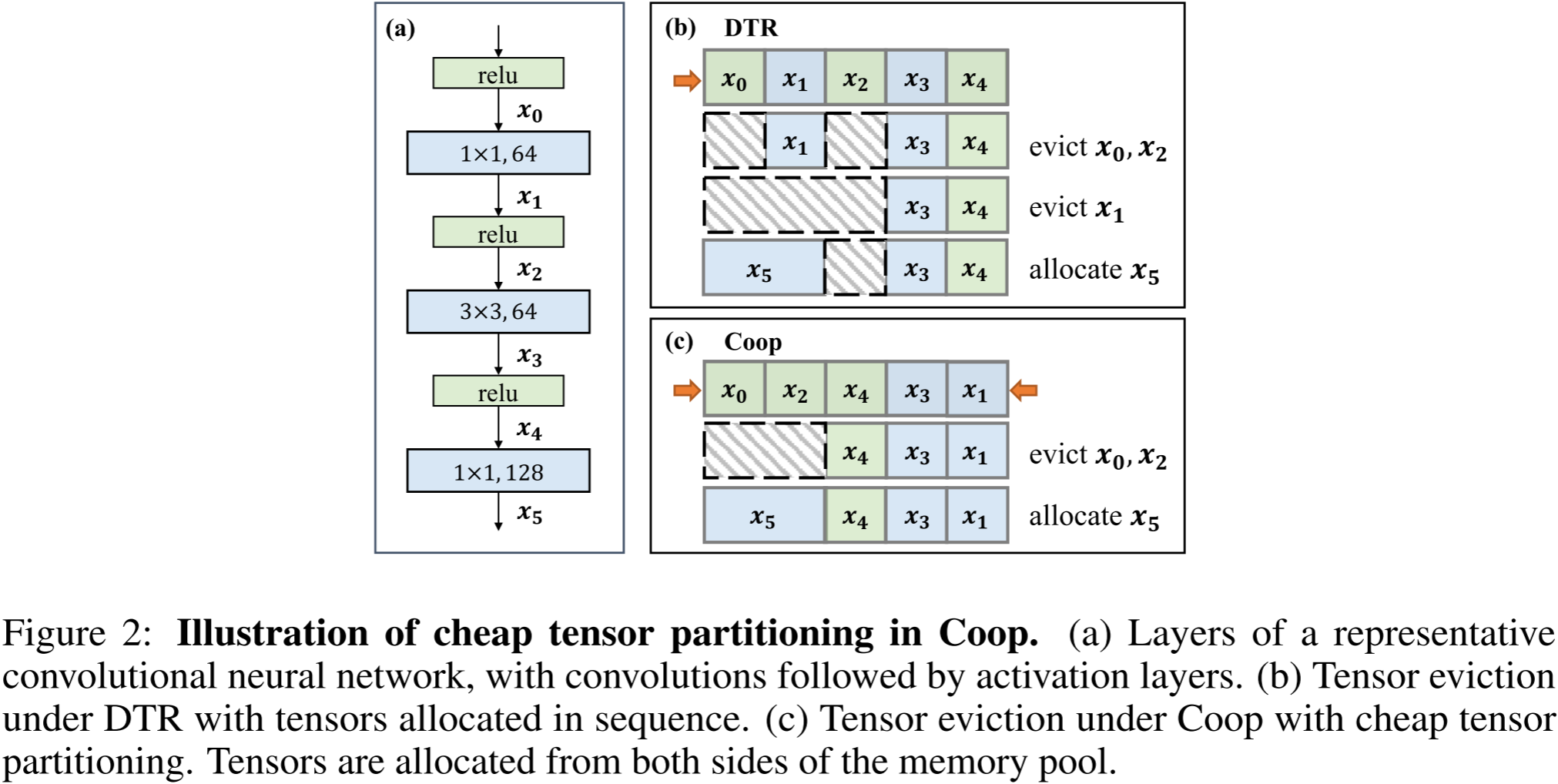
图 2:Coop 中低成本张量划分的示意图。
我们观察到,神经网络中的大多数算子可以按照计算复杂度简单地归类为两类:超线性(super-linear)(如矩阵乘法 matmul 和卷积 conv)以及线性/次线性(linear/sub-linear)(如逐元素操作 element-wise ops)。在大多数情况下,超线性操作的成本密度比其他算子高一个数量级。
(a) 典型卷积神经网络的层结构,卷积层后接激活层。
图 2(a) 展示了一个典型的卷积神经网络示例,其中每个卷积层后都跟随一个激活函数。在此,我们未包含批量归一化(Batch Normalization),因为其计算成本密度与激活层相似,且并非所有神经网络都必须包含该操作。
(b) DTR 下的张量逐出,张量按顺序分配。
假设张量 x 0 , . . . , x 4 x_0, ..., x_4 x0,...,x4 在训练开始时生成,因此按顺序存储在内存中。如果内存已满且需要额外的 100 MB 来存储 x 5 x_5 x5,根据 DTR 的策略,两个由激活层生成的张量( x 0 x_0 x0 和 x 2 x_2 x2,每个 50 MB)将被优先驱逐( x 0 x_0 x0 是内存中最旧且成本最低的张量,其驱逐会增加 x 1 x_1 x1 的启发式成本)。然而,由于释放的内存块不连续,仍需额外驱逐其他张量(例如 x 1 x_1 x1),这会引入无效驱逐并导致内存碎片化(如图 2(b))。
© Coop 采用低成本张量划分进行张量逐出,张量从内存池的两侧进行分配。
我们通过从内存池的最左端和最右端分配张量来实现低成本张量分区(如图 2©),该方法是可行的,因为用户在训练前已指定内存预算。我们使用**成本密度(计算成本除以内存大小)**来衡量张量的驱逐成本大小。在模型的前向传播过程中,具有相同数量级成本密度的张量被分配到内存池的同一端。
3) 2023_ICML_A会_MODeL: Memory Optimizations for Deep Learning
MODeL 使用整数线性规划来解决算子排序和张量内存布局的问题。
动机:深度学习框架面临的内存碎片化问题 + 深度学习框架未针对张量的生命周期进行优化。
总结:MODeL 通过分析深度神经网络的数据流图,寻找算子之间的拓扑排序。MODeL 将最小化深度神经网络训练所需峰值内存的问题建模为一个整数线性规划 (integer linear program, ILP),以共同优化张量的生命周期 (lifetime) 和内存位置 (memory location),从而最小化深度神经网络训练需要分配的内存峰值,并减少内存碎片。
摘抄:
- 当前流行的深度学习框架(如 PyTorch 和 TensorFlow)并未充分利用有限的内存资源。类似于传统的动态内存分配器(如 tcmalloc 和 jemalloc),这些框架在运行时维护一个空闲内存块池。当接收到内存请求时,它们会在内存池中查找足够大的空闲块,若无法满足请求,则直接从物理内存中分配新块。当空闲内存块的大小与实际分配请求不匹配时,就会导致内存碎片化,而这种情况经常发生。
- 此外,深度神经网络框架未对张量的生命周期进行优化。PyTorch 按照程序中定义的顺序执行操作,而 TensorFlow 维护一个就绪队列,并采用先进先出的方式执行运算。因此,张量可能会被提前分配或延迟释放,从而浪费宝贵的内存。
- PyTorch 和 TensorFlow 等机器学习框架允许部分算子将其生成的数据存储在输入张量之一中,从而避免额外分配输出张量。这种方法称为 就地更新(inplace-update),可以节省内存。然而,用户需要手动修改神经网络以利用这一特性,并且如果使用不当,可能会导致计算错误。
图表:
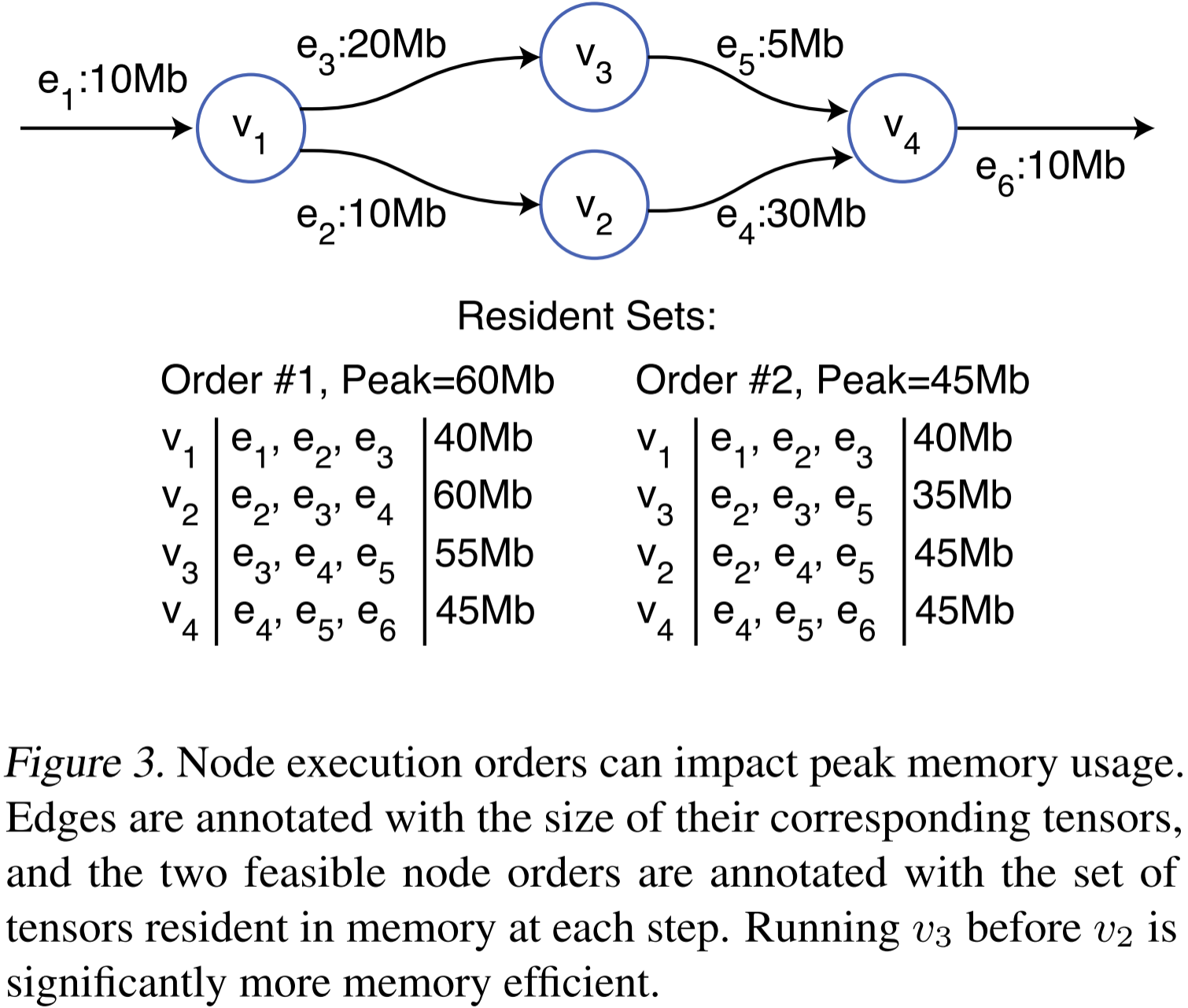
图 3:节点执行顺序会影响峰值内存占用。边上标注了对应张量的大小,两种可行的节点执行顺序分别标注了每个步骤内存中驻留的张量集合。在 v3 先于 v2 运行的情况下,内存使用效率显著提高。
峰值驻留集合(peak resident set) 是整个神经网络执行过程中规模最大的驻留集合。算子执行顺序会影响张量的生命周期,因此也影响内存的峰值占用。图 3 展示了一个简单示例,说明如何通过调整算子执行顺序显著改善内存使用情况。在所有可能的节点执行顺序中,优先执行能够释放大量数据且自身生成少量输出数据的节点通常更具内存效率。然而,已有研究表明,在通用 有向无环图(DAG, Directed Acyclic Graph) 上寻找最优调度是一个 NP 完全(NP-complete) 问题,无法通过简单的贪心策略解决。
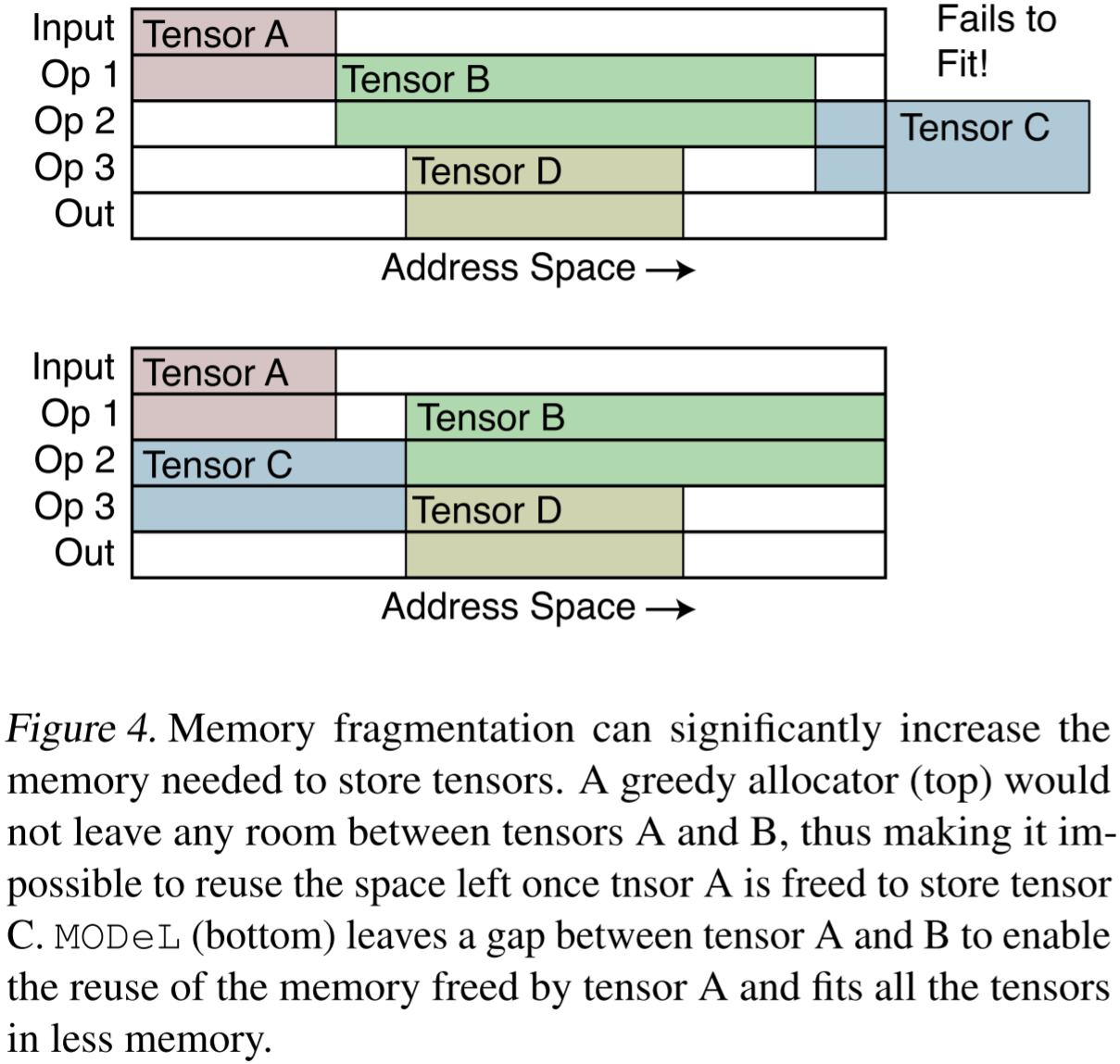
图 4:内存碎片化可能大幅增加存储张量所需的内存。贪心分配器(上图)不会在张量 A 和 B 之间留下任何空隙,因此当张量 A 释放后,无法利用其腾出的空间存储张量 C。而 MODeL(下图)在张量 A 和 B 之间预留了空隙,使得张量 A 释放后的内存可被重用,从而在更少的内存中容纳所有张量。
类似于 malloc 风格的内存分配器,典型的深度学习框架采用在线(online)方式进行张量分配,因此同样会面临内存碎片化问题。事实上,空闲内存通常被分割成小块,并被已分配的张量所隔开,导致大量可用内存因碎片化而无法有效利用,因为这些零散的小块不足以容纳一个完整的张量。图 4 说明了这一现象,并展示了如何通过预先规划每个张量的存储位置来大幅减少内存峰值占用。
4) 2023_arXiv:2310.19295_v1_ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
ROAM 和 MODeL 优化的都是算子排序 (operator ordering) 和内存布局 (memory layout),而且最终都把问题形式化为整数线性规划问题。
动机:尽管卸载、重计算和压缩等高层技术可以缓解内存压力,但它们也会引入额外的开销。然而,一个具备合理算子执行顺序和张量内存布局的内存高效执行计划可以显著提升模型的内存效率,并减少高层技术带来的开销。
总结:ROAM 在计算图层面进行优化。为了降低理论峰值内存,ROAM 将算子执行顺序的优化转换为张量生命周期的优化,并引入多个约束条件,以确保优化后的张量生命周期与有效的算子执行顺序相对应,优化目标是最小化理论峰值内存。为了提高内存布局效率,ROAM 最关键的约束是确保生命周期重叠的张量不能占据重叠的地址空间,优化目标是最小化所需内存空间的大小。ROAM 使用整数线性规划求得上述两个问题的近似最优解,并通过一种子图树拆分算法将整体大任务转换为多个小任务,以提高求解过程的执行效率,解决大型复杂图中的优化挑战。
摘抄:
- 当前的深度学习编译器和框架依赖于基本的拓扑排序算法,这些算法并未考虑峰值内存使用情况。然而,这些执行顺序通常并不具备内存高效性。
- Pytorch 按照程序中定义的顺序执行算子。
- Tensorflow 维护一个就绪算子队列,并根据进入队列的时间执行它们。
- 已有研究证明,有向无环图(DAG)的最优调度问题以及内存布局优化问题(也称为**动态存储分配问题,Dynamic Storage Allocation, DSA)**分别是典型的 **NP 完全(NP-Complete)**问题和 **NP 难(NP-Hard)**问题。因此,在多项式时间内找到最优解是具有挑战性的。
图表:
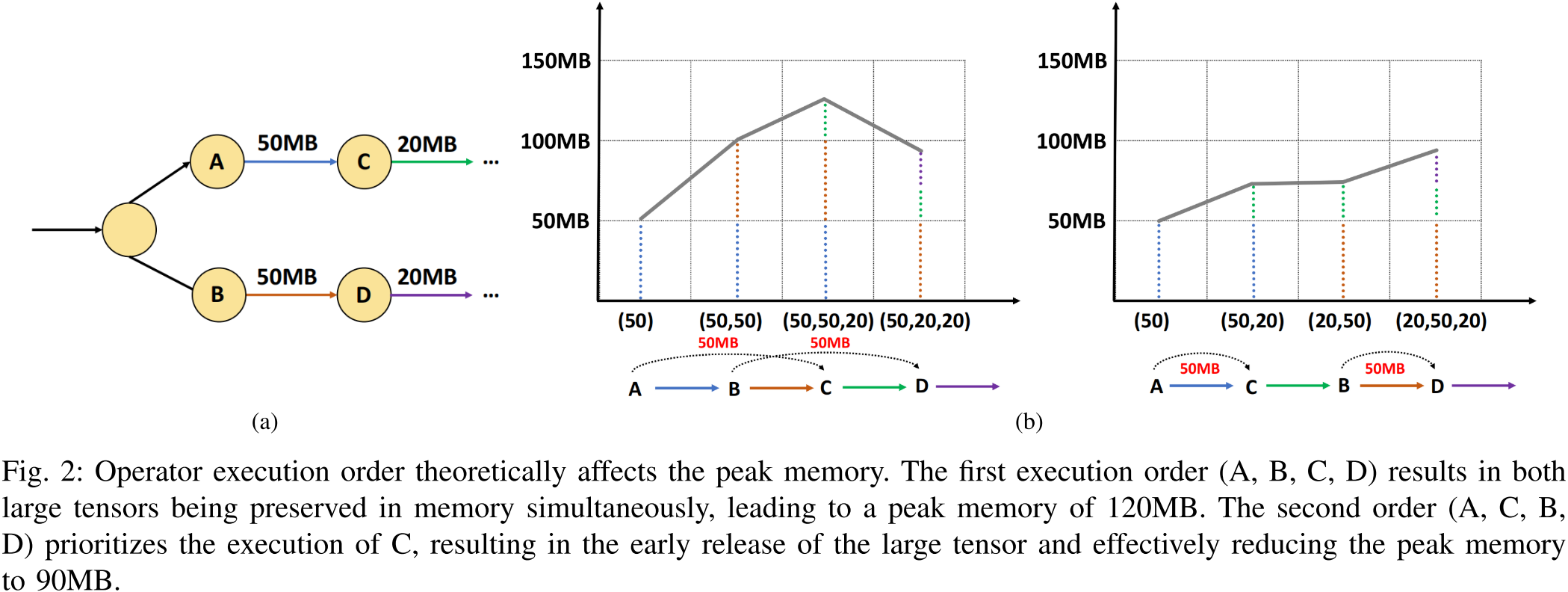
图 2:运算符执行顺序在理论上会影响峰值内存占用。第一种执行顺序(A、B、C、D)会导致两个大张量同时保留在内存中,导致峰值内存达到 120MB。而第二种执行顺序(A、C、B、D)优先执行 C,从而使大张量得以及早释放,有效地将峰值内存降低至 90MB。
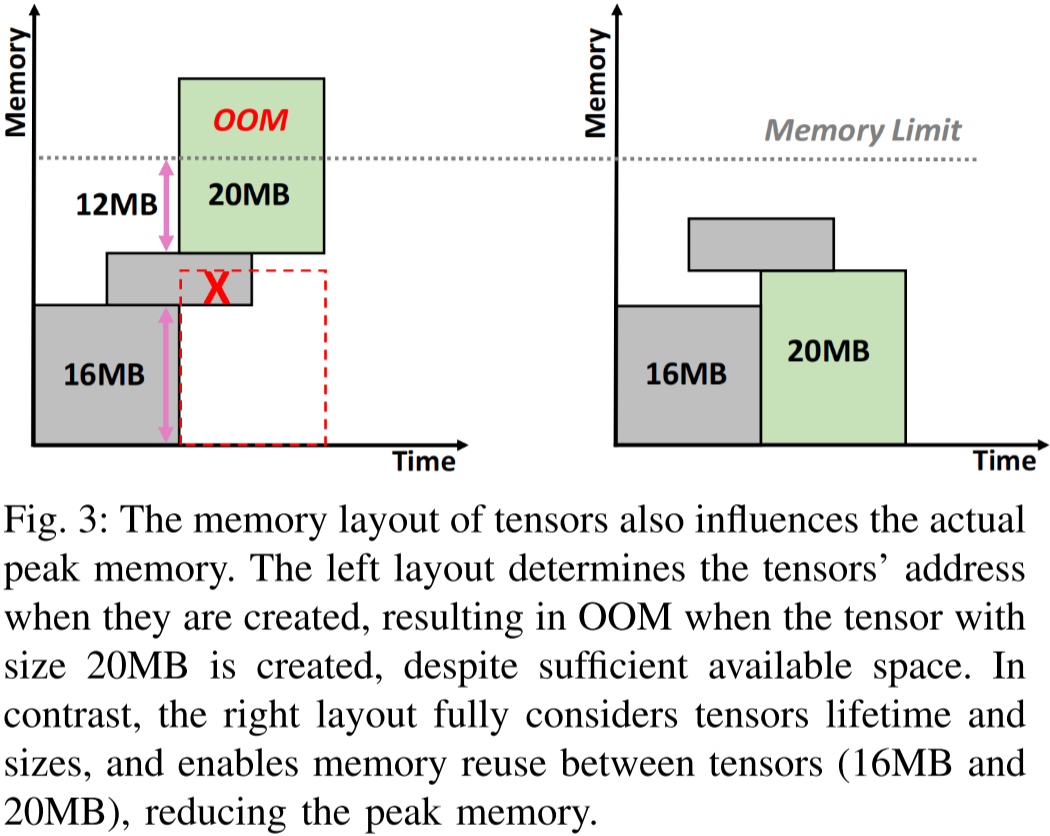
图 3:张量的内存布局同样会影响实际的峰值内存。左侧的布局在创建张量时决定了它们的地址,尽管存在足够的可用空间,但在创建大小为 20MB 的张量时仍然发生 OOM(内存溢出)。相比之下,右侧的布局充分考虑了张量的生命周期和大小,使得张量(16MB 和 20MB)之间的内存得以复用,从而降低峰值内存占用。
此外,内存布局的低效性会对实际的内存需求产生显著影响。张量的不合理内存布局会导致较低的内存复用效率,在内存中相邻的两个张量之间产生数据碎片,如图 3 所示。
现有的深度学习框架通常在运行时从内存池中搜索足够大的空闲内存块,或者选择直接从物理内存中分配所需的内存。它们在决定张量的内存偏移时仅考虑其生成时间。然而,内存复用还与张量的大小和生命周期密切相关。因此,这种运行时分配方法难以通过内存复用充分降低内存需求。由于不同张量的生命周期和大小存在差异,在动态分配过程中经常会出现内存碎片化问题,这可能导致因缺乏连续内存而分配失败。
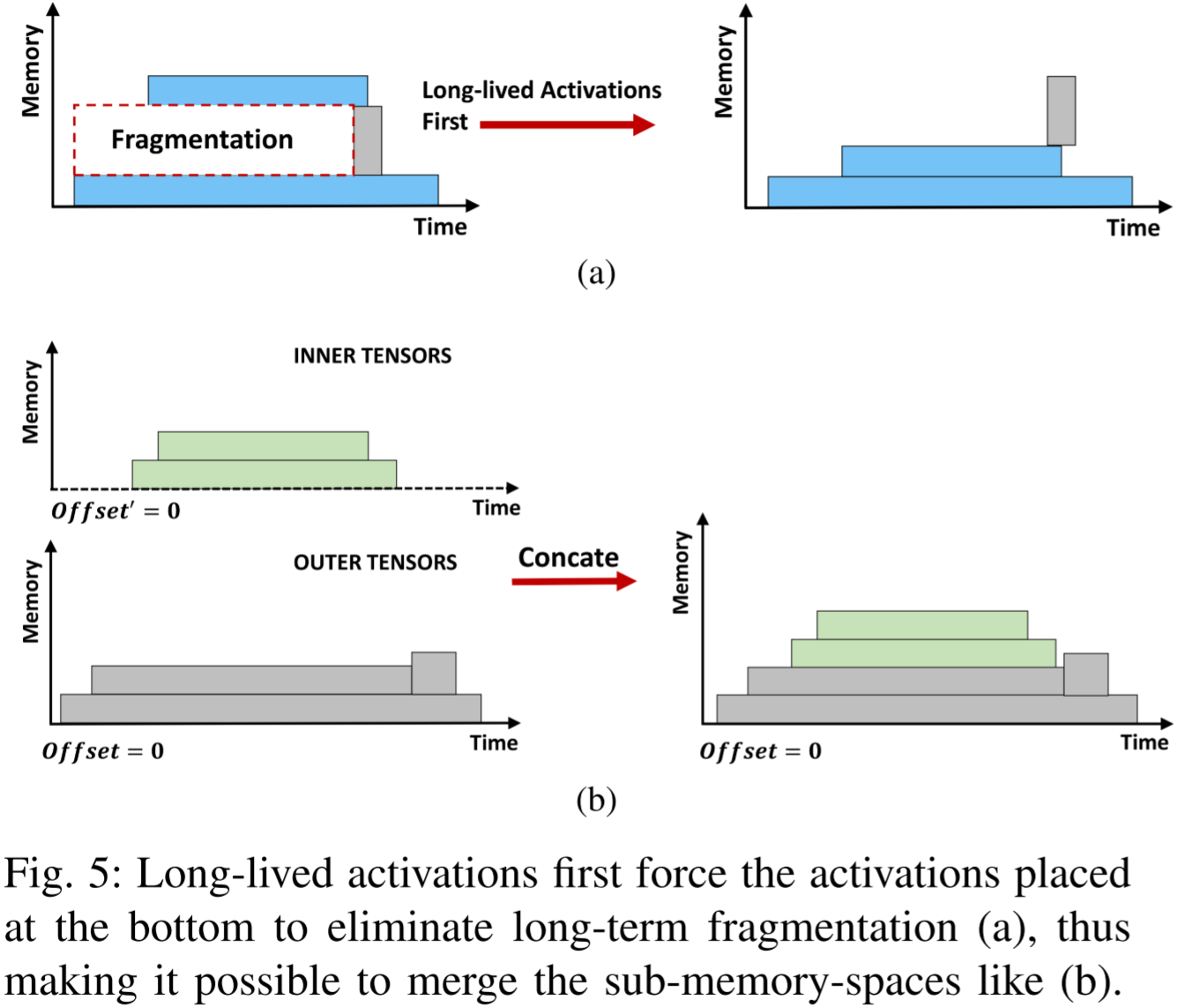
图 5:长生命周期的激活首先迫使底部的激活张量排列,以消除长期的内存碎片化 (a),从而使得子内存空间可以像 (b) 那样合并。
临时缓冲区和激活被分配到不同的内存布局中,可能会导致长期碎片化,如图 5a 所示。
为了解决这一问题,我们施加了约束,强制激活在较低偏移量处连续放置,从而防止激活与临时缓冲区之间的交错。
如图 5b 所示,涉及将生命周期较短的内存布局放置在另一个布局之上。这种方法利用长期存在的激活的累积大小作为基础偏移量,有效地减轻了长期碎片化问题。
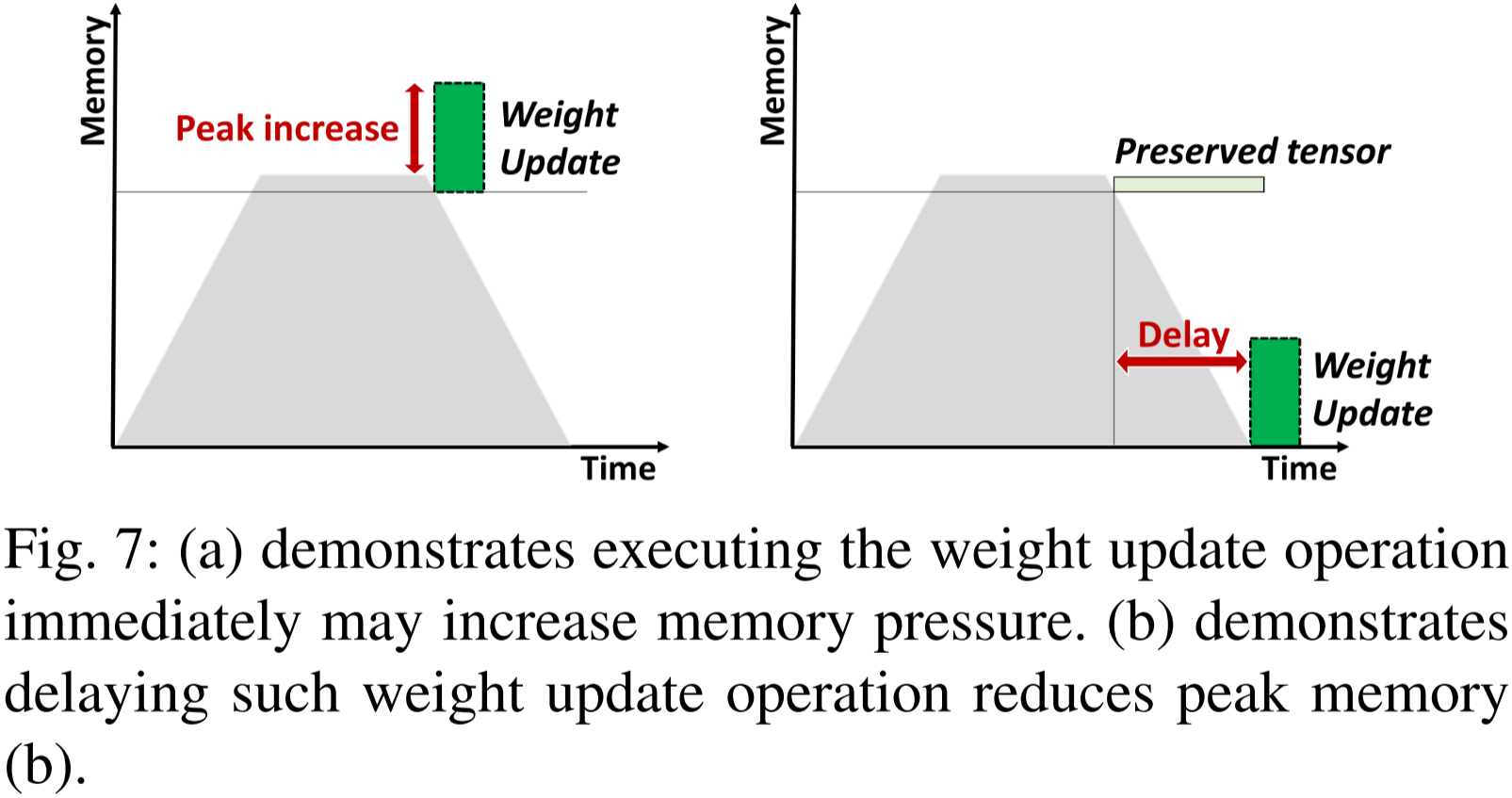
图 7:(a) 说明立即执行权重更新操作可能会增加内存压力。(b) 说明延迟执行权重更新操作可以降低峰值内存占用。
一旦生成梯度,相应的权重更新操作就可以安排执行。因此,权重更新操作的调度表现出强大的灵活性。权重更新操作的调度时间步可以显著影响峰值内存。考虑两种极端情况,一是梯度生成后立即调度权重更新,二是所有权重更新操作都在完成反向传播过程后再调度。
如图 7 所示,
- 在内存消耗较大时,例如大多数激活张量都被保留在内存中,尽早执行权重更新可能会产生许多大的临时缓冲区,导致更大的内存压力。
- 然而,选择将所有权重更新操作延迟执行并不是一个理想的方案,因为每个梯度必须被保留相当长的时间。
- 因此,将权重更新操作分配到合适的独立段并进行调度是非常重要的。
5) 2024_ASPLOS_A会_GMLake: Efficient and Transparent GPU Memory Defragmentation for Large-scale DNN Training with Virtual Memory Stitching
GMLake 用到了 CUDA VMM API,是虚拟内存拼接机制的首个工作,出现的时间与 PyTorch 的 Expandable Segments 相似,但都晚于 TensorFlow 的。GMLake 提供了多个版本的 PyTorch 实现,同时也是质量很高的一篇论文。
关于 CUDA VMM API 和 PyTorch 的 Expandable Segments,感兴趣的读者可以阅读:PyTorch 源码学习:GPU 内存管理之初步探索 expandable_segments
动机:尽管优化方法(重计算、卸载、分布式训练和低秩适配)能够有效减少训练或微调大规模 DNN 模型的内存占用,但它们可能会导致较低的内存利用率。其原因在于,这些方法会引入大量规律性和动态性的内存分配请求,从而导致 GPU 内存碎片率最高可达 30%。
总结:GMLake 针对内存优化技术导致的严重内存碎片化问题,利用 CUDA 提供的虚拟内存管理接口,提出了一种虚拟内存拼接机制,通过虚拟内存地址映射组合非连续的物理内存块,从而缓解了内存碎片问题。
笔者对这篇论文进行了翻译,具体内容见:【翻译】GMLake_ASPLOS 2024
6) 2024_ISMM_内存领域_A Heuristic for Periodic Memory Allocation with Little Fragmentation to Train Neural Networks
考虑到该文献使用模拟退火 (Simulated Annealing, SA) 算法解决动态存储分配 (Dynamic Storage Allocation, DSA) 问题,所以笔者将其简称为 DSA-SA。另外,作者在论文中也解释了该工作的局限性:“总体而言,尽管我们的方法是离线的,其适用性受到一定限制,但在需要针对特定工作负载进行高度优化的场景下,我们的方法能够实现接近满负载的资源利用率,并且一旦完成分配规划,就不会产生任何运行时开销,因此我们认为其性能最佳。” DSA-SA 的开销主要体现在第一次迭代。
动机:DSA 问题是 NP-hard 的,因此通过精确算法的优化成本过高。已有大量关于多项式时间近似算法的研究。然而,这些算法主要关注理论界限,其实际实现通常采用诸如首次适应(first-fit)或最佳适应(best-fit)与合并(coalescing)等启发式方法。……我们的工作主要是受到重计算引起的内存碎片化问题的推动。
总结:DSA-SA 利用了神经网络训练过程中内存分配的周期性,在第一次迭代期间获取内存的分配模式。DSA-SA 将离线 DSA 问题表述为寻找一个最优的分配之间的拓扑排序,并通过基于模拟退火的启发式算法来解决这个 NP-hard 问题,从而可以确定一个碎片化程度最小的分配计划。
摘抄:
- PyTorch 的 CUDA 缓存分配器使用一组块来管理保留的 GPU 内存。这组块类似于 dlmalloc 中的块,后者最初用于 glibc。……此实现具有低延迟,并且通常对典型的神经网络应用表现良好,因为训练或推理过程中有许多相同大小的分配,并且大多数分配可以通过保留的空块处理,而无需调用
cudaMalloc。此外,由于训练和/或推理需要重复计算,缓存策略表现尤为出色,直到资源耗尽,此时缓存将通过使用cudaFree释放一些未拆分的块来销毁。 - 现有的缓存分配器中的碎片减少技术:PyTorch 的 CUDA 缓存分配器提供了几种选项来配置算法,以防止 OOM 错误。
- 如前所述,未使用的拆分块会导致 CUDA 缓存分配器中的碎片。为了防止将大块拆分为小分配,PyTorch 为小型(最多1MB)和大型分配使用两个块池。拆分大块通常是有益的,因为它可以重复使用保留的区域,但也可能导致严重的碎片化。为了防止这种情况,可以配置缓存分配器在使用阈值时不拆分大块。当这些大块不再需要时,可以随时使用
cudaFree释放它们;然而,同步的cudaFree可能会降低执行吞吐量。 - 此外,缓存分配器可以配置为将每个分配的大小四舍五入到最接近的 2 的幂,以防止灾难性的碎片化。然而,在大多数工作负载中,这种配置可能会导致更多碎片。
- 如前所述,未使用的拆分块会导致 CUDA 缓存分配器中的碎片。为了防止将大块拆分为小分配,PyTorch 为小型(最多1MB)和大型分配使用两个块池。拆分大块通常是有益的,因为它可以重复使用保留的区域,但也可能导致严重的碎片化。为了防止这种情况,可以配置缓存分配器在使用阈值时不拆分大块。当这些大块不再需要时,可以随时使用
- PyTorch 采用了专门的 CUDA 缓存分配器,以减少
cudaMalloc和cudaFree之类的阻塞函数调用的频率。该缓存分配器优化了内存分配和释放操作,显著提升了 PyTorch 框架中 GPU 操作的整体性能。PyTorch 分配器使用了一种高效的在线 DSA 算法。
图表:
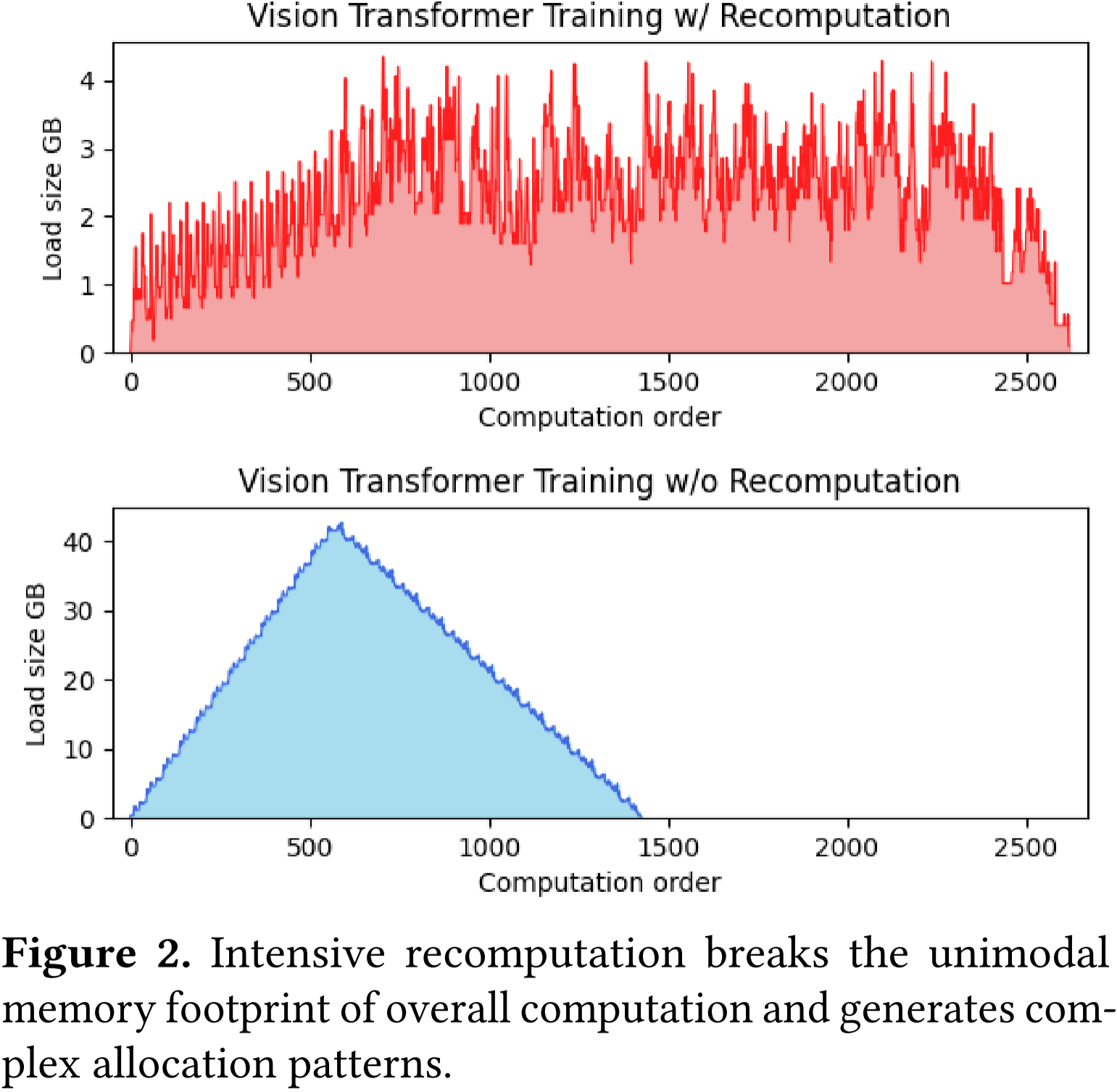
图 2:高强度的重计算破坏了整体计算的单峰内存占用模式,并生成复杂的分配模式。
我们在图 2 中绘制了内存消耗和计算顺序,即每个算子的运行进度。没有重计算时,内存消耗模式是单峰的(前向传递时增加,反向传递时减少),并且大多数分配器算法在峰值内存消耗时几乎没有碎片化。
然而,启用重计算时,内存的分配和释放在计算过程中交替进行,导致复杂的模式。此外,鉴于重计算的固有特性,PyTorch 缓存分配器可能会因大量小的内存分配和大内存分配之间的间隔而遭受严重的碎片化。
这种碎片化不仅浪费了 GPU 资源,还减慢了训练过程。这是因为 PyTorch 的 CUDA 缓存分配器在需要释放缓存块以腾出空间时,使用了阻塞的 cudaMalloc 和 cudaFree 操作。

图 4:PyTorch 缓存分配器(左)导致的碎片化,以及 GMLake 进行的碎片整理技术(中)和离线规划(右)。每个加粗的框表示该内存段上存在某些阻塞的 CUDA API 调用。
GMLake 通过将物理内存块拼接成连续的虚拟范围在线运行,离线规划的适用性有限,因为它需要对分配模式做出假设,但它能够在没有运行时开销的情况下实现最大化的资源利用。
相关文章:

【笔记】深度学习模型训练的 GPU 内存优化之旅⑤:内存分配篇
开设此专题,目的一是梳理文献,目的二是分享知识。因为笔者读研期间的研究方向是单卡上的显存优化,所以最初思考的专题名称是“显存突围:深度学习模型训练的 GPU 内存优化之旅”,英文缩写是 “MLSys_GPU_Memory_Opt”。…...

【5G 架构】边缘计算平台是如何与3GPP网络连接的?
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G技术研究。 博客内容主要围绕…...
)
5.0.0 GripSpliter的使用(探讨水平竖直对齐参数)
布局控件Grid 配合 GridSplitter 无需编写任何代码 就能实现网格大小可拖动。 其HorizontalAlignment、VerticalAlignment属性的使用非常具有迷惑性;本文做了一些一些实验,总结为把这两个属性均设置为strech即可。 总结如下:经过实验,发现以下情况可以正常工作。 水平方向…...

python如何把pdf转word
在Python中将PDF转换为Word文档(.docx)比反向转换(Word转PDF)更具挑战性,因为PDF是固定格式,而Word是可编辑格式。以下是几种可行的方法及详细步骤: 方法1:使用 pdf2docx 库 pdf2do…...

go实现双向链表
需求 实现双向链表的节点生成、正反向遍历、指定删除。 实现 package mainimport ("fmt" )type zodiac_sign struct {number intdizhi stringanimal stringyear intprevious *zodiac_signnext *zodiac_sign }// 添加 // func add_node_by_order(pr…...

33、VS中提示“以下文件中的行尾不一致。是否将行尾标准化?“是什么意思?
在Visual Studio(VS)中遇到提示“以下文件中的行尾不一致。是否将行尾标准化?”时,意味着当前打开或正在编辑的文件内部存在行尾符(EOL,End-Of-Line)格式不统一的情况。以下是详细解释和应对建议…...
)
C 语言 第五章 指针(5)
目录 函数参数传递机制:地址传递 值传递 简单变量指针作为形参 举例1: 举例2: 举例3: 数组作为形参 举例: 函数参数传递机制:地址传递 值传递 void test(int a, int b) { a 10; b 20; print…...
)
Python项目源码69:Excel数据筛选器1.0(tkinter+sqlite3+pandas)
功能说明:以下是一个使用Tkinter和Pandas实现的完整示例,支持Excel数据读取、双表格展示和高级条件筛选功能: 1.文件操作:点击"打开文件"按钮选择Excel文件(支持.xlsx和.xls格式),自…...

机器人--架构及设备
机器人的四大组成部分 控制系统 驱控系统 驱控驱动系统控制系统。 注意,这里的控制系统不是机器人层面的控制系统,属于更小层级的,驱控系统的控制系统。 驱动系统: 一般指硬件设备,比如电机驱动器,I/O…...

机器人--主机--控制系统
机器人主机 机器人主机,即控制系统。 作用 机器人主机的核心功能 传感器数据处理:处理摄像头、激光雷达、IMU等数据。 运行SLAM/导航算法:如Google Cartographer、RTAB-Map。 路径规划与控制:执行A*、DWA等算法。 通信管理&a…...

Stm32 烧录 Micropython
目录 前言 准备工作 开始操作 问题回顾 后记 前言 去年曾经尝试Pico制作openmv固件,由于知识储备不够最后失败了,留了一个大坑,有了前几天的基础,慢慢补齐知识,最近这一周一直在学习如何编译Stm固件并烧录到单片机…...

leetcode 977. Squares of a Sorted Array
题目描述 双指针法一 用right表示原数组中负数和非负数的分界线。 nums[0,right-1]的是负数,nums[right,nums.size()-1]是非负数。 然后用合并两个有序数组的方法。合并即可。 class Solution { public:vector<int> sortedSquares(vector<int>&…...

使用Nexus搭建远程maven仓库
1、Nexus介绍 Nexus 是 Sonatype 公司的一款用于搭建私服的产品,使用非常广泛。在早期,我们都拿Nexus当maven私服仓库,后来,随着版本不断更新,它支持的数据类型越来越多,比如npm仓库,nuget仓库&…...

坚鹏:工行《DEEPSEEK赋能银行智能办公及数字化营销服务》培训
中国工商银行上海市分行《DEEPSEEK赋能银行智能办公及数字化营销服务》培训圆满落幕 中国工商银行作为全球领先的综合性金融服务集团,始终走在金融科技创新的前沿。截至2024年末,工商银行总资产规模突破40万亿元,连续多年稳居全球银行榜首。在…...

操作系统OS是如何指挥外围设备的呢?
众所周知,OS的职责之一就是管理外围设备,比如常见的磁盘、硬盘、显示器、麦克风等,但并不是外围设备的一切都必须由OS管理,比如无线鼠标上的开关键,当你通过它关闭鼠标时,这个操作并不会经过OS,…...

实现Sentinel与Nacos的规则双向同步
实现Sentinel与Nacos的规则双向同步:完整解决方案 前言 在微服务架构中,流量控制和熔断降级是保障系统稳定性的重要手段。阿里开源的Sentinel作为一款轻量级的流量控制组件,常被用于实现这些功能。然而,在实际生产环境中&#x…...

2025五一杯数学建模A题:支路车流量推测问题,思路分析+模型代码
一持续更新,见文末名片 二、问题背景 想象一下,城市的道路如同一张巨大的脉络图,主路如同大动脉,配备着车流量监测设备,能实时记录车流量数据,就像我们身体的传感器一样。然而,当多条支路像毛细…...

Linux51 安装baidunetdisk yum install rpm -ivh
推测网卡 感觉是不是以前哪里设置了下 deepseek说的这个设置 我没有设置过 这个不会弄啊 准备用虚拟机安个软件 神奇 换了这个命令又能打开网卡了 参考了这个 参考 之前地址我觉得配置错误 动态分配 我就删掉ip地址了 路由表中无ip地址吗? OK 卸载 运…...

【Python-Day 8】从入门到精通:Python 条件判断 if-elif-else 语句全解析
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...
)
若依 FastAPI + Vue3 项目 Docker 部署笔记( 启动器打包教程)
本文记录了将 start.bat 打包成 .exe 启动器的详细教程,适合项目交付或导师演示用。 🧭 一、如何将 start.bat 打包为启动器 .exe(含图标 自动打开浏览器) ✅ 1. 创建三大功能脚本 start.bat → 启动项目(docke…...

Lebesgue测度和积分理论发展概观
1. 发展背景 积分可以从两个角度来理解。首先,积分是微分的逆函数,因此积分是反导数(译注:但积分是独立于微分的,不能微分的函数也可能可积)。然而,这是一个非常抽象的概念。其次,两点之间的积分可以看…...

算法题题型总结
二叉树题型 解法综述:二叉树的解法,基本上都是依赖遍历,再加上递归的思路来做的。那递归又分为深度优先和广度优先。深度优先算法,前序,中序,后序。广度优先,利用先进先出队列,一层…...

网络编程——TCP和UDP详细讲解
文章目录 TCP/UDP全面详解什么是TCP和UDP?TCP如何保证可靠性?1. 序列号(Sequence Number)2. 确认应答(ACK)3. 超时重传(Timeout Retransmission)4. 窗口控制(Sliding Win…...

Qt多线程TCP服务器实现指南
在Qt中实现多线程TCP服务器可以通过为每个客户端连接分配独立的线程来处理,以提高并发性能。以下是一个分步实现的示例: 1. 自定义工作线程类(处理客户端通信) // workerthread.h #include <QObject> #include <QTcpSo…...
)
【经管数据】A股上市公司资产定价效率数据(2000-2023年)
数据简介:资产定价效率是衡量市场是否能够有效、准确地反映资产内在价值的重要指标。在理想的市场条件下,资产的市场价格应该与其内在价值保持一致,即市场定价效率达到最高。然而,在实际市场中,由于信息不对称、交易摩…...

打包 Python 项目为 Windows 可执行文件:高效部署指南
Hypackpy 是一款由白月黑羽开发的 Python 项目打包工具,它与 PyInstaller 等传统工具不同,通过直接打包解释器环境和项目代码,并允许开发者修改配置文件以排除不需要的内容,从而创建方便用户一键运行的可执行程序。以下是使用 Hyp…...

【QNX+Android虚拟化方案】138 - USB 底层传输原理
【QNX+Android虚拟化方案】138 - USB 底层传输原理 1. USB 数据包的格式2. 数据传输事务过程3. 四种传输类型3.1 批量传输3.2 中断传输3.3 实时传输3.4 控制传输4. USB 设备枚举过程4.1 Attached: 发送控制传输,读取设备描述符4.2 Power -> Default 这个状态无数据传输4.3 …...
篇三:阅读与注释类 QAbstractSpinBox ,这是螺旋框的基类,附上源码)
QT6 源(66)篇三:阅读与注释类 QAbstractSpinBox ,这是螺旋框的基类,附上源码
(9)所有代码来自于头文件 qabstractspinbox . h : #ifndef QABSTRACTSPINBOX_H #define QABSTRACTSPINBOX_H#include <QtWidgets/qtwidgetsglobal.h> #include <QtWidgets/qwidget.h> #include <QtGui/qvalidator.h>/* QT_CONFIG宏实…...

MCP入门
什么是mcp mcp(model context protocol,模型上下文协议) 标准化协议:让大模型用统一的方式来调用工具,是llm和工具之间的桥梁 A2A:Agent-to-Agent协议 mcp通信机制 提供mcp服务查询的平台 具有工具合集…...

FPGA中级项目8———UART-RAM-TFT
FPGA中级项目8———UART-RAM-TFT UART串口我们学过,RAM IP核学过,TFT同样也学过。那如何将它们联合起来呢? 言简意赅:实现从串口写入图像到RAM并且由TFT显示屏输出! 首先第一步,便是要将UART_RX与RAM之间…...

Ocelot\Consul\.NetCore的微服务应用案例
案例资料链接:https://download.csdn.net/download/ly1h1/90733765 1.效果 实现两个微服务ServerAPI1和ServerAPI2的负载均衡以及高可用。具体原理,看以下示意图。 2.部署条件 1、腾讯云的轻量化服务器 2、WindowServer2016 3、.NETCore7.0 4、Negut …...

数值求解Eikonal方程的方法及开源实现
Eikonal方程是一类非线性偏微分方程,形式为 ( |\nabla u(x)| f(x) ),常见于波传播、几何光学、最短路径等问题。以下是数值求解Eikonal方程的方法及开源实现参考: 一、数值求解方法 有限差分法(FDM) 快速行进法&#…...

Http详解
🧱 一、从 TCP 三次握手到访问网页:两层过程 🧩 1. TCP 三次握手(网络传输层) 这是 建立连接 的前提,跟 HTTP 无关,但 HTTP 要依赖它。 举例:你打开浏览器访问 https://example.c…...

实验五 完整性
一、引言 本次上机实验的目的主要是让学生掌握数据库完整性的三大类型(实体完整性、参照完整性、用户自定义完整性),并通过实际建库建表和数据操作加深理解。 下面将为分别展示 student、course、sc 三个表的创建语句,并设置对应的…...

《原码、反码与补码:计算机中的数字奥秘》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、原码:最直观的表示法1. 正数的原码2. 负数的原码3. 原码的特点 二、反码:原码的“反转”1. 正数的反码2. 负数的反码3. 反码的特…...

论文笔记——QWen2.5 VL
目录 引言架构创新数据整理与训练策略性能与基准测试精细感知能力应用与现实世界影响与现有模型比较结论 引言 视觉理解和自然语言处理的集成一直是人工智能研究的一个重要焦点,促成了日益复杂的视觉语言模型 (VLMs) 的发展。由阿里巴巴集团 Qwen 团队开发的 Qwe…...

前端HTML基础知识
1.HTML介绍 HTML(HyperText Markup Language,超文本标记语言)是构成网页的基本元素,是一种用于创建网页的标准化标记语言。HTML不是一种编程语言,而是一种标记语言,通过标签来描述网页的结构和内容。 超文本:超文本是…...

程序代码篇---ESP32云开发
文章目录 前言 前言 本文简单介绍了实现 ESP32-S3 传感器数据上传至云平台 手机远程控制电机 的完整方案,涵盖推荐的云平台、手机端。 一、推荐云平台及工具 云平台选择 阿里云 IoT 平台 优势:国内稳定、支持大规模设备接入、提供完整设备管理及安全…...

【C语言】文本操作函数fseek、ftell、rewind
一、fseek int fseek ( FILE * stream, long int offset, int origin ); 重新定位文件指针的位置,使其指向以origin为基准、偏移offset字节的位置。 成功返回0,失败返回非零值(通常为-1)。 origin有如下三种:分别是…...

ARM ASM
ARM ASM ARM寄存器集 列出了ARM的16个程序员可见寄存器(r0~r15)以及它的状态寄存器。 ARM共有14个通用寄存器r0~r13。寄存器r13被保留用作栈指针,r14存放子程 序返回地址,r15为程序计数器。 由于r15能够被程序员访问,…...

【五一培训】Day1
注: 1. 本次培训内容的记录将以“Topic”的方式来呈现,用于记录个人对知识点的理解。 2. 由于培训期间,作者受限于一些现实条件,本文的排版及图片等相关优化,需要过一段时间才能完成。 Topic 1:使用DeepS…...

SpringBoot使用分组校验解决同一个实体对象在不同场景下需要不同校验规则的问题
背景 添加分类的接口不需要id字段,但更新分类的接口需要id字段,当在id字段上使用NotNull注解时,会导致使用添加分类接口报id字段不能为空的错误 解决 定义分组 pojo/Category.java // 如果没有指定分组,则默认属于Default分组…...
))
Hibernate与MybatisPlus的混用问题(Invalid bound statement (not found))
当项目里已经有了Hibernate后: spring:jpa:hibernate:ddl-auto: updateshow-sql: trueproperties:hibernate:format_sql: true 再配置yml文件就会失效: mybatis-plus:mapper-locations: classpath:mapper/*.xml# 全局策略global-config:db-config:# 自…...

【音视频】ffplay数据结构分析
struct VideoState 播放器封装 typedef struct VideoState {SDL_Thread *read_tid; // 读线程句柄AVInputFormat *iformat; // 指向demuxerint abort_request; // 1时请求退出播放int force_refresh; // 1时需要刷新画⾯,请求⽴即刷新画⾯的意思int paused; // 1时…...

PV操作:宣帧闯江湖武林客栈版学习笔记【操作系统】
P,V,S江湖话翻译 P(申请) 江湖侠客拔剑大喊“掌柜的,给我一间上房!”(申请资源,房不够就蹲门口等)-要房令牌 V(释放) 江湖侠客退房时甩出一锭银子,大喊“…...
)
精品推荐-湖仓一体电商数据分析平台实践教程合集(视频教程+设计文档+完整项目代码)
精品推荐,湖仓一体电商数据分析平台实践教程合集,包含视频教程、设计文档及完整项目代码等资料,供大家学习。 1、项目背景介绍及项目架构 2、项目使用技术版本及组件搭建 3、项目数据种类与采集 4、实时业务统计指标分析一——ODS分层设计与…...

对计网考研中的信道、传输时延、传播时延的理解
对计网考研中的信道、传输时延、传播时延的理解 在学习数据链路层流量控制和可靠传输那一节的三个协议的最大信道利用率时产生的疑惑 情景: 假如A主机和B主机通过集线器连接,A和集线器是光纤连接,B和集线器也是光纤连接,A给B发…...

RAGFlow报错:ESConnection.sql got exception
环境: Ragflowv0.17.2 问题描述: RAGFlow报错:ESConnection.sql got exception _ming_cheng_tks, 浙江, operatorOR;minimum_should_match30%) 2025-04-25 15:55:06,862 INFO 244867 POST http://localhost:1200/_sql?formatjson […...

报错:函数或变量 ‘calcmie‘ 无法识别。
1、具体报错 运行网上一个开源代码,但是运行报如下错: TT_para_gen 函数或变量 calcmie 无法识别。 出错 TT_para_gen>Mie (第 46 行) [S, C, ang,~] calcmie(rad, ns, nm, lambda, nang, ... 出错 TT_para_gen (第 17 行) [~,ang,Miee,C] …...

蓝桥杯获奖后心得体会
文章目录 获奖项备考心得📖 蓝桥杯 Java 研究生组备考心得📌 一、备考规划📌 二、考试技巧📌 三、心理调整📌 四、总结 获奖项 JAVA研究生组省二 备考心得 好!我来给你写一篇蓝桥杯研究生组Java方向的备…...