日志之ClickHouse部署及替换ELK中的Elasticsearch
文章目录
- 1 ELK替换
- 1.1 Elasticsearch vs ClickHouse
- 1.2 环境部署
- 1.2.1 zookeeper 集群部署
- 1.2.2 Kafka 集群部署
- 1.2.3 FileBeat 部署
- 1.2.4 clickhouse 部署
- 1.2.4.1 准备步骤
- 1.2.4.2 添加官方存储库
- 1.2.4.3 部署&启动&连接
- 1.2.4.5 基本配置服务
- 1.2.4.6 测试创建数据库和表
- 1.2.4.7 部署遇到问题
- 1.2.4.7.1 clikhouse 客户端无法查询 kafka 引擎表
- 1.2.4.7.2 clickhouse 创建本地节点表,无法开启本地表 macro
- 1.2.4.7.3 clickhouse 中节点数据已经存在
- 1.2.4.7.4 分布式集群表无法查询
- 1.2.4.8 clickhouse其他表
- 1.2.4.8.1 分布式表
- 1.2.4.8.2 物化视图
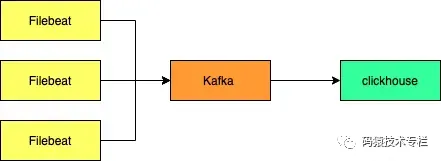
1 ELK替换
点击了解 日志之ELK使用讲解
1.1 Elasticsearch vs ClickHouse
ClickHouse 是一款高性能列式分布式数据库管理系统,对 ClickHouse 进行了测试,发现有下列优势:
ClickHouse写入吞吐量大
单服务器日志写入量在50MB到200MB/s,每秒写入超过60w记录数,是 ES 的 5 倍以上。
在ES中比较常见的写Rejected导致数据丢失、写入延迟等问题,在ClickHouse中不容易发生。- 查询速度快
官方宣称数据在pagecache中,单服务器查询速率大约在2-30GB/s;没在pagecache的情况下,查询速度取决于磁盘的读取速率和数据的压缩率。经测试ClickHouse的查询速度比 ES 快 5-30 倍以上。 - ClickHouse 比 ES 服务器成本更低
一方面ClickHouse的数据压缩比比 ES 高,相同数据占用的磁盘空间只有 ES 的 1/3 到 1/30,节省了磁盘空间的同时,也能有效的减少磁盘 IO,这也是ClickHouse查询效率更高的原因之一。
另一方面ClickHouse比ES占用更少的内存,消耗更少的 CPU 资源。预估用 ClickHouse 处理日志可以将服务器成本降低一半。
| 支持功能\开源项目 | ElasticSearch | ClickHouse |
|---|---|---|
| 查询 | java | c++ |
| 存储类型 | 文档存储 | 列式数据库 |
| 分布式支持 | 分片和副本都支持 | 分片和副本都支持 |
| 扩展性 | 高 | 低 |
| 写入速度 | 慢 | 快 |
| CPU/内存占用 | 高 | 低 |
| 存储占用(54G日志数据导入) | 高 94G(174%) | 低 23G(42.6%) |
| 精确匹配查询速度 | 一般 | 快 |
| 模糊匹配查询速度 | 快 | 慢 |
| 权限管理 | 支持 | 支持 |
| 查询难度 | 低 | 高 |
| 可视化支持 | 高 | 低 |
| 使用案例 | 很多 | 携程 |
| 维护难度 | 低 | 高 |
- 成本分析
在没有任何折扣的情况下,基于 aliyun 分析
| 成本项 | 标准 | 费用 | 说明 | 总费用 |
|---|---|---|---|---|
| zookeeper 集群 | 2核4g 共享计算型 n4 50G SSD 云盘 | 222/月 | 3台高可用 | 666/月 |
| kafka 集群 | 4核 8g 共享标准型 s650G SSD 云盘300G 数据盘 | 590/月 | 3台高可用 | 1770/月 |
| filebeat 部署 | 混部相关的应用,会产生一定的内存以及磁盘开销,对应用的可用性会造成一定的影响。 | |||
| clickhouse | 16核32g 共享计算型 n450G SSD 云盘1000G 数据盘 | 2652/月 | 2台高可用 | 5304/月 |
| 总费用 | 7740/月 |
1.2 环境部署
1.2.1 zookeeper 集群部署
点击了解 zookeeper之Linux环境下的安装
yum install java-1.8.0-openjdk-devel.x86_64
/etc/profile 配置环境变量
更新系统时间
yum install ntpdate
ntpdate asia.pool.ntp.orgmkdir zookeeper
mkdir ./zookeeper/data
mkdir ./zookeeper/logs
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
tar -zvxf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/zookeeperexport ZOOKEEPER_HOME=/usr/zookeeper/apache-zookeeper-3.7.1-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH进入ZooKeeper配置目录
cd$ZOOKEEPER_HOME/conf新建配置文件
vi zoo.cfgtickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/data
dataLogDir=/usr/zookeeper/logs
clientPort=2181
server.1=zk1:2888:3888
server.2=zk2:2888:3888
server.3=zk3:2888:3888在每台服务器上执行,给zookeeper创建myid
echo"1" > /usr/zookeeper/data/myid
echo"2" > /usr/zookeeper/data/myid
echo"3" > /usr/zookeeper/data/myid进入ZooKeeper bin目录
cd$ZOOKEEPER_HOME/bin
sh zkServer.sh start
1.2.2 Kafka 集群部署
点击了解 Kafka安装以及验证
mkdir -p /usr/kafka
chmod 777 -R /usr/kafka
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.2.0/kafka_2.12-3.2.0.tgz
tar -zvxf kafka_2.12-3.2.0.tgz -C /usr/kafka不同的broker Id 设置不一样,比如 1,2,3
broker.id=1
listeners=PLAINTEXT://ip:9092
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dir=/usr/kafka/logs
num.partitions=5
num.recovery.threads.per.data.dir=3
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zookeeper.connection.timeout.ms=30000
group.initial.rebalance.delay.ms=0后台常驻进程启动kafka
nohup /usr/kafka/kafka_2.12-3.2.0/bin/kafka-server-start.sh /usr/kafka/kafka_2.12-3.2.0/config/server.properties >/usr/kafka/logs/kafka.log >&1 &/usr/kafka/kafka_2.12-3.2.0/bin/kafka-server-stop.sh$KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server ip:9092$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server ip:9092 --topic test --from-beginning$KAFKA_HOME/bin/kafka-topics.sh --create --bootstrap-server ip:9092 --replication-factor 2 --partitions 3 --topic xxx_data
1.2.3 FileBeat 部署
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
Create a file with a .repo extension (for example, elastic.repo) in your /etc/yum.repos.d/ directory and add the following lines:
在/etc/yum.repos.d/ 目录下创建elastic.repo[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdyum install filebeat
systemctl enable filebeat
chkconfig --add filebeat
FileBeat 配置文件说明,坑点 1(需设置 keys_under_root: true)。如果不设置kafka 的消息字段如下:
文件目录:/etc/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /root/logs/xxx/inner/*.logjson:
如果不设置该索性,所有的数据都存储在message里面,这样设置以后数据会平铺。keys_under_root: true
output.kafka:hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]topic: 'xxx_data_clickhouse'partition.round_robin:reachable_only: falserequired_acks: 1compression: gzip
processors:
剔除filebeat 无效的字段数据- drop_fields: fields: ["input", "agent", "ecs", "log", "metadata", "timestamp"]ignore_missing: falsenohup ./filebeat -e -c /etc/filebeat/filebeat.yml > /user/filebeat/filebeat.log &
输出到filebeat.log文件中,方便排查
1.2.4 clickhouse 部署
1.2.4.1 准备步骤
ClickHouse 官方 RPM 包通常针对 x86_64 架构编译,并依赖 SSE 4.2 指令集,检查当前CPU是否支持SSE 4.2,如果不支持,需要通过源代码编译构建
grep -q sse4_2 /proc/cpuinfo && echo"SSE 4.2 supported" || echo"SSE 4.2 not supported"
返回 "SSE 4.2 supported" 表示支持,返回 "SSE 4.2 not supported" 表示不支持
创建数据保存目录,将它创建到大容量磁盘挂载的路径
mkdir -p /data/clickhouse
修改/etc/hosts文件,添加clickhouse节点
举例:
10.190.85.92 bigdata-clickhouse-01
10.190.85.93 bigdata-clickhouse-02
服务器性能参数设置
- cpu频率调节,将CPU频率固定工作在其支持的最高运行频率上,而不动态调节,性能最好
echo'performance' | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor - 内存调节,不要禁用
overcommit
echo 0 | tee /proc/sys/vm/overcommit_memory - 始终禁用透明大页(
transparent huge pages),它会干扰内存分配器,从而导致显着的性能下降
echo 'never' | tee /sys/kernel/mm/transparent_hugepage/enabled
1.2.4.2 添加官方存储库
# 安装 yum-utils(用于管理 YUM 仓库)
yum install yum-utils # 导入 ClickHouse 的 GPG 密钥(用于验证包的真实性)
rpm --import https://repo.clickhouse.com/CLICKHOUSE-KEY.GPG#运行命令后,可以检查是否成功导入密钥
# 如果成功导入,你会看到类似 gpg-pubkey-... --> GPG key for ClickHouse 的输出
rpm -q gpg-pubkey --qf '%{name}-%{version}-%{release} --> %{summary}\n'# 添加 ClickHouse 仓库
yum-config-manager --add-repo https://repo.clickhouse.com/rpm/stable/x86_64
1.2.4.3 部署&启动&连接
部署服务,ClickHouse 提供两个主要包:clickhouse-server(服务端)和 clickhouse-client(客户端)
# 查看clickhouse可安装的版本
yum list | grep clickhouse# 安装 ClickHouse 服务端和客户端
yum -y install clickhouse-server clickhouse-client
# 如果要指定版本
# yum install -y clickhouse-server-23.4.2.1 clickhouse-client-23.4.2.1# 检查 ClickHouse 版本以确认安装成功:
clickhouse-client --version
输出示例:
ClickHouse client version 24.3.2.1 (official build).
启动服务,ClickHouse 安装后会创建一个 systemd 服务,名为 clickhouse-server。
# 启动服务
systemctl start clickhouse-server#设置开机自启:
systemctl enable clickhouse-server#检查服务状态:
systemctl status clickhouse-server#检查服务日志:
cat /var/log/clickhouse-server/clickhouse-server.log
常见问题可能是权限或配置错误
连接服务,使用 clickhouse-client 连接到服务端,测试是否正常工作
#本地连接
clickhouse-client
默认连接 localhost:9000,用户为 default,无密码。#如果设置了密码,可以用:
clickhouse-client --password运行简单查询
在客户端提示符下运行:
SELECT 1;
1.2.4.5 基本配置服务
ClickHouse 的配置文件默认位于 /etc/clickhouse-server/,主要文件为 config.xml 和 users.xml
修改监听地址(允许远程访问): 默认只监听本地(127.0.0.1)。若需远程访问,编辑 /etc/clickhouse-server/config.xml
vi /etc/clickhouse-server/config.xml找到 <listen_host>,修改为:<listen_host>0.0.0.0</listen_host>
0.0.0.0 表示监听所有网络接口。
设置默认用户密码: 编辑 /etc/clickhouse-server/users.xml
vi /etc/clickhouse-server/users.xml
找到 <default> 用户的配置,添加或修改密码:<password>your_password</password>或者使用 SHA256 哈希密码:echo -n "your_password" | sha256sum
将哈希值填入:<password_sha256_hex>your_hashed_password</password_sha256_hex>#重启服务以应用配置:
systemctl restart clickhouse-server
修改日志级别为information,默认是trace,修改/etc/clickhouse-server/config.xml配置文件
<level>information</level>
执行日志所在目录:
- 正常日志:
/var/log/clickhouse-server/clickhouse-server.log - 异常错误日志:
/var/log/clickhouse-server/clickhouse-server.err.log
1.2.4.6 测试创建数据库和表
进入客户端:clickhouse-client
-- 创建数据库:
CREATE DATABASE test;
-- 使用数据库:
USE test;
-- 创建表:
CREATE TABLE visits (id UInt64,duration Float64,url String,created DateTime
) ENGINE = MergeTree()
PRIMARY KEY id
ORDER BY id;-- 插入数据:
INSERT INTO visits (id, duration, url, created) VALUES (1, 10.5, 'example.com', now());-- 查询数据:
SELECT * FROM visits;
1.2.4.7 部署遇到问题
clickhouse 部署过程中遇到的一些问题如下:
1.2.4.7.1 clikhouse 客户端无法查询 kafka 引擎表
Kafka 引擎的特性:
ClickHouse的Kafka 引擎表是一种流式引擎(stream-like engine),设计目的是从Kafka消费数据,并将其传递给其他表(通常是物化视图或普通表)进行存储和处理。- 默认情况下,
ClickHouse禁止直接查询Kafka 引擎表(SELECT操作),因为:Kafka 引擎表本质上是一个数据流,每次查询都会触发从Kafka消费数据的操作,可能导致重复消费或不一致的结果。Kafka引擎表不存储数据,数据仅在Kafka中,查询可能会消耗大量资源(例如从 Kafka 的最早偏移量开始读取)。
ClickHouse引入了安全限制,防止用户意外执行可能导致性能问题或数据不一致的查询
CREATE TABLE default.kafka_clickhouse_inner_log ON CLUSTER clickhouse_cluster (log_uuid String ,date_partition UInt32 ,event_name String ,activity_name String ,activity_type String ,activity_id UInt16
) ENGINE = Kafka SETTINGSkafka_broker_list = 'kafka1:9092,kafka2:9092,kafka3:9092',kafka_topic_list = 'data_clickhouse',kafka_group_name = 'clickhouse_xxx',kafka_format = 'JSONEachRow',kafka_row_delimiter = '\n',kafka_num_consumers = 1;
ON CLUSTER clickhouse_cluster 是 ClickHouse 的 DDL 语法,用于在集群的所有节点上同步执行 DDL 语句。
解决方案:
需要在clickhouse client 创建加上 --stream_like_engine_allow_direct_select 1
1.2.4.7.2 clickhouse 创建本地节点表,无法开启本地表 macro
Code: 62. DB::Exception: There was an error on [127.0.0.1:9000]: Code: 62. DB::Exception: No macro 'shard' in config while processing substitutions in '/clickhouse/tables/default/bi_inner_log_local/{shard}' at '50' or macro is not supported here. (SYNTAX_ERROR) (version 22.5.2.53 (official build)). (SYNTAX_ERROR) (version 22.5.2.53 (official build))
创建本地表(使用复制去重表引擎)
create table default.bi_inner_log_local ON CLUSTER clickhouse_cluster (log_uuid String ,date_partition UInt32 ,event_name String ,activity_name String ,credits_bring Int16 ,activity_type String ,activity_id UInt16
) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/default/bi_inner_log_local/{shard}','{replica}')PARTITION BY date_partitionORDER BY (event_name,date_partition,log_uuid)SETTINGS index_granularity = 8192;
解决方案:在不同的 clickhouse 节点上配置不同的 shard,每一个节点的 shard 名称不能一致。
<macros><shard>01</shard><replica>example01-01-1</replica>
</macros>
1.2.4.7.3 clickhouse 中节点数据已经存在
报错:
Code: 253. DB::Exception: There was an error on : Code: 253. DB::Exception: Replica /clickhouse/tables/default/bi_inner_log_local/01/replicas/example01-01-1 already exists. (REPLICA_IS_ALREADY_EXIST) (version 22.5.2.53 (official build)). (REPLICA_IS_ALREADY_EXIST) (version 22.5.2.53 (official build))
解决方案:进入 zookeeper 客户端删除相关节点,然后再重新创建 ReplicatedReplacingMergeTree 表。这样可以保障每一个 clickhouse 节点都会去消费 kafka partition 的数据。
1.2.4.7.4 分布式集群表无法查询
报错:
Code: 516. DB::Exception: Received from 127.0.0.1:9000. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name. (AUTHENTICATION_FAILED) (version 22.5.2.53 (official build))
解决方案:
<!--分布式表配置-->
<remote_servers><clickhouse_cluster><!--集群名称, 可以自定义, 后面在新建库、表的时候需要用到集群名称--><shard><!--内部复制(默认false), 开启后, 在分布式表引擎下, 数据写入时--><!--每个分片只会去寻找一个节点写, 并不是每个都写--><internal_replication>true</internal_replication><replica><host>ip1</host><port>9000</port><user>default</user><password>xxxx</password></replica></shard><shard><internal_replication>true</internal_replication><replica><host>ip2</host><port>9000</port><user>default</user><password>xxxx</password></replica></shard></clickhouse_cluster>
</remote_servers>
1.2.4.8 clickhouse其他表
1.2.4.8.1 分布式表
创建分布式表(根据 log_uuid 对数据进行分发,相同的 log_uuid 会发送到同一个 shard 分片上,用于后续合并时的数据去重):
CREATE TABLE default.bi_inner_log_all ON CLUSTER clickhouse_cluster
AS default.bi_inner_log_local
ENGINE = Distributed(clickhouse_cluster, default, bi_inner_log_local, xxHash32(log_uuid));
AS default.bi_inner_log_local:表示新表 default.bi_inner_log_all 的表结构(列定义)与已有表 default.bi_inner_log_local 相同。复制 default.bi_inner_log_local 的列定义(列名、类型等),但不复制数据。
ENGINE = Distributed(clickhouse_cluster, default, bi_inner_log_local, xxHash32(log_uuid)):指定表的引擎为 Distributed,表示这是一个分布式表。
Distributed 引擎的参数:
clickhouse_cluster:集群名称,指定查询分发的目标集群(与 ON CLUSTER 的集群名一致)。default:本地表的数据库名,表示目标本地表位于 default 数据库。bi_inner_log_local:本地表名,表示分布式表会将查询分发到名为 bi_inner_log_local 的本地表。xxHash32(log_uuid):分片键(sharding key),用于决定数据分发到哪个分片。
xxHash32是一个哈希函数,对 log_uuid 列计算哈希值。
ClickHouse根据哈希值将数据或查询分发到不同的分片,确保负载均衡。
Distributed 引擎的作用
- 不存储数据:
分布式表(default.bi_inner_log_all)本身不存储数据,仅作为一个逻辑层。
它将查询分发到集群中所有节点的本地表(default.bi_inner_log_local),并汇总结果。 - 查询分发:
当查询分布式表时,例如:SELECT * FROM default.bi_inner_log_all WHERE date_partition = 20230101;
ClickHouse 会将查询分发到集群中所有节点的default.bi_inner_log_local表。
每个节点独立执行查询,返回结果。
当前节点(发起查询的节点)汇总所有节点的结果,返回给客户端。 - 数据写入:
如果向分布式表插入数据,例如:INSERT INTO default.bi_inner_log_all VALUES (...);
ClickHouse会根据分片键(xxHash32(log_uuid))计算哈希值,将数据分发到对应的分片(节点)的default.bi_inner_log_local表。 - 分片键 xxHash32(log_uuid)
分片键决定数据如何分发到集群中的分片。
xxHash32(log_uuid) 对 log_uuid 列计算 32 位哈希值,ClickHouse 根据哈希值决定数据存储在哪个分片。
1.2.4.8.2 物化视图
创建物化视图,把 Kafka 消费表消费的数据同步到 ClickHouse 分布式表。
CREATE MATERIALIZED VIEW default.view_bi_inner_log ON CLUSTER clickhouse_cluster TO default.bi_inner_log_all AS
SELECT log_uuid ,
date_partition ,
event_name ,
activity_name ,
credits_bring ,
activity_type ,
activity_id
FROM default.kafka_clickhouse_inner_log;
TO default.bi_inner_log_all:
TO是物化视图的语法,用于指定目标表(target table)。default.bi_inner_log_all是目标表的名称,表示物化视图会将查询结果插入到 default 数据库中的 bi_inner_log_all 表。
作用:- 物化视图会自动监听源表(default.kafka_clickhouse_inner_log)的新数据。
- 每次有新数据插入到源表时,物化视图会执行 SELECT 查询,并将结果插入到目标表 default.bi_inner_log_all
AS:
- AS 是物化视图语法的固定部分,用于引入物化视图的 SELECT 查询。
- 它表示:物化视图的逻辑是基于后面的 SELECT 语句定义的。
相关文章:

日志之ClickHouse部署及替换ELK中的Elasticsearch
文章目录 1 ELK替换1.1 Elasticsearch vs ClickHouse1.2 环境部署1.2.1 zookeeper 集群部署1.2.2 Kafka 集群部署1.2.3 FileBeat 部署1.2.4 clickhouse 部署1.2.4.1 准备步骤1.2.4.2 添加官方存储库1.2.4.3 部署&启动&连接1.2.4.5 基本配置服务1.2.4.6 测试创建数据库和…...
)
Git 基本操作(一)
目录 git add git commit git log git status git diff git 版本回退 git reset git add git add 指令为添加工作区中的文件到暂存区中。 git add file_name; //将工作区名称为file_name的文件添加进暂存区 git add .; //将工作区中的所有文件添加进暂存区 git comm…...

加密解密记录
一、RSA 加密解密 密钥对生成 1.前端加密解密 (1).vue页面引入 npm install jsencrypt(2)工具 jsencrypt.js import JSEncrypt from jsencrypt/bin/jsencrypt.min// 密钥对生成 http://web.chacuo.net/netrsakeypairconst p…...

Playwright MCP 入门实战:自动化测试与 Copilot 集成指南
什么是 MCP? MCP(Model Context Protocol) 是一种为大语言模型(LLM)设计的协议,MCP充当 LLM 与实际应用之间的桥梁或“翻译器”,将自然语言转化为结构化指令,使得模型可以更精确、高…...

存算一体架构下的新型AI加速范式:从Samsung HBM-PIM看近内存计算趋势
引言:突破"内存墙"的物理革命 冯诺依曼架构的"存储-计算分离"设计正面临根本性挑战——在GPT-4等万亿参数模型中,数据搬运能耗已达计算本身的200倍。存算一体(Processing-In-Memory, PIM)技术通过在存储介…...
-任何手柄、无人机手柄、摇杆、方向盘)
为 Unity 项目添加自定义 USB HID 设备支持 (适用于 PC 和 Android/VR)-任何手柄、无人机手柄、摇杆、方向盘
这是一份关于如何在 Unity 中为特定 USB HID 设备(如 Phoenix SM600 手柄)添加支持,并确保其在打包成 APK 安装到独立 VR 设备后仍能正常工作的教程。 目标: 使 Unity 能够识别并处理特定 USB HID(Human Interface Device&#x…...

恒流源电路
常见的是上面这几种, 运放恒流电路一般搭配三极管使用 比赛用的模块可以用这种,会准一点...

python2反编译部分
文章目录 1、所需环境2、确认打包工具(没成功)3、 解包.exe文件(以PyInstaller为例) - useful【***总的来说这一步对我有用】4、定位关键文件 - useful5、 修复.pyc文件头(关键步骤!)- maybe-ig…...

Selenium3自动化测试,Python3测试开发教程视频测试用例设计
Selenium3自动化测试,Python3测试开发教程视频测试用例设计25套高级软件测试,性能测试,功能测试,自动化测试,接口测试,移动端测试,手机测试,WEB测试,渗透测试,…...

PyTorch 2.0编译器技术深度解析:如何自动生成高性能CUDA代码
引言:编译革命的范式转移 PyTorch 2.0的torch.compile不仅是简单的即时编译器(JIT),更标志着深度学习框架从解释执行到编译优化的范式跃迁。本文通过逆向工程编译过程,揭示PyTorch如何将动态图转换为高性能CU…...

ctfshow web入门 web44
信息收集 依旧是把所有输出丢弃,这一次多了flag的过滤,没啥好说的,用*或者?代替就可以了 if(isset($_GET[c])){$c$_GET[c];if(!preg_match("/;|cat|flag/i", $c)){system($c." >/dev/null 2>&1");} }else{h…...

三生原理的离散生成逻辑如何与复分析结合?
AI辅助创作: 三生原理离散生成逻辑与复分析结合路径分析 一、生成规则与解析延拓的协同 参数化联动机制向复数域延伸 三生原理的离散素数生成公式(如p=3(2n+1)+2(2n+m+1))通过引入复数参数 n,m∈C,可扩展为复平面上的解析函数,从而建立与黎曼ζ函数的关联通道。…...
)
数据升降级:医疗数据的“时空穿梭“系统工程(分析与架构篇)
一、核心挑战与量化分析 1. 版本演化困境的深度解析 (1) 格式断层的结构化危机 数据转换黑洞:某医疗信息平台(2021-2023)统计显示: 数据类型CDA R1→R2转换失败率R2→FHIR转换失败率关键失败点诊断记录28.4%19.7%ICD编码版本冲突(18.7%)用药记录15.2%12.3%剂量单位标准化…...

简单句练习--语法基础
文章目录 谓语和非谓语及物与不及物动词及物不及物主语必须由名词性质的成分充当谓语和非谓语 与中文不同,英语中的动词分为谓语形式和非谓语形式。 以“do”为例, 可以充当谓语的形式有:do,does,did, 以及其他各种时态,如:have done,is doing等。不可独立充当谓语的有…...

基于若依RuoYi-Vue3-FastAPI 的 Docker 部署记录
最近在参与导师项目开发过程中,我选择基于若依 FastAPI Vue3 模板作为系统框架,通过 Docker 实现前后端、数据库和缓存环境的容器化部署。 RuoYi-Vue3-FastAPI的github地址:https://github.com/insistence/RuoYi-Vue3-FastAPI 🛠…...

基于开源AI智能名片链动2+1模式S2B2C商城小程序的电商直播流量转化路径研究
摘要:在电商直播单场GMV突破2.28亿元的流量狂欢背后,传统直播模式正面临"流量过载而转化低效"的困境。本文提出以开源AI智能名片链动21模式S2B2C商城小程序重构流量转化路径,通过智能内容引擎、动态激励体系、供应链协同三大技术模…...
)
【Linux系统】Linux进程信号(产生,保存信号)
1. 信号快速认识 1-1 基本结论 如何识别信号?识别信号是内置的,进程识别信号,是内核程序员写的内置特性。信号产生之后,是知道怎么处理的,同理,如果信号没有产生,也是知道怎么处理信号的。所以…...

llamafactory-cli webui启动报错TypeError: argument of type ‘bool‘ is not iterable
一、问题 在阿里云NoteBook上启动llamafactory-cli webui报错TypeError: argument of type ‘bool’ is not iterable This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run gradio deploy from the terminal in the working directory t…...

工 厂 模 式
冷知识,当我们需要使用平底锅时,我们并不需要知道平底锅是怎么造的,坏了只需要再买就好了。至于造平底锅,全部交给我们的生产工厂就好。 蕴含这种创建对象思路的设计方法,我们称为“工厂模式”。 核心思想 工厂模式&…...

synchronized与Lock深度对比
Java并发编程:synchronized与Lock深度对比 基本概念 1.1 synchronized synchronized是Java内置的关键字,属于JVM层面的锁机制。它通过对象监视器(Monitor)实现同步,具有自动获取和释放锁的特性。 // 同步方法 public synchronized void sy…...

LeetCode —— 94. 二叉树的中序遍历
94. 二叉树的中序遍历 题目:94. 二叉树的中序遍历 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) :…...

【无标题】四色拓扑收缩模型中环形套嵌结构的颜色保真确定方法
#### **1. 环形嵌套结构的局部保真机制** - **零点虚边与环形嵌套**:在顶点 \( v \) 处引入环形嵌套结构(如环面 \( T^2 \)),通过虚边连接形成闭合路径。该结构作为“颜色记忆单元”,存储相邻区域的色彩信息࿰…...

Curl 全面使用指南
Curl(Client URL)是一个跨平台命令行工具,支持多种协议(HTTP/HTTPS/FTP/SFTP等),用于数据传输、API调试、文件上传/下载等场景。以下从 核心功能、用户疑问解答、高级技巧 三方面系统总结,并整合…...

vscode 的空格和 tab 设置 与 Rime 自建词库
自动保存(多用于失去焦点时保存) Files: Auto Save 推荐不勾 保存时格式化(Pritter 插件的功能,自动使用 Pritter 的格式) Editor: Format On Save 推荐不勾 tab 的空格数量,2 或 4 Editor: Tab Size 推荐…...

Spark-小练试刀
任务1:HDFS上有三份文件,分别为student.txt(学生信息表)result_bigdata.txt(大数据基础成绩表), result_math.txt(数学成绩表)。 加载student.txt为名称为student的RDD…...

Python爬虫实战:获取jd商城最新5060ti 16g显卡销量排行榜商品数据并做分析,为显卡选购做参考
一、引言 1.1 研究目的 本研究旨在利用 Python 爬虫技术,从京东商城获取 “5060ti 16g” 型号显卡的商品数据,并对这些数据进行深入分析。具体目标包括: 实现京东商城的模拟登录,突破登录验证机制,获取登录后的访问权限。高效稳定地爬取按销量排名前 20 的 “5060ti 16g…...
失效)
【Vue bug】:deep()失效
vue 组件中使用了 element-plus 组件 <template><el-dialog:model-value"visible":title"title":width"width px":before-close"onClose"><div class"container" :style"{height:height px}"&g…...
)
基于数字图像处理的裂缝检测与识别系统(Matlab)
【优化】Matlab裂缝检测与识别系统 基于数字图像处理的裂缝检测与识别系统(Matlab) (基本常在线秒回,有兴趣可以随时联系博主) 系统主要的内容包括: 1.图像加载与初始化 选择图像文件并加载:…...

day12:遗传算法及常见优化算法分享
遗传算法这些常见优化算法简直是 “宝藏素材”!用好了,轻轻松松就能填满论文一整节内容;要是研究透彻,甚至能独立撑起一整个章节。今天不打算深入展开,有个基础认知就行。等之后写论文真要用到这些算法了,咱…...

【计算机视觉】语义分割:MMSegmentation:OpenMMLab开源语义分割框架实战指南
深度解析MMSegmentation:OpenMMLab开源语义分割框架实战指南 技术架构与设计哲学系统架构概览核心技术特性 环境配置与安装指南硬件配置建议详细安装步骤环境验证 实战全流程解析1. 数据集准备2. 配置文件定制3. 模型训练与优化4. 模型评估与推理 核心功能扩展1. 自…...

25_04_30Linux架构篇、第1章_02源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62
Linux_基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62 版本号: 1.0,0 作者: 老王要学习 日期: 2025.05.01 适用环境: Centos7 文档说明 本文…...

【重走C++学习之路】25、特殊类设计
目录 一、不能被拷贝的类 二、堆上创建对象的类 三、栈上创建对象的类 四、不能被继承的类 五、单例模式 结语 一、不能被拷贝的类 如何实现一个不能被拷贝的类?在看到这个要求的第一反应就是禁掉类的拷贝构造函数和赋值运算符重载函数,再往深了探…...

基于Redis实现-用户签到
基于Redis实现-用户签到 这个功能将使用到Redis中的BitMap来实现。 我们按照月来统计用户签到信息,签到记录为1,未签到则记录为0 把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路称为位图(BitMap)。…...

利用Redisson分布式锁解决多服务器数据刷新问题
利用Redisson分布式锁解决多服务器数据刷新问题 一、业务背景二、代码实现1、引入Redisson依赖2、配置Redisson,实际项目中Redis为集群配置3、自定义拒绝策略4、异步刷新网元服务 三、项目结构及源码 一、业务背景 最近有个需求需要自动刷新网元服务,由…...

25.4.30数据结构|并查集 路径压缩
前言 在QuickUnion快速合并的过程中,每次都要找根ID,而路径压缩让找根ID变得更加迅速直接。 路径压缩 针对的是findRootIndex()【查找根ID】进行的压缩。 需要实现的是: 在找根节点的过程中,记录这条路径上的所有信息,…...

react学习笔记3——基于React脚手架
React路由 相关理解 SPA的理解 单页Web应用(single page web application,SPA)。整个应用只有一个完整的页面。点击页面中的链接不会刷新页面,只会做页面的局部更新。数据都需要通过ajax请求获取, 并在前端异步展现。 路由的理…...

C#中的LINQ:简化数据查询与操作
引言 在现代软件开发中,处理和操作数据是不可避免的任务。无论是从数据库读取信息,还是对内存中的集合进行筛选、排序等操作,开发者都需要一种高效且易于使用的方法。C#中的LINQ(Language Integrated Query)正是为此而…...

OkHttp3.X 工具类封装:链式调用,支持HTTPS、重试、文件上传【内含常用设计模式设计示例】
OkHttp3.X 工具类封装:链式调用,支持HTTPS、重试、文件上传 基于OkHttp3.X封装,提供链式调用API,简化GET/POST请求,支持HTTPS、自动重试、文件上传等功能,提升开发效率。 在 Android 和 Java 开发中&#x…...
Unity SpriteEditor(精灵图片编辑器)
🏆 个人愚见,没事写写笔记 🏆《博客内容》:Unity3D开发内容 🏆🎉欢迎 👍点赞✍评论⭐收藏 🔎SpriteEditor: 精灵图片编辑器 📌用于编辑2D游戏开发中使用的Sp…...

雅思写作--70个高频表达
文章目录 1. learn new skills学生通过户外活动学到很多新技2. take immediate action to do各国采取有效行动以保护环境政府采取了必要行动以减少失业。你应该立即采取行动来解3. communication skills4. grow significantly5. have many advantages1. learn new skills “lea…...

Anaconda中配置Pyspark的Spark开发环境
Anaconda中配置Pyspark的Spark开发环境 目录 1.在控制台中测试ipython是否启动正常2.安装好Java3.安装Spark并配置环境变量4.PySpark配置5.修改spark\conf下的spark-env文件6.测试Pyspark是否安装成功 1.在控制台中测试ipython是否启动正常 anaconda正常安装 这里先检查ipyt…...

Spring 提供了多种依赖注入的方式
构造器注入(Constructor Injection) 构造器注入是通过类的构造函数来注入依赖项。这是 Spring 推荐的方式,因为它提供了不可变性和更好的可测试性。 import org.springframework.stereotype.Component;Component public class ServiceA {pub…...

面经-计算机网络——OSI七层模型与TCP/IP四层模型的对比详解
OSI七层模型与TCP/IP四层模型的对比详解 一、图示解析:分层封装结构 你提供的图清晰展示了网络通信中从应用层到物理层的封装过程,每一层都会对上层的数据加上自己的头部信息(Header): 应用层: 应用…...

网络安全知识问答微信小程序的设计与实现
网络安全知识问答微信小程序的设计与实现,说白了,就是搭建一款网络安全知识问答微信小程序,类似网络安全百科直通车。三步走。 需求沟通 进行需求沟通,此处省略1000字。 画草图 根据沟通的需求,进行整理,…...
)
Canvas特效实例:黑客帝国-字母矩阵(字母雨)
黑客帝国-字幕矩阵(字母雨) 效果预览代码实现思路解析遗留问题 效果预览 话不多说,我们直接上效果:当页面加载完成,屏幕上会落下如瀑布般的绿色字母流,不断向下滑动,仿佛进入了黑客帝国的数字世…...

「Mac畅玩AIGC与多模态11」开发篇07 - 使用自定义名言插件开发智能体应用
一、概述 本篇介绍如何在 macOS 环境下,通过编写自定义 OpenAPI Schema,将无需认证的名言服务接入 Dify 平台,并开发基于外部公共数据的智能体应用。本案例继续实践 GET 请求型 API 的实际调用技巧。 二、环境准备 1. 确认本地开发环境 macOS 系统Dify 平台已部署并可访问…...

快速上手非关系型数据库-MongoDB
简介 MongoDB 是一个基于文档的 NoSQL 数据库,由 MongoDB Inc. 开发。 NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。 MongoDB 的设计理念是为了应对大数据量、…...

响应式布局,在飞帆平台中如此简单
这些控件都是可以自己动手去实现的。也可以将这些控件复制到自己名下进行修改。 响应式布局https://fvi.cn/782...
)
UN R79 关于车辆转向装置形式认证的统一规定(正文部分1)
UN R79法规是针对转向装置的型式认证法规,涉及A/B1/C类的横向控制辅助驾驶功能,对各功能的功能边界、性能要求、状态提示、故障警示以及型式认证要提交的信息做了规范,本文结合百度文心一言对法规进行翻译,并结合个人理解对部分内…...

深度学习系统学习系列【1】之基本知识
文章目录 说明基础知识人工智能、机器学习、深度学习的关系机器学习传统机器学习的缺陷选择深度学习的原因深度学习的关键问题深度学习的应用深度学习的加速硬件GPU环境搭建主流深度学习框架对比 说明 文章属于个人学习笔记内容,仅供学习和交流。内容参考深度学习原…...