day12:遗传算法及常见优化算法分享
遗传算法这些常见优化算法简直是 “宝藏素材”!用好了,轻轻松松就能填满论文一整节内容;要是研究透彻,甚至能独立撑起一整个章节。今天不打算深入展开,有个基础认知就行。等之后写论文真要用到这些算法了,咱们再一起深入钻研!
一、数据预处理与模型基线搭建
老规矩,先运行之前预处理好的代码。咱们的目标是用这些优化算法找到机器学习模型的最佳超参数,所以得先把数据准备好,跑一个基线模型出来。
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
数据处理完了,接下来用随机森林分类器跑个基线模型。我给大家加了个time库,记录一下训练和预测的耗时,这样以后别人跑代码心里也有个数。
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))
运行结果如下:
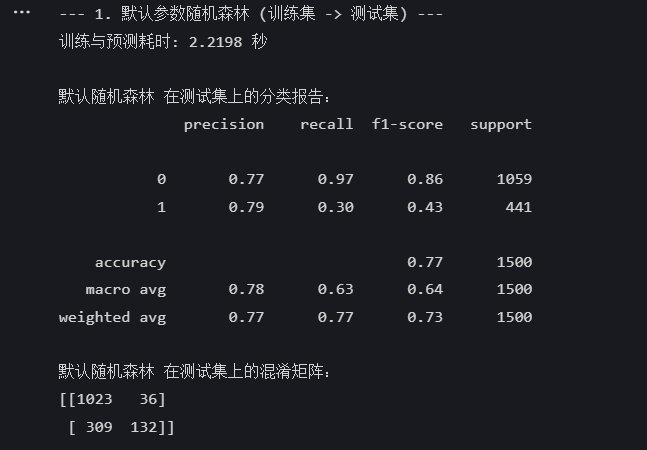
这个就是咱们的基线模型结果了,接下来就靠优化算法来超越它!
二、核心思想:优化算法的 “寻宝逻辑”
在说具体算法之前,先和大家唠唠这些启发式算法的核心思想。咱们的目标是找到一组超参数,让机器学习模型在某个指标(比如验证集准确率)上表现最好。这就好比在一片复杂的大山上找最高峰,但这座山的地形特别复杂,没有现成的地图(也就是不知道参数空间每一处的精确梯度)。而这些启发式算法就像是一群聪明的 “探险家”,它们各自用不同的策略去寻找这座最高峰。有的模仿生物进化,有的模拟物理现象,总之各有各的绝活。
三、遗传算法:生物进化的奇妙映射
遗传算法(Genetic Algorithm - GA)的灵感来源于生物进化,也就是达尔文提出的 “适者生存” 理论。我是这么理解的:把不同的超参数组合想象成一群 “个体”。那些在验证集上表现好的个体,就像自然界里适应环境的生物,更有机会 “繁殖”—— 说白了,就是它们的参数组合会被借鉴和混合,产生新的参数组合。在这个过程中,还可能发生 “变异”,也就是参数会随机地小改动。而表现差的个体,就慢慢被淘汰了。这样一代一代进化下去,整个种群就会越来越适应环境,咱们也就一步步逼近最佳超参数了。这种算法给我的感觉就是在大范围 “撒网” 搜索,特别适合参数空间很大、情况很复杂的场景。下面是用遗传算法优化随机森林的代码,这里用了DEAP库,它是专门用来搞遗传算法和进化计算的。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report, confusion_matrix
import warnings
warnings.filterwarnings("ignore")
import time
from deap import base, creator, tools, algorithms # DEAP是一个用于遗传算法和进化计算的Python库
import random
import numpy as np# --- 2. 遗传算法优化随机森林 ---
print("\n--- 2. 遗传算法优化随机森林 (训练集 -> 测试集) ---")# 定义适应度函数和个体类型
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)# 定义超参数范围
n_estimators_range = (50, 200)
max_depth_range = (10, 30)
min_samples_split_range = (2, 10)
min_samples_leaf_range = (1, 4)# 初始化工具盒
toolbox = base.Toolbox()# 定义基因生成器
toolbox.register("attr_n_estimators", random.randint, *n_estimators_range)
toolbox.register("attr_max_depth", random.randint, *max_depth_range)
toolbox.register("attr_min_samples_split", random.randint, *min_samples_split_range)
toolbox.register("attr_min_samples_leaf", random.randint, *min_samples_leaf_range)# 定义个体生成器
toolbox.register("individual", tools.initCycle, creator.Individual,(toolbox.attr_n_estimators, toolbox.attr_max_depth,toolbox.attr_min_samples_split, toolbox.attr_min_samples_leaf), n=1)# 定义种群生成器
toolbox.register("population", tools.initRepeat, list, toolbox.individual)# 定义评估函数
def evaluate(individual):n_estimators, max_depth, min_samples_split, min_samples_leaf = individualmodel = RandomForestClassifier(n_estimators=n_estimators,max_depth=max_depth,min_samples_split=min_samples_split,min_samples_leaf=min_samples_leaf,random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)return accuracy,# 注册评估函数
toolbox.register("evaluate", evaluate)# 注册遗传操作
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutUniformInt, low=[n_estimators_range[0], max_depth_range[0],min_samples_split_range[0], min_samples_leaf_range[0]],up=[n_estimators_range[1], max_depth_range[1],min_samples_split_range[1], min_samples_leaf_range[1]], indpb=0.1)
toolbox.register("select", tools.selTournament, tournsize=3)# 初始化种群
pop = toolbox.population(n=20)# 遗传算法参数
NGEN = 10
CXPB = 0.5
MUTPB = 0.2start_time = time.time()
# 运行遗传算法
for gen in range(NGEN):offspring = algorithms.varAnd(pop, toolbox, cxpb=CXPB, mutpb=MUTPB)fits = toolbox.map(toolbox.evaluate, offspring)for fit, ind in zip(fits, offspring):ind.fitness.values = fitpop = toolbox.select(offspring, k=len(pop))end_time = time.time()# 找到最优个体
best_ind = tools.selBest(pop, k=1)[0]
best_n_estimators, best_max_depth, best_min_samples_split, best_min_samples_leaf = best_indprint(f"遗传算法优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", {'n_estimators': best_n_estimators,'max_depth': best_max_depth,'min_samples_split': best_min_samples_split,'min_samples_leaf': best_min_samples_leaf
})# 使用最佳参数的模型进行预测
best_model = RandomForestClassifier(n_estimators=best_n_estimators,max_depth=best_max_depth,min_samples_split=best_min_samples_split,min_samples_leaf=best_min_samples_leaf,random_state=42)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n遗传算法优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("遗传算法优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
运行结果如下:
--- 2. 遗传算法优化随机森林 (训练集 -> 测试集) ---
遗传算法优化耗时: 251.5941 秒
最佳参数: {'n_estimators': 158, 'max_depth': 25, 'min_samples_split': 10, 'min_samples_leaf': 1}遗传算法优化后的随机森林 在测试集上的分类报告:precision recall f1-score support0 0.77 0.98 0.86 10591 0.83 0.28 0.42 441accuracy 0.77 1500macro avg 0.80 0.63 0.64 1500
weighted avg 0.79 0.77 0.73 1500遗传算法优化后的随机森林 在测试集上的混淆矩阵:
[[1034 25][ 316 125]]
不过说实话,这段代码看着确实复杂,而且复用性也不高。就算我花时间搞懂了,对我的提升也有限,因为很难基于它做改进。所以我觉得,在 AI 时代,咱们没必要死磕这些代码细节。咱们只需要关注三个重点:输入输出的数据格式、算法的原理和适用场景、模型的大致实现逻辑(如果用得少,这部分甚至可以跳过,直接让 AI 帮忙)。
四、粒子群优化:鸟群觅食的智慧
粒子群优化(Particle Swarm Optimization - PSO)的灵感来自鸟群或鱼群觅食。想象一下,每个超参数组合都是一只 “粒子鸟”,它们在参数空间里 “飞来飞去”。每只鸟都会记住自己飞过的最好位置,同时也会参考整个鸟群发现的最好位置,然后综合这两个信息,调整自己的飞行方向和速度,当然这个过程也会带点随机性。
这种算法给我的感觉就是一群探险家一边探索,一边互相分享信息,大家齐心协力找目标。而且通常来说,它收敛的速度比遗传算法还要快一些。
粒子群方法的思想比较简单,所以甚至可以不调库自己实现。
# --- 2. 粒子群优化算法优化随机森林 ---
print("\n--- 2. 粒子群优化算法优化随机森林 (训练集 -> 测试集) ---")# 定义适应度函数,本质就是构建了一个函数实现 参数--> 评估指标的映射
def fitness_function(params): n_estimators, max_depth, min_samples_split, min_samples_leaf = params # 序列解包,允许你将一个可迭代对象(如列表、元组、字符串等)中的元素依次赋值给多个变量。model = RandomForestClassifier(n_estimators=int(n_estimators),max_depth=int(max_depth),min_samples_split=int(min_samples_split),min_samples_leaf=int(min_samples_leaf),random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)return accuracy# 粒子群优化算法实现
def pso(num_particles, num_iterations, c1, c2, w, bounds): # 粒子群优化算法核心函数# num_particles:粒子的数量,即算法中用于搜索最优解的个体数量。# num_iterations:迭代次数,算法运行的最大循环次数。# c1:认知学习因子,用于控制粒子向自身历史最佳位置移动的程度。# c2:社会学习因子,用于控制粒子向全局最佳位置移动的程度。# w:惯性权重,控制粒子的惯性,影响粒子在搜索空间中的移动速度和方向。# bounds:超参数的取值范围,是一个包含多个元组的列表,每个元组表示一个超参数的最小值和最大值。num_params = len(bounds) particles = np.array([[random.uniform(bounds[i][0], bounds[i][1]) for i in range(num_params)] for _ inrange(num_particles)])velocities = np.array([[0] * num_params for _ in range(num_particles)])personal_best = particles.copy()personal_best_fitness = np.array([fitness_function(p) for p in particles])global_best_index = np.argmax(personal_best_fitness)global_best = personal_best[global_best_index]global_best_fitness = personal_best_fitness[global_best_index]for _ in range(num_iterations):r1 = np.array([[random.random() for _ in range(num_params)] for _ in range(num_particles)])r2 = np.array([[random.random() for _ in range(num_params)] for _ in range(num_particles)])velocities = w * velocities + c1 * r1 * (personal_best - particles) + c2 * r2 * (global_best - particles)particles = particles + velocitiesfor i in range(num_particles):for j in range(num_params):if particles[i][j] < bounds[j][0]:particles[i][j] = bounds[j][0]elif particles[i][j] > bounds[j][1]:particles[i][j] = bounds[j][1]fitness_values = np.array([fitness_function(p) for p in particles])improved_indices = fitness_values > personal_best_fitnesspersonal_best[improved_indices] = particles[improved_indices]personal_best_fitness[improved_indices] = fitness_values[improved_indices]current_best_index = np.argmax(personal_best_fitness)if personal_best_fitness[current_best_index] > global_best_fitness:global_best = personal_best[current_best_index]global_best_fitness = personal_best_fitness[current_best_index]return global_best, global_best_fitness# 超参数范围
bounds = [(50, 200), (10, 30), (2, 10), (1, 4)] # n_estimators, max_depth, min_samples_split, min_samples_leaf# 粒子群优化算法参数
num_particles = 20
num_iterations = 10
c1 = 1.5
c2 = 1.5
w = 0.5start_time = time.time()
best_params, best_fitness = pso(num_particles, num_iterations, c1, c2, w, bounds)
end_time = time.time()print(f"粒子群优化算法优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", {'n_estimators': int(best_params[0]),'max_depth': int(best_params[1]),'min_samples_split': int(best_params[2]),'min_samples_leaf': int(best_params[3])
})# 使用最佳参数的模型进行预测
best_model = RandomForestClassifier(n_estimators=int(best_params[0]),max_depth=int(best_params[1]),min_samples_split=int(best_params[2]),min_samples_leaf=int(best_params[3]),random_state=42)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n粒子群优化算法优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("粒子群优化算法优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
运行结果如下:
--- 2. 粒子群优化算法优化随机森林 (训练集 -> 测试集) ---
粒子群优化算法优化耗时: 374.1755 秒
最佳参数: {'n_estimators': 200, 'max_depth': 18, 'min_samples_split': 4, 'min_samples_leaf': 1}粒子群优化算法优化后的随机森林 在测试集上的分类报告:precision recall f1-score support0 0.77 0.98 0.86 10591 0.83 0.29 0.43 441accuracy 0.77 1500macro avg 0.80 0.63 0.64 1500
weighted avg 0.79 0.77 0.73 1500粒子群优化算法优化后的随机森林 在测试集上的混淆矩阵:
[[1034 25][ 315 126]]
五、退火算法:模拟退火的奇妙探索
模拟退火(Simulated Annealing - SA)的灵感来源于金属冶炼中的退火过程,也就是通过缓慢冷却使金属达到最低能量稳定态。
简单理解这个算法就是,从一个随机的超参数组合开始,然后随机尝试对参数进行一点改变。如果新的参数组合能让模型表现更好,那就直接接受它;但如果新组合反而更差了,也还是有一定概率接受它,尤其是在算法执行的早期,也就是 “高温” 阶段。随着算法的运行,这个接受较差解的概率会像温度下降一样,慢慢变小。
这种算法就像一个一开始有点 “冲动” 的探险家,愿意去尝试一些看起来不太好的路径,这样做是为了避免陷入局部最优的困境;而到了后期,它就变得越来越 “保守”,专注于在当前找到的较好区域附近进行精细搜索,所以它很擅长避免陷入局部最优解。
# --- 2. 模拟退火算法优化随机森林 ---
print("\n--- 2. 模拟退火算法优化随机森林 (训练集 -> 测试集) ---")# 定义适应度函数
def fitness_function(params): n_estimators, max_depth, min_samples_split, min_samples_leaf = paramsmodel = RandomForestClassifier(n_estimators=int(n_estimators),max_depth=int(max_depth),min_samples_split=int(min_samples_split),min_samples_leaf=int(min_samples_leaf),random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)return accuracy# 模拟退火算法实现
def simulated_annealing(initial_solution, bounds, initial_temp, final_temp, alpha):current_solution = initial_solutioncurrent_fitness = fitness_function(current_solution)best_solution = current_solutionbest_fitness = current_fitnesstemp = initial_tempwhile temp > final_temp:# 生成邻域解neighbor_solution = []for i in range(len(current_solution)):new_val = current_solution[i] + random.uniform(-1, 1) * (bounds[i][1] - bounds[i][0]) * 0.1new_val = max(bounds[i][0], min(bounds[i][1], new_val))neighbor_solution.append(new_val)neighbor_fitness = fitness_function(neighbor_solution)delta_fitness = neighbor_fitness - current_fitnessif delta_fitness > 0 or random.random() < np.exp(delta_fitness / temp):current_solution = neighbor_solutioncurrent_fitness = neighbor_fitnessif current_fitness > best_fitness:best_solution = current_solutionbest_fitness = current_fitnesstemp *= alphareturn best_solution, best_fitness# 超参数范围
bounds = [(50, 200), (10, 30), (2, 10), (1, 4)] # n_estimators, max_depth, min_samples_split, min_samples_leaf# 模拟退火算法参数
initial_temp = 100 # 初始温度
final_temp = 0.1 # 终止温度
alpha = 0.95 # 温度衰减系数# 初始化初始解
initial_solution = [random.uniform(bounds[i][0], bounds[i][1]) for i in range(len(bounds))]start_time = time.time()
best_params, best_fitness = simulated_annealing(initial_solution, bounds, initial_temp, final_temp, alpha)
end_time = time.time()print(f"模拟退火算法优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", {'n_estimators': int(best_params[0]),'max_depth': int(best_params[1]),'min_samples_split': int(best_params[2]),'min_samples_leaf': int(best_params[3])
})# 使用最佳参数的模型进行预测
best_model = RandomForestClassifier(n_estimators=int(best_params[0]),max_depth=int(best_params[1]),min_samples_split=int(best_params[2]),min_samples_leaf=int(best_params[3]),random_state=42)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)print("\n模拟退火算法优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("模拟退火算法优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
运行结果如下:
--- 2. 模拟退火算法优化随机森林 (训练集 -> 测试集) ---
模拟退火算法优化耗时: 129.1660 秒
最佳参数: {'n_estimators': 98, 'max_depth': 16, 'min_samples_split': 7, 'min_samples_leaf': 2}模拟退火算法优化后的随机森林 在测试集上的分类报告:precision recall f1-score support0 0.77 0.98 0.86 10591 0.86 0.29 0.43 441accuracy 0.78 1500macro avg 0.82 0.63 0.65 1500
weighted avg 0.80 0.78 0.73 1500模拟退火算法优化后的随机森林 在测试集上的混淆矩阵:
[[1039 20][ 315 126]]
![]() @浙大疏锦行
@浙大疏锦行
相关文章:

day12:遗传算法及常见优化算法分享
遗传算法这些常见优化算法简直是 “宝藏素材”!用好了,轻轻松松就能填满论文一整节内容;要是研究透彻,甚至能独立撑起一整个章节。今天不打算深入展开,有个基础认知就行。等之后写论文真要用到这些算法了,咱…...

【计算机视觉】语义分割:MMSegmentation:OpenMMLab开源语义分割框架实战指南
深度解析MMSegmentation:OpenMMLab开源语义分割框架实战指南 技术架构与设计哲学系统架构概览核心技术特性 环境配置与安装指南硬件配置建议详细安装步骤环境验证 实战全流程解析1. 数据集准备2. 配置文件定制3. 模型训练与优化4. 模型评估与推理 核心功能扩展1. 自…...

25_04_30Linux架构篇、第1章_02源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62
Linux_基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62 版本号: 1.0,0 作者: 老王要学习 日期: 2025.05.01 适用环境: Centos7 文档说明 本文…...

【重走C++学习之路】25、特殊类设计
目录 一、不能被拷贝的类 二、堆上创建对象的类 三、栈上创建对象的类 四、不能被继承的类 五、单例模式 结语 一、不能被拷贝的类 如何实现一个不能被拷贝的类?在看到这个要求的第一反应就是禁掉类的拷贝构造函数和赋值运算符重载函数,再往深了探…...

基于Redis实现-用户签到
基于Redis实现-用户签到 这个功能将使用到Redis中的BitMap来实现。 我们按照月来统计用户签到信息,签到记录为1,未签到则记录为0 把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路称为位图(BitMap)。…...

利用Redisson分布式锁解决多服务器数据刷新问题
利用Redisson分布式锁解决多服务器数据刷新问题 一、业务背景二、代码实现1、引入Redisson依赖2、配置Redisson,实际项目中Redis为集群配置3、自定义拒绝策略4、异步刷新网元服务 三、项目结构及源码 一、业务背景 最近有个需求需要自动刷新网元服务,由…...

25.4.30数据结构|并查集 路径压缩
前言 在QuickUnion快速合并的过程中,每次都要找根ID,而路径压缩让找根ID变得更加迅速直接。 路径压缩 针对的是findRootIndex()【查找根ID】进行的压缩。 需要实现的是: 在找根节点的过程中,记录这条路径上的所有信息,…...

react学习笔记3——基于React脚手架
React路由 相关理解 SPA的理解 单页Web应用(single page web application,SPA)。整个应用只有一个完整的页面。点击页面中的链接不会刷新页面,只会做页面的局部更新。数据都需要通过ajax请求获取, 并在前端异步展现。 路由的理…...

C#中的LINQ:简化数据查询与操作
引言 在现代软件开发中,处理和操作数据是不可避免的任务。无论是从数据库读取信息,还是对内存中的集合进行筛选、排序等操作,开发者都需要一种高效且易于使用的方法。C#中的LINQ(Language Integrated Query)正是为此而…...

OkHttp3.X 工具类封装:链式调用,支持HTTPS、重试、文件上传【内含常用设计模式设计示例】
OkHttp3.X 工具类封装:链式调用,支持HTTPS、重试、文件上传 基于OkHttp3.X封装,提供链式调用API,简化GET/POST请求,支持HTTPS、自动重试、文件上传等功能,提升开发效率。 在 Android 和 Java 开发中&#x…...
Unity SpriteEditor(精灵图片编辑器)
🏆 个人愚见,没事写写笔记 🏆《博客内容》:Unity3D开发内容 🏆🎉欢迎 👍点赞✍评论⭐收藏 🔎SpriteEditor: 精灵图片编辑器 📌用于编辑2D游戏开发中使用的Sp…...

雅思写作--70个高频表达
文章目录 1. learn new skills学生通过户外活动学到很多新技2. take immediate action to do各国采取有效行动以保护环境政府采取了必要行动以减少失业。你应该立即采取行动来解3. communication skills4. grow significantly5. have many advantages1. learn new skills “lea…...

Anaconda中配置Pyspark的Spark开发环境
Anaconda中配置Pyspark的Spark开发环境 目录 1.在控制台中测试ipython是否启动正常2.安装好Java3.安装Spark并配置环境变量4.PySpark配置5.修改spark\conf下的spark-env文件6.测试Pyspark是否安装成功 1.在控制台中测试ipython是否启动正常 anaconda正常安装 这里先检查ipyt…...

Spring 提供了多种依赖注入的方式
构造器注入(Constructor Injection) 构造器注入是通过类的构造函数来注入依赖项。这是 Spring 推荐的方式,因为它提供了不可变性和更好的可测试性。 import org.springframework.stereotype.Component;Component public class ServiceA {pub…...

面经-计算机网络——OSI七层模型与TCP/IP四层模型的对比详解
OSI七层模型与TCP/IP四层模型的对比详解 一、图示解析:分层封装结构 你提供的图清晰展示了网络通信中从应用层到物理层的封装过程,每一层都会对上层的数据加上自己的头部信息(Header): 应用层: 应用…...

网络安全知识问答微信小程序的设计与实现
网络安全知识问答微信小程序的设计与实现,说白了,就是搭建一款网络安全知识问答微信小程序,类似网络安全百科直通车。三步走。 需求沟通 进行需求沟通,此处省略1000字。 画草图 根据沟通的需求,进行整理,…...
)
Canvas特效实例:黑客帝国-字母矩阵(字母雨)
黑客帝国-字幕矩阵(字母雨) 效果预览代码实现思路解析遗留问题 效果预览 话不多说,我们直接上效果:当页面加载完成,屏幕上会落下如瀑布般的绿色字母流,不断向下滑动,仿佛进入了黑客帝国的数字世…...

「Mac畅玩AIGC与多模态11」开发篇07 - 使用自定义名言插件开发智能体应用
一、概述 本篇介绍如何在 macOS 环境下,通过编写自定义 OpenAPI Schema,将无需认证的名言服务接入 Dify 平台,并开发基于外部公共数据的智能体应用。本案例继续实践 GET 请求型 API 的实际调用技巧。 二、环境准备 1. 确认本地开发环境 macOS 系统Dify 平台已部署并可访问…...

快速上手非关系型数据库-MongoDB
简介 MongoDB 是一个基于文档的 NoSQL 数据库,由 MongoDB Inc. 开发。 NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。 MongoDB 的设计理念是为了应对大数据量、…...

响应式布局,在飞帆平台中如此简单
这些控件都是可以自己动手去实现的。也可以将这些控件复制到自己名下进行修改。 响应式布局https://fvi.cn/782...
)
UN R79 关于车辆转向装置形式认证的统一规定(正文部分1)
UN R79法规是针对转向装置的型式认证法规,涉及A/B1/C类的横向控制辅助驾驶功能,对各功能的功能边界、性能要求、状态提示、故障警示以及型式认证要提交的信息做了规范,本文结合百度文心一言对法规进行翻译,并结合个人理解对部分内…...

深度学习系统学习系列【1】之基本知识
文章目录 说明基础知识人工智能、机器学习、深度学习的关系机器学习传统机器学习的缺陷选择深度学习的原因深度学习的关键问题深度学习的应用深度学习的加速硬件GPU环境搭建主流深度学习框架对比 说明 文章属于个人学习笔记内容,仅供学习和交流。内容参考深度学习原…...
)
python3GUI--视频监控管理平台 By:PyQt5(详细讲解)
文章目录 一.前言二.相关知识1.PyQt52.RTSP协议📌 简介:🧩 特点:📡 工作方式: 2. **RTMP(Real-Time Messaging Protocol)**📌 简介:&a…...

第十一届蓝桥杯 2020 C/C++组 既约分数
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: 既约分数 - 蓝桥云课 思路&a…...

如何让Steam下载速度解除封印?!
平时一直没注意到家里的路由器在偷懒。最近成功榨干家里的带宽,把平时一直20mb/s左右下载速度的路由器一番改造后成功steam下载速度稳定85Mb/s。平时一直都只发挥了他的1/3不到,真是太可惜了。 硬件 首先检查硬件,就千兆路由器而言…...

HOOK上瘾思维模型——AI与思维模型【88】
一、定义 HOOK上瘾思维模型是一种通过设计一系列的触发(Trigger)、行动(Action)、奖励(Reward)和投入(Investment)环节,来促使用户形成习惯并持续使用产品或服务的思维框…...

基于开源AI智能名片链动2+1模式S2B2C商城小程序的IP开发泡沫破局与价值重构研究
摘要:当前IP开发领域普遍存在"冒进式泡沫"现象,企业将初级IP包装为超级IP运营,导致资源错配与价值虚化。本文通过实证分析开源AI智能名片链动21模式S2B2C商城小程序的技术架构与商业逻辑,揭示其通过智能内容引擎、合规化…...
)
深⼊理解指针(8)
1.对上一篇的补充内容 typedef int* ptr_t #define PTR_T int* 这两种写法都是可以的 ptr_t p1, p2; //p1, p2 都是指针变量 PTR_T p3, p4; //p3 是指针变量, p4是整型变量 为什么p3 是指针变量, p4是整型变量呢? 因为PTR_T 真的被改为了 int* 在编译器中…...

【iview】icon样式
A. 工程中引入样式文件 iview源码工程中的example工程中如何引入iview样式 image.png 自定义工程中如何引入iview样式 一般在src/main.js中引入(在index.html中也可以,当然app.vue中也可以) import "iview/dist/styles/iview.css"B…...

【计算机视觉】三维视觉:Nerfstudio:模块化神经辐射场框架的技术突破与实战指南
深度解析Nerfstudio:模块化神经辐射场框架的技术突破与实战指南 技术架构与核心创新系统架构设计关键技术特性 环境配置与安装指南硬件要求全平台安装流程 实战全流程解析1. 数据采集与预处理2. 模型训练与优化3. 可视化与导出 核心技术深度解析1. 混合表示网络2. 渐…...

第二章 OpenCV篇-图像阈值的综合操作-Python
目录 一.图像阈值 二.图像平滑 1.均值滤波 2.方框滤波 3.高斯滤波 4.中值滤波 5.双边滤波 此章节主要讲解:图像阈值、图像平滑处理、均值滤波、方框滤波、高斯滤波、中值滤波、双边滤波。 这里先讲作者使用matplotlib模块出现错误的解决方法。 首先作者在这…...

WPF处理大规模激光数据计算与安全传输处理
WPF大规模激光数据处理与安全传输系统设计方案 一、系统架构设计 1. 整体架构 ┌─────────────────────────────────────────────┐ │ WPF客户端应用 │ ├───────────────┬…...
)
vue 常见ui库对比(element、ant、antV等)
Element UI 1. 简介 Element UI 是一个基于 Vue 2 和 Vue 3 的企业级 UI 组件库,提供了丰富的组件和主题定制功能。官方网站:Element UI 2. 主要特点 丰富的组件:包括表单、表格、布局、导航、弹窗等多种组件。主题定制:支持主…...

【c++】【STL】stack详解
目录 stack类的作用什么是容器适配器stack的接口构造函数emptysizetoppushpopswap关系运算符重载 stack类的实现 stack类的作用 stack是stl库提供的一种容器适配器,也就是我们数据结构中学到的栈,是非常常用的数据结构,特点是遵循LIFO&#…...

单片机-89C51部分:12 pwm 呼吸灯 直流电机
飞书文档https://x509p6c8to.feishu.cn/wiki/JkzfwSoFBiUKc4kh8IoccTfyndg 一、什么是PWM? PWM是脉冲宽度调制的缩写,它是一种通过调整脉冲信号的高电平和低电平时间比例来控制电路输出的技术。简单来说,PWM是一种控制电子设备输出电压或电…...

WPF实现数据库操作与日志记录
1. 数据库操作实现 1.1 数据库连接基类 public abstract class DatabaseBase : IDisposable {protected string ConnectionString { get; }protected IDbConnection Connection { get; private set; }protected DatabaseBase(string connectionString){ConnectionString = co…...

用spring-boot-maven-plugin打包成单个jar有哪些缺点优化方案
Spring Boot 的 Fat JAR(通过 spring-boot-maven-plugin 打包)虽然简化了部署,但也存在一些潜在缺点,需根据场景权衡: 1. 启动速度较慢 原因: Fat JAR 需要在启动时解压并加载所有依赖的 JAR 文件到类路径…...

Spring Boot 使用 WebMagic 爬虫框架入门
1. 创建 Spring Boot 项目 使用 Spring Initializr 创建一个 Spring Boot 项目,选择需要的依赖,如 Spring Web 等。 2. 添加 WebMagic 依赖 在项目的 pom.xml 文件中添加 WebMagic 的核心和扩展依赖: <dependency><groupId>u…...
)
【软件设计师:复习】上午题核心知识点总结(二)
一、计算机网络(常考) 1.网络模型与协议(必考) 1.OSI七层模型 vs. TCP/IP四层模型 OSI七层TCP/IP四层核心协议/设备功能应用层(Application)应用层HTTP、FTP、DNS、SMTP提供用户接口和服务表示层(Presentation)SSL/TLS、JPEG、ASCII数据格式转换、加密/解密会话层(S…...

TensorRt10学习第一章
建立TensorRt时必须要有Public ILogger,因为createInferBuiler和createruntime要用,是一个接口 出错打印 和...

【LeetCode Hot100】回溯篇
前言 本文用于整理LeetCode Hot100中题目解答,因题目比较简单且更多是为了面试快速写出正确思路,只做简单题意解读和一句话题解方便记忆。但代码会全部给出,方便大家整理代码思路。 46. 全排列 一句话题意 给定一个无重复数字的序列…...

Go 语言中一个功能强大且广泛使用的数据验证库github.com/go-playground/validator/v10
github.com/go-playground/validator/v10 是 Go 语言中一个功能强大且广泛使用的数据验证库,主要用于对结构体字段进行数据校验,确保数据的合法性和完整性。以下是其核心作用、使用场景及代码案例的详细说明: 核心作用 数据校验 支持对结构体…...
)
Java 多线程进阶:线程安全、synchronized、死锁、wait/notify 全解析(含代码示例)
在 Java 并发编程中,“线程安全” 是核心议题之一。本文将深入讲解线程安全的实现手段、synchronized 的使用方式、可重入锁、死锁的成因与避免、wait/notify 通信机制等,并配合实际代码案例,帮助你彻底搞懂 Java 线程协作机制。 一、线程安全…...

windows电脑端SSH连接开termux的安卓端
(确保你此前已经安装好了ssh)在手机termux当中输入: 查看状态:ssh 启动服务:sshd 查看IP:ifconfig 然后在电脑端:...

Java 期中考试练习题
一、引言 Java 作为一门广泛应用的编程语言,在计算机相关专业的课程体系中占据重要地位。期中考试是检验同学们对 Java 知识掌握程度的重要环节。本文将呈现一些典型的 Java 期中考试试题,并进行详细讲解,希望能帮助大家更好地理解和掌握 Ja…...

【Unity】 组件库分类详解
1️⃣ Audio(音频组件) 用于处理游戏中的声音。 Audio Source 读音[ˈɔːdiəʊ ˈsɔːs],音频源组件,用于播放音频文件,可设置音量、Pitch、循环播放等属性,是音频播放的核心组件。 Audio Listener 读音…...

Java 中使用正则表达式
1. 引入包 在使用正则表达式之前,需要引入包: import java.util.regex.Matcher; import java.util.regex.Pattern; 2. 常用模式规则 元字符 :这些是正则表达式中的特殊字符,用于匹配特定的模式。 . :匹配任意单个字…...

如何降低LabVIEW开发费用
在 LabVIEW 开发过程中,开发费用是用户和开发者共同关注的重点。过高的开发成本可能会压缩项目利润空间,甚至影响项目的可行性。下面将介绍降低 LabVIEW 开发费用的有效方法。 合理规划项目需求,避免后期增加 在项目启动阶段ÿ…...

WPF使用SQLSugar和Nlog
WPF应用中使用SQLSugar和NLog实现数据库操作与日志记录 1. 准备工作 首先,通过NuGet安装必要的包: Install-Package SQLSugarCore Install-Package NLog Install-Package NLog.Config Install-Package NLog.Targets.File 2. 配置NLog 在项目中添加nlog.config文件: <…...

Python10天冲刺-设计模型之策略模式
策略模式是一种行为设计模式,它允许你在运行时动态地改变对象的行为。这种模式的核心思想是将一组相关的算法封装在一起,并让它们相互替换。 下面是使用 Python 实现策略模式的一个示例: 示例代码 假设我们有一个简单的购物车系统…...