ES搜索知识
GET /categories/1/10?name=手机 // 按名称过滤
GET /categories/1/10?type=电子产品 // 按类型过滤
GET /categories/1/10?name=手机&type=电子产品 // 组合过滤
- 查询参数
@ApiOperation(value = "获取商品分类分页列表")@GetMapping("{page}/{limit}")public Result index(@ApiParam(name = "page", value = "当前页码", required = true)@PathVariable Long page,@ApiParam(name = "limit", value = "每页记录数", required = true)@PathVariable Long limit,@ApiParam(name = "categoryQueryVo", value = "查询对象", required = false)CategoryQueryVo categoryQueryVo) {Page<Category> pageParam = new Page<>(page, limit);IPage<Category> pageModel = categoryService.selectPage(pageParam, categoryQueryVo);return Result.ok(pageModel);}
- CategoryQueryVo categoryQueryVo存储查询参数。
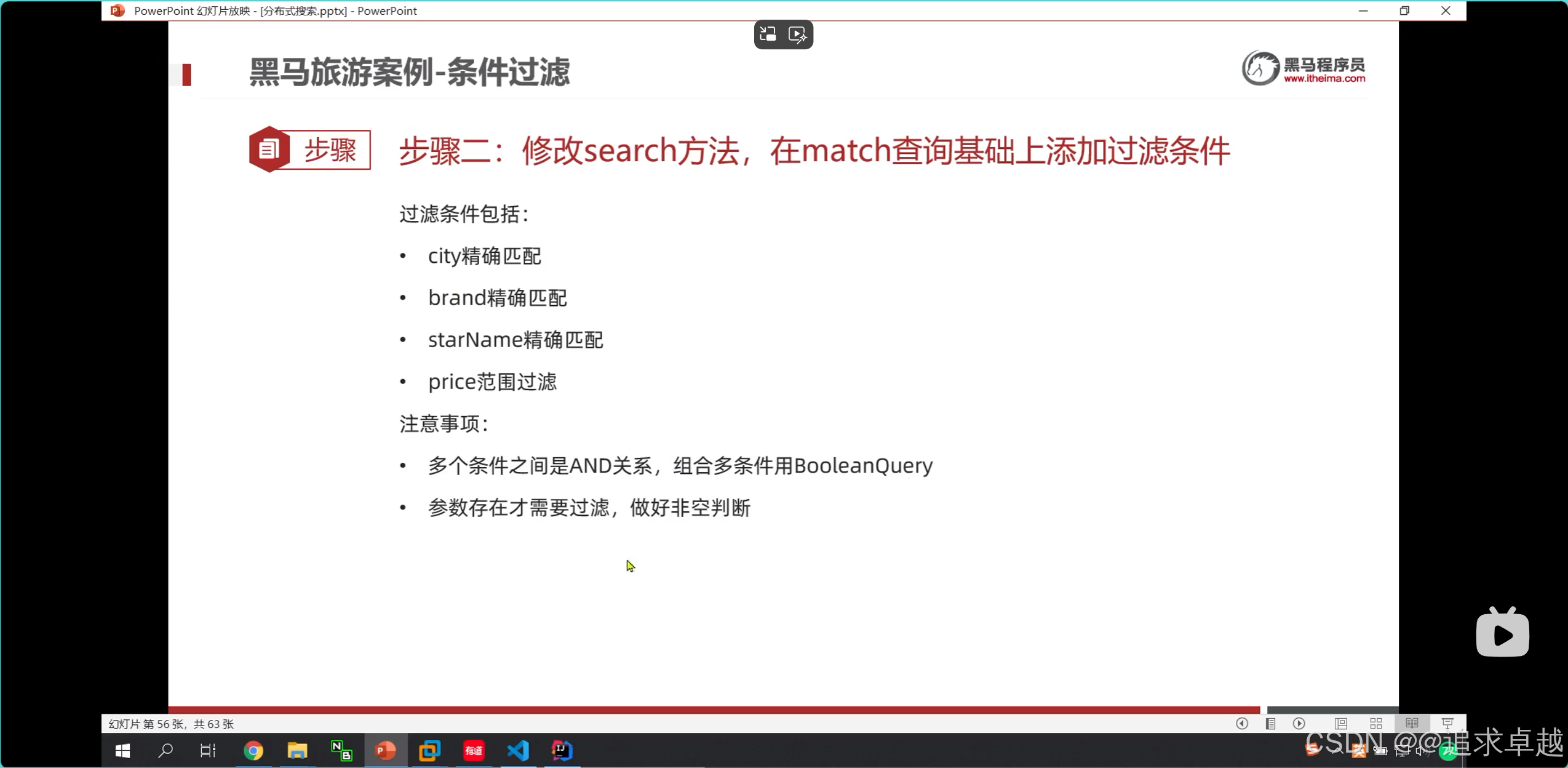
在基于Nacos的服务注册与发现机制中,服务之间通过以下步骤完成数据发送:
一、服务注册与发现阶段
1. 服务提供者(service-provider)注册到Nacos
- 动作:
服务提供者(端口8070)启动时,向Nacos Server(端口8848)发送注册请求,携带自身信息:{"serviceName": "service-provider","ip": "192.168.1.100","port": 8070,"metadata": {"version": "2018"} // 图中标注的"2018"可能是版本号或其他元数据 } - 目的:
告知Nacos自己的存在,成为可被调用的服务实例。
2. 服务消费者(service-consumer)发现服务提供者
- 动作:
服务消费者(端口8080)向Nacos查询服务名为service-provider的可用实例列表。
Nacos返回服务提供者的地址信息:http://192.168.1.100:8070/。
二、服务间数据发送阶段
3. 消费者发起HTTP请求
- 动作:
服务消费者根据Nacos返回的地址,构造HTTP请求并发送:
或通过POST请求传递数据(具体方法由接口定义决定)。GET http://192.168.1.100:8070/echo?param=hello,2018
4. 提供者处理请求并返回响应
- 动作:
服务提供者接收到请求后,执行echo(string)方法处理参数:public String echo(String input) {return input.split(",")[1]; // 示例中返回"2018" } - 响应:
返回HTTP响应体:2018(即从输入中提取的元数据)。
三、关键技术细节
1. HTTP协议通信
- 通信方式:
服务消费者通过HTTP协议(RESTful API)调用服务提供者。
示例:- 请求路径:
/echo - 参数传递:通过URL参数(
param=hello,2018)或请求体(JSON/XML)。
- 请求路径:
2. 服务标识解耦
- 服务名代替硬编码IP:
消费者通过服务名(service-provider)调用服务,而非直接依赖IP地址。
优势:- 动态扩缩容:提供者实例变化时,Nacos自动更新可用地址列表。
- 负载均衡:Nacos支持返回多个实例,消费者可轮询或随机选择(需集成Ribbon等组件)。
3. 元数据(Metadata)传递
- 用途:
注册时携带的元数据(如version=2018)可用于:- 灰度发布:根据版本号路由请求。
- 环境隔离:区分测试/生产环境实例。
调用示例:
消费者可通过元数据筛选特定实例(如请求version=2018的提供者)。
四、完整流程示例
1. 服务提供者启动 → 注册到Nacos(IP:8070,元数据version=2018)
2. 消费者启动 → 向Nacos查询service-provider地址 → 获得http://192.168.1.100:8070/
3. 消费者发送HTTP请求 → GET http://192.168.1.100:8070/echo?param=hello,2018
4. 提供者处理请求 → 提取"2018" → 返回HTTP响应"2018"
5. 消费者收到响应 → 完成数据交互
五、扩展场景
1. 负载均衡
- 多实例场景:
若存在多个service-provider实例(如8070、8071、8072),Nacos返回所有实例地址。
消费者行为:
可结合Ribbon实现负载均衡(如轮询、随机选择实例)。
2. 健康检查
- 自动剔除故障节点:
Nacos定期检查提供者心跳,若8070端口服务宕机,自动从列表中移除,确保消费者不会调用失效实例。
3. 动态配置
- 配置中心集成:
Nacos可管理服务配置(如超时时间、路由规则),服务重启时自动同步最新配置。
总结
服务间数据发送的核心流程为:
注册(Provider → Nacos)→ 发现(Consumer ← Nacos)→ 调用(HTTP请求)→ 响应。
通过Nacos解耦服务依赖,结合HTTP协议实现灵活通信,是微服务架构中高效协作的基础。
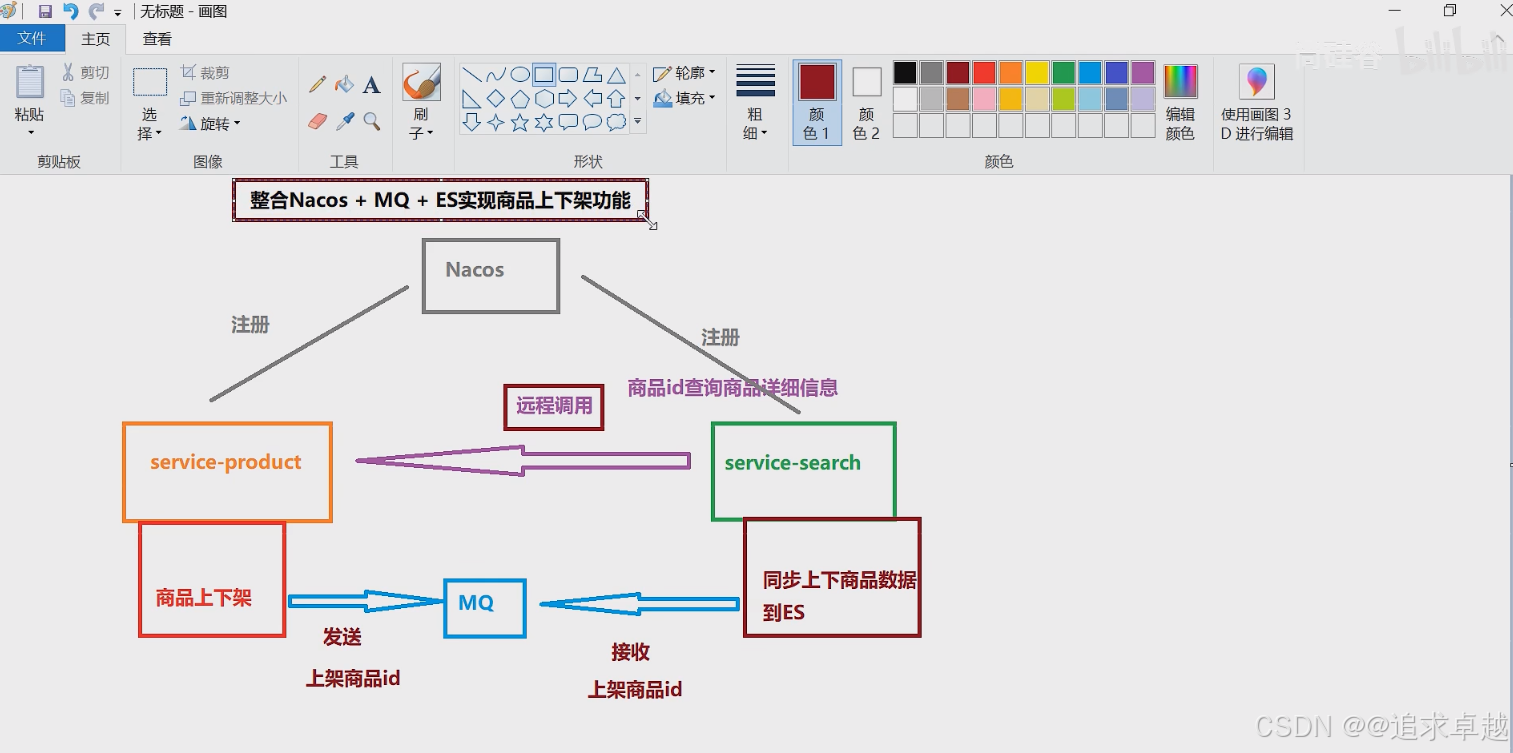
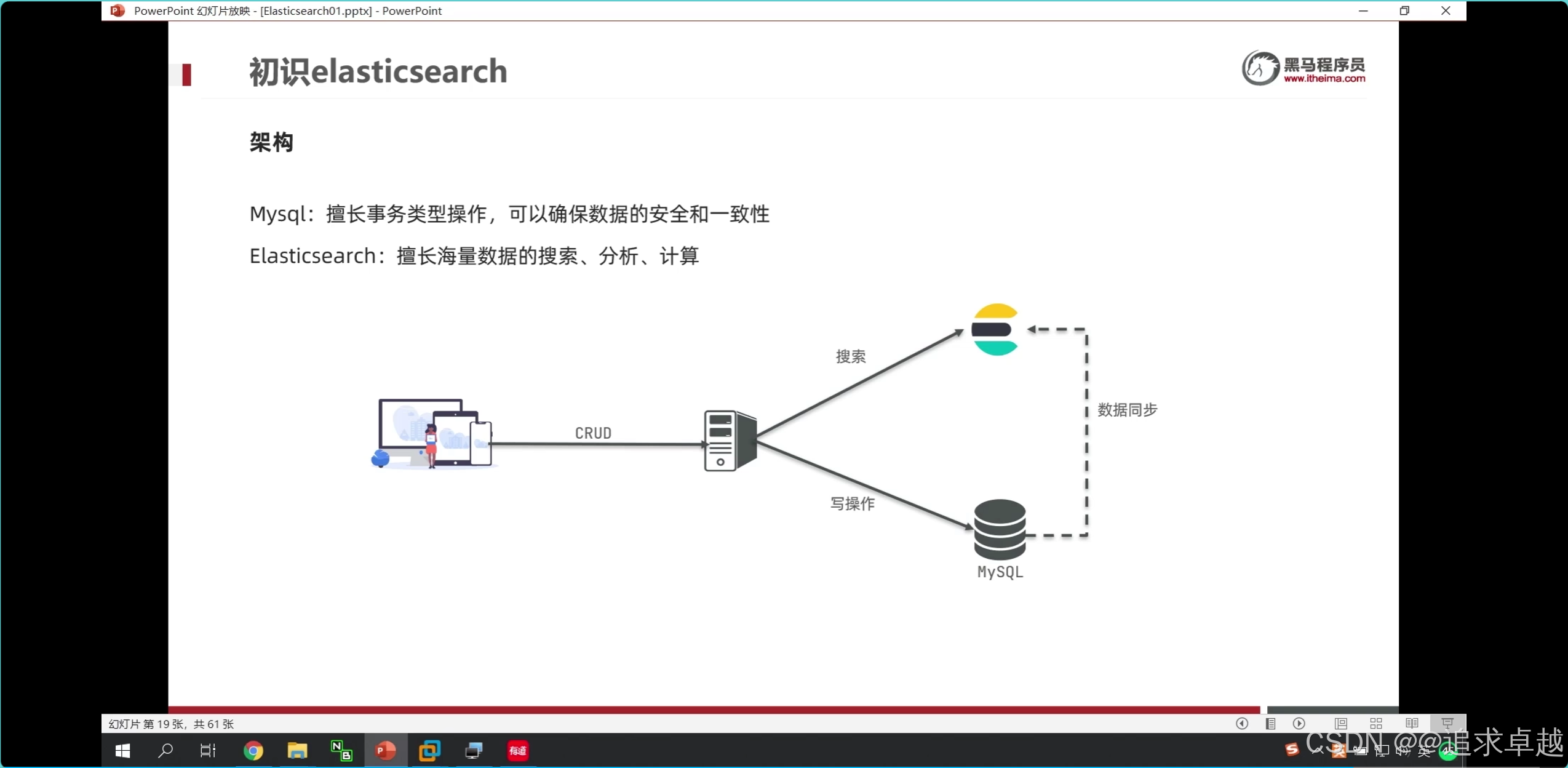
- 商品上下架过程中,修改数据库表上下架状态,之后通过RabbitMQ发送消息,最终实现ES中数据同步。
- Binding Key:队列绑定到交换机时设定的 “路由规则”(收件规则)。
Routing Key:生产者发送消息时指定的 “消息标签”(快递单号)。
匹配结果:交换机根据两者的匹配关系,决定消息投递到哪些队列。
话题交换机
- bindingkey和routingkey是可以(多个 routingKey 之间以.分割)。广播和定向是只能一个。
- 交换机是具体的名字。routingkey是固定的名字,bingkey是可以有#。
bindkey相当于信箱的收件规则;routeingkey是消息的快递号。
ES

- 手机% 才会对索引生效。
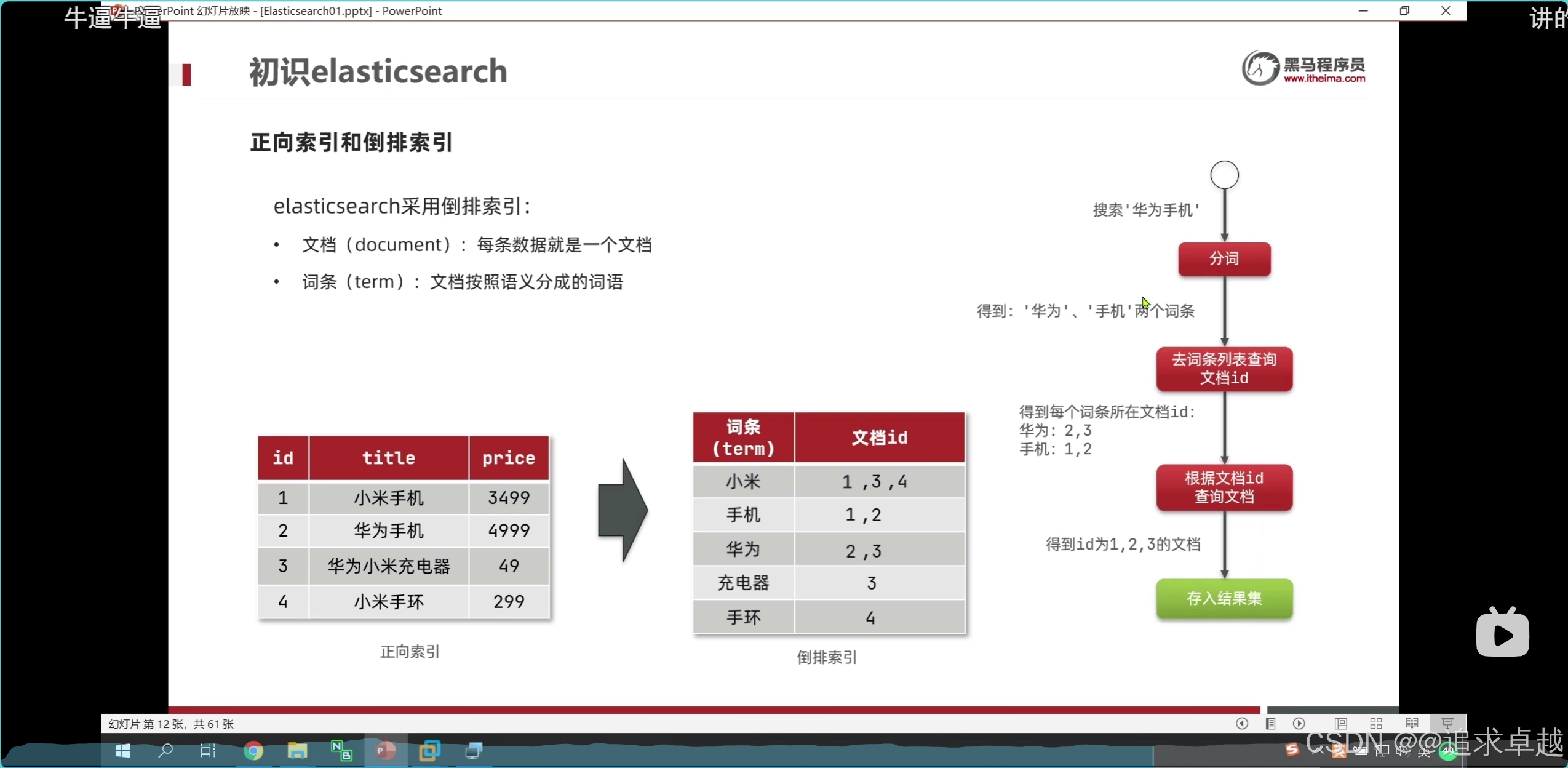

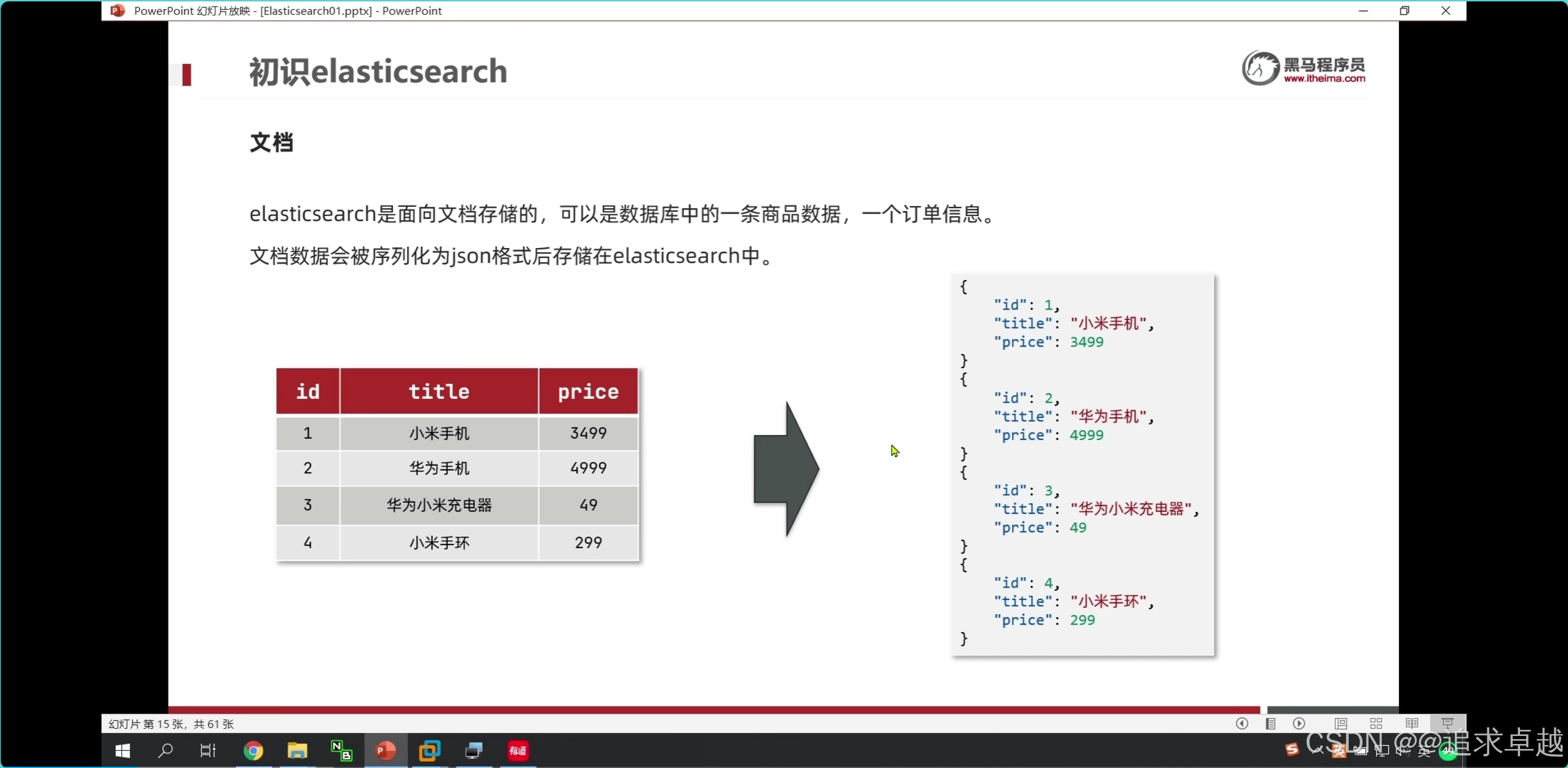




- ik分词器是创建倒排索引和搜索分词的。
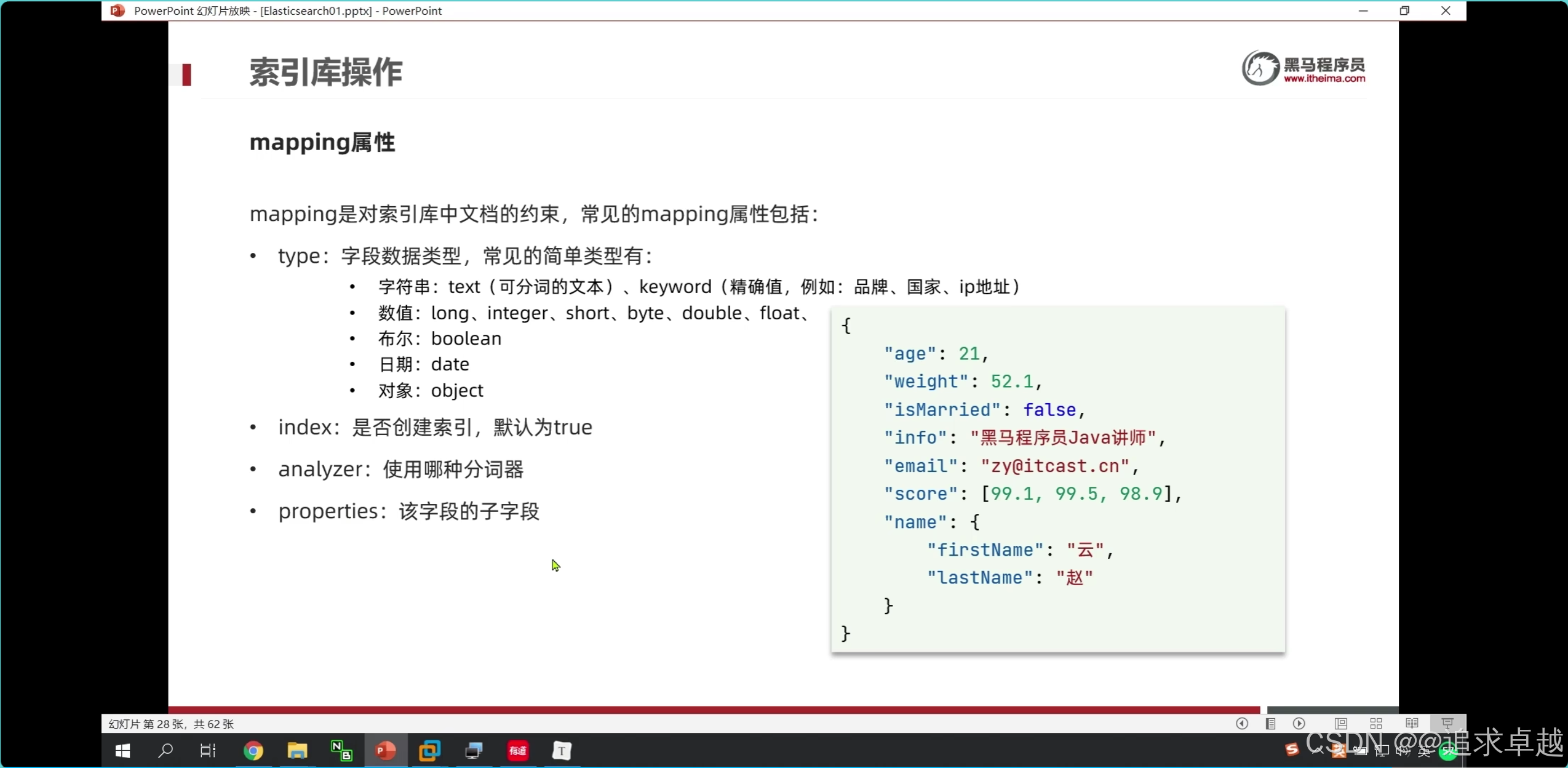

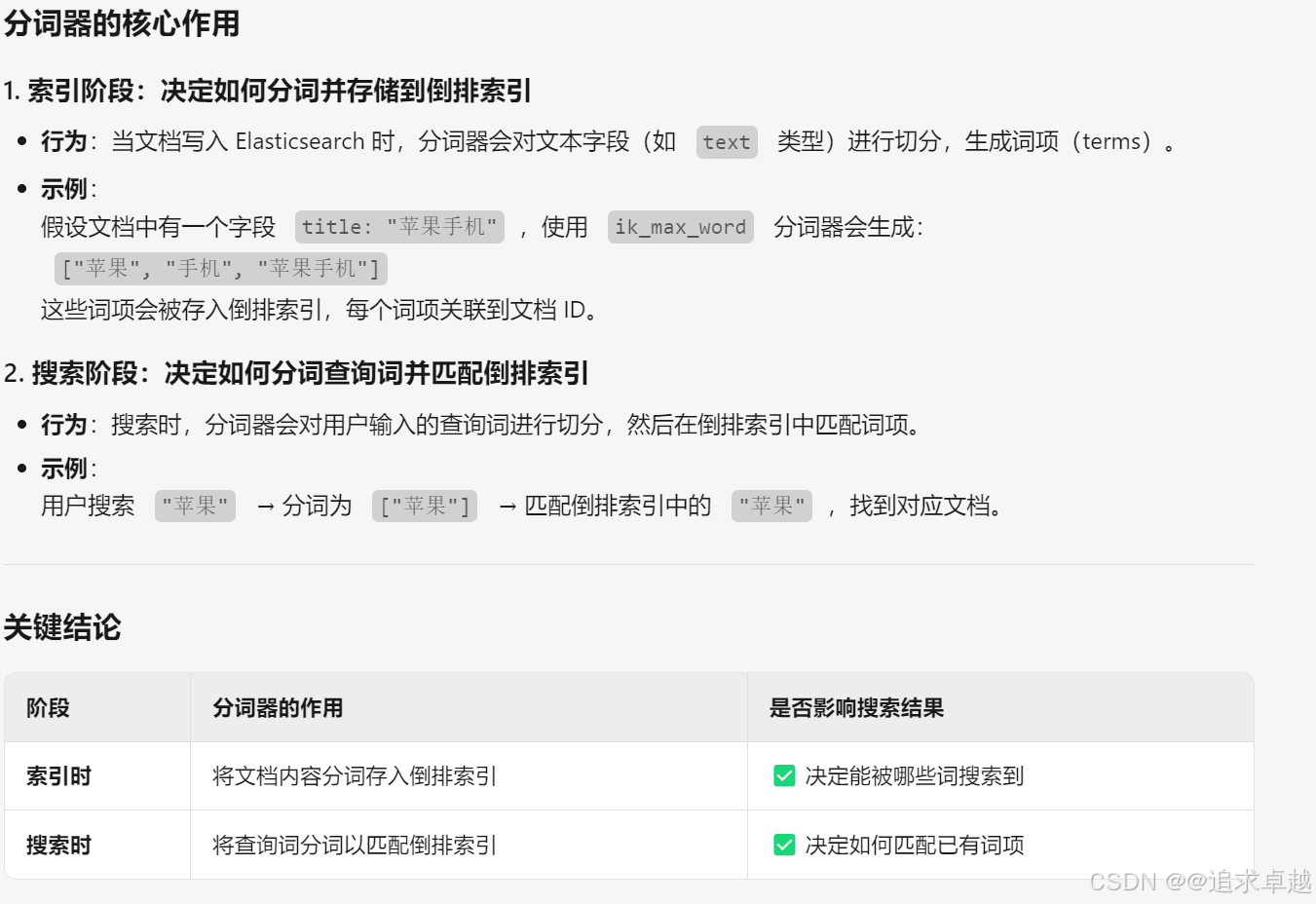
问题

结论:
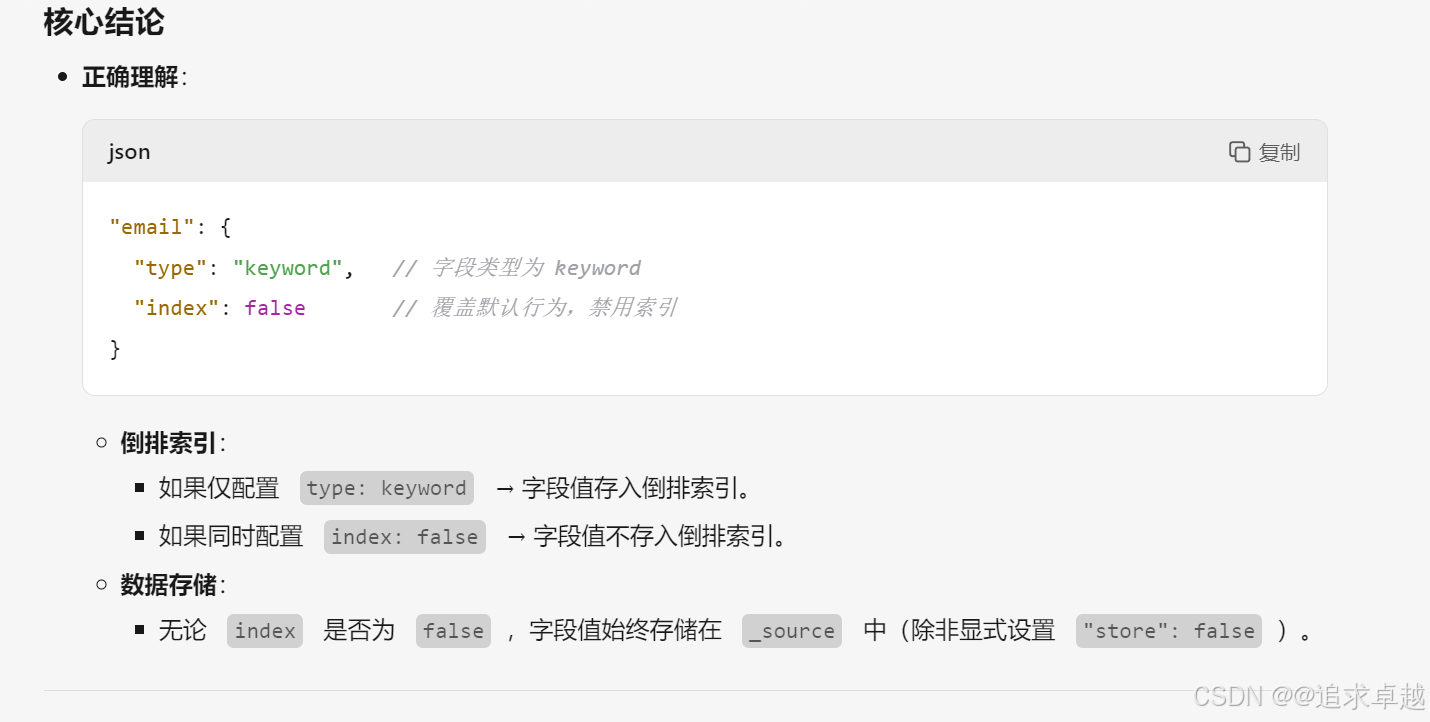
- text是创建到倒排索引的,而且会分词。
- keyword也会创建倒排,但是如果使用index:false的话是不会创建的。所以不会放到倒排中。
问题 :索引库和倒排索引有什么关系?
- 索引库就是存储到es中的文档数据。
- 倒排索引就是基于索引库的文档创建的。
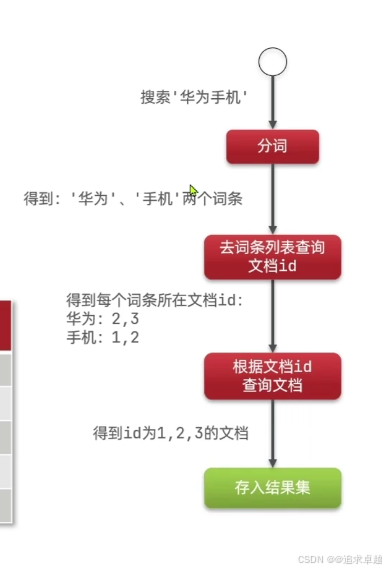
- 搜索就是根据分词器先分词之后匹配倒排索引库。之后查询。
- 存储就是先分词和存储索引库。

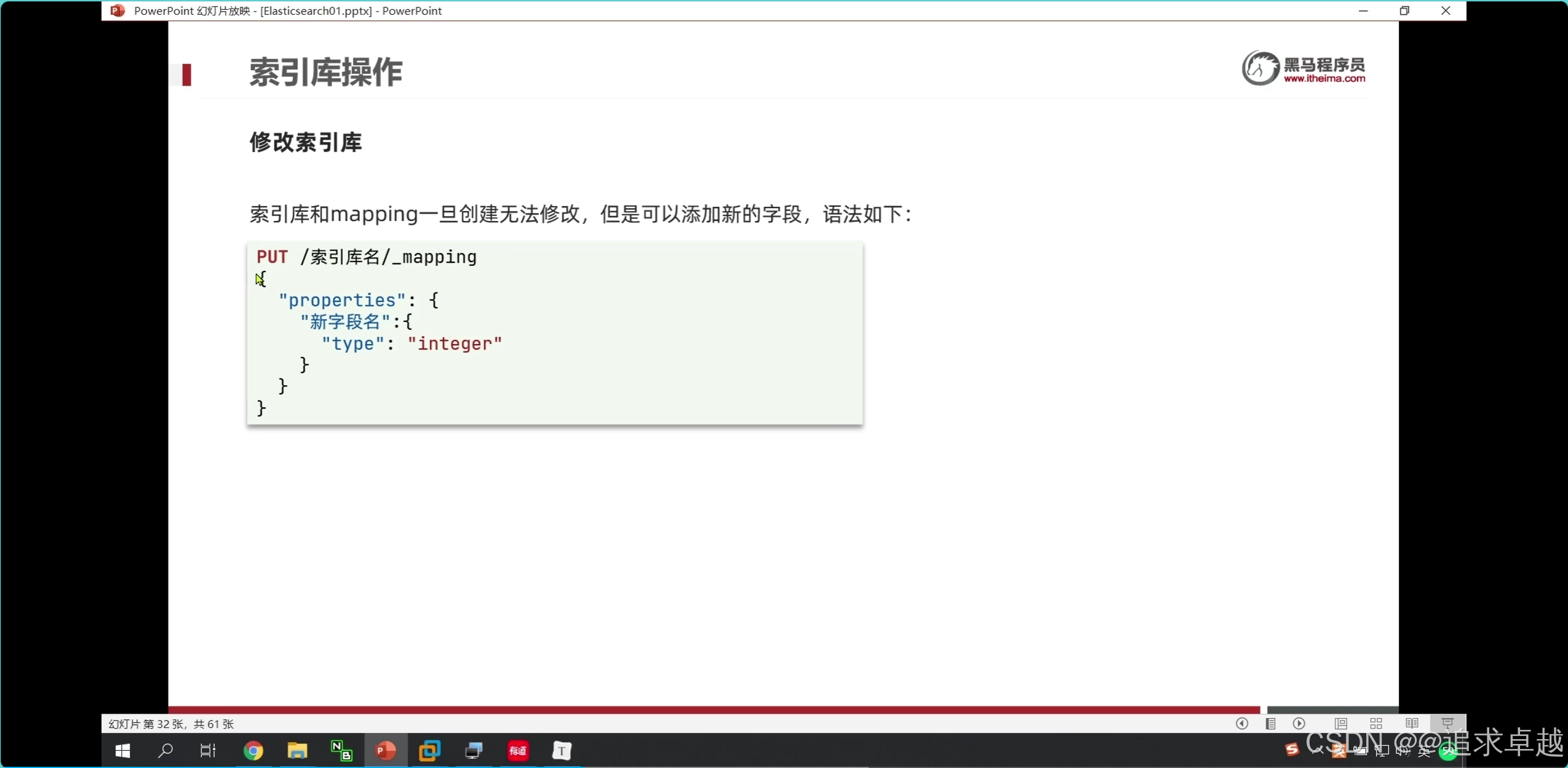
- put用于操作索引库的字段和新增字段。全量修改。
- 新增使用post
- 获得使用get
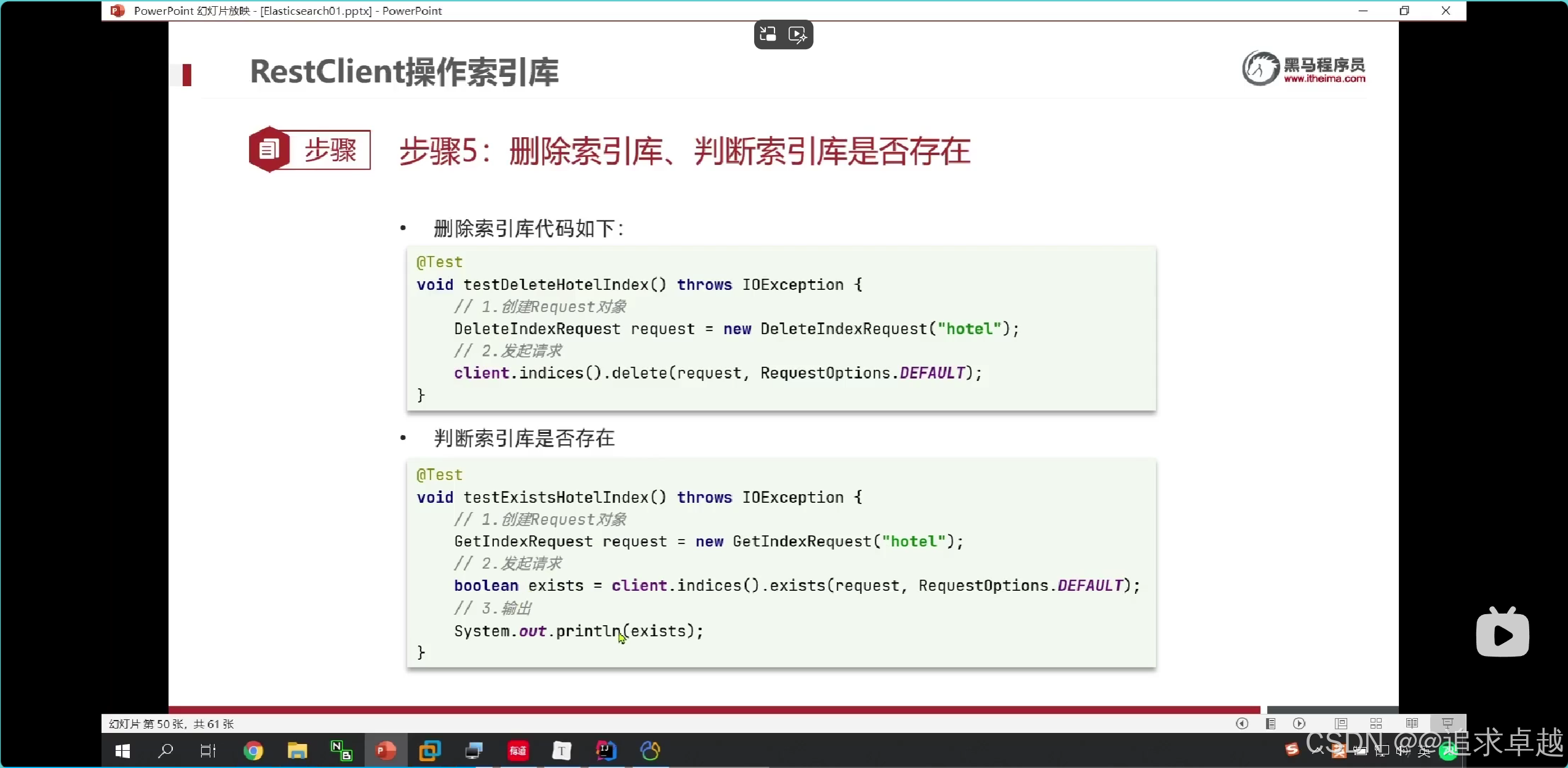
- 删除delete。

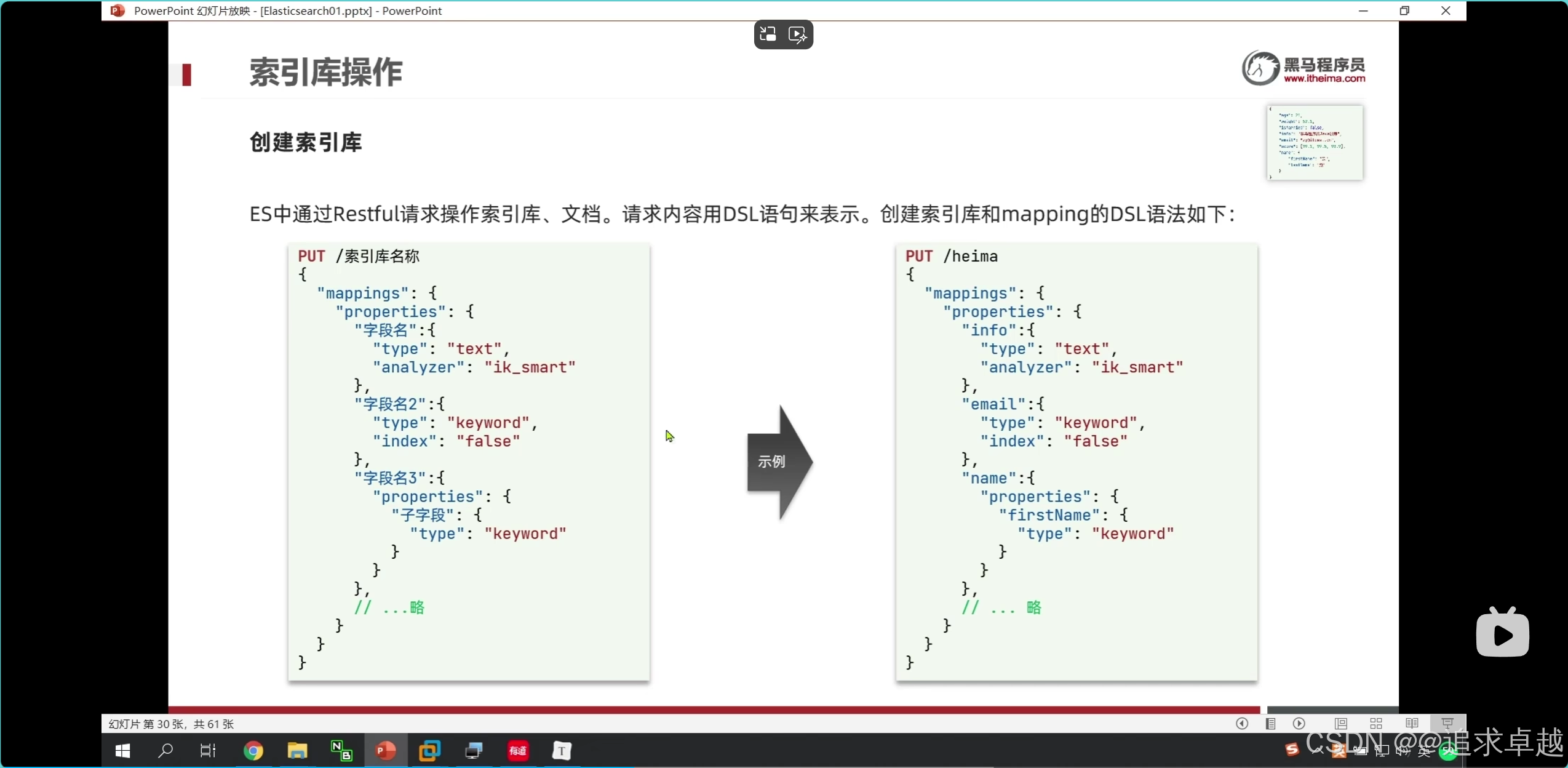
PUT /hotel
{"mappings": {"properties": {"id":{"type":"keyword"},"name":{"type":"text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type":"keyword","index":false},"price":{"type":"integer"},"score":{"type":"integer"},"brand":{"type":"keyword","copy_to": "all"},"city":{"type":"keyword"},"starName":{"type":"keyword"},"business":{"type":"keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type":"keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
- id在es中是不可分割的。
- 把品牌和名字和商圈给到all.就是参与复合搜索。
public void test2() throws IOException {CreateIndexRequest request=new CreateIndexRequest("hotel1");request.source(MAPPING_TEMPLATE,XContentType.JSON);client.indices().create(request,RequestOptions.DEFAULT);}酒店的crud
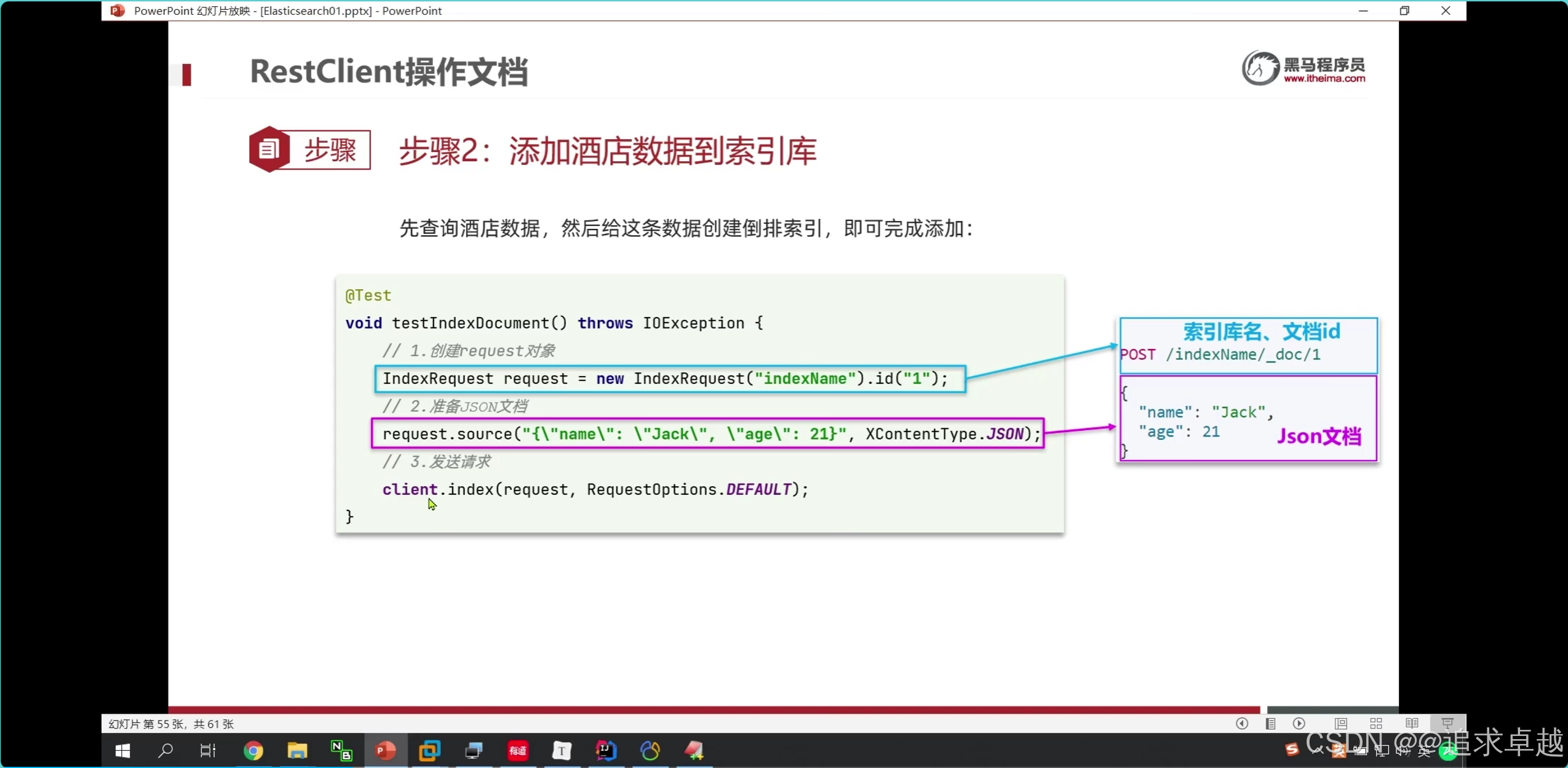
新增就是post /hotel/_doc/1
- 第一次都是从数据库获得对应数据,之后存储到es中。
- es和mysql的pojo是需要两个的。因为es的维度经度是一个。javabean是两个。
@Testpublic void test5() throws IOException {Hotel byId = hotelService.getById(38609);System.out.println(byId);HotelDoc hotelDoc = new HotelDoc(byId);// post /hotel/_doc/1IndexRequest hotel = new IndexRequest("hotel").id(hotelDoc.getId().toString());hotel.source(JSON.toJSONString(hotelDoc), XContentType.JSON);client.index(hotel, RequestOptions.DEFAULT);// IndexRequest indexRequest=new IndexRequest("hotel1").id("1");
// indexRequest.source("",RequestOptions.DEFAULT);
// client.index(indexRequest,RequestOptions.DEFAULT);}
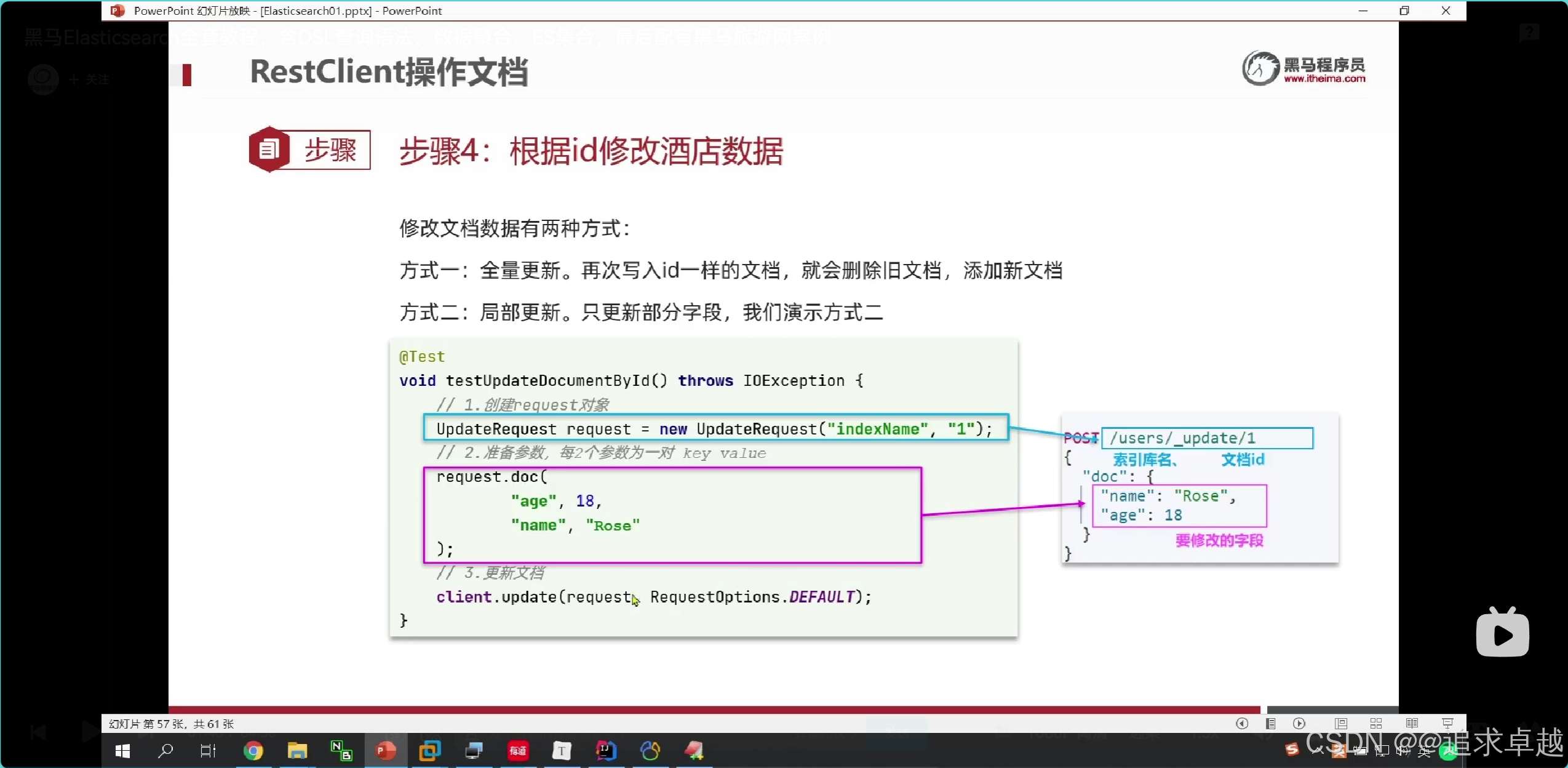
// post /hotel/_update/1
// 更新@Testpublic void test7() throws IOException {UpdateRequest hotel = new UpdateRequest("hotel", "38609");hotel.doc("price", 100,"city","上海浦东");client.update(hotel,RequestOptions.DEFAULT);}- DELETE /hotel/_doc/38609
搜索数据

全局搜索
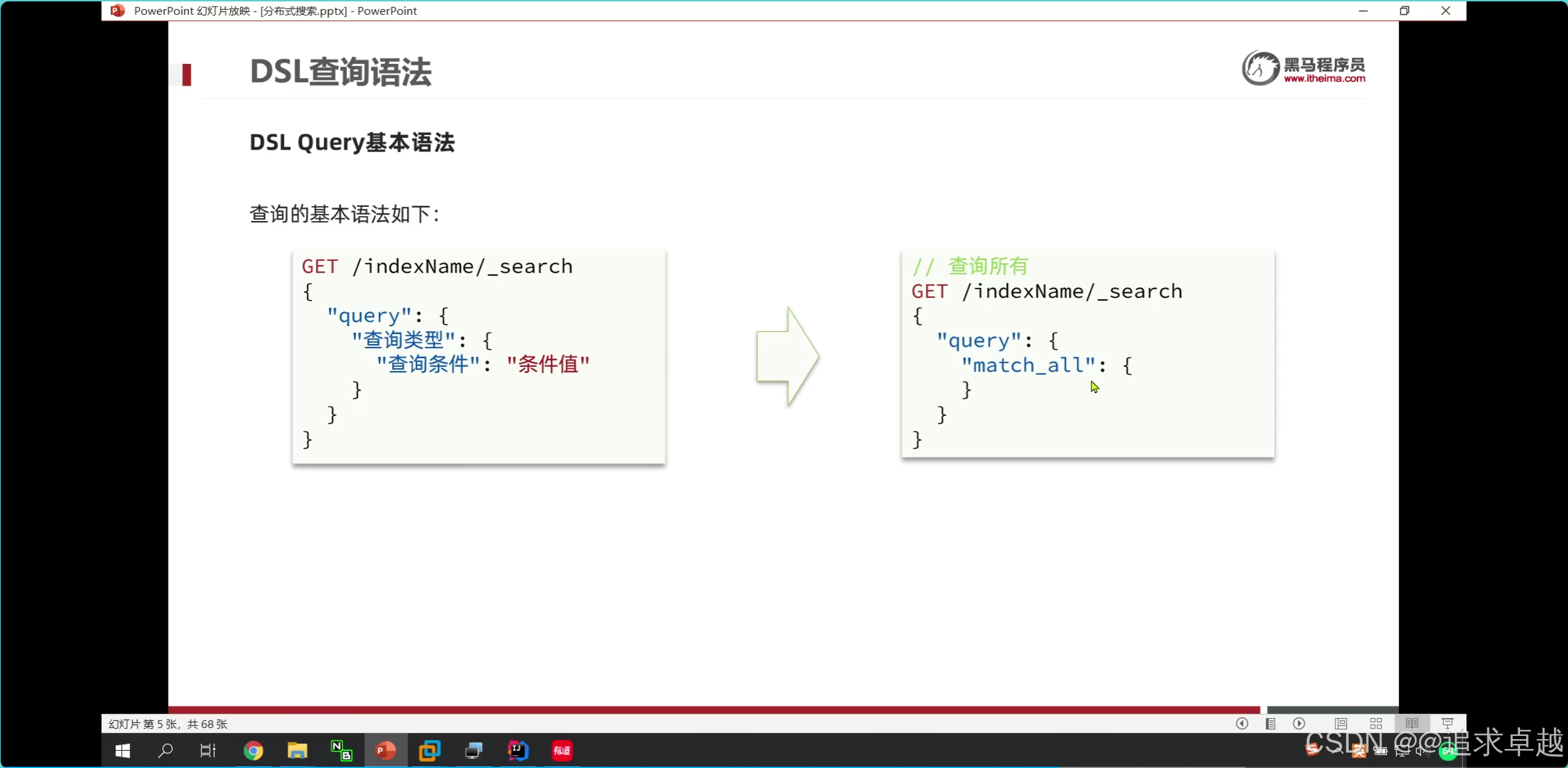

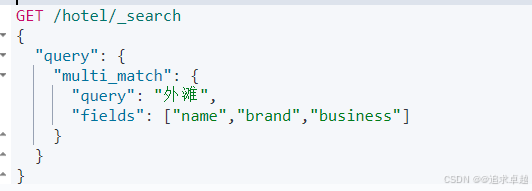
GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}GET /hotel/_search
{"query": {"multi_match": {"query": "外滩","fields": ["name","brand","business"]}}
}
- name brand business是分词的字段。
- query 里面就是查询类型。
- match_all就是查询所有类型。
全文检索:对词语进行分词,之后查询索引库,获得索引。
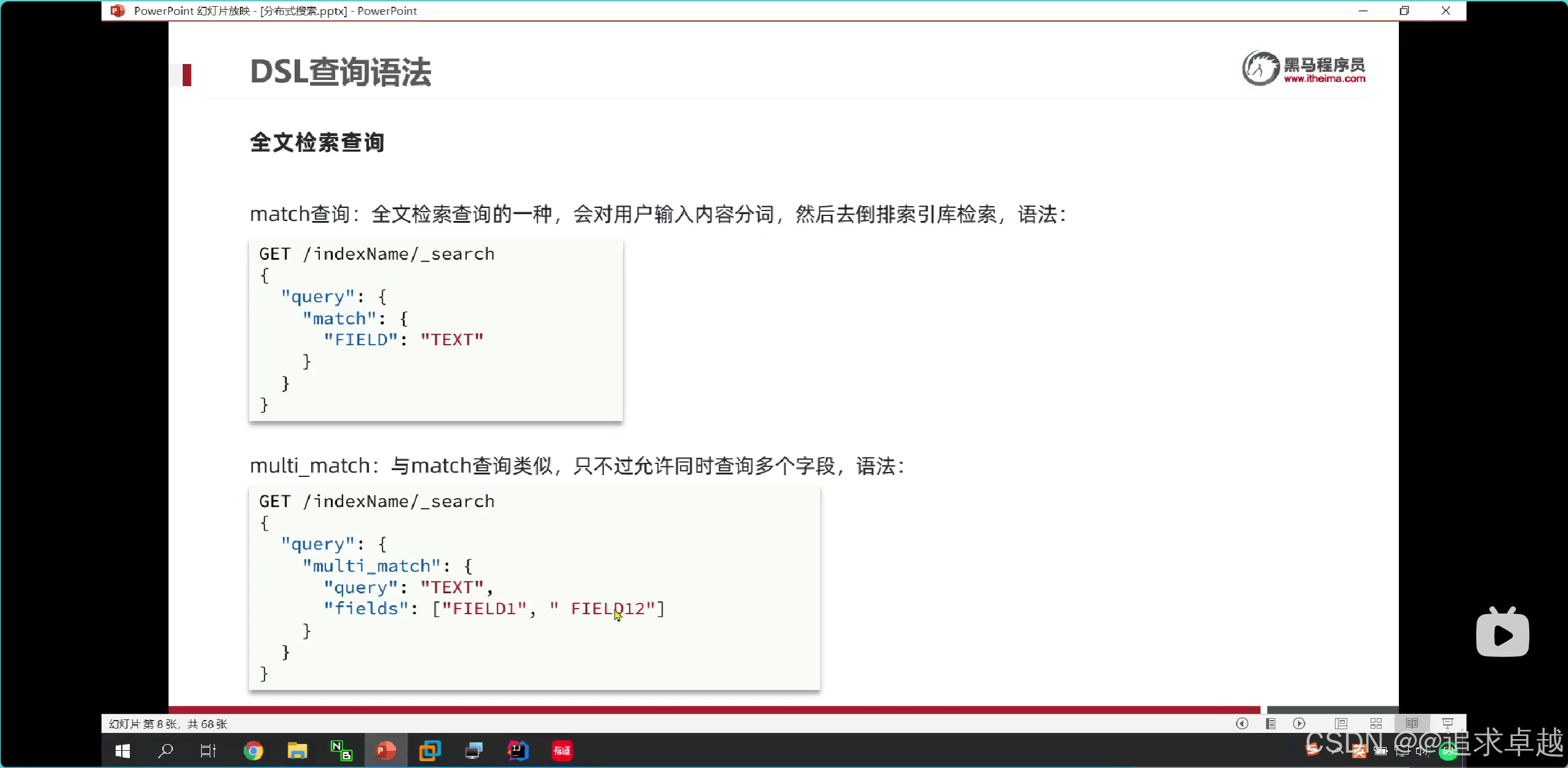
GET /hotel/_search
{"query": {"match_all": {}}
}GET /hotel/_search
{"query": {"match": {"all": "外滩如家"}}
}- 第一个是查询全部的。
- 第二个是查询一个字段的。
- 查询出来的相关度越高排名越靠前。
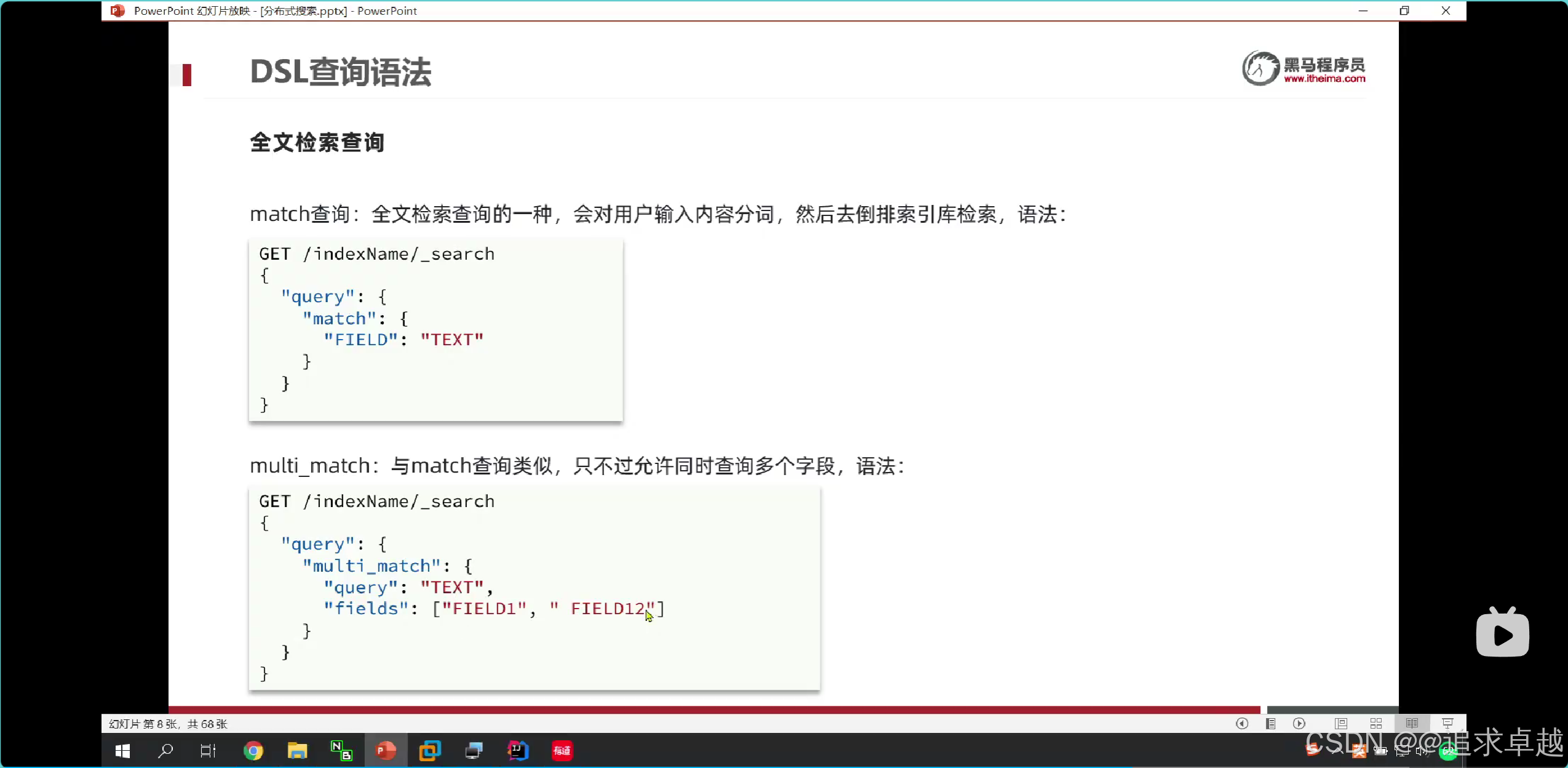
- 可以查询多个索引库。
为什么使用all更快呢?
- 因为每个被分词的字段都会被构建一个索引库,所以有时候需要查询多个。
- 但是all也是分词的,只需要查询一遍索引库。
- 要给字段类型给 “type”: “text”。
普通多字段查询(如 multi_match):
- 需要分别检索每个字段的倒排索引,例如同时查询 name、address、 escription 三个字段。
性能损耗:
多次倒排索引查找(每个字段一次)
合并多个字段的匹配结果(相关性计算更复杂)
可能涉及不同字段的分词器和词项差异 - all 字段查询:
所有目标字段的内容在 索引阶段 已合并到 all 字段中,只需检索一个倒排索引。
性能优势:
单次倒排索引查找
统一的分词器(确保词项一致性)
无需跨字段合并结果
📊 性能对比示例
假设 name、address、description 各有独立的倒排索引:
- 查询方式 倒排索引访问次数 词项合并复杂度
multi_match 3次 高
all 字段 1次 低
问题: 一般是不是经常在搜索框的是字段用分词,在下面固定的使用不分词
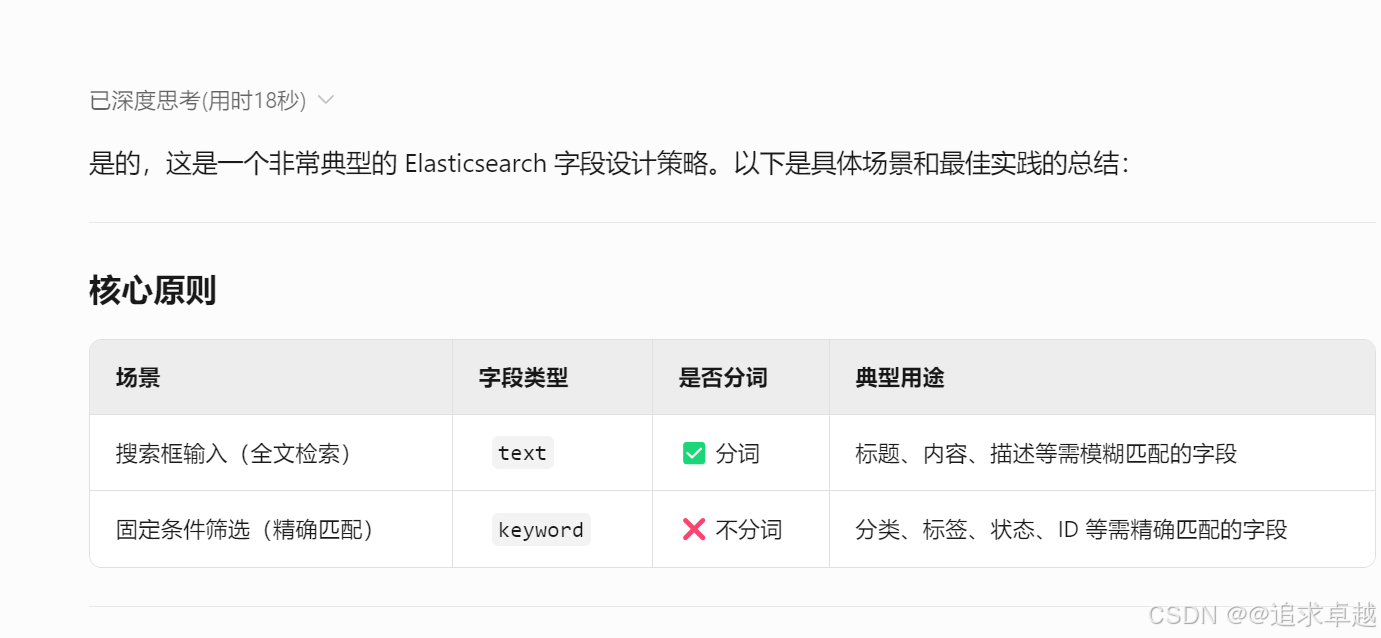
精确查询:无需进行分词

#range查询
GET /hotel/_search
{"query": {"range": {"price": {"gte": 200,"lte": 300}} }
}
- 范围查询。对于integer类型很好用。
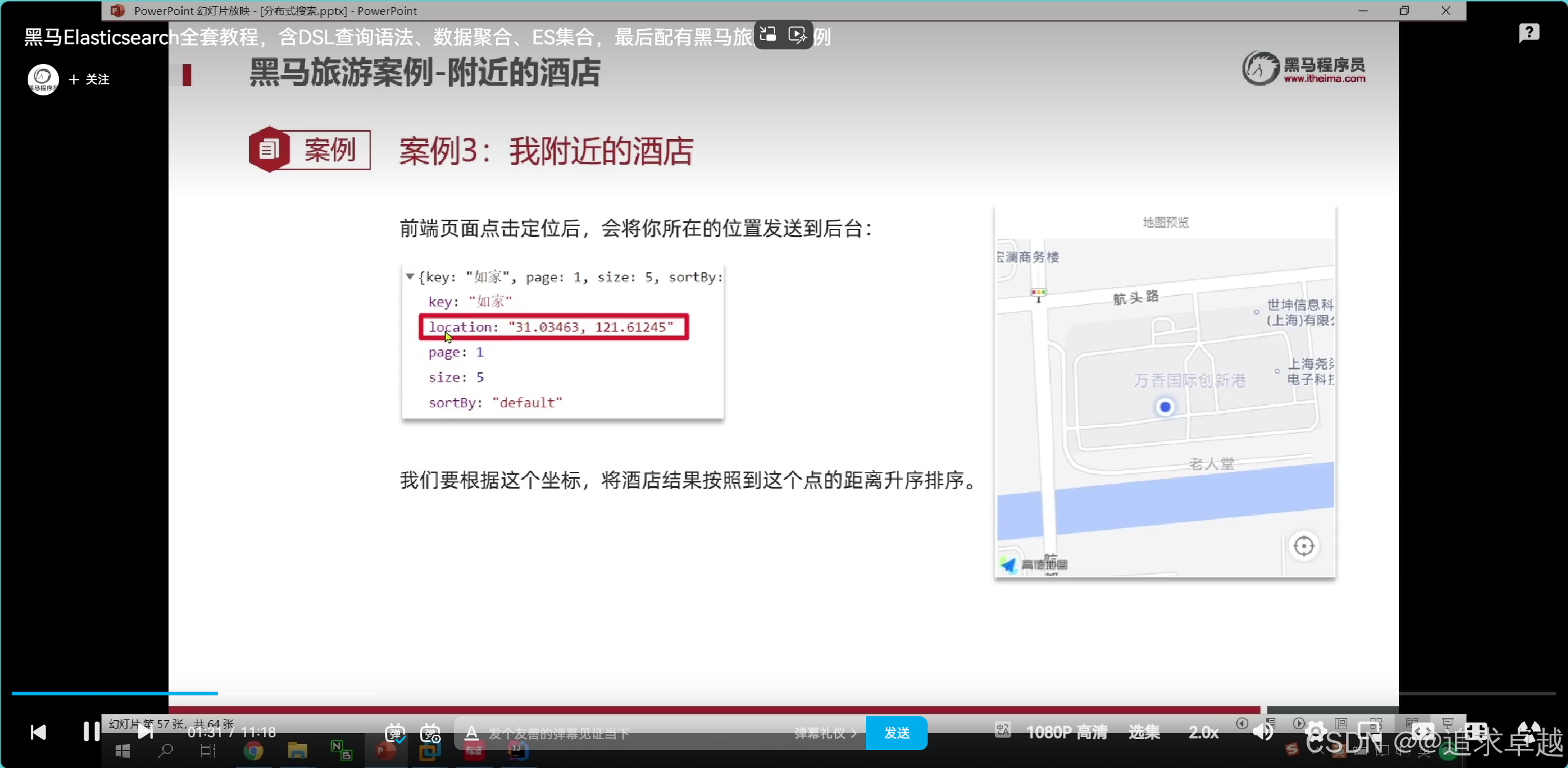
经纬度查询
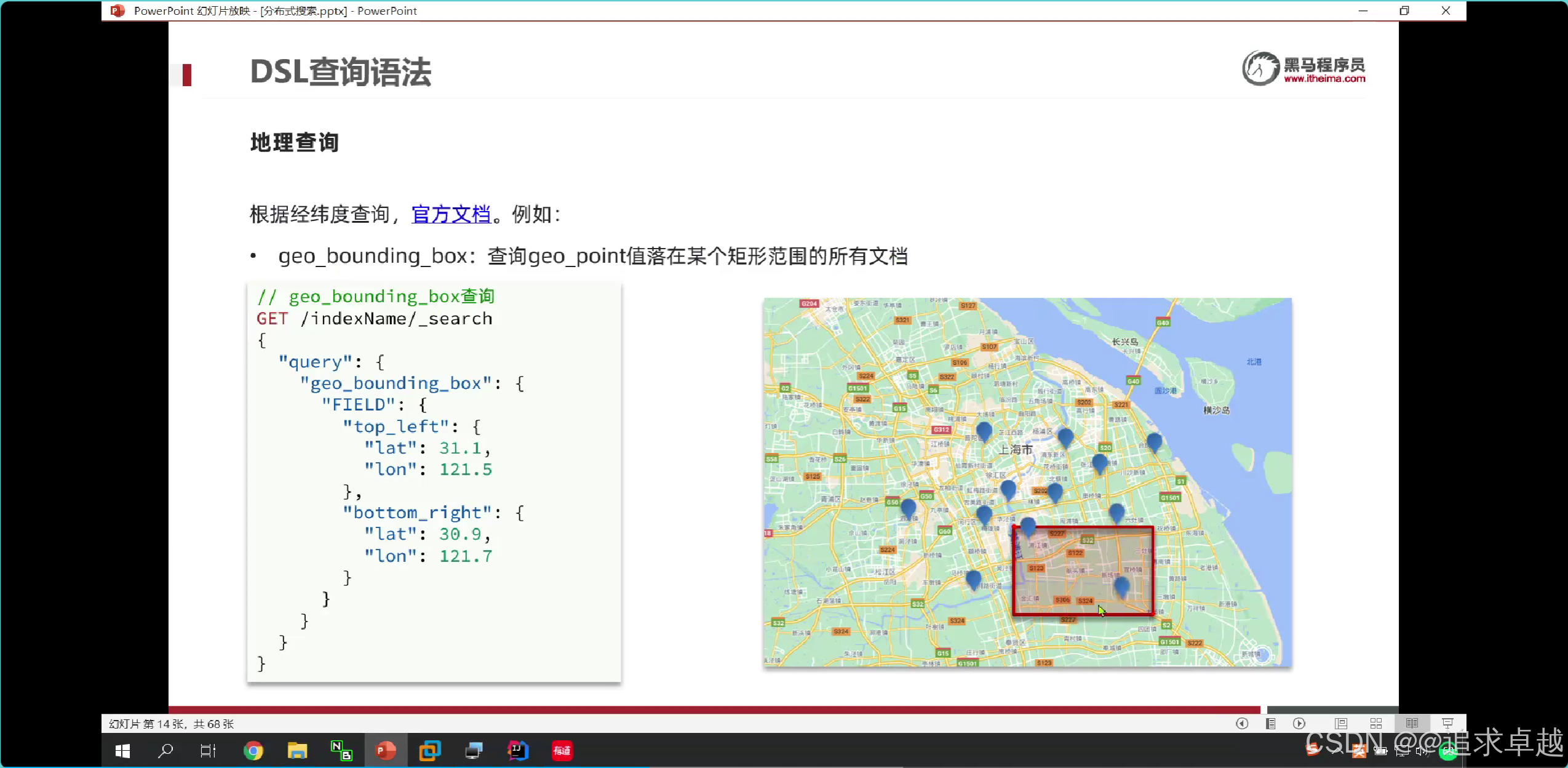
# 已自己为中心点。周围5km。
GET /hotel/_search
{"query": {"geo_distance": {"distance":"5km","location":"40.048969, 116.619566"} }
}
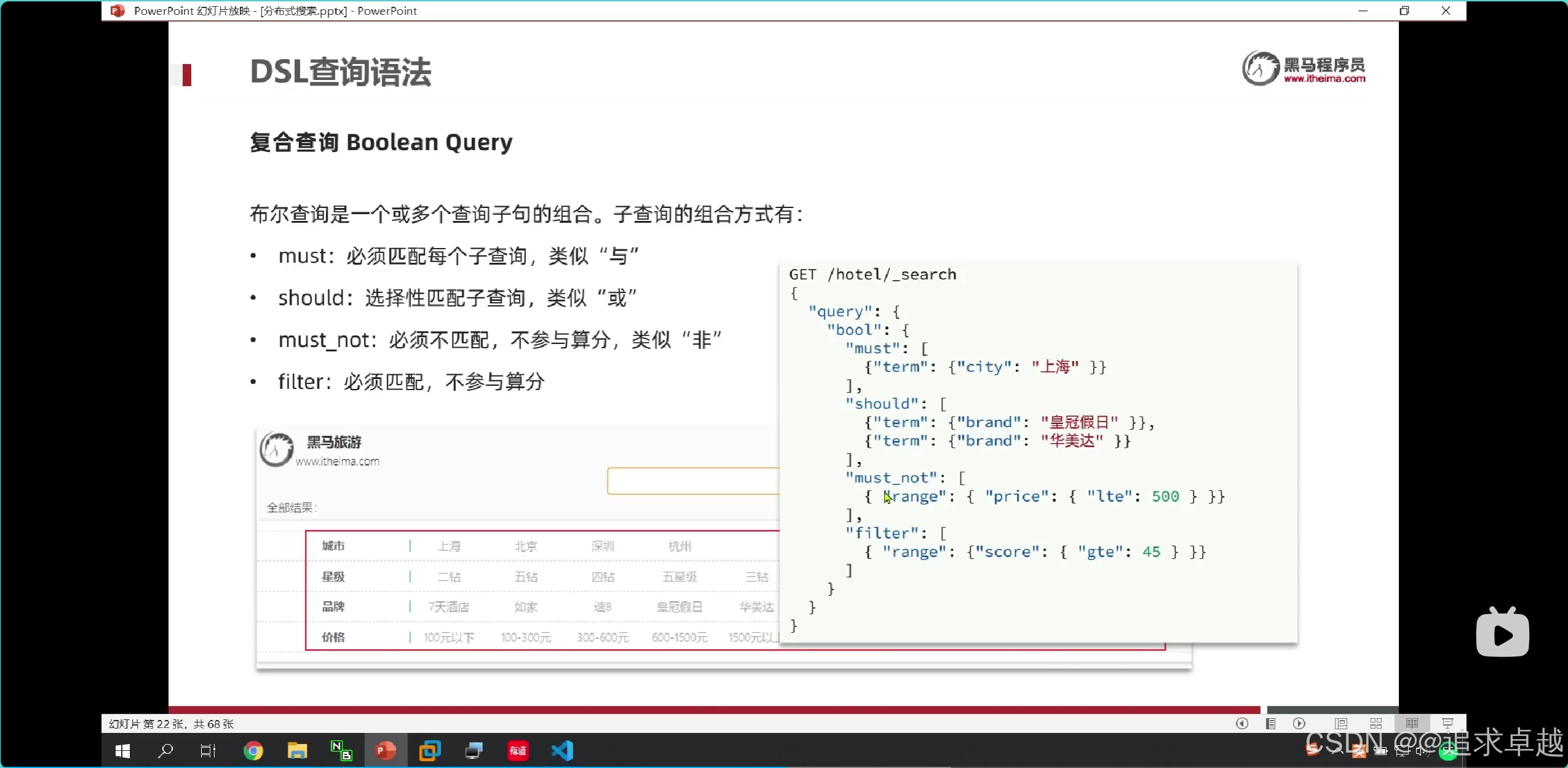
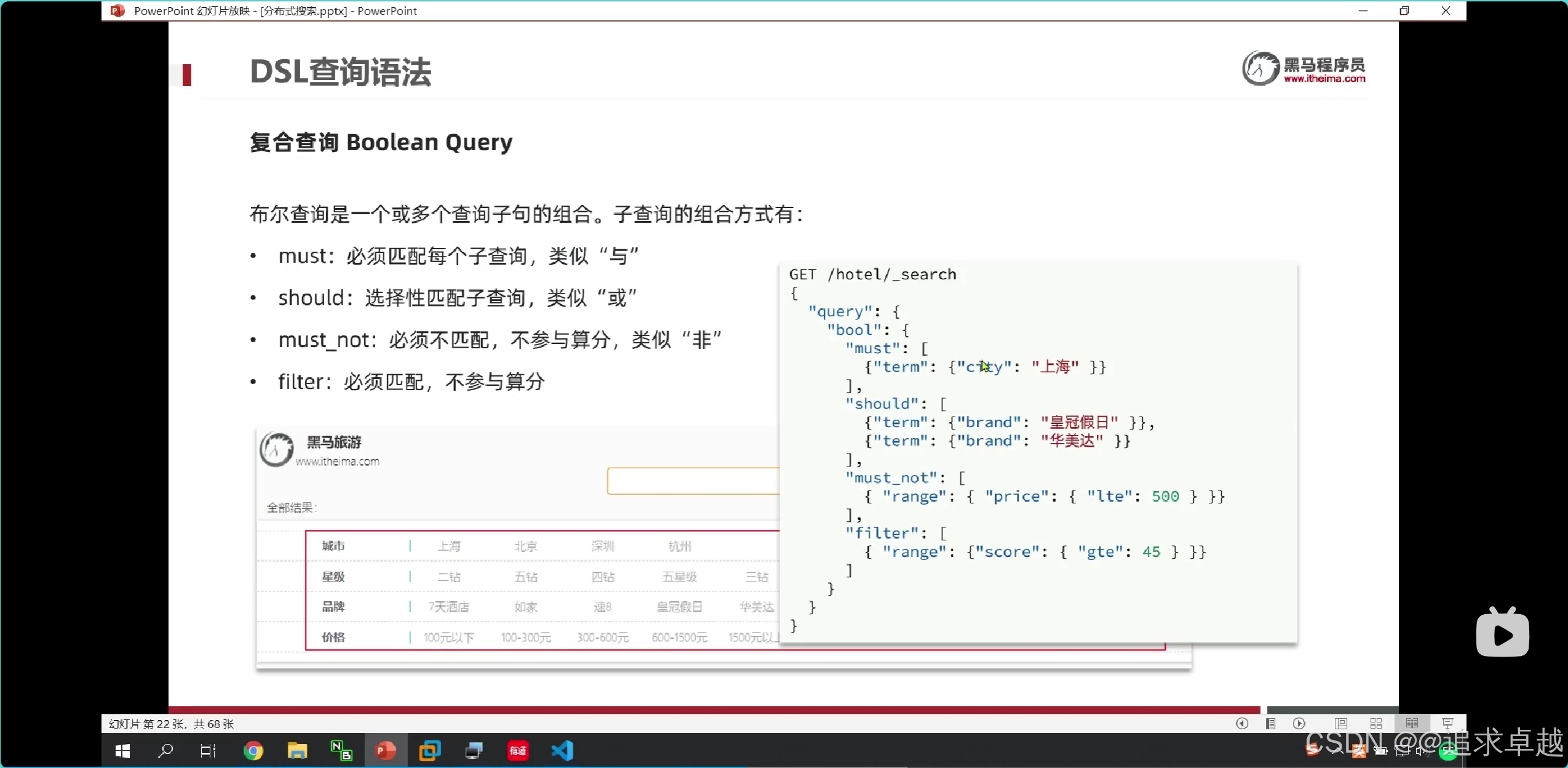
{"query": {"bool": {"must": [ ... ], // AND 逻辑(必须满足)"should": [ ... ], // OR 逻辑(至少满足一个)"must_not": [ ... ], // NOT 逻辑(必须不满足)"filter": [ ... ] // 精确过滤(不计算相关性得分,性能更高)}}
}
- 在多条件查询中,必须在外面bool。
- query -> bool -> must、should、must_not、filter。
GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海"}}],"should": [{"term":{"brand":"如家"}},{"term":{"brand":"华美达"}}],"must_not": [{"range":{"price": {"gte": 300}}}],"filter": [{"range": {"score": {"gte": 30,"lte": 40}}}]}}
}
- match和multi_match是分词查询的。
- term是精确
- range是范围
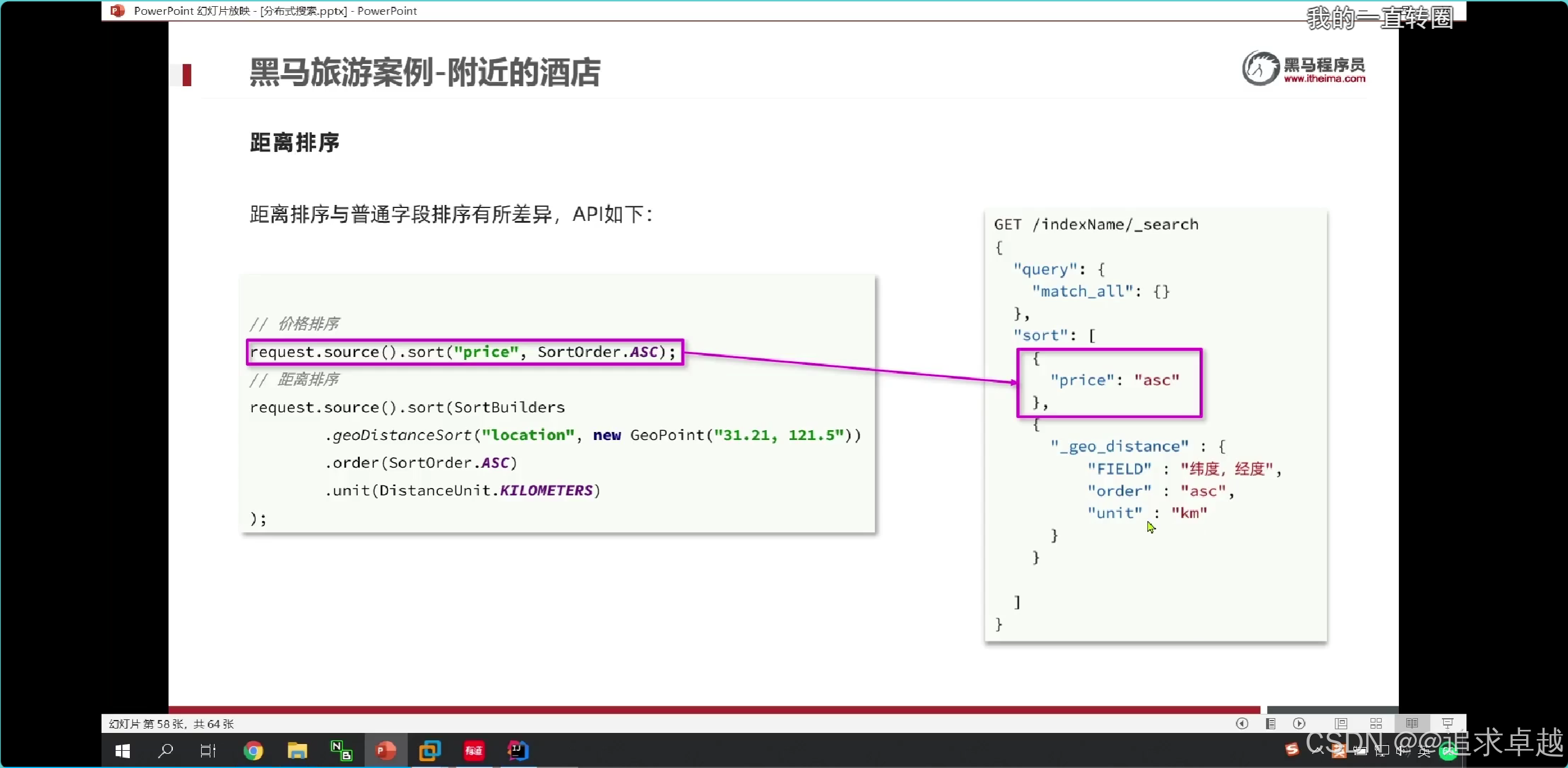
排序
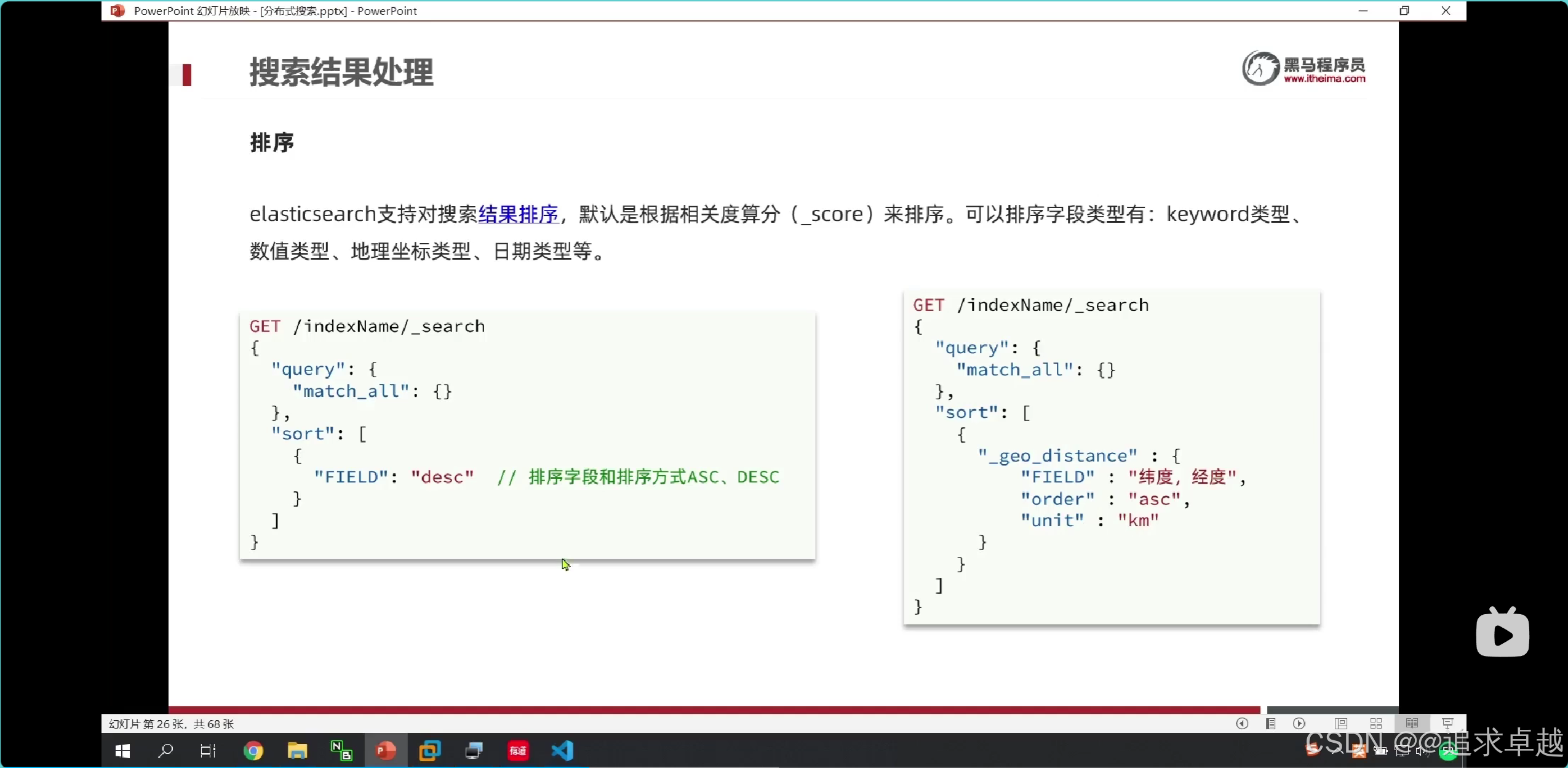
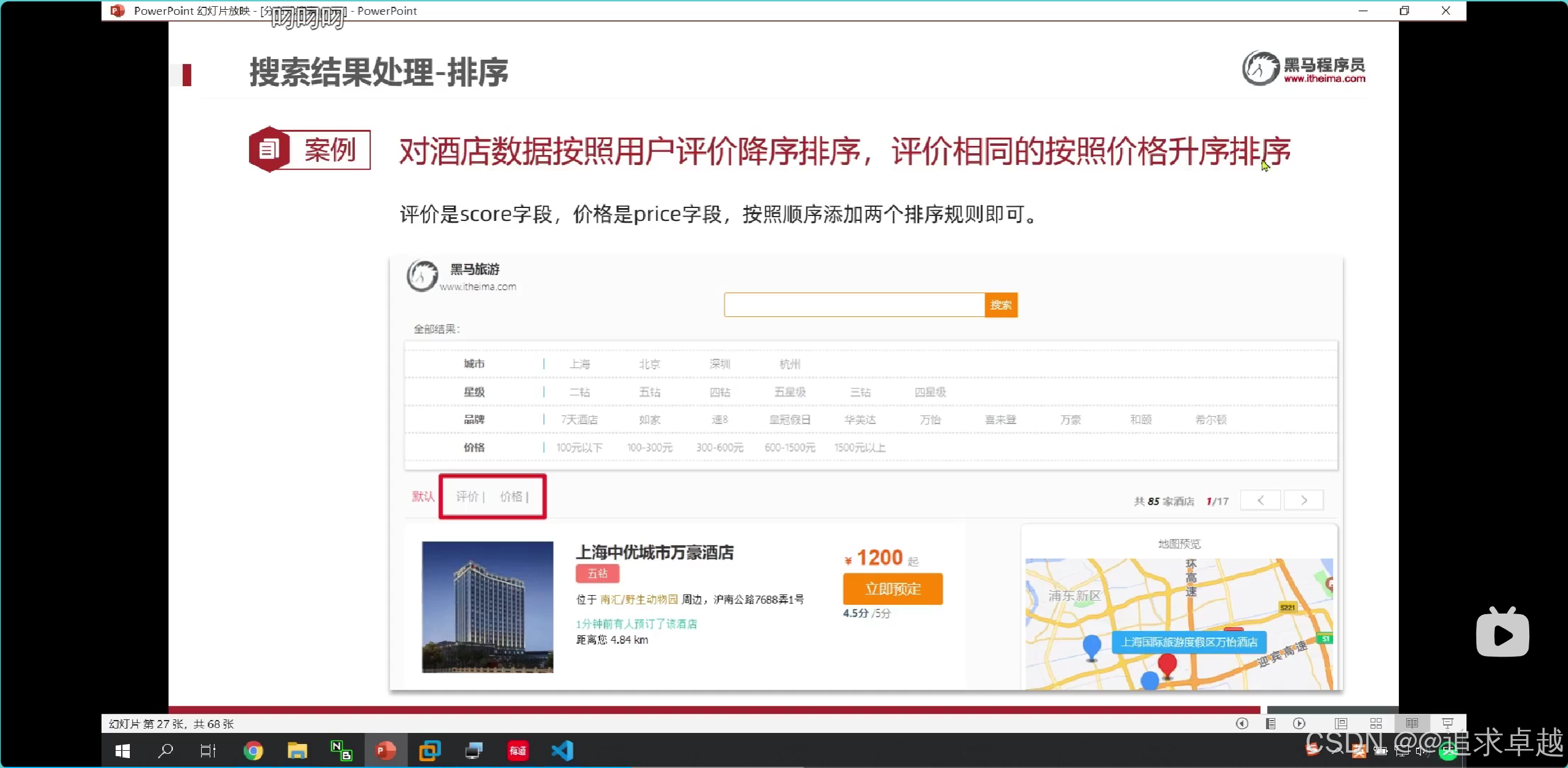
# 排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": {"order": "asc"},"price": {"order": "desc"}}]
}
# 地图排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 31.034661,"lon": 121.612282},"order": "asc","unit": "km"}}]
}
分页:es获得990到1000的数据,是先找出0-1000数据,之后进行截取的,不擅长做这个。
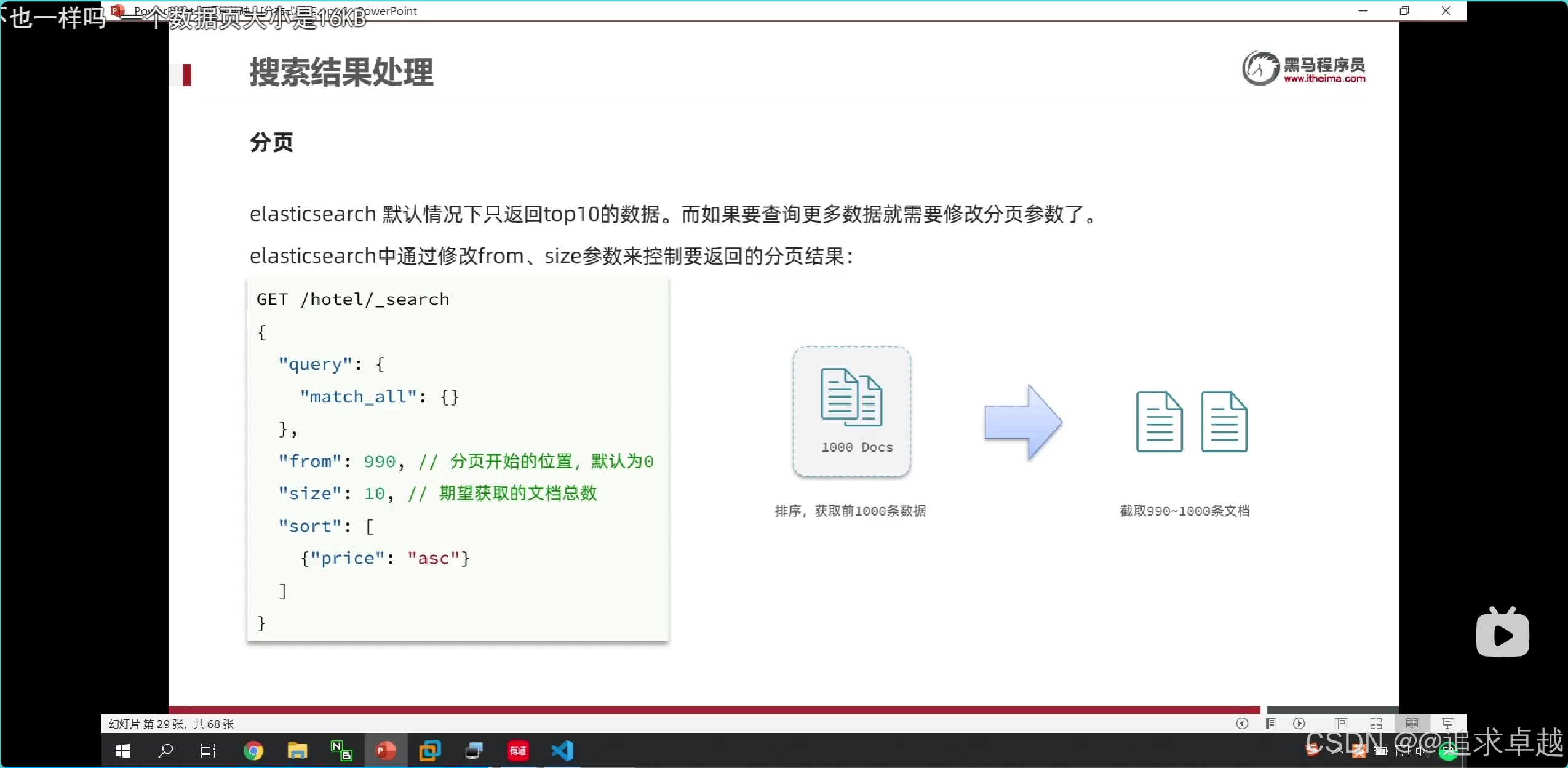
+
GET /hotel/_search
{"query": {"match_all": {}},"from":1,"size":10
}
在这里插入图片描述
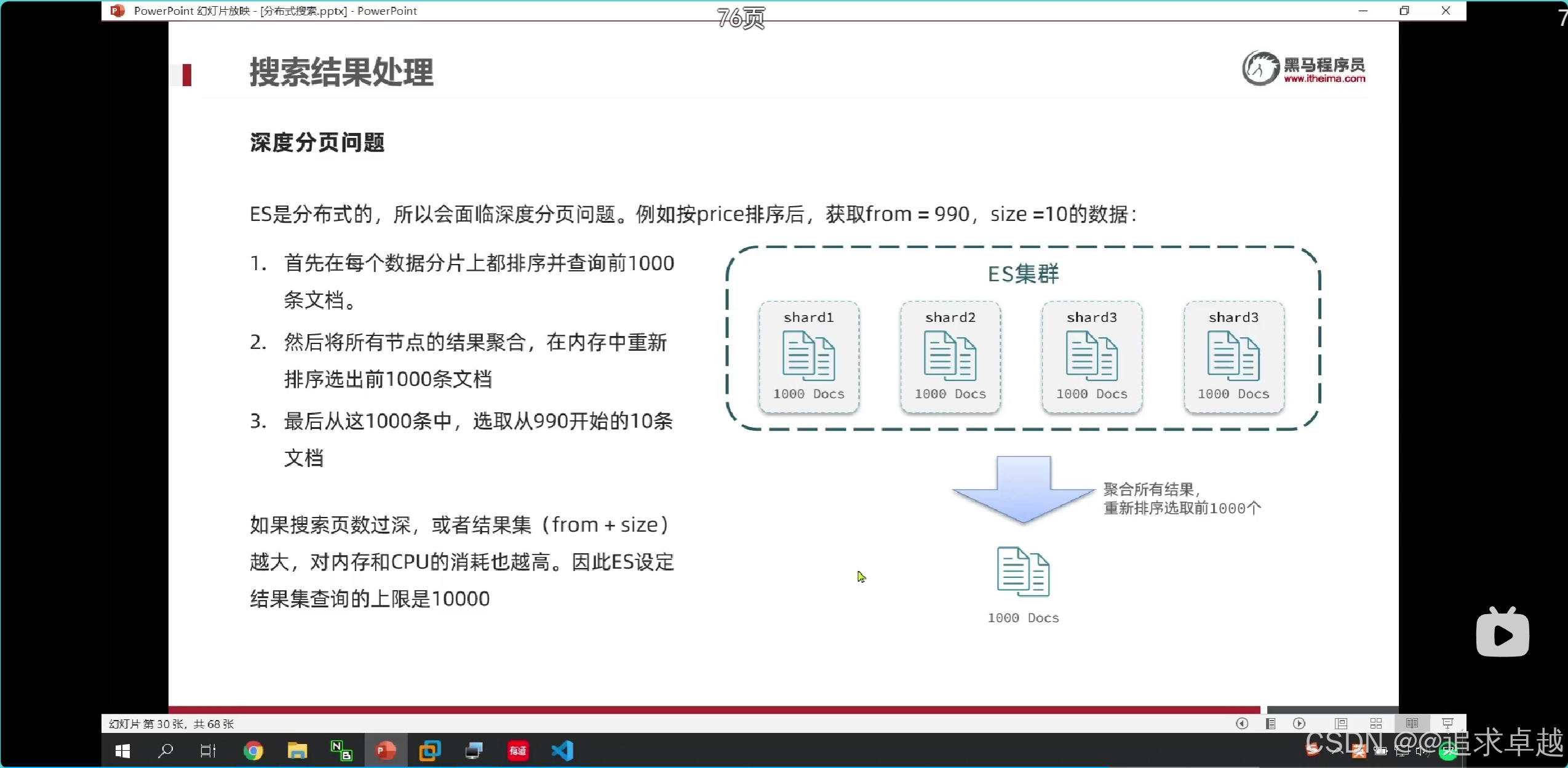
- 一个es就是排序之后获得前面1000,之后进行截取。
- 多个就是先排序获得前面1000,之后合在一个,进行排序获得前面1000,之后进行截取。
高亮处理
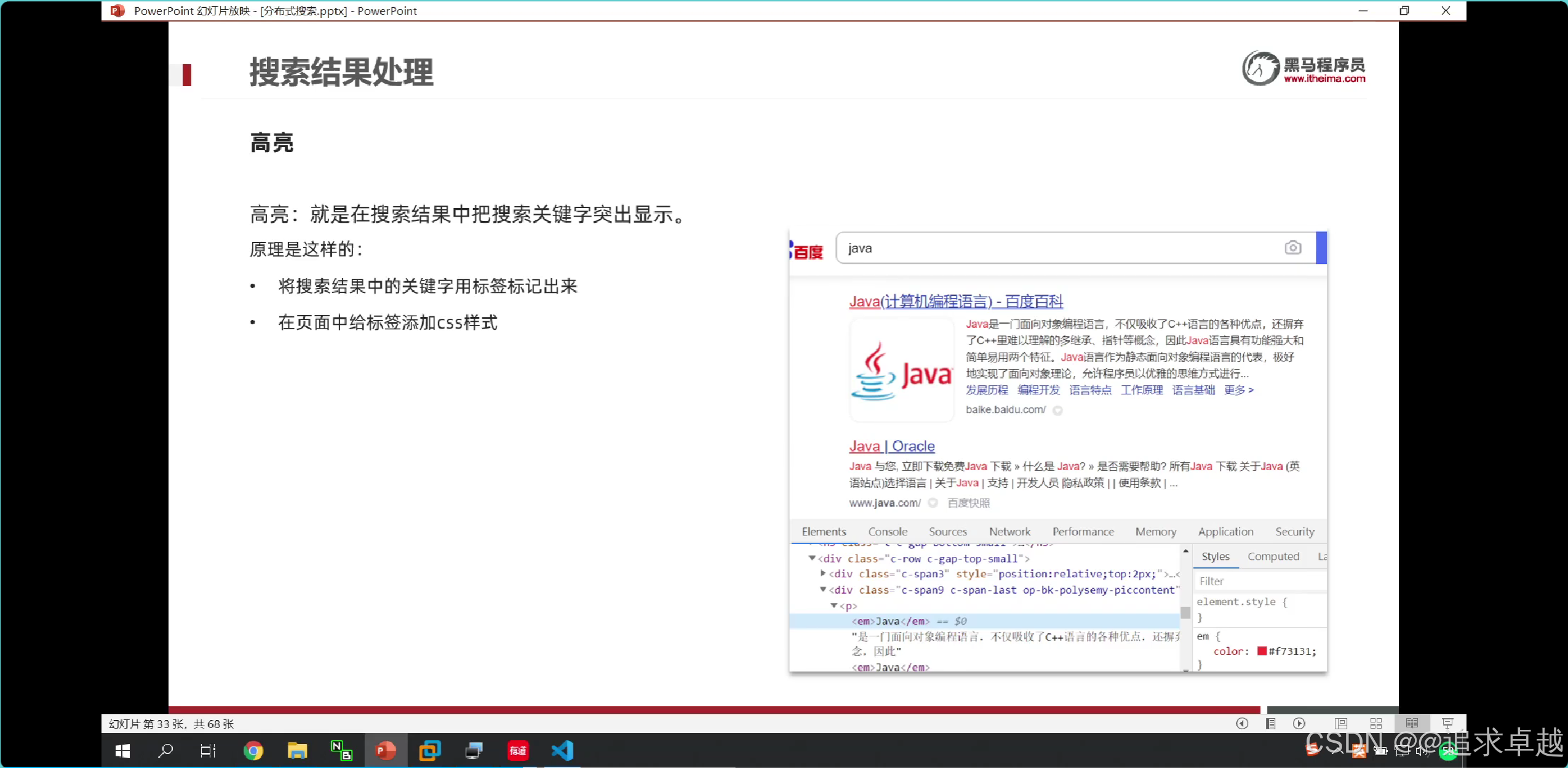
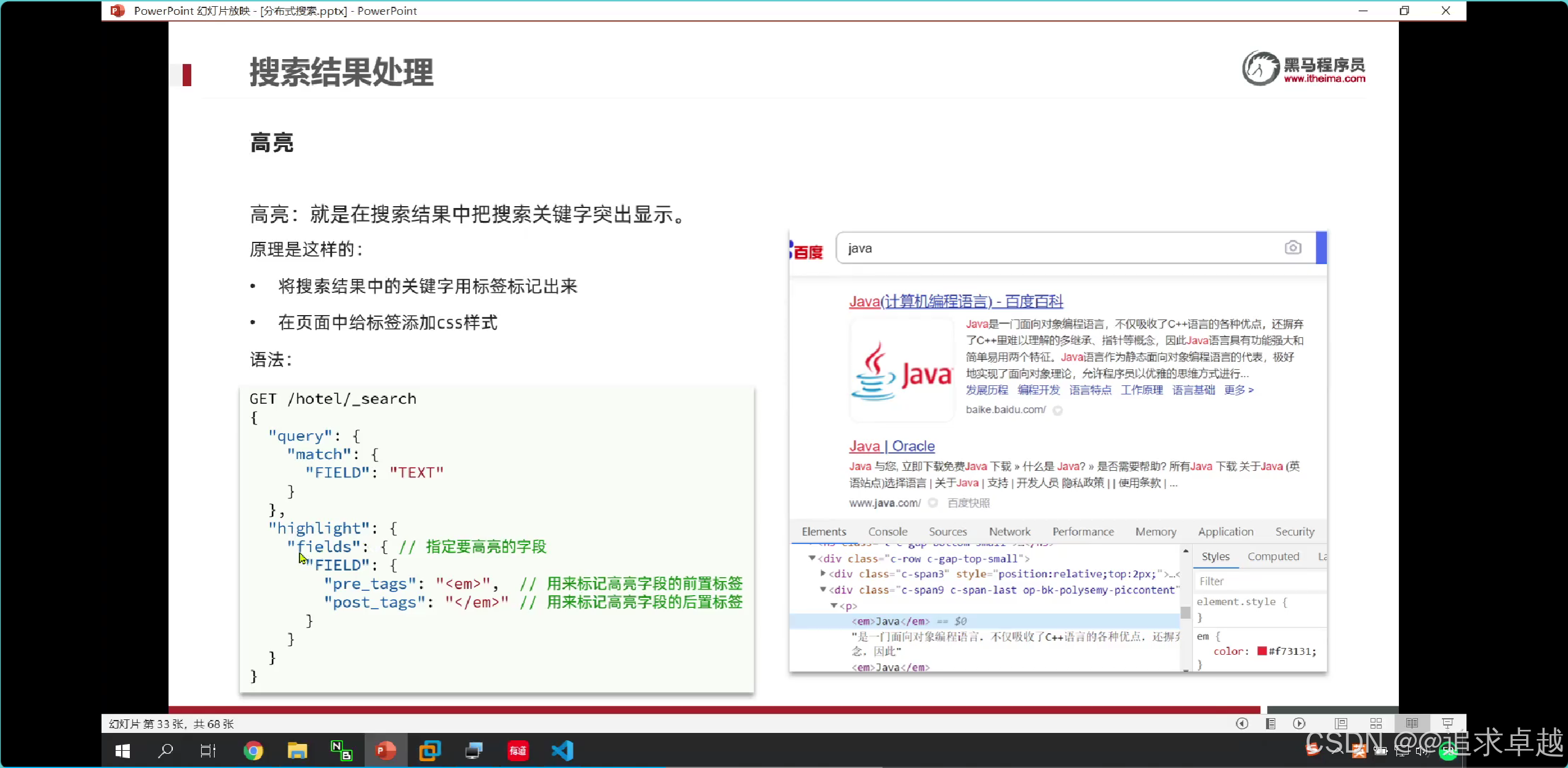
- 这种不是前端写的
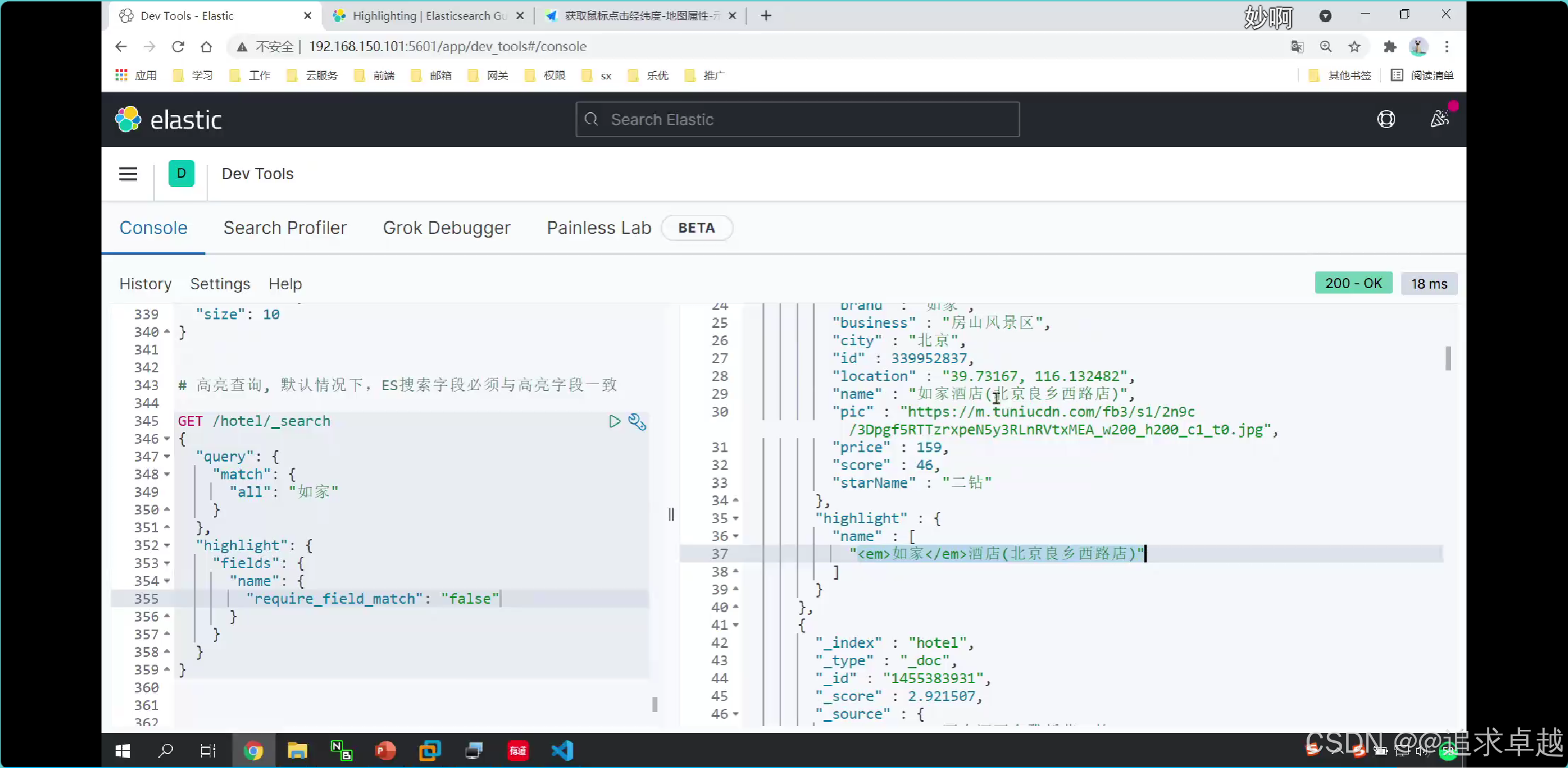

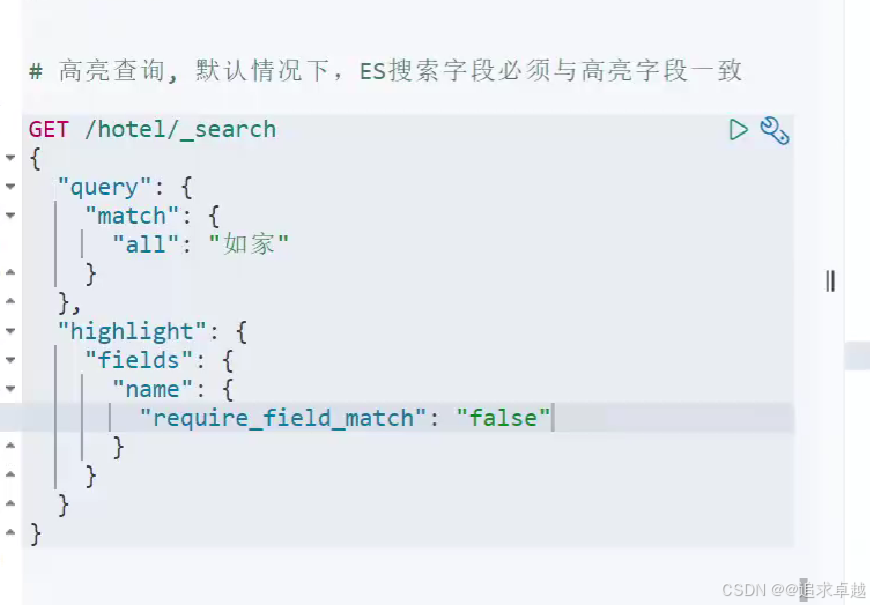
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {"require_field_match": "false"}}}
}
DSL查询作用
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.blobstore.DeleteResult;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;import static cn.itcast.hotel.constants.HotelIndexConstants.MAPPING_TEMPLATE;@SpringBootTest
class HotelIndexTest {private RestHighLevelClient client;@Testvoid testCreateIndex() throws IOException {// 1.准备Request PUT /hotelCreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求参数request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);}@Testvoid testExistsIndex() throws IOException {// 1.准备RequestGetIndexRequest request = new GetIndexRequest("hotel");// 3.发送请求boolean isExists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println(isExists ? "存在" : "不存在");}@Testvoid testDeleteIndex() throws IOException {// 1.准备RequestDeleteIndexRequest request = new DeleteIndexRequest("hotel");// 3.发送请求client.indices().delete(request, RequestOptions.DEFAULT);}@BeforeEachvoid setUp() {
// client = new RestHighLevelClient(RestClient.builder(
// HttpHost.create("http://192.168.150.101:9200")
// ));this.client= new RestHighLevelClient(RestClient.builder(HttpHost.create("http://127.0.0.1:9200")));}@AfterEachvoid tearDown() throws IOException {client.close();}@Testpublic void test1(){System.out.println(client);}@Testpublic void test2() throws IOException {CreateIndexRequest request=new CreateIndexRequest("hotel1");request.source(MAPPING_TEMPLATE,XContentType.JSON);client.indices().create(request,RequestOptions.DEFAULT);}@Testpublic void test3() throws IOException {DeleteIndexRequest request=new DeleteIndexRequest("hotel1");client.indices().delete(request,RequestOptions.DEFAULT);}@Testpublic void test4() throws IOException {GetIndexRequest hotel1 = new GetIndexRequest("hotel1");boolean exists = client.indices().exists(hotel1, RequestOptions.DEFAULT);System.out.println(exists);}@Autowiredprivate IHotelService hotelService;@Testpublic void test5() throws IOException {Hotel byId = hotelService.getById(38609);System.out.println(byId);HotelDoc hotelDoc = new HotelDoc(byId);// post /hotel/_doc/1IndexRequest hotel = new IndexRequest("hotel").id(hotelDoc.getId().toString());hotel.source(JSON.toJSONString(hotelDoc), XContentType.JSON);client.index(hotel, RequestOptions.DEFAULT);// IndexRequest indexRequest=new IndexRequest("hotel1").id("1");
// indexRequest.source("",RequestOptions.DEFAULT);
// client.index(indexRequest,RequestOptions.DEFAULT);}@Testpublic void test6() throws IOException {GetRequest hotel = new GetRequest("hotel", "38609");GetResponse documentFields = client.get(hotel, RequestOptions.DEFAULT);String sourceAsString = documentFields.getSourceAsString();System.out.println(sourceAsString);HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);System.out.println(hotelDoc);}
// post /hotel/_update/1
// 更新@Testpublic void test7() throws IOException {UpdateRequest hotel = new UpdateRequest("hotel", "38609");hotel.doc("price", 100,"city","上海浦东");client.update(hotel,RequestOptions.DEFAULT);}@Test //删除public void test8() throws IOException {DeleteRequest deleteRequest = new DeleteRequest("hotel","38609");client.delete(deleteRequest, RequestOptions.DEFAULT);}// 这是一个从数据库很多数据拿到拿到es中。@Testpublic void test9() throws IOException {BulkRequest bulkRequest = new BulkRequest();List<Hotel> hotelList = hotelService.list();for (Hotel hotel : hotelList) {HotelDoc hotelDoc = new HotelDoc(hotel);bulkRequest.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}client.bulk(bulkRequest, RequestOptions.DEFAULT);}
}
- 这是一个存储的。
多条件查询。
GET /your_index/_search
{"query": {"match": {"all": "搜索关键词" // 在 all 字段中匹配关键词}},"from": 0, // 分页起始位置(页码-1)*每页数量"size": 10, // 每页返回文档数"sort": [ // 排序规则(可多字段){ "price": "desc" }, // 按价格降序{ "_score": "desc" } // 按相关性评分降序(可选)]
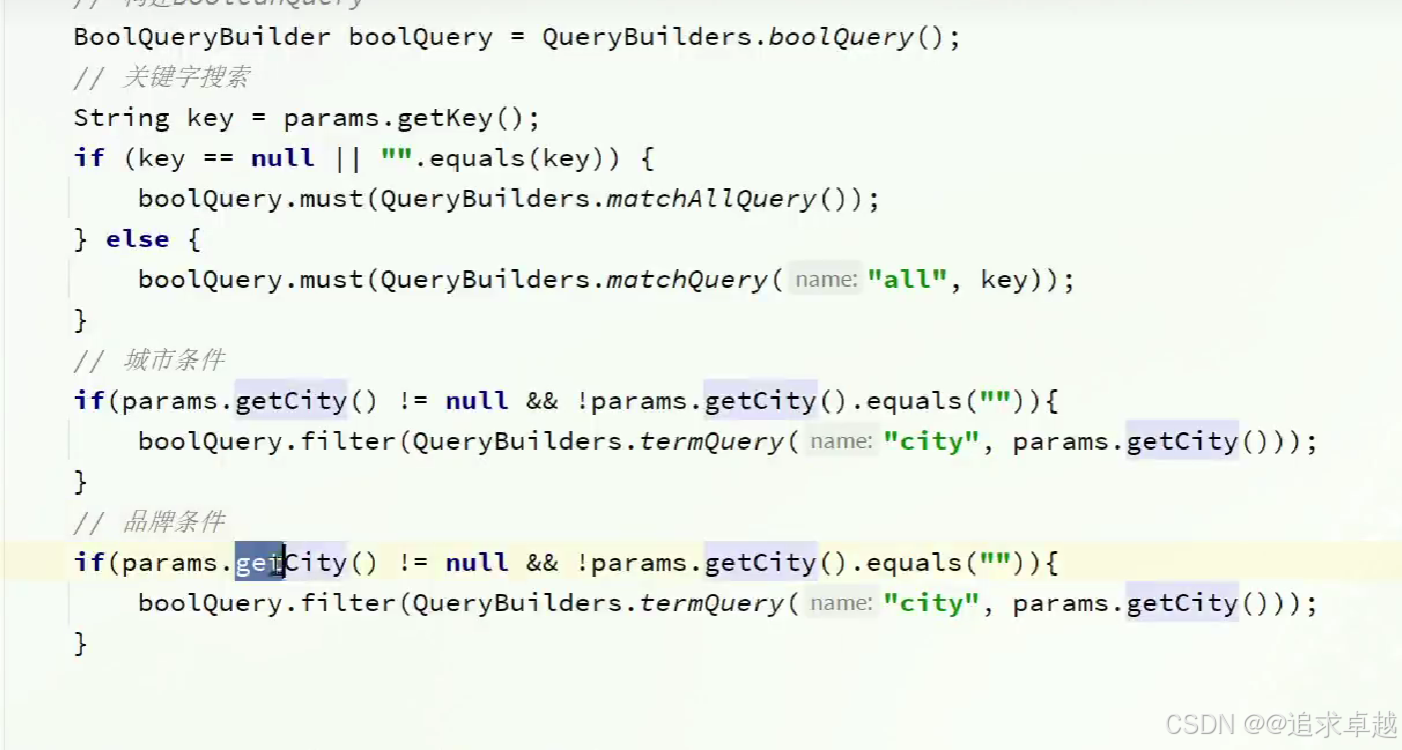
}@Overridepublic PageResult search(RequestParams params) throws IOException {SearchRequest hotel = new SearchRequest("hotel");
// 这个是分词查找,all是字段if(params.getKey() != null||params.getKey()!=""){hotel.source().query(QueryBuilders.matchQuery("all", params.getKey()));} else{hotel.source().query(QueryBuilders.matchAllQuery());}//分页int page = params.getPage();int size = params.getSize();hotel.source().from((page-1)*size).size(size);//高亮显示hotel.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));SearchResponse search = restClient.search(hotel, RequestOptions.DEFAULT);return handleResponse(search);}public PageResult handleResponse(SearchResponse response) {List<HotelDoc> arrayList = new ArrayList<>();SearchHits hits = response.getHits();
//获得个数。long value = hits.getTotalHits().value;SearchHit[] hits1 = hits.getHits();for (SearchHit hit : hits1) {String sourceAsString = hit.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);arrayList.add(hotelDoc);}return new PageResult(value,arrayList);}
- 搜索一个字段下面每个都一个字段还有分页操作。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name", "泳池")) // 条件1.should(QueryBuilders.boolQuery() // 嵌套条件2.must(QueryBuilders.matchQuery("address", "外滩")).must(QueryBuilders.rangeQuery("price").lte(600)));
- 只有一个的话不需要
- 多个条件的话就是BoolQueryBuilder。
多条件问题
- must是and ,should是or ,must_no是非。
- term是准确,match 是分词,range范围.
距离排序
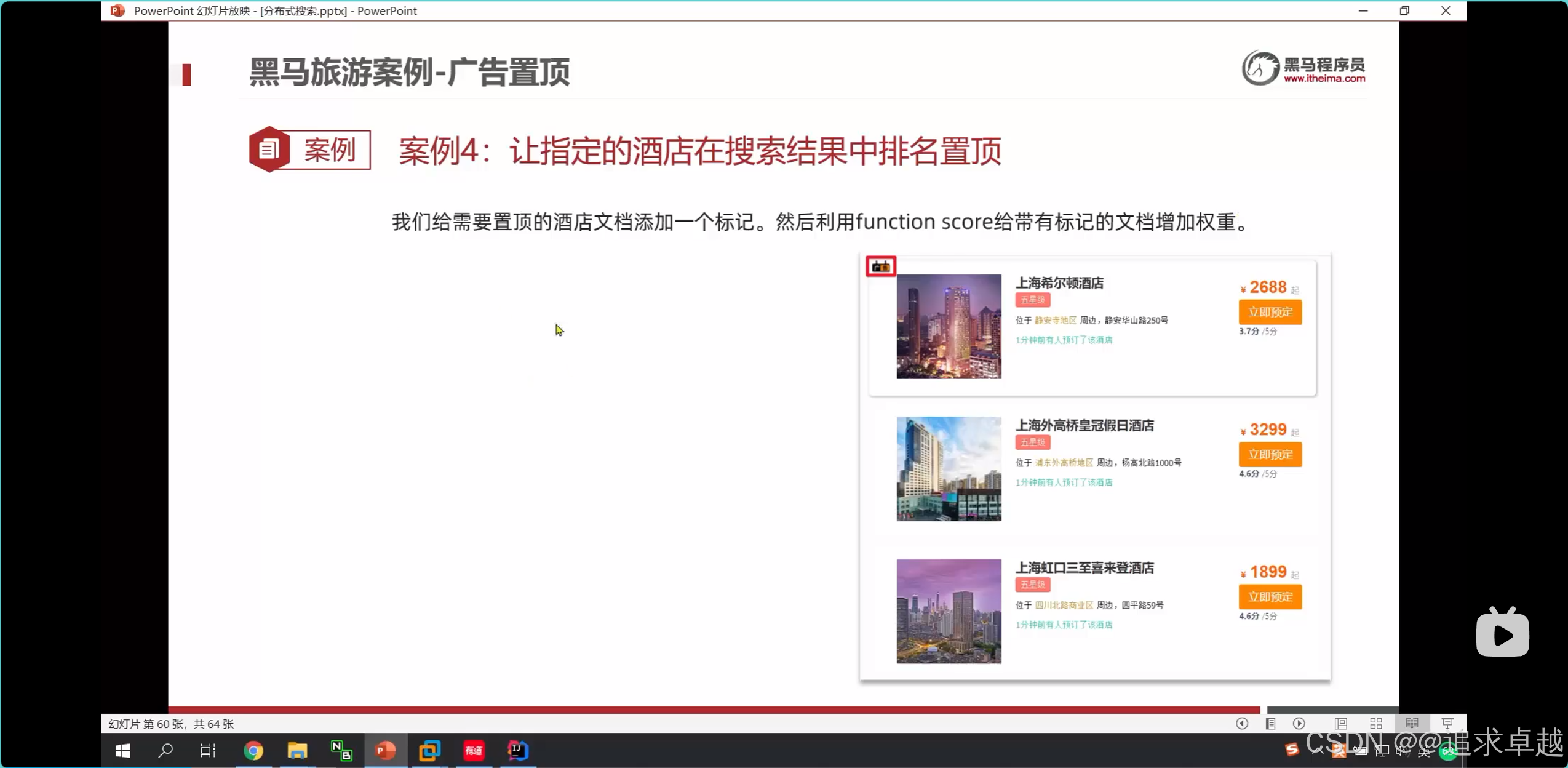
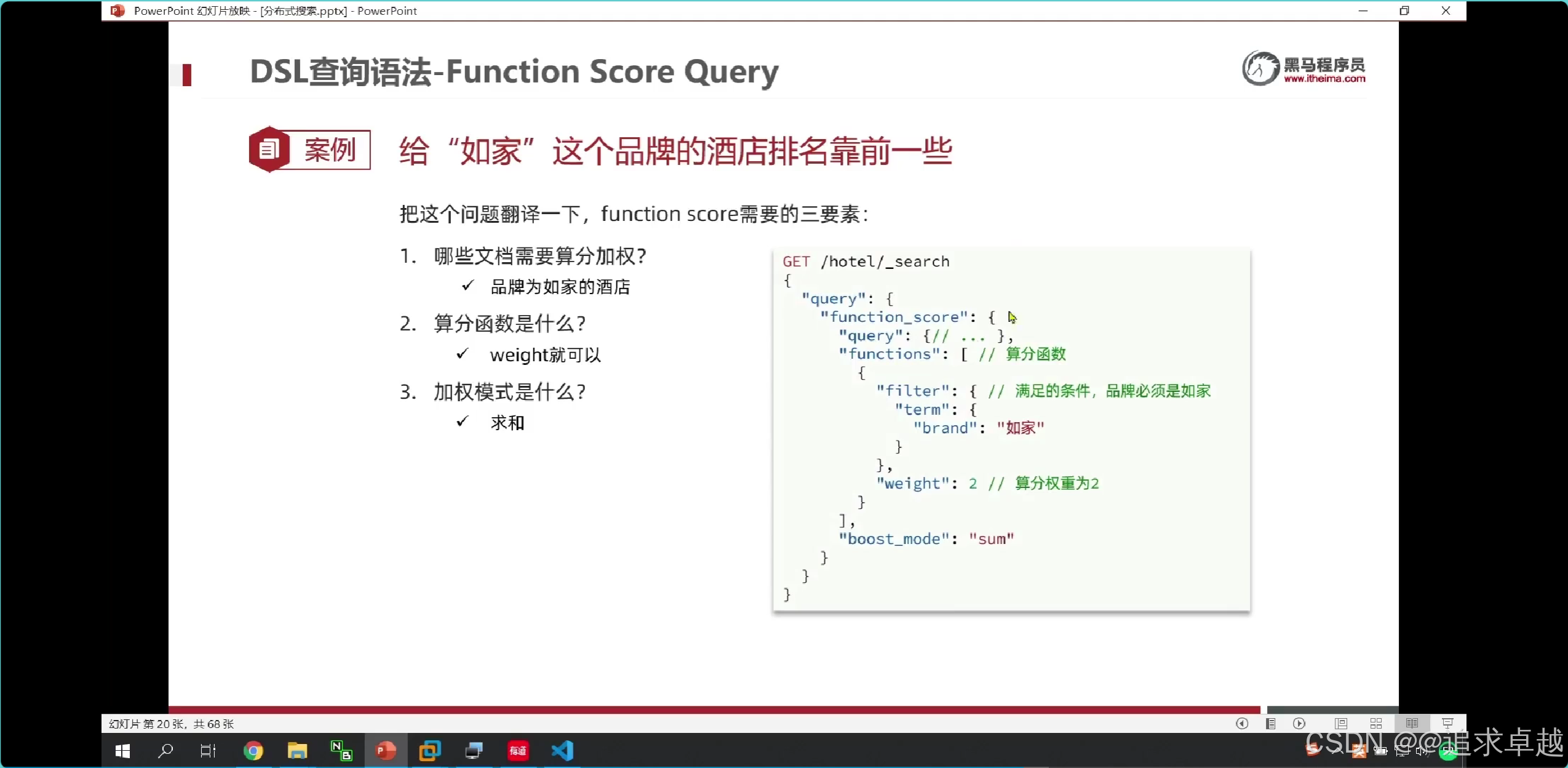
广告定制
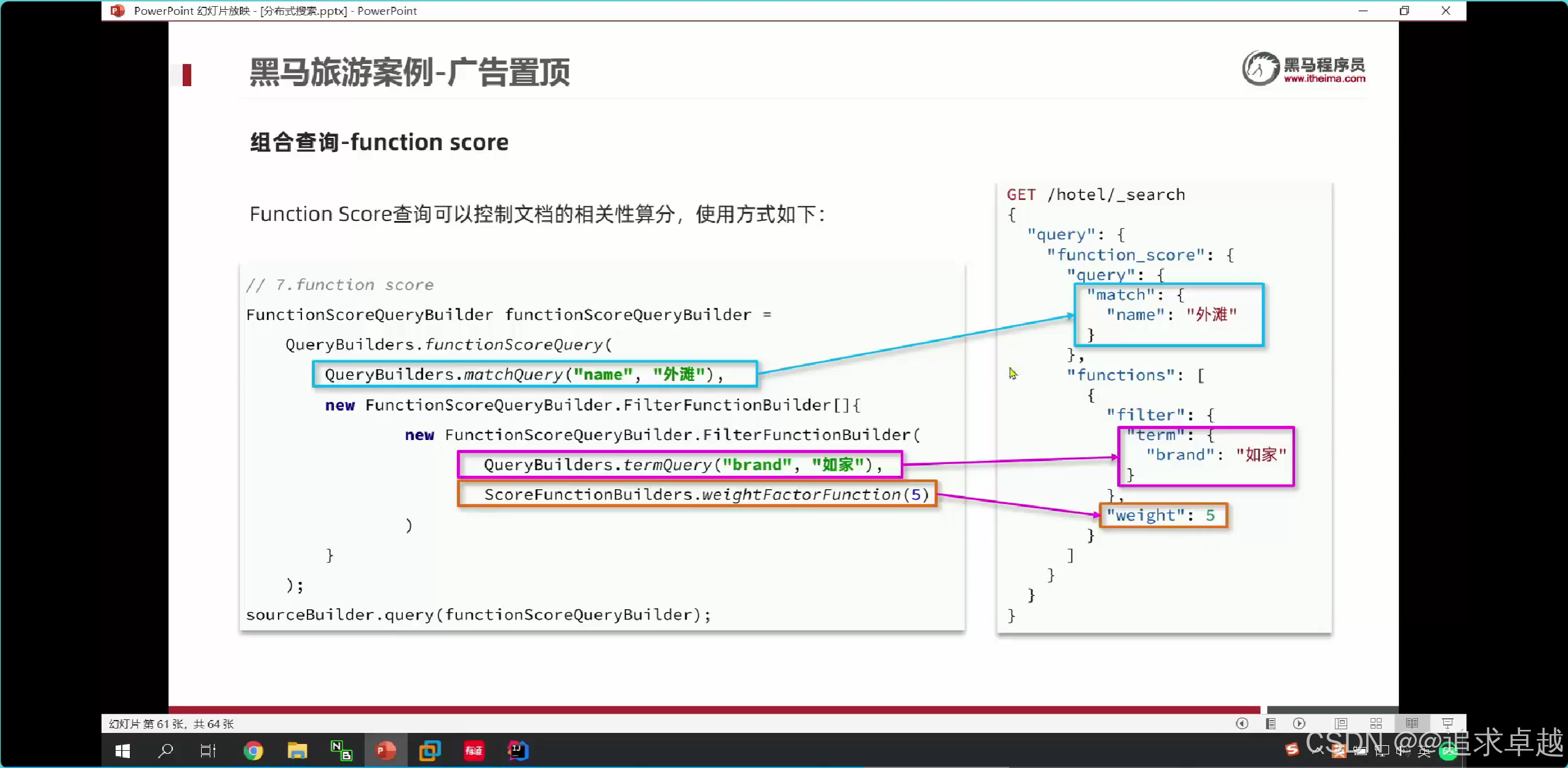
- functionScore是增加算分的。
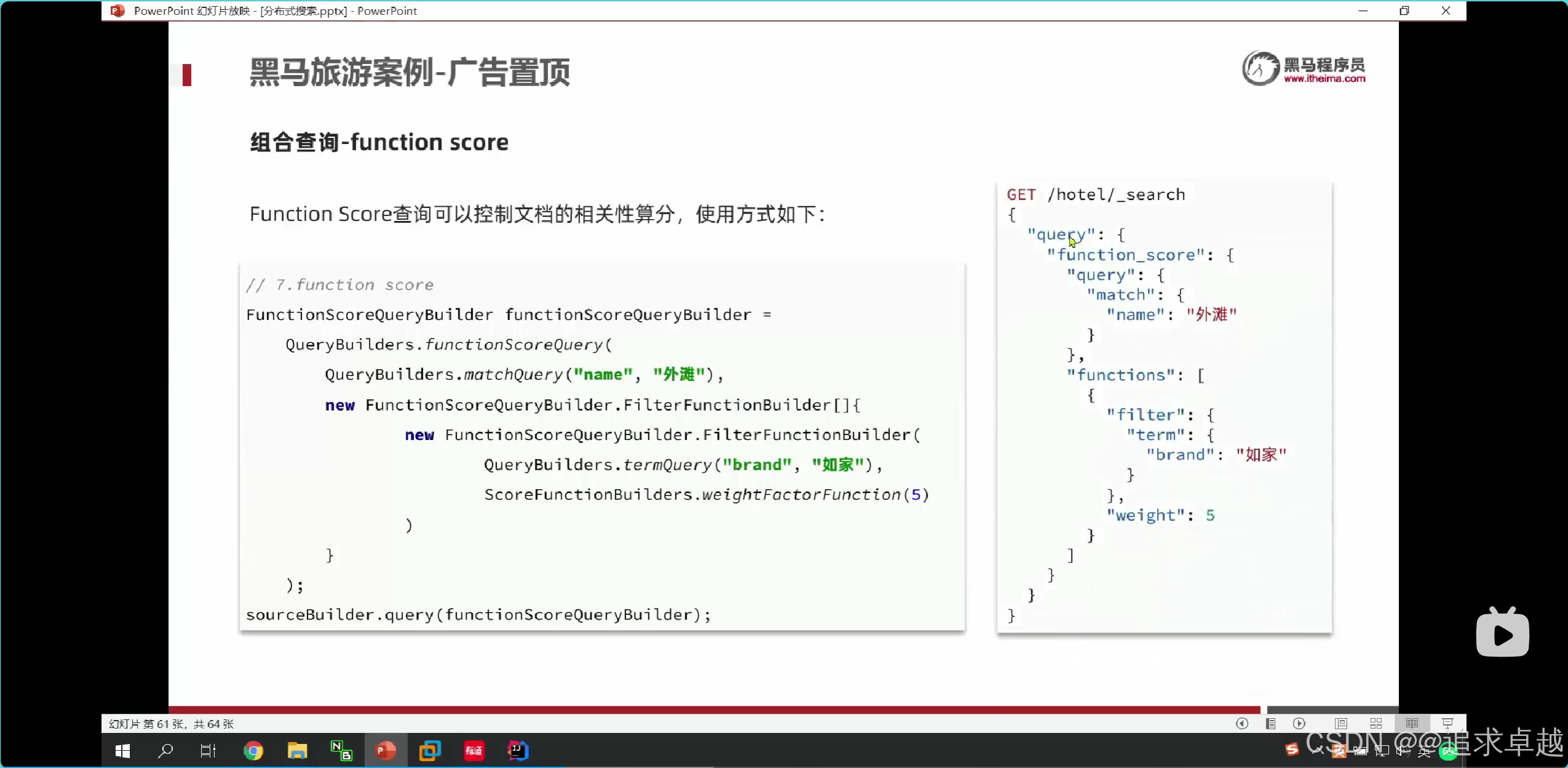
{"from": (page-1)*size,"size": size,"query": {"function_score": {"query": {"bool": {"must": [{"match": {"all": "用户输入的关键词"}}],"filter": [{"term": {"city": "城市参数"}},{"term": {"brand": "品牌参数"}},{"term": {"starName": "星级参数"}},{"range": {"price": {"gte": 最低价,"lte": 最高价}}}]}},"functions": [{"filter": {"term": {"isAD": true}},"weight": 10}]}},"sort": [{"_geo_distance": {"location": "纬度,经度","order": "asc","unit": "km"}}]
}拼音分词
GET /_analyze
{"text": ["如家酒店"], "analyzer": "ik_max_word"
}
GET /_analyze
{"text": ["如家酒店"], "analyzer": "pinyin"
}
- 使用pinyin的话是, 他只有一个字一个拼音。
# 自定义分词器。
PUT /test1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_full_pinyin": false,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name":{"type":"text","analyzer": "my_analyzer"}}}
}- 只会影响 name 字段.
分词器,会把分词字段分到倒排索引中;自定义分词器是分出拼音和汉字到倒排中。
GET /test1/_analyze
{"text": ["如家酒店"], "analyzer": "my_analyzer"
}# 自定义分词器。
PUT /test1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_full_pinyin": false,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name":{"type":"text","analyzer": "my_analyzer"}}}
}- 拼音分词器就是name把所有的词语有中文、英文变到倒排索引库中。
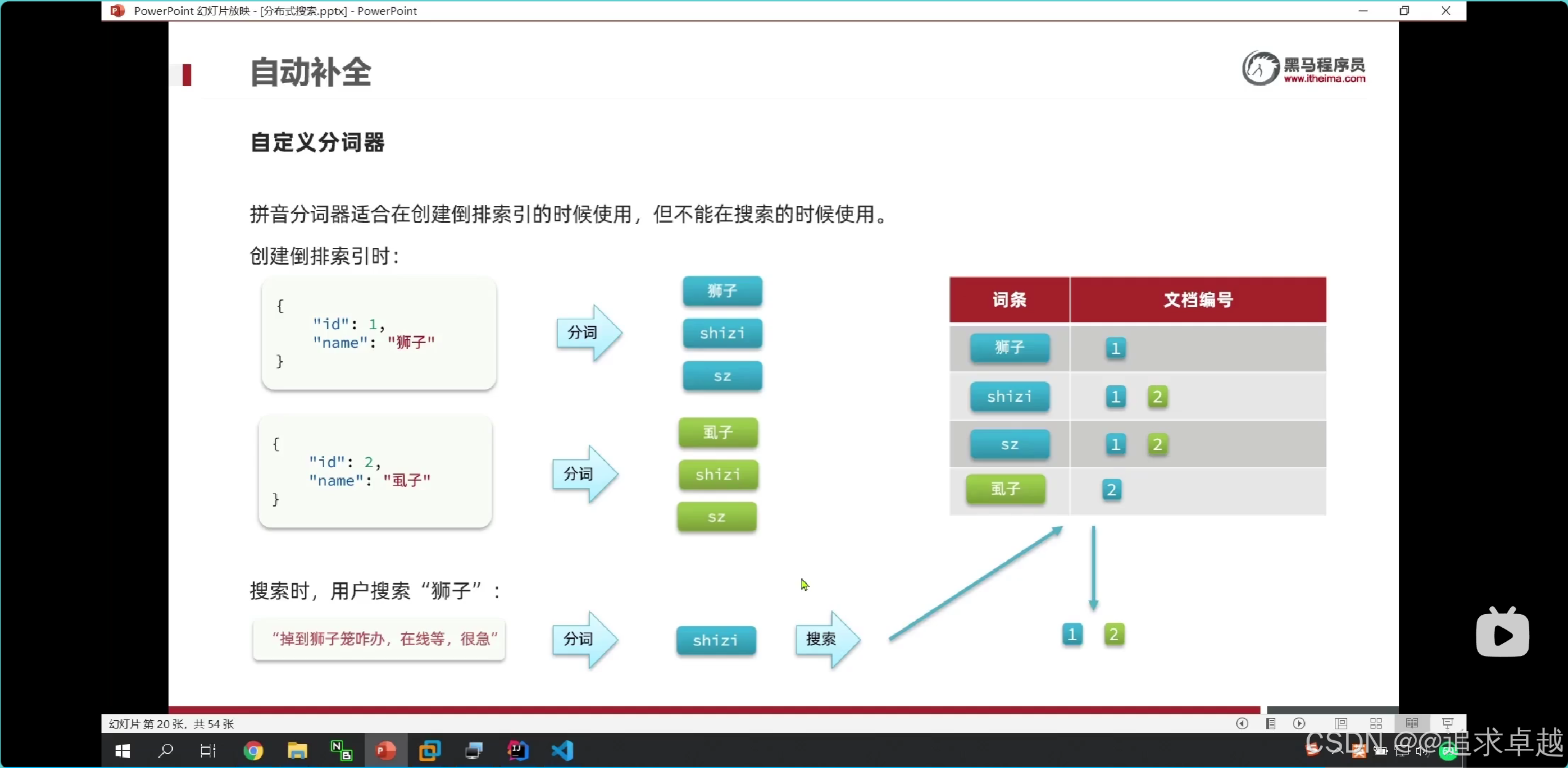
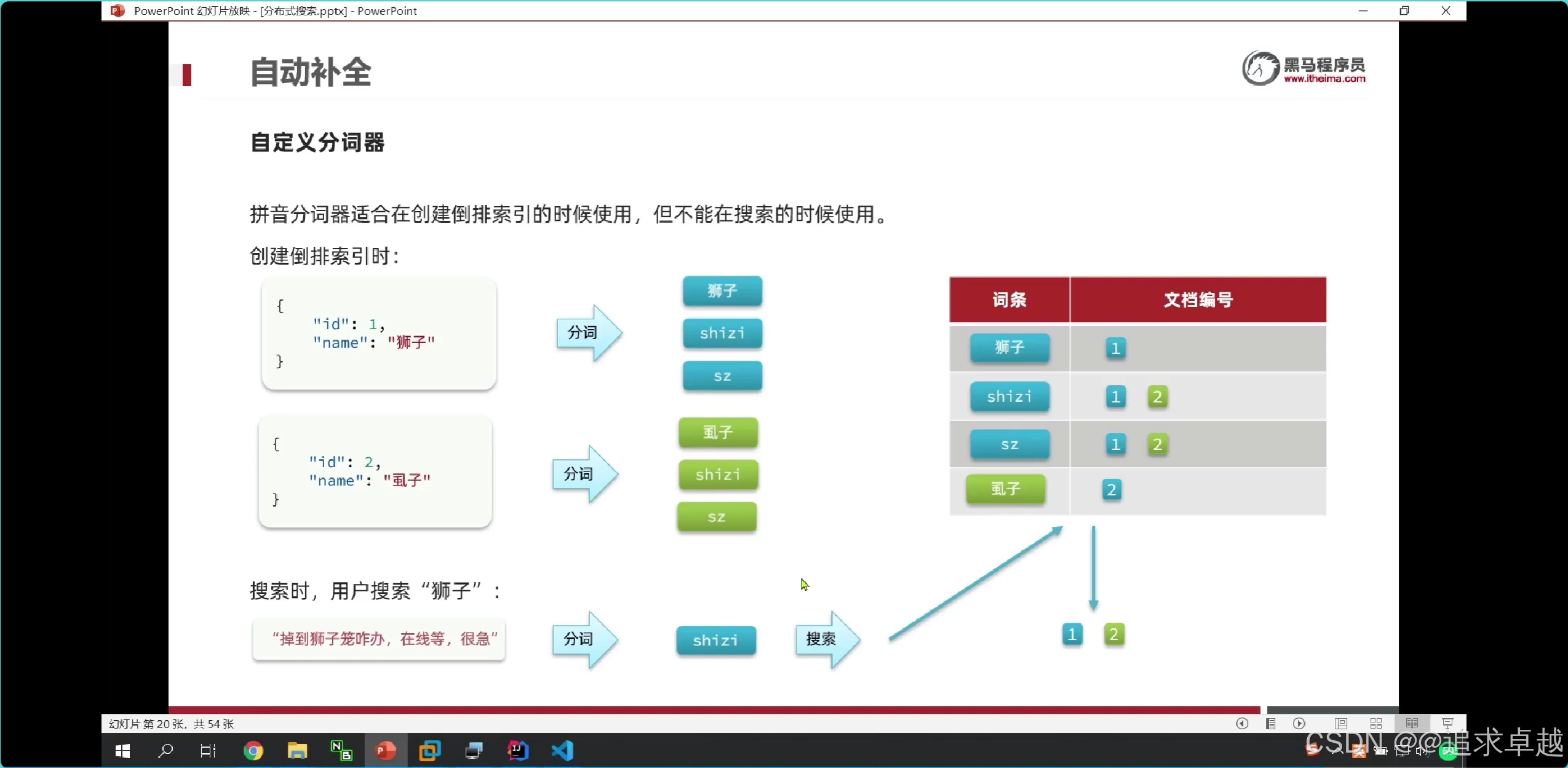
- 在shizi拼音的时候可以有1,2。查询狮子就只有一个1.
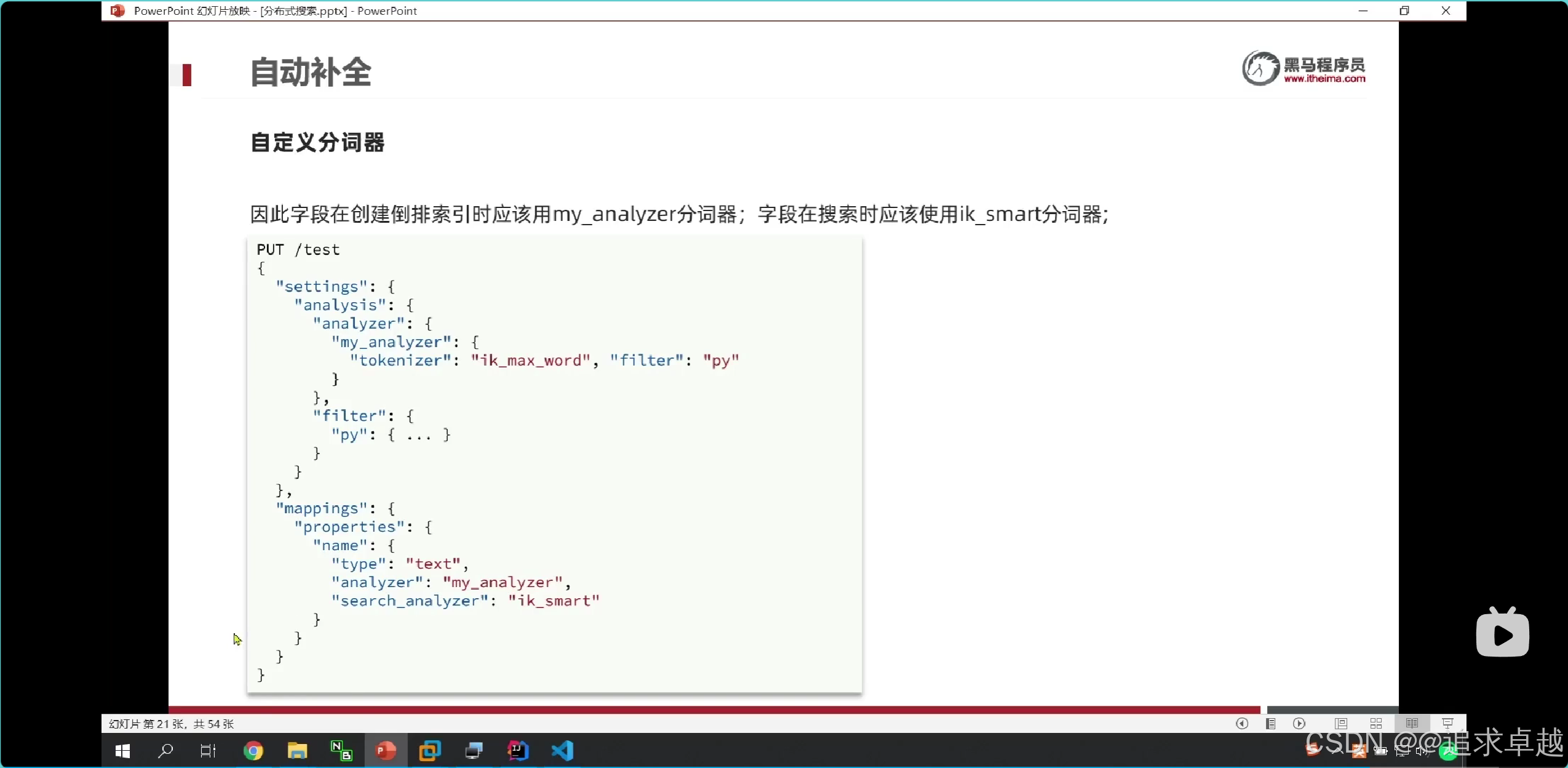
- 在存储的时候是拼音中文都存出倒排索引中。
- 在搜索的时候只能中文查询中文,拼音查询拼音的。只有使用ik分词器。
GET /test1
POST /test1/_doc
{"name":"狮子","id":1
}
POST /test1/_doc
{"name":"师资","id":2
}GET /test1/_search
{"query": {"match": {"name": "师资"}}
}

自动补全
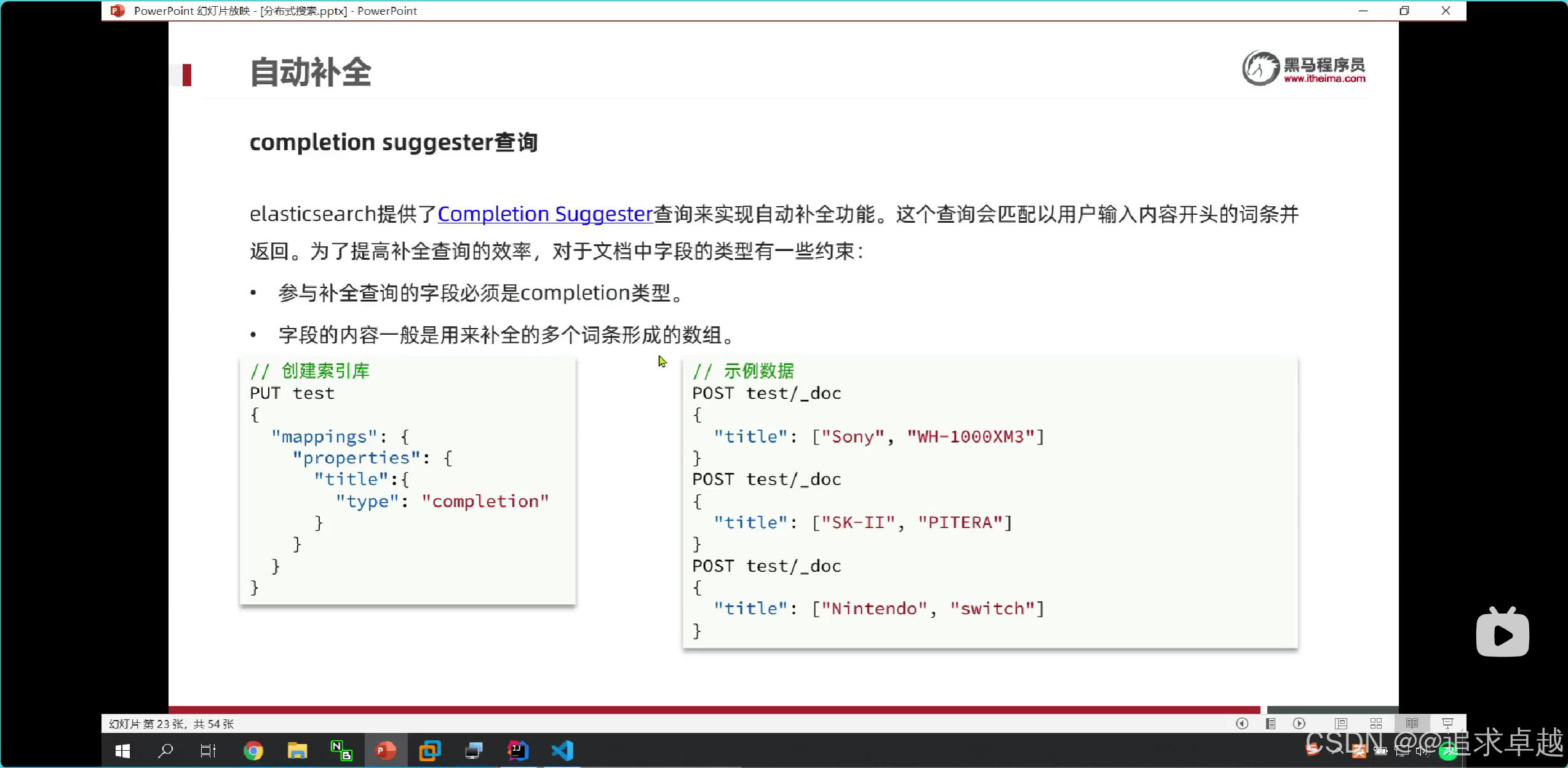
+
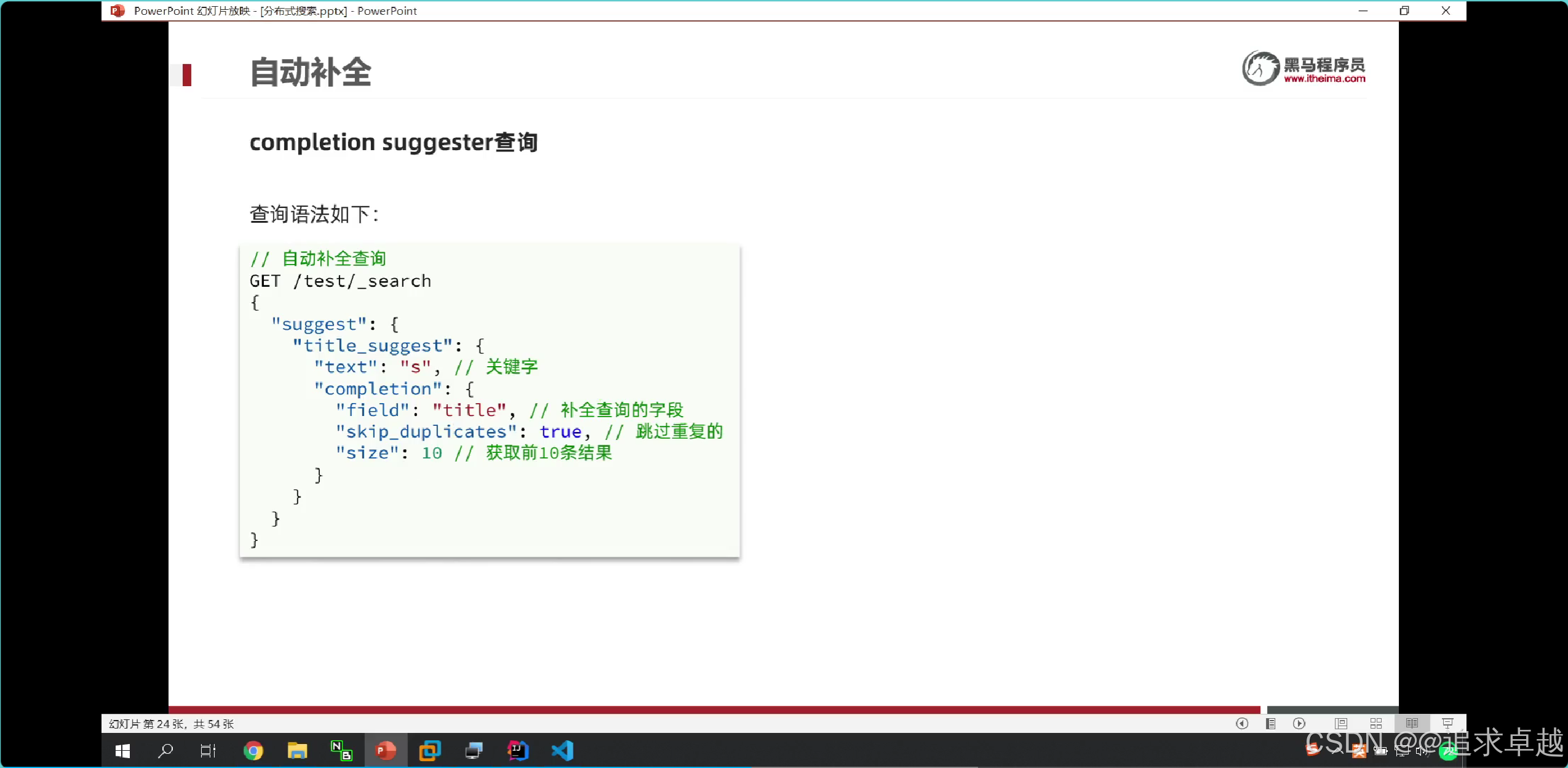
# 自定义分词器。
PUT /test1
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_joined_full_pinyin": true,"keep_full_pinyin": false,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name":{"type":"completion","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}DELETE /test1
GET /test1
POST /test1/_doc
{"name":"狮子","id":1
}
POST /test1/_doc
{"name":"师资","id":2
}GET /test1/_search
{"query": {"match": {"name": "师资"}}
}POST test1/_doc
{"name":["Sony","WH-1000XM3"]
}POST test1/_doc
{"name":["Sk-II","POYera"]
}
GET /test1/_search
{"suggest": {"name_suggest": {"text": "so","completion": {"field": "name","skip_duplicates":true,"size":10}}}
}
上面就是给title设置一个自定义分词器,让倒排索引有拼音和中文混合的。但是搜索就用ik分词;之后给这个字段设置类型,之后给他搜索词。
酒店数据补全
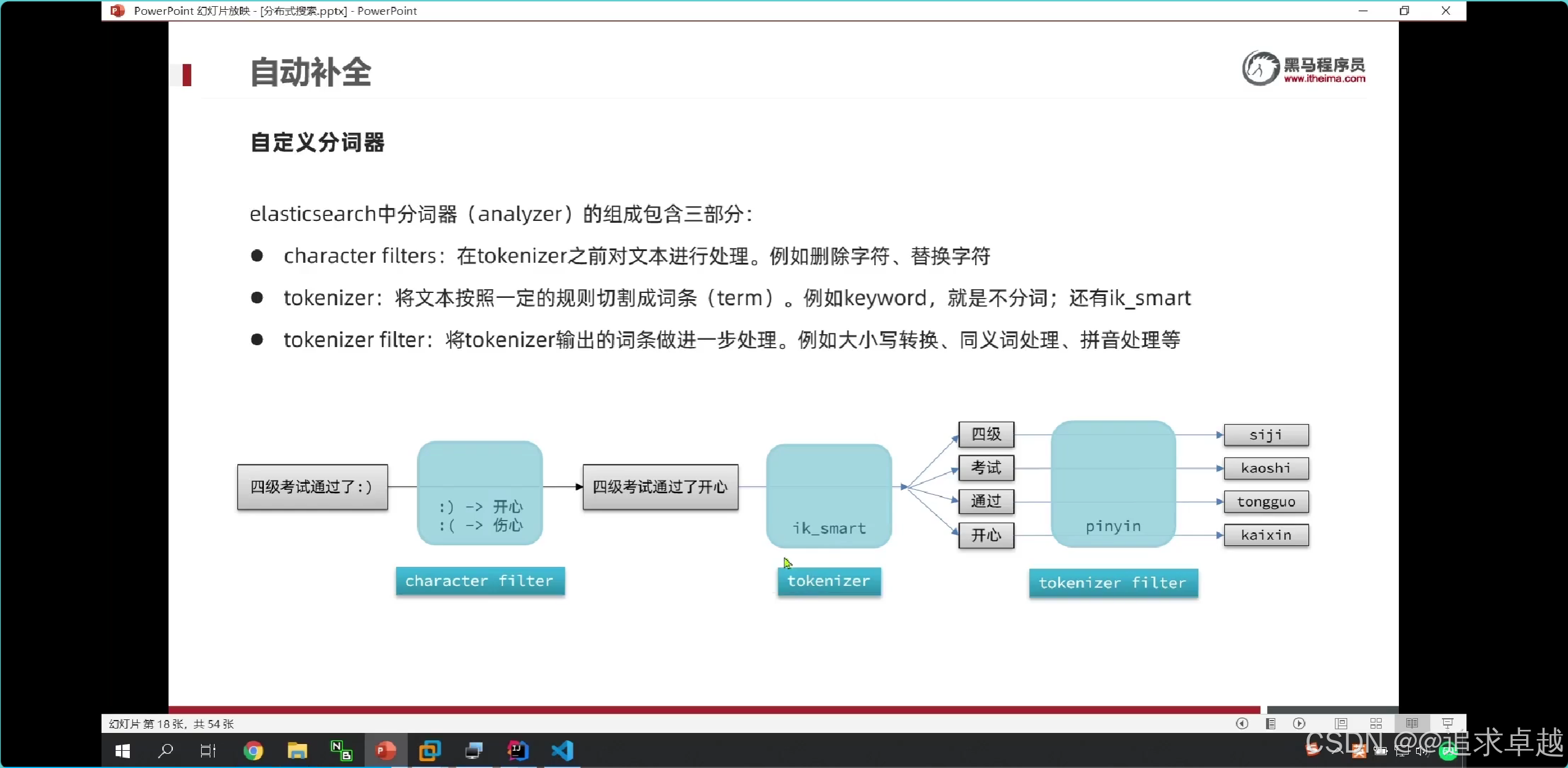
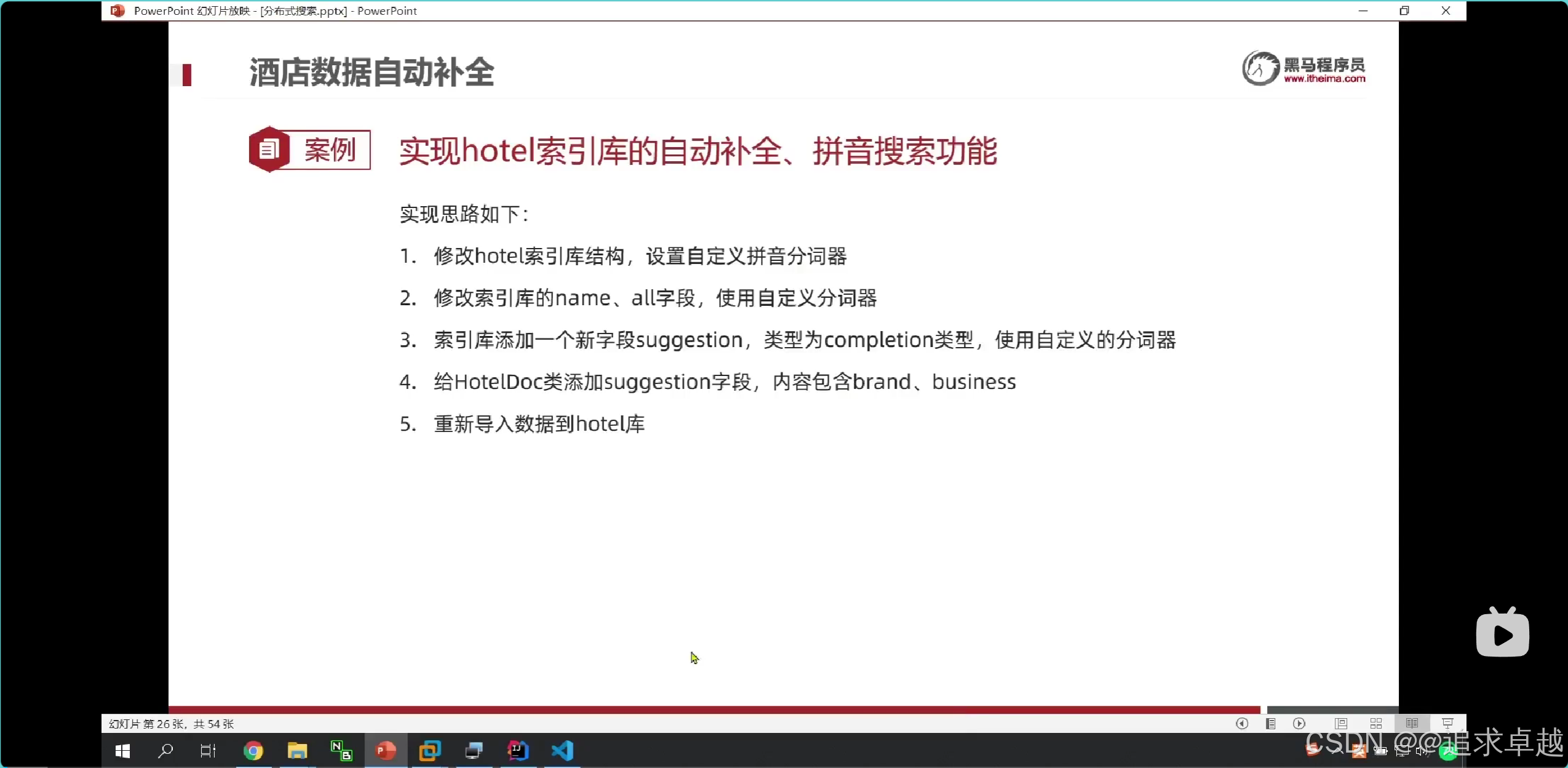 ## 自动补全字段的是分词器里面是使用keyword的。
## 自动补全字段的是分词器里面是使用keyword的。
相关文章:

ES搜索知识
GET /categories/1/10?name手机 // 按名称过滤 GET /categories/1/10?type电子产品 // 按类型过滤 GET /categories/1/10?name手机&type电子产品 // 组合过滤 查询参数 ApiOperation(value "获取商品分类分页列表")GetMapping("{page}/{limit}")…...
)
Java高阶程序员学习计划(详细到天,需有一定Java基础)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息文章目录 Java高阶程序员学习计划(详细到天,需有一定Java基础)第一阶段(30天)Java基础:Java生态工具链:设计模式与编码规范:第二阶段(15天…...

SALOME源码分析: SMESH模块
本文分析SALOME GEOM模块。 注1:限于研究水平,分析难免不当,欢迎批评指正。 注2:文章内容会不定期更新。 一、核心组件 1.1 SMESHGUI 二、关键流程 网络资料 SALOME: Introduction to MESH Modulehttps://docs.salome-platform…...

提高程序灵活性和效率的利器:Natasha动态编译库【.Net】
从零学习构建一个完整的系统 今天推荐一个针对C#动态编译库,动态编译的使用场景有很多: 1、动态代码生成:可以根据用户的输入或者系统配置动态执行C#代码,比如很多Web在线编译器,就是这个原理; 2、代码反…...

Cangjie Magic在医疗领域的应用:智能体技术如何重塑医疗数字化
文章目录 1. Cangjie Magic是什么?有什么优势?2. Cangjie Magic与Python的区别与优势对比技术特性对比医疗场景案例对比案例1:电子病历自然语言处理案例2:ICU实时监护系统 3. Cangjie Magic的学习成本与性价比学习门槛性价比优势 …...
)
MySQL基础关键_002_DQL(一)
目 录 一、初始化 二、简单查询 1.部分语法规则 2.查询一个字段 (1)查询员工编号 (2)查询员工姓名 3.查询多个字段 (1)查询员工编号、姓名 (2)查询部门编号、名称、位置 …...

从高端制造到民生场景:天元轻量化软件的“破局”之路
近期,清华大学航空发动机研究院(以下简称“清华航发院”)正式引入天元轻量化软件,用于其相关设计与3D可视化研究工作。 作为国内领先的3D轻量化解决方案提供商,天元轻量化软件一直致力于为各行业提供高效、灵活、安全…...

本地部署大模型的方式有哪些
本地部署大模型的方式主要分为 应用部署 和 源码部署 两大类,具体分类及特点如下: 一、应用部署(适合新手) 特点:无需编程基础,通过厂商提供的工具直接安装使用,支持图形化界面和命令行操作&am…...

libevent详解
目录 一、安装libevent库 二、libevent 三、基于 libevent 实现信号处理与定时任务 四、基于 libevent 的事件驱动 TCP 服务端代码 一、安装libevent库 sudo su apt install libevent-dev 二、libevent libevent 是一个轻量级网络i/o库,i/o框架库,…...

Solon Cloud Gateway 补充
说明 在「使用 Solon Cloud Gateway 替换Spring Cloud Gateway 」的文章中,有评论说不知道响应式。当时看的是 Solon Cloud Gateway 使用响应式接口,由 Solon-Rx 来实现,是基于 reactive-streams 封装的 RxJava 极简版。目前仅一个接口 Com…...

海外社交软件技术深潜:实时互动系统与边缘计算的极限优化
一、毫秒级延迟之战:下一代实时通信架构 1.1 全球实时消息投递体系设计 图表 代码 性能基准测试(跨大西洋传输): 协议/算法组合 平均延迟 99分位延迟 丢包恢复率 WebSocketTLSBBRv2 142ms 298ms 78% QUIC自定义CC 112ms 201ms 92%…...

直播美颜SDK是什么?跨平台美颜SDK开发与接入全解析
当下,越来越多的直播平台、短视频App、社交娱乐应用,开始在画面美化方面加大投入。本文将围绕直播美颜SDK是什么、其背后的核心技术、如何实现跨平台开发、以及接入流程等关键问题,为你全面解析这一技术热点。 一、直播美颜SDK到底是什么&am…...
————芯片锁死问题及成功解锁流程)
自学S32k144(18)————芯片锁死问题及成功解锁流程
1.锁死原因 温度过高flash异常操作静电等电压异常问题。。。。 本人出现情况:之前开发板不知什么原因,发生短路,重新置换芯片后,发现芯片在S32DS中无法正常烧录 判断可能是由于焊接时温度过高导致锁死。需解锁芯片。 2.解决方法…...
)
【免费数据】2000-2020年中国4km分辨率逐日气象栅格数据(含9个气象变量)
逐日气象数据是在很多研究中都会用到的数据,例如验证气候模拟、分析陆地生态系统变化以及识别气候变化下的极端天气条件等研究,尤其是高精度的逐日气象数据对于研究者来说更为常用。 本次我们为大家带来的是2000-2020年中国4km分辨率逐日气象栅格数据&a…...

Android Compose 无网络状态处理全指南:从基础到高级实践
Android Compose 无网络状态界面处理全方案 引言 在移动应用开发中,网络连接不稳定是常见场景。优雅地处理无网络状态能显著提升用户体验。Jetpack Compose 提供了强大的工具来实现各种网络状态下的界面展示。本文将全面介绍在 Compose 中处理无网络状态的多种方案…...

网络规划和设计
1.结构化综合布线系统包括建筑物综合布线系统PDS,智能大夏布线系统IBS和工业布线系统IDS 2.GB 50311-2016综合布线系统工程设计规范 GB/T 50312-2016综合布线系统工程验收规范 3.结构化布线系统分为6个子系统: 工作区子系统;水平布线子系…...

Learning vtkjs之ImageMarchingSquares
体积 等值线处理 介绍 vtkImageMarchingSquares - 对图像(或来自体积的切片)进行等值线处理 给定一个指定的等值,使用Marching Squares算法(3D Marching Cubes算法的2D版本)生成等值线。 效果 自己增加了两个小球&…...

前端跨域问题详解:原因、解决方案与最佳实践
引言 在现代Web开发中,跨域问题是前端工程师几乎每天都会遇到的挑战。随着前后端分离架构的普及和微服务的发展,跨域请求变得愈发常见。本文将深入探讨跨域问题的本质、各种解决方案以及在实际开发中的最佳实践。 一、什么是跨域问题? 1.1…...
参会通知)
第五届图像、视觉与智能系统国际会议(ICIVIS 2025)参会通知
大会官网: http://www.icivis.net/ 官方邮箱:icivis163.com 会议地点:杭州师范大学仓前校区(余杭塘路2318号) 会议时间:2025年5月23日-5月25日 主办单位:杭州师范大学 1.一般会员注册 提交注册表以后…...
基本布局要求)
PCB设计工艺规范(二)基本布局要求
基本布局要求 1.PCBA加工工序2.对器件以及PCB布局要求 资料来自网络,仅供学习使用。 1.PCBA加工工序 制成板的元件布局应保证制成板的加工工序合理,以便于提高制成板加工效率和直通率。 PCB 布局选用的加工流程应使加工效率最高。 常用 PCBA 的6种主流…...

SWIG 和 JNA / JNI 等 C 接口封装工具及进行 C 接口的封装
SWIG 相关 SWIG 是什么 SWIG 是一个软件开发工具,是一个 封装 C/C++ 动态库供其他编程语言调用的神器。 使用它可以简化不同语言与与 C/C++ 语言的交互。简单点说,SWIG 是一个编译器,它以 C/C++的声明为输入,创建从其他语言包括常见的脚本语言如 Javascript、Perl、PHP、…...

【Bootstrap V4系列】学习入门教程之 布局
Bootstrap V4 学习入门教程之 布局 一、容器1.1 All-in-one 一体化1.2 Fluid 流体1.3 Responsive 快速响应 二、栅格系统2.1 网格选项2.2 自动布局列等宽等宽多线 2.3、设置一列宽度2.4、可变宽度内容 一、容器 容器是Bootstrap中最基本的布局元素,在使用我们的默认…...

Nginx功能全解析:你的高性能Web服务器解决方案
Nginx是一款开源的高性能HTTP和反向代理服务器,同时也是IMAP/POP3/SMTP代理服务器。自2004年推出以来,Nginx因其卓越的性能、稳定性和丰富的功能而广泛应用于各种规模的网站。本文将深入解析Nginx的主要功能,帮助你充分利用这款强大的Web服务…...

OpenAI 2025 4月最新动态综述
2025年4月,OpenAI在人工智能领域持续引领创新浪潮,发布了多项重磅新产品和技术,推动AI进入更加实用和智能的新阶段。以下是近期OpenAI的重点动态整理: 1. GPT-5预览版发布,迈入通用AI工业化时代 2025年4月15日&#…...
)
综合案例建模(1)
文章目录 滚花手扭螺丝机箱封盖螺丝螺丝孔锥形垫片 滚花手扭螺丝 前视基准面画草图,旋转生成主体 倒角0.5 顶面,草图转换实体引用,去复制边线 生成螺旋线路径 顶面绘制草图 上一步画的草图沿螺旋线扫描切除 镜像扫描特征 阵列镜像扫描特征 创…...

ComfyUI 学习笔记,案例3:img2img
背景 ComfyUI 学习笔记,第三个案例 img2img,官网文档的 安装篇 部分找到桌面版,于是就下载了桌面版本,运行第三个案例。 注意要点: 桌面版安装时检测到本机设备不符合时,需要手动选择安装配置࿰…...

水利水电安全员A证考试核心知识点
水利水电安全员A证考试核心知识点 水利水电安全员A证考试主要考查安全生产管理、法律法规、专业技术及应急处理能力,以下是核心知识点: 1. 安全生产法律法规 《安全生产法》:明确企业主体责任、从业人员权利与义务、事故追责等。 《水利工…...

Verilog仿真模块--真随机数生成器
前言 在进行功能仿真时,总是希望仿真条件能覆盖尽量多的情况,因此,经常需要产生随机数作为仿真的输入。Verilog 和 SV 中有能够产生随机数的系统函数 $random,可惜的是此函数产生的随机数是伪随机数,重新再跑一次仿真&…...

融合AI助力医疗提效,华奥系医务系统助力医院数字化升级!
医疗资源供需优化一直是医院关注的重点问题。据此,华奥系科技推出华奥系智能医务管理系统,并基于DeepSeek-R1大模型,自主研发将AI智能诊疗助手融入系统。以“智能驱动效率、数据赋能管理”为核心,打造覆盖医院全场景的数字化解决方…...

UDP报文结构
文章目录 简介UDP报文结构解析UDP的特点使用 UDP 的注意事项 简介 用户数据报协议(User Datagram Protocol,UDP)是传输层的一种无连接协议,它与TCP相比,没有复杂的连接建立、维护和拆解过程,在传输效率上具…...

综合开发-手机APP远程控制PLC1500柱灯的亮灭
要通过 Unity3D 开发的手机 App 控制 电气柜上面的柱灯,需要WIFI模块作为桥梁,按照以下步骤实现: 1. 硬件准备(硬件部分) 所需材料 ESP32开发板(如ESP32-WROOM-32&a…...

4:机器人目标识别无序抓取程序二次开发
判断文件是否存在 //判断文件在不在 int HandEyeCalib::AnsysFileExists(QString FileAddr) {QFile File1(FileAddr);if(!File1.exists()){QMessageBox::warning(this,QString::fromLocal8Bit("提示"),FileAddrQString::fromLocal8Bit("文件不存在"));retu…...
)
数据结构篇:线性表的另一表达—链表之单链表(下篇)
目录 1.前言 2.是否使用二级指针 3.插入/删除 3.1 pos位置前/后插入 3.2 查找函数 3.3 pos位置删除 3.4 pos位置后面删除 3.5 函数的销毁 4.断言问题 4.1 断言pphead 4.2 断言*pphead 5.三个文件的代码 5.1 头文件 5.2 具体函数实现 5.3 测试用例 1.前言 之前是讲…...

C# 异步详解
C# 异步编程详解 一、异步编程基础概念 1. 同步 vs 异步 同步(Synchronous):任务按顺序执行,前一个任务完成后才会执行下一个异步(Asynchronous):任务可以非阻塞地启动,主线程可以继续执行其他操作 2. 异步编…...

X²+1素数问题
X1素数问题是与哥德巴赫猜想和孪生素数猜想同时代的著名数学难题。是否有无穷个正整数x,使得x1总是素数? 其困难程度不亚于哥德巴赫猜想。特别是100多年以来,许许多多一流数论学者对这个问题进行了研究。 X1素数 X1素数是一个著名的猜想&…...

【自定义控件实现最大高度和最大宽度实现】
背景 开发中偶尔遇到控件宽度或者高度在自适应的情况下,有个边界值,也就是最大值。 比如高度自适应的情况下最大高度300dp这种场景。 实现 关键节点代码: Overrideprotected void onMeasure(int widthMeasureSpec, int heightMeasureSpec)…...

基于C++的IOT网关和平台4:github项目ctGateway交互协议
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 源码指引:github源码指引_初级代码游戏的博客-CSDN博客 …...

DeepSeek谈《凤凰项目 一个IT运维的传奇故事》
《凤凰项目:一个IT运维的传奇故事》(The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win)是Gene Kim、Kevin Behr和George Spafford合著的一部小说,通过虚构的故事生动展现了IT运维中的核心挑战和Dev…...
)
Spyglass:官方Hands-on Training(一)
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 本文是对Spyglass Hands-on Training中第一个实验的翻译(有删改),Lab文件可以从以下链接获取。Spyglass Hands-on Traininghttps:…...

10.idea中创建springboot项目_jdk17
10.idea中创建springboot项目_jdk17 1. 准备工作 安装 JDK 17: 确保已安装 JDK 17,并配置环境变量 JAVA_HOME 指向 JDK 17 的安装路径。在 IntelliJ IDEA 中验证 JDK 配置:File → Project Structure → SDKs。 安装 IntelliJ IDEA&#x…...
和线程级并行(TLP)的区别,GCC -O3优化会展开循环吗?)
指令级并行(ILP)和线程级并行(TLP)的区别,GCC -O3优化会展开循环吗?
1. GCC 自动循环展开是怎么展开的? 当你使用 -O3 这样的优化选项时,GCC 会分析你的循环。如果它认为展开循环有利可图,它会做类似这样的事情(概念上的): 原始循环 (Conceptual C Code): for (int i 0; i …...

hadoop伪分布式模式
以下是 Hadoop 伪分布式模式(Pseudo-Distributed Mode)的环境搭建步骤。伪分布式模式下,Hadoop 的各个组件(如 HDFS、YARN、MapReduce)以独立进程运行,但所有服务均部署在单台机器上,模拟多节点…...

C++入门小馆: 模板
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...

# 基于 Python 和 jieba 的中文文本自动摘要工具
基于 Python 和 jieba 的中文文本自动摘要工具 在信息爆炸的时代,快速准确地提取文本核心内容变得至关重要。今天,我将介绍一个基于 Python 和 jieba 的中文文本自动摘要工具,帮助你高效地从长文本中提取关键信息。 一、背景与需求 在处理…...
)
.NET平台用C#在PDF中创建可交互的表单域(Form Field)
在日常办公系统开发中,涉及 PDF 处理相关的开发时,生成可填写的 PDF 表单是一种常见需求,例如员工信息登记表、用户注册表、问卷调查或协议确认页等。与静态 PDF 不同,带有**表单域(Form Field)**的文档支持…...

Azure AI Foundry实战:从零开始构建智能应用
1. 引言 在人工智能快速发展的今天,如何高效地开发和部署AI应用已成为众多开发者和企业关注的焦点。微软的Azure AI Foundry应运而生,为AI应用开发提供了一站式解决方案。本文将带您深入了解Azure AI Foundry,并通过实战指南,帮助您从零开始构建智能应用。 2. Azure AI Found…...

YOLO视觉模型可视化训练与推理测试工具
推荐一款YOLO可视化训练测试工具: 对于yolo的训练,新手小白往往无从下手,本章推荐的这款工具可以非常轻易的帮您从模型训练到测试到部署。 下载地址http://www.voouer.com/yolo 可以点击此处跳转。 下载成功后打开这款工具,将会出现图形化界面,类似于下图所示: 当前页是可视…...

数据清洗的定义跟实际操作
数据清洗的定义 数据清洗(Data Cleaning) 是指对原始数据进行处理,以纠正、删除或填补不完整、不准确、重复或无关的数据,使其符合分析或建模的要求。数据清洗是数据预处理的关键步骤,直接影响后续分析和机器学习模型…...

如何用AI生成个人职业照/西装照?
一、核心工具推荐与对比 1. 搜狐简单AI • 特点: • 一键生成:上传1张生活照,AI自动生成职业照/西装照,支持商务精英、韩系女主等20模板。 • 自然微调:优化五官比例、柔化法令纹,保留个人特色࿰…...

Ecology中拦截jquery.ajax请求接口后的数据
功能:获取调用接口之后的数据在进行返回参数重写 首先ecology中一般直接看不到源码的,为什么知道是jquery.ajax请求呢,需要用到开发者工具 点开这里之后就能知道调用接口具体走的是什么逻辑然后返回值又做了哪些操作 一般来说,文…...