开源项目实战学习之YOLO11:ultralytics-cfg-models-fastsam(九)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 1. __init__.py
- 2. model.py
- 3. predict.py
- 4. utils.py
- 5. val.py
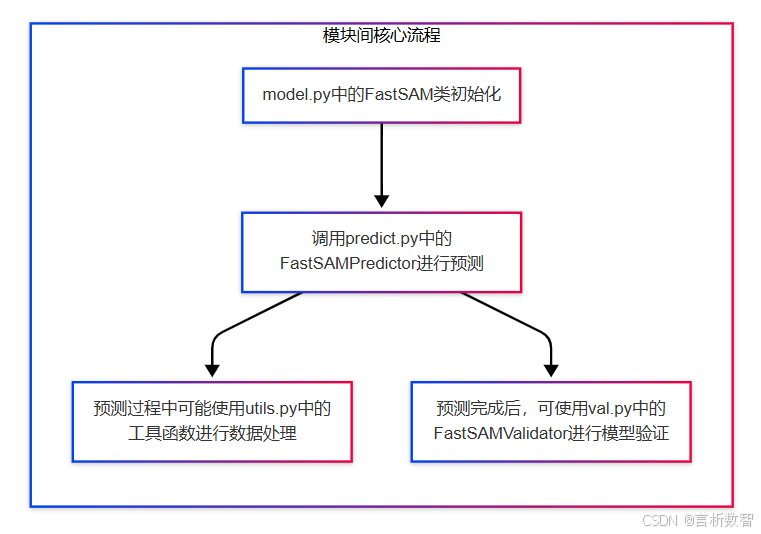
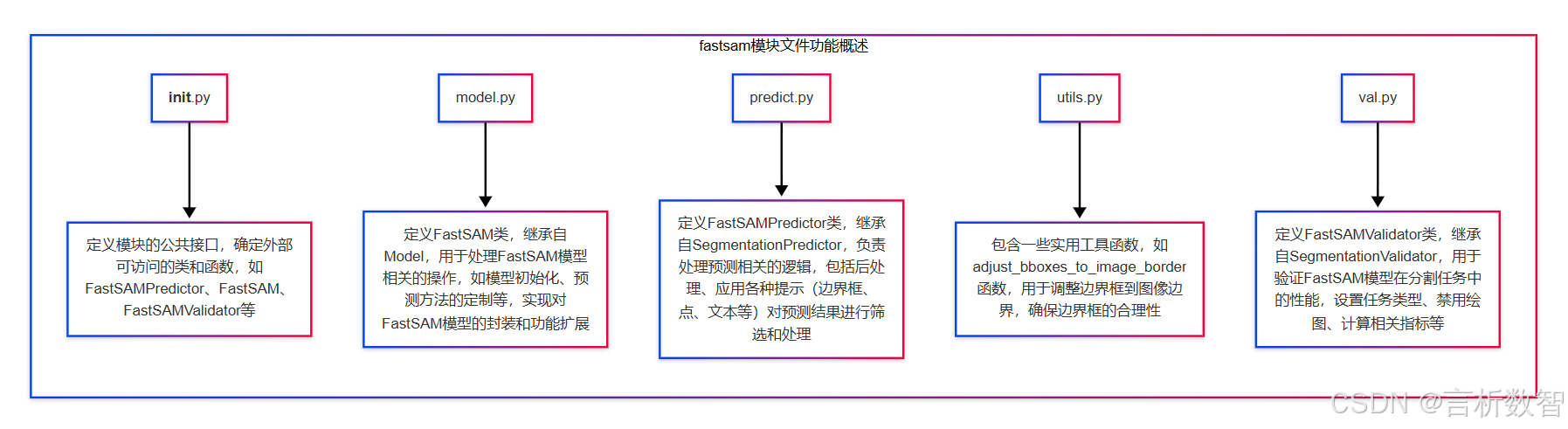
FastSAM 是一种目标检测和图像分割模型,Ultralytics 是一个在计算机视觉领域广泛使用的库,用于各种深度学习模型的训练、推理和评估等任务。- ultralytics-cfg-models-fastsam 这个路径下可能包含了 FastSAM 模型的配置文件,这些配置文件用于
定义模型的结构、超参数(如学习率、批次大小、训练轮数等)以及数据预处理和后处理的方式等。 - 同时,该路径也可能包含已经训练好的 FastSAM 模型权重文件,以便在进行推理或进一步微调时使用。
通过这些配置和模型文件,用户可以方便地使用 Ultralytics 库来加载 FastSAM 模型,进行图像分割任务,例如对输入的图像进行目标检测和分割,识别出图像中的不同物体并为其生成相应的分割掩码。- 此外,也可以基于这些配置和模型文件进行模型的训练和优化,以适应不同的数据集和应用场景。
1. init.py
-
from .model import FastSAM # 从当前目录的model模块中导入FastSAM类from .predict import FastSAMPredictor # 从当前目录的predict模块中导入FastSAMPredictor类from .val import FastSAMValidator # 从当前目录的val模块中导入FastSAMValidator类# 定义模块的公共接口,即可以通过from module import *导入的名称列表 __all__ = "FastSAMPredictor", "FastSAM", "FastSAMValidator"
2. model.py
- FastSAM 即 Fast Segment Anything Model
- 一种
高效的图像分割模型,依托于 Ultralytics 的开发生态,在多领域展现出独特价值- 模型架构与原理: 它可能基于 Transformer 架构,通过对图像特征的深度挖掘,实现对各类物体的精准分割。
在处理复杂场景图像时,能有效捕捉物体的边缘和细节信息,以较低的计算成本快速生成高质量的分割结果。
- 模型架构与原理: 它可能基于 Transformer 架构,通过对图像特征的深度挖掘,实现对各类物体的精准分割。
- 功能特点
- 快速处理: 相比传统的图像分割模型,
FastSAM 在保证分割精度的同时,大幅提升了处理速度。在实时性要求较高的场景,如自动驾驶的道路场景分割、直播内容的实时物体分割等,能快速处理图像或视频流,满足实时性需求。 - 多模态提示支持: 支持
多种提示方式进行分割,如边界框(bounding boxes)、点(points)、标签(labels)和文本(texts)。用户可根据具体需求,灵活选择提示信息,引导模型对特定目标进行分割。 - 通用性强: 可应用于多种图像分割任务,
包括但不限于实例分割、语义分割和全景分割。无论是自然场景图像、医学影像,还是工业检测图像,都能展现出良好的分割性能。
- 快速处理: 相比传统的图像分割模型,
- 应用场景
- 计算机视觉研究: 为研究人员提供了一个高效的图像分割工具,可用于探索新的分割算法、验证研究思路。在新型神经网络架构的研究中,利用 FastSAM 快速获取分割结果,评估架构的有效性。
- 自动驾驶: 用于
识别道路上的车辆、行人、交通标志等目标,为自动驾驶汽车的决策提供关键信息。通过实时分割道路场景图像,帮助车辆准确感知周围环境,实现安全行驶。 - 医学影像分析: 在医学领域,能辅助医生对医学影像(如 X 光、CT、MRI 等)进行分析。
帮助医生快速分割出病变组织、器官等感兴趣区域,提高诊断效率和准确性。 - 工业检测: 在工业生产中,对产品表面缺陷进行检测时,可
分割出缺陷区域,判断产品是否合格。对电子芯片、机械零部件等进行质量检测,及时发现生产过程中的问题。
-
from pathlib import Path # 导入 Path 类,用于处理文件路径from ultralytics.engine.model import Model # 从 ultralytics 引擎模块导入 Model 基类from .predict import FastSAMPredictor # 从当前包中导入 FastSAMPredictor 类,用于进行预测操作from .val import FastSAMValidator # 从当前包中导入 FastSAMValidator 类,用于进行验证操作class FastSAM(Model):"""FastSAM model interface for segment anything tasks.# FastSAM 模型接口,用于处理任意图像分割任务# 该类继承自 Model 基类,为 FastSAM(快速任意分割模型)实现提供特定功能,可实现高效且准确的图像分割Attributes:model (str): Path to the pre - trained FastSAM model file.# 预训练的 FastSAM 模型文件的路径task (str): The task type, set to "segment" for FastSAM models.# 任务类型,对于 FastSAM 模型,设置为 "segment"(分割)Examples:>>> from ultralytics import FastSAM>>> model = FastSAM("last.pt")>>> results = model.predict("ultralytics/assets/bus.jpg")# 使用示例,展示如何导入 FastSAM 类、初始化模型并进行预测"""def __init__(self, model="FastSAM-x.pt"):"""Initialize the FastSAM model with the specified pre - trained weights.# 使用指定的预训练权重初始化 FastSAM 模型Args:model (str): Path to the pre - trained FastSAM model file. Defaults to "FastSAM-x.pt".# 预训练的 FastSAM 模型文件的路径,默认为 "FastSAM-x.pt""""if str(model) == "FastSAM.pt":model = "FastSAM-x.pt"# 如果传入的模型名称是 "FastSAM.pt",则将其替换为 "FastSAM-x.pt"assert Path(model).suffix not in {".yaml", ".yml"}, "FastSAM models only support pre - trained models."# 断言传入的模型文件后缀不是 .yaml 或 .yml,因为 FastSAM 模型仅支持预训练模型super().__init__(model=model, task="segment")# 调用父类 Model 的构造函数,传入模型路径和任务类型def predict(self, source, stream=False, bboxes=None, points=None, labels=None, texts=None, **kwargs):"""# 对图像或视频源进行分割预测# 支持使用边界框、点、标签和文本进行提示分割。该方法将这些提示信息打包并传递给父类的 predict 方法Args:source (str | PIL.Image | numpy.ndarray): Input source for prediction, can be a file path, URL, PIL image,or numpy array.# 预测的输入源,可以是文件路径、URL、PIL 图像或 numpy 数组stream (bool): Whether to enable real - time streaming mode for video inputs.# 是否为视频输入启用实时流模式# 用于提示分割的边界框坐标,格式为 [[x1, y1, x2, y2], ...]# 用于提示分割的点坐标,格式为 [[x, y], ...]# 用于提示分割的类别标签# 用于分割引导的文本提示# 传递给预测器的其他关键字参数Returns:# 包含预测结果的 Results 对象列表"""prompts = dict(bboxes=bboxes, points=points, labels=labels, texts=texts)# 将边界框、点、标签和文本提示信息打包成字典return super().predict(source, stream, prompts=prompts, **kwargs)# 调用父类的 predict 方法,传入输入源、流模式、提示信息和其他关键字参数,并返回预测结果@propertydef task_map(self):"""# 返回一个字典,将分割任务映射到相应的预测器和验证器类"""return {"segment": {"predictor": FastSAMPredictor, "validator": FastSAMValidator}}# 返回一个字典,键为 "segment",值为包含预测器和验证器类的字典
- 一种
3. predict.py
- 关键词: 图像分割预测、边界框的交并比、缩放掩码
- CLIP模型
CLIP(Contrastive Language-Image Pretraining)模型是 OpenAI 开发的一种开创性的神经网络,通过互联网上大量多样的(图像,文本)对进行训练,具备强大的跨模态理解能力,能够将自然语言与图像信息紧密联系起来。- 模型架构
- 图像编码器: 可选用
Vision Transformer(ViT)或 ResNet 等架构。以 ViT 为例,它将图像划分为多个小块,然后像处理文本序列一样处理这些图像块,通过多头注意力机制捕捉图像的全局特征。 - 文本编码器: 基于文本 Transformer,把文本转换为连续的向量表示,在这个过程中理解文本语义和结构信息。
- 共享嵌入空间: 两个编码器将图像和文本投影到同一个向量空间,在这个空间中,语义相似的图像和文本对其向量距离更近,为后续的匹配任务奠定基础。
- 图像编码器: 可选用
- 零样本学习能力:
CLIP 最显著的优势是零样本学习。在 ImageNet 分类任务中,它无需使用 ImageNet 训练集中 128 万张标记示例进行训练,就能达到与原始 ResNet50 模型相匹配的性能。使用时,只要提供文本描述(如 “一只猫”“一辆汽车”),CLIP 模型就能对图像进行分类,判断图像内容是否与文本匹配。
ViT-B/32ViT-B/32 是 CLIP 模型中使用的一种视觉 Transformer(Vision Transformer,ViT)架构的具体变体。- 模型结构:
“ViT”:代表视觉 Transformer,是一种将 Transformer 架构应用于计算机视觉任务的模型。它将图像分割成一系列的图像块(patches),并将这些图像块作为输入序列,类似于自然语言处理中 Transformer 对文本序列的处理方式。通过这种方式,ViT 可以有效地学习图像中的全局信息和长期依赖关系。“B”:通常表示基础(Base)版本,指的是模型的规模和复杂度处于中等水平。例如,在参数数量、层数、隐藏层维度等方面,基础版本具有一定的设定,是一种相对较为平衡的模型配置,既能够在性能和计算资源之间取得较好的权衡,又能在多种视觉任务上取得不错的效果。“32”:表示图像块的大小为 32×32 像素。这意味着在将图像输入到 ViT 模型之前,会先将图像分割成边长为 32 像素的正方形小块。较小的图像块大小可以捕捉到更精细的图像细节,但也会增加模型的计算量和参数量;而较大的图像块大小则可以减少计算量,但可能会丢失一些细节信息。
import torch# 导入PyTorch库,用于深度学习相关的张量计算和模型操作from PIL import Image# 导入PIL库的Image模块,用于处理图像from ultralytics.models.yolo.segment import SegmentationPredictor# 从ultralytics的yolo模型的segment模块中导入SegmentationPredictor类,可能是用于图像分割预测的基类from ultralytics.utils import DEFAULT_CFG, checks# 从ultralytics的utils模块中导入DEFAULT_CFG(可能是默认配置)和checks(可能用于检查某些条件或配置)from ultralytics.utils.metrics import box_iou# 从ultralytics的utils模块的metrics子模块中导入box_iou函数,可能用于计算边界框的交并比from ultralytics.utils.ops import scale_masks# 从ultralytics的utils模块的ops子模块中导入scale_masks函数,可能用于缩放掩码from .utils import adjust_bboxes_to_image_border# 从当前目录的utils模块中导入adjust_bboxes_to_image_border函数,可能用于调整边界框以适应图像边界class FastSAMPredictor(SegmentationPredictor):# FastSAMPredictor类,继承自SegmentationPredictor,用于图像分割预测,并支持多种提示方式。def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):""" 初始化函数。Args:cfg (dict, optional): 配置字典,默认为DEFAULT_CFG。overrides (dict, optional): 用于覆盖默认配置的字典。_callbacks (list, optional): 回调函数列表。"""super().__init__(cfg, overrides, _callbacks)# 初始化一个空字典,用于存储各种提示信息(边界框、点、标签、文本等)self.prompts = {}def postprocess(self, preds, img, orig_imgs):""" 对模型预测结果进行后处理。Args:preds (torch.Tensor): 模型的预测结果。img (torch.Tensor): 输入的图像张量。orig_imgs (list): 原始图像列表。Returns:list: 经过后处理和提示应用后的结果列表。"""# 从prompts字典中弹出【边界框】提示信息,如果不存在则返回Nonebboxes = self.prompts.pop("bboxes", None)# 从prompts字典中弹出【点】提示信息,如果不存在则返回Nonepoints = self.prompts.pop("points", None)# 从prompts字典中弹出【标签】提示信息,如果不存在则返回Nonelabels = self.prompts.pop("labels", None)# 从prompts字典中弹出【文本】提示信息,如果不存在则返回Nonetexts = self.prompts.pop("texts", None)# 调用父类的postprocess方法进行基本的后处理results = super().postprocess(preds, img, orig_imgs)for result in results:# 创建一个表示整个图像边界的张量,格式为 [x1, y1, x2, y2]full_box = torch.tensor([0, 0, result.orig_shape[1], result.orig_shape[0]], device=preds[0].device, dtype=torch.float32)# 调整预测的边界框,使其适应原始图像的边界boxes = adjust_bboxes_to_image_border(result.boxes.xyxy, result.orig_shape)# 计算【全图像边界框与调整后的边界框】之间的交并比,找到【交并比大于0.9的索引】idx = torch.nonzero(box_iou(full_box[None], boxes) > 0.9).flatten()if idx.numel() != 0:# 如果存在【交并比大于0.9的边界框,则将其设置为全图像边界】result.boxes.xyxy[idx] = full_box# 调用prompt方法,应用各种提示信息到结果中return self.prompt(results, bboxes=bboxes, points=points, labels=labels, texts=texts)def prompt(self, results, bboxes=None, points=None, labels=None, texts=None):"""根据提供的提示信息(边界框、点、标签、文本)对分割结果进行筛选和处理。Args:results (list or object): 分割结果,可以是【单个结果或结果列表】。bboxes (list, optional): 边界框提示信息,格式为 [[x1, y1, x2, y2], ...]。points (list, optional): 点提示信息,格式为 [[x, y], ...]。labels (list, optional): 标签提示信息,与点提示信息对应。texts (list, optional): 文本提示信息。Returns:list: 经过提示筛选后的结果列表。"""if bboxes is None and points is None and texts is None:# 如果没有提供任何提示信息,则直接返回原始结果return resultsprompt_results = []if not isinstance(results, list):# 如果结果不是列表,则将其转换为列表results = [results]for result in results:if len(result) == 0:# 如果结果为空,则直接添加到提示结果列表中prompt_results.append(result)continuemasks = result.masks.dataif masks.shape[1:] != result.orig_shape:# 如果【掩码的形状与原始图像形状不一致】,则缩放掩码masks = scale_masks(masks[None], result.orig_shape)[0]# 初始化一个布尔张量,用于标记符合条件的分割结果idx = torch.zeros(len(result), dtype=torch.bool, device=self.device)if bboxes is not None:# 将边界框提示信息转换为张量bboxes = torch.as_tensor(bboxes, dtype=torch.int32, device=self.device)if bboxes.ndim == 1:# 如果边界框是一维的,则将其转换为二维bboxes = bboxes[None]# 计算每个边界框的面积bbox_areas = (bboxes[:, 3] - bboxes[:, 1]) * (bboxes[:, 2] - bboxes[:, 0])# 计算每个掩码与边界框重叠部分的面积mask_areas = torch.stack([masks[:, b[1] : b[3], b[0] : b[2]].sum(dim=(1, 2)) for b in bboxes])# 计算每个掩码的总面积full_mask_areas = torch.sum(masks, dim=(1, 2))# 计算边界框与掩码的并集面积union = bbox_areas[:, None] + full_mask_areas - mask_areas# 找到重叠面积与并集面积比值最大的索引,并将其对应的idx位置设为Trueidx[torch.argmax(mask_areas / union, dim=1)] = Trueif points is not None:# 将点提示信息转换为张量points = torch.as_tensor(points, dtype=torch.int32, device=self.device)if points.ndim == 1:# 如果点是一维的,则将其转换为二维points = points[None]if labels is None:# 如果没有提供标签,则创建全为1的标签张量labels = torch.ones(points.shape[0])# 将标签转换为张量labels = torch.as_tensor(labels, dtype=torch.int32, device=self.device)assert len(labels) == len(points), (f"Expected `labels` to have the same size as `point`, but got {len(labels)} and {len(points)}")# 根据标签的总和初始化point_idx,如果【标签总和为0(即全为负点)】,则设为全True,否则设为全Falsepoint_idx = (torch.ones(len(result), dtype=torch.bool, device=self.device)if labels.sum() == 0else torch.zeros(len(result), dtype=torch.bool, device=self.device))for point, label in zip(points, labels):# 根据点的位置和标签,更新point_idxpoint_idx[torch.nonzero(masks[:, point[1], point[0]], as_tuple=True)[0]] = bool(label)# 将point_idx与idx进行逻辑或操作idx |= point_idxif texts is not None:if isinstance(texts, str):# 如果文本提示是字符串,则将其转换为列表 ???texts = [texts]crop_ims, filter_idx = [], []for i, b in enumerate(result.boxes.xyxy.tolist()):x1, y1, x2, y2 = (int(x) for x in b)if masks[i].sum() <= 100:# 如果掩码的总和小于等于100,则将其索引添加到filter_idx中并跳过filter_idx.append(i)continue# 从原始图像中裁剪出边界框对应的区域,并转换为PIL图像crop_ims.append(Image.fromarray(result.orig_img[y1:y2, x1:x2, ::-1]))# 使用CLIP模型计算裁剪图像与文本提示之间的相似度similarity = self._clip_inference(crop_ims, texts)# 找到相似度最大的索引text_idx = torch.argmax(similarity, dim=-1)if len(filter_idx):# 如果存在过滤索引,则调整text_idxtext_idx += (torch.tensor(filter_idx, device=self.device)[None] <= int(text_idx)).sum(0)# 将text_idx对应的idx位置设为Trueidx[text_idx] = True# 将符合条件的结果添加到提示结果列表中prompt_results.append(result[idx])return prompt_resultsdef _clip_inference(self, images, texts):""" 使用CLIP模型进行推理,计算图像与文本之间的相似度。Args:images (list): PIL图像列表。texts (list): 文本提示列表。Returns: torch.Tensor: 图像与文本之间的相似度矩阵,形状为 (M, N),M为文本数量,N为图像数量。"""try:import clipexcept ImportError:# 如果CLIP库未安装,则检查并安装checks.check_requirements("git+https://github.com/ultralytics/CLIP.git")import clipif (not hasattr(self, "clip_model")) or (not hasattr(self, "clip_preprocess")):# 如果当前对象没有CLIP模型和预处理函数,则加载CLIP模型和预处理函数self.clip_model, self.clip_preprocess = clip.load("ViT-B/32", device=self.device)# 对图像进行预处理,并将其转换为张量images = torch.stack([self.clip_preprocess(image).to(self.device) for image in images])# 对文本进行分词,并将其转换为张量tokenized_text = clip.tokenize(texts).to(self.device)# 使用CLIP模型对图像进行编码,得到图像特征image_features = self.clip_model.encode_image(images)# 使用CLIP模型对文本进行编码,得到文本特征text_features = self.clip_model.encode_text(tokenized_text)# 对图像特征进行归一化image_features /= image_features.norm(dim=-1, keepdim=True)# 对文本特征进行归一化text_features /= text_features.norm(dim=-1, keepdim=True)# 计算图像特征与文本特征之间的相似度,并返回相似度矩阵return (image_features * text_features[:, None]).sum(-1)def set_prompts(self, prompts):"""设置提示信息字典。Args:prompts (dict): 包含各种提示信息的字典,如 "bboxes", "points", "labels", "texts" 等。"""self.prompts = prompts```
4. utils.py
-
def adjust_bboxes_to_image_border(boxes, image_shape, threshold=20):"""将边界框调整到图像边界附近,确保边界框不会超出合理范围。Args:boxes (torch.Tensor或numpy.ndarray): 边界框的张量或数组,形状通常为 (N, 4),N表示边界框的数量,每个边界框包含四个坐标值 (x1, y1, x2, y2),分别代表左上角和右下角的坐标。image_shape (tuple): 图像的形状,格式为 (高度, 宽度)。threshold (int, 可选): 接近边界的阈值。如果边界框的坐标值与图像边界的距离小于该阈值,则将边界框的坐标调整到边界上。默认为20。Returns:torch.Tensor或numpy.ndarray: 调整后的边界框张量或数组,形状与输入的boxes相同。"""# 获取图像的高度和宽度h, w = image_shape# 调整靠近图像左边界的边界框的x1坐标boxes[boxes[:, 0] < threshold, 0] = 0 # x1# 调整靠近图像上边界的边界框的y1坐标boxes[boxes[:, 1] < threshold, 1] = 0 # y1# 调整靠近图像右边界的边界框的x2坐标boxes[boxes[:, 2] > w - threshold, 2] = w # x2# 调整靠近图像下边界的边界框的y2坐标boxes[boxes[:, 3] > h - threshold, 3] = h # y2return boxes
5. val.py
-
from ultralytics.models.yolo.segment import SegmentationValidator # 从ultralytics的yolo模型的segment模块导入SegmentationValidator类from ultralytics.utils.metrics import SegmentMetrics # 从ultralytics的utils模块的metrics子模块导入SegmentMetrics类class FastSAMValidator(SegmentationValidator): # 定义FastSAMValidator类,继承自SegmentationValidatordef __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):"""初始化FastSAMValidator类的实例。Args:dataloader (DataLoader, 可选): 数据加载器,用于加载验证数据。默认为None。save_dir (str, 可选): 保存验证结果的目录。默认为None。pbar (tqdm.tqdm, 可选): 进度条对象,用于显示验证过程的进度。默认为None。args (Namespace, 可选): 包含验证参数的命名空间。默认为None。_callbacks (list, 可选): 回调函数列表,用于在验证过程中执行特定的操作。默认为None。"""super().__init__(dataloader, save_dir, pbar, args, _callbacks) # 调用父类的初始化方法self.args.task = "segment" # 设置任务类型为"segment"(分割)self.args.plots = False # 禁用混淆矩阵和其他绘图,以避免错误self.metrics = SegmentMetrics(save_dir=self.save_dir) # 创建SegmentMetrics对象,用于计算分割任务的指标,并指定保存目录
相关文章:
)
开源项目实战学习之YOLO11:ultralytics-cfg-models-fastsam(九)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 1. __init__.py2. model.py3. predict.py4. utils.py5. val.py FastSAM 是一种目标检测和图像分割模型,Ultralytics 是一个在计算机视觉领域广泛使用的库&#x…...

使用frpc链接内网的mysql
以下是配置 frpc 连接内网 MySQL 服务的详细步骤: 1. 准备工作 frps 服务器:已部署在公网 IP 11.117.11.245,假设 frps 的默认端口为 7000。 内网 MySQL 服务:运行在内网机器的 3306 端口。 目标:通过公网 IP 11.117…...

分享:VTK版本的选择 - WPF空域问题
在早期版本中,ActiViz 对 Windows Presentation Foundation (WPF) 框架的支持是通过 WindowsFormHost 组件实现的,这种方式依赖于 WindowsForm 和 WPF 的互操作性。然而,这种方法存在一个众所周知的“空域问题”(airspace issue&a…...

MIPS架构详解:定义、应用与其他架构对比
一、MIPS架构的定义 MIPS(Microprocessor without Interlocked Pipeline Stages) 是一种经典的精简指令集(RISC)处理器架构,由斯坦福大学John Hennessy团队于1981年提出,强调高效流水线设计和硬件简化。 核…...

项目剖析:基于Agent的个人知识管理系统如何设计
为什么写这篇文章?最近在思考如果想要构建一个个人知识管理的Agent应该怎样设计才好,然后最近看到这样一个项目,就想剖析一下它的架构,看一下它的设计思想。然后一些剖析得过程就沉淀到本文当中。本文档主要从整体架构、dataflow的视角剖析khoj项目,分析应该一个知识管理A…...

Python魔法函数深度解析
一、魔法函数是什么? 魔法函数(Magic Methods)是Python中以双下划线(__xx__)包裹的特殊方法,它们为类提供了一种与Python内置语法深度集成的能力。这些方法由解释器自动调用,无需显式调用&…...
概述)
PCB设计工艺规范(一)概述
PCB设计工艺规范(一) 1.概述2.关键词及引用标准3.PCB板材要求3.1 确定PCB使用板材以及TG值3.2 确定 PCB 的表面处理镀层 4.热设计要求5.器件库选项要求 资料来自网络,仅供学习使用。 1.概述 规范产品的 PCB 工艺设计,规定 PCB 工…...

Github开通第三方平台OAuth登录及Java对接步骤
调研起因: 准备搞AI Agent海外项目,有相当一部分用户群体是程序员,所以当然要接入Github这个全球最大的同性交友网站了,让用户使用Github账号一键完成注册或登录。 本教程基于Web H5界面进行对接,同时也提供了spring-…...

DeepSeek V1:初代模型的架构与性能
DeepSeek V1(又称DeepSeek-MoE)是DeepSeek系列的首代大规模语言模型,它采用Transformer结合稀疏混合专家(MoE)的创新架构,实现了在受控算力下的大容量模型。本文将深入解析DeepSeek V1的架构设计与技术细节,包括其关键机制、训练优化策略,以及在各类NLP任务上的表现。 …...

Java ResourceBundle 资源绑定详解
Java ResourceBundle 资源绑定详解 ResourceBundle 是 Java 提供的国际化(i18n)资源管理工具,位于 java.util 包。它专门用于加载本地化的 .properties 资源文件,支持多语言切换,是国际化和本地化开发的核心类。 1. 核心特性 (1)基本特点 基于 .properties 文件管理键…...

flutter 专题 六十一 支持上拉加载更多的自定义横向滑动表格
在股票软件中,经常会看到如下所示的效果(ps:由于公司数据敏感,所以使用另一个朋友的一个图)。 分析需要后,我先在网上找了下支持横向滑动的组件,最后找到了这个:flutter_horizontal…...

暗夜模式续
之前写过一篇笨拙的方式实现暗夜模式,但是当真正去适配的时候发现简直恶心至极;然后想通过一些方式可以把笨拙的方式变得优雅; 之前实现暗夜模式的快速通道,这篇文章在基于这个基础上优化而来 目录 背景 优化步骤 OK…...
)
[吾爱出品] 文件夹迁移工具(DirMapper)
文件夹迁移工具(DirMapper) 链接:https://pan.xunlei.com/s/VOP4Uf6vu3dalYLaZ1iZUhJ1A1?pwdfhzi# 文件夹迁移工具(DirMapper) 智能识别源文件夹分类 复制/移动两种迁移模式 冲突解决方案(覆盖/跳过/合…...

DeepSeek 4月30日发布新模型:DeepSeek-Prover-V2-671B 可进一步降低数学AI应用门槛,推动教育、科研领域的智能化升级
DeepSeek-Prover-V2-671B模型特点: 一、超大参数规模与数学推理能力 参数规模跃升 模型参数量高达6710亿,是前代数学推理模型Prover-V1.5(70亿参数)的近100倍,表明其具备更强的复杂问题处理能力。 前代Prover-V1.5在高…...
)
GitHub修炼法则:第一次提交代码教学(Liunx系统)
前言 github是广大程序员们必须要掌握的一个技能,万事开头难,如果成功提交了第一次代码,那么后来就会简单很多。网上的相关资料往往都不是从第一次开始,导致很多新手们会在过程中遇到很多权限认证相关的问题,进而被卡…...

百家号等新媒体私信入口是否可以聚合到企业微信的客服,如何实现
一、技术实现路径 1. 百家号 API 对接 接口权限申请: 登录百度开发者平台,创建应用并获取 API 密钥(app_id和app_token)。申请私信相关接口权限(如消息通知、粉丝查询),需满足百家号的审核要求…...

【来自AI】RS485,Rs232,Modbus的区别和联系是什么
RS485、RS232 和 Modbus 是常用于工业自动化和通信中的技术标准,它们有不同的特点和应用。下面是它们的区别和联系: RS232 (Recommended Standard 232) 定义:RS232 是一种串行通信标准,通常用于短距离(一般最多15米&…...

java实现序列化与反序列化
va 实现序列化与反序列化 序列化(Serialization) 是将 Java 对象转换为字节流(二进制数据),以便存储或网络传输。 反序列化(Deserialization) 则是将字节流恢复为 Java 对象。 Java 提供了 ja…...

harmonyOS 手机,双折叠,平板,PC端屏幕适配
由于HarmonyOS设备的屏幕尺寸和分辨率各不相同,开发者需要采取适当的措施来适配不同的屏幕。 1.EntryAbility.ets文件里:onWindowStageCreate方法里判断设备类型, 如果是pad,需全屏展示(按客户需求来,本次…...

Qt Creator环境编译的Release软件放在其他电脑上使用方法
本文解决的问题:将Qt Creator环境编译的exe可执行程序放到其他电脑上不可用情况 1、寻找windeployqt工具所在路径" D:\Qt5.12.10\5.12.10\msvc2015_64\bin" ,将此路径配置到环境变量; 2、用Qt Creator环境编译出Release版本可执行…...

electron+vite+vue3 快速入门教程
Electron、Vite 和 Vue 3 结合使用可以创建强大的跨平台桌面应用程序,下面是一个快速入门教程,帮助你搭建一个基于 Electron Vite Vue 3 的项目。 环境准备 Node.js: 首先确保你的机器上已经安装了 Node.js。你可以通过以下命令来检查是否已安装&…...

添加了addResourceHandlers 但没用
B站黑马的视频 public class WebMvcConfig extends WebMvcConfigurationSupport { /** * 设置静态资源映射 * param registry */ Override protected void addResourceHandlers(ResourceHandlerRegistry registry) { log.info("开始进…...

uniapp如何获取安卓原生的Intent对象
通过第三方app唤起,并且获取第三方app唤起时携带的参数 因为应用a唤起应用b时,应用b第一时间就要拿到参数token,所以需要将获取参数的方法写在APP.vue中的onLaunch钩子里,如果其他地方要用可以选择vuex或者采用本地缓存。 uniapp中plus.run…...

国标GB28181视频平台EasyGBS在物业视频安防管理服务中的应用方案
一、方案背景 在现代物业服务中,高效的安全管理与便捷的服务运营至关重要。随着科技的不断发展,物业行业对智能化、集成化管理系统的需求日益增长。EasyGBS作为一款基于国标GB28181协议的视频监控平台,具备强大的视频管理与集成能力&#…...

Linux容器大师:K8s集群部署入门指南
引言 在云原生时代,Kubernetes就像一位"集群调度大师"🎮,轻松管理成千上万的容器化应用!本文将带你从零开始搭建生产级K8s集群,从基础概念到实战部署,从核心组件到安全运维。无论你是要搭建开发…...

Vue 3 中纯 template 标签
发现 Vue 3 中纯 template 标签不会被渲染。 可以加 v-if"1" 即可 https://andi.cn/page/622155.html...

极光PDF编辑器:高效编辑,轻松管理PDF文档
在日常工作和学习中,PDF文件的使用越来越普遍。无论是学术论文、工作报告还是电子书籍,PDF格式因其稳定性和兼容性而被广泛采用。然而,编辑PDF文件往往比编辑Word文档更加复杂。今天,我们要介绍的 极光PDF编辑器,就是这…...

《可信数据空间 技术架构》技术文件正式发布
可信数据空间 技术架构发布了 国家数据基础设施技术文件发布有几个月了,成为数据要素圈内必读的白皮书,接着今日国家数据局正式发布了《可信数据空间 技术架构》,笔者有幸见证了该文件出炉的过程,在这两个文件重,对数…...
图像与通道拼接函数-----合并三个单通道图像(GMat)为一个多通道图像的函数merge3())
OpenCV 图形API(74)图像与通道拼接函数-----合并三个单通道图像(GMat)为一个多通道图像的函数merge3()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 从3个单通道矩阵创建一个3通道矩阵。 此函数将多个矩阵合并以生成一个单一的多通道矩阵。即,输出矩阵的每个元素将是输入矩阵元素的…...

Redis应用场景实战:穿透/雪崩/击穿解决方案与分布式锁深度剖析
一、缓存异常场景全解与工业级解决方案 1.1 缓存穿透:穿透防御的三重门 典型场景 恶意爬虫持续扫描不存在的用户ID 参数注入攻击(如SQL注入式查询) 业务设计缺陷导致无效查询泛滥 解决方案进化论 第一层防护:布隆过滤器&am…...

负载均衡技术全景指南:架构、算法与发展趋势
负载均衡技术全景指南:架构、算法与发展趋势 一、负载均衡技术概述二、应用层负载均衡(一)HTTP 重定向(二)反向代理服务器 三、传输层负载均衡(一)DNS 域名解析负载均衡(二ÿ…...

DeepSeek-V3 解析第二篇:DeepSeekMoE
这篇文章是我们 DeepSeek-V3 系列的第二篇,聚焦于 DeepSeek 模型 [1, 2, 3] 的一个关键架构突破:DeepSeekMoE。 📚 本文也是我们【LLM 架构演化系列】的第二篇,聚焦 DeepSeek-V3 的 MoE 架构创新。如果你正研究大模型性能优化或架…...

【ArcGISPro学习笔记】布局输出时图例总是有省略号怎么办?
在用ArcGISPro制图时,发现布局输出时图例总是有省略号,例如下图: 调整半天都搞不定,必须把图例框拉很宽才没有省略号,非常影响布局体验 后来发现只需调整一个地方就把省略号弄没了,就是在图例排列这里&…...

驱散养生伪识阴霾,重铸科学养生晴空
在健康意识日益觉醒的当下,养生已然成为人们生活中备受瞩目的焦点。然而,各类养生伪知识如同阴霾,遮蔽了科学养生的光芒,误导着人们的养生实践。只有彻底驱散这些伪识阴霾,才能重铸科学养生的朗朗晴空,让健…...
 A. Boboniu Chats with Du)
【补题】Codeforces Round 664 (Div. 1) A. Boboniu Chats with Du
题意:给出n,d,m三个值,分别代表,有多少个值ai,使用超过m的ai,需要禁言d天,如果不足也能使用,m代表区分点,问能得到最大的值有多少。 思路: …...

大语言模型 06 - 从0开始训练GPT 0.25B参数量 - MiniMind 实机配置 GPT训练基本流程概念
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

Java进阶--设计模式
设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了重用代码、让代码更容易被他人理解、保证代码可靠性。设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样࿰…...

同时启动俩个tomcat压缩版
下载解压tomcat压缩版 复制一份,换个名字 更改任意一个tomcat的配置文件用记事本打开 修改三个位置 1.<Server port"8005" shutdown"SHUTDOWN"> 2. <Connector port"8080" protocol"HTTP/1.1" …...

ZYNQ MPSOC之PL与PS数据交互DMA方式
ZYNQ MPSOC之PL与PS数据交互DMA方式 1 摘要 XILINX ZYNQ 以及 ZYNQ MPSOC主要优势在于异构 ARM+FPGA。其中非常关键的一点使用了 AXI 总线进行高速互联。而且这个 AXI 总线是开放给我们用户使用的。在前面的文章中我们详解了使用了AXI-HP方式PL到PS端进行数据交互。本文主要涉…...

Qwen3本地化部署,准备工作:SGLang
文章目录 SGLang安装deepseek运行Qwen3-30B-A3B官网:https://github.com/sgl-project/sglang SGLang SGLang 是一个面向大语言模型和视觉语言模型的高效服务框架。它通过协同设计后端运行时和前端编程语言,使模型交互更快速且具备更高可控性。核心特性包括: 1. 快速后端运…...

一种动态分配内存错误的解决办法
1、项目背景 一款2年前开发的无线网络通信软件在最近的使用过程中出现网络中传感器离线的问题,此软件之前已经使用的几年了,基本功能还算稳定。这次为什么出了问题。 先派工程师去现场调试一下,初步的结果是网络信号弱,并且有个别…...

golang接口和具体实现之间的类型转换
在 Go 语言中,如果你有一个接口类型的变量,并且你知道它的具体实现类型,你可以使用类型断言将其转换为具体类型。类型断言的语法是 value, ok : interfaceVar.(ConcreteType),其中 interfaceVar 是接口变量,ConcreteTy…...

独立站SaaS平台源码搭建全流程指南:从零到部署
一、什么是独立站SaaS? 独立站SaaS(Software as a Service)指通过自主搭建的云平台为用户提供软件服务,与第三方平台(如Shopify)相比,具有以下优势: 完全自主控制:可自…...

零基础学指针2
零基础学指针---大端和小端 零基础学指针---什么是指针 零基础学指针---取值运算符*和地址运算符& 零基础学指针---结构体大小 零基础学指针5---数据类型转换 零基础学指针6---指针数组和数组指针 零基础学指针7---指针函数和函数指针 零基础学指针8---函数指针数组…...

TM1668芯片学习心得二
一、该芯片包括的指令:显示模式设置命令、数据命令设置、地址命令设置、显示控制; 1、显示模式设置 2、数据命令设置 3、地址命令设置 4、显示控制...

[FPGA VIDEO IP] VCU
Xilinx H.264/H.265 Video Codec Unit IP (PG252) 详细介绍 概述 Xilinx LogiCORE™ IP H.264/H.265 Video Codec Unit(VCU,PG252)是一个专为 Zynq UltraScale MPSoC 设备设计的硬件加速视频编解码模块,支持 H.264(A…...

Git从入门到精通-第一章-基础概念
目录 为什么要版本控制? 版本控制系统 本地版本控制系统 集中化的版本控制系统 分布式版本控制系统 Git是什么? 直接记录快照 几乎所有操作都是本地执行 保证完整性 Git一般只添加数据 三种状态! Git的三种状态 Git的三个阶段…...

简单表管理
1.创建表(学生表,课程表,成绩表) --首先创建数据库 STUxxx CREATE DATABASE STU065; USE STU065; --创建学生表 CREATE TABLE SSS065(SNO CHAR(10) NOT NULL PRIMARY KEY, -- 学号SNAME VARCHAR(20) NOT NULL, -- 姓名DEPA VARCHAR(20), -- 系别AGE INT…...
:从原理到工业级应用实践)
C#静态类与单例模式深度解析(七):从原理到工业级应用实践
一、静态类:全局工具箱的设计艺术 1.1 静态类的本质特性 public static class MathUtils {// 静态字段(线程安全需自行处理)public static readonly double GoldenRatio = 1.618;// 静态方法public static double CircleArea(double radius){return Math.PI * radius * ra…...

2025年深圳杯-东三省联赛赛题浅析-助攻快速选题
深圳杯作为竞赛时长一个月,上半年度数模竞赛中难度最大的竞赛,会被各种省级竞赛、高校作为选拔赛进行选拔。本文为了能够帮助大家快速的上手该题目,将从涉及背景、解题所需模型、求解算法、实际求解中可能遇到的问题等详细进行描述࿰…...