DeepSeek-V3 解析第二篇:DeepSeekMoE
这篇文章是我们 DeepSeek-V3 系列的第二篇,聚焦于 DeepSeek 模型 [1, 2, 3] 的一个关键架构突破:DeepSeekMoE。
📚 本文也是我们【LLM 架构演化系列】的第二篇,聚焦 DeepSeek-V3 的 MoE 架构创新。如果你正研究大模型性能优化或架构设计,欢迎参考本系列其他内容,我们也整理了多份内部实验图与流程笔记,读者留言即可交流获取。

Vegapunk №02——One Piece 角色,由 ChatGPT 生成插画
在本文里,我们会聊聊什么是 Mixture-of-Experts(MoE)、它为什么在 LLM 里越来越火,以及它带来的挑战。我们还会看看专家专精和知识共享之间的平衡,以及 DeepSeekMoE 如何优化这笔买卖。
最妙的是:为了让概念更直观,我们会用「餐厅」的比喻,把 MoE 的每个元素都对应到厨房里的厨师角色上来讲。
如果你想看 DeepSeek 系列其他文章,戳这里:
• Part 1:Multi-head Latent Attention
本文目录:
• 背景:介绍 MoE 的运作方式、优势与挑战,并聊聊专家专精与知识共享的取舍。
• DeepSeekMoE 架构:细说细粒度专家分段与共享专家隔离。
• 评测:通过一系列实验展示 DeepSeekMoE 的表现。
• 总结。
• 参考文献。
背景
LLM 里的 MoE(Mixture-of-Experts)
在 LLM 语境下,MoE 通常是把 Transformer 里的 FFN 层换成 MoE 层,下图示意:
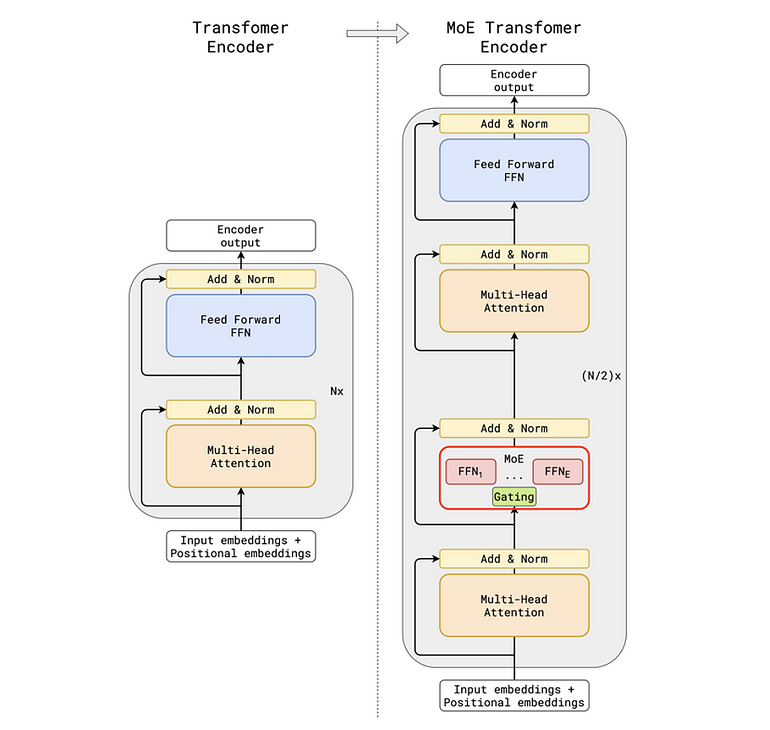
图 1. MoE 层示意,图片摘自 GShard 论文 。
左边是一堆 N 层 Transformer,每层有一个 MHA 子层 + 一个 FFN 子层。右边是一堆 N/2 层 Transformer,隔一层就把 FFN 换成 MoE。所以说,MoE 层按配置间隔取代 FFN。
往 MoE 层里看,它有一个 Gating 操作,再跟多个 FFN——这些 FFN 结构跟普通 FFN 一样,被叫作「专家」。Gate 训练来决定给定输入该叫哪个专家上场。
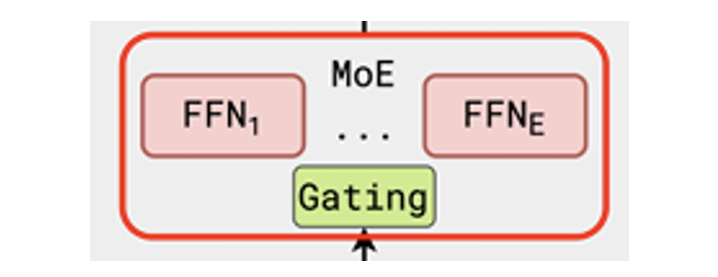
图 2. MoE 层:Gate + 多个 FFN 专家。图片来自 。
MoE 的通用公式(沿用 [4] 的公式编号):
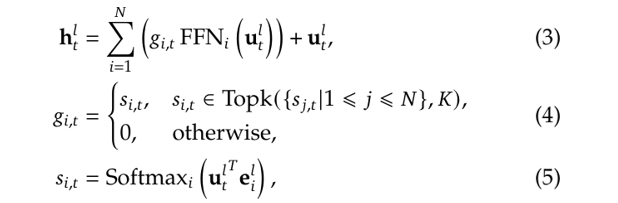
其中:
• u^l_t 和 h^l_t 分别是第 l 层、t 号 token 的输入/输出隐藏态。
• FFN_i 是第 i 个专家,总共 N 个。
• g_{i, t} 是 token t 对专家 i 的 gate 值,由 softmax 后 TopK 得到。
• e^l_i 是式 (5) 里的专家 i 的「质心」,把之前路由到该专家的所有输入 token 聚合得来。
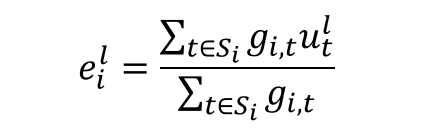
下面我们倒着过一遍 (5)→(3):
• 式 (5):u^l_t 跟 e^l_i 做内积,算 token 跟专家平均输入的相似度。直觉上,之前常服务于类似输入的专家更合适。一通 softmax 把分数弄成概率分布。N 个专家就出 N 个 s_{i, t}。
• 式 (4):对全部 s_{i, t} 做 TopK,得到稀疏的 g_{i, t}。
• 式 (3):用稀疏 g_{i, t} 选 K 个专家算输出。
也就是说,N 个里面只激活 K 个专家(通常 K 很小)。总参数暴涨,但每次前向只用到一小部分。
“总参数 236B,但每个 token 只激活 21B……”
那多搞 MoE、参数陡增到底图啥?
MoE 的好处与挑战
MoE 的妙处跟很多现实系统一个路数,用比喻很好懂。
想象开一家中餐+意大利餐的饭店,招厨子有俩方案:
• 方案1:找一个中意都精通的大厨,单刷所有菜——对应普通 Transformer,一个 FFN 顶所有 token。
• 方案2:请一批专攻中餐或意餐的厨子,再配一个主厨指派订单——对应 MoE:每个厨子是专家,主厨是 Gate。
显然方案2更好招人,菜也更地道;方案1想找通天大厨难如登天。
回到 LLM,MoE 背后的动力有「尺度假设」:模型越大越容易蹦出涌现能力。GPT 从 117M 升到 175B 就是例子。但不是谁都烧得起巨额算力。MoE 折中:整体模型规模上去,算力/显存成本靠「稀疏激活」压下来。
[4] 里演示:2B 模型只激活 0.3B,16B 激活 2.8B,145B 激活 22.2B,激活比例约 1/7,训练推理都省。
但设计都有坑。MoE 很吃 Gate,路由不准就「专家塌缩」——部分专家被用爆,其他吃灰;负载失衡、稳定性差,全来。
所以负载均衡是 MoE 的热门议题。DeepSeekMoE 也有招,这篇先讲核心创新,负载均衡(比如无辅助损的均衡 [8])下回说。
💡 MoE 在工业部署中涉及多个设计抉择,如专家分配策略、负载均衡方法、通用 vs 专精结构取舍等,我们在实际工程里踩过不少坑。如你在工程实现过程中有类似困惑,欢迎一起探讨,我们将持续整理 DeepSeekMoE 的复现与对比实践细节。
知识专精 vs. 知识共享
招厨子时,也在权衡全能 vs. 专精:方案1 偏全能但深度有限,方案2 偏专精。MoE 里同样:每个专家只见部分 token,自然应各有侧重,同时共享参数让知识有交集。但度不好量化。
过度专精 → 不稳、路由错位掉性能、容量浪费。
过度雷同 → 多出来的参数没产出,浪费算力。
接下来看看 DeepSeekMoE 怎么调这个平衡。
DeepSeekMoE 架构
DeepSeekMoE 用两招调专精/共享:细粒度专家分段 + 共享专家隔离。
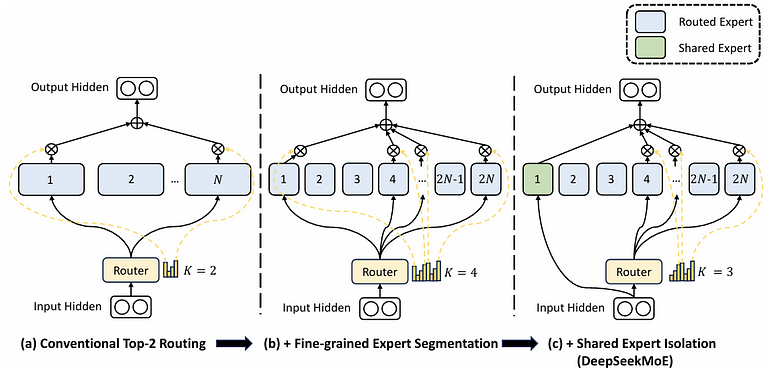
图 3. DeepSeekMoE 示意。
细粒度专家分段
为了鼓励专精,DeepSeekMoE 把专家细分。直觉:一个 token 激活更多专家,知识被拆分分配给多个专家的概率大。
餐厅比喻:原本一个厨子包全部中餐、另一个包全部意餐;细分后,多位厨子各负责中餐里的炒、蒸、煮,或意餐里的面、酱、烤,如下图。
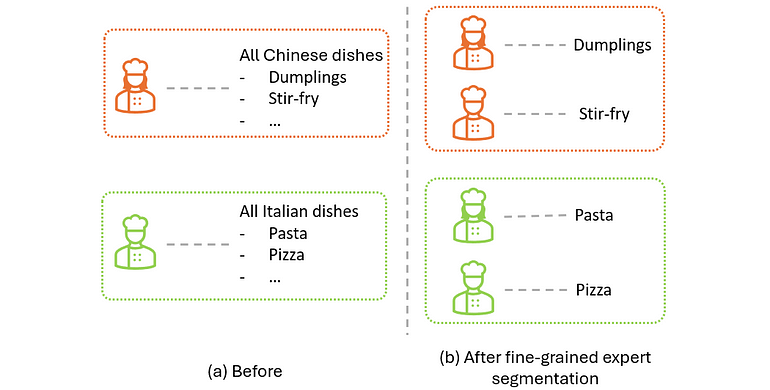
图 4. (a) 细分前 vs. (b) 细分后,餐厅示意。作者自绘。
图 3 里 (a) 每 token 路由到 N 个专家里的 2 个;(b) 把专家数量翻 m 倍到 2N,每个专家宽度缩 1/m,每 token 路由 4 个专家,计算量持平。
作者虽没给理论证明,但实验验证了,评测部分见。
共享专家隔离
第二招:隔离出「共享专家」减少冗余。直觉:留几位专家学通用知识,剩下专家更专注专精。
餐厅比喻:再把厨师分两组——上半是通用技法(刀工、火候、基本调味),下半各自研究招牌菜,如下图。
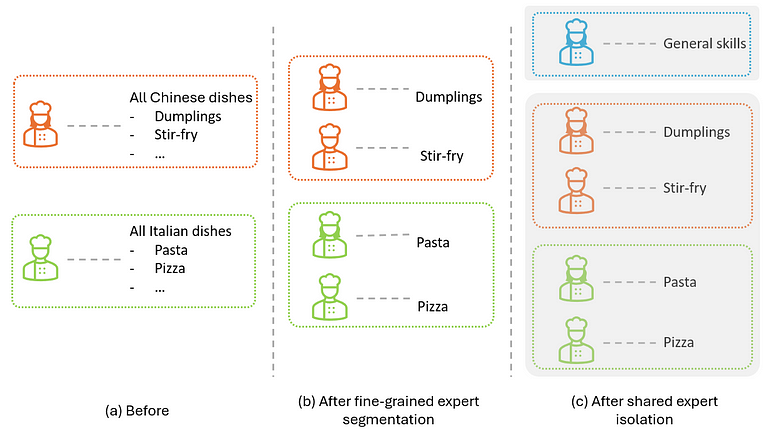
图 5. 在图 4 基础上加共享专家隔离示意。作者自绘。
图 3 © 里,一个专家标绿,作为共享专家:所有 token 都直接进它,不过路由器;同时把专精专家激活数从 4 减到 3,总激活数跟图 3 (b) 持平。
合起来,如下图右侧把 DeepSeekMoE 公式化,并跟通用 MoE 对比。
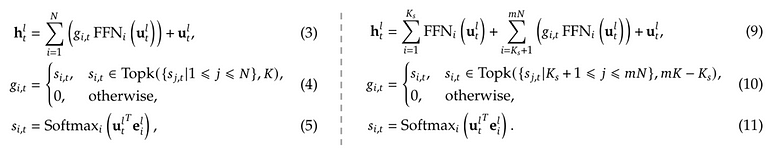
图 6. 左:通用 MoE;右:DeepSeekMoE。作者按 [4] 公式绘制。
其中:
• 式 (11) 同旧式 (5);
• 式 (10) 类似 (4),但在 (mN – K_s) 个专家里 TopK 选 (mK – K_s) 个,K_s 是共享专家数;
• 式 (9) 把 (3) 的第一项拆成共享专家 + 路由专家两项。
虽然无严格理论证明,但下节评测表明,共享专家提升表现并减冗余。
评测
上文两招听着靠谱,但到底多大用?问三点:
• DeepSeekMoE 结果到底更好吗?
• 细粒度专家分段到底多大程度促专精?
• 共享专家隔离能多大程度降冗余?
作者设计了一系列实验。
DeepSeekMoE 结果更好吗?
先看整体性能:训练一批总参/激活参近似的模型,多任务评估,主结果如下,最佳指标加粗。
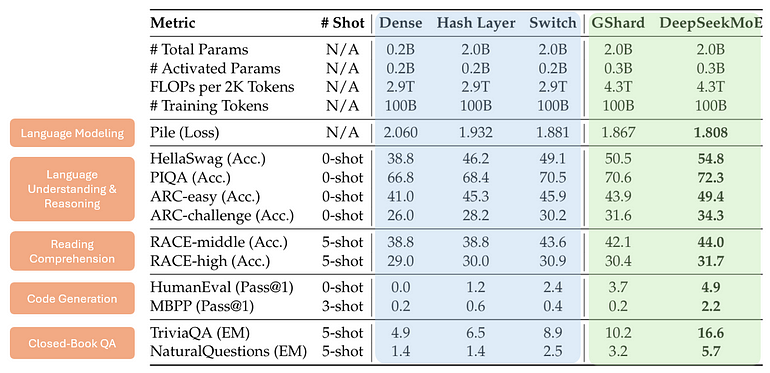
图 7. 整体表现。作者依据 [4] 表 1 绘制。
要点:
• 蓝列:普通 Transformer(Dense) vs. Hash Layer [6] / Switch Transformer [7] 两种 MoE,同激活参下,MoE 明显强。
• 绿列:DeepSeekMoE vs. GShard [5],同激活参下,DeepSeekMoE 更强。
但整体好 ≠ 专精/共享平衡好,所以继续测。
细粒度分段真促专精吗?
直接量化专精难,于是作者反向操作:禁用最常被路由的专家看看掉多少分。更加专精 → 更难被替换 → 性能掉得多。
实验:禁用部分顶流专家,比 DeepSeekMoE 和基线 GShard x 1.5(两者禁用前 Pile loss 相近)。
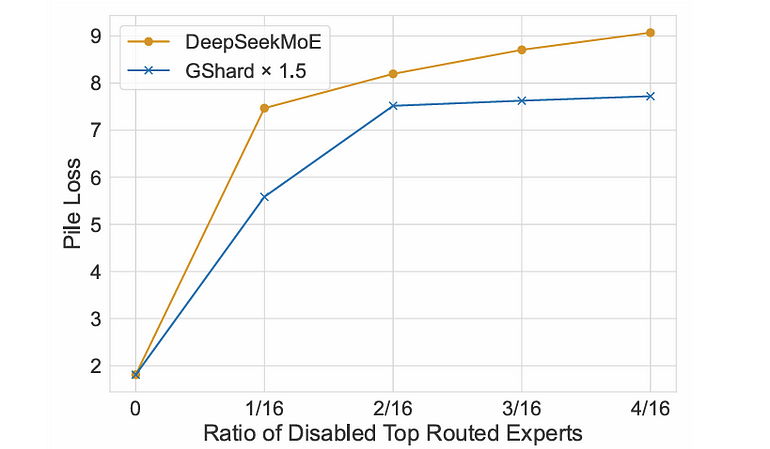
图 8. 禁用顶流专家后的 Pile loss。图片来自 [4]。
禁用比例越高,DeepSeekMoE 的 loss 一直更高,说明其专家更专精、替换性更差。
共享专家隔离真降冗余吗?
同理,作者把共享专家关掉,再多开一个路由专家,看看能否顶上。结果 Pile loss 从 1.808 飙到 2.414,说明共享专家掌握的知识独特,路由专家顶不上——冗余更少,专精更高。
总结
本文用餐厅比喻讲了 DeepSeekMoE——DeepSeek-V2 / V3 用到的关键架构创新。
我们先介绍了 MoE 的工作原理、优缺点和专精 vs. 共享的取舍,然后说明了 DeepSeekMoE 的两大招:细粒度专家分段、共享专家隔离,并在评测里看它们带来的提升。
核心 takeaway:DeepSeekMoE 通过促进专家专精,在与通用 MoE 近似的计算成本下提升了效果,算力利用更高效。
📘 这只是 DeepSeekMoE 架构探索的开篇。未也有时间我们还将深入分析其负载均衡机制,并对比主流 MoE 实现。如果你想系统理解 MoE 架构的工程化落地,可留言「MoE实践」获取我们内部使用的调优策略图和模型结构对比表。
参考文献
[1] DeepSeek
[2] DeepSeek-V3 技术报告
[3] DeepSeek-V2:一种强大、经济且高效的专家混合语言模型
[4] DeepSeekMoE:迈向专家混合语言模型的终极专家特化
[5] GShard:通过条件计算与自动分片扩展巨型模型
[6] Hash Layers:用于大型稀疏模型的哈希层
[7] Switch Transformers:通过简单高效的稀疏性扩展到万亿参数模型
[8] 无辅助损失的专家混合负载均衡策略
相关文章:

DeepSeek-V3 解析第二篇:DeepSeekMoE
这篇文章是我们 DeepSeek-V3 系列的第二篇,聚焦于 DeepSeek 模型 [1, 2, 3] 的一个关键架构突破:DeepSeekMoE。 📚 本文也是我们【LLM 架构演化系列】的第二篇,聚焦 DeepSeek-V3 的 MoE 架构创新。如果你正研究大模型性能优化或架…...

【ArcGISPro学习笔记】布局输出时图例总是有省略号怎么办?
在用ArcGISPro制图时,发现布局输出时图例总是有省略号,例如下图: 调整半天都搞不定,必须把图例框拉很宽才没有省略号,非常影响布局体验 后来发现只需调整一个地方就把省略号弄没了,就是在图例排列这里&…...

驱散养生伪识阴霾,重铸科学养生晴空
在健康意识日益觉醒的当下,养生已然成为人们生活中备受瞩目的焦点。然而,各类养生伪知识如同阴霾,遮蔽了科学养生的光芒,误导着人们的养生实践。只有彻底驱散这些伪识阴霾,才能重铸科学养生的朗朗晴空,让健…...
 A. Boboniu Chats with Du)
【补题】Codeforces Round 664 (Div. 1) A. Boboniu Chats with Du
题意:给出n,d,m三个值,分别代表,有多少个值ai,使用超过m的ai,需要禁言d天,如果不足也能使用,m代表区分点,问能得到最大的值有多少。 思路: …...

大语言模型 06 - 从0开始训练GPT 0.25B参数量 - MiniMind 实机配置 GPT训练基本流程概念
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

Java进阶--设计模式
设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了重用代码、让代码更容易被他人理解、保证代码可靠性。设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样࿰…...

同时启动俩个tomcat压缩版
下载解压tomcat压缩版 复制一份,换个名字 更改任意一个tomcat的配置文件用记事本打开 修改三个位置 1.<Server port"8005" shutdown"SHUTDOWN"> 2. <Connector port"8080" protocol"HTTP/1.1" …...

ZYNQ MPSOC之PL与PS数据交互DMA方式
ZYNQ MPSOC之PL与PS数据交互DMA方式 1 摘要 XILINX ZYNQ 以及 ZYNQ MPSOC主要优势在于异构 ARM+FPGA。其中非常关键的一点使用了 AXI 总线进行高速互联。而且这个 AXI 总线是开放给我们用户使用的。在前面的文章中我们详解了使用了AXI-HP方式PL到PS端进行数据交互。本文主要涉…...

Qwen3本地化部署,准备工作:SGLang
文章目录 SGLang安装deepseek运行Qwen3-30B-A3B官网:https://github.com/sgl-project/sglang SGLang SGLang 是一个面向大语言模型和视觉语言模型的高效服务框架。它通过协同设计后端运行时和前端编程语言,使模型交互更快速且具备更高可控性。核心特性包括: 1. 快速后端运…...

一种动态分配内存错误的解决办法
1、项目背景 一款2年前开发的无线网络通信软件在最近的使用过程中出现网络中传感器离线的问题,此软件之前已经使用的几年了,基本功能还算稳定。这次为什么出了问题。 先派工程师去现场调试一下,初步的结果是网络信号弱,并且有个别…...

golang接口和具体实现之间的类型转换
在 Go 语言中,如果你有一个接口类型的变量,并且你知道它的具体实现类型,你可以使用类型断言将其转换为具体类型。类型断言的语法是 value, ok : interfaceVar.(ConcreteType),其中 interfaceVar 是接口变量,ConcreteTy…...

独立站SaaS平台源码搭建全流程指南:从零到部署
一、什么是独立站SaaS? 独立站SaaS(Software as a Service)指通过自主搭建的云平台为用户提供软件服务,与第三方平台(如Shopify)相比,具有以下优势: 完全自主控制:可自…...

零基础学指针2
零基础学指针---大端和小端 零基础学指针---什么是指针 零基础学指针---取值运算符*和地址运算符& 零基础学指针---结构体大小 零基础学指针5---数据类型转换 零基础学指针6---指针数组和数组指针 零基础学指针7---指针函数和函数指针 零基础学指针8---函数指针数组…...

TM1668芯片学习心得二
一、该芯片包括的指令:显示模式设置命令、数据命令设置、地址命令设置、显示控制; 1、显示模式设置 2、数据命令设置 3、地址命令设置 4、显示控制...

[FPGA VIDEO IP] VCU
Xilinx H.264/H.265 Video Codec Unit IP (PG252) 详细介绍 概述 Xilinx LogiCORE™ IP H.264/H.265 Video Codec Unit(VCU,PG252)是一个专为 Zynq UltraScale MPSoC 设备设计的硬件加速视频编解码模块,支持 H.264(A…...

Git从入门到精通-第一章-基础概念
目录 为什么要版本控制? 版本控制系统 本地版本控制系统 集中化的版本控制系统 分布式版本控制系统 Git是什么? 直接记录快照 几乎所有操作都是本地执行 保证完整性 Git一般只添加数据 三种状态! Git的三种状态 Git的三个阶段…...

简单表管理
1.创建表(学生表,课程表,成绩表) --首先创建数据库 STUxxx CREATE DATABASE STU065; USE STU065; --创建学生表 CREATE TABLE SSS065(SNO CHAR(10) NOT NULL PRIMARY KEY, -- 学号SNAME VARCHAR(20) NOT NULL, -- 姓名DEPA VARCHAR(20), -- 系别AGE INT…...
:从原理到工业级应用实践)
C#静态类与单例模式深度解析(七):从原理到工业级应用实践
一、静态类:全局工具箱的设计艺术 1.1 静态类的本质特性 public static class MathUtils {// 静态字段(线程安全需自行处理)public static readonly double GoldenRatio = 1.618;// 静态方法public static double CircleArea(double radius){return Math.PI * radius * ra…...

2025年深圳杯-东三省联赛赛题浅析-助攻快速选题
深圳杯作为竞赛时长一个月,上半年度数模竞赛中难度最大的竞赛,会被各种省级竞赛、高校作为选拔赛进行选拔。本文为了能够帮助大家快速的上手该题目,将从涉及背景、解题所需模型、求解算法、实际求解中可能遇到的问题等详细进行描述࿰…...

springboot集成Lucene详细使用
以下是 Spring Boot 集成 Lucene 的详细步骤: 添加依赖 在 Spring Boot 项目的 pom.xml 文件中添加 Lucene 的依赖,常用的核心依赖和中文分词器依赖如下: <dependency><groupId>org.apache.lucene</groupId><artifac…...

【数据链路层】网络通信的“桥梁建设者”
目录 一、核心定位二、关键技术详解1. MAC地址体系2. 帧结构剖析(以太网V2为例)3. 典型协议对比 三、关键设备原理1. 交换机工作原理2. ARP协议流程 四、高级应用场景1. VLAN虚拟局域网2. 生成树协议(STP) 五、典型故障排查1. MAC…...

《多端统一的终极答案:X5内核增强版的渲染优化全解析》
跨端应用的需求呈爆发式增长,无论是电商购物、社交互动,还是金融理财类应用,都期望能够在不同平台上为用户提供一致且流畅的体验。而在这一过程中,跨端渲染技术成为了关键瓶颈。腾讯X5内核增强版的出现,犹如一道曙光&a…...

【MySQL数据库】事务
目录 1,事务的详细介绍 2,事务的属性 3,事务常见的操作方式 1,事务的详细介绍 在MySQL数据库中,事务是指一组SQL语句作为一个指令去执行相应的操作,这些操作要么全部成功提交,对数据库产生影…...

《Python实战进阶》No45:性能分析工具 cProfile 与 line_profiler
Python实战进阶 No45:性能分析工具 cProfile 与 line_profiler 摘要 在AI模型开发中,代码性能直接影响训练效率和资源消耗。本节通过cProfile和line_profiler工具,实战演示如何定位Python代码中的性能瓶颈,并结合NumPy向量化操作…...

intellij idea最新版git开启Local Changes
习惯了在idea的git插件里,查看项目已修改的文件,但是新版idea默认不展示了,用起来很难受。 参考网上教程开启方法如下: 1. 确保安装Git Modal Commit Interface插件并开启该插件 2. 在Advanced Settings开启Use Modal Commit In…...

C++ RAII 编程范式详解
C RAII 编程范式详解 一、RAII 核心概念 RAII(Resource Acquisition Is Initialization,资源获取即初始化) 是 C 的核心编程范式,通过将资源生命周期与对象生命周期绑定实现安全、自动化的资源管理。 核心原则: 资源…...

什么是美颜SDK?美颜SDK安卓与iOS端开发指南
在视频拍摄场景,一个出色的美颜SDK,正在悄然支撑起整个视觉体验体系。那么,什么是美颜SDK?它的底层原理、应用场景、核心功能有哪些?安卓与iOS平台又该如何开发与集成美颜SDK?本文将为你详细解析࿰…...

为什么沟通是设计传递和验证的关键
设计转移和验证流程是研发(R&D)规划与项目执行之间的关键桥梁。这一阶段确保设计能够准确转化为生产,将代价高昂的延误降至最低,并保证产品质量。最近,我有幸与乔希・古德曼(Josh Goodman)进…...

计算机考研精炼 操作系统
第 14 章 操作系统概述 14.1 基本概念 14.1.1 操作系统的基本概念 如图 14 - 1 所示,操作系统是计算机系统中的一个重要组成部分,它位于计算机硬件和用户程序(用户)之间,负责管理计算机的硬件资源,为用户和…...

多商户电商系统整套源码开源,支持二次开发,构建多店铺高效联动运营方案
在数字化浪潮席卷全球的今天,电商行业竞争愈发激烈,多商户电商平台凭借其独特的生态优势,成为众多企业和创业者的热门选择。一套优质的多商户电商系统不仅能为商家提供稳定的销售渠道,还能为平台运营者创造巨大的商业价值。分享一…...

MS31860T——8 通道串行接口低边驱动器
MS31860T 是一款 8 通道低边驱动器,包含 SPI 串口通信、 PWM斩波器配置、过流保护、短路保护、欠压锁定和过热关断功能, 芯片可以读取每个通道的状态。MS31860T 可以诊断开路的负载情况,并可以读取故障信息。外部故障引脚指示芯片的故障状态。…...

解决GoLand无法Debug的问题
文章目录 解决GoLand无法Debug的问题问题描述解决方案方法一:安装并替换Delve调试工具方法二:通过GoLand自动安装方法三:配置自定义Delve路径 验证解决方案常见问题排查总结 解决GoLand无法Debug的问题 问题描述 在使用GoLand进行Go语言开发…...

centos升级glibc
描述 参考的文章 基于CentOS更新 glibc - 解决 GLIBC_2.29‘ not found_glibc2.29-CSDN博客 执行步骤 # 下载资源 wget https://ftp.gnu.org/gnu/libc/glibc-2.34.tar.gztar xvf glibc-2.34.tar.gz 服务器上可以能会出现下载较慢的情况,可以再自己的电脑上下载&…...

【Unity】如何解决UI中的Button无法绑定带参数方法的问题
问题描述: 1.直接为Button绑定一个带参数方法,报错了。 解决办法: 将该方法通过另一个方法进行封装即可。...

回收铼树脂RCX-5143
Tulsimer RCX-5143 是一种专为回收铼(Re)设计的大孔弱碱阴离子交换树脂,其核心功能是从酸性浸出液中选择性吸附高铼酸根,并通过高效洗脱实现铼的富集与纯化。以下从技术参数、工艺应用、经济性及行业案例等维度展开分析࿱…...

蓝桥杯赛后总结
首先需要声明一下,编程小白博主参加的是第十六届蓝桥杯大赛(软件赛)C/C组。 个人感受而言,第十六届蓝桥杯软件赛C/C组是比较有难度的,特别是填空题,一共两道题,小白的我是一道填空题也不会做&a…...
走线要求)
PCB设计工艺规范(三)走线要求
走线要求 1.走线要求2.固定孔、安装孔、过孔要求3.基准点要求4.丝印要求 1.走线要求 印制板距板边距离:V-CUT 边大于 0.75mm,铣槽边大于0.3mm。为了保证 PCB 加工时不出现露铜的缺陷,要求所有的走线及铜箔距离板边:V-CUT边大于 0.75mm,铣槽边…...

第十节:文本编辑
理论知识 文本编辑器的基本概念:文本编辑器是用于创建和编辑文本文件的工具。在 Linux 系统中,常见的文本编辑器有 vi、vim、nano 等。vi 和 vim 编辑器:vi 是一款经典的文本编辑器,vim 是 vi 的增强版,提供了更多的功…...

【Hive入门】Hive性能优化:执行计划分析EXPLAIN命令的使用
目录 1 EXPLAIN命令简介 1.1 什么是EXPLAIN命令? 1.2 EXPLAIN命令的语法 2 解读执行计划中的MapReduce阶段 2.1 执行计划的结构 2.2 Hive查询执行流程 2.3 MapReduce阶段的详细解读 3 识别性能瓶颈 3.1 数据倾斜 3.2 Shuffle开销 3.3 性能瓶颈识别与优化 4 总结 在大…...

Spring AI应用系列——基于ARK实现多模态模型应用
ARK 在这里指的是阿里云推出的 AIGC 研发平台 ARK,是阿里云面向开发者和企业用户打造的一站式 AIGC(AI Generated Content,人工智能生成内容)开发平台。 1. 引言 本文将深入探讨 ARK Multi-Model 的实现原理、架构设计以及关键参…...

从边缘到云端:边缘计算与云计算的协同未来
在数字化转型的浪潮中,云计算和边缘计算作为两种重要的计算范式,正在深刻改变着我们的生活和工作方式。云计算以其强大的计算能力和数据存储能力,已经成为企业数字化转型的核心支撑;而边缘计算则凭借其低延迟和高效率的特点&#…...

基于策略模式实现灵活可扩展的短信服务架构
基于策略模式实现灵活可扩展的短信服务架构 引言 在企业级应用开发中,短信服务是不可或缺的基础功能之一。随着业务发展,我们可能需要接入多个短信服务提供商(如阿里云、腾讯云、第三方短信网关等),并能够在不修改核…...

安全指南 | MCP安全检查清单:AI工具生态系统的隐形守护者
随着大型语言模型(LLM)技术的迅猛发展,MCP(Model Context Protocol)已经成为连接AI模型与外部工具、数据源的关键桥梁。它为AI应用(如Claude Desktop、Cursor等)提供了更高效的集成体验…...

ChipCN IDE KF32 导入工程后,无法编译的问题
使用ChipON IDE for KungFu32 导入已有的工程是时,发现能够编译,但是点击,同时选择硬件调试时 没有任何响应。查看工程调试配置时,发现如下问题: 没有看到添加有启动配置,说明就是这里的问题了(应该是IDE的…...

Win下的Kafka安装配置
一、准备工作(可以不做,毕竟最新版kafka也不需要zk) 1、Windows下安装Zookeeper (1)官网下载Zookeeper 官网下载地址 (2)解压Zookeeper安装包到指定目录C:\DevelopApp\zookeeper\apache-zoo…...

Vue2 vs Vue2.7 深度对比
Vue2 vs Vue2.7 深度对比 前言 作为 Vue 生态中承前启后的重要版本,Vue2.7 在保留 Vue2 核心特性的同时,引入了 Vue3 的诸多创新设计。本文将深入解析二者差异,通过架构对比、代码实战和性能基准测试,为企业技术选型提供决策依据…...

WPF使用高性能图表
WPF高性能图表实现方案 一、WPF图表技术选型对比 技术方案优点缺点适用场景WPF原生控件无需第三方依赖,完全可控开发成本高,性能有限简单图表需求OxyPlot轻量级,跨平台,开源功能相对基础中小型应用LiveCharts现代API,支持动画复杂场景性能一般中…...

当算力遇上贫困补助:能否让补助精准到户?
目录 一、让"贫困画像"从模糊到高清 二、破解扶贫"三大世界难题" 三、算力扶贫路上的三座大山 算力应该温暖谁? 以往扶贫的画面是“扶贫干部背着米面油翻山越岭”,当算力发展到一定程度,会呈现出一种新的画面:农民伯伯用手机扫描…...

基于连接感知的实时困倦分类图神经网络
疲劳驾驶是导致交通事故的主要原因之一。脑电图(EEG)是一种直接从大脑活动中检测睡意的方法,已广泛用于实时检测驾驶员的睡意。最近的研究表明,使用基于脑电图数据构建的大脑连接图来预测困倦状态的巨大潜力。然而,传统的脑连接网络与下游预测…...

Set系列之HashSet源码分析:原理剖析与实战对比
引言:哈希集合的基石 1.1 集合框架的核心地位 数据存储的三大特性:唯一性、无序性、快速访问HashSet的市场占有率:Java集合框架中使用率TOP3(占日常开发场景的45%) 1.2 为什么需要深入理解HashSet? 隐藏…...