树的序列化 - 学习笔记
树的序列化可以有很多种类:可以变成 dfs 序,可以变成欧拉序,还有什么括号序的科技。
但是除了第一个以外其他的都没什么用(要么也可以被已有的算法给替代掉)。所以表面上是讲树的序列化,实际上还是讲的 dfs 序的运用(dfs 序的基础知识没什么,但是其运用可以变得相当毒瘤)。
Q:为什么要把树序列化呢?
A:因为有些时候直接在树上面做可能会很复杂,甚至很难做,这是因为树的结构过于错综复杂了。如果把树变成一个简单的序列,那么线性 dp、区间 dp 等在树上不能搞的东西都可以搞了。
dfs 序
dfs 序,顾名思义就是 dfs 的顺序,更加具体的来说,就是在树上 dfs 搜索到的结点顺序(显然如果不加任何约束条件的话 dfs 序不唯一,因为这和搜索的顺序有关)。如果不会 dfs 的话左转出门。
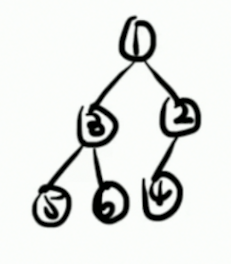
假若我们有这样的一棵树。很容易根据 dfs 将其标号:
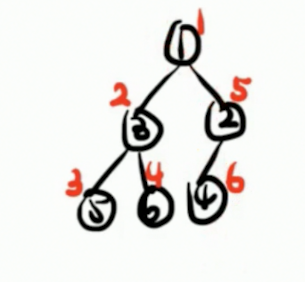
把每一个 dfs 序对应的结点记录下来,就会得到一个数组: { 1 , 3 , 5 , 6 , 2 , 4 } \{1,3,5,6,2,4\} {1,3,5,6,2,4}。注意是 dfs 对应的结点,而不是每一个结点对应的 dfs 序,它们俩是顺序不同的!
于是 dfs 序的定义就被讲完了,很简单是不是!(?
实际上 dfs 序的一个运用我们早就见过了:tarjan 全家桶。
时间戳
为什么我一定要强调这是顺序对应结点呢?这是因为 dfs 序是由两个东西构成的,一个是正宗的 dfs 序,一个是时间戳。
时间戳的定义貌似只可意会不可言传,具体是这么一个东西:
对于每一个结点,dfs 刚遍历到这个结点时,把这个点加入到时间戳的数组末尾的位置;要回溯的时候,也要把这个点加入到时间戳的数组末尾的位置。
还是沿用上面的树,很容易地出来时间戳: { 1 , 3 , 5 , 5 , 6 , 6 , 3 , 2 , 4 , 4 , 2 , 1 } \{1,3,5,5,6,6,3,2,4,4,2,1\} {1,3,5,5,6,6,3,2,4,4,2,1}。也就是每一个点刚被递归到的时候加一遍,回溯的时候也加一遍。
那么它有着怎样的性质呢?
对于每一个结点 u u u 为根的子树,这个子树在序列中会对应一个区间,且这个区间一定是 [ u 刚被遍历到的时候加入数组的位置 , u 回溯的时候加入数组的位置 ] [u \ 刚被遍历到的时候加入数组的位置,\ u\ 回溯的时候加入数组的位置] [u 刚被遍历到的时候加入数组的位置, u 回溯的时候加入数组的位置]。
这个性质有一些显然,因为一个点子树里面的所有点进入一定比这个点进入的晚,出来一定比这个点出来的早,所以就构成了一个区间的包含关系。
于是借助这个结论,就可以很容易的完成整个子树的遍历,也可以很快速的获取整个子树里面所有的结点。
例如 { 3 , 5 , 6 } \{3,5,6\} {3,5,6} 这个结点的子树,很容易在里面找到 { 3 , 5 , 5 , 6 , 6 , 3 } \{3,5,5,6,6,3\} {3,5,5,6,6,3} 这个区间,恰好就对应的整个子树。这样会使很多的问题都处理地简单一些,尤其是关于子树的问题。
当我们遇到一些大力的 ds 题目的时候,例如需要快速修改子树里面的东西,可以不使用树链剖分,而是直接使用时间戳 + 线段树就行了。
另一个性质:如果把每一个点回溯时加入的数都删掉,剩余的数组成的就是 dfs 序。
这个东西很简单,由定义就可以很容易的证明。
void dfs(int u, int pre) {lpos[u] = ++dfn, id[dfn] = u;//刚刚遍历了这个结点,第一次加入for (auto i : v[u])if (i != pre)dfs(i, u);rpos[u] = dfn;//快要回溯了,第二次加入
}
代码很好理解。lpos 表示的是子树区间的左边界,rpos 表示的是子树区间的右边界。
CF877E Danil and a Part-time Job
我前面说过,这两个东西的定义和求解都是简单的,但是套到题目中就不一定简单了。所以我们现在开始讲题。
虽然这道题也是很简单的。
显然这个就是区间修改,有点像开关那道题目,直接先套上一个时间戳然后再线段树区间修改即可。
因为如果直接使用时间戳的话一个点会被计算两次,所以最后要 /2.
#include <bits/stdc++.h>
using namespace std;
const int N = 400010;
int val[N];
int c, a, b;
int n, m;int l[N], r[N], to[N], dfn;
vector<int> v[N];struct tree {int l, r, sum, add;
} t[N * 4];void build(int u, int x, int y) {t[u].l = x;t[u].r = y;if (x == y) {t[u].sum = val[to[x]];return ;}int mid = (x + y) >> 1;build(u * 2, x, mid);build(u * 2 + 1, mid + 1, y);t[u].sum = t[u * 2].sum + t[u * 2 + 1].sum;
}void tag(int u) {if (t[u].add == 0)return;t[u * 2].sum = t[u * 2].r - t[u * 2].l + 1 - t[u * 2].sum;t[u * 2 + 1].sum = t[u * 2 + 1].r - t[u * 2 + 1].l + 1 - t[u * 2 + 1].sum;if (t[u * 2].add == 0)t[u * 2].add = 1;elset[u * 2].add = 0;if (t[u * 2 + 1].add == 0)t[u * 2 + 1].add = 1;elset[u * 2 + 1].add = 0;t[u].add = 0;
}void change(int u, int l, int r) {if (l <= t[u].l && t[u].r <= r) {t[u].sum = t[u].r - t[u].l + 1 - t[u].sum;if (t[u].add == 0)t[u].add = 1;elset[u].add = 0;return ;}tag(u);int mid = (t[u].l + t[u].r) >> 1;if (a <= mid)change(u * 2, l, r);if (b > mid)change(u * 2 + 1, l, r);t[u].sum = t[u * 2].sum + t[u * 2 + 1].sum;
}int ask(int u, int l, int r) {if (l <= t[u].l && r >= t[u].r)return t[u].sum;tag(u);int mid = (t[u].l + t[u].r) / 2;int ans = 0;if (a <= mid)ans += ask(u * 2, l, r);if (b > mid)ans += ask(u * 2 + 1, l, r);return ans;
}void dfs(int u) {l[u] = ++dfn, to[dfn] = u;for (auto i : v[u])dfs(i);r[u] = ++dfn, to[dfn] = u;
}int main() {cin >> n;for (int i = 2; i <= n; i++) {int f;cin >> f;v[f].push_back(i);}for (int i = 1; i <= n; i++)cin >> val[i];dfs(1);build(1, 1, n * 2);cin >> m;for (int i = 1; i <= m; i++) {string c;int x;cin >> c >> x;a = l[x], b = r[x];if (c == "pow")change(1, l[x], r[x]);elsecout << ask(1, l[x], r[x]) / 2 << endl;}return 0;
}
代码长,思维简单。
CF1891F A Growing Tree
给定一棵树,一开始只含了 1 1 1 个结点,编号为 1 1 1,初始权值为 0 0 0。设树的大小为 s z sz sz。
有 q q q 次操作:
-
1 x 1\ x 1 x,在 x x x 下面挂一个结点,编号为 s z + 1 sz+1 sz+1,初始的权值为 0 0 0。
-
2 x v 2\ x\ v 2 x v,将当前 x x x 子树中所有结点的权值加上 v v v。
乍一看好像无从下手:你这个加入会影响到很多结点的时间戳的值啊!于是正着在线处理操作是不行的。
这个时候有一个很重要的思想:正难则反。你正着加点不行,我反着来不行吗!
考虑离线处理操作。于是我们一开始就可以得出来把点全部加完之后的树。
如果遇到了 2 2 2 操作,就像上一道题目一样使用区间修改维护即可。
如果遇到了 1 1 1 操作,那么这个点先前的东西全部应该不算(到了这个时候这个点才加进来!它的整个子树也是一样!),所以要把整个子树都减去自己现在的权值。
所以就只需要一个支持区间加单点查询的数据结构即可,很容易想到使用树状数组加上差分,因为线段树 lazytag 还是太难写了。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int t;
int n;
const int N = 1000010;struct node {int op, x, v;
} a[N];
vector<int> v[N];
int ans[N], x[N];
int l[N], r[N], dfn;void dfs(int u) {l[u] = ++dfn;for (auto i : v[u])dfs(i);r[u] = ++dfn;
}struct BIT {int tree[N];void clear() {for (int i = 1; i <= n * 2; i++)tree[i] = 0;}void add(int pos, int val) {for (; pos <= n * 2; pos += pos & -pos)tree[pos] += val;}int query(int pos) {int ans = 0;for (; pos; pos -= pos & -pos)ans += tree[pos];return ans;}
} st;signed main() {cin >> t;while (t--) {cin >> n;dfn = 0;int sz = 1;for (int i = 1; i <= n; i++) {cin >> a[i].op;if (a[i].op == 2)cin >> a[i].x >> a[i].v;elsecin >> a[i].x, v[a[i].x].push_back(++sz), x[i] = sz;}dfs(1);st.clear();for (int i = 1; i <= n; i++) {if (a[i].op == 2) {st.add(l[a[i].x], a[i].v);st.add(r[a[i].x] + 1, -a[i].v);} else if (!ans[x[i]]) {int a = st.query(l[x[i]]);st.add(l[x[i]], -a), st.add(r[x[i]] + 1, a);}}for (int i = 1; i <= sz; i++)cout << st.query(l[i]) << " ";cout << endl;for (int i = 1; i <= sz; i++)v[i].clear(), l[i] = r[i] = 0, ans[i] = 0, x[i] = 0;}return 0;
}
AT_abc294_g [ABC294G] Distance Queries on a Tree
给定一棵 n n n 点的树,带边权,进行 Q Q Q 次操作,共有两种:
-
1 i w将第 i i i 条边的边权改为 w w w。 -
2 u v询问 u , v u,v u,v 两点的距离。
设 1 1 1 为树根。
很显然,第二个询问可以使用 LCA 来求解(因为树的形态始终不变,LCA 也不会变)。设 d i d_i di 表示 1 → i 1 \to i 1→i 的边权和,那么 u , v u,v u,v 的距离为 d u + d v − 2 × d l c a ( u , v ) d_u + d_v - 2\times d_{lca(u,v)} du+dv−2×dlca(u,v)。所以第二个询问可以 O ( log n ) O(\log n) O(logn) 快速求解。
考虑如何处理第一个询问。很显然,设 i i i 为 u → v u \to v u→v 的边(不妨让 u u u 的深度比 v v v 浅),则当 u → v u\to v u→v 的边权改变的时候(设相比原来多了 w w w),有且仅有 v v v 子树里面的 d d d 值会发生改变,具体地,改变幅度就是 w w w。
所以就是子树修改,可以直接序列化。
好久之前做的了,可能和现在的码风略有不同。
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int MAX_N = 2e5 + 5, LOG_MAX_N = 19;int n;
struct Edge {int u, v, w;
};
Edge edge[MAX_N];
vector<int> adj[MAX_N];
int q;int n_ind, start_ind[MAX_N], end_ind[MAX_N];
int anc[MAX_N][LOG_MAX_N];
void dfs(int u) {start_ind[u] = ++n_ind;for (auto& v : adj[u]) {if (start_ind[v]) anc[u][0] = v;else dfs(v);}end_ind[u] = n_ind;
}bool is_anc(int u, int v) {return start_ind[u] <= start_ind[v] && start_ind[v] <= end_ind[u];
}
int lca(int u, int v) {if (is_anc(u, v)) return u;if (is_anc(v, u)) return v;for (int i = ceil(log2(n)); i >= 0; i--) {if (anc[u][i] == 0 || is_anc(anc[u][i], v)) continue;u = anc[u][i];}return anc[u][0]; }int segtree[4 * MAX_N];
void update(int l, int r, int x, int u = 1, int lo = 1, int hi = n) {if (l <= lo && hi <= r) {segtree[u] += x;return;}int mid = (lo + hi) / 2;if (l <= mid) update(l, r, x, 2 * u, lo, mid);if (r > mid) update(l, r, x, 2 * u + 1, mid + 1, hi);
}
int query(int i, int u = 1, int lo = 1, int hi = n) {if (lo == hi)return segtree[u];int mid = (lo + hi) / 2;if (i <= mid) return segtree[u] + query(i, 2 * u, lo, mid);else return segtree[u] + query(i, 2 * u + 1, mid + 1, hi);
}signed main() {// freopen("dist.in", "r", stdin);// freopen("dist.out", "w", stdout);cin >> n;for (int i = 1; i < n; i++) {int u, v, w; cin >> u >> v >> w;edge[i] = {u, v, w};adj[u].push_back(v);adj[v].push_back(u);}cin >> q;dfs(1);for (int i = 1; i <= ceil(log2(n)); i++) {for (int j = 1; j <= n; j++) {anc[j][i] = anc[anc[j][i - 1]][i - 1];}}for (int i = 1; i < n; i++) {int u = edge[i].u, v = edge[i].v;if (start_ind[u] > start_ind[v]) swap(u, v);update(start_ind[v], end_ind[v], edge[i].w); } for (int xq = 1; xq <= q; xq++) {int t, a, b; cin >> t >> a >> b;if (t == 1) {int u = edge[a].u, v = edge[a].v;if (start_ind[u] > start_ind[v]) swap(u, v);update(start_ind[v], end_ind[v], b - edge[a].w);edge[a].w = b;} else {int ans = query(start_ind[a]) + query(start_ind[b]) - 2 * query(start_ind[lca(a, b)]);cout << ans << '\n';}}
}
CF1328E Tree Queries
接下来开始讲蓝紫题,坐稳了!
前情提要:
我很好奇为什么 CF 要搞这么多测试点。
进入正题。给你一个 1 1 1 为根的有根树,每次询问 k k k 个结点 v 1 , v 2 , ⋯ , v k v_1,v_2,\cdots,v_k v1,v2,⋯,vk,求是否有一条以根结点为一端的链使得询问的每一个结点到这条链的距离都是 ≤ 1 \le 1 ≤1。
这道题看似很不友善,实际上全部的过程就只有两句话。
个人感觉这道题还是很妙的,可能是我太菜了吧。
首先,考虑如何判断多个点在同一条一端为根的链上。
这个任务非常的简单,好像有一万种方法,这也使得选择较为困难。
考虑挖掘性质。首先,这一条链上面的每一个深度都最多出现一次,这是显然的。所以对深度排序。
排序完了之后咋办呢?显然,这样的一条链上的相邻两个点都是由祖先的关系。所以如果这堆点在同一条链上面的话,排序之后相邻的点一定存在祖孙关系。
这个时候又有了一万种方法,但是我们要选择最快的。既然都出现祖孙关系了,那么还不够启发吗?显然,祖先的子树里面一定包含子孙,所以直接使用时间戳判断区间包含即可。
也可以使用 lca 来判断。
但是,上面的东西和题目只有一点关联。因为题目要我们求的是距离 ≤ 1 \le 1 ≤1。
**继续挖掘性质!**这个链的一端是根结点,所以可以得出两个结论:
-
如果一个结点在这条链上,则其父亲也一定在链上,也就是距离 = 0 =0 =0 一定在链上。(废话)
-
如果一个结点的父亲不在链上,则它也一定不会在链上,则就是距离 > 1 >1 >1 的时候一定不在链上。
也就是,一个点距离这条链的距离是否 ≤ 1 \le 1 ≤1,和它的父亲是不是在链上有关。
所以每一个点变成它的父亲,然后再判断是不是在一条链上面即可。
注意,这里设根结点的父亲是它自己,要不然就出问题了。
#include <bits/stdc++.h>
using namespace std;
int n, m;
const int N = 200010;
int fa[N];
vector<int> v[N];
bool fg[N];
int f[N][30];
int cnt;
int a[N], dep[N];
bool ok;void dfs(int u, int pre) {f[u][0] = pre;dep[u] = dep[pre] + 1;for (int i = 1; i <= 20; ++i)f[u][i] = f[f[u][i - 1]][i - 1];for (auto i : v[u])if (i != pre)dfs(i, u);
}int lca(int x, int y) {if (dep[x] > dep[y])swap(x, y);for (int i = 20; i >= 0; --i)if (dep[f[y][i]] >= dep[x])y = f[y][i];if (y == x)return x;for (int i = 20; i >= 0; --i)if (f[y][i] != f[x][i])y = f[y][i], x = f[x][i];return f[x][0];
}void get_fa(int u, int pre) {fa[u] = pre;for (auto i : v[u])if (i != pre)get_fa(i, u);
}bool cmp(int x, int y) {return dep[x] < dep[y];
}int main() {cin >> n >> m;for (int i = 1; i < n; i++) {int x, y;cin >> x >> y;v[x].push_back(y);v[y].push_back(x);}get_fa(1, 0);dfs(1, 0);while (m--) {int k;cin >> k;int tot = 0;for (int i = 1; i <= k; i++) {int x;cin >> x;if (x != 1)a[++tot] = fa[x], fg[fa[x]] = 1;}sort(a + 1, a + tot + 1, cmp);cnt = unique(a + 1, a + tot + 1) - a - 1;ok = 1;for (int i = 1; i < cnt; i++)if (lca(a[i], a[i + 1]) != a[i])ok = 0;for (int i = 1; i <= cnt; i++)fg[a[i]] = 0;if (ok)cout << "YES\n";elsecout << "NO\n";}return 0;
}
CF383C Propagating tree
有一棵树,上面有 n n n 个结点。它的根是 1 1 1 号节点。
这棵橡树每个点都有一个权值,你需要完成这两种操作:
1 1 1 u u u v a l val val 表示给 u u u 节点的权值增加 v a l val val。
2 2 2 u u u 表示查询 u u u 节点的权值。
它还有个神奇的性质:当某个节点的权值增加 v a l val val 时,它的子节点权值都增加 − v a l -val −val,它子节点的子节点权值增加 − ( − v a l ) -(-val) −(−val)… 如此一直进行到树的底部。
很显然直接把树的深度分成奇偶性,每一个开一个线段树再记录一下 dfs 序,然后分类讨论即可。
有一些细节。
// LUOGU_RID: 168542341
#include <bits/stdc++.h>
#define ls(x) (x<<1)
#define rs(x) (x<<1|1)
#define mid ((l+r)>>1)
using namespace std;
const int N = 200010;
int n, m;
int val[N];
int dd[N * 2][2]; //两个dfs序,一个是奇数层,一个是偶数层的
int tot;
vector<int> v[N];
int dep[N];//深度void dfs(int u, int pre) { //求dfs序dep[u] = dep[pre] + 1;tot++;dd[tot][dep[u] % 2] = u;for (auto i : v[u])if (i != pre)dfs(i, u);tot++;dd[tot][dep[u] % 2] = u;
}struct segment_tree {int seg[N * 4 * 2], lazy[N * 4 * 2];void pushup(int now) {seg[now] = seg[ls(now)] + seg[rs(now)];}void pushdown(int now, int l, int r) {if (lazy[now] != 0) {lazy[ls(now)] += lazy[now];lazy[rs(now)] += lazy[now];seg[ls(now)] += (mid - l + 1) * lazy[now];seg[rs(now)] += (r - mid) * lazy[now];lazy[now] = 0;}}void build(int now, int l, int r, int wh) {lazy[now] = 0;if (l == r) {seg[now] = val[dd[l][wh]];return ;}build(ls(now), l, mid, wh);build(rs(now), mid + 1, r, wh);pushup(now);}void update(int now, int l, int r, int ql, int qr, int val) {if (l >= ql && r <= qr) {lazy[now] += val;seg[now] += (r - l + 1) * val;return ;}pushdown(now, l, r);if (ql <= mid)update(ls(now), l, mid, ql, qr, val);if (qr > mid)update(rs(now), mid + 1, r, ql, qr, val);pushup(now);}int query(int now, int l, int r, int pos) {if (l == r)return seg[now];pushdown(now, l, r);if (pos <= mid)return query(ls(now), l, mid, pos);elsereturn query(rs(now), mid + 1, r, pos);}
} sg1, sg2;
int pot[N][2];int main() {ios::sync_with_stdio(0);cin >> n >> m;for (int i = 1; i <= n; i++)cin >> val[i];for (int i = 1; i < n; i++) {int x, y;cin >> x >> y;v[x].push_back(y);v[y].push_back(x);}dfs(1, 0);sg1.build(1, 1, 2 * n, 0);sg2.build(1, 1, 2 * n, 1);for (int i = 1; i <= 2 * n; i++) {if (pot[dd[i][0]][0] == 0)pot[dd[i][0]][0] = i;elsepot[dd[i][0]][1] = i;if (pot[dd[i][1]][0] == 0)pot[dd[i][1]][0] = i;elsepot[dd[i][1]][1] = i;}while (m--) {int op;cin >> op;if (op == 1) {int x, y;cin >> x >> y;sg1.update(1, 1, 2 * n, pot[x][0], pot[x][1], (dep[x] % 2 == 1 ? -y : y));sg2.update(1, 1, 2 * n, pot[x][0], pot[x][1], (dep[x] % 2 == 0 ? -y : y));} else {int x;cin >> x;if (dep[x] % 2 == 0)cout << sg1.query(1, 1, 2 * n, pot[x][0]) << endl;elsecout << sg2.query(1, 1, 2 * n, pot[x][0]) << endl;}}return 0;
}
相关文章:

树的序列化 - 学习笔记
树的序列化可以有很多种类:可以变成 dfs 序,可以变成欧拉序,还有什么括号序的科技。 但是除了第一个以外其他的都没什么用(要么也可以被已有的算法给替代掉)。所以表面上是讲树的序列化,实际上还是讲的 df…...

数电发票整理:免费实用工具如何高效解析 XML 发票数据
如今数字电子发票越来越普及,但是数电发票的整理还是颇有讲究~ 今天给大家介绍一个 XML 发票阅读器。使用它完全不收取任何费用,且无广告干扰,对财务人员而言十分实用。 01 软件介绍 这款软件就是XML格式(数电票)阅读…...

ubuntu22.04 qemu arm64 环境搭建
目录 创建 安装 Qemu 启动 # 进入qemu虚拟机后执行 qemu编译器安装 创建 qemu-img create ubuntu22.04_arm64.img 40G 安装 qemu-system-aarch64 -m 4096 -cpu cortex-a57 -smp 4 -M virt -bios QEMU_EFI.fd -nographic -drive ifnone,fileubuntu-22.04.5-live-server-a…...
)
数据转储(go)
随着时间推移,数据库中的数据量不断累积,可能导致查询性能下降、存储压力增加等问题。数据转储作为一种有效的数据管理策略,能够将历史数据从生产数据库中转移到其他存储介质,从而减轻数据库负担,提高系统性能&…...

LeetCode167_两数之和 Ⅱ - 输入有序数组
LeetCode167_两数之和 Ⅱ - 输入有序数组 标签:#数组 #双指针 #二分查找Ⅰ. 题目Ⅱ. 示例 0. 个人方法官方题解一:二分查找官方题解二:双指针 标签:#数组 #双指针 #二分查找 Ⅰ. 题目 给你一个下标从 1 开始的整数数组 numbers …...

【AI平台】n8n入门5:创建MCP服务,及vscode调用MCP测试
前言 用n8n搭建一个MCP服务,然后用开发环境的MCP测试工具,测试调用一下。例子简单,只为了解原理。在开发环境,安装测试mcp服务的工具,vscode和Trae操作类似,而且在一个机器上的话,安装的插件公…...

第六部分:实战项目与拓展
欢迎来到 OpenCV 教程的第六部分!你已经走过了从像素操作到特征提取、再到基础目标检测的旅程。现在,我们将迎接更激动人心的挑战:将这些技术结合起来,构建更贴近实际应用的系统。 本部分将带领你从更高层面思考如何设计一个计算…...

SQL Server连接异常 证书链是由不受信任的颁发机构颁发的
使用SQL Server连接数据库时报错如下: 标题: 连接到服务器 ------------------------------ 无法连接到 DESKTOP-N2KOQ8J\SQLEXPRESS。 ------------------------------ 其他信息: A connection was successfully established with the server, but then an erro…...

WebGL图形编程实战【5】:层次构建 × Shader初始化深度剖析
层次结构模型 三维模型和现实中的人类或机器人不一样,它的部件并没有真正连接在一起。如果直接转动上臂,那么肘部以下的部分,包括前臂、手掌和手指,只会留在原地,这样手臂就断开了。 所以,当上臂绕肩关节转…...

126. 单词接龙 II
题目 按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足: 每对相邻的单词之间仅有单个字母不同。转换过程中的每个…...

【LeetCode Hot100】二叉树篇
前言 本文用于整理LeetCode Hot100中题目解答,因题目比较简单且更多是为了面试快速写出正确思路,只做简单题意解读和一句话题解方便记忆。但代码会全部给出,方便大家整理代码思路。 94. 二叉树的中序遍历 一句话题意 返回二叉树中序遍历的数…...

MySQL基础关键_002_DQL
目 录 一、初始化 二、简单查询 1.部分语法规则 2.查询一个字段 (1)查询员工编号 (2)查询员工姓名 3.查询多个字段 (1)查询员工编号、姓名 (2)查询部门编号、名称、位置 …...

游戏引擎学习第249天:清理调试宏
欢迎大家,让我们直接进入调试代码的改进工作 接下来,我们来看一下上次停留的位置。如果我没记错的话,上一场直播的结尾我有提到一些我想做的事情,并且在代码中留下了一个待办事项。所以也许我们今天首先做的就是解决这个问题。但…...

TwinCAT数据类型,%MX,%MD这些特殊符号
在 TwinCAT(Beckhoff PLC 编程环境)中,%MX、%MD 等符号是 IEC 61131-3 标准的地址表示法,用于直接访问 PLC 的物理 I/O 或内存区域。这些符号通常用于 变量声明 或 直接寻址,特别是在 TwinCAT 2 和 传统 PLC 编程 中较…...

力扣——20有效的括号
目录 1.题目描述: 2.算法思路: 3.代码展示: 1.题目描述: 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须…...

正点原子STM32H743单片机实现ADC多通道检测
目标 使用STM32CubeMX工具,配置ADC相关参数,实现在STM32H743单片机上获取ADC多通道电压值。共14个ADC引脚,ADC2有5个,ADC3有9个,全部设置单通道 ADC引脚 PF3PF4PF5PF10PC0PC2PC3PH2PH3PA3PB0PB1PA4PA5PA6 STM32cube…...

前端封装WebSocket工具n
Web API 提供的 WebSocket 类,封装一个 Socket 类 // socket.js import modal from /plugins/modal const baseURL import.meta.env.VITE_APP_BASE_WS; const EventTypes [open, close, message, error, reconnect]; const DEFAULT_CHECK_TIME 55 * 1000; // 心…...

Docker进入MySQL之后如何用sql文件初始化数据
关闭Docker-compose.yml里面所有容器 docker compose -f docker_compose.yml down后台形式开启Docker-compose.yml所有容器 docker compose -f docker_compose.yml up -d罗列出所有启动过的(包括退出过的)容器 docker ps -a进入指定容器ID内部 docke…...

Docker搜索镜像报错
科学上网最方便。。。。 尝试一: 报错处理 Error response from daemon: Get https://index.docker.io/v1/search?qmysql&n25: dial tcp 31.13.84.2:443: i/o timeout 国内从 DockerHub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。Docke…...

【Unity笔记】基于距离驱动的参数映射器 InverseDistanceMapper 设计与实现
需求: 当用户距离目标位置越近,参数值越大。 可用于控制场景亮度、动画进度、交互强度等多种效果。 一、需求背景:如何让“距离”成为设计的一部分? 在虚拟现实(VR)、增强现实(AR)乃…...

【Spring AI】Java结合ollama实现大模型调用
在较新的Java版本中,编译器已经支持了接入各种AI模型工具进行开发,这篇文章我会介绍如何利用Spring AI进行大模型的调用的基础方法。 环境准备 由于这篇文章是结合ollama进行演示,所以在开始前需要先安装ollama服务,这个的具体步…...
,工程改造记录)
docker制作python大模型镜像(miniconda环境),工程改造记录
**环境说明:**从系统镜像开始打造python大模型镜像,之前是人工手动装的方式,并且模型和依赖在公网中,对于离线交付环境不太友好,所以打造的离线化交付版本 Dockerfile: FROM centos:7.9 ENV PYTHONIOENCODINGutf-8 E…...

在油气地震资料积分法偏移成像中,起伏地表处理
在油气地震资料积分法偏移成像中,起伏地表情况会带来波场传播路径畸变、静校正问题以及成像精度下降等挑战。以下是处理起伏地表的常用方法和技术要点: 1. 静校正预处理 高程静校正:将地表各接收点校正到统一基准面(浮动基准面或…...

经典算法 独立任务最优调度问题
独立任务最优调度问题 题目描述 用2 台处理机A 和B 处理n 个作业。设第i 个作业交给机器A 处理时需要时间ai ,若由机器B 来处理,则需要时间bi 。由于各作业的特点和机器的性能关系,很可能对于某些i,有ai >bi,而对…...

在TensorFlow中,`Dense`和`Activation`是深度学习模型构建里常用的层
在TensorFlow中,Dense和Activation是深度学习模型构建里常用的层,下面就详细解释它们的使用语法和含义。 1. Dense层 含义 Dense层也就是全连接层,这是神经网络里最基础的层。在全连接层中,每一个输入神经元都和输出神经元相连…...

基于 Rancher 部署 Kubernetes 集群的工程实践指南
一、现状分析 在当今的云计算和容器化领域,Kubernetes(K8S)已经成为了容器编排和管理的事实标准。根据 Gartner 的数据,超过 70% 的企业在生产环境中使用 K8S 来管理容器化应用。然而,K8S 的安装和管理对于许多企业来…...

Seaborn
1. Seaborn概述:Seaborn是基于Matplotlib的Python数据可视化库,专注绘制统计图形。它简化可视化流程,提供高级接口与美观默认主题,能以少量代码实现复杂图形绘制。 2. 安装与导入:安装Seaborn可使用 pip install seabo…...
)
0基础FWT详解2(巩固)
FWT巩固1 FWT巩固1卡常技巧巩固习题luogu6097CF662Cluogu4221FWT巩固1 在 上篇文章 中,我们学习了 F W T FWT FWT,本文将带读者一起做几道题,巩固对 F W T FWT FWT 的使用 卡常技巧 一个常数大的 F W T FWT FWT 是非常不利于做题的,所以我们需要卡常。 作者简单总结…...

阿里云 ECS 服务器进阶指南:存储扩展、成本优化与架构设计
一、弹性存储架构:块存储深度解析与挂载实践 (一)块存储类型与技术特性 阿里云块存储作为 ECS 核心存储方案,提供三种主流类型: ESSD 云盘 性能等级:PL0/PL1/PL2/PL3,最高支持 100 万 IOPS …...

运维打铁: 存储方案全解析
文章目录 一、引言二、思维导图三、常见存储方案介绍3.1 直接附加存储(DAS,Direct Attached Storage)1. 原理2. 优缺点3. 适用场景 3.2 网络附加存储(NAS,Network Attached Storage)1. 原理2. 优缺点3. 适用…...

Semtech公司简介以及主流产品
Semtech 公司是一家美国的半导体公司,总部位于加利福尼亚州卡马里洛。以下是其简介和主流产品介绍: 公司简介 成立时间与地点:1960 年成立于加利福尼亚州纽伯里帕克。发展历程:最初为军事和航空航天公司提供零部件,1…...

flutter 专题 五十六 Google 2020开发者大会Flutter专题
由于疫情的原因,今年的Google 开发者大会 (Google Developer Summit) 在线上举行,本次大会以“代码不止”为主题,全面介绍了产品更新以及一系列面向本地开发者的技术支持内容。我比较关注的是移动开发,在本次大会上,关…...

93. 后台线程与主线程更新UI Maui例子 C#例子
在.NET MAUI开发中,多线程是常见的需求,但UI更新必须在主线程上执行。今天,我们来探讨一个简单而优雅的解决方案:MainThread.InvokeOnMainThreadAsync。 一、背景 在跨平台应用开发中,后台线程常用于执行耗时操作&am…...

5.运输层
5. 运输层 1. 概述 第2~4章依次介绍了计算机网络体系结构中的物理层、数据链路层和网络层,它们共同解决了将主机通过异构网络互联起来所面临的问题,实现了主机到主机的通信然而在计算机网络中实际进行通信的真正实体,是位于通信两端主机中的…...
)
ActiveMQ 可靠性保障:消息确认与重发机制(二)
ActiveMQ 重发机制 重发机制的原理与触发条件 ActiveMQ 的重发机制是确保消息可靠传输的重要手段。当消息发送到 ActiveMQ 服务器后,如果消费者由于某些原因未能成功处理消息,ActiveMQ 会依据配置的重发策略,将消息重新放入队列或主题中&am…...

Vue+tdesign t-input-number 设置长度和显示X号
一、需求 Vuetdesign t-input-number 想要设置input的maxlen和显示X号 二、实现 t-input,可以直接使用maxlength和clearable属性 <t-input v-model"value" clearable maxlength10 placeholder"请输入" clear"onClear" blur&q…...

机器学习|通过线性回归了解算法流程
1.线性回归引入 2.决策函数 3. 损失函数 4.目标函数 5.目标函数优化问题 6.过拟合 7.正则化...

两向量平行公式、向量与平面平行公式、两平面平行公式;两向量垂直公式、向量与平面垂直公式、两平面垂直公式
目录 一、两向量平行公式 二、向量与平面平行公式 三、两平面平行公式 四、两向量垂直公式 五、向量与平面垂直公式 六、两平面垂直公式 观察与总结 一、两向量平行公式 二、向量与平面平行公式 三、两平面平行公式 四、两向量垂直公式 五、向量与平…...

vscode 个性化
vscode 个性化 设置 吸顶效果 使用前使用后 设置方法 VS Code 的粘性滚动预览 - 类似于 Excel 的冻结首行 插件 代码片段分享 - CodeSnap 使用方式 CtrlShiftP输入CodeSnap 唤起插件选择代码 行内报错提示 - Error Lens 使用前使用后 VSCode Error Lens插件介绍&…...

OpenHarmony-简单的HDF驱动
学习于:https://docs.openharmony.cn/pages/v5.0/zh-cn/device-dev/driver/driver-hdf-manage.md 首先,OpenHarmony系统里的HDF(Hardware Driver Foundation)驱动框架,已经规范设备驱动的模型、设备节点的配置与统一的…...

Copilot重磅更新:引用文件夹创建Word文档
大家好,AI技术笔记为您带来一则好消息: 根据广大用户的反馈,Microsoft 365 Copilot在Word中的引用能力全面升级啦! 不管是撰写、审阅还是定稿文档,现在你可以更快、更高效地引用更多资料! ✨三大重磅改进…...

SQL Server数据库提权的几种方法——提权教程
SQL Server数据库提权的几种方法——提权教程 一、简介 在利用系统溢出漏洞没有效果的情况下,可以采用数据库进行提权。 数据库提权的前提条件: 1、服务器开启数据库服务 2、获取到最高权限用户密码 (除Access数据库外,其他数据库基本都存在数据库提权的可能) 二、使用x…...

解决在Mac上无法使用“ll”命令
在 macOS 上,ll 命令是一个常见的别名,它通常是指向 ls -l 的。但是,如果你看到 zsh: command not found: ll,这意味着你当前的 zsh 配置中没有设置 ll 作为别名。 解决方法: 1. 使用 ls -l 命令 如果只是想查看目录…...

Dockerfile最佳实践:构建高效、安全的容器镜像
一、前言 Dockerfile是一个文本文档,它包含用户可以在命令行上调用的所有指令,每一条指令构建一层镜像。在日常开发中我们常常需要自己编写Dockerfile来构建镜像,而构建一个精巧、实用且高品质的镜像对运行环境来说尤为重要。下面我们来排一排如何构建这样的镜像。 二、目…...

mac电脑pytest生成测试报告
时隔了好久再写代码,感觉我之前的积累都白费了,全部忘记了,看来每一步都有记录对于我来说才是最好的。 最近又要重新搞接口自动化,然而是在mac电脑,对于我长期使用windows的人来说真的是个考验,对此次过程…...

鸿蒙 应用开发 项目资源结构及资源访问
三层工程结构 模块分类 使用...

C#学习第20天:垃圾回收
什么是垃圾回收? 定义:垃圾回收是一种自动内存管理机制,负责回收不再使用的对象所占用的内存。目的:通过自动化内存回收,减少内存泄漏的风险,并简化开发者的工作。 垃圾回收的核心概念 1. 垃圾回收器的工…...

C#学习笔记 项目引用添加异常
这个问题出现多次了 我觉得有必要记录一下 场景 同一个解决方案下添加了多个项目 我想在单元测试项目中引用一下项目1,按照步骤:添加引用- 项目- 浏览- 在指定目录下找到项目的工程文件XXXSystem.csproj- 确定 然后就触发了异常 解决方案 首先 清理解决…...

使用模块中的`XPath`语法提取非结构化数据
想要在代码中使用Xpath进行处理,就需要模块lxml 模块安装 pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simplelxml的使用 使用lxml转化为Element对象 from lxml import etreetext <div> <ul> <li class"item-1"><a …...
)
复杂度和顺序表(双指针方法)
目录 目录 目录 前言: 一、时间复杂度和空间复杂度 1.1概念 1.2规则 二、顺序表 2.1静态顺序表 2.2动态顺序表 三、双指针法 四、总结 前言: 时间复杂度和空间复杂度是用于判断算法好坏的指标,程序性能的核心指标。时间复杂度主要衡…...