【LLM】MOE混合专家大模型综述(重要模块原理)
note
- 当前的 MoE 架构就是一个用显存换训练时长/推理延迟的架构
- MoE 目前的架构基本集中在于将原先 GPT 每层的 FFN 复制多份作为 n 个 expert,并增加一个 router,用来计算每个 token 对应到哪个 FFN(一般采用每个 token 固定指派 n 个 expert 的方案),也就是类似 Mixtral 7x8B 的结构。
- 之后 deepspeed 和 qwen 都陆续采用了更细的 granularity,也就是在不改变参数数量的情况下,将单个 FFN 变窄,FFN 数量变多,以及采用了 shared expert+,也就是所有 token 都会共享一部分 FFN 的方案。
文章目录
- note
- 一、相关综述和MOE介绍
- 相关MOE大模型
- 二、MOE模型的重要模块
- 基础回顾
- 路由模块
- 负载均衡
- 借助Switch Transformer简化MoE
- 三、MOE原理
- 1. 现状
- 2. 算法层面
- 3. 工程层面
- 四、Deepseek MoE代码
- 五、视觉模型中的混合专家
- 六、MOE和dense模型的对比
- Mixtral 8x7B的活跃参数与稀疏参数
- 七、常见问题
- 第一个问题:MoE 为什么能够实现在低成本下训练更大的模型。
- 第二个问题:MoE 如何解决训练稳定性问题?
- 第三个问题:MoE 如何解决 Fine-Tuning 过程中的过拟合问题?
- Reference
一、相关综述和MOE介绍
Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., & Huang, J. (2024).
A Survey on Mixture of Experts.
arXiv preprint arXiv:2407.06204v2.
Retrieved from https://arxiv.org/abs/2407.06204
MoE基于Transformer架构,主要由两部分组成:
- 稀疏 MoE 层:MoE层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”模型,每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构。
- 门控网络或路由: 这个部分用于决定哪些 token 被发送到哪个专家。例如,在上图中,“More”这个 token 可能被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。同时,一个 token 也可以被发送到多个专家。token 的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。例如Google的Switch Transformer,模型大小是T5-XXL的15倍,在相同计算资源下,Switch Transformer模型在达到固定困惑度 PPL 时,比T5-XXL模型快4倍。
国内的团队DeepSeek 开源了国内首个 MoE 大模型 DeepSeekMoE。DeepSeekMoE 2B可接近2B Dense,仅用了17.5%计算量。DeepSeekMoE 16B性能比肩 LLaMA2 7B 的同时,仅用了40%计算量。 DeepSeekMoE 145B 优于Google 的MoE大模型GShard,而且仅用 28.5%计算量即可匹配 67B Dense 模型的性能。
此外,MoE大模型的优点还有:
- 训练速度更快,效果更好。
- 相同参数,推理成本低。
- 扩展能力强,允许模型在保持计算成本不变的情况下增加参数数量,这使得它能够扩展到非常大的模型规模,如万亿参数模型。
- 多任务学习能力,MoE在多任务学习中具备很好的性能。
MoE结合大模型属于老树发新芽,MOE大模型的崛起是因为大模型的发展已经到了一个瓶颈期,包括大模型的“幻觉”问题、逻辑理解能力、数学推理能力等,想要解决这些问题就不得不继续增加模型的复杂度。随着应用场景的复杂化和细分化,垂直领域应用更加碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,尤其在多模态大模型的发展浪潮之下,每个数据集可能完全不同,有来自文本的数据、图像的数据、语音的数据等,数据特征可能非常不同,MoE是一种性价比更高的选择。
相关MOE大模型
MOE中文MOE模型汇总:
DeepSeekMoE-16B:https://sota.jiqizhixin.com/project/deepseek-moe
XVERSE-MoE-A4.2B:https://sota.jiqizhixin.com/project/xverse-moe
Qwen1.5-MoE-A2.7B:https://sota.jiqizhixin.com/project/qwen1-5
Qwen3系列模型
其他:Mixtral 8x7B模型(MoE)
[1] Mixtral 8x7B是一款改变游戏规则的AI模型
[2] https://arxiv.org/abs/2401.04088
[3] 被OpenAI、Mistral AI带火的MoE是怎么回事?一文贯通专家混合架构部署
二、MOE模型的重要模块
基础回顾
稍微复习下decocde only LLM里在LN层归一化后,一般会加上Feedforward Neural Network (FFNN)前馈网络:

路由模块
模型如何知道使用哪些专家呢:可以在专家层之前添加一个路由(也称为门控网络),它是专门训练用来选择针对特定词元的专家。
路由:路由(或门控网络)也是一个前馈神经网络(FFNN),用于根据特定输入选择专家。它可以输出概率,用于选择最匹配的专家:

路由与专家(其中只有少数被选择)共同构成MoE层:

负载均衡
我们希望在训练和推理期间让专家之间保持均等的重要性,这称为负载均衡。这样可以防止对同一专家的过度拟合。
对路由进行负载均衡的一种方式是借助"KeepTopK"(https://arxiv.org/pdf/1701.06538)直接扩展。通过引入可训练的(高斯)噪声,可以避免重复选择相同的专家。

平衡专家利用率(Balancing Expert Utilization):
论文指出,门控网络倾向于收玫到一种状态,总是为相同的几个专家产生大的权重。这种不平衡是自我强化的,因为受到青睐的专家训练得更快,因此被门控网络更多地选择。这种不平衡可能导致训练效率低下,因为某些专家可能从未被使用过。
为了解决这个问题,论文提出了一种软约束方法。作者定义了专家相对于一批训练样本的重要性 Importance( X \boldsymbol{X} X ),就是该专家在这批样本中门控值的总和。然后,他们定义了一个额外的损失函数 L importance ( X ) L_{\text {importance }}(\boldsymbol{X}) Limportance (X) ,这个损失函数被添加到模型的整体损失函数中。这个损失函数等于重要性值集合的CV(coefficient of variation)平方,乘以一个手动调整的缩放因子 w importance w_{\text {importance }} wimportance 。这个额外的损失鼓励所有专家具有相等的重要性,具体计算公式如下所示:
Importance ( X ) = ∑ x ∈ X G ( x ) L importance ( X ) = w importance ⋅ C V ( Importance ( X ) ) 2 \begin{gathered} \text { Importance }(\boldsymbol{X})=\sum_{\boldsymbol{x} \in \boldsymbol{X}} G(\boldsymbol{x}) \\ L_{\text {importance }}(\boldsymbol{X})=w_{\text {importance }} \cdot C V(\text { Importance }(\boldsymbol{X}))^2 \end{gathered} Importance (X)=x∈X∑G(x)Limportance (X)=wimportance ⋅CV( Importance (X))2
借助Switch Transformer简化MoE
首批解决了基于Transformer的MoE(例如负载均衡等)训练不稳定性问题的模型之一是Switch Transformer
三、MOE原理
1. 现状
MoE 目前的架构基本集中在于将原先 GPT 每层的 FFN 复制多份作为 n 个 expert,并增加一个 router,用来计算每个 token 对应到哪个 FFN(一般采用每个 token 固定指派 n 个 expert 的方案),也就是类似 Mixtral 7x8B 的结构。
之后 deepspeed 和 qwen 都陆续采用了更细的 granularity,也就是在不改变参数数量的情况下,将单个 FFN 变窄,FFN 数量变多,以及采用了 shared expert+,也就是所有 token 都会共享一部分 FFN 的方案。这方面推荐阅读 deepspeed 的这篇论文:《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》
论文:https://arxiv.org/abs/2401.06066
2. 算法层面
目前已有的开源模型普遍有这样的一个特点,就是当使用相同的预训练数据从零训练时,一个参数量为 N 的 dense 模型与一个参数量在 2N,激活参数量在 0.4N 的 MoE 模型能力基本相仿。这里的能力主要指在常规 benchmark,如 MMLU、C-Eval 上的分数。这种对比在 Qwen-1.5-MoE-A2.7B 和 Qwen2-57B-A14B 中最为明显。在一些小规模经验中,也基本看到了这样的结论。
https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B
https://huggingface.co/Qwen/Qwen2-57B-A14B
那么我们可以认为当前的 MoE 架构就是一个用显存换训练时长/推理延迟的架构。而对于非端侧模型,这样的 trade off 无疑是很值得的。所以我认为在算法层面上,对现阶段有指导价值的工作是围绕这个 trade off 的 Pareto 曲线,类似于如果我们可以对标一个 7B dense 模型,那么激活参数数多少的 MoE 需要多少参数,vice versa。这样的指标对于 LLM 的实际应用会很有帮助。
3. 工程层面
主要是需要实现更高效的 MoE 训练/推理基建。我对推理不太熟,主要说下训练方向,我认为主要是分 2 个方向。
一块是如何优化高稀疏度、高 granularity 的 grouped matmul kernel,让 MoE 训练的端到端速度逐步追赶同激活参数数的 dense 模型。这方面可能还是要看 cutlass 官方的一些进展,如这里:hopper_grouped_gemm。如果想自己上手的话,可以考虑类似 together.ai 的这篇博文:Supercharging NVIDIA H200 and H100 GPU Cluster Performance With Together Kernel Collection,
或者看 flash attention 3 的流水的方式来整体优化一下 FFN。这里完全对齐 dense 应该是很难的,毕竟存多了,但从经验来看,如果稀疏度不是太离谱,估计做到 dense 端到端的 80%-90% 还是很常规的。
https://github.com/NVIDIA/cutlass/tree/main/examples/57_hopper_grouped_gemmhttps://www.together.ai/blog/nvidia-h200-and-h100-gpu-cluster-performance-together-kernel-collectionhttps://tridao.me/blog/2024/flash3/
四、Deepseek MoE代码
一个demo例子:
- 定义expert类:由线性层和激活函数构成
- 定义MOE类:
- self.num_experts:专家的数量,也就是上面提到的“并列线性层”的个数,训练后的每个专家的权重都是不同的,代表它们所掌握的“知识”是不同的。
- self.top_k:每个输入token激活的专家数量。
- self.expert_capacity:代表计算每组token时,每个专家能被选择的最多次数。
- self.gate:路由网络,一般是一个线性层,用来计算每个专家被选择的概率。
- self.experts:实例化Expert类,生成多个专家。
- 损失函数包含2部分:专家利用率均衡和样本分配均衡。
import torch
import torch.nn as nn
import torch.nn.functional as F
# import torch_npu
# from torch_npu.contrib import transfer_to_npuclass Expert(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super().__init__()self.net = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.GELU(),nn.Linear(hidden_dim, output_dim))def forward(self, x):return self.net(x)class MoE(nn.Module):def __init__(self, input_dim, num_experts, top_k, expert_capacity, hidden_dim, output_dim):super().__init__()self.num_experts = num_expertsself.top_k = top_kself.expert_capacity = expert_capacity# 路由网络self.gate = nn.Linear(input_dim, num_experts)# 专家集合self.experts = nn.ModuleList([Expert(input_dim, hidden_dim, output_dim) for _ in range(num_experts)])def forward(self, x):batch_size, input_dim = x.shapedevice = x.device# 路由计算logits = self.gate(x)probs = torch.softmax(logits, dim=-1)print("probs: ", probs)topk_probs, topk_indices = torch.topk(probs, self.top_k, dim=-1)print("topk_probs: ", topk_probs)print("topk_indices: ", topk_indices)# 辅助损失计算if self.training:# 重要性损失(专家利用率均衡):如果每个专家被选择的概率相近,那么说明分配越均衡,损失函数越小importance = probs.sum(0)importance_loss = torch.var(importance) / (self.num_experts ** 2)# 负载均衡损失(样本分配均衡)mask = torch.zeros_like(probs, dtype=torch.bool)mask.scatter_(1, topk_indices, True)routing_probs = probs * maskexpert_usage = mask.float().mean(0)routing_weights = routing_probs.mean(0)load_balance_loss = self.num_experts * (expert_usage * routing_weights).sum()aux_loss = importance_loss + load_balance_losselse:aux_loss = 0.0# 专家分配逻辑flat_indices = topk_indices.view(-1)flat_probs = topk_probs.view(-1)sample_indices = torch.arange(batch_size, device=device)[:, None]\.expand(-1, self.top_k).flatten()print("sample_indices: ", sample_indices)# 初始化输出outputs = torch.zeros(batch_size, self.experts[0].net[-1].out_features, device=device)# 处理每个专家for expert_idx in range(self.num_experts):print("expert_idx: ", expert_idx)# 获取分配给当前专家的样本expert_mask = flat_indices == expert_idxprint("expert_mask: ", expert_mask)expert_samples = sample_indices[expert_mask]print("expert_samples: ", expert_samples)expert_weights = flat_probs[expert_mask]print("expert_weights: ", expert_weights)# 容量控制if len(expert_samples) > self.expert_capacity:expert_samples = expert_samples[:self.expert_capacity]expert_weights = expert_weights[:self.expert_capacity]if len(expert_samples) == 0:continue# 处理专家计算expert_input = x[expert_samples]print("expert_input: ", expert_input)expert_output = self.experts[expert_idx](expert_input)weighted_output = expert_output * expert_weights.unsqueeze(-1)# 累加输出outputs.index_add_(0, expert_samples, weighted_output)return outputs, aux_loss# 测试示例
if __name__ == "__main__":input_dim = 5output_dim = 10num_experts = 8top_k = 3expert_capacity = 32hidden_dim = 512batch_size = 10# add# device = torch.device("npu:4" if torch.npu.is_available() else "cpu")device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")moe = MoE(input_dim, num_experts, top_k, expert_capacity, hidden_dim, output_dim).to(device)# x.shape: (batch_size, input_dim)x = torch.randn(batch_size, input_dim).to(device)moe.eval()output, _ = moe(x)print(f"Eval output shape: {output.shape}") # torch.Size([64, 256])
其他参考:
https://github.com/deepseek-ai/DeepSeek-MoE
通过对比不同配置下的Dense模型和MoE模型,我们清楚地看到了MoE架构在提升性能和优化计算资源方面的巨大潜力。MoE模型不仅在相同参数量下表现优异,更在激活参数减少的情况下依然保持了高效的训练效果。特别是DeepSeek MoE模型,通过增加专家层数量和引入share expert的创新机制,大幅提升了计算效率和模型效果。DeepSeek MoE在使用更少激活参数的前提下,依然能够达到与大型Dense模型相当的性能,展示了其在处理复杂任务中的独特优势。
参考:探索混合专家(MoE)模型预训练:开源项目实操
五、视觉模型中的混合专家
图片分patch切分,分别对应图片token。

六、MOE和dense模型的对比
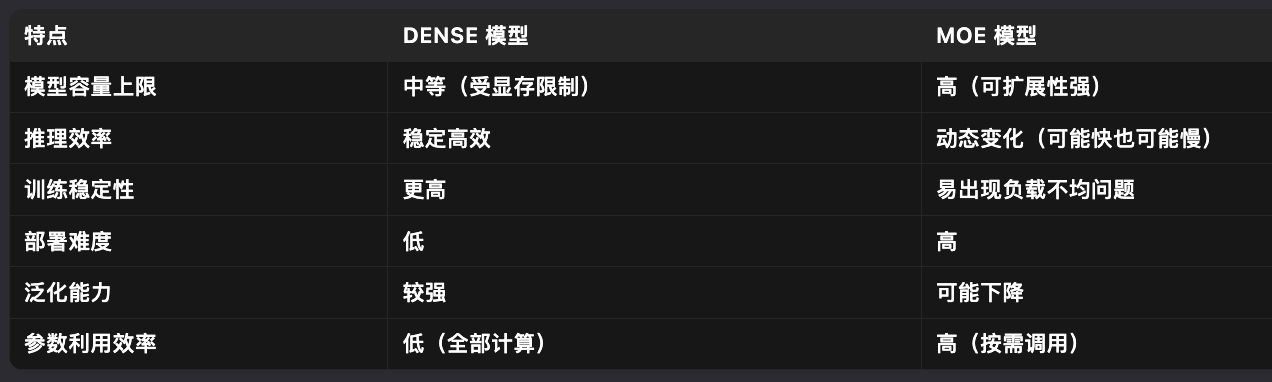
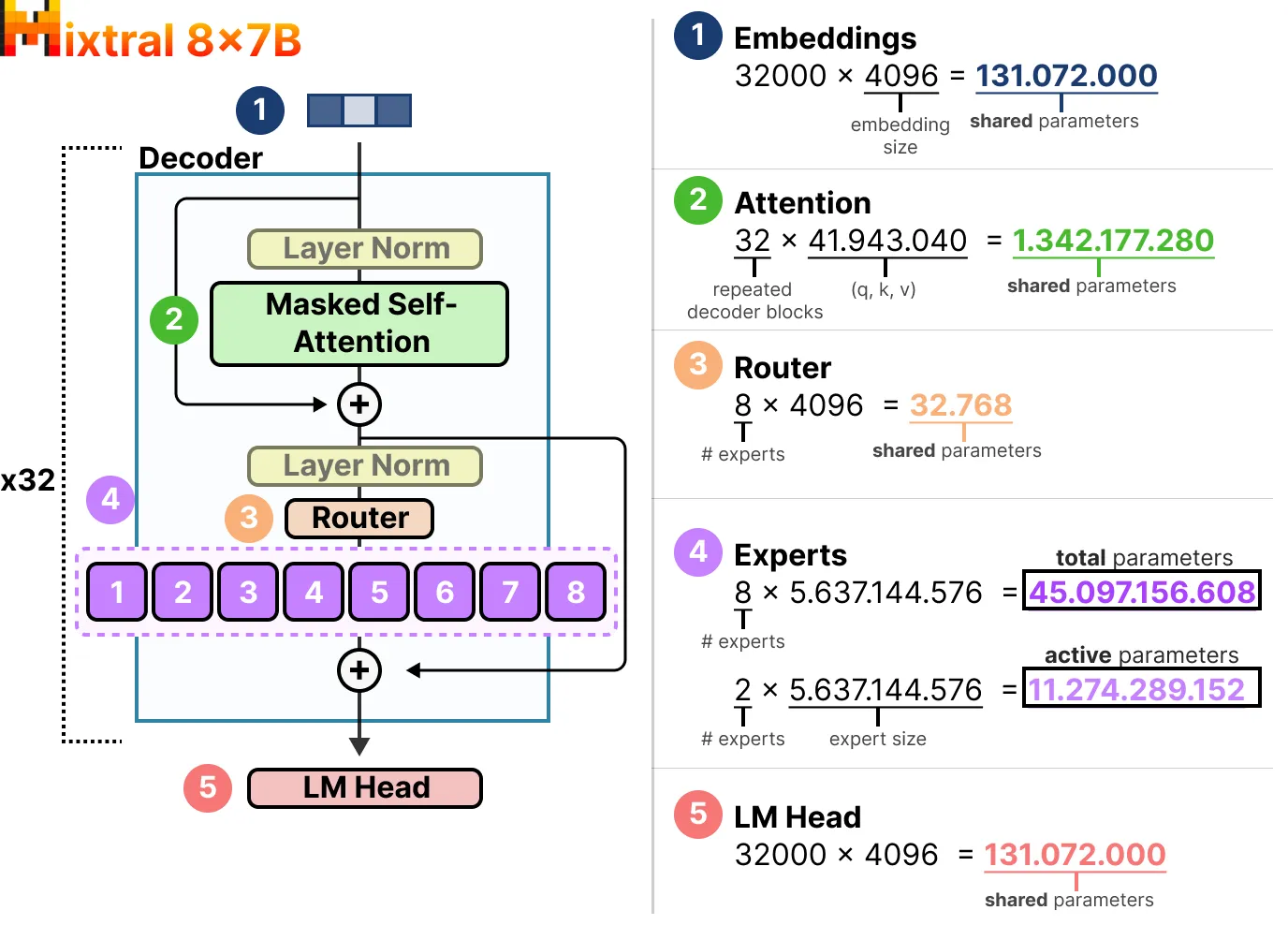
Mixtral 8x7B的活跃参数与稀疏参数
以Mixtral 8x7B来探讨稀疏参数与活跃参数的数量:
七、常见问题
第一个问题:MoE 为什么能够实现在低成本下训练更大的模型。
这主要是因为稀疏路由的原因,每个 token 只会选择 top-k 个专家进行计算。同时可以使用模型并行、专家并行和数据并行,优化 MoE 的训练效率。而负载均衡损失可提升每个 device 的利用率。
第二个问题:MoE 如何解决训练稳定性问题?
可以通过混合精度训练、更小的参数初始化,以及 Router z-loss 提升训练的稳定性。
第三个问题:MoE 如何解决 Fine-Tuning 过程中的过拟合问题?
可以通过更大的 dropout (主要针对 expert)、更大的学习率、更小的 batch size。目前看到的主要是预训练的优化,针对 Fine-Tuning 的优化主要是一些常规的手段。
Reference
[1] Qwen1.5-MoE模型:2.7B的激活参数量达到7B模型的性能
[2] 开源MOE再添一员:通义团队Qwen1.5 MOE A2.7B大模型
[3] https://qwenlm.github.io/blog/qwen-moe/
[4] AIR学术|微软副总裁高剑峰:Brain-inspired Efficient AI Modeling
[5] 某乎:朱小霖:https://www.zhihu.com/question/664040671/answer/3655141787
[6] MoE模型的前世今生
[7] Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., & Huang, J. (2024). A Survey on Mixture of Experts. arXiv preprint arXiv:2407.06204v2. Retrieved from https://arxiv.org/abs/2407.06204
[8] 图解MOE:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
[9] 群魔乱舞:MoE大模型详解
其他中文reference:
快速了解MOE架构!多专家大模型如何实现效果最佳
【论文】混合专家模型(MoE)综述
专题解读 | 混合专家模型在大模型微调领域进展.北邮
为什么最新的LLM采用 MoE(混合专家)架构?
探索混合专家(MoE)模型预训练:开源项目实操
从ACL 2024录用论文看混合专家模型(MoE)最新研究进展
50张图,直观理解混合专家(MoE)大模型
大模型:混合专家模型(MoE)概述
稀疏大模型一览:从MoE、Sparse Attention到GLaM
DeepSeek模型MOE结构代码详解
其他英文reference:
[1] Zoph, Barret, et al. “St-moe: Designing stable and transferable sparse expert models. arXiv 2022.” arXiv preprint arXiv:2202.08906.
[2] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[3] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[4] Lepikhin, Dmitry, et al. “Gshard: Scaling giant models with conditional computation and automatic sharding.” arXiv preprint arXiv:2006.16668 (2020).
[5] Fedus, William, Barret Zoph, and Noam Shazeer. “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.” Journal of Machine Learning Research 23.120 (2022): 1-39.
[6] Dosovitskiy, Alexey. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[7] Riquelme, Carlos, et al. “Scaling vision with sparse mixture of experts.” Advances in Neural Information Processing Systems 34 (2021): 8583-8595.
[8] Puigcerver, Joan, et al. “From sparse to soft mixtures of experts.” arXiv preprint arXiv:2308.00951 (2023).
[9] Jiang, Albert Q., et al. “Mixtral of experts.” arXiv preprint arXiv:2401.04088 (2024).
相关文章:
)
【LLM】MOE混合专家大模型综述(重要模块原理)
note 当前的 MoE 架构就是一个用显存换训练时长/推理延迟的架构MoE 目前的架构基本集中在于将原先 GPT 每层的 FFN 复制多份作为 n 个 expert,并增加一个 router,用来计算每个 token 对应到哪个 FFN(一般采用每个 token 固定指派 n 个 exper…...

量子机器学习中的GPU加速实践:基于CUDA Quantum的混合编程模型探索
引言:量子机器学习的新范式 在量子计算与经典机器学习交叉融合的前沿领域,量子机器学习(Quantum Machine Learning, QML)正经历着革命性突破。然而,随着量子比特规模的增长和算法复杂度的提升,传统计算架构…...

CentOS Linux 环境二进制方式安装 MySQL 5.7.32
文章目录 安装依赖包新建用户解压初始化配置文件启动服务登录MySQL修改密码停止数据库 安装依赖包 yum -y install libaio perl perl-devel libncurses* autoconf numactl新建用户 useradd mysql解压 tar xf mysql-5.7.32-linux-glibc2.12-x86_64.tar.gz mv mysql-5.7.32-l…...

数学:拉马努金如何想出计算圆周率的公式?
拉马努金(Srinivasa Ramanujan)提出的圆周率(π)计算公式,源于他对数学模式的超凡直觉、对无穷级数和模形式的深刻洞察,以及独特的非传统数学思维方式。尽管他的思考过程带有强烈的个人色彩,甚至…...

Java 未来技术栈:从云原生到 AI 融合的企业级技术演进路线
一、云原生架构:重构 Java 应用的运行范式 1.1 微服务架构的深度进化 Java 在微服务领域的实践正从 Spring Cloud 向服务网格(Service Mesh)演进。以 Istio 为代表的服务网格技术,通过 Sidecar 模式实现服务间通信的透明化管理&…...

mid360驱动安装以及联合相机标定
1 mid360 安装 1.1 安装 一定要使用 SDK2和 ROS2驱动(livox_ros_driver2) 先安装SDK2,再安装livox_ros_driver2 GitHub - Livox-SDK/Livox-SDK2: Drivers for receiving LiDAR data and controlling lidar, support Lidar HAP and Mid-360. GitHub - Livox-SDK/l…...

LeetCode —— 572. 另一棵树的子树
572. 另一棵树的子树 题目:给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。 二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所…...
)
模型部署技巧(一)
模型部署技巧(一) 以下内容是参考CUDA与TensorRT模型部署内容第六章,主要针对图像的前/后处理中的trick。 参考: 1.部署分类器-int8-calibration 2. cudnn安装地址 3. 如何查找Tensor版本,与cuda 和 cudnn匹配 4. ti…...

PostgreSQL中的SSL
PGSQL数据库的默认隔离级别是读提交,并且同时支持可重复读和序列化模式。但是在9.1之前的版本中,序列化模式等价于快照隔离,并非是真正的序列化模式。 这样的话就会存在一个问题,那就是写偏序(Write Skew)…...

使用 Spring Data Redis 实现 Redis 数据存储详解
使用 Spring Data Redis 实现 Redis 数据存储详解 Spring Data Redis 是 Spring 生态中操作 Redis 的核心模块,它封装了 Redis 客户端的底层细节(如 Jedis 或 Lettuce),提供了统一的 API 来操作 Redis 的数据结构。以下是详细实现…...

短视频矩阵系统贴牌开发实战:批量剪辑文件夹功能设计与实现
摘要:在短视频矩阵系统的开发中,批量处理功能是提升运营效率的关键。本文将深入探讨如何实现基于文件夹的短视频批量剪辑功能,涵盖技术选型、核心功能实现及代码示例。 一、需求背景与场景价值 在短视频矩阵运营场景中,运营者常面…...

2025年消防设施操作员考试题库及答案
一、判断题 25.防火门顺序器使用半个月后,需检查所有的螺钉,对固定螺钉进行加固拧紧,后续每月进行一次。() 答案:错误 解析:本题考查的是防火门顺序器的保养。防火门顺序器使用一周后&#x…...

ASP.NET MVC后端控制器用模型 接收前端ajax数据为空
1、前端js代码 如下: const formData {DeptName: D001,Phone: 12345678900 };$.ajax({url: "/Phone/SavePhone1",type: "POST",contentType: "application/json",data: JSON.stringify(formData), //必须要JSON.stringifysuccess:…...

ES基本使用方式
ES基本使用 文章目录 ES基本使用1.es的访问使用URL访问 2.mapping的理解Dynamic Mappingkeyword 与 text的区别基础定义与核心差异主字段,子字段 创建mapping 3.创建索引4.查看索引列表5.删除索引6.添加数据7.查询数据 重置es密码,初始用户elastic el…...

【中间件】bthread效率为什么高?
bthread效率为什么更高? 1 基本概念 bthread是brpc中的用户态线程,也是协程的一种实现。其采用M:N模型,即多个用户线程映射到少量的系统线程上。 2 高效做法 用户态调度:避免内核态和用户态之间的切换开销,上下文切…...
Transformer架构指南:从原理到实战资源全更新
🌟 什么是Transformer? 2017年Google提出的Transformer架构,彻底颠覆了传统RNN/LSTM的序列建模方式,通过自注意力机制实现全局上下文建模,成为GPT、BERT等大模型的底层基石。其核心优势在于并行化计算和长距离依赖捕捉…...

数据库规范
数据库版本相关 版本:mysql8.0 引擎:InnoDB 字符集:utf8mb4_general_ci 表名称 字段名称te 不允许使用大写字母,尽量使用英文或英文缩写,中间用下划线连接 数据表前缀为zzt_ 同一功能模块的表(特别是附表)尽量保持…...

Java 核心--泛型枚举
作者:IvanCodes 发布时间:2025年4月30日🤓 专栏:Java教程 各位 CSDN伙伴们,大家好!👋 写了那么多代码,有没有遇到过这样的“惊喜”:满心欢喜地从 ArrayList 里取出数据…...

使用skywalking进行go的接口监控和报警
安装 helm upgrade --install skywalking ./skywalking-v1 --namespace skywalking --create-namespace 查看安装结果 kubectl get pod -n skywalking NAME READY STATUS RESTARTS AGE elasticsearch-6c4ccbf99f-ng6sk 1/1 …...

基于Docker的Elasticsearch ARM64架构镜像构建实践
一、前言 Elasticsearch(以下简称为ES) 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次…...

【Token系列】14|Prompt不是文本,是token结构工程
文章目录 14|Prompt不是文本,是token结构工程一、很多人写的是“自然语言”,模型读的是“token序列”二、Prompt写法会直接影响token结构密度三、token分布影响Attention矩阵的聚焦方式四、token数 ≠ 有效信息量五、Prompt结构设计建议&…...

在宝塔面板中安装OpenJDK-17的三种方法
title: 在宝塔面板中安装OpenJDK-17的三种方法 date: 2025-4-30 categories: 技术教程 tags: [Minecraft, 服务器搭建, 宝塔面板, Java] 如果你的宝塔面板软件商店中缺少 OpenJDK-17(例如搭建 Minecraft 1.17 服务器时),本文提供三种解决方…...

瑞昱点屏芯片RTD2785T带旋转功能
一、产品概述 RTD2785T是瑞昱半导体(Realtek)推出的新一代高性能显示驱动芯片,专为高端显示器、嵌入式系统、工业控制及专业影像设备设计。该芯片集成多接口输入(HDMI、DP、DVI、VGA)与多种输出接口(eDP、…...
省赛回忆)
蓝桥杯Python(B)省赛回忆
Q:为什么我要写这篇博客? A:在蓝桥杯软件类竞赛(Python B组)的备赛过程中我在网上搜索关于蓝桥杯的资料,感谢你们提供的参赛经历,对我的备赛起到了整体调整的帮助,让我知道如何以更…...

自主采集高质量三维重建数据集指南:面向3DGS与NeRF的图像与视频拍摄技巧【2025最新版!!】
一、✨ 引言 随着三维重建技术的飞速发展,NeRF(Neural Radiance Fields)与 3D Gaussian Splatting(3DGS)等方法成为重建真实场景和物体几何细节的前沿方案。这些方法在大规模场景建模、机器人感知、文物数字化、工业检…...

为Mac用户定制的云服务器Vultr 保姆级教程
以下是专为 Mac 用户 定制的 Vultr 保姆级教程,涵盖从注册、部署服务器到常见问题解决的全流程指南,配合实际案例和故障排查,确保流畅使用。 一、Vultr 基础介绍 1.Vultr 是什么? Vultr 是一家美国云计算服务商,提供…...

广州创科——湖北房县汪家河水库除险加固信息化工程
汪家河水库 汪家河水库位于湖北省房县,建于1971年,其地利可谓是天公之作,东西二山蜿蜒起伏,山峰相连,峰峰比高,无有尽头,东边陡峭,西边相对平坦,半山腰有一条乡村道路&am…...

LeetCode392_判断子序列
LeetCode392_判断子序列 标签:#双指针 #字符串 #动态规划Ⅰ. 题目Ⅱ. 示例 0. 个人方法官方题解一:双指针官方题解二:动态规划 标签:#双指针 #字符串 #动态规划 Ⅰ. 题目 给定字符串 s 和 t ,判断 s 是否为 t 的子序…...

力扣第447场周赛
这次终于赶上力扣的周赛了, 赛时成绩如下(依旧还是三题 ): 1. 统计被覆盖的建筑 给你一个正整数 n,表示一个 n x n 的城市,同时给定一个二维数组 buildings,其中 buildings[i] [x, y] 表示位于坐标 [x, y] 的一个 唯一 建筑。 如…...

kotlin中Triple的作用
在 Kotlin 里,Triple 是标准库提供的一个类,其作用是创建一个包含三个元素的不可变容器。以下是关于它的详细介绍: 基本作用 Triple 类让你能够把三个不同类型的值组合成一个单一对象,方便在函数间传递或者存储这三个相关的值。…...

jmeter读取CSV文件中文乱码的解决方案
原因分析 CSV文件出现中文乱码通常是因为文件编码与JMeter读取编码不一致。常见场景: 文件保存为GBK/GB2312编码,但JMeter以UTF-8读取。文件包含BOM头(如Windows记事本保存的UTF-8),但JMeter未正确处理。脚本读取文…...

Mysql查询异常【Truncated incorrect INTEGER value】
文章目录 异常原因分析1、数据类型不一致2、数据长度超长3、数据格式要正确 处理方案模拟案例创建表数据查询 异常 在执行MySQL的语句时,在控制台报错如下所示。 Data truncation: Truncated incorrect INTEGER value 原因分析 1、数据类型不一致 必须要保证数据…...

vue+django农产品价格预测和推荐可视化系统[带知识图谱]
文章结尾部分有CSDN官方提供的学长 联系方式名片 文章结尾部分有CSDN官方提供的学长 联系方式名片 关注B站,有好处! ✅编号:D010 vue django 前后端分离架构搭建的系统带有推荐算法、价格预测、可视化、知识图谱数据从爬虫获取可以更新到最…...
)
2025年天梯题解(L1-8 + L2)
L1-112 现代战争 题目 既然是从大到小轰炸,将所有点存储为三元组(value, x, y)。 排序之后, 记录行列被轰炸的编号,进行 k 次挑选即可。 #include <bits/stdc.h> using namespace std;constexpr int MAXN 1000; struct …...

AndroidStudio生成AAR
Android Studio 2024.3 版本。如何生成 AAR 文件呢? 操作步骤 1、菜单栏,找到 Build 2、清除项目 Clean Project 3、构建项目 Assemble Project生成 AAR 路径 在 我们构建 lib 库下面。 build/outputs/aar/ xxxx下面截图为证: 我的…...

Vue3 后台管理系统模板
Vue3 后台管理系统模板 gie仓库地址 一个基于 Vue3 TypeScript Element Plus 的后台管理系统模板,集成了动态路由和权限管理功能。 技术栈 Vue 3.2TypeScript 4.5Vue Router 4Vuex 4Element Plus 2.9AxiosLess 功能特性 🚀 基于 Vue3 最新技术栈开…...

RPG4.设置角色输入
这一篇是进行玩家移动和视角移动的介绍。 1.在玩家内进行移动覆写 virtual void SetupPlayerInputComponent(UInputComponent* PlayerInputComponent) override; 2.创建增强输入资产的变量创建 UPROPERTY(EditDefaultsOnly, BlueprintReadOnly, Category "CharacterD…...

生产模块-备货生产
特点 从狭义的角度来看,备货生产场景主要出现在产品定制化需求低,产品工艺流程稳定可以大批生产,市场行情可预测的企业。为了实现订单快速交付,缩短交货周期,企业往往会结合公司历史订单数据和当前市场情况安排提前生产…...

GRE隧道
1.在锐捷网络设备中,tunnel mode gre ip 和 tunnel mode gre multipoint 是两种不同的 GRE(Generic Routing Encapsulation)隧道模式,主要区别在于连接拓扑和使用场景: 1. tunnel mode gre ip(点到点 GRE …...

ASP.NET MVC 入门与提高指南六
31. 事件驱动架构与 MVC 集成 31.1 事件驱动架构概念 事件驱动架构(Event - Driven Architecture,EDA)是一种软件设计模式,系统中的组件通过发布和订阅事件来进行通信。在这种架构中,当某个事件发生时,相…...

【MongoDB篇】MongoDB的文档操作!
目录 引言第一节:C - Create - 创建文档 (Insert) 👶➕第二节:R - Read - 读取文档 (Query) 📚👀第三节:U - Update - 更新文档 (Update) 🔄✍️第四节:D - Delete - 删除文档 (Dele…...

详解具身智能机器人开源数据集:RoboMIND
一、RoboMIND基础信息 RoboMIND 发布时间:2024年12月 创建方:国家地方共建具身智能机器人创新中心与北京大学计算机学院联合创建。 所使用的机器人:单臂机器人(Franka Emika Panda 、UR5e )、双臂机器人(…...
)
施磊老师rpc(一)
文章目录 mprpc项目**项目概述**:深入学习到什么**前置学习建议**:核心内容其他技术与工具**项目特点与要求**:**环境准备**: 技术栈集群和分布式理论单机聊天服务器案例分析集群聊天服务器分析分布式系统介绍多个模块的局限引入分…...

视觉问答大模型速递:Skywork-R1V2-38B
Skywork-R1V2-38B速读 一、模型概述 Skywork-R1V2-38B是一种最先进的开源多模态推理模型,在多项基准测试中表现卓越。它在MMMU测试中以73.6%的得分位居所有开源模型之首,在OlympiadBench测试中以62.6%的得分大幅领先于其他开源模型。此外,R…...

Spring Boot 中集成 Kafka 并实现延迟消息队列
在 Spring Boot 中集成 Kafka 并实现延迟消息队列,需要结合 Kafka 的基础功能与自定义逻辑来处理延迟投递。以下是完整的实现步骤和示例代码,涵盖配置、生产者、消费者、延迟队列设计和消息重试机制。 一、环境准备与依赖配置 添加依赖 在 pom.xml 中添加 Spring Kafka 依赖:…...

【算法学习】哈希表篇:哈希表的使用场景和使用方法
算法学习: https://blog.csdn.net/2301_80220607/category_12922080.html?spm1001.2014.3001.5482 前言: 在之前学习数据结构时我们就学习了哈希表的使用方法,这里我们主要是针对哈希表的做题方法进行讲解,都是leetcode上的经典…...
LCD显示红外遥控相关数据(Delay延时函数)(LCD1602教程)(Int0和Timer0外部中断教程)(IR红外遥控模块教程))
(51单片机)LCD显示红外遥控相关数据(Delay延时函数)(LCD1602教程)(Int0和Timer0外部中断教程)(IR红外遥控模块教程)
前言: 本次Timer0模块改装了一下,注意!!! 演示视频: 红外遥控 源代码: 如上图将9个文放在Keli5 中即可,然后烧录在单片机中就行了 烧录软件用的是STC-ISP,不知道怎么安…...

农产品园区展示系统——仙盟创梦IDE开发
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>农业大数据平台</title><style>* {margi…...

Copilot:您的AI伴侣-微软50周年系列更新
回顾微软五十年来持续创新带来的深远影响,比尔盖茨当年"让每张办公桌、每个家庭都拥有电脑"的宏伟愿景至今仍激励着我们。微软AI团队正秉承同样的精神,打造属于每个人的AI伙伴——Copilot。 这意味着什么?它是什么模样?…...

【人工智能】深入探索Python中的自然语言理解:实现实体识别系统
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 自然语言理解(NLU)是人工智能(AI)领域中的重要研究方向之一,其目标是让计算机理解和处理人类语言。在NLU的众多应用中,实体识别(Nam…...