Gradio全解20——Streaming:流式传输的多媒体应用(1)——流式传输音频:魔力8号球
Gradio全解20——Streaming:Streaming:流式传输的多媒体应用(1)——流式传输音频:魔力8号球
- 前言
- 本篇摘要
- 20. Streaming:流式传输的多媒体应用
- 20.1 流式传输音频:魔力8号球
- 20.1.1 工作原理
- 20.1.2 Inference API:在服务器上运行推理
- 1. text_to_image:文生图任务
- 2. chat_completion:生成响应
- 20.1.3 Spaces ZeroGPU:动态GPU分配方案
- 1. ZeroGPU Spaces使用与托管指南
- 2. 其它技术性说明
- 3. ZeroGPU快速入门
- 20.1.4 用户界面
- 20.1.5 转录语音与生成回答
- 20.1.6 语音合成与流式传输
- 参考文献:
前言
本系列文章主要介绍WEB界面工具Gradio。Gradio是Hugging Face发布的简易WebUI开发框架,它基于FastAPI和svelte,可以使用机器学习模型、python函数或API开发多功能界面,并可部署人工智能模型,是当前热门的非常易于展示机器学习大语言模型LLM及扩散模型DM的WebUI框架。
本系列文章分为六部分:Gradio介绍、HuggingFace资源与工具库、Gradio基础功能实战、LangChain详解、Gradio与大模型融合实战及Agent代理实战、Gradio高级功能实战。第一部分Gradio介绍,方便读者对Gradio整体把握,包括三章内容:第一章先介绍Gradio的概念,包括详细技术架构、历史、应用场景、与其他框架Gradio/NiceGui/StreamLit/Dash/PyWebIO的区别,然后详细讲述Gradio的安装与运行,安装包括Linux/Win/Mac三类系统安装,运行包括普通方式和热重载方式;第二章介绍Gradio的4种部署方式,包括本地部署launch()、huggingface托管、FastAPI挂载和Gradio-Lite浏览器集成;第三章介绍Gradio的三种客户端(Client),包括python客户端、javascript客户端和curl客户端。第二部分讲述著名网站Hugging Face的各类资源和工具库,因为Gradio演示中经常用到Hugging Face的models,还有某些场景需要部署在Spaces,以及经常用到的transformers及datasets库,包括两章内容:第四章详解三类资源models/datasets/spaces的使用,第五章实战六类工具库transformers/diffusers/datasets/PEFT/accelerate/optimum实战。第三部分实战Gradio基础功能,进入本系列文章的核心,包括四章内容:第六章讲解Gradio库的模块架构和环境变量,第七章讲解Gradio高级抽象界面类Interface,第八章讲解Gradio底层区块类Blocks,第九章讲解补充特性Additional Features。第四部分讲述LangChain,包括四章内容:第十章讲述LangChain基础知识详述,内容有优势分析、学习资料、架构及LCEL,第十一章讲述LangChain组件Chat models,第十二章讲述组件Tools/Toolkits,第十三章讲述其它五类主要组件:Text splitters/Document loaders/Embedding models/Vector stores/Retrievers。第五部分是Gradio与大模型融合及Agent代理实战,包括四章内容:第十四章讲解融合大模型的多模态聊天机器人组件Chatbot,第十五章讲解使用transformers.agents构建Gradio,第十六章讲述使用LangChain Agents构建Gradio及Gradio Tools,第十七章讲述使用LangGraph构建Gradio。第六部分讲述Gradio其它高级功能,包括三章内容:第十八章讲述从Gradio App创建Discord Bot/Slack Bot/Website Widget,第十九章讲述数据科学与绘图Data Science And Plots,第二十章讲述流式传输Streaming。
本系列文章讲解细致,涵盖Gradio及相关框架的大部分组件和功能,代码均可运行并附有大量运行截图,方便读者理解并应用到开发中,Gradio一定会成为每个技术人员实现各种奇思妙想的最称手工具。
本系列文章目录如下:
- 《Gradio全解1——Gradio简介》
- 《Gradio全解1——Gradio的安装与运行》
- 《Gradio全解2——Gradio的3+1种部署方式实践》
- 《Gradio全解2——浏览器集成Gradio-Lite》
- 《Gradio全解3——Gradio Client:python客户端》
- 《Gradio全解3——Gradio Client:javascript客户端》
- 《Gradio全解3——Gradio Client:curl客户端》
- 《Gradio全解4——剖析Hugging Face:详解三类资源models/datasets/spaces》
- 《Gradio全解5——剖析Hugging Face:实战六类工具库transformers/diffusers/datasets/PEFT/accelerate/optimum》
- 《Gradio全解6——Gradio库的模块架构和环境变量》
- 《Gradio全解7——Interface:高级抽象界面类(上)》
- 《Gradio全解7——Interface:高级抽象界面类(下)》
- 《Gradio全解8——Blocks:底层区块类(上)》
- 《Gradio全解8——Blocks:底层区块类(下)》
- 《Gradio全解9——Additional Features:补充特性(上)》
- 《Gradio全解9——Additional Features:补充特性(下)》
- 《Gradio全解10——LangChain基础知识详述》
- 《Gradio全解11——LangChain组件Chat models详解》
- 《Gradio全解12——LangChain组件Tools/Toolkits详解》
- 《Gradio全解13——LangChain其它五类组件详解》
- 《Gradio全解14——Chatbot:融合大模型的多模态聊天机器人》
- 《Gradio全解15——使用transformers.agents构建Gradio》
- 《Gradio全解16——使用LangChain Agents构建Gradio及Gradio Tools》
- 《Gradio全解17——使用LangGraph构建Gradio》
- 《Gradio全解18——从Gradio App创建Discord Bot/Slack Bot/Website Widget》
- 《Gradio全解19——Data Science And Plots:数据科学与绘图》
- 《Gradio全解20——Streaming:流式传输的多媒体应用》
本章目录如下:
- 《Gradio全解20——Streaming:流式传输的多媒体应用(1)——流式传输人工智能生成的音频》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(2)——构建对话式聊天机器人》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(3)——实时语音识别技术》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(4)——基于Groq的带自动语音检测功能的多模态Gradio应用》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(5)——基于WebRTC的摄像头实时目标检测》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(6)——构建视频流目标检测系统》;
本篇摘要
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。
20. Streaming:流式传输的多媒体应用
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。音频应用包括流式传输音频、构建音频对话式聊天机器人、实时语音识别技术和自动语音检测功能;图像应用包括基于WebRTC的摄像头实时目标检测;视频应用包括构建视频流目标检测系统。
20.1 流式传输音频:魔力8号球
在本指南中,我们将构建一个新颖的AI应用:会说话的魔力8号球🎱(Magic 8 Ball),以展示Gradio的音频流式输出功能。Magic 8 Ball是一种玩具,在你摇晃它后,它会回答任何问题,而我们的应用不仅能给出回答,还会用语音播报答案!这篇博客不会涵盖所有实现细节,但代码已在Hugging Face Spaces上开源:gradio/magic-8-ball。
20.1.1 工作原理
本例会说话的魔力8号球的工作原理:和经典的Magic 8 Ball一样,用户需要口头提问,然后等待回应。在后台,我们将使用Whisper进行语音转录,再通过大语言模型(LLM)生成Magic 8 Ball风格的答案,最后用Parler TTS将回答朗读出来。
在讲述逻辑实现之前,需要先学习一下要用到的知识点:Inference API和ZeroGPU,已掌握这两个知识点的读者可直接跳过。
20.1.2 Inference API:在服务器上运行推理
推理是使用训练好的模型对新数据进行预测的过程,由于该过程可能计算密集,在专用或外部服务上运行是一个值得考虑的选择,关于Hugging Face 的推理请参阅: Run Inference on servers。huggingface_hub库提供了统一接口,可对托管在Hugging Face Hub上的模型使用多种服务来运行推理,比如:
- HF Inference API:一种无服务器解决方案,可以免费在Hugging Face的基础设施上运行模型推理。该服务是快速入门、测试不同模型和原型化AI产品的便捷途径;
- 第三方供应商:由外部供应商provider(如Together、Sambanova等)提供的各类无服务器解决方案。这些供应商按用量付费模式(pay-as-you-go)提供生产就绪的API,这是以免维护、可扩展的解决方案将AI集成至产品中的最快方式。在支持的供应商和任务章节列出了具体供应商信息: Supported providers and tasks;
- 推理终端节点:一个可将模型轻松部署至生产环境的产品,推理由Hugging Face在用户选择的云供应商提供的专用全托管基础设施上运行。
这些服务均可通过InferenceClient对象调用,该对象替代了旧版InferenceApi客户端,新增了对特定任务和第三方供应商的支持,从旧版客户端迁移至新客户端的方法请参阅Legacy InferenceAPI client。
InferenceClient是一个通过HTTP调用与官方API交互的Python客户端。如果用户希望直接使用常用工具(如curl、Postman等)发起HTTP请求,请参阅Inference API或Inference Endpoints文档页面。对于网页开发,官方已发布JS Client。如果用户从事游戏开发,可以关注官方的 C# project。
1. text_to_image:文生图任务
让我们从一个文生图任务开始入门:
from huggingface_hub import InferenceClient# Example with an external provider (e.g. replicate)
replicate_client = InferenceClient(provider="replicate",api_key="my_replicate_api_key",
)
replicate_image = replicate_client.text_to_image("A flying car crossing a futuristic cityscape.",model="black-forest-labs/FLUX.1-schnell",
)
replicate_image.save("flying_car.png")
在上述示例中,我们使用第三方服务提供商Replicate初始化了一个 InferenceClient。当使用第三方提供商时,必须指定要使用的模型,该模型ID 必须是Hugging Face Hub上的模型标识符,而非第三方提供商自身的模型ID。在本例中,我们通过文本提示生成了一张图像,返回值为PIL.Image对象,可保存为文件,更多细节请参阅文档:text_to_image()。
2. chat_completion:生成响应
接下来让我们看一个使用chat_completion() API的示例,该任务利用大语言模型根据消息列表生成响应:
from huggingface_hub import InferenceClientmessages = [{"role": "user","content": "What is the capital of France?",}
]
client = InferenceClient(provider="together",model="meta-llama/Meta-Llama-3-8B-Instruct",api_key="my_together_api_key",
)
client.chat_completion(messages, max_tokens=100)
输出为:
ChatCompletionOutput(choices=[ChatCompletionOutputComplete(finish_reason="eos_token",index=0,message=ChatCompletionOutputMessage(role="assistant", content="The capital of France is Paris.", name=None, tool_calls=None),logprobs=None,)],created=1719907176,id="",model="meta-llama/Meta-Llama-3-8B-Instruct",object="text_completion",system_fingerprint="2.0.4-sha-f426a33",usage=ChatCompletionOutputUsage(completion_tokens=8, prompt_tokens=17, total_tokens=25),
)
在上述示例中,我们创建客户端时使用了第三方服务提供商(Together AI)并指定了所需模型(“meta-llama/Meta-Llama-3-8B-Instruct”)。随后我们提供了待补全的消息列表(此处为单个问题),并向API传递了额外参数(max_token=100)。
输出结果为遵循OpenAI规范的ChatCompletionOutput对象,生成内容可通过output.choices[0].message.content获取。更多细节请参阅chat_completion()文档。该API设计简洁,但并非所有参数和选项都会向终端用户开放或说明,如需了解各任务支持的全部参数,请查阅Inference Providers - API Reference。
20.1.3 Spaces ZeroGPU:动态GPU分配方案
ZeroGPU是Hugging Face Spaces平台上专为AI模型和演示优化的GPU共用基础设施,采用动态分配机制实现NVIDIA A100显卡的按需调用与释放,其主要特性包括:
- 免费GPU资源:为Spaces用户提供零成本GPU算力支持;
- 多GPU并发:支持Spaces上的单个应用同时调用多块显卡进行运算。
与传统单GPU分配模式相比,ZeroGPU的高效系统通过资源利用率最大化和能效比最优化,有效降低了开发者、研究机构及企业部署AI模型的技术门槛。更多信息请参阅:Spaces ZeroGPU: Dynamic GPU Allocation for Spaces。
1. ZeroGPU Spaces使用与托管指南
使用ZeroGPU,就要用到ZeroGPU Spaces。对于使用现有ZeroGPU Spaces:
- 所有用户均可免费使用(可查看精选Space列表:ZeroGPU Spaces);
- PRO用户在使用任何ZeroGPU Spaces时,享有5倍的每日使用配额和GPU队列的最高优先级。
用户也可托管自有ZeroGPU Spaces,但个人和企业需订阅不同版本:
- 个人账户:需订阅PRO版,在新建Gradio SDK Space时可选择ZeroGPU硬件配置,最多创建10个ZeroGPU Space;
- 企业用户:需订阅Enterprise Hub,即可为全体成员启用ZeroGPU Spaces功能,最多创建50个ZeroGPU Space。
2. 其它技术性说明
技术规格:
- GPU类型:NVIDIA A100;
- 可用显存:每个工作负载为40GB
兼容性说明:ZeroGPU Spaces设计为兼容大多数基于PyTorch的GPU Spaces,虽然对Hugging Face高级库(如transformers和diffusers)的兼容性更优,但用户需注意以下事项:
- 目前ZeroGPU Spaces仅兼容Gradio SDK;
- 与标准GPU Spaces相比,ZeroGPU Spaces的兼容性可能受限;
- 某些场景下可能出现意外问题。
支持版本:
- Gradio:4+;
- PyTorch:2.0.1、2.1.2、2.2.2、2.4.0(注:由于PyTorch漏洞,不支持2.3.x版本);
- Python:3.10.13
3. ZeroGPU快速入门
用户的Space中使用ZeroGPU需遵循以下步骤:
- 确保在Space设置中已选择ZeroGPU硬件;
- 导入spaces模块;
- 使用@spaces.GPU装饰器标记依赖GPU的函数。
此装饰机制使得Space能在函数调用时申请GPU资源,并在执行完成后自动释放。示例如下:
import spaces
from diffusers import DiffusionPipelinepipe = DiffusionPipeline.from_pretrained(...)
pipe.to('cuda')
@spaces.GPU
def generate(prompt):return pipe(prompt).images
gr.Interface(fn=generate,inputs=gr.Text(),outputs=gr.Gallery(),
).launch()
注:@spaces.GPU装饰器在非ZeroGPU环境中将不产生任何作用,以确保不同配置下的兼容性。另外,@spaces.GPU装饰器还可设置时长管理。若函数预计超过默认的60秒GPU运行时长,可指定自定义时长:
@spaces.GPU(duration=120)
def generate(prompt):return pipe(prompt).images
该设置将函数最大运行时限定为120秒,但为快速执行的函数指定更短时长,可提升Space访客的队列优先级。
通过ZeroGPU,开发者能创建更高效、可扩展的Space,在最大化GPU利用率的同时实现成本优化。
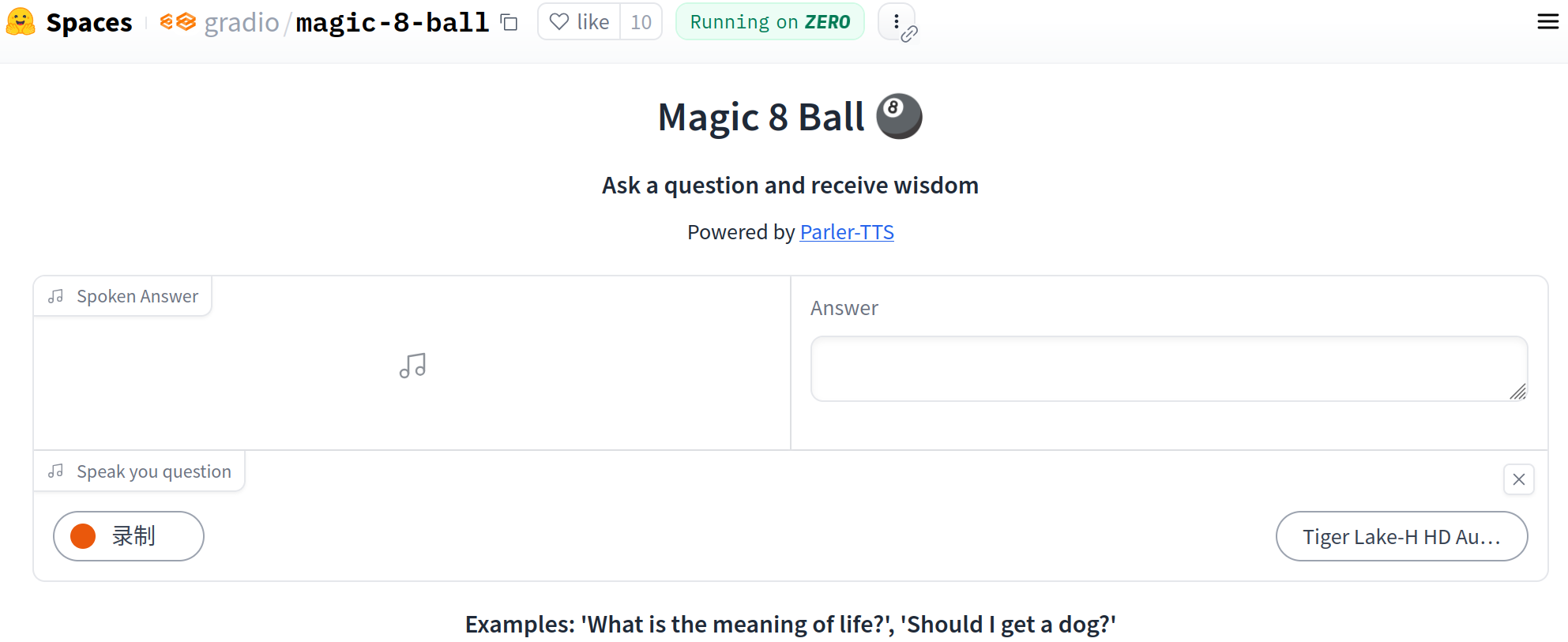
20.1.4 用户界面
首先,我们定义UI界面,并为所有Python逻辑预留占位符。
import gradio as grwith gr.Blocks() as block:gr.HTML(f"""<h1 style='text-align: center;'> Magic 8 Ball 🎱 </h1><h3 style='text-align: center;'> Ask a question and receive wisdom </h3><p style='text-align: center;'> Powered by <a href="https://github.com/huggingface/parler-tts"> Parler-TTS</a>""")with gr.Group():with gr.Row():audio_out = gr.Audio(label="Spoken Answer", streaming=True, autoplay=True)answer = gr.Textbox(label="Answer")state = gr.State()with gr.Row():audio_in = gr.Audio(label="Speak your question", sources="microphone", type="filepath")audio_in.stop_recording(generate_response, audio_in, [state, answer, audio_out])\.then(fn=read_response, inputs=state, outputs=[answer, audio_out])block.launch()
我们将音频输出组件、文本框组件和音频输入组件分别放置在不同行中。为了实现服务器端的音频流式传输,我们会在输出音频组件中设置streaming=True。同时,我们还会启用autoplay=True,以便音频在准备就绪时自动播放。此外,我们将利用音频输入组件的stop_recording事件,在用户停止麦克风录音时触发应用逻辑。
我们将逻辑分为两部分:
- generate_response:负责接收录音音频,进行语音转录,并通过大语言模型生成回答。生成的回答会存储在gr.State变量中,并传递给下一步的read_response函数。
- read_response:负责将文本回答转换为语音音频。
这样拆分的原因是,由于生成回答的部分可以通过Hugging Face的Inference API完成,无需占用GPU配额,因此我们避免将这部分逻辑放在GPU函数中,以节省资源。而只有read_response需要GPU资源,它将运行在Hugging Face的ZeroGPU上,该服务有基于时长的配额限制,因此去掉generate_response可以降低费用。
20.1.5 转录语音与生成回答
如上所述,我们将使用Hugging Face的Inference API来转录音频,并通过LLM 生成回答。逻辑实现时,首先实例化客户端,调用automatic_speech_recognition方法来转录音频,该方法会自动使用 Hugging Face推理服务器上的Whisper模型。接着将问题输入LLM模型Mistral-7B-Instruct生成回答,我们通过系统格式消息(system message)让LLM模拟Magic 8 Ball的风格进行回复。
generate_response函数还会向输出文本框和音频组件发送空更新(即返回 None)。这样做的目的是:显示 Gradio 的进度指示器(progress tracker),让用户感知处理状态;延迟显示答案,直到音频生成完成,确保文字和语音同步呈现。代码如下:
from huggingface_hub import InferenceClientclient = InferenceClient(token=os.getenv("HF_TOKEN"))def generate_response(audio):gr.Info("Transcribing Audio", duration=5)question = client.automatic_speech_recognition(audio).textmessages = [{"role": "system", "content": ("You are a magic 8 ball.""Someone will present to you a situation or question and your job ""is to answer with a cryptic adage or proverb such as ""'curiosity killed the cat' or 'The early bird gets the worm'.""Keep your answers short and do not include the phrase 'Magic 8 Ball' in your response. If the question does not make sense or is off-topic, say 'Foolish questions get foolish answers.'""For example, 'Magic 8 Ball, should I get a dog?', 'A dog is ready for you but are you ready for the dog?'")},{"role": "user", "content": f"Magic 8 Ball please answer this question - {question}"}]response = client.chat_completion(messages, max_tokens=64, seed=random.randint(1, 5000),model="mistralai/Mistral-7B-Instruct-v0.3")response = response.choices[0].message.content.replace("Magic 8 Ball", "").replace(":", "")return response, None, None
20.1.6 语音合成与流式传输
现在我们有了文本响应,我们将使用Parler TTS将其朗读出来。read_response 函数是一个Python生成器,生成器将在音频准备好时逐块产生下一段音频。函数中,我们将使用Mini v0.1进行特征提取,但使用Jenny微调版本进行语音生成,以确保语音在多次生成中保持一致。
Parler-TTS Mini v0.1是一个轻量级文本转语音(TTS)模型,它经过10.5千小时的音频数据训练,可以生成高质量、自然的声音,并通过简单的文本提示控制声音特征(例如性别、背景噪音、语速、音调和混响等),它是Parler-TTS项目的首个发布模型,该项目旨在为社区提供TTS训练资源和数据集预处理代码。Jenny微调版本是Parler-TTS Mini v0.1的微调版本,基于Jenny(爱尔兰口音)30小时单人高品质数据集进行训练,适合用于训练TTS模型。使用方法与 Parler-TTS v0.1大致相同,只需在语音描述中指定关键字“Jenny”即可。
使用Transformers进行流式音频传输需要一个自定义的Streamer类,可以在这里查看实现细节:magic-8-ball/streamer.py。此外,我们会将输出转换为字节流,以便从后端更快地流式传输。
from streamer import ParlerTTSStreamer
from transformers import AutoTokenizer, AutoFeatureExtractor, set_seed
import numpy as np
import spaces
import torch
from threading import Threaddevice = "cuda:0" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
torch_dtype = torch.float16 if device != "cpu" else torch.float32
repo_id = "parler-tts/parler_tts_mini_v0.1"
jenny_repo_id = "ylacombe/parler-tts-mini-jenny-30H"model = ParlerTTSForConditionalGeneration.from_pretrained(jenny_repo_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
).to(device)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)
sampling_rate = model.audio_encoder.config.sampling_rate
frame_rate = model.audio_encoder.config.frame_rate@spaces.GPU
def read_response(answer):play_steps_in_s = 2.0play_steps = int(frame_rate * play_steps_in_s)description = "Jenny speaks at an average pace with a calm delivery in a very confined sounding environment with clear audio quality."description_tokens = tokenizer(description, return_tensors="pt").to(device)streamer = ParlerTTSStreamer(model, device=device, play_steps=play_steps)prompt = tokenizer(answer, return_tensors="pt").to(device)generation_kwargs = dict(input_ids=description_tokens.input_ids,prompt_input_ids=prompt.input_ids,streamer=streamer,do_sample=True,temperature=1.0,min_new_tokens=10,)set_seed(42)thread = Thread(target=model.generate, kwargs=generation_kwargs)thread.start()for new_audio in streamer:print(f"Sample of length: {round(new_audio.shape[0] / sampling_rate, 2)} seconds")yield answer, numpy_to_mp3(new_audio, sampling_rate=sampling_rate)
运行界面如下:
参考文献:
- Streaming AI Generated Audio
- Run Inference on servers
- Spaces ZeroGPU: Dynamic GPU Allocation for Spaces
相关文章:
——流式传输音频:魔力8号球)
Gradio全解20——Streaming:流式传输的多媒体应用(1)——流式传输音频:魔力8号球
Gradio全解20——Streaming:Streaming:流式传输的多媒体应用(1)——流式传输音频:魔力8号球 前言本篇摘要20. Streaming:流式传输的多媒体应用20.1 流式传输音频:魔力8号球20.1.1 工作原理20.1.…...

Netflix系统架构解析
Netflix系统架构解析 Netflix架构旨在高效可靠地同时为数百万用户提供内容。以下是其特性和组件的详细分析。 是否曾好奇Netflix如何让您目不转睛地享受无中断的流畅播放体验?幕后功臣正是Netflix架构,它负责提供吸引全球观众的无缝流媒体体验。Netflix的…...

宝塔面板运行docker的jenkins
1.在宝塔面板装docker,以及jenkins 2.ip:端口访问jenkins 3.获取密钥(点击日志) 4.配置容器内的jdk和maven环境(直接把jdk和maven文件夹放到jenkins容器映射的data文件下) 点击容器-->管理-->数据存储卷--.把相…...

【计算机视觉】目标检测:深度解析Detectron2:Meta开源目标检测与图像分割框架实战指南
深度解析Detectron2:Meta开源目标检测与图像分割框架实战指南 技术架构与设计哲学核心设计理念关键技术组件 环境配置与安装硬件建议配置详细安装步骤 实战流程详解1. 自定义数据集准备2. 模型配置与训练3. 模型评估与推理 核心功能扩展1. 自定义模型架构2. 混合精度…...

Notepad编辑器实现换行符替换
在不同的Note编辑器中,批量把换行替换为空的方法有所不同,以下是常见编辑器的操作方法: Notepad 打开文件后,按CtrlH打开“查找和替换”对话框,在“查找”字段中输入\r\n,在“替换为”字段中输入一个空格…...

【数据通信完全指南】从物理层到协议栈的深度解析
目录 1. 通信技术演进与核心挑战1.1 从电报到5G的技术变迁1.2 现代通信系统的三大瓶颈 2. 通信系统架构深度解构2.1 OSI七层模型运作原理2.2 TCP/IP协议栈实战解析 3. 物理层关键技术实现3.1 信号调制技术演进路线3.2 信道复用方案对比 4. 数据传输可靠性保障4.1 CRC校验算法数…...

SpringBoot多工程项目微服务install时如何不安装到本地仓库
在 Spring Boot 微服务项目中,比如各业务微服务模块由于不存在相互依赖度的问题,因此执行maven install时无需安装到本地仓库,但仍然需要参与构建(如 mvn compile 或 mvn package)。公共模块(如辅助工具…...

强化学习_Paper_2017_Curiosity-driven Exploration by Self-supervised Prediction
paper Link: ICM: Curiosity-driven Exploration by Self-supervised Prediction GITHUB Link: 官方: noreward-rl 1- 主要贡献 对好奇心进行定义与建模 好奇心定义:next state的prediction error作为该state novelty 如果智能体真的“懂”一个state,那…...

iview内存泄漏
iview在升级到view-design之前,是存在严重的内存泄漏问题的,而如果你在项目中大量使用了iview组件,就可能面临大量的升级工作要做,因为样式很多是不兼容的。 我们今天就看一下iview的源码,看看到底问题在哪里ÿ…...

【Hive入门】Hive高级特性:事务表与ACID特性详解
目录 1 Hive事务概述 2 ACID特性详解 3 Hive事务表的配置与启用 3.1 启用Hive事务支持 3.2 创建事务表 4 Hive事务操作流程 5 并发控制与隔离级别 5.1 Hive的锁机制 5.2 隔离级别 6 Hive事务的限制与优化 6.1 主要限制 6.2 性能优化建议 7 事务表操作示例 7.1 基本…...

Modbus转PROFIBUS网关:电动机保护新突破!
Modbus转PROFIBUS网关:电动机保护新突破! 在现代工业自动化领域,Modbus RTU和PROFIBUS DP是两种常见且重要的通讯协议。它们各自具有独特的优势和应用场景,但在实际工程中,我们常常需要将这两种不同协议的设备进行互联…...

大数据应用开发和项目实战-Seaborn
设计目标 seaborn 建立在 matplotlib 之上,专注于统计数据可视化,简化绘图过程,提供高级接口和美观的默认主题 Seaborn的安装: 1.pip install seaborn -i 2.conda install seaborn (清华源:https://pypi.t…...

弹窗探索鸿蒙之旅:揭秘弹窗的本质与奥秘
嘿,小伙伴们!👋 今天我们要一起探索那些在日常应用中无处不在的小精灵——弹窗!💬 🤔 弹窗到底是什么? 简单来说,弹窗就是应用程序中突然冒出来的交互元素,它们像…...

“技术创新+全球视野”良性驱动,首航新能的2025新征程正式起航
撰稿 | 行星 来源 | 贝多财经 近日,备受瞩目的“2025年光伏第一股”深圳市首航新能源股份有限公司(301658.SZ,下称“首航新能”)对外发布了上市后的首份年报,交出了一份量质齐升的业绩答卷,构筑更加强大的…...

黑群晖Moments视频无缩略图,安装第三方ffmpeg解决
黑群晖Moments视频无缩略图,安装第三方ffmpeg解决 1. 设置套件来源 黑群晖Moments视频无缩略图,安装第三方ffmpeg解决 基于这个文章,补充一下: 1. 设置套件来源 设置套件来源时(http://packages.synocommunity.com),…...

工业控制「混合架构」PK大战 —— 神经网络 + MPC vs 模糊 PID+MPC 的场景选型与实战指南
1. 引言 在工业控制领域,传统的 PID 控制器因其结构简单、稳定性好而被广泛应用,但面对复杂非线性系统时往往力不从心。模型预测控制(MPC)作为一种基于模型的先进控制策略,能够有效处理多变量、多约束问题,…...

树莓派智能摄像头实战指南:基于TensorFlow Lite的端到端AI部署
引言:嵌入式AI的革新力量 在物联网与人工智能深度融合的今天,树莓派这一信用卡大小的计算机正在成为边缘计算的核心载体。本文将手把手教你打造一款基于TensorFlow Lite的低功耗智能监控设备,通过MobileNetV2模型实现实时物体检测࿰…...
图像与通道拼接函数-----执行 查找表操作图像处理函数LUT())
OpenCV 图形API(73)图像与通道拼接函数-----执行 查找表操作图像处理函数LUT()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 对矩阵执行查找表变换。 函数 LUT 使用来自查找表中的值填充输出矩阵。输入矩阵中的值作为查找表的索引。也就是说,函数对 src 中的…...
)
【MySQL】增删改查(CRUD)
目录 一. CRUD是什么 二. Create(新增数据) 2.1 单行数据全列插入 2.2 单行数据指定列插入 2.3 多行数据指定列插入 三. Retrieve (检索/查询) 3.1 全列查询 3.2 指定列查询 3.3 查询字段为表达式 3.4 为查询结果指定别名 3…...

iview 如何设置sider宽度
iview layout组件中,sider设置了默认宽度和最大宽度,在css样式文件中修改无效,原因是iview默认样式设置在了element.style中,只能通过行内样式修改 样式如下: image.png image.png 修改方式: 1.官方文档中写…...
:深度图优化)
Unity URP RenderTexture优化(二):深度图优化
目录 前言: 一、定位深度信息 1.1:k_DepthStencilFormat 1.2:k_DepthBufferBits 1.3:_CameraDepthTexture精度与大小 1.4:_CameraDepthAttachment数量 二、全代码 前言: 在上一篇文章:Un…...

iview表单提交验证时,出现空值参数被过滤掉不提交的问题解决
如图所示 有时候在表单提交的时候 个别参数是空值,但是看提交接口的反馈 发现空值的参数根本没传 这是因为表单验证给过滤掉了空值,有时候如果空值传不传都不无所谓,那可以不用管,但如果就算是空值也得传的吗,那就需要…...

GEO vs SEO:从搜索引擎到生成引擎的优化新思路
随着人工智能技术的快速发展,生成引擎优化(GEO)作为一种新兴的优化策略,逐渐成为企业和内容创作者关注的焦点。与传统的搜索引擎优化(SEO)相比,GEO不仅关注如何提升内容在搜索结果中的排名&…...
及csv语法详细分享)
Python-pandas-操作csv文件(读取数据/写入数据)及csv语法详细分享
Python-pandas-操作csv文件(读取数据/写入数据) 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个…...

如何在Windows上实现MacOS中的open命令
在MacOS的终端中,想要快速便捷的在Finder中打开当前目录,直接使用oepn即可。 open . 但是Windows中没有直接提供类似open这样的命令,既然没有直接提供,我们就间接手搓一个实现它。 步骤1:创建open.bat echo OFF expl…...

读论文笔记-LLaVA:Visual Instruction Tuning
读论文笔记-LLaVA:Visual Instruction Tuning 《Visual Instruction Tuning》 研究机构:Microsoft Research 发表于2023的NeurIPS Problems 填补指令微调方法(包括数据、模型、基准等)在多模态领域的空白。 Motivations 人工…...

Vue3源码学习3-结合vitetest来实现mini-vue
文章目录 前言✅ 当前已实现模块汇总(mini-vue)✅ 每个模块简要源码摘要1. reactive.ts2. effect.ts3. computed.ts4. ref.ts5. toRef.ts6. toRefs.ts ✅ 下一阶段推荐目标所有核心模块对应的 __tests__ 测试文件,**带完整注释**✅ reactive.…...

K8S - 从零构建 Docker 镜像与容器
一、基础概念 1.1 镜像(Image) “软件的标准化安装包” ,包含代码、环境和配置的只读模板。 技术解析 镜像由多个层组成,每层对应一个Dockerfile指令: 应用代码 → 运行时环境 → 系统工具链 → 启动配置核心特性…...

贪心算法求解边界最大数
贪心算法求解边界最大数(拼多多2504、排列问题) 多多有两个仅由正整数构成的数列 s1 和 s2,多多可以对 s1 进行任意次操作,每次操作可以置换 s1 中任意两个数字的位置。多多想让数列 s1 构成的数字尽可能大,但是不能比…...
)
C++类和对象(中)
类的默认成员函数 默认成员函数就是用户没有显式实现,编译器会自动生成的成员函数。一个类,我们不写的情况下编译器会默认生成6个默认成员函数,C11以后还会增加两个默认成员函数,移动构造和移动赋值。默认成员函数 很重要&#x…...
Gin学习笔记(五)会话控制与参数验证:Cookie使用、Sessions使用、结构体验证参数、自定义验证参数)
(Go Gin)Gin学习笔记(五)会话控制与参数验证:Cookie使用、Sessions使用、结构体验证参数、自定义验证参数
1. Cookie介绍 HTTP是无状态协议,服务器不能记录浏览器的访问状态,也就是说服务器不能区分两次请求是否由同一个客户端发出Cookie就是解决HTTP协议无状态的方案之一,中文是小甜饼的意思Cookie实际上就是服务器保存在浏览器上的一段信息。浏览…...

Windows 10 环境二进制方式安装 MySQL 8.0.41
文章目录 初始化数据库配置文件注册成服务启停服务链接服务器登录之后重置密码卸载 初始化数据库 D:\MySQL\MySQL8.0.41\mysql-8.0.41-winx64\mysql-8.0.41-winx64\bin\mysqld -I --console --basedirD:\MySQL\MySQL8.0.41\mysql-8.0.41-winx64\mysql-8.0.41-winx64 --datadi…...

Day.js一个2k轻量级的时间日期处理库
dayjs介绍 dayjs是一个极简快速2kB的JavaScript库,可以为浏览器处理解析、验证、操作和显示日期和时间,它的设计目标是提供一个简单、快速且功能强大的日期处理工具,同时保持极小的体积(仅 2KB 左右)。 Day.js 的 API…...

SQL实战:05之间隔连续数问题求解
概述 最近刷题时遇到一些比较有意思的题目,之前多次遇到一些求解连续数的问题,这次遇到了他们的变种,连续数可以间隔指定的数也视为是一个完整的“连续”。针对连续数的这类问题我们之前讲的可以利用等差数列的思想来解决,然而现…...

Windows下Dify安装及使用
Dify安装及使用 Dify 是开源的 LLM 应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。比 LangChain 更易用。 前置条件 windows下安装了docker环境-Windows11安装Docker-CSDN博客 下载 Git下载…...

回归分析丨基于R语言复杂数据回归与混合效应模型【多水平/分层/嵌套】技术与代码
回归分析是科学研究特别是生态学领域科学研究和数据分析十分重要的统计工具,可以回答众多科学问题,如环境因素对物种、种群、群落及生态系统或气候变化的影响;物种属性和系统发育对物种分布(多度)的影响等。纵观涉及数…...

EasyRTC嵌入式音视频实时通话SDK技术,打造低延迟、高安全的远程技术支持
一、背景 在当今数字化时代,远程技术支持已成为解决各类技术问题的关键手段。随着企业业务的拓展和技术的日益复杂,快速、高效地解决远程设备与系统的技术难题变得至关重要。EasyRTC作为一款高性能的实时通信解决方案,为远程技术支持提供了创…...

webrtc ICE 打洞总结
要搞清webrtc ICE连接是否能成功 , 主要是搞懂NAT NAT 类型 简单来说 一 是本地的ip和端口 决定外部的 ip和端口(和目的Ip和端口无关) , (这种情况又分为 , 无限制,仅限制 ip , 限制ip和port , 也就是…...
,更换镜像源,Dockerfile,部署Python项目)
AI开发者的Docker实践:汉化(中文),更换镜像源,Dockerfile,部署Python项目
AI开发者的Docker实践:汉化(中文),更换镜像源,Dockerfile,部署Python项目 Dcoker官网1、核心概念镜像 (Image)容器 (Container)仓库 (Repository)DockerfileDocker Compose 2、Docker 的核心组件Docker 引擎…...

4.30阅读
一. 原文阅读 Passage 7(推荐阅读时间:6 - 7分钟) In department stores and closets all over the world, they are waiting. Their outward appearance seems rather appealing because they come in a variety of styles, textures, and …...

区块链:跨链协的技术突破与产业重构
引言:区块链的“孤岛困境”与跨链的使命 区块链技术自诞生以来,凭借去中心化、透明性和安全性重塑了金融、供应链、身份认证等领域。然而,不同区块链平台间的互操作性缺失,如同“数据与价值的孤岛”,严重限制…...

Github 热点项目 Qwen3 通义千问全面发布 新一代智能语言模型系统
阿里云Qwen3模型真是黑科技!两大模式超贴心——深度思考能解高数题,快速应答秒回日常梗。支持百种语言互译,跨国客服用它沟通零障碍!打工人福音是内置API工具,查天气做报表张口就来。字) 1Qwen3 今日星标 …...

有状态服务与无状态服务:差异、特点及应用场景全解
有状态服务和无状态服务是在分布式系统和网络编程中常提到的概念,下面为你详细介绍: 一、无状态服务 无状态服务指的是该服务的单次请求处理不依赖之前的请求信息,每个请求都是独立的。服务端不会存储客户端的上下文信息,每次请…...

【网络入侵检测】基于源码分析Suricata的引擎日志配置解析
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 Suricata 的引擎日志记录系统主要记录该引擎在启动、运行以及关闭期间应用程序的相关信息,如错误信息和其他诊断信息,…...

Attention层的FLOPs计算
前置知识 设矩阵 A 的维度为 mn,矩阵 B 的维度为 np,则它们相乘后得到矩阵 C 的维度为 mp。其中,C 中每个元素的计算需要进行 n 次乘法和 n−1 次加法。也就是说,总的浮点运算次数(FLOPs)约为 m p (2n) …...

支付APP如何做好网络安全防护
支付APP的网络安全防护需要从技术、管理、用户行为等多层面综合施策,以下为核心措施: 一、技术防御:构建安全底层 数据加密 传输加密:使用最新协议(如TLS 1.3)对交易数据加密&…...

Missashe考研日记-day31
Missashe考研日记-day31 0 写在前面 芜湖,五一前最后一天学习圆满结束,又到了最喜欢的放假环节,回来再努力了。 1 专业课408 学习时间:2h学习内容: OK啊,今天把文件系统前两节的内容全部学完了…...
)
二叉树的路径总和问题(递归遍历,回溯算法)
112. 路径总和 - 力扣(LeetCode) class Solution { private: bool traversal(TreeNode*cur,int count){if(!cur->left&&!cur->right&&count0){return true;}if(!cur->left&&!cur->right){return false;}if(cur-…...
)
Java学习计划与资源推荐(入门到进阶、高阶、实战)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息文章目录 Java学习计划与资源推荐**一、筑基阶段(2-3个月)****二、进阶开发阶段(2个月)****三、高级突破阶段(2-3个月)****四、项目实战与竞…...

动态规划 -- 子数组问题
本篇文章中主要讲解动态规划系列中的几个经典的子数组问题。 1 最大子数组和 53. 最大子数组和 - 力扣(LeetCode) 解析题目: 子数组是一个数组中的连续部分,也就是说,如果一个数组以 nums[i]结尾,那么有两…...