【MySQL】增删改查(CRUD)
 目录
目录
一. CRUD是什么
二. Create(新增数据)
2.1 单行数据全列插入
2.2 单行数据指定列插入
2.3 多行数据指定列插入
三. Retrieve (检索/查询)
3.1 全列查询
3.2 指定列查询
3.3 查询字段为表达式
3.4 为查询结果指定别名
3.5 结果去重查询
3.6 where条件查询(重点)
3.6.1 比较运算符
3.6.2 逻辑运算符
重点注意事项
3.7 order by(排序)
3.8 分页查询
四. Update(修改)
五. Delete(删除)
六. 截断表
6.1 truncate和delete的区别
七. 插入查询数据
八. 聚合函数
8.1 count函数
8.2 sum函数
8.3 avg函数
8.4 max函数
8.5 min函数
九. group by分组查询
9.1 having子句
9.2 having子句和where的区别
一. CRUD是什么
CURD是对数据库中表里面的数据进行基本的增删改查操作的简称:
- Create(创建)
- Retrieve(读取)
- Update(更新)
- Delete(删除)
在讲解这几个操作之前,我们先创建一个学生表:
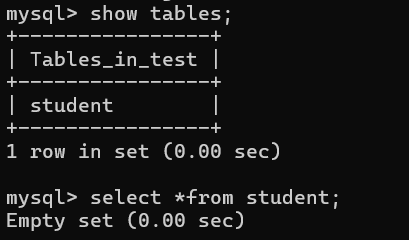
查看表中数据的语法:
select *from 表名此时sutdent表中是没有任何数据的。
二. Create(新增数据)
新增数据的语法:
INSERT [INTO] table_name[(column [, column] ...)]
VALUES(value_list) [, (value_list)] ...
value_list: value, [, value] ...2.1 单行数据全列插入
此时我们的学生表为空,现在我需要为当前表添加一条数据:
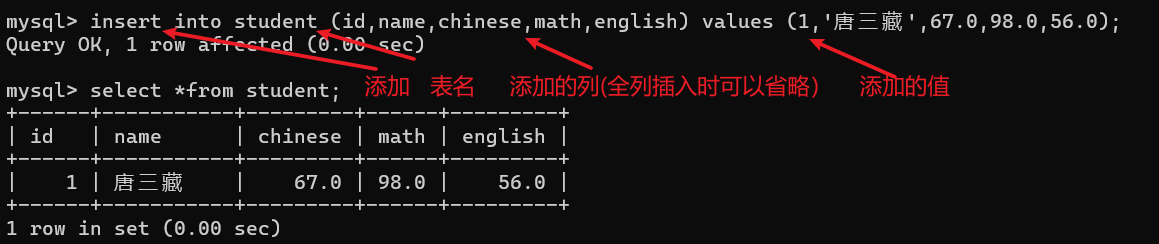
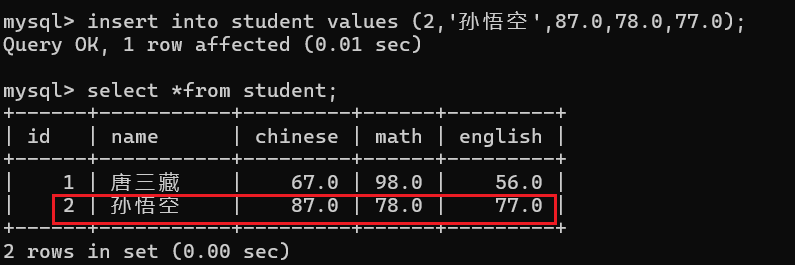
此时学生表中就添加了这么一条学生数据 ,那么全列插入还有第二种写法(省略说明要插入的列):
2.2 单行数据指定列插入
插入是可以指定列插入的,假设我们现在要添加一名学生的 编号、姓名、语文成绩:
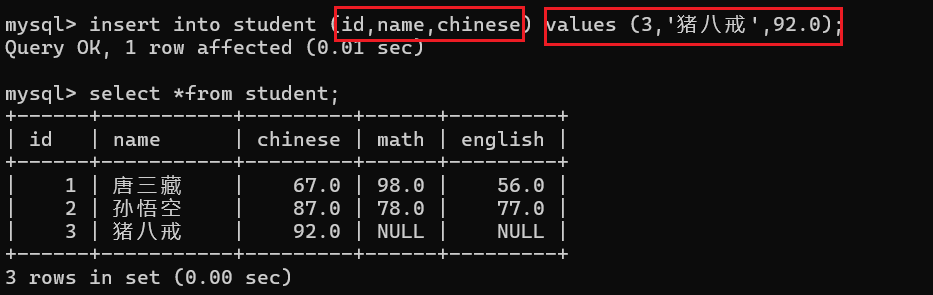
这里需要注意的是:指定了列,后面插入的数据必须是与列对应的(并且插入数据的类型也要是匹配的),否则就会报错:
![]()

2.3 多行数据指定列插入
在insert语句中也可以实现一次性插入多行数据:
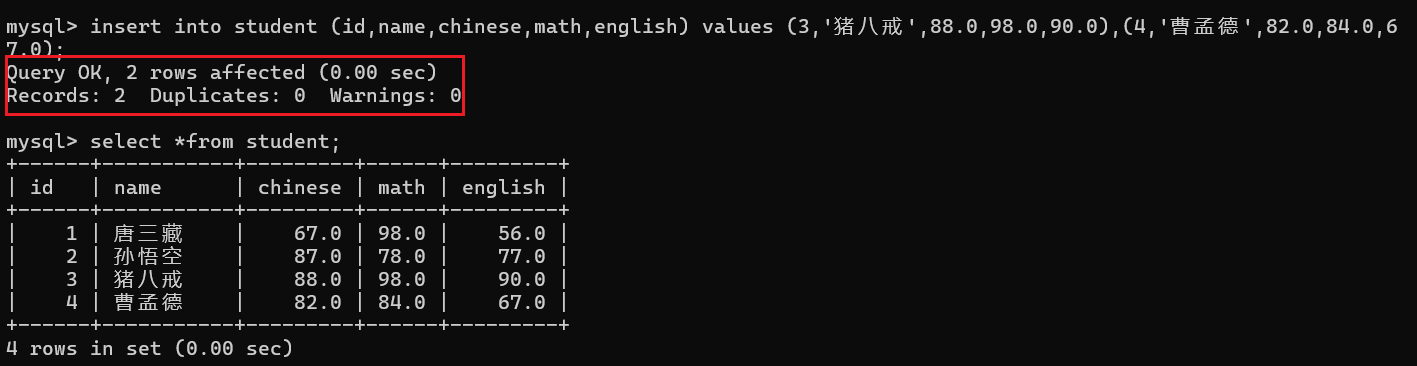
三. Retrieve (检索/查询)
查询数据的语法:
SELECT[DISTINCT] //去重查询select_expr [, select_expr] ...//查询的列[FROM table_references] //从哪个表查[WHERE where_condition] //条件判断[GROUP BY {col_name | expr}, ...] [HAVING where_condition][ORDER BY {col_name | expr } [ASC | DESC], ... ] //排序[LIMIT {[offset,] row_count | row_count OFFSET offset}]从查询数据的语法中来看,查询数据的方式有很多,接下来我们就一个一个来看。
3.1 全列查询
全列查询就是查询当前表中所有列的数据,语法:
select *from 表名;//select--查询
// *---表示全部
// from---从哪里查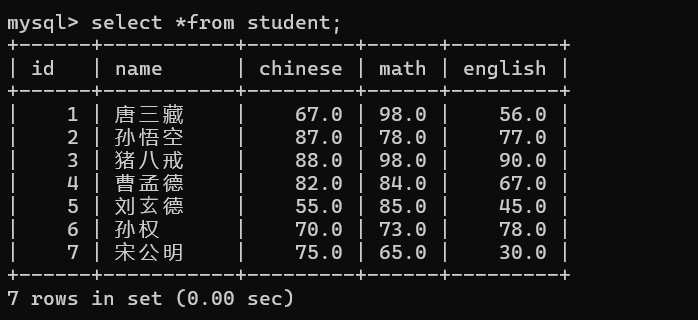
3.2 指定列查询
查询语法:
select 字段1,字段2.... from 表名;在查询的过程中我们可以指定我们想要查询的列,比如说我现在想要查询每个同学的语文成绩:
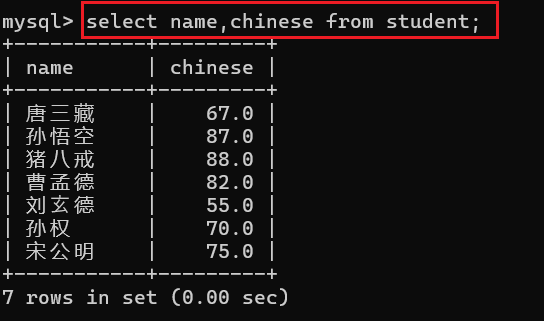
3.3 查询字段为表达式
假设我现在想要查询每个同学的总分:
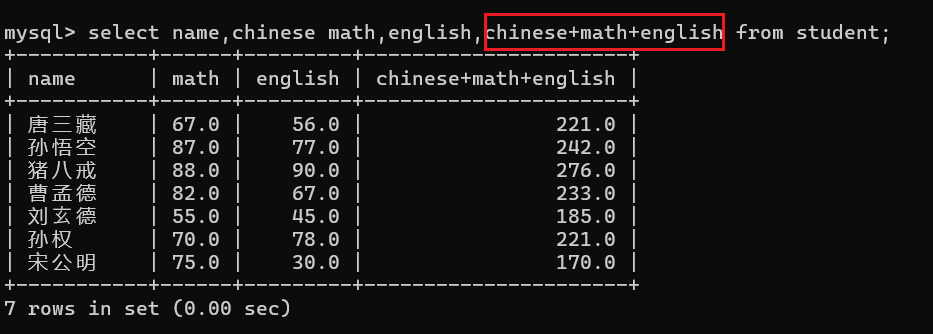
该字段不仅可以是列中的数据,还可以是一个常量数值和一个字符串字段:
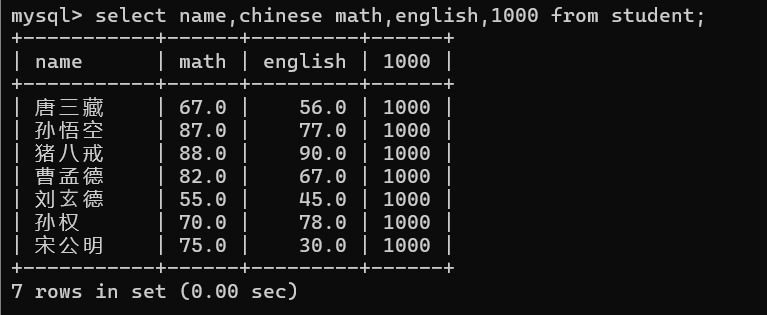
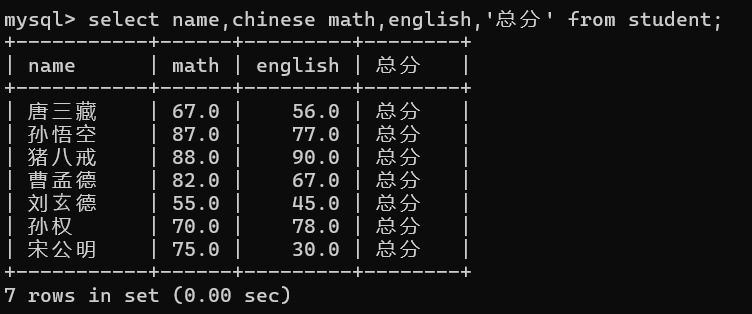
那么假设现在我想要查询出来的数据是每个同学的语文成绩加10分:
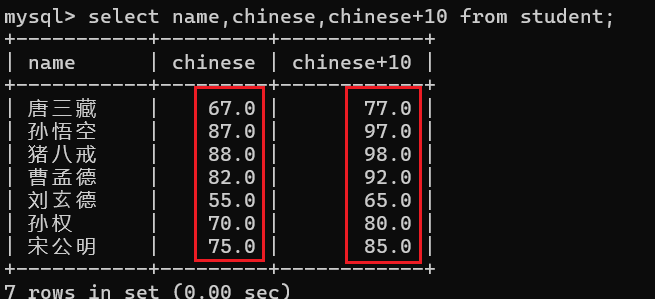
此时表中的原有的数据是不会受到影响的,这是为什么呢?

只要是通过select关键字查询出来的数据都是临时表中存放的数据!
那么现在我在语文成绩后面加上一个NULL会发生什么呢?
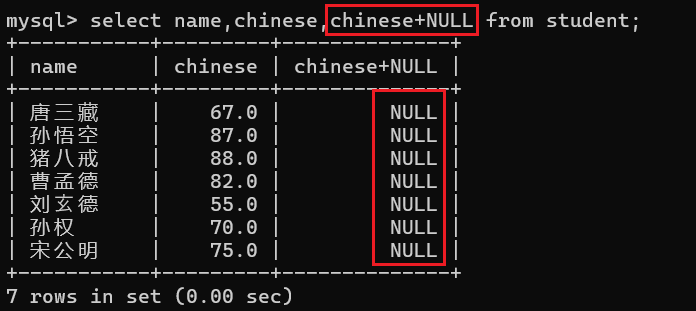
注意:NULL加上任何数都是等于NULL的,这点与我们java中NULL默认为0不同 !
3.4 为查询结果指定别名
刚才我们通过查询字段表达式的方式查询了每个同学的总分,但是查询出来的数据名称为chinese+math+english,这个名称就显得非常不美观,那么这时候我们就要进行指定别名来查询该结果:
语法:
select column [AS] alias_name [, ...] from table_name;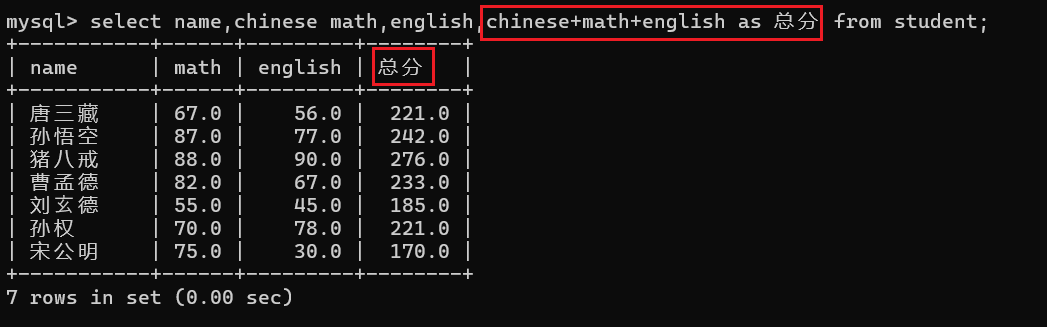
这里的as关键字是可以省略的v
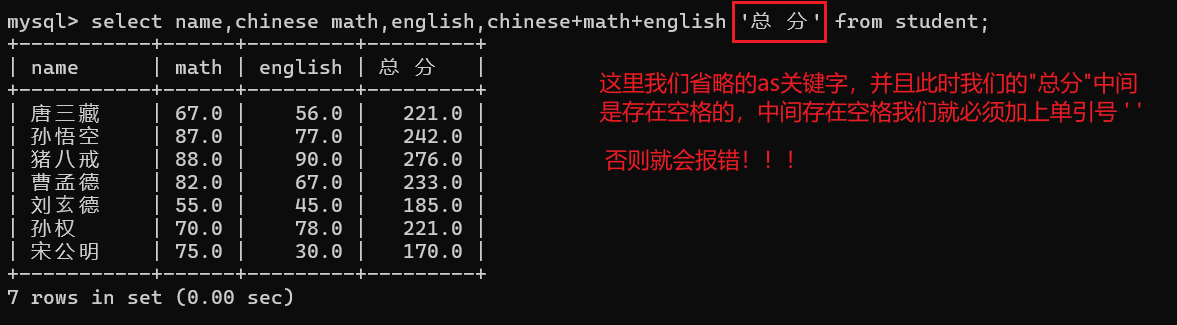

3.5 结果去重查询
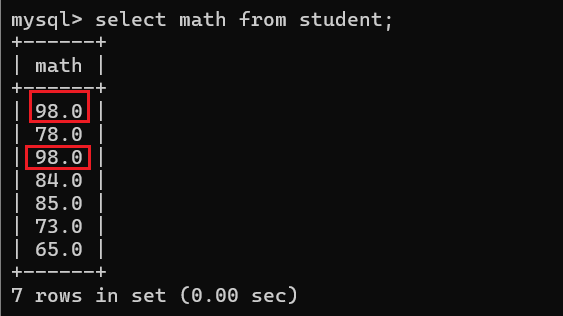
从上图可以看出,有两名同学的数学成绩是一样的,那么现在我需要对重复的值进行去重查询该怎么办呢?
去重查询关键字:distinct
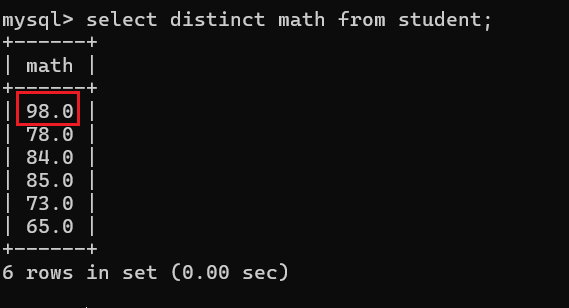
那么当两个行中的所有列的值都相同,才能判定为两个数据行相同,才可以去重:
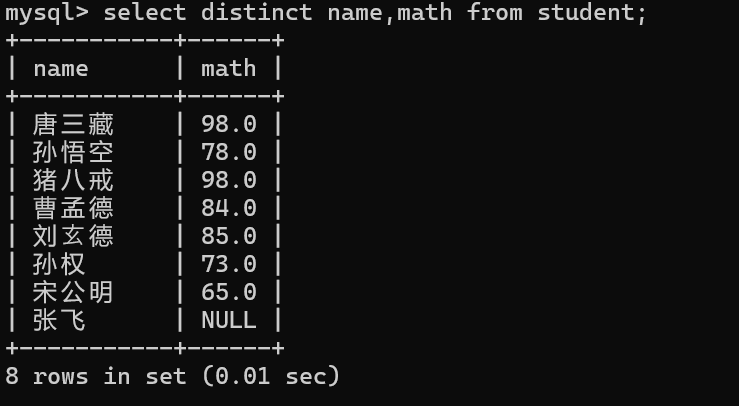
此时前面的名字是不相同的,所以这里是不会进行排序的!
此时后面重复的数据就进行了去重操作,这里有几个注意事项:
- 使⽤DISCTINCT去重时,只有查询列表中所有列的值都相同才会判定为重复
- 查询时不加限制条件会返回表中所有结果,如果表中的数据量过⼤,会把服务器的资源消耗殆尽
- 在⽣产环境不要使不加限制条件的查询
3.6 where条件查询(重点)
上述说的,如果表中的数据量过大会将服务器的资源消耗殆尽,所以我们就需要对表中的数据进行条件查询(查询满足条件的值)
语法:
SELECTselect_expr [, select_expr] ... [FROM table_references]WHERE where_condition在学习条件查询之前,我们先来看看几个用于条件查询中的运算符
3.6.1 比较运算符
| 运算符 | 说明 |
| >,>=,<,<= | 跟java中的一样(比较) |
| = | 等于,这里是比较相不相等(与java中==对应)对NULL的比较是不安全的,NULL=NULL结果还是NULL |
| <=> | 等于,对NULL的比较是安全的,NULL=NULL结果是True(1) |
| !=,<> | 不等于 |
| between | 范围查询,【a0,a1】,not between则取反 |
| value in() | 如果value值在列表中,则返回True,not in则取反 |
| is NULL | 判断是不是NULL |
| is not NULL | 判断是不是 不是NULL |
| like | 模糊匹配, % 表⽰任意多个(包括0个)字符;_ 表⽰任意⼀个字符,NOT LIKE则取反 |
接下来我们来看看这些比较运算符怎么用的,表中默认的数据:
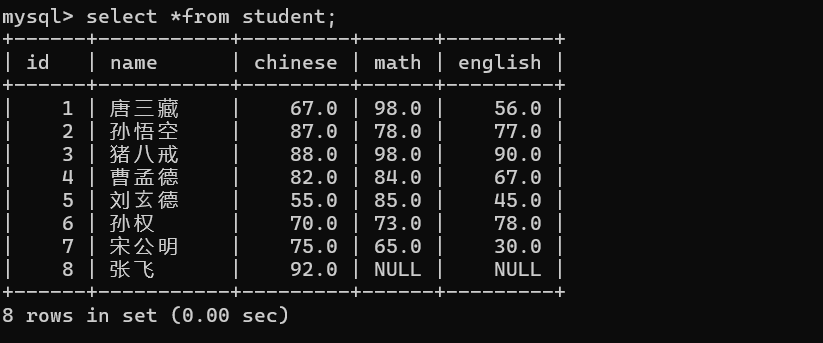
-- 查询数学成绩大于70的学生
mysql> select name,math from student where math>70;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98.0 |
| 孙悟空 | 78.0 |
| 猪八戒 | 98.0 |
| 曹孟德 | 84.0 |
| 刘⽞德 | 85.0 |
| 孙权 | 73.0 |
+-----------+------+
6 rows in set (0.00 sec)-- 查询英语成绩小于语文成绩的同学
mysql> select name,english,math from student where english<chinese;
+-----------+---------+------+
| name | english | math |
+-----------+---------+------+
| 唐三藏 | 56.0 | 98.0 |
| 孙悟空 | 77.0 | 78.0 |
| 曹孟德 | 67.0 | 84.0 |
| 刘⽞德 | 45.0 | 85.0 |
| 宋公明 | 30.0 | 65.0 |
+-----------+---------+------+
5 rows in set (0.00 sec)-- 查询语文成绩在70-90之间的同学
mysql> select name,chinese from student where chinese between 70 and 90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87.0 |
| 猪八戒 | 88.0 |
| 曹孟德 | 82.0 |
| 孙权 | 70.0 |
| 宋公明 | 75.0 |
+-----------+---------+
5 rows in set (0.01 sec)-- 查询数学成绩为98、65、78的同学
mysql> select name,math from student where math in(98,78,65);
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98.0 |
| 孙悟空 | 78.0 |
| 猪八戒 | 98.0 |
| 宋公明 | 65.0 |
+-----------+------+
4 rows in set (0.00 sec)-- 查询数学成绩为NULL的同学
mysql> select name,math from student where math is null;
+--------+------+
| name | math |
+--------+------+
| 张飞 | NULL |
+--------+------+
1 row in set (0.00 sec)-- 查询英语成绩不为NULL的同学
mysql> select name,english from student where math is not null;
+-----------+---------+
| name | english |
+-----------+---------+
| 唐三藏 | 56.0 |
| 孙悟空 | 77.0 |
| 猪八戒 | 90.0 |
| 曹孟德 | 67.0 |
| 刘⽞德 | 45.0 |
| 孙权 | 78.0 |
| 宋公明 | 30.0 |
+-----------+---------+
7 rows in set (0.00 sec)-- 模糊匹配,查询孙开头的名字的同学
mysql> select id,name from student where name like '孙%';
+------+-----------+
| id | name |
+------+-----------+
| 2 | 孙悟空 |
| 6 | 孙权 |
+------+-----------+
2 rows in set (0.00 sec)-- 模糊匹配,查询姓为孙,名为两个字的同学
mysql> select id,name from student where name like '孙__';
+------+-----------+
| id | name |
+------+-----------+
| 2 | 孙悟空 |
+------+-----------+
1 row in set (0.00 sec)
3.6.2 逻辑运算符
| 运算符 | 说明 |
| and | 同时满足为True |
| or | 任意一个条件满足为True |
| not | 取反 |
示例演示:
-- 查询语文成绩和英语成绩都大于60分的同学
mysql> select name,chinese,english from student where chinese>60 and english>60;
+-----------+---------+---------+
| name | chinese | english |
+-----------+---------+---------+
| 孙悟空 | 87.0 | 77.0 |
| 猪八戒 | 88.0 | 90.0 |
| 曹孟德 | 82.0 | 67.0 |
| 孙权 | 70.0 | 78.0 |
+-----------+---------+---------+
4 rows in set (0.00 sec)-- 查询数学成绩或者英语成绩大于85的同学
mysql> select name,math,english from student where math>85 or english>85;
+-----------+------+---------+
| name | math | english |
+-----------+------+---------+
| 唐三藏 | 98.0 | 56.0 |
| 猪八戒 | 98.0 | 90.0 |
+-----------+------+---------+
2 rows in set (0.00 sec)
重点注意事项
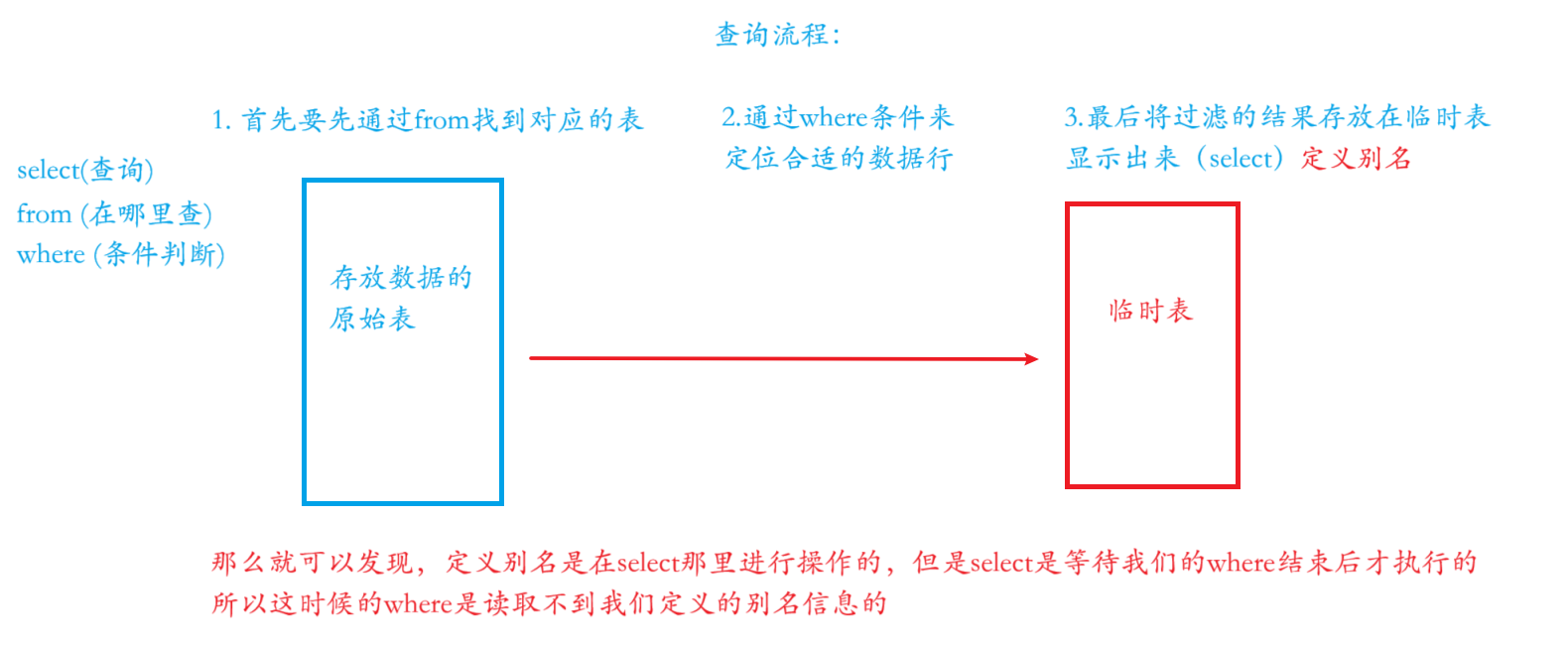
这里使用条件查询where的时候,我们能不能对重命名的字段进行查询呢?
假设我现在要对总分超过230分的同学进行查询:

这里是不行的,为什么不行的?我给大家画个图分析一下:
3.7 order by(排序)
在查询数据的时候,我们往往需要根据数据的大小进行排序查询,这就引入了order by关键字:
-- ASC 为升序(从⼩到⼤)
-- DESC 为降序(从⼤到⼩)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY {col_name | expr } [ASC |
DESC], ... ;示例演示:
-- 按照数学成绩从小到大进行排序
mysql> select name,math from student order by math asc;
+-----------+------+
| name | math |
+-----------+------+
| 张飞 | NULL |
| 宋公明 | 65.0 |
| 孙权 | 73.0 |
| 孙悟空 | 78.0 |
| 曹孟德 | 84.0 |
| 刘⽞德 | 85.0 |
| 唐三藏 | 98.0 |
| 猪八戒 | 98.0 |
+-----------+------+
8 rows in set (0.00 sec)-- 按照语文成绩从大到小排序
mysql> select name,chinese from student order by chinese desc;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 张飞 | 92.0 |
| 猪八戒 | 88.0 |
| 孙悟空 | 87.0 |
| 曹孟德 | 82.0 |
| 宋公明 | 75.0 |
| 孙权 | 70.0 |
| 唐三藏 | 67.0 |
| 刘⽞德 | 55.0 |
+-----------+---------+
8 rows in set (0.00 sec)-- 按照总分从大到小进行排序
mysql> select id,name,chinese+math+english as 总分 from student order by 总分 desc;
+------+-----------+--------+
| id | name | 总分 |
+------+-----------+--------+
| 3 | 猪八戒 | 276.0 |
| 2 | 孙悟空 | 242.0 |
| 4 | 曹孟德 | 233.0 |
| 1 | 唐三藏 | 221.0 |
| 6 | 孙权 | 221.0 |
| 5 | 刘⽞德 | 185.0 |
| 7 | 宋公明 | 170.0 |
| 8 | 张飞 | NULL |
+------+-----------+--------+
8 rows in set (0.00 sec)
在这里我们通过总分进行排序,这里我使用了别名进行排序,那么这里为什么可以使用别名进行排序呢?
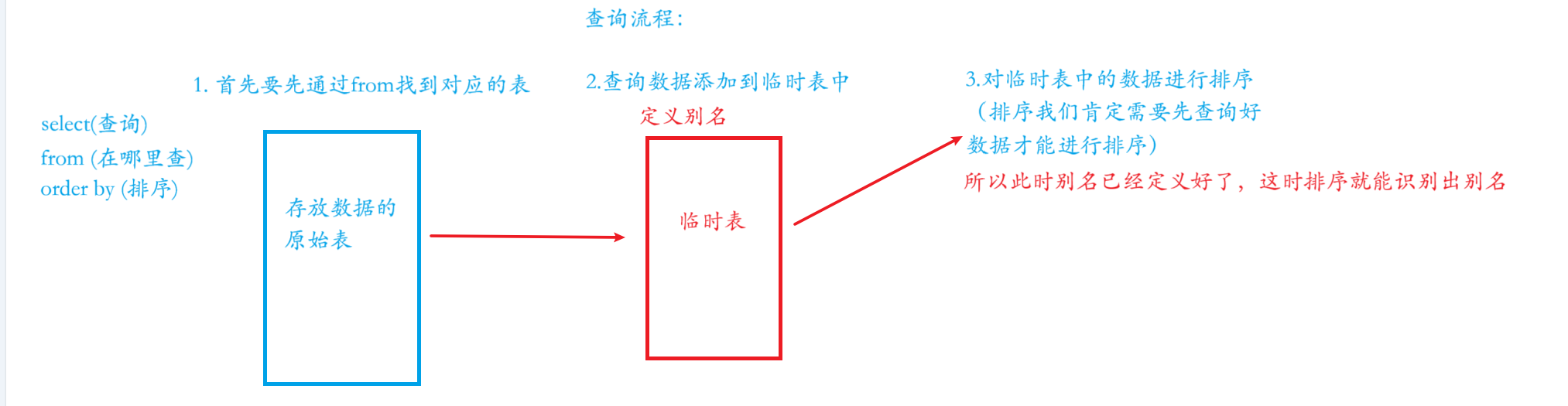
排序这里有个重点:
-- 查询同学各⻔成绩,依次按数学降序,英语升序,语⽂升序的⽅式显⽰
mysql> select name math,english,chinese from student order by math desc,english asc,chinese asc;
+-----------+---------+---------+
| math | english | chinese |
+-----------+---------+---------+
| 猪八戒 | 90.0 | 88.0 |
| 曹孟德 | 67.0 | 82.0 |
| 张飞 | NULL | 92.0 |
| 宋公明 | 30.0 | 75.0 |
| 孙权 | 78.0 | 70.0 |
| 孙悟空 | 77.0 | 87.0 |
| 唐三藏 | 56.0 | 67.0 |
| 刘⽞德 | 45.0 | 55.0 |
+-----------+---------+---------+
8 rows in set (0.01 sec)这里的对多个列进行排序,是在前一个排序规则的基础上不影响前一个排序结果的情况下再进行排序的,这里我们就是先对数学成绩进行排序接着是英语成绩、语文成绩。
3.8 分页查询
当一个页面的显示不出全部的数据时,就要采用分页查询的方式来显示当前页面的信息,分页查询语法:
-- 起始下标为 0
-- 从 0 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num;
-- 从 start 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT start, num;
-- 从 start 开始,筛选 num 条结果,⽐第⼆种⽤法更明确,建议使⽤
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num OFFSET start;那么分页查询有三种不同方式的写法,我们就来一个一个演示一下:
-- 查询student表中的第1-3条数据
mysql> select *from student limit 3;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.0 | 78.0 | 77.0 |
| 3 | 猪八戒 | 88.0 | 98.0 | 90.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)--查询student表中第3条数据开始的后三条数据
mysql> select *from student limit 3,3;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘⽞德 | 55.0 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)--查询student表中第1条数据开始的后4条数据
mysql> select *from student limit 4 offset 1;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.0 | 78.0 | 77.0 |
| 3 | 猪八戒 | 88.0 | 98.0 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘⽞德 | 55.0 | 85.0 | 45.0 |
+------+-----------+---------+------+---------+
4 rows in set (0.00 sec)那如果我查询的范围超出了表中的数据量会发生什么呢?
-- 查询student表中0-100条数据
mysql> select *from student limit 0,100;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.0 | 78.0 | 77.0 |
| 3 | 猪八戒 | 88.0 | 98.0 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘⽞德 | 55.0 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 8 | 张飞 | 92.0 | NULL | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
(表中有多少数据就会显示多少数据)-- 查询student表中第100条数据开始的后3条数据
mysql> select *from student limit 100,3;
Empty set (0.00 sec)
(查询出来就是一个空集合,因为并没有第100条数据)这里的两个注意事项:
- 查询的数据量超出了表中所有的数据时,那么表中有多少数据就会显示多少数据
- 当查询的位置不在表中数据的范围时,那么返回的集合就是一个空集合
四. Update(修改)
接下来我们来学习一下对数据的修改,语法演示:
UPDATE [LOW_PRIORITY] [IGNORE] table_referenceSET assignment [, assignment] ...[WHERE where_condition][ORDER BY ...][LIMIT row_count]示例演示:
-- student表中初始数据:
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.0 | 78.0 | 77.0 |
| 3 | 猪八戒 | 88.0 | 98.0 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘⽞德 | 55.0 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 8 | 张飞 | 92.0 | NULL | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)-- 将孙悟空同学的数学成绩变为80分
mysql> update student set math=80 where name='孙悟空';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name,math from student where name='孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 80.0 |
+-----------+------+
1 row in set (0.00 sec)-- 将唐三藏同学的数学成绩变为60分,语文成绩变为70分
mysql> update student set math=60,chinese=70 where name='唐三藏';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name,math,chinese from student where name='唐三藏';
+-----------+------+---------+
| name | math | chinese |
+-----------+------+---------+
| 唐三藏 | 60.0 | 70.0 |
+-----------+------+---------+
1 row in set (0.00 sec)-- 将成绩倒数前三的3位同学数学成绩加上30分
mysql> select name,math,chinese+math+english as 总分 from student where chinese+math+english is not null order by 总分 asc limit 3;
+-----------+------+--------+
| name | math | 总分 |
+-----------+------+--------+
| 宋公明 | 65.0 | 170.0 |
| 刘⽞德 | 85.0 | 185.0 |
| 唐三藏 | 60.0 | 186.0 |
+-----------+------+--------+
3 rows in set (0.00 sec)mysql> select name,math,chinese+math+english as 总分 from student where chinese+math+english is not null order by 总分 asc limit 3;
+-----------+------+--------+
| name | math | 总分 |
+-----------+------+--------+
| 宋公明 | 95 | 200 |
| 刘⽞德 | 115 | 215 |
| 唐三藏 | 90 | 216 |
+-----------+------+--------+
3 rows in set (0.00 sec)--将所有人的英语成绩变为原来的两倍
mysql> select name,chinese from student;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 唐三藏 | 140 |
| 孙悟空 | 174 |
| 猪八戒 | 176 |
| 曹孟德 | 164 |
| 刘⽞德 | 110 |
| 孙权 | 140 |
| 宋公明 | 150 |
| 张飞 | 184 |
+-----------+---------+
8 rows in set (0.00 sec)update使用的注意事项:
- 以原值的基础上做变更时,不能使⽤math += 30这样的语法
- 不加where条件时,会导致全表数据被列新,谨慎操作
五. Delete(删除)
语法演示:
DELETE FROM tbl_name [WHERE where_condition] [ORDER BY ...] [LIMIT row_count]示例演示:
-- 删除猪八戒同学的考试成绩
mysql> delete from student where name='孙悟空';
Query OK, 1 row affected (0.01 sec)mysql> select * from student;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 140 | 90 | 56 |
| 3 | 猪八戒 | 176 | 98 | 90 |
| 4 | 曹孟德 | 164 | 84 | 67 |
| 5 | 刘⽞德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
| 8 | 张飞 | 184 | NULL | NULL |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
删除整张表的数据:
mysql> delete from *student;delete使用注意事项 :
当使用删除时,如果不加条件进行删除,那么删除的就是整张表的数据
六. 截断表
截断表其实就是将表恢复到表刚创建的状态(也就是没有任何数据的状态),语法演示:
TRUNCATE [TABLE] tbl_name;在示例演示之前,我们先创建一个测试表:
CREATE TABLE t_truncate(id INT PRIMARY KEY AUTO_INCREMENT,`name` VARCHAR(20)
);
(AUTO_INCREMENT表示自增,当插入一条数据时,当前id值会自己加1,这个操作是数据库帮我们维护的,这个值会被记录在数据库内部)-- 插入数据
insert into t_truncate (name) values ('张三'),('李四'),('王五');mysql> select * from t_truncate;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+----+--------+
3 rows in set (0.00 sec)--对于这个自增值id,我们可以通过查看表结构的方式来进行查看这个自增值:
mysql> show create table t_truncate;
+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t_truncate | CREATE TABLE `t_truncate` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
(因为刚才我插入了3条数据,所以此时的AUTO_INCREMENT值就来到的4)那么现在我们来看看截断表的使用:
-- 将t_truncate表恢复到刚创建表的状态
mysql> truncate table t_truncate;
Query OK, 0 rows affected (0.03 sec)mysql> select *from t_truncate;
Empty set (0.00 sec)mysql> show create table t_truncate;
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t_truncate | CREATE TABLE `t_truncate` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
(此时的AUTO_INCREMENT的值也被恢复成默认值(1))6.1 truncate和delete的区别
- 执行truncate后表恢复到最初的状态(是直接清空磁盘中的数据),delete删除整个表中的数据是一条一条进行删除,所以truncate的效率比delete高
- delete只是删除表中的数据,不会对表自身的状态进行修改(也就是删除后,id不会发生改变,插入之后是多少,删除后还是多少)
七. 插入查询数据
在以后的工作中,原始表中的数据一般不会主动删除,但是真正的查询是不需要重复的数据的,但是每次查询都使用Distinct去重操作会严重影响效率,这时候我们就可以创建一个与原始表结构相同的表,将去重后的数据重新写入到新表中,以后查询的时候都从新表中查询,这样原始的数据不会发生丢失又能保证查询效率。
创建一个测试表:
-- 创建表
mysql> CREATE TABLE t_recored (id int, name varchar(20));
Query OK, 0 rows affected (0.02 sec)-- 添加数据
insert into t_recored values(1,'张三'),(1,'张三'),(2,'李四'),(2,'李四'),(2,'李四'),(3,'王五');mysql> select * from t_recored;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 1 | 张三 |
| 2 | 李四 |
| 2 | 李四 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
6 rows in set (0.00 sec)
那么现在开始将原始表中的数据去重后添加到新表中:
-- 创建一个和原始表结构相同的新表
mysql> create table t_recored_new like t_recored;
Query OK, 0 rows affected (0.02 sec)--将原始表的数据去重后写入新表
mysql> insert into t_recored_new select distinct *from t_recored;
(将查询出来的去重后的集合作为新的数据添加到新表中)
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select *from t_recored_new;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)-- 重命名新表和原始表
mysql> rename table t_recored to t_recored_old,t_recored_new to t_recored;
Query OK, 0 rows affected (0.02 sec)-- 查询重命名后表中的记录,实现需求且原来中的记录不受影响
mysql> select * from t_recored;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)mysql> select * from t_recored_old;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 1 | 张三 |
| 2 | 李四 |
| 2 | 李四 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
6 rows in set (0.00 sec)八. 聚合函数
聚合函数是MySQL中自带的函数,接下来我们看看几个常用函数:
| 函数 | 说明 |
| count() | 返回查询到的数据数量 |
| sum() | 返回查询到的数据的总和,不是数字则没有意义 |
| avg() | 返回查询到的数据的平均值,不是数字则没有意义 |
| max() | 返回查询到的数据的最大值,不是数字则没有意义 |
| min() | 返回查询到的数据的最小值,不是数字则没有意义 |
8.1 count函数
count函数的三种使用方式:
count(*)
count(常量值)
count(指定列)
示例演示:
-- 初始student表的数据
mysql> select * from student;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 140 | 90 | 56 |
| 3 | 猪八戒 | 176 | 98 | 90 |
| 4 | 曹孟德 | 164 | 84 | 67 |
| 5 | 刘⽞德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
| 8 | 张飞 | 184 | NULL | NULL |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)-- 查询student表中有多少条数据
mysql> select count(*)from student;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.01 sec)mysql> select count(1) from student;
+----------+
| count(1) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)mysql> select count(id) from student;
+-----------+
| count(id) |
+-----------+
| 7 |
+-----------+
1 row in set (0.00 sec)-- 统计数学成绩小于60分的学生个数
mysql> select count(math) from student where math<60;
+-------------+
| count(math) |
+-------------+
| 0 |
+-------------+
1 row in set (0.00 sec)那么这三种方式我们更推荐使用哪个呢?
其实是更推荐使用count(*)这种方式:因为这种方式是SQL语言级别的标准,对于所有的数据库软件都通用,并且在MYISAM存储引擎中是有一个变量记录了表中的记录数,count(*)是可以直接通过这个变量直接读取,效率非常高,那么对于其他的存储引擎也有不同的方式实现
8.2 sum函数
示例演示:
-- 统计所有同学的语文成绩总分
mysql> select sum(chinese) from student;
+--------------+
| sum(chinese) |
+--------------+
| 1064 |
+--------------+
1 row in set (0.00 sec)--统计所有同学英语成绩的总分
mysql> select sum(english) from student;
+--------------+
| sum(english) |
+--------------+
| 366 |
+--------------+
1 row in set (0.00 sec)
(这里需要注意,这里是不能统计值为NULL的数据的)--并且不能统计非数值的列
mysql> select sum(name) from student;
+-----------+
| sum(name) |
+-----------+
| 0 |
+-----------+
1 row in set, 7 warnings (0.00 sec)-- 查看警告信息
mysql> show warnings;
+---------+------+-----------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------+
| Warning | 1292 | Truncated incorrect DOUBLE value: '唐三藏' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '猪八戒' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '曹孟德' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '刘⽞德' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '孙权' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '宋公明' |
| Warning | 1292 | Truncated incorrect DOUBLE value: '张飞' |
+---------+------+-----------------------------------------------+
7 rows in set (0.00 sec)8.3 avg函数
示例演示:
-- 查看总分的平均值
mysql> select avg(chinese+math+english) from student;
+---------------------------+
| avg(chinese+math+english) |
+---------------------------+
| 300.1666666666667 |
+---------------------------+
1 row in set (0.00 sec)--查看语文成绩的平均值
mysql> select avg(chinese) from student;
+--------------+
| avg(chinese) |
+--------------+
| 152 |
+--------------+
1 row in set (0.00 sec)8.4 max函数
示例演示:
-- 查询总分最大值
mysql> select max(chinese+math+english) from student;
+---------------------------+
| max(chinese+math+english) |
+---------------------------+
| 364 |
+---------------------------+
1 row in set (0.00 sec)
8.5 min函数
示例演示:
-- 查询语文成绩>70分的最低分
mysql> select min(chinese) from student where chinese>70;
+--------------+
| min(chinese) |
+--------------+
| 110 |
+--------------+
1 row in set (0.00 sec)-- 查询语文成绩的最高分和数学成绩的最低分
mysql> select max(chinese),min(math) from student where chinese or math is not null;
+--------------+-----------+
| max(chinese) | min(math) |
+--------------+-----------+
| 184 | 73 |
+--------------+-----------+
1 row in set (0.00 sec)九. group by分组查询
SELECT {col_name | expr} ,... ,aggregate_function (aggregate_expr)FROM table_referencesGROUP BY {col_name | expr}, ... [HAVING where_condition]
- col_name | expr:要查询的列或表达式,可以有多个,必须在 GROUP BY ⼦句中作为分组的依据
- aggregate_function:聚合函数,⽐如COUNT(), SUM(), AVG(), MAX(), MIN()
- aggregate_expr:聚合函数传⼊的列或表达式,如果列或表达式不在 GOURP BY ⼦句中,必须包含中聚合函数中
准备一份测试表:
-- 创建测试表
create table school_emp(id bigint comment'编号',name varchar(20) comment'身份',posts varchar(20)comment'职位',`day` BIGINT comment'在学校的天数'
);-- 插入数据
insert into school_emp values(1,'吴校长','校长',1200);
insert into school_emp values(2,'张校长','校长',1100);
insert into school_emp values(3,'王主任','主任',1056);
insert into school_emp values(4,'郑主任','主任',1000);
insert into school_emp values(5,'吴老师','老师',970);
insert into school_emp values(6,'张老师','老师',860);
insert into school_emp values(7,'小明','学生',585);
insert into school_emp values(8,'小红','学生',548);mysql> select *from school_emp;
+------+-----------+--------+------+
| id | name | posts | day |
+------+-----------+--------+------+
| 1 | 吴校长 | 校长 | 1200 |
| 2 | 张校长 | 校长 | 1100 |
| 3 | 王主任 | 主任 | 1056 |
| 4 | 郑主任 | 主任 | 1000 |
| 5 | 吴老师 | 老师 | 970 |
| 6 | 张老师 | 老师 | 860 |
| 7 | 小明 | 学生 | 585 |
| 8 | 小红 | 学生 | 548 |
+------+-----------+--------+------+
8 rows in set (0.00 sec)示例演示:
-- 统计每个职位的人数
mysql> select posts,count(*) from school_emp group by posts;
(查询posts列和每个职位的人数通过posts列进行分组)
+--------+----------+
| posts | count(*) |
+--------+----------+
| 校长 | 2 |
| 主任 | 2 |
| 老师 | 2 |
| 学生 | 2 |
+--------+----------+
4 rows in set (0.00 sec)-- 统计每个职位的平均在校天数
mysql> select posts,avg(day) from school_emp group by posts;
+--------+-----------+
| posts | avg(day) |
+--------+-----------+
| 校长 | 1150.0000 |
| 主任 | 1028.0000 |
| 老师 | 915.0000 |
| 学生 | 566.5000 |
+--------+-----------+
4 rows in set (0.00 sec)9.1 having子句
在使用group by 对结果进行分组处理后,对分组的结果进行过滤时不能使用where,而要使用having子句
示例演示:
-- 显示平均在校天数小于800天的职位和平均在校天数
mysql> select posts,avg(day) from school_emp group by posts having avg(day)<800;
+--------+----------+
| posts | avg(day) |
+--------+----------+
| 学生 | 566.5000 |
+--------+----------+
1 row in set (0.00 sec)9.2 having子句和where的区别
- Having ⽤于对分组结果的条件过滤
- Where ⽤于对表中真实数据的条件过滤

相关文章:
)
【MySQL】增删改查(CRUD)
目录 一. CRUD是什么 二. Create(新增数据) 2.1 单行数据全列插入 2.2 单行数据指定列插入 2.3 多行数据指定列插入 三. Retrieve (检索/查询) 3.1 全列查询 3.2 指定列查询 3.3 查询字段为表达式 3.4 为查询结果指定别名 3…...

iview 如何设置sider宽度
iview layout组件中,sider设置了默认宽度和最大宽度,在css样式文件中修改无效,原因是iview默认样式设置在了element.style中,只能通过行内样式修改 样式如下: image.png image.png 修改方式: 1.官方文档中写…...
:深度图优化)
Unity URP RenderTexture优化(二):深度图优化
目录 前言: 一、定位深度信息 1.1:k_DepthStencilFormat 1.2:k_DepthBufferBits 1.3:_CameraDepthTexture精度与大小 1.4:_CameraDepthAttachment数量 二、全代码 前言: 在上一篇文章:Un…...

iview表单提交验证时,出现空值参数被过滤掉不提交的问题解决
如图所示 有时候在表单提交的时候 个别参数是空值,但是看提交接口的反馈 发现空值的参数根本没传 这是因为表单验证给过滤掉了空值,有时候如果空值传不传都不无所谓,那可以不用管,但如果就算是空值也得传的吗,那就需要…...

GEO vs SEO:从搜索引擎到生成引擎的优化新思路
随着人工智能技术的快速发展,生成引擎优化(GEO)作为一种新兴的优化策略,逐渐成为企业和内容创作者关注的焦点。与传统的搜索引擎优化(SEO)相比,GEO不仅关注如何提升内容在搜索结果中的排名&…...
及csv语法详细分享)
Python-pandas-操作csv文件(读取数据/写入数据)及csv语法详细分享
Python-pandas-操作csv文件(读取数据/写入数据) 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个…...

如何在Windows上实现MacOS中的open命令
在MacOS的终端中,想要快速便捷的在Finder中打开当前目录,直接使用oepn即可。 open . 但是Windows中没有直接提供类似open这样的命令,既然没有直接提供,我们就间接手搓一个实现它。 步骤1:创建open.bat echo OFF expl…...

读论文笔记-LLaVA:Visual Instruction Tuning
读论文笔记-LLaVA:Visual Instruction Tuning 《Visual Instruction Tuning》 研究机构:Microsoft Research 发表于2023的NeurIPS Problems 填补指令微调方法(包括数据、模型、基准等)在多模态领域的空白。 Motivations 人工…...

Vue3源码学习3-结合vitetest来实现mini-vue
文章目录 前言✅ 当前已实现模块汇总(mini-vue)✅ 每个模块简要源码摘要1. reactive.ts2. effect.ts3. computed.ts4. ref.ts5. toRef.ts6. toRefs.ts ✅ 下一阶段推荐目标所有核心模块对应的 __tests__ 测试文件,**带完整注释**✅ reactive.…...

K8S - 从零构建 Docker 镜像与容器
一、基础概念 1.1 镜像(Image) “软件的标准化安装包” ,包含代码、环境和配置的只读模板。 技术解析 镜像由多个层组成,每层对应一个Dockerfile指令: 应用代码 → 运行时环境 → 系统工具链 → 启动配置核心特性…...

贪心算法求解边界最大数
贪心算法求解边界最大数(拼多多2504、排列问题) 多多有两个仅由正整数构成的数列 s1 和 s2,多多可以对 s1 进行任意次操作,每次操作可以置换 s1 中任意两个数字的位置。多多想让数列 s1 构成的数字尽可能大,但是不能比…...
)
C++类和对象(中)
类的默认成员函数 默认成员函数就是用户没有显式实现,编译器会自动生成的成员函数。一个类,我们不写的情况下编译器会默认生成6个默认成员函数,C11以后还会增加两个默认成员函数,移动构造和移动赋值。默认成员函数 很重要&#x…...
Gin学习笔记(五)会话控制与参数验证:Cookie使用、Sessions使用、结构体验证参数、自定义验证参数)
(Go Gin)Gin学习笔记(五)会话控制与参数验证:Cookie使用、Sessions使用、结构体验证参数、自定义验证参数
1. Cookie介绍 HTTP是无状态协议,服务器不能记录浏览器的访问状态,也就是说服务器不能区分两次请求是否由同一个客户端发出Cookie就是解决HTTP协议无状态的方案之一,中文是小甜饼的意思Cookie实际上就是服务器保存在浏览器上的一段信息。浏览…...

Windows 10 环境二进制方式安装 MySQL 8.0.41
文章目录 初始化数据库配置文件注册成服务启停服务链接服务器登录之后重置密码卸载 初始化数据库 D:\MySQL\MySQL8.0.41\mysql-8.0.41-winx64\mysql-8.0.41-winx64\bin\mysqld -I --console --basedirD:\MySQL\MySQL8.0.41\mysql-8.0.41-winx64\mysql-8.0.41-winx64 --datadi…...

Day.js一个2k轻量级的时间日期处理库
dayjs介绍 dayjs是一个极简快速2kB的JavaScript库,可以为浏览器处理解析、验证、操作和显示日期和时间,它的设计目标是提供一个简单、快速且功能强大的日期处理工具,同时保持极小的体积(仅 2KB 左右)。 Day.js 的 API…...

SQL实战:05之间隔连续数问题求解
概述 最近刷题时遇到一些比较有意思的题目,之前多次遇到一些求解连续数的问题,这次遇到了他们的变种,连续数可以间隔指定的数也视为是一个完整的“连续”。针对连续数的这类问题我们之前讲的可以利用等差数列的思想来解决,然而现…...

Windows下Dify安装及使用
Dify安装及使用 Dify 是开源的 LLM 应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。比 LangChain 更易用。 前置条件 windows下安装了docker环境-Windows11安装Docker-CSDN博客 下载 Git下载…...

回归分析丨基于R语言复杂数据回归与混合效应模型【多水平/分层/嵌套】技术与代码
回归分析是科学研究特别是生态学领域科学研究和数据分析十分重要的统计工具,可以回答众多科学问题,如环境因素对物种、种群、群落及生态系统或气候变化的影响;物种属性和系统发育对物种分布(多度)的影响等。纵观涉及数…...

EasyRTC嵌入式音视频实时通话SDK技术,打造低延迟、高安全的远程技术支持
一、背景 在当今数字化时代,远程技术支持已成为解决各类技术问题的关键手段。随着企业业务的拓展和技术的日益复杂,快速、高效地解决远程设备与系统的技术难题变得至关重要。EasyRTC作为一款高性能的实时通信解决方案,为远程技术支持提供了创…...

webrtc ICE 打洞总结
要搞清webrtc ICE连接是否能成功 , 主要是搞懂NAT NAT 类型 简单来说 一 是本地的ip和端口 决定外部的 ip和端口(和目的Ip和端口无关) , (这种情况又分为 , 无限制,仅限制 ip , 限制ip和port , 也就是…...
,更换镜像源,Dockerfile,部署Python项目)
AI开发者的Docker实践:汉化(中文),更换镜像源,Dockerfile,部署Python项目
AI开发者的Docker实践:汉化(中文),更换镜像源,Dockerfile,部署Python项目 Dcoker官网1、核心概念镜像 (Image)容器 (Container)仓库 (Repository)DockerfileDocker Compose 2、Docker 的核心组件Docker 引擎…...

4.30阅读
一. 原文阅读 Passage 7(推荐阅读时间:6 - 7分钟) In department stores and closets all over the world, they are waiting. Their outward appearance seems rather appealing because they come in a variety of styles, textures, and …...

区块链:跨链协的技术突破与产业重构
引言:区块链的“孤岛困境”与跨链的使命 区块链技术自诞生以来,凭借去中心化、透明性和安全性重塑了金融、供应链、身份认证等领域。然而,不同区块链平台间的互操作性缺失,如同“数据与价值的孤岛”,严重限制…...

Github 热点项目 Qwen3 通义千问全面发布 新一代智能语言模型系统
阿里云Qwen3模型真是黑科技!两大模式超贴心——深度思考能解高数题,快速应答秒回日常梗。支持百种语言互译,跨国客服用它沟通零障碍!打工人福音是内置API工具,查天气做报表张口就来。字) 1Qwen3 今日星标 …...

有状态服务与无状态服务:差异、特点及应用场景全解
有状态服务和无状态服务是在分布式系统和网络编程中常提到的概念,下面为你详细介绍: 一、无状态服务 无状态服务指的是该服务的单次请求处理不依赖之前的请求信息,每个请求都是独立的。服务端不会存储客户端的上下文信息,每次请…...

【网络入侵检测】基于源码分析Suricata的引擎日志配置解析
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 Suricata 的引擎日志记录系统主要记录该引擎在启动、运行以及关闭期间应用程序的相关信息,如错误信息和其他诊断信息,…...

Attention层的FLOPs计算
前置知识 设矩阵 A 的维度为 mn,矩阵 B 的维度为 np,则它们相乘后得到矩阵 C 的维度为 mp。其中,C 中每个元素的计算需要进行 n 次乘法和 n−1 次加法。也就是说,总的浮点运算次数(FLOPs)约为 m p (2n) …...

支付APP如何做好网络安全防护
支付APP的网络安全防护需要从技术、管理、用户行为等多层面综合施策,以下为核心措施: 一、技术防御:构建安全底层 数据加密 传输加密:使用最新协议(如TLS 1.3)对交易数据加密&…...

Missashe考研日记-day31
Missashe考研日记-day31 0 写在前面 芜湖,五一前最后一天学习圆满结束,又到了最喜欢的放假环节,回来再努力了。 1 专业课408 学习时间:2h学习内容: OK啊,今天把文件系统前两节的内容全部学完了…...
)
二叉树的路径总和问题(递归遍历,回溯算法)
112. 路径总和 - 力扣(LeetCode) class Solution { private: bool traversal(TreeNode*cur,int count){if(!cur->left&&!cur->right&&count0){return true;}if(!cur->left&&!cur->right){return false;}if(cur-…...
)
Java学习计划与资源推荐(入门到进阶、高阶、实战)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息文章目录 Java学习计划与资源推荐**一、筑基阶段(2-3个月)****二、进阶开发阶段(2个月)****三、高级突破阶段(2-3个月)****四、项目实战与竞…...

动态规划 -- 子数组问题
本篇文章中主要讲解动态规划系列中的几个经典的子数组问题。 1 最大子数组和 53. 最大子数组和 - 力扣(LeetCode) 解析题目: 子数组是一个数组中的连续部分,也就是说,如果一个数组以 nums[i]结尾,那么有两…...

Sehll编程的函数于数组
目录 一、函数 1.1、定义函数 1.2、查看、删除函数 1.3、函数的返回值 1.4、函数的参数传递 1.5、函数的作用范围 1.6、函数递归 二、数组 2.1、声明数组 2.2、数组格式定义 2.3、数组调用 2.4、删除数组 一、函数 shell编程中,函数用于封装一段可以重…...

flutter 专题 六十四 在原生项目中集成Flutter
概述 使用Flutter从零开始开发App是一件轻松惬意的事情,但对于一些成熟的产品来说,完全摒弃原有App的历史沉淀,全面转向Flutter是不现实的。因此使用Flutter去统一Android、iOS技术栈,把它作为已有原生App的扩展能力,…...
)
AI生成Flutter UI代码实践(一)
之前的杂谈中有提到目前的一些主流AI编程工具,比如Cursor,Copilot,Trea等。因为我是Android 开发,日常使用Android Studio,所以日常使用最多的还是Copilot,毕竟Github月月送我会员,白嫖还是挺香…...

spring boot中@Validated
在 Spring Boot 中,Validated 是用于触发参数校验的注解,通常与 JSR-303/JSR-380(Bean Validation)提供的校验注解一起使用。以下是常见的校验注解及其用法: 1. 基本校验注解 这些注解可以直接用于字段…...

VBA代码解决方案第二十四讲:EXCEL中,如何删除重复数据行
《VBA代码解决方案》(版权10028096)这套教程是我最早推出的教程,目前已经是第三版修订了。这套教程定位于入门后的提高,在学习这套教程过程中,侧重点是要理解及掌握我的“积木编程”思想。要灵活运用教程中的实例像搭积木一样把自己喜欢的代码…...

SpringBoot+EasyExcel+Mybatis+H2实现导入
文章目录 SpringBootEasyExcelMybatisH2实现导入1.准备工作1.1 依赖管理1.2 配置信息properties1.3 H2数据库1.4 Spring Boot 基础概念1.5 Mybatis核心概念 1.6 EasyExcel核心概念 2.生成Excel数据工具类-随机字符串编写生成Excel的java文件 3.导入功能并且存入数据库3.1 返回结…...

算法四 习题 1.3
数组实现栈 #include <iostream> #include <vector> #include <stdexcept> using namespace std;class MyStack { private:vector<int> data; // 用于存储栈元素的数组public:// 构造函数MyStack() {}// 入栈操作void push(int val) {data.push_back…...
)
el-tabs与table样式冲突导致高度失效问题解决(vue2+elementui)
背景 正常的el-table能根据父容器自动计算剩余高度,并会在列表中判断自适应去放出滚动条。而el-tabs本身就是自适应el-tab-pane内容的高度来进行自适应调节,这样就会导致el-table计算不了当前剩余的高度,所以当el-tabs里面包含el-table时&am…...

Access开发:轻松一键将 Access 全库表格导出为 Excel
hi,大家好呀! 在日常工作中,Access 常常是我们忠实的数据管家,默默守护着项目信息、客户列表或是库存记录。它结构清晰,录入便捷,对于许多中小型应用场景来说,无疑是个得力助手。然而ÿ…...

合并多个Excel文件到一个文件,并保留格式
合并多个Excel文件到一个文件,并保留格式 需求介绍第一步:创建目标文件第二步:创建任务列表第三步:合并文件第四步:处理合并后的文件之调用程序打开并保存一次之前生成的Excel文件第五步:处理合并后的文件之…...
)
使用ZYNQ芯片和LVGL框架实现用户高刷新UI设计系列教程(第十讲)
这一期我们讲解demo中登录、ok按键的回调函数以及界面的美化,以下是上期界面的图片如图所示: 首先点击界面在右侧的工具栏中调配颜色渐变色,具体设置如下图所示: 然后是关于界面内框也就是容器的美化,具体如下图所示…...
论文笔记(八十二)Transformers without Normalization
Transformers without Normalization 文章概括Abstract1 引言2 背景:归一化层3 归一化层做什么?4 动态 Tanh (Dynamic Tanh (DyT))5 实验6 分析6.1 DyT \text{DyT} DyT 的效率6.2 tanh \text{tanh} tanh 和 α α α 的消融实验…...

Mysql之数据库基础
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习Mysql的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...
)
shell(5)
位置参数变量 1.介绍 当我们执行一个shell脚本时,如果希望获取到命令行的参数信息,就可以使用到位置参数变量. 比如:./myshell.sh100 200,这就是一个执行shell的命令行,可以在myshell脚本中获取到参数信息. 2.基本语法 $n(功能描述:n为数字,$0代表命令…...

VARIAN安捷伦真空泵维修清洁保养操作SOP换油操作流程内部转子图文并茂内部培训手侧
VARIAN安捷伦真空泵维修清洁保养操作SOP换油操作流程内部转子图文并茂内部培训手侧...

动画震动效果
项目场景: 提示:这里简述项目相关背景: 在有的相关目中特别是在C端一般都要求做的炫酷一些,这就需要一些简易的动画效果,这里就弄了一个简易的震动的效果如下视频所示 让图标一大一小的震动视频 分析: 提…...

DB-GPT V0.7.1 版本更新:支持多模态模型、支持 Qwen3 系列,GLM4 系列模型 、支持Oracle数据库等
V0.7.1版本主要新增、增强了以下核心特性 🍀DB-GPT支持多模态模型。 🍀DB-GPT支持 Qwen3 系列,GLM4 系列模型。 🍀 MCP支持 SSE 权限认证和 SSL/TLS 安全通信。 🍀 支持Oracle数据库。 🍀 支持 Infini…...
 对象 (P2136R3))
C++23 std::invoke_r:调用可调用 (Callable) 对象 (P2136R3)
文章目录 引言背景知识回顾可调用对象C17的std::invoke std::invoke_r的诞生提案背景std::invoke_r的定义参数和返回值异常说明 std::invoke_r的使用场景指定返回类型丢弃返回值 std::invoke_r与std::invoke的对比功能差异使用场景差异 结论 引言 在C的发展历程中,…...