训练神经网络的批量标准化(使用 PyTorch)
构建神经网络是一门艺术,而非一个结果固定的过程。你无法预知最终能否得到有效的模型,而且有很多因素可能导致你的机器学习项目失败。
然而,随着时间的推移,您还将学会一套特定的笔触,这将大大提高您成功的几率。
在现代神经网络理论中,批量标准化可能是您在寻求信息时会遇到的关键概念之一。
这跟基于批量数据进行规范化有点关系……对吧?没错,但这其实就是用不同的词重复了名称。
事实上,批量标准化可以帮助你克服一种叫做内部协变量偏移的现象。这是什么?批量标准化是如何工作的?我们将在这篇博客中解答这些问题。
随后,我们将介绍批量标准化。在这里,我们还将了解它的含义、工作原理、作用以及重要性。这样,您将了解如何使用它来加速训练,甚至避免出现不收敛的情况。
本博客将涵盖:
- 批量标准化在高层次上的作用是什么。
nn.BatchNorm1dPyTorch 中和之间的区别nn.BatchNorm2d。- 如何使用 PyTorch 实现批量标准化。
它还包括一次测试运行,以查看与不应用它相比它是否真的能表现得更好。
准备好了吗?出发!
内部协变量偏移:训练缓慢和不收敛的可能解释
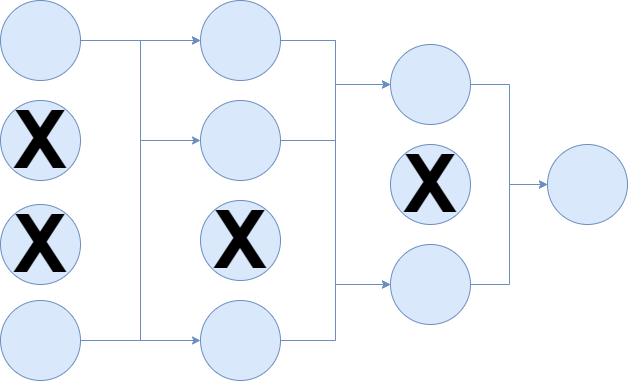
假设你有一个像这样的神经网络,它配备了 Dropout 神经元:
你可能还记得高级监督机器学习过程,训练神经网络包括对训练集进行前馈操作。在此操作过程中,数据被输入到神经网络,神经网络会为每个样本生成一个预测,该预测可以与目标数据(即真实值)进行比较。
这会产生由某些损失函数计算出的损失值。
基于损失函数,反向传播会计算所谓的梯度来改善损失,而梯度下降或自适应优化器实际上会改变神经网络神经元的权重。基于这种变化,模型有望在下一次迭代中表现更好,因为下一次迭代会重复这个过程。
改变输入分布
现在,让我们换个视角。你很可能在阅读上一节时,就已经将神经网络视为一个整体了。这完全没问题,这正是我们想要的效果。但现在,让我们将注意力集中到网络本身,把它看作是一堆堆叠在一起但又各自独立的层的集合。
每一层都会接收一些输入,通过与其权重的交互对其进行转换,然后输出结果,供下游的第一层使用。显然,对于输入层(以原始样本作为输入)和输出层(没有后续层)来说,情况并非如此,但你明白我的意思。
现在假设我们将整个训练集输入到神经网络中。第一层会将这些数据转换为其他值。然而,从统计学角度来看,这也是一个样本,因此它具有样本均值和样本标准差。这个过程在每一层都会重复:输入数据可以表示为具有均值 μ 和标准差 σ 的统计样本。
内部协变量偏移
现在请注意两件事:
- 首先,上面的讨论意味着,某些特定层的输入数据分布取决于所有上游层中发生的所有交互。
- 其次,这意味着上游层处理数据的方式的改变将改变该层的输入分布。
训练模型时会发生什么?实际上,你可以通过改变权重来改变层处理数据的方式。
Ioffe & Szegedy (2015) 在他们的论文《批量标准化:通过减少内部协变量偏移加速深度网络训练》中将此过程称为“内部协变量偏移”。他们定义如下:
由于训练期间网络参数的变化导致网络激活分布的变化。
I offe, S. 和 Szegedy, C. (2015)。批量归一化:通过减少内部协变量偏移加速深度网络训练。arXiv 预印本 arXiv:1502.03167。
为什么这很糟糕?
简单来说:它会减慢训练速度。
如果你使用非常严格的方法来定义监督机器学习模型,那么你会说机器学习会产生一个函数,该函数根据某些学习到的映射将某些输入映射到某些输出,这等于由数据中的真实底层映射所做的映射。
对于每一层来说也是如此:每一层本质上都是一个学习将某些输入映射到某些输出的函数,以便整个系统将原始输入映射到所需的输出。
现在想象一下,你从远处观察训练过程。缓慢但稳定地,每一层都在学习表示内部映射,整个系统开始表现出所需的行为。完美,不是吗?
是的,不过你也看到了过程中的一些波动。确实,你可以看到这些层在训练过程中会犯一些微小的错误,因为它们期望输入是某种类型的,但输入却略有不同。它们知道如何处理这种情况,因为变化非常小,但每次遇到这种变化时,它们都必须重新调整。因此,整个过程会花费更长的时间。
实际的机器学习过程也是如此。内部协方差偏移,即每个隐藏层输入数据分布的变化,意味着每一层都需要一些额外的时间来学习权重,从而使整个系统能够最小化整个神经网络的损失值。在极端情况下,虽然这种情况并不常见,但这种偏移甚至可能导致不收敛,或者无法整体学习映射。这种情况尤其发生在未经归一化且因此不适合机器学习的数据集中。
批量标准化简介
说到这种规范化:与其把它留给机器学习工程师,我们难道不能(至少部分地)在神经网络本身中解决这个问题吗?
正是这种思维方式促使 Ioffe & Szegedy (2015) 提出了批量标准化的概念:通过将每一层的输入标准化为可能接近 (μ= 0.0, σ = 1.0) 的学习表征,可以显著降低内部协方差偏移。因此,预计训练过程的速度将显著提升。
但它是如何工作的呢?
让我们来一探究竟。
小批量的每个特征的归一化
关于批量标准化,首先要理解的重要一点是它是基于每个特征进行的。
这意味着,例如,对于特征向量x= [0.23, 1.26, -2.41],并不是对每个维度进行同等的归一化。而是根据样本参数对每个维度进行单独的归一化。方面。
关于批量标准化,第二个需要理解的重要点是它利用小批量(minibatches)来执行标准化过程(Ioffe & Szegedy, 2015)。它避免了使用整个训练集的计算负担,同时假设如果小批量足够大,它们会接近数据集的样本分布。这是一个非常好的想法。
四步流程
现在来看看算法。对于特征向量x _B 中的每个特征 x_B^{(k)}(对于你的隐藏层来说,它不包含你的特征,而是该特定层的输入),批量归一化会在你的小批量 B 上通过四步过程对这些值进行归一化(Ioffe & Szegedy,2015):
- 计算小批量的平均值:
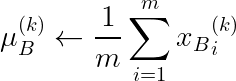
2.计算小批量的方差:
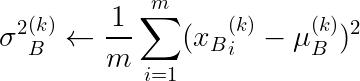
3.标准化值:
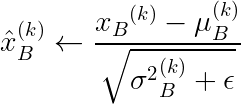
4.缩放和平移:
![]()
计算平均值和方差
前两个步骤很简单,非常常见,也是标准化步骤中必需的:计算小批量样本 x_B 的第 k 维的平均值 μ 和方差 σ²。
规范化
这些随后用于标准化步骤,其中只要小批量中的样本具有相同的分布并且忽略 ε 的值,预期分布就是 (0, 1) (Ioffe & Szegedy, 2015)。
你可能会问:确实,这个ε,它为什么在那里?
它是为了数值稳定性(Ioffe & Szegedy,2015)。如果方差 σ² 为零,就会出现除以零的误差。这意味着模型会变得数值不稳定。ε 的值可以通过取一个非常小但非零的值来抵消这种影响。
缩放和平移
现在,终于到了第四步:对标准化的输入值进行缩放和平移。我能理解为什么这很奇怪,因为我们在第三步就已经完成了标准化。
请注意,简单地对某一层的每个输入进行归一化可能会改变该层所能表示的内容。例如,对 S 型函数的输入进行归一化会将其限制在非线性函数的线性范围内。为了解决这个问题,我们确保插入到网络中的变换能够表示恒等变换。为此,我们为每个激活函数 x^{(k)} 引入一对参数 γ^{(k)} 和 β^{(k)},它们对归一化值进行缩放和平移:
![]()
Ioffe, S. 和 Szegedy, C. (2015)。批量归一化:通过减少内部协变量偏移来加速深度网络训练。arXiv 预印本 arXiv:1502.03167。
非线性的线性区域?代表恒等变换吗?这些是什么?
让我们将相当学术性的英语简化为更简单的版本。
首先,我们来谈谈“非线性的线性机制”。假设我们使用Sigmoid 激活函数,它是一个非线性激活函数(也称“非线性”),在 Ioffe & Szegedy 的论文发表于 2015 年时,这种函数仍然相当常见。
它看起来像这样:
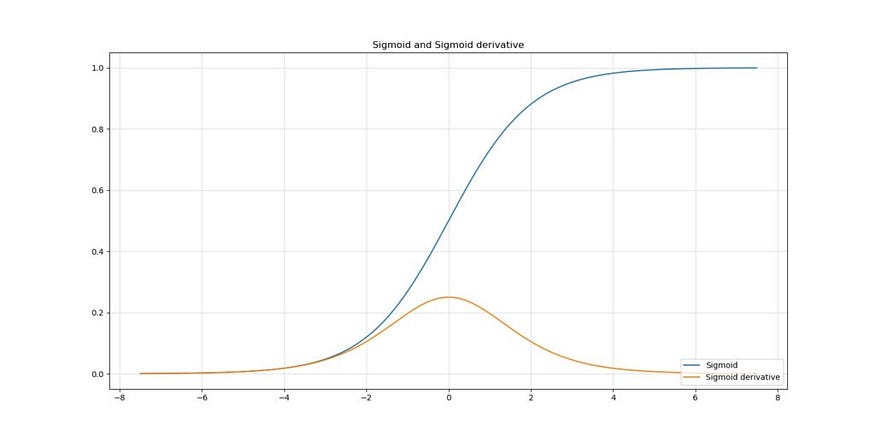
假设我们将其添加到某个任意层。
如果没有批量标准化,该层的输入就不会具有近似(0,1)的分布,因此理论上更有可能取相当大的值(例如 2.5623423...)。
假设我们的层除了传递数据之外什么都不做(为了使我们的情况更简单),这些输入值的激活会产生具有非线性斜率的输出:如您在上图中所看到的,对于域 [2, 4] 中的激活函数的输入,输出会弯曲一点。
然而,对于 ≈ 0 的输入,情况并非如此:在近似 [-0.5, 0.5] 的输入域中,输出没有弯曲,实际上看起来像是一个线性函数。这完全降低了非线性激活的效果,从而降低了模型的性能,这可能不是我们想要的!
等等:我们不是已经标准化为(0, 1)了吗?这意味着我们激活函数的输入在每一层都可能位于 [-1, 1] 的取值范围内吗?哎呀!
这就是为什么作者引入了一个具有一些参数 γ 和 β 的缩放和平移操作,利用这些参数可以在训练期间调整标准化,在极端情况下甚至可以“表示身份变换”(即输入的内容会再次出现 - 完全消除批量标准化步骤)。
这些参数是在训练期间与其他参数一起学习的(Ioffe & Szegedy,2015)。
继续我们的小例子
现在,让我们修改上面的小例子,我们的特征向量x = [0.23, 1.26, -2.41]。
假设我们使用了每批 2 个样本的小批量方法(我知道有点少,但足以解释),集合中还有另一个向量x _a = [0.56, 0.75, 1.00],我们的批量标准化步骤将如下所示(假设 γ = β = 1):
<span style="background-color:#f9f9f9"><span style="color:#242424">| 特征 | 平均值 | 方差 | 输入 | 输出 |
| [0.23,0.56] | 0.395 | 0.054 | 0.23 | -0.710 |
| [1.26,0.75] | 1.005 | 0.130 | 1.26 | 0.707 |
| [-2.41,1.000] | -0.705| 5.81 | -2.41 | -0.707 | </span></span>我们可以看到,当 γ =β=1 时,我们的值被标准化为大约 (0, 1) 的分布 — 其中带有一些 ε 项。
批量标准化的好处
理论上,在神经网络中使用批量标准化有一些假定的好处(Ioffe & Szegedy,2015):
- 该模型对超参数调整不太敏感。也就是说,以前较大的学习率会导致模型无用,但现在较大的学习率是可以接受的。
- 现在,权重初始化不再那么重要了。
- 可以删除用于添加噪声以利于训练的 Dropout。
推理过程中的批量标准化
虽然小批量方法可以加快训练过程,但它“在推理过程中既不必要也不理想”(Ioffe & Szegedy,2015)。例如,在推断新样本的类别时,你希望基于整个训练集对其进行归一化,因为这样可以产生更好的估计,并且在计算上也是可行的。
因此,在推理过程中,批量标准化步骤如下:
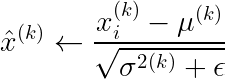
其中 x ∈ X,X 代表完整的训练数据,而不是一些小批量 X_b。
使用 PyTorch 实现批量标准化
在这里,你将继续使用 PyTorch 库实现深度学习的批量标准化。这涉及以下几个步骤:
- 看一下
nn.BatchNorm2d和之间的区别nn.BatchNorm1d。 - 编写你的神经网络并构建受批量标准化影响的训练循环。
- 将所有内容整合到完整代码中。
BatchNorm2d 和 BatchNorm1d 之间的区别
首先,PyTorch 中二维和一维 Batch Normalization 的区别。
- 二维批量标准化由 提供
[nn.BatchNorm2d](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html)。 - 对于一维批量标准化,您可以使用
[nn.BatchNorm1d](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm1d.html)
一维批量标准化在PyTorch网站上的定义如下:
对 2D 或 3D 输入应用批量标准化(具有可选附加通道维度的 1D 输入的小批量)(...)
PyTorch(nd)
…二维批量标准化是这样描述的:
对 4D 输入(具有附加通道维度的 2D 输入的小批量)应用批量标准化 (...)
PyTorch(nd)
让我们总结一下:
- 一维批量标准化(
nn.BatchNorm1d)对二维或三维输入(一批具有可能通道维度的一维输入)应用批量标准化。 - 二维 BatchNormalization(
nn.BatchNorm2d)将其应用于 4D 输入(一批具有可能的通道维度的2D输入)。
创建一个文件——例如batchnorm.py——并在代码编辑器中打开它。同时,请确保您torchvision的系统上已安装 Python、PyTorch(或在您的 Python 环境中可用)。开始吧!
说明进口
首先,我们要说明我们的进口情况。
- 我们需要
os基于定义来正确下载数据集。 torchPyTorch 需要所有基于的导入:torch它本身、nn(又名神经网络)模块以及DataLoader用于加载我们将在今天的神经网络中使用的数据集。- 从中
torchvision,我们加载CIFAR10数据集 - 以及transforms在训练神经网络之前将应用于数据集的一些(主要是图像规范化)。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">导入</span>os<span style="color:#aa0d91">从</span>torch
<span style="color:#aa0d91">导入</span>torch<span style="color:#aa0d91">导入</span>nn<span style="color:#aa0d91">从</span>torchvision.datasets<span style="color:#aa0d91">导入</span>CIFAR10<span style="color:#aa0d91">从</span>torch.utils.data<span style="color:#aa0d91">导入</span>DataLoader<span style="color:#aa0d91">从</span>torchvision<span style="color:#aa0d91">导入</span>transforms</span></span>使用批量标准化定义 nn.Module
接下来是定义nn.Module。事实上,我们今天不使用Conv层——这可能会改善你的神经网络。相反,我们会立即将 32x32x3 的输入展平,然后进一步将其处理成 10 类结果(因为 CIFAR10 有 10 个类)。
如你所见,我们之所以BatchNorm1d在这里应用,是因为我们使用了全连接(又称Linear)层。请注意,BatchNorm 层的输入数量必须等于该层的输出Linear数量。
它清楚地展示了如何将批量标准化与 PyTorch 一起应用。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">class </span> MLP (nn.Module): <span style="color:#c41a16">'''多层感知器。''' </span><span style="color:#aa0d91">def </span> __init__ ( <span style="color:#5c2699">self</span> ): <span style="color:#5c2699">super</span> ().__init__() self.layers = nn.Sequential( nn.Flatten(), nn.Linear( <span style="color:#1c00cf">32</span> * <span style="color:#1c00cf">32</span> * <span style="color:#1c00cf">3</span> , <span style="color:#1c00cf">64</span> ), nn.BatchNorm1d( <span style="color:#1c00cf">64</span> ), nn.ReLU(), nn.Linear( <span style="color:#1c00cf">64</span> , <span style="color:#1c00cf">32</span> ), nn.BatchNorm1d( <span style="color:#1c00cf">32</span> ), nn.ReLU(), nn.Linear( <span style="color:#1c00cf">32</span> , <span style="color:#1c00cf">10</span> ) ) <span style="color:#aa0d91">def </span> forward ( <span style="color:#5c2699">self, x</span> ): <span style="color:#c41a16">'''前向传递''' </span><span style="color:#aa0d91">return</span> self.layers(x)</span></span>编写训练循环
接下来是编写训练循环。我们不会在这里详细讨论它,因为我们在关于如何开始使用第一个 PyTorch 模型的专题文章中已经写过了:
不过,为了简单总结一下发生的事情,请看下面:
- 首先,我们将随机数生成器的种子向量设置为一个固定值。这确保了任何差异都是由于数字生成过程的随机性造成的,而不是由于数字生成器本身的伪随机性。
- 然后,我们准备 CIFAR-10 数据集,初始化 MLP 并定义损失函数和优化器。
- 接下来,我们会进行迭代,将当前损失设为 0.0,并开始在数据加载器上进行迭代。我们将梯度设为零,执行前向传播,计算损失,然后执行后向传播,最后进行优化。这实际上就是监督机器学习过程中发生的事情。
- 我们打印通过模型前馈的每个小批次的统计数据。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">if</span> __name__ == <span style="color:#c41a16">'__main__'</span> : <span style="color:#007400"># 设置固定随机数种子</span>torch.manual_seed( <span style="color:#1c00cf">42</span> ) <span style="color:#007400"># 准备 CIFAR-10 数据集</span>dataset = CIFAR10(os.getcwd(), download= <span style="color:#aa0d91">True</span> , transform=transforms.ToTensor()) trainloader = torch.utils.data.DataLoader(dataset, batch_size= <span style="color:#1c00cf">10</span> , shuffle= <span style="color:#aa0d91">True</span> , num_workers= <span style="color:#1c00cf">1</span> ) <span style="color:#007400"># 初始化 MLP</span>mlp = MLP() <span style="color:#007400"># 定义损失函数和优化器</span>loss_function = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(mlp.parameters(), lr= <span style="color:#1c00cf">1e-4</span> ) <span style="color:#007400"># 运行训练循环</span><span style="color:#aa0d91">for</span> epoch <span style="color:#aa0d91">in </span> <span style="color:#5c2699">range</span> ( <span style="color:#1c00cf">0</span> , <span style="color:#1c00cf">5</span> ): <span style="color:#007400"># 最多 5 个 epoch </span><span style="color:#007400"># 打印 epoch </span><span style="color:#5c2699">print</span> ( <span style="color:#c41a16">f'Starting epoch <span style="color:#000000">{epoch+ <span style="color:#1c00cf">1</span> }</span> '</span> ) <span style="color:#007400"># 设置当前损失值</span>current_loss = <span style="color:#1c00cf">0.0 </span><span style="color:#007400"># 遍历 DataLoader 获取训练数据</span><span style="color:#aa0d91">for</span> i, data <span style="color:#aa0d91">in </span> <span style="color:#5c2699">enumerate</span> (trainloader, <span style="color:#1c00cf">0</span> ): <span style="color:#007400"># 获取输入</span>inputs, targets = data <span style="color:#007400"># 将梯度清零</span>optimizer.zero_grad() <span style="color:#007400"># 执行前向传递</span>outputs = mlp(inputs) <span style="color:#007400"># 计算损失</span>loss = loss_function(outputs, targets) <span style="color:#007400"># 执行后向传递</span>loss.backward() <span style="color:#007400"># 执行优化</span>optimizer.step() <span style="color:#007400"># 打印统计数据</span>current_loss += loss.item() <span style="color:#aa0d91">if</span> i % <span style="color:#1c00cf">500</span> == <span style="color:#1c00cf">499</span> : <span style="color:#5c2699">print</span> ( <span style="color:#c41a16">'小批量 %5d 后的损失: %.3f'</span> % (i + <span style="color:#1c00cf">1</span> , current_loss / <span style="color:#1c00cf">500</span> )) current_loss = <span style="color:#1c00cf">0.0 </span><span style="color:#007400"># 过程完成。</span><span style="color:#5c2699">print</span> ( <span style="color:#c41a16">'训练过程已完成。'</span> )</span></span>完整型号代码
也可在后台私我获取到。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">导入</span>操作系统<span style="color:#aa0d91">从</span>torch
<span style="color:#aa0d91">导入</span>torch<span style="color:#aa0d91">导入</span>nn<span style="color:#aa0d91">从</span>torchvision.datasets<span style="color:#aa0d91">导入</span>CIFAR10<span style="color:#aa0d91">从</span>torch.utils.data<span style="color:#aa0d91">导入</span>DataLoader<span style="color:#aa0d91">从</span>torchvision<span style="color:#aa0d91">导入</span>transforms<span style="color:#aa0d91">类</span>MLP (nn.Module): <span style="color:#c41a16">'''</span><span style="color:#c41a16"> 多层感知器。</span><span style="color:#c41a16"> ''' </span><span style="color:#aa0d91">def </span>__init__ ( <span style="color:#5c2699">self</span> ): <span style="color:#5c2699">super</span> ().__init__() self.layers = nn.Sequential( nn.Flatten(), nn.Linear( <span style="color:#1c00cf">32</span> * <span style="color:#1c00cf">32</span> * <span style="color:#1c00cf">3</span> , <span style="color:#1c00cf">64</span> ), nn.BatchNorm1d( <span style="color:#1c00cf">64</span> ), nn.ReLU(), nn.Linear( <span style="color:#1c00cf">64</span> , <span style="color:#1c00cf">32</span> ), nn.BatchNorm1d( <span style="color:#1c00cf">32</span> ), nn.ReLU(), nn.Linear( <span style="color:#1c00cf">32</span> , <span style="color:#1c00cf">10</span> ) ) <span style="color:#aa0d91">def </span>forward ( <span style="color:#5c2699">self, x</span> ): <span style="color:#c41a16">'''前向传播''' </span><span style="color:#aa0d91">return</span> self.layers(x) <span style="color:#aa0d91">if</span> __name__ == <span style="color:#c41a16">'__main__'</span> : <span style="color:#007400"># 设置固定随机数种子</span> torch.manual_seed( <span style="color:#1c00cf">42</span> ) <span style="color:#007400"># 准备 CIFAR-10 数据集</span> dataset = CIFAR10(os.getcwd(), download= <span style="color:#aa0d91">True</span> , transform=transforms.ToTensor()) trainloader = torch.utils.data.DataLoader(dataset, batch_size= <span style="color:#1c00cf">10</span> , shuffle= <span style="color:#aa0d91">True</span> , num_workers= <span style="color:#1c00cf">1</span> ) <span style="color:#007400"># 初始化 MLP</span> mlp = MLP() <span style="color:#007400"># 定义损失函数和优化器</span> loss_function = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(mlp.parameters(), lr= <span style="color:#1c00cf">1e-4</span> ) <span style="color:#007400"># 运行训练循环</span><span style="color:#aa0d91">for</span> epoch <span style="color:#aa0d91">in </span><span style="color:#5c2699">range</span> ( <span style="color:#1c00cf">0</span> , <span style="color:#1c00cf">5</span> ): <span style="color:#007400"># 最多 5 个 epoch </span><span style="color:#007400"># 打印 epoch </span><span style="color:#5c2699">print</span> ( <span style="color:#c41a16">f'Starting epoch </span><span style="color:#c41a16"><span style="color:#000000">{epoch+ </span></span><span style="color:#c41a16"><span style="color:#000000"><span style="color:#1c00cf">1</span></span></span><span style="color:#c41a16"><span style="color:#000000"> }</span></span><span style="color:#c41a16"> '</span> ) <span style="color:#007400"># 设置当前损失值</span> current_loss = <span style="color:#1c00cf">0.0 </span><span style="color:#007400"># 遍历 DataLoader 获取训练数据</span><span style="color:#aa0d91">for</span> i, data <span style="color:#aa0d91">in </span><span style="color:#5c2699">enumerate</span> (trainloader, <span style="color:#1c00cf">0</span> ): <span style="color:#007400"># 获取输入</span> input, target = data <span style="color:#007400"># 将梯度归零</span>optimizer.zero_grad() <span style="color:#007400"># 执行前向传递</span>outputs = mlp(inputs) <span style="color:#007400"># 计算损失</span>loss = loss_function(outputs, targets) <span style="color:#007400"># 执行后向传递</span>loss.backward() <span style="color:#007400"># 执行优化</span>optimizer.step() <span style="color:#007400"># 打印统计数据</span>current_loss += loss.item() <span style="color:#aa0d91">if</span> i % <span style="color:#1c00cf">500</span> == <span style="color:#1c00cf">499</span> : <span style="color:#5c2699">print</span> ( <span style="color:#c41a16">'小批量 %5d 后的损失: %.3f'</span> % (i + <span style="color:#1c00cf">1</span> , current_loss / <span style="color:#1c00cf">500</span> )) current_loss = <span style="color:#1c00cf">0.0 </span><span style="color:#007400"># 过程完成。</span><span style="color:#5c2699">print</span> ( <span style="color:#c41a16">'训练过程已完成。'</span> )</span></span>结果
以下是在 CIFAR-10 数据集上对我们的 MLP 进行 5 个 epoch 训练并使用批量标准化后得到的结果:
<span style="background-color:#f9f9f9"><span style="color:#242424">起始 epoch 5
小批量 500 后的损失:1.573
小批量 1000 后的损失:1.570
小批量 1500 后的损失:1.594
小批量 2000 后的损失:1.568
小批量 2500 后的损失:1.609
小批量 3000 后的损失:1.573
小批量 3500 后的损失:1.570
小批量 4000 后的损失:1.571
小批量 4500 后的损失:1.571
小批量 5000 后的损失:1.584</span></span>相同,但没有批量标准化:
<span style="background-color:#f9f9f9"><span style="color:#242424">起始 epoch 5
小批量 500 后的损失:1.650
小批量 1000 后的损失:1.656
小批量 1500 后的损失:1.668
小批量 2000 后的损失:1.651
小批量 2500 后的损失:1.664
小批量 3000 后的损失:1.649
小批量 3500 后的损失:1.647
小批量 4000 后的损失:1.648
小批量 4500 后的损失:1.620
小批量 5000 后的损失:1.648</span></span>显然,但并不令人意外的是,基于批量标准化的模型表现更好。
概括
在这篇博文中,我们探讨了训练过程相对缓慢且不收敛的问题,并指出批量归一化可能有助于减少神经网络的这些问题。批量归一化通过将输入数据的分布缩减至 (0, 1),并逐层执行,理论上有望减少所谓的“内部协方差偏移”,从而加快学习速度。
相关文章:
)
训练神经网络的批量标准化(使用 PyTorch)
构建神经网络是一门艺术,而非一个结果固定的过程。你无法预知最终能否得到有效的模型,而且有很多因素可能导致你的机器学习项目失败。 然而,随着时间的推移,您还将学会一套特定的笔触,这将大大提高您成功的几率。 在…...

阿里Qwen3 8款模型全面开源,免费商用,成本仅为 DeepSeek-R1 的三分之一
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。 1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其…...
)
Vue常用的修饰符有哪些有什么应用场景(含deep seek讲解)
Vue.js 事件修饰符的功能与具体应用场景 一、事件修饰符 .stop .stop 的主要作用是 阻止事件冒泡,防止事件从子元素传播到父元素。这在处理嵌套组件或多层 DOM 结构时非常有用。 <div click"parentClick">Parent<button click.stop"chi…...

案例分享|20倍提效!水力设备电磁仿真的云端实战
在现代水力设备制造领域,电磁仿真是贯穿设计、研发到故障诊断的核心技术之一。而随着"双碳"目标驱动下清洁能源设备的迭代加速,水轮机、水泵等设备研发的多物理场耦合特性对仿真精度提出前所未有的挑战。传统仿真工具在处理复杂多物理场耦合等…...
)
ShenNiusModularity项目源码学习(25:ShenNius.Admin.Mvc项目分析-10)
本文学习并分析ShenNiusModularity项目中的留言管理页面、回收站页面。 1、留言管理页面 留言管理页面用于检索、删除系统中的留言数据,该页面对应的文件Index.cshtml位于ShenNius.Admin.Mvc项目的Areas\Cms\Views\Message内。页面使用的控制器类MessageController…...

github使用记录
1. 首次上传本地项目到 GitHub 1.1 准备 GitHub 仓库 登录 GitHub,点击右上角 → New repository输入仓库名称(建议与本地目录同名)选择公开(Public)或私有(Private)不要勾选 "Initiali…...

NFS-网络文件系统
NFS介绍 NFS ( Network File System ) 即网络文件系统 ,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样NFS的好…...

Andorid车机UI适配,AndroidUI图px的单位,如何适配1920x720,PPI100的屏幕设备
在 Android 开发中,针对 1920720 分辨率、PPI 100 的屏幕设备进行 UI 适配,需要综合考虑 像素密度(PPI)、屏幕尺寸 和 Android 的密度无关像素(dp) 体系。以下是完整的适配方案: 📌 …...

4.2.4 MYSQL的缓存策略
文章目录 4.2.4 MYSQL的缓存策略1. MYSQL缓存方案用来干什么 2. 缓存相关知识1. mysql主从复制2. 为什么需要缓冲层3. 还有哪些类型数据库 3. 那些方式会提升MYSQL读写性能1. mysql读写分离2. 连接池3. 异步连接 4. 缓存方案是怎么解决的1. redis和MYSQL一致性状态分析1. 流程&…...

省科学技术奖申报答辩PPT设计制作美化
自然科学奖、技术发明奖和科技进步奖是科学技术奖励体系中的三大核心奖项 省科学技术奖的含金量极高,主要体现在经济激励、社会认可、创新驱动及资源整合等方面。其价值不仅在于奖金和荣誉,更在于对科研生态的长远影响,国家科学技术奖的敲门…...

基于 ARM 的自动跟拍云台设计
标题:基于 ARM 的自动跟拍云台设计 内容:1.摘要 摘要:随着摄影和监控需求的不断增长,自动跟拍云台的应用越来越广泛。本设计的目的是开发一款基于 ARM 的自动跟拍云台,以实现对目标的精准跟拍。采用 ARM 微控制器作为核心控制单元࿰…...
_关机和重启的过程)
Linux电源管理(3)_关机和重启的过程
原文:Linux电源管理(3)_Generic PM之重新启动过程 1.前言 在使用计算机的过程中,关机和重启是最先学会的两个操作。同样,这两个操作在Linux中也存在,可以关机和重启。这就是这里要描述的对象。在Linux Ke…...

SQLMesh增量模型实战指南:时间范围分区
引言 在数据工程领域,处理大规模数据集和高频率数据更新是一项挑战。SQLMesh作为一款强大的数据编排工具,提供了增量模型功能,帮助数据工程师高效地管理和更新数据。本文将详细介绍如何使用SQLMesh创建和管理基于时间范围的增量模型…...

LeetCode -160.相交链表
题目 160. 相交链表 - 力扣(LeetCode) 解法一 哈希表 哈希表解决方案的思路 这个使用哈希表(unordered_set)的解决方案基于一个简单的观察:如果两个链表相交,那么相交点及之后的所有节点都是两个链表共…...

针对Linux挂载NAS供Minio使用及数据恢复的需求
针对Linux挂载NAS供Minio使用及数据恢复的需求,设计以下分阶段解决方案: 一、存储架构设计 存储拓扑 [Minio Server] --> [NAS挂载点 (/mnt/nas/minio-data)] --> [企业级NAS设备]│└─[备份服务器/存储] (可选异地备份)组件版本要求 Minio版本&a…...

【大厂实战】API网关进化史:从统一入口到智能AB分流,如何构建灰度无感知系统?
【大厂实战】API网关进化史:从统一入口到智能AB分流,如何构建灰度无感知系统? 1. 为什么API网关是AB面架构的天然起点? 在分布式微服务架构中,API网关(API Gateway)承担着重要职责:…...

开放平台架构方案- GraphQL 详细解释
GraphQL 详细解释 GraphQL 是一种用于 API 的查询语言,由 Facebook 开发并开源,旨在提供一种更高效、灵活且强大的数据获取和操作方式。它与传统的 REST API 有显著不同,通过类型系统和灵活的查询能力,解决了 REST 中常见的过度获…...
)
使用 TypeScript 开发并发布一个 npm 包(完整指南)
本教程将一步步教你从零开发、打包并发布一个 TypeScript 工具库到 npm。以日期时间格式化工具为例,涵盖项目初始化、Vite 打包、类型声明输出、npm 配置、实际发布等完整流程,适合开发者直接套用。 文章目录 📁 项目结构预览🧱 初…...

在Anolis OS 8上部署Elasticsearch 7.16.1与JDK 11的完整指南
目录 1. 环境与版本选择 1.1 操作系统选择:Anolis OS 8 1.2 版本匹配说明 1.3 前置条件检查 2. JDK 11安装与配置 2.1 安装流程 2.2 配置详解 3. Elasticsearch 7.16.1安装与优化 3.1 基础安装 3.2 目录规划与权限 3.3 核心配置文件详解 3.4 JVM调优 4. 用户权限管…...

SELinux 从理论到实践:深入解析与实战指南
文章目录 引言:为什么需要 SELinux?第一部分:SELinux 核心理论1.1 SELinux 的三大核心模型1.2 安全上下文(Security Context)1.3 策略语言与模块化 第二部分:实战操作指南2.1 SELinux 状态管理2.2 文件上下…...

巧用 `unittest.mock` 模块实现依赖服务隔离测试
巧用 unittest.mock 模块实现依赖服务隔离测试 引言 在软件开发过程中,单元测试是保障代码质量的核心手段。然而,许多代码依赖于外部服务,如数据库、API 或文件系统,直接进行测试可能会导致: 环境不可控:测试数据可能变化,影响测试结果的稳定性。执行时间长:依赖外部…...

水利三维可视化平台怎么做?快速上手的3步指南
分享大纲: 1、了解水利三维可视化平台 2、选择合适的开发平台 3、快速搭建水利三维可视化平台 第一步:了解水利三维可视化平台 水利三维可视化平台是利用大数据、物联网、数字孪生等技术,将物理实体数字化建模,并通过三维可视化技…...

【DB2】逻辑导出导入注意事项
DB2异构操作系统之间迁移需选择逻辑备份恢复 导出环节 1、设置字符集,源端创建导出目录,并导出数据库DDL db2set db2codepage1208 db2stop force db2start db2look -d YS-e -l -o -createdb db2look_YS.sql导出文件:db2look_YS.sql –详细参数请参考…...
)
Fiddler抓取APP端,HTTPS报错全解析及解决方案(一篇解决常见问题)
环境:雷电模拟器Android9系统 你所遇到的fiddler中抓取HTTPS的问题可以分为三类:一类是你自己证书安装上逻辑错误,另一种是APP中使用了“证书固定”的手段。三类fiddler中生成证书时的参数过程。 1.Fiddler证书安装上的逻辑错误 更新Opt…...
:C 语言强制类型转换详解)
C语言教程(二十三):C 语言强制类型转换详解
一、强制类型转换的概念 强制类型转换是指在程序中手动将一个数据类型的值转换为另一种数据类型。在某些情况下,编译器可能不会自动进行类型转换,或者自动转换的结果不符合我们的预期,这时就需要使用强制类型转换来明确指定要进行的类型转换。…...

阿里云服务器 篇十二:加入 Project Honey Pot 和使用 http:BL
文章目录 系列文章背景前提条件注册和准备注册安装蜜罐捐赠MX记录(可选)添加 QuickLinks(快速链接)使用 http:BL(HTTP黑名单)获取Access Key(访问秘钥)Apache自动拦截黑名单IP模块Http:BL API文档更多实现案例监控IP空间系列文章 阿里云服务器 篇一:申请和初始化 阿里…...

Android 手动删除 AAR jar 包 中的文件
Duplicate class com.xxxa.naviauto.sdk.listener.OnChangeListener found in modules jetified-xxxa-sdk-v1.1.2-release-runtime (:xxx-sdk-v1.1.2-release:) and jetified-xxxb-sdk-1.1.3-runtime (:xxxb-sdk-1.1.3:) A.aar B.aar 有类冲突; 使用 exclude 排除本地aar无效…...

Tomcat 部署配置指南
## 1. 环境要求 - JDK 8 或更高版本 - Tomcat 8.5/9.x/10.x - Windows 操作系统 ## 2. 安装步骤 ### 2.1 安装JDK 1. 下载并安装JDK 2. 配置环境变量: - JAVA_HOME: JDK安装目录 - Path: 添加 %JAVA_HOME%\bin 3. 验证安装:打开命令提示符&#…...

阿里千问Qwen3技术解析与部署指南 :混合推理架构突破性优势与对DeepSeek R1的全面超越
阿里千问Qwen3技术解析:突破性优势与对DeepSeek R1的全面超越 在2025年4月29日,阿里巴巴发布了新一代开源大模型Qwen3(通义千问3),凭借其创新架构与显著性能提升,迅速成为全球开源AI领域的焦点。本文将从技…...

宾馆一次性拖鞋很重要,扬州卓韵酒店用品详细介绍其材质与卫生标准
宾馆一次性拖鞋在旅途中很重要。它的卫生情况受大家关注。它的舒适度也受大家关注。扬州卓韵酒店用品在这方面经验丰富。其产品质量优良。下面为你详细介绍宾馆一次性拖鞋。 材质选择目前宾馆一次性拖鞋材质多样。常见的有布质、纸质和塑料的。布质拖鞋相对环保舒适。能给脚部…...

推荐系统中 Label 回收机制之【时间窗口设计】
目录 引言一、业务需求:目标导向的窗口设计1.1 用户行为周期决定窗口基础1.2 业务目标驱动窗口粒度1.3 动态场景下的弹性调整 二、数据特性:窗口设计的底层约束2.1 数据分布与稀疏性适配2.2 数据延迟与完整性保障2.3 特征时效性分层 三、算法模型&#x…...

DevExpressWinForms-XtraMessageBox-使用教程
XtraMessageBox-使用教程 一、基础使用:快速弹出标准消息框 XtraMessageBox 的基础使用非常简单,只需调用XtraMessageBox.Show方法即可弹出一个标准的消息框。根据不同的使用需求,Show方法有多种重载形式。 1.1 仅显示提示信息 当我们仅仅…...

ETL数据集成与数据资产的紧密关联,解锁数据价值新密码
数据已然成为企业最为珍贵的资产之一。无论是传统行业巨头,还是新兴的互联网企业,都在积极挖掘数据背后所蕴含的巨大商业价值。而在这个过程中,ETL(Extract,Transform,Load)作为数据处理的关键环…...

【无报错,亲测有效】如何在Windows和Linux系统中查看MySQL版本
如何在Windows和Linux系统中查看MySQL版本 MySQL作为最流行的开源关系型数据库管理系统之一,了解如何查看其版本信息对于开发者和数据库管理员来说是常用的一个基本操作。本文将详细介绍在Windows和Linux系统中查看MySQL版本的方法。 文章目录 如何在Windows和Linu…...

【Leetcode 每日一题】2962. 统计最大元素出现至少 K 次的子数组
问题背景 给你一个整数数组 n u m s nums nums 和一个 正整数 k k k。 请你统计有多少满足 「 n u m s nums nums 中的 最大 元素」至少出现 k k k 次的子数组,并返回满足这一条件的子数组的数目。 子数组是数组中的一个连续元素序列。 数据约束 1 ≤ n u m s …...

网络爬取需谨慎:警惕迷宫陷阱
一、技术背景:网络爬虫与数据保护的博弈升级 1. 问题根源:AI训练数据爬取的无序性 数据需求爆炸:GPT-4、Gemini等大模型依赖数万亿网页数据训练,但大量爬虫无视网站的robots.txt协议(非法律强制),未经许可抓取内容(如新闻、学术论文、代码),引发版权争议(如OpenAI被…...

‘WebDriver‘ object has no attribute ‘find_element_by_class‘
在使用Selenium进行Web自动化测试时,如果你遇到了错误信息:“‘WebDriver’ object has no attribute ‘find_element_by_class’”,这通常是因为在Selenium 4及以上版本中,find_element_by_* 和 find_elements_by_* 这类方法已经…...

ComfyUI 学习笔记,案例1:2_pass_txt2img
背景 ComfyUI 官方案例学习笔记,本文是跑出的第三个案例,但确是官网案例的第一个,所以运行起来总体比较顺利。整理几点页面使用技巧: 是网页版本,没有 IDEA,而且画布上没有滚动条,想看清楚内容…...

代码颜色模式python
1. CMYK(印刷场景) 例子:某出版社设计书籍封面时,使用 Adobe Illustrator 绘制图案。 红色封面的 CMYK 值可能为:C0, M100, Y100, K0(通过洋红和黄色油墨混合呈现红色)。印刷前需将设计文件转…...
)
Android第五次面试总结之网络篇(修)
一、域名解析到服务器的过程(DNS 解析流程) 当应用发起网络请求(如https://www.example.com)时,操作系统需先将域名转换为服务器 IP 地址,这一过程通过 DNS(域名系统) 完成…...

JavaScript 作用域全面总结
JavaScript 作用域全面总结 作用域(Scope)是JavaScript中一个核心概念,决定了变量、函数和对象的可访问性。以下是JavaScript作用域的全面总结,结合表格和箭头图进行讲解。 一、作用域类型 JavaScript 作用域类型详解 JavaScript 中有四种主要的作用…...

Redis核心与底层实现场景题深度解析
Redis核心与底层实现场景题深度解析 在互联网大厂Java求职者的面试中,经常会被问到关于Redis的核心与底层实现相关的场景题。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我们公司的面试现场。…...

代发考试战报:4月份 思科认证,华为认证,考试战报分享
CCNP 300-410考试通过战报,350-401 考试通过战报,CCNA 200-301 考试通过战报,HCIP数通 H12-821考试通过,H12-831考试通过,HCSP 行业金融 H19-611考试通过,HCSE 行业金融 H21-293 考试通过 报名考试一定要找…...

Linux 内核中 TCP 协议的支撑解析
在 Linux 网络协议栈中,TCP(传输控制协议)作为面向连接的可靠传输协议,其实现依赖于一系列复杂的内核机制。本文通过分析四个关键函数(cookie_v4_init_sequence、tcp_fastopen_ctx_destroy、sk_forced_mem_schedule 和 sk_stream_alloc_skb),探讨它们如何共同保障 TCP 的…...
)
std::string的底层实现 (详解)
目录 std::string的底层实现* 写时复制原理探究 CowString代码初步实现 短字符串优化(SSO) 最佳策略 std::string的底层实现* 我们都知道, std::string的一些基本功能和用法了,但它底层到底是如何实现的呢? 其实在std::stri…...

蓝桥杯 11. 最大距离
最大距离 原题目链接 题目描述 在数列 a1, a2, ⋯, an 中,定义两个元素 ai 和 aj 的距离为: |i - j| |ai - aj|即元素下标的距离加上元素值的差的绝对值,其中 |x| 表示 x 的绝对值。 给定一个数列,请找出元素之间最大的元素…...

【运维】使用 DataX 实现 MySQL 到 PostgreSQL 的数据同步
🚀 使用 DataX 实现 MySQL 到 PostgreSQL 的数据同步 在日常的数据开发工作中,数据同步是一项极其常见的任务。而 DataX 作为阿里开源的一款通用数据同步工具,支持多种数据源之间的互通,使用简单,扩展性强,非常适合进行结构化数据的迁移和同步。 本文将详细介绍如何通…...

Mangodb基本概念和介绍,Mango三个重要的概念:数据库,集合,文档
MongoDB基本概念和介绍 MongoDB 是一个开源的、基于分布式文件存储的NoSQL数据库,由 C 编写。 它的主要特点是: 使用**面向文档(Document-Oriented)**的存储方式,不是传统的表格行列模式。存储的数据格式是BSON&…...

什么是ICSP编程
ICSP编程介绍 ICSP 编程(In-Circuit Serial Programming),即“在线串行编程”,是一种通过 SPI 协议 直接对微控制器(如 Arduino 的 ATmega328P)进行编程的技术,无需移除芯片。它常用于以下场景…...

LeetCode 155题解 | 最小栈
最小栈 一、题目链接二、题目三、算法原理思路1:用一个变量存储最小元素思路2:双栈普通栈和最小栈 四、编写代码五、时间复杂度 一、题目链接 最小栈 二、题目 三、算法原理 栈用数组、链表实现都行,最主要的就是在能在常数时间内检索到最…...