leetcode继续c++10/100
不应该是10-13=-3吗
ChatGLM
![]()
引用
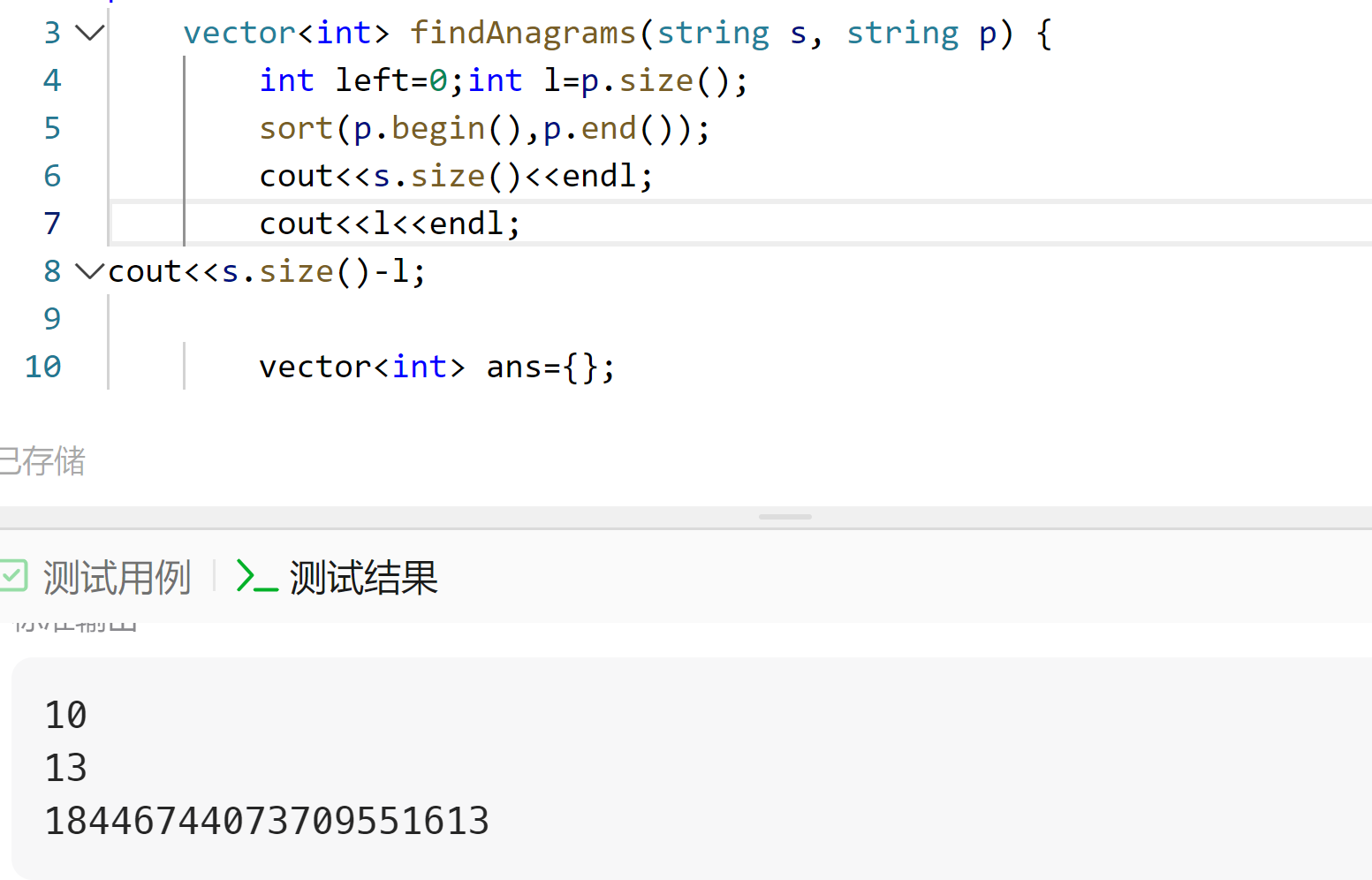
从代码片段来看,函数 findAnagrams 的目的是在字符串 s 中找到所有与字符串 p 是字母异位词的子串的起始索引。
代码中有一些调试输出语句,这些语句可能会影响程序的正常逻辑。具体来说:
cpp
复制
cout << s.size() << endl;
cout << l << endl;
cout << s.size() - 1;
这些输出语句会打印出 s 的大小、l(即 p 的大小)和 s.size() - 1 的值。但这些并不是计算字母异位词的逻辑部分。
根据测试结果中的输出:
复制
10
13
18446744073709551613
我们可以看到输出的三个数字分别是 10, 13 和一个非常大的数 18446744073709551613。这个非常大的数实际上是 INT_MAX 的值,通常表示某种错误或异常情况。
考虑到你的问题 “不应该是10-13=-3吗”,可能是在期望某种特定的计算结果。然而,从当前代码来看,并没有直接进行 10 - 13 这样的操作。可能是你在期望某个逻辑上的结果,但当前的代码实现并不符合那个预期。
如果你希望得到 10 - 13 = -3 这样的结果,你可能需要检查并修正代码的逻辑部分,确保它正确地实现了寻找字母异位词的功能,并且没有多余的调试输出干扰正常的程序流程。
另外,确保 vector<int> ans; 被正确初始化和使用来存储结果,而不是仅仅声明了一个空的向量。
解决:只要单独拎出s.size()设为ls,ls-l就是正常的-3了,具体原因未可知、、
函数和方法的区别
ChatGLM

在编程中,函数(Function)和方法(Method)是两个经常被提及的概念,它们在某些方面相似,但也存在一些关键的区别。以下是它们的主要区别:
-
定义和作用范围:
- 函数:通常是指在程序中定义的一系列语句,用于完成特定的任务。函数可以独立于任何对象而存在,可以在全局作用域或局部作用域中定义。
- 方法:是特定于对象的函数,通常与面向对象编程(OOP)相关。方法是在类的定义中声明,并且与类的实例(对象)相关联。
-
调用方式:
- 函数:可以直接通过函数名调用,不需要与任何对象关联。
- 方法:必须通过对象或类来调用。在面向对象编程中,方法调用通常与特定的对象实例相关联。
-
访问对象的属性:
- 函数:通常不直接访问对象的属性,除非通过参数传递。
- 方法:可以访问所属对象的属性和其他方法,因为它们与特定的对象实例相关联。
-
继承和多态:
- 函数:通常不涉及继承和多态的概念。
- 方法:在面向对象编程中,方法可以被子类继承和重写,实现多态性。
-
语法:
- 函数:在许多编程语言中,函数的定义不依赖于任何类或对象。
- 方法:在面向对象编程语言中,方法的定义通常包含在类的定义中。
以下是一些示例,展示了函数和方法的区别:
Python 示例:
python
复制
# 函数
def add(a, b):return a + b# 类和它的方法
class Calculator:def add(self, a, b):return a + b# 调用函数
result = add(2, 3)# 创建对象并调用方法
calc = Calculator()
result = calc.add(2, 3)
Java 示例:
java
复制
// 函数
public class Main {public static int add(int a, int b) {return a + b;}// 类和它的方法class Calculator {public int add(int a, int b) {return a + b;}}public static void main(String[] args) {// 调用函数int result = add(2, 3);// 创建对象并调用方法Calculator calc = new Calculator();int result = calc.add(2, 3);}
}
在这些示例中,add 函数是独立于任何对象的,而 add 方法是与 Calculator 类的实例相关联的。

用户_uBiEPA
计算前缀和的时间复杂度
ChatGLM
计算前缀和的时间复杂度通常是 O(n),其中 n 是数组的长度。前缀和是一种常用的技术,用于快速计算数组中某个区间的元素之和。
前缀和的定义
前缀和数组 prefixSum 是一个长度为 n+1 的数组,其中 prefixSum[i] 表示原数组中从第一个元素到第 i-1 个元素的和。具体来说:
prefixSum[0] = 0(表示没有元素的和)prefixSum[1] = arr[0]prefixSum[2] = arr[0] + arr[1]- …
prefixSum[i] = arr[0] + arr[1] + ... + arr[i-1]
计算过程
计算前缀和的伪代码如下:
plaintext
复制
prefixSum[0] = 0
for i from 1 to n:prefixSum[i] = prefixSum[i-1] + arr[i-1]
时间复杂度分析
- 初始化:
prefixSum[0] = 0,这一步是 O(1)。 - 循环计算:从 i=1 到 n,每次计算
prefixSum[i]只需要 O(1) 的时间。
因此,整个循环的时间复杂度是 O(n)。
应用
一旦计算了前缀和数组,你可以用 O(1) 的时间复杂度来查询任意子数组的和。例如,要查询数组 arr 中从索引 l 到 r 的子数组和,可以使用:
plaintext
复制
sum(l, r) = prefixSum[r+1] - prefixSum[l]
总结
- 计算前缀和的时间复杂度:O(n)
- 查询子数组和的时间复杂度:O(1)
这种高效性使得前缀和在许多算法和问题中非常有用,特别是在需要频繁查询数组区间和的场景中。
用户_uBiEPA
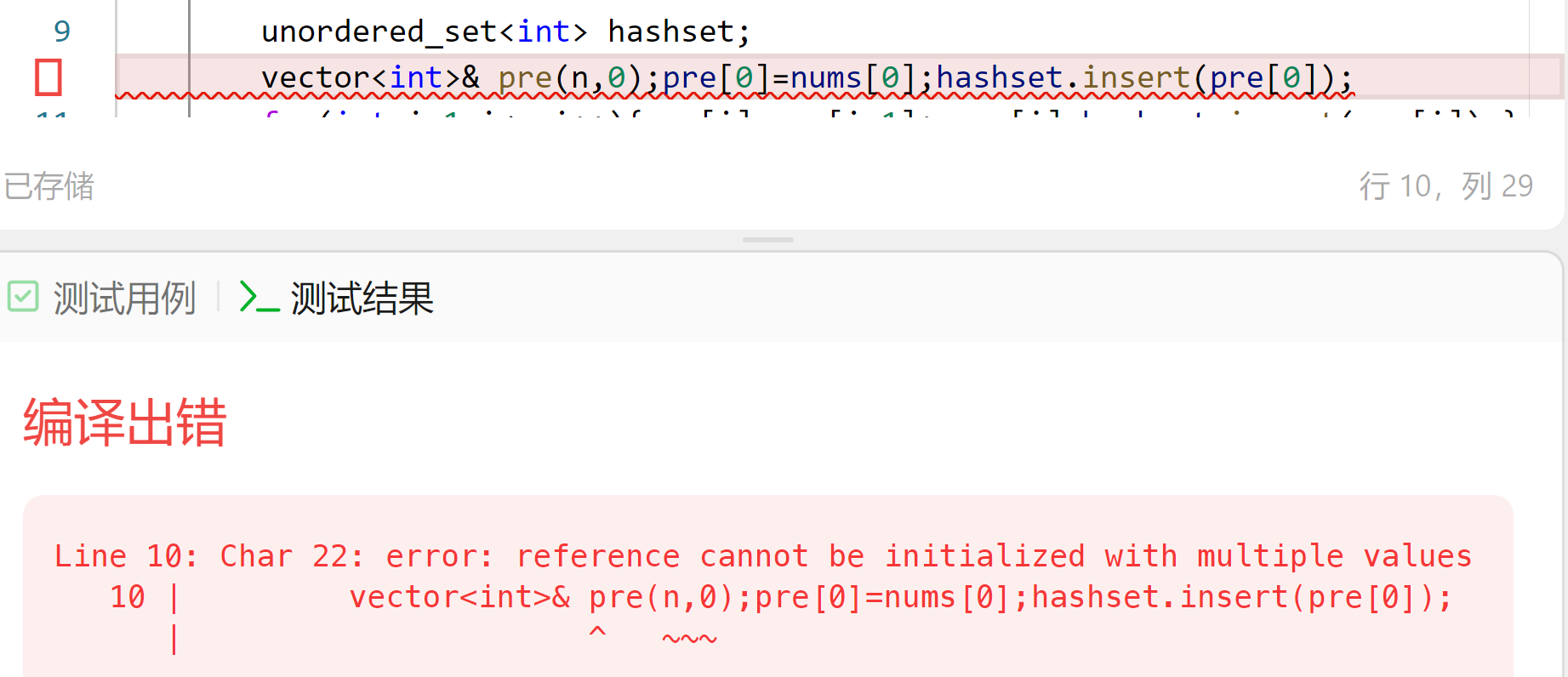
vector初始化,如果指定了个数,不能带&符号
ChatGLM

是的,这段代码中的初始化确实有问题。错误信息指出“reference cannot be initialized with multiple values”,意思是引用不能被多个值初始化。
具体来说,问题在于 vector<int>& pre(n, 0); 这一行。这里尝试将 pre 初始化为一个大小为 n 且值为 0 的 vector<int>,但同时又将 pre 声明为一个对 vector<int> 的引用。这是不允许的,因为引用必须在声明时绑定到一个具体的变量,而不能同时指定大小和初始值。
正确的做法是将 pre 声明为一个普通的 vector<int> 变量,并在之后进行初始化。下面是修正后的代码:
cpp
复制
unordered_set<int> hashset;
vector<int> pre(n, 0); // 正确的初始化方式
pre[0] = nums[0];
hashset.insert(pre[0]);
这样,pre 就会被正确地初始化为一个大小为 n 且所有元素都为 0 的 vector<int>,然后你可以继续使用 pre 进行后续的操作。

详尽版vector初始化
在 C++ 中,vector 是一个能够存储多个同类型元素的动态数组,它提供了许多方便的成员函数用于元素的初始化、插入、删除等操作。当你声明并初始化一个 vector 时,你不能使用 & 符号,因为 & 是引用声明符,而 vector 不是引用类型。
以下是一些 vector 初始化的示例:
-
声明一个空的
vector:cpp
复制
std::vector<int> vec; -
初始化一个具有特定大小且所有元素都为 0 的
vector:cpp
复制
std::vector<int> vec(10); // 10 个元素,每个元素都是 0 -
初始化一个具有特定大小且所有元素都为特定值的
vector:cpp
复制
std::vector<int> vec(10, 42); // 10 个元素,每个元素都是 42 -
使用初始化列表来初始化
vector:cpp
复制
std::vector<int> vec = {1, 2, 3, 4, 5}; // 5 个元素,分别是 1, 2, 3, 4, 5 -
使用数组和数组大小来初始化
vector:cpp
复制
int arr[] = {1, 2, 3, 4, 5}; std::vector<int> vec(std::begin(arr), std::end(arr)); // 使用数组初始化 -
拷贝另一个
vector:cpp
复制
std::vector<int> vec1 = {1, 2, 3, 4, 5}; std::vector<int> vec2 = vec1; // 拷贝构造函数
为什么不能使用 & 符号?
& 符号在 C++ 中用于声明引用。引用是已存在变量的别名,而 vector 是一个对象,它不是引用类型。当你声明一个 vector 时,你是在创建一个新的对象,而不是在引用一个已存在的对象。
如果你尝试使用 & 符号来声明一个 vector,你会得到一个编译错误,因为 vector 不是引用类型。例如:
cpp
复制
std::vector<int>& vec(10); // 错误:不能将 vector 初始化为引用
正确的初始化方法
如果你需要声明一个 vector 的引用,你可以在声明时使用 & 符号,但必须在初始化之后再进行。例如:
cpp
复制
std::vector<int> vec = {1, 2, 3, 4, 5};
std::vector<int>& vecRef = vec; // 正确:vecRef 是 vec 的引用
在这种情况下,vecRef 是 vec 的引用,任何对 vecRef 的修改都会反映到 vec 上。
总结来说,vector 的初始化不需要使用 & 符号,因为 vector 不是引用类型。你只需要使用上述的正确初始化方法即可。
hashset有3个0,我像只去掉一个0
ChatGLM
如果你想在 unordered_set<int> 中只保留一个 0 而去除多余的,你可以直接使用 unordered_set 的特性,因为它本身就会自动去重。当你尝试插入相同的值时,unordered_set 会忽略后续的插入操作,只保留一个。
如果你已经有一个包含多个 0 的 unordered_set<int>,并且想要确保只保留一个 0,你可以先清除所有的 0,然后再次插入一个 0。以下是相应的代码示例:
cpp
复制
#include <iostream>
#include <unordered_set>
#include <vector>int main() {std::unordered_set<int> hashset;std::vector<int> nums = {0, 1, 0, 2, 0, 3}; // 示例数组// 假设我们想将nums中的元素插入到hashset中for (int num : nums) {hashset.insert(num);}// 如果hashset中0的数量多于1个,我们只保留一个0if (hashset.count(0) > 1) {hashset.erase(0); // 先清除所有的0hashset.insert(0); // 再插入一个0}// 输出hashset中的元素for (int num : hashset) {std::cout << num << " ";}return 0;
}
在这个示例中,我们首先将一个包含多个 0 的数组 nums 的元素插入到 hashset 中。然后,我们检查 hashset 中 0 的数量,如果多于一个,我们就先清除所有的 0,然后再插入一个 0。这样,hashset 中就只会有一个 0。
请注意,这个方法会在 hashset 中保留一个 0,即使原始数组 nums 中没有 0。如果你希望只有在原始数组中至少有一个 0 时才保留 0,你可以先检查 hashset 中是否包含 0,然后再进行去重操作。

用户_uBiEPA
hashset自动去重,多次insert(0) 那会hashset.count(0) 增加吗
ChatGLM

不会。在C++中,unordered_set(哈希集合)是一个集合容器,用于存储唯一元素,即自动去重。当你尝试向unordered_set中插入一个已经存在的元素时,该操作将不会改变集合的内容,因此hashset.count(0)不会增加。
count成员函数用于返回集合中具有特定值的元素的数量。由于unordered_set只存储唯一元素,所以对于任何给定的值,count函数的返回值只能是0或1。
如果你多次执行hashset.insert(0),只要0已经存在于集合中,后续的插入操作将不会生效,hashset.count(0)将始终返回1。
这里是一个简单的示例来演示这一点:
cpp
复制
#include <iostream>
#include <unordered_set>int main() {std::unordered_set<int> hashset;// 插入0多次hashset.insert(0);hashset.insert(0);hashset.insert(0);// 输出0在集合中的数量std::cout << "Count of 0 in hashset: " << hashset.count(0) << std::endl;return 0;
}
无论你执行多少次hashset.insert(0),输出都将始终是:
复制
Count of 0 in hashset: 1
这表明unordered_set中只保留了一个0,并且count函数的返回值没有增加。

用户_uBiEPA
set呢
ChatGLM

在C++中,std::set也是一个集合容器,它存储唯一元素并自动保持元素有序。与std::unordered_set类似,std::set也会自动去重。当你尝试向std::set中插入一个已经存在的元素时,该操作不会改变集合的内容,因此set.count(0)也不会增加。
std::set的count成员函数同样用于返回集合中具有特定值的元素的数量。由于std::set只存储唯一元素,所以对于任何给定的值,count函数的返回值只能是0或1。
这里是一个简单的示例来演示std::set的行为:
cpp
复制
#include <iostream>
#include <set>int main() {std::set<int> mySet;// 插入0多次mySet.insert(0);mySet.insert(0);mySet.insert(0);// 输出0在集合中的数量std::cout << "Count of 0 in set: " << mySet.count(0) << std::endl;return 0;
}
无论你执行多少次mySet.insert(0),输出都将始终是:
复制
Count of 0 in set: 1
这表明std::set中只保留了一个0,并且count函数的返回值没有增加。
总结来说,无论是std::unordered_set还是std::set,它们都保证元素的唯一性,多次插入相同的元素不会增加该元素在集合中的计数。

用户_uBiEPA
想要知道一个元素出现了几次,用什么‘
ChatGLM

如果你想要知道一个元素在集合中出现了几次,那么你应该使用一个能够记录元素出现次数的数据结构。在C++中,常用的数据结构包括:
-
std::map:这是一个有序的键值对容器,可以存储键和对应的值。你可以使用元素作为键,其出现次数作为值。
-
std::unordered_map:这是一个无序的键值对容器,与std::map类似,但是它不保证元素的顺序,通常提供更快的访问速度。
下面是使用std::unordered_map来记录元素出现次数的示例:
cpp
复制
#include <iostream>
#include <unordered_map>int main() {std::unordered_map<int, int> countMap;// 假设我们有一些元素int elements[] = {0, 1, 2, 0, 3, 0, 1};// 记录每个元素出现的次数for (int elem : elements) {countMap[elem]++;}// 查询元素0出现的次数std::cout << "Element 0 appears " << countMap[0] << " times." << std::endl;return 0;
}
在这个示例中,我们遍历了一个元素数组,并使用countMap[elem]++来增加每个元素在unordered_map中的计数。然后,我们可以通过countMap[0]来查询元素0出现的次数。
如果你只需要记录元素是否出现,而不关心出现的次数,那么可以使用std::set或std::unordered_set。但是,如果你需要知道元素出现的具体次数,那么std::map或std::unordered_map是更合适的选择。
用户_uBiEPA
td::unordered\_map<int, int\> countMap; // 假设我们有一些元素 int elements\[\] = {0, 1, 2, 0, 3, 0, 1}; // 记录每个元素出现的次数 for (int elem : elements) { countMap\[elem\]++; } // 查询元素0出现的次数 std::cout << "Element 0 appears " << countMap\[0\] << " times." << std::endl; return 0;
这是默认初始建对应的值为0吗
ChatGLM
![]()
引用
是的,当你使用 std::unordered_map(或 std::map)并尝试访问一个不存在的键时,它会自动为该键创建一个默认初始化的值。对于内置类型如 int,默认初始化的值是 0。因此,在代码中,当你第一次尝试增加 countMap[elem] 的值时,如果 elem 还没有作为键存在于 countMap 中,unordered_map 会自动创建一个键值对,其中键是 elem,值是默认初始化的 0。
在接下来的代码中:
cpp
复制
for (int elem : elements) {countMap[elem]++;
}
对于数组 elements 中的每个元素,countMap[elem]++ 的操作会先检查 elem 是否已经作为键存在于 countMap 中。如果不存在,它会创建一个新键 elem 并将其值初始化为 0,然后立即增加其值到 1。如果 elem 已经存在,它只会增加现有键的值。
因此,当你查询 countMap[0] 时,它会返回元素 0 出现的次数,因为每次 0 出现在数组中时,它的计数就会增加。在这个特定的例子中,元素 0 出现了三次,所以 countMap[0] 的值将是 3。
sort(字符串)
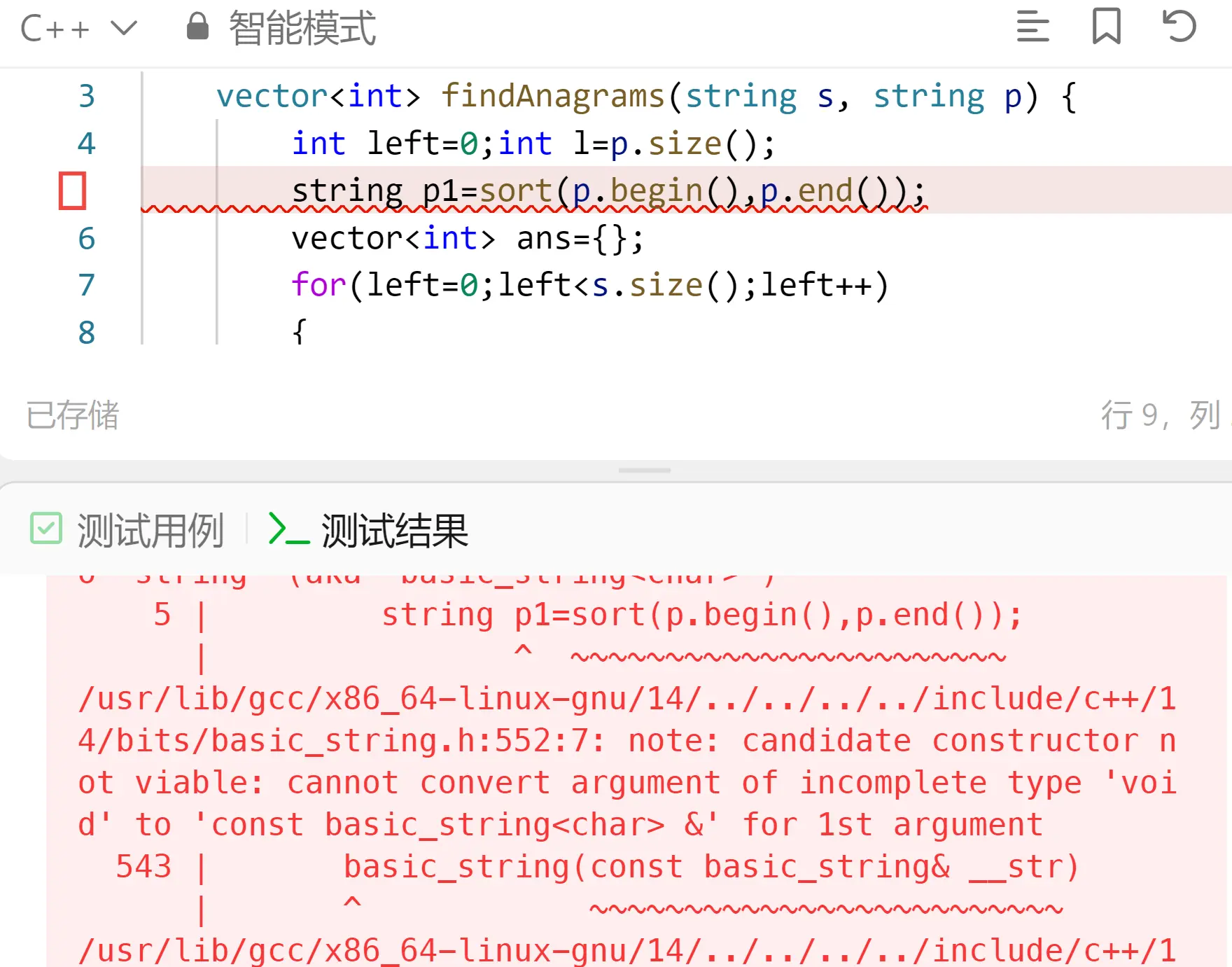 从图片中可以看到,代码在编译时出现了错误。错误信息指出,无法将一个不完整的类型(void)转换为字符串类型(const basic_string<char>&)。具体来说,问题出在以下这一行:
从图片中可以看到,代码在编译时出现了错误。错误信息指出,无法将一个不完整的类型(void)转换为字符串类型(const basic_string<char>&)。具体来说,问题出在以下这一行:
cpp
复制
string p1 = sort(p.begin(), p.end());
这个问题的原因是 sort() 函数返回的是指向最后一个元素的迭代器,而不是排序后的子串。因此,不能直接将其赋值给一个字符串。
要解决这个问题,可以创建一个新的字符串来存储排序后的结果。例如:
cpp
复制
string p1 = string(p.begin(), p.end()); // 先复制一份p
sort(p1.begin(), p1.end()); // 对复制的字符串进行排序
这样就可以正确地得到排序后的字符串了。
在C++中,没有直接的sort(str)这种用法来对字符串进行排序。但是,C++提供了强大的标准库,其中包括<algorithm>头文件,里面有一个sort函数可以用来对各种容器进行排序,包括字符串。
如果你想要对字符串中的字符进行排序,你可以使用如下代码:
cpp
复制
#include <iostream>
#include <string>
#include <algorithm>int main() {std::string str = "hello";std::sort(str.begin(), str.end());std::cout << "Sorted string: " << str << std::endl;return 0;
}
这段代码会将字符串"hello"中的字符按照字典序进行排序,输出结果为"ehllo"。
需要注意的是,sort函数默认使用小于比较符进行排序,如果你需要其他类型的排序(比如降序),你可以提供自定义的比较函数。
例如,如果你想按照降序排序,你可以这样做:
cpp
复制
#include <iostream>
#include <string>
#include <algorithm>int main() {std::string str = "hello";std::sort(str.begin(), str.end(), std::greater<char>());std::cout << "Sorted string: " << str << std::endl;return 0;
}
这样输出结果就会是"ollhe"。
所以,虽然C++没有直接的sort(str)这种用法,但是通过标准库中的sort函数,你可以很容易地对字符串进行排序。
相关文章:

leetcode继续c++10/100
不应该是10-13-3吗 ChatGLM 引用 从代码片段来看,函数 findAnagrams 的目的是在字符串 s 中找到所有与字符串 p 是字母异位词的子串的起始索引。 代码中有一些调试输出语句,这些语句可能会影响程序的正常逻辑。具体来说: cpp 复制 cout …...

Kubernetes集群使用Harbor容器镜像仓库
实验环境 一、容器镜像仓库Harbor部署 1、配置主机名 192.168.10.14: hostnamectl set-hostname harbor 2、安装Docker wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum -y install docker-…...

归并排序排序总结
1. 归并排序 1.1 基本思想 归并排序(Merge Sort)是采用分治法(Divide and Conquer)的一个非常典型的应用。它的基本思想是将一个数组分成两个子数组,分别对这两个子数组进行排序,然后将排好序的子数组合并…...

面试手撕——快速排序
思路 partition方法将整个区间分为两部分,一部分比pivot小,一部分比pivot大, i表示,小于等于pivot的下标,j表示当前遍历到哪一个元素了,如果发现当前元素j小于等于pivot,i,在i1的位…...

大模型微调之LLaMA-Factory 系列教程大纲
LLaMA-Factory 系列教程大纲 一、基础入门篇:环境搭建与核心功能解析 环境部署与框架特性 硬件要求: 单机训练:推荐 24GB 显存 GPU(如 RTX 4090),支持 7B-32B 模型 LoRA 微调。分布式训练:2 块…...

26考研 | 王道 | 计算机网络 | 第一章 计算机网络的体系结构
26考研 | 王道 | 第一章 计算机网络的体系结构 文章目录 26考研 | 王道 | 第一章 计算机网络的体系结构1.1 计算机网络概述1.计算机网络的概念2.计算机网络的组成**从组成部分看****从工作方式看****从逻辑功能看** 3.计算机网络的功能4.电路交换、报文交换、分组交换1. 电路交…...

CentosLinux系统crontab发现执行删除命令失效解决方法
权限或安全策略限制 可能场景: ### 目录权限冲突: 你的目录权限为 drwxr-xr-x(属主 mssql),但 cron 任务以 root 执行。 风险点:若目录内文件属主为 mssql 且权限为 700&…...

UniApp页面路由详解
一、路由系统概述 1.1 路由机制原理 UniApp基于Vue.js实现了一套跨平台的路由管理系统,其核心原理是通过维护页面栈来管理应用内不同页面之间的跳转关系。在小程序端,UniApp的路由系统会映射到对应平台的原生导航机制;在H5端则基于HTML5 Hi…...

探索无人机模拟环境的多元景象及AI拓展
无人驾驶飞行器(UAVs)在各行各业的迅速普及,从农业和检测到空中操作和人机交互等令人兴奋的前沿领域,都引发了一个关键需求:强大而逼真的模拟环境。直接在物理硬件上测试尖端算法存在固有的风险——成本高昂的坠机、中…...

Java后端开发day39--方法引用
(以下内容全部来自上述课程) 1.1 含义 把已经有的方法拿过来用,当作函数式接口中抽象方法的方法体。 已经有的方法:可以是Java自己写的,也可以是第三方的。 示例语句: ::是方法引…...

C# 14 field keyword:属性简化新利器
引言 在 C# 的不断发展历程中,每一个新版本都带来了令人期待的新特性,而 C# 14 中的 field keyword 无疑是其中一颗璀璨的明星 。对于广大 C# 开发者来说,属性的使用频率极高,而 field keyword 的出现,为我们简化属性…...

破茧成蝶:一家传统制造企业的年轻化转型之路
2004 年,在长三角的轻工业重镇杭集,一家专注于植毛机器设备研发的小工厂悄然诞生。那时,它以 “齿轮与钢铁” 为语言,为全国近千家牙刷生产企业提供核心装备,用机械臂的精准律动,编织着传统制造业的经纬。然…...

【语法】C++的继承
目录 继承基本语法: protected访问限定符: 子类和父类之间的赋值兼容规则: 重定义(隐藏): 继承中的友元/继承中的静态成员: 子类中的默认成员函数 构造函数/拷贝构造函数: 赋值重载函数ÿ…...

如何知道Ubuntu的端口是否被占用,被那个进程占用?如何终止进程
要检查Ubuntu系统中某个端口,比如5034,是否被占用及终止对应进程,请按以下步骤操作: 1. 检查端口占用情况 方法一:使用 lsof 命令 sudo lsof -i :5034输出结果会显示占用该端口的进程名、PID等信息。 方法二&#x…...

verdi使用tcl脚本批量添加波形
打开verdi console功能 在verdi的tools 里使能工具中的console功能; 在console执行tcl脚本 set cell_list { ts_0_lockup_latchn_clkc45_intno45811_i u_rst_scan_n_tp/u_scan_crl_reg/u_cell u_scan_crl_reg/u_cell u_scan_crl_reg/u_cell } ## specify the waveform window…...

【行业特化篇3】制造业简历优化指南:技术参数与标准化流程的关键词植入艺术
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...

oracle怎样通过固化较优执行计划来优化慢sql
一 问题描述 有次生产环境cpu使用率增高,ADDM报告提示某条sql比较耗费cpu: 提示: 在分析期间, 此 SQL 语句至少利用了 6 个不同的执行计划 #查看该sql都有哪些执行计划 SELECT * FROM table(DBMS_XPLAN.DISPLAY_AWR(sqlid值)); 我手动执…...

【无标题】好用的远程链接插件
现在在做后端开发有的时候需要链接到远程服务器,有很多插件看不到整体的目录结构 推荐 trae的 ssh Client 有很清晰的目录结构...

Plant Simulation MultiPortalCrane Store 小案例
一个天车从库区移动商品到指定地点的案例 库区商品:库区上随机位置摆放商品,在源上绑定方法(应该也可以直接在库区上生成,我这里是使用源可以改变生成多少个商品) // 源的self.OnExit var Store : object : 存储 var …...

MyBatis 使用 POJO 参数动态查询教程
项目结构概览(基于图片描述): mybatis02 ├─ src/main/java │ └─ cn.cjxy │ ├─ domain # 实体类(如 Emp.java) │ ├─ mapper # Mapper 接口(如 EmpMapper.java) │…...
:MCP之微服务架构)
【MCP Node.js SDK 全栈进阶指南】高级篇(5):MCP之微服务架构
引言 在软件架构中,微服务模式已成为构建可扩展系统的主流方案。 将MCP与微服务架构结合,能够为AI驱动的应用带来显著优势。 本文将探讨如何在微服务环境中集成和部署MCP服务,以及如何利用云原生技术实现高可用、高性能的MCP应用。 目录 MCP在微服务中的角色服务网格集成容…...
)
UBUS 通信接口的使用——添加一个object对象(ubus call)
1,引入 ubus提供了一种多进程通信的机制。存在一个守护进程ubusd,所以进程都注册到ubusd,ubusd进行消息的接收、分发管理。 ubus对多线程支持的不好,例如在多个线程中去请求同一个服务,就有可能出现不可预知的结果。 …...

强化学习贝尔曼方程推导
引言 强化学习中贝尔曼方程的重要性就不说了,本文利用高中生都能看懂的数学知识推导贝尔曼方程。 回报 折扣回报 G t G_t Gt的定义为: G t R t 1 γ R t 2 γ 2 R t 3 ⋯ ∑ k 0 ∞ γ k R t k 1 (1) G_t R_{t1} \gamma R_{t2} \gamm…...
:MCP高性能服务优化)
【MCP Node.js SDK 全栈进阶指南】高级篇(2):MCP高性能服务优化
前言 随着MCP应用规模的扩大和用户量的增加,性能优化成为系统稳定运行的关键因素。高性能的MCP服务不仅能提供更好的用户体验,还能降低运营成本,提高系统的可扩展性。本文将深入探讨MCP TypeScript-SDK的性能优化策略,帮助开发者构建高效、稳定的MCP服务。 1. 性能瓶颈识…...

图片识别为提示词,背景信息提取 -从头设计数字生命第7课, demucs——仙盟创梦IDE
1. 图像内容理解与标注 用途:在大规模图像数据集的整理和标注工作中,通过特定提示词可引导图片识别系统更准确地提取图像中的背景信息,并进行标注。例如在医学图像库标注中,使用 “疾病相关背景特征” 作为提示词,系统…...

域对齐是什么
域对齐(Domain Alignment)是在机器学习和计算机视觉等领域中常用的技术 定义 域对齐旨在将不同域(Domain)的数据映射到一个共同的特征空间中,使得来自不同域的数据在该空间中具有相似的分布。这里的“域”可以指代不…...

opencv 直方图均衡化
直方图均衡化 1. 啥叫直方图2. 绘制直方图3. 直方图均衡化3.1 自适应直方图均衡化(cv2.equalizeHist())3.2 对比度受限的自适应直方图均衡化(cv2.createCLAHE()) 1. 啥叫直方图 直方图是对数据进行统计的一种方法,并且将统计值组织到一系列实…...

JDK 8 函数式接口全集
JDK 8 函数式接口全集 函数式接口如何定义关于注解 FunctionalInterface 函数式接口的分类与简单使用生产型接口 Supplier使用 消费型接口 Consumer使用 函数型接口(Function)实例(合并字符串) 断言型接口(Predicate)…...

网站防护无惧DDoS攻击:2025年实战指南
在数字化时代,DDoS攻击已成为企业生存的“生死线”。2024年全球日均攻击峰值突破5.4Tbps(Cloudflare数据),电商、金融行业更是重灾区。本文将结合最新技术趋势和实战案例,为你提供一套低成本、高可靠的防御方案。 一、…...

【AI论文】BitNet v2:针对1位LLM的原生4位激活和哈达玛变换
摘要:激活异常值阻碍了1位大型语言模型(LLM)的有效部署,这使得低比特宽度的量化变得复杂。 我们介绍了BitNet v2,这是一个新的框架,支持1位LLM的原生4位激活量化。 为了解决注意力和前馈网络激活中的异常值…...

windows 使用 FFmpeg 放大视频原声
问题:原视频声音太小,就算把视频音量调到最大,声音也听不太清 一、下载 下载地址:Download FFmpeg 根据需要选择合适版本下载解压,如浏览器下载速度慢,可使用迅雷下载 二、配置环境变量 1.把解压的文件放…...

RHCE第七章:SElinux
一、SElinux SELinux 是一套安全策略系统 1.作用: (1)SELinux 域限制:对服务程序的功能进行限制,以确保服务程序做不了出格的事 (2)SELinux 安全上下文:对文件资源的访问限制&am…...
)
一文简单记录打通K8s+Kibana流程如何启动(Windows下的Docker版本)
为ES和Kibana组建Docker网络 docker network create elastic下载8.18.0版本镜像Es并启动 docker run --name es-node01 --net elastic -p 9200:9200 -p 9300:9300 -t docker.elastic.co/elasticsearch/elasticsearch:8.18.0启动Kibana(简单一些直接咯和ES对应版本…...

【系统参数合法性校验】spring-boot-starter-validation
JSR303校验 统一校验的需求 前端请求后端接口传输参数,是在controller中校验还是在Service中校验? 答案是都需要校验,只是分工不同。 Contoller中校验请求参数的合法性,包括:必填项校验,数据格式校验&…...

蓝桥杯 10. 凯撒加密
凯撒加密 原题目链接 题目描述 给定一个单词,请使用凯撒密码将这个单词加密。 凯撒密码是一种替换加密的技术,单词中的所有字母都在字母表上向后偏移 3 位后被替换成密文。 即: a → db → e⋯w → zx → ay → bz → c 输入描述 输入…...

Discord多账号注册登录:如何同时管理多个账户?
Discord是许多人、特别是游戏玩家和社区管理者的重要沟通工具。随着用户需求的增长,越来越多的人开始在Discord上注册多个账号进行管理。例如,个人和工作账号的区分,多个游戏社区的参与,或者通过不同的身份进行更灵活的社交互动。…...

Harbor默认Redis与Notary组件弱口令漏洞分析与修复指南
一、 背景 某资源池控制面和运行面生产环境部署的harbor被漏扫出弱口令需要进行整改,主要涉及 default、server、signer用户存在弱口令。 二、 分析与处理 首先需求确认这三个用户是harbor那个组件使用,最好确认的是default这个用户,它是r…...

【Prometheus-Postgres Exporter安装配置指南,开机自启】
目录 内容概述 一、安装步骤1. 安装 PostgreSQL Exporter2. 创建 PostgreSQL 监控用户3. 配置 Systemd 服务4. 启动并验证服务5. 集成到 Prometheus 内容概述 本教程详细指导如何安装 PostgreSQL Exporter(版本 0.15.0),包括: 软…...
)
leetcode:3005. 最大频率元素计数(python3解法)
难度:简单 给你一个由 正整数 组成的数组 nums 。 返回数组 nums 中所有具有 最大 频率的元素的 总频率 。 元素的 频率 是指该元素在数组中出现的次数。 示例 1: 输入:nums [1,2,2,3,1,4] 输出:4 解释:元素 1 和 2 的…...

论文导读 - 基于特征融合的电子鼻多任务深度学习模型研究
基于特征融合的电子鼻多任务深度学习模型研究 原论文地址:https://www.sciencedirect.com/science/article/pii/S0925400524009365 引用此论文(GB/T 7714-2015): NI W, WANG T, WU Y, et al. Multi-task deep learning model f…...
)
VSCode突然连接不上服务器(已解决)
可恶,不知道昨天还好好的VSCode还可以连接到服务器,今天打开就连接不上了,搜了一圈很多都说是服务端的vscode-server这个文件里面保存的commitID与当前我们VSCode上的ID不一致导致连接失败(据说是因为VSCode自动更新导致的&#x…...

解决Ollama run qwen3:32b: Error: unable to load model问题
问题描述 在尝试使用Ollama部署Qwen3模型时,许多用户遇到了以下错误: ollama run qwen3:32b Error: unable to load model: /Users/xxxx/.ollama/models/blobs/sha256-3291abe70f16ee9682de7bfae08db5373ea9d6497e614aaad63340ad421d6312这个错误通常会…...
)
C++ 单例对象自动释放(保姆级讲解)
目录 单例对象自动释放(重点*) 方式一:利用另一个对象的生命周期管理资源 方式二:嵌套类 静态对象(重点) 方式三:atexit destroy 方式四:atexit pthread_once 单例对象自动释…...

李录谈卖出股票的时机:价值投资的动态决策框架
作为最贴近芒格与巴菲特投资理念的中国投资人,李录对卖出时机的思考融合了价值投资的核心逻辑与实战经验。通过其在哥伦比亚大学的多场演讲及访谈(主要集中于2006年、2013年及后续公开内容),我们可以将其观点归纳为以下五个维度&a…...
)
Docker的简单使用(不全)
Docker Hello World Docker 允许在容器内运行应用程序,使用docker run命令来在容器内运行一个应用程序 输出Hello World runoobrunoob:~$ docker run ubuntu:15.10 /bin/echo "Hello world"Hello world docker:Docker的二进制执行文件 run…...

A2A与MCP:理解它们的区别以及何时使用
随着AI不断深入到商业工作流中,多个AI代理(Agent)之间的无缝协作成为了一个主要挑战。 为了解决这个问题,Google Cloud推出了一种名为Agent2Agent(A2A)的开放协议,旨在使不同平台和系统中的AI代…...

AI Agent开源技术栈
构建和编排Agent的框架 如果您是从头开始构建,请从这里开始。这些工具可以帮助您构建Agent的逻辑——做什么、何时做以及如何处理工具。您可以将其视为将原始语言模型转化为更自主的模型的核心大脑。 2. 计算机和浏览器的使用 一旦你的Agent能够规划,…...

判断用户选择的Excel单元格区域是否跨页?
VBA应用程序开发过程中,经常需要处理用户选中的单元格区域,有的应用场景中,需要限制用户选中区域位于同一页中(以打印预览显示的分页划分),但是VBA对象模型中并没有提供相应的接口,用于快速查询…...
:走进Linux内核时钟子系统 —— 硬件基础全解析)
驱动开发硬核特训 · Day 24(上篇):走进Linux内核时钟子系统 —— 硬件基础全解析
一、前言 在 SoC(System on Chip)设计中,“时钟(Clock)”不仅是信号同步的基石,也是各个模块协调运作的前提。没有合理的时钟体系,CPU无法运行,外设无法通信,存储器无法…...
技术详解)
【GPU 微架构技术】Pending Request Table(PRT)技术详解
PRT(Pending Request Table)是 GPU 中用于管理 未完成内存请求(outstanding memory requests)的一种硬件结构,旨在高效处理大规模并行线程的内存访问需求。与传统的 MSHR(Miss Status Handling Registers&a…...